diff --git a/applications/ChatGPT/.gitignore b/applications/ChatGPT/.gitignore
new file mode 100644
index 000000000..40f3f6deb
--- /dev/null
+++ b/applications/ChatGPT/.gitignore
@@ -0,0 +1,146 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+docs/.build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# IDE
+.idea/
+.vscode/
+
+# macos
+*.DS_Store
+#data/
+
+docs/.build
+
+# pytorch checkpoint
+*.pt
+
+# ignore version.py generated by setup.py
+colossalai/version.py
diff --git a/applications/ChatGPT/LICENSE b/applications/ChatGPT/LICENSE
new file mode 100644
index 000000000..0528c89ea
--- /dev/null
+++ b/applications/ChatGPT/LICENSE
@@ -0,0 +1,202 @@
+Copyright 2021- HPC-AI Technology Inc. All rights reserved.
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2021- HPC-AI Technology Inc.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/applications/ChatGPT/README.md b/applications/ChatGPT/README.md
new file mode 100644
index 000000000..dce59ad4b
--- /dev/null
+++ b/applications/ChatGPT/README.md
@@ -0,0 +1,80 @@
+# RLHF - ColossalAI
+
+Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by ColossalAI. It supports distributed training and offloading, which can fit extremly large models.
+
+
+ +
+
+
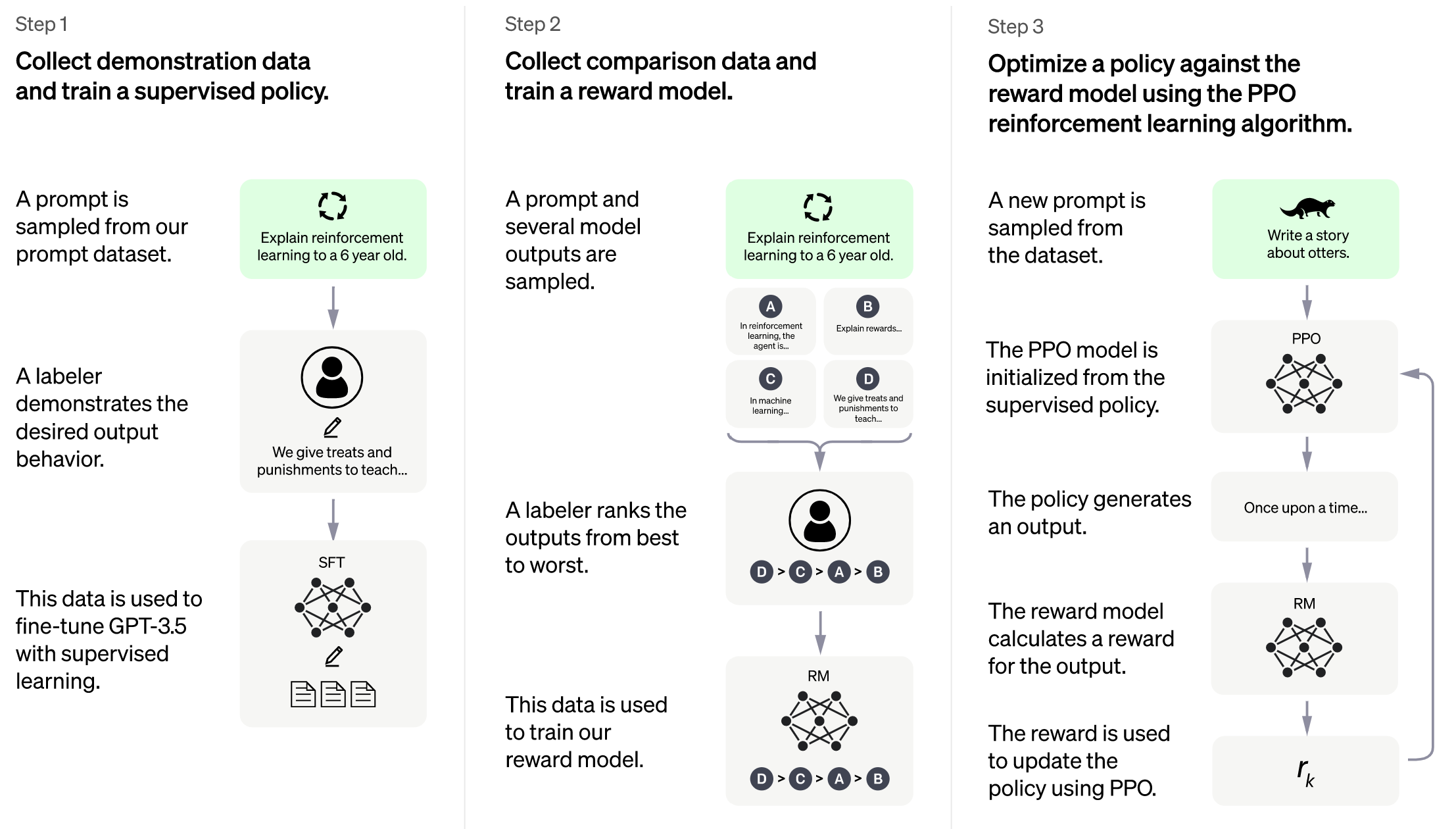
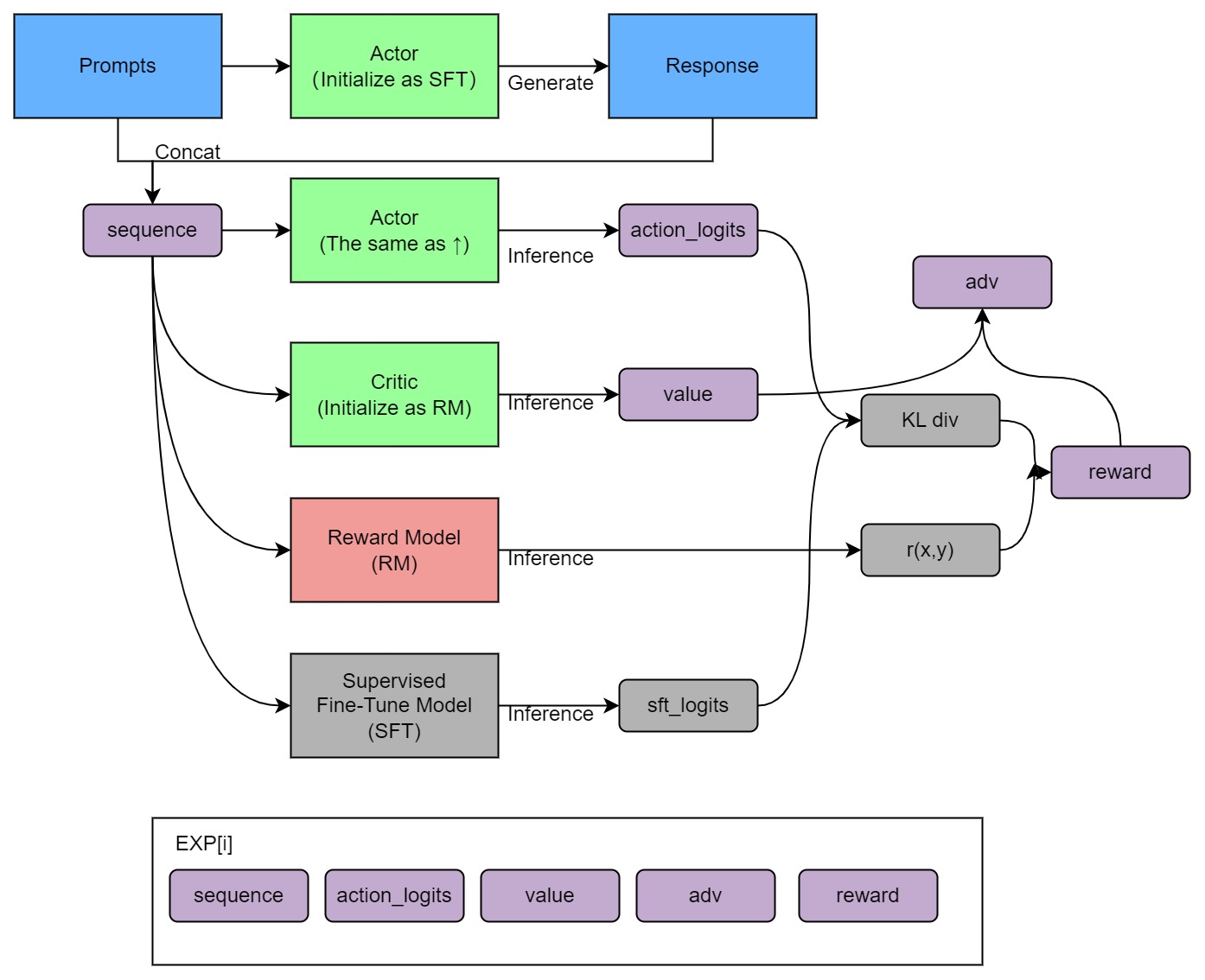
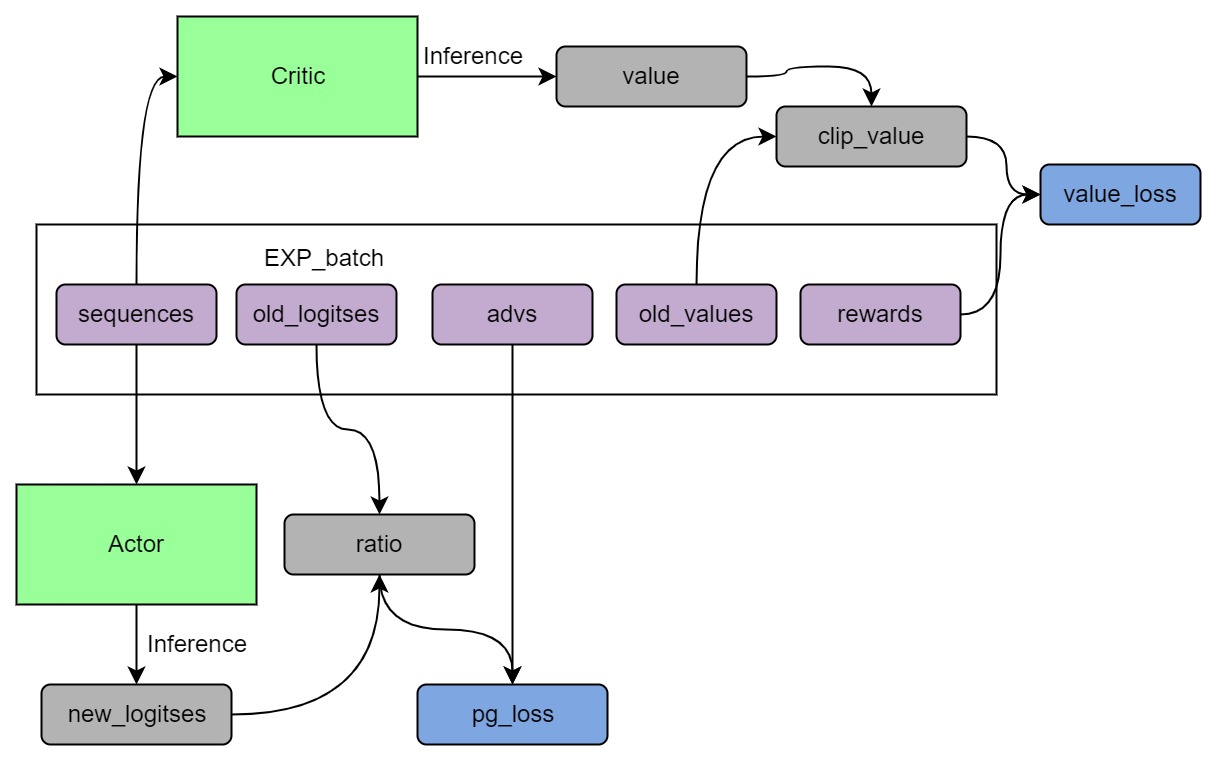
+## Training process (step 3)
+
+ +
+
+
+ +
+
+
+
+## Install
+```shell
+pip install .
+```
+
+
+## Usage
+
+The main entrypoint is `Trainer`. We only support PPO trainer now. We support many training strategies:
+
+- NaiveStrategy: simplest strategy. Train on single GPU.
+- DDPStrategy: use `torch.nn.parallel.DistributedDataParallel`. Train on multi GPUs.
+- ColossalAIStrategy: use Gemini and Zero of ColossalAI. It eliminates model duplication on each GPU and supports offload. It's very useful when training large models on multi GPUs.
+
+Simplest usage:
+
+```python
+from chatgpt.trainer import PPOTrainer
+from chatgpt.trainer.strategies import ColossalAIStrategy
+
+strategy = ColossalAIStrategy()
+
+with strategy.model_init_context():
+ # init your model here
+ actor = Actor()
+ critic = Critic()
+
+trainer = PPOTrainer(actor = actor, critic= critic, strategy, ...)
+
+trainer.fit(dataset, ...)
+```
+
+For more details, see `examples/`.
+
+We also support training reward model with true-world data. See `examples/train_reward_model.py`.
+
+## Todo
+
+- [x] implement PPO training
+- [x] implement training reward model
+- [x] support LoRA
+- [ ] implement PPO-ptx fine-tuning
+- [ ] integrate with Ray
+- [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL)
+
+## Citations
+
+```bibtex
+@article{Hu2021LoRALA,
+ title = {LoRA: Low-Rank Adaptation of Large Language Models},
+ author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
+ journal = {ArXiv},
+ year = {2021},
+ volume = {abs/2106.09685}
+}
+
+@article{ouyang2022training,
+ title={Training language models to follow instructions with human feedback},
+ author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
+ journal={arXiv preprint arXiv:2203.02155},
+ year={2022}
+}
+```
diff --git a/applications/ChatGPT/benchmarks/README.md b/applications/ChatGPT/benchmarks/README.md
new file mode 100644
index 000000000..f7212fc89
--- /dev/null
+++ b/applications/ChatGPT/benchmarks/README.md
@@ -0,0 +1,94 @@
+# Benchmarks
+
+## Benchmark GPT on dummy prompt data
+
+We provide various GPT models (string in parentheses is the corresponding model name used in this script):
+
+- GPT2-S (s)
+- GPT2-M (m)
+- GPT2-L (l)
+- GPT2-XL (xl)
+- GPT2-4B (4b)
+- GPT2-6B (6b)
+- GPT2-8B (8b)
+- GPT2-10B (10b)
+- GPT2-12B (12b)
+- GPT2-15B (15b)
+- GPT2-18B (18b)
+- GPT2-20B (20b)
+- GPT2-24B (24b)
+- GPT2-28B (28b)
+- GPT2-32B (32b)
+- GPT2-36B (36b)
+- GPT2-40B (40b)
+- GPT3 (175b)
+
+We also provide various training strategies:
+
+- ddp: torch DDP
+- colossalai_gemini: ColossalAI GeminiDDP with `placement_policy="cuda"`, like zero3
+- colossalai_gemini_cpu: ColossalAI GeminiDDP with `placement_policy="cpu"`, like zero3-offload
+- colossalai_zero2: ColossalAI zero2
+- colossalai_zero2_cpu: ColossalAI zero2-offload
+- colossalai_zero1: ColossalAI zero1
+- colossalai_zero1_cpu: ColossalAI zero1-offload
+
+We only support `torchrun` to launch now. E.g.
+
+```shell
+# run GPT2-S on single-node single-GPU with min batch size
+torchrun --standalone --nproc_pero_node 1 benchmark_gpt_dummy.py --model s --strategy ddp --experience_batch_size 1 --train_batch_size 1
+# run GPT2-XL on single-node 4-GPU
+torchrun --standalone --nproc_per_node 4 benchmark_gpt_dummy.py --model xl --strategy colossalai_zero2
+# run GPT3 on 8-node 8-GPU
+torchrun --nnodes 8 --nproc_per_node 8 \
+ --rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR \
+ benchmark_gpt_dummy.py --model 175b --strategy colossalai_gemini
+```
+
+> ⚠ Batch sizes in CLI args and outputed throughput/TFLOPS are all values of per GPU.
+
+In this benchmark, we assume the model architectures/sizes of actor and critic are the same for simplicity. But in practice, to reduce training cost, we may use a smaller critic.
+
+We also provide a simple shell script to run a set of benchmarks. But it only supports benchmark on single node. However, it's easy to run on multi-nodes by modifying launch command in this script.
+
+Usage:
+
+```shell
+# run for GPUS=(1 2 4 8) x strategy=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu") x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
+./benchmark_gpt_dummy.sh
+# run for GPUS=2 x strategy=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu") x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
+./benchmark_gpt_dummy.sh 2
+# run for GPUS=2 x strategy=ddp x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
+./benchmark_gpt_dummy.sh 2 ddp
+# run for GPUS=2 x strategy=ddp x model=l x batch_size=(1 2 4 8 16 32 64 128 256)
+./benchmark_gpt_dummy.sh 2 ddp l
+```
+
+## Benchmark OPT with LoRA on dummy prompt data
+
+We provide various OPT models (string in parentheses is the corresponding model name used in this script):
+
+- OPT-125M (125m)
+- OPT-350M (350m)
+- OPT-700M (700m)
+- OPT-1.3B (1.3b)
+- OPT-2.7B (2.7b)
+- OPT-3.5B (3.5b)
+- OPT-5.5B (5.5b)
+- OPT-6.7B (6.7b)
+- OPT-10B (10b)
+- OPT-13B (13b)
+
+We only support `torchrun` to launch now. E.g.
+
+```shell
+# run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
+torchrun --standalone --nproc_pero_node 1 benchmark_opt_lora_dummy.py --model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
+# run OPT-350M with lora_rank=4 on single-node 4-GPU
+torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 350m --strategy colossalai_zero2 --lora_rank 4
+```
+
+> ⚠ Batch sizes in CLI args and outputed throughput/TFLOPS are all values of per GPU.
+
+In this benchmark, we assume the model architectures/sizes of actor and critic are the same for simplicity. But in practice, to reduce training cost, we may use a smaller critic.
diff --git a/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.py b/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.py
new file mode 100644
index 000000000..8474f3ba7
--- /dev/null
+++ b/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.py
@@ -0,0 +1,183 @@
+import argparse
+from copy import deepcopy
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from chatgpt.nn import GPTActor, GPTCritic, RewardModel
+from chatgpt.nn.generation_utils import gpt_prepare_inputs_fn, update_model_kwargs_fn
+from chatgpt.trainer import PPOTrainer
+from chatgpt.trainer.callbacks import PerformanceEvaluator
+from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, Strategy
+from torch.optim import Adam
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def get_model_numel(model: nn.Module, strategy: Strategy) -> int:
+ numel = sum(p.numel() for p in model.parameters())
+ if isinstance(strategy, ColossalAIStrategy) and strategy.stage == 3 and strategy.shard_init:
+ numel *= dist.get_world_size()
+ return numel
+
+
+def preprocess_batch(samples) -> dict:
+ input_ids = torch.stack(samples)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.long)
+ return {'input_ids': input_ids, 'attention_mask': attention_mask}
+
+
+def print_rank_0(*args, **kwargs) -> None:
+ if dist.get_rank() == 0:
+ print(*args, **kwargs)
+
+
+def print_model_numel(model_dict: dict) -> None:
+ B = 1024**3
+ M = 1024**2
+ K = 1024
+ outputs = ''
+ for name, numel in model_dict.items():
+ outputs += f'{name}: '
+ if numel >= B:
+ outputs += f'{numel / B:.2f} B\n'
+ elif numel >= M:
+ outputs += f'{numel / M:.2f} M\n'
+ elif numel >= K:
+ outputs += f'{numel / K:.2f} K\n'
+ else:
+ outputs += f'{numel}\n'
+ print_rank_0(outputs)
+
+
+def get_gpt_config(model_name: str) -> GPT2Config:
+ model_map = {
+ 's': GPT2Config(),
+ 'm': GPT2Config(n_embd=1024, n_layer=24, n_head=16),
+ 'l': GPT2Config(n_embd=1280, n_layer=36, n_head=20),
+ 'xl': GPT2Config(n_embd=1600, n_layer=48, n_head=25),
+ '2b': GPT2Config(n_embd=2048, n_layer=40, n_head=16),
+ '4b': GPT2Config(n_embd=2304, n_layer=64, n_head=16),
+ '6b': GPT2Config(n_embd=4096, n_layer=30, n_head=16),
+ '8b': GPT2Config(n_embd=4096, n_layer=40, n_head=16),
+ '10b': GPT2Config(n_embd=4096, n_layer=50, n_head=16),
+ '12b': GPT2Config(n_embd=4096, n_layer=60, n_head=16),
+ '15b': GPT2Config(n_embd=4096, n_layer=78, n_head=16),
+ '18b': GPT2Config(n_embd=4096, n_layer=90, n_head=16),
+ '20b': GPT2Config(n_embd=8192, n_layer=25, n_head=16),
+ '24b': GPT2Config(n_embd=8192, n_layer=30, n_head=16),
+ '28b': GPT2Config(n_embd=8192, n_layer=35, n_head=16),
+ '32b': GPT2Config(n_embd=8192, n_layer=40, n_head=16),
+ '36b': GPT2Config(n_embd=8192, n_layer=45, n_head=16),
+ '40b': GPT2Config(n_embd=8192, n_layer=50, n_head=16),
+ '175b': GPT2Config(n_positions=2048, n_embd=12288, n_layer=96, n_head=96),
+ }
+ try:
+ return model_map[model_name]
+ except KeyError:
+ raise ValueError(f'Unknown model "{model_name}"')
+
+
+def main(args):
+ if args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif args.strategy == 'colossalai_gemini_cpu':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cpu', initial_scale=2**5)
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2_cpu':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
+ elif args.strategy == 'colossalai_zero1':
+ strategy = ColossalAIStrategy(stage=1, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero1_cpu':
+ strategy = ColossalAIStrategy(stage=1, placement_policy='cpu')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ model_config = get_gpt_config(args.model)
+
+ with strategy.model_init_context():
+ actor = GPTActor(config=model_config).cuda()
+ critic = GPTCritic(config=model_config).cuda()
+
+ initial_model = deepcopy(actor).cuda()
+ reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
+
+ actor_numel = get_model_numel(actor, strategy)
+ critic_numel = get_model_numel(critic, strategy)
+ initial_model_numel = get_model_numel(initial_model, strategy)
+ reward_model_numel = get_model_numel(reward_model, strategy)
+ print_model_numel({
+ 'Actor': actor_numel,
+ 'Critic': critic_numel,
+ 'Initial model': initial_model_numel,
+ 'Reward model': reward_model_numel
+ })
+ performance_evaluator = PerformanceEvaluator(actor_numel,
+ critic_numel,
+ initial_model_numel,
+ reward_model_numel,
+ enable_grad_checkpoint=False,
+ ignore_episodes=1)
+
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
+ critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=5e-6)
+ critic_optim = Adam(critic.parameters(), lr=5e-6)
+
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+
+ trainer = PPOTrainer(strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ experience_batch_size=args.experience_batch_size,
+ tokenizer=preprocess_batch,
+ max_length=512,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ prepare_inputs_fn=gpt_prepare_inputs_fn,
+ update_model_kwargs_fn=update_model_kwargs_fn,
+ callbacks=[performance_evaluator])
+
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
+ trainer.fit(random_prompts,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+ print_rank_0(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.2f} GB')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', default='s')
+ parser.add_argument('--strategy',
+ choices=[
+ 'ddp', 'colossalai_gemini', 'colossalai_gemini_cpu', 'colossalai_zero2',
+ 'colossalai_zero2_cpu', 'colossalai_zero1', 'colossalai_zero1_cpu'
+ ],
+ default='ddp')
+ parser.add_argument('--num_episodes', type=int, default=3)
+ parser.add_argument('--max_timesteps', type=int, default=8)
+ parser.add_argument('--update_timesteps', type=int, default=8)
+ parser.add_argument('--max_epochs', type=int, default=3)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.sh b/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.sh
new file mode 100755
index 000000000..d70f88725
--- /dev/null
+++ b/applications/ChatGPT/benchmarks/benchmark_gpt_dummy.sh
@@ -0,0 +1,45 @@
+#!/usr/bin/env bash
+# Usage: $0
+set -xu
+
+BASE=$(realpath $(dirname $0))
+
+
+PY_SCRIPT=${BASE}/benchmark_gpt_dummy.py
+export OMP_NUM_THREADS=8
+
+function tune_batch_size() {
+ # we found when experience batch size is equal to train batch size
+ # peak CUDA memory usage of making experience phase is less than or equal to that of training phase
+ # thus, experience batch size can be larger than or equal to train batch size
+ for bs in 1 2 4 8 16 32 64 128 256; do
+ torchrun --standalone --nproc_per_node $1 $PY_SCRIPT --model $2 --strategy $3 --experience_batch_size $bs --train_batch_size $bs || return 1
+ done
+}
+
+if [ $# -eq 0 ]; then
+ num_gpus=(1 2 4 8)
+else
+ num_gpus=($1)
+fi
+
+if [ $# -le 1 ]; then
+ strategies=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu")
+else
+ strategies=($2)
+fi
+
+if [ $# -le 2 ]; then
+ models=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b")
+else
+ models=($3)
+fi
+
+
+for num_gpu in ${num_gpus[@]}; do
+ for strategy in ${strategies[@]}; do
+ for model in ${models[@]}; do
+ tune_batch_size $num_gpu $model $strategy || break
+ done
+ done
+done
diff --git a/applications/ChatGPT/benchmarks/benchmark_opt_lora_dummy.py b/applications/ChatGPT/benchmarks/benchmark_opt_lora_dummy.py
new file mode 100644
index 000000000..accbc4155
--- /dev/null
+++ b/applications/ChatGPT/benchmarks/benchmark_opt_lora_dummy.py
@@ -0,0 +1,178 @@
+import argparse
+from copy import deepcopy
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from chatgpt.nn import OPTActor, OPTCritic, RewardModel
+from chatgpt.nn.generation_utils import opt_prepare_inputs_fn, update_model_kwargs_fn
+from chatgpt.trainer import PPOTrainer
+from chatgpt.trainer.callbacks import PerformanceEvaluator
+from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, Strategy
+from torch.optim import Adam
+from transformers import AutoTokenizer
+from transformers.models.opt.configuration_opt import OPTConfig
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def get_model_numel(model: nn.Module, strategy: Strategy) -> int:
+ numel = sum(p.numel() for p in model.parameters())
+ if isinstance(strategy, ColossalAIStrategy) and strategy.stage == 3 and strategy.shard_init:
+ numel *= dist.get_world_size()
+ return numel
+
+
+def preprocess_batch(samples) -> dict:
+ input_ids = torch.stack(samples)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.long)
+ return {'input_ids': input_ids, 'attention_mask': attention_mask}
+
+
+def print_rank_0(*args, **kwargs) -> None:
+ if dist.get_rank() == 0:
+ print(*args, **kwargs)
+
+
+def print_model_numel(model_dict: dict) -> None:
+ B = 1024**3
+ M = 1024**2
+ K = 1024
+ outputs = ''
+ for name, numel in model_dict.items():
+ outputs += f'{name}: '
+ if numel >= B:
+ outputs += f'{numel / B:.2f} B\n'
+ elif numel >= M:
+ outputs += f'{numel / M:.2f} M\n'
+ elif numel >= K:
+ outputs += f'{numel / K:.2f} K\n'
+ else:
+ outputs += f'{numel}\n'
+ print_rank_0(outputs)
+
+
+def get_gpt_config(model_name: str) -> OPTConfig:
+ model_map = {
+ '125m': OPTConfig.from_pretrained('facebook/opt-125m'),
+ '350m': OPTConfig(hidden_size=1024, ffn_dim=4096, num_hidden_layers=24, num_attention_heads=16),
+ '700m': OPTConfig(hidden_size=1280, ffn_dim=5120, num_hidden_layers=36, num_attention_heads=20),
+ '1.3b': OPTConfig.from_pretrained('facebook/opt-1.3b'),
+ '2.7b': OPTConfig.from_pretrained('facebook/opt-2.7b'),
+ '3.5b': OPTConfig(hidden_size=3072, ffn_dim=12288, num_hidden_layers=32, num_attention_heads=32),
+ '5.5b': OPTConfig(hidden_size=3840, ffn_dim=15360, num_hidden_layers=32, num_attention_heads=32),
+ '6.7b': OPTConfig.from_pretrained('facebook/opt-6.7b'),
+ '10b': OPTConfig(hidden_size=5120, ffn_dim=20480, num_hidden_layers=32, num_attention_heads=32),
+ '13b': OPTConfig.from_pretrained('facebook/opt-13b'),
+ }
+ try:
+ return model_map[model_name]
+ except KeyError:
+ raise ValueError(f'Unknown model "{model_name}"')
+
+
+def main(args):
+ if args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif args.strategy == 'colossalai_gemini_cpu':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cpu', initial_scale=2**5)
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2_cpu':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
+ elif args.strategy == 'colossalai_zero1':
+ strategy = ColossalAIStrategy(stage=1, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero1_cpu':
+ strategy = ColossalAIStrategy(stage=1, placement_policy='cpu')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ torch.cuda.set_per_process_memory_fraction(args.cuda_mem_frac)
+
+ model_config = get_gpt_config(args.model)
+
+ with strategy.model_init_context():
+ actor = OPTActor(config=model_config, lora_rank=args.lora_rank).cuda()
+ critic = OPTCritic(config=model_config, lora_rank=args.lora_rank).cuda()
+
+ initial_model = deepcopy(actor).cuda()
+ reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
+
+ actor_numel = get_model_numel(actor, strategy)
+ critic_numel = get_model_numel(critic, strategy)
+ initial_model_numel = get_model_numel(initial_model, strategy)
+ reward_model_numel = get_model_numel(reward_model, strategy)
+ print_model_numel({
+ 'Actor': actor_numel,
+ 'Critic': critic_numel,
+ 'Initial model': initial_model_numel,
+ 'Reward model': reward_model_numel
+ })
+ performance_evaluator = PerformanceEvaluator(actor_numel,
+ critic_numel,
+ initial_model_numel,
+ reward_model_numel,
+ enable_grad_checkpoint=False,
+ ignore_episodes=1)
+
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
+ critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=5e-6)
+ critic_optim = Adam(critic.parameters(), lr=5e-6)
+
+ tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
+ tokenizer.pad_token = tokenizer.eos_token
+
+ trainer = PPOTrainer(strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ experience_batch_size=args.experience_batch_size,
+ tokenizer=preprocess_batch,
+ max_length=512,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ prepare_inputs_fn=opt_prepare_inputs_fn,
+ update_model_kwargs_fn=update_model_kwargs_fn,
+ callbacks=[performance_evaluator])
+
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
+ trainer.fit(random_prompts,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+ print_rank_0(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.2f} GB')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', default='125m')
+ parser.add_argument('--strategy',
+ choices=[
+ 'ddp', 'colossalai_gemini', 'colossalai_gemini_cpu', 'colossalai_zero2',
+ 'colossalai_zero2_cpu', 'colossalai_zero1', 'colossalai_zero1_cpu'
+ ],
+ default='ddp')
+ parser.add_argument('--num_episodes', type=int, default=3)
+ parser.add_argument('--max_timesteps', type=int, default=8)
+ parser.add_argument('--update_timesteps', type=int, default=8)
+ parser.add_argument('--max_epochs', type=int, default=3)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=4)
+ parser.add_argument('--cuda_mem_frac', type=float, default=1.0)
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/ChatGPT/chatgpt/__init__.py b/applications/ChatGPT/chatgpt/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/applications/ChatGPT/chatgpt/dataset/__init__.py b/applications/ChatGPT/chatgpt/dataset/__init__.py
new file mode 100644
index 000000000..2f330ee67
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/dataset/__init__.py
@@ -0,0 +1,3 @@
+from .reward_dataset import RewardDataset
+
+__all__ = ['RewardDataset']
diff --git a/applications/ChatGPT/chatgpt/dataset/reward_dataset.py b/applications/ChatGPT/chatgpt/dataset/reward_dataset.py
new file mode 100644
index 000000000..14edcce30
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/dataset/reward_dataset.py
@@ -0,0 +1,52 @@
+from typing import Callable
+
+from torch.utils.data import Dataset
+from tqdm import tqdm
+
+
+class RewardDataset(Dataset):
+ """
+ Dataset for reward model
+
+ Args:
+ dataset: dataset for reward model
+ tokenizer: tokenizer for reward model
+ max_length: max length of input
+ """
+
+ def __init__(self, dataset, tokenizer: Callable, max_length: int) -> None:
+ super().__init__()
+ self.chosen = []
+ self.reject = []
+ for data in tqdm(dataset):
+ prompt = data['prompt']
+
+ chosen = prompt + data['chosen'] + "<|endoftext|>"
+ chosen_token = tokenizer(chosen,
+ max_length=max_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt")
+ self.chosen.append({
+ "input_ids": chosen_token['input_ids'],
+ "attention_mask": chosen_token['attention_mask']
+ })
+
+ reject = prompt + data['rejected'] + "<|endoftext|>"
+ reject_token = tokenizer(reject,
+ max_length=max_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt")
+ self.reject.append({
+ "input_ids": reject_token['input_ids'],
+ "attention_mask": reject_token['attention_mask']
+ })
+
+ def __len__(self):
+ length = len(self.chosen)
+ return length
+
+ def __getitem__(self, idx):
+ return self.chosen[idx]["input_ids"], self.chosen[idx]["attention_mask"], self.reject[idx][
+ "input_ids"], self.reject[idx]["attention_mask"]
diff --git a/applications/ChatGPT/chatgpt/experience_maker/__init__.py b/applications/ChatGPT/chatgpt/experience_maker/__init__.py
new file mode 100644
index 000000000..39ca7576b
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/experience_maker/__init__.py
@@ -0,0 +1,4 @@
+from .base import Experience, ExperienceMaker
+from .naive import NaiveExperienceMaker
+
+__all__ = ['Experience', 'ExperienceMaker', 'NaiveExperienceMaker']
diff --git a/applications/ChatGPT/chatgpt/experience_maker/base.py b/applications/ChatGPT/chatgpt/experience_maker/base.py
new file mode 100644
index 000000000..61895322c
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/experience_maker/base.py
@@ -0,0 +1,77 @@
+from abc import ABC, abstractmethod
+from dataclasses import dataclass
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from chatgpt.nn.actor import Actor
+
+
+@dataclass
+class Experience:
+ """Experience is a batch of data.
+ These data should have the the sequence length and number of actions.
+ Left padding for sequences is applied.
+
+ Shapes of each tensor:
+ sequences: (B, S)
+ action_log_probs: (B, A)
+ values: (B)
+ reward: (B)
+ advatanges: (B)
+ attention_mask: (B, S)
+ action_mask: (B, A)
+
+ "A" is the number of actions.
+ """
+ sequences: torch.Tensor
+ action_log_probs: torch.Tensor
+ values: torch.Tensor
+ reward: torch.Tensor
+ advantages: torch.Tensor
+ attention_mask: Optional[torch.LongTensor]
+ action_mask: Optional[torch.BoolTensor]
+
+ @torch.no_grad()
+ def to_device(self, device: torch.device) -> None:
+ self.sequences = self.sequences.to(device)
+ self.action_log_probs = self.action_log_probs.to(device)
+ self.values = self.values.to(device)
+ self.reward = self.reward.to(device)
+ self.advantages = self.advantages.to(device)
+ if self.attention_mask is not None:
+ self.attention_mask = self.attention_mask.to(device)
+ if self.action_mask is not None:
+ self.action_mask = self.action_mask.to(device)
+
+ def pin_memory(self):
+ self.sequences = self.sequences.pin_memory()
+ self.action_log_probs = self.action_log_probs.pin_memory()
+ self.values = self.values.pin_memory()
+ self.reward = self.reward.pin_memory()
+ self.advantages = self.advantages.pin_memory()
+ if self.attention_mask is not None:
+ self.attention_mask = self.attention_mask.pin_memory()
+ if self.action_mask is not None:
+ self.action_mask = self.action_mask.pin_memory()
+ return self
+
+
+class ExperienceMaker(ABC):
+
+ def __init__(self,
+ actor: Actor,
+ critic: nn.Module,
+ reward_model: nn.Module,
+ initial_model: Actor,
+ kl_coef: float = 0.1) -> None:
+ super().__init__()
+ self.actor = actor
+ self.critic = critic
+ self.reward_model = reward_model
+ self.initial_model = initial_model
+ self.kl_coef = kl_coef
+
+ @abstractmethod
+ def make_experience(self, input_ids: torch.Tensor, **generate_kwargs) -> Experience:
+ pass
diff --git a/applications/ChatGPT/chatgpt/experience_maker/naive.py b/applications/ChatGPT/chatgpt/experience_maker/naive.py
new file mode 100644
index 000000000..f4fd2078c
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/experience_maker/naive.py
@@ -0,0 +1,36 @@
+import torch
+from chatgpt.nn.utils import compute_reward, normalize
+
+from .base import Experience, ExperienceMaker
+
+
+class NaiveExperienceMaker(ExperienceMaker):
+ """
+ Naive experience maker.
+ """
+
+ @torch.no_grad()
+ def make_experience(self, input_ids: torch.Tensor, **generate_kwargs) -> Experience:
+ self.actor.eval()
+ self.critic.eval()
+ self.initial_model.eval()
+ self.reward_model.eval()
+
+ sequences, attention_mask, action_mask = self.actor.generate(input_ids,
+ return_action_mask=True,
+ **generate_kwargs)
+ num_actions = action_mask.size(1)
+
+ action_log_probs = self.actor(sequences, num_actions, attention_mask)
+ base_action_log_probs = self.initial_model(sequences, num_actions, attention_mask)
+ value = self.critic(sequences, action_mask, attention_mask)
+ r = self.reward_model(sequences, attention_mask)
+
+ reward = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
+
+ advantage = reward - value
+ # TODO(ver217): maybe normalize adv
+ if advantage.ndim == 1:
+ advantage = advantage.unsqueeze(-1)
+
+ return Experience(sequences, action_log_probs, value, reward, advantage, attention_mask, action_mask)
diff --git a/applications/ChatGPT/chatgpt/nn/__init__.py b/applications/ChatGPT/chatgpt/nn/__init__.py
new file mode 100644
index 000000000..c728d7df3
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/__init__.py
@@ -0,0 +1,18 @@
+from .actor import Actor
+from .bloom_actor import BLOOMActor
+from .bloom_critic import BLOOMCritic
+from .bloom_rm import BLOOMRM
+from .critic import Critic
+from .gpt_actor import GPTActor
+from .gpt_critic import GPTCritic
+from .gpt_rm import GPTRM
+from .loss import PairWiseLoss, PolicyLoss, PPOPtxActorLoss, ValueLoss
+from .opt_actor import OPTActor
+from .opt_critic import OPTCritic
+from .opt_rm import OPTRM
+from .reward_model import RewardModel
+
+__all__ = [
+ 'Actor', 'Critic', 'RewardModel', 'PolicyLoss', 'ValueLoss', 'PPOPtxActorLoss', 'PairWiseLoss', 'GPTActor',
+ 'GPTCritic', 'GPTRM', 'BLOOMActor', 'BLOOMCritic', 'BLOOMRM', 'OPTActor', 'OPTCritic', 'OPTRM'
+]
diff --git a/applications/ChatGPT/chatgpt/nn/actor.py b/applications/ChatGPT/chatgpt/nn/actor.py
new file mode 100644
index 000000000..c4c0d579d
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/actor.py
@@ -0,0 +1,62 @@
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .generation import generate
+from .lora import LoRAModule
+from .utils import log_probs_from_logits
+
+
+class Actor(LoRAModule):
+ """
+ Actor model base class.
+
+ Args:
+ model (nn.Module): Actor Model.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self, model: nn.Module, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
+ super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
+ self.model = model
+ self.convert_to_lora()
+
+ @torch.no_grad()
+ def generate(
+ self,
+ input_ids: torch.Tensor,
+ return_action_mask: bool = True,
+ **kwargs
+ ) -> Union[Tuple[torch.LongTensor, torch.LongTensor], Tuple[torch.LongTensor, torch.LongTensor, torch.BoolTensor]]:
+ sequences = generate(self.model, input_ids, **kwargs)
+ attention_mask = None
+ pad_token_id = kwargs.get('pad_token_id', None)
+ if pad_token_id is not None:
+ attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
+ if not return_action_mask:
+ return sequences, attention_mask
+ input_len = input_ids.size(1)
+ eos_token_id = kwargs.get('eos_token_id', None)
+ if eos_token_id is None:
+ action_mask = torch.ones_like(sequences, dtype=torch.bool)
+ else:
+ # left padding may be applied, only mask action
+ action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
+ action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
+ action_mask[:, :input_len] = False
+ action_mask = action_mask[:, 1:]
+ return sequences, attention_mask, action_mask[:, -(sequences.size(1) - input_len):]
+
+ def forward(self,
+ sequences: torch.LongTensor,
+ num_actions: int,
+ attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Returns action log probs
+ """
+ output = self.model(sequences, attention_mask=attention_mask)
+ logits = output['logits']
+ log_probs = log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
+ return log_probs[:, -num_actions:]
diff --git a/applications/ChatGPT/chatgpt/nn/bloom_actor.py b/applications/ChatGPT/chatgpt/nn/bloom_actor.py
new file mode 100644
index 000000000..103536bc3
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/bloom_actor.py
@@ -0,0 +1,35 @@
+from typing import Optional
+
+import torch
+from transformers import BloomConfig, BloomForCausalLM, BloomModel
+
+from .actor import Actor
+
+
+class BLOOMActor(Actor):
+ """
+ BLOOM Actor model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (BloomConfig): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: str = None,
+ config: Optional[BloomConfig] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = BloomForCausalLM.from_pretrained(pretrained)
+ elif config is not None:
+ model = BloomForCausalLM(config)
+ else:
+ model = BloomForCausalLM(BloomConfig())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ super().__init__(model, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/bloom_critic.py b/applications/ChatGPT/chatgpt/nn/bloom_critic.py
new file mode 100644
index 000000000..3b03471a3
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/bloom_critic.py
@@ -0,0 +1,37 @@
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from transformers import BloomConfig, BloomForCausalLM, BloomModel
+
+from .critic import Critic
+
+
+class BLOOMCritic(Critic):
+ """
+ BLOOM Critic model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (BloomConfig): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: str = None,
+ config: Optional[BloomConfig] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = BloomModel.from_pretrained(pretrained)
+ elif config is not None:
+ model = BloomModel(config)
+ else:
+ model = BloomModel(BloomConfig())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ value_head = nn.Linear(model.config.hidden_size, 1)
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/bloom_rm.py b/applications/ChatGPT/chatgpt/nn/bloom_rm.py
new file mode 100644
index 000000000..0d4dd43fa
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/bloom_rm.py
@@ -0,0 +1,37 @@
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from transformers import BloomConfig, BloomForCausalLM, BloomModel
+
+from .reward_model import RewardModel
+
+
+class BLOOMRM(RewardModel):
+ """
+ BLOOM Reward model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (BloomConfig): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: str = None,
+ config: Optional[BloomConfig] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = BloomModel.from_pretrained(pretrained)
+ elif config is not None:
+ model = BloomModel(config)
+ else:
+ model = BloomModel(BloomConfig())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ value_head = nn.Linear(model.config.hidden_size, 1)
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/critic.py b/applications/ChatGPT/chatgpt/nn/critic.py
new file mode 100644
index 000000000..f3a123854
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/critic.py
@@ -0,0 +1,47 @@
+from typing import Optional
+
+import torch
+import torch.nn as nn
+
+from .lora import LoRAModule
+from .utils import masked_mean
+
+
+class Critic(LoRAModule):
+ """
+ Critic model base class.
+
+ Args:
+ model (nn.Module): Critic model.
+ value_head (nn.Module): Value head to get value.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ model: nn.Module,
+ value_head: nn.Module,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+
+ super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
+ self.model = model
+ self.value_head = value_head
+ self.convert_to_lora()
+
+ def forward(self,
+ sequences: torch.LongTensor,
+ action_mask: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ outputs = self.model(sequences, attention_mask=attention_mask)
+ last_hidden_states = outputs['last_hidden_state']
+
+ values = self.value_head(last_hidden_states).squeeze(-1)[:, :-1]
+
+ if action_mask is not None:
+ num_actions = action_mask.size(1)
+ values = values[:, -num_actions:]
+ value = masked_mean(values, action_mask, dim=1)
+ return value
+ value = values.mean(dim=1).squeeze(1)
+ return value
diff --git a/applications/ChatGPT/chatgpt/nn/generation.py b/applications/ChatGPT/chatgpt/nn/generation.py
new file mode 100644
index 000000000..4ee797561
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/generation.py
@@ -0,0 +1,137 @@
+from typing import Any, Callable, Optional
+
+import torch
+import torch.nn as nn
+
+try:
+ from transformers.generation_logits_process import (
+ LogitsProcessorList,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ )
+except ImportError:
+ from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
+
+
+def prepare_logits_processor(top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None) -> LogitsProcessorList:
+ processor_list = LogitsProcessorList()
+ if temperature is not None and temperature != 1.0:
+ processor_list.append(TemperatureLogitsWarper(temperature))
+ if top_k is not None and top_k != 0:
+ processor_list.append(TopKLogitsWarper(top_k))
+ if top_p is not None and top_p < 1.0:
+ processor_list.append(TopPLogitsWarper(top_p))
+ return processor_list
+
+
+def sample(model: nn.Module,
+ input_ids: torch.Tensor,
+ max_length: int,
+ early_stopping: bool = False,
+ eos_token_id: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
+ update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
+ **model_kwargs) -> torch.Tensor:
+ if input_ids.size(1) >= max_length:
+ return input_ids
+
+ logits_processor = prepare_logits_processor(top_k, top_p, temperature)
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+
+ for _ in range(input_ids.size(1), max_length):
+ model_inputs = prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {
+ 'input_ids': input_ids
+ }
+ outputs = model(**model_inputs)
+
+ next_token_logits = outputs['logits'][:, -1, :]
+ # pre-process distribution
+ next_token_logits = logits_processor(input_ids, next_token_logits)
+ # sample
+ probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ # update generated ids, model inputs for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if update_model_kwargs_fn is not None:
+ model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id is not None:
+ unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
+
+ # stop when each sentence is finished if early_stopping=True
+ if early_stopping and unfinished_sequences.max() == 0:
+ break
+
+ return input_ids
+
+
+def generate(model: nn.Module,
+ input_ids: torch.Tensor,
+ max_length: int,
+ num_beams: int = 1,
+ do_sample: bool = True,
+ early_stopping: bool = False,
+ eos_token_id: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
+ update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
+ **model_kwargs) -> torch.Tensor:
+ """Generate token sequence. The returned sequence is input_ids + generated_tokens.
+
+ Args:
+ model (nn.Module): model
+ input_ids (torch.Tensor): input sequence
+ max_length (int): max length of the returned sequence
+ num_beams (int, optional): number of beams. Defaults to 1.
+ do_sample (bool, optional): whether to do sample. Defaults to True.
+ early_stopping (bool, optional): if True, the sequence length may be smaller than max_length due to finding eos. Defaults to False.
+ eos_token_id (Optional[int], optional): end of sequence token id. Defaults to None.
+ pad_token_id (Optional[int], optional): pad token id. Defaults to None.
+ top_k (Optional[int], optional): the number of highest probability vocabulary tokens to keep for top-k-filtering. Defaults to None.
+ top_p (Optional[float], optional): If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation. Defaults to None.
+ temperature (Optional[float], optional): The value used to module the next token probabilities. Defaults to None.
+ prepare_inputs_fn (Optional[Callable[[torch.Tensor, Any], dict]], optional): Function to preprocess model inputs. Arguments of this function should be input_ids and model_kwargs. Defaults to None.
+ update_model_kwargs_fn (Optional[Callable[[dict, Any], dict]], optional): Function to update model_kwargs based on outputs. Arguments of this function should be outputs and model_kwargs. Defaults to None.
+ """
+ is_greedy_gen_mode = ((num_beams == 1) and do_sample is False)
+ is_sample_gen_mode = ((num_beams == 1) and do_sample is True)
+ is_beam_gen_mode = ((num_beams > 1) and do_sample is False)
+ if is_greedy_gen_mode:
+ # run greedy search
+ raise NotImplementedError
+ elif is_sample_gen_mode:
+ # run sample
+ return sample(model,
+ input_ids,
+ max_length,
+ early_stopping=early_stopping,
+ eos_token_id=eos_token_id,
+ pad_token_id=pad_token_id,
+ top_k=top_k,
+ top_p=top_p,
+ temperature=temperature,
+ prepare_inputs_fn=prepare_inputs_fn,
+ update_model_kwargs_fn=update_model_kwargs_fn,
+ **model_kwargs)
+ elif is_beam_gen_mode:
+ raise NotImplementedError
+ else:
+ raise ValueError("Unsupported generation mode")
diff --git a/applications/ChatGPT/chatgpt/nn/generation_utils.py b/applications/ChatGPT/chatgpt/nn/generation_utils.py
new file mode 100644
index 000000000..c7bc1b383
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/generation_utils.py
@@ -0,0 +1,92 @@
+from typing import Optional
+
+import torch
+
+
+def gpt_prepare_inputs_fn(input_ids: torch.Tensor, past: Optional[torch.Tensor] = None, **kwargs) -> dict:
+ token_type_ids = kwargs.get("token_type_ids", None)
+ # only last token for inputs_ids if past is defined in kwargs
+ if past:
+ input_ids = input_ids[:, -1].unsqueeze(-1)
+ if token_type_ids is not None:
+ token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
+
+ attention_mask = kwargs.get("attention_mask", None)
+ position_ids = kwargs.get("position_ids", None)
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past:
+ position_ids = position_ids[:, -1].unsqueeze(-1)
+ else:
+ position_ids = None
+ return {
+ "input_ids": input_ids,
+ "past_key_values": past,
+ "use_cache": kwargs.get("use_cache"),
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ "token_type_ids": token_type_ids,
+ }
+
+
+def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
+ if "past_key_values" in outputs:
+ model_kwargs["past"] = outputs["past_key_values"]
+ else:
+ model_kwargs["past"] = None
+
+ # update token_type_ids with last value
+ if "token_type_ids" in model_kwargs:
+ token_type_ids = model_kwargs["token_type_ids"]
+ model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
+
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
+
+ return model_kwargs
+
+
+def opt_prepare_inputs_fn(input_ids: torch.Tensor,
+ past: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ **kwargs) -> dict:
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+
+ if past:
+ input_ids = input_ids[:, -1:]
+ # first step, decoder_cached_states are empty
+ return {
+ "input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
+ "attention_mask": attention_mask,
+ "past_key_values": past,
+ "use_cache": use_cache,
+ }
+
+
+def bloom_prepare_inputs_fn(input_ids: torch.Tensor,
+ past: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ **kwargs) -> dict:
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+
+ if past:
+ input_ids = input_ids[:, -1:]
+ # first step, decoder_cached_states are empty
+ return {
+ "input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
+ "attention_mask": attention_mask,
+ "past_key_values": past,
+ "use_cache": use_cache,
+ }
diff --git a/applications/ChatGPT/chatgpt/nn/gpt_actor.py b/applications/ChatGPT/chatgpt/nn/gpt_actor.py
new file mode 100644
index 000000000..491182ffa
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/gpt_actor.py
@@ -0,0 +1,31 @@
+from typing import Optional
+
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
+
+from .actor import Actor
+
+
+class GPTActor(Actor):
+ """
+ GPT Actor model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (GPT2Config): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[GPT2Config] = None,
+ checkpoint: bool = False) -> None:
+ if pretrained is not None:
+ model = GPT2LMHeadModel.from_pretrained(pretrained)
+ elif config is not None:
+ model = GPT2LMHeadModel(config)
+ else:
+ model = GPT2LMHeadModel(GPT2Config())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ super().__init__(model)
diff --git a/applications/ChatGPT/chatgpt/nn/gpt_critic.py b/applications/ChatGPT/chatgpt/nn/gpt_critic.py
new file mode 100644
index 000000000..b0a001f4a
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/gpt_critic.py
@@ -0,0 +1,33 @@
+from typing import Optional
+
+import torch.nn as nn
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+from transformers.models.gpt2.modeling_gpt2 import GPT2Model
+
+from .critic import Critic
+
+
+class GPTCritic(Critic):
+ """
+ GPT Critic model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (GPT2Config): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[GPT2Config] = None,
+ checkpoint: bool = False) -> None:
+ if pretrained is not None:
+ model = GPT2Model.from_pretrained(pretrained)
+ elif config is not None:
+ model = GPT2Model(config)
+ else:
+ model = GPT2Model(GPT2Config())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ value_head = nn.Linear(model.config.n_embd, 1)
+ super().__init__(model, value_head)
diff --git a/applications/ChatGPT/chatgpt/nn/gpt_rm.py b/applications/ChatGPT/chatgpt/nn/gpt_rm.py
new file mode 100644
index 000000000..c6c41a45a
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/gpt_rm.py
@@ -0,0 +1,33 @@
+from typing import Optional
+
+import torch.nn as nn
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+from transformers.models.gpt2.modeling_gpt2 import GPT2Model
+
+from .reward_model import RewardModel
+
+
+class GPTRM(RewardModel):
+ """
+ GPT Reward model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (GPT2Config): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[GPT2Config] = None,
+ checkpoint: bool = False) -> None:
+ if pretrained is not None:
+ model = GPT2Model.from_pretrained(pretrained)
+ elif config is not None:
+ model = GPT2Model(config)
+ else:
+ model = GPT2Model(GPT2Config())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ value_head = nn.Linear(model.config.n_embd, 1)
+ super().__init__(model, value_head)
diff --git a/applications/ChatGPT/chatgpt/nn/lora.py b/applications/ChatGPT/chatgpt/nn/lora.py
new file mode 100644
index 000000000..46a43ec91
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/lora.py
@@ -0,0 +1,127 @@
+import math
+from typing import Optional
+
+import loralib as lora
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class LoraLinear(lora.LoRALayer, nn.Module):
+ """Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear.
+ """
+
+ def __init__(
+ self,
+ weight: nn.Parameter,
+ bias: Optional[nn.Parameter],
+ r: int = 0,
+ lora_alpha: int = 1,
+ lora_dropout: float = 0.,
+ fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
+ merge_weights: bool = True,
+ ):
+ nn.Module.__init__(self)
+ lora.LoRALayer.__init__(self,
+ r=r,
+ lora_alpha=lora_alpha,
+ lora_dropout=lora_dropout,
+ merge_weights=merge_weights)
+ self.weight = weight
+ self.bias = bias
+
+ out_features, in_features = weight.shape
+ self.in_features = in_features
+ self.out_features = out_features
+
+ self.fan_in_fan_out = fan_in_fan_out
+ # Actual trainable parameters
+ if r > 0:
+ self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
+ self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
+ self.scaling = self.lora_alpha / self.r
+ # Freezing the pre-trained weight matrix
+ self.weight.requires_grad = False
+ self.reset_parameters()
+ if fan_in_fan_out:
+ self.weight.data = self.weight.data.T
+
+ def reset_parameters(self):
+ if hasattr(self, 'lora_A'):
+ # initialize A the same way as the default for nn.Linear and B to zero
+ nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
+ nn.init.zeros_(self.lora_B)
+
+ def train(self, mode: bool = True):
+
+ def T(w):
+ return w.T if self.fan_in_fan_out else w
+
+ nn.Module.train(self, mode)
+ if self.merge_weights and self.merged:
+ # Make sure that the weights are not merged
+ if self.r > 0:
+ self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
+ self.merged = False
+
+ def eval(self):
+
+ def T(w):
+ return w.T if self.fan_in_fan_out else w
+
+ nn.Module.eval(self)
+ if self.merge_weights and not self.merged:
+ # Merge the weights and mark it
+ if self.r > 0:
+ self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
+ self.merged = True
+
+ def forward(self, x: torch.Tensor):
+
+ def T(w):
+ return w.T if self.fan_in_fan_out else w
+
+ if self.r > 0 and not self.merged:
+ result = F.linear(x, T(self.weight), bias=self.bias)
+ if self.r > 0:
+ result = result + (self.lora_dropout(x) @ self.lora_A.t() @ self.lora_B.t()) * self.scaling
+ return result
+ else:
+ return F.linear(x, T(self.weight), bias=self.bias)
+
+
+def lora_linear_wrapper(linear: nn.Linear, lora_rank: int) -> LoraLinear:
+ assert lora_rank <= linear.in_features, f'LoRA rank ({lora_rank}) must be less than or equal to in features ({linear.in_features})'
+ lora_linear = LoraLinear(linear.weight, linear.bias, r=lora_rank, merge_weights=False)
+ return lora_linear
+
+
+def convert_to_lora_recursively(module: nn.Module, lora_rank: int) -> None:
+ for name, child in module.named_children():
+ if isinstance(child, nn.Linear):
+ setattr(module, name, lora_linear_wrapper(child, lora_rank))
+ else:
+ convert_to_lora_recursively(child, lora_rank)
+
+
+class LoRAModule(nn.Module):
+ """A LoRA module base class. All derived classes should call `convert_to_lora()` at the bottom of `__init__()`.
+ This calss will convert all torch.nn.Linear layer to LoraLinear layer.
+
+ Args:
+ lora_rank (int, optional): LoRA rank. 0 means LoRA is not applied. Defaults to 0.
+ lora_train_bias (str, optional): Whether LoRA train biases.
+ 'none' means it doesn't train biases. 'all' means it trains all biases. 'lora_only' means it only trains biases of LoRA layers.
+ Defaults to 'none'.
+ """
+
+ def __init__(self, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
+ super().__init__()
+ self.lora_rank = lora_rank
+ self.lora_train_bias = lora_train_bias
+
+ def convert_to_lora(self) -> None:
+ if self.lora_rank <= 0:
+ return
+ convert_to_lora_recursively(self, self.lora_rank)
+ lora.mark_only_lora_as_trainable(self, self.lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/loss.py b/applications/ChatGPT/chatgpt/nn/loss.py
new file mode 100644
index 000000000..0ebcfea06
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/loss.py
@@ -0,0 +1,105 @@
+from typing import Optional
+
+import torch
+import torch.nn as nn
+
+from .utils import masked_mean
+
+
+class GPTLMLoss(nn.Module):
+ """
+ GPT Language Model Loss
+ """
+
+ def __init__(self):
+ super().__init__()
+ self.loss = nn.CrossEntropyLoss()
+
+ def forward(self, logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ return self.loss(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+
+
+class PolicyLoss(nn.Module):
+ """
+ Policy Loss for PPO
+ """
+
+ def __init__(self, clip_eps: float = 0.2) -> None:
+ super().__init__()
+ self.clip_eps = clip_eps
+
+ def forward(self,
+ log_probs: torch.Tensor,
+ old_log_probs: torch.Tensor,
+ advantages: torch.Tensor,
+ action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ ratio = (log_probs - old_log_probs).exp()
+ surr1 = ratio * advantages
+ surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
+ loss = -torch.min(surr1, surr2)
+ if action_mask is not None:
+ loss = masked_mean(loss, action_mask)
+ loss = loss.mean()
+ return loss
+
+
+class ValueLoss(nn.Module):
+ """
+ Value Loss for PPO
+ """
+
+ def __init__(self, clip_eps: float = 0.4) -> None:
+ super().__init__()
+ self.clip_eps = clip_eps
+
+ def forward(self,
+ values: torch.Tensor,
+ old_values: torch.Tensor,
+ reward: torch.Tensor,
+ action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ values_clipped = old_values + (values - old_values).clamp(-self.clip_eps, self.clip_eps)
+ surr1 = (values_clipped - reward)**2
+ surr2 = (values - reward)**2
+ loss = torch.max(surr1, surr2)
+ loss = loss.mean()
+ return loss
+
+
+class PPOPtxActorLoss(nn.Module):
+ """
+ To Do:
+
+ PPO-ptx Actor Loss
+ """
+
+ def __init__(self, policy_clip_eps: float = 0.2, pretrain_coef: float = 0.0, pretrain_loss_fn=GPTLMLoss()) -> None:
+ super().__init__()
+ self.pretrain_coef = pretrain_coef
+ self.policy_loss_fn = PolicyLoss(clip_eps=policy_clip_eps)
+ self.pretrain_loss_fn = pretrain_loss_fn
+
+ def forward(self,
+ log_probs: torch.Tensor,
+ old_log_probs: torch.Tensor,
+ advantages: torch.Tensor,
+ lm_logits: torch.Tensor,
+ lm_input_ids: torch.Tensor,
+ action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ policy_loss = self.policy_loss_fn(log_probs, old_log_probs, advantages, action_mask=action_mask)
+ lm_loss = self.pretrain_loss_fn(lm_logits, lm_input_ids)
+ return policy_loss + self.pretrain_coef * lm_loss
+
+
+class PairWiseLoss(nn.Module):
+ """
+ Pairwise Loss for Reward Model
+ """
+
+ def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
+ probs = torch.sigmoid(chosen_reward - reject_reward)
+ log_probs = torch.log(probs)
+ loss = -log_probs.mean()
+ return loss
diff --git a/applications/ChatGPT/chatgpt/nn/opt_actor.py b/applications/ChatGPT/chatgpt/nn/opt_actor.py
new file mode 100644
index 000000000..ff2bf7c00
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/opt_actor.py
@@ -0,0 +1,35 @@
+from typing import Optional
+
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.models.opt.modeling_opt import OPTForCausalLM
+
+from .actor import Actor
+
+
+class OPTActor(Actor):
+ """
+ OPT Actor model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (OPTConfig): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ lora_rank (int): Rank of the low-rank approximation.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[OPTConfig] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = OPTForCausalLM.from_pretrained(pretrained)
+ elif config is not None:
+ model = OPTForCausalLM(config)
+ else:
+ model = OPTForCausalLM(OPTConfig())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ super().__init__(model, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/opt_critic.py b/applications/ChatGPT/chatgpt/nn/opt_critic.py
new file mode 100644
index 000000000..9c9cb873f
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/opt_critic.py
@@ -0,0 +1,37 @@
+from typing import Optional
+
+import torch.nn as nn
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.models.opt.modeling_opt import OPTModel
+
+from .critic import Critic
+
+
+class OPTCritic(Critic):
+ """
+ OPT Critic model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (OPTConfig): Model config.
+ checkpoint (bool): Enable gradient checkpointing.
+ lora_rank (int): Rank of the low-rank approximation.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[OPTConfig] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = OPTModel.from_pretrained(pretrained)
+ elif config is not None:
+ model = OPTModel(config)
+ else:
+ model = OPTModel(OPTConfig())
+ if checkpoint:
+ model.gradient_checkpointing_enable()
+ value_head = nn.Linear(model.config.hidden_size, 1)
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/opt_rm.py b/applications/ChatGPT/chatgpt/nn/opt_rm.py
new file mode 100644
index 000000000..150f832e0
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/opt_rm.py
@@ -0,0 +1,33 @@
+from typing import Optional
+
+import torch.nn as nn
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.models.opt.modeling_opt import OPTModel
+
+from .reward_model import RewardModel
+
+
+class OPTRM(RewardModel):
+ """
+ OPT Reward model.
+
+ Args:
+ pretrained (str): Pretrained model name or path.
+ config (OPTConfig): Model config.
+ lora_rank (int): Rank of the low-rank approximation.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ config: Optional[OPTConfig] = None,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = OPTModel.from_pretrained(pretrained)
+ elif config is not None:
+ model = OPTModel(config)
+ else:
+ model = OPTModel(OPTConfig())
+ value_head = nn.Linear(model.config.hidden_size, 1)
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
diff --git a/applications/ChatGPT/chatgpt/nn/reward_model.py b/applications/ChatGPT/chatgpt/nn/reward_model.py
new file mode 100644
index 000000000..5108f61a6
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/reward_model.py
@@ -0,0 +1,41 @@
+from typing import Optional
+
+import torch
+import torch.nn as nn
+
+from .lora import LoRAModule
+
+
+class RewardModel(LoRAModule):
+ """
+ Reward model base class.
+
+ Args:
+ model (nn.Module): Reward model.
+ value_head (nn.Module): Value head to get reward score.
+ lora_rank (int): LoRA rank.
+ lora_train_bias (str): LoRA bias training mode.
+ """
+
+ def __init__(self,
+ model: nn.Module,
+ value_head: Optional[nn.Module] = None,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
+ self.model = model
+ if value_head is not None:
+ if value_head.out_features != 1:
+ raise ValueError("The value head of reward model's output dim should be 1!")
+ self.value_head = value_head
+
+ else:
+ self.value_head = nn.Linear(model.config.n_embd, 1)
+ self.convert_to_lora()
+
+ def forward(self, sequences: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ outputs = self.model(sequences, attention_mask=attention_mask)
+ last_hidden_states = outputs['last_hidden_state']
+ values = self.value_head(last_hidden_states)[:, :-1]
+ value = values.mean(dim=1).squeeze(1) # ensure shape is (B)
+ return value
diff --git a/applications/ChatGPT/chatgpt/nn/utils.py b/applications/ChatGPT/chatgpt/nn/utils.py
new file mode 100644
index 000000000..0ff13181f
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/nn/utils.py
@@ -0,0 +1,92 @@
+from typing import Optional, Union
+
+import loralib as lora
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def compute_approx_kl(log_probs: torch.Tensor,
+ log_probs_base: torch.Tensor,
+ action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """
+ Compute the approximate KL divergence between two distributions.
+ Schulman blog: http://joschu.net/blog/kl-approx.html
+
+ Args:
+ log_probs: Log probabilities of the new distribution.
+ log_probs_base: Log probabilities of the base distribution.
+ action_mask: Mask for actions.
+ """
+
+ log_ratio = log_probs - log_probs_base
+ approx_kl = (log_ratio.exp() - 1) - log_ratio
+ if action_mask is not None:
+ approx_kl = masked_mean(approx_kl, action_mask, dim=1)
+ return approx_kl
+ approx_kl = approx_kl.mean(dim=1)
+ return approx_kl
+
+
+def compute_reward(r: Union[torch.Tensor, float],
+ kl_coef: float,
+ log_probs: torch.Tensor,
+ log_probs_base: torch.Tensor,
+ action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ if kl_coef <= 0.0:
+ return r
+ kl = compute_approx_kl(log_probs, log_probs_base, action_mask=action_mask)
+ reward = r - kl_coef * kl
+ return reward
+
+
+def log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
+ log_probs = F.log_softmax(logits, dim=-1)
+ log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
+ return log_probs_labels.squeeze(-1)
+
+
+def masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch.Tensor:
+ tensor = tensor * mask
+ tensor = tensor.sum(dim=dim)
+ mask_sum = mask.sum(dim=dim)
+ mean = tensor / (mask_sum + 1e-8)
+ return mean
+
+
+def masked_normalize(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1, eps: float = 1e-8) -> torch.Tensor:
+ tensor = tensor * mask
+ mean = masked_mean(tensor, mask, dim=dim)
+ mean_centered = tensor - mean
+ var = masked_mean(mean_centered**2, mask, dim=dim)
+ return mean_centered * var.clamp(min=eps).rsqrt()
+
+
+def normalize(tensor: torch.Tensor, dim: int = 0, eps: float = 1e-8) -> torch.Tensor:
+ mean = tensor.mean(dim)
+ mean_centered = tensor - mean
+ var = (mean_centered**2).mean(dim)
+ norm = mean_centered * var.clamp(min=eps).rsqrt()
+ return norm
+
+
+def convert_to_lora(model: nn.Module,
+ input_size: int,
+ output_size: int,
+ lora_rank: int = 16,
+ lora_alpha: int = 1,
+ lora_dropout: float = 0.,
+ fan_in_fan_out: bool = False,
+ merge_weights: bool = True):
+ if lora_rank > min(input_size, output_size):
+ raise ValueError(f"LoRA rank {lora_rank} must be less or equal than {min(input_size, output_size)}")
+
+ for name, module in model.named_modules():
+ if isinstance(module, nn.Linear):
+ module._modules[name] = lora.Linear(input_size,
+ output_size,
+ r=lora_rank,
+ lora_alpha=lora_alpha,
+ lora_dropout=lora_dropout,
+ fan_in_fan_out=fan_in_fan_out,
+ merge_weights=merge_weights)
diff --git a/applications/ChatGPT/chatgpt/replay_buffer/__init__.py b/applications/ChatGPT/chatgpt/replay_buffer/__init__.py
new file mode 100644
index 000000000..1ebf60382
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/replay_buffer/__init__.py
@@ -0,0 +1,4 @@
+from .base import ReplayBuffer
+from .naive import NaiveReplayBuffer
+
+__all__ = ['ReplayBuffer', 'NaiveReplayBuffer']
diff --git a/applications/ChatGPT/chatgpt/replay_buffer/base.py b/applications/ChatGPT/chatgpt/replay_buffer/base.py
new file mode 100644
index 000000000..5036b0904
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/replay_buffer/base.py
@@ -0,0 +1,43 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+from chatgpt.experience_maker.base import Experience
+
+
+class ReplayBuffer(ABC):
+ """Replay buffer base class. It stores experience.
+
+ Args:
+ sample_batch_size (int): Batch size when sampling.
+ limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
+ """
+
+ def __init__(self, sample_batch_size: int, limit: int = 0) -> None:
+ super().__init__()
+ self.sample_batch_size = sample_batch_size
+ # limit <= 0 means unlimited
+ self.limit = limit
+
+ @abstractmethod
+ def append(self, experience: Experience) -> None:
+ pass
+
+ @abstractmethod
+ def clear(self) -> None:
+ pass
+
+ @abstractmethod
+ def sample(self) -> Experience:
+ pass
+
+ @abstractmethod
+ def __len__(self) -> int:
+ pass
+
+ @abstractmethod
+ def __getitem__(self, idx: int) -> Any:
+ pass
+
+ @abstractmethod
+ def collate_fn(self, batch: Any) -> Experience:
+ pass
diff --git a/applications/ChatGPT/chatgpt/replay_buffer/naive.py b/applications/ChatGPT/chatgpt/replay_buffer/naive.py
new file mode 100644
index 000000000..3fc53da65
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/replay_buffer/naive.py
@@ -0,0 +1,57 @@
+import random
+from typing import List
+
+import torch
+from chatgpt.experience_maker.base import Experience
+
+from .base import ReplayBuffer
+from .utils import BufferItem, make_experience_batch, split_experience_batch
+
+
+class NaiveReplayBuffer(ReplayBuffer):
+ """Naive replay buffer class. It stores experience.
+
+ Args:
+ sample_batch_size (int): Batch size when sampling.
+ limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
+ cpu_offload (bool, optional): Whether to offload experience to cpu when sampling. Defaults to True.
+ """
+
+ def __init__(self, sample_batch_size: int, limit: int = 0, cpu_offload: bool = True) -> None:
+ super().__init__(sample_batch_size, limit)
+ self.cpu_offload = cpu_offload
+ self.target_device = torch.device(f'cuda:{torch.cuda.current_device()}')
+ # TODO(ver217): add prefetch
+ self.items: List[BufferItem] = []
+
+ @torch.no_grad()
+ def append(self, experience: Experience) -> None:
+ if self.cpu_offload:
+ experience.to_device(torch.device('cpu'))
+ items = split_experience_batch(experience)
+ self.items.extend(items)
+ if self.limit > 0:
+ samples_to_remove = len(self.items) - self.limit
+ if samples_to_remove > 0:
+ self.items = self.items[samples_to_remove:]
+
+ def clear(self) -> None:
+ self.items.clear()
+
+ @torch.no_grad()
+ def sample(self) -> Experience:
+ items = random.sample(self.items, self.sample_batch_size)
+ experience = make_experience_batch(items)
+ if self.cpu_offload:
+ experience.to_device(self.target_device)
+ return experience
+
+ def __len__(self) -> int:
+ return len(self.items)
+
+ def __getitem__(self, idx: int) -> BufferItem:
+ return self.items[idx]
+
+ def collate_fn(self, batch) -> Experience:
+ experience = make_experience_batch(batch)
+ return experience
diff --git a/applications/ChatGPT/chatgpt/replay_buffer/utils.py b/applications/ChatGPT/chatgpt/replay_buffer/utils.py
new file mode 100644
index 000000000..752f16704
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/replay_buffer/utils.py
@@ -0,0 +1,73 @@
+from dataclasses import dataclass
+from typing import List, Optional
+
+import torch
+import torch.nn.functional as F
+from chatgpt.experience_maker.base import Experience
+
+
+@dataclass
+class BufferItem:
+ """BufferItem is an item of experience data.
+
+ Shapes of each tensor:
+ sequences: (S)
+ action_log_probs: (A)
+ values: (1)
+ reward: (1)
+ advatanges: (1)
+ attention_mask: (S)
+ action_mask: (A)
+
+ "A" is the number of actions.
+ """
+ sequences: torch.Tensor
+ action_log_probs: torch.Tensor
+ values: torch.Tensor
+ reward: torch.Tensor
+ advantages: torch.Tensor
+ attention_mask: Optional[torch.LongTensor]
+ action_mask: Optional[torch.BoolTensor]
+
+
+def split_experience_batch(experience: Experience) -> List[BufferItem]:
+ batch_size = experience.sequences.size(0)
+ batch_kwargs = [{} for _ in range(batch_size)]
+ keys = ('sequences', 'action_log_probs', 'values', 'reward', 'advantages', 'attention_mask', 'action_mask')
+ for key in keys:
+ value = getattr(experience, key)
+ if isinstance(value, torch.Tensor):
+ vals = torch.unbind(value)
+ else:
+ # None
+ vals = [value for _ in range(batch_size)]
+ assert batch_size == len(vals)
+ for i, v in enumerate(vals):
+ batch_kwargs[i][key] = v
+ items = [BufferItem(**kwargs) for kwargs in batch_kwargs]
+ return items
+
+
+def zero_pad_sequences(sequences: List[torch.Tensor], side: str = 'left') -> torch.Tensor:
+ assert side in ('left', 'right')
+ max_len = max(seq.size(0) for seq in sequences)
+ padded_sequences = []
+ for seq in sequences:
+ pad_len = max_len - seq.size(0)
+ padding = (pad_len, 0) if side == 'left' else (0, pad_len)
+ padded_sequences.append(F.pad(seq, padding))
+ return torch.stack(padded_sequences, dim=0)
+
+
+def make_experience_batch(items: List[BufferItem]) -> Experience:
+ kwargs = {}
+ to_pad_keys = set(('action_log_probs', 'action_mask'))
+ keys = ('sequences', 'action_log_probs', 'values', 'reward', 'advantages', 'attention_mask', 'action_mask')
+ for key in keys:
+ vals = [getattr(item, key) for item in items]
+ if key in to_pad_keys:
+ batch_data = zero_pad_sequences(vals)
+ else:
+ batch_data = torch.stack(vals, dim=0)
+ kwargs[key] = batch_data
+ return Experience(**kwargs)
diff --git a/applications/ChatGPT/chatgpt/trainer/__init__.py b/applications/ChatGPT/chatgpt/trainer/__init__.py
new file mode 100644
index 000000000..c47c76347
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/__init__.py
@@ -0,0 +1,5 @@
+from .base import Trainer
+from .ppo import PPOTrainer
+from .rm import RewardModelTrainer
+
+__all__ = ['Trainer', 'PPOTrainer', 'RewardModelTrainer']
diff --git a/applications/ChatGPT/chatgpt/trainer/base.py b/applications/ChatGPT/chatgpt/trainer/base.py
new file mode 100644
index 000000000..42547af78
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/base.py
@@ -0,0 +1,162 @@
+import random
+from abc import ABC, abstractmethod
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from chatgpt.experience_maker import Experience, ExperienceMaker
+from chatgpt.replay_buffer import ReplayBuffer
+from torch import Tensor
+from torch.utils.data import DistributedSampler
+from tqdm import tqdm
+
+from .callbacks import Callback
+from .strategies import Strategy
+from .utils import is_rank_0
+
+
+class Trainer(ABC):
+ """
+ Base class for rlhf trainers.
+
+ Args:
+ strategy (Strategy):the strategy to use for training
+ experience_maker (ExperienceMaker): the experience maker to use for produce experience to fullfill replay buffer
+ replay_buffer (ReplayBuffer): the replay buffer to use for training
+ experience_batch_size (int, defaults to 8): the batch size to use for experience generation
+ max_epochs (int, defaults to 1): the number of epochs of training process
+ tokenizer (Callable, optional): the tokenizer to use for tokenizing the input
+ sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
+ data_loader_pin_memory (bool, defaults to True): whether to pin memory for data loader
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
+ generate_kwargs (dict, optional): the kwargs to use while model generating
+ """
+
+ def __init__(self,
+ strategy: Strategy,
+ experience_maker: ExperienceMaker,
+ replay_buffer: ReplayBuffer,
+ experience_batch_size: int = 8,
+ max_epochs: int = 1,
+ tokenizer: Optional[Callable[[Any], dict]] = None,
+ sample_replay_buffer: bool = False,
+ dataloader_pin_memory: bool = True,
+ callbacks: List[Callback] = [],
+ **generate_kwargs) -> None:
+ super().__init__()
+ self.strategy = strategy
+ self.experience_maker = experience_maker
+ self.replay_buffer = replay_buffer
+ self.experience_batch_size = experience_batch_size
+ self.max_epochs = max_epochs
+ self.tokenizer = tokenizer
+ self.generate_kwargs = generate_kwargs
+ self.sample_replay_buffer = sample_replay_buffer
+ self.dataloader_pin_memory = dataloader_pin_memory
+ self.callbacks = callbacks
+
+ @abstractmethod
+ def training_step(self, experience: Experience) -> Dict[str, Any]:
+ pass
+
+ def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
+ if isinstance(inputs, Tensor):
+ return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
+ elif isinstance(inputs, dict):
+ return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
+ else:
+ raise ValueError(f'Unsupported input type "{type(inputs)}"')
+
+ def _sample_prompts(self, prompts) -> list:
+ indices = list(range(len(prompts)))
+ sampled_indices = random.sample(indices, self.experience_batch_size)
+ return [prompts[i] for i in sampled_indices]
+
+ def _learn(self):
+ # replay buffer may be empty at first, we should rebuild at each training
+ if not self.sample_replay_buffer:
+ dataloader = self.strategy.setup_dataloader(self.replay_buffer, self.dataloader_pin_memory)
+ device = torch.cuda.current_device()
+ if self.sample_replay_buffer:
+ pbar = tqdm(range(self.max_epochs), desc='Train epoch', disable=not is_rank_0())
+ for _ in pbar:
+ experience = self.replay_buffer.sample()
+ metrics = self.training_step(experience)
+ pbar.set_postfix(metrics)
+ else:
+ for epoch in range(self.max_epochs):
+ self._on_learn_epoch_start(epoch)
+ if isinstance(dataloader.sampler, DistributedSampler):
+ dataloader.sampler.set_epoch(epoch)
+ pbar = tqdm(dataloader, desc=f'Train epoch [{epoch+1}/{self.max_epochs}]', disable=not is_rank_0())
+ for experience in pbar:
+ self._on_learn_batch_start()
+ experience.to_device(device)
+ metrics = self.training_step(experience)
+ self._on_learn_batch_end(metrics, experience)
+ pbar.set_postfix(metrics)
+ self._on_learn_epoch_end(epoch)
+
+ def fit(self, prompts, num_episodes: int = 50000, max_timesteps: int = 500, update_timesteps: int = 5000) -> None:
+ time = 0
+ self._on_fit_start()
+ for episode in range(num_episodes):
+ self._on_episode_start(episode)
+ for timestep in tqdm(range(max_timesteps),
+ desc=f'Episode [{episode+1}/{num_episodes}]',
+ disable=not is_rank_0()):
+ time += 1
+ rand_prompts = self._sample_prompts(prompts)
+ if self.tokenizer is not None:
+ inputs = self.tokenizer(rand_prompts)
+ else:
+ inputs = rand_prompts
+ self._on_make_experience_start()
+ experience = self._make_experience(inputs)
+ self._on_make_experience_end(experience)
+ self.replay_buffer.append(experience)
+ if time % update_timesteps == 0:
+ self._learn()
+ self.replay_buffer.clear()
+ self._on_episode_end(episode)
+ self._on_fit_end()
+
+ # TODO(ver217): maybe simplify these code using context
+ def _on_fit_start(self) -> None:
+ for callback in self.callbacks:
+ callback.on_fit_start()
+
+ def _on_fit_end(self) -> None:
+ for callback in self.callbacks:
+ callback.on_fit_end()
+
+ def _on_episode_start(self, episode: int) -> None:
+ for callback in self.callbacks:
+ callback.on_episode_start(episode)
+
+ def _on_episode_end(self, episode: int) -> None:
+ for callback in self.callbacks:
+ callback.on_episode_end(episode)
+
+ def _on_make_experience_start(self) -> None:
+ for callback in self.callbacks:
+ callback.on_make_experience_start()
+
+ def _on_make_experience_end(self, experience: Experience) -> None:
+ for callback in self.callbacks:
+ callback.on_make_experience_end(experience)
+
+ def _on_learn_epoch_start(self, epoch: int) -> None:
+ for callback in self.callbacks:
+ callback.on_learn_epoch_start(epoch)
+
+ def _on_learn_epoch_end(self, epoch: int) -> None:
+ for callback in self.callbacks:
+ callback.on_learn_epoch_end(epoch)
+
+ def _on_learn_batch_start(self) -> None:
+ for callback in self.callbacks:
+ callback.on_learn_batch_start()
+
+ def _on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
+ for callback in self.callbacks:
+ callback.on_learn_batch_end(metrics, experience)
diff --git a/applications/ChatGPT/chatgpt/trainer/callbacks/__init__.py b/applications/ChatGPT/chatgpt/trainer/callbacks/__init__.py
new file mode 100644
index 000000000..79ea9ffcd
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/callbacks/__init__.py
@@ -0,0 +1,4 @@
+from .base import Callback
+from .performance_evaluator import PerformanceEvaluator
+
+__all__ = ['Callback', 'PerformanceEvaluator']
diff --git a/applications/ChatGPT/chatgpt/trainer/callbacks/base.py b/applications/ChatGPT/chatgpt/trainer/callbacks/base.py
new file mode 100644
index 000000000..0b01345f7
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/callbacks/base.py
@@ -0,0 +1,39 @@
+from abc import ABC
+
+from chatgpt.experience_maker import Experience
+
+
+class Callback(ABC):
+ """
+ Base callback class. It defines the interface for callbacks.
+ """
+
+ def on_fit_start(self) -> None:
+ pass
+
+ def on_fit_end(self) -> None:
+ pass
+
+ def on_episode_start(self, episode: int) -> None:
+ pass
+
+ def on_episode_end(self, episode: int) -> None:
+ pass
+
+ def on_make_experience_start(self) -> None:
+ pass
+
+ def on_make_experience_end(self, experience: Experience) -> None:
+ pass
+
+ def on_learn_epoch_start(self, epoch: int) -> None:
+ pass
+
+ def on_learn_epoch_end(self, epoch: int) -> None:
+ pass
+
+ def on_learn_batch_start(self) -> None:
+ pass
+
+ def on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
+ pass
diff --git a/applications/ChatGPT/chatgpt/trainer/callbacks/performance_evaluator.py b/applications/ChatGPT/chatgpt/trainer/callbacks/performance_evaluator.py
new file mode 100644
index 000000000..faa38af1b
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/callbacks/performance_evaluator.py
@@ -0,0 +1,133 @@
+from time import time
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+from chatgpt.experience_maker import Experience
+
+from .base import Callback
+
+
+def get_world_size() -> int:
+ if dist.is_initialized():
+ return dist.get_world_size()
+ return 1
+
+
+def print_rank_0(*args, **kwargs) -> None:
+ if not dist.is_initialized() or dist.get_rank() == 0:
+ print(*args, **kwargs)
+
+
+@torch.no_grad()
+def all_reduce_mean(x: float, world_size: int) -> float:
+ if world_size == 1:
+ return x
+ tensor = torch.tensor([x], device=torch.cuda.current_device())
+ dist.all_reduce(tensor)
+ tensor = tensor / world_size
+ return tensor.item()
+
+
+class PerformanceEvaluator(Callback):
+ """
+ Callback for valuate the performance of the model.
+ Args:
+ actor_num_params: The number of parameters of the actor model.
+ critic_num_params: The number of parameters of the critic model.
+ initial_model_num_params: The number of parameters of the initial model.
+ reward_model_num_params: The number of parameters of the reward model.
+ enable_grad_checkpoint: Whether to enable gradient checkpointing.
+ ignore_episodes: The number of episodes to ignore when calculating the performance.
+ """
+
+ def __init__(self,
+ actor_num_params: int,
+ critic_num_params: int,
+ initial_model_num_params: int,
+ reward_model_num_params: int,
+ enable_grad_checkpoint: bool = False,
+ ignore_episodes: int = 0) -> None:
+ super().__init__()
+ self.world_size = get_world_size()
+ self.actor_num_params = actor_num_params
+ self.critic_num_params = critic_num_params
+ self.initial_model_num_params = initial_model_num_params
+ self.reward_model_num_params = reward_model_num_params
+ self.enable_grad_checkpoint = enable_grad_checkpoint
+ self.ignore_episodes = ignore_episodes
+ self.disable: bool = False
+
+ self.make_experience_duration: float = 0.
+ self.make_experience_start_time: Optional[float] = None
+ self.make_experience_num_samples: int = 0
+ self.make_experience_flop: int = 0
+ self.learn_duration: float = 0.
+ self.learn_start_time: Optional[float] = None
+ self.learn_num_samples: int = 0
+ self.learn_flop: int = 0
+
+ def on_episode_start(self, episode: int) -> None:
+ self.disable = self.ignore_episodes > 0 and episode < self.ignore_episodes
+
+ def on_make_experience_start(self) -> None:
+ if self.disable:
+ return
+ self.make_experience_start_time = time()
+
+ def on_make_experience_end(self, experience: Experience) -> None:
+ if self.disable:
+ return
+ self.make_experience_duration += time() - self.make_experience_start_time
+
+ batch_size, seq_len = experience.sequences.shape
+
+ self.make_experience_num_samples += batch_size
+
+ # actor generate
+ num_actions = experience.action_mask.size(1)
+ input_len = seq_len - num_actions
+ total_seq_len = (input_len + seq_len - 1) * num_actions / 2
+ self.make_experience_flop += self.actor_num_params * batch_size * total_seq_len * 2
+ # actor forward
+ self.make_experience_flop += self.actor_num_params * batch_size * seq_len * 2
+ # critic forward
+ self.make_experience_flop += self.critic_num_params * batch_size * seq_len * 2
+ # initial model forward
+ self.make_experience_flop += self.initial_model_num_params * batch_size * seq_len * 2
+ # reward model forward
+ self.make_experience_flop += self.reward_model_num_params * batch_size * seq_len * 2
+
+ def on_learn_batch_start(self) -> None:
+ if self.disable:
+ return
+ self.learn_start_time = time()
+
+ def on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
+ if self.disable:
+ return
+ self.learn_duration += time() - self.learn_start_time
+
+ batch_size, seq_len = experience.sequences.shape
+
+ self.learn_num_samples += batch_size
+
+ # actor forward-backward, 3 means forward(1) + backward(2)
+ self.learn_flop += self.actor_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
+ # critic foward-backward
+ self.learn_flop += self.critic_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
+
+ def on_fit_end(self) -> None:
+ avg_make_experience_duration = all_reduce_mean(self.make_experience_duration, self.world_size)
+ avg_learn_duration = all_reduce_mean(self.learn_duration, self.world_size)
+
+ avg_make_experience_throughput = self.make_experience_num_samples / (avg_make_experience_duration + 1e-12)
+ avg_make_experience_tflops = self.make_experience_flop / 1e12 / (avg_make_experience_duration + 1e-12)
+
+ avg_learn_throughput = self.learn_num_samples / (avg_learn_duration + 1e-12)
+ avg_learn_tflops = self.learn_flop / 1e12 / (avg_learn_duration + 1e-12)
+
+ print_rank_0(
+ f'Making experience throughput: {avg_make_experience_throughput:.3f} samples/sec, TFLOPS: {avg_make_experience_tflops:.3f}'
+ )
+ print_rank_0(f'Learning throughput: {avg_learn_throughput:.3f} samples/sec, TFLOPS: {avg_learn_tflops:.3f}')
diff --git a/applications/ChatGPT/chatgpt/trainer/ppo.py b/applications/ChatGPT/chatgpt/trainer/ppo.py
new file mode 100644
index 000000000..85beb223e
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/ppo.py
@@ -0,0 +1,104 @@
+from typing import Any, Callable, Dict, List, Optional
+
+import torch.nn as nn
+from chatgpt.experience_maker import Experience, NaiveExperienceMaker
+from chatgpt.nn import Actor, Critic, PolicyLoss, ValueLoss
+from chatgpt.replay_buffer import NaiveReplayBuffer
+from torch.optim import Optimizer
+
+from .base import Trainer
+from .callbacks import Callback
+from .strategies import Strategy
+
+
+class PPOTrainer(Trainer):
+ """
+ Trainer for PPO algorithm.
+
+ Args:
+ strategy (Strategy): the strategy to use for training
+ actor (Actor): the actor model in ppo algorithm
+ critic (Critic): the critic model in ppo algorithm
+ reward_model (nn.Module): the reward model in rlhf algorithm to make reward of sentences
+ initial_model (Actor): the initial model in rlhf algorithm to generate reference logits to limit the update of actor
+ actor_optim (Optimizer): the optimizer to use for actor model
+ critic_optim (Optimizer): the optimizer to use for critic model
+ kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
+ train_batch_size (int, defaults to 8): the batch size to use for training
+ buffer_limit (int, defaults to 0): the max_size limitaiton of replay buffer
+ buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
+ eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
+ value_clip (float, defaults to 0.4): the clip coefficient of value loss
+ experience_batch_size (int, defaults to 8): the batch size to use for experience generation
+ max_epochs (int, defaults to 1): the number of epochs of training process
+ tokenier (Callable, optional): the tokenizer to use for tokenizing the input
+ sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
+ dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
+ generate_kwargs (dict, optional): the kwargs to use while model generating
+ """
+
+ def __init__(self,
+ strategy: Strategy,
+ actor: Actor,
+ critic: Critic,
+ reward_model: nn.Module,
+ initial_model: Actor,
+ actor_optim: Optimizer,
+ critic_optim: Optimizer,
+ kl_coef: float = 0.1,
+ train_batch_size: int = 8,
+ buffer_limit: int = 0,
+ buffer_cpu_offload: bool = True,
+ eps_clip: float = 0.2,
+ value_clip: float = 0.4,
+ experience_batch_size: int = 8,
+ max_epochs: int = 1,
+ tokenizer: Optional[Callable[[Any], dict]] = None,
+ sample_replay_buffer: bool = False,
+ dataloader_pin_memory: bool = True,
+ callbacks: List[Callback] = [],
+ **generate_kwargs) -> None:
+ actor = Actor(strategy.setup_model(actor.model))
+ critic = strategy.setup_model(critic)
+ reward_model = strategy.setup_model(reward_model)
+ initial_model = Actor(strategy.setup_model(initial_model.model))
+ experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef)
+ replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
+ super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer,
+ sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs)
+ self.actor = actor
+ self.critic = critic
+
+ self.actor_loss_fn = PolicyLoss(eps_clip)
+ self.critic_loss_fn = ValueLoss(value_clip)
+
+ self.actor_optim = strategy.setup_optimizer(actor_optim, self.actor.model)
+ self.critic_optim = strategy.setup_optimizer(critic_optim, self.critic)
+
+ def training_step(self, experience: Experience) -> Dict[str, float]:
+ self.actor.train()
+ self.critic.train()
+
+ num_actions = experience.action_mask.size(1)
+ action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask)
+ actor_loss = self.actor_loss_fn(action_log_probs,
+ experience.action_log_probs,
+ experience.advantages,
+ action_mask=experience.action_mask)
+ self.strategy.backward(actor_loss, self.actor, self.actor_optim)
+ self.strategy.optimizer_step(self.actor_optim)
+ self.actor_optim.zero_grad()
+
+ values = self.critic(experience.sequences,
+ action_mask=experience.action_mask,
+ attention_mask=experience.attention_mask)
+ critic_loss = self.critic_loss_fn(values,
+ experience.values,
+ experience.reward,
+ action_mask=experience.action_mask)
+ self.strategy.backward(critic_loss, self.critic, self.critic_optim)
+ self.strategy.optimizer_step(self.critic_optim)
+ self.critic_optim.zero_grad()
+
+ return {'actor_loss': actor_loss.item(), 'critic_loss': critic_loss.item()}
diff --git a/applications/ChatGPT/chatgpt/trainer/rm.py b/applications/ChatGPT/chatgpt/trainer/rm.py
new file mode 100644
index 000000000..c24289502
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/rm.py
@@ -0,0 +1,77 @@
+from abc import ABC
+
+import loralib as lora
+from chatgpt.dataset import RewardDataset
+from chatgpt.nn import PairWiseLoss
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+
+class RewardModelTrainer(ABC):
+ """
+ Trainer to use while training reward model.
+
+ Args:
+ model (torch.nn.Module): the model to train
+ train_dataset (RewardDataset): the dataset to use for training
+ eval_dataset (RewardDataset): the dataset to use for evaluation
+ batch_size (int, defaults to 1): the batch size while training
+ num_epochs (int, defaults to 2): the number of epochs to train
+ optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer
+ """
+
+ def __init__(self,
+ model,
+ train_dataset: RewardDataset,
+ eval_dataset: RewardDataset,
+ batch_size: int = 1,
+ num_epochs: int = 2,
+ optim_kwargs: dict = {'lr': 1e-4}) -> None:
+ super().__init__()
+ self.model = model
+ self.train_dataloader = DataLoader(train_dataset, batch_size=batch_size)
+ self.eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size)
+ self.loss_fn = PairWiseLoss()
+ self.optimizer = Adam(self.model.parameters(), **optim_kwargs)
+ self.epochs = num_epochs
+
+ def fit(self, use_lora):
+ epoch_bar = tqdm(range(self.epochs), desc='Train epoch')
+ for epoch in range(self.epochs):
+ step_bar = tqdm(range(self.train_dataloader.__len__()), desc='Train step of epoch %d' % epoch)
+ # train
+ if use_lora > 0:
+ print("Using Lora")
+ lora.mark_only_lora_as_trainable(self.model)
+ else:
+ self.model.train()
+ for chosen_ids, c_mask, reject_ids, r_mask in self.train_dataloader:
+ chosen_ids = chosen_ids.squeeze(1).cuda()
+ c_mask = c_mask.squeeze(1).cuda()
+ reject_ids = reject_ids.squeeze(1).cuda()
+ r_mask = r_mask.squeeze(1).cuda()
+ chosen_reward = self.model(chosen_ids, attention_mask=c_mask)
+ reject_reward = self.model(reject_ids, attention_mask=r_mask)
+ loss = self.loss_fn(chosen_reward, reject_reward)
+ loss.backward()
+ self.optimizer.step()
+ self.optimizer.zero_grad()
+ step_bar.update()
+ step_bar.set_postfix({'loss': loss.item()})
+
+ # eval
+ self.model.eval()
+ for chosen_ids, c_mask, reject_ids, r_mask in self.eval_dataloader:
+ dist = 0
+ chosen_ids = chosen_ids.squeeze(1).cuda()
+ c_mask = c_mask.squeeze(1).cuda()
+ reject_ids = reject_ids.squeeze(1).cuda()
+ r_mask = r_mask.squeeze(1).cuda()
+ chosen_reward = self.model(chosen_ids, attention_mask=c_mask)
+ reject_reward = self.model(reject_ids, attention_mask=r_mask)
+ dist += (chosen_reward - reject_reward)
+ dist_mean = dist / self.eval_dataloader.__len__()
+ epoch_bar.update()
+ step_bar.set_postfix({'loss': loss.item(), 'dist_mean': dist_mean.item()})
+ step_bar.close()
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/__init__.py b/applications/ChatGPT/chatgpt/trainer/strategies/__init__.py
new file mode 100644
index 000000000..f258c9b8a
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/__init__.py
@@ -0,0 +1,6 @@
+from .base import Strategy
+from .colossalai import ColossalAIStrategy
+from .ddp import DDPStrategy
+from .naive import NaiveStrategy
+
+__all__ = ['Strategy', 'NaiveStrategy', 'DDPStrategy', 'ColossalAIStrategy']
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/base.py b/applications/ChatGPT/chatgpt/trainer/strategies/base.py
new file mode 100644
index 000000000..3a2923b8c
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/base.py
@@ -0,0 +1,45 @@
+from abc import ABC, abstractmethod
+from contextlib import nullcontext
+
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from chatgpt.replay_buffer import ReplayBuffer
+from torch.utils.data import DataLoader
+
+
+class Strategy(ABC):
+ """
+ Base class for training strategies.
+ """
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.setup_distributed()
+
+ @abstractmethod
+ def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
+ pass
+
+ @abstractmethod
+ def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
+ pass
+
+ @abstractmethod
+ def setup_distributed(self) -> None:
+ pass
+
+ @abstractmethod
+ def setup_model(self, model: nn.Module) -> nn.Module:
+ pass
+
+ @abstractmethod
+ def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
+ pass
+
+ @abstractmethod
+ def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
+ pass
+
+ def model_init_context(self):
+ return nullcontext()
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
new file mode 100644
index 000000000..665bfa913
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
@@ -0,0 +1,125 @@
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.optim as optim
+
+import colossalai
+from colossalai.nn.optimizer import CPUAdam, HybridAdam
+from colossalai.nn.parallel import zero_model_wrapper, zero_optim_wrapper
+from colossalai.tensor import ProcessGroup, ShardSpec
+from colossalai.utils import get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+
+from .ddp import DDPStrategy
+
+
+class ColossalAIStrategy(DDPStrategy):
+ """
+ The strategy for training with ColossalAI.
+
+ Args:
+ stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
+ seed(int): The seed for the random number generator.
+ shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
+ placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')
+ If it is “cpu”, parameters, gradients and optimizer states will be offloaded to CPU,
+ If it is “cuda”, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.
+ pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.
+ force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.
+ search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.
+ hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.
+ min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.
+ gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.
+ reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.
+ overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.
+ initial_scale(float): The initial scale for the optimizer.
+ growth_factor(float): The growth factor for the optimizer.
+ backoff_factor(float): The backoff factor for the optimizer.
+ growth_interval(int): The growth interval for the optimizer.
+ hysteresis(int): The hysteresis for the optimizer.
+ min_scale(float): The minimum scale for the optimizer.
+ max_scale(float): The maximum scale for the optimizer.
+ max_norm(float): The maximum norm for the optimizer.
+ norm_type(float): The norm type for the optimizer.
+
+ """
+
+ def __init__(
+ self,
+ stage: int = 3,
+ seed: int = 42,
+ shard_init: bool = True, # only for stage 3
+ placement_policy: str = 'cuda',
+ pin_memory: bool = True, # only for stage 3
+ force_outputs_fp32: bool = False, # only for stage 3
+ search_range_mb: int = 32, # only for stage 3
+ hidden_dim: Optional[int] = None, # only for stage 3
+ min_chunk_size_mb: float = 32, # only for stage 3
+ gpu_margin_mem_ratio: float = 0.0, # only for stage 3
+ reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2
+ overlap_communication: bool = True, # only for stage 1&2
+ initial_scale: float = 2**16,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ min_scale: float = 1,
+ max_scale: float = 2**32,
+ max_norm: float = 0.0,
+ norm_type: float = 2.0) -> None:
+ super().__init__(seed)
+ assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
+ self.stage = stage
+ self.shard_init = shard_init
+ self.gemini_config = dict(device=get_current_device(),
+ placement_policy=placement_policy,
+ pin_memory=pin_memory,
+ force_outputs_fp32=force_outputs_fp32,
+ strict_ddp_mode=shard_init,
+ search_range_mb=search_range_mb,
+ hidden_dim=hidden_dim,
+ min_chunk_size_mb=min_chunk_size_mb)
+ if stage == 3:
+ self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)
+ else:
+ self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,
+ overlap_communication=overlap_communication,
+ cpu_offload=(placement_policy == 'cpu'))
+ self.optim_kwargs = dict(initial_scale=initial_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ min_scale=min_scale,
+ max_scale=max_scale,
+ max_norm=max_norm,
+ norm_type=norm_type)
+
+ def setup_distributed(self) -> None:
+ colossalai.launch_from_torch({}, seed=self.seed)
+
+ def model_init_context(self):
+ if self.stage == 3:
+ world_size = dist.get_world_size()
+ shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None
+ default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None
+ return ColoInitContext(device=get_current_device(),
+ dtype=torch.half,
+ default_pg=shard_pg,
+ default_dist_spec=default_dist_spec)
+ return super().model_init_context()
+
+ def setup_model(self, model: nn.Module) -> nn.Module:
+ return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
+
+ def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
+ assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'
+ return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)
+
+ def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
+ optimizer.backward(loss)
+
+ def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
+ optimizer.step()
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/ddp.py b/applications/ChatGPT/chatgpt/trainer/strategies/ddp.py
new file mode 100644
index 000000000..b636515b4
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/ddp.py
@@ -0,0 +1,59 @@
+import os
+import random
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from chatgpt.replay_buffer import ReplayBuffer
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.utils.data import DataLoader, DistributedSampler
+
+from .naive import NaiveStrategy
+
+
+class DDPStrategy(NaiveStrategy):
+ """
+ Strategy for distributed training using torch.distributed.
+ """
+
+ def __init__(self, seed: int = 42) -> None:
+ self.seed = seed
+ super().__init__()
+
+ def setup_distributed(self) -> None:
+ try:
+ rank = int(os.environ['RANK'])
+ local_rank = int(os.environ['LOCAL_RANK'])
+ world_size = int(os.environ['WORLD_SIZE'])
+ host = os.environ['MASTER_ADDR']
+ port = int(os.environ['MASTER_PORT'])
+ except KeyError as e:
+ raise RuntimeError(
+ f"Could not find {e} in the torch environment, visit https://www.colossalai.org/ for more information on launching with torch"
+ )
+ dist.init_process_group('nccl', init_method=f'tcp://[{host}]:{port}', world_size=world_size, rank=rank)
+ self.set_seed(self.seed)
+ torch.cuda.set_device(local_rank)
+
+ def set_seed(self, seed: int) -> None:
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+
+ def setup_model(self, model: nn.Module) -> nn.Module:
+ device = torch.cuda.current_device()
+ return DDP(model, device_ids=[device])
+
+ def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
+ sampler = DistributedSampler(replay_buffer,
+ num_replicas=dist.get_world_size(),
+ rank=dist.get_rank(),
+ shuffle=True,
+ seed=self.seed,
+ drop_last=True)
+ return DataLoader(replay_buffer,
+ batch_size=replay_buffer.sample_batch_size,
+ sampler=sampler,
+ pin_memory=pin_memory,
+ collate_fn=replay_buffer.collate_fn)
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/naive.py b/applications/ChatGPT/chatgpt/trainer/strategies/naive.py
new file mode 100644
index 000000000..1bb472ae6
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/naive.py
@@ -0,0 +1,36 @@
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from chatgpt.replay_buffer import ReplayBuffer
+from torch.utils.data import DataLoader
+
+from .base import Strategy
+
+
+class NaiveStrategy(Strategy):
+ """
+ Strategy for single GPU. No parallelism is used.
+ """
+
+ def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
+ loss.backward()
+
+ def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
+ optimizer.step()
+
+ def setup_distributed(self) -> None:
+ pass
+
+ def setup_model(self, model: nn.Module) -> nn.Module:
+ return model
+
+ def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
+ return optimizer
+
+ def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
+ return DataLoader(replay_buffer,
+ batch_size=replay_buffer.sample_batch_size,
+ shuffle=True,
+ drop_last=True,
+ pin_memory=pin_memory,
+ collate_fn=replay_buffer.collate_fn)
diff --git a/applications/ChatGPT/chatgpt/trainer/utils.py b/applications/ChatGPT/chatgpt/trainer/utils.py
new file mode 100644
index 000000000..6c9f7f085
--- /dev/null
+++ b/applications/ChatGPT/chatgpt/trainer/utils.py
@@ -0,0 +1,5 @@
+import torch.distributed as dist
+
+
+def is_rank_0() -> bool:
+ return not dist.is_initialized() or dist.get_rank() == 0
diff --git a/applications/ChatGPT/examples/README.md b/applications/ChatGPT/examples/README.md
new file mode 100644
index 000000000..5f9d8698d
--- /dev/null
+++ b/applications/ChatGPT/examples/README.md
@@ -0,0 +1,105 @@
+# Examples
+
+## Install requirements
+
+```shell
+pip install -r requirements.txt
+```
+
+## Train with dummy prompt data
+
+This script supports 3 strategies:
+
+- naive
+- ddp
+- colossalai
+
+It uses random generated prompt data.
+
+Naive strategy only support single GPU training:
+
+```shell
+python train_dummy.py --strategy naive
+# display cli help
+python train_dummy.py -h
+```
+
+DDP strategy and ColossalAI strategy support multi GPUs training:
+
+```shell
+# run DDP on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
+# run ColossalAI on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai
+```
+
+## Train with real prompt data
+
+We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
+
+You should download `prompts.csv` first.
+
+This script also supports 3 strategies.
+
+```shell
+# display cli help
+python train_dummy.py -h
+# run naive on 1 GPU
+python train_prompts.py prompts.csv --strategy naive
+# run DDP on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
+# run ColossalAI on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai
+```
+
+## Train the reward model
+We use [rm-static](https://huggingface.co/datasets/Dahoas/rm-static) as dataset to train our reward model. It is a dataset of chosen & rejected response of the same prompt.
+
+You can download the dataset from huggingface automatically.
+
+Use these code to train your reward model.
+
+```shell
+# Naive reward model training
+python train_reward_model.py --pretrain
+# if to use LoRA
+python train_reward_model.py --pretrain --lora_rank 16
+```
+
+## Support Model
+
+### GPT
+- [ ] GPT2-S (s)
+- [ ] GPT2-M (m)
+- [ ] GPT2-L (l)
+- [ ] GPT2-XL (xl)
+- [ ] GPT2-4B (4b)
+- [ ] GPT2-6B (6b)
+- [ ] GPT2-8B (8b)
+- [ ] GPT2-10B (10b)
+- [ ] GPT2-12B (12b)
+- [ ] GPT2-15B (15b)
+- [ ] GPT2-18B (18b)
+- [ ] GPT2-20B (20b)
+- [ ] GPT2-24B (24b)
+- [ ] GPT2-28B (28b)
+- [ ] GPT2-32B (32b)
+- [ ] GPT2-36B (36b)
+- [ ] GPT2-40B (40b)
+- [ ] GPT3 (175b)
+
+### BLOOM
+- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
+- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [ ] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
+- [ ] [BLOOM-7b](https://huggingface.co/bigscience/bloomz-7b1)
+- [ ] BLOOM-175b
+
+### OPT
+- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
+- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
+- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
+- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
+- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
+- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
+- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
diff --git a/applications/ChatGPT/examples/requirements.txt b/applications/ChatGPT/examples/requirements.txt
new file mode 100644
index 000000000..6c5dac292
--- /dev/null
+++ b/applications/ChatGPT/examples/requirements.txt
@@ -0,0 +1 @@
+pandas>=1.4.1
diff --git a/applications/ChatGPT/examples/test_ci.sh b/applications/ChatGPT/examples/test_ci.sh
new file mode 100755
index 000000000..c4a5ead1d
--- /dev/null
+++ b/applications/ChatGPT/examples/test_ci.sh
@@ -0,0 +1,27 @@
+#!/usr/bin/env bash
+
+set -xue
+
+if [ -z "$PROMPT_PATH" ]; then
+ echo "Please set \$PROMPT_PATH to the path to prompts csv."
+ exit 1
+fi
+
+BASE=$(realpath $(dirname $0))
+
+export OMP_NUM_THREADS=8
+
+# install requirements
+pip install -r ${BASE}/requirements.txt
+
+# train dummy
+python ${BASE}/train_dummy.py --strategy naive --num_episodes 3 --max_timesteps 3 --update_timesteps 3 --max_epochs 3 --train_batch_size 2
+for strategy in ddp colossalai_gemini colossalai_zero2; do
+ torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py --strategy ${strategy} --num_episodes 3 --max_timesteps 3 --update_timesteps 3 --max_epochs 3 --train_batch_size 2
+done
+
+# train prompts
+python ${BASE}/train_prompts.py $PROMPT_PATH --strategy naive --num_episodes 3 --max_timesteps 3 --update_timesteps 3 --max_epochs 3
+for strategy in ddp colossalai_gemini colossalai_zero2; do
+ torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH --strategy ${strategy} --num_episodes 3 --max_timesteps 3 --update_timesteps 3 --max_epochs 3 --train_batch_size 2
+done
diff --git a/applications/ChatGPT/examples/train_dummy.py b/applications/ChatGPT/examples/train_dummy.py
new file mode 100644
index 000000000..313be2c3b
--- /dev/null
+++ b/applications/ChatGPT/examples/train_dummy.py
@@ -0,0 +1,121 @@
+import argparse
+from copy import deepcopy
+
+import torch
+from chatgpt.nn import BLOOMActor, BLOOMCritic, GPTActor, GPTCritic, OPTActor, OPTCritic, RewardModel
+from chatgpt.nn.generation_utils import (
+ bloom_prepare_inputs_fn,
+ gpt_prepare_inputs_fn,
+ opt_prepare_inputs_fn,
+ update_model_kwargs_fn,
+)
+from chatgpt.trainer import PPOTrainer
+from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def preprocess_batch(samples):
+ input_ids = torch.stack(samples)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.long)
+ return {'input_ids': input_ids, 'attention_mask': attention_mask}
+
+
+def main(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor().cuda()
+ critic = GPTCritic().cuda()
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
+ critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
+ elif args.model == 'opt':
+ actor = OPTActor().cuda()
+ critic = OPTCritic().cuda()
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ initial_model = deepcopy(actor).cuda()
+ reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
+ critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=5e-6)
+ critic_optim = Adam(critic.parameters(), lr=5e-6)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ prepare_inputs_fn = gpt_prepare_inputs_fn
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ prepare_inputs_fn = bloom_prepare_inputs_fn
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ prepare_inputs_fn = opt_prepare_inputs_fn
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure trainer
+ trainer = PPOTrainer(strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ tokenizer=preprocess_batch,
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ prepare_inputs_fn=prepare_inputs_fn,
+ update_model_kwargs_fn=update_model_kwargs_fn)
+
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 64), device=torch.cuda.current_device())
+ trainer.fit(random_prompts,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', type=str, default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--num_episodes', type=int, default=50)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/ChatGPT/examples/train_dummy.sh b/applications/ChatGPT/examples/train_dummy.sh
new file mode 100755
index 000000000..559d338ee
--- /dev/null
+++ b/applications/ChatGPT/examples/train_dummy.sh
@@ -0,0 +1,18 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 1
+
+python train_dummy.py --model bloom --pretrain '/data2/users/lczht/bloom-560m' --lora_rank 16
diff --git a/applications/ChatGPT/examples/train_prompts.py b/applications/ChatGPT/examples/train_prompts.py
new file mode 100644
index 000000000..994b10fe0
--- /dev/null
+++ b/applications/ChatGPT/examples/train_prompts.py
@@ -0,0 +1,113 @@
+import argparse
+from copy import deepcopy
+
+import pandas as pd
+from chatgpt.nn import BLOOMActor, BLOOMCritic, GPTActor, GPTCritic, OPTActor, OPTCritic, RewardModel
+from chatgpt.nn.generation_utils import gpt_prepare_inputs_fn, update_model_kwargs_fn
+from chatgpt.trainer import PPOTrainer
+from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def main(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor().cuda()
+ critic = GPTCritic().cuda()
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
+ critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
+ elif args.model == 'opt':
+ actor = OPTActor(lora_rank=args.lora_rank).cuda()
+ critic = OPTCritic(lora_rank=args.lora_rank).cuda()
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ initial_model = deepcopy(actor)
+ reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
+ critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=5e-6)
+ critic_optim = Adam(critic.parameters(), lr=5e-6)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ dataset = pd.read_csv(args.prompt_path)['prompt']
+
+ def tokenize_fn(texts):
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding=True, truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ # configure trainer
+ trainer = PPOTrainer(strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ tokenizer=tokenize_fn,
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ prepare_inputs_fn=gpt_prepare_inputs_fn,
+ update_model_kwargs_fn=update_model_kwargs_fn)
+
+ trainer.fit(dataset,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('prompt_path')
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/ChatGPT/examples/train_prompts.sh b/applications/ChatGPT/examples/train_prompts.sh
new file mode 100755
index 000000000..0b82d3f1c
--- /dev/null
+++ b/applications/ChatGPT/examples/train_prompts.sh
@@ -0,0 +1,18 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 1
+
+python train_prompts.py prompts.csv --pretrain '/data2/users/lczht/bloom-560m' --lora_rank 16
diff --git a/applications/ChatGPT/examples/train_reward_model.py b/applications/ChatGPT/examples/train_reward_model.py
new file mode 100644
index 000000000..fd78a2ac6
--- /dev/null
+++ b/applications/ChatGPT/examples/train_reward_model.py
@@ -0,0 +1,53 @@
+import argparse
+
+import loralib as lora
+import torch
+from chatgpt.dataset import RewardDataset
+from chatgpt.nn import BLOOMRM
+from chatgpt.trainer import RewardModelTrainer
+from datasets import load_dataset
+from transformers import BloomTokenizerFast
+
+
+def train(args):
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ model = BLOOMRM(pretrained=args.pretrain)
+
+ model.cuda()
+
+ max_len = 1024
+
+ # prepare for data and dataset
+ data = load_dataset(args.dataset)
+ train_data = data["train"]
+ eval_data = data['test']
+ train_dataset = RewardDataset(train_data, tokenizer, max_len)
+ eval_dataset = RewardDataset(eval_data, tokenizer, max_len)
+
+ # batch_size here is expected to be C(k,2), k means # response of each prompt
+ # be limited with the format of dataset 'Dahoas/rm-static', we'd better use batch_size as 1
+ trainer = RewardModelTrainer(model=model,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ batch_size=args.batch_size,
+ num_epochs=args.max_epochs)
+
+ trainer.fit(use_lora=args.lora_rank)
+
+ if args.lora_rank > 0:
+ torch.save({'model_state_dict': lora.lora_state_dict(trainer.model)}, args.save_path)
+ else:
+ torch.save(trainer.model, args.save_path)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--dataset', type=str, default='Dahoas/rm-static')
+ parser.add_argument('--save_path', type=str, default='rm_ckpt.pth')
+ parser.add_argument('--max_epochs', type=int, default=2)
+ parser.add_argument('--batch_size', type=int, default=1)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ args = parser.parse_args()
+ train(args)
diff --git a/applications/ChatGPT/examples/train_rm.sh b/applications/ChatGPT/examples/train_rm.sh
new file mode 100755
index 000000000..bf46d7e43
--- /dev/null
+++ b/applications/ChatGPT/examples/train_rm.sh
@@ -0,0 +1,18 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 1
+
+python train_reward_model.py --pretrain '/data2/users/lczht/bloom-560m' --lora_rank 16
diff --git a/applications/ChatGPT/pytest.ini b/applications/ChatGPT/pytest.ini
new file mode 100644
index 000000000..01e5cd217
--- /dev/null
+++ b/applications/ChatGPT/pytest.ini
@@ -0,0 +1,6 @@
+[pytest]
+markers =
+ cpu: tests which can run on CPU
+ gpu: tests which requires a single GPU
+ dist: tests which are run in a multi-GPU or multi-machine environment
+ experiment: tests for experimental features
diff --git a/applications/ChatGPT/requirements/requirements-test.txt b/applications/ChatGPT/requirements/requirements-test.txt
new file mode 100644
index 000000000..e079f8a60
--- /dev/null
+++ b/applications/ChatGPT/requirements/requirements-test.txt
@@ -0,0 +1 @@
+pytest
diff --git a/applications/ChatGPT/requirements/requirements.txt b/applications/ChatGPT/requirements/requirements.txt
new file mode 100644
index 000000000..87f6a52cc
--- /dev/null
+++ b/applications/ChatGPT/requirements/requirements.txt
@@ -0,0 +1,6 @@
+transformers>=4.20.1
+tqdm
+datasets
+loralib
+colossalai>=0.2.4
+torch
diff --git a/applications/ChatGPT/setup.py b/applications/ChatGPT/setup.py
new file mode 100644
index 000000000..f9607190a
--- /dev/null
+++ b/applications/ChatGPT/setup.py
@@ -0,0 +1,42 @@
+from setuptools import find_packages, setup
+
+
+def fetch_requirements(path):
+ with open(path, 'r') as fd:
+ return [r.strip() for r in fd.readlines()]
+
+
+def fetch_readme():
+ with open('README.md', encoding='utf-8') as f:
+ return f.read()
+
+
+def fetch_version():
+ with open('version.txt', 'r') as f:
+ return f.read().strip()
+
+
+setup(
+ name='chatgpt',
+ version=fetch_version(),
+ packages=find_packages(exclude=(
+ 'tests',
+ 'benchmarks',
+ 'requirements',
+ '*.egg-info',
+ )),
+ description='A RLFH implementation (ChatGPT) powered by ColossalAI',
+ long_description=fetch_readme(),
+ long_description_content_type='text/markdown',
+ license='Apache Software License 2.0',
+ url='https://github.com/hpcaitech/ChatGPT',
+ install_requires=fetch_requirements('requirements/requirements.txt'),
+ python_requires='>=3.6',
+ classifiers=[
+ 'Programming Language :: Python :: 3',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Environment :: GPU :: NVIDIA CUDA',
+ 'Topic :: Scientific/Engineering :: Artificial Intelligence',
+ 'Topic :: System :: Distributed Computing',
+ ],
+)
diff --git a/applications/ChatGPT/tests/__init__.py b/applications/ChatGPT/tests/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/applications/ChatGPT/tests/test_data.py b/applications/ChatGPT/tests/test_data.py
new file mode 100644
index 000000000..b0a9433c2
--- /dev/null
+++ b/applications/ChatGPT/tests/test_data.py
@@ -0,0 +1,117 @@
+import os
+from copy import deepcopy
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+from chatgpt.experience_maker import NaiveExperienceMaker
+from chatgpt.nn import GPTActor, GPTCritic, RewardModel
+from chatgpt.replay_buffer import NaiveReplayBuffer
+from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
+
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.utils import free_port
+
+
+def get_data(batch_size: int, seq_len: int = 10) -> dict:
+ input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
+ attention_mask = torch.ones_like(input_ids)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def gather_and_equal(tensor: torch.Tensor) -> bool:
+ world_size = dist.get_world_size()
+ outputs = [torch.empty_like(tensor) for _ in range(world_size)]
+ dist.all_gather(outputs, tensor.contiguous())
+ for t in outputs[1:]:
+ if not torch.equal(outputs[0], t):
+ return False
+ return True
+
+
+def run_test_data(strategy):
+ EXPERINCE_BATCH_SIZE = 4
+ SAMPLE_BATCH_SIZE = 2
+
+ if strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif strategy == 'colossalai':
+ strategy = ColossalAIStrategy(placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ actor = GPTActor().cuda()
+ critic = GPTCritic().cuda()
+
+ initial_model = deepcopy(actor)
+ reward_model = RewardModel(deepcopy(critic.model)).cuda()
+
+ experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model)
+ replay_buffer = NaiveReplayBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
+
+ # experience of all ranks should be the same
+ for _ in range(2):
+ data = get_data(EXPERINCE_BATCH_SIZE)
+ assert gather_and_equal(data['input_ids'])
+ assert gather_and_equal(data['attention_mask'])
+ experience = experience_maker.make_experience(**data,
+ do_sample=True,
+ max_length=16,
+ eos_token_id=50256,
+ pad_token_id=50256)
+ assert gather_and_equal(experience.sequences)
+ assert gather_and_equal(experience.action_log_probs)
+ assert gather_and_equal(experience.values)
+ assert gather_and_equal(experience.reward)
+ assert gather_and_equal(experience.advantages)
+ assert gather_and_equal(experience.action_mask)
+ assert gather_and_equal(experience.attention_mask)
+ replay_buffer.append(experience)
+
+ # replay buffer's data should be the same
+ buffer_size = torch.tensor([len(replay_buffer)], device='cuda')
+ assert gather_and_equal(buffer_size)
+ for item in replay_buffer.items:
+ assert gather_and_equal(item.sequences)
+ assert gather_and_equal(item.action_log_probs)
+ assert gather_and_equal(item.values)
+ assert gather_and_equal(item.reward)
+ assert gather_and_equal(item.advantages)
+ assert gather_and_equal(item.action_mask)
+ assert gather_and_equal(item.attention_mask)
+
+ # dataloader of each rank should have the same size and different batch
+ dataloader = strategy.setup_dataloader(replay_buffer)
+ dataloader_size = torch.tensor([len(dataloader)], device='cuda')
+ assert gather_and_equal(dataloader_size)
+ for experience in dataloader:
+ assert not gather_and_equal(experience.sequences)
+ assert not gather_and_equal(experience.action_log_probs)
+ assert not gather_and_equal(experience.values)
+ assert not gather_and_equal(experience.reward)
+ assert not gather_and_equal(experience.advantages)
+ # action mask and attention mask may be same
+
+
+def run_dist(rank, world_size, port, strategy):
+ os.environ['RANK'] = str(rank)
+ os.environ['LOCAL_RANK'] = str(rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ os.environ['MASTER_ADDR'] = 'localhost'
+ os.environ['MASTER_PORT'] = str(port)
+ run_test_data(strategy)
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [2])
+@pytest.mark.parametrize('strategy', ['ddp', 'colossalai'])
+@rerun_if_address_is_in_use()
+def test_data(world_size, strategy):
+ run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_data(2, 'colossalai')
diff --git a/applications/ChatGPT/version.txt b/applications/ChatGPT/version.txt
new file mode 100644
index 000000000..6e8bf73aa
--- /dev/null
+++ b/applications/ChatGPT/version.txt
@@ -0,0 +1 @@
+0.1.0