diff --git a/.circleci/config.yml b/.circleci/config.yml
index d8ccf68f..daab703b 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -17,6 +17,4 @@ workflows:
mapping: |
.circleci/.* run-all-workflows true
gpt4all-backend/.* run-all-workflows true
- gpt4all-bindings/python/.* run-python-workflow true
- gpt4all-bindings/typescript/.* run-ts-workflow true
gpt4all-chat/.* run-chat-workflow true
diff --git a/.circleci/continue_config.yml b/.circleci/continue_config.yml
index 05c78eca..8adbee8e 100644
--- a/.circleci/continue_config.yml
+++ b/.circleci/continue_config.yml
@@ -8,15 +8,9 @@ parameters:
run-all-workflows:
type: boolean
default: false
- run-python-workflow:
- type: boolean
- default: false
run-chat-workflow:
type: boolean
default: false
- run-ts-workflow:
- type: boolean
- default: false
job-macos-executor: &job-macos-executor
macos:
@@ -1266,25 +1260,6 @@ jobs:
paths:
- ../.ccache
- build-ts-docs:
- docker:
- - image: cimg/base:stable
- steps:
- - checkout
- - node/install:
- node-version: "18.16"
- - run: node --version
- - run: corepack enable
- - node/install-packages:
- pkg-manager: npm
- app-dir: gpt4all-bindings/typescript
- override-ci-command: npm install --ignore-scripts
- - run:
- name: build docs ts yo
- command: |
- cd gpt4all-bindings/typescript
- npm run docs:build
-
deploy-docs:
docker:
- image: circleci/python:3.8
@@ -1295,532 +1270,17 @@ jobs:
command: |
sudo apt-get update
sudo apt-get -y install python3 python3-pip
- sudo pip3 install awscli --upgrade
- sudo pip3 install mkdocs mkdocs-material mkautodoc 'mkdocstrings[python]' markdown-captions pillow cairosvg
+ sudo pip3 install -Ur requirements-docs.txt awscli
- run:
name: Make Documentation
- command: |
- cd gpt4all-bindings/python
- mkdocs build
+ command: mkdocs build
- run:
name: Deploy Documentation
- command: |
- cd gpt4all-bindings/python
- aws s3 sync --delete site/ s3://docs.gpt4all.io/
+ command: aws s3 sync --delete site/ s3://docs.gpt4all.io/
- run:
name: Invalidate docs.gpt4all.io cloudfront
command: aws cloudfront create-invalidation --distribution-id E1STQOW63QL2OH --paths "/*"
- build-py-linux:
- machine:
- image: ubuntu-2204:current
- steps:
- - checkout
- - restore_cache:
- keys:
- - ccache-gpt4all-linux-amd64-
- - run:
- <<: *job-linux-install-backend-deps
- - run:
- name: Build C library
- no_output_timeout: 30m
- command: |
- export PATH=$PATH:/usr/local/cuda/bin
- git submodule update --init --recursive
- ccache -o "cache_dir=${PWD}/../.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- cmake -B build -G Ninja \
- -DCMAKE_BUILD_TYPE=Release \
- -DCMAKE_C_COMPILER=clang-19 \
- -DCMAKE_CXX_COMPILER=clang++-19 \
- -DCMAKE_CXX_COMPILER_AR=ar \
- -DCMAKE_CXX_COMPILER_RANLIB=ranlib \
- -DCMAKE_C_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CUDA_COMPILER_LAUNCHER=ccache \
- -DKOMPUTE_OPT_DISABLE_VULKAN_VERSION_CHECK=ON \
- -DCMAKE_CUDA_ARCHITECTURES='50-virtual;52-virtual;61-virtual;70-virtual;75-virtual'
- cmake --build build -j$(nproc)
- ccache -s
- - run:
- name: Build wheel
- command: |
- cd gpt4all-bindings/python/
- python setup.py bdist_wheel --plat-name=manylinux1_x86_64
- - store_artifacts:
- path: gpt4all-bindings/python/dist
- - save_cache:
- key: ccache-gpt4all-linux-amd64-{{ epoch }}
- when: always
- paths:
- - ../.ccache
- - persist_to_workspace:
- root: gpt4all-bindings/python/dist
- paths:
- - "*.whl"
-
- build-py-macos:
- <<: *job-macos-executor
- steps:
- - checkout
- - restore_cache:
- keys:
- - ccache-gpt4all-macos-
- - run:
- <<: *job-macos-install-deps
- - run:
- name: Install dependencies
- command: |
- pip install setuptools wheel cmake
- - run:
- name: Build C library
- no_output_timeout: 30m
- command: |
- git submodule update --init # don't use --recursive because macOS doesn't use Kompute
- ccache -o "cache_dir=${PWD}/../.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- cmake -B build \
- -DCMAKE_BUILD_TYPE=Release \
- -DCMAKE_C_COMPILER=/opt/homebrew/opt/llvm/bin/clang \
- -DCMAKE_CXX_COMPILER=/opt/homebrew/opt/llvm/bin/clang++ \
- -DCMAKE_RANLIB=/usr/bin/ranlib \
- -DCMAKE_C_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
- -DBUILD_UNIVERSAL=ON \
- -DCMAKE_OSX_DEPLOYMENT_TARGET=12.6 \
- -DGGML_METAL_MACOSX_VERSION_MIN=12.6
- cmake --build build --parallel
- ccache -s
- - run:
- name: Build wheel
- command: |
- cd gpt4all-bindings/python
- python setup.py bdist_wheel --plat-name=macosx_10_15_universal2
- - store_artifacts:
- path: gpt4all-bindings/python/dist
- - save_cache:
- key: ccache-gpt4all-macos-{{ epoch }}
- when: always
- paths:
- - ../.ccache
- - persist_to_workspace:
- root: gpt4all-bindings/python/dist
- paths:
- - "*.whl"
-
- build-py-windows:
- machine:
- image: windows-server-2022-gui:2024.04.1
- resource_class: windows.large
- shell: powershell.exe -ExecutionPolicy Bypass
- steps:
- - checkout
- - run:
- name: Update Submodules
- command: |
- git submodule sync
- git submodule update --init --recursive
- - restore_cache:
- keys:
- - ccache-gpt4all-win-amd64-
- - run:
- name: Install dependencies
- command:
- choco install -y ccache cmake ninja wget --installargs 'ADD_CMAKE_TO_PATH=System'
- - run:
- name: Install VulkanSDK
- command: |
- wget.exe "https://sdk.lunarg.com/sdk/download/1.3.261.1/windows/VulkanSDK-1.3.261.1-Installer.exe"
- .\VulkanSDK-1.3.261.1-Installer.exe --accept-licenses --default-answer --confirm-command install
- - run:
- name: Install CUDA Toolkit
- command: |
- wget.exe "https://developer.download.nvidia.com/compute/cuda/11.8.0/network_installers/cuda_11.8.0_windows_network.exe"
- .\cuda_11.8.0_windows_network.exe -s cudart_11.8 nvcc_11.8 cublas_11.8 cublas_dev_11.8
- - run:
- name: Install Python dependencies
- command: pip install setuptools wheel cmake
- - run:
- name: Build C library
- no_output_timeout: 30m
- command: |
- $vsInstallPath = & "C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -property installationpath
- Import-Module "${vsInstallPath}\Common7\Tools\Microsoft.VisualStudio.DevShell.dll"
- Enter-VsDevShell -VsInstallPath "$vsInstallPath" -SkipAutomaticLocation -DevCmdArguments '-arch=x64 -no_logo'
-
- $Env:PATH += ";C:\VulkanSDK\1.3.261.1\bin"
- $Env:VULKAN_SDK = "C:\VulkanSDK\1.3.261.1"
- ccache -o "cache_dir=${pwd}\..\.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- cmake -B build -G Ninja `
- -DCMAKE_BUILD_TYPE=Release `
- -DCMAKE_C_COMPILER_LAUNCHER=ccache `
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache `
- -DCMAKE_CUDA_COMPILER_LAUNCHER=ccache `
- -DKOMPUTE_OPT_DISABLE_VULKAN_VERSION_CHECK=ON `
- -DCMAKE_CUDA_ARCHITECTURES='50-virtual;52-virtual;61-virtual;70-virtual;75-virtual'
- cmake --build build --parallel
- ccache -s
- - run:
- name: Build wheel
- command: |
- cd gpt4all-bindings/python
- python setup.py bdist_wheel --plat-name=win_amd64
- - store_artifacts:
- path: gpt4all-bindings/python/dist
- - save_cache:
- key: ccache-gpt4all-win-amd64-{{ epoch }}
- when: always
- paths:
- - ..\.ccache
- - persist_to_workspace:
- root: gpt4all-bindings/python/dist
- paths:
- - "*.whl"
-
- deploy-wheels:
- docker:
- - image: circleci/python:3.8
- steps:
- - setup_remote_docker
- - attach_workspace:
- at: /tmp/workspace
- - run:
- name: Install dependencies
- command: |
- sudo apt-get update
- sudo apt-get install -y build-essential cmake
- pip install setuptools wheel twine
- - run:
- name: Upload Python package
- command: |
- twine upload /tmp/workspace/*.whl --username __token__ --password $PYPI_CRED
- - store_artifacts:
- path: /tmp/workspace
-
- build-bindings-backend-linux:
- machine:
- image: ubuntu-2204:current
- steps:
- - checkout
- - run:
- name: Update Submodules
- command: |
- git submodule sync
- git submodule update --init --recursive
- - restore_cache:
- keys:
- - ccache-gpt4all-linux-amd64-
- - run:
- <<: *job-linux-install-backend-deps
- - run:
- name: Build Libraries
- no_output_timeout: 30m
- command: |
- export PATH=$PATH:/usr/local/cuda/bin
- ccache -o "cache_dir=${PWD}/../.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- mkdir -p runtimes/build
- cd runtimes/build
- cmake ../.. -G Ninja \
- -DCMAKE_BUILD_TYPE=Release \
- -DCMAKE_C_COMPILER=clang-19 \
- -DCMAKE_CXX_COMPILER=clang++-19 \
- -DCMAKE_CXX_COMPILER_AR=ar \
- -DCMAKE_CXX_COMPILER_RANLIB=ranlib \
- -DCMAKE_BUILD_TYPE=Release \
- -DCMAKE_C_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CUDA_COMPILER_LAUNCHER=ccache \
- -DKOMPUTE_OPT_DISABLE_VULKAN_VERSION_CHECK=ON
- cmake --build . -j$(nproc)
- ccache -s
- mkdir ../linux-x64
- cp -L *.so ../linux-x64 # otherwise persist_to_workspace seems to mess symlinks
- - save_cache:
- key: ccache-gpt4all-linux-amd64-{{ epoch }}
- when: always
- paths:
- - ../.ccache
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - runtimes/linux-x64/*.so
-
- build-bindings-backend-macos:
- <<: *job-macos-executor
- steps:
- - checkout
- - run:
- name: Update Submodules
- command: |
- git submodule sync
- git submodule update --init --recursive
- - restore_cache:
- keys:
- - ccache-gpt4all-macos-
- - run:
- <<: *job-macos-install-deps
- - run:
- name: Build Libraries
- no_output_timeout: 30m
- command: |
- ccache -o "cache_dir=${PWD}/../.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- mkdir -p runtimes/build
- cd runtimes/build
- cmake ../.. \
- -DCMAKE_BUILD_TYPE=Release \
- -DCMAKE_C_COMPILER=/opt/homebrew/opt/llvm/bin/clang \
- -DCMAKE_CXX_COMPILER=/opt/homebrew/opt/llvm/bin/clang++ \
- -DCMAKE_RANLIB=/usr/bin/ranlib \
- -DCMAKE_C_COMPILER_LAUNCHER=ccache \
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
- -DBUILD_UNIVERSAL=ON \
- -DCMAKE_OSX_DEPLOYMENT_TARGET=12.6 \
- -DGGML_METAL_MACOSX_VERSION_MIN=12.6
- cmake --build . --parallel
- ccache -s
- mkdir ../osx-x64
- cp -L *.dylib ../osx-x64
- cp ../../llama.cpp-mainline/*.metal ../osx-x64
- ls ../osx-x64
- - save_cache:
- key: ccache-gpt4all-macos-{{ epoch }}
- when: always
- paths:
- - ../.ccache
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - runtimes/osx-x64/*.dylib
- - runtimes/osx-x64/*.metal
-
- build-bindings-backend-windows:
- machine:
- image: windows-server-2022-gui:2024.04.1
- resource_class: windows.large
- shell: powershell.exe -ExecutionPolicy Bypass
- steps:
- - checkout
- - run:
- name: Update Submodules
- command: |
- git submodule sync
- git submodule update --init --recursive
- - restore_cache:
- keys:
- - ccache-gpt4all-win-amd64-
- - run:
- name: Install dependencies
- command: |
- choco install -y ccache cmake ninja wget --installargs 'ADD_CMAKE_TO_PATH=System'
- - run:
- name: Install VulkanSDK
- command: |
- wget.exe "https://sdk.lunarg.com/sdk/download/1.3.261.1/windows/VulkanSDK-1.3.261.1-Installer.exe"
- .\VulkanSDK-1.3.261.1-Installer.exe --accept-licenses --default-answer --confirm-command install
- - run:
- name: Install CUDA Toolkit
- command: |
- wget.exe "https://developer.download.nvidia.com/compute/cuda/11.8.0/network_installers/cuda_11.8.0_windows_network.exe"
- .\cuda_11.8.0_windows_network.exe -s cudart_11.8 nvcc_11.8 cublas_11.8 cublas_dev_11.8
- - run:
- name: Build Libraries
- no_output_timeout: 30m
- command: |
- $vsInstallPath = & "C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -property installationpath
- Import-Module "${vsInstallPath}\Common7\Tools\Microsoft.VisualStudio.DevShell.dll"
- Enter-VsDevShell -VsInstallPath "$vsInstallPath" -SkipAutomaticLocation -DevCmdArguments '-arch=x64 -no_logo'
-
- $Env:Path += ";C:\VulkanSDK\1.3.261.1\bin"
- $Env:VULKAN_SDK = "C:\VulkanSDK\1.3.261.1"
- ccache -o "cache_dir=${pwd}\..\.ccache" -o max_size=500M -p -z
- cd gpt4all-backend
- mkdir runtimes/win-x64_msvc
- cd runtimes/win-x64_msvc
- cmake -S ../.. -B . -G Ninja `
- -DCMAKE_BUILD_TYPE=Release `
- -DCMAKE_C_COMPILER_LAUNCHER=ccache `
- -DCMAKE_CXX_COMPILER_LAUNCHER=ccache `
- -DCMAKE_CUDA_COMPILER_LAUNCHER=ccache `
- -DKOMPUTE_OPT_DISABLE_VULKAN_VERSION_CHECK=ON
- cmake --build . --parallel
- ccache -s
- cp bin/Release/*.dll .
- - save_cache:
- key: ccache-gpt4all-win-amd64-{{ epoch }}
- when: always
- paths:
- - ..\.ccache
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - runtimes/win-x64_msvc/*.dll
-
- build-nodejs-linux:
- docker:
- - image: cimg/base:stable
- steps:
- - checkout
- - attach_workspace:
- at: /tmp/gpt4all-backend
- - node/install:
- install-yarn: true
- node-version: "18.16"
- - run: node --version
- - run: corepack enable
- - node/install-packages:
- app-dir: gpt4all-bindings/typescript
- pkg-manager: yarn
- override-ci-command: yarn install
- - run:
- command: |
- cd gpt4all-bindings/typescript
- yarn prebuildify -t 18.16.0 --napi
- - run:
- command: |
- mkdir -p gpt4all-backend/prebuilds/linux-x64
- mkdir -p gpt4all-backend/runtimes/linux-x64
- cp /tmp/gpt4all-backend/runtimes/linux-x64/*-*.so gpt4all-backend/runtimes/linux-x64
- cp gpt4all-bindings/typescript/prebuilds/linux-x64/*.node gpt4all-backend/prebuilds/linux-x64
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - prebuilds/linux-x64/*.node
- - runtimes/linux-x64/*-*.so
-
- build-nodejs-macos:
- <<: *job-macos-executor
- steps:
- - checkout
- - attach_workspace:
- at: /tmp/gpt4all-backend
- - node/install:
- install-yarn: true
- node-version: "18.16"
- - run: node --version
- - run: corepack enable
- - node/install-packages:
- app-dir: gpt4all-bindings/typescript
- pkg-manager: yarn
- override-ci-command: yarn install
- - run:
- command: |
- cd gpt4all-bindings/typescript
- yarn prebuildify -t 18.16.0 --napi
- - run:
- name: "Persisting all necessary things to workspace"
- command: |
- mkdir -p gpt4all-backend/prebuilds/darwin-x64
- mkdir -p gpt4all-backend/runtimes/darwin
- cp /tmp/gpt4all-backend/runtimes/osx-x64/*-*.* gpt4all-backend/runtimes/darwin
- cp gpt4all-bindings/typescript/prebuilds/darwin-x64/*.node gpt4all-backend/prebuilds/darwin-x64
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - prebuilds/darwin-x64/*.node
- - runtimes/darwin/*-*.*
-
- build-nodejs-windows:
- executor:
- name: win/default
- size: large
- shell: powershell.exe -ExecutionPolicy Bypass
- steps:
- - checkout
- - attach_workspace:
- at: /tmp/gpt4all-backend
- - run: choco install wget -y
- - run:
- command: |
- wget.exe "https://nodejs.org/dist/v18.16.0/node-v18.16.0-x86.msi" -P C:\Users\circleci\Downloads\
- MsiExec.exe /i C:\Users\circleci\Downloads\node-v18.16.0-x86.msi /qn
- - run:
- command: |
- Start-Process powershell -verb runAs -Args "-start GeneralProfile"
- nvm install 18.16.0
- nvm use 18.16.0
- - run: node --version
- - run: corepack enable
- - run:
- command: |
- npm install -g yarn
- cd gpt4all-bindings/typescript
- yarn install
- - run:
- command: |
- cd gpt4all-bindings/typescript
- yarn prebuildify -t 18.16.0 --napi
- - run:
- command: |
- mkdir -p gpt4all-backend/prebuilds/win32-x64
- mkdir -p gpt4all-backend/runtimes/win32-x64
- cp /tmp/gpt4all-backend/runtimes/win-x64_msvc/*-*.dll gpt4all-backend/runtimes/win32-x64
- cp gpt4all-bindings/typescript/prebuilds/win32-x64/*.node gpt4all-backend/prebuilds/win32-x64
-
- - persist_to_workspace:
- root: gpt4all-backend
- paths:
- - prebuilds/win32-x64/*.node
- - runtimes/win32-x64/*-*.dll
-
- deploy-npm-pkg:
- docker:
- - image: cimg/base:stable
- steps:
- - attach_workspace:
- at: /tmp/gpt4all-backend
- - checkout
- - node/install:
- install-yarn: true
- node-version: "18.16"
- - run: node --version
- - run: corepack enable
- - run:
- command: |
- cd gpt4all-bindings/typescript
- # excluding llmodel. nodejs bindings dont need llmodel.dll
- mkdir -p runtimes/win32-x64/native
- mkdir -p prebuilds/win32-x64/
- cp /tmp/gpt4all-backend/runtimes/win-x64_msvc/*-*.dll runtimes/win32-x64/native/
- cp /tmp/gpt4all-backend/prebuilds/win32-x64/*.node prebuilds/win32-x64/
-
- mkdir -p runtimes/linux-x64/native
- mkdir -p prebuilds/linux-x64/
- cp /tmp/gpt4all-backend/runtimes/linux-x64/*-*.so runtimes/linux-x64/native/
- cp /tmp/gpt4all-backend/prebuilds/linux-x64/*.node prebuilds/linux-x64/
-
- # darwin has univeral runtime libraries
- mkdir -p runtimes/darwin/native
- mkdir -p prebuilds/darwin-x64/
-
- cp /tmp/gpt4all-backend/runtimes/darwin/*-*.* runtimes/darwin/native/
-
- cp /tmp/gpt4all-backend/prebuilds/darwin-x64/*.node prebuilds/darwin-x64/
-
- # Fallback build if user is not on above prebuilds
- mv -f binding.ci.gyp binding.gyp
-
- mkdir gpt4all-backend
- cd ../../gpt4all-backend
- mv llmodel.h llmodel.cpp llmodel_c.cpp llmodel_c.h sysinfo.h dlhandle.h ../gpt4all-bindings/typescript/gpt4all-backend/
-
- # Test install
- - node/install-packages:
- app-dir: gpt4all-bindings/typescript
- pkg-manager: yarn
- override-ci-command: yarn install
- - run:
- command: |
- cd gpt4all-bindings/typescript
- yarn run test
- - run:
- command: |
- cd gpt4all-bindings/typescript
- npm set //registry.npmjs.org/:_authToken=$NPM_TOKEN
- npm publish
-
# only run a job on the main branch
job_only_main: &job_only_main
filters:
@@ -1849,8 +1309,6 @@ workflows:
not:
or:
- << pipeline.parameters.run-all-workflows >>
- - << pipeline.parameters.run-python-workflow >>
- - << pipeline.parameters.run-ts-workflow >>
- << pipeline.parameters.run-chat-workflow >>
- equal: [ << pipeline.trigger_source >>, scheduled_pipeline ]
jobs:
@@ -2079,87 +1537,9 @@ workflows:
when:
and:
- equal: [ << pipeline.git.branch >>, main ]
- - or:
- - << pipeline.parameters.run-all-workflows >>
- - << pipeline.parameters.run-python-workflow >>
+ - << pipeline.parameters.run-all-workflows >>
- not:
equal: [ << pipeline.trigger_source >>, scheduled_pipeline ]
jobs:
- deploy-docs:
context: gpt4all
- build-python:
- when:
- and:
- - or: [ << pipeline.parameters.run-all-workflows >>, << pipeline.parameters.run-python-workflow >> ]
- - not:
- equal: [ << pipeline.trigger_source >>, scheduled_pipeline ]
- jobs:
- - pypi-hold:
- <<: *job_only_main
- type: approval
- - hold:
- type: approval
- - build-py-linux:
- requires:
- - hold
- - build-py-macos:
- requires:
- - hold
- - build-py-windows:
- requires:
- - hold
- - deploy-wheels:
- <<: *job_only_main
- context: gpt4all
- requires:
- - pypi-hold
- - build-py-windows
- - build-py-linux
- - build-py-macos
- build-bindings:
- when:
- and:
- - or: [ << pipeline.parameters.run-all-workflows >>, << pipeline.parameters.run-ts-workflow >> ]
- - not:
- equal: [ << pipeline.trigger_source >>, scheduled_pipeline ]
- jobs:
- - backend-hold:
- type: approval
- - nodejs-hold:
- type: approval
- - npm-hold:
- <<: *job_only_main
- type: approval
- - docs-hold:
- type: approval
- - build-bindings-backend-linux:
- requires:
- - backend-hold
- - build-bindings-backend-macos:
- requires:
- - backend-hold
- - build-bindings-backend-windows:
- requires:
- - backend-hold
- - build-nodejs-linux:
- requires:
- - nodejs-hold
- - build-bindings-backend-linux
- - build-nodejs-windows:
- requires:
- - nodejs-hold
- - build-bindings-backend-windows
- - build-nodejs-macos:
- requires:
- - nodejs-hold
- - build-bindings-backend-macos
- - build-ts-docs:
- requires:
- - docs-hold
- - deploy-npm-pkg:
- <<: *job_only_main
- requires:
- - npm-hold
- - build-nodejs-linux
- - build-nodejs-windows
- - build-nodejs-macos
diff --git a/.github/ISSUE_TEMPLATE/bindings-bug.md b/.github/ISSUE_TEMPLATE/bindings-bug.md
deleted file mode 100644
index cbf0d49d..00000000
--- a/.github/ISSUE_TEMPLATE/bindings-bug.md
+++ /dev/null
@@ -1,35 +0,0 @@
----
-name: "\U0001F6E0 Bindings Bug Report"
-about: A bug report for the GPT4All Bindings
-labels: ["bindings", "bug-unconfirmed"]
----
-
-
-
-### Bug Report
-
-
-
-### Example Code
-
-
-
-### Steps to Reproduce
-
-
-
-1.
-2.
-3.
-
-### Expected Behavior
-
-
-
-### Your Environment
-
-- Bindings version (e.g. "Version" from `pip show gpt4all`):
-- Operating System:
-- Chat model used (if applicable):
-
-
diff --git a/MAINTAINERS.md b/MAINTAINERS.md
index 6838a0b8..6907aa1e 100644
--- a/MAINTAINERS.md
+++ b/MAINTAINERS.md
@@ -29,13 +29,6 @@ Jared Van Bortel ([@cebtenzzre](https://github.com/cebtenzzre))
E-mail: jared@nomic.ai
Discord: `@cebtenzzre`
- gpt4all-backend
-- Python binding
-- Python CLI app
-
-Jacob Nguyen ([@jacoobes](https://github.com/jacoobes))
-Discord: `@jacoobes`
-E-mail: `jacoobes@sern.dev`
-- TypeScript binding
Dominik ([@cosmic-snow](https://github.com/cosmic-snow))
E-mail: cosmic-snow@mailfence.com
@@ -45,7 +38,7 @@ Discord: `@cosmic__snow`
Max Cembalest ([@mcembalest](https://github.com/mcembalest))
E-mail: max@nomic.ai
Discord: `@maxcembalest.`
-- Official documentation (gpt4all-bindings/python/docs -> https://docs.gpt4all.io/)
+- Official documentation (docs -> https://docs.gpt4all.io/)
Thiago Ramos ([@thiagojramos](https://github.com/thiagojramos))
E-mail: thiagojramos@outlook.com
diff --git a/README.md b/README.md
index 4450198c..13c812d1 100644
--- a/README.md
+++ b/README.md
@@ -32,7 +32,7 @@ GPT4All is made possible by our compute partner
-  Windows Installer
+
Windows Installer
+  Windows Installer
—
Windows Installer
—
@@ -42,12 +42,12 @@ GPT4All is made possible by our compute partner
-  macOS Installer
+
macOS Installer
+  macOS Installer
—
macOS Installer
—
—
-  Ubuntu Installer
+
Ubuntu Installer
+  Ubuntu Installer
—
Ubuntu Installer
—
@@ -74,24 +74,6 @@ See the full [System Requirements](gpt4all-chat/system_requirements.md) for more
-## Install GPT4All Python
-
-`gpt4all` gives you access to LLMs with our Python client around [`llama.cpp`](https://github.com/ggerganov/llama.cpp) implementations.
-
-Nomic contributes to open source software like [`llama.cpp`](https://github.com/ggerganov/llama.cpp) to make LLMs accessible and efficient **for all**.
-
-```bash
-pip install gpt4all
-```
-
-```python
-from gpt4all import GPT4All
-model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf") # downloads / loads a 4.66GB LLM
-with model.chat_session():
- print(model.generate("How can I run LLMs efficiently on my laptop?", max_tokens=1024))
-```
-
-
## Integrations
:parrot::link: [Langchain](https://python.langchain.com/v0.2/docs/integrations/providers/gpt4all/)
@@ -119,7 +101,7 @@ Please see CONTRIBUTING.md and follow the issues, bug reports, and PR markdown t
Check project discord, with project owners, or through existing issues/PRs to avoid duplicate work.
Please make sure to tag all of the above with relevant project identifiers or your contribution could potentially get lost.
-Example tags: `backend`, `bindings`, `python-bindings`, `documentation`, etc.
+Example tags: `backend`, `documentation`, etc.
## Citation
diff --git a/gpt4all-bindings/python/docs/assets/add.png b/docs/assets/add.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/add.png
rename to docs/assets/add.png
diff --git a/gpt4all-bindings/python/docs/assets/add_model_gpt4.png b/docs/assets/add_model_gpt4.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/add_model_gpt4.png
rename to docs/assets/add_model_gpt4.png
diff --git a/gpt4all-bindings/python/docs/assets/attach_spreadsheet.png b/docs/assets/attach_spreadsheet.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/attach_spreadsheet.png
rename to docs/assets/attach_spreadsheet.png
diff --git a/gpt4all-bindings/python/docs/assets/baelor.png b/docs/assets/baelor.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/baelor.png
rename to docs/assets/baelor.png
diff --git a/gpt4all-bindings/python/docs/assets/before_first_chat.png b/docs/assets/before_first_chat.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/before_first_chat.png
rename to docs/assets/before_first_chat.png
diff --git a/gpt4all-bindings/python/docs/assets/chat_window.png b/docs/assets/chat_window.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/chat_window.png
rename to docs/assets/chat_window.png
diff --git a/gpt4all-bindings/python/docs/assets/closed_chat_panel.png b/docs/assets/closed_chat_panel.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/closed_chat_panel.png
rename to docs/assets/closed_chat_panel.png
diff --git a/gpt4all-bindings/python/docs/assets/configure_doc_collection.png b/docs/assets/configure_doc_collection.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/configure_doc_collection.png
rename to docs/assets/configure_doc_collection.png
diff --git a/gpt4all-bindings/python/docs/assets/disney_spreadsheet.png b/docs/assets/disney_spreadsheet.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/disney_spreadsheet.png
rename to docs/assets/disney_spreadsheet.png
diff --git a/gpt4all-bindings/python/docs/assets/download.png b/docs/assets/download.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/download.png
rename to docs/assets/download.png
diff --git a/gpt4all-bindings/python/docs/assets/download_llama.png b/docs/assets/download_llama.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/download_llama.png
rename to docs/assets/download_llama.png
diff --git a/gpt4all-bindings/python/docs/assets/explore.png b/docs/assets/explore.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/explore.png
rename to docs/assets/explore.png
diff --git a/gpt4all-bindings/python/docs/assets/explore_models.png b/docs/assets/explore_models.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/explore_models.png
rename to docs/assets/explore_models.png
diff --git a/gpt4all-bindings/python/docs/assets/favicon.ico b/docs/assets/favicon.ico
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/favicon.ico
rename to docs/assets/favicon.ico
diff --git a/gpt4all-bindings/python/docs/assets/good_tyrion.png b/docs/assets/good_tyrion.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/good_tyrion.png
rename to docs/assets/good_tyrion.png
diff --git a/gpt4all-bindings/python/docs/assets/got_docs_ready.png b/docs/assets/got_docs_ready.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/got_docs_ready.png
rename to docs/assets/got_docs_ready.png
diff --git a/gpt4all-bindings/python/docs/assets/got_done.png b/docs/assets/got_done.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/got_done.png
rename to docs/assets/got_done.png
diff --git a/gpt4all-bindings/python/docs/assets/gpt4all_home.png b/docs/assets/gpt4all_home.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/gpt4all_home.png
rename to docs/assets/gpt4all_home.png
diff --git a/gpt4all-bindings/python/docs/assets/gpt4all_xlsx_attachment.mp4 b/docs/assets/gpt4all_xlsx_attachment.mp4
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/gpt4all_xlsx_attachment.mp4
rename to docs/assets/gpt4all_xlsx_attachment.mp4
diff --git a/gpt4all-bindings/python/docs/assets/installed_models.png b/docs/assets/installed_models.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/installed_models.png
rename to docs/assets/installed_models.png
diff --git a/gpt4all-bindings/python/docs/assets/linux.png b/docs/assets/linux.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/linux.png
rename to docs/assets/linux.png
diff --git a/gpt4all-bindings/python/docs/assets/local_embed.gif b/docs/assets/local_embed.gif
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/local_embed.gif
rename to docs/assets/local_embed.gif
diff --git a/gpt4all-bindings/python/docs/assets/mac.png b/docs/assets/mac.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/mac.png
rename to docs/assets/mac.png
diff --git a/gpt4all-bindings/python/docs/assets/models_page_icon.png b/docs/assets/models_page_icon.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/models_page_icon.png
rename to docs/assets/models_page_icon.png
diff --git a/gpt4all-bindings/python/docs/assets/new_docs_annotated.png b/docs/assets/new_docs_annotated.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/new_docs_annotated.png
rename to docs/assets/new_docs_annotated.png
diff --git a/gpt4all-bindings/python/docs/assets/new_docs_annotated_filled.png b/docs/assets/new_docs_annotated_filled.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/new_docs_annotated_filled.png
rename to docs/assets/new_docs_annotated_filled.png
diff --git a/gpt4all-bindings/python/docs/assets/new_first_chat.png b/docs/assets/new_first_chat.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/new_first_chat.png
rename to docs/assets/new_first_chat.png
diff --git a/gpt4all-bindings/python/docs/assets/no_docs.png b/docs/assets/no_docs.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/no_docs.png
rename to docs/assets/no_docs.png
diff --git a/gpt4all-bindings/python/docs/assets/no_models.png b/docs/assets/no_models.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/no_models.png
rename to docs/assets/no_models.png
diff --git a/gpt4all-bindings/python/docs/assets/no_models_tiny.png b/docs/assets/no_models_tiny.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/no_models_tiny.png
rename to docs/assets/no_models_tiny.png
diff --git a/gpt4all-bindings/python/docs/assets/nomic.png b/docs/assets/nomic.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/nomic.png
rename to docs/assets/nomic.png
diff --git a/gpt4all-bindings/python/docs/assets/obsidian_adding_collection.png b/docs/assets/obsidian_adding_collection.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/obsidian_adding_collection.png
rename to docs/assets/obsidian_adding_collection.png
diff --git a/gpt4all-bindings/python/docs/assets/obsidian_docs.png b/docs/assets/obsidian_docs.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/obsidian_docs.png
rename to docs/assets/obsidian_docs.png
diff --git a/gpt4all-bindings/python/docs/assets/obsidian_response.png b/docs/assets/obsidian_response.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/obsidian_response.png
rename to docs/assets/obsidian_response.png
diff --git a/gpt4all-bindings/python/docs/assets/obsidian_sources.png b/docs/assets/obsidian_sources.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/obsidian_sources.png
rename to docs/assets/obsidian_sources.png
diff --git a/gpt4all-bindings/python/docs/assets/open_chat_panel.png b/docs/assets/open_chat_panel.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/open_chat_panel.png
rename to docs/assets/open_chat_panel.png
diff --git a/gpt4all-bindings/python/docs/assets/open_local_docs.png b/docs/assets/open_local_docs.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/open_local_docs.png
rename to docs/assets/open_local_docs.png
diff --git a/gpt4all-bindings/python/docs/assets/open_sources.png b/docs/assets/open_sources.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/open_sources.png
rename to docs/assets/open_sources.png
diff --git a/gpt4all-bindings/python/docs/assets/osbsidian_user_interaction.png b/docs/assets/osbsidian_user_interaction.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/osbsidian_user_interaction.png
rename to docs/assets/osbsidian_user_interaction.png
diff --git a/gpt4all-bindings/python/docs/assets/search_mistral.png b/docs/assets/search_mistral.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/search_mistral.png
rename to docs/assets/search_mistral.png
diff --git a/gpt4all-bindings/python/docs/assets/search_settings.png b/docs/assets/search_settings.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/search_settings.png
rename to docs/assets/search_settings.png
diff --git a/gpt4all-bindings/python/docs/assets/spreadsheet_chat.png b/docs/assets/spreadsheet_chat.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/spreadsheet_chat.png
rename to docs/assets/spreadsheet_chat.png
diff --git a/gpt4all-bindings/python/docs/assets/syrio_snippets.png b/docs/assets/syrio_snippets.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/syrio_snippets.png
rename to docs/assets/syrio_snippets.png
diff --git a/gpt4all-bindings/python/docs/assets/three_model_options.png b/docs/assets/three_model_options.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/three_model_options.png
rename to docs/assets/three_model_options.png
diff --git a/gpt4all-bindings/python/docs/assets/ubuntu.svg b/docs/assets/ubuntu.svg
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/ubuntu.svg
rename to docs/assets/ubuntu.svg
diff --git a/gpt4all-bindings/python/docs/assets/windows.png b/docs/assets/windows.png
similarity index 100%
rename from gpt4all-bindings/python/docs/assets/windows.png
rename to docs/assets/windows.png
diff --git a/gpt4all-bindings/python/docs/css/custom.css b/docs/css/custom.css
similarity index 100%
rename from gpt4all-bindings/python/docs/css/custom.css
rename to docs/css/custom.css
diff --git a/gpt4all-bindings/python/docs/gpt4all_api_server/home.md b/docs/gpt4all_api_server/home.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_api_server/home.md
rename to docs/gpt4all_api_server/home.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/chat_templates.md b/docs/gpt4all_desktop/chat_templates.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/chat_templates.md
rename to docs/gpt4all_desktop/chat_templates.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/chats.md b/docs/gpt4all_desktop/chats.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/chats.md
rename to docs/gpt4all_desktop/chats.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md b/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md
similarity index 82%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md
rename to docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md
index 2660c38d..1bf128d0 100644
--- a/gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md
+++ b/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-Obsidian.md
@@ -46,7 +46,7 @@ Obsidian for Desktop is a powerful management and note-taking software designed
- 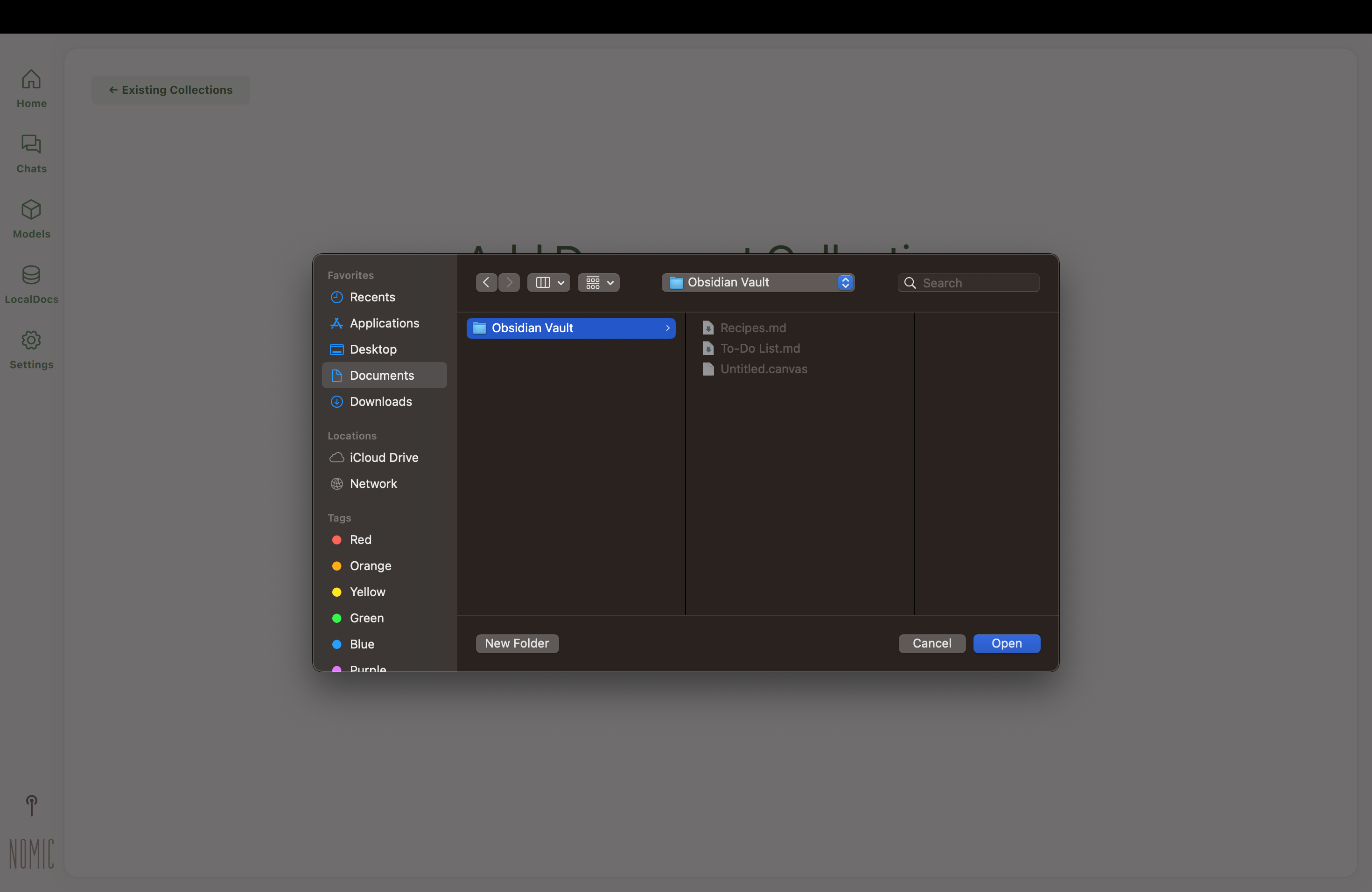 +
+ 
|
@@ -65,7 +65,7 @@ Obsidian for Desktop is a powerful management and note-taking software designed
- 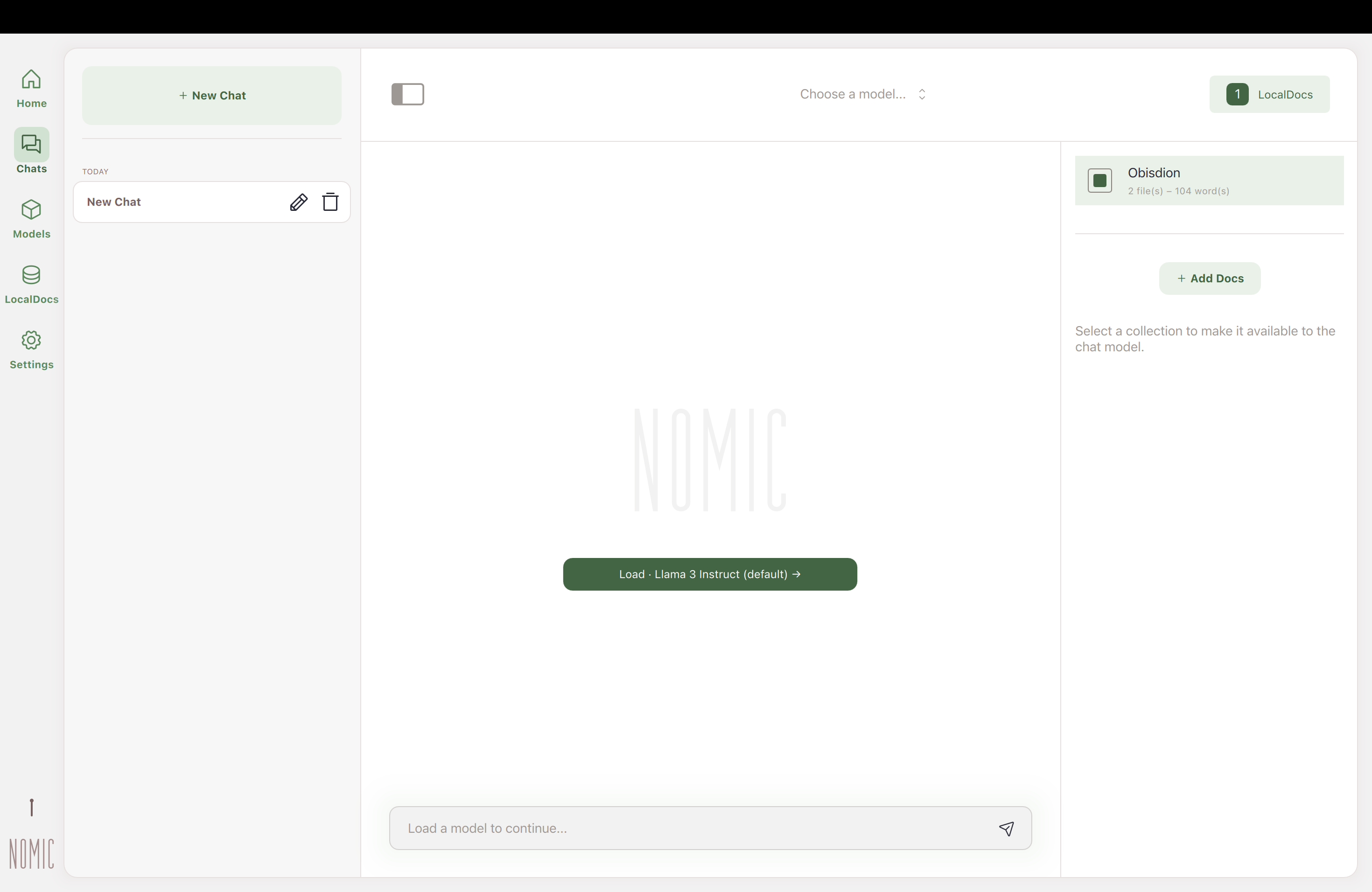 +
+ 
|
@@ -76,7 +76,7 @@ Obsidian for Desktop is a powerful management and note-taking software designed
-  +
+ 
|
@@ -84,7 +84,7 @@ Obsidian for Desktop is a powerful management and note-taking software designed
- 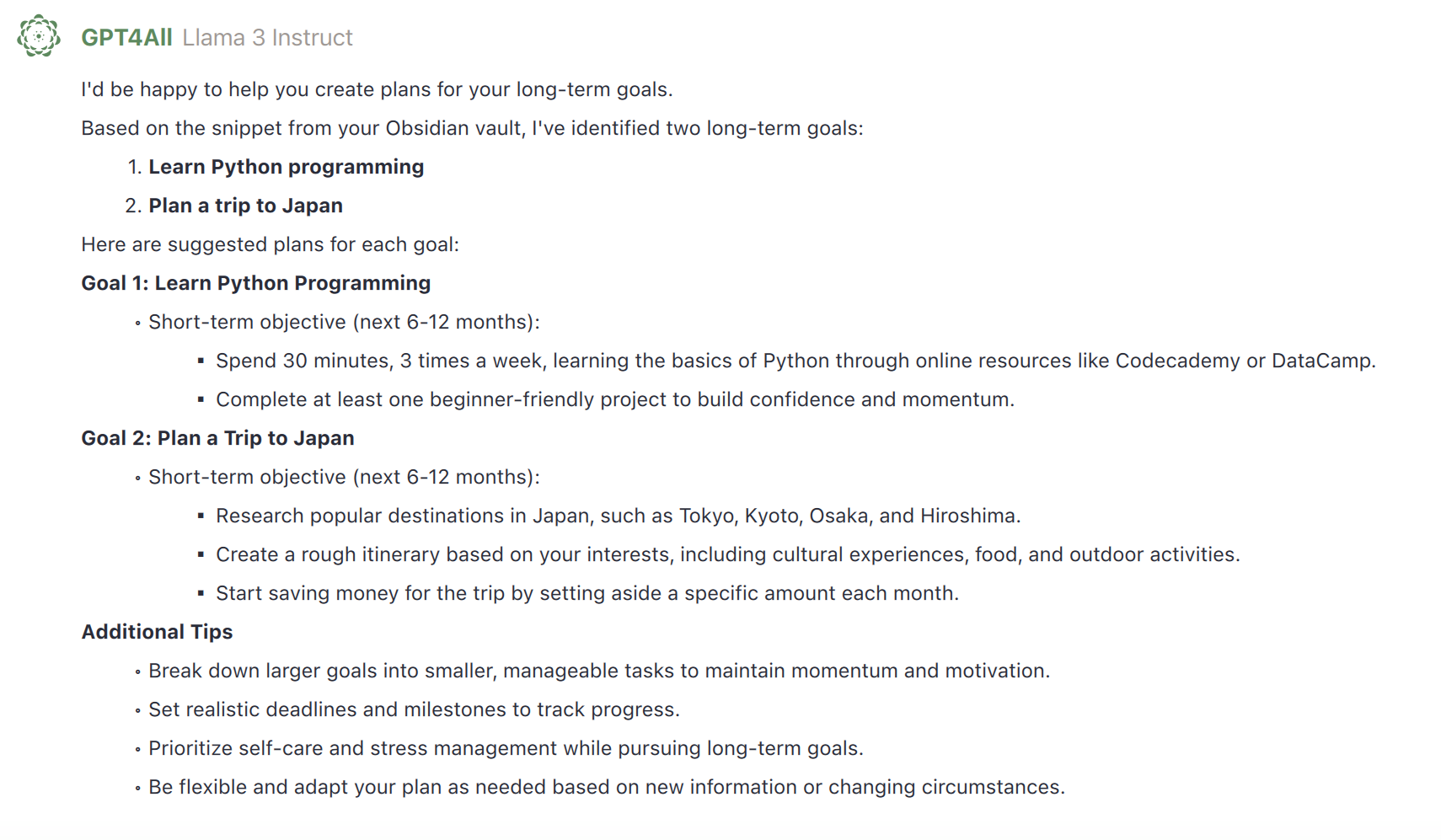 +
+ 
|
@@ -96,7 +96,7 @@ Obsidian for Desktop is a powerful management and note-taking software designed
-  +
+ 
|
@@ -104,6 +104,3 @@ Obsidian for Desktop is a powerful management and note-taking software designed
## How It Works
Obsidian for Desktop syncs your Obsidian notes to your computer, while LocalDocs integrates these files into your LLM chats using embedding models. These models find semantically similar snippets from your files to enhance the context of your interactions.
-
-To learn more about embedding models and explore further, refer to the [Nomic Python SDK documentation](https://docs.nomic.ai/atlas/capabilities/embeddings).
-
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-One-Drive.md b/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-One-Drive.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-One-Drive.md
rename to docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-One-Drive.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-google-drive.md b/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-google-drive.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-google-drive.md
rename to docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-google-drive.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-microsoft-excel.md b/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-microsoft-excel.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-microsoft-excel.md
rename to docs/gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-microsoft-excel.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/localdocs.md b/docs/gpt4all_desktop/localdocs.md
similarity index 93%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/localdocs.md
rename to docs/gpt4all_desktop/localdocs.md
index c3290a92..906279ad 100644
--- a/gpt4all-bindings/python/docs/gpt4all_desktop/localdocs.md
+++ b/docs/gpt4all_desktop/localdocs.md
@@ -44,5 +44,3 @@ LocalDocs brings the information you have from files on-device into your LLM cha
## How It Works
A LocalDocs collection uses Nomic AI's free and fast on-device embedding models to index your folder into text snippets that each get an **embedding vector**. These vectors allow us to find snippets from your files that are semantically similar to the questions and prompts you enter in your chats. We then include those semantically similar snippets in the prompt to the LLM.
-
-To try the embedding models yourself, we recommend using the [Nomic Python SDK](https://docs.nomic.ai/atlas/capabilities/embeddings)
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/models.md b/docs/gpt4all_desktop/models.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/models.md
rename to docs/gpt4all_desktop/models.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/quickstart.md b/docs/gpt4all_desktop/quickstart.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/quickstart.md
rename to docs/gpt4all_desktop/quickstart.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_desktop/settings.md b/docs/gpt4all_desktop/settings.md
similarity index 100%
rename from gpt4all-bindings/python/docs/gpt4all_desktop/settings.md
rename to docs/gpt4all_desktop/settings.md
diff --git a/gpt4all-bindings/python/docs/gpt4all_help/faq.md b/docs/gpt4all_help/faq.md
similarity index 51%
rename from gpt4all-bindings/python/docs/gpt4all_help/faq.md
rename to docs/gpt4all_help/faq.md
index c94b0d04..eb12bb10 100644
--- a/gpt4all-bindings/python/docs/gpt4all_help/faq.md
+++ b/docs/gpt4all_help/faq.md
@@ -6,32 +6,16 @@
We support models with a `llama.cpp` implementation which have been uploaded to [HuggingFace](https://huggingface.co/).
-### Which embedding models are supported?
-
-We support SBert and Nomic Embed Text v1 & v1.5.
-
## Software
### What software do I need?
All you need is to [install GPT4all](../index.md) onto you Windows, Mac, or Linux computer.
-### Which SDK languages are supported?
-
-Our SDK is in Python for usability, but these are light bindings around [`llama.cpp`](https://github.com/ggerganov/llama.cpp) implementations that we contribute to for efficiency and accessibility on everyday computers.
-
### Is there an API?
Yes, you can run your model in server-mode with our [OpenAI-compatible API](https://platform.openai.com/docs/api-reference/completions), which you can configure in [settings](../gpt4all_desktop/settings.md#application-settings)
-### Can I monitor a GPT4All deployment?
-
-Yes, GPT4All [integrates](../gpt4all_python/monitoring.md) with [OpenLIT](https://github.com/openlit/openlit) so you can deploy LLMs with user interactions and hardware usage automatically monitored for full observability.
-
-### Is there a command line interface (CLI)?
-
-[Yes](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-bindings/cli), we have a lightweight use of the Python client as a CLI. We welcome further contributions!
-
## Hardware
### What hardware do I need?
diff --git a/gpt4all-bindings/python/docs/gpt4all_help/troubleshooting.md b/docs/gpt4all_help/troubleshooting.md
similarity index 97%
rename from gpt4all-bindings/python/docs/gpt4all_help/troubleshooting.md
rename to docs/gpt4all_help/troubleshooting.md
index ba132616..da5ac261 100644
--- a/gpt4all-bindings/python/docs/gpt4all_help/troubleshooting.md
+++ b/docs/gpt4all_help/troubleshooting.md
@@ -2,7 +2,7 @@
## Error Loading Models
-It is possible you are trying to load a model from HuggingFace whose weights are not compatible with our [backend](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-bindings).
+It is possible you are trying to load a model from HuggingFace whose weights are not compatible with our [backend](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-backend).
Try downloading one of the officially supported models listed on the main models page in the application. If the problem persists, please share your experience on our [Discord](https://discord.com/channels/1076964370942267462).
diff --git a/gpt4all-bindings/python/docs/index.md b/docs/index.md
similarity index 54%
rename from gpt4all-bindings/python/docs/index.md
rename to docs/index.md
index 0b200bf4..19b9ef73 100644
--- a/gpt4all-bindings/python/docs/index.md
+++ b/docs/index.md
@@ -12,17 +12,3 @@ No API calls or GPUs required - you can just download the application and [get s
[Download for Mac](https://gpt4all.io/installers/gpt4all-installer-darwin.dmg)
[Download for Linux](https://gpt4all.io/installers/gpt4all-installer-linux.run)
-
-!!! note "Python SDK"
- Use GPT4All in Python to program with LLMs implemented with the [`llama.cpp`](https://github.com/ggerganov/llama.cpp) backend and [Nomic's C backend](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-backend). Nomic contributes to open source software like [`llama.cpp`](https://github.com/ggerganov/llama.cpp) to make LLMs accessible and efficient **for all**.
-
- ```bash
- pip install gpt4all
- ```
-
- ```python
- from gpt4all import GPT4All
- model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf") # downloads / loads a 4.66GB LLM
- with model.chat_session():
- print(model.generate("How can I run LLMs efficiently on my laptop?", max_tokens=1024))
- ```
diff --git a/gpt4all-bindings/python/docs/old/gpt4all_chat.md b/docs/old/gpt4all_chat.md
similarity index 100%
rename from gpt4all-bindings/python/docs/old/gpt4all_chat.md
rename to docs/old/gpt4all_chat.md
diff --git a/gpt4all-bindings/README.md b/gpt4all-bindings/README.md
deleted file mode 100644
index 722159fd..00000000
--- a/gpt4all-bindings/README.md
+++ /dev/null
@@ -1,21 +0,0 @@
-# GPT4All Language Bindings
-These are the language bindings for the GPT4All backend. They provide functionality to load GPT4All models (and other llama.cpp models), generate text, and (in the case of the Python bindings) embed text as a vector representation.
-
-See their respective folders for language-specific documentation.
-
-### Languages
-- [Python](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-bindings/python) (Nomic official, maintained by [@cebtenzzre](https://github.com/cebtenzzre))
-- [Node.js/Typescript](https://github.com/nomic-ai/gpt4all/tree/main/gpt4all-bindings/typescript) (community, maintained by [@jacoobes](https://github.com/jacoobes) and [@iimez](https://github.com/iimez))
-
-
-
-
-Archived Bindings
-
-
-The following bindings have been removed from this repository due to lack of maintenance. If adopted, they can be brought back—feel free to message a developer on Dicsord if you are interested in maintaining one of them. Below are links to their last available version (not necessarily the last working version).
-- C#: [41c9013f](https://github.com/nomic-ai/gpt4all/tree/41c9013fa46a194b3e4fee6ced1b9d1b65e177ac/gpt4all-bindings/csharp)
-- Java: [41c9013f](https://github.com/nomic-ai/gpt4all/tree/41c9013fa46a194b3e4fee6ced1b9d1b65e177ac/gpt4all-bindings/java)
-- Go: [41c9013f](https://github.com/nomic-ai/gpt4all/tree/41c9013fa46a194b3e4fee6ced1b9d1b65e177ac/gpt4all-bindings/golang)
-
-
-:snake: Official Python Bindings
-
-
-
-:computer: Official Typescript Bindings
-
-
:speech_balloon: Official Web Chat Interface
@@ -74,8 +66,6 @@ Find the most up-to-date information on the [GPT4All Website](https://gpt4all.io
Note this model is only compatible with the C++ bindings found [here](https://github.com/nomic-ai/gpt4all-chat). It will not work with any existing llama.cpp bindings as we had to do a large fork of llama.cpp. GPT4All will support the ecosystem around this new C++ backend going forward.
-Python bindings are imminent and will be integrated into this [repository](https://github.com/nomic-ai/pyllamacpp). Stay tuned on the [GPT4All discord](https://discord.gg/mGZE39AS3e) for updates.
-
## Training GPT4All-J
Please see [GPT4All-J Technical Report](https://static.nomic.ai/gpt4all/2023_GPT4All-J_Technical_Report_2.pdf) for details.
@@ -146,43 +136,6 @@ This model had all refusal to answer responses removed from training. Try it wit
-----------
Note: the full model on GPU (16GB of RAM required) performs much better in our qualitative evaluations.
-# Python Client
-## CPU Interface
-To run GPT4All in python, see the new [official Python bindings](https://github.com/nomic-ai/pyllamacpp).
-
-The old bindings are still available but now deprecated. They will not work in a notebook environment.
-To get running using the python client with the CPU interface, first install the [nomic client](https://github.com/nomic-ai/nomic) using `pip install nomic`
-Then, you can use the following script to interact with GPT4All:
-```
-from nomic.gpt4all import GPT4All
-m = GPT4All()
-m.open()
-m.prompt('write me a story about a lonely computer')
-```
-
-## GPU Interface
-There are two ways to get up and running with this model on GPU.
-The setup here is slightly more involved than the CPU model.
-1. clone the nomic client [repo](https://github.com/nomic-ai/nomic) and run `pip install .[GPT4All]` in the home dir.
-2. run `pip install nomic` and install the additional deps from the wheels built [here](https://github.com/nomic-ai/nomic/tree/main/bin)
-
-Once this is done, you can run the model on GPU with a script like the following:
-```
-from nomic.gpt4all import GPT4AllGPU
-m = GPT4AllGPU(LLAMA_PATH)
-config = {'num_beams': 2,
- 'min_new_tokens': 10,
- 'max_length': 100,
- 'repetition_penalty': 2.0}
-out = m.generate('write me a story about a lonely computer', config)
-print(out)
-```
-Where LLAMA_PATH is the path to a Huggingface Automodel compliant LLAMA model.
-Nomic is unable to distribute this file at this time.
-We are working on a GPT4All that does not have this limitation right now.
-
-You can pass any of the [huggingface generation config params](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig) in the config.
-
# GPT4All Compatibility Ecosystem
Edge models in the GPT4All Ecosystem. Please PR as the [community grows](https://huggingface.co/models?sort=modified&search=4bit).
Feel free to convert this to a more structured table.
diff --git a/gpt4all-bindings/python/mkdocs.yml b/mkdocs.yml
similarity index 86%
rename from gpt4all-bindings/python/mkdocs.yml
rename to mkdocs.yml
index 651366a3..7280cfa1 100644
--- a/gpt4all-bindings/python/mkdocs.yml
+++ b/mkdocs.yml
@@ -22,10 +22,6 @@ nav:
- 'Local AI Chat with your OneDrive': 'gpt4all_desktop/cookbook/use-local-ai-models-to-privately-chat-with-One-Drive.md'
- 'API Server':
- 'gpt4all_api_server/home.md'
- - 'Python SDK':
- - 'gpt4all_python/home.md'
- - 'Monitoring': 'gpt4all_python/monitoring.md'
- - 'SDK Reference': 'gpt4all_python/ref.md'
- 'Help':
- 'FAQ': 'gpt4all_help/faq.md'
- 'Troubleshooting': 'gpt4all_help/troubleshooting.md'
@@ -73,14 +69,6 @@ extra_css:
plugins:
- search
- - mkdocstrings:
- handlers:
- python:
- options:
- show_root_heading: True
- heading_level: 4
- show_root_full_path: false
- docstring_section_style: list
- material/social:
cards_layout_options:
font_family: Roboto
diff --git a/requirements-docs.txt b/requirements-docs.txt
new file mode 100644
index 00000000..475cbcdc
--- /dev/null
+++ b/requirements-docs.txt
@@ -0,0 +1,3 @@
+markdown-captions
+mkdocs
+mkdocs-material[imaging]