diff --git a/applications/ColossalChat/coati/distributed/README.md b/applications/ColossalChat/coati/distributed/README.md
index 21647a8cc..4f3fe94f6 100644
--- a/applications/ColossalChat/coati/distributed/README.md
+++ b/applications/ColossalChat/coati/distributed/README.md
@@ -14,6 +14,7 @@ This repository implements a distributed Reinforcement Learning (RL) training fr
* **Rollout and Policy Decoupling**: Efficient generation and consumption of data through parallel inferencer-trainer architecture.
* **Evaluation Integration**: Easily plug in task-specific eval datasets.
* **Checkpoints and Logging**: Configurable intervals and directories.
+* **[New]**: Zero Bubble training framework that supports GRPO and DAPO. [(read more)](./zero_bubble/README.md)
---
diff --git a/applications/ColossalChat/coati/distributed/zero_bubble/README.md b/applications/ColossalChat/coati/distributed/zero_bubble/README.md
new file mode 100644
index 000000000..ec140684b
--- /dev/null
+++ b/applications/ColossalChat/coati/distributed/zero_bubble/README.md
@@ -0,0 +1,73 @@
+# Zero Bubble Distributed RL Framework for Language Model Fine-Tuning
+
+This folder contains code for the Zero Bubble distributed RL framework. It currently supports **GRPO** and **DAPO**. See the [main README](../README.md) for general installation instructions and usage.
+
+**Note:** This project is under active development — expect changes.
+
+## 🛠 Installation
+
+1. Follow the general installation guide in the [main README](../README.md).
+2. Install [pygloo](https://github.com/ray-project/pygloo). Build pygloo for Ray from source following the instructions in its repository README.
+
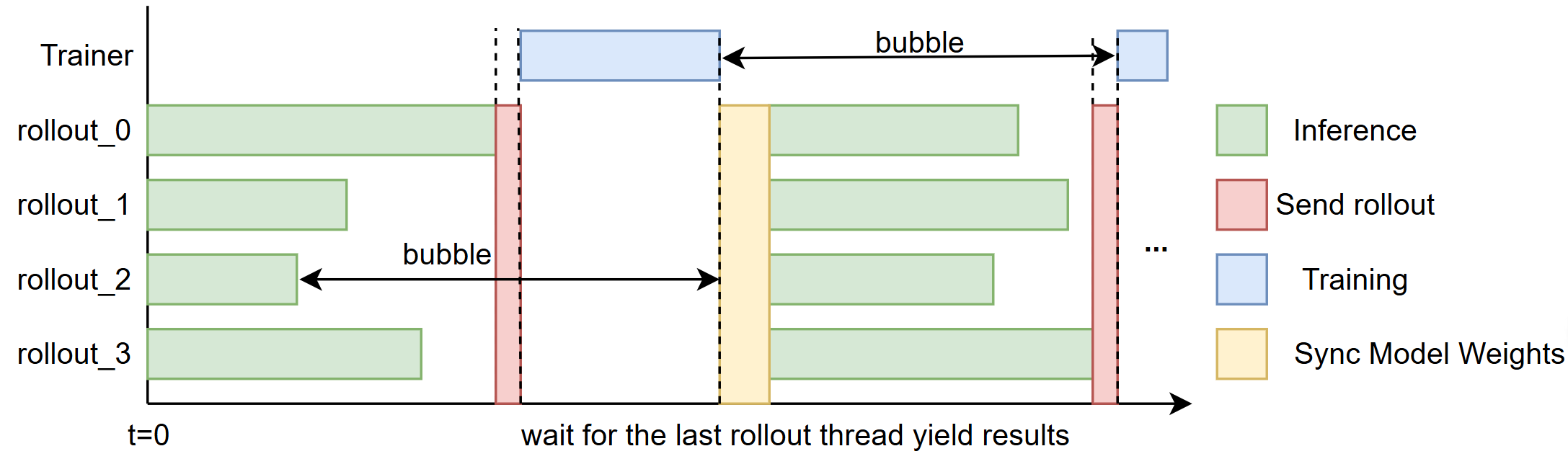
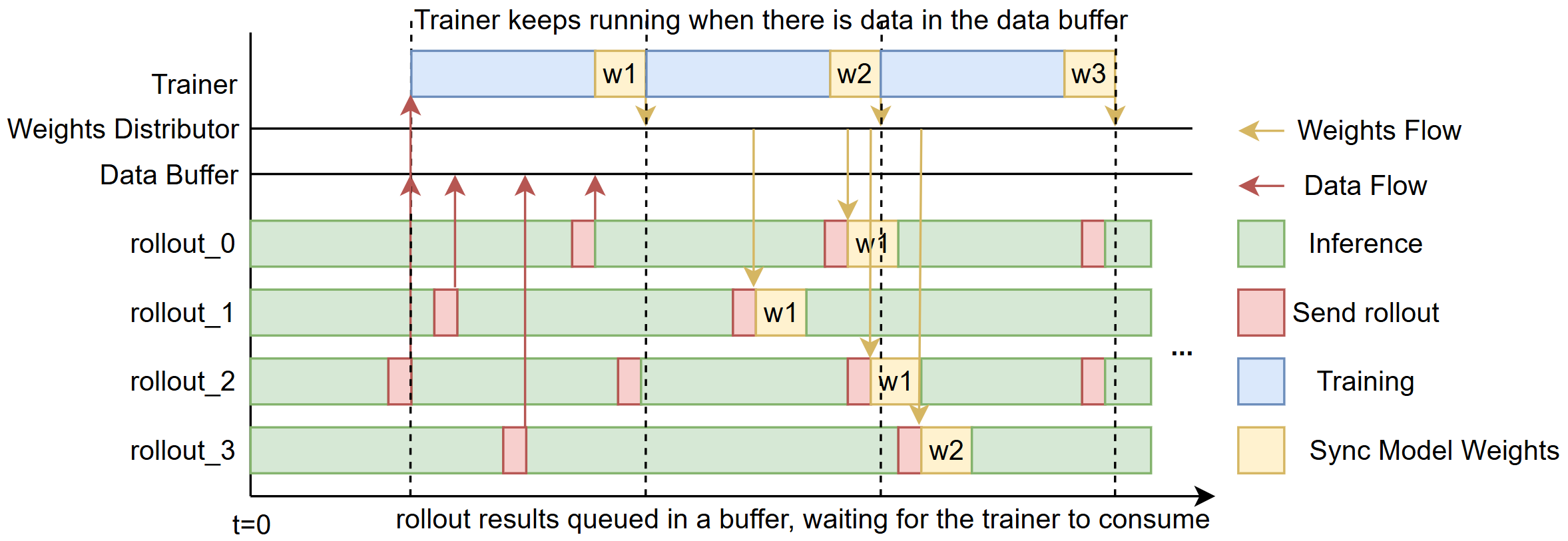
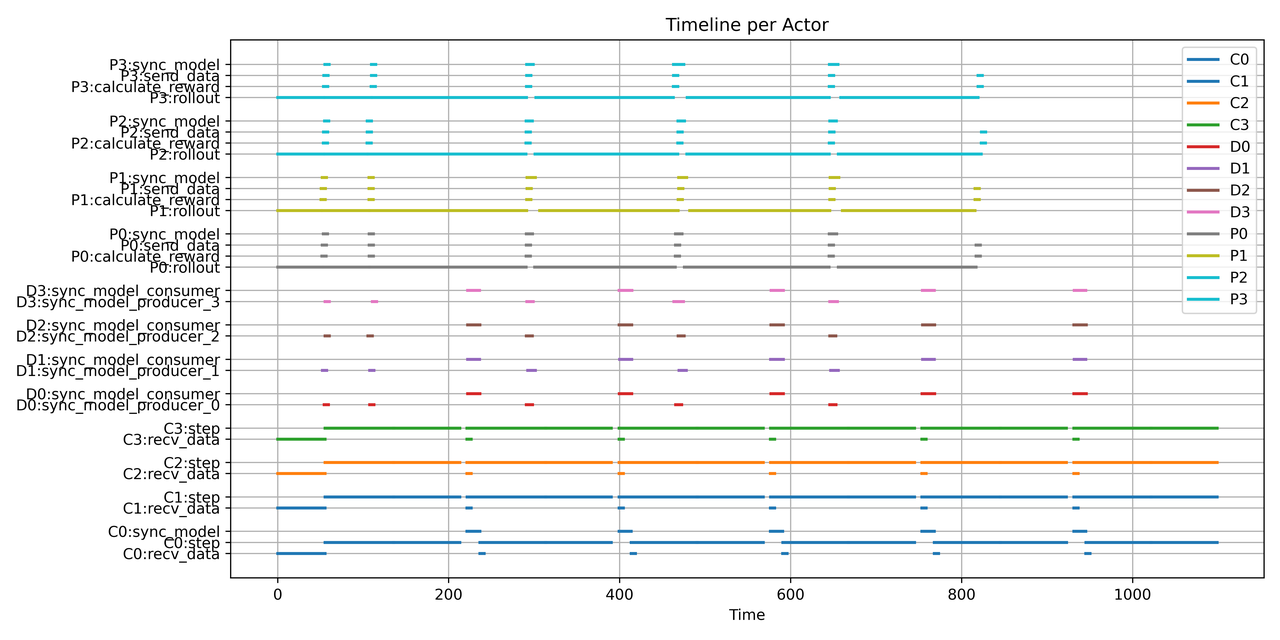
+## Design idea
+
+We aim to reduce the *“bubble”* — the idle time that occurs between rollouts and training steps (illustrated in Fig. 1).
+
+
+
+  +
+
+
+
+  +
+
+
+
+  +
+
+