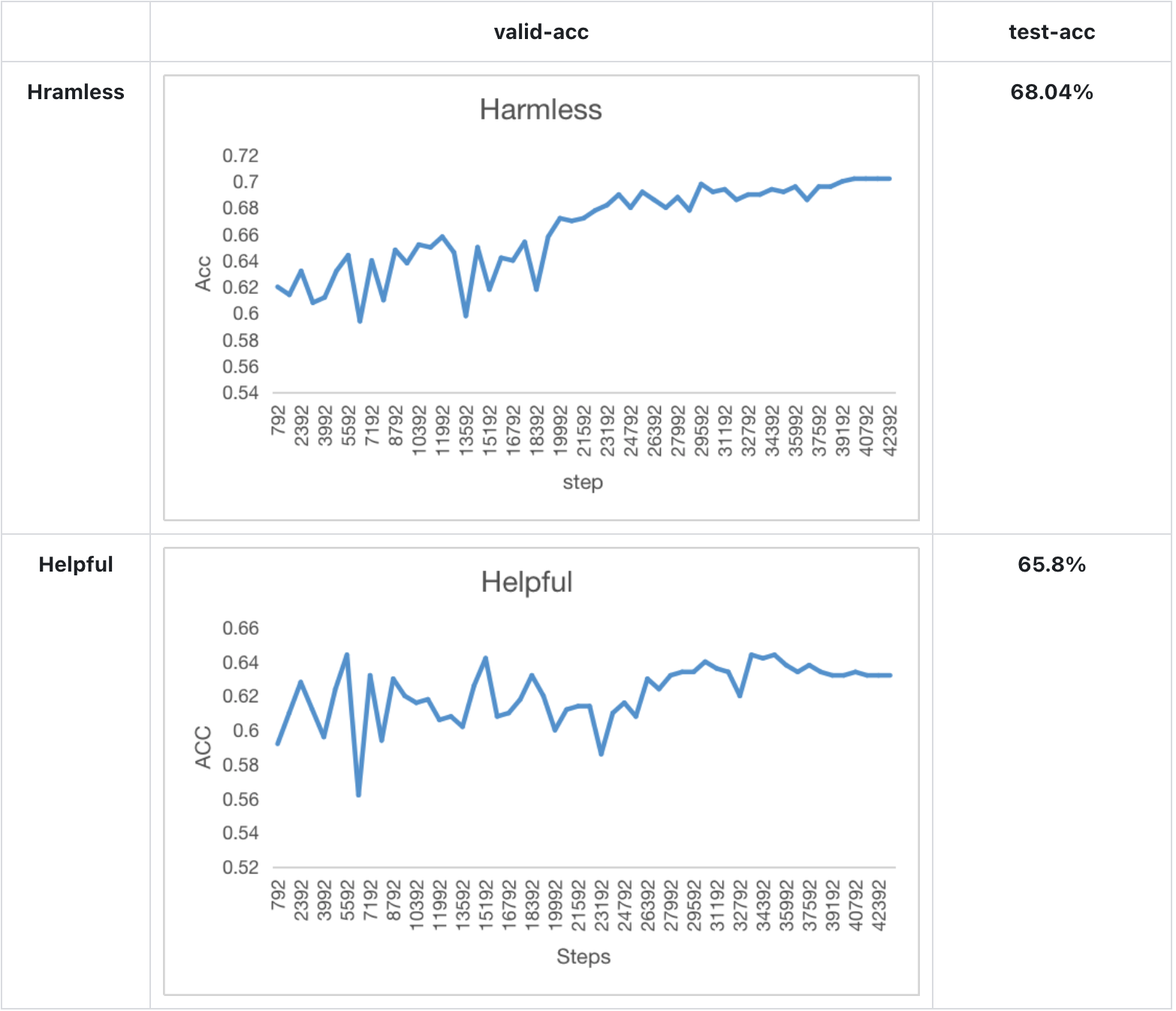
-
-
-
-## Train with dummy prompt data (Stage 3)
-
-This script supports 4 kinds of strategies:
-
-- naive
-- ddp
-- colossalai_zero2
-- colossalai_gemini
-
-It uses random generated prompt data.
-
-Naive strategy only support single GPU training:
-
-```shell
-python train_dummy.py --strategy naive
-# display cli help
-python train_dummy.py -h
-```
-
-DDP strategy and ColossalAI strategy support multi GPUs training:
-
-```shell
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
-```
-
-## Train with real prompt data (Stage 3)
-
-We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
-
-You should download `prompts.csv` first.
-
-This script also supports 4 strategies.
-
-```shell
-# display cli help
-python train_dummy.py -h
-# run naive on 1 GPU
-python train_prompts.py prompts.csv --strategy naive
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
-```
-
-## Inference example(After Stage3)
-We support naive inference demo after training.
-```shell
-# inference, using pretrain path to configure model
-python inference.py --model_path --model --pretrain
-# example
-python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
-```
-
-## Attention
-The examples is just a demo for testing our progress of RM and PPO training.
-
-
-#### data
-- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
-- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
-- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
-- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
-- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
-
-## Support Model
-
-### GPT
-- [x] GPT2-S (s)
-- [x] GPT2-M (m)
-- [x] GPT2-L (l)
-- [ ] GPT2-XL (xl)
-- [x] GPT2-4B (4b)
-- [ ] GPT2-6B (6b)
-- [ ] GPT2-8B (8b)
-- [ ] GPT2-10B (10b)
-- [ ] GPT2-12B (12b)
-- [ ] GPT2-15B (15b)
-- [ ] GPT2-18B (18b)
-- [ ] GPT2-20B (20b)
-- [ ] GPT2-24B (24b)
-- [ ] GPT2-28B (28b)
-- [ ] GPT2-32B (32b)
-- [ ] GPT2-36B (36b)
-- [ ] GPT2-40B (40b)
-- [ ] GPT3 (175b)
-
-### BLOOM
-- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
-- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
-- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
-- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
-- [ ] BLOOM-175b
-
-### OPT
-- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
-- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
-- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
-- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
-- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
-- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
-- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
diff --git a/applications/ChatGPT/examples/inference.py b/applications/ChatGPT/examples/inference.py
deleted file mode 100644
index 08885c33b..000000000
--- a/applications/ChatGPT/examples/inference.py
+++ /dev/null
@@ -1,59 +0,0 @@
-import argparse
-
-import torch
-from chatgpt.models.bloom import BLOOMActor
-from chatgpt.models.gpt import GPTActor
-from chatgpt.models.opt import OPTActor
-from transformers import AutoTokenizer
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-
-def eval(args):
- # configure model
- if args.model == 'gpt2':
- actor = GPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
- elif args.model == 'bloom':
- actor = BLOOMActor(pretrained=args.pretrain).to(torch.cuda.current_device())
- elif args.model == 'opt':
- actor = OPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- state_dict = torch.load(args.model_path)
- actor.model.load_state_dict(state_dict)
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- actor.eval()
- input = args.input
- input_ids = tokenizer.encode(input, return_tensors='pt').to(torch.cuda.current_device())
- outputs = actor.generate(input_ids,
- max_length=args.max_length,
- do_sample=True,
- top_k=50,
- top_p=0.95,
- num_return_sequences=1)
- output = tokenizer.batch_decode(outputs[0], skip_special_tokens=True)
- print(output)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
- # We suggest to use the pretrained model from HuggingFace, use pretrain to configure model
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--model_path', type=str, default=None)
- parser.add_argument('--input', type=str, default='Question: How are you ? Answer:')
- parser.add_argument('--max_length', type=int, default=100)
- args = parser.parse_args()
- eval(args)
diff --git a/applications/ChatGPT/examples/requirements.txt b/applications/ChatGPT/examples/requirements.txt
deleted file mode 100644
index 40e6edc7e..000000000
--- a/applications/ChatGPT/examples/requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-pandas>=1.4.1
-sentencepiece
diff --git a/applications/ChatGPT/examples/test_ci.sh b/applications/ChatGPT/examples/test_ci.sh
deleted file mode 100755
index 1d05c4c58..000000000
--- a/applications/ChatGPT/examples/test_ci.sh
+++ /dev/null
@@ -1,97 +0,0 @@
-#!/usr/bin/env bash
-
-set -xue
-
-if [ -z "$PROMPT_PATH" ]; then
- echo "Please set \$PROMPT_PATH to the path to prompts csv."
- exit 1
-fi
-
-BASE=$(realpath $(dirname $0))
-
-export OMP_NUM_THREADS=8
-
-# install requirements
-pip install -r ${BASE}/requirements.txt
-
-# train dummy
-python ${BASE}/train_dummy.py --strategy naive --num_episodes 1 \
- --max_timesteps 2 --update_timesteps 2 \
- --max_epochs 1 --train_batch_size 2 --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy ddp --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'gpt2' --model gpt2
-
-rm -rf ${BASE}/actor_checkpoint_dummy.pt
-
-# train prompts
-python ${BASE}/train_prompts.py $PROMPT_PATH --strategy naive --num_episodes 1 \
- --max_timesteps 2 --update_timesteps 2 \
- --max_epochs 1 --train_batch_size 2 --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'facebook/opt-350m' --model opt
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy ddp --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
-
-rm -rf ${BASE}/actor_checkpoint_prompts.pt
-
-# train rm
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'facebook/opt-350m' --model 'opt' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'gpt2' --model 'gpt2' \
- --strategy colossalai_gemini --loss_fn 'log_exp'\
- --dataset 'Dahoas/rm-static' --test True --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'bigscience/bloom-560m' --model 'bloom' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'microsoft/deberta-v3-large' --model 'deberta' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
-
-rm -rf ${BASE}/rm_ckpt.pt
diff --git a/applications/ChatGPT/examples/train_dummy.py b/applications/ChatGPT/examples/train_dummy.py
deleted file mode 100644
index c0ebf8f9b..000000000
--- a/applications/ChatGPT/examples/train_dummy.py
+++ /dev/null
@@ -1,148 +0,0 @@
-import argparse
-from copy import deepcopy
-
-import torch
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.models.opt import OPTActor, OPTCritic
-from chatgpt.trainer import PPOTrainer
-from chatgpt.trainer.callbacks import SaveCheckpoint
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from torch.optim import Adam
-from transformers import AutoTokenizer, BloomTokenizerFast
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-
-def preprocess_batch(samples):
- input_ids = torch.stack(samples)
- attention_mask = torch.ones_like(input_ids, dtype=torch.long)
- return {'input_ids': input_ids, 'attention_mask': attention_mask}
-
-
-def main(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'gpt2':
- actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'bloom':
- actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'opt':
- actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- initial_model = deepcopy(actor).to(torch.cuda.current_device())
- reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
- critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
- else:
- actor_optim = Adam(actor.parameters(), lr=5e-6)
- critic_optim = Adam(critic.parameters(), lr=5e-6)
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
-
- callbacks = []
- if args.save_ckpt_path:
- ckpt_callback = SaveCheckpoint(
- args.save_ckpt_path,
- args.save_ckpt_interval,
- strategy,
- actor,
- critic,
- actor_optim,
- critic_optim,
- )
- callbacks.append(ckpt_callback)
-
- # configure trainer
-
- trainer = PPOTrainer(strategy,
- actor,
- critic,
- reward_model,
- initial_model,
- actor_optim,
- critic_optim,
- max_epochs=args.max_epochs,
- train_batch_size=args.train_batch_size,
- tokenizer=preprocess_batch,
- max_length=128,
- do_sample=True,
- temperature=1.0,
- top_k=50,
- pad_token_id=tokenizer.pad_token_id,
- eos_token_id=tokenizer.eos_token_id,
- callbacks=callbacks)
-
- random_prompts = torch.randint(tokenizer.vocab_size, (1000, 64), device=torch.cuda.current_device())
- trainer.fit(random_prompts,
- num_episodes=args.num_episodes,
- max_timesteps=args.max_timesteps,
- update_timesteps=args.update_timesteps)
-
- # save model checkpoint after fitting
- strategy.save_model(actor, args.save_path, only_rank0=True)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(actor_optim,
- 'actor_optim_checkpoint_dummy_%d.pt' % (torch.cuda.current_device()),
- only_rank0=False)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', type=str, default='gpt2', choices=['gpt2', 'bloom', 'opt'])
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='actor_checkpoint_dummy.pt')
- parser.add_argument('--need_optim_ckpt', type=bool, default=False)
- parser.add_argument('--num_episodes', type=int, default=50)
- parser.add_argument('--max_timesteps', type=int, default=10)
- parser.add_argument('--update_timesteps', type=int, default=10)
- parser.add_argument('--max_epochs', type=int, default=5)
- parser.add_argument('--train_batch_size', type=int, default=8)
- parser.add_argument('--experience_batch_size', type=int, default=8)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument('--save_ckpt_path',
- type=str,
- default=None,
- help="path to save checkpoint, None means not to save")
- parser.add_argument('--save_ckpt_interval', type=int, default=1, help="the interval of episode to save checkpoint")
- args = parser.parse_args()
- main(args)
diff --git a/applications/ChatGPT/examples/train_dummy.sh b/applications/ChatGPT/examples/train_dummy.sh
deleted file mode 100755
index 595da573e..000000000
--- a/applications/ChatGPT/examples/train_dummy.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
- | tail -n +2 \
- | nl -v 0 \
- | tee /dev/tty \
- | sort -g -k 2 \
- | awk '{print $1}' \
- | head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 2
-
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
diff --git a/applications/ChatGPT/examples/train_prompts.py b/applications/ChatGPT/examples/train_prompts.py
deleted file mode 100644
index 8f48a11c3..000000000
--- a/applications/ChatGPT/examples/train_prompts.py
+++ /dev/null
@@ -1,132 +0,0 @@
-import argparse
-from copy import deepcopy
-
-import pandas as pd
-import torch
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.models.opt import OPTActor, OPTCritic
-from chatgpt.trainer import PPOTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from torch.optim import Adam
-from transformers import AutoTokenizer, BloomTokenizerFast
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-
-def main(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'gpt2':
- actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'bloom':
- actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'opt':
- actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- initial_model = deepcopy(actor)
- reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
- critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
- else:
- actor_optim = Adam(actor.parameters(), lr=5e-6)
- critic_optim = Adam(critic.parameters(), lr=5e-6)
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- dataset = pd.read_csv(args.prompt_path)['prompt']
-
- def tokenize_fn(texts):
- # MUST padding to max length to ensure inputs of all ranks have the same length
- # Different length may lead to hang when using gemini, as different generation steps
- batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
- return {k: v.cuda() for k, v in batch.items()}
-
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
-
- # configure trainer
- trainer = PPOTrainer(
- strategy,
- actor,
- critic,
- reward_model,
- initial_model,
- actor_optim,
- critic_optim,
- max_epochs=args.max_epochs,
- train_batch_size=args.train_batch_size,
- experience_batch_size=args.experience_batch_size,
- tokenizer=tokenize_fn,
- max_length=128,
- do_sample=True,
- temperature=1.0,
- top_k=50,
- pad_token_id=tokenizer.pad_token_id,
- eos_token_id=tokenizer.eos_token_id,
- )
-
- trainer.fit(dataset,
- num_episodes=args.num_episodes,
- max_timesteps=args.max_timesteps,
- update_timesteps=args.update_timesteps)
- # save model checkpoint after fitting
- strategy.save_model(actor, args.save_path, only_rank0=True)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(actor_optim,
- 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
- only_rank0=False)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('prompt_path')
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
- parser.add_argument('--need_optim_ckpt', type=bool, default=False)
- parser.add_argument('--num_episodes', type=int, default=10)
- parser.add_argument('--max_timesteps', type=int, default=10)
- parser.add_argument('--update_timesteps', type=int, default=10)
- parser.add_argument('--max_epochs', type=int, default=5)
- parser.add_argument('--train_batch_size', type=int, default=8)
- parser.add_argument('--experience_batch_size', type=int, default=8)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- args = parser.parse_args()
- main(args)
diff --git a/applications/ChatGPT/examples/train_prompts.sh b/applications/ChatGPT/examples/train_prompts.sh
deleted file mode 100755
index db73ac8e8..000000000
--- a/applications/ChatGPT/examples/train_prompts.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
- | tail -n +2 \
- | nl -v 0 \
- | tee /dev/tty \
- | sort -g -k 2 \
- | awk '{print $1}' \
- | head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 2
-
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
diff --git a/applications/ChatGPT/examples/train_reward_model.py b/applications/ChatGPT/examples/train_reward_model.py
deleted file mode 100644
index a9c844b7b..000000000
--- a/applications/ChatGPT/examples/train_reward_model.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import argparse
-
-import loralib as lora
-import torch
-from chatgpt.dataset import HhRlhfDataset, RmStaticDataset
-from chatgpt.models import LogSigLoss, LogExpLoss
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMRM
-from chatgpt.models.gpt import GPTRM
-from chatgpt.models.opt import OPTRM
-from chatgpt.models.deberta import DebertaRM
-from chatgpt.trainer import RewardModelTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from datasets import load_dataset
-from random import randint
-from torch.optim import Adam
-from transformers import AutoTokenizer, BloomTokenizerFast, DebertaV2Tokenizer
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-def train(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'bloom':
- model = BLOOMRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'opt':
- model = OPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'gpt2':
- model = GPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'deberta':
- model = DebertaRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- if args.model_path is not None:
- state_dict = torch.load(args.model_path)
- model.load_state_dict(state_dict)
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained('bigscience/bloom-560m')
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- elif args.model == 'deberta':
- tokenizer = DebertaV2Tokenizer.from_pretrained('microsoft/deberta-v3-large')
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
- max_len = args.max_len
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- optim = HybridAdam(model.parameters(), lr=1.5e-5)
- else:
- optim = Adam(model.parameters(), lr=1.5e-5)
-
- # configure loss function
- if args.loss_fn == 'log_sig':
- loss_fn = LogSigLoss()
- elif args.loss_fn == 'log_exp':
- loss_fn = LogExpLoss()
- else:
- raise ValueError(f'Unsupported loss function "{args.loss_fn}"')
-
- # prepare for data and dataset
- if args.subset is not None:
- data = load_dataset(args.dataset, data_dir=args.subset)
- else:
- data = load_dataset(args.dataset)
-
- if args.test:
- train_data = data['train'].select(range(100))
- eval_data = data['test'].select(range(10))
- else:
- train_data = data['train']
- eval_data = data['test']
- valid_data = data['test'].select((randint(0, len(eval_data) - 1) for _ in range(len(eval_data)//10)))
-
- if args.dataset == 'Dahoas/rm-static':
- train_dataset = RmStaticDataset(train_data, tokenizer, max_len)
- valid_dataset = RmStaticDataset(valid_data, tokenizer, max_len)
- eval_dataset = RmStaticDataset(eval_data, tokenizer, max_len)
- elif args.dataset == 'Anthropic/hh-rlhf':
- train_dataset = HhRlhfDataset(train_data, tokenizer, max_len)
- valid_dataset = HhRlhfDataset(valid_data, tokenizer, max_len)
- eval_dataset = HhRlhfDataset(eval_data, tokenizer, max_len)
- else:
- raise ValueError(f'Unsupported dataset "{args.dataset}"')
-
- trainer = RewardModelTrainer(model=model,
- strategy=strategy,
- optim=optim,
- loss_fn = loss_fn,
- train_dataset=train_dataset,
- valid_dataset=valid_dataset,
- eval_dataset=eval_dataset,
- batch_size=args.batch_size,
- max_epochs=args.max_epochs)
-
- trainer.fit()
- # save model checkpoint after fitting on only rank0
- strategy.save_model(trainer.model, args.save_path, only_rank0=True)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(trainer.optimizer, 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()), only_rank0=False)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'deberta'], default='bloom')
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--model_path', type=str, default=None)
- parser.add_argument('--need_optim_ckpt', type=bool, default=False)
- parser.add_argument('--dataset', type=str,
- choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static'],
- default='Dahoas/rm-static')
- parser.add_argument('--subset', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='rm_ckpt.pt')
- parser.add_argument('--max_epochs', type=int, default=1)
- parser.add_argument('--batch_size', type=int, default=1)
- parser.add_argument('--max_len', type=int, default=512)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument('--loss_fn', type=str, default='log_sig', choices=['log_sig', 'log_exp'])
- parser.add_argument('--test', type=bool, default=False)
- args = parser.parse_args()
- train(args)
diff --git a/applications/ChatGPT/examples/train_rm.sh b/applications/ChatGPT/examples/train_rm.sh
deleted file mode 100755
index 4f9f55b6b..000000000
--- a/applications/ChatGPT/examples/train_rm.sh
+++ /dev/null
@@ -1,8 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES 1
-
-python train_reward_model.py --pretrain 'microsoft/deberta-v3-large' \
- --model 'deberta' \
- --strategy naive \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
- --test True
diff --git a/applications/ChatGPT/examples/train_sft.py b/applications/ChatGPT/examples/train_sft.py
deleted file mode 100644
index ffbf89ccd..000000000
--- a/applications/ChatGPT/examples/train_sft.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import argparse
-
-import loralib as lora
-import torch
-import torch.distributed as dist
-from torch.utils.data.distributed import DistributedSampler
-from chatgpt.dataset import SFTDataset, AlpacaDataset, AlpacaDataCollator
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMLM
-from chatgpt.models.gpt import GPTLM
-from chatgpt.models.opt import OPTLM
-from chatgpt.models.llama import LlamaLM
-from chatgpt.trainer import SFTTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from chatgpt.utils import prepare_llama_tokenizer_and_embedding
-from datasets import load_dataset
-from torch.optim import Adam
-from torch.utils.data import DataLoader
-from transformers import AutoTokenizer, BloomTokenizerFast
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-from colossalai.logging import get_dist_logger
-
-
-def train(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'bloom':
- model = BLOOMLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'opt':
- model = OPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'gpt2':
- model = GPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'llama':
- model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- elif args.model == 'llama':
- tokenizer = AutoTokenizer.from_pretrained(
- args.pretrain,
- padding_side="right",
- use_fast=False,
- )
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- if args.model == 'llama':
- tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
- else:
- tokenizer.pad_token = tokenizer.eos_token
-
- max_len = 512
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- optim = HybridAdam(model.parameters(), lr=5e-5)
- else:
- optim = Adam(model.parameters(), lr=5e-5)
-
- logger = get_dist_logger()
-
- # configure dataset
- if args.dataset == 'yizhongw/self_instruct':
- train_data = load_dataset(args.dataset, 'super_natural_instructions', split='train')
- eval_data = load_dataset(args.dataset, 'super_natural_instructions', split='test')
-
- train_dataset = SFTDataset(train_data, tokenizer, max_len)
- eval_dataset = SFTDataset(eval_data, tokenizer, max_len)
-
- elif 'alpaca' in args.dataset:
- train_dataset = AlpacaDataset(tokenizer=tokenizer, data_path=args.dataset)
- eval_dataset = None
- data_collator = AlpacaDataCollator(tokenizer=tokenizer)
-
- if dist.is_initialized() and dist.get_world_size() > 1:
- train_sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True)
- if eval_dataset is not None:
- eval_sampler = DistributedSampler(eval_dataset, shuffle=False, seed=42, drop_last=False)
- else:
- train_sampler = None
- eval_sampler = None
-
- train_dataloader = DataLoader(train_dataset, shuffle=(train_sampler is None), sampler=train_sampler, batch_size=args.batch_size, collate_fn=data_collator)
- if eval_dataset is not None:
- eval_dataloader = DataLoader(eval_dataset, shuffle=(eval_sampler is None), sampler=eval_sampler, batch_size=args.batch_size, collate_fn=data_collator)
- else:
- eval_dataloader = None
-
- trainer = SFTTrainer(model=model,
- strategy=strategy,
- optim=optim,
- train_dataloader=train_dataloader,
- eval_dataloader=eval_dataloader,
- batch_size=args.batch_size,
- max_epochs=args.max_epochs)
-
- trainer.fit(logger=logger, use_lora=args.lora_rank, log_interval=args.log_interval)
-
- # save model checkpoint after fitting on only rank0
- strategy.save_model(model, 'sft_checkpoint.pt', only_rank0=True)
- # save optimizer checkpoint on all ranks
- strategy.save_optimizer(optim, 'sft_optim_checkpoint_%d.pt' % (torch.cuda.current_device()), only_rank0=False)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom')
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--dataset', type=str, default='yizhongw/self_instruct')
- parser.add_argument('--save_path', type=str, default='sft_ckpt.pth')
- parser.add_argument('--max_epochs', type=int, default=1)
- parser.add_argument('--batch_size', type=int, default=4)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument('--log_interval', type=int, default=100, help="how many steps to log")
- args = parser.parse_args()
- train(args)
-
diff --git a/applications/ChatGPT/examples/train_sft.sh b/applications/ChatGPT/examples/train_sft.sh
deleted file mode 100755
index 1b85e83b6..000000000
--- a/applications/ChatGPT/examples/train_sft.sh
+++ /dev/null
@@ -1,26 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
- | tail -n +2 \
- | nl -v 0 \
- | tee /dev/tty \
- | sort -g -k 2 \
- | awk '{print $1}' \
- | head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 8
-
-#torchrun --standalone --nproc_per_node=2 train_sft.py --pretrain 'bigscience/bloomz-560m' --model 'bloom' --strategy colossalai_zero2 --log_interval 10
-#torchrun --standalone --nproc_per_node=8 train_sft.py --model 'gpt2' --strategy colossalai_zero2 --batch_size 1 --log_interval 10
-torchrun --standalone --nproc_per_node=8 train_sft.py \
- --pretrain "/data/personal/nus-mql/LLAMA-7B" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --log_interval 10 \
- --save_path /data/personal/nus-mql/Coati-7B \
- --dataset /data/personal/nus-mql/stanford_alpaca/alpaca_data.json
diff --git a/applications/ChatGPT/pytest.ini b/applications/ChatGPT/pytest.ini
deleted file mode 100644
index 01e5cd217..000000000
--- a/applications/ChatGPT/pytest.ini
+++ /dev/null
@@ -1,6 +0,0 @@
-[pytest]
-markers =
- cpu: tests which can run on CPU
- gpu: tests which requires a single GPU
- dist: tests which are run in a multi-GPU or multi-machine environment
- experiment: tests for experimental features
diff --git a/applications/ChatGPT/requirements-test.txt b/applications/ChatGPT/requirements-test.txt
deleted file mode 100644
index e079f8a60..000000000
--- a/applications/ChatGPT/requirements-test.txt
+++ /dev/null
@@ -1 +0,0 @@
-pytest
diff --git a/applications/ChatGPT/requirements.txt b/applications/ChatGPT/requirements.txt
deleted file mode 100644
index 346911192..000000000
--- a/applications/ChatGPT/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-transformers>=4.20.1
-tqdm
-datasets
-loralib
-colossalai>=0.2.4
-torch==1.12.1
-langchain
diff --git a/applications/ChatGPT/setup.py b/applications/ChatGPT/setup.py
deleted file mode 100644
index deec10e0c..000000000
--- a/applications/ChatGPT/setup.py
+++ /dev/null
@@ -1,41 +0,0 @@
-from setuptools import find_packages, setup
-
-
-def fetch_requirements(path):
- with open(path, 'r') as fd:
- return [r.strip() for r in fd.readlines()]
-
-
-def fetch_readme():
- with open('README.md', encoding='utf-8') as f:
- return f.read()
-
-
-def fetch_version():
- with open('version.txt', 'r') as f:
- return f.read().strip()
-
-
-setup(
- name='chatgpt',
- version=fetch_version(),
- packages=find_packages(exclude=(
- 'tests',
- 'benchmarks',
- '*.egg-info',
- )),
- description='A RLFH implementation (ChatGPT) powered by ColossalAI',
- long_description=fetch_readme(),
- long_description_content_type='text/markdown',
- license='Apache Software License 2.0',
- url='https://github.com/hpcaitech/ChatGPT',
- install_requires=fetch_requirements('requirements.txt'),
- python_requires='>=3.6',
- classifiers=[
- 'Programming Language :: Python :: 3',
- 'License :: OSI Approved :: Apache Software License',
- 'Environment :: GPU :: NVIDIA CUDA',
- 'Topic :: Scientific/Engineering :: Artificial Intelligence',
- 'Topic :: System :: Distributed Computing',
- ],
-)
diff --git a/applications/ChatGPT/tests/__init__.py b/applications/ChatGPT/tests/__init__.py
deleted file mode 100644
index e69de29bb..000000000
diff --git a/applications/ChatGPT/tests/test_checkpoint.py b/applications/ChatGPT/tests/test_checkpoint.py
deleted file mode 100644
index 1bbd133f7..000000000
--- a/applications/ChatGPT/tests/test_checkpoint.py
+++ /dev/null
@@ -1,98 +0,0 @@
-import os
-import tempfile
-from contextlib import nullcontext
-from functools import partial
-
-import pytest
-import torch
-import torch.distributed as dist
-import torch.multiprocessing as mp
-from chatgpt.models.gpt import GPTActor
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
-from transformers.models.gpt2.configuration_gpt2 import GPT2Config
-
-from colossalai.nn.optimizer import HybridAdam
-from colossalai.testing import rerun_if_address_is_in_use
-from colossalai.utils import free_port
-
-GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
-
-
-def get_data(batch_size: int, seq_len: int = 10) -> dict:
- input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
- attention_mask = torch.ones_like(input_ids)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
-
-
-def run_test_checkpoint(strategy):
- BATCH_SIZE = 2
-
- if strategy == 'ddp':
- strategy = DDPStrategy()
- elif strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
- elif strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{strategy}"')
-
- with strategy.model_init_context():
- actor = GPTActor(config=GPT_CONFIG).cuda()
-
- actor_optim = HybridAdam(actor.parameters())
-
- actor, actor_optim = strategy.prepare((actor, actor_optim))
-
- def run_step():
- data = get_data(BATCH_SIZE)
- action_mask = torch.ones_like(data['attention_mask'], dtype=torch.bool)
- action_log_probs = actor(data['input_ids'], action_mask.size(1), data['attention_mask'])
- loss = action_log_probs.sum()
- strategy.backward(loss, actor, actor_optim)
- strategy.optimizer_step(actor_optim)
-
- run_step()
-
- ctx = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
-
- with ctx as dirname:
- rank0_dirname = [dirname]
- dist.broadcast_object_list(rank0_dirname)
- rank0_dirname = rank0_dirname[0]
-
- model_path = os.path.join(rank0_dirname, 'model.pt')
- optim_path = os.path.join(rank0_dirname, f'optim-r{dist.get_rank()}.pt')
-
- strategy.save_model(actor, model_path, only_rank0=True)
- strategy.save_optimizer(actor_optim, optim_path, only_rank0=False)
-
- dist.barrier()
-
- strategy.load_model(actor, model_path, strict=False)
- strategy.load_optimizer(actor_optim, optim_path)
-
- dist.barrier()
-
- run_step()
-
-
-def run_dist(rank, world_size, port, strategy):
- os.environ['RANK'] = str(rank)
- os.environ['LOCAL_RANK'] = str(rank)
- os.environ['WORLD_SIZE'] = str(world_size)
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = str(port)
- run_test_checkpoint(strategy)
-
-
-@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [2])
-@pytest.mark.parametrize('strategy', ['ddp', 'colossalai_zero2', 'colossalai_gemini'])
-@rerun_if_address_is_in_use()
-def test_checkpoint(world_size, strategy):
- run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
- mp.spawn(run_func, nprocs=world_size)
-
-
-if __name__ == '__main__':
- test_checkpoint(2, 'colossalai_zero2')
diff --git a/applications/ChatGPT/tests/test_data.py b/applications/ChatGPT/tests/test_data.py
deleted file mode 100644
index 3d8fe912c..000000000
--- a/applications/ChatGPT/tests/test_data.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import os
-from copy import deepcopy
-from functools import partial
-
-import pytest
-import torch
-import torch.distributed as dist
-import torch.multiprocessing as mp
-from chatgpt.experience_maker import NaiveExperienceMaker
-from chatgpt.models.base import RewardModel
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.replay_buffer import NaiveReplayBuffer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
-from transformers.models.gpt2.configuration_gpt2 import GPT2Config
-
-from colossalai.testing import rerun_if_address_is_in_use
-from colossalai.utils import free_port
-
-GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
-
-
-def get_data(batch_size: int, seq_len: int = 10) -> dict:
- input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
- attention_mask = torch.ones_like(input_ids)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
-
-
-def gather_and_equal(tensor: torch.Tensor) -> bool:
- world_size = dist.get_world_size()
- outputs = [torch.empty_like(tensor) for _ in range(world_size)]
- dist.all_gather(outputs, tensor.contiguous())
- for t in outputs[1:]:
- if not torch.equal(outputs[0], t):
- return False
- return True
-
-
-def run_test_data(strategy):
- EXPERINCE_BATCH_SIZE = 4
- SAMPLE_BATCH_SIZE = 2
-
- if strategy == 'ddp':
- strategy = DDPStrategy()
- elif strategy == 'colossalai':
- strategy = ColossalAIStrategy(placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{strategy}"')
-
- actor = GPTActor(config=GPT_CONFIG).cuda()
- critic = GPTCritic(config=GPT_CONFIG).cuda()
-
- initial_model = deepcopy(actor)
- reward_model = RewardModel(deepcopy(critic.model)).cuda()
-
- experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model)
- replay_buffer = NaiveReplayBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
-
- # experience of all ranks should be the same
- for _ in range(2):
- data = get_data(EXPERINCE_BATCH_SIZE)
- assert gather_and_equal(data['input_ids'])
- assert gather_and_equal(data['attention_mask'])
- experience = experience_maker.make_experience(**data,
- do_sample=True,
- max_length=16,
- eos_token_id=50256,
- pad_token_id=50256)
- assert gather_and_equal(experience.sequences)
- assert gather_and_equal(experience.action_log_probs)
- assert gather_and_equal(experience.values)
- assert gather_and_equal(experience.reward)
- assert gather_and_equal(experience.advantages)
- assert gather_and_equal(experience.action_mask)
- assert gather_and_equal(experience.attention_mask)
- replay_buffer.append(experience)
-
- # replay buffer's data should be the same
- buffer_size = torch.tensor([len(replay_buffer)], device='cuda')
- assert gather_and_equal(buffer_size)
- for item in replay_buffer.items:
- assert gather_and_equal(item.sequences)
- assert gather_and_equal(item.action_log_probs)
- assert gather_and_equal(item.values)
- assert gather_and_equal(item.reward)
- assert gather_and_equal(item.advantages)
- assert gather_and_equal(item.action_mask)
- assert gather_and_equal(item.attention_mask)
-
- # dataloader of each rank should have the same size and different batch
- dataloader = strategy.setup_dataloader(replay_buffer)
- dataloader_size = torch.tensor([len(dataloader)], device='cuda')
- assert gather_and_equal(dataloader_size)
- for experience in dataloader:
- assert not gather_and_equal(experience.sequences)
- assert not gather_and_equal(experience.action_log_probs)
- assert not gather_and_equal(experience.values)
- assert not gather_and_equal(experience.reward)
- assert not gather_and_equal(experience.advantages)
- # action mask and attention mask may be same
-
-
-def run_dist(rank, world_size, port, strategy):
- os.environ['RANK'] = str(rank)
- os.environ['LOCAL_RANK'] = str(rank)
- os.environ['WORLD_SIZE'] = str(world_size)
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = str(port)
- run_test_data(strategy)
-
-
-@pytest.mark.skip
-@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [2])
-@pytest.mark.parametrize('strategy', ['ddp', 'colossalai'])
-@rerun_if_address_is_in_use()
-def test_data(world_size, strategy):
- run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
- mp.spawn(run_func, nprocs=world_size)
-
-
-if __name__ == '__main__':
- test_data(2, 'colossalai')
diff --git a/applications/ChatGPT/version.txt b/applications/ChatGPT/version.txt
deleted file mode 100644
index 3eefcb9dd..000000000
--- a/applications/ChatGPT/version.txt
+++ /dev/null
@@ -1 +0,0 @@
-1.0.0
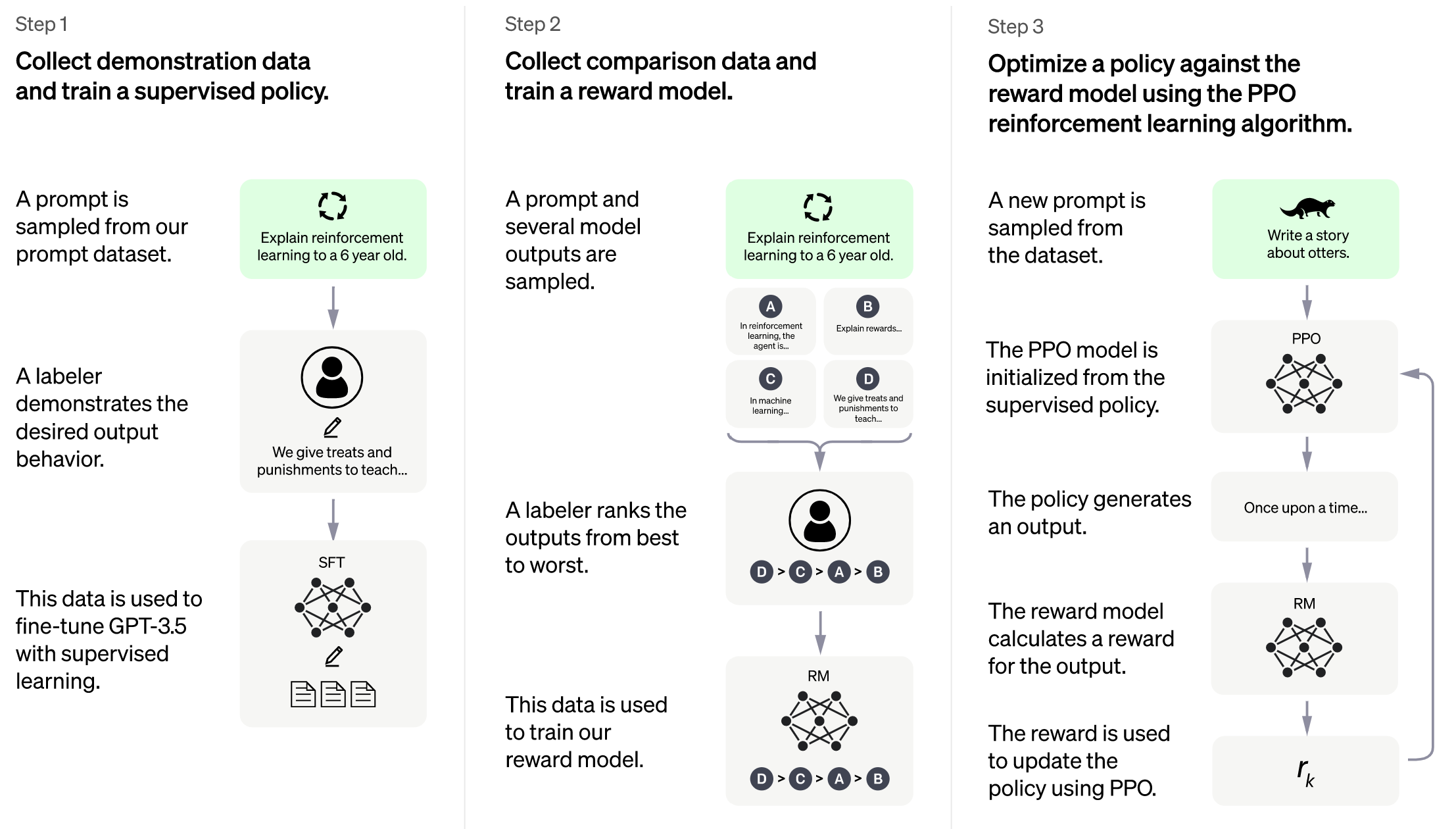 -
-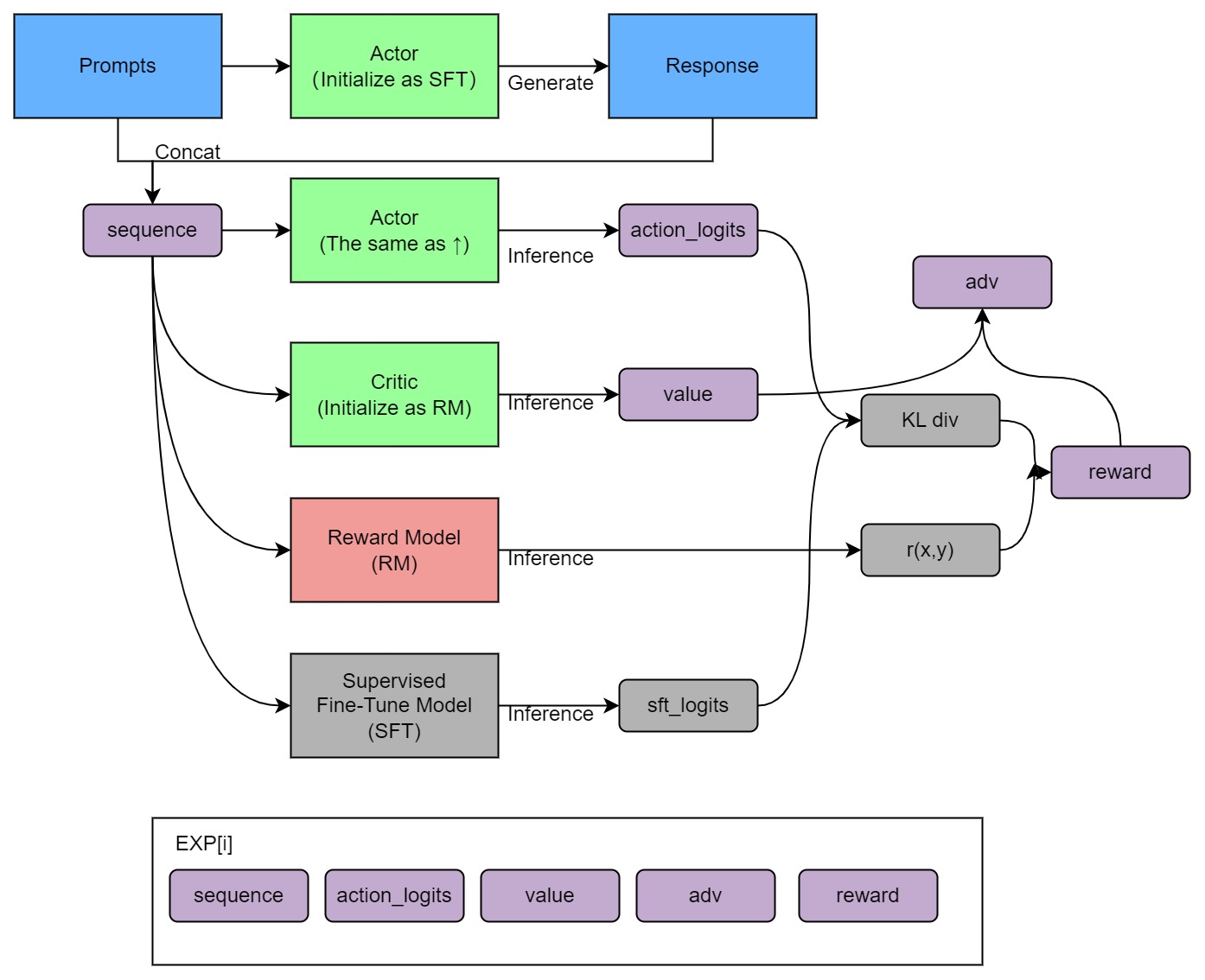 -
-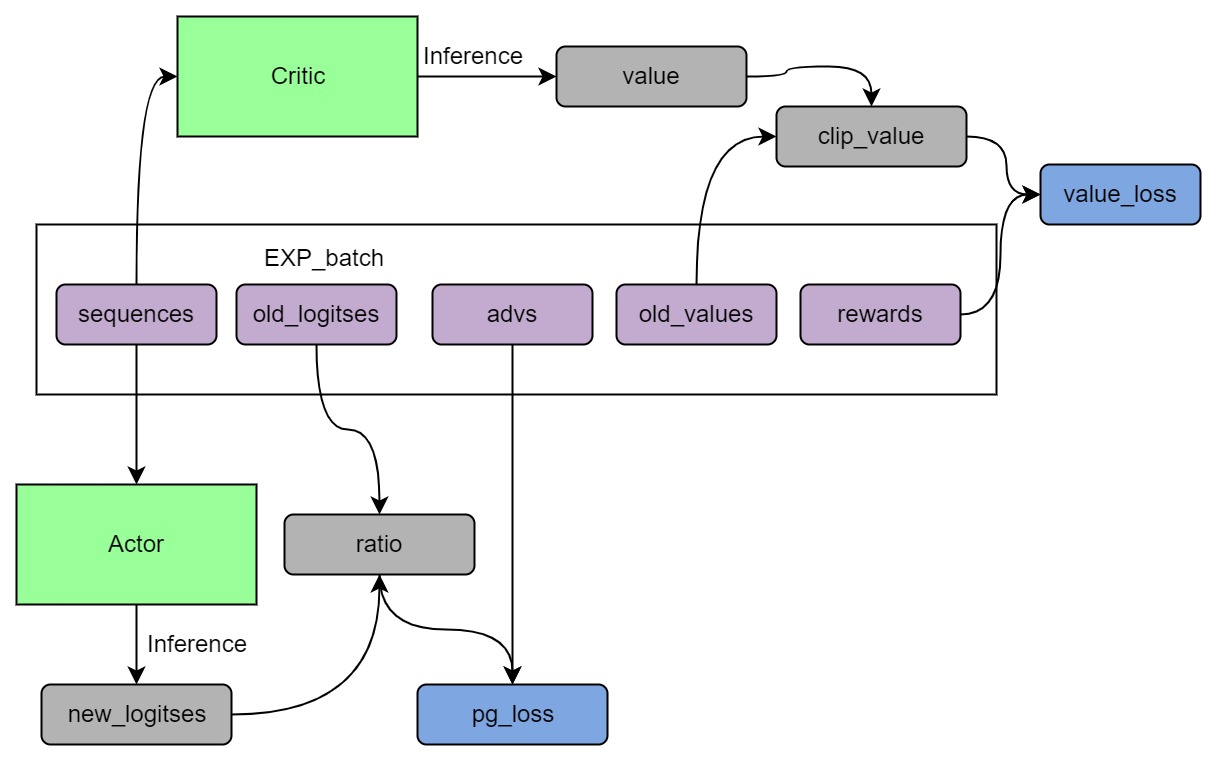 -
- -
- -
- -
- -
-
-
-