diff --git a/README-zh-Hans.md b/README-zh-Hans.md
index 904753c8e..8dd28d670 100644
--- a/README-zh-Hans.md
+++ b/README-zh-Hans.md
@@ -28,7 +28,7 @@
为何选择 Colossal-AI
特点
- 展示样例
+ 并行样例展示
+
+ 单GPU样例展示
+
+
安装
@@ -83,7 +90,7 @@ Colossal-AI 为您提供了一系列并行训练组件。我们的目标是让
- 基于参数文件的并行化
(返回顶端)
-## 展示样例
+## 并行样例展示
### ViT
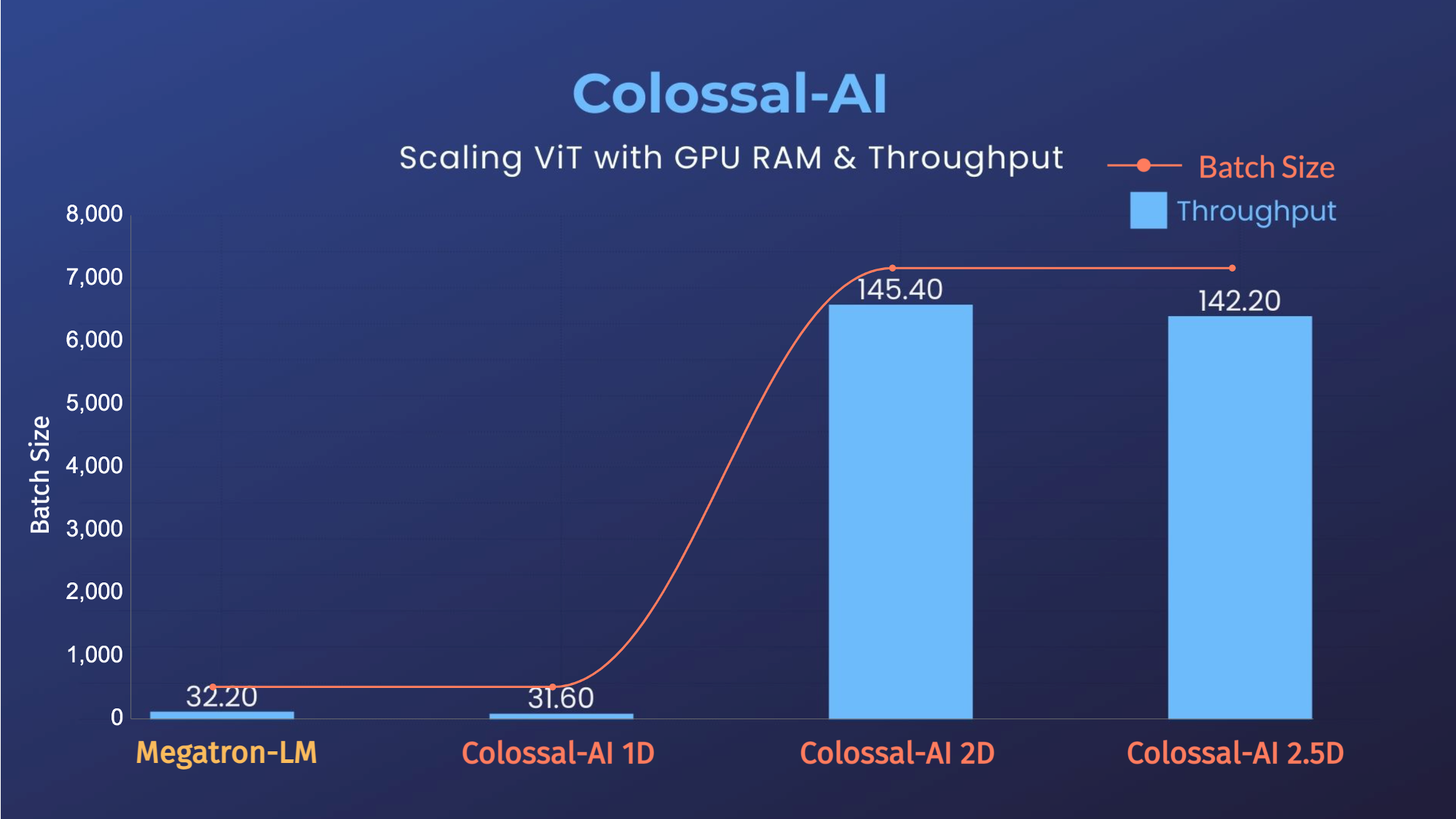 @@ -120,43 +127,49 @@ Colossal-AI 为您提供了一系列并行训练组件。我们的目标是让
@@ -120,43 +127,49 @@ Colossal-AI 为您提供了一系列并行训练组件。我们的目标是让
(返回顶端)
+## 单GPU样例展示
+
+### GPT-2
+
+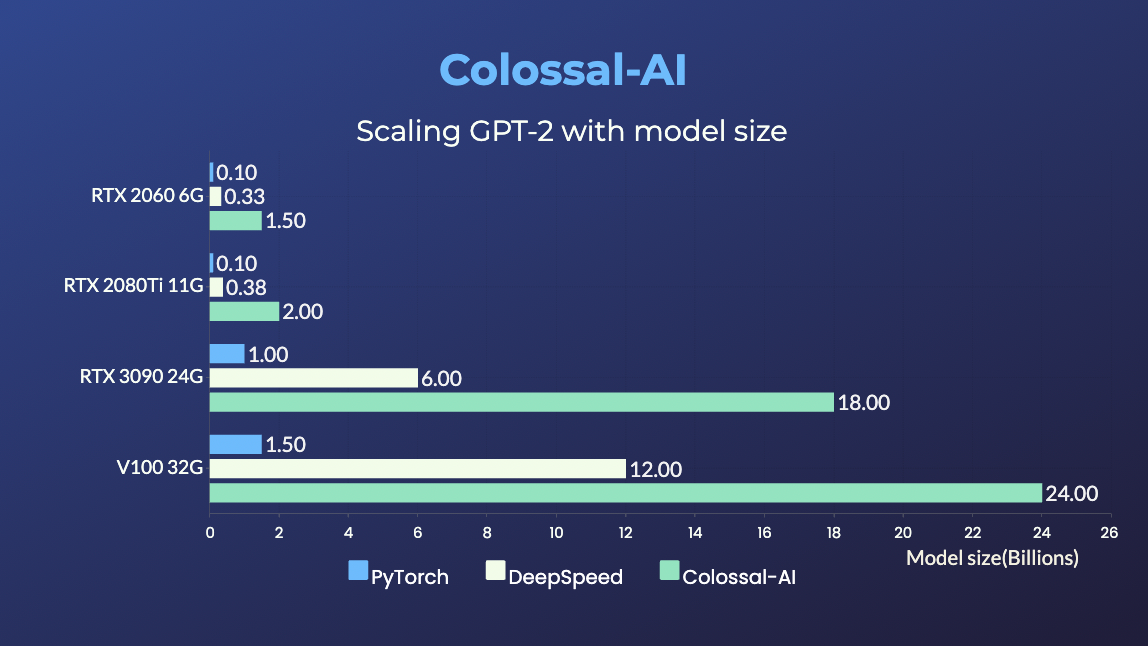 +
+
+
+- 用相同的硬件条件训练20倍大的模型
+
+### PaLM
+
+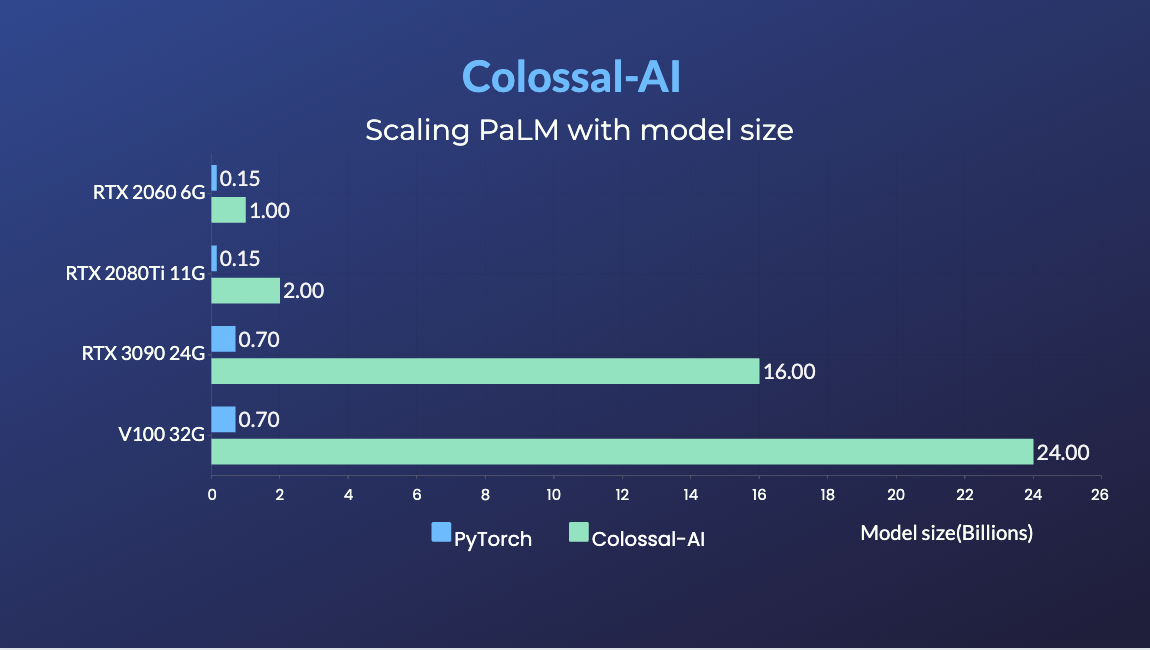 +
+
+
+- 用相同的硬件条件训练34倍大的模型
+
+(back to top)
+
## 安装
-### PyPI
+### 从官方安装
-```bash
-pip install colossalai
-```
-该命令将会安装 CUDA extension, 如果你已安装 CUDA, NVCC 和 torch。
+您可以访问我们[下载](/download)页面来安装Colossal-AI,在这个页面上发布的版本都预编译了CUDA扩展。
-如果你不想安装 CUDA extension, 可在命令中添加`--global-option="--no_cuda_ext"`, 例如:
-```bash
-pip install colossalai --global-option="--no_cuda_ext"
-```
+### 从源安装
-如果你想使用 `ZeRO`, 你可以使用:
-```bash
-pip install colossalai[zero]
-```
-
-### 从源代码安装
-
-> Colossal-AI 的版本将与该项目的主分支保持一致。欢迎通过 issue 反馈你遇到的任何问题 :)
+> 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue :)
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
-# 安装依赖
+
+# install dependency
pip install -r requirements/requirements.txt
-# 安装 colossalai
+# install colossalai
pip install .
```
-如果你不想安装和使用 CUDA kernel fusion (使用 fused 优化器需安装):
+如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装):
```shell
-pip install --global-option="--no_cuda_ext" .
+NO_CUDA_EXT=1 pip install .
```
(返回顶端)
@@ -201,78 +214,23 @@ docker run -ti --gpus all --rm --ipc=host colossalai bash
### 几行代码开启分布式训练
```python
-import colossalai
-from colossalai.utils import get_dataloader
-
-
-# my_config 可以是 config 文件的路径或字典对象
-# 'localhost' 仅适用于单节点,在多节点时需指明节点名
-colossalai.launch(
- config=my_config,
- rank=rank,
- world_size=world_size,
- backend='nccl',
- port=29500,
- host='localhost'
+parallel = dict(
+ pipeline=2,
+ tensor=dict(mode='2.5d', depth = 1, size=4)
)
-
-# 构建模型
-model = ...
-
-# 构建数据集, dataloader 会默认处理分布式数据 sampler
-train_dataset = ...
-train_dataloader = get_dataloader(dataset=dataset,
- shuffle=True
- )
-
-
-# 构建优化器
-optimizer = ...
-
-# 构建损失函数
-criterion = ...
-
-# 初始化 colossalai
-engine, train_dataloader, _, _ = colossalai.initialize(
- model=model,
- optimizer=optimizer,
- criterion=criterion,
- train_dataloader=train_dataloader
-)
-
-# 开始训练
-engine.train()
-for epoch in range(NUM_EPOCHS):
- for data, label in train_dataloader:
- engine.zero_grad()
- output = engine(data)
- loss = engine.criterion(output, label)
- engine.backward(loss)
- engine.step()
-
```
-### 构建一个简单的2维并行模型
-
-假设我们有一个非常巨大的 MLP 模型,它巨大的 hidden size 使得它难以被单个 GPU 容纳。我们可以将该模型的权重以二维网格的形式分配到多个 GPU 上,且保持你熟悉的模型构建方式。
+### 几行代码开启异构训练
```python
-from colossalai.nn import Linear2D
-import torch.nn as nn
-
-
-class MLP_2D(nn.Module):
-
- def __init__(self):
- super().__init__()
- self.linear_1 = Linear2D(in_features=1024, out_features=16384)
- self.linear_2 = Linear2D(in_features=16384, out_features=1024)
-
- def forward(self, x):
- x = self.linear_1(x)
- x = self.linear_2(x)
- return x
-
+zero = dict(
+ model_config=dict(
+ tensor_placement_policy='auto',
+ shard_strategy=TensorShardStrategy(),
+ reuse_fp16_shard=True
+ ),
+ optimizer_config=dict(initial_scale=2**5, gpu_margin_mem_ratio=0.2)
+)
```
(返回顶端)
diff --git a/README.md b/README.md
index 843127b89..9c9171715 100644
--- a/README.md
+++ b/README.md
@@ -28,7 +28,7 @@
Why Colossal-AI
Features
- Demo
+ Parallel Demo
+
+ Single GPU Demo
+
+
Installation
@@ -88,7 +95,7 @@ distributed training in a few lines.
(back to top)
-## Demo
+## Parallel Demo
### ViT
@@ -124,27 +131,39 @@ Please visit our [documentation and tutorials](https://www.colossalai.org/) for
(back to top)
+## Single GPU Demo
+
+### GPT-2
+
+
+
+
+- 20x larger model size on the same hardware
+
+### PaLM
+
+
+
+
+- 34x larger model size on the same hardware
+
+(back to top)
+
## Installation
-### PyPI
+### Download From Official Releases
-```bash
-pip install colossalai
-```
-This command will install CUDA extension if your have installed CUDA, NVCC and torch.
+You can visit the [Download](/download) page to download Colossal-AI with pre-built CUDA extensions.
-If you don't want to install CUDA extension, you should add `--global-option="--no_cuda_ext"`, like:
-```bash
-pip install colossalai --global-option="--no_cuda_ext"
-```
-### Install From Source
+### Download From Source
-> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to create an issue if you encounter any problems. :-)
+> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem. :)
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
+
# install dependency
pip install -r requirements/requirements.txt
@@ -155,7 +174,7 @@ pip install .
If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
```shell
-pip install --global-option="--no_cuda_ext" .
+NO_CUDA_EXT=1 pip install .
```
(back to top)
@@ -200,80 +219,23 @@ Thanks so much to all of our amazing contributors!
### Start Distributed Training in Lines
```python
-import colossalai
-from colossalai.utils import get_dataloader
-
-
-# my_config can be path to config file or a dictionary obj
-# 'localhost' is only for single node, you need to specify
-# the node name if using multiple nodes
-colossalai.launch(
- config=my_config,
- rank=rank,
- world_size=world_size,
- backend='nccl',
- port=29500,
- host='localhost'
+parallel = dict(
+ pipeline=2,
+ tensor=dict(mode='2.5d', depth = 1, size=4)
)
-
-# build your model
-model = ...
-
-# build you dataset, the dataloader will have distributed data
-# sampler by default
-train_dataset = ...
-train_dataloader = get_dataloader(dataset=dataset,
- shuffle=True
- )
-
-
-# build your optimizer
-optimizer = ...
-
-# build your loss function
-criterion = ...
-
-# initialize colossalai
-engine, train_dataloader, _, _ = colossalai.initialize(
- model=model,
- optimizer=optimizer,
- criterion=criterion,
- train_dataloader=train_dataloader
-)
-
-# start training
-engine.train()
-for epoch in range(NUM_EPOCHS):
- for data, label in train_dataloader:
- engine.zero_grad()
- output = engine(data)
- loss = engine.criterion(output, label)
- engine.backward(loss)
- engine.step()
-
```
-### Write a Simple 2D Parallel Model
-
-Let's say we have a huge MLP model and its very large hidden size makes it difficult to fit into a single GPU. We can
-then distribute the model weights across GPUs in a 2D mesh while you still write your model in a familiar way.
+### Start Heterogeneous Training in Lines
```python
-from colossalai.nn import Linear2D
-import torch.nn as nn
-
-
-class MLP_2D(nn.Module):
-
- def __init__(self):
- super().__init__()
- self.linear_1 = Linear2D(in_features=1024, out_features=16384)
- self.linear_2 = Linear2D(in_features=16384, out_features=1024)
-
- def forward(self, x):
- x = self.linear_1(x)
- x = self.linear_2(x)
- return x
+zero = dict(
+ model_config=dict(
+ tensor_placement_policy='auto',
+ shard_strategy=TensorShardStrategy(),
+ reuse_fp16_shard=True
+ ),
+ optimizer_config=dict(initial_scale=2**5, gpu_margin_mem_ratio=0.2)
+)
```