mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2025-09-11 13:59:08 +00:00
Update metainfo patch branch (#2517)
* init
* rename and remove useless func
* basic chunk
* add evoformer
* align evoformer
* add meta
* basic chunk
* basic memory
* finish basic inference memory estimation
* finish memory estimation
* fix bug
* finish memory estimation
* add part of index tracer
* finish basic index tracer
* add doc string
* add doc str
* polish code
* polish code
* update active log
* polish code
* add possible region search
* finish region search loop
* finish chunk define
* support new op
* rename index tracer
* finishi codegen on msa
* redesign index tracer, add source and change compute
* pass outproduct mean
* code format
* code format
* work with outerproductmean and msa
* code style
* code style
* code style
* code style
* change threshold
* support check_index_duplicate
* support index dupilictae and update loop
* support output
* update memory estimate
* optimise search
* fix layernorm
* move flow tracer
* refactor flow tracer
* format code
* refactor flow search
* code style
* adapt codegen to prepose node
* code style
* remove abandoned function
* remove flow tracer
* code style
* code style
* reorder nodes
* finish node reorder
* update run
* code style
* add chunk select class
* add chunk select
* code style
* add chunksize in emit, fix bug in reassgin shape
* code style
* turn off print mem
* add evoformer openfold init
* init openfold
* add benchmark
* add print
* code style
* code style
* init openfold
* update openfold
* align openfold
* use max_mem to control stratge
* update source add
* add reorder in mem estimator
* improve reorder efficeincy
* support ones_like, add prompt if fit mode search fail
* fix a bug in ones like, dont gen chunk if dim size is 1
* fix bug again
* update min memory stratege, reduce mem usage by 30%
* last version of benchmark
* refactor structure
* restruct dir
* update test
* rename
* take apart chunk code gen
* close mem and code print
* code format
* rename ambiguous variable
* seperate flow tracer
* seperate input node dim search
* seperate prepose_nodes
* seperate non chunk input
* seperate reorder
* rename
* ad reorder graph
* seperate trace flow
* code style
* code style
* fix typo
* set benchmark
* rename test
* update codegen test
* Fix state_dict key missing issue of the ZeroDDP (#2363)
* Fix state_dict output for ZeroDDP duplicated parameters
* Rewrite state_dict based on get_static_torch_model
* Modify get_static_torch_model to be compatible with the lower version (ZeroDDP)
* update codegen test
* update codegen test
* add chunk search test
* code style
* add available
* [hotfix] fix gpt gemini example (#2404)
* [hotfix] fix gpt gemini example
* [example] add new assertions
* remove autochunk_available
* [workflow] added nightly release to pypi (#2403)
* add comments
* code style
* add doc for search chunk
* [doc] updated readme regarding pypi installation (#2406)
* add doc for search
* [doc] updated kernel-related optimisers' docstring (#2385)
* [doc] updated kernel-related optimisers' docstring
* polish doc
* rename trace_index to trace_indice
* rename function from index to indice
* rename
* rename in doc
* [polish] polish code for get_static_torch_model (#2405)
* [gemini] polish code
* [testing] remove code
* [gemini] make more robust
* rename
* rename
* remove useless function
* [worfklow] added coverage test (#2399)
* [worfklow] added coverage test
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* add doc for trace indice
* [docker] updated Dockerfile and release workflow (#2410)
* add doc
* update doc
* add available
* change imports
* add test in import
* [workflow] refactored the example check workflow (#2411)
* [workflow] refactored the example check workflow
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* Update parallel_context.py (#2408)
* [hotfix] add DISTPAN argument for benchmark (#2412)
* change the benchmark config file
* change config
* revert config file
* rename distpan to distplan
* [workflow] added precommit check for code consistency (#2401)
* [workflow] added precommit check for code consistency
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* adapt new fx
* [workflow] added translation for non-english comments (#2414)
* [setup] refactored setup.py for dependency graph (#2413)
* change import
* update doc
* [workflow] auto comment if precommit check fails (#2417)
* [hotfix] add norm clearing for the overflow step (#2416)
* [examples] adding tflops to PaLM (#2365)
* [workflow]auto comment with test coverage report (#2419)
* [workflow]auto comment with test coverage report
* polish code
* polish yaml
* [doc] added documentation for CI/CD (#2420)
* [doc] added documentation for CI/CD
* polish markdown
* polish markdown
* polish markdown
* [example] removed duplicated stable diffusion example (#2424)
* [zero] add inference mode and its unit test (#2418)
* [workflow] report test coverage even if below threshold (#2431)
* [example] improved the clarity yof the example readme (#2427)
* [example] improved the clarity yof the example readme
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* [ddp] add is_ddp_ignored (#2434)
[ddp] rename to is_ddp_ignored
* [workflow] make test coverage report collapsable (#2436)
* [autoparallel] add shard option (#2423)
* [fx] allow native ckpt trace and codegen. (#2438)
* [cli] provided more details if colossalai run fail (#2442)
* [autoparallel] integrate device mesh initialization into autoparallelize (#2393)
* [autoparallel] integrate device mesh initialization into autoparallelize
* add megatron solution
* update gpt autoparallel examples with latest api
* adapt beta value to fit the current computation cost
* [zero] fix state_dict and load_state_dict for ddp ignored parameters (#2443)
* [ddp] add is_ddp_ignored
[ddp] rename to is_ddp_ignored
* [zero] fix state_dict and load_state_dict
* fix bugs
* [zero] update unit test for ZeroDDP
* [example] updated the hybrid parallel tutorial (#2444)
* [example] updated the hybrid parallel tutorial
* polish code
* [zero] add warning for ignored parameters (#2446)
* [example] updated large-batch optimizer tutorial (#2448)
* [example] updated large-batch optimizer tutorial
* polish code
* polish code
* [example] fixed seed error in train_dreambooth_colossalai.py (#2445)
* [workflow] fixed the on-merge condition check (#2452)
* [workflow] automated the compatiblity test (#2453)
* [workflow] automated the compatiblity test
* polish code
* [autoparallel] update binary elementwise handler (#2451)
* [autoparallel] update binary elementwise handler
* polish
* [workflow] automated bdist wheel build (#2459)
* [workflow] automated bdist wheel build
* polish workflow
* polish readme
* polish readme
* Fix False warning in initialize.py (#2456)
* Update initialize.py
* pre-commit run check
* [examples] update autoparallel tutorial demo (#2449)
* [examples] update autoparallel tutorial demo
* add test_ci.sh
* polish
* add conda yaml
* [cli] fixed hostname mismatch error (#2465)
* [example] integrate autoparallel demo with CI (#2466)
* [example] integrate autoparallel demo with CI
* polish code
* polish code
* polish code
* polish code
* [zero] low level optim supports ProcessGroup (#2464)
* [example] update vit ci script (#2469)
* [example] update vit ci script
* [example] update requirements
* [example] update requirements
* [example] integrate seq-parallel tutorial with CI (#2463)
* [zero] polish low level optimizer (#2473)
* polish pp middleware (#2476)
Co-authored-by: Ziyue Jiang <ziyue.jiang@gmail.com>
* [example] update gpt gemini example ci test (#2477)
* [zero] add unit test for low-level zero init (#2474)
* [workflow] fixed the skip condition of example weekly check workflow (#2481)
* [example] stable diffusion add roadmap
* add dummy test_ci.sh
* [example] stable diffusion add roadmap (#2482)
* [CI] add test_ci.sh for palm, opt and gpt (#2475)
* polish code
* [example] titans for gpt
* polish readme
* remove license
* polish code
* update readme
* [example] titans for gpt (#2484)
* [autoparallel] support origin activation ckpt on autoprallel system (#2468)
* [autochunk] support evoformer tracer (#2485)
support full evoformer tracer, which is a main module of alphafold. previously we just support a simplifed version of it.
1. support some evoformer's op in fx
2. support evoformer test
3. add repos for test code
* [example] fix requirements (#2488)
* [zero] add unit testings for hybrid parallelism (#2486)
* [hotfix] gpt example titans bug #2493
* polish code and fix dataloader bugs
* [hotfix] gpt example titans bug #2493 (#2494)
* [fx] allow control of ckpt_codegen init (#2498)
* [fx] allow control of ckpt_codegen init
Currently in ColoGraphModule, ActivationCheckpointCodeGen will be set automatically in __init__. But other codegen can't be set if so.
So I add an arg to control whether to set ActivationCheckpointCodeGen in __init__.
* code style
* [example] dreambooth example
* add test_ci.sh to dreambooth
* [autochunk] support autochunk on evoformer (#2497)
* Revert "Update parallel_context.py (#2408)"
This reverts commit 7d5640b9db.
* add avg partition (#2483)
Co-authored-by: Ziyue Jiang <ziyue.jiang@gmail.com>
* [auto-chunk] support extramsa (#3) (#2504)
* [utils] lazy init. (#2148)
* [utils] lazy init.
* [utils] remove description.
* [utils] complete.
* [utils] finalize.
* [utils] fix names.
* [autochunk] support parsing blocks (#2506)
* [zero] add strict ddp mode (#2508)
* [zero] add strict ddp mode
* [polish] add comments for strict ddp mode
* [zero] fix test error
* [doc] update opt and tutorial links (#2509)
* [workflow] fixed changed file detection (#2515)
Co-authored-by: oahzxl <xuanlei.zhao@gmail.com>
Co-authored-by: eric8607242 <e0928021388@gmail.com>
Co-authored-by: HELSON <c2h214748@gmail.com>
Co-authored-by: Frank Lee <somerlee.9@gmail.com>
Co-authored-by: Haofan Wang <haofanwang.ai@gmail.com>
Co-authored-by: Jiarui Fang <fangjiarui123@gmail.com>
Co-authored-by: ZijianYY <119492445+ZijianYY@users.noreply.github.com>
Co-authored-by: YuliangLiu0306 <72588413+YuliangLiu0306@users.noreply.github.com>
Co-authored-by: Super Daniel <78588128+super-dainiu@users.noreply.github.com>
Co-authored-by: ver217 <lhx0217@gmail.com>
Co-authored-by: Ziyue Jiang <ziyue.jiang97@gmail.com>
Co-authored-by: Ziyue Jiang <ziyue.jiang@gmail.com>
Co-authored-by: oahzxl <43881818+oahzxl@users.noreply.github.com>
Co-authored-by: binmakeswell <binmakeswell@gmail.com>
Co-authored-by: Fazzie-Maqianli <55798671+Fazziekey@users.noreply.github.com>
Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com>
This commit is contained in:
@@ -1,15 +1,45 @@
|
||||
# Auto-Parallelism with ResNet
|
||||
# Auto-Parallelism
|
||||
|
||||
## Table of contents
|
||||
|
||||
- [Auto-Parallelism](#auto-parallelism)
|
||||
- [Table of contents](#table-of-contents)
|
||||
- [📚 Overview](#-overview)
|
||||
- [🚀 Quick Start](#-quick-start)
|
||||
- [Setup](#setup)
|
||||
- [Auto-Parallel Tutorial](#auto-parallel-tutorial)
|
||||
- [Auto-Checkpoint Tutorial](#auto-checkpoint-tutorial)
|
||||
|
||||
|
||||
## 📚 Overview
|
||||
|
||||
This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this diretory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
|
||||
|
||||
## 🚀 Quick Start
|
||||
|
||||
### Setup
|
||||
|
||||
1. Create a conda environment
|
||||
|
||||
## 🚀Quick Start
|
||||
### Auto-Parallel Tutorial
|
||||
1. Install `pulp` and `coin-or-cbc` for the solver.
|
||||
```bash
|
||||
pip install pulp
|
||||
conda create -n auto python=3.8
|
||||
conda activate auto
|
||||
```
|
||||
|
||||
2. Install `requirements` and `coin-or-cbc` for the solver.
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
conda install -c conda-forge coin-or-cbc
|
||||
```
|
||||
2. Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
|
||||
|
||||
|
||||
### Auto-Parallel Tutorial
|
||||
|
||||
Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
|
||||
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
```
|
||||
|
||||
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
|
||||
@@ -17,57 +47,6 @@ You should expect to the log like this. This log shows the edge cost on the comp
|
||||
|
||||
|
||||
### Auto-Checkpoint Tutorial
|
||||
1. Stay in the `auto_parallel` folder.
|
||||
2. Install the dependencies.
|
||||
```bash
|
||||
pip install matplotlib transformers
|
||||
```
|
||||
3. Run a simple resnet50 benchmark to automatically checkpoint the model.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model resnet50
|
||||
```
|
||||
|
||||
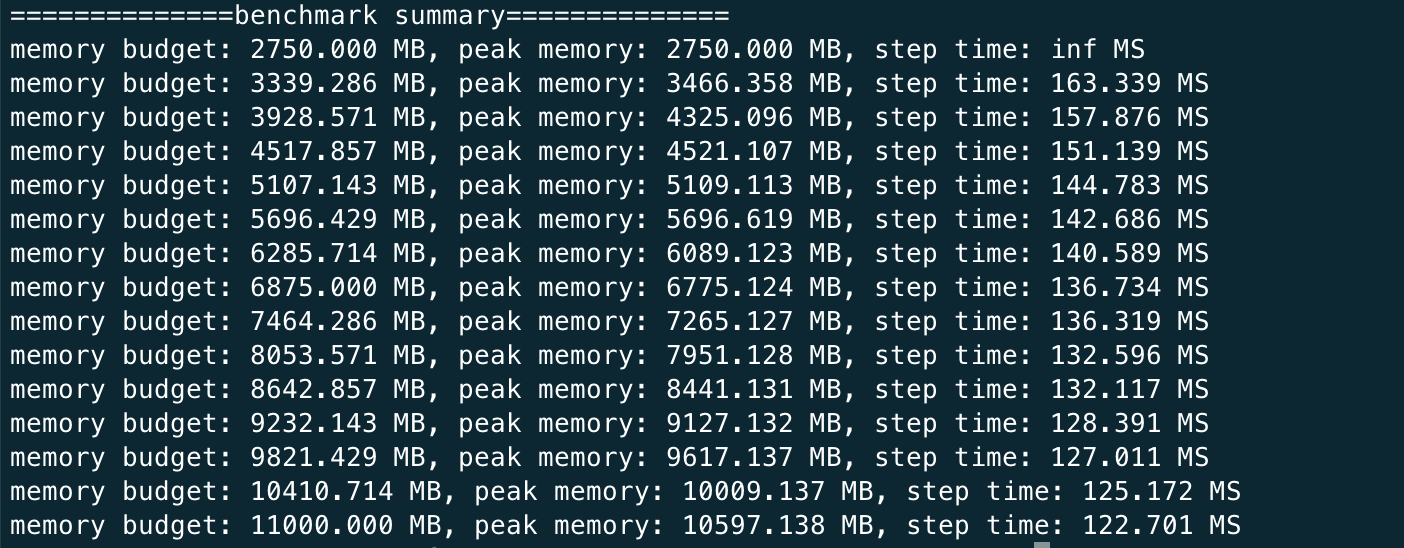
You should expect the log to be like this
|
||||
|
||||
|
||||
This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model gpt2
|
||||
```
|
||||
|
||||
4. Run a simple benchmark to find the optimal batch size for checkpointed model.
|
||||
```bash
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
You can expect the log to be like
|
||||

|
||||
|
||||
|
||||
## Prepare Dataset
|
||||
|
||||
We use CIFAR10 dataset in this example. You should invoke the `donwload_cifar10.py` in the tutorial root directory or directly run the `auto_parallel_with_resnet.py`.
|
||||
The dataset will be downloaded to `colossalai/examples/tutorials/data` by default.
|
||||
If you wish to use customized directory for the dataset. You can set the environment variable `DATA` via the following command.
|
||||
|
||||
```bash
|
||||
export DATA=/path/to/data
|
||||
```
|
||||
|
||||
## extra requirements to use autoparallel
|
||||
|
||||
```bash
|
||||
pip install pulp
|
||||
conda install coin-or-cbc
|
||||
```
|
||||
|
||||
## Run on 2*2 device mesh
|
||||
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
```
|
||||
|
||||
## Auto Checkpoint Benchmarking
|
||||
|
||||
We prepare two bechmarks for you to test the performance of auto checkpoint
|
||||
|
||||
@@ -86,21 +65,3 @@ python auto_ckpt_solver_test.py --model resnet50
|
||||
# tun auto_ckpt_batchsize_test.py
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
There are some results for your reference
|
||||
|
||||
## Auto Checkpoint Solver Test
|
||||
|
||||
### ResNet 50
|
||||
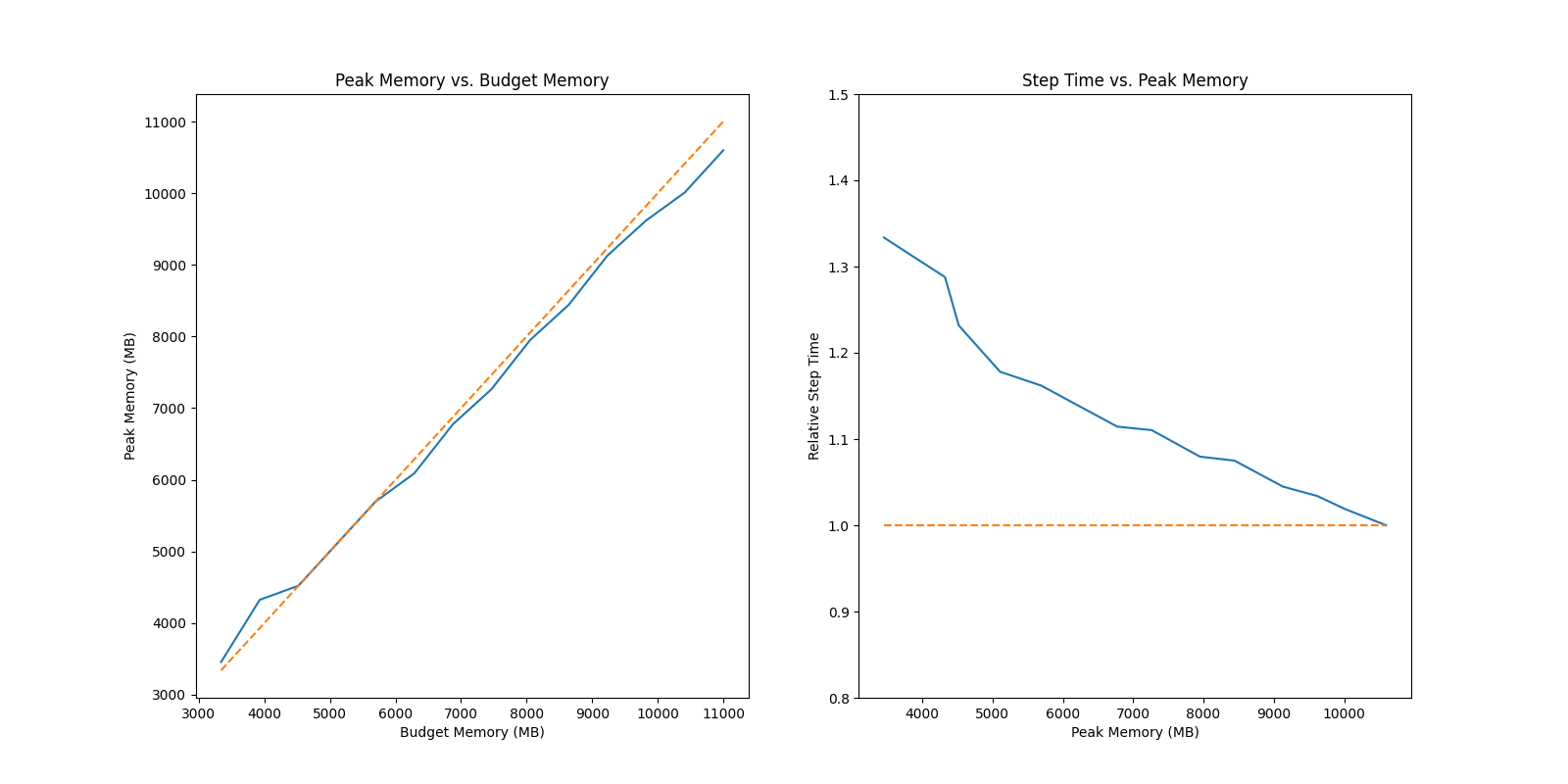
|
||||
|
||||
### GPT2 Medium
|
||||
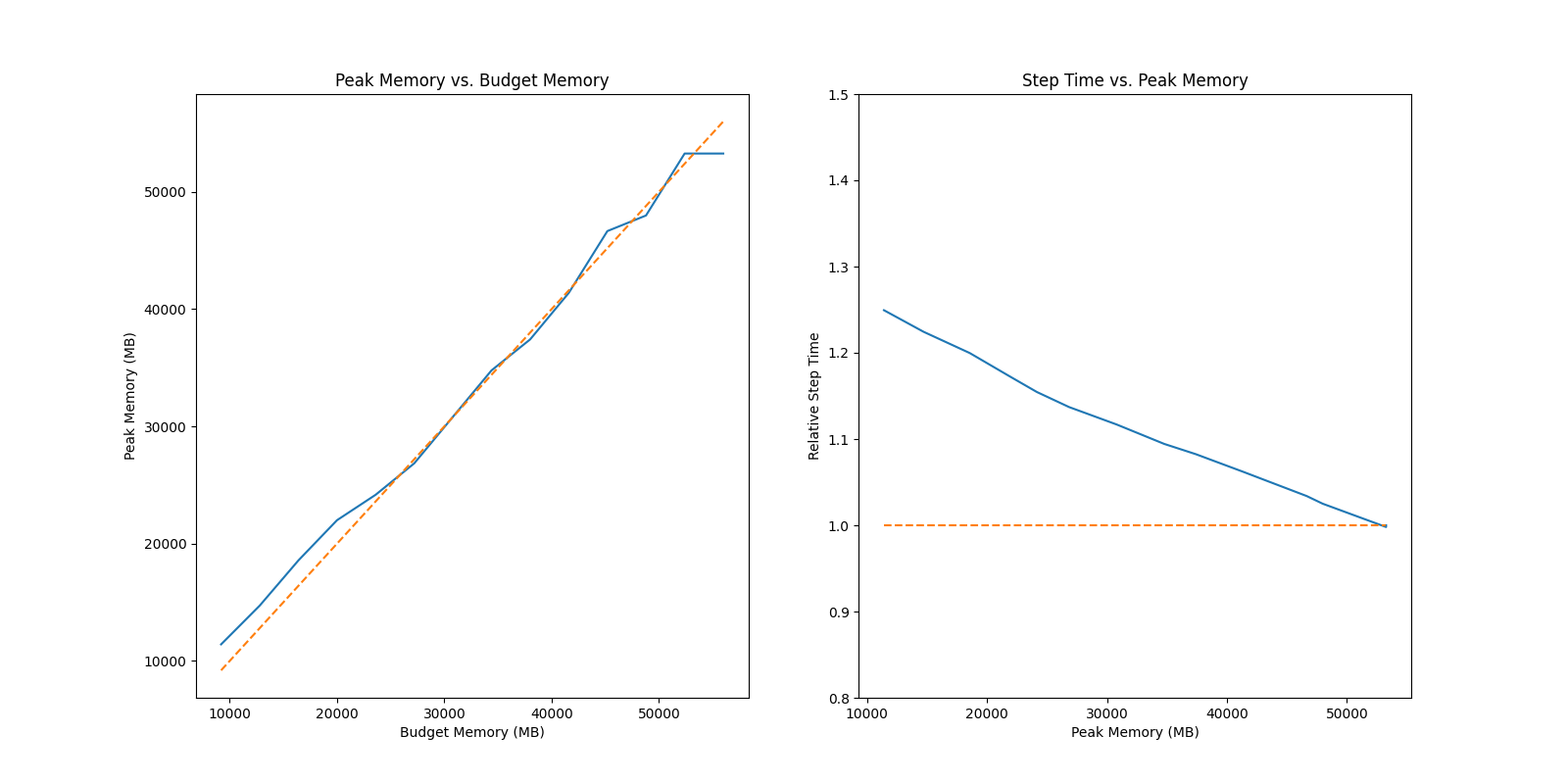
|
||||
|
||||
## Auto Checkpoint Batch Size Test
|
||||
```bash
|
||||
===============test summary================
|
||||
batch_size: 512, peak memory: 73314.392 MB, through put: 254.286 images/s
|
||||
batch_size: 1024, peak memory: 73316.216 MB, through put: 397.608 images/s
|
||||
batch_size: 2048, peak memory: 72927.837 MB, through put: 277.429 images/s
|
||||
```
|
||||
|
||||
@@ -1,37 +1,12 @@
|
||||
import argparse
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from titans.utils import barrier_context
|
||||
from torch.fx import GraphModule
|
||||
from torchvision import transforms
|
||||
from torchvision.datasets import CIFAR10
|
||||
from torchvision.models import resnet50
|
||||
from tqdm import tqdm
|
||||
|
||||
import colossalai
|
||||
from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply_pass
|
||||
from colossalai.auto_parallel.passes.runtime_preparation_pass import runtime_preparation_pass
|
||||
from colossalai.auto_parallel.tensor_shard.solver.cost_graph import CostGraph
|
||||
from colossalai.auto_parallel.tensor_shard.solver.graph_analysis import GraphAnalyser
|
||||
from colossalai.auto_parallel.tensor_shard.solver.options import DataloaderOption, SolverOptions
|
||||
from colossalai.auto_parallel.tensor_shard.solver.solver import Solver
|
||||
from colossalai.auto_parallel.tensor_shard.solver.strategies_constructor import StrategiesConstructor
|
||||
from colossalai.auto_parallel.tensor_shard.initialize import autoparallelize
|
||||
from colossalai.core import global_context as gpc
|
||||
from colossalai.device.device_mesh import DeviceMesh
|
||||
from colossalai.fx.tracer.tracer import ColoTracer
|
||||
from colossalai.logging import get_dist_logger
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingLR
|
||||
from colossalai.utils import get_dataloader
|
||||
|
||||
DATA_ROOT = Path(os.environ.get('DATA', '../data')).absolute()
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('-s', '--synthetic', action="store_true", help="use synthetic dataset instead of CIFAR10")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def synthesize_data():
|
||||
@@ -41,82 +16,15 @@ def synthesize_data():
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
colossalai.launch_from_torch(config='./config.py')
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
if not args.synthetic:
|
||||
with barrier_context():
|
||||
# build dataloaders
|
||||
train_dataset = CIFAR10(root=DATA_ROOT,
|
||||
download=True,
|
||||
transform=transforms.Compose([
|
||||
transforms.RandomCrop(size=32, padding=4),
|
||||
transforms.RandomHorizontalFlip(),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],
|
||||
std=[0.2023, 0.1994, 0.2010]),
|
||||
]))
|
||||
|
||||
test_dataset = CIFAR10(root=DATA_ROOT,
|
||||
train=False,
|
||||
transform=transforms.Compose([
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
|
||||
]))
|
||||
|
||||
train_dataloader = get_dataloader(
|
||||
dataset=train_dataset,
|
||||
add_sampler=True,
|
||||
shuffle=True,
|
||||
batch_size=gpc.config.BATCH_SIZE,
|
||||
pin_memory=True,
|
||||
)
|
||||
|
||||
test_dataloader = get_dataloader(
|
||||
dataset=test_dataset,
|
||||
add_sampler=True,
|
||||
batch_size=gpc.config.BATCH_SIZE,
|
||||
pin_memory=True,
|
||||
)
|
||||
else:
|
||||
train_dataloader, test_dataloader = None, None
|
||||
|
||||
# initialize device mesh
|
||||
physical_mesh_id = torch.arange(0, 4)
|
||||
mesh_shape = (2, 2)
|
||||
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
|
||||
|
||||
# trace the model with meta data
|
||||
tracer = ColoTracer()
|
||||
model = resnet50(num_classes=10).cuda()
|
||||
input_sample = {'x': torch.rand([gpc.config.BATCH_SIZE * torch.distributed.get_world_size(), 3, 32, 32]).to('meta')}
|
||||
graph = tracer.trace(root=model, meta_args=input_sample)
|
||||
gm = GraphModule(model, graph, model.__class__.__name__)
|
||||
gm.recompile()
|
||||
|
||||
# prepare info for solver
|
||||
solver_options = SolverOptions(dataloader_option=DataloaderOption.DISTRIBUTED)
|
||||
strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
|
||||
strategies_constructor.build_strategies_and_cost()
|
||||
cost_graph = CostGraph(strategies_constructor.leaf_strategies)
|
||||
cost_graph.simplify_graph()
|
||||
graph_analyser = GraphAnalyser(gm)
|
||||
|
||||
# solve the solution
|
||||
solver = Solver(gm.graph, strategies_constructor, cost_graph, graph_analyser)
|
||||
ret = solver.call_solver_serialized_args()
|
||||
solution = list(ret[0])
|
||||
if gpc.get_global_rank() == 0:
|
||||
for index, node in enumerate(graph.nodes):
|
||||
print(node.name, node.strategies_vector[solution[index]].name)
|
||||
|
||||
# process the graph for distributed training ability
|
||||
gm, sharding_spec_dict, origin_spec_dict, comm_actions_dict = runtime_preparation_pass(gm, solution, device_mesh)
|
||||
gm = runtime_apply_pass(gm)
|
||||
gm.recompile()
|
||||
|
||||
model = autoparallelize(model, input_sample)
|
||||
# build criterion
|
||||
criterion = torch.nn.CrossEntropyLoss()
|
||||
|
||||
@@ -127,65 +35,45 @@ def main():
|
||||
lr_scheduler = CosineAnnealingLR(optimizer, total_steps=gpc.config.NUM_EPOCHS)
|
||||
|
||||
for epoch in range(gpc.config.NUM_EPOCHS):
|
||||
gm.train()
|
||||
model.train()
|
||||
|
||||
if args.synthetic:
|
||||
# if we use synthetic data
|
||||
# we assume it only has 30 steps per epoch
|
||||
num_steps = range(30)
|
||||
|
||||
else:
|
||||
# we use the actual number of steps for training
|
||||
num_steps = range(len(train_dataloader))
|
||||
data_iter = iter(train_dataloader)
|
||||
# if we use synthetic data
|
||||
# we assume it only has 10 steps per epoch
|
||||
num_steps = range(10)
|
||||
progress = tqdm(num_steps)
|
||||
|
||||
for _ in progress:
|
||||
if args.synthetic:
|
||||
# generate fake data
|
||||
img, label = synthesize_data()
|
||||
else:
|
||||
# get the real data
|
||||
img, label = next(data_iter)
|
||||
# generate fake data
|
||||
img, label = synthesize_data()
|
||||
|
||||
img = img.cuda()
|
||||
label = label.cuda()
|
||||
optimizer.zero_grad()
|
||||
output = gm(img, sharding_spec_dict, origin_spec_dict, comm_actions_dict)
|
||||
output = model(img)
|
||||
train_loss = criterion(output, label)
|
||||
train_loss.backward(train_loss)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
|
||||
# run evaluation
|
||||
gm.eval()
|
||||
model.eval()
|
||||
correct = 0
|
||||
total = 0
|
||||
|
||||
if args.synthetic:
|
||||
# if we use synthetic data
|
||||
# we assume it only has 10 steps for evaluation
|
||||
num_steps = range(30)
|
||||
|
||||
else:
|
||||
# we use the actual number of steps for training
|
||||
num_steps = range(len(test_dataloader))
|
||||
data_iter = iter(test_dataloader)
|
||||
# if we use synthetic data
|
||||
# we assume it only has 10 steps for evaluation
|
||||
num_steps = range(10)
|
||||
progress = tqdm(num_steps)
|
||||
|
||||
for _ in progress:
|
||||
if args.synthetic:
|
||||
# generate fake data
|
||||
img, label = synthesize_data()
|
||||
else:
|
||||
# get the real data
|
||||
img, label = next(data_iter)
|
||||
# generate fake data
|
||||
img, label = synthesize_data()
|
||||
|
||||
img = img.cuda()
|
||||
label = label.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = gm(img, sharding_spec_dict, origin_spec_dict, comm_actions_dict)
|
||||
output = model(img)
|
||||
test_loss = criterion(output, label)
|
||||
pred = torch.argmax(output, dim=-1)
|
||||
correct += torch.sum(pred == label)
|
||||
|
||||
@@ -1,2 +1,2 @@
|
||||
BATCH_SIZE = 128
|
||||
NUM_EPOCHS = 10
|
||||
BATCH_SIZE = 32
|
||||
NUM_EPOCHS = 2
|
||||
|
||||
@@ -1,2 +1,7 @@
|
||||
colossalai >= 0.1.12
|
||||
torch >= 1.8.1
|
||||
torch
|
||||
colossalai
|
||||
titans
|
||||
pulp
|
||||
datasets
|
||||
matplotlib
|
||||
transformers
|
||||
|
||||
13
examples/tutorial/auto_parallel/setup.py
Normal file
13
examples/tutorial/auto_parallel/setup.py
Normal file
@@ -0,0 +1,13 @@
|
||||
from setuptools import find_packages, setup
|
||||
|
||||
setup(
|
||||
name='auto_parallel',
|
||||
version='0.0.1',
|
||||
description='',
|
||||
packages=find_packages(),
|
||||
install_requires=[
|
||||
'torch',
|
||||
'numpy',
|
||||
'tqdm',
|
||||
],
|
||||
)
|
||||
6
examples/tutorial/auto_parallel/test_ci.sh
Normal file
6
examples/tutorial/auto_parallel/test_ci.sh
Normal file
@@ -0,0 +1,6 @@
|
||||
#!/bin/bash
|
||||
set -euxo pipefail
|
||||
|
||||
pip install -r requirements.txt
|
||||
conda install -c conda-forge coin-or-cbc
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
Reference in New Issue
Block a user