diff --git a/applications/ColossalChat/coati/distributed/comm.py b/applications/ColossalChat/coati/distributed/comm.py
index 3824303f5..ae50c9aa5 100644
--- a/applications/ColossalChat/coati/distributed/comm.py
+++ b/applications/ColossalChat/coati/distributed/comm.py
@@ -55,3 +55,32 @@ def ray_broadcast_tensor_dict(
if rank == src:
out_dict = tensor_dict
return out_dict
+
+
+def ray_broadcast_tensor_dict_and_load(
+ producer_obj, tensor_dict: Dict[str, torch.Tensor], src: int = 0, device=None, group_name: str = "default"
+):
+ rank = cc.get_rank(group_name)
+ if rank == src:
+ metadata = []
+ for k, v in tensor_dict.items():
+ metadata.append((k, v.shape, v.dtype))
+ else:
+ metadata = None
+ metadata = ray_broadcast_object(metadata, src, device, group_name)
+ for k, shape, dtype in metadata:
+ if "consumer_global_step" == k:
+ continue
+ if rank == src:
+ tensor = tensor_dict[k]
+ else:
+ out_dict = {}
+ tensor = torch.empty(shape, dtype=dtype, device=device)
+ cc.broadcast(tensor, src, group_name)
+ if rank != src:
+ out_dict[k] = tensor
+ producer_obj.load_state_dict(out_dict)
+ del out_dict
+ torch.npu.empty_cache()
+ if rank == src:
+ out_dict = tensor_dict
diff --git a/applications/ColossalChat/coati/distributed/consumer.py b/applications/ColossalChat/coati/distributed/consumer.py
index c3e97861b..9c64067c1 100644
--- a/applications/ColossalChat/coati/distributed/consumer.py
+++ b/applications/ColossalChat/coati/distributed/consumer.py
@@ -15,7 +15,7 @@ from colossalai.booster.plugin import HybridParallelPlugin
from colossalai.initialize import launch
from colossalai.nn.optimizer import HybridAdam
-from .comm import ray_broadcast_tensor_dict
+from .comm import ray_broadcast_tensor_dict, ray_broadcast_tensor_dict_and_load
from .utils import bind_batch, post_recv, unbind_batch
@@ -172,6 +172,8 @@ class BaseConsumer:
)
self.profiler.enter("step")
loss = self.step(i, pbar, **batch, **raw_mini_batches_metric_dict)
+ del batch
+ del raw_mini_batches_metric_dict
self.profiler.exit("step")
self.buffer = self.buffer[
effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1 :
@@ -303,7 +305,8 @@ class BaseConsumer:
state_dict = self.state_dict()
if self.pp_size > 1:
if self.tp_rank == 0 and self.dp_rank == 0:
- ray_broadcast_tensor_dict(
+ ray_broadcast_tensor_dict_and_load(
+ None,
state_dict,
src=self.num_producers,
device=self.device,
@@ -311,8 +314,12 @@ class BaseConsumer:
)
else:
if self.rank == 0:
- ray_broadcast_tensor_dict(
- state_dict, src=self.num_producers, device=self.device, group_name="sync_model"
+ ray_broadcast_tensor_dict_and_load(
+ None,
+ state_dict,
+ src=self.num_producers,
+ device=self.device,
+ group_name="sync_model",
)
del state_dict
torch.npu.empty_cache()
diff --git a/applications/ColossalChat/coati/distributed/grpo_consumer.py b/applications/ColossalChat/coati/distributed/grpo_consumer.py
index 5dcf3e051..03971e255 100644
--- a/applications/ColossalChat/coati/distributed/grpo_consumer.py
+++ b/applications/ColossalChat/coati/distributed/grpo_consumer.py
@@ -62,6 +62,7 @@ class GRPOConsumer(BaseConsumer):
batch_size,
model_config,
plugin_config,
+ generate_config,
minibatch_size,
save_interval=save_interval,
save_dir=save_dir,
diff --git a/applications/ColossalChat/coati/distributed/producer.py b/applications/ColossalChat/coati/distributed/producer.py
index 8d4de9eed..4be1507d9 100644
--- a/applications/ColossalChat/coati/distributed/producer.py
+++ b/applications/ColossalChat/coati/distributed/producer.py
@@ -17,7 +17,7 @@ from ray.util.collective.types import ReduceOp
from torch.utils.data import DataLoader, DistributedSampler
from transformers import AutoTokenizer
-from .comm import ray_broadcast_tensor_dict
+from .comm import ray_broadcast_tensor_dict, ray_broadcast_tensor_dict_and_load
from .inference_backend import BACKEND_MAP
from .utils import safe_append_to_jsonl_file
@@ -191,6 +191,7 @@ class BaseProducer:
)
else:
cc.init_collective_group(self.num_producers + 1, self.producer_idx, backend="hccl", group_name="sync_model")
+ cc.init_collective_group(self.num_producers, self.producer_idx, backend="hccl", group_name="producer_group")
def rollout(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
raise NotImplementedError
@@ -340,25 +341,16 @@ class BaseProducer:
print(
f"[P{self.producer_idx}] Sync model PP stage {pp_idx} episode {episode} step {(i + 1) // self.num_microbatches - 1}"
)
- state_dict = ray_broadcast_tensor_dict(
- None, self.num_producers, device=self.device, group_name=f"sync_model_{pp_idx}"
+ ray_broadcast_tensor_dict_and_load(
+ self, None, self.num_producers, device=self.device, group_name=f"sync_model_{pp_idx}"
)
- if "consumer_global_step" in state_dict:
- self.consumer_global_step = state_dict.pop("consumer_global_step").item()
- self.load_state_dict(state_dict)
else:
print(
f"[P{self.producer_idx}] Sync model episode {episode} step {(i + 1) // self.num_microbatches - 1}"
)
- state_dict = ray_broadcast_tensor_dict(
- None, self.num_producers, device=self.device, group_name="sync_model"
+ ray_broadcast_tensor_dict_and_load(
+ self, None, self.num_producers, device=self.device, group_name=f"sync_model"
)
- if "consumer_global_step" in state_dict:
- self.consumer_global_step = state_dict.pop("consumer_global_step").item()
- self.load_state_dict(state_dict)
- self.profiler.exit("sync_model")
- del state_dict
- torch.npu.empty_cache()
if isinstance(self.model, BACKEND_MAP["vllm"]) and self.model.model_config.get(
"enable_sleep_mode", False
):
diff --git a/applications/ColossalChat/rl_example.py b/applications/ColossalChat/rl_example.py
index 46ce7cdd7..11233d61a 100644
--- a/applications/ColossalChat/rl_example.py
+++ b/applications/ColossalChat/rl_example.py
@@ -166,6 +166,7 @@ if __name__ == "__main__":
parser.add_argument(
"--enable_profiling", action="store_true", default=False, help="Enable profiling for the training process."
)
+ parser.add_argument("--cpu_offload", action="store_true", default=False, help="Cpu offload.")
args = parser.parse_args()
if args.train_minibatch_size is None:
@@ -251,7 +252,7 @@ if __name__ == "__main__":
)
generate_config.update(
dict(
- max_tokens=args.max_new_tokens, # max new tokens
+ max_tokens=args.max_new_tokens + args.max_prompt_tokens, # max new tokens
include_stop_str_in_output=True,
stop=[""] if args.reward_type == "think_answer_tags" else None,
ignore_eos=True if args.reward_type == "think_answer_tags" else False,
@@ -344,6 +345,7 @@ if __name__ == "__main__":
1, args.train_microbatch_size // args.pipeline_parallel_size
), # microbatch size should be set to train_microbatch_size // pp_size
"zero_stage": args.zero_stage,
+ "cpu_offload": args.cpu_offload,
"max_norm": 1.0,
"enable_flash_attention": True,
"sp_size": args.tensor_parallel_size,
diff --git a/colossalai/shardformer/modeling/qwen2.py b/colossalai/shardformer/modeling/qwen2.py
index de838185d..69dced5ca 100644
--- a/colossalai/shardformer/modeling/qwen2.py
+++ b/colossalai/shardformer/modeling/qwen2.py
@@ -12,10 +12,7 @@ from transformers.modeling_outputs import (
)
try:
- from transformers.modeling_attn_mask_utils import (
- _prepare_4d_causal_attention_mask,
- _prepare_4d_causal_attention_mask_for_sdpa,
- )
+ from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
from transformers.models.qwen2.modeling_qwen2 import (
Qwen2Attention,
Qwen2ForCausalLM,
@@ -132,46 +129,20 @@ class Qwen2PipelineForwards:
else:
position_ids = position_ids.view(-1, seq_length).long()
- if (
- not shard_config.enable_flash_attention
- and attention_mask is not None
- and self._attn_implementation == "flash_attention_2"
- and use_cache
- ):
- is_padding_right = attention_mask[:, -1].sum().item() != batch_size
- if is_padding_right:
- raise ValueError(
- "You are attempting to perform batched generation with padding_side='right'"
- " this may lead to unexpected behaviour for Flash Attention version of Qwen2. Make sure to "
- " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
- )
# embed positions, for the first stage, hidden_states is the input embeddings,
# for the other stages, hidden_states is the output of the previous stage
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
attention_mask = None
else:
- if self._attn_implementation == "flash_attention_2":
- # 2d mask is passed through the layers
- attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
- elif self._attn_implementation == "sdpa" and not output_attentions:
- # output_attentions=True can not be supported when using SDPA, and we fall back on
- # the manual implementation that requires a 4D causal mask in all cases.
- attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
- attention_mask,
- (batch_size, seq_length),
- inputs_embeds,
- past_key_values_length,
- )
- else:
- # 4d mask is passed through the layers
- attention_mask = _prepare_4d_causal_attention_mask(
- attention_mask,
- (batch_size, seq_length),
- hidden_states,
- past_key_values_length,
- sliding_window=self.config.sliding_window,
- )
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ hidden_states,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
if stage_manager.is_first_stage():
if shard_config.enable_sequence_parallelism:
diff --git a/examples/language/performance_evaluator.py b/examples/language/performance_evaluator.py
index def5ebce2..af7e8a165 100644
--- a/examples/language/performance_evaluator.py
+++ b/examples/language/performance_evaluator.py
@@ -161,18 +161,18 @@ class PerformanceEvaluator:
) * (
1.0 + (seq_len / (6.0 * self.hidden_size)) + (self.vocab_size / (16.0 * self.num_layers * self.hidden_size))
)
- self.flop += batch_size * seq_len * self.model_numel * 2 * (3 + int(self.enable_grad_checkpoint))
+ self.flop += batch_size * (seq_len // 1024) * self.model_numel * (3 + int(self.enable_grad_checkpoint))
def on_fit_end(self) -> None:
avg_duration = all_reduce_mean(self.timer.duration, self.coordinator.world_size)
avg_throughput = self.num_samples * self.dp_world_size / (avg_duration + 1e-12)
mp_world_size = self.coordinator.world_size // self.dp_world_size
- avg_tflops_per_gpu_megatron = self.flop_megatron / 1e12 / (avg_duration + 1e-12) / mp_world_size
+ self.flop_megatron / 1e12 / (avg_duration + 1e-12) / mp_world_size
avg_tflops_per_gpu = self.flop / 1e12 / (avg_duration + 1e-12) / mp_world_size
self.coordinator.print_on_master(
f"num_samples: {self.num_samples}, dp_world_size: {self.dp_world_size}, flop_megatron: {self.flop_megatron}, flop: {self.flop}, avg_duration: {avg_duration}, "
f"avg_throughput: {avg_throughput}"
)
self.coordinator.print_on_master(
- f"Throughput: {avg_throughput:.2f} samples/sec, TFLOPS per GPU by Megatron: {avg_tflops_per_gpu_megatron:.2f}, TFLOPS per GPU: {avg_tflops_per_gpu:.2f}"
+ f"Throughput: {avg_throughput:.2f} samples/sec, TFLOPS per GPU: {avg_tflops_per_gpu:.2f}"
)
diff --git a/examples/language/qwen2/README.md b/examples/language/qwen2/README.md
new file mode 100644
index 000000000..fa0c6dc07
--- /dev/null
+++ b/examples/language/qwen2/README.md
@@ -0,0 +1,127 @@
+# Pretraining LLaMA-1/2/3: best practices for building LLaMA-1/2/3-like base models
+### LLaMA3
+
+ +
+
+
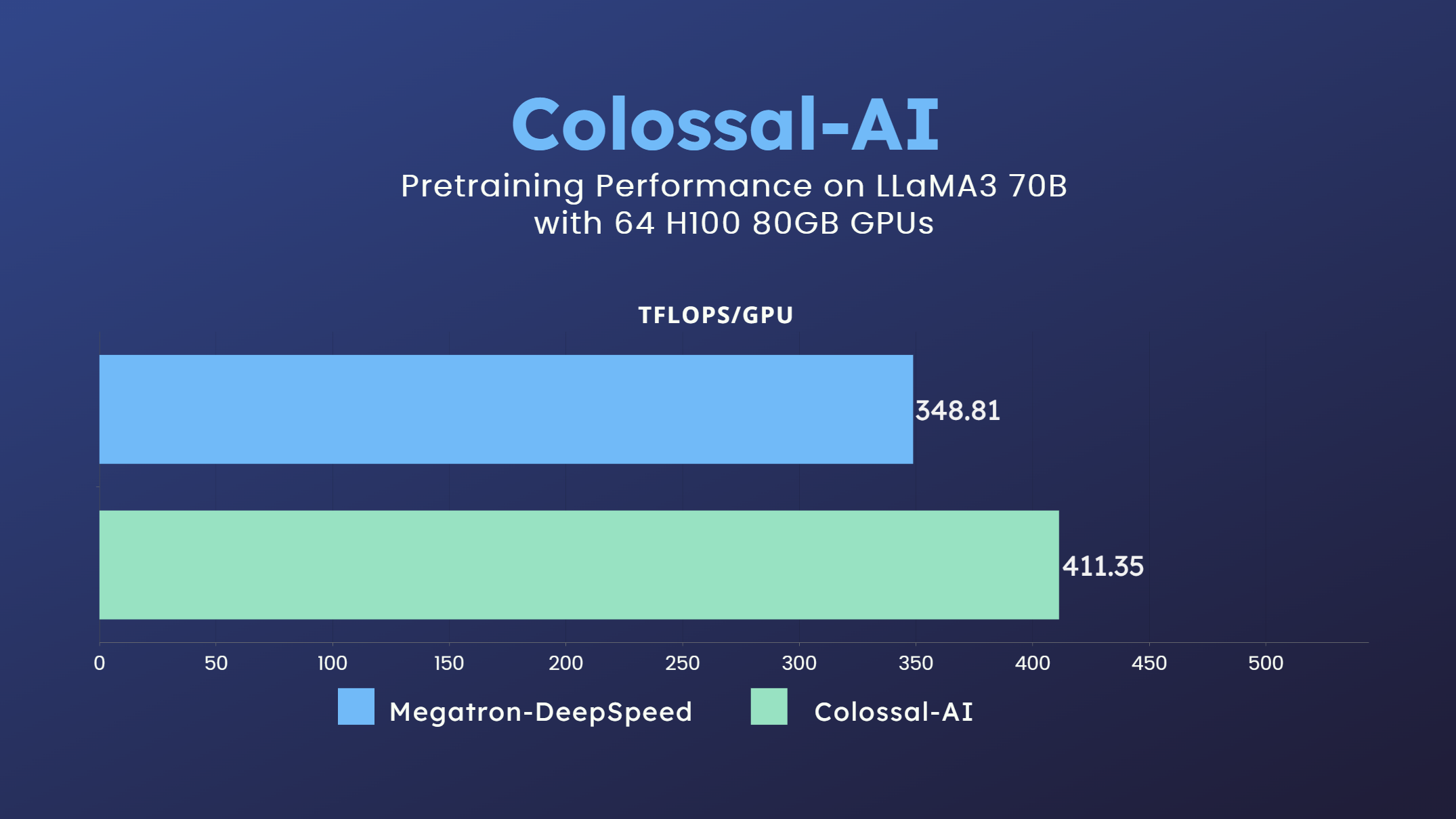
+- 70 billion parameter LLaMA3 model training accelerated by 18%
+
+### LLaMA2
+
+ +
+
+
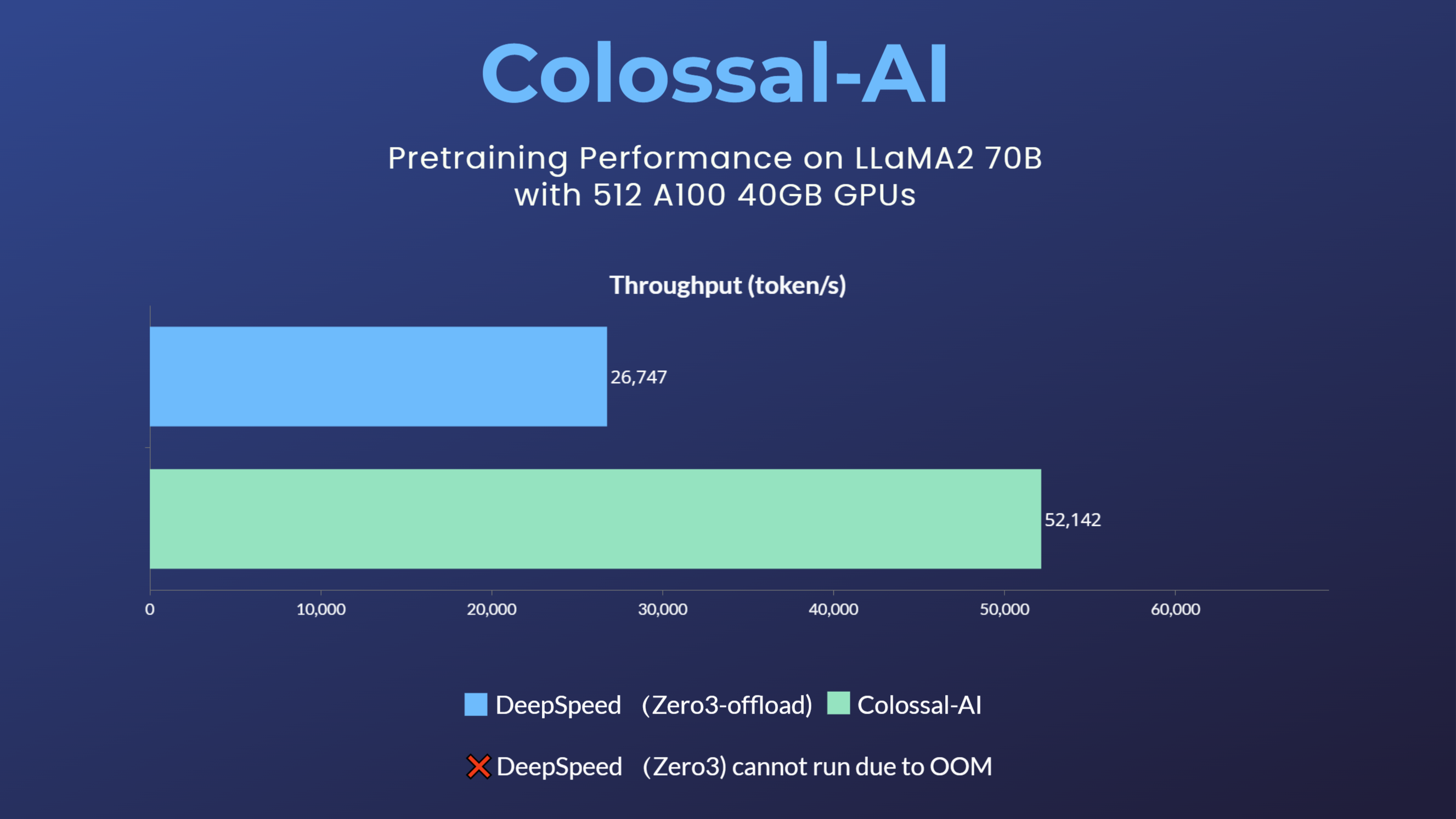
+- 70 billion parameter LLaMA2 model training accelerated by 195%
+[[blog]](https://www.hpc-ai.tech/blog/70b-llama2-training)
+
+### LLaMA1
+
+ +
+
+
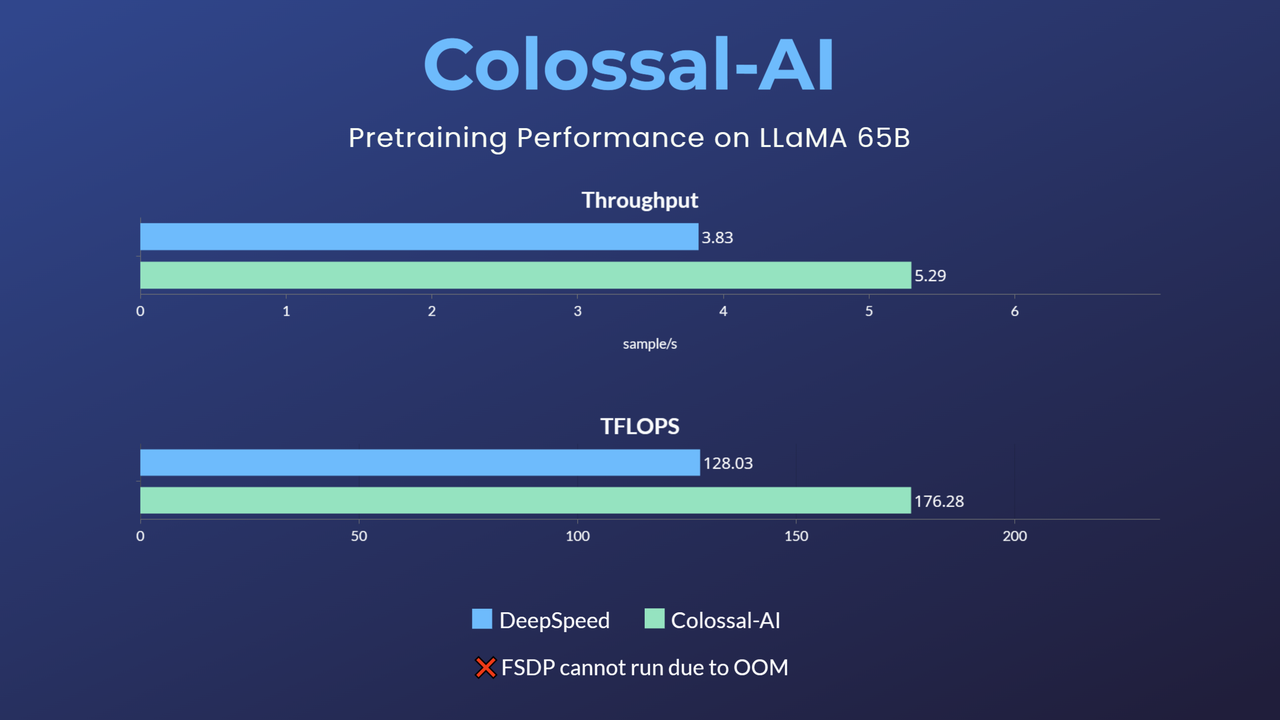
+- 65-billion-parameter large model pretraining accelerated by 38%
+[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
+
+## Usage
+
+> ⚠ This example only has benchmarking script. For training/finetuning, please refer to the [applications/Colossal-LLaMA](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA).
+
+### 1. Installation
+
+Please install the latest ColossalAI from source.
+
+```bash
+BUILD_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
+```
+
+Then install other dependencies.
+
+```bash
+pip install -r requirements.txt
+```
+
+### 4. Shell Script Examples
+
+For your convenience, we provide some shell scripts to run benchmark with various configurations.
+
+You can find them in `scripts/benchmark_7B` and `scripts/benchmark_70B` directory. The main command should be in the format of:
+```bash
+colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
+benchmark.py --OTHER_CONFIGURATIONS
+```
+Here we will show an example of how to run training
+llama pretraining with `gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True`.
+
+#### a. Running environment
+This experiment was performed on 4 computing nodes with 32 A800/H800 80GB GPUs in total for LLaMA-1 65B or LLaMA-2 70B. The nodes are
+connected with RDMA and GPUs within one node are fully connected with NVLink.
+
+#### b. Running command
+
+```bash
+cd scripts/benchmark_7B
+```
+
+First, put your host file (`hosts.txt`) in this directory with your real host ip or host name.
+
+Here is a sample `hosts.txt`:
+```text
+hostname1
+hostname2
+hostname3
+hostname4
+```
+
+Then add environment variables to script if needed.
+
+Finally, run the following command to start training:
+
+```bash
+bash gemini.sh
+```
+
+If you encounter out-of-memory(OOM) error during training with script `gemini.sh`, changing to script `gemini_auto.sh` might be a solution, since gemini_auto will set a upper limit on GPU memory usage through offloading part of the model parameters and optimizer states back to CPU memory. But there's a trade-off: `gemini_auto.sh` will be a bit slower, since more data are transmitted between CPU and GPU.
+
+#### c. Results
+If you run the above command successfully, you will get the following results:
+`max memory usage: 55491.10 MB, throughput: 24.26 samples/s, TFLOPS/GPU: 167.43`.
+
+
+## Reference
+```
+@article{bian2021colossal,
+ title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
+ author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
+ journal={arXiv preprint arXiv:2110.14883},
+ year={2021}
+}
+```
+
+```bibtex
+@software{openlm2023openllama,
+ author = {Geng, Xinyang and Liu, Hao},
+ title = {OpenLLaMA: An Open Reproduction of LLaMA},
+ month = May,
+ year = 2023,
+ url = {https://github.com/openlm-research/open_llama}
+}
+```
+
+```bibtex
+@software{together2023redpajama,
+ author = {Together Computer},
+ title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
+ month = April,
+ year = 2023,
+ url = {https://github.com/togethercomputer/RedPajama-Data}
+}
+```
+
+```bibtex
+@article{touvron2023llama,
+ title={Llama: Open and efficient foundation language models},
+ author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
+ journal={arXiv preprint arXiv:2302.13971},
+ year={2023}
+}
+```
diff --git a/examples/language/qwen2/benchmark.py b/examples/language/qwen2/benchmark.py
new file mode 100644
index 000000000..d37132fd2
--- /dev/null
+++ b/examples/language/qwen2/benchmark.py
@@ -0,0 +1,282 @@
+import argparse
+import resource
+import time
+import warnings
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+from data_utils import RandomDataset
+from performance_evaluator import PerformanceEvaluator, get_profile_context
+from tqdm import tqdm
+from transformers import AutoConfig, Qwen2ForCausalLM
+from transformers.models.qwen2.configuration_qwen2 import Qwen2Config
+
+import colossalai
+from colossalai.accelerator import get_accelerator
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin
+from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.shardformer import PipelineGradientCheckpointConfig
+
+warnings.filterwarnings("ignore")
+# ==============================
+# Constants
+# ==============================
+
+# We have lots of qwen2 for your choice!
+MODEL_CONFIGS = {
+ "7b": Qwen2Config(
+ hidden_size=3584,
+ intermediate_size=18944,
+ num_hidden_layers=28,
+ num_attention_heads=28,
+ num_key_value_heads=4,
+ max_position_embeddings=131072,
+ ),
+ "72b": Qwen2Config(
+ hidden_size=8192,
+ intermediate_size=29568,
+ num_hidden_layers=80,
+ num_attention_heads=64,
+ num_key_value_heads=8,
+ max_position_embeddings=131072,
+ ),
+}
+
+
+def main():
+ # ==============================
+ # Parse Arguments
+ # ==============================
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-c", "--config", type=str, default="7b", help="Model configuration")
+ parser.add_argument("-model", "--model_path", type=str, help="Model path")
+ parser.add_argument(
+ "-p",
+ "--plugin",
+ choices=["gemini", "gemini_auto", "fsdp", "fsdp_cpu", "3d", "3d_cpu"],
+ default="gemini",
+ help="Choose which plugin to use",
+ )
+ parser.add_argument("-b", "--batch_size", type=int, default=2, help="Batch size")
+ parser.add_argument("-s", "--num_steps", type=int, default=10, help="Number of steps to run")
+ parser.add_argument("-i", "--ignore_steps", type=int, default=3, help="Number of steps to ignore")
+ parser.add_argument("-g", "--grad_checkpoint", action="store_true", help="Use gradient checkpointing")
+ parser.add_argument("-l", "--max_length", type=int, default=4096, help="Max sequence length")
+ parser.add_argument(
+ "-w", "--warmup_ratio", type=float, default=0.8, help="warm up ratio of non-model data. Only for gemini-auto"
+ )
+ parser.add_argument("-m", "--memory_limit", type=int, help="Gemini memory limit in mb")
+ parser.add_argument("-x", "--xformers", action="store_true", help="Use xformers")
+ parser.add_argument("--shard_param_frac", type=float, default=1.0, help="Shard param fraction. Only for gemini")
+ parser.add_argument("--offload_optim_frac", type=float, default=0.0, help="Offload optim fraction. Only for gemini")
+ parser.add_argument("--offload_param_frac", type=float, default=0.0, help="Offload param fraction. Only for gemini")
+ parser.add_argument("--tp", type=int, default=1, help="Tensor parallel size")
+ parser.add_argument("--sp", type=int, default=1, help="Sequence parallel size")
+ parser.add_argument("--extra_dp", type=int, default=1, help="Extra data parallel size, used for Gemini")
+ parser.add_argument("--pp", type=int, default=1, help="Pipeline parallel size")
+ parser.add_argument("--mbs", type=int, default=1, help="Micro batch size of pipeline parallel")
+ parser.add_argument("--zero", type=int, default=0, help="Zero Stage when hybrid plugin is enabled")
+ parser.add_argument("--custom-ckpt", action="store_true", help="Customize checkpoint", default=False)
+
+ parser.add_argument("--pp_style", default="1f1b", choices=["1f1b", "interleaved", "zbv"])
+ parser.add_argument("--n_chunks", default=1, help="number of model chunks", type=eval)
+ parser.add_argument("--profile", action="store_true", help="Profile the code")
+ parser.add_argument(
+ "--nsys",
+ action="store_true",
+ help="Use nsys for profiling. \
+ You should put something like this before colossalai launch: \
+ nsys profile -w true -t cuda,cudnn,cublas -s cpu --capture-range=cudaProfilerApi --capture-range-end=stop --cudabacktrace=true -x true --python-backtrace=cuda -o prof_out",
+ )
+ parser.add_argument("--disable-async-reduce", action="store_true", help="Disable the asynchronous reduce operation")
+ parser.add_argument("--prefetch_num", type=int, default=0, help="chunk prefetch max number")
+ parser.add_argument("--no_cache", action="store_true")
+ parser.add_argument("--use_fp8_comm", action="store_true", default=False, help="for using fp8 during communication")
+ parser.add_argument("--use_fp8", action="store_true", default=False, help="for using fp8 linear")
+ parser.add_argument("--overlap_p2p", action="store_true", default=True, help="for using overlap p2p")
+ parser.add_argument("--overlap_allgather", action="store_true")
+ parser.add_argument(
+ "--sp_mode",
+ default="all_to_all",
+ choices=["all_to_all", "ring_attn", "ring", "split_gather"],
+ help="Sequence parallelism mode",
+ )
+ args = parser.parse_args()
+
+ colossalai.launch_from_torch()
+ coordinator = DistCoordinator()
+
+ def empty_init():
+ pass
+
+ # ckpt config for LLaMA3-70B on 64 H100 GPUs
+ hybrid_kwargs = (
+ {
+ "gradient_checkpoint_config": PipelineGradientCheckpointConfig(
+ num_ckpt_layers_per_stage=[19, 19, 19, 13],
+ ),
+ "num_layers_per_stage": [19, 20, 20, 21],
+ "pp_style": "interleaved",
+ }
+ if args.custom_ckpt
+ else {}
+ )
+
+ # ==============================
+ # Initialize Booster
+ # ==============================
+ if args.config in MODEL_CONFIGS:
+ config = MODEL_CONFIGS[args.config]
+ else:
+ config = AutoConfig.from_pretrained(args.config, trust_remote_code=True)
+
+ if args.plugin == "3d":
+ scheduler_nodes = None
+ plugin = HybridParallelPlugin(
+ tp_size=args.tp,
+ pp_size=args.pp,
+ pp_style=args.pp_style,
+ num_model_chunks=args.n_chunks,
+ zero_stage=args.zero,
+ sp_size=args.sp,
+ sequence_parallelism_mode=args.sp_mode,
+ enable_sequence_parallelism=args.sp > 1,
+ enable_fused_normalization=get_accelerator().is_available(),
+ enable_flash_attention=args.xformers,
+ microbatch_size=args.mbs,
+ precision="bf16",
+ enable_metadata_cache=not args.no_cache,
+ overlap_allgather=args.overlap_allgather,
+ use_fp8=args.use_fp8,
+ fp8_communication=args.use_fp8_comm,
+ scheduler_nodes=scheduler_nodes,
+ **hybrid_kwargs,
+ )
+ elif args.plugin == "3d_cpu":
+ plugin = HybridParallelPlugin(
+ tp_size=args.tp,
+ pp_size=args.pp,
+ pp_style=args.pp_style,
+ num_model_chunks=args.n_chunks,
+ zero_stage=args.zero,
+ cpu_offload=True,
+ enable_fused_normalization=get_accelerator().is_available(),
+ enable_flash_attention=args.xformers,
+ microbatch_size=args.mbs,
+ initial_scale=2**8,
+ precision="bf16",
+ overlap_p2p=args.overlap_p2p,
+ use_fp8=args.use_fp8,
+ fp8_communication=args.use_fp8_comm,
+ )
+ else:
+ raise ValueError(f"Unknown plugin {args.plugin}")
+
+ booster = Booster(plugin=plugin)
+
+ # ==============================
+ # Initialize Dataset and Dataloader
+ # ==============================
+ dp_size = getattr(plugin, "dp_size", coordinator.world_size)
+
+ if args.config in MODEL_CONFIGS:
+ config = MODEL_CONFIGS[args.config]
+ else:
+ config = AutoConfig.from_pretrained(args.config, trust_remote_code=True)
+ get_accelerator().manual_seed(42)
+
+ dataset = RandomDataset(
+ num_samples=args.batch_size * args.num_steps * dp_size, max_length=args.max_length, vocab_size=config.vocab_size
+ )
+ dataloader = plugin.prepare_dataloader(dataset, batch_size=args.batch_size, shuffle=True, drop_last=True, seed=42)
+
+ # ==============================
+ # Initialize Model and Optimizer
+ # ==============================
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
+ else nullcontext()
+ )
+
+ model = Qwen2ForCausalLM.from_pretrained(
+ MODEL_PATH, trust_remote_code=True, use_flash_attention_2=False, use_cache=False, attn_implementation="eager"
+ )
+ if args.grad_checkpoint:
+ model.gradient_checkpointing_enable()
+
+ model_numel = 14480488529920
+ num_layers = model.config.num_hidden_layers
+ performance_evaluator = PerformanceEvaluator(
+ model_numel,
+ num_layers,
+ model.config.hidden_size,
+ model.config.vocab_size,
+ args.grad_checkpoint,
+ args.ignore_steps,
+ dp_world_size=dp_size,
+ )
+
+ optimizer = HybridAdam(model.parameters())
+ torch.set_default_dtype(torch.bfloat16)
+ model, optimizer, _, dataloader, _ = booster.boost(model, optimizer, dataloader=dataloader)
+
+ torch.set_default_dtype(torch.float)
+ coordinator.print_on_master(
+ f"Booster init max device memory: {get_accelerator().max_memory_allocated()/1024**2:.2f} MB"
+ )
+ coordinator.print_on_master(
+ f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024:.2f} MB"
+ )
+
+ with get_profile_context(
+ args.profile,
+ args.ignore_steps,
+ 1, # avoid creating massive log files
+ save_dir=f"./profile/{time.strftime('%H:%M', time.localtime())}-{args.plugin}-qwen2-{args.config}",
+ nsys=args.nsys,
+ ) as prof:
+ if isinstance(plugin, HybridParallelPlugin) and args.pp > 1:
+ data_iter = iter(dataloader)
+ for step in tqdm(range(len(dataloader)), desc="Step", disable=not coordinator.is_master()):
+ performance_evaluator.on_step_start(step)
+ outputs = booster.execute_pipeline(
+ data_iter,
+ model,
+ criterion=lambda outputs, inputs: outputs[0],
+ optimizer=optimizer,
+ return_loss=True,
+ )
+ loss = outputs["loss"]
+ if coordinator.is_last_process():
+ print(f"Step {step} loss: {loss}")
+ optimizer.step()
+ optimizer.zero_grad()
+
+ performance_evaluator.on_step_end(input_ids=torch.empty(args.batch_size, args.max_length))
+ prof.step()
+ else:
+ for step, batch in enumerate(tqdm(dataloader, desc="Step", disable=not coordinator.is_master())):
+ performance_evaluator.on_step_start(step)
+ outputs = model(**batch)
+ loss = outputs[0]
+ del outputs # free memory
+
+ if dist.get_rank() == dist.get_world_size() - 1:
+ print(f"Step {step} loss: {loss}")
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ performance_evaluator.on_step_end(**batch)
+ prof.step()
+ performance_evaluator.on_fit_end()
+ coordinator.print_on_master(f"Max device memory usage: {get_accelerator().max_memory_allocated()/1024**2:.2f} MB")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/language/qwen2/data_utils.py b/examples/language/qwen2/data_utils.py
new file mode 120000
index 000000000..2da9822df
--- /dev/null
+++ b/examples/language/qwen2/data_utils.py
@@ -0,0 +1 @@
+../data_utils.py
\ No newline at end of file
diff --git a/examples/language/qwen2/hosts.txt b/examples/language/qwen2/hosts.txt
new file mode 100644
index 000000000..e69de29bb
diff --git a/examples/language/qwen2/hybrid_test_N1C8.sh b/examples/language/qwen2/hybrid_test_N1C8.sh
new file mode 100644
index 000000000..36919901d
--- /dev/null
+++ b/examples/language/qwen2/hybrid_test_N1C8.sh
@@ -0,0 +1,10 @@
+#!/bin/bash
+
+################
+#Load your environments and modules here
+################
+
+export OMP_NUM_THREADS=8
+
+#hybird: zero2+flash_atten+grad_ckpt+bs4
+colossalai run --nproc_per_node 8 benchmark.py -m "/home/grpo/models/Qwen2.5-7B/" -p "3d" -x -g --zero 1 -b 32 --mbs 1 --tp 2 --pp 2 -l 4096
diff --git a/examples/language/qwen2/model_utils.py b/examples/language/qwen2/model_utils.py
new file mode 120000
index 000000000..73c6818a8
--- /dev/null
+++ b/examples/language/qwen2/model_utils.py
@@ -0,0 +1 @@
+../model_utils.py
\ No newline at end of file
diff --git a/examples/language/qwen2/performance_evaluator.py b/examples/language/qwen2/performance_evaluator.py
new file mode 120000
index 000000000..f4736354b
--- /dev/null
+++ b/examples/language/qwen2/performance_evaluator.py
@@ -0,0 +1 @@
+../performance_evaluator.py
\ No newline at end of file
diff --git a/examples/language/qwen2/requirements.txt b/examples/language/qwen2/requirements.txt
new file mode 100644
index 000000000..438a4999a
--- /dev/null
+++ b/examples/language/qwen2/requirements.txt
@@ -0,0 +1,8 @@
+colossalai>=0.3.6
+datasets
+numpy
+tqdm
+transformers
+flash-attn>=2.0.0
+SentencePiece==0.1.99
+tensorboard==2.14.0
diff --git a/examples/language/qwen2/test_ci.sh b/examples/language/qwen2/test_ci.sh
new file mode 100755
index 000000000..e69de29bb