mirror of
https://github.com/csunny/DB-GPT.git
synced 2025-10-23 01:49:58 +00:00
feat(ChatKnowledge):add similarity score and query rewrite (#880)
This commit is contained in:
@@ -1 +1,111 @@
|
||||
# RAG Parameter Adjustment
|
||||
# RAG Parameter Adjustment
|
||||
Each knowledge space supports argument customization, including the relevant arguments for vector retrieval and the arguments for knowledge question-answering prompts.
|
||||
|
||||
As shown in the figure below, clicking on the "Knowledge" will trigger a pop-up dialog box. Click the "Arguments" button to enter the parameter tuning interface.
|
||||

|
||||
|
||||
|
||||
<Tabs
|
||||
defaultValue="Embedding"
|
||||
values={[
|
||||
{label: 'Embedding Argument', value: 'Embedding'},
|
||||
{label: 'Prompt Argument', value: 'Prompt'},
|
||||
{label: 'Summary Argument', value: 'Summary'},
|
||||
]}>
|
||||
<TabItem value="Embedding" label="Embedding Argument">
|
||||
|
||||

|
||||
|
||||
:::tip Embedding Arguments
|
||||
* topk:the top k vectors based on similarity score.
|
||||
* recall_score:set a similarity threshold score for the retrieval of similar vectors. between 0 and 1. default 0.3.
|
||||
* recall_type:recall type. now nly support topk by vector similarity.
|
||||
* model:A model used to create vector representations of text or other data.
|
||||
* chunk_size:The size of the data chunks used in processing.default 500.
|
||||
* chunk_overlap:The amount of overlap between adjacent data chunks.default 50.
|
||||
:::
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="Prompt" label="Prompt Argument">
|
||||
|
||||

|
||||
|
||||
:::tip Prompt Arguments
|
||||
* scene:A contextual parameter used to define the setting or environment in which the prompt is being used.
|
||||
* template:A pre-defined structure or format for the prompt, which can help ensure that the AI system generates responses that are consistent with the desired style or tone.
|
||||
* max_token:The maximum number of tokens or words allowed in a prompt.
|
||||
:::
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="Summary" label="Summary Argument">
|
||||
|
||||

|
||||
|
||||
:::tip summary arguments
|
||||
* max_iteration: summary max iteration call with llm, default 5. the bigger and better for document summary but time will cost longer.
|
||||
* concurrency_limit: default summary concurrency call with llm, default 3.
|
||||
:::
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
# Knowledge Query Rewrite
|
||||
set ``KNOWLEDGE_SEARCH_REWRITE=True`` in ``.env`` file, and restart the server.
|
||||
|
||||
```shell
|
||||
# Whether to enable Chat Knowledge Search Rewrite Mode
|
||||
KNOWLEDGE_SEARCH_REWRITE=True
|
||||
```
|
||||
|
||||
# Change Vector Database
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
<Tabs
|
||||
defaultValue="Chroma"
|
||||
values={[
|
||||
{label: 'Chroma', value: 'Chroma'},
|
||||
{label: 'Milvus', value: 'Milvus'},
|
||||
{label: 'Weaviate', value: 'Weaviate'},
|
||||
]}>
|
||||
<TabItem value="Chroma" label="Chroma">
|
||||
|
||||
set ``VECTOR_STORE_TYPE`` in ``.env`` file.
|
||||
|
||||
```shell
|
||||
### Chroma vector db config
|
||||
VECTOR_STORE_TYPE=Chroma
|
||||
#CHROMA_PERSIST_PATH=/root/DB-GPT/pilot/data
|
||||
```
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="Milvus" label="Milvus">
|
||||
|
||||
|
||||
set ``VECTOR_STORE_TYPE`` in ``.env`` file
|
||||
|
||||
```shell
|
||||
### Milvus vector db config
|
||||
VECTOR_STORE_TYPE=Milvus
|
||||
MILVUS_URL=127.0.0.1
|
||||
MILVUS_PORT=19530
|
||||
#MILVUS_USERNAME
|
||||
#MILVUS_PASSWORD
|
||||
#MILVUS_SECURE=
|
||||
```
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="Weaviate" label="Weaviate">
|
||||
|
||||
set ``VECTOR_STORE_TYPE`` in ``.env`` file
|
||||
|
||||
```shell
|
||||
### Weaviate vector db config
|
||||
VECTOR_STORE_TYPE=Weaviate
|
||||
#WEAVIATE_URL=https://kt-region-m8hcy0wc.weaviate.network
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
@@ -1,2 +0,0 @@
|
||||
# FAQ
|
||||
If you encounter any problems, you can submit an [issue](https://github.com/eosphoros-ai/DB-GPT/issues) on Github.
|
||||
55
docs/docs/faq/chatdata.md
Normal file
55
docs/docs/faq/chatdata.md
Normal file
@@ -0,0 +1,55 @@
|
||||
ChatData & ChatDB
|
||||
==================================
|
||||
ChatData generates SQL from natural language and executes it. ChatDB involves conversing with metadata from the
|
||||
Database, including metadata about databases, tables, and
|
||||
fields.
|
||||
|
||||
### 1.Choose Datasource
|
||||
|
||||
If you are using DB-GPT for the first time, you need to add a data source and set the relevant connection information
|
||||
for the data source.
|
||||
|
||||
```{tip}
|
||||
there are some example data in DB-GPT-NEW/DB-GPT/docker/examples
|
||||
|
||||
you can execute sql script to generate data.
|
||||
```
|
||||
|
||||
#### 1.1 Datasource management
|
||||
|
||||
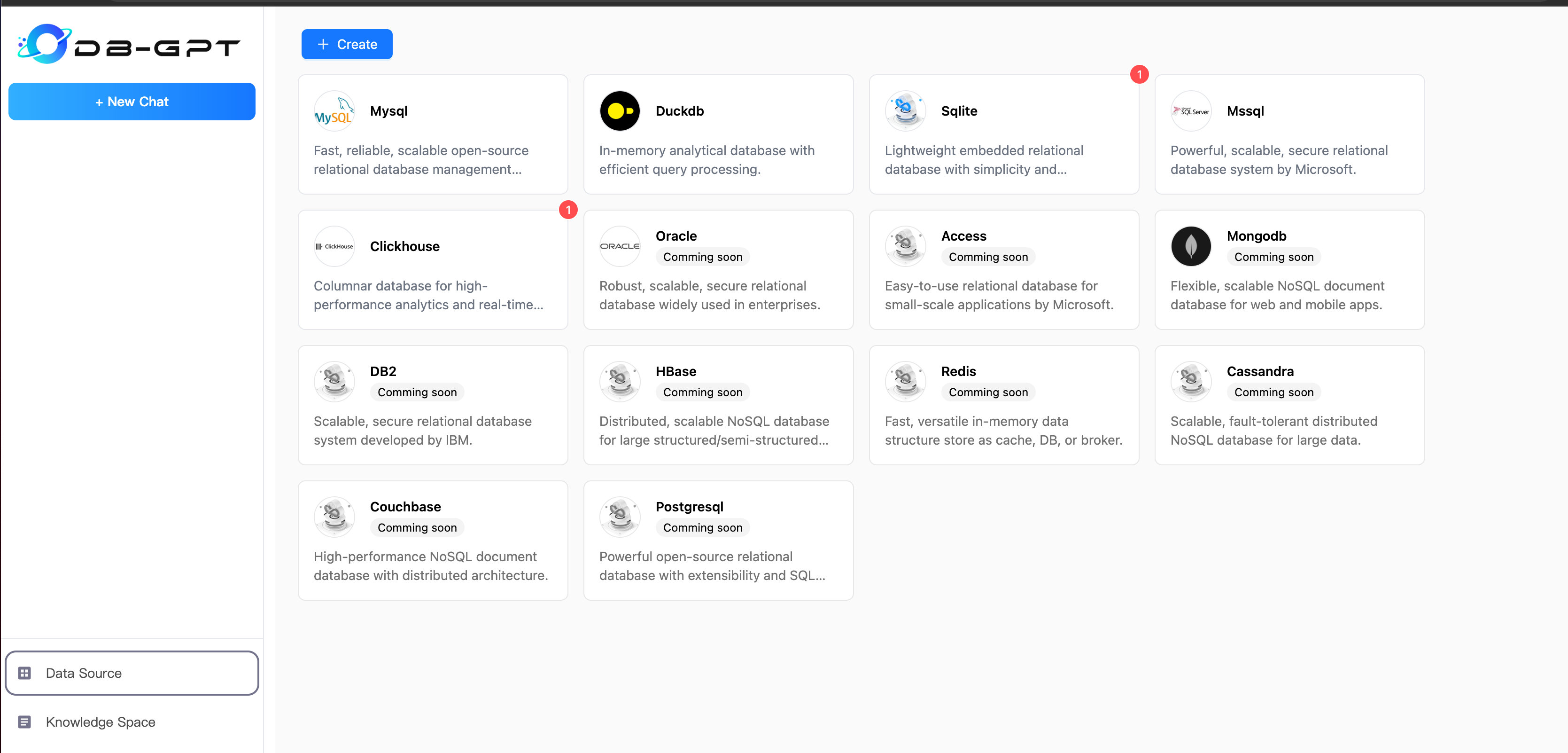
|
||||
|
||||
#### 1.2 Connection management
|
||||
|
||||
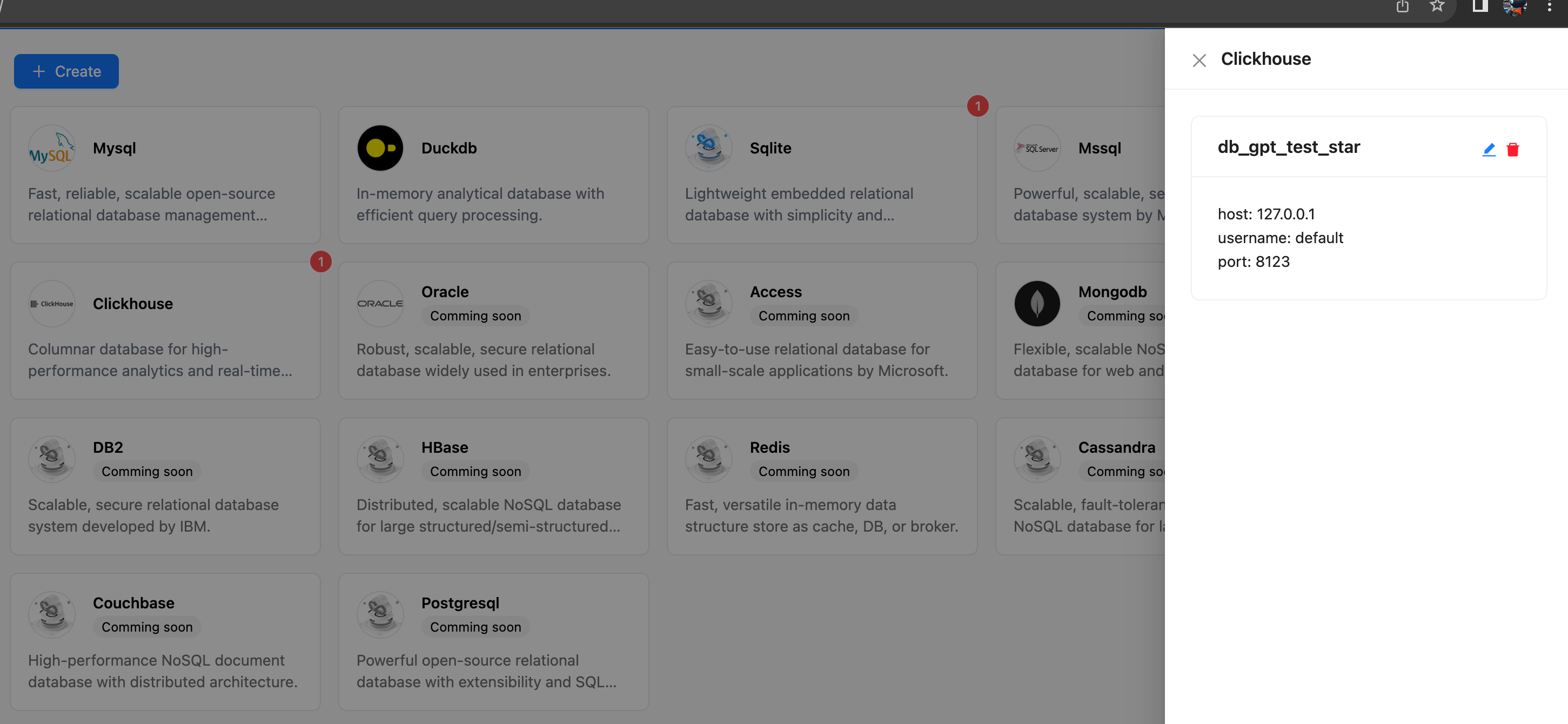
|
||||
|
||||
#### 1.3 Add Datasource
|
||||
|
||||
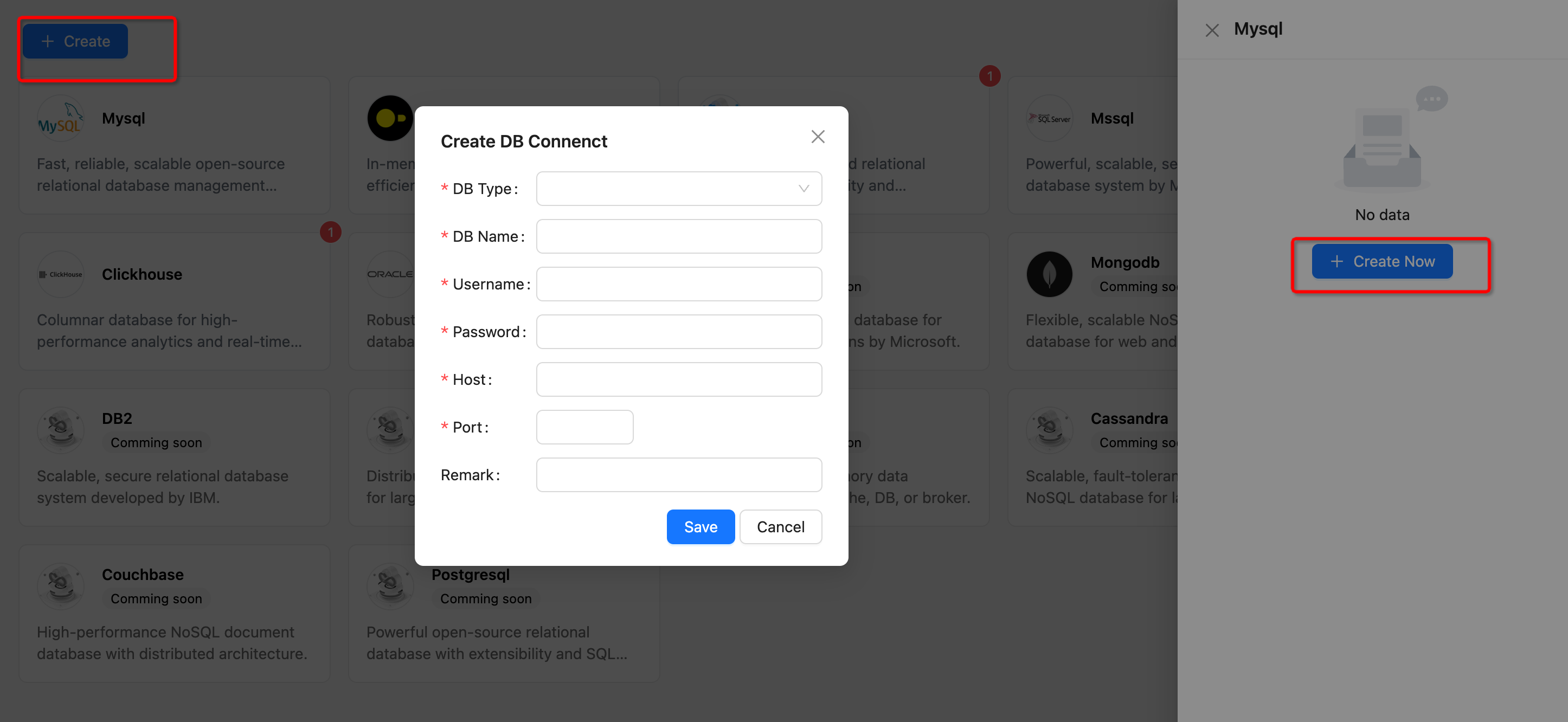
|
||||
|
||||
```{note}
|
||||
now DB-GPT support Datasource Type
|
||||
|
||||
* Mysql
|
||||
* Sqlite
|
||||
* DuckDB
|
||||
* Clickhouse
|
||||
* Mssql
|
||||
```
|
||||
|
||||
### 2.ChatData
|
||||
##### Preview Mode
|
||||
After successfully setting up the data source, you can start conversing with the database. You can ask it to generate
|
||||
SQL for you or inquire about relevant information on the database's metadata.
|
||||
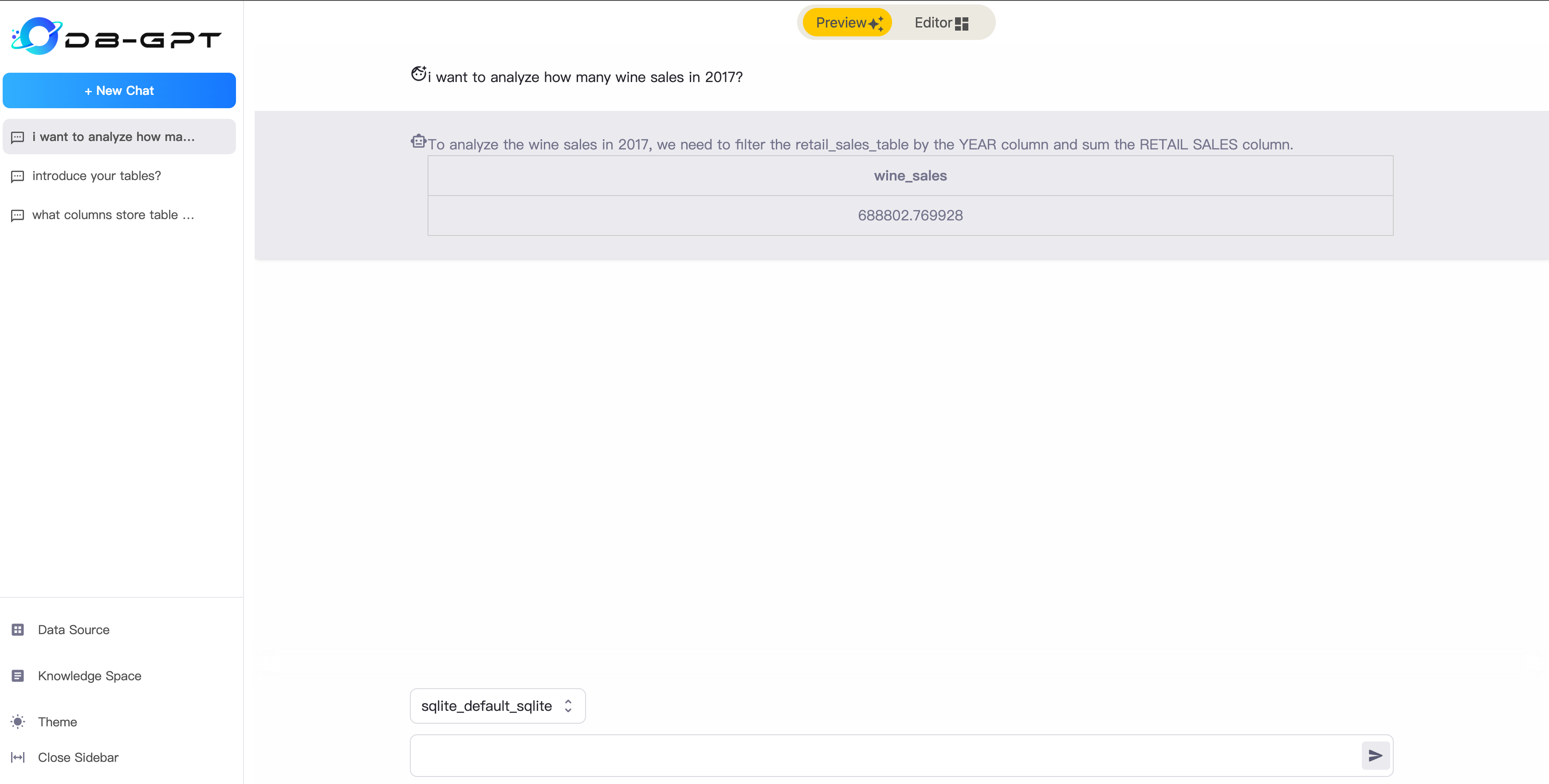
|
||||
|
||||
##### Editor Mode
|
||||
In Editor Mode, you can edit your sql and execute it.
|
||||
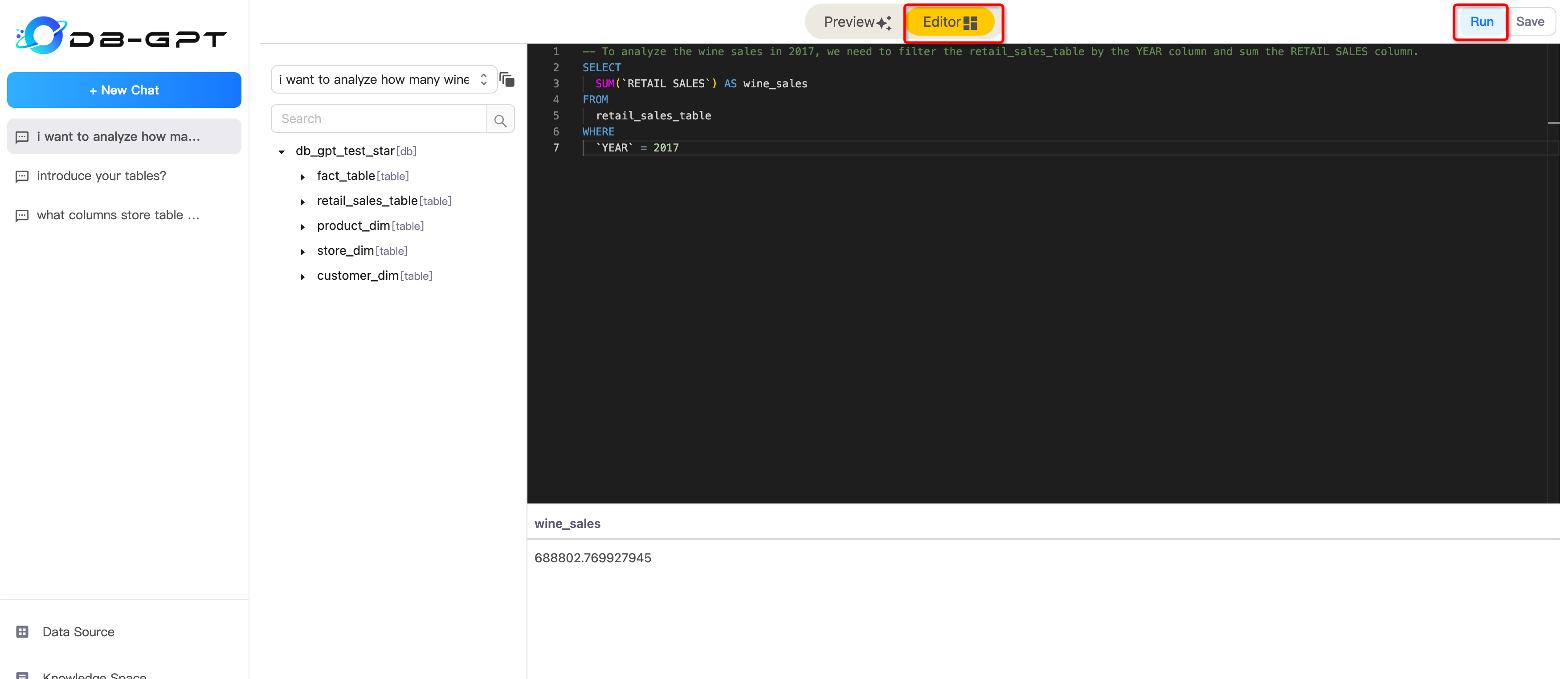
|
||||
|
||||
|
||||
### 3.ChatDB
|
||||
|
||||

|
||||
|
||||
|
||||
73
docs/docs/faq/install.md
Normal file
73
docs/docs/faq/install.md
Normal file
@@ -0,0 +1,73 @@
|
||||
Installation FAQ
|
||||
==================================
|
||||
|
||||
|
||||
##### Q1: sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) unable to open database file
|
||||
|
||||
make sure you pull latest code or create directory with mkdir pilot/data
|
||||
|
||||
##### Q2: The model keeps getting killed.
|
||||
|
||||
your GPU VRAM size is not enough, try replace your hardware or replace other llms.
|
||||
|
||||
##### Q3: How to access website on the public network
|
||||
|
||||
You can try to use gradio's [network](https://github.com/gradio-app/gradio/blob/main/gradio/networking.py) to achieve.
|
||||
```python
|
||||
import secrets
|
||||
from gradio import networking
|
||||
token=secrets.token_urlsafe(32)
|
||||
local_port=5000
|
||||
url = networking.setup_tunnel('0.0.0.0', local_port, token)
|
||||
print(f'Public url: {url}')
|
||||
time.sleep(60 * 60 * 24)
|
||||
```
|
||||
|
||||
Open `url` with your browser to see the website.
|
||||
|
||||
##### Q4: (Windows) execute `pip install -e .` error
|
||||
|
||||
The error log like the following:
|
||||
```
|
||||
× python setup.py bdist_wheel did not run successfully.
|
||||
│ exit code: 1
|
||||
╰─> [11 lines of output]
|
||||
running bdist_wheel
|
||||
running build
|
||||
running build_py
|
||||
creating build
|
||||
creating build\lib.win-amd64-cpython-310
|
||||
creating build\lib.win-amd64-cpython-310\cchardet
|
||||
copying src\cchardet\version.py -> build\lib.win-amd64-cpython-310\cchardet
|
||||
copying src\cchardet\__init__.py -> build\lib.win-amd64-cpython-310\cchardet
|
||||
running build_ext
|
||||
building 'cchardet._cchardet' extension
|
||||
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
|
||||
[end of output]
|
||||
```
|
||||
|
||||
Download and install `Microsoft C++ Build Tools` from [visual-cpp-build-tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/)
|
||||
|
||||
|
||||
|
||||
##### Q5: `Torch not compiled with CUDA enabled`
|
||||
|
||||
```
|
||||
2023-08-19 16:24:30 | ERROR | stderr | raise AssertionError("Torch not compiled with CUDA enabled")
|
||||
2023-08-19 16:24:30 | ERROR | stderr | AssertionError: Torch not compiled with CUDA enabled
|
||||
```
|
||||
|
||||
1. Install [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit-archive)
|
||||
2. Reinstall PyTorch [start-locally](https://pytorch.org/get-started/locally/#start-locally) with CUDA support.
|
||||
|
||||
|
||||
##### Q6: `How to migrate meta table chat_history and connect_config from duckdb to sqlite`
|
||||
```commandline
|
||||
python docker/examples/metadata/duckdb2sqlite.py
|
||||
```
|
||||
|
||||
##### Q7: `How to migrate meta table chat_history and connect_config from duckdb to mysql`
|
||||
```commandline
|
||||
1. update your mysql username and password in docker/examples/metadata/duckdb2mysql.py
|
||||
2. python docker/examples/metadata/duckdb2mysql.py
|
||||
```
|
||||
70
docs/docs/faq/kbqa.md
Normal file
70
docs/docs/faq/kbqa.md
Normal file
@@ -0,0 +1,70 @@
|
||||
KBQA FAQ
|
||||
==================================
|
||||
|
||||
##### Q1: text2vec-large-chinese not found
|
||||
|
||||
make sure you have download text2vec-large-chinese embedding model in right way
|
||||
|
||||
```tip
|
||||
centos:yum install git-lfs
|
||||
ubuntu:apt-get install git-lfs -y
|
||||
macos:brew install git-lfs
|
||||
```
|
||||
```bash
|
||||
cd models
|
||||
git lfs clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
|
||||
```
|
||||
|
||||
##### Q2:How to change Vector DB Type in DB-GPT.
|
||||
|
||||
Update .env file and set VECTOR_STORE_TYPE.
|
||||
|
||||
DB-GPT currently support Chroma(Default), Milvus(>2.1), Weaviate vector database.
|
||||
If you want to change vector db, Update your .env, set your vector store type, VECTOR_STORE_TYPE=Chroma (now only support Chroma and Milvus(>2.1), if you set Milvus, please set MILVUS_URL and MILVUS_PORT)
|
||||
If you want to support more vector db, you can integrate yourself.[how to integrate](https://db-gpt.readthedocs.io/en/latest/modules/vector.html)
|
||||
```commandline
|
||||
#*******************************************************************#
|
||||
#** VECTOR STORE SETTINGS **#
|
||||
#*******************************************************************#
|
||||
VECTOR_STORE_TYPE=Chroma
|
||||
#MILVUS_URL=127.0.0.1
|
||||
#MILVUS_PORT=19530
|
||||
#MILVUS_USERNAME
|
||||
#MILVUS_PASSWORD
|
||||
#MILVUS_SECURE=
|
||||
|
||||
#WEAVIATE_URL=https://kt-region-m8hcy0wc.weaviate.network
|
||||
```
|
||||
##### Q3:When I use vicuna-13b, found some illegal character like this.
|
||||
<p align="left">
|
||||
<img src="https://github.com/eosphoros-ai/DB-GPT/assets/13723926/088d1967-88e3-4f72-9ad7-6c4307baa2f8" width="800px" />
|
||||
</p>
|
||||
|
||||
Set KNOWLEDGE_SEARCH_TOP_SIZE smaller or set KNOWLEDGE_CHUNK_SIZE smaller, and reboot server.
|
||||
|
||||
##### Q4:space add error (pymysql.err.OperationalError) (1054, "Unknown column 'knowledge_space.context' in 'field list'")
|
||||
|
||||
1.shutdown dbgpt_server(ctrl c)
|
||||
|
||||
2.add column context for table knowledge_space
|
||||
|
||||
```commandline
|
||||
mysql -h127.0.0.1 -uroot -p {your_password}
|
||||
```
|
||||
|
||||
3.execute sql ddl
|
||||
|
||||
```commandline
|
||||
mysql> use knowledge_management;
|
||||
mysql> ALTER TABLE knowledge_space ADD COLUMN context TEXT COMMENT "arguments context";
|
||||
```
|
||||
|
||||
4.restart dbgpt serve
|
||||
|
||||
##### Q5:Use Mysql, how to use DB-GPT KBQA
|
||||
|
||||
build Mysql KBQA system database schema.
|
||||
|
||||
```bash
|
||||
$ mysql -h127.0.0.1 -uroot -p{your_password} < ./assets/schema/knowledge_management.sql
|
||||
```
|
||||
52
docs/docs/faq/llm.md
Normal file
52
docs/docs/faq/llm.md
Normal file
@@ -0,0 +1,52 @@
|
||||
LLM USE FAQ
|
||||
==================================
|
||||
##### Q1:how to use openai chatgpt service
|
||||
change your LLM_MODEL
|
||||
````shell
|
||||
LLM_MODEL=proxyllm
|
||||
````
|
||||
|
||||
set your OPENAPI KEY
|
||||
|
||||
````shell
|
||||
PROXY_API_KEY={your-openai-sk}
|
||||
PROXY_SERVER_URL=https://api.openai.com/v1/chat/completions
|
||||
````
|
||||
|
||||
make sure your openapi API_KEY is available
|
||||
|
||||
##### Q2 What difference between `python dbgpt_server --light` and `python dbgpt_server`
|
||||
|
||||
:::tip
|
||||
python dbgpt_server --light` dbgpt_server does not start the llm service. Users can deploy the llm service separately by using `python llmserver`, and dbgpt_server accesses the llm service through set the LLM_SERVER environment variable in .env. The purpose is to allow for the separate deployment of dbgpt's backend service and llm service.
|
||||
|
||||
python dbgpt_server service and the llm service are deployed on the same instance. when dbgpt_server starts the service, it also starts the llm service at the same time.
|
||||
:::
|
||||
|
||||
##### Q3 how to use MultiGPUs
|
||||
|
||||
DB-GPT will use all available gpu by default. And you can modify the setting `CUDA_VISIBLE_DEVICES=0,1` in `.env` file
|
||||
to use the specific gpu IDs.
|
||||
|
||||
Optionally, you can also specify the gpu ID to use before the starting command, as shown below:
|
||||
|
||||
````shell
|
||||
# Specify 1 gpu
|
||||
CUDA_VISIBLE_DEVICES=0 python3 pilot/server/dbgpt_server.py
|
||||
|
||||
# Specify 4 gpus
|
||||
CUDA_VISIBLE_DEVICES=3,4,5,6 python3 pilot/server/dbgpt_server.py
|
||||
````
|
||||
|
||||
You can modify the setting `MAX_GPU_MEMORY=xxGib` in `.env` file to configure the maximum memory used by each GPU.
|
||||
|
||||
##### Q4 Not Enough Memory
|
||||
|
||||
DB-GPT supported 8-bit quantization and 4-bit quantization.
|
||||
|
||||
You can modify the setting `QUANTIZE_8bit=True` or `QUANTIZE_4bit=True` in `.env` file to use quantization(8-bit quantization is enabled by default).
|
||||
|
||||
Llama-2-70b with 8-bit quantization can run with 80 GB of VRAM, and 4-bit quantization can run with 48 GB of VRAM.
|
||||
|
||||
Note: you need to install the latest dependencies according to [requirements.txt](https://github.com/eosphoros-ai/DB-GPT/blob/main/requirements.txt).
|
||||
Note: you need to install the latest dependencies according to [requirements.txt](https://github.com/eosphoros-ai/DB-GPT/blob/main/requirements.txt).
|
||||
@@ -200,8 +200,27 @@ const sidebars = {
|
||||
},
|
||||
|
||||
{
|
||||
type: "doc",
|
||||
id:"faq"
|
||||
type: "category",
|
||||
label: "FAQ",
|
||||
collapsed: true,
|
||||
items: [
|
||||
{
|
||||
type: 'doc',
|
||||
id: 'faq/install',
|
||||
}
|
||||
,{
|
||||
type: 'doc',
|
||||
id: 'faq/llm',
|
||||
}
|
||||
,{
|
||||
type: 'doc',
|
||||
id: 'faq/kbqa',
|
||||
}
|
||||
,{
|
||||
type: 'doc',
|
||||
id: 'faq/chatdata',
|
||||
},
|
||||
],
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
Reference in New Issue
Block a user