mirror of
https://github.com/hwchase17/langchain.git
synced 2025-09-16 23:13:31 +00:00
docs: templates updated titles (#25646)
Updated titles into a consistent format. Fixed links to the diagrams. Fixed typos. Note: The Templates menu in the navbar is now sorted by the file names. I'll try sorting the navbar menus by the page titles, not the page file names.
This commit is contained in:
@@ -1,15 +1,14 @@
|
||||
|
||||
# rag-gemini-multi-modal
|
||||
# RAG - Gemini multi-modal
|
||||
|
||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||
|
||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||
|
||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
||||
It uses `OpenCLIP` embeddings to embed all the slide images and stores them in Chroma.
|
||||
|
||||
Given a question, relevant slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||
|
||||

|
||||
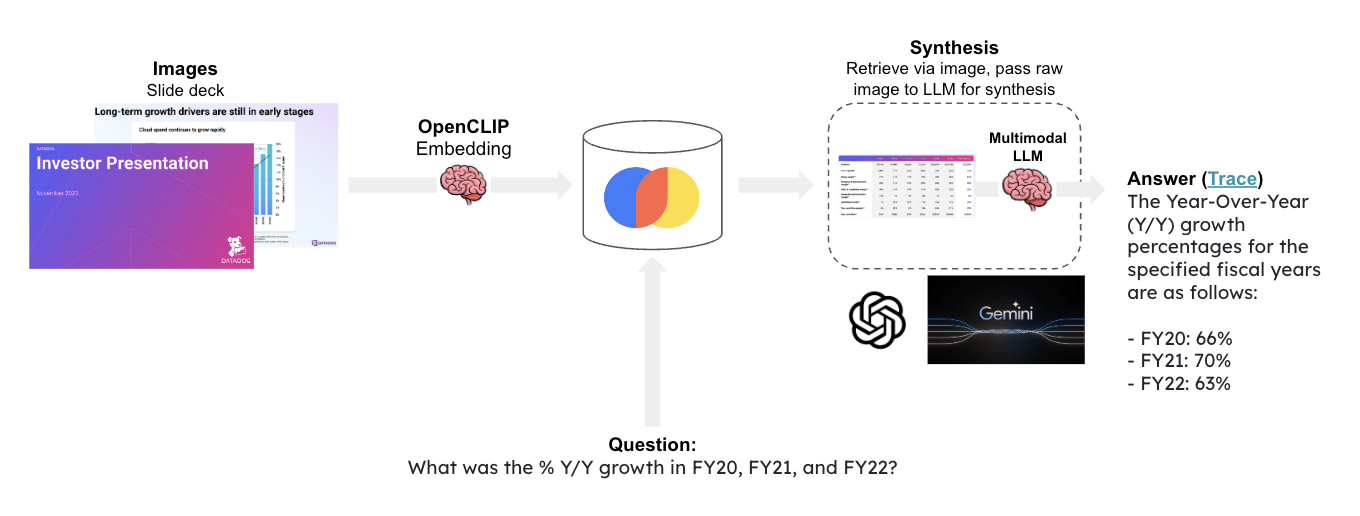 "Workflow Diagram for Visual Assistant Using Multi-modal LLM"
|
||||
|
||||
## Input
|
||||
|
||||
|
||||
Reference in New Issue
Block a user