mirror of
https://github.com/csunny/DB-GPT.git
synced 2025-07-27 13:57:46 +00:00
feat(ChatKnowledge):add similarity score and query rewrite (#880)
This commit is contained in:
parent
13fb9d03a7
commit
54d5b0b804
@ -78,6 +78,8 @@ KNOWLEDGE_SEARCH_TOP_SIZE=5
|
|||||||
#KNOWLEDGE_CHUNK_OVERLAP=50
|
#KNOWLEDGE_CHUNK_OVERLAP=50
|
||||||
# Control whether to display the source document of knowledge on the front end.
|
# Control whether to display the source document of knowledge on the front end.
|
||||||
KNOWLEDGE_CHAT_SHOW_RELATIONS=False
|
KNOWLEDGE_CHAT_SHOW_RELATIONS=False
|
||||||
|
# Whether to enable Chat Knowledge Search Rewrite Mode
|
||||||
|
KNOWLEDGE_SEARCH_REWRITE=False
|
||||||
## EMBEDDING_TOKENIZER - Tokenizer to use for chunking large inputs
|
## EMBEDDING_TOKENIZER - Tokenizer to use for chunking large inputs
|
||||||
## EMBEDDING_TOKEN_LIMIT - Chunk size limit for large inputs
|
## EMBEDDING_TOKEN_LIMIT - Chunk size limit for large inputs
|
||||||
# EMBEDDING_MODEL=all-MiniLM-L6-v2
|
# EMBEDDING_MODEL=all-MiniLM-L6-v2
|
||||||
@ -92,16 +94,15 @@ KNOWLEDGE_CHAT_SHOW_RELATIONS=False
|
|||||||
|
|
||||||
|
|
||||||
#*******************************************************************#
|
#*******************************************************************#
|
||||||
#** DATABASE SETTINGS **#
|
#** DB-GPT METADATA DATABASE SETTINGS **#
|
||||||
#*******************************************************************#
|
#*******************************************************************#
|
||||||
### SQLite database (Current default database)
|
### SQLite database (Current default database)
|
||||||
LOCAL_DB_PATH=data/default_sqlite.db
|
|
||||||
LOCAL_DB_TYPE=sqlite
|
LOCAL_DB_TYPE=sqlite
|
||||||
|
|
||||||
### MYSQL database
|
### MYSQL database
|
||||||
# LOCAL_DB_TYPE=mysql
|
# LOCAL_DB_TYPE=mysql
|
||||||
# LOCAL_DB_USER=root
|
# LOCAL_DB_USER=root
|
||||||
# LOCAL_DB_PASSWORD=aa12345678
|
# LOCAL_DB_PASSWORD={your_password}
|
||||||
# LOCAL_DB_HOST=127.0.0.1
|
# LOCAL_DB_HOST=127.0.0.1
|
||||||
# LOCAL_DB_PORT=3306
|
# LOCAL_DB_PORT=3306
|
||||||
# LOCAL_DB_NAME=dbgpt
|
# LOCAL_DB_NAME=dbgpt
|
||||||
|
|||||||
54
docker/examples/metadata/duckdb2mysql.py
Normal file
54
docker/examples/metadata/duckdb2mysql.py
Normal file
@ -0,0 +1,54 @@
|
|||||||
|
import duckdb
|
||||||
|
import pymysql
|
||||||
|
|
||||||
|
""" migrate duckdb to mysql"""
|
||||||
|
|
||||||
|
mysql_config = {
|
||||||
|
"host": "127.0.0.1",
|
||||||
|
"user": "root",
|
||||||
|
"password": "your_password",
|
||||||
|
"db": "dbgpt",
|
||||||
|
"charset": "utf8mb4",
|
||||||
|
"cursorclass": pymysql.cursors.DictCursor,
|
||||||
|
}
|
||||||
|
|
||||||
|
duckdb_files_to_tables = {
|
||||||
|
"pilot/message/chat_history.db": "chat_history",
|
||||||
|
"pilot/message/connect_config.db": "connect_config",
|
||||||
|
}
|
||||||
|
|
||||||
|
conn_mysql = pymysql.connect(**mysql_config)
|
||||||
|
|
||||||
|
|
||||||
|
def migrate_table(duckdb_file_path, source_table, destination_table, conn_mysql):
|
||||||
|
conn_duckdb = duckdb.connect(duckdb_file_path)
|
||||||
|
try:
|
||||||
|
cursor = conn_duckdb.cursor()
|
||||||
|
cursor.execute(f"SELECT * FROM {source_table}")
|
||||||
|
column_names = [
|
||||||
|
desc[0] for desc in cursor.description if desc[0].lower() != "id"
|
||||||
|
]
|
||||||
|
select_columns = ", ".join(column_names)
|
||||||
|
|
||||||
|
cursor.execute(f"SELECT {select_columns} FROM {source_table}")
|
||||||
|
results = cursor.fetchall()
|
||||||
|
|
||||||
|
with conn_mysql.cursor() as cursor_mysql:
|
||||||
|
for row in results:
|
||||||
|
placeholders = ", ".join(["%s"] * len(row))
|
||||||
|
insert_query = f"INSERT INTO {destination_table} ({', '.join(column_names)}) VALUES ({placeholders})"
|
||||||
|
cursor_mysql.execute(insert_query, row)
|
||||||
|
conn_mysql.commit()
|
||||||
|
finally:
|
||||||
|
conn_duckdb.close()
|
||||||
|
|
||||||
|
|
||||||
|
try:
|
||||||
|
for duckdb_file, table in duckdb_files_to_tables.items():
|
||||||
|
print(f"Migrating table {table} from {duckdb_file}...")
|
||||||
|
migrate_table(duckdb_file, table, table, conn_mysql)
|
||||||
|
print(f"Table {table} migrated successfully.")
|
||||||
|
finally:
|
||||||
|
conn_mysql.close()
|
||||||
|
|
||||||
|
print("Migration completed.")
|
||||||
48
docker/examples/metadata/duckdb2sqlite.py
Normal file
48
docker/examples/metadata/duckdb2sqlite.py
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
import duckdb
|
||||||
|
import sqlite3
|
||||||
|
|
||||||
|
""" migrate duckdb to sqlite"""
|
||||||
|
|
||||||
|
duckdb_files_to_tables = {
|
||||||
|
"pilot/message/chat_history.db": "chat_history",
|
||||||
|
"pilot/message/connect_config.db": "connect_config",
|
||||||
|
}
|
||||||
|
|
||||||
|
sqlite_db_path = "pilot/meta_data/dbgpt.db"
|
||||||
|
|
||||||
|
conn_sqlite = sqlite3.connect(sqlite_db_path)
|
||||||
|
|
||||||
|
|
||||||
|
def migrate_table(duckdb_file_path, source_table, destination_table, conn_sqlite):
|
||||||
|
conn_duckdb = duckdb.connect(duckdb_file_path)
|
||||||
|
try:
|
||||||
|
cursor_duckdb = conn_duckdb.cursor()
|
||||||
|
cursor_duckdb.execute(f"SELECT * FROM {source_table}")
|
||||||
|
column_names = [
|
||||||
|
desc[0] for desc in cursor_duckdb.description if desc[0].lower() != "id"
|
||||||
|
]
|
||||||
|
select_columns = ", ".join(column_names)
|
||||||
|
|
||||||
|
cursor_duckdb.execute(f"SELECT {select_columns} FROM {source_table}")
|
||||||
|
results = cursor_duckdb.fetchall()
|
||||||
|
|
||||||
|
cursor_sqlite = conn_sqlite.cursor()
|
||||||
|
for row in results:
|
||||||
|
placeholders = ", ".join(["?"] * len(row))
|
||||||
|
insert_query = f"INSERT INTO {destination_table} ({', '.join(column_names)}) VALUES ({placeholders})"
|
||||||
|
cursor_sqlite.execute(insert_query, row)
|
||||||
|
conn_sqlite.commit()
|
||||||
|
cursor_sqlite.close()
|
||||||
|
finally:
|
||||||
|
conn_duckdb.close()
|
||||||
|
|
||||||
|
|
||||||
|
try:
|
||||||
|
for duckdb_file, table in duckdb_files_to_tables.items():
|
||||||
|
print(f"Migrating table {table} from {duckdb_file} to SQLite...")
|
||||||
|
migrate_table(duckdb_file, table, table, conn_sqlite)
|
||||||
|
print(f"Table {table} migrated to SQLite successfully.")
|
||||||
|
finally:
|
||||||
|
conn_sqlite.close()
|
||||||
|
|
||||||
|
print("Migration to SQLite completed.")
|
||||||
@ -1 +1,111 @@
|
|||||||
# RAG Parameter Adjustment
|
# RAG Parameter Adjustment
|
||||||
|
Each knowledge space supports argument customization, including the relevant arguments for vector retrieval and the arguments for knowledge question-answering prompts.
|
||||||
|
|
||||||
|
As shown in the figure below, clicking on the "Knowledge" will trigger a pop-up dialog box. Click the "Arguments" button to enter the parameter tuning interface.
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
<Tabs
|
||||||
|
defaultValue="Embedding"
|
||||||
|
values={[
|
||||||
|
{label: 'Embedding Argument', value: 'Embedding'},
|
||||||
|
{label: 'Prompt Argument', value: 'Prompt'},
|
||||||
|
{label: 'Summary Argument', value: 'Summary'},
|
||||||
|
]}>
|
||||||
|
<TabItem value="Embedding" label="Embedding Argument">
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
:::tip Embedding Arguments
|
||||||
|
* topk:the top k vectors based on similarity score.
|
||||||
|
* recall_score:set a similarity threshold score for the retrieval of similar vectors. between 0 and 1. default 0.3.
|
||||||
|
* recall_type:recall type. now nly support topk by vector similarity.
|
||||||
|
* model:A model used to create vector representations of text or other data.
|
||||||
|
* chunk_size:The size of the data chunks used in processing.default 500.
|
||||||
|
* chunk_overlap:The amount of overlap between adjacent data chunks.default 50.
|
||||||
|
:::
|
||||||
|
</TabItem>
|
||||||
|
|
||||||
|
<TabItem value="Prompt" label="Prompt Argument">
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
:::tip Prompt Arguments
|
||||||
|
* scene:A contextual parameter used to define the setting or environment in which the prompt is being used.
|
||||||
|
* template:A pre-defined structure or format for the prompt, which can help ensure that the AI system generates responses that are consistent with the desired style or tone.
|
||||||
|
* max_token:The maximum number of tokens or words allowed in a prompt.
|
||||||
|
:::
|
||||||
|
|
||||||
|
</TabItem>
|
||||||
|
|
||||||
|
<TabItem value="Summary" label="Summary Argument">
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
:::tip summary arguments
|
||||||
|
* max_iteration: summary max iteration call with llm, default 5. the bigger and better for document summary but time will cost longer.
|
||||||
|
* concurrency_limit: default summary concurrency call with llm, default 3.
|
||||||
|
:::
|
||||||
|
|
||||||
|
</TabItem>
|
||||||
|
|
||||||
|
</Tabs>
|
||||||
|
|
||||||
|
# Knowledge Query Rewrite
|
||||||
|
set ``KNOWLEDGE_SEARCH_REWRITE=True`` in ``.env`` file, and restart the server.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
# Whether to enable Chat Knowledge Search Rewrite Mode
|
||||||
|
KNOWLEDGE_SEARCH_REWRITE=True
|
||||||
|
```
|
||||||
|
|
||||||
|
# Change Vector Database
|
||||||
|
import Tabs from '@theme/Tabs';
|
||||||
|
import TabItem from '@theme/TabItem';
|
||||||
|
|
||||||
|
<Tabs
|
||||||
|
defaultValue="Chroma"
|
||||||
|
values={[
|
||||||
|
{label: 'Chroma', value: 'Chroma'},
|
||||||
|
{label: 'Milvus', value: 'Milvus'},
|
||||||
|
{label: 'Weaviate', value: 'Weaviate'},
|
||||||
|
]}>
|
||||||
|
<TabItem value="Chroma" label="Chroma">
|
||||||
|
|
||||||
|
set ``VECTOR_STORE_TYPE`` in ``.env`` file.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
### Chroma vector db config
|
||||||
|
VECTOR_STORE_TYPE=Chroma
|
||||||
|
#CHROMA_PERSIST_PATH=/root/DB-GPT/pilot/data
|
||||||
|
```
|
||||||
|
</TabItem>
|
||||||
|
|
||||||
|
<TabItem value="Milvus" label="Milvus">
|
||||||
|
|
||||||
|
|
||||||
|
set ``VECTOR_STORE_TYPE`` in ``.env`` file
|
||||||
|
|
||||||
|
```shell
|
||||||
|
### Milvus vector db config
|
||||||
|
VECTOR_STORE_TYPE=Milvus
|
||||||
|
MILVUS_URL=127.0.0.1
|
||||||
|
MILVUS_PORT=19530
|
||||||
|
#MILVUS_USERNAME
|
||||||
|
#MILVUS_PASSWORD
|
||||||
|
#MILVUS_SECURE=
|
||||||
|
```
|
||||||
|
</TabItem>
|
||||||
|
|
||||||
|
<TabItem value="Weaviate" label="Weaviate">
|
||||||
|
|
||||||
|
set ``VECTOR_STORE_TYPE`` in ``.env`` file
|
||||||
|
|
||||||
|
```shell
|
||||||
|
### Weaviate vector db config
|
||||||
|
VECTOR_STORE_TYPE=Weaviate
|
||||||
|
#WEAVIATE_URL=https://kt-region-m8hcy0wc.weaviate.network
|
||||||
|
```
|
||||||
|
|
||||||
|
</TabItem>
|
||||||
|
</Tabs>
|
||||||
|
|||||||
@ -1,2 +0,0 @@
|
|||||||
# FAQ
|
|
||||||
If you encounter any problems, you can submit an [issue](https://github.com/eosphoros-ai/DB-GPT/issues) on Github.
|
|
||||||
55
docs/docs/faq/chatdata.md
Normal file
55
docs/docs/faq/chatdata.md
Normal file
@ -0,0 +1,55 @@
|
|||||||
|
ChatData & ChatDB
|
||||||
|
==================================
|
||||||
|
ChatData generates SQL from natural language and executes it. ChatDB involves conversing with metadata from the
|
||||||
|
Database, including metadata about databases, tables, and
|
||||||
|
fields.
|
||||||
|
|
||||||
|
### 1.Choose Datasource
|
||||||
|
|
||||||
|
If you are using DB-GPT for the first time, you need to add a data source and set the relevant connection information
|
||||||
|
for the data source.
|
||||||
|
|
||||||
|
```{tip}
|
||||||
|
there are some example data in DB-GPT-NEW/DB-GPT/docker/examples
|
||||||
|
|
||||||
|
you can execute sql script to generate data.
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 1.1 Datasource management
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 1.2 Connection management
|
||||||
|
|
||||||
|
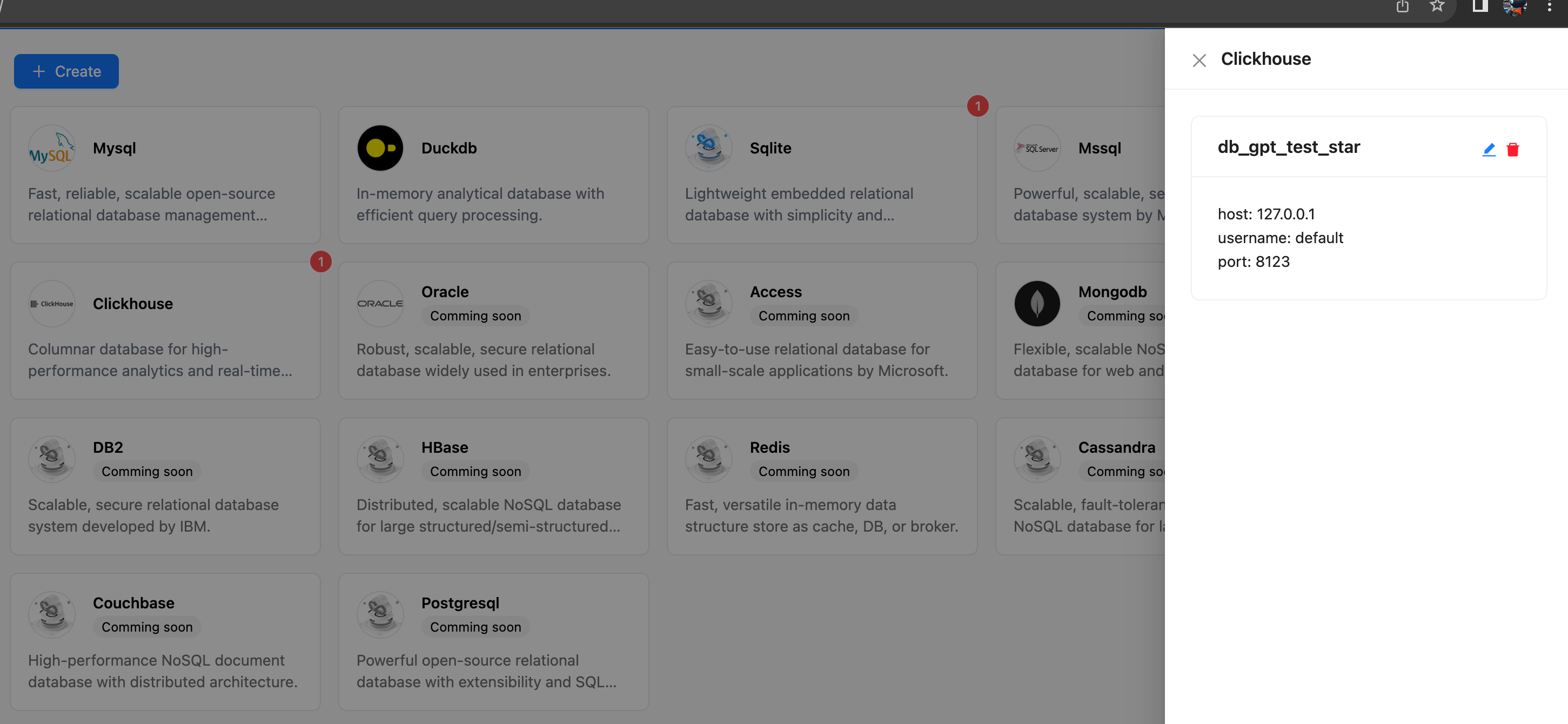
|
||||||
|
|
||||||
|
#### 1.3 Add Datasource
|
||||||
|
|
||||||
|
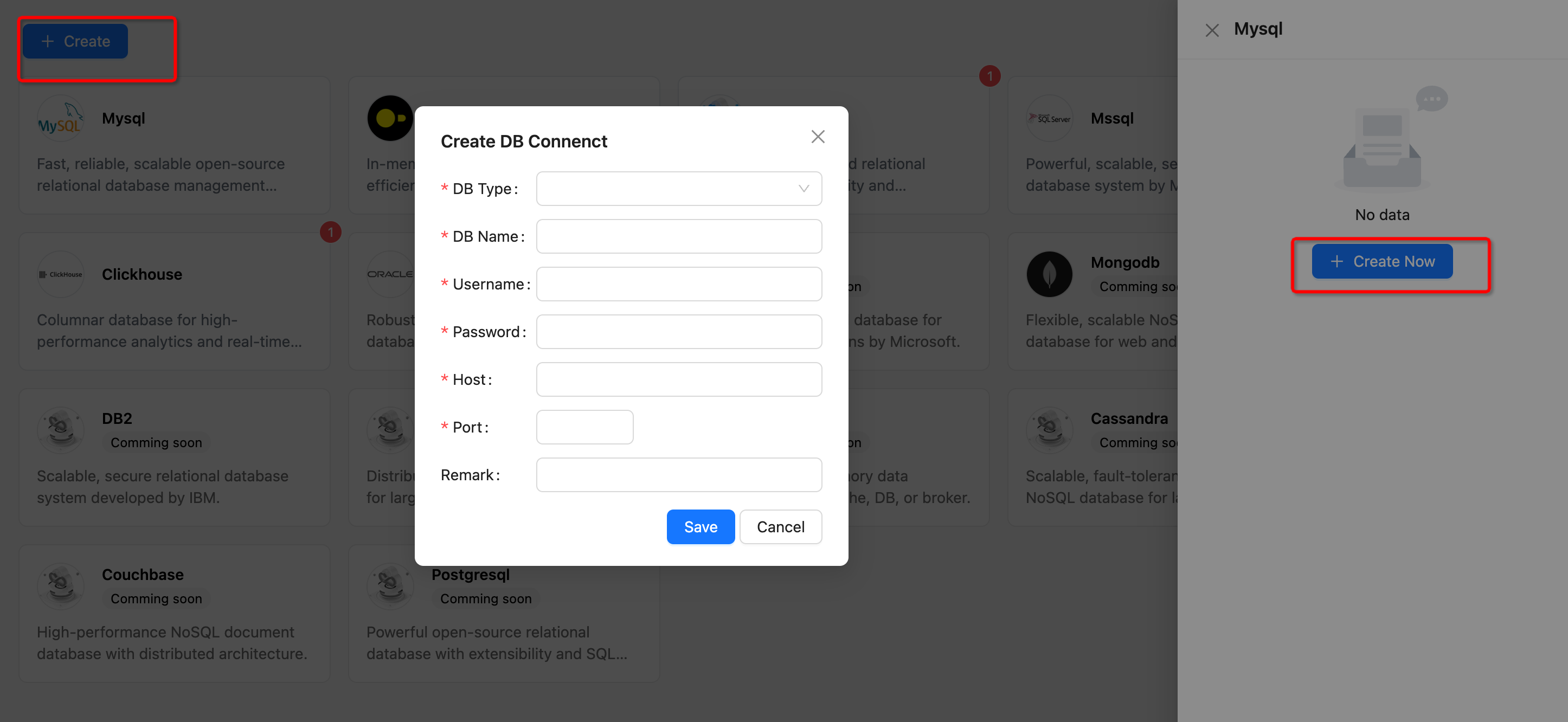
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
now DB-GPT support Datasource Type
|
||||||
|
|
||||||
|
* Mysql
|
||||||
|
* Sqlite
|
||||||
|
* DuckDB
|
||||||
|
* Clickhouse
|
||||||
|
* Mssql
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2.ChatData
|
||||||
|
##### Preview Mode
|
||||||
|
After successfully setting up the data source, you can start conversing with the database. You can ask it to generate
|
||||||
|
SQL for you or inquire about relevant information on the database's metadata.
|
||||||
|
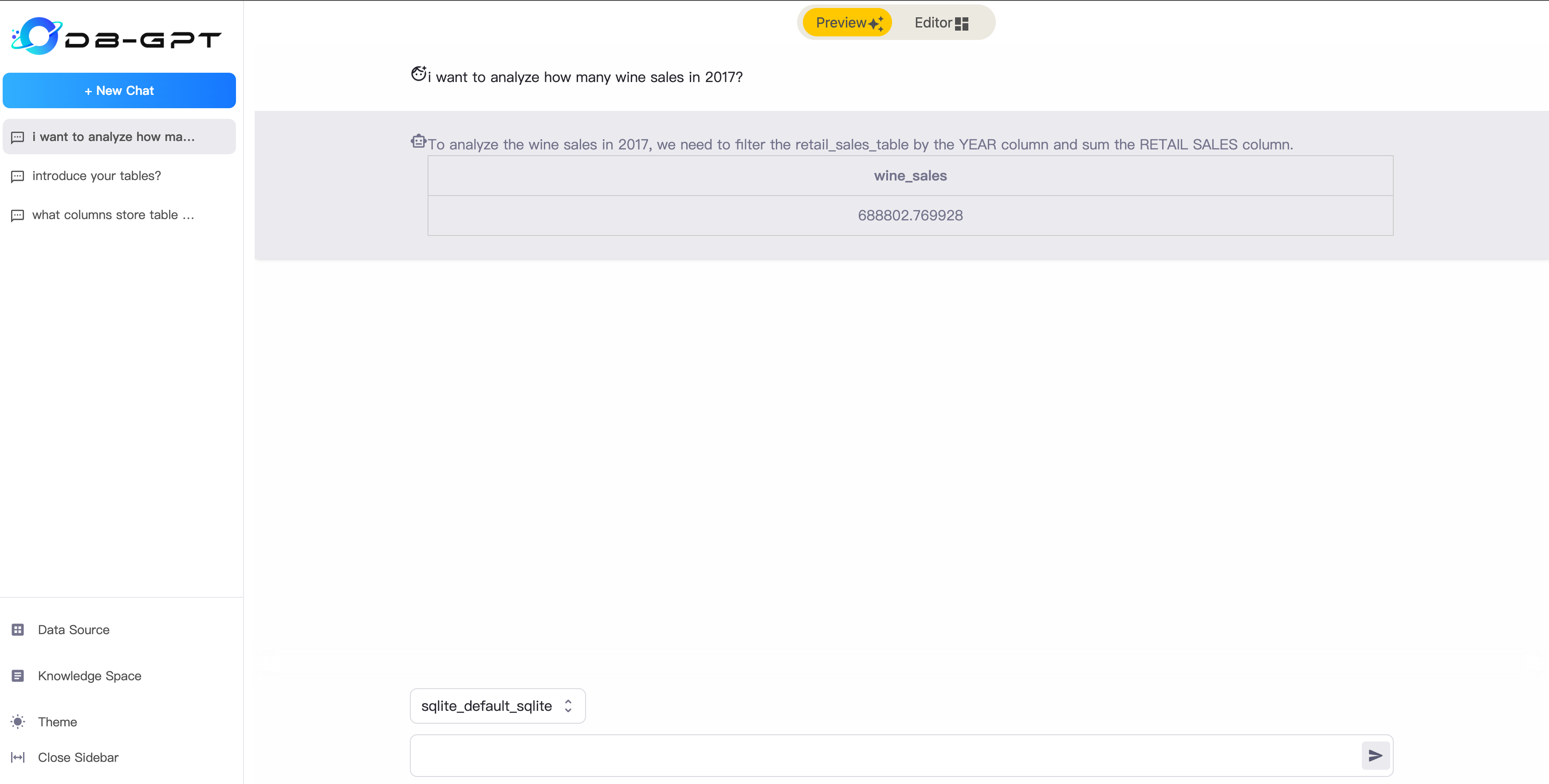
|
||||||
|
|
||||||
|
##### Editor Mode
|
||||||
|
In Editor Mode, you can edit your sql and execute it.
|
||||||
|
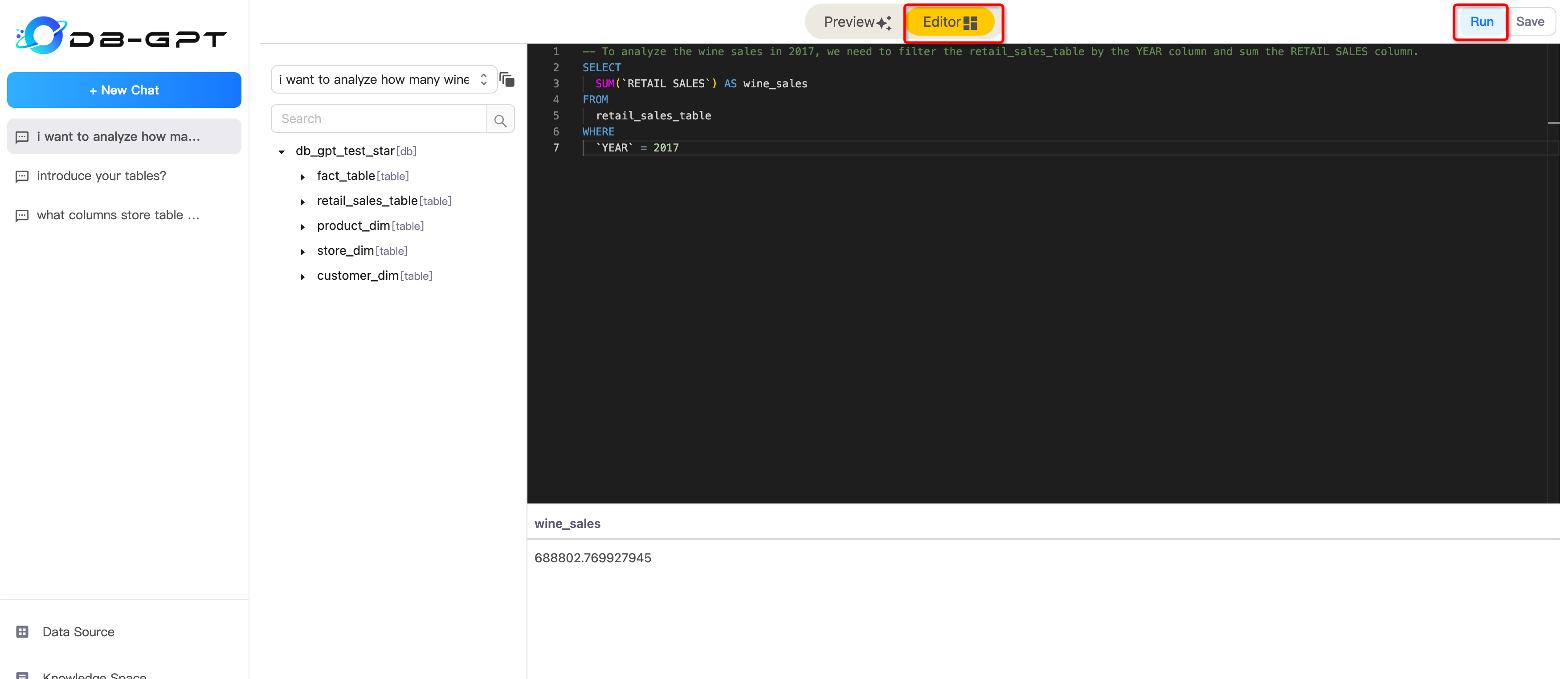
|
||||||
|
|
||||||
|
|
||||||
|
### 3.ChatDB
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
73
docs/docs/faq/install.md
Normal file
73
docs/docs/faq/install.md
Normal file
@ -0,0 +1,73 @@
|
|||||||
|
Installation FAQ
|
||||||
|
==================================
|
||||||
|
|
||||||
|
|
||||||
|
##### Q1: sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) unable to open database file
|
||||||
|
|
||||||
|
make sure you pull latest code or create directory with mkdir pilot/data
|
||||||
|
|
||||||
|
##### Q2: The model keeps getting killed.
|
||||||
|
|
||||||
|
your GPU VRAM size is not enough, try replace your hardware or replace other llms.
|
||||||
|
|
||||||
|
##### Q3: How to access website on the public network
|
||||||
|
|
||||||
|
You can try to use gradio's [network](https://github.com/gradio-app/gradio/blob/main/gradio/networking.py) to achieve.
|
||||||
|
```python
|
||||||
|
import secrets
|
||||||
|
from gradio import networking
|
||||||
|
token=secrets.token_urlsafe(32)
|
||||||
|
local_port=5000
|
||||||
|
url = networking.setup_tunnel('0.0.0.0', local_port, token)
|
||||||
|
print(f'Public url: {url}')
|
||||||
|
time.sleep(60 * 60 * 24)
|
||||||
|
```
|
||||||
|
|
||||||
|
Open `url` with your browser to see the website.
|
||||||
|
|
||||||
|
##### Q4: (Windows) execute `pip install -e .` error
|
||||||
|
|
||||||
|
The error log like the following:
|
||||||
|
```
|
||||||
|
× python setup.py bdist_wheel did not run successfully.
|
||||||
|
│ exit code: 1
|
||||||
|
╰─> [11 lines of output]
|
||||||
|
running bdist_wheel
|
||||||
|
running build
|
||||||
|
running build_py
|
||||||
|
creating build
|
||||||
|
creating build\lib.win-amd64-cpython-310
|
||||||
|
creating build\lib.win-amd64-cpython-310\cchardet
|
||||||
|
copying src\cchardet\version.py -> build\lib.win-amd64-cpython-310\cchardet
|
||||||
|
copying src\cchardet\__init__.py -> build\lib.win-amd64-cpython-310\cchardet
|
||||||
|
running build_ext
|
||||||
|
building 'cchardet._cchardet' extension
|
||||||
|
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
|
||||||
|
[end of output]
|
||||||
|
```
|
||||||
|
|
||||||
|
Download and install `Microsoft C++ Build Tools` from [visual-cpp-build-tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
##### Q5: `Torch not compiled with CUDA enabled`
|
||||||
|
|
||||||
|
```
|
||||||
|
2023-08-19 16:24:30 | ERROR | stderr | raise AssertionError("Torch not compiled with CUDA enabled")
|
||||||
|
2023-08-19 16:24:30 | ERROR | stderr | AssertionError: Torch not compiled with CUDA enabled
|
||||||
|
```
|
||||||
|
|
||||||
|
1. Install [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit-archive)
|
||||||
|
2. Reinstall PyTorch [start-locally](https://pytorch.org/get-started/locally/#start-locally) with CUDA support.
|
||||||
|
|
||||||
|
|
||||||
|
##### Q6: `How to migrate meta table chat_history and connect_config from duckdb to sqlite`
|
||||||
|
```commandline
|
||||||
|
python docker/examples/metadata/duckdb2sqlite.py
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Q7: `How to migrate meta table chat_history and connect_config from duckdb to mysql`
|
||||||
|
```commandline
|
||||||
|
1. update your mysql username and password in docker/examples/metadata/duckdb2mysql.py
|
||||||
|
2. python docker/examples/metadata/duckdb2mysql.py
|
||||||
|
```
|
||||||
70
docs/docs/faq/kbqa.md
Normal file
70
docs/docs/faq/kbqa.md
Normal file
@ -0,0 +1,70 @@
|
|||||||
|
KBQA FAQ
|
||||||
|
==================================
|
||||||
|
|
||||||
|
##### Q1: text2vec-large-chinese not found
|
||||||
|
|
||||||
|
make sure you have download text2vec-large-chinese embedding model in right way
|
||||||
|
|
||||||
|
```tip
|
||||||
|
centos:yum install git-lfs
|
||||||
|
ubuntu:apt-get install git-lfs -y
|
||||||
|
macos:brew install git-lfs
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
cd models
|
||||||
|
git lfs clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Q2:How to change Vector DB Type in DB-GPT.
|
||||||
|
|
||||||
|
Update .env file and set VECTOR_STORE_TYPE.
|
||||||
|
|
||||||
|
DB-GPT currently support Chroma(Default), Milvus(>2.1), Weaviate vector database.
|
||||||
|
If you want to change vector db, Update your .env, set your vector store type, VECTOR_STORE_TYPE=Chroma (now only support Chroma and Milvus(>2.1), if you set Milvus, please set MILVUS_URL and MILVUS_PORT)
|
||||||
|
If you want to support more vector db, you can integrate yourself.[how to integrate](https://db-gpt.readthedocs.io/en/latest/modules/vector.html)
|
||||||
|
```commandline
|
||||||
|
#*******************************************************************#
|
||||||
|
#** VECTOR STORE SETTINGS **#
|
||||||
|
#*******************************************************************#
|
||||||
|
VECTOR_STORE_TYPE=Chroma
|
||||||
|
#MILVUS_URL=127.0.0.1
|
||||||
|
#MILVUS_PORT=19530
|
||||||
|
#MILVUS_USERNAME
|
||||||
|
#MILVUS_PASSWORD
|
||||||
|
#MILVUS_SECURE=
|
||||||
|
|
||||||
|
#WEAVIATE_URL=https://kt-region-m8hcy0wc.weaviate.network
|
||||||
|
```
|
||||||
|
##### Q3:When I use vicuna-13b, found some illegal character like this.
|
||||||
|
<p align="left">
|
||||||
|
<img src="https://github.com/eosphoros-ai/DB-GPT/assets/13723926/088d1967-88e3-4f72-9ad7-6c4307baa2f8" width="800px" />
|
||||||
|
</p>
|
||||||
|
|
||||||
|
Set KNOWLEDGE_SEARCH_TOP_SIZE smaller or set KNOWLEDGE_CHUNK_SIZE smaller, and reboot server.
|
||||||
|
|
||||||
|
##### Q4:space add error (pymysql.err.OperationalError) (1054, "Unknown column 'knowledge_space.context' in 'field list'")
|
||||||
|
|
||||||
|
1.shutdown dbgpt_server(ctrl c)
|
||||||
|
|
||||||
|
2.add column context for table knowledge_space
|
||||||
|
|
||||||
|
```commandline
|
||||||
|
mysql -h127.0.0.1 -uroot -p {your_password}
|
||||||
|
```
|
||||||
|
|
||||||
|
3.execute sql ddl
|
||||||
|
|
||||||
|
```commandline
|
||||||
|
mysql> use knowledge_management;
|
||||||
|
mysql> ALTER TABLE knowledge_space ADD COLUMN context TEXT COMMENT "arguments context";
|
||||||
|
```
|
||||||
|
|
||||||
|
4.restart dbgpt serve
|
||||||
|
|
||||||
|
##### Q5:Use Mysql, how to use DB-GPT KBQA
|
||||||
|
|
||||||
|
build Mysql KBQA system database schema.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ mysql -h127.0.0.1 -uroot -p{your_password} < ./assets/schema/knowledge_management.sql
|
||||||
|
```
|
||||||
52
docs/docs/faq/llm.md
Normal file
52
docs/docs/faq/llm.md
Normal file
@ -0,0 +1,52 @@
|
|||||||
|
LLM USE FAQ
|
||||||
|
==================================
|
||||||
|
##### Q1:how to use openai chatgpt service
|
||||||
|
change your LLM_MODEL
|
||||||
|
````shell
|
||||||
|
LLM_MODEL=proxyllm
|
||||||
|
````
|
||||||
|
|
||||||
|
set your OPENAPI KEY
|
||||||
|
|
||||||
|
````shell
|
||||||
|
PROXY_API_KEY={your-openai-sk}
|
||||||
|
PROXY_SERVER_URL=https://api.openai.com/v1/chat/completions
|
||||||
|
````
|
||||||
|
|
||||||
|
make sure your openapi API_KEY is available
|
||||||
|
|
||||||
|
##### Q2 What difference between `python dbgpt_server --light` and `python dbgpt_server`
|
||||||
|
|
||||||
|
:::tip
|
||||||
|
python dbgpt_server --light` dbgpt_server does not start the llm service. Users can deploy the llm service separately by using `python llmserver`, and dbgpt_server accesses the llm service through set the LLM_SERVER environment variable in .env. The purpose is to allow for the separate deployment of dbgpt's backend service and llm service.
|
||||||
|
|
||||||
|
python dbgpt_server service and the llm service are deployed on the same instance. when dbgpt_server starts the service, it also starts the llm service at the same time.
|
||||||
|
:::
|
||||||
|
|
||||||
|
##### Q3 how to use MultiGPUs
|
||||||
|
|
||||||
|
DB-GPT will use all available gpu by default. And you can modify the setting `CUDA_VISIBLE_DEVICES=0,1` in `.env` file
|
||||||
|
to use the specific gpu IDs.
|
||||||
|
|
||||||
|
Optionally, you can also specify the gpu ID to use before the starting command, as shown below:
|
||||||
|
|
||||||
|
````shell
|
||||||
|
# Specify 1 gpu
|
||||||
|
CUDA_VISIBLE_DEVICES=0 python3 pilot/server/dbgpt_server.py
|
||||||
|
|
||||||
|
# Specify 4 gpus
|
||||||
|
CUDA_VISIBLE_DEVICES=3,4,5,6 python3 pilot/server/dbgpt_server.py
|
||||||
|
````
|
||||||
|
|
||||||
|
You can modify the setting `MAX_GPU_MEMORY=xxGib` in `.env` file to configure the maximum memory used by each GPU.
|
||||||
|
|
||||||
|
##### Q4 Not Enough Memory
|
||||||
|
|
||||||
|
DB-GPT supported 8-bit quantization and 4-bit quantization.
|
||||||
|
|
||||||
|
You can modify the setting `QUANTIZE_8bit=True` or `QUANTIZE_4bit=True` in `.env` file to use quantization(8-bit quantization is enabled by default).
|
||||||
|
|
||||||
|
Llama-2-70b with 8-bit quantization can run with 80 GB of VRAM, and 4-bit quantization can run with 48 GB of VRAM.
|
||||||
|
|
||||||
|
Note: you need to install the latest dependencies according to [requirements.txt](https://github.com/eosphoros-ai/DB-GPT/blob/main/requirements.txt).
|
||||||
|
Note: you need to install the latest dependencies according to [requirements.txt](https://github.com/eosphoros-ai/DB-GPT/blob/main/requirements.txt).
|
||||||
@ -200,8 +200,27 @@ const sidebars = {
|
|||||||
},
|
},
|
||||||
|
|
||||||
{
|
{
|
||||||
type: "doc",
|
type: "category",
|
||||||
id:"faq"
|
label: "FAQ",
|
||||||
|
collapsed: true,
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'doc',
|
||||||
|
id: 'faq/install',
|
||||||
|
}
|
||||||
|
,{
|
||||||
|
type: 'doc',
|
||||||
|
id: 'faq/llm',
|
||||||
|
}
|
||||||
|
,{
|
||||||
|
type: 'doc',
|
||||||
|
id: 'faq/kbqa',
|
||||||
|
}
|
||||||
|
,{
|
||||||
|
type: 'doc',
|
||||||
|
id: 'faq/chatdata',
|
||||||
|
},
|
||||||
|
],
|
||||||
},
|
},
|
||||||
|
|
||||||
{
|
{
|
||||||
|
|||||||
@ -14,7 +14,7 @@ from pilot.configs.config import Config
|
|||||||
|
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
logger = logging.getLogger(__name__)
|
||||||
|
# DB-GPT meta_data database config, now support mysql and sqlite
|
||||||
CFG = Config()
|
CFG = Config()
|
||||||
default_db_path = os.path.join(os.getcwd(), "meta_data")
|
default_db_path = os.path.join(os.getcwd(), "meta_data")
|
||||||
|
|
||||||
@ -26,6 +26,7 @@ db_name = META_DATA_DATABASE
|
|||||||
db_path = default_db_path + f"/{db_name}.db"
|
db_path = default_db_path + f"/{db_name}.db"
|
||||||
connection = sqlite3.connect(db_path)
|
connection = sqlite3.connect(db_path)
|
||||||
|
|
||||||
|
|
||||||
if CFG.LOCAL_DB_TYPE == "mysql":
|
if CFG.LOCAL_DB_TYPE == "mysql":
|
||||||
engine_temp = create_engine(
|
engine_temp = create_engine(
|
||||||
f"mysql+pymysql://"
|
f"mysql+pymysql://"
|
||||||
@ -81,18 +82,10 @@ os.makedirs(default_db_path + "/alembic/versions", exist_ok=True)
|
|||||||
|
|
||||||
alembic_cfg.set_main_option("script_location", default_db_path + "/alembic")
|
alembic_cfg.set_main_option("script_location", default_db_path + "/alembic")
|
||||||
|
|
||||||
# 将模型和会话传递给Alembic配置
|
|
||||||
alembic_cfg.attributes["target_metadata"] = Base.metadata
|
alembic_cfg.attributes["target_metadata"] = Base.metadata
|
||||||
alembic_cfg.attributes["session"] = session
|
alembic_cfg.attributes["session"] = session
|
||||||
|
|
||||||
|
|
||||||
# # 创建表
|
|
||||||
# Base.metadata.create_all(engine)
|
|
||||||
#
|
|
||||||
# # 删除表
|
|
||||||
# Base.metadata.drop_all(engine)
|
|
||||||
|
|
||||||
|
|
||||||
def ddl_init_and_upgrade(disable_alembic_upgrade: bool):
|
def ddl_init_and_upgrade(disable_alembic_upgrade: bool):
|
||||||
"""Initialize and upgrade database metadata
|
"""Initialize and upgrade database metadata
|
||||||
|
|
||||||
@ -105,10 +98,6 @@ def ddl_init_and_upgrade(disable_alembic_upgrade: bool):
|
|||||||
)
|
)
|
||||||
return
|
return
|
||||||
|
|
||||||
# Base.metadata.create_all(bind=engine)
|
|
||||||
# 生成并应用迁移脚本
|
|
||||||
# command.upgrade(alembic_cfg, 'head')
|
|
||||||
# subprocess.run(["alembic", "revision", "--autogenerate", "-m", "Added account table"])
|
|
||||||
with engine.connect() as connection:
|
with engine.connect() as connection:
|
||||||
alembic_cfg.attributes["connection"] = connection
|
alembic_cfg.attributes["connection"] = connection
|
||||||
heads = command.heads(alembic_cfg)
|
heads = command.heads(alembic_cfg)
|
||||||
|
|||||||
@ -104,13 +104,6 @@ class Config(metaclass=Singleton):
|
|||||||
self.use_mac_os_tts = False
|
self.use_mac_os_tts = False
|
||||||
self.use_mac_os_tts = os.getenv("USE_MAC_OS_TTS")
|
self.use_mac_os_tts = os.getenv("USE_MAC_OS_TTS")
|
||||||
|
|
||||||
# milvus or zilliz cloud configuration
|
|
||||||
self.milvus_addr = os.getenv("MILVUS_ADDR", "localhost:19530")
|
|
||||||
self.milvus_username = os.getenv("MILVUS_USERNAME")
|
|
||||||
self.milvus_password = os.getenv("MILVUS_PASSWORD")
|
|
||||||
self.milvus_collection = os.getenv("MILVUS_COLLECTION", "dbgpt")
|
|
||||||
self.milvus_secure = os.getenv("MILVUS_SECURE", "False").lower() == "true"
|
|
||||||
|
|
||||||
self.authorise_key = os.getenv("AUTHORISE_COMMAND_KEY", "y")
|
self.authorise_key = os.getenv("AUTHORISE_COMMAND_KEY", "y")
|
||||||
self.exit_key = os.getenv("EXIT_KEY", "n")
|
self.exit_key = os.getenv("EXIT_KEY", "n")
|
||||||
self.image_provider = os.getenv("IMAGE_PROVIDER", True)
|
self.image_provider = os.getenv("IMAGE_PROVIDER", True)
|
||||||
@ -190,7 +183,7 @@ class Config(metaclass=Singleton):
|
|||||||
self.LOCAL_DB_PASSWORD = os.getenv("LOCAL_DB_PASSWORD", "aa123456")
|
self.LOCAL_DB_PASSWORD = os.getenv("LOCAL_DB_PASSWORD", "aa123456")
|
||||||
self.LOCAL_DB_POOL_SIZE = int(os.getenv("LOCAL_DB_POOL_SIZE", 10))
|
self.LOCAL_DB_POOL_SIZE = int(os.getenv("LOCAL_DB_POOL_SIZE", 10))
|
||||||
|
|
||||||
self.CHAT_HISTORY_STORE_TYPE = os.getenv("CHAT_HISTORY_STORE_TYPE", "duckdb")
|
self.CHAT_HISTORY_STORE_TYPE = os.getenv("CHAT_HISTORY_STORE_TYPE", "db")
|
||||||
|
|
||||||
### LLM Model Service Configuration
|
### LLM Model Service Configuration
|
||||||
self.LLM_MODEL = os.getenv("LLM_MODEL", "vicuna-13b-v1.5")
|
self.LLM_MODEL = os.getenv("LLM_MODEL", "vicuna-13b-v1.5")
|
||||||
@ -232,10 +225,18 @@ class Config(metaclass=Singleton):
|
|||||||
self.KNOWLEDGE_CHUNK_SIZE = int(os.getenv("KNOWLEDGE_CHUNK_SIZE", 100))
|
self.KNOWLEDGE_CHUNK_SIZE = int(os.getenv("KNOWLEDGE_CHUNK_SIZE", 100))
|
||||||
self.KNOWLEDGE_CHUNK_OVERLAP = int(os.getenv("KNOWLEDGE_CHUNK_OVERLAP", 50))
|
self.KNOWLEDGE_CHUNK_OVERLAP = int(os.getenv("KNOWLEDGE_CHUNK_OVERLAP", 50))
|
||||||
self.KNOWLEDGE_SEARCH_TOP_SIZE = int(os.getenv("KNOWLEDGE_SEARCH_TOP_SIZE", 5))
|
self.KNOWLEDGE_SEARCH_TOP_SIZE = int(os.getenv("KNOWLEDGE_SEARCH_TOP_SIZE", 5))
|
||||||
|
# default recall similarity score, between 0 and 1
|
||||||
|
self.KNOWLEDGE_SEARCH_RECALL_SCORE = float(
|
||||||
|
os.getenv("KNOWLEDGE_SEARCH_RECALL_SCORE", 0.3)
|
||||||
|
)
|
||||||
self.KNOWLEDGE_SEARCH_MAX_TOKEN = int(
|
self.KNOWLEDGE_SEARCH_MAX_TOKEN = int(
|
||||||
os.getenv("KNOWLEDGE_SEARCH_MAX_TOKEN", 2000)
|
os.getenv("KNOWLEDGE_SEARCH_MAX_TOKEN", 2000)
|
||||||
)
|
)
|
||||||
### Control whether to display the source document of knowledge on the front end.
|
# Whether to enable Chat Knowledge Search Rewrite Mode
|
||||||
|
self.KNOWLEDGE_SEARCH_REWRITE = (
|
||||||
|
os.getenv("KNOWLEDGE_SEARCH_REWRITE", "False").lower() == "true"
|
||||||
|
)
|
||||||
|
# Control whether to display the source document of knowledge on the front end.
|
||||||
self.KNOWLEDGE_CHAT_SHOW_RELATIONS = (
|
self.KNOWLEDGE_CHAT_SHOW_RELATIONS = (
|
||||||
os.getenv("KNOWLEDGE_CHAT_SHOW_RELATIONS", "False").lower() == "true"
|
os.getenv("KNOWLEDGE_CHAT_SHOW_RELATIONS", "False").lower() == "true"
|
||||||
)
|
)
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
from typing import List
|
from sqlalchemy import Column, Integer, String, Index, Text, text
|
||||||
from sqlalchemy import Column, Integer, String, Index, DateTime, func, Boolean, Text
|
|
||||||
from sqlalchemy import UniqueConstraint
|
from sqlalchemy import UniqueConstraint
|
||||||
|
|
||||||
from pilot.base_modules.meta_data.base_dao import BaseDao
|
from pilot.base_modules.meta_data.base_dao import BaseDao
|
||||||
@ -12,15 +11,18 @@ from pilot.base_modules.meta_data.meta_data import (
|
|||||||
|
|
||||||
|
|
||||||
class ConnectConfigEntity(Base):
|
class ConnectConfigEntity(Base):
|
||||||
|
"""db connect config entity"""
|
||||||
|
|
||||||
__tablename__ = "connect_config"
|
__tablename__ = "connect_config"
|
||||||
id = Column(
|
id = Column(
|
||||||
Integer, primary_key=True, autoincrement=True, comment="autoincrement id"
|
Integer, primary_key=True, autoincrement=True, comment="autoincrement id"
|
||||||
)
|
)
|
||||||
|
|
||||||
db_type = Column(String(255), nullable=False, comment="db type")
|
db_type = Column(String(255), nullable=False, comment="db type")
|
||||||
db_name = Column(String(255), nullable=False, comment="db name")
|
db_name = Column(String(255), nullable=False, comment="db name")
|
||||||
db_path = Column(String(255), nullable=True, comment="file db path")
|
db_path = Column(String(255), nullable=True, comment="file db path")
|
||||||
db_host = Column(String(255), nullable=True, comment="db connect host(not file db)")
|
db_host = Column(String(255), nullable=True, comment="db connect host(not file db)")
|
||||||
db_port = Column(String(255), nullable=True, comment="db cnnect port(not file db)")
|
db_port = Column(String(255), nullable=True, comment="db connect port(not file db)")
|
||||||
db_user = Column(String(255), nullable=True, comment="db user")
|
db_user = Column(String(255), nullable=True, comment="db user")
|
||||||
db_pwd = Column(String(255), nullable=True, comment="db password")
|
db_pwd = Column(String(255), nullable=True, comment="db password")
|
||||||
comment = Column(Text, nullable=True, comment="db comment")
|
comment = Column(Text, nullable=True, comment="db comment")
|
||||||
@ -29,10 +31,13 @@ class ConnectConfigEntity(Base):
|
|||||||
__table_args__ = (
|
__table_args__ = (
|
||||||
UniqueConstraint("db_name", name="uk_db"),
|
UniqueConstraint("db_name", name="uk_db"),
|
||||||
Index("idx_q_db_type", "db_type"),
|
Index("idx_q_db_type", "db_type"),
|
||||||
|
{"mysql_charset": "utf8mb4", "mysql_collate": "utf8mb4_unicode_ci"},
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
class ConnectConfigDao(BaseDao[ConnectConfigEntity]):
|
class ConnectConfigDao(BaseDao[ConnectConfigEntity]):
|
||||||
|
"""db connect config dao"""
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
super().__init__(
|
super().__init__(
|
||||||
database=META_DATA_DATABASE,
|
database=META_DATA_DATABASE,
|
||||||
@ -42,6 +47,7 @@ class ConnectConfigDao(BaseDao[ConnectConfigEntity]):
|
|||||||
)
|
)
|
||||||
|
|
||||||
def update(self, entity: ConnectConfigEntity):
|
def update(self, entity: ConnectConfigEntity):
|
||||||
|
"""update db connect info"""
|
||||||
session = self.get_session()
|
session = self.get_session()
|
||||||
try:
|
try:
|
||||||
updated = session.merge(entity)
|
updated = session.merge(entity)
|
||||||
@ -51,6 +57,7 @@ class ConnectConfigDao(BaseDao[ConnectConfigEntity]):
|
|||||||
session.close()
|
session.close()
|
||||||
|
|
||||||
def delete(self, db_name: int):
|
def delete(self, db_name: int):
|
||||||
|
""" "delete db connect info"""
|
||||||
session = self.get_session()
|
session = self.get_session()
|
||||||
if db_name is None:
|
if db_name is None:
|
||||||
raise Exception("db_name is None")
|
raise Exception("db_name is None")
|
||||||
@ -61,10 +68,177 @@ class ConnectConfigDao(BaseDao[ConnectConfigEntity]):
|
|||||||
session.commit()
|
session.commit()
|
||||||
session.close()
|
session.close()
|
||||||
|
|
||||||
def get_by_name(self, db_name: str) -> ConnectConfigEntity:
|
def get_by_names(self, db_name: str) -> ConnectConfigEntity:
|
||||||
|
"""get db connect info by name"""
|
||||||
session = self.get_session()
|
session = self.get_session()
|
||||||
db_connect = session.query(ConnectConfigEntity)
|
db_connect = session.query(ConnectConfigEntity)
|
||||||
db_connect = db_connect.filter(ConnectConfigEntity.db_name == db_name)
|
db_connect = db_connect.filter(ConnectConfigEntity.db_name == db_name)
|
||||||
result = db_connect.first()
|
result = db_connect.first()
|
||||||
session.close()
|
session.close()
|
||||||
return result
|
return result
|
||||||
|
|
||||||
|
def add_url_db(
|
||||||
|
self,
|
||||||
|
db_name,
|
||||||
|
db_type,
|
||||||
|
db_host: str,
|
||||||
|
db_port: int,
|
||||||
|
db_user: str,
|
||||||
|
db_pwd: str,
|
||||||
|
comment: str = "",
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
add db connect info
|
||||||
|
Args:
|
||||||
|
db_name: db name
|
||||||
|
db_type: db type
|
||||||
|
db_host: db host
|
||||||
|
db_port: db port
|
||||||
|
db_user: db user
|
||||||
|
db_pwd: db password
|
||||||
|
comment: comment
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
session = self.get_session()
|
||||||
|
|
||||||
|
from sqlalchemy import text
|
||||||
|
|
||||||
|
insert_statement = text(
|
||||||
|
"""
|
||||||
|
INSERT INTO connect_config (
|
||||||
|
db_name, db_type, db_path, db_host, db_port, db_user, db_pwd, comment
|
||||||
|
) VALUES (
|
||||||
|
:db_name, :db_type, :db_path, :db_host, :db_port, :db_user, :db_pwd, :comment
|
||||||
|
)
|
||||||
|
"""
|
||||||
|
)
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"db_name": db_name,
|
||||||
|
"db_type": db_type,
|
||||||
|
"db_path": "",
|
||||||
|
"db_host": db_host,
|
||||||
|
"db_port": db_port,
|
||||||
|
"db_user": db_user,
|
||||||
|
"db_pwd": db_pwd,
|
||||||
|
"comment": comment,
|
||||||
|
}
|
||||||
|
session.execute(insert_statement, params)
|
||||||
|
session.commit()
|
||||||
|
session.close()
|
||||||
|
except Exception as e:
|
||||||
|
print("add db connect info error!" + str(e))
|
||||||
|
|
||||||
|
def update_db_info(
|
||||||
|
self,
|
||||||
|
db_name,
|
||||||
|
db_type,
|
||||||
|
db_path: str = "",
|
||||||
|
db_host: str = "",
|
||||||
|
db_port: int = 0,
|
||||||
|
db_user: str = "",
|
||||||
|
db_pwd: str = "",
|
||||||
|
comment: str = "",
|
||||||
|
):
|
||||||
|
"""update db connect info"""
|
||||||
|
old_db_conf = self.get_db_config(db_name)
|
||||||
|
if old_db_conf:
|
||||||
|
try:
|
||||||
|
session = self.get_session()
|
||||||
|
if not db_path:
|
||||||
|
update_statement = text(
|
||||||
|
f"UPDATE connect_config set db_type='{db_type}', db_host='{db_host}', db_port={db_port}, db_user='{db_user}', db_pwd='{db_pwd}', comment='{comment}' where db_name='{db_name}'"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
update_statement = text(
|
||||||
|
f"UPDATE connect_config set db_type='{db_type}', db_path='{db_path}', comment='{comment}' where db_name='{db_name}'"
|
||||||
|
)
|
||||||
|
session.execute(update_statement)
|
||||||
|
session.commit()
|
||||||
|
session.close()
|
||||||
|
except Exception as e:
|
||||||
|
print("edit db connect info error!" + str(e))
|
||||||
|
return True
|
||||||
|
raise ValueError(f"{db_name} not have config info!")
|
||||||
|
|
||||||
|
def add_file_db(self, db_name, db_type, db_path: str, comment: str = ""):
|
||||||
|
"""add file db connect info"""
|
||||||
|
try:
|
||||||
|
session = self.get_session()
|
||||||
|
insert_statement = text(
|
||||||
|
"""
|
||||||
|
INSERT INTO connect_config(
|
||||||
|
db_name, db_type, db_path, db_host, db_port, db_user, db_pwd, comment
|
||||||
|
) VALUES (
|
||||||
|
:db_name, :db_type, :db_path, :db_host, :db_port, :db_user, :db_pwd, :comment
|
||||||
|
)
|
||||||
|
"""
|
||||||
|
)
|
||||||
|
params = {
|
||||||
|
"db_name": db_name,
|
||||||
|
"db_type": db_type,
|
||||||
|
"db_path": db_path,
|
||||||
|
"db_host": "",
|
||||||
|
"db_port": 0,
|
||||||
|
"db_user": "",
|
||||||
|
"db_pwd": "",
|
||||||
|
"comment": comment,
|
||||||
|
}
|
||||||
|
|
||||||
|
session.execute(insert_statement, params)
|
||||||
|
|
||||||
|
session.commit()
|
||||||
|
session.close()
|
||||||
|
except Exception as e:
|
||||||
|
print("add db connect info error!" + str(e))
|
||||||
|
|
||||||
|
def get_db_config(self, db_name):
|
||||||
|
"""get db config by name"""
|
||||||
|
session = self.get_session()
|
||||||
|
if db_name:
|
||||||
|
select_statement = text(
|
||||||
|
"""
|
||||||
|
SELECT
|
||||||
|
*
|
||||||
|
FROM
|
||||||
|
connect_config
|
||||||
|
WHERE
|
||||||
|
db_name = :db_name
|
||||||
|
"""
|
||||||
|
)
|
||||||
|
params = {"db_name": db_name}
|
||||||
|
result = session.execute(select_statement, params)
|
||||||
|
|
||||||
|
else:
|
||||||
|
raise ValueError("Cannot get database by name" + db_name)
|
||||||
|
|
||||||
|
fields = [field[0] for field in result.cursor.description]
|
||||||
|
row_dict = {}
|
||||||
|
row_1 = list(result.cursor.fetchall()[0])
|
||||||
|
for i, field in enumerate(fields):
|
||||||
|
row_dict[field] = row_1[i]
|
||||||
|
return row_dict
|
||||||
|
|
||||||
|
def get_db_list(self):
|
||||||
|
"""get db list"""
|
||||||
|
session = self.get_session()
|
||||||
|
result = session.execute(text("SELECT * FROM connect_config"))
|
||||||
|
|
||||||
|
fields = [field[0] for field in result.cursor.description]
|
||||||
|
data = []
|
||||||
|
for row in result.cursor.fetchall():
|
||||||
|
row_dict = {}
|
||||||
|
for i, field in enumerate(fields):
|
||||||
|
row_dict[field] = row[i]
|
||||||
|
data.append(row_dict)
|
||||||
|
return data
|
||||||
|
|
||||||
|
def delete_db(self, db_name):
|
||||||
|
"""delete db connect info"""
|
||||||
|
session = self.get_session()
|
||||||
|
delete_statement = text("""DELETE FROM connect_config where db_name=:db_name""")
|
||||||
|
params = {"db_name": db_name}
|
||||||
|
session.execute(delete_statement, params)
|
||||||
|
session.commit()
|
||||||
|
session.close()
|
||||||
|
return True
|
||||||
|
|||||||
@ -2,6 +2,7 @@ import threading
|
|||||||
import asyncio
|
import asyncio
|
||||||
|
|
||||||
from pilot.configs.config import Config
|
from pilot.configs.config import Config
|
||||||
|
from pilot.connections import ConnectConfigDao
|
||||||
from pilot.connections.manages.connect_storage_duckdb import DuckdbConnectConfig
|
from pilot.connections.manages.connect_storage_duckdb import DuckdbConnectConfig
|
||||||
from pilot.common.schema import DBType
|
from pilot.common.schema import DBType
|
||||||
from pilot.component import SystemApp, ComponentType
|
from pilot.component import SystemApp, ComponentType
|
||||||
@ -28,6 +29,8 @@ CFG = Config()
|
|||||||
|
|
||||||
|
|
||||||
class ConnectManager:
|
class ConnectManager:
|
||||||
|
"""db connect manager"""
|
||||||
|
|
||||||
def get_all_subclasses(self, cls):
|
def get_all_subclasses(self, cls):
|
||||||
subclasses = cls.__subclasses__()
|
subclasses = cls.__subclasses__()
|
||||||
for subclass in subclasses:
|
for subclass in subclasses:
|
||||||
@ -49,45 +52,32 @@ class ConnectManager:
|
|||||||
if cls.db_type == db_type:
|
if cls.db_type == db_type:
|
||||||
result = cls
|
result = cls
|
||||||
if not result:
|
if not result:
|
||||||
raise ValueError("Unsupport Db Type!" + db_type)
|
raise ValueError("Unsupported Db Type!" + db_type)
|
||||||
return result
|
return result
|
||||||
|
|
||||||
def __init__(self, system_app: SystemApp):
|
def __init__(self, system_app: SystemApp):
|
||||||
self.storage = DuckdbConnectConfig()
|
"""metadata database management initialization"""
|
||||||
|
# self.storage = DuckdbConnectConfig()
|
||||||
|
self.storage = ConnectConfigDao()
|
||||||
self.db_summary_client = DBSummaryClient(system_app)
|
self.db_summary_client = DBSummaryClient(system_app)
|
||||||
# self.__load_config_db()
|
# self.__load_config_db()
|
||||||
|
|
||||||
def __load_config_db(self):
|
# def __load_config_db(self):
|
||||||
if CFG.LOCAL_DB_HOST:
|
# if CFG.LOCAL_DB_HOST:
|
||||||
# default mysql
|
# # default mysql
|
||||||
if CFG.LOCAL_DB_NAME:
|
# if CFG.LOCAL_DB_NAME:
|
||||||
self.storage.add_url_db(
|
# self.storage.add_url_db(
|
||||||
CFG.LOCAL_DB_NAME,
|
# CFG.LOCAL_DB_NAME,
|
||||||
DBType.Mysql.value(),
|
# DBType.Mysql.value(),
|
||||||
CFG.LOCAL_DB_HOST,
|
# CFG.LOCAL_DB_HOST,
|
||||||
CFG.LOCAL_DB_PORT,
|
# CFG.LOCAL_DB_PORT,
|
||||||
CFG.LOCAL_DB_USER,
|
# CFG.LOCAL_DB_USER,
|
||||||
CFG.LOCAL_DB_PASSWORD,
|
# CFG.LOCAL_DB_PASSWORD,
|
||||||
"",
|
# "",
|
||||||
)
|
# )
|
||||||
else:
|
# else:
|
||||||
# get all default mysql database
|
# # get all default mysql database
|
||||||
default_mysql = Database.from_uri(
|
# default_mysql = Database.from_uri(
|
||||||
"mysql+pymysql://"
|
|
||||||
+ CFG.LOCAL_DB_USER
|
|
||||||
+ ":"
|
|
||||||
+ CFG.LOCAL_DB_PASSWORD
|
|
||||||
+ "@"
|
|
||||||
+ CFG.LOCAL_DB_HOST
|
|
||||||
+ ":"
|
|
||||||
+ str(CFG.LOCAL_DB_PORT),
|
|
||||||
engine_args={
|
|
||||||
"pool_size": CFG.LOCAL_DB_POOL_SIZE,
|
|
||||||
"pool_recycle": 3600,
|
|
||||||
"echo": True,
|
|
||||||
},
|
|
||||||
)
|
|
||||||
# default_mysql = MySQLConnect.from_uri(
|
|
||||||
# "mysql+pymysql://"
|
# "mysql+pymysql://"
|
||||||
# + CFG.LOCAL_DB_USER
|
# + CFG.LOCAL_DB_USER
|
||||||
# + ":"
|
# + ":"
|
||||||
@ -96,43 +86,47 @@ class ConnectManager:
|
|||||||
# + CFG.LOCAL_DB_HOST
|
# + CFG.LOCAL_DB_HOST
|
||||||
# + ":"
|
# + ":"
|
||||||
# + str(CFG.LOCAL_DB_PORT),
|
# + str(CFG.LOCAL_DB_PORT),
|
||||||
# engine_args={"pool_size": 10, "pool_recycle": 3600, "echo": True},
|
# engine_args={
|
||||||
|
# "pool_size": CFG.LOCAL_DB_POOL_SIZE,
|
||||||
|
# "pool_recycle": 3600,
|
||||||
|
# "echo": True,
|
||||||
|
# },
|
||||||
# )
|
# )
|
||||||
dbs = default_mysql.get_database_list()
|
# dbs = default_mysql.get_database_list()
|
||||||
for name in dbs:
|
# for name in dbs:
|
||||||
self.storage.add_url_db(
|
# self.storage.add_url_db(
|
||||||
name,
|
# name,
|
||||||
DBType.Mysql.value(),
|
# DBType.Mysql.value(),
|
||||||
CFG.LOCAL_DB_HOST,
|
# CFG.LOCAL_DB_HOST,
|
||||||
CFG.LOCAL_DB_PORT,
|
# CFG.LOCAL_DB_PORT,
|
||||||
CFG.LOCAL_DB_USER,
|
# CFG.LOCAL_DB_USER,
|
||||||
CFG.LOCAL_DB_PASSWORD,
|
# CFG.LOCAL_DB_PASSWORD,
|
||||||
"",
|
# "",
|
||||||
)
|
# )
|
||||||
db_type = DBType.of_db_type(CFG.LOCAL_DB_TYPE)
|
# db_type = DBType.of_db_type(CFG.LOCAL_DB_TYPE)
|
||||||
if db_type.is_file_db():
|
# if db_type.is_file_db():
|
||||||
db_name = CFG.LOCAL_DB_NAME
|
# db_name = CFG.LOCAL_DB_NAME
|
||||||
db_type = CFG.LOCAL_DB_TYPE
|
# db_type = CFG.LOCAL_DB_TYPE
|
||||||
db_path = CFG.LOCAL_DB_PATH
|
# db_path = CFG.LOCAL_DB_PATH
|
||||||
if not db_type:
|
# if not db_type:
|
||||||
# Default file database type
|
# # Default file database type
|
||||||
db_type = DBType.DuckDb.value()
|
# db_type = DBType.DuckDb.value()
|
||||||
if not db_name:
|
# if not db_name:
|
||||||
db_type, db_name = self._parse_file_db_info(db_type, db_path)
|
# db_type, db_name = self._parse_file_db_info(db_type, db_path)
|
||||||
if db_name:
|
# if db_name:
|
||||||
print(
|
# print(
|
||||||
f"Add file db, db_name: {db_name}, db_type: {db_type}, db_path: {db_path}"
|
# f"Add file db, db_name: {db_name}, db_type: {db_type}, db_path: {db_path}"
|
||||||
)
|
# )
|
||||||
self.storage.add_file_db(db_name, db_type, db_path)
|
# self.storage.add_file_db(db_name, db_type, db_path)
|
||||||
|
|
||||||
def _parse_file_db_info(self, db_type: str, db_path: str):
|
# def _parse_file_db_info(self, db_type: str, db_path: str):
|
||||||
if db_type is None or db_type == DBType.DuckDb.value():
|
# if db_type is None or db_type == DBType.DuckDb.value():
|
||||||
# file db is duckdb
|
# # file db is duckdb
|
||||||
db_name = self.storage.get_file_db_name(db_path)
|
# db_name = self.storage.get_file_db_name(db_path)
|
||||||
db_type = DBType.DuckDb.value()
|
# db_type = DBType.DuckDb.value()
|
||||||
else:
|
# else:
|
||||||
db_name = DBType.parse_file_db_name_from_path(db_type, db_path)
|
# db_name = DBType.parse_file_db_name_from_path(db_type, db_path)
|
||||||
return db_type, db_name
|
# return db_type, db_name
|
||||||
|
|
||||||
def get_connect(self, db_name):
|
def get_connect(self, db_name):
|
||||||
db_config = self.storage.get_db_config(db_name)
|
db_config = self.storage.get_db_config(db_name)
|
||||||
@ -178,7 +172,7 @@ class ConnectManager:
|
|||||||
return self.storage.get_db_list()
|
return self.storage.get_db_list()
|
||||||
|
|
||||||
def get_db_names(self):
|
def get_db_names(self):
|
||||||
return self.storage.get_db_names()
|
return self.storage.get_by_name()
|
||||||
|
|
||||||
def delete_db(self, db_name: str):
|
def delete_db(self, db_name: str):
|
||||||
return self.storage.delete_db(db_name)
|
return self.storage.delete_db(db_name)
|
||||||
|
|||||||
@ -16,6 +16,27 @@ class EmbeddingEngine:
|
|||||||
2.similar_search: similarity search from vector_store
|
2.similar_search: similarity search from vector_store
|
||||||
how to use reference:https://db-gpt.readthedocs.io/en/latest/modules/knowledge.html
|
how to use reference:https://db-gpt.readthedocs.io/en/latest/modules/knowledge.html
|
||||||
how to integrate:https://db-gpt.readthedocs.io/en/latest/modules/knowledge/pdf/pdf_embedding.html
|
how to integrate:https://db-gpt.readthedocs.io/en/latest/modules/knowledge/pdf/pdf_embedding.html
|
||||||
|
Example:
|
||||||
|
.. code-block:: python
|
||||||
|
embedding_model = "your_embedding_model"
|
||||||
|
vector_store_type = "Chroma"
|
||||||
|
chroma_persist_path = "your_persist_path"
|
||||||
|
vector_store_config = {
|
||||||
|
"vector_store_name": "document_test",
|
||||||
|
"vector_store_type": vector_store_type,
|
||||||
|
"chroma_persist_path": chroma_persist_path,
|
||||||
|
}
|
||||||
|
|
||||||
|
# it can be .md,.pdf,.docx, .csv, .html
|
||||||
|
document_path = "your_path/test.md"
|
||||||
|
embedding_engine = EmbeddingEngine(
|
||||||
|
knowledge_source=document_path,
|
||||||
|
knowledge_type=KnowledgeType.DOCUMENT.value,
|
||||||
|
model_name=embedding_model,
|
||||||
|
vector_store_config=vector_store_config,
|
||||||
|
)
|
||||||
|
# embedding document content to vector store
|
||||||
|
embedding_engine.knowledge_embedding()
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
@ -74,7 +95,8 @@ class EmbeddingEngine:
|
|||||||
)
|
)
|
||||||
|
|
||||||
def similar_search(self, text, topk):
|
def similar_search(self, text, topk):
|
||||||
"""vector db similar search
|
"""vector db similar search in vector database.
|
||||||
|
Return topk docs.
|
||||||
Args:
|
Args:
|
||||||
- text: query text
|
- text: query text
|
||||||
- topk: top k
|
- topk: top k
|
||||||
@ -84,8 +106,22 @@ class EmbeddingEngine:
|
|||||||
)
|
)
|
||||||
# https://github.com/chroma-core/chroma/issues/657
|
# https://github.com/chroma-core/chroma/issues/657
|
||||||
ans = vector_client.similar_search(text, topk)
|
ans = vector_client.similar_search(text, topk)
|
||||||
# except NotEnoughElementsException:
|
return ans
|
||||||
# ans = vector_client.similar_search(text, 1)
|
|
||||||
|
def similar_search_with_scores(self, text, topk, score_threshold: float = 0.3):
|
||||||
|
"""
|
||||||
|
similar_search_with_score in vector database.
|
||||||
|
Return docs and relevance scores in the range [0, 1].
|
||||||
|
Args:
|
||||||
|
doc(str): query text
|
||||||
|
topk(int): return docs nums. Defaults to 4.
|
||||||
|
score_threshold(float): score_threshold: Optional, a floating point value between 0 to 1 to
|
||||||
|
filter the resulting set of retrieved docs,0 is dissimilar, 1 is most similar.
|
||||||
|
"""
|
||||||
|
vector_client = VectorStoreConnector(
|
||||||
|
self.vector_store_config["vector_store_type"], self.vector_store_config
|
||||||
|
)
|
||||||
|
ans = vector_client.similar_search_with_scores(text, topk, score_threshold)
|
||||||
return ans
|
return ans
|
||||||
|
|
||||||
def vector_exist(self):
|
def vector_exist(self):
|
||||||
|
|||||||
0
pilot/rag/extracter/__init__.py
Normal file
0
pilot/rag/extracter/__init__.py
Normal file
19
pilot/rag/extracter/base.py
Normal file
19
pilot/rag/extracter/base.py
Normal file
@ -0,0 +1,19 @@
|
|||||||
|
from abc import abstractmethod, ABC
|
||||||
|
from typing import List, Dict
|
||||||
|
|
||||||
|
from langchain.schema import Document
|
||||||
|
|
||||||
|
|
||||||
|
class Extractor(ABC):
|
||||||
|
"""Extractor Base class, it's apply for Summary Extractor, Keyword Extractor, Triplets Extractor, Question Extractor, etc."""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def extract(self, chunks: List[Document]) -> List[Dict]:
|
||||||
|
"""Extracts chunks.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
nodes (Sequence[Document]): nodes to extract metadata from
|
||||||
|
"""
|
||||||
95
pilot/rag/extracter/summary.py
Normal file
95
pilot/rag/extracter/summary.py
Normal file
@ -0,0 +1,95 @@
|
|||||||
|
from typing import List, Dict
|
||||||
|
|
||||||
|
from langchain.schema import Document
|
||||||
|
|
||||||
|
from pilot.common.llm_metadata import LLMMetadata
|
||||||
|
from pilot.rag.extracter.base import Extractor
|
||||||
|
|
||||||
|
|
||||||
|
class SummaryExtractor(Extractor):
|
||||||
|
"""Summary Extractor, it can extract document summary."""
|
||||||
|
|
||||||
|
def __init__(self, model_name: str = None, llm_metadata: LLMMetadata = None):
|
||||||
|
self.model_name = (model_name,)
|
||||||
|
self.llm_metadata = (llm_metadata or LLMMetadata,)
|
||||||
|
|
||||||
|
async def extract(self, chunks: List[Document]) -> str:
|
||||||
|
"""async document extract summary
|
||||||
|
Args:
|
||||||
|
- model_name: str
|
||||||
|
- chunk_docs: List[Document]
|
||||||
|
"""
|
||||||
|
texts = [doc.page_content for doc in chunks]
|
||||||
|
from pilot.common.prompt_util import PromptHelper
|
||||||
|
|
||||||
|
prompt_helper = PromptHelper()
|
||||||
|
from pilot.scene.chat_knowledge.summary.prompt import prompt
|
||||||
|
|
||||||
|
texts = prompt_helper.repack(prompt_template=prompt.template, text_chunks=texts)
|
||||||
|
return await self._mapreduce_extract_summary(
|
||||||
|
docs=texts, model_name=self.model_name, llm_metadata=self.llm_metadata
|
||||||
|
)
|
||||||
|
|
||||||
|
async def _mapreduce_extract_summary(
|
||||||
|
self,
|
||||||
|
docs,
|
||||||
|
model_name,
|
||||||
|
llm_metadata: LLMMetadata,
|
||||||
|
):
|
||||||
|
"""Extract summary by mapreduce mode
|
||||||
|
map -> multi async call llm to generate summary
|
||||||
|
reduce -> merge the summaries by map process
|
||||||
|
Args:
|
||||||
|
docs:List[str]
|
||||||
|
model_name:model name str
|
||||||
|
llm_metadata:LLMMetadata
|
||||||
|
Returns:
|
||||||
|
Document: refine summary context document.
|
||||||
|
"""
|
||||||
|
from pilot.scene.base import ChatScene
|
||||||
|
from pilot.common.chat_util import llm_chat_response_nostream
|
||||||
|
import uuid
|
||||||
|
|
||||||
|
tasks = []
|
||||||
|
if len(docs) == 1:
|
||||||
|
return docs[0]
|
||||||
|
else:
|
||||||
|
max_iteration = (
|
||||||
|
llm_metadata.max_chat_iteration
|
||||||
|
if len(docs) > llm_metadata.max_chat_iteration
|
||||||
|
else len(docs)
|
||||||
|
)
|
||||||
|
for doc in docs[0:max_iteration]:
|
||||||
|
chat_param = {
|
||||||
|
"chat_session_id": uuid.uuid1(),
|
||||||
|
"current_user_input": "",
|
||||||
|
"select_param": doc,
|
||||||
|
"model_name": model_name,
|
||||||
|
"model_cache_enable": True,
|
||||||
|
}
|
||||||
|
tasks.append(
|
||||||
|
llm_chat_response_nostream(
|
||||||
|
ChatScene.ExtractSummary.value(), **{"chat_param": chat_param}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
from pilot.common.chat_util import run_async_tasks
|
||||||
|
|
||||||
|
summary_iters = await run_async_tasks(
|
||||||
|
tasks=tasks, concurrency_limit=llm_metadata.concurrency_limit
|
||||||
|
)
|
||||||
|
summary_iters = list(
|
||||||
|
filter(
|
||||||
|
lambda content: "LLMServer Generate Error" not in content,
|
||||||
|
summary_iters,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
from pilot.common.prompt_util import PromptHelper
|
||||||
|
from pilot.scene.chat_knowledge.summary.prompt import prompt
|
||||||
|
|
||||||
|
prompt_helper = PromptHelper()
|
||||||
|
summary_iters = prompt_helper.repack(
|
||||||
|
prompt_template=prompt.template, text_chunks=summary_iters
|
||||||
|
)
|
||||||
|
return await self._mapreduce_extract_summary(
|
||||||
|
summary_iters, model_name, max_iteration, llm_metadata.concurrency_limit
|
||||||
|
)
|
||||||
0
pilot/rag/graph_engine/__init__.py
Normal file
0
pilot/rag/graph_engine/__init__.py
Normal file
@ -6,8 +6,8 @@ from langchain.text_splitter import RecursiveCharacterTextSplitter
|
|||||||
|
|
||||||
from pilot.embedding_engine import KnowledgeType
|
from pilot.embedding_engine import KnowledgeType
|
||||||
from pilot.embedding_engine.knowledge_type import get_knowledge_embedding
|
from pilot.embedding_engine.knowledge_type import get_knowledge_embedding
|
||||||
from pilot.graph_engine.index_struct import KG
|
from pilot.rag.graph_engine.index_struct import KG
|
||||||
from pilot.graph_engine.node import TextNode
|
from pilot.rag.graph_engine.node import TextNode
|
||||||
from pilot.utils import utils
|
from pilot.utils import utils
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
logger = logging.getLogger(__name__)
|
||||||
@ -121,64 +121,9 @@ class RAGGraphEngine:
|
|||||||
self.graph_store.upsert_triplet(*triplet)
|
self.graph_store.upsert_triplet(*triplet)
|
||||||
index_struct.add_node([subj, obj], text_node)
|
index_struct.add_node([subj, obj], text_node)
|
||||||
return index_struct
|
return index_struct
|
||||||
# num_threads = 5
|
|
||||||
# chunk_size = (
|
|
||||||
# len(documents)
|
|
||||||
# if (len(documents) < num_threads)
|
|
||||||
# else len(documents) // num_threads
|
|
||||||
# )
|
|
||||||
#
|
|
||||||
# import concurrent
|
|
||||||
# triples = []
|
|
||||||
# future_tasks = []
|
|
||||||
# with concurrent.futures.ThreadPoolExecutor() as executor:
|
|
||||||
# for i in range(num_threads):
|
|
||||||
# start = i * chunk_size
|
|
||||||
# end = start + chunk_size if i < num_threads - 1 else None
|
|
||||||
# # doc = documents[start:end]
|
|
||||||
# future_tasks.append(
|
|
||||||
# executor.submit(
|
|
||||||
# self._extract_triplets_task,
|
|
||||||
# documents[start:end],
|
|
||||||
# index_struct,
|
|
||||||
# )
|
|
||||||
# )
|
|
||||||
# # for doc in documents[start:end]:
|
|
||||||
# # future_tasks.append(
|
|
||||||
# # executor.submit(
|
|
||||||
# # self._extract_triplets_task,
|
|
||||||
# # doc,
|
|
||||||
# # index_struct,
|
|
||||||
# # )
|
|
||||||
# # )
|
|
||||||
#
|
|
||||||
# # result = [future.result() for future in future_tasks]
|
|
||||||
# completed_futures, _ = concurrent.futures.wait(future_tasks, return_when=concurrent.futures.ALL_COMPLETED)
|
|
||||||
# for future in completed_futures:
|
|
||||||
# # 获取已完成的future的结果并添加到results列表中
|
|
||||||
# result = future.result()
|
|
||||||
# triplets.extend(result)
|
|
||||||
# print(f"total triplets-{triples}")
|
|
||||||
# for triplet in triplets:
|
|
||||||
# subj, _, obj = triplet
|
|
||||||
# self.graph_store.upsert_triplet(*triplet)
|
|
||||||
# # index_struct.add_node([subj, obj], text_node)
|
|
||||||
# return index_struct
|
|
||||||
# for doc in documents:
|
|
||||||
# triplets = self._extract_triplets(doc.page_content)
|
|
||||||
# if len(triplets) == 0:
|
|
||||||
# continue
|
|
||||||
# text_node = TextNode(text=doc.page_content, metadata=doc.metadata)
|
|
||||||
# logger.info(f"extracted knowledge triplets: {triplets}")
|
|
||||||
# for triplet in triplets:
|
|
||||||
# subj, _, obj = triplet
|
|
||||||
# self.graph_store.upsert_triplet(*triplet)
|
|
||||||
# index_struct.add_node([subj, obj], text_node)
|
|
||||||
#
|
|
||||||
# return index_struct
|
|
||||||
|
|
||||||
def search(self, query):
|
def search(self, query):
|
||||||
from pilot.graph_engine.graph_search import RAGGraphSearch
|
from pilot.rag.graph_engine.graph_search import RAGGraphSearch
|
||||||
|
|
||||||
graph_search = RAGGraphSearch(graph_engine=self)
|
graph_search = RAGGraphSearch(graph_engine=self)
|
||||||
return graph_search.search(query)
|
return graph_search.search(query)
|
||||||
@ -200,8 +145,3 @@ class RAGGraphEngine:
|
|||||||
)
|
)
|
||||||
triple_results.extend(triplets)
|
triple_results.extend(triplets)
|
||||||
return triple_results
|
return triple_results
|
||||||
# for triplet in triplets:
|
|
||||||
# subj, _, obj = triplet
|
|
||||||
# self.graph_store.upsert_triplet(*triplet)
|
|
||||||
# self.graph_store.upsert_triplet(*triplet)
|
|
||||||
# index_struct.add_node([subj, obj], text_node)
|
|
||||||
@ -20,7 +20,7 @@ class DefaultRAGGraphFactory(RAGGraphFactory):
|
|||||||
super().__init__(system_app=system_app)
|
super().__init__(system_app=system_app)
|
||||||
self._default_model_name = default_model_name
|
self._default_model_name = default_model_name
|
||||||
self.kwargs = kwargs
|
self.kwargs = kwargs
|
||||||
from pilot.graph_engine.graph_engine import RAGGraphEngine
|
from pilot.rag.graph_engine.graph_engine import RAGGraphEngine
|
||||||
|
|
||||||
self.rag_engine = RAGGraphEngine(model_name="proxyllm")
|
self.rag_engine = RAGGraphEngine(model_name="proxyllm")
|
||||||
|
|
||||||
@ -6,8 +6,8 @@ from typing import List, Optional, Dict, Any, Set, Callable
|
|||||||
|
|
||||||
from langchain.schema import Document
|
from langchain.schema import Document
|
||||||
|
|
||||||
from pilot.graph_engine.node import BaseNode, TextNode, NodeWithScore
|
from pilot.rag.graph_engine.node import BaseNode, TextNode, NodeWithScore
|
||||||
from pilot.graph_engine.search import BaseSearch, SearchMode
|
from pilot.rag.graph_engine.search import BaseSearch, SearchMode
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
logger = logging.getLogger(__name__)
|
||||||
DEFAULT_NODE_SCORE = 1000.0
|
DEFAULT_NODE_SCORE = 1000.0
|
||||||
@ -45,7 +45,7 @@ class RAGGraphSearch(BaseSearch):
|
|||||||
**kwargs: Any,
|
**kwargs: Any,
|
||||||
) -> None:
|
) -> None:
|
||||||
"""Initialize params."""
|
"""Initialize params."""
|
||||||
from pilot.graph_engine.graph_engine import RAGGraphEngine
|
from pilot.rag.graph_engine.graph_engine import RAGGraphEngine
|
||||||
|
|
||||||
self.graph_engine: RAGGraphEngine = graph_engine
|
self.graph_engine: RAGGraphEngine = graph_engine
|
||||||
self.model_name = model_name or self.graph_engine.model_name
|
self.model_name = model_name or self.graph_engine.model_name
|
||||||
@ -12,8 +12,8 @@ from typing import Dict, List, Optional, Sequence, Set
|
|||||||
from dataclasses_json import DataClassJsonMixin
|
from dataclasses_json import DataClassJsonMixin
|
||||||
|
|
||||||
|
|
||||||
from pilot.graph_engine.index_type import IndexStructType
|
from pilot.rag.graph_engine.index_type import IndexStructType
|
||||||
from pilot.graph_engine.node import TextNode, BaseNode
|
from pilot.rag.graph_engine.node import TextNode, BaseNode
|
||||||
|
|
||||||
# TODO: legacy backport of old Node class
|
# TODO: legacy backport of old Node class
|
||||||
Node = TextNode
|
Node = TextNode
|
||||||
0
pilot/rag/retriever/__init__.py
Normal file
0
pilot/rag/retriever/__init__.py
Normal file
53
pilot/rag/retriever/reinforce.py
Normal file
53
pilot/rag/retriever/reinforce.py
Normal file
@ -0,0 +1,53 @@
|
|||||||
|
from typing import List
|
||||||
|
|
||||||
|
from pilot.scene.base import ChatScene
|
||||||
|
from pilot.scene.base_chat import BaseChat
|
||||||
|
|
||||||
|
|
||||||
|
class QueryReinforce:
|
||||||
|
"""
|
||||||
|
query reinforce, include query rewrite, query correct
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, query: str = None, model_name: str = None, llm_chat: BaseChat = None
|
||||||
|
):
|
||||||
|
"""query reinforce
|
||||||
|
Args:
|
||||||
|
- query: str, user query
|
||||||
|
- model_name: str, llm model name
|
||||||
|
"""
|
||||||
|
self.query = query
|
||||||
|
self.model_name = model_name
|
||||||
|
self.llm_chat = llm_chat
|
||||||
|
|
||||||
|
async def rewrite(self) -> List[str]:
|
||||||
|
"""query rewrite"""
|
||||||
|
from pilot.common.chat_util import llm_chat_response_nostream
|
||||||
|
import uuid
|
||||||
|
|
||||||
|
chat_param = {
|
||||||
|
"chat_session_id": uuid.uuid1(),
|
||||||
|
"current_user_input": self.query,
|
||||||
|
"select_param": 2,
|
||||||
|
"model_name": self.model_name,
|
||||||
|
"model_cache_enable": False,
|
||||||
|
}
|
||||||
|
tasks = [
|
||||||
|
llm_chat_response_nostream(
|
||||||
|
ChatScene.QueryRewrite.value(), **{"chat_param": chat_param}
|
||||||
|
)
|
||||||
|
]
|
||||||
|
from pilot.common.chat_util import run_async_tasks
|
||||||
|
|
||||||
|
queries = await run_async_tasks(tasks=tasks, concurrency_limit=1)
|
||||||
|
queries = list(
|
||||||
|
filter(
|
||||||
|
lambda content: "LLMServer Generate Error" not in content,
|
||||||
|
queries,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
return queries[0]
|
||||||
|
|
||||||
|
def correct(self) -> List[str]:
|
||||||
|
pass
|
||||||
87
pilot/rag/retriever/rerank.py
Normal file
87
pilot/rag/retriever/rerank.py
Normal file
@ -0,0 +1,87 @@
|
|||||||
|
from abc import ABC
|
||||||
|
from typing import List, Tuple, Optional
|
||||||
|
|
||||||
|
|
||||||
|
class Ranker(ABC):
|
||||||
|
"""Base Ranker"""
|
||||||
|
|
||||||
|
def __init__(self, topk: int, rank_fn: Optional[callable] = None):
|
||||||
|
"""
|
||||||
|
abstract base ranker
|
||||||
|
Args:
|
||||||
|
topk: int
|
||||||
|
rank_fn: Optional[callable]
|
||||||
|
"""
|
||||||
|
self.topk = topk
|
||||||
|
self.rank_fn = rank_fn
|
||||||
|
|
||||||
|
def rank(self, candidates_with_scores: List, topk: int):
|
||||||
|
"""rank algorithm implementation return topk documents by candidates similarity score
|
||||||
|
Args:
|
||||||
|
candidates_with_scores: List[Tuple]
|
||||||
|
topk: int
|
||||||
|
Return:
|
||||||
|
List[Document]
|
||||||
|
"""
|
||||||
|
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _filter(self, candidates_with_scores: List):
|
||||||
|
"""filter duplicate candidates documents"""
|
||||||
|
candidates_with_scores = sorted(
|
||||||
|
candidates_with_scores, key=lambda x: x[1], reverse=True
|
||||||
|
)
|
||||||
|
visited_docs = set()
|
||||||
|
new_candidates = []
|
||||||
|
for candidate_doc, score in candidates_with_scores:
|
||||||
|
if candidate_doc.page_content not in visited_docs:
|
||||||
|
new_candidates.append((candidate_doc, score))
|
||||||
|
visited_docs.add(candidate_doc.page_content)
|
||||||
|
return new_candidates
|
||||||
|
|
||||||
|
|
||||||
|
class DefaultRanker(Ranker):
|
||||||
|
"""Default Ranker"""
|
||||||
|
|
||||||
|
def __init__(self, topk: int, rank_fn: Optional[callable] = None):
|
||||||
|
super().__init__(topk, rank_fn)
|
||||||
|
|
||||||
|
def rank(self, candidates_with_scores: List[Tuple]):
|
||||||
|
"""Default rank algorithm implementation
|
||||||
|
return topk documents by candidates similarity score
|
||||||
|
Args:
|
||||||
|
candidates_with_scores: List[Tuple]
|
||||||
|
Return:
|
||||||
|
List[Document]
|
||||||
|
"""
|
||||||
|
candidates_with_scores = self._filter(candidates_with_scores)
|
||||||
|
if self.rank_fn is not None:
|
||||||
|
candidates_with_scores = self.rank_fn(candidates_with_scores)
|
||||||
|
else:
|
||||||
|
candidates_with_scores = sorted(
|
||||||
|
candidates_with_scores, key=lambda x: x[1], reverse=True
|
||||||
|
)
|
||||||
|
return [
|
||||||
|
(candidate_doc, score) for candidate_doc, score in candidates_with_scores
|
||||||
|
][: self.topk]
|
||||||
|
|
||||||
|
|
||||||
|
class RRFRanker(Ranker):
|
||||||
|
"""RRF(Reciprocal Rank Fusion) Ranker"""
|
||||||
|
|
||||||
|
def __init__(self, topk: int, rank_fn: Optional[callable] = None):
|
||||||
|
super().__init__(topk, rank_fn)
|
||||||
|
|
||||||
|
def rank(self, candidates_with_scores: List):
|
||||||
|
"""RRF rank algorithm implementation
|
||||||
|
This code implements an algorithm called Reciprocal Rank Fusion (RRF), is a method for combining multiple result sets with different relevance indicators into a single result set. RRF requires no tuning, and the different relevance indicators do not have to be related to each other to achieve high-quality results.
|
||||||
|
RRF uses the following formula to determine the score for ranking each document:
|
||||||
|
score = 0.0
|
||||||
|
for q in queries:
|
||||||
|
if d in result(q):
|
||||||
|
score += 1.0 / ( k + rank( result(q), d ) )
|
||||||
|
return score
|
||||||
|
reference:https://www.elastic.co/guide/en/elasticsearch/reference/current/rrf.html
|
||||||
|
"""
|
||||||
|
# it will be implemented soon when multi recall is implemented
|
||||||
|
return candidates_with_scores
|
||||||
@ -106,6 +106,9 @@ class ChatScene(Enum):
|
|||||||
ExtractEntity = Scene(
|
ExtractEntity = Scene(
|
||||||
"extract_entity", "Extract Entity", "Extract Entity", ["Extract Select"], True
|
"extract_entity", "Extract Entity", "Extract Entity", ["Extract Select"], True
|
||||||
)
|
)
|
||||||
|
QueryRewrite = Scene(
|
||||||
|
"query_rewrite", "query_rewrite", "query_rewrite", ["query_rewrite"], True
|
||||||
|
)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def of_mode(mode):
|
def of_mode(mode):
|
||||||
|
|||||||
@ -203,7 +203,7 @@ class BaseChat(ABC):
|
|||||||
payload = await self.__call_base()
|
payload = await self.__call_base()
|
||||||
|
|
||||||
self.skip_echo_len = len(payload.get("prompt").replace("</s>", " ")) + 11
|
self.skip_echo_len = len(payload.get("prompt").replace("</s>", " ")) + 11
|
||||||
logger.info(f"Requert: \n{payload}")
|
logger.info(f"payload request: \n{payload}")
|
||||||
ai_response_text = ""
|
ai_response_text = ""
|
||||||
span = root_tracer.start_span(
|
span = root_tracer.start_span(
|
||||||
"BaseChat.stream_call", metadata=self._get_span_metadata(payload)
|
"BaseChat.stream_call", metadata=self._get_span_metadata(payload)
|
||||||
@ -214,7 +214,7 @@ class BaseChat(ABC):
|
|||||||
async for output in await self._model_stream_operator.call_stream(
|
async for output in await self._model_stream_operator.call_stream(
|
||||||
call_data={"data": payload}
|
call_data={"data": payload}
|
||||||
):
|
):
|
||||||
### Plug-in research in result generation
|
# Plugin research in result generation
|
||||||
msg = self.prompt_template.output_parser.parse_model_stream_resp_ex(
|
msg = self.prompt_template.output_parser.parse_model_stream_resp_ex(
|
||||||
output, self.skip_echo_len
|
output, self.skip_echo_len
|
||||||
)
|
)
|
||||||
@ -227,7 +227,7 @@ class BaseChat(ABC):
|
|||||||
span.end()
|
span.end()
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(traceback.format_exc())
|
print(traceback.format_exc())
|
||||||
logger.error("model response parase failed!" + str(e))
|
logger.error("model response parse failed!" + str(e))
|
||||||
self.current_message.add_view_message(
|
self.current_message.add_view_message(
|
||||||
f"""<span style=\"color:red\">ERROR!</span>{str(e)}\n {ai_response_text} """
|
f"""<span style=\"color:red\">ERROR!</span>{str(e)}\n {ai_response_text} """
|
||||||
)
|
)
|
||||||
|
|||||||
@ -18,6 +18,7 @@ class ChatFactory(metaclass=Singleton):
|
|||||||
from pilot.scene.chat_knowledge.extract_entity.chat import ExtractEntity
|
from pilot.scene.chat_knowledge.extract_entity.chat import ExtractEntity
|
||||||
from pilot.scene.chat_knowledge.summary.chat import ExtractSummary
|
from pilot.scene.chat_knowledge.summary.chat import ExtractSummary
|
||||||
from pilot.scene.chat_knowledge.refine_summary.chat import ExtractRefineSummary
|
from pilot.scene.chat_knowledge.refine_summary.chat import ExtractRefineSummary
|
||||||
|
from pilot.scene.chat_knowledge.rewrite.chat import QueryRewrite
|
||||||
from pilot.scene.chat_data.chat_excel.excel_analyze.chat import ChatExcel
|
from pilot.scene.chat_data.chat_excel.excel_analyze.chat import ChatExcel
|
||||||
from pilot.scene.chat_agent.chat import ChatAgent
|
from pilot.scene.chat_agent.chat import ChatAgent
|
||||||
|
|
||||||
|
|||||||
0
pilot/scene/chat_knowledge/rewrite/__init__.py
Normal file
0
pilot/scene/chat_knowledge/rewrite/__init__.py
Normal file
36
pilot/scene/chat_knowledge/rewrite/chat.py
Normal file
36
pilot/scene/chat_knowledge/rewrite/chat.py
Normal file
@ -0,0 +1,36 @@
|
|||||||
|
from typing import Dict
|
||||||
|
|
||||||
|
from pilot.scene.base_chat import BaseChat
|
||||||
|
from pilot.scene.base import ChatScene
|
||||||
|
from pilot.configs.config import Config
|
||||||
|
|
||||||
|
from pilot.scene.chat_knowledge.rewrite.prompt import prompt
|
||||||
|
|
||||||
|
CFG = Config()
|
||||||
|
|
||||||
|
|
||||||
|
class QueryRewrite(BaseChat):
|
||||||
|
chat_scene: str = ChatScene.QueryRewrite.value()
|
||||||
|
|
||||||
|
"""query rewrite by llm"""
|
||||||
|
|
||||||
|
def __init__(self, chat_param: Dict):
|
||||||
|
""" """
|
||||||
|
chat_param["chat_mode"] = ChatScene.QueryRewrite
|
||||||
|
super().__init__(
|
||||||
|
chat_param=chat_param,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.nums = chat_param["select_param"]
|
||||||
|
self.current_user_input = chat_param["current_user_input"]
|
||||||
|
|
||||||
|
async def generate_input_values(self):
|
||||||
|
input_values = {
|
||||||
|
"nums": self.nums,
|
||||||
|
"original_query": self.current_user_input,
|
||||||
|
}
|
||||||
|
return input_values
|
||||||
|
|
||||||
|
@property
|
||||||
|
def chat_type(self) -> str:
|
||||||
|
return ChatScene.QueryRewrite.value
|
||||||
47
pilot/scene/chat_knowledge/rewrite/out_parser.py
Normal file
47
pilot/scene/chat_knowledge/rewrite/out_parser.py
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
import logging
|
||||||
|
from typing import List, Tuple
|
||||||
|
|
||||||
|
from pilot.out_parser.base import BaseOutputParser, T
|
||||||
|
from pilot.configs.config import Config
|
||||||
|
|
||||||
|
CFG = Config()
|
||||||
|
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
class QueryRewriteParser(BaseOutputParser):
|
||||||
|
def __init__(self, sep: str, is_stream_out: bool):
|
||||||
|
super().__init__(sep=sep, is_stream_out=is_stream_out)
|
||||||
|
|
||||||
|
def parse_prompt_response(self, response, max_length: int = 128):
|
||||||
|
lowercase = True
|
||||||
|
try:
|
||||||
|
results = []
|
||||||
|
response = response.strip()
|
||||||
|
|
||||||
|
if response.startswith("queries:"):
|
||||||
|
response = response[len("queries:") :]
|
||||||
|
|
||||||
|
queries = response.split(",")
|
||||||
|
if len(queries) == 1:
|
||||||
|
queries = response.split(",")
|
||||||
|
if len(queries) == 1:
|
||||||
|
queries = response.split("?")
|
||||||
|
if len(queries) == 1:
|
||||||
|
queries = response.split("?")
|
||||||
|
for k in queries:
|
||||||
|
rk = k
|
||||||
|
if lowercase:
|
||||||
|
rk = rk.lower()
|
||||||
|
s = rk.strip()
|
||||||
|
if s == "":
|
||||||
|
continue
|
||||||
|
results.append(s)
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"parse query rewrite prompt_response error: {e}")
|
||||||
|
return []
|
||||||
|
return results
|
||||||
|
|
||||||
|
def parse_view_response(self, speak, data) -> str:
|
||||||
|
return data
|
||||||
47
pilot/scene/chat_knowledge/rewrite/prompt.py
Normal file
47
pilot/scene/chat_knowledge/rewrite/prompt.py
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
from pilot.prompts.prompt_new import PromptTemplate
|
||||||
|
from pilot.configs.config import Config
|
||||||
|
from pilot.scene.base import ChatScene
|
||||||
|
from pilot.common.schema import SeparatorStyle
|
||||||
|
|
||||||
|
from .out_parser import QueryRewriteParser
|
||||||
|
|
||||||
|
CFG = Config()
|
||||||
|
|
||||||
|
|
||||||
|
PROMPT_SCENE_DEFINE = """You are a helpful assistant that generates multiple search queries based on a single input query."""
|
||||||
|
|
||||||
|
_DEFAULT_TEMPLATE_ZH = """请根据原问题优化生成{nums}个相关的搜索查询,这些查询应与原始查询相似并且是人们可能会提出的可回答的搜索问题。请勿使用任何示例中提到的内容,确保所有生成的查询均独立于示例,仅基于提供的原始查询。请按照以下逗号分隔的格式提供: 'queries:<queries>':
|
||||||
|
"original_query:{original_query}\n"
|
||||||
|
"queries:\n"
|
||||||
|
"""
|
||||||
|
|
||||||
|
_DEFAULT_TEMPLATE_EN = """
|
||||||
|
Generate {nums} search queries related to: {original_query}, Provide following comma-separated format: 'queries: <queries>'\n":
|
||||||
|
"original query:: {original_query}\n"
|
||||||
|
"queries:\n"
|
||||||
|
"""
|
||||||
|
|
||||||
|
_DEFAULT_TEMPLATE = (
|
||||||
|
_DEFAULT_TEMPLATE_EN if CFG.LANGUAGE == "en" else _DEFAULT_TEMPLATE_ZH
|
||||||
|
)
|
||||||
|
|
||||||
|
PROMPT_RESPONSE = """"""
|
||||||
|
|
||||||
|
PROMPT_SEP = SeparatorStyle.SINGLE.value
|
||||||
|
|
||||||
|
PROMPT_NEED_NEED_STREAM_OUT = True
|
||||||
|
|
||||||
|
prompt = PromptTemplate(
|
||||||
|
template_scene=ChatScene.QueryRewrite.value(),
|
||||||
|
input_variables=["nums", "original_query"],
|
||||||
|
response_format=None,
|
||||||
|
template_define=PROMPT_SCENE_DEFINE,
|
||||||
|
template=_DEFAULT_TEMPLATE + PROMPT_RESPONSE,
|
||||||
|
stream_out=PROMPT_NEED_NEED_STREAM_OUT,
|
||||||
|
output_parser=QueryRewriteParser(
|
||||||
|
sep=PROMPT_SEP, is_stream_out=PROMPT_NEED_NEED_STREAM_OUT
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
CFG.prompt_template_registry.register(prompt, is_default=True)
|
||||||
|
from ..v1 import prompt_chatglm
|
||||||
@ -1,18 +1,22 @@
|
|||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
|
from functools import reduce
|
||||||
from typing import Dict, List
|
from typing import Dict, List
|
||||||
|
|
||||||
from pilot.component import ComponentType
|
|
||||||
from pilot.scene.base_chat import BaseChat
|
from pilot.scene.base_chat import BaseChat
|
||||||
from pilot.scene.base import ChatScene
|
from pilot.scene.base import ChatScene
|
||||||
from pilot.configs.config import Config
|
from pilot.configs.config import Config
|
||||||
|
|
||||||
from pilot.configs.model_config import (
|
from pilot.configs.model_config import (
|
||||||
KNOWLEDGE_UPLOAD_ROOT_PATH,
|
|
||||||
EMBEDDING_MODEL_CONFIG,
|
EMBEDDING_MODEL_CONFIG,
|
||||||
)
|
)
|
||||||
|
|
||||||
from pilot.scene.chat_knowledge.v1.prompt import prompt
|
from pilot.scene.chat_knowledge.v1.prompt import prompt
|
||||||
|
from pilot.server.knowledge.chunk_db import DocumentChunkDao, DocumentChunkEntity
|
||||||
|
from pilot.server.knowledge.document_db import (
|
||||||
|
KnowledgeDocumentDao,
|
||||||
|
KnowledgeDocumentEntity,
|
||||||
|
)
|
||||||
from pilot.server.knowledge.service import KnowledgeService
|
from pilot.server.knowledge.service import KnowledgeService
|
||||||
from pilot.utils.executor_utils import blocking_func_to_async
|
from pilot.utils.executor_utils import blocking_func_to_async
|
||||||
from pilot.utils.tracer import root_tracer, trace
|
from pilot.utils.tracer import root_tracer, trace
|
||||||
@ -47,6 +51,11 @@ class ChatKnowledge(BaseChat):
|
|||||||
if self.space_context is None
|
if self.space_context is None
|
||||||
else int(self.space_context["embedding"]["topk"])
|
else int(self.space_context["embedding"]["topk"])
|
||||||
)
|
)
|
||||||
|
self.recall_score = (
|
||||||
|
CFG.KNOWLEDGE_SEARCH_RECALL_SCORE
|
||||||
|
if self.space_context is None
|
||||||
|
else float(self.space_context["embedding"]["recall_score"])
|
||||||
|
)
|
||||||
self.max_token = (
|
self.max_token = (
|
||||||
CFG.KNOWLEDGE_SEARCH_MAX_TOKEN
|
CFG.KNOWLEDGE_SEARCH_MAX_TOKEN
|
||||||
if self.space_context is None or self.space_context.get("prompt") is None
|
if self.space_context is None or self.space_context.get("prompt") is None
|
||||||
@ -65,11 +74,16 @@ class ChatKnowledge(BaseChat):
|
|||||||
embedding_factory=embedding_factory,
|
embedding_factory=embedding_factory,
|
||||||
)
|
)
|
||||||
self.prompt_template.template_is_strict = False
|
self.prompt_template.template_is_strict = False
|
||||||
|
self.relations = None
|
||||||
|
self.chunk_dao = DocumentChunkDao()
|
||||||
|
document_dao = KnowledgeDocumentDao()
|
||||||
|
documents = document_dao.get_documents(
|
||||||
|
query=KnowledgeDocumentEntity(space=self.knowledge_space)
|
||||||
|
)
|
||||||
|
if len(documents) > 0:
|
||||||
|
self.document_ids = [document.id for document in documents]
|
||||||
|
|
||||||
async def stream_call(self):
|
async def stream_call(self):
|
||||||
input_values = await self.generate_input_values()
|
|
||||||
# Source of knowledge file
|
|
||||||
relations = input_values.get("relations")
|
|
||||||
last_output = None
|
last_output = None
|
||||||
async for output in super().stream_call():
|
async for output in super().stream_call():
|
||||||
last_output = output
|
last_output = output
|
||||||
@ -78,76 +92,118 @@ class ChatKnowledge(BaseChat):
|
|||||||
if (
|
if (
|
||||||
CFG.KNOWLEDGE_CHAT_SHOW_RELATIONS
|
CFG.KNOWLEDGE_CHAT_SHOW_RELATIONS
|
||||||
and last_output
|
and last_output
|
||||||
and type(relations) == list
|
and type(self.relations) == list
|
||||||
and len(relations) > 0
|
and len(self.relations) > 0
|
||||||
and hasattr(last_output, "text")
|
and hasattr(last_output, "text")
|
||||||
):
|
):
|
||||||
last_output.text = (
|
last_output.text = (
|
||||||
last_output.text + "\n\nrelations:\n\n" + ",".join(relations)
|
last_output.text + "\n\nrelations:\n\n" + ",".join(self.relations)
|
||||||
)
|
)
|
||||||
reference = f"\n\n{self.parse_source_view(self.sources)}"
|
reference = f"\n\n{self.parse_source_view(self.chunks_with_score)}"
|
||||||
last_output = last_output + reference
|
last_output = last_output + reference
|
||||||
yield last_output
|
yield last_output
|
||||||
|
|
||||||
def stream_call_reinforce_fn(self, text):
|
def stream_call_reinforce_fn(self, text):
|
||||||
"""return reference"""
|
"""return reference"""
|
||||||
return text + f"\n\n{self.parse_source_view(self.sources)}"
|
return text + f"\n\n{self.parse_source_view(self.chunks_with_score)}"
|
||||||
|
|
||||||
@trace()
|
@trace()
|
||||||
async def generate_input_values(self) -> Dict:
|
async def generate_input_values(self) -> Dict:
|
||||||
if self.space_context and self.space_context.get("prompt"):
|
if self.space_context and self.space_context.get("prompt"):
|
||||||
self.prompt_template.template_define = self.space_context["prompt"]["scene"]
|
self.prompt_template.template_define = self.space_context["prompt"]["scene"]
|
||||||
self.prompt_template.template = self.space_context["prompt"]["template"]
|
self.prompt_template.template = self.space_context["prompt"]["template"]
|
||||||
docs = await blocking_func_to_async(
|
from pilot.rag.retriever.reinforce import QueryReinforce
|
||||||
self._executor,
|
|
||||||
self.knowledge_embedding_client.similar_search,
|
|
||||||
self.current_user_input,
|
|
||||||
self.top_k,
|
|
||||||
)
|
|
||||||
self.sources = _merge_by_key(
|
|
||||||
list(map(lambda doc: doc.metadata, docs)), "source"
|
|
||||||
)
|
|
||||||
|
|
||||||
if not docs or len(docs) == 0:
|
# query reinforce, get similar queries
|
||||||
|
query_reinforce = QueryReinforce(
|
||||||
|
query=self.current_user_input, model_name=self.llm_model
|
||||||
|
)
|
||||||
|
queries = []
|
||||||
|
if CFG.KNOWLEDGE_SEARCH_REWRITE:
|
||||||
|
queries = await query_reinforce.rewrite()
|
||||||
|
print("rewrite queries:", queries)
|
||||||
|
queries.append(self.current_user_input)
|
||||||
|
from pilot.common.chat_util import run_async_tasks
|
||||||
|
|
||||||
|
# similarity search from vector db
|
||||||
|
tasks = [self.execute_similar_search(query) for query in queries]
|
||||||
|
docs_with_scores = await run_async_tasks(tasks=tasks, concurrency_limit=1)
|
||||||
|
candidates_with_scores = reduce(lambda x, y: x + y, docs_with_scores)
|
||||||
|
# candidates document rerank
|
||||||
|
from pilot.rag.retriever.rerank import DefaultRanker
|
||||||
|
|
||||||
|
ranker = DefaultRanker(self.top_k)
|
||||||
|
candidates_with_scores = ranker.rank(candidates_with_scores)
|
||||||
|
self.chunks_with_score = []
|
||||||
|
if not candidates_with_scores or len(candidates_with_scores) == 0:
|
||||||
print("no relevant docs to retrieve")
|
print("no relevant docs to retrieve")
|
||||||
context = "no relevant docs to retrieve"
|
context = "no relevant docs to retrieve"
|
||||||
else:
|
else:
|
||||||
context = [d.page_content for d in docs]
|
self.chunks_with_score = []
|
||||||
|
for d, score in candidates_with_scores:
|
||||||
|
chucks = self.chunk_dao.get_document_chunks(
|
||||||
|
query=DocumentChunkEntity(content=d.page_content),
|
||||||
|
document_ids=self.document_ids,
|
||||||
|
)
|
||||||
|
if len(chucks) > 0:
|
||||||
|
self.chunks_with_score.append((chucks[0], score))
|
||||||
|
|
||||||
|
context = [doc.page_content for doc, _ in candidates_with_scores]
|
||||||
|
|
||||||
context = context[: self.max_token]
|
context = context[: self.max_token]
|
||||||
relations = list(
|
self.relations = list(
|
||||||
set([os.path.basename(str(d.metadata.get("source", ""))) for d in docs])
|
set(
|
||||||
|
[
|
||||||
|
os.path.basename(str(d.metadata.get("source", "")))
|
||||||
|
for d, _ in candidates_with_scores
|
||||||
|
]
|
||||||
|
)
|
||||||
)
|
)
|
||||||
input_values = {
|
input_values = {
|
||||||
"context": context,
|
"context": context,
|
||||||
"question": self.current_user_input,
|
"question": self.current_user_input,
|
||||||
"relations": relations,
|
"relations": self.relations,
|
||||||
}
|
}
|
||||||
return input_values
|
return input_values
|
||||||
|
|
||||||
def parse_source_view(self, sources: List):
|
def parse_source_view(self, chunks_with_score: List):
|
||||||
"""
|
"""
|
||||||
build knowledge reference view message to web
|
format knowledge reference view message to web
|
||||||
|
<references title="'References'" references="'[{name:aa.pdf,chunks:[{10:text},{11:text}]},{name:bb.pdf,chunks:[{12,text}]}]'"> </references>
|
||||||
|
"""
|
||||||
|
import xml.etree.ElementTree as ET
|
||||||
|
|
||||||
|
references_ele = ET.Element("references")
|
||||||
|
title = "References"
|
||||||
|
references_ele.set("title", title)
|
||||||
|
references_dict = {}
|
||||||
|
for chunk, score in chunks_with_score:
|
||||||
|
doc_name = chunk.doc_name
|
||||||
|
if doc_name not in references_dict:
|
||||||
|
references_dict[doc_name] = {
|
||||||
|
"name": doc_name,
|
||||||
|
"chunks": [
|
||||||
{
|
{
|
||||||
"title":"References",
|
"id": chunk.id,
|
||||||
"references":[{
|
"content": chunk.content,
|
||||||
"name":"aa.pdf",
|
"meta_info": chunk.meta_info,
|
||||||
"pages":["1","2","3"]
|
"recall_score": score,
|
||||||
}]
|
}
|
||||||
|
],
|
||||||
|
}
|
||||||
|
else:
|
||||||
|
references_dict[doc_name]["chunks"].append(
|
||||||
|
{
|
||||||
|
"id": chunk.id,
|
||||||
|
"content": chunk.content,
|
||||||
|
"meta_info": chunk.meta_info,
|
||||||
|
"recall_score": score,
|
||||||
}
|
}
|
||||||
"""
|
|
||||||
references = {"title": "References", "references": []}
|
|
||||||
for item in sources:
|
|
||||||
reference = {}
|
|
||||||
source = item["source"] if "source" in item else ""
|
|
||||||
reference["name"] = source
|
|
||||||
pages = item["pages"] if "pages" in item else []
|
|
||||||
if len(pages) > 0:
|
|
||||||
reference["pages"] = pages
|
|
||||||
references["references"].append(reference)
|
|
||||||
html = (
|
|
||||||
f"""<references>{json.dumps(references, ensure_ascii=False)}</references>"""
|
|
||||||
)
|
)
|
||||||
return html
|
references_list = list(references_dict.values())
|
||||||
|
references_ele.set("references", json.dumps(references_list))
|
||||||
|
html = ET.tostring(references_ele, encoding="utf-8")
|
||||||
|
return html.decode("utf-8")
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def chat_type(self) -> str:
|
def chat_type(self) -> str:
|
||||||
@ -157,26 +213,12 @@ class ChatKnowledge(BaseChat):
|
|||||||
service = KnowledgeService()
|
service = KnowledgeService()
|
||||||
return service.get_space_context(space_name)
|
return service.get_space_context(space_name)
|
||||||
|
|
||||||
|
async def execute_similar_search(self, query):
|
||||||
def _merge_by_key(data, key):
|
"""execute similarity search"""
|
||||||
result = {}
|
return await blocking_func_to_async(
|
||||||
for item in data:
|
self._executor,
|
||||||
if item.get(key):
|
self.knowledge_embedding_client.similar_search_with_scores,
|
||||||
item_key = os.path.basename(item.get(key))
|
query,
|
||||||
if item_key in result:
|
self.top_k,
|
||||||
if "pages" in result[item_key] and "page" in item:
|
self.recall_score,
|
||||||
result[item_key]["pages"].append(str(item["page"]))
|
)
|
||||||
elif "page" in item:
|
|
||||||
result[item_key]["pages"] = [
|
|
||||||
result[item_key]["pages"],
|
|
||||||
str(item["page"]),
|
|
||||||
]
|
|
||||||
else:
|
|
||||||
if "page" in item:
|
|
||||||
result[item_key] = {
|
|
||||||
"source": item_key,
|
|
||||||
"pages": [str(item["page"])],
|
|
||||||
}
|
|
||||||
else:
|
|
||||||
result[item_key] = {"source": item_key}
|
|
||||||
return list(result.values())
|
|
||||||
|
|||||||
@ -184,7 +184,6 @@ class EmbeddingEngingOperator(MapOperator[ChatContext, ChatContext]):
|
|||||||
from pilot.configs.model_config import EMBEDDING_MODEL_CONFIG
|
from pilot.configs.model_config import EMBEDDING_MODEL_CONFIG
|
||||||
from pilot.embedding_engine.embedding_engine import EmbeddingEngine
|
from pilot.embedding_engine.embedding_engine import EmbeddingEngine
|
||||||
from pilot.embedding_engine.embedding_factory import EmbeddingFactory
|
from pilot.embedding_engine.embedding_factory import EmbeddingFactory
|
||||||
from pilot.scene.chat_knowledge.v1.chat import _merge_by_key
|
|
||||||
|
|
||||||
# TODO, decompose the current operator into some atomic operators
|
# TODO, decompose the current operator into some atomic operators
|
||||||
knowledge_space = input_value.select_param
|
knowledge_space = input_value.select_param
|
||||||
@ -223,7 +222,6 @@ class EmbeddingEngingOperator(MapOperator[ChatContext, ChatContext]):
|
|||||||
input_value.current_user_input,
|
input_value.current_user_input,
|
||||||
top_k,
|
top_k,
|
||||||
)
|
)
|
||||||
sources = _merge_by_key(list(map(lambda doc: doc.metadata, docs)), "source")
|
|
||||||
if not docs or len(docs) == 0:
|
if not docs or len(docs) == 0:
|
||||||
print("no relevant docs to retrieve")
|
print("no relevant docs to retrieve")
|
||||||
context = "no relevant docs to retrieve"
|
context = "no relevant docs to retrieve"
|
||||||
|
|||||||
@ -61,7 +61,9 @@ class DocumentChunkDao(BaseDao):
|
|||||||
session.commit()
|
session.commit()
|
||||||
session.close()
|
session.close()
|
||||||
|
|
||||||
def get_document_chunks(self, query: DocumentChunkEntity, page=1, page_size=20):
|
def get_document_chunks(
|
||||||
|
self, query: DocumentChunkEntity, page=1, page_size=20, document_ids=None
|
||||||
|
):
|
||||||
session = self.get_session()
|
session = self.get_session()
|
||||||
document_chunks = session.query(DocumentChunkEntity)
|
document_chunks = session.query(DocumentChunkEntity)
|
||||||
if query.id is not None:
|
if query.id is not None:
|
||||||
@ -74,6 +76,10 @@ class DocumentChunkDao(BaseDao):
|
|||||||
document_chunks = document_chunks.filter(
|
document_chunks = document_chunks.filter(
|
||||||
DocumentChunkEntity.doc_type == query.doc_type
|
DocumentChunkEntity.doc_type == query.doc_type
|
||||||
)
|
)
|
||||||
|
if query.content is not None:
|
||||||
|
document_chunks = document_chunks.filter(
|
||||||
|
DocumentChunkEntity.content == query.content
|
||||||
|
)
|
||||||
if query.doc_name is not None:
|
if query.doc_name is not None:
|
||||||
document_chunks = document_chunks.filter(
|
document_chunks = document_chunks.filter(
|
||||||
DocumentChunkEntity.doc_name == query.doc_name
|
DocumentChunkEntity.doc_name == query.doc_name
|
||||||
@ -82,6 +88,10 @@ class DocumentChunkDao(BaseDao):
|
|||||||
document_chunks = document_chunks.filter(
|
document_chunks = document_chunks.filter(
|
||||||
DocumentChunkEntity.meta_info == query.meta_info
|
DocumentChunkEntity.meta_info == query.meta_info
|
||||||
)
|
)
|
||||||
|
if document_ids is not None:
|
||||||
|
document_chunks = document_chunks.filter(
|
||||||
|
DocumentChunkEntity.document_id.in_(document_ids)
|
||||||
|
)
|
||||||
|
|
||||||
document_chunks = document_chunks.order_by(DocumentChunkEntity.id.asc())
|
document_chunks = document_chunks.order_by(DocumentChunkEntity.id.asc())
|
||||||
document_chunks = document_chunks.offset((page - 1) * page_size).limit(
|
document_chunks = document_chunks.offset((page - 1) * page_size).limit(
|
||||||
@ -116,12 +126,6 @@ class DocumentChunkDao(BaseDao):
|
|||||||
session.close()
|
session.close()
|
||||||
return count
|
return count
|
||||||
|
|
||||||
# def update_knowledge_document(self, document:KnowledgeDocumentEntity):
|
|
||||||
# session = self.get_session()
|
|
||||||
# updated_space = session.merge(document)
|
|
||||||
# session.commit()
|
|
||||||
# return updated_space.id
|
|
||||||
|
|
||||||
def delete(self, document_id: int):
|
def delete(self, document_id: int):
|
||||||
session = self.get_session()
|
session = self.get_session()
|
||||||
if document_id is None:
|
if document_id is None:
|
||||||
|
|||||||
@ -56,7 +56,12 @@ class SyncStatus(Enum):
|
|||||||
FINISHED = "FINISHED"
|
FINISHED = "FINISHED"
|
||||||
|
|
||||||
|
|
||||||
# @singleton
|
# default summary max iteration call with llm.
|
||||||
|
DEFAULT_SUMMARY_MAX_ITERATION = 5
|
||||||
|
# default summary concurrency call with llm.
|
||||||
|
DEFAULT_SUMMARY_CONCURRENCY_LIMIT = 3
|
||||||
|
|
||||||
|
|
||||||
class KnowledgeService:
|
class KnowledgeService:
|
||||||
"""KnowledgeService
|
"""KnowledgeService
|
||||||
Knowledge Management Service:
|
Knowledge Management Service:
|
||||||
@ -425,7 +430,7 @@ class KnowledgeService:
|
|||||||
f"async_knowledge_graph, doc:{doc.doc_name}, chunk_size:{len(chunk_docs)}, begin embedding to graph store"
|
f"async_knowledge_graph, doc:{doc.doc_name}, chunk_size:{len(chunk_docs)}, begin embedding to graph store"
|
||||||
)
|
)
|
||||||
try:
|
try:
|
||||||
from pilot.graph_engine.graph_factory import RAGGraphFactory
|
from pilot.rag.graph_engine.graph_factory import RAGGraphFactory
|
||||||
|
|
||||||
rag_engine = CFG.SYSTEM_APP.get_component(
|
rag_engine = CFG.SYSTEM_APP.get_component(
|
||||||
ComponentType.RAG_GRAPH_DEFAULT.value, RAGGraphFactory
|
ComponentType.RAG_GRAPH_DEFAULT.value, RAGGraphFactory
|
||||||
@ -502,7 +507,7 @@ class KnowledgeService:
|
|||||||
context_template = {
|
context_template = {
|
||||||
"embedding": {
|
"embedding": {
|
||||||
"topk": CFG.KNOWLEDGE_SEARCH_TOP_SIZE,
|
"topk": CFG.KNOWLEDGE_SEARCH_TOP_SIZE,
|
||||||
"recall_score": 0.0,
|
"recall_score": CFG.KNOWLEDGE_SEARCH_RECALL_SCORE,
|
||||||
"recall_type": "TopK",
|
"recall_type": "TopK",
|
||||||
"model": EMBEDDING_MODEL_CONFIG[CFG.EMBEDDING_MODEL].rsplit("/", 1)[-1],
|
"model": EMBEDDING_MODEL_CONFIG[CFG.EMBEDDING_MODEL].rsplit("/", 1)[-1],
|
||||||
"chunk_size": CFG.KNOWLEDGE_CHUNK_SIZE,
|
"chunk_size": CFG.KNOWLEDGE_CHUNK_SIZE,
|
||||||
@ -514,8 +519,8 @@ class KnowledgeService:
|
|||||||
"template": _DEFAULT_TEMPLATE,
|
"template": _DEFAULT_TEMPLATE,
|
||||||
},
|
},
|
||||||
"summary": {
|
"summary": {
|
||||||
"max_iteration": 5,
|
"max_iteration": DEFAULT_SUMMARY_MAX_ITERATION,
|
||||||
"concurrency_limit": 3,
|
"concurrency_limit": DEFAULT_SUMMARY_CONCURRENCY_LIMIT,
|
||||||
},
|
},
|
||||||
}
|
}
|
||||||
context_template_string = json.dumps(context_template, indent=4)
|
context_template_string = json.dumps(context_template, indent=4)
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@ -1 +1 @@
|
|||||||
self.__BUILD_MANIFEST=function(s,c,a,t,e,n,d,b,f,k,h,i){return{__rewrites:{beforeFiles:[],afterFiles:[],fallback:[]},"/":["static/chunks/29107295-90b90cb30c825230.js",s,c,a,n,d,b,f,"static/chunks/412-b911d4a677c64b70.js","static/chunks/981-ff77d5cc3ab95298.js","static/chunks/pages/index-b82ae16bc13b2207.js"],"/_error":["static/chunks/pages/_error-dee72aff9b2e2c12.js"],"/agent":[s,c,t,n,e,d,"static/chunks/pages/agent-0ee536125426fba0.js"],"/chat":["static/chunks/pages/chat-84fbba4764166684.js"],"/chat/[scene]/[id]":["static/chunks/pages/chat/[scene]/[id]-f665336966e79cc9.js"],"/database":[s,c,a,t,e,b,k,"static/chunks/643-d8f53f40dd3c5b40.js","static/chunks/pages/database-2f26b925c44f1b12.js"],"/knowledge":[h,s,c,t,n,e,d,b,"static/chunks/551-266086fbfa0925ec.js","static/chunks/pages/knowledge-8ada4ce8fa909bf5.js"],"/knowledge/chunk":[t,e,"static/chunks/pages/knowledge/chunk-9f117a5ed799edd3.js"],"/models":[h,s,c,a,i,k,"static/chunks/pages/models-80218c46bc1d8cfa.js"],"/prompt":[s,c,a,i,"static/chunks/837-e6d4d1eb9e057050.js",f,"static/chunks/607-b224c640f6907e4b.js","static/chunks/pages/prompt-7f839dfd56bc4c20.js"],sortedPages:["/","/_app","/_error","/agent","/chat","/chat/[scene]/[id]","/database","/knowledge","/knowledge/chunk","/models","/prompt"]}}("static/chunks/64-91b49d45b9846775.js","static/chunks/479-b20198841f9a6a1e.js","static/chunks/9-bb2c54d5c06ba4bf.js","static/chunks/442-197e6cbc1e54109a.js","static/chunks/813-cce9482e33f2430c.js","static/chunks/553-a47bd28b47047f83.js","static/chunks/924-ba8e16df4d61ff5c.js","static/chunks/411-d9eba2657c72f766.js","static/chunks/270-2f094a936d056513.js","static/chunks/928-74244889bd7f2699.js","static/chunks/75fc9c18-a784766a129ec5fb.js","static/chunks/947-5980a3ff49069ddd.js"),self.__BUILD_MANIFEST_CB&&self.__BUILD_MANIFEST_CB();
|
self.__BUILD_MANIFEST=function(s,c,a,e,t,d,n,f,k,h,i,b){return{__rewrites:{beforeFiles:[],afterFiles:[],fallback:[]},"/":["static/chunks/29107295-90b90cb30c825230.js",s,c,a,d,n,f,k,"static/chunks/412-b911d4a677c64b70.js","static/chunks/981-ff77d5cc3ab95298.js","static/chunks/pages/index-d1740e3bc6dba7f5.js"],"/_error":["static/chunks/pages/_error-dee72aff9b2e2c12.js"],"/agent":[s,c,e,d,t,n,"static/chunks/pages/agent-92e9dce47267e88d.js"],"/chat":["static/chunks/pages/chat-84fbba4764166684.js"],"/chat/[scene]/[id]":["static/chunks/pages/chat/[scene]/[id]-f665336966e79cc9.js"],"/database":[s,c,a,e,t,f,h,"static/chunks/643-d8f53f40dd3c5b40.js","static/chunks/pages/database-3140f507fe61ccb8.js"],"/knowledge":[i,s,c,e,d,t,n,f,"static/chunks/551-266086fbfa0925ec.js","static/chunks/pages/knowledge-8ada4ce8fa909bf5.js"],"/knowledge/chunk":[e,t,"static/chunks/pages/knowledge/chunk-9f117a5ed799edd3.js"],"/models":[i,s,c,a,b,h,"static/chunks/pages/models-80218c46bc1d8cfa.js"],"/prompt":[s,c,a,b,"static/chunks/837-e6d4d1eb9e057050.js",k,"static/chunks/607-b224c640f6907e4b.js","static/chunks/pages/prompt-7f839dfd56bc4c20.js"],sortedPages:["/","/_app","/_error","/agent","/chat","/chat/[scene]/[id]","/database","/knowledge","/knowledge/chunk","/models","/prompt"]}}("static/chunks/64-91b49d45b9846775.js","static/chunks/479-b20198841f9a6a1e.js","static/chunks/9-bb2c54d5c06ba4bf.js","static/chunks/442-197e6cbc1e54109a.js","static/chunks/813-cce9482e33f2430c.js","static/chunks/553-df5701294eedae07.js","static/chunks/924-ba8e16df4d61ff5c.js","static/chunks/411-d9eba2657c72f766.js","static/chunks/270-2f094a936d056513.js","static/chunks/928-74244889bd7f2699.js","static/chunks/75fc9c18-a784766a129ec5fb.js","static/chunks/947-5980a3ff49069ddd.js"),self.__BUILD_MANIFEST_CB&&self.__BUILD_MANIFEST_CB();
|
||||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@ -1,4 +1,5 @@
|
|||||||
from abc import ABC, abstractmethod
|
from abc import ABC, abstractmethod
|
||||||
|
import math
|
||||||
|
|
||||||
|
|
||||||
class VectorStoreBase(ABC):
|
class VectorStoreBase(ABC):
|
||||||
@ -28,3 +29,14 @@ class VectorStoreBase(ABC):
|
|||||||
def delete_vector_name(self, vector_name):
|
def delete_vector_name(self, vector_name):
|
||||||
"""delete vector name."""
|
"""delete vector name."""
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
def _normalization_vectors(self, vectors):
|
||||||
|
"""normalization vectors to scale[0,1]"""
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
norm = np.linalg.norm(vectors)
|
||||||
|
return vectors / norm
|
||||||
|
|
||||||
|
def _default_relevance_score_fn(self, distance: float) -> float:
|
||||||
|
"""Return a similarity score on a scale [0, 1]."""
|
||||||
|
return 1.0 - distance / math.sqrt(2)
|
||||||
|
|||||||
@ -42,7 +42,25 @@ class ChromaStore(VectorStoreBase):
|
|||||||
|
|
||||||
def similar_search(self, text, topk, **kwargs: Any) -> None:
|
def similar_search(self, text, topk, **kwargs: Any) -> None:
|
||||||
logger.info("ChromaStore similar search")
|
logger.info("ChromaStore similar search")
|
||||||
return self.vector_store_client.similarity_search(text, topk)
|
return self.vector_store_client.similarity_search(text, topk, **kwargs)
|
||||||
|
|
||||||
|
def similar_search_with_scores(self, text, topk, score_threshold) -> None:
|
||||||
|
"""
|
||||||
|
Chroma similar_search_with_score.
|
||||||
|
Return docs and relevance scores in the range [0, 1].
|
||||||
|
Args:
|
||||||
|
text(str): query text
|
||||||
|
topk(int): return docs nums. Defaults to 4.
|
||||||
|
score_threshold(float): score_threshold: Optional, a floating point value between 0 to 1 to
|
||||||
|
filter the resulting set of retrieved docs,0 is dissimilar, 1 is most similar.
|
||||||
|
"""
|
||||||
|
logger.info("ChromaStore similar search")
|
||||||
|
docs_and_scores = (
|
||||||
|
self.vector_store_client.similarity_search_with_relevance_scores(
|
||||||
|
query=text, k=topk, score_threshold=score_threshold
|
||||||
|
)
|
||||||
|
)
|
||||||
|
return docs_and_scores
|
||||||
|
|
||||||
def vector_name_exists(self):
|
def vector_name_exists(self):
|
||||||
logger.info(f"Check persist_dir: {self.persist_dir}")
|
logger.info(f"Check persist_dir: {self.persist_dir}")
|
||||||
@ -58,7 +76,6 @@ class ChromaStore(VectorStoreBase):
|
|||||||
texts = [doc.page_content for doc in documents]
|
texts = [doc.page_content for doc in documents]
|
||||||
metadatas = [doc.metadata for doc in documents]
|
metadatas = [doc.metadata for doc in documents]
|
||||||
ids = self.vector_store_client.add_texts(texts=texts, metadatas=metadatas)
|
ids = self.vector_store_client.add_texts(texts=texts, metadatas=metadatas)
|
||||||
self.vector_store_client.persist()
|
|
||||||
return ids
|
return ids
|
||||||
|
|
||||||
def delete_vector_name(self, vector_name):
|
def delete_vector_name(self, vector_name):
|
||||||
|
|||||||
@ -42,6 +42,18 @@ class VectorStoreConnector:
|
|||||||
"""
|
"""
|
||||||
return self.client.similar_search(doc, topk)
|
return self.client.similar_search(doc, topk)
|
||||||
|
|
||||||
|
def similar_search_with_scores(self, doc: str, topk: int, score_threshold: float):
|
||||||
|
"""
|
||||||
|
similar_search_with_score in vector database..
|
||||||
|
Return docs and relevance scores in the range [0, 1].
|
||||||
|
Args:
|
||||||
|
doc(str): query text
|
||||||
|
topk(int): return docs nums. Defaults to 4.
|
||||||
|
score_threshold(float): score_threshold: Optional, a floating point value between 0 to 1 to
|
||||||
|
filter the resulting set of retrieved docs,0 is dissimilar, 1 is most similar.
|
||||||
|
"""
|
||||||
|
return self.client.similar_search_with_scores(doc, topk, score_threshold)
|
||||||
|
|
||||||
def vector_name_exists(self):
|
def vector_name_exists(self):
|
||||||
"""is vector store name exist."""
|
"""is vector store name exist."""
|
||||||
return self.client.vector_name_exists()
|
return self.client.vector_name_exists()
|
||||||
|
|||||||
@ -1,89 +0,0 @@
|
|||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding:utf-8 -*-
|
|
||||||
|
|
||||||
import os
|
|
||||||
|
|
||||||
from langchain.embeddings import HuggingFaceEmbeddings
|
|
||||||
from langchain.text_splitter import CharacterTextSplitter
|
|
||||||
from langchain.vectorstores import Chroma
|
|
||||||
|
|
||||||
from pilot.configs.model_config import DATASETS_DIR, VECTORE_PATH
|
|
||||||
from pilot.model.llm_out.vicuna_llm import VicunaEmbeddingLLM
|
|
||||||
|
|
||||||
embeddings = VicunaEmbeddingLLM()
|
|
||||||
|
|
||||||
|
|
||||||
def knownledge_tovec(filename):
|
|
||||||
with open(filename, "r") as f:
|
|
||||||
knownledge = f.read()
|
|
||||||
|
|
||||||
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
|
|
||||||
texts = text_splitter.split_text(knownledge)
|
|
||||||
docsearch = Chroma.from_texts(
|
|
||||||
texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]
|
|
||||||
)
|
|
||||||
return docsearch
|
|
||||||
|
|
||||||
|
|
||||||
def knownledge_tovec_st(filename):
|
|
||||||
"""Use sentence transformers to embedding the document.
|
|
||||||
https://github.com/UKPLab/sentence-transformers
|
|
||||||
"""
|
|
||||||
from pilot.configs.model_config import EMBEDDING_MODEL_CONFIG
|
|
||||||
from pilot.embedding_engine.embedding_factory import DefaultEmbeddingFactory
|
|
||||||
|
|
||||||
embeddings = DefaultEmbeddingFactory().create(
|
|
||||||
model_name=EMBEDDING_MODEL_CONFIG["sentence-transforms"]
|
|
||||||
)
|
|
||||||
|
|
||||||
with open(filename, "r") as f:
|
|
||||||
knownledge = f.read()
|
|
||||||
|
|
||||||
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
|
|
||||||
|
|
||||||
texts = text_splitter.split_text(knownledge)
|
|
||||||
docsearch = Chroma.from_texts(
|
|
||||||
texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]
|
|
||||||
)
|
|
||||||
return docsearch
|
|
||||||
|
|
||||||
|
|
||||||
def load_knownledge_from_doc():
|
|
||||||
"""Loader Knownledge from current datasets
|
|
||||||
# TODO if the vector store is exists, just use it.
|
|
||||||
"""
|
|
||||||
|
|
||||||
if not os.path.exists(DATASETS_DIR):
|
|
||||||
print(
|
|
||||||
"Not Exists Local DataSets, We will answers the Question use model default."
|
|
||||||
)
|
|
||||||
|
|
||||||
from pilot.configs.model_config import EMBEDDING_MODEL_CONFIG
|
|
||||||
from pilot.embedding_engine.embedding_factory import DefaultEmbeddingFactory
|
|
||||||
|
|
||||||
embeddings = DefaultEmbeddingFactory().create(
|
|
||||||
model_name=EMBEDDING_MODEL_CONFIG["sentence-transforms"]
|
|
||||||
)
|
|
||||||
|
|
||||||
files = os.listdir(DATASETS_DIR)
|
|
||||||
for file in files:
|
|
||||||
if not os.path.isdir(file):
|
|
||||||
filename = os.path.join(DATASETS_DIR, file)
|
|
||||||
with open(filename, "r") as f:
|
|
||||||
knownledge = f.read()
|
|
||||||
|
|
||||||
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_owerlap=0)
|
|
||||||
texts = text_splitter.split_text(knownledge)
|
|
||||||
docsearch = Chroma.from_texts(
|
|
||||||
texts,
|
|
||||||
embeddings,
|
|
||||||
metadatas=[{"source": str(i)} for i in range(len(texts))],
|
|
||||||
persist_directory=os.path.join(VECTORE_PATH, ".vectore"),
|
|
||||||
)
|
|
||||||
return docsearch
|
|
||||||
|
|
||||||
|
|
||||||
def get_vector_storelist():
|
|
||||||
if not os.path.exists(VECTORE_PATH):
|
|
||||||
return []
|
|
||||||
return os.listdir(VECTORE_PATH)
|
|
||||||
@ -1,113 +0,0 @@
|
|||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding: utf-8 -*-
|
|
||||||
|
|
||||||
import os
|
|
||||||
|
|
||||||
from langchain.chains import VectorDBQA
|
|
||||||
from langchain.document_loaders import (
|
|
||||||
TextLoader,
|
|
||||||
UnstructuredFileLoader,
|
|
||||||
UnstructuredPDFLoader,
|
|
||||||
)
|
|
||||||
from langchain.embeddings import HuggingFaceEmbeddings
|
|
||||||
from langchain.prompts import PromptTemplate
|
|
||||||
from langchain.text_splitter import CharacterTextSplitter
|
|
||||||
from langchain.vectorstores import Chroma
|
|
||||||
|
|
||||||
from pilot.configs.model_config import (
|
|
||||||
DATASETS_DIR,
|
|
||||||
EMBEDDING_MODEL_CONFIG,
|
|
||||||
VECTORE_PATH,
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
class KnownLedge2Vector:
|
|
||||||
|
|
||||||
"""KnownLedge2Vector class is order to load document to vector
|
|
||||||
and persist to vector store.
|
|
||||||
|
|
||||||
Args:
|
|
||||||
- model_name
|
|
||||||
|
|
||||||
Usage:
|
|
||||||
k2v = KnownLedge2Vector()
|
|
||||||
persist_dir = os.path.join(VECTORE_PATH, ".vectordb")
|
|
||||||
print(persist_dir)
|
|
||||||
for s, dc in k2v.query("what is oceanbase?"):
|
|
||||||
print(s, dc.page_content, dc.metadata)
|
|
||||||
|
|
||||||
"""
|
|
||||||
|
|
||||||
embeddings: object = None
|
|
||||||
model_name = EMBEDDING_MODEL_CONFIG["sentence-transforms"]
|
|
||||||
|
|
||||||
def __init__(self, model_name=None) -> None:
|
|
||||||
if not model_name:
|
|
||||||
# use default embedding model
|
|
||||||
from pilot.embedding_engine.embedding_factory import DefaultEmbeddingFactory
|
|
||||||
|
|
||||||
self.embeddings = DefaultEmbeddingFactory().create(
|
|
||||||
model_name=self.model_name
|
|
||||||
)
|
|
||||||
|
|
||||||
def init_vector_store(self):
|
|
||||||
persist_dir = os.path.join(VECTORE_PATH, ".vectordb")
|
|
||||||
print("Vector store Persist address is: ", persist_dir)
|
|
||||||
if os.path.exists(persist_dir):
|
|
||||||
# Loader from local file.
|
|
||||||
print("Loader data from local persist vector file...")
|
|
||||||
vector_store = Chroma(
|
|
||||||
persist_directory=persist_dir, embedding_function=self.embeddings
|
|
||||||
)
|
|
||||||
# vector_store.add_documents(documents=documents)
|
|
||||||
else:
|
|
||||||
documents = self.load_knownlege()
|
|
||||||
# reinit
|
|
||||||
vector_store = Chroma.from_documents(
|
|
||||||
documents=documents,
|
|
||||||
embedding=self.embeddings,
|
|
||||||
persist_directory=persist_dir,
|
|
||||||
)
|
|
||||||
vector_store.persist()
|
|
||||||
return vector_store
|
|
||||||
|
|
||||||
def load_knownlege(self):
|
|
||||||
docments = []
|
|
||||||
for root, _, files in os.walk(DATASETS_DIR, topdown=False):
|
|
||||||
for file in files:
|
|
||||||
filename = os.path.join(root, file)
|
|
||||||
docs = self._load_file(filename)
|
|
||||||
# update metadata.
|
|
||||||
new_docs = []
|
|
||||||
for doc in docs:
|
|
||||||
doc.metadata = {
|
|
||||||
"source": doc.metadata["source"].replace(DATASETS_DIR, "")
|
|
||||||
}
|
|
||||||
print("Documents to vector running, please wait...", doc.metadata)
|
|
||||||
new_docs.append(doc)
|
|
||||||
docments += new_docs
|
|
||||||
return docments
|
|
||||||
|
|
||||||
def _load_file(self, filename):
|
|
||||||
# Loader file
|
|
||||||
if filename.lower().endswith(".pdf"):
|
|
||||||
loader = UnstructuredFileLoader(filename)
|
|
||||||
text_splitor = CharacterTextSplitter()
|
|
||||||
docs = loader.load_and_split(text_splitor)
|
|
||||||
else:
|
|
||||||
loader = UnstructuredFileLoader(filename, mode="elements")
|
|
||||||
text_splitor = CharacterTextSplitter()
|
|
||||||
docs = loader.load_and_split(text_splitor)
|
|
||||||
return docs
|
|
||||||
|
|
||||||
def _load_from_url(self, url):
|
|
||||||
"""Load data from url address"""
|
|
||||||
pass
|
|
||||||
|
|
||||||
def query(self, q):
|
|
||||||
"""Query similar doc from Vector"""
|
|
||||||
vector_store = self.init_vector_store()
|
|
||||||
docs = vector_store.similarity_search_with_score(q, k=self.top_k)
|
|
||||||
for doc in docs:
|
|
||||||
dc, s = doc
|
|
||||||
yield s, dc
|
|
||||||
@ -15,6 +15,7 @@ class MilvusStore(VectorStoreBase):
|
|||||||
"""Milvus database"""
|
"""Milvus database"""
|
||||||
|
|
||||||
def __init__(self, ctx: {}) -> None:
|
def __init__(self, ctx: {}) -> None:
|
||||||
|
"""MilvusStore init."""
|
||||||
from pymilvus import Collection, DataType, connections, utility
|
from pymilvus import Collection, DataType, connections, utility
|
||||||
|
|
||||||
"""init a milvus storage connection.
|
"""init a milvus storage connection.
|
||||||
@ -155,6 +156,7 @@ class MilvusStore(VectorStoreBase):
|
|||||||
index = self.index_params
|
index = self.index_params
|
||||||
# milvus index
|
# milvus index
|
||||||
collection.create_index(vector_field, index)
|
collection.create_index(vector_field, index)
|
||||||
|
collection.load()
|
||||||
schema = collection.schema
|
schema = collection.schema
|
||||||
for x in schema.fields:
|
for x in schema.fields:
|
||||||
self.fields.append(x.name)
|
self.fields.append(x.name)
|
||||||
@ -178,7 +180,10 @@ class MilvusStore(VectorStoreBase):
|
|||||||
"""add text data into Milvus."""
|
"""add text data into Milvus."""
|
||||||
insert_dict: Any = {self.text_field: list(texts)}
|
insert_dict: Any = {self.text_field: list(texts)}
|
||||||
try:
|
try:
|
||||||
insert_dict[self.vector_field] = self.embedding.embed_documents(list(texts))
|
import numpy as np
|
||||||
|
|
||||||
|
text_vector = self.embedding.embed_documents(list(texts))
|
||||||
|
insert_dict[self.vector_field] = self._normalization_vectors(text_vector)
|
||||||
except NotImplementedError:
|
except NotImplementedError:
|
||||||
insert_dict[self.vector_field] = [
|
insert_dict[self.vector_field] = [
|
||||||
self.embedding.embed_query(x) for x in texts
|
self.embedding.embed_query(x) for x in texts
|
||||||
@ -236,7 +241,61 @@ class MilvusStore(VectorStoreBase):
|
|||||||
)
|
)
|
||||||
for doc, _, _ in docs_and_scores
|
for doc, _, _ in docs_and_scores
|
||||||
]
|
]
|
||||||
# return [doc for doc, _, _ in docs_and_scores]
|
|
||||||
|
def similar_search_with_scores(self, text, topk, score_threshold):
|
||||||
|
"""Perform a search on a query string and return results with score.
|
||||||
|
|
||||||
|
For more information about the search parameters, take a look at the pymilvus
|
||||||
|
documentation found here:
|
||||||
|
https://milvus.io/api-reference/pymilvus/v2.2.6/Collection/search().md
|
||||||
|
|
||||||
|
Args:
|
||||||
|
embedding (List[float]): The embedding vector being searched.
|
||||||
|
k (int, optional): The amount of results to return. Defaults to 4.
|
||||||
|
param (dict): The search params for the specified index.
|
||||||
|
Defaults to None.
|
||||||
|
expr (str, optional): Filtering expression. Defaults to None.
|
||||||
|
timeout (int, optional): How long to wait before timeout error.
|
||||||
|
Defaults to None.
|
||||||
|
kwargs: Collection.search() keyword arguments.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
List[Tuple[Document, float]]: Result doc and score.
|
||||||
|
"""
|
||||||
|
from pymilvus import Collection
|
||||||
|
|
||||||
|
self.col = Collection(self.collection_name)
|
||||||
|
schema = self.col.schema
|
||||||
|
for x in schema.fields:
|
||||||
|
self.fields.append(x.name)
|
||||||
|
if x.auto_id:
|
||||||
|
self.fields.remove(x.name)
|
||||||
|
if x.is_primary:
|
||||||
|
self.primary_field = x.name
|
||||||
|
from pymilvus import DataType
|
||||||
|
|
||||||
|
if x.dtype == DataType.FLOAT_VECTOR or x.dtype == DataType.BINARY_VECTOR:
|
||||||
|
self.vector_field = x.name
|
||||||
|
_, docs_and_scores = self._search(text, topk)
|
||||||
|
if any(score < 0.0 or score > 1.0 for _, score, id in docs_and_scores):
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
"similarity score need between" f" 0 and 1, got {docs_and_scores}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if score_threshold is not None:
|
||||||
|
docs_and_scores = [
|
||||||
|
(doc, score)
|
||||||
|
for doc, score, id in docs_and_scores
|
||||||
|
if score >= score_threshold
|
||||||
|
]
|
||||||
|
if len(docs_and_scores) == 0:
|
||||||
|
warnings.warn(
|
||||||
|
"No relevant docs were retrieved using the relevance score"
|
||||||
|
f" threshold {score_threshold}"
|
||||||
|
)
|
||||||
|
return docs_and_scores
|
||||||
|
|
||||||
def _search(
|
def _search(
|
||||||
self,
|
self,
|
||||||
@ -257,7 +316,8 @@ class MilvusStore(VectorStoreBase):
|
|||||||
index_type = self.col.indexes[0].params["index_type"]
|
index_type = self.col.indexes[0].params["index_type"]
|
||||||
param = self.index_params_map[index_type]
|
param = self.index_params_map[index_type]
|
||||||
# query text embedding.
|
# query text embedding.
|
||||||
data = [self.embedding.embed_query(query)]
|
query_vector = self.embedding.embed_query(query)
|
||||||
|
data = [self._normalization_vectors(query_vector)]
|
||||||
# Determine result metadata fields.
|
# Determine result metadata fields.
|
||||||
output_fields = self.fields[:]
|
output_fields = self.fields[:]
|
||||||
output_fields.remove(self.vector_field)
|
output_fields.remove(self.vector_field)
|
||||||
@ -271,7 +331,7 @@ class MilvusStore(VectorStoreBase):
|
|||||||
output_fields=output_fields,
|
output_fields=output_fields,
|
||||||
partition_names=partition_names,
|
partition_names=partition_names,
|
||||||
round_decimal=round_decimal,
|
round_decimal=round_decimal,
|
||||||
timeout=timeout,
|
timeout=60,
|
||||||
**kwargs,
|
**kwargs,
|
||||||
)
|
)
|
||||||
ret = []
|
ret = []
|
||||||
@ -280,7 +340,7 @@ class MilvusStore(VectorStoreBase):
|
|||||||
ret.append(
|
ret.append(
|
||||||
(
|
(
|
||||||
Document(page_content=meta.pop(self.text_field), metadata=meta),
|
Document(page_content=meta.pop(self.text_field), metadata=meta),
|
||||||
result.distance,
|
self._default_relevance_score_fn(result.distance),
|
||||||
result.id,
|
result.id,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user