mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2025-09-03 18:19:58 +00:00
[devops] remove post commit ci (#5566)
* [devops] remove post commit ci * [misc] run pre-commit on all files * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
This commit is contained in:
@@ -5,13 +5,7 @@ from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.prompt.prompt import (
|
||||
PROMPT_DISAMBIGUATE_ZH,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
SUMMARY_PROMPT_ZH,
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
)
|
||||
from colossalqa.prompt.prompt import ZH_RETRIEVAL_QA_REJECTION_ANSWER, ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
@@ -116,13 +110,13 @@ class RAG_ChatBot:
|
||||
def split_docs(self, documents):
|
||||
doc_splits = self.text_splitter.split_documents(documents)
|
||||
return doc_splits
|
||||
|
||||
|
||||
def clear_docs(self, **kwargs):
|
||||
self.documents = []
|
||||
self.docs_names = []
|
||||
self.info_retriever.clear_documents()
|
||||
self.memory.initiate_document_retrieval_chain(self.llm, kwargs["gen_qa_prompt"], self.info_retriever)
|
||||
|
||||
|
||||
def reset_config(self, rag_config):
|
||||
self.rag_config = rag_config
|
||||
self.set_embed_model(**self.rag_config["embed"])
|
||||
|
||||
@@ -115,4 +115,4 @@ python webui.py --http_host "your-backend-api-host" --http_port "your-backend-ap
|
||||
|
||||
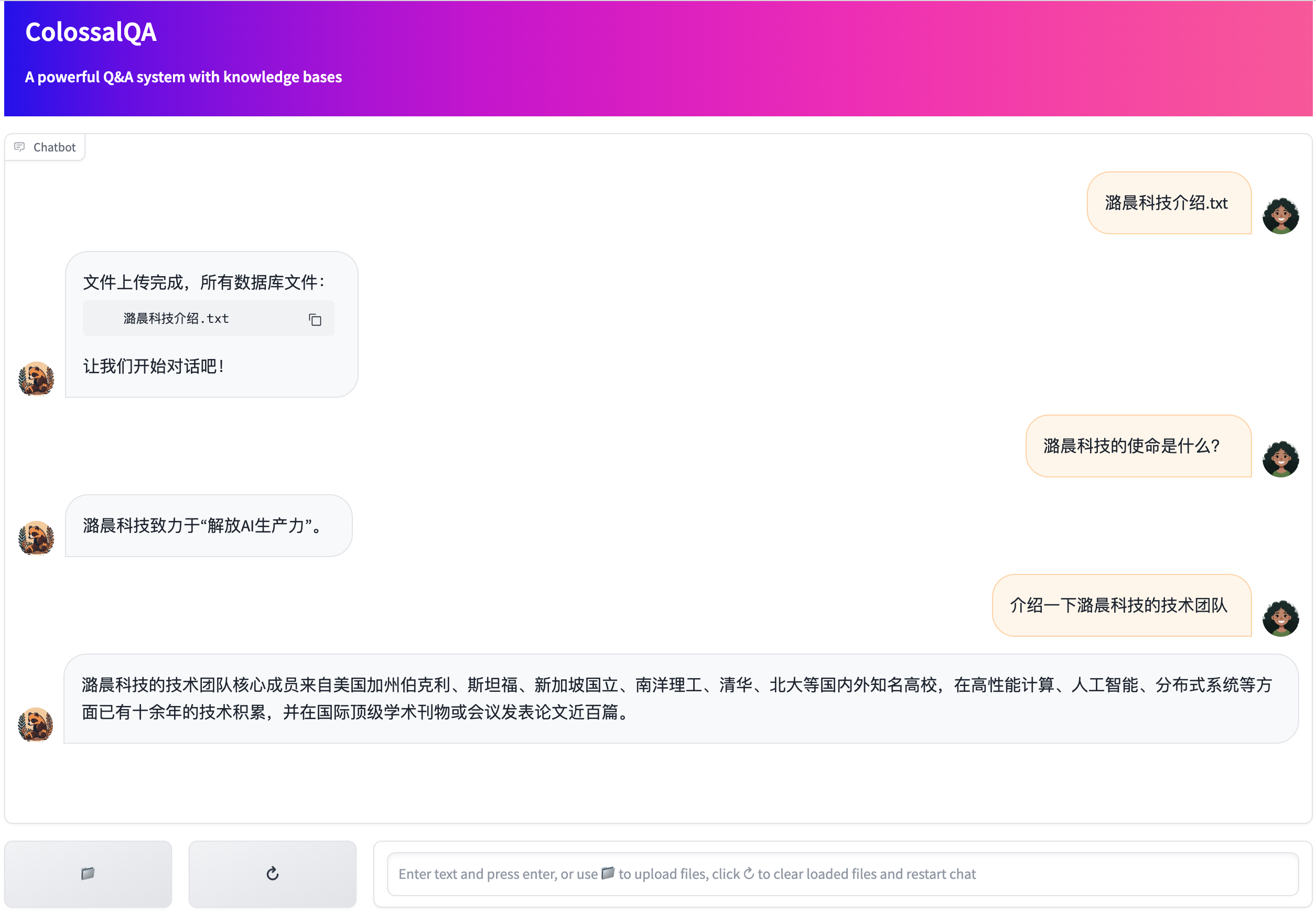
After launching the script, you can upload files and engage with the chatbot through your web browser.
|
||||
|
||||
|
||||

|
||||
|
||||
@@ -1,58 +1,30 @@
|
||||
from colossalqa.prompt.prompt import (
|
||||
PROMPT_DISAMBIGUATE_ZH,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
SUMMARY_PROMPT_ZH,
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
)
|
||||
from colossalqa.prompt.prompt import PROMPT_DISAMBIGUATE_ZH, PROMPT_RETRIEVAL_QA_ZH, SUMMARY_PROMPT_ZH
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
|
||||
ALL_CONFIG = {
|
||||
"embed": {
|
||||
"embed_name": "m3e", # embedding model name
|
||||
"embed_model_name_or_path": "moka-ai/m3e-base", # path to embedding model, could be a local path or a huggingface path
|
||||
"embed_model_device": {
|
||||
"device": "cpu"
|
||||
}
|
||||
"embed_model_device": {"device": "cpu"},
|
||||
},
|
||||
"model": {
|
||||
"mode": "api", # "local" for loading models, "api" for using model api
|
||||
"model_name": "chatgpt_api", # local model name, "chatgpt_api" or "pangu_api"
|
||||
"model_path": "", # path to the model, could be a local path or a huggingface path. don't need if using an api
|
||||
"device": {
|
||||
"device": "cuda"
|
||||
}
|
||||
},
|
||||
"splitter": {
|
||||
"name": ChineseTextSplitter
|
||||
},
|
||||
"retrieval": {
|
||||
"retri_top_k": 3,
|
||||
"retri_kb_file_path": "./", # path to store database files
|
||||
"verbose": True
|
||||
"model_path": "", # path to the model, could be a local path or a huggingface path. don't need if using an api
|
||||
"device": {"device": "cuda"},
|
||||
},
|
||||
"splitter": {"name": ChineseTextSplitter},
|
||||
"retrieval": {"retri_top_k": 3, "retri_kb_file_path": "./", "verbose": True}, # path to store database files
|
||||
"chain": {
|
||||
"mem_summary_prompt": SUMMARY_PROMPT_ZH, # summary prompt template
|
||||
"mem_human_prefix": "用户",
|
||||
"mem_ai_prefix": "Assistant",
|
||||
"mem_max_tokens": 2000,
|
||||
"mem_llm_kwargs": {
|
||||
"max_new_tokens": 50,
|
||||
"temperature": 1,
|
||||
"do_sample": True
|
||||
},
|
||||
"mem_llm_kwargs": {"max_new_tokens": 50, "temperature": 1, "do_sample": True},
|
||||
"disambig_prompt": PROMPT_DISAMBIGUATE_ZH, # disambiguate prompt template
|
||||
"disambig_llm_kwargs": {
|
||||
"max_new_tokens": 30,
|
||||
"temperature": 1,
|
||||
"do_sample": True
|
||||
},
|
||||
"gen_llm_kwargs": {
|
||||
"max_new_tokens": 100,
|
||||
"temperature": 1,
|
||||
"do_sample": True
|
||||
},
|
||||
"disambig_llm_kwargs": {"max_new_tokens": 30, "temperature": 1, "do_sample": True},
|
||||
"gen_llm_kwargs": {"max_new_tokens": 100, "temperature": 1, "do_sample": True},
|
||||
"gen_qa_prompt": PROMPT_RETRIEVAL_QA_ZH, # generation prompt template
|
||||
"verbose": True
|
||||
}
|
||||
}
|
||||
"verbose": True,
|
||||
},
|
||||
}
|
||||
|
||||
@@ -1,27 +1,18 @@
|
||||
import argparse
|
||||
import os
|
||||
from typing import List, Union
|
||||
|
||||
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.retrieval_conversation_zh import ChineseRetrievalConversation
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from enum import Enum
|
||||
from fastapi import FastAPI, Request
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
from pydantic import BaseModel, Field
|
||||
import uvicorn
|
||||
|
||||
import config
|
||||
import uvicorn
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.mylogging import get_logger
|
||||
from fastapi import FastAPI, Request
|
||||
from pydantic import BaseModel
|
||||
from RAG_ChatBot import RAG_ChatBot
|
||||
from utils import DocAction
|
||||
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
def parseArgs():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--http_host", default="0.0.0.0")
|
||||
@@ -36,6 +27,7 @@ class DocUpdateReq(BaseModel):
|
||||
doc_files: Union[List[str], str, None] = None
|
||||
action: DocAction = DocAction.ADD
|
||||
|
||||
|
||||
class GenerationTaskReq(BaseModel):
|
||||
user_input: str
|
||||
|
||||
@@ -45,7 +37,7 @@ def update_docs(data: DocUpdateReq, request: Request):
|
||||
if data.action == "add":
|
||||
if isinstance(data.doc_files, str):
|
||||
data.doc_files = [data.doc_files]
|
||||
chatbot.load_doc_from_files(files = data.doc_files)
|
||||
chatbot.load_doc_from_files(files=data.doc_files)
|
||||
all_docs = ""
|
||||
for doc in chatbot.docs_names:
|
||||
all_docs += f"\t{doc}\n\n"
|
||||
@@ -79,17 +71,18 @@ if __name__ == "__main__":
|
||||
elif all_config["model"]["mode"] == "api":
|
||||
if model_name == "pangu_api":
|
||||
from colossalqa.local.pangu_llm import Pangu
|
||||
|
||||
|
||||
gen_config = {
|
||||
"user": "User",
|
||||
"max_tokens": all_config["chain"]["disambig_llm_kwargs"]["max_new_tokens"],
|
||||
"temperature": all_config["chain"]["disambig_llm_kwargs"]["temperature"],
|
||||
"n": 1 # the number of responses generated
|
||||
"n": 1, # the number of responses generated
|
||||
}
|
||||
llm = Pangu(gen_config=gen_config)
|
||||
llm.set_auth_config() # verify user's auth info here
|
||||
elif model_name == "chatgpt_api":
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI()
|
||||
else:
|
||||
raise ValueError("Unsupported mode.")
|
||||
|
||||
@@ -1,24 +1,26 @@
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import requests
|
||||
|
||||
import gradio as gr
|
||||
|
||||
import requests
|
||||
from utils import DocAction
|
||||
|
||||
|
||||
def parseArgs():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--http_host", default="0.0.0.0")
|
||||
parser.add_argument("--http_port", type=int, default=13666)
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def get_response(data, url):
|
||||
headers = {"Content-type": "application/json"}
|
||||
response = requests.post(url, json=data, headers=headers)
|
||||
response = json.loads(response.content)
|
||||
return response
|
||||
|
||||
|
||||
def add_text(history, text):
|
||||
history = history + [(text, None)]
|
||||
return history, gr.update(value=None, interactive=True)
|
||||
@@ -28,35 +30,28 @@ def add_file(history, files):
|
||||
files_string = "\n".join([os.path.basename(file.name) for file in files])
|
||||
|
||||
doc_files = [file.name for file in files]
|
||||
data = {
|
||||
"doc_files": doc_files,
|
||||
"action": DocAction.ADD
|
||||
}
|
||||
data = {"doc_files": doc_files, "action": DocAction.ADD}
|
||||
response = get_response(data, update_url)["response"]
|
||||
history = history + [(files_string, response)]
|
||||
return history
|
||||
|
||||
def bot(history):
|
||||
data = {
|
||||
"user_input": history[-1][0].strip()
|
||||
}
|
||||
|
||||
def bot(history):
|
||||
data = {"user_input": history[-1][0].strip()}
|
||||
response = get_response(data, gen_url)
|
||||
|
||||
if response["error"] != "":
|
||||
raise gr.Error(response["error"])
|
||||
|
||||
|
||||
history[-1][1] = response["response"]
|
||||
yield history
|
||||
|
||||
|
||||
def restart(chatbot, txt):
|
||||
# Reset the conversation state and clear the chat history
|
||||
data = {
|
||||
"doc_files": "",
|
||||
"action": DocAction.CLEAR
|
||||
}
|
||||
response = get_response(data, update_url)
|
||||
|
||||
data = {"doc_files": "", "action": DocAction.CLEAR}
|
||||
get_response(data, update_url)
|
||||
|
||||
return gr.update(value=None), gr.update(value=None, interactive=True)
|
||||
|
||||
|
||||
@@ -97,7 +92,7 @@ with gr.Blocks(css=CSS) as demo:
|
||||
|
||||
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)
|
||||
# Clear the original textbox
|
||||
txt_msg.then(lambda: gr.update(value=None, interactive=True), None, [txt], queue=False)
|
||||
txt_msg.then(lambda: gr.update(value=None, interactive=True), None, [txt], queue=False)
|
||||
# Click Upload Button: 1. upload files 2. send config to backend, initalize model 3. get response "conversation_ready" = True/False
|
||||
file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user