mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2025-09-13 13:11:05 +00:00
[inference] Refactor inference architecture (#5057)
* [inference] support only TP (#4998) * support only tp * enable tp * add support for bloom (#5008) * [refactor] refactor gptq and smoothquant llama (#5012) * refactor gptq and smoothquant llama * fix import error * fix linear import torch-int * fix smoothquant llama import error * fix import accelerate error * fix bug * fix import smooth cuda * fix smoothcuda * [Inference Refactor] Merge chatglm2 with pp and tp (#5023) merge chatglm with pp and tp * [Refactor] remove useless inference code (#5022) * remove useless code * fix quant model * fix test import bug * mv original inference legacy * fix chatglm2 * [Refactor] refactor policy search and quant type controlling in inference (#5035) * [Refactor] refactor policy search and quant type controling in inference * [inference] update readme (#5051) * update readme * update readme * fix architecture * fix table * fix table * [inference] udpate example (#5053) * udpate example * fix run.sh * fix rebase bug * fix some errors * update readme * add some features * update interface * update readme * update benchmark * add requirements-infer --------- Co-authored-by: Bin Jia <45593998+FoolPlayer@users.noreply.github.com> Co-authored-by: Zhongkai Zhao <kanezz620@gmail.com>
This commit is contained in:
@@ -1,6 +1,14 @@
|
||||
# 🚀 Colossal-Inference
|
||||
|
||||
## Table of contents
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [💡 Introduction](#introduction)
|
||||
- [🔗 Design](#design)
|
||||
- [🔨 Usage](#usage)
|
||||
- [Quick start](#quick-start)
|
||||
- [Example](#example)
|
||||
- [📊 Performance](#performance)
|
||||
|
||||
## Introduction
|
||||
|
||||
@@ -8,22 +16,23 @@
|
||||
|
||||
## Design
|
||||
|
||||
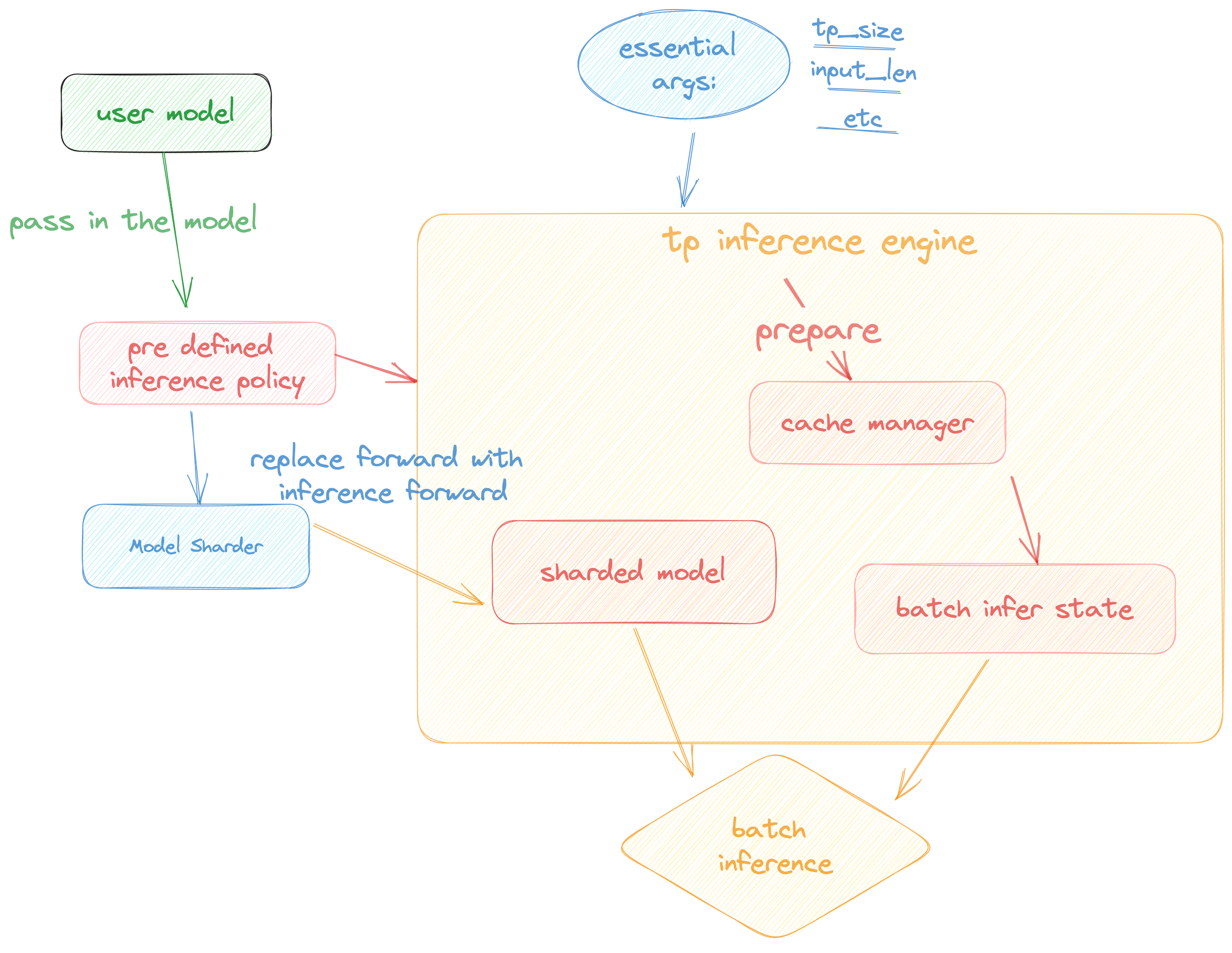
Colossal Inference is composed of two main components:
|
||||
Colossal Inference is composed of three main components:
|
||||
|
||||
1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
||||
2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
|
||||
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
||||
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
||||
3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
|
||||
1. `engine.TPInferEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel) inference:
|
||||
1. `HybridEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel, pipline parallel) inference:
|
||||
2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
|
||||
3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
|
||||
|
||||
## Pipeline of inference:
|
||||
|
||||
## Architecture of inference:
|
||||
|
||||
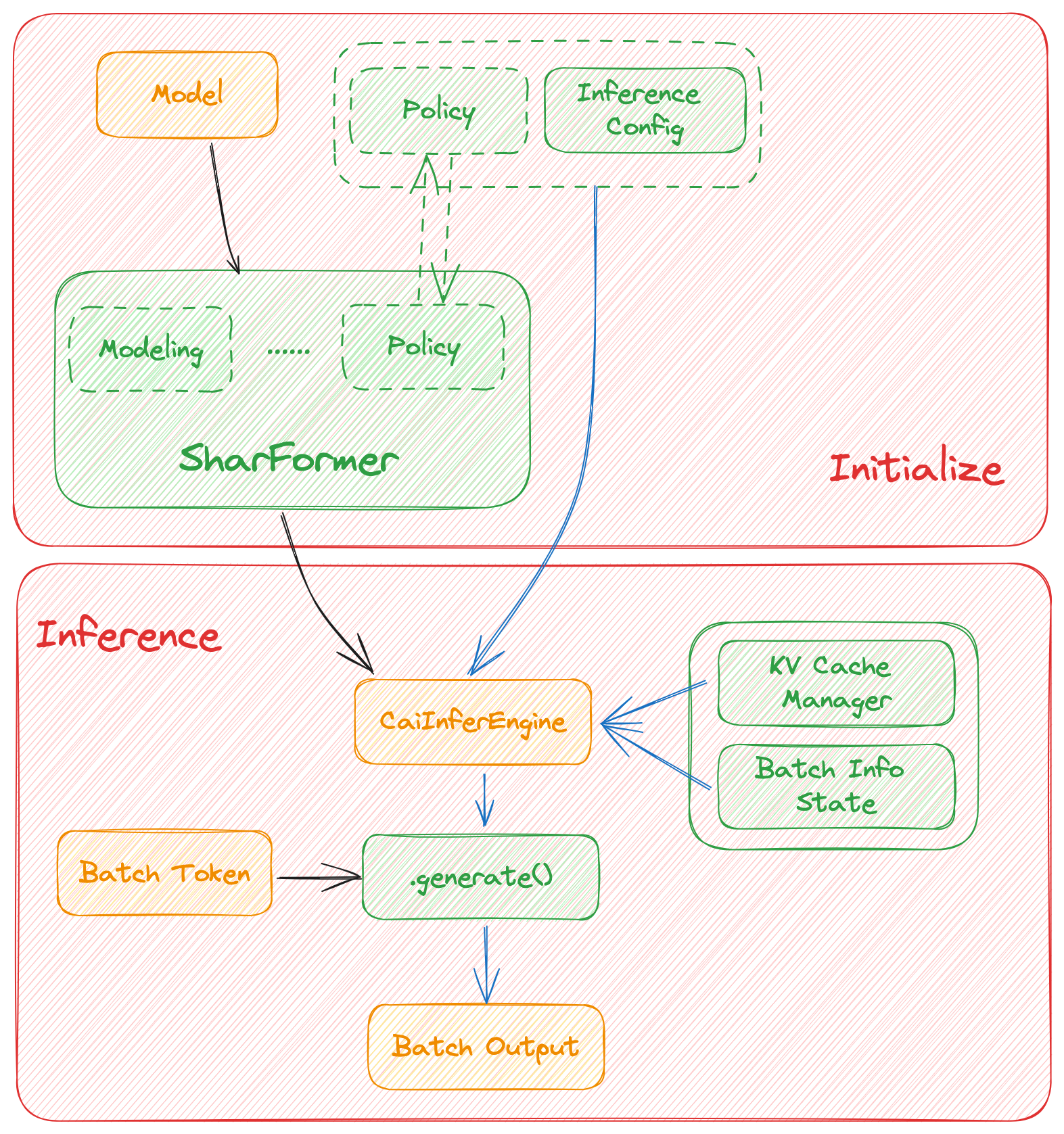
In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
|
||||
|
||||
|
||||
|
||||
|
||||
## Roadmap of our implementation
|
||||
|
||||
@@ -35,12 +44,14 @@ In this section we discuss how the colossal inference works and integrates with
|
||||
- [x] context forward
|
||||
- [x] token forward
|
||||
- [x] support flash-decoding
|
||||
- [ ] Replace the kernels with `faster-transformer` in token-forward stage
|
||||
- [ ] Support all models
|
||||
- [x] Support all models
|
||||
- [x] Llama
|
||||
- [x] Llama-2
|
||||
- [x] Bloom
|
||||
- [x] Chatglm2
|
||||
- [x] Quantization
|
||||
- [x] GPTQ
|
||||
- [x] SmoothQuant
|
||||
- [ ] Benchmarking for all models
|
||||
|
||||
## Get started
|
||||
@@ -53,27 +64,19 @@ pip install -e .
|
||||
|
||||
### Requirements
|
||||
|
||||
dependencies
|
||||
Install dependencies.
|
||||
|
||||
```bash
|
||||
pytorch= 1.13.1 (gpu)
|
||||
cuda>= 11.6
|
||||
transformers= 4.30.2
|
||||
triton
|
||||
# for install flash-attention
|
||||
flash-attention
|
||||
pip install -r requirements/requirements-infer.txt
|
||||
|
||||
# install lightllm since we depend on lightllm triton kernels
|
||||
git clone https://github.com/ModelTC/lightllm
|
||||
cd lightllm
|
||||
git checkout 28c1267cfca536b7b4f28e921e03de735b003039
|
||||
pip3 install -e .
|
||||
|
||||
|
||||
# install flash-attention
|
||||
git clone -recursive https://github.com/Dao-AILab/flash-attention
|
||||
cd flash-attention
|
||||
pip install -e .
|
||||
# if you want use smoothquant quantization, please install torch-int
|
||||
git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
|
||||
cd torch-int
|
||||
git checkout 65266db1eadba5ca78941b789803929e6e6c6856
|
||||
pip install -r requirements.txt
|
||||
source environment.sh
|
||||
bash build_cutlass.sh
|
||||
python setup.py install
|
||||
```
|
||||
|
||||
### Docker
|
||||
@@ -89,26 +92,60 @@ docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcai
|
||||
cd /path/to/CollossalAI
|
||||
pip install -e .
|
||||
|
||||
# install lightllm
|
||||
git clone https://github.com/ModelTC/lightllm
|
||||
cd lightllm
|
||||
git checkout 28c1267cfca536b7b4f28e921e03de735b003039
|
||||
pip3 install -e .
|
||||
|
||||
# install flash-attention
|
||||
git clone -recursive https://github.com/Dao-AILab/flash-attention
|
||||
cd flash-attention
|
||||
pip install -e .
|
||||
|
||||
```
|
||||
|
||||
### Dive into fast-inference!
|
||||
## Usage
|
||||
### Quick start
|
||||
|
||||
example files are in
|
||||
|
||||
```bash
|
||||
cd colossalai.examples
|
||||
python xx
|
||||
cd ColossalAI/examples
|
||||
python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Example
|
||||
```python
|
||||
# import module
|
||||
from colossalai.inference import CaiInferEngine
|
||||
import colossalai
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
#launch distributed environment
|
||||
colossalai.launch_from_torch(config={})
|
||||
|
||||
# load original model and tokenizer
|
||||
model = LlamaForCausalLM.from_pretrained("/path/to/model")
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
|
||||
|
||||
# generate token ids
|
||||
input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
|
||||
data = tokenizer(input, return_tensors='pt')
|
||||
|
||||
# set parallel parameters
|
||||
tp_size=2
|
||||
pp_size=2
|
||||
max_output_len=32
|
||||
micro_batch_size=1
|
||||
|
||||
# initial inference engine
|
||||
engine = CaiInferEngine(
|
||||
tp_size=tp_size,
|
||||
pp_size=pp_size,
|
||||
model=model,
|
||||
max_output_len=max_output_len,
|
||||
micro_batch_size=micro_batch_size,
|
||||
)
|
||||
|
||||
# inference
|
||||
output = engine.generate(data)
|
||||
|
||||
# get results
|
||||
if dist.get_rank() == 0:
|
||||
assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
|
||||
|
||||
```
|
||||
|
||||
## Performance
|
||||
@@ -123,7 +160,9 @@ For various models, experiments were conducted using multiple batch sizes under
|
||||
|
||||
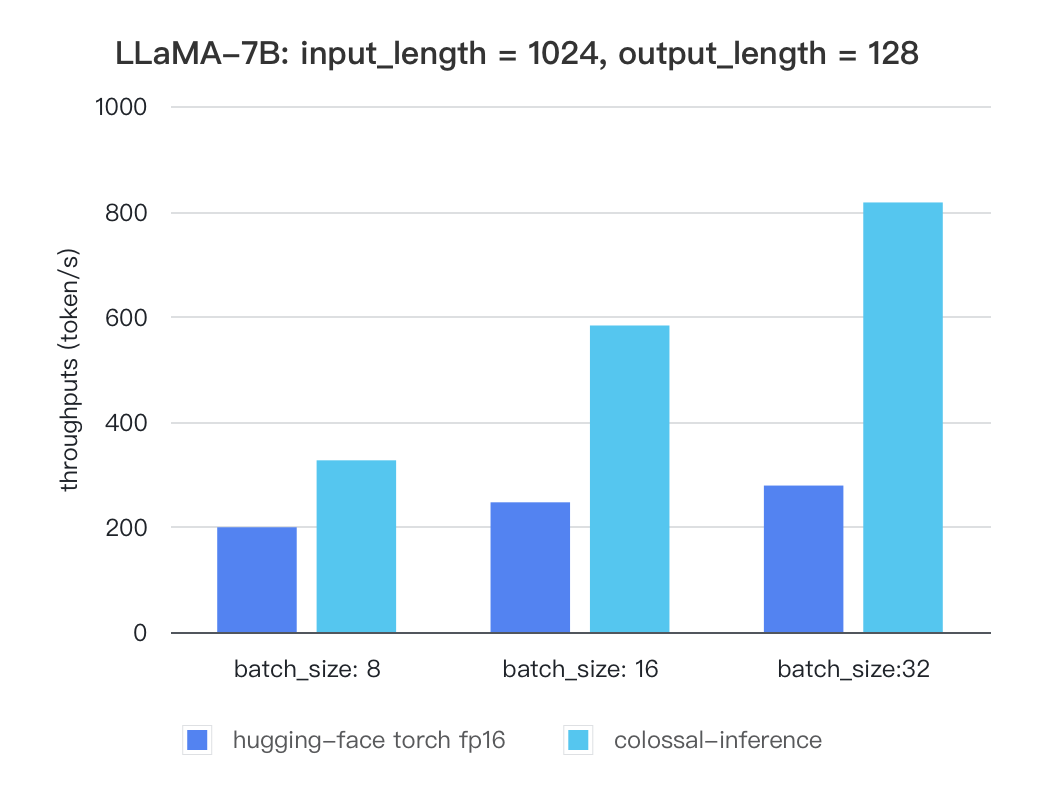
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
|
||||
|
||||
#### Llama
|
||||
### Tensor Parallelism Inference
|
||||
|
||||
##### Llama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
@@ -132,7 +171,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
|
||||
|
||||
|
||||
|
||||
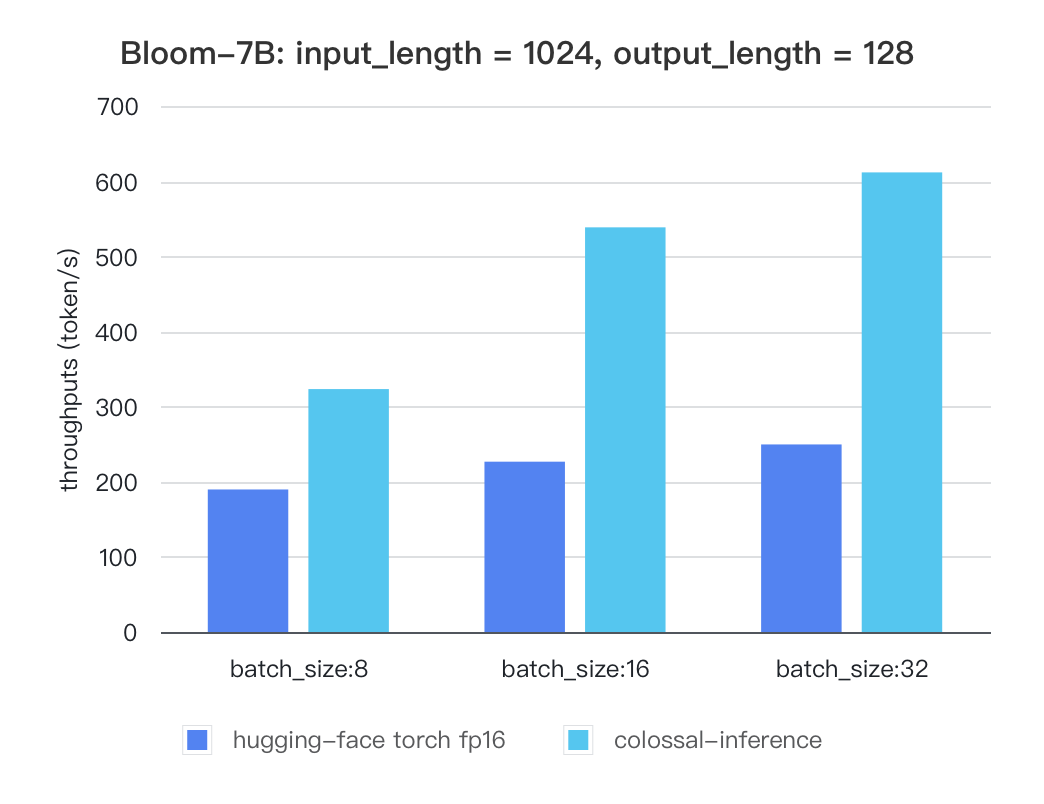
### Bloom
|
||||
#### Bloom
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
@@ -141,4 +180,50 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
|
||||
|
||||
|
||||
|
||||
|
||||
### Pipline Parallelism Inference
|
||||
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
|
||||
|
||||
|
||||
#### A10 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
|
||||
| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
|
||||
| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
|
||||
|
||||
|
||||
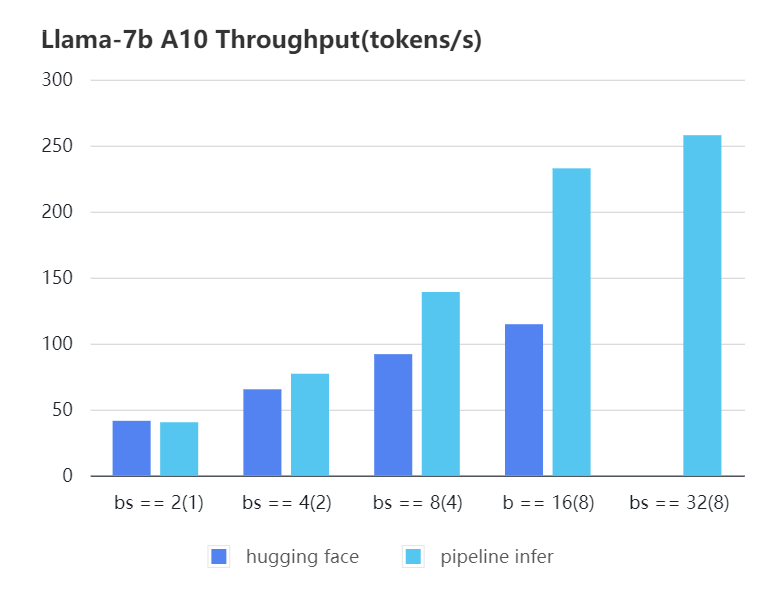
|
||||
|
||||
#### A10 13b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
|
||||
| :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
||||
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
||||
|
||||
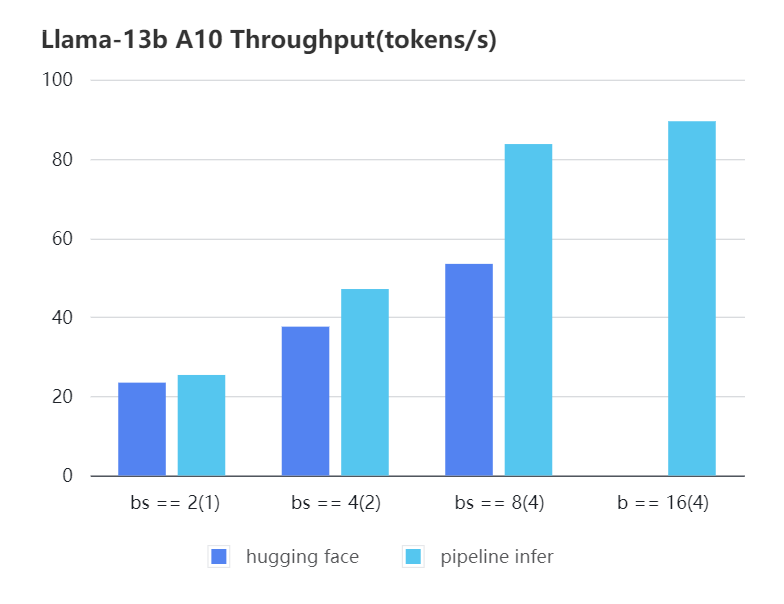
|
||||
|
||||
|
||||
#### A800 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
||||
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
||||
|
||||
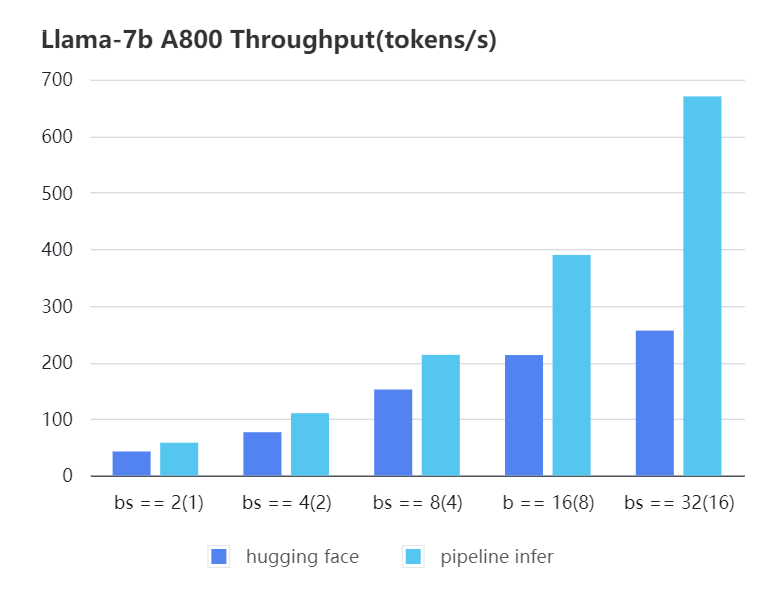
|
||||
|
||||
### Quantization LLama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
||||
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
||||
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
||||
|
||||
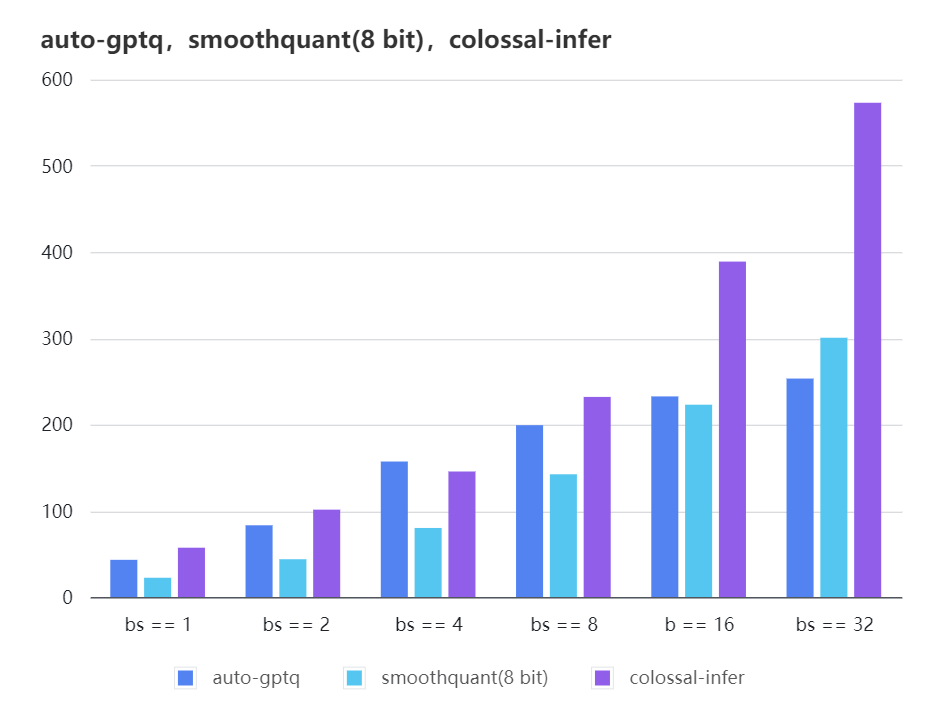
|
||||
|
||||
|
||||
|
||||
The results of more models are coming soon!
|
||||
|
||||
Reference in New Issue
Block a user