 +
+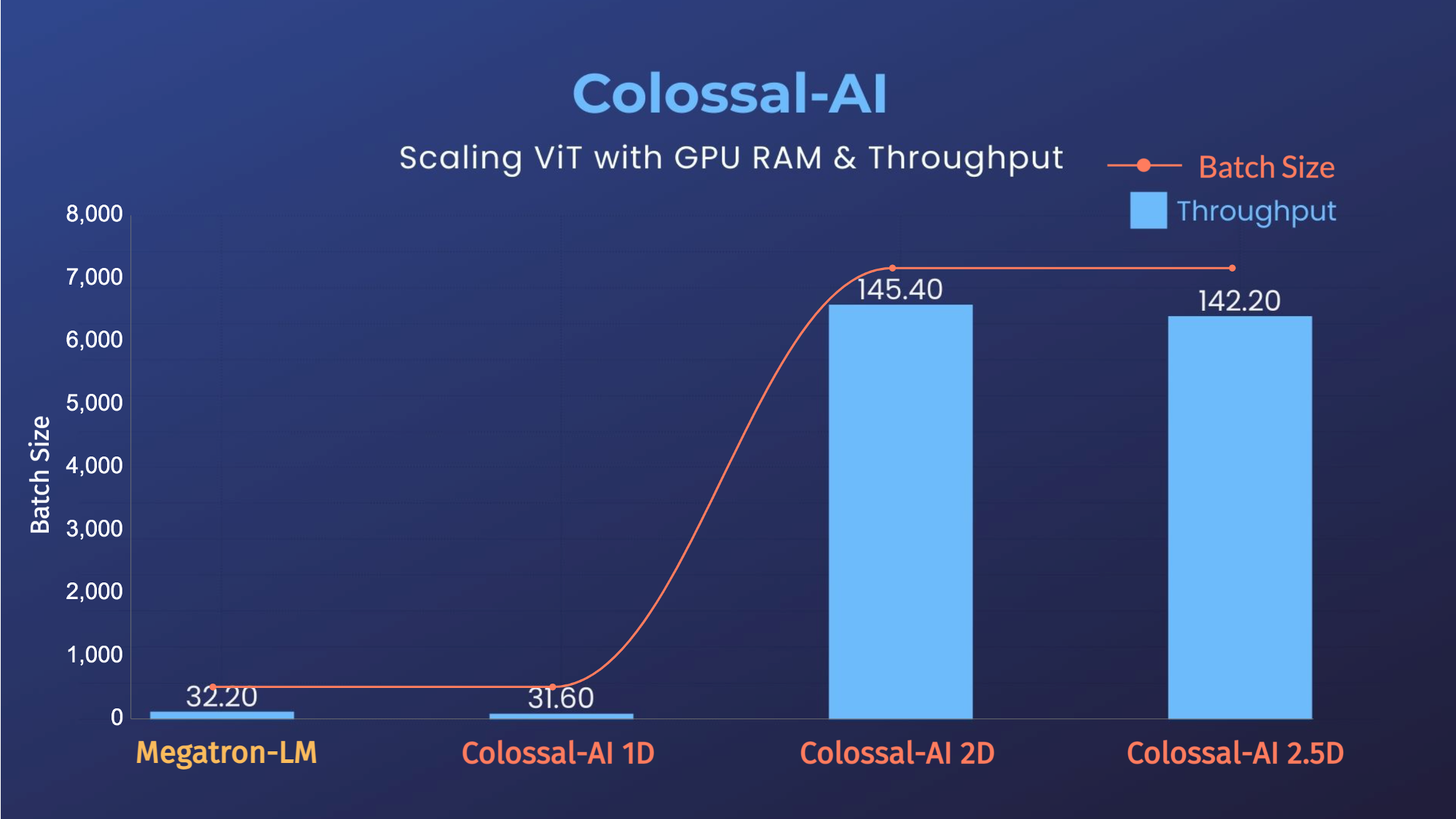 - 14x larger batch size, and 5x faster training for Tensor Parallel = 64
### GPT-3
-
-
- 14x larger batch size, and 5x faster training for Tensor Parallel = 64
### GPT-3
-
- +
+ - Free 50% GPU resources, or 10.7% acceleration
### GPT-2
-
- Free 50% GPU resources, or 10.7% acceleration
### GPT-2
- +
+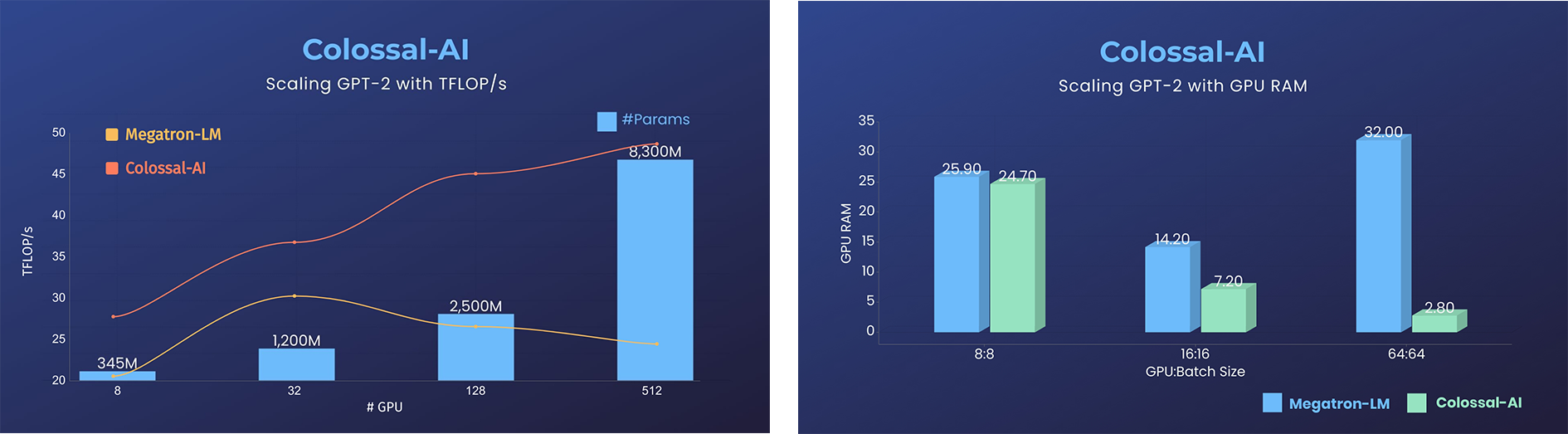 - 11x lower GPU RAM, or superlinear scaling
### BERT
-
- 11x lower GPU RAM, or superlinear scaling
### BERT
- +
+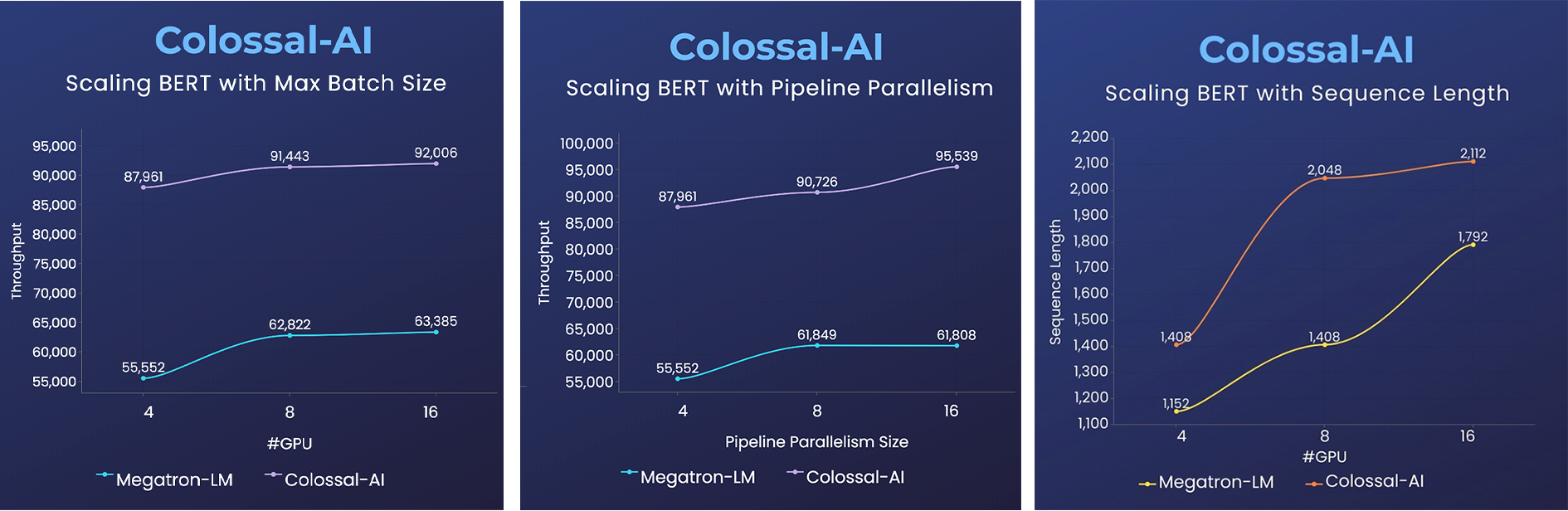 - 2x faster training, or 50% longer sequence length
- 2x faster training, or 50% longer sequence length