+
+
+
+## Train with dummy prompt data (Stage 3)
+
+This script supports 4 kinds of strategies:
+
+- naive
+- ddp
+- colossalai_zero2
+- colossalai_gemini
+
+It uses random generated prompt data.
+
+Naive strategy only support single GPU training:
+
+```shell
+python train_dummy.py --strategy naive
+# display cli help
+python train_dummy.py -h
+```
+
+DDP strategy and ColossalAI strategy support multi GPUs training:
+
+```shell
+# run DDP on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
+# run ColossalAI on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
+```
+
+## Train with real prompt data (Stage 3)
+
+We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
+
+You should download `prompts.csv` first.
+
+This script also supports 4 strategies.
+
+```shell
+# display cli help
+python train_dummy.py -h
+# run naive on 1 GPU
+python train_prompts.py prompts.csv --strategy naive
+# run DDP on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
+# run ColossalAI on 2 GPUs
+torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
+```
+
+## Inference example(After Stage3)
+We support naive inference demo after training.
+```shell
+# inference, using pretrain path to configure model
+python inference.py --model_path --model --pretrain
+# example
+python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
+```
+
+## Attention
+The examples is just a demo for testing our progress of RM and PPO training.
+
+
+#### data
+- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
+- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
+- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
+- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
+- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
+
+## Support Model
+
+### GPT
+- [x] GPT2-S (s)
+- [x] GPT2-M (m)
+- [x] GPT2-L (l)
+- [ ] GPT2-XL (xl)
+- [x] GPT2-4B (4b)
+- [ ] GPT2-6B (6b)
+- [ ] GPT2-8B (8b)
+- [ ] GPT2-10B (10b)
+- [ ] GPT2-12B (12b)
+- [ ] GPT2-15B (15b)
+- [ ] GPT2-18B (18b)
+- [ ] GPT2-20B (20b)
+- [ ] GPT2-24B (24b)
+- [ ] GPT2-28B (28b)
+- [ ] GPT2-32B (32b)
+- [ ] GPT2-36B (36b)
+- [ ] GPT2-40B (40b)
+- [ ] GPT3 (175b)
+
+### BLOOM
+- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
+- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
+- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
+- [ ] BLOOM-175b
+
+### OPT
+- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
+- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
+- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
+- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
+- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
+- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
+- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
diff --git a/applications/Chat/examples/inference.py b/applications/Chat/examples/inference.py
new file mode 100644
index 000000000..f75950804
--- /dev/null
+++ b/applications/Chat/examples/inference.py
@@ -0,0 +1,59 @@
+import argparse
+
+import torch
+from coati.models.bloom import BLOOMActor
+from coati.models.gpt import GPTActor
+from coati.models.opt import OPTActor
+from transformers import AutoTokenizer
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+
+def eval(args):
+ # configure model
+ if args.model == 'gpt2':
+ actor = GPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain).to(torch.cuda.current_device())
+ elif args.model == 'opt':
+ actor = OPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ state_dict = torch.load(args.model_path)
+ actor.model.load_state_dict(state_dict)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ actor.eval()
+ input = args.input
+ input_ids = tokenizer.encode(input, return_tensors='pt').to(torch.cuda.current_device())
+ outputs = actor.generate(input_ids,
+ max_length=args.max_length,
+ do_sample=True,
+ top_k=50,
+ top_p=0.95,
+ num_return_sequences=1)
+ output = tokenizer.batch_decode(outputs[0], skip_special_tokens=True)
+ print(output)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ # We suggest to use the pretrained model from HuggingFace, use pretrain to configure model
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--model_path', type=str, default=None)
+ parser.add_argument('--input', type=str, default='Question: How are you ? Answer:')
+ parser.add_argument('--max_length', type=int, default=100)
+ args = parser.parse_args()
+ eval(args)
diff --git a/applications/Chat/examples/requirements.txt b/applications/Chat/examples/requirements.txt
new file mode 100644
index 000000000..40e6edc7e
--- /dev/null
+++ b/applications/Chat/examples/requirements.txt
@@ -0,0 +1,2 @@
+pandas>=1.4.1
+sentencepiece
diff --git a/applications/Chat/examples/test_ci.sh b/applications/Chat/examples/test_ci.sh
new file mode 100755
index 000000000..db1d0b64e
--- /dev/null
+++ b/applications/Chat/examples/test_ci.sh
@@ -0,0 +1,97 @@
+#!/usr/bin/env bash
+
+set -xue
+
+if [ -z "$PROMPT_PATH" ]; then
+ echo "Please set \$PROMPT_PATH to the path to prompts csv."
+ exit 1
+fi
+
+BASE=$(realpath $(dirname $0))
+
+export OMP_NUM_THREADS=8
+
+# install requirements
+pip install -r ${BASE}/requirements.txt
+
+# train dummy
+python ${BASE}/train_dummy.py --strategy naive --num_episodes 1 \
+ --max_timesteps 2 --update_timesteps 2 \
+ --max_epochs 1 --train_batch_size 2 --lora_rank 4
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
+ --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_dummy.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
+ --strategy ddp --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_dummy.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
+ --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'gpt2' --model gpt2 --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_dummy.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'gpt2' --model gpt2
+
+rm -rf ${BASE}/actor_checkpoint_dummy.pt
+
+# train prompts
+python ${BASE}/train_prompts.py $PROMPT_PATH --strategy naive --num_episodes 1 \
+ --max_timesteps 2 --update_timesteps 2 \
+ --max_epochs 1 --train_batch_size 2 --lora_rank 4
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
+ --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_prompts.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'facebook/opt-350m' --model opt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
+ --strategy ddp --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'gpt2' --model gpt2 --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_prompts.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
+ --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
+ --pretrain 'gpt2' --model gpt2 --lora_rank 4\
+ --save_path ${BASE}/actor_checkpoint_prompts.pt
+python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
+
+rm -rf ${BASE}/actor_checkpoint_prompts.pt
+
+# train rm
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
+ --pretrain 'facebook/opt-350m' --model 'opt' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig'\
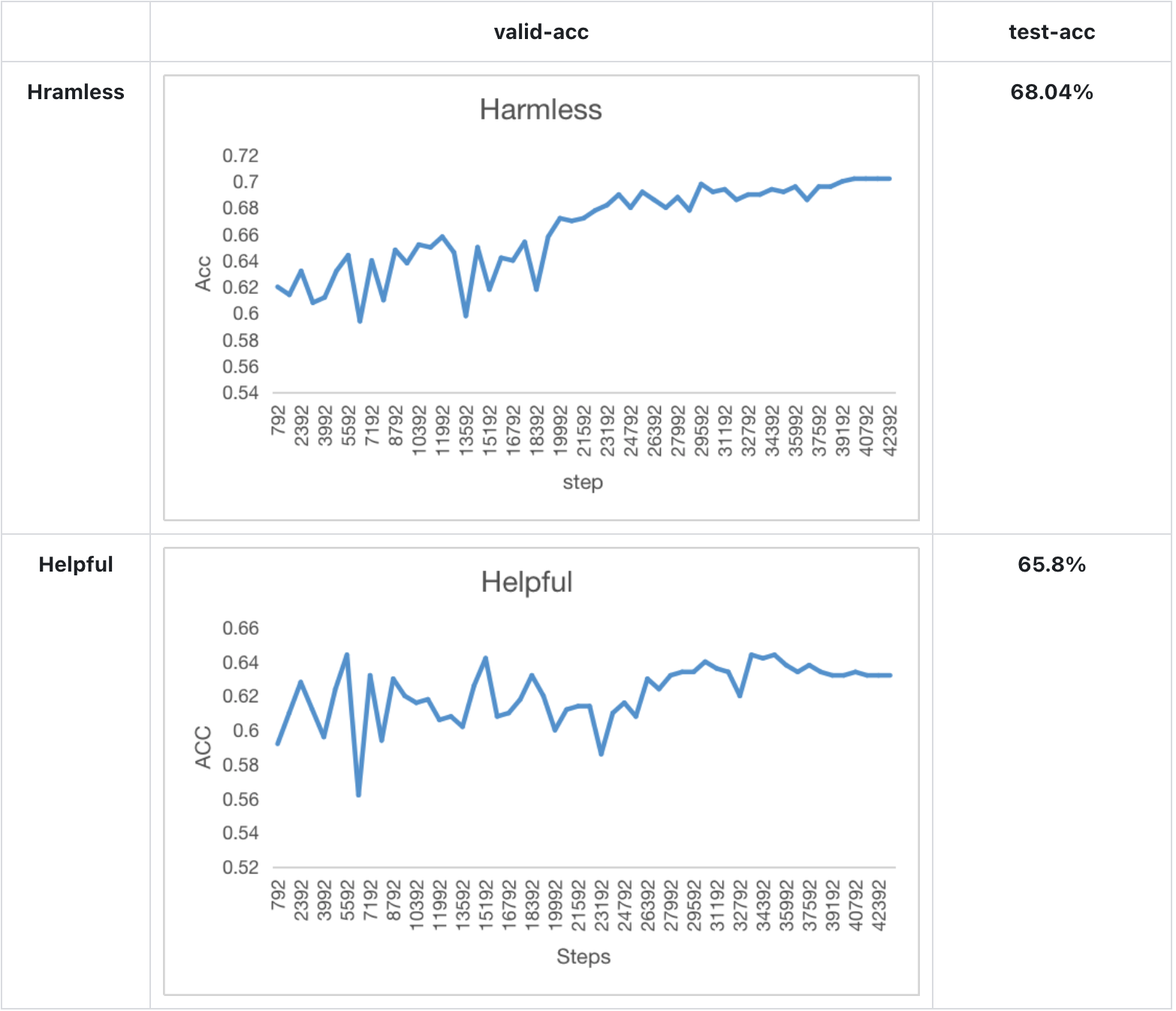
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
+ --test True --lora_rank 4
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
+ --pretrain 'gpt2' --model 'gpt2' \
+ --strategy colossalai_gemini --loss_fn 'log_exp'\
+ --dataset 'Dahoas/rm-static' --test True --lora_rank 4
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
+ --pretrain 'bigscience/bloom-560m' --model 'bloom' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig'\
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
+ --test True --lora_rank 4
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
+ --pretrain 'microsoft/deberta-v3-large' --model 'deberta' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig'\
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
+ --test True --lora_rank 4
+
+rm -rf ${BASE}/rm_ckpt.pt
diff --git a/applications/Chat/examples/train_dummy.py b/applications/Chat/examples/train_dummy.py
new file mode 100644
index 000000000..d944b018d
--- /dev/null
+++ b/applications/Chat/examples/train_dummy.py
@@ -0,0 +1,148 @@
+import argparse
+from copy import deepcopy
+
+import torch
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.models.opt import OPTActor, OPTCritic
+from coati.trainer import PPOTrainer
+from coati.trainer.callbacks import SaveCheckpoint
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def preprocess_batch(samples):
+ input_ids = torch.stack(samples)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.long)
+ return {'input_ids': input_ids, 'attention_mask': attention_mask}
+
+
+def main(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'opt':
+ actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ initial_model = deepcopy(actor).to(torch.cuda.current_device())
+ reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
+ critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=5e-6)
+ critic_optim = Adam(critic.parameters(), lr=5e-6)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
+ (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
+
+ callbacks = []
+ if args.save_ckpt_path:
+ ckpt_callback = SaveCheckpoint(
+ args.save_ckpt_path,
+ args.save_ckpt_interval,
+ strategy,
+ actor,
+ critic,
+ actor_optim,
+ critic_optim,
+ )
+ callbacks.append(ckpt_callback)
+
+ # configure trainer
+
+ trainer = PPOTrainer(strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ tokenizer=preprocess_batch,
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ callbacks=callbacks)
+
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 64), device=torch.cuda.current_device())
+ trainer.fit(random_prompts,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+ # save model checkpoint after fitting
+ trainer.save_model(args.save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(actor_optim,
+ 'actor_optim_checkpoint_dummy_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', type=str, default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_dummy.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=50)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--save_ckpt_path',
+ type=str,
+ default=None,
+ help="path to save checkpoint, None means not to save")
+ parser.add_argument('--save_ckpt_interval', type=int, default=1, help="the interval of episode to save checkpoint")
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/Chat/examples/train_dummy.sh b/applications/Chat/examples/train_dummy.sh
new file mode 100755
index 000000000..595da573e
--- /dev/null
+++ b/applications/Chat/examples/train_dummy.sh
@@ -0,0 +1,18 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
diff --git a/applications/Chat/examples/train_prompts.py b/applications/Chat/examples/train_prompts.py
new file mode 100644
index 000000000..c573f5e6f
--- /dev/null
+++ b/applications/Chat/examples/train_prompts.py
@@ -0,0 +1,199 @@
+import argparse
+
+import pandas as pd
+import torch
+import torch.distributed as dist
+from coati.dataset import DataCollatorForSupervisedDataset, PromptDataset, SupervisedDataset
+from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTRM, GPTActor, GPTCritic
+from coati.models.llama import LlamaActor
+from coati.models.opt import OPTRM, OPTActor, OPTCritic
+from coati.trainer import PPOTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer, LlamaTokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def main(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ if args.rm_path is not None:
+ state_dict = torch.load(args.rm_path, map_location='cpu')
+
+ # configure model
+ if args.model == 'gpt2':
+ initial_model = GPTActor(pretrained=args.pretrain)
+ reward_model = GPTRM(pretrained=args.rm_pretrain)
+ elif args.model == 'bloom':
+ initial_model = BLOOMActor(pretrained=args.pretrain)
+ reward_model = BLOOMRM(pretrained=args.rm_pretrain)
+ elif args.model == 'opt':
+ initial_model = OPTActor(pretrained=args.pretrain)
+ reward_model = OPTRM(pretrained=args.rm_pretrain)
+ elif args.model == 'llama':
+ initial_model = LlamaActor(pretrained=args.pretrain)
+ reward_model = BLOOMRM(pretrained=args.rm_pretrain)
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ if args.rm_path is not None:
+ reward_model.load_state_dict(state_dict)
+
+ if args.strategy != 'colossalai_gemini':
+ initial_model.to(torch.float16).to(torch.cuda.current_device())
+ reward_model.to(torch.float16).to(torch.cuda.current_device())
+
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = GPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'opt':
+ actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = OPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'llama':
+ actor = LlamaActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ if args.rm_path is not None:
+ critic.load_state_dict(state_dict)
+ del state_dict
+
+ if args.strategy != 'colossalai_gemini':
+ critic.to(torch.float16).to(torch.cuda.current_device())
+ actor.to(torch.float16).to(torch.cuda.current_device())
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=1e-7)
+ critic_optim = HybridAdam(critic.parameters(), lr=1e-7)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=1e-7)
+ critic_optim = Adam(critic.parameters(), lr=1e-7)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained('bigscience/bloom-560m')
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'llama':
+ tokenizer = LlamaTokenizer.from_pretrained(args.pretrain)
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, actor)
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+
+ prompt_dataset = PromptDataset(tokenizer=tokenizer, data_path=args.prompt_path, max_datasets_size=16384)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ prompt_sampler = DistributedSampler(prompt_dataset, shuffle=True, seed=42, drop_last=True)
+ prompt_dataloader = DataLoader(prompt_dataset,
+ shuffle=(prompt_sampler is None),
+ sampler=prompt_sampler,
+ batch_size=args.train_batch_size)
+
+ pretrain_dataset = SupervisedDataset(tokenizer=tokenizer, data_path=args.pretrain_dataset, max_datasets_size=16384)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ pretrain_sampler = DistributedSampler(pretrain_dataset, shuffle=True, seed=42, drop_last=True)
+ pretrain_dataloader = DataLoader(pretrain_dataset,
+ shuffle=(pretrain_sampler is None),
+ sampler=pretrain_sampler,
+ batch_size=args.ptx_batch_size,
+ collate_fn=data_collator)
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.to(torch.cuda.current_device()) for k, v in batch.items()}
+
+ (actor, actor_optim), (critic, critic_optim) = strategy.prepare((actor, actor_optim), (critic, critic_optim))
+
+ # configure trainer
+ trainer = PPOTrainer(
+ strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ kl_coef=args.kl_coef,
+ ptx_coef=args.ptx_coef,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ experience_batch_size=args.experience_batch_size,
+ tokenizer=tokenize_fn,
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ )
+
+ trainer.fit(prompt_dataloader=prompt_dataloader,
+ pretrain_dataloader=pretrain_dataloader,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+ # save model checkpoint after fitting
+ trainer.save_model(args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(actor_optim,
+ 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--prompt_path', type=str, default=None, help='path to the prompt dataset')
+ parser.add_argument('--pretrain_dataset', type=str, default=None, help='path to the pretrained dataset')
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive',
+ help='strategy to use')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt', 'llama'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--rm_path', type=str, default=None)
+ parser.add_argument('--rm_pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--ptx_batch_size', type=int, default=1)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--kl_coef', type=float, default=0.1)
+ parser.add_argument('--ptx_coef', type=float, default=0.9)
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/Chat/examples/train_prompts.sh b/applications/Chat/examples/train_prompts.sh
new file mode 100755
index 000000000..db73ac8e8
--- /dev/null
+++ b/applications/Chat/examples/train_prompts.sh
@@ -0,0 +1,18 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
diff --git a/applications/Chat/examples/train_reward_model.py b/applications/Chat/examples/train_reward_model.py
new file mode 100644
index 000000000..729dfa231
--- /dev/null
+++ b/applications/Chat/examples/train_reward_model.py
@@ -0,0 +1,160 @@
+import argparse
+from random import randint
+
+import loralib as lora
+import torch
+from coati.dataset import HhRlhfDataset, RmStaticDataset
+from coati.models import LogExpLoss, LogSigLoss
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMRM
+from coati.models.deberta import DebertaRM
+from coati.models.gpt import GPTRM
+from coati.models.llama import LlamaRM
+from coati.models.opt import OPTRM
+from coati.trainer import RewardModelTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from datasets import load_dataset
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast, DebertaV2Tokenizer, LlamaTokenizer
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def train(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'bloom':
+ model = BLOOMRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'opt':
+ model = OPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'gpt2':
+ model = GPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'deberta':
+ model = DebertaRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'llama':
+ model = LlamaRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ if args.model_path is not None:
+ state_dict = torch.load(args.model_path)
+ model.load_state_dict(state_dict)
+
+ model = model.to(torch.float16)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained('bigscience/bloom-560m')
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'deberta':
+ tokenizer = DebertaV2Tokenizer.from_pretrained('microsoft/deberta-v3-large')
+ elif args.model == 'llama':
+ tokenizer = LlamaTokenizer.from_pretrained(args.pretrain)
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ max_len = args.max_len
+
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ optim = HybridAdam(model.parameters(), lr=5e-6)
+ else:
+ optim = Adam(model.parameters(), lr=5e-6)
+
+ # configure loss function
+ if args.loss_fn == 'log_sig':
+ loss_fn = LogSigLoss()
+ elif args.loss_fn == 'log_exp':
+ loss_fn = LogExpLoss()
+ else:
+ raise ValueError(f'Unsupported loss function "{args.loss_fn}"')
+
+ # prepare for data and dataset
+ if args.subset is not None:
+ data = load_dataset(args.dataset, data_dir=args.subset)
+ else:
+ data = load_dataset(args.dataset)
+
+ if args.test:
+ train_data = data['train'].select(range(100))
+ eval_data = data['test'].select(range(10))
+ else:
+ train_data = data['train']
+ eval_data = data['test']
+ valid_data = data['test'].select((randint(0, len(eval_data) - 1) for _ in range(len(eval_data) // 5)))
+
+ if args.dataset == 'Dahoas/rm-static':
+ train_dataset = RmStaticDataset(train_data, tokenizer, max_len)
+ valid_dataset = RmStaticDataset(valid_data, tokenizer, max_len)
+ eval_dataset = RmStaticDataset(eval_data, tokenizer, max_len)
+ elif args.dataset == 'Anthropic/hh-rlhf':
+ train_dataset = HhRlhfDataset(train_data, tokenizer, max_len)
+ valid_dataset = HhRlhfDataset(valid_data, tokenizer, max_len)
+ eval_dataset = HhRlhfDataset(eval_data, tokenizer, max_len)
+ else:
+ raise ValueError(f'Unsupported dataset "{args.dataset}"')
+
+ trainer = RewardModelTrainer(model=model,
+ strategy=strategy,
+ optim=optim,
+ loss_fn=loss_fn,
+ train_dataset=train_dataset,
+ valid_dataset=valid_dataset,
+ eval_dataset=eval_dataset,
+ batch_size=args.batch_size,
+ max_epochs=args.max_epochs)
+
+ trainer.fit()
+ # save model checkpoint after fitting on only rank0
+ trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(trainer.optimizer,
+ 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'deberta', 'llama'], default='bloom')
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--model_path', type=str, default=None)
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--dataset',
+ type=str,
+ choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static'],
+ default='Dahoas/rm-static')
+ parser.add_argument('--subset', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='rm_ckpt')
+ parser.add_argument('--max_epochs', type=int, default=1)
+ parser.add_argument('--batch_size', type=int, default=1)
+ parser.add_argument('--max_len', type=int, default=512)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--loss_fn', type=str, default='log_sig', choices=['log_sig', 'log_exp'])
+ parser.add_argument('--test', type=bool, default=False)
+ args = parser.parse_args()
+ train(args)
diff --git a/applications/Chat/examples/train_rm.sh b/applications/Chat/examples/train_rm.sh
new file mode 100755
index 000000000..4f9f55b6b
--- /dev/null
+++ b/applications/Chat/examples/train_rm.sh
@@ -0,0 +1,8 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES 1
+
+python train_reward_model.py --pretrain 'microsoft/deberta-v3-large' \
+ --model 'deberta' \
+ --strategy naive \
+ --loss_fn 'log_exp'\
+ --save_path 'rmstatic.pt' \
+ --test True
diff --git a/applications/Chat/examples/train_sft.py b/applications/Chat/examples/train_sft.py
new file mode 100644
index 000000000..035d5a1de
--- /dev/null
+++ b/applications/Chat/examples/train_sft.py
@@ -0,0 +1,184 @@
+import argparse
+import os
+
+import loralib as lora
+import torch
+import torch.distributed as dist
+from coati.dataset import DataCollatorForSupervisedDataset, SFTDataset, SupervisedDataset
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMLM
+from coati.models.gpt import GPTLM
+from coati.models.llama import LlamaLM
+from coati.models.opt import OPTLM
+from coati.trainer import SFTTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from datasets import load_dataset
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.logging import get_dist_logger
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.tensor import ColoParameter
+
+
+def train(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'bloom':
+ model = BLOOMLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'opt':
+ model = OPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'gpt2':
+ model = GPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'llama':
+ model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank,
+ checkpoint=True).to(torch.float16).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'llama':
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrain,
+ padding_side="right",
+ use_fast=False,
+ )
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ tokenizer.pad_token = tokenizer.eos_token
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
+
+ if args.strategy == 'colossalai_gemini':
+ # this is a hack to deal with the resized embedding
+ # to make sure all parameters are ColoParameter for Colossal-AI Gemini Compatiblity
+ for name, param in model.named_parameters():
+ if not isinstance(param, ColoParameter):
+ sub_module_name = '.'.join(name.split('.')[:-1])
+ weight_name = name.split('.')[-1]
+ sub_module = model.get_submodule(sub_module_name)
+ setattr(sub_module, weight_name, ColoParameter(param))
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ optim = HybridAdam(model.parameters(), lr=args.lr, clipping_norm=1.0)
+ else:
+ optim = Adam(model.parameters(), lr=args.lr)
+
+ logger = get_dist_logger()
+
+ # configure dataset
+ if args.dataset == 'yizhongw/self_instruct':
+ train_data = load_dataset(args.dataset, 'super_natural_instructions', split='train')
+ eval_data = load_dataset(args.dataset, 'super_natural_instructions', split='test')
+
+ train_dataset = SFTDataset(train_data, tokenizer)
+ eval_dataset = SFTDataset(eval_data, tokenizer)
+
+ else:
+ train_dataset = SupervisedDataset(tokenizer=tokenizer,
+ data_path=args.dataset,
+ max_datasets_size=args.max_datasets_size)
+ eval_dataset = None
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ train_sampler = DistributedSampler(train_dataset,
+ shuffle=True,
+ seed=42,
+ drop_last=True,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ if eval_dataset is not None:
+ eval_sampler = DistributedSampler(eval_dataset,
+ shuffle=False,
+ seed=42,
+ drop_last=False,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ else:
+ train_sampler = None
+ eval_sampler = None
+
+ train_dataloader = DataLoader(train_dataset,
+ shuffle=(train_sampler is None),
+ sampler=train_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ if eval_dataset is not None:
+ eval_dataloader = DataLoader(eval_dataset,
+ shuffle=(eval_sampler is None),
+ sampler=eval_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ else:
+ eval_dataloader = None
+
+ trainer = SFTTrainer(model=model,
+ strategy=strategy,
+ optim=optim,
+ train_dataloader=train_dataloader,
+ eval_dataloader=eval_dataloader,
+ batch_size=args.batch_size,
+ max_epochs=args.max_epochs,
+ accimulation_steps=args.accimulation_steps)
+
+ trainer.fit(logger=logger, log_interval=args.log_interval)
+
+ # save model checkpoint after fitting on only rank0
+ trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(trainer.optimizer,
+ 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom')
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--dataset', type=str, default=None)
+ parser.add_argument('--max_datasets_size', type=int, default=None)
+ parser.add_argument('--save_path', type=str, default='output')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--max_epochs', type=int, default=3)
+ parser.add_argument('--batch_size', type=int, default=4)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--log_interval', type=int, default=100, help="how many steps to log")
+ parser.add_argument('--lr', type=float, default=5e-6)
+ parser.add_argument('--accimulation_steps', type=int, default=8)
+ args = parser.parse_args()
+ train(args)
diff --git a/applications/Chat/examples/train_sft.sh b/applications/Chat/examples/train_sft.sh
new file mode 100755
index 000000000..73710d1b1
--- /dev/null
+++ b/applications/Chat/examples/train_sft.sh
@@ -0,0 +1,12 @@
+torchrun --standalone --nproc_per_node=4 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 4 \
+ --accimulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
new file mode 100644
index 000000000..3fb330748
--- /dev/null
+++ b/applications/Chat/inference/README.md
@@ -0,0 +1,111 @@
+# Inference
+
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
+
+We support 8-bit quantization (RTN), which is powered by [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) and [transformers](https://github.com/huggingface/transformers). And 4-bit quantization (GPTQ), which is powered by [gptq](https://github.com/IST-DASLab/gptq) and [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). We also support FP16 inference.
+
+We only support LLaMA family models now.
+
+## Choosing precision (quantization)
+
+**FP16**: Fastest, best output quality, highest memory usage
+
+**8-bit**: Slow, easier setup (originally supported by transformers), lower output quality (due to RTN), **recommended for first-timers**
+
+**4-bit**: Faster, lowest memory usage, higher output quality (due to GPTQ), but more difficult setup
+
+## Hardware requirements for LLaMA
+
+Tha data is from [LLaMA Int8 4bit ChatBot Guide v2](https://rentry.org/llama-tard-v2).
+
+### 8-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
+| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
+| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
+| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
+
+### 4-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
+| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
+| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
+| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
+
+## 8-bit setup
+
+8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
+
+Please ensure you have downloaded HF-format model weights of LLaMA models.
+
+Usage:
+
+```python
+from transformers import LlamaForCausalLM
+
+USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
+
+model = LlamaForCausalLM.from_pretrained(
+ "pretrained/path",
+ load_in_8bit=USE_8BIT,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+if not USE_8BIT:
+ model.half() # use fp16
+model.eval()
+```
+
+**Troubleshooting**: if you get error indicating your CUDA-related libraries not found when loading 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
+
+E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
+
+## 4-bit setup
+
+Please ensure you have downloaded HF-format model weights of LLaMA models first.
+
+Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight convertion script.
+
+After installing this lib, we may convert the original HF-format LLaMA model weights to 4-bit version.
+
+```shell
+CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
+```
+
+Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
+
+**Troubleshooting**: if you get error about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+
+## Online inference server
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16, will listen on 0.0.0.0:7070 by default
+python server.py /path/to/pretrained
+# 8-bit, will listen on localhost:8080
+python server.py /path/to/pretrained --quant 8bit --http_host localhost --http_port 8080
+# 4-bit
+python server.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+## Benchmark
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16
+python benchmark.py /path/to/pretrained
+# 8-bit
+python benchmark.py /path/to/pretrained --quant 8bit
+# 4-bit
+python benchmark.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+This benchmark will record throughput and peak CUDA memory usage.
diff --git a/applications/Chat/inference/benchmark.py b/applications/Chat/inference/benchmark.py
new file mode 100644
index 000000000..59cd1eeea
--- /dev/null
+++ b/applications/Chat/inference/benchmark.py
@@ -0,0 +1,132 @@
+# Adapted from https://github.com/tloen/alpaca-lora/blob/main/generate.py
+
+import argparse
+from time import time
+
+import torch
+from llama_gptq import load_quant
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+
+
+def generate_prompt(instruction, input=None):
+ if input:
+ return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Input:
+{input}
+
+### Response:"""
+ else:
+ return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Response:"""
+
+
+@torch.no_grad()
+def evaluate(
+ model,
+ tokenizer,
+ instruction,
+ input=None,
+ temperature=0.1,
+ top_p=0.75,
+ top_k=40,
+ num_beams=4,
+ max_new_tokens=128,
+ **kwargs,
+):
+ prompt = generate_prompt(instruction, input)
+ inputs = tokenizer(prompt, return_tensors="pt")
+ input_ids = inputs["input_ids"].cuda()
+ generation_config = GenerationConfig(
+ temperature=temperature,
+ top_p=top_p,
+ top_k=top_k,
+ num_beams=num_beams,
+ **kwargs,
+ )
+ generation_output = model.generate(
+ input_ids=input_ids,
+ generation_config=generation_config,
+ return_dict_in_generate=True,
+ output_scores=True,
+ max_new_tokens=max_new_tokens,
+ do_sample=True,
+ )
+ s = generation_output.sequences[0]
+ output = tokenizer.decode(s)
+ n_new_tokens = s.size(0) - input_ids.size(1)
+ return output.split("### Response:")[1].strip(), n_new_tokens
+
+
+instructions = [
+ "Tell me about alpacas.",
+ "Tell me about the president of Mexico in 2019.",
+ "Tell me about the king of France in 2019.",
+ "List all Canadian provinces in alphabetical order.",
+ "Write a Python program that prints the first 10 Fibonacci numbers.",
+ "Write a program that prints the numbers from 1 to 100. But for multiples of three print 'Fizz' instead of the number and for the multiples of five print 'Buzz'. For numbers which are multiples of both three and five print 'FizzBuzz'.",
+ "Tell me five words that rhyme with 'shock'.",
+ "Translate the sentence 'I have no mouth but I must scream' into Spanish.",
+ "Count up from 1 to 500.",
+ # ===
+ "How to play support in legends of league",
+ "Write a Python program that calculate Fibonacci numbers.",
+]
+inst = [instructions[0]] * 4
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ total_tokens = 0
+ start = time()
+ for instruction in instructions:
+ print(f"Instruction: {instruction}")
+ resp, tokens = evaluate(model, tokenizer, instruction, temparature=0.2, num_beams=1)
+ total_tokens += tokens
+ print(f"Response: {resp}")
+ print('\n----------------------------\n')
+ duration = time() - start
+ print(f'Total time: {duration:.3f} s, {total_tokens/duration:.3f} tokens/s')
+ print(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.3f} GB')
diff --git a/applications/Chat/inference/llama_gptq/__init__.py b/applications/Chat/inference/llama_gptq/__init__.py
new file mode 100644
index 000000000..51c8d6316
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/__init__.py
@@ -0,0 +1,5 @@
+from .loader import load_quant
+
+__all__ = [
+ 'load_quant',
+]
diff --git a/applications/Chat/inference/llama_gptq/loader.py b/applications/Chat/inference/llama_gptq/loader.py
new file mode 100644
index 000000000..a5c6ac7d1
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/loader.py
@@ -0,0 +1,41 @@
+import torch
+import torch.nn as nn
+import transformers
+from transformers import LlamaConfig, LlamaForCausalLM
+
+from .model_utils import find_layers
+from .quant import make_quant
+
+
+def load_quant(pretrained: str, checkpoint: str, wbits: int, groupsize: int):
+ config = LlamaConfig.from_pretrained(pretrained)
+
+ def noop(*args, **kwargs):
+ pass
+
+ torch.nn.init.kaiming_uniform_ = noop
+ torch.nn.init.uniform_ = noop
+ torch.nn.init.normal_ = noop
+
+ torch.set_default_dtype(torch.half)
+ transformers.modeling_utils._init_weights = False
+ torch.set_default_dtype(torch.half)
+ model = LlamaForCausalLM(config)
+ torch.set_default_dtype(torch.float)
+ model = model.eval()
+ layers = find_layers(model)
+ for name in ['lm_head']:
+ if name in layers:
+ del layers[name]
+ make_quant(model, layers, wbits, groupsize)
+
+ print(f'Loading model with {wbits} bits...')
+ if checkpoint.endswith('.safetensors'):
+ from safetensors.torch import load_file as safe_load
+ model.load_state_dict(safe_load(checkpoint))
+ else:
+ model.load_state_dict(torch.load(checkpoint))
+ model.seqlen = 2048
+ print('Done.')
+
+ return model
diff --git a/applications/Chat/inference/llama_gptq/model_utils.py b/applications/Chat/inference/llama_gptq/model_utils.py
new file mode 100644
index 000000000..62db171ab
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/model_utils.py
@@ -0,0 +1,13 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/modelutils.py
+
+import torch
+import torch.nn as nn
+
+
+def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=''):
+ if type(module) in layers:
+ return {name: module}
+ res = {}
+ for name1, child in module.named_children():
+ res.update(find_layers(child, layers=layers, name=name + '.' + name1 if name != '' else name1))
+ return res
diff --git a/applications/Chat/inference/llama_gptq/quant.py b/applications/Chat/inference/llama_gptq/quant.py
new file mode 100644
index 000000000..f7d5b7ce4
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/quant.py
@@ -0,0 +1,283 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/quant.py
+
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+
+def quantize(x, scale, zero, maxq):
+ q = torch.clamp(torch.round(x / scale) + zero, 0, maxq)
+ return scale * (q - zero)
+
+
+class Quantizer(nn.Module):
+
+ def __init__(self, shape=1):
+ super(Quantizer, self).__init__()
+ self.register_buffer('maxq', torch.tensor(0))
+ self.register_buffer('scale', torch.zeros(shape))
+ self.register_buffer('zero', torch.zeros(shape))
+
+ def configure(self, bits, perchannel=False, sym=True, mse=False, norm=2.4, grid=100, maxshrink=.8):
+ self.maxq = torch.tensor(2**bits - 1)
+ self.perchannel = perchannel
+ self.sym = sym
+ self.mse = mse
+ self.norm = norm
+ self.grid = grid
+ self.maxshrink = maxshrink
+
+ def find_params(self, x, weight=False):
+ dev = x.device
+ self.maxq = self.maxq.to(dev)
+
+ shape = x.shape
+ if self.perchannel:
+ if weight:
+ x = x.flatten(1)
+ else:
+ if len(shape) == 4:
+ x = x.permute([1, 0, 2, 3])
+ x = x.flatten(1)
+ if len(shape) == 3:
+ x = x.reshape((-1, shape[-1])).t()
+ if len(shape) == 2:
+ x = x.t()
+ else:
+ x = x.flatten().unsqueeze(0)
+
+ tmp = torch.zeros(x.shape[0], device=dev)
+ xmin = torch.minimum(x.min(1)[0], tmp)
+ xmax = torch.maximum(x.max(1)[0], tmp)
+
+ if self.sym:
+ xmax = torch.maximum(torch.abs(xmin), xmax)
+ tmp = xmin < 0
+ if torch.any(tmp):
+ xmin[tmp] = -xmax[tmp]
+ tmp = (xmin == 0) & (xmax == 0)
+ xmin[tmp] = -1
+ xmax[tmp] = +1
+
+ self.scale = (xmax - xmin) / self.maxq
+ if self.sym:
+ self.zero = torch.full_like(self.scale, (self.maxq + 1) / 2)
+ else:
+ self.zero = torch.round(-xmin / self.scale)
+
+ if self.mse:
+ best = torch.full([x.shape[0]], float('inf'), device=dev)
+ for i in range(int(self.maxshrink * self.grid)):
+ p = 1 - i / self.grid
+ xmin1 = p * xmin
+ xmax1 = p * xmax
+ scale1 = (xmax1 - xmin1) / self.maxq
+ zero1 = torch.round(-xmin1 / scale1) if not self.sym else self.zero
+ q = quantize(x, scale1.unsqueeze(1), zero1.unsqueeze(1), self.maxq)
+ q -= x
+ q.abs_()
+ q.pow_(self.norm)
+ err = torch.sum(q, 1)
+ tmp = err < best
+ if torch.any(tmp):
+ best[tmp] = err[tmp]
+ self.scale[tmp] = scale1[tmp]
+ self.zero[tmp] = zero1[tmp]
+ if not self.perchannel:
+ if weight:
+ tmp = shape[0]
+ else:
+ tmp = shape[1] if len(shape) != 3 else shape[2]
+ self.scale = self.scale.repeat(tmp)
+ self.zero = self.zero.repeat(tmp)
+
+ if weight:
+ shape = [-1] + [1] * (len(shape) - 1)
+ self.scale = self.scale.reshape(shape)
+ self.zero = self.zero.reshape(shape)
+ return
+ if len(shape) == 4:
+ self.scale = self.scale.reshape((1, -1, 1, 1))
+ self.zero = self.zero.reshape((1, -1, 1, 1))
+ if len(shape) == 3:
+ self.scale = self.scale.reshape((1, 1, -1))
+ self.zero = self.zero.reshape((1, 1, -1))
+ if len(shape) == 2:
+ self.scale = self.scale.unsqueeze(0)
+ self.zero = self.zero.unsqueeze(0)
+
+ def quantize(self, x):
+ if self.ready():
+ return quantize(x, self.scale, self.zero, self.maxq)
+ return x
+
+ def enabled(self):
+ return self.maxq > 0
+
+ def ready(self):
+ return torch.all(self.scale != 0)
+
+
+try:
+ import quant_cuda
+except:
+ print('CUDA extension not installed.')
+
+# Assumes layer is perfectly divisible into 256 * 256 blocks
+
+
+class QuantLinear(nn.Module):
+
+ def __init__(self, bits, groupsize, infeatures, outfeatures):
+ super().__init__()
+ if bits not in [2, 3, 4, 8]:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ self.infeatures = infeatures
+ self.outfeatures = outfeatures
+ self.bits = bits
+ if groupsize != -1 and groupsize < 32 and groupsize != int(math.pow(2, int(math.log2(groupsize)))):
+ raise NotImplementedError("groupsize supports powers of 2 greater than 32. (e.g. : 32,64,128,etc)")
+ groupsize = groupsize if groupsize != -1 else infeatures
+ self.groupsize = groupsize
+ self.register_buffer(
+ 'qzeros', torch.zeros((math.ceil(infeatures / groupsize), outfeatures // 256 * (bits * 8)),
+ dtype=torch.int))
+ self.register_buffer('scales', torch.zeros((math.ceil(infeatures / groupsize), outfeatures)))
+ self.register_buffer('bias', torch.zeros(outfeatures))
+ self.register_buffer('qweight', torch.zeros((infeatures // 256 * (bits * 8), outfeatures), dtype=torch.int))
+ self._initialized_quant_state = False
+
+ def pack(self, linear, scales, zeros):
+ scales = scales.t().contiguous()
+ zeros = zeros.t().contiguous()
+ scale_zeros = zeros * scales
+ self.scales = scales.clone()
+ if linear.bias is not None:
+ self.bias = linear.bias.clone()
+
+ intweight = []
+ for idx in range(self.infeatures):
+ g_idx = idx // self.groupsize
+ intweight.append(
+ torch.round((linear.weight.data[:, idx] + scale_zeros[g_idx]) / self.scales[g_idx]).to(torch.int)[:,
+ None])
+ intweight = torch.cat(intweight, dim=1)
+ intweight = intweight.t().contiguous()
+ intweight = intweight.numpy().astype(np.uint32)
+ qweight = np.zeros((intweight.shape[0] // 256 * (self.bits * 8), intweight.shape[1]), dtype=np.uint32)
+ i = 0
+ row = 0
+ while row < qweight.shape[0]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qweight[row] |= intweight[j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ row += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i))
+ i += 10
+ qweight[row] |= intweight[i] << 30
+ row += 1
+ qweight[row] |= (intweight[i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 1)
+ i += 10
+ qweight[row] |= intweight[i] << 31
+ row += 1
+ qweight[row] |= (intweight[i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 2)
+ i += 10
+ row += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qweight = qweight.astype(np.int32)
+ self.qweight = torch.from_numpy(qweight)
+
+ zeros -= 1
+ zeros = zeros.numpy().astype(np.uint32)
+ qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // 256 * (self.bits * 8)), dtype=np.uint32)
+ i = 0
+ col = 0
+ while col < qzeros.shape[1]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ col += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i))
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 30
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 1)
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 31
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 2)
+ i += 10
+ col += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qzeros = qzeros.astype(np.int32)
+ self.qzeros = torch.from_numpy(qzeros)
+
+ def forward(self, x):
+ intermediate_dtype = torch.float32
+
+ if not self._initialized_quant_state:
+ # Do we even have a bias? Check for at least one non-zero element.
+ if self.bias is not None and bool(torch.any(self.bias != 0)):
+ # Then make sure it's the right type.
+ self.bias.data = self.bias.data.to(intermediate_dtype)
+ else:
+ self.bias = None
+
+ outshape = list(x.shape)
+ outshape[-1] = self.outfeatures
+ x = x.reshape(-1, x.shape[-1])
+ if self.bias is None:
+ y = torch.zeros(x.shape[0], outshape[-1], dtype=intermediate_dtype, device=x.device)
+ else:
+ y = self.bias.clone().repeat(x.shape[0], 1)
+
+ output_dtype = x.dtype
+ x = x.to(intermediate_dtype)
+ if self.bits == 2:
+ quant_cuda.vecquant2matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 3:
+ quant_cuda.vecquant3matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 4:
+ quant_cuda.vecquant4matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 8:
+ quant_cuda.vecquant8matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ y = y.to(output_dtype)
+ return y.reshape(outshape)
+
+
+def make_quant(module, names, bits, groupsize, name=''):
+ if isinstance(module, QuantLinear):
+ return
+ for attr in dir(module):
+ tmp = getattr(module, attr)
+ name1 = name + '.' + attr if name != '' else attr
+ if name1 in names:
+ setattr(module, attr, QuantLinear(bits, groupsize, tmp.in_features, tmp.out_features))
+ for name1, child in module.named_children():
+ make_quant(child, names, bits, groupsize, name + '.' + name1 if name != '' else name1)
diff --git a/applications/Chat/inference/locustfile.py b/applications/Chat/inference/locustfile.py
new file mode 100644
index 000000000..51cdc6812
--- /dev/null
+++ b/applications/Chat/inference/locustfile.py
@@ -0,0 +1,27 @@
+from json import JSONDecodeError
+
+from locust import HttpUser, task
+
+samples = [[
+ dict(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ dict(instruction='continue this talk', response=''),
+], [
+ dict(instruction='Who is the best player in the history of NBA?', response=''),
+]]
+
+
+class GenerationUser(HttpUser):
+
+ @task
+ def generate(self):
+ for sample in samples:
+ data = {'max_new_tokens': 64, 'history': sample}
+ with self.client.post('/generate', json=data, catch_response=True) as response:
+ if response.status_code in (200, 406):
+ response.success()
+ else:
+ response.failure('Response wrong')
diff --git a/applications/Chat/inference/requirements.txt b/applications/Chat/inference/requirements.txt
new file mode 100644
index 000000000..67a9874e5
--- /dev/null
+++ b/applications/Chat/inference/requirements.txt
@@ -0,0 +1,10 @@
+fastapi
+locustio
+numpy
+pydantic
+safetensors
+slowapi
+sse_starlette
+torch
+uvicorn
+git+https://github.com/huggingface/transformers
diff --git a/applications/Chat/inference/server.py b/applications/Chat/inference/server.py
new file mode 100644
index 000000000..46a8b9a05
--- /dev/null
+++ b/applications/Chat/inference/server.py
@@ -0,0 +1,165 @@
+import argparse
+import os
+from threading import Lock
+from typing import Dict, Generator, List, Optional
+
+import torch
+import uvicorn
+from fastapi import FastAPI, HTTPException, Request
+from fastapi.middleware.cors import CORSMiddleware
+from llama_gptq import load_quant
+from pydantic import BaseModel, Field
+from slowapi import Limiter, _rate_limit_exceeded_handler
+from slowapi.errors import RateLimitExceeded
+from slowapi.util import get_remote_address
+from sse_starlette.sse import EventSourceResponse
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+from utils import ChatPromptProcessor, Dialogue, LockedIterator, sample_streamingly, update_model_kwargs_fn
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+MAX_LEN = 2048
+running_lock = Lock()
+
+
+class GenerationTaskReq(BaseModel):
+ max_new_tokens: int = Field(gt=0, le=512, example=64)
+ history: List[Dialogue] = Field(min_items=1)
+ top_k: Optional[int] = Field(default=None, gt=0, example=50)
+ top_p: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.5)
+ temperature: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.7)
+
+
+limiter = Limiter(key_func=get_remote_address)
+app = FastAPI()
+app.state.limiter = limiter
+app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
+
+# set CORS
+origin_spec_from_env = os.environ.get('CORS_ORIGIN', None)
+
+if origin_spec_from_env is not None:
+ # allow CORS from the specified origins
+ origins = os.environ['CORS_ORIGIN'].split(',')
+else:
+ # allow CORS from all origins
+ origins = ["*"]
+
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=origins,
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"],
+)
+
+
+def generate_streamingly(prompt, max_new_tokens, top_k, top_p, temperature):
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ model_kwargs = {
+ 'max_generate_tokens': max_new_tokens,
+ 'early_stopping': True,
+ 'top_k': top_k,
+ 'top_p': top_p,
+ 'temperature': temperature,
+ 'prepare_inputs_fn': model.prepare_inputs_for_generation,
+ 'update_model_kwargs_fn': update_model_kwargs_fn,
+ }
+ is_first_word = True
+ generator = LockedIterator(sample_streamingly(model, **inputs, **model_kwargs), running_lock)
+ for output in generator:
+ output = output.cpu()
+ tokens = tokenizer.convert_ids_to_tokens(output, skip_special_tokens=True)
+ current_sub_tokens = []
+ for token in tokens:
+ if token in tokenizer.all_special_tokens:
+ continue
+ current_sub_tokens.append(token)
+ if current_sub_tokens:
+ out_string = tokenizer.sp_model.decode(current_sub_tokens)
+ if is_first_word:
+ out_string = out_string.lstrip()
+ is_first_word = False
+ elif current_sub_tokens[0].startswith('▁'):
+ # whitespace will be ignored by the frontend
+ out_string = ' ' + out_string
+ yield out_string
+
+
+async def event_generator(request: Request, generator: Generator):
+ while True:
+ if await request.is_disconnected():
+ break
+ try:
+ yield {'event': 'generate', 'data': next(generator)}
+ except StopIteration:
+ yield {'event': 'end', 'data': ''}
+ break
+
+
+@app.post('/generate/stream')
+@limiter.limit('1/second')
+def generate(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ event_source = event_generator(
+ request, generate_streamingly(prompt, data.max_new_tokens, data.top_k, data.top_p, data.temperature))
+ return EventSourceResponse(event_source)
+
+
+@app.post('/generate')
+@limiter.limit('1/second')
+def generate_no_stream(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ with running_lock:
+ output = model.generate(**inputs, **data.dict(exclude={'history'}))
+ output = output.cpu()
+ prompt_len = inputs['input_ids'].size(1)
+ response = output[0, prompt_len:]
+ out_string = tokenizer.decode(response, skip_special_tokens=True)
+ return out_string.lstrip()
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ parser.add_argument('--http_host', default='0.0.0.0')
+ parser.add_argument('--http_port', type=int, default=7070)
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+ prompt_processor = ChatPromptProcessor(tokenizer, CONTEXT, MAX_LEN)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ config = uvicorn.Config(app, host=args.http_host, port=args.http_port)
+ server = uvicorn.Server(config=config)
+ server.run()
diff --git a/applications/Chat/inference/tests/test_chat_prompt.py b/applications/Chat/inference/tests/test_chat_prompt.py
new file mode 100644
index 000000000..f5737ebe8
--- /dev/null
+++ b/applications/Chat/inference/tests/test_chat_prompt.py
@@ -0,0 +1,56 @@
+import os
+
+from transformers import AutoTokenizer
+from utils import ChatPromptProcessor, Dialogue
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+tokenizer = AutoTokenizer.from_pretrained(os.environ['PRETRAINED_PATH'])
+
+samples = [
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\nThe best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 200,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 211,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(instruction='Who is the best player in the history of NBA?', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\n'
+ ),
+]
+
+
+def test_chat_prompt_processor():
+ processor = ChatPromptProcessor(tokenizer, CONTEXT, 256)
+ for history, max_new_tokens, result in samples:
+ prompt = processor.preprocess_prompt(history, max_new_tokens)
+ assert prompt == result
+
+
+if __name__ == '__main__':
+ test_chat_prompt_processor()
diff --git a/applications/Chat/inference/utils.py b/applications/Chat/inference/utils.py
new file mode 100644
index 000000000..3d04aa57d
--- /dev/null
+++ b/applications/Chat/inference/utils.py
@@ -0,0 +1,179 @@
+from threading import Lock
+from typing import Any, Callable, Generator, List, Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from pydantic import BaseModel, Field
+
+try:
+ from transformers.generation_logits_process import (
+ LogitsProcessorList,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ )
+except ImportError:
+ from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
+
+
+def prepare_logits_processor(top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None) -> LogitsProcessorList:
+ processor_list = LogitsProcessorList()
+ if temperature is not None and temperature != 1.0:
+ processor_list.append(TemperatureLogitsWarper(temperature))
+ if top_k is not None and top_k != 0:
+ processor_list.append(TopKLogitsWarper(top_k))
+ if top_p is not None and top_p < 1.0:
+ processor_list.append(TopPLogitsWarper(top_p))
+ return processor_list
+
+
+def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ # consider DP
+ unfinished_sequences = unfinished_sequences.clone()
+ dist.all_reduce(unfinished_sequences)
+ return unfinished_sequences.max() == 0
+
+
+def sample_streamingly(model: nn.Module,
+ input_ids: torch.Tensor,
+ max_generate_tokens: int,
+ early_stopping: bool = False,
+ eos_token_id: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
+ update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
+ **model_kwargs) -> Generator:
+
+ logits_processor = prepare_logits_processor(top_k, top_p, temperature)
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+
+ for _ in range(max_generate_tokens):
+ model_inputs = prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {
+ 'input_ids': input_ids
+ }
+ outputs = model(**model_inputs)
+
+ next_token_logits = outputs['logits'][:, -1, :]
+ # pre-process distribution
+ next_token_logits = logits_processor(input_ids, next_token_logits)
+ # sample
+ probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ yield next_tokens
+
+ # update generated ids, model inputs for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if update_model_kwargs_fn is not None:
+ model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id is not None:
+ unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
+
+ # stop when each sentence is finished if early_stopping=True
+ if early_stopping and _is_sequence_finished(unfinished_sequences):
+ break
+
+
+def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
+ if "past_key_values" in outputs:
+ model_kwargs["past"] = outputs["past_key_values"]
+ else:
+ model_kwargs["past"] = None
+
+ # update token_type_ids with last value
+ if "token_type_ids" in model_kwargs:
+ token_type_ids = model_kwargs["token_type_ids"]
+ model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
+
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
+
+ return model_kwargs
+
+
+class Dialogue(BaseModel):
+ instruction: str = Field(min_length=1, example='Count up from 1 to 500.')
+ response: str = Field(example='')
+
+
+def _format_dialogue(instruction: str, response: str = ''):
+ return f'\n\n### Instruction:\n{instruction}\n\n### Response:\n{response}'
+
+
+class ChatPromptProcessor:
+
+ def __init__(self, tokenizer, context: str, max_len: int = 2048):
+ self.tokenizer = tokenizer
+ self.context = context
+ self.max_len = max_len
+ # These will be initialized after the first call of preprocess_prompt()
+ self.context_len: Optional[int] = None
+ self.dialogue_placeholder_len: Optional[int] = None
+
+ def preprocess_prompt(self, history: List[Dialogue], max_new_tokens: int) -> str:
+ if self.context_len is None:
+ self.context_len = len(self.tokenizer(self.context)['input_ids'])
+ if self.dialogue_placeholder_len is None:
+ self.dialogue_placeholder_len = len(
+ self.tokenizer(_format_dialogue(''), add_special_tokens=False)['input_ids'])
+ prompt = self.context
+ # the last dialogue must be in the prompt
+ last_dialogue = history.pop()
+ # the response of the last dialogue is empty
+ assert last_dialogue.response == ''
+ if len(self.tokenizer(_format_dialogue(last_dialogue.instruction), add_special_tokens=False)
+ ['input_ids']) + max_new_tokens + self.context_len >= self.max_len:
+ # to avoid truncate placeholder, apply truncate to the original instruction
+ instruction_truncated = self.tokenizer(last_dialogue.instruction,
+ add_special_tokens=False,
+ truncation=True,
+ max_length=(self.max_len - max_new_tokens - self.context_len -
+ self.dialogue_placeholder_len))['input_ids']
+ instruction_truncated = self.tokenizer.decode(instruction_truncated).lstrip()
+ prompt += _format_dialogue(instruction_truncated)
+ return prompt
+
+ res_len = self.max_len - max_new_tokens - len(self.tokenizer(prompt)['input_ids'])
+
+ rows = []
+ for dialogue in history[::-1]:
+ text = _format_dialogue(dialogue.instruction, dialogue.response)
+ cur_len = len(self.tokenizer(text, add_special_tokens=False)['input_ids'])
+ if res_len - cur_len < 0:
+ break
+ res_len -= cur_len
+ rows.insert(0, text)
+ prompt += ''.join(rows) + _format_dialogue(last_dialogue.instruction)
+ return prompt
+
+
+class LockedIterator:
+
+ def __init__(self, it, lock: Lock) -> None:
+ self.lock = lock
+ self.it = iter(it)
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ with self.lock:
+ return next(self.it)
diff --git a/applications/Chat/pytest.ini b/applications/Chat/pytest.ini
new file mode 100644
index 000000000..01e5cd217
--- /dev/null
+++ b/applications/Chat/pytest.ini
@@ -0,0 +1,6 @@
+[pytest]
+markers =
+ cpu: tests which can run on CPU
+ gpu: tests which requires a single GPU
+ dist: tests which are run in a multi-GPU or multi-machine environment
+ experiment: tests for experimental features
diff --git a/applications/Chat/requirements-test.txt b/applications/Chat/requirements-test.txt
new file mode 100644
index 000000000..e079f8a60
--- /dev/null
+++ b/applications/Chat/requirements-test.txt
@@ -0,0 +1 @@
+pytest
diff --git a/applications/Chat/requirements.txt b/applications/Chat/requirements.txt
new file mode 100644
index 000000000..af7ff6786
--- /dev/null
+++ b/applications/Chat/requirements.txt
@@ -0,0 +1,13 @@
+transformers>=4.20.1
+tqdm
+datasets
+loralib
+colossalai>=0.2.4
+torch<2.0.0, >=1.12.1
+langchain
+tokenizers
+fastapi
+sse_starlette
+wandb
+sentencepiece
+gpustat
diff --git a/applications/Chat/setup.py b/applications/Chat/setup.py
new file mode 100644
index 000000000..a285a6dff
--- /dev/null
+++ b/applications/Chat/setup.py
@@ -0,0 +1,41 @@
+from setuptools import find_packages, setup
+
+
+def fetch_requirements(path):
+ with open(path, 'r') as fd:
+ return [r.strip() for r in fd.readlines()]
+
+
+def fetch_readme():
+ with open('README.md', encoding='utf-8') as f:
+ return f.read()
+
+
+def fetch_version():
+ with open('version.txt', 'r') as f:
+ return f.read().strip()
+
+
+setup(
+ name='coati',
+ version=fetch_version(),
+ packages=find_packages(exclude=(
+ 'tests',
+ 'benchmarks',
+ '*.egg-info',
+ )),
+ description='Colossal-AI Talking Intelligence',
+ long_description=fetch_readme(),
+ long_description_content_type='text/markdown',
+ license='Apache Software License 2.0',
+ url='https://github.com/hpcaitech/Coati',
+ install_requires=fetch_requirements('requirements.txt'),
+ python_requires='>=3.6',
+ classifiers=[
+ 'Programming Language :: Python :: 3',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Environment :: GPU :: NVIDIA CUDA',
+ 'Topic :: Scientific/Engineering :: Artificial Intelligence',
+ 'Topic :: System :: Distributed Computing',
+ ],
+)
diff --git a/applications/Chat/tests/__init__.py b/applications/Chat/tests/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/applications/Chat/tests/test_checkpoint.py b/applications/Chat/tests/test_checkpoint.py
new file mode 100644
index 000000000..8c7848525
--- /dev/null
+++ b/applications/Chat/tests/test_checkpoint.py
@@ -0,0 +1,98 @@
+import os
+import tempfile
+from contextlib import nullcontext
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+from coati.models.gpt import GPTActor
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.utils import free_port
+
+GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
+
+
+def get_data(batch_size: int, seq_len: int = 10) -> dict:
+ input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
+ attention_mask = torch.ones_like(input_ids)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def run_test_checkpoint(strategy):
+ BATCH_SIZE = 2
+
+ if strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ with strategy.model_init_context():
+ actor = GPTActor(config=GPT_CONFIG).cuda()
+
+ actor_optim = HybridAdam(actor.parameters())
+
+ actor, actor_optim = strategy.prepare((actor, actor_optim))
+
+ def run_step():
+ data = get_data(BATCH_SIZE)
+ action_mask = torch.ones_like(data['attention_mask'], dtype=torch.bool)
+ action_log_probs = actor(data['input_ids'], action_mask.size(1), data['attention_mask'])
+ loss = action_log_probs.sum()
+ strategy.backward(loss, actor, actor_optim)
+ strategy.optimizer_step(actor_optim)
+
+ run_step()
+
+ ctx = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
+
+ with ctx as dirname:
+ rank0_dirname = [dirname]
+ dist.broadcast_object_list(rank0_dirname)
+ rank0_dirname = rank0_dirname[0]
+
+ model_path = os.path.join(rank0_dirname, 'model.pt')
+ optim_path = os.path.join(rank0_dirname, f'optim-r{dist.get_rank()}.pt')
+
+ strategy.save_model(actor, model_path, only_rank0=True)
+ strategy.save_optimizer(actor_optim, optim_path, only_rank0=False)
+
+ dist.barrier()
+
+ strategy.load_model(actor, model_path, strict=False)
+ strategy.load_optimizer(actor_optim, optim_path)
+
+ dist.barrier()
+
+ run_step()
+
+
+def run_dist(rank, world_size, port, strategy):
+ os.environ['RANK'] = str(rank)
+ os.environ['LOCAL_RANK'] = str(rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ os.environ['MASTER_ADDR'] = 'localhost'
+ os.environ['MASTER_PORT'] = str(port)
+ run_test_checkpoint(strategy)
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [2])
+@pytest.mark.parametrize('strategy', ['ddp', 'colossalai_zero2', 'colossalai_gemini'])
+@rerun_if_address_is_in_use()
+def test_checkpoint(world_size, strategy):
+ run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_checkpoint(2, 'colossalai_zero2')
diff --git a/applications/Chat/tests/test_data.py b/applications/Chat/tests/test_data.py
new file mode 100644
index 000000000..577309a0f
--- /dev/null
+++ b/applications/Chat/tests/test_data.py
@@ -0,0 +1,122 @@
+import os
+from copy import deepcopy
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+from coati.experience_maker import NaiveExperienceMaker
+from coati.models.base import RewardModel
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.replay_buffer import NaiveReplayBuffer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.utils import free_port
+
+GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
+
+
+def get_data(batch_size: int, seq_len: int = 10) -> dict:
+ input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
+ attention_mask = torch.ones_like(input_ids)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def gather_and_equal(tensor: torch.Tensor) -> bool:
+ world_size = dist.get_world_size()
+ outputs = [torch.empty_like(tensor) for _ in range(world_size)]
+ dist.all_gather(outputs, tensor.contiguous())
+ for t in outputs[1:]:
+ if not torch.equal(outputs[0], t):
+ return False
+ return True
+
+
+def run_test_data(strategy):
+ EXPERINCE_BATCH_SIZE = 4
+ SAMPLE_BATCH_SIZE = 2
+
+ if strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif strategy == 'colossalai':
+ strategy = ColossalAIStrategy(placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ actor = GPTActor(config=GPT_CONFIG).cuda()
+ critic = GPTCritic(config=GPT_CONFIG).cuda()
+
+ initial_model = deepcopy(actor)
+ reward_model = RewardModel(deepcopy(critic.model)).cuda()
+
+ experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model)
+ replay_buffer = NaiveReplayBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
+
+ # experience of all ranks should be the same
+ for _ in range(2):
+ data = get_data(EXPERINCE_BATCH_SIZE)
+ assert gather_and_equal(data['input_ids'])
+ assert gather_and_equal(data['attention_mask'])
+ experience = experience_maker.make_experience(**data,
+ do_sample=True,
+ max_length=16,
+ eos_token_id=50256,
+ pad_token_id=50256)
+ assert gather_and_equal(experience.sequences)
+ assert gather_and_equal(experience.action_log_probs)
+ assert gather_and_equal(experience.values)
+ assert gather_and_equal(experience.reward)
+ assert gather_and_equal(experience.advantages)
+ assert gather_and_equal(experience.action_mask)
+ assert gather_and_equal(experience.attention_mask)
+ replay_buffer.append(experience)
+
+ # replay buffer's data should be the same
+ buffer_size = torch.tensor([len(replay_buffer)], device='cuda')
+ assert gather_and_equal(buffer_size)
+ for item in replay_buffer.items:
+ assert gather_and_equal(item.sequences)
+ assert gather_and_equal(item.action_log_probs)
+ assert gather_and_equal(item.values)
+ assert gather_and_equal(item.reward)
+ assert gather_and_equal(item.advantages)
+ assert gather_and_equal(item.action_mask)
+ assert gather_and_equal(item.attention_mask)
+
+ # dataloader of each rank should have the same size and different batch
+ dataloader = strategy.setup_dataloader(replay_buffer)
+ dataloader_size = torch.tensor([len(dataloader)], device='cuda')
+ assert gather_and_equal(dataloader_size)
+ for experience in dataloader:
+ assert not gather_and_equal(experience.sequences)
+ assert not gather_and_equal(experience.action_log_probs)
+ assert not gather_and_equal(experience.values)
+ assert not gather_and_equal(experience.reward)
+ assert not gather_and_equal(experience.advantages)
+ # action mask and attention mask may be same
+
+
+def run_dist(rank, world_size, port, strategy):
+ os.environ['RANK'] = str(rank)
+ os.environ['LOCAL_RANK'] = str(rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ os.environ['MASTER_ADDR'] = 'localhost'
+ os.environ['MASTER_PORT'] = str(port)
+ run_test_data(strategy)
+
+
+@pytest.mark.skip
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [2])
+@pytest.mark.parametrize('strategy', ['ddp', 'colossalai'])
+@rerun_if_address_is_in_use()
+def test_data(world_size, strategy):
+ run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_data(2, 'colossalai')
diff --git a/applications/Chat/version.txt b/applications/Chat/version.txt
new file mode 100644
index 000000000..3eefcb9dd
--- /dev/null
+++ b/applications/Chat/version.txt
@@ -0,0 +1 @@
+1.0.0
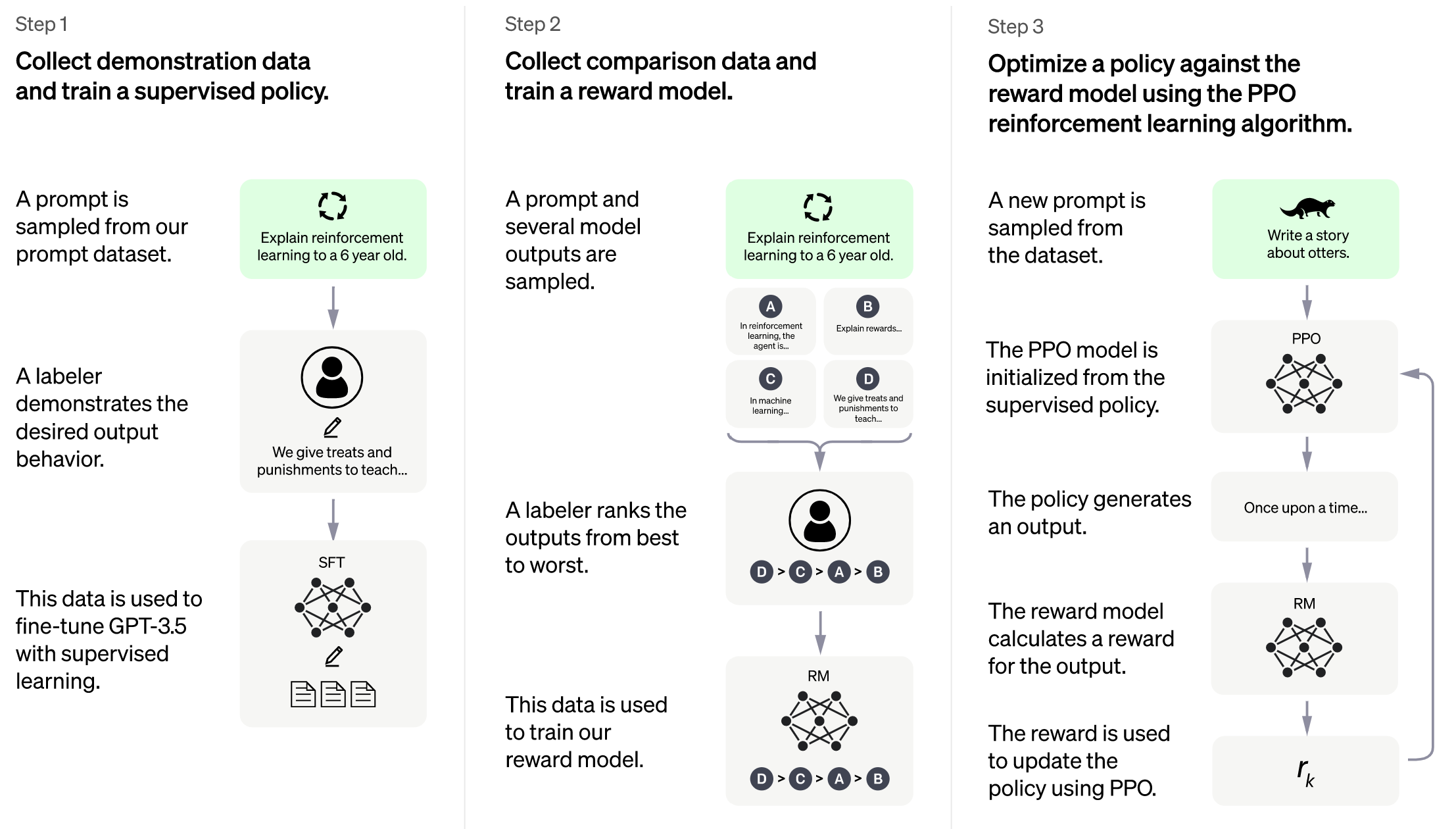 +
+ +
+ +
+ +
+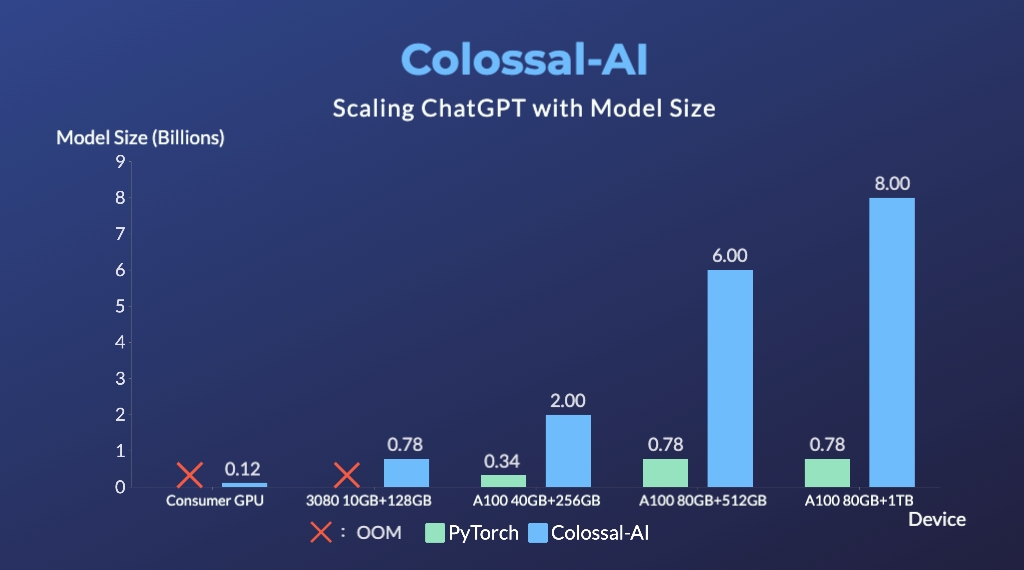 +
+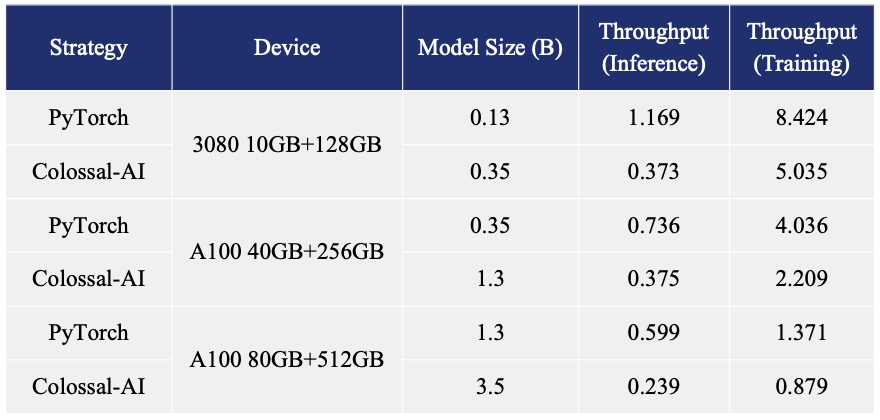 +
+ +
+
+
+