mirror of
https://github.com/hwchase17/langchain.git
synced 2025-07-02 03:15:11 +00:00
docs: templates updated titles (#25646)
Updated titles into a consistent format. Fixed links to the diagrams. Fixed typos. Note: The Templates menu in the navbar is now sorted by the file names. I'll try sorting the navbar menus by the page titles, not the page file names.
This commit is contained in:
parent
1b2ae40d45
commit
163ef35dd1
@ -102,11 +102,11 @@ langchain serve
|
|||||||
This now gives a fully deployed LangServe application.
|
This now gives a fully deployed LangServe application.
|
||||||
For example, you get a playground out-of-the-box at [http://127.0.0.1:8000/pirate-speak/playground/](http://127.0.0.1:8000/pirate-speak/playground/):
|
For example, you get a playground out-of-the-box at [http://127.0.0.1:8000/pirate-speak/playground/](http://127.0.0.1:8000/pirate-speak/playground/):
|
||||||
|
|
||||||

|
 "LangServe Playground Interface"
|
||||||
|
|
||||||
Access API documentation at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
Access API documentation at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||||
|
|
||||||

|
 "API Documentation Interface"
|
||||||
|
|
||||||
Use the LangServe python or js SDK to interact with the API as if it were a regular [Runnable](https://python.langchain.com/docs/expression_language/).
|
Use the LangServe python or js SDK to interact with the API as if it were a regular [Runnable](https://python.langchain.com/docs/expression_language/).
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# Anthropic - iterative search
|
||||||
# anthropic-iterative-search
|
|
||||||
|
|
||||||
This template will create a virtual research assistant with the ability to search Wikipedia to find answers to your questions.
|
This template will create a virtual research assistant with the ability to search Wikipedia to find answers to your questions.
|
||||||
|
|
||||||
|
|||||||
@ -1,10 +1,10 @@
|
|||||||
# basic-critique-revise
|
# Basic critique revise
|
||||||
|
|
||||||
Iteratively generate schema candidates and revise them based on errors.
|
Iteratively generate schema candidates and revise them based on errors.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
This template uses OpenAI function calling, so you will need to set the `OPENAI_API_KEY` environment variable in order to use this template.
|
This template uses `OpenAI function calling`, so you will need to set the `OPENAI_API_KEY` environment variable in order to use this template.
|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
|
|||||||
@ -1,12 +1,13 @@
|
|||||||
# Bedrock JCVD 🕺🥋
|
# Bedrock - JCVD 🕺🥋
|
||||||
|
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
LangChain template that uses [Anthropic's Claude on Amazon Bedrock](https://aws.amazon.com/bedrock/claude/) to behave like JCVD.
|
LangChain template that uses [Anthropic's Claude on Amazon Bedrock](https://aws.amazon.com/bedrock/claude/)
|
||||||
|
to behave like `Jean-Claude Van Damme` (`JCVD`).
|
||||||
|
|
||||||
> I am the Fred Astaire of Chatbots! 🕺
|
> I am the Fred Astaire of Chatbots! 🕺
|
||||||
|
|
||||||
'
|
 "Jean-Claude Van Damme Dancing"
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
@ -78,4 +79,4 @@ We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/d
|
|||||||
|
|
||||||
We can also access the playground at [http://127.0.0.1:8000/bedrock-jcvd/playground](http://127.0.0.1:8000/bedrock-jcvd/playground)
|
We can also access the playground at [http://127.0.0.1:8000/bedrock-jcvd/playground](http://127.0.0.1:8000/bedrock-jcvd/playground)
|
||||||
|
|
||||||

|
 "JCVD Playground"
|
||||||
@ -1,7 +1,7 @@
|
|||||||
|
# Cassandra - Entomology RAG
|
||||||
|
|
||||||
# cassandra-entomology-rag
|
This template will perform RAG using `Apache Cassandra®` or `Astra DB`
|
||||||
|
through `CQL` (`Cassandra` vector store class)
|
||||||
This template will perform RAG using Apache Cassandra® or Astra DB through CQL (`Cassandra` vector store class)
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
|
# Cassandra - synonym caching
|
||||||
|
|
||||||
# cassandra-synonym-caching
|
This template provides a simple chain template showcasing the usage
|
||||||
|
of LLM Caching backed by `Apache Cassandra®` or `Astra DB` through `CQL`.
|
||||||
This template provides a simple chain template showcasing the usage of LLM Caching backed by Apache Cassandra® or Astra DB through CQL.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,8 @@
|
|||||||
# Chain-of-Note (Wikipedia)
|
# Chain-of-Note - Wikipedia
|
||||||
|
|
||||||
Implements Chain-of-Note as described in https://arxiv.org/pdf/2311.09210.pdf by Yu, et al. Uses Wikipedia for retrieval.
|
Implements `Chain-of-Note` as described in [CHAIN-OF-NOTE: ENHANCING ROBUSTNESS IN
|
||||||
|
RETRIEVAL-AUGMENTED LANGUAGE MODELS](https://arxiv.org/pdf/2311.09210.pdf) paper
|
||||||
|
by Yu, et al. Uses `Wikipedia` for retrieval.
|
||||||
|
|
||||||
Check out the prompt being used here https://smith.langchain.com/hub/bagatur/chain-of-note-wiki.
|
Check out the prompt being used here https://smith.langchain.com/hub/bagatur/chain-of-note-wiki.
|
||||||
|
|
||||||
|
|||||||
@ -1,19 +1,20 @@
|
|||||||
# Chat Bot Feedback Template
|
# Chatbot feedback
|
||||||
|
|
||||||
This template shows how to evaluate your chat bot without explicit user feedback. It defines a simple chat bot in [chain.py](https://github.com/langchain-ai/langchain/blob/master/templates/chat-bot-feedback/chat_bot_feedback/chain.py) and custom evaluator that scores bot response effectiveness based on the subsequent user response. You can apply this run evaluator to your own chat bot by calling `with_config` on the chat bot before serving. You can also directly deploy your chat app using this template.
|
This template shows how to evaluate your chatbot without explicit user feedback.
|
||||||
|
It defines a simple chatbot in [chain.py](https://github.com/langchain-ai/langchain/blob/master/templates/chat-bot-feedback/chat_bot_feedback/chain.py) and custom evaluator that scores bot response effectiveness based on the subsequent user response. You can apply this run evaluator to your own chat bot by calling `with_config` on the chat bot before serving. You can also directly deploy your chat app using this template.
|
||||||
|
|
||||||
[Chat bots](https://python.langchain.com/docs/use_cases/chatbots) are one of the most common interfaces for deploying LLMs. The quality of chat bots varies, making continuous development important. But users are wont to leave explicit feedback through mechanisms like thumbs-up or thumbs-down buttons. Furthermore, traditional analytics such as "session length" or "conversation length" often lack clarity. However, multi-turn conversations with a chat bot can provide a wealth of information, which we can transform into metrics for fine-tuning, evaluation, and product analytics.
|
[Chatbots](https://python.langchain.com/docs/use_cases/chatbots) are one of the most common interfaces for deploying LLMs. The quality of chat bots varies, making continuous development important. But users are wont to leave explicit feedback through mechanisms like thumbs-up or thumbs-down buttons. Furthermore, traditional analytics such as "session length" or "conversation length" often lack clarity. However, multi-turn conversations with a chat bot can provide a wealth of information, which we can transform into metrics for fine-tuning, evaluation, and product analytics.
|
||||||
|
|
||||||
Taking [Chat Langchain](https://chat.langchain.com/) as a case study, only about 0.04% of all queries receive explicit feedback. Yet, approximately 70% of the queries are follow-ups to previous questions. A significant portion of these follow-up queries continue useful information we can use to infer the quality of the previous AI response.
|
Taking [Chat Langchain](https://chat.langchain.com/) as a case study, only about 0.04% of all queries receive explicit feedback. Yet, approximately 70% of the queries are follow-ups to previous questions. A significant portion of these follow-up queries continue useful information we can use to infer the quality of the previous AI response.
|
||||||
|
|
||||||
|
|
||||||
This template helps solve this "feedback scarcity" problem. Below is an example invocation of this chat bot:
|
This template helps solve this "feedback scarcity" problem. Below is an example invocation of this chat bot:
|
||||||
|
|
||||||
[](https://smith.langchain.com/public/3378daea-133c-4fe8-b4da-0a3044c5dbe8/r?runtab=1)
|
["Chat Bot Interaction Example"](https://smith.langchain.com/public/3378daea-133c-4fe8-b4da-0a3044c5dbe8/r?runtab=1)
|
||||||
|
|
||||||
When the user responds to this ([link](https://smith.langchain.com/public/a7e2df54-4194-455d-9978-cecd8be0df1e/r)), the response evaluator is invoked, resulting in the following evaluationrun:
|
When the user responds to this ([link](https://smith.langchain.com/public/a7e2df54-4194-455d-9978-cecd8be0df1e/r)), the response evaluator is invoked, resulting in the following evaluation run:
|
||||||
|
|
||||||
[](https://smith.langchain.com/public/534184ee-db8f-4831-a386-3f578145114c/r)
|
 ["Chat Bot Evaluator Run"](https://smith.langchain.com/public/534184ee-db8f-4831-a386-3f578145114c/r)
|
||||||
|
|
||||||
As shown, the evaluator sees that the user is increasingly frustrated, indicating that the prior response was not effective
|
As shown, the evaluator sees that the user is increasingly frustrated, indicating that the prior response was not effective
|
||||||
|
|
||||||
|
|||||||
@ -1,11 +1,14 @@
|
|||||||
|
# Cohere - Librarian
|
||||||
|
|
||||||
# cohere-librarian
|
This template turns `Cohere` into a librarian.
|
||||||
|
|
||||||
This template turns Cohere into a librarian.
|
It demonstrates the use of:
|
||||||
|
- a router to switch between chains that handle different things
|
||||||
|
- a vector database with Cohere embeddings
|
||||||
|
- a chat bot that has a prompt with some information about the library
|
||||||
|
- a RAG chatbot that has access to the internet.
|
||||||
|
|
||||||
It demonstrates the use of a router to switch between chains that can handle different things: a vector database with Cohere embeddings; a chat bot that has a prompt with some information about the library; and finally a RAG chatbot that has access to the internet.
|
For a fuller demo of the book recommendation, consider replacing `books_with_blurbs.csv` with a larger sample from the following dataset: https://www.kaggle.com/datasets/jdobrow/57000-books-with-metadata-and-blurbs/ .
|
||||||
|
|
||||||
For a fuller demo of the book recomendation, consider replacing books_with_blurbs.csv with a larger sample from the following dataset: https://www.kaggle.com/datasets/jdobrow/57000-books-with-metadata-and-blurbs/ .
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# CSV agent
|
||||||
|
|
||||||
# csv-agent
|
This template uses a [CSV agent](https://python.langchain.com/docs/integrations/toolkits/csv) with tools (Python REPL) and memory (vectorstore) for interaction (question-answering) with text data.
|
||||||
|
|
||||||
This template uses a [csv agent](https://python.langchain.com/docs/integrations/toolkits/csv) with tools (Python REPL) and memory (vectorstore) for interaction (question-answering) with text data.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -38,4 +38,4 @@ langchain template serve
|
|||||||
This will spin up endpoints, documentation, and playground for this chain.
|
This will spin up endpoints, documentation, and playground for this chain.
|
||||||
For example, you can access the playground at [http://127.0.0.1:8000/playground/](http://127.0.0.1:8000/playground/)
|
For example, you can access the playground at [http://127.0.0.1:8000/playground/](http://127.0.0.1:8000/playground/)
|
||||||
|
|
||||||

|
 "LangServe Playground Interface"
|
||||||
|
|||||||
@ -1,9 +1,9 @@
|
|||||||
|
# Elasticsearch - query generator
|
||||||
|
|
||||||
# elastic-query-generator
|
This template allows interacting with `Elasticsearch` analytics databases
|
||||||
|
in natural language using LLMs.
|
||||||
|
|
||||||
This template allows interacting with Elasticsearch analytics databases in natural language using LLMs.
|
It builds search queries via the `Elasticsearch DSL API` (filters and aggregations).
|
||||||
|
|
||||||
It builds search queries via the Elasticsearch DSL API (filters and aggregations).
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# Extraction - Anthropic functions
|
||||||
# extraction-anthropic-functions
|
|
||||||
|
|
||||||
This template enables [Anthropic function calling](https://python.langchain.com/docs/integrations/chat/anthropic_functions).
|
This template enables [Anthropic function calling](https://python.langchain.com/docs/integrations/chat/anthropic_functions).
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# Extraction - OpenAI functions
|
||||||
# extraction-openai-functions
|
|
||||||
|
|
||||||
This template uses [OpenAI function calling](https://python.langchain.com/docs/modules/chains/how_to/openai_functions) for extraction of structured output from unstructured input text.
|
This template uses [OpenAI function calling](https://python.langchain.com/docs/modules/chains/how_to/openai_functions) for extraction of structured output from unstructured input text.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# Gemini functions - agent
|
||||||
|
|
||||||
# gemini-functions-agent
|
This template creates an agent that uses `Google Gemini function calling` to communicate its decisions on what actions to take.
|
||||||
|
|
||||||
This template creates an agent that uses Google Gemini function calling to communicate its decisions on what actions to take.
|
This example creates an agent that optionally looks up information on the internet using `Tavily's` search engine.
|
||||||
|
|
||||||
This example creates an agent that can optionally look up information on the internet using Tavily's search engine.
|
|
||||||
|
|
||||||
[See an example LangSmith trace here](https://smith.langchain.com/public/0ebf1bd6-b048-4019-b4de-25efe8d3d18c/r)
|
[See an example LangSmith trace here](https://smith.langchain.com/public/0ebf1bd6-b048-4019-b4de-25efe8d3d18c/r)
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# Guardrails - output parser
|
||||||
# guardrails-output-parser
|
|
||||||
|
|
||||||
This template uses [guardrails-ai](https://github.com/guardrails-ai/guardrails) to validate LLM output.
|
This template uses [guardrails-ai](https://github.com/guardrails-ai/guardrails) to validate LLM output.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,10 @@
|
|||||||
# Hybrid Search in Weaviate
|
# Hybrid search - Weaviate
|
||||||
This template shows you how to use the hybrid search feature in Weaviate. Hybrid search combines multiple search algorithms to improve the accuracy and relevance of search results.
|
|
||||||
|
|
||||||
Weaviate uses both sparse and dense vectors to represent the meaning and context of search queries and documents. The results use a combination of `bm25` and vector search ranking to return the top results.
|
This template shows you how to use the hybrid search feature in `Weaviate` vector store.
|
||||||
|
Hybrid search combines multiple search algorithms to improve the accuracy and relevance of search results.
|
||||||
|
|
||||||
|
`Weaviate` uses both sparse and dense vectors to represent the meaning and context of search queries and documents.
|
||||||
|
The results use a combination of `bm25` and `vector search ranking` to return the top results.
|
||||||
|
|
||||||
## Configurations
|
## Configurations
|
||||||
Connect to your hosted Weaviate Vectorstore by setting a few env variables in `chain.py`:
|
Connect to your hosted Weaviate Vectorstore by setting a few env variables in `chain.py`:
|
||||||
|
|||||||
@ -1,15 +1,14 @@
|
|||||||
|
# Hypothetical Document Embeddings (HyDE)
|
||||||
|
|
||||||
# hyde
|
This template uses `HyDE` with RAG.
|
||||||
|
|
||||||
This template uses HyDE with RAG.
|
`Hyde` is a retrieval method that stands for `Hypothetical Document Embeddings`. It is a method used to enhance retrieval by generating a hypothetical document for an incoming query.
|
||||||
|
|
||||||
Hyde is a retrieval method that stands for Hypothetical Document Embeddings (HyDE). It is a method used to enhance retrieval by generating a hypothetical document for an incoming query.
|
|
||||||
|
|
||||||
The document is then embedded, and that embedding is utilized to look up real documents that are similar to the hypothetical document.
|
The document is then embedded, and that embedding is utilized to look up real documents that are similar to the hypothetical document.
|
||||||
|
|
||||||
The underlying concept is that the hypothetical document may be closer in the embedding space than the query.
|
The underlying concept is that the hypothetical document may be closer in the embedding space than the query.
|
||||||
|
|
||||||
For a more detailed description, see the paper [here](https://arxiv.org/abs/2212.10496).
|
For a more detailed description, see the[Precise Zero-Shot Dense Retrieval without Relevance Labels](https://arxiv.org/abs/2212.10496) paper.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,8 @@
|
|||||||
# RAG example on Intel Xeon
|
# RAG - Intel Xeon
|
||||||
This template performs RAG using Chroma and Text Generation Inference on Intel® Xeon® Scalable Processors.
|
|
||||||
Intel® Xeon® Scalable processors feature built-in accelerators for more performance-per-core and unmatched AI performance, with advanced security technologies for the most in-demand workload requirements—all while offering the greatest cloud choice and application portability, please check [Intel® Xeon® Scalable Processors](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html).
|
This template performs RAG using `Chroma` and `Hugging Face Text Generation Inference`
|
||||||
|
on `Intel® Xeon® Scalable` Processors.
|
||||||
|
`Intel® Xeon® Scalable` processors feature built-in accelerators for more performance-per-core and unmatched AI performance, with advanced security technologies for the most in-demand workload requirements—all while offering the greatest cloud choice and application portability, please check [Intel® Xeon® Scalable Processors](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
To use [🤗 text-generation-inference](https://github.com/huggingface/text-generation-inference) on Intel® Xeon® Scalable Processors, please follow these steps:
|
To use [🤗 text-generation-inference](https://github.com/huggingface/text-generation-inference) on Intel® Xeon® Scalable Processors, please follow these steps:
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# Llama.cpp functions
|
||||||
|
|
||||||
# llama2-functions
|
This template performs extraction of structured data from unstructured data using [Llama.cpp package with the LLaMA2 model that supports a specified JSON output schema](https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md).
|
||||||
|
|
||||||
This template performs extraction of structured data from unstructured data using a [LLaMA2 model that supports a specified JSON output schema](https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md).
|
|
||||||
|
|
||||||
The extraction schema can be set in `chain.py`.
|
The extraction schema can be set in `chain.py`.
|
||||||
|
|
||||||
|
|||||||
@ -1,14 +1,14 @@
|
|||||||
# mongo-parent-document-retrieval
|
# MongoDB - Parent-Document Retrieval RAG
|
||||||
|
|
||||||
This template performs RAG using MongoDB and OpenAI.
|
This template performs RAG using `MongoDB` and `OpenAI`.
|
||||||
It does a more advanced form of RAG called Parent-Document Retrieval.
|
It does a more advanced form of RAG called `Parent-Document Retrieval`.
|
||||||
|
|
||||||
In this form of retrieval, a large document is first split into medium sized chunks.
|
In this form of retrieval, a large document is first split into medium-sized chunks.
|
||||||
From there, those medium size chunks are split into small chunks.
|
From there, those medium size chunks are split into small chunks.
|
||||||
Embeddings are created for the small chunks.
|
Embeddings are created for the small chunks.
|
||||||
When a query comes in, an embedding is created for that query and compared to the small chunks.
|
When a query comes in, an embedding is created for that query and compared to the small chunks.
|
||||||
But rather than passing the small chunks directly to the LLM for generation, the medium-sized chunks
|
But rather than passing the small chunks directly to the LLM for generation, the medium-sized chunks
|
||||||
from whence the smaller chunks came are passed.
|
from where the smaller chunks came are passed.
|
||||||
This helps enable finer-grained search, but then passing of larger context (which can be useful during generation).
|
This helps enable finer-grained search, but then passing of larger context (which can be useful during generation).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
@ -99,15 +99,15 @@ We will first follow the standard MongoDB Atlas setup instructions [here](https:
|
|||||||
|
|
||||||
This can be done by going to the deployment overview page and connecting to you database
|
This can be done by going to the deployment overview page and connecting to you database
|
||||||
|
|
||||||

|
 "MongoDB Atlas Connect Button"
|
||||||
|
|
||||||
We then look at the drivers available
|
We then look at the drivers available
|
||||||
|
|
||||||

|
 "MongoDB Atlas Drivers Section"
|
||||||
|
|
||||||
Among which we will see our URI listed
|
Among which we will see our URI listed
|
||||||
|
|
||||||

|
 "MongoDB Atlas URI Display"
|
||||||
|
|
||||||
Let's then set that as an environment variable locally:
|
Let's then set that as an environment variable locally:
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,7 @@
|
|||||||
# neo4j-advanced-rag
|
# Neo4j - advanced RAG
|
||||||
|
|
||||||
This template allows you to balance precise embeddings and context retention by implementing advanced retrieval strategies.
|
This template allows you to balance precise embeddings and context retention
|
||||||
|
by implementing advanced retrieval strategies.
|
||||||
|
|
||||||
## Strategies
|
## Strategies
|
||||||
|
|
||||||
|
|||||||
@ -1,15 +1,14 @@
|
|||||||
|
# Neo4j Cypher full-text index
|
||||||
|
|
||||||
# neo4j-cypher-ft
|
This template allows you to interact with a `Neo4j` graph database using natural language, leveraging OpenAI's LLM.
|
||||||
|
|
||||||
This template allows you to interact with a Neo4j graph database using natural language, leveraging OpenAI's LLM.
|
Its main function is to convert natural language questions into `Cypher` queries (the language used to query Neo4j databases), execute these queries, and provide natural language responses based on the query's results.
|
||||||
|
|
||||||
Its main function is to convert natural language questions into Cypher queries (the language used to query Neo4j databases), execute these queries, and provide natural language responses based on the query's results.
|
The package utilizes a `full-text index` for efficient mapping of text values to database entries, thereby enhancing the generation of accurate Cypher statements.
|
||||||
|
|
||||||
The package utilizes a full-text index for efficient mapping of text values to database entries, thereby enhancing the generation of accurate Cypher statements.
|
|
||||||
|
|
||||||
In the provided example, the full-text index is used to map names of people and movies from the user's query to corresponding database entries.
|
In the provided example, the full-text index is used to map names of people and movies from the user's query to corresponding database entries.
|
||||||
|
|
||||||

|
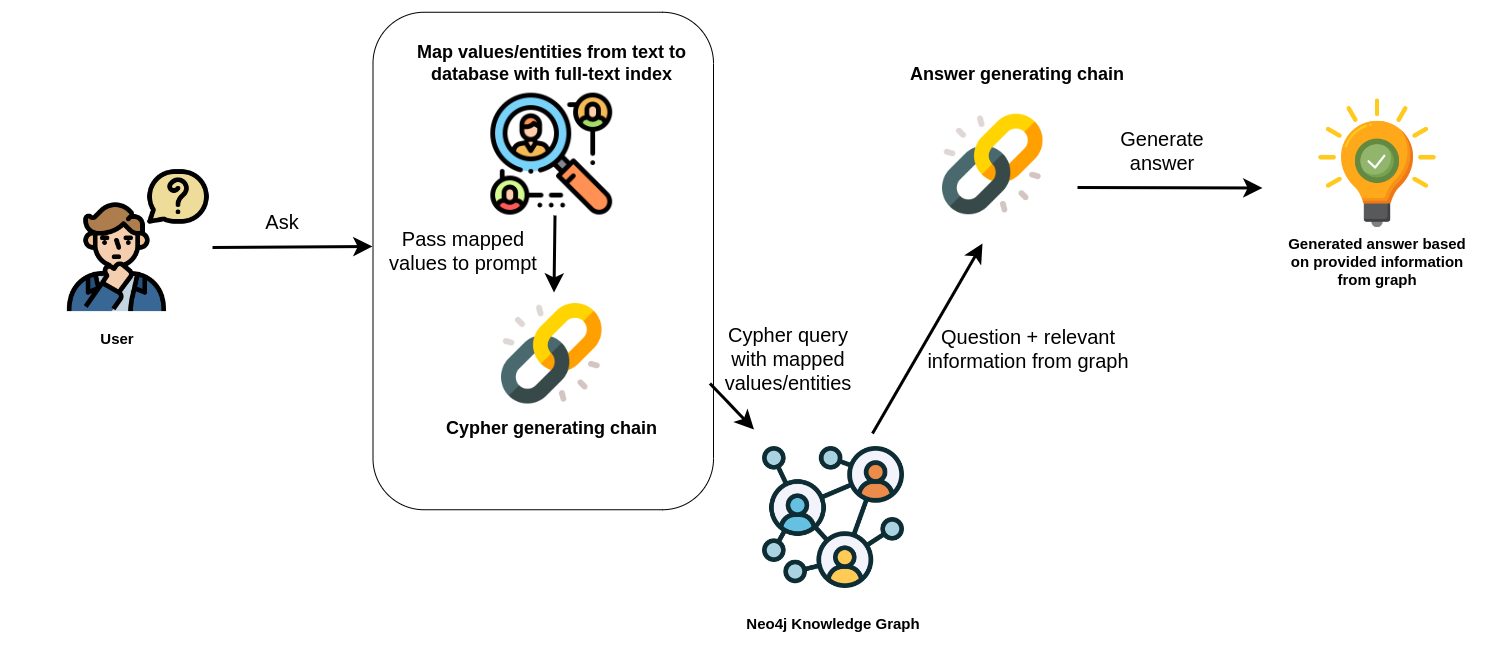 "Neo4j Cypher Workflow Diagram"
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,13 +1,12 @@
|
|||||||
|
# Neo4j Cypher memory
|
||||||
|
|
||||||
# neo4j-cypher-memory
|
This template allows you to have conversations with a `Neo4j` graph database in natural language, using an OpenAI LLM.
|
||||||
|
It transforms a natural language question into a `Cypher` query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
|
||||||
This template allows you to have conversations with a Neo4j graph database in natural language, using an OpenAI LLM.
|
Additionally, it features a `conversational memory` module that stores the dialogue history in the Neo4j graph database.
|
||||||
It transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
|
|
||||||
Additionally, it features a conversational memory module that stores the dialogue history in the Neo4j graph database.
|
|
||||||
The conversation memory is uniquely maintained for each user session, ensuring personalized interactions.
|
The conversation memory is uniquely maintained for each user session, ensuring personalized interactions.
|
||||||
To facilitate this, please supply both the `user_id` and `session_id` when using the conversation chain.
|
To facilitate this, please supply both the `user_id` and `session_id` when using the conversation chain.
|
||||||
|
|
||||||

|
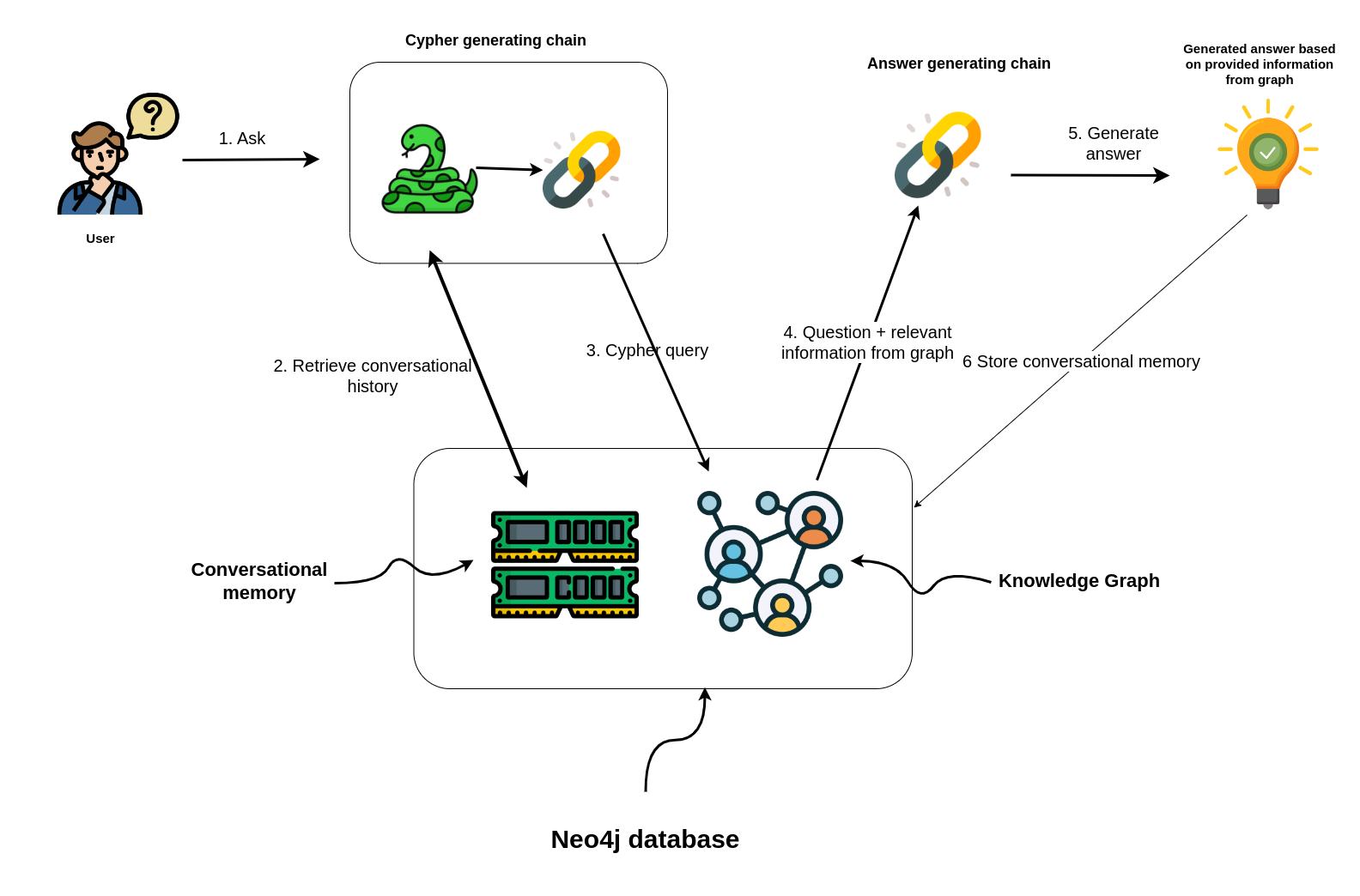 "Neo4j Cypher Memory Workflow Diagram"
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,11 +1,13 @@
|
|||||||
|
# Neo4j Cypher
|
||||||
|
|
||||||
# neo4j_cypher
|
This template allows you to interact with a `Neo4j` graph database
|
||||||
|
in natural language, using an `OpenAI` LLM.
|
||||||
|
|
||||||
This template allows you to interact with a Neo4j graph database in natural language, using an OpenAI LLM.
|
It transforms a natural language question into a `Cypher` query
|
||||||
|
(used to fetch data from `Neo4j` databases), executes the query,
|
||||||
|
and provides a natural language response based on the query results.
|
||||||
|
|
||||||
It transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
|
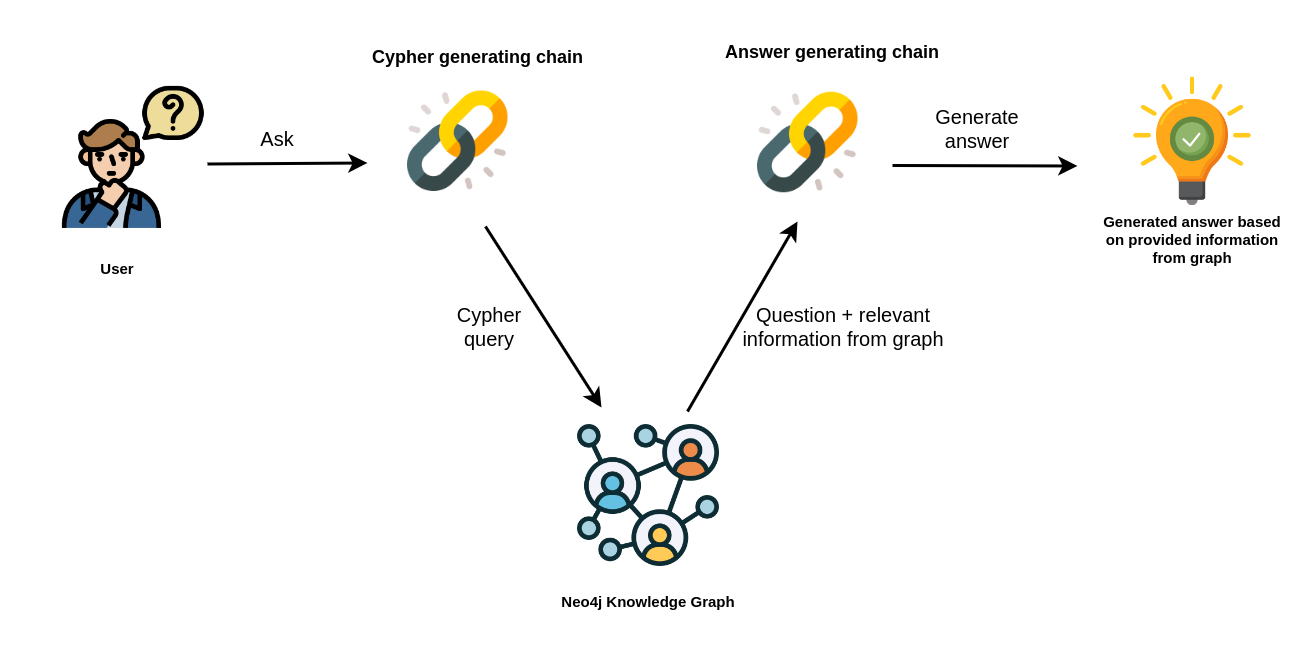 "Neo4j Cypher Workflow Diagram"
|
||||||
|
|
||||||
[](https://medium.com/neo4j/langchain-cypher-search-tips-tricks-f7c9e9abca4d)
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
|
# Neo4j AuraDB - generation
|
||||||
|
|
||||||
# neo4j-generation
|
This template pairs LLM-based knowledge graph extraction with `Neo4j AuraDB`,
|
||||||
|
a fully managed cloud graph database.
|
||||||
This template pairs LLM-based knowledge graph extraction with Neo4j AuraDB, a fully managed cloud graph database.
|
|
||||||
|
|
||||||
You can create a free instance on [Neo4j Aura](https://neo4j.com/cloud/platform/aura-graph-database?utm_source=langchain&utm_content=langserve).
|
You can create a free instance on [Neo4j Aura](https://neo4j.com/cloud/platform/aura-graph-database?utm_source=langchain&utm_content=langserve).
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,12 @@
|
|||||||
|
# Neo4j - hybrid parent-child retrieval
|
||||||
|
|
||||||
# neo4j-parent
|
This template allows you to balance precise embeddings and context retention
|
||||||
|
by splitting documents into smaller chunks and retrieving their original
|
||||||
|
or larger text information.
|
||||||
|
|
||||||
This template allows you to balance precise embeddings and context retention by splitting documents into smaller chunks and retrieving their original or larger text information.
|
Using a `Neo4j` vector index, the package queries child nodes using
|
||||||
|
vector similarity search and retrieves the corresponding parent's text
|
||||||
Using a Neo4j vector index, the package queries child nodes using vector similarity search and retrieves the corresponding parent's text by defining an appropriate `retrieval_query` parameter.
|
by defining an appropriate `retrieval_query` parameter.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,14 +1,14 @@
|
|||||||
# neo4j-semantic-layer
|
# Neo4j - Semantic Layer
|
||||||
|
|
||||||
This template is designed to implement an agent capable of interacting with a graph database like Neo4j through a semantic layer using OpenAI function calling.
|
This template is designed to implement an agent capable of interacting with a graph database like `Neo4j` through a semantic layer using `OpenAI function calling`.
|
||||||
The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph database based on the user's intent.
|
The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph database based on the user's intent.
|
||||||
Learn more about the semantic layer template in the [corresponding blog post](https://medium.com/towards-data-science/enhancing-interaction-between-language-models-and-graph-databases-via-a-semantic-layer-0a78ad3eba49).
|
Learn more about the semantic layer template in the [corresponding blog post](https://medium.com/towards-data-science/enhancing-interaction-between-language-models-and-graph-databases-via-a-semantic-layer-0a78ad3eba49).
|
||||||
|
|
||||||

|
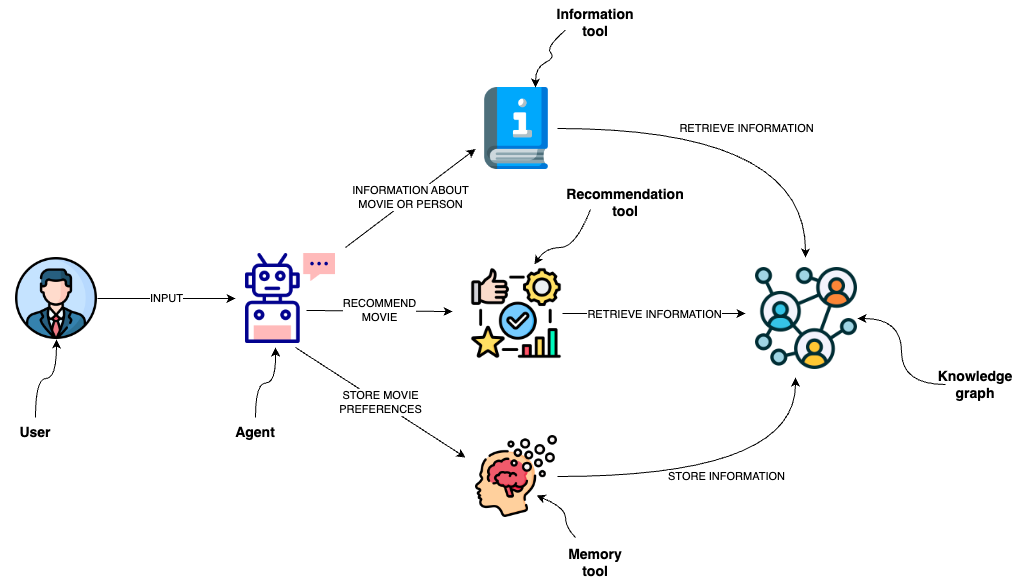 "Neo4j Semantic Layer Workflow Diagram"
|
||||||
|
|
||||||
## Tools
|
## Tools
|
||||||
|
|
||||||
The agent utilizes several tools to interact with the Neo4j graph database effectively:
|
The agent utilizes several tools to interact with the `Neo4j` graph database effectively:
|
||||||
|
|
||||||
1. **Information tool**:
|
1. **Information tool**:
|
||||||
- Retrieves data about movies or individuals, ensuring the agent has access to the latest and most relevant information.
|
- Retrieves data about movies or individuals, ensuring the agent has access to the latest and most relevant information.
|
||||||
|
|||||||
@ -1,10 +1,14 @@
|
|||||||
# neo4j-semantic-ollama
|
# Neo4j, Ollama - Semantic Layer
|
||||||
|
|
||||||
This template is designed to implement an agent capable of interacting with a graph database like Neo4j through a semantic layer using Mixtral as a JSON-based agent.
|
This template is designed to implement an agent capable of interacting with a
|
||||||
The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph database based on the user's intent.
|
graph database like `Neo4j` through a semantic layer using `Mixtral` as
|
||||||
Learn more about the semantic layer template in the [corresponding blog post](https://medium.com/towards-data-science/enhancing-interaction-between-language-models-and-graph-databases-via-a-semantic-layer-0a78ad3eba49) and specifically about [Mixtral agents with Ollama](https://blog.langchain.dev/json-based-agents-with-ollama-and-langchain/).
|
a JSON-based agent.
|
||||||
|
The semantic layer equips the agent with a suite of robust tools,
|
||||||
|
allowing it to interact with the graph database based on the user's intent.
|
||||||
|
Learn more about the semantic layer template in the
|
||||||
|
[corresponding blog post](https://medium.com/towards-data-science/enhancing-interaction-between-language-models-and-graph-databases-via-a-semantic-layer-0a78ad3eba49) and specifically about [Mixtral agents with `Ollama` package](https://blog.langchain.dev/json-based-agents-with-ollama-and-langchain/).
|
||||||
|
|
||||||

|
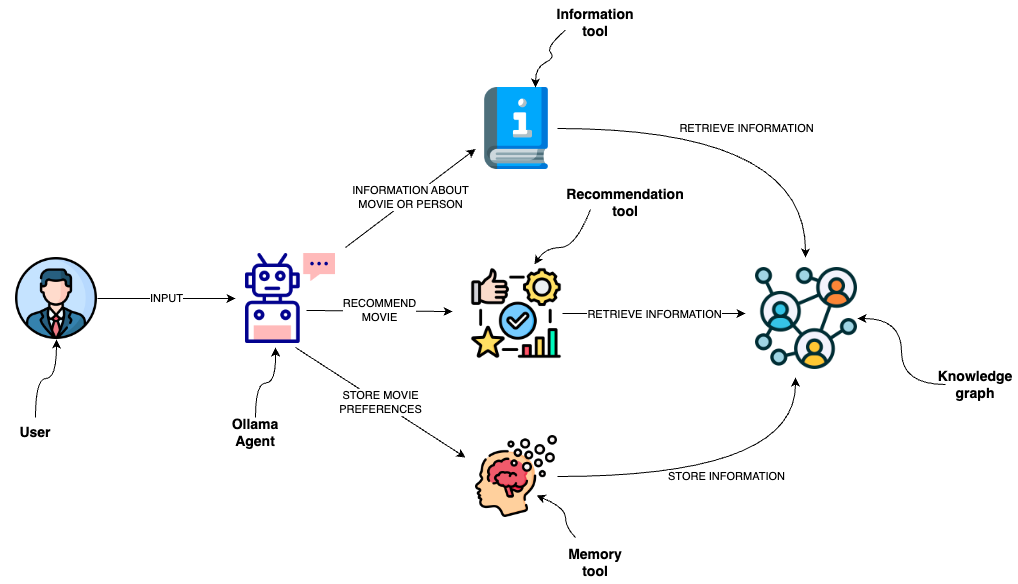 "Neo4j Semantic Layer Workflow Diagram"
|
||||||
|
|
||||||
## Tools
|
## Tools
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,14 @@
|
|||||||
|
# Neo4j - vector memory
|
||||||
|
|
||||||
# neo4j-vector-memory
|
This template allows you to integrate an LLM with a vector-based
|
||||||
|
retrieval system using `Neo4j` as the vector store.
|
||||||
|
|
||||||
This template allows you to integrate an LLM with a vector-based retrieval system using Neo4j as the vector store.
|
Additionally, it uses the graph capabilities of the `Neo4j` database to
|
||||||
Additionally, it uses the graph capabilities of the Neo4j database to store and retrieve the dialogue history of a specific user's session.
|
store and retrieve the dialogue history of a specific user's session.
|
||||||
Having the dialogue history stored as a graph allows for seamless conversational flows but also gives you the ability to analyze user behavior and text chunk retrieval through graph analytics.
|
|
||||||
|
Having the dialogue history stored as a graph allows for
|
||||||
|
seamless conversational flows but also gives you the ability
|
||||||
|
to analyze user behavior and text chunk retrieval through graph analytics.
|
||||||
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
|
# Nvidia, Milvus - canonical RAG
|
||||||
|
|
||||||
# nvidia-rag-canonical
|
This template performs RAG using `Milvus` Vector Store
|
||||||
|
and `NVIDIA` Models (Embedding and Chat).
|
||||||
This template performs RAG using Milvus Vector Store and NVIDIA Models (Embedding and Chat).
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,12 +1,18 @@
|
|||||||
# OpenAI Functions Agent - Gmail
|
# OpenAI functions - Gmail agent
|
||||||
|
|
||||||
Ever struggled to reach inbox zero?
|
Ever struggled to reach inbox zero?
|
||||||
|
|
||||||
Using this template, you can create and customize your very own AI assistant to manage your Gmail account. Using the default Gmail tools, it can read, search through, and draft emails to respond on your behalf. It also has access to a Tavily search engine so it can search for relevant information about any topics or people in the email thread before writing, ensuring the drafts include all the relevant information needed to sound well-informed.
|
Using this template, you can create and customize your very own AI assistant
|
||||||
|
to manage your `Gmail` account. Using the default `Gmail` tools,
|
||||||
|
it can read, search through, and draft emails to respond on your behalf.
|
||||||
|
It also has access to a `Tavily` search engine so it can search for
|
||||||
|
relevant information about any topics or people in the email
|
||||||
|
thread before writing, ensuring the drafts include all
|
||||||
|
the relevant information needed to sound well-informed.
|
||||||
|
|
||||||

|
 "Gmail Agent Playground Interface"
|
||||||
|
|
||||||
## The details
|
## Details
|
||||||
|
|
||||||
This assistant uses OpenAI's [function calling](https://python.langchain.com/docs/modules/chains/how_to/openai_functions) support to reliably select and invoke the tools you've provided
|
This assistant uses OpenAI's [function calling](https://python.langchain.com/docs/modules/chains/how_to/openai_functions) support to reliably select and invoke the tools you've provided
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
[tool.poetry]
|
[tool.poetry]
|
||||||
name = "openai-functions-agent-gmail"
|
name = "openai-functions-agent-gmail"
|
||||||
version = "0.1.0"
|
version = "0.1.0"
|
||||||
description = "Agent using OpenAI function calling to execute functions, including search"
|
description = "Agent using OpenAI function calling to execute functions, including Gmail managing"
|
||||||
authors = [
|
authors = [
|
||||||
"Lance Martin <lance@langchain.dev>",
|
"Lance Martin <lance@langchain.dev>",
|
||||||
]
|
]
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# OpenAI functions - agent
|
||||||
|
|
||||||
# openai-functions-agent
|
This template creates an agent that uses `OpenAI function calling` to communicate its decisions on what actions to take.
|
||||||
|
|
||||||
This template creates an agent that uses OpenAI function calling to communicate its decisions on what actions to take.
|
This example creates an agent that can optionally look up information on the internet using `Tavily`'s search engine.
|
||||||
|
|
||||||
This example creates an agent that can optionally look up information on the internet using Tavily's search engine.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# openai-functions-tool-retrieval-agent
|
# OpenAI functions - tool retrieval agent
|
||||||
|
|
||||||
The novel idea introduced in this template is the idea of using retrieval to select the set of tools to use to answer an agent query. This is useful when you have many many tools to select from. You cannot put the description of all the tools in the prompt (because of context length issues) so instead you dynamically select the N tools you do want to consider using at run time.
|
The novel idea introduced in this template is the idea of using retrieval to select the set of tools to use to answer an agent query. This is useful when you have many many tools to select from. You cannot put the description of all the tools in the prompt (because of context length issues) so instead you dynamically select the N tools you do want to consider using at run time.
|
||||||
|
|
||||||
@ -10,9 +10,9 @@ This template is based on [this Agent How-To](https://python.langchain.com/v0.2/
|
|||||||
|
|
||||||
The following environment variables need to be set:
|
The following environment variables need to be set:
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the `OpenAI` models.
|
||||||
|
|
||||||
Set the `TAVILY_API_KEY` environment variable to access Tavily.
|
Set the `TAVILY_API_KEY` environment variable to access `Tavily`.
|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,10 @@
|
|||||||
# pii-protected-chatbot
|
# PII-protected chatbot
|
||||||
|
|
||||||
This template creates a chatbot that flags any incoming PII and doesn't pass it to the LLM.
|
This template creates a chatbot that flags any incoming
|
||||||
|
`Personal Identification Information` (`PII`) and doesn't pass it to the LLM.
|
||||||
|
|
||||||
|
It uses the [Microsoft Presidio](https://microsoft.github.io/presidio/),
|
||||||
|
the Data Protection and De-identification SDK.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# pirate-speak-configurable
|
# Pirate speak configurable
|
||||||
|
|
||||||
This template converts user input into pirate speak. It shows how you can allow
|
This template converts user input into pirate speak. It shows how you can allow
|
||||||
`configurable_alternatives` in the Runnable, allowing you to select from
|
`configurable_alternatives` in the Runnable, allowing you to select from
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# Pirate speak
|
||||||
|
|
||||||
# pirate-speak
|
This template converts user input into `pirate speak`.
|
||||||
|
|
||||||
This template converts user input into pirate speak.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,11 +1,10 @@
|
|||||||
|
# Plate chain
|
||||||
|
|
||||||
# plate-chain
|
This template enables parsing of data from `laboratory plates`.
|
||||||
|
|
||||||
This template enables parsing of data from laboratory plates.
|
|
||||||
|
|
||||||
In the context of biochemistry or molecular biology, laboratory plates are commonly used tools to hold samples in a grid-like format.
|
In the context of biochemistry or molecular biology, laboratory plates are commonly used tools to hold samples in a grid-like format.
|
||||||
|
|
||||||
This can parse the resulting data into standardized (e.g., JSON) format for further processing.
|
This can parse the resulting data into standardized (e.g., `JSON`) format for further processing.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
# propositional-retrieval
|
# Propositional retrieval
|
||||||
|
|
||||||
This template demonstrates the multi-vector indexing strategy proposed by Chen, et. al.'s [Dense X Retrieval: What Retrieval Granularity Should We Use?](https://arxiv.org/abs/2312.06648). The prompt, which you can [try out on the hub](https://smith.langchain.com/hub/wfh/proposal-indexing), directs an LLM to generate de-contextualized "propositions" which can be vectorized to increase the retrieval accuracy. You can see the full definition in `proposal_chain.py`.
|
This template demonstrates the multi-vector indexing strategy proposed by Chen, et. al.'s [Dense X Retrieval: What Retrieval Granularity Should We Use?](https://arxiv.org/abs/2312.06648). The prompt, which you can [try out on the hub](https://smith.langchain.com/hub/wfh/proposal-indexing), directs an LLM to generate de-contextualized "propositions" which can be vectorized to increase the retrieval accuracy. You can see the full definition in `proposal_chain.py`.
|
||||||
|
|
||||||

|
 "Retriever Diagram"
|
||||||
|
|
||||||
## Storage
|
## Storage
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,7 @@
|
|||||||
# python-lint
|
# Python linting
|
||||||
|
|
||||||
This agent specializes in generating high-quality Python code with a focus on proper formatting and linting. It uses `black`, `ruff`, and `mypy` to ensure the code meets standard quality checks.
|
This agent specializes in generating high-quality `Python` code with
|
||||||
|
a focus on proper formatting and linting. It uses `black`, `ruff`, and `mypy` to ensure the code meets standard quality checks.
|
||||||
|
|
||||||
This streamlines the coding process by integrating and responding to these checks, resulting in reliable and consistent code output.
|
This streamlines the coding process by integrating and responding to these checks, resulting in reliable and consistent code output.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - AstraDB
|
||||||
|
|
||||||
# rag-astradb
|
This template will perform RAG using `AstraDB` (`AstraDB` vector store class)
|
||||||
|
|
||||||
This template will perform RAG using Astra DB (`AstraDB` vector store class)
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - AWS Bedrock
|
||||||
|
|
||||||
# rag-aws-bedrock
|
This template is designed to connect with the `AWS Bedrock` service, a managed server that offers a set of foundation models.
|
||||||
|
|
||||||
This template is designed to connect with the AWS Bedrock service, a managed server that offers a set of foundation models.
|
|
||||||
|
|
||||||
It primarily uses the `Anthropic Claude` for text generation and `Amazon Titan` for text embedding, and utilizes FAISS as the vectorstore.
|
It primarily uses the `Anthropic Claude` for text generation and `Amazon Titan` for text embedding, and utilizes FAISS as the vectorstore.
|
||||||
|
|
||||||
|
|||||||
@ -1,10 +1,14 @@
|
|||||||
# rag-aws-kendra
|
# RAG - AWS Kendra
|
||||||
|
|
||||||
This template is an application that utilizes Amazon Kendra, a machine learning powered search service, and Anthropic Claude for text generation. The application retrieves documents using a Retrieval chain to answer questions from your documents.
|
This template is an application that utilizes `Amazon Kendra`,
|
||||||
|
a machine learning powered search service,
|
||||||
|
and `Anthropic Claude` for text generation.
|
||||||
|
The application retrieves documents using a Retrieval chain to answer
|
||||||
|
questions from your documents.
|
||||||
|
|
||||||
It uses the `boto3` library to connect with the Bedrock service.
|
It uses the `boto3` library to connect with the `Bedrock` service.
|
||||||
|
|
||||||
For more context on building RAG applications with Amazon Kendra, check [this page](https://aws.amazon.com/blogs/machine-learning/quickly-build-high-accuracy-generative-ai-applications-on-enterprise-data-using-amazon-kendra-langchain-and-large-language-models/).
|
For more context on building RAG applications with `Amazon Kendra`, check [this page](https://aws.amazon.com/blogs/machine-learning/quickly-build-high-accuracy-generative-ai-applications-on-enterprise-data-using-amazon-kendra-langchain-and-large-language-models/).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
# rag-azure-search
|
# RAG - Azure AI Search
|
||||||
|
|
||||||
This template performs RAG on documents using [Azure AI Search](https://learn.microsoft.com/azure/search/search-what-is-azure-search) as the vectorstore and Azure OpenAI chat and embedding models.
|
This template performs RAG on documents using [Azure AI Search](https://learn.microsoft.com/azure/search/search-what-is-azure-search) as the vectorstore and Azure OpenAI chat and embedding models.
|
||||||
|
|
||||||
For additional details on RAG with Azure AI Search, refer to [this notebook](https://github.com/langchain-ai/langchain/blob/master/docs/docs/integrations/vectorstores/azuresearch.ipynb).
|
For additional details on RAG with `Azure AI Search`, refer to [this notebook](https://github.com/langchain-ai/langchain/blob/master/docs/docs/integrations/vectorstores/azuresearch.ipynb).
|
||||||
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|||||||
@ -1,15 +1,18 @@
|
|||||||
|
# RAG - Chroma multi-modal multi-vector
|
||||||
|
|
||||||
# rag-chroma-multi-modal-multi-vector
|
`Multi-modal LLMs` enable visual assistants that can perform
|
||||||
|
question-answering about images.
|
||||||
|
|
||||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
This template create a visual assistant for slide decks,
|
||||||
|
which often contain visuals such as graphs or figures.
|
||||||
|
|
||||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
It uses `GPT-4V` to create image summaries for each slide,
|
||||||
|
embeds the summaries, and stores them in `Chroma`.
|
||||||
It uses GPT-4V to create image summaries for each slide, embeds the summaries, and stores them in Chroma.
|
|
||||||
|
|
||||||
Given a question, relevant slides are retrieved and passed to GPT-4V for answer synthesis.
|
Given a question, relevant slides are retrieved and passed
|
||||||
|
to GPT-4V for answer synthesis.
|
||||||
|
|
||||||

|
 "Multi-modal LLM Process Diagram"
|
||||||
|
|
||||||
## Input
|
## Input
|
||||||
|
|
||||||
|
|||||||
@ -1,15 +1,14 @@
|
|||||||
|
# RAG - Chroma multi-modal
|
||||||
# rag-chroma-multi-modal
|
|
||||||
|
|
||||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||||
|
|
||||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||||
|
|
||||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
It uses `OpenCLIP` embeddings to embed all the slide images and stores them in `Chroma`.
|
||||||
|
|
||||||
Given a question, relevant slides are retrieved and passed to GPT-4V for answer synthesis.
|
Given a question, relevant slides are retrieved and passed to `GPT-4V` for answer synthesis.
|
||||||
|
|
||||||

|
 "Workflow Diagram for Multi-modal LLM Visual Assistant"
|
||||||
|
|
||||||
## Input
|
## Input
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - Chroma, Ollama, Gpt4all - private
|
||||||
# rag-chroma-private
|
|
||||||
|
|
||||||
This template performs RAG with no reliance on external APIs.
|
This template performs RAG with no reliance on external APIs.
|
||||||
|
|
||||||
It utilizes Ollama the LLM, GPT4All for embeddings, and Chroma for the vectorstore.
|
It utilizes `Ollama` the LLM, `GPT4All` for embeddings, and `Chroma` for the vectorstore.
|
||||||
|
|
||||||
The vectorstore is created in `chain.py` and by default indexes a [popular blog posts on Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) for question-answering.
|
The vectorstore is created in `chain.py` and by default indexes a [popular blog posts on Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) for question-answering.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Chroma
|
||||||
|
|
||||||
# rag-chroma
|
This template performs RAG using `Chroma` and `OpenAI`.
|
||||||
|
|
||||||
This template performs RAG using Chroma and OpenAI.
|
|
||||||
|
|
||||||
The vectorstore is created in `chain.py` and by default indexes a [popular blog posts on Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) for question-answering.
|
The vectorstore is created in `chain.py` and by default indexes a [popular blog posts on Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) for question-answering.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - codellama, Fireworks
|
||||||
# rag-codellama-fireworks
|
|
||||||
|
|
||||||
This template performs RAG on a codebase.
|
This template performs RAG on a codebase.
|
||||||
|
|
||||||
It uses codellama-34b hosted by Fireworks' [LLM inference API](https://blog.fireworks.ai/accelerating-code-completion-with-fireworks-fast-llm-inference-f4e8b5ec534a).
|
It uses `codellama-34b` hosted by `Fireworks` [LLM inference API](https://blog.fireworks.ai/accelerating-code-completion-with-fireworks-fast-llm-inference-f4e8b5ec534a).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# rag-conversation-zep
|
# RAG - Zep - conversation
|
||||||
|
|
||||||
This template demonstrates building a RAG conversation app using Zep.
|
This template demonstrates building a RAG conversation app using `Zep`.
|
||||||
|
|
||||||
Included in this template:
|
Included in this template:
|
||||||
- Populating a [Zep Document Collection](https://docs.getzep.com/sdk/documents/) with a set of documents (a Collection is analogous to an index in other Vector Databases).
|
- Populating a [Zep Document Collection](https://docs.getzep.com/sdk/documents/) with a set of documents (a Collection is analogous to an index in other Vector Databases).
|
||||||
@ -9,12 +9,15 @@ Included in this template:
|
|||||||
- Prompts, a simple chat history data structure, and other components required to build a RAG conversation app.
|
- Prompts, a simple chat history data structure, and other components required to build a RAG conversation app.
|
||||||
- The RAG conversation chain.
|
- The RAG conversation chain.
|
||||||
|
|
||||||
## About [Zep - Fast, scalable building blocks for LLM Apps](https://www.getzep.com/)
|
## About Zep
|
||||||
|
|
||||||
|
[Zep - Fast, scalable building blocks for LLM Apps](https://www.getzep.com/)
|
||||||
|
|
||||||
Zep is an open source platform for productionizing LLM apps. Go from a prototype built in LangChain or LlamaIndex, or a custom app, to production in minutes without rewriting code.
|
Zep is an open source platform for productionizing LLM apps. Go from a prototype built in LangChain or LlamaIndex, or a custom app, to production in minutes without rewriting code.
|
||||||
|
|
||||||
Key Features:
|
Key Features:
|
||||||
|
|
||||||
- Fast! Zep’s async extractors operate independently of the your chat loop, ensuring a snappy user experience.
|
- Fast! Zep’s async extractors operate independently of the chat loop, ensuring a snappy user experience.
|
||||||
- Long-term memory persistence, with access to historical messages irrespective of your summarization strategy.
|
- Long-term memory persistence, with access to historical messages irrespective of your summarization strategy.
|
||||||
- Auto-summarization of memory messages based on a configurable message window. A series of summaries are stored, providing flexibility for future summarization strategies.
|
- Auto-summarization of memory messages based on a configurable message window. A series of summaries are stored, providing flexibility for future summarization strategies.
|
||||||
- Hybrid search over memories and metadata, with messages automatically embedded on creation.
|
- Hybrid search over memories and metadata, with messages automatically embedded on creation.
|
||||||
@ -22,7 +25,7 @@ Key Features:
|
|||||||
- Auto-token counting of memories and summaries, allowing finer-grained control over prompt assembly.
|
- Auto-token counting of memories and summaries, allowing finer-grained control over prompt assembly.
|
||||||
- Python and JavaScript SDKs.
|
- Python and JavaScript SDKs.
|
||||||
|
|
||||||
Zep project: https://github.com/getzep/zep | Docs: https://docs.getzep.com/
|
`Zep` project: https://github.com/getzep/zep | Docs: https://docs.getzep.com/
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# RAG - Pinecone - conversation
|
||||||
# rag-conversation
|
|
||||||
|
|
||||||
This template is used for [conversational](https://python.langchain.com/docs/expression_language/cookbook/retrieval#conversational-retrieval-chain) [retrieval](https://python.langchain.com/docs/use_cases/question_answering/), which is one of the most popular LLM use-cases.
|
This template is used for [conversational](https://python.langchain.com/docs/expression_language/cookbook/retrieval#conversational-retrieval-chain) [retrieval](https://python.langchain.com/docs/use_cases/question_answering/), which is one of the most popular LLM use-cases.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - Elasticsearch
|
||||||
# rag-elasticsearch
|
|
||||||
|
|
||||||
This template performs RAG using [Elasticsearch](https://python.langchain.com/docs/integrations/vectorstores/elasticsearch).
|
This template performs RAG using [Elasticsearch](https://python.langchain.com/docs/integrations/vectorstores/elasticsearch).
|
||||||
|
|
||||||
It relies on sentence transformer `MiniLM-L6-v2` for embedding passages and questions.
|
It relies on `Hugging Face sentence transformer` `MiniLM-L6-v2` for embedding passages and questions.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,12 @@
|
|||||||
|
# RAG - Pinecone - fusion
|
||||||
|
|
||||||
# rag-fusion
|
This template enables `RAG fusion` using a re-implementation of
|
||||||
|
the project found [here](https://github.com/Raudaschl/rag-fusion).
|
||||||
|
|
||||||
This template enables RAG fusion using a re-implementation of the project found [here](https://github.com/Raudaschl/rag-fusion).
|
It performs multiple query generation and `Reciprocal Rank Fusion`
|
||||||
|
to re-rank search results.
|
||||||
|
|
||||||
It performs multiple query generation and Reciprocal Rank Fusion to re-rank search results.
|
It uses the `Pinecone` vectorstore and the `OpenAI` chat and embedding models.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,15 +1,14 @@
|
|||||||
|
# RAG - Gemini multi-modal
|
||||||
# rag-gemini-multi-modal
|
|
||||||
|
|
||||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||||
|
|
||||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||||
|
|
||||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
It uses `OpenCLIP` embeddings to embed all the slide images and stores them in Chroma.
|
||||||
|
|
||||||
Given a question, relevant slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
Given a question, relevant slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||||
|
|
||||||

|
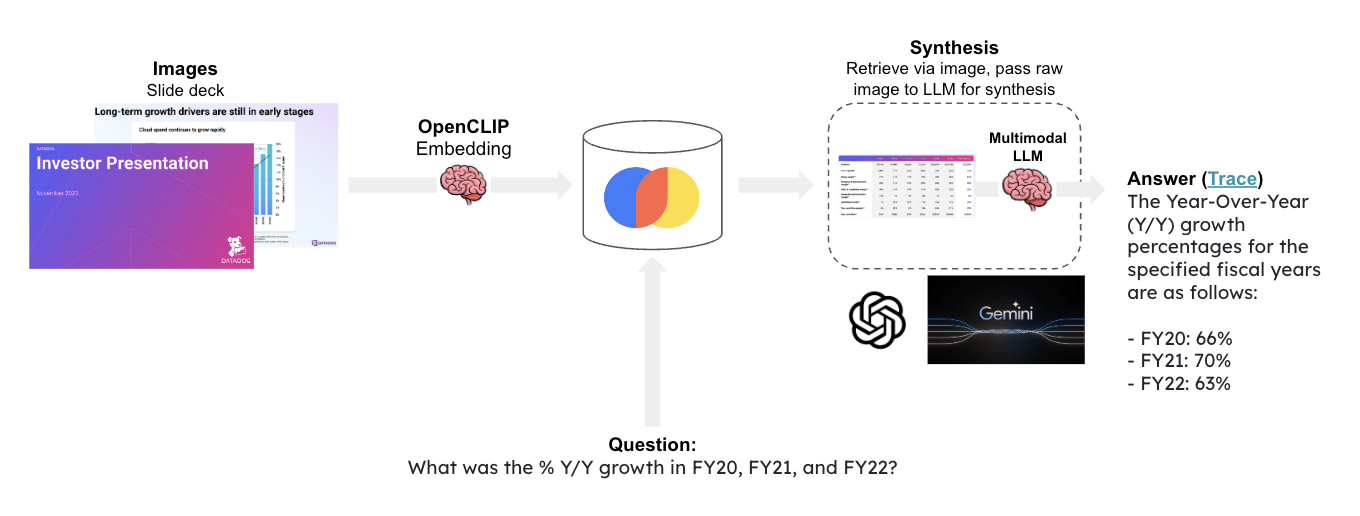 "Workflow Diagram for Visual Assistant Using Multi-modal LLM"
|
||||||
|
|
||||||
## Input
|
## Input
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,9 @@
|
|||||||
# rag-google-cloud-sensitive-data-protection
|
# RAG - Google Cloud Sensitive Data Protection
|
||||||
|
|
||||||
This template is an application that utilizes Google Vertex AI Search, a machine learning powered search service, and
|
This template is an application that utilizes `Google Vertex AI Search`, a machine learning powered search service, and
|
||||||
PaLM 2 for Chat (chat-bison). The application uses a Retrieval chain to answer questions based on your documents.
|
PaLM 2 for Chat (chat-bison). The application uses a Retrieval chain to answer questions based on your documents.
|
||||||
|
|
||||||
This template is an application that utilizes Google Sensitive Data Protection, a service for detecting and redacting
|
This template is an application that utilizes `Google Sensitive Data Protection`, a service for detecting and redacting
|
||||||
sensitive data in text, and PaLM 2 for Chat (chat-bison), although you can use any model.
|
sensitive data in text, and PaLM 2 for Chat (chat-bison), although you can use any model.
|
||||||
|
|
||||||
For more context on using Sensitive Data Protection,
|
For more context on using Sensitive Data Protection,
|
||||||
|
|||||||
@ -1,9 +1,10 @@
|
|||||||
# rag-google-cloud-vertexai-search
|
# RAG - Google Cloud Vertex AI Search
|
||||||
|
|
||||||
This template is an application that utilizes Google Vertex AI Search, a machine learning powered search service, and
|
This template is an application that utilizes `Google Vertex AI Search`,
|
||||||
|
a machine learning powered search service, and
|
||||||
PaLM 2 for Chat (chat-bison). The application uses a Retrieval chain to answer questions based on your documents.
|
PaLM 2 for Chat (chat-bison). The application uses a Retrieval chain to answer questions based on your documents.
|
||||||
|
|
||||||
For more context on building RAG applications with Vertex AI Search,
|
For more context on building RAG applications with `Vertex AI Search`,
|
||||||
check [here](https://cloud.google.com/generative-ai-app-builder/docs/enterprise-search-introduction).
|
check [here](https://cloud.google.com/generative-ai-app-builder/docs/enterprise-search-introduction).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - GPT-crawler
|
||||||
|
|
||||||
# rag-gpt-crawler
|
`GPT-crawler` crawls websites to produce files for use in custom GPTs or other apps (RAG).
|
||||||
|
|
||||||
GPT-crawler will crawl websites to produce files for use in custom GPTs or other apps (RAG).
|
|
||||||
|
|
||||||
This template uses [gpt-crawler](https://github.com/BuilderIO/gpt-crawler) to build a RAG app
|
This template uses [gpt-crawler](https://github.com/BuilderIO/gpt-crawler) to build a RAG app
|
||||||
|
|
||||||
@ -11,7 +10,7 @@ Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
|||||||
|
|
||||||
## Crawling
|
## Crawling
|
||||||
|
|
||||||
Run GPT-crawler to extact content from a set of urls, using the config file in GPT-crawler repo.
|
Run GPT-crawler to extract content from a set of urls, using the config file in GPT-crawler repo.
|
||||||
|
|
||||||
Here is example config for LangChain use-case docs:
|
Here is example config for LangChain use-case docs:
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - JaguarDB
|
||||||
|
|
||||||
# rag-jaguardb
|
This template performs RAG using `JaguarDB` and OpenAI.
|
||||||
|
|
||||||
This template performs RAG using JaguarDB and OpenAI.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
[tool.poetry]
|
[tool.poetry]
|
||||||
name = "rag-jaguardb"
|
name = "rag-jaguardb"
|
||||||
version = "0.1.0"
|
version = "0.1.0"
|
||||||
description = "RAG w/ JaguarDB"
|
description = "RAG with JaguarDB"
|
||||||
authors = [
|
authors = [
|
||||||
"Daniel Ung <daniel.ung@sjsu.edu>",
|
"Daniel Ung <daniel.ung@sjsu.edu>",
|
||||||
]
|
]
|
||||||
|
|||||||
@ -1,8 +1,9 @@
|
|||||||
# rag-lancedb
|
# RAG - LanceDB
|
||||||
|
|
||||||
This template performs RAG using LanceDB and OpenAI.
|
This template performs RAG using `LanceDB` and `OpenAI`.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Lantern
|
||||||
|
|
||||||
# rag_lantern
|
This template performs RAG with `Lantern`.
|
||||||
|
|
||||||
This template performs RAG with Lantern.
|
|
||||||
|
|
||||||
[Lantern](https://lantern.dev) is an open-source vector database built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL). It enables vector search and embedding generation inside your database.
|
[Lantern](https://lantern.dev) is an open-source vector database built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL). It enables vector search and embedding generation inside your database.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - Google Cloud Matching Engine
|
||||||
|
|
||||||
# rag-matching-engine
|
This template performs RAG using [Google Cloud Vertex Matching Engine](https://cloud.google.com/blog/products/ai-machine-learning/vertex-matching-engine-blazing-fast-and-massively-scalable-nearest-neighbor-search).
|
||||||
|
|
||||||
This template performs RAG using Google Cloud Platform's Vertex AI with the matching engine.
|
It utilizes a previously created index to retrieve relevant documents or contexts based on user-provided questions.
|
||||||
|
|
||||||
It will utilize a previously created index to retrieve relevant documents or contexts based on user-provided questions.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
[tool.poetry]
|
[tool.poetry]
|
||||||
name = "rag-matching-engine"
|
name = "rag-matching-engine"
|
||||||
version = "0.0.1"
|
version = "0.0.1"
|
||||||
description = "RAG using Google Cloud Platform's Vertex AI"
|
description = "RAG using Google Cloud Platform's Vertex AI Matching Engine"
|
||||||
authors = ["Leonid Kuligin"]
|
authors = ["Leonid Kuligin"]
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# rag-milvus
|
# RAG - Milvus
|
||||||
|
|
||||||
This template performs RAG using Milvus and OpenAI.
|
This template performs RAG using `Milvus` and `OpenAI`.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# rag-momento-vector-index
|
# RAG - Momento Vector Index
|
||||||
|
|
||||||
This template performs RAG using Momento Vector Index (MVI) and OpenAI.
|
This template performs RAG using `Momento Vector Index` (`MVI`) and `OpenAI`.
|
||||||
|
|
||||||
> MVI: the most productive, easiest to use, serverless vector index for your data. To get started with MVI, simply sign up for an account. There's no need to handle infrastructure, manage servers, or be concerned about scaling. MVI is a service that scales automatically to meet your needs. Combine with other Momento services such as Momento Cache to cache prompts and as a session store or Momento Topics as a pub/sub system to broadcast events to your application.
|
> MVI: the most productive, easiest to use, serverless vector index for your data. To get started with MVI, simply sign up for an account. There's no need to handle infrastructure, manage servers, or be concerned about scaling. MVI is a service that scales automatically to meet your needs. Combine with other Momento services such as Momento Cache to cache prompts and as a session store or Momento Topics as a pub/sub system to broadcast events to your application.
|
||||||
|
|
||||||
@ -8,7 +8,7 @@ To sign up and access MVI, visit the [Momento Console](https://console.gomomento
|
|||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
This template uses Momento Vector Index as a vectorstore and requires that `MOMENTO_API_KEY`, and `MOMENTO_INDEX_NAME` are set.
|
This template uses `Momento Vector Index` as a vectorstore and requires that `MOMENTO_API_KEY`, and `MOMENTO_INDEX_NAME` are set.
|
||||||
|
|
||||||
Go to the [console](https://console.gomomento.com/) to get an API key.
|
Go to the [console](https://console.gomomento.com/) to get an API key.
|
||||||
|
|
||||||
|
|||||||
@ -1,11 +1,10 @@
|
|||||||
|
# RAG - MongoDB
|
||||||
|
|
||||||
# rag-mongo
|
This template performs RAG using `MongoDB` and `OpenAI`.
|
||||||
|
|
||||||
This template performs RAG using MongoDB and OpenAI.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
You should export two environment variables, one being your MongoDB URI, the other being your OpenAI API KEY.
|
You should export two environment variables, one being your `MongoDB` URI, the other being your OpenAI API KEY.
|
||||||
If you do not have a MongoDB URI, see the `Setup Mongo` section at the bottom for instructions on how to do so.
|
If you do not have a MongoDB URI, see the `Setup Mongo` section at the bottom for instructions on how to do so.
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
@ -97,15 +96,15 @@ We will first follow the standard MongoDB Atlas setup instructions [here](https:
|
|||||||
|
|
||||||
This can be done by going to the deployment overview page and connecting to you database
|
This can be done by going to the deployment overview page and connecting to you database
|
||||||
|
|
||||||

|
 "MongoDB Atlas Connect Button"
|
||||||
|
|
||||||
We then look at the drivers available
|
We then look at the drivers available
|
||||||
|
|
||||||

|
 "MongoDB Atlas Drivers Section"
|
||||||
|
|
||||||
Among which we will see our URI listed
|
Among which we will see our URI listed
|
||||||
|
|
||||||

|
 "MongoDB URI Example"
|
||||||
|
|
||||||
Let's then set that as an environment variable locally:
|
Let's then set that as an environment variable locally:
|
||||||
|
|
||||||
@ -131,23 +130,23 @@ Note that you can (and should!) change this to ingest data of your choice
|
|||||||
|
|
||||||
We can first connect to the cluster where our database lives
|
We can first connect to the cluster where our database lives
|
||||||
|
|
||||||

|
 "MongoDB Atlas Cluster Overview"
|
||||||
|
|
||||||
We can then navigate to where all our collections are listed
|
We can then navigate to where all our collections are listed
|
||||||
|
|
||||||

|
 "MongoDB Atlas Collections Overview"
|
||||||
|
|
||||||
We can then find the collection we want and look at the search indexes for that collection
|
We can then find the collection we want and look at the search indexes for that collection
|
||||||
|
|
||||||

|
 "MongoDB Atlas Search Indexes"
|
||||||
|
|
||||||
That should likely be empty, and we want to create a new one:
|
That should likely be empty, and we want to create a new one:
|
||||||
|
|
||||||

|
 "MongoDB Atlas Create Index Button"
|
||||||
|
|
||||||
We will use the JSON editor to create it
|
We will use the JSON editor to create it
|
||||||
|
|
||||||

|
 "MongoDB Atlas JSON Editor Option"
|
||||||
|
|
||||||
And we will paste the following JSON in:
|
And we will paste the following JSON in:
|
||||||
|
|
||||||
@ -165,6 +164,6 @@ And we will paste the following JSON in:
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||

|
 "MongoDB Atlas Search Index JSON Configuration"
|
||||||
|
|
||||||
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!
|
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!
|
||||||
@ -1,4 +1,4 @@
|
|||||||
# RAG with Multiple Indexes (Fusion)
|
# RAG - multiple indexes (Fusion)
|
||||||
|
|
||||||
A QA application that queries multiple domain-specific retrievers and selects the most relevant documents from across all retrieved results.
|
A QA application that queries multiple domain-specific retrievers and selects the most relevant documents from across all retrieved results.
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# RAG with Multiple Indexes (Routing)
|
# RAG - multiple indexes (Routing)
|
||||||
|
|
||||||
A QA application that routes between different domain-specific retrievers given a user question.
|
A QA application that routes between different domain-specific retrievers given a user question.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Ollama, Nomic, Chroma - multi-modal, local
|
||||||
|
|
||||||
# rag-multi-modal-local
|
Visual search is a familiar application to many with iPhones or Android devices. It allows user to search photos using natural language.
|
||||||
|
|
||||||
Visual search is a famililar application to many with iPhones or Android devices. It allows user to search photos using natural language.
|
|
||||||
|
|
||||||
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
||||||
|
|
||||||
@ -11,7 +10,7 @@ It uses [`nomic-embed-vision-v1`](https://huggingface.co/nomic-ai/nomic-embed-vi
|
|||||||
|
|
||||||
Given a question, relevant photos are retrieved and passed to an open source multi-modal LLM of your choice for answer synthesis.
|
Given a question, relevant photos are retrieved and passed to an open source multi-modal LLM of your choice for answer synthesis.
|
||||||
|
|
||||||

|
 "Visual Search Process Diagram"
|
||||||
|
|
||||||
## Input
|
## Input
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Ollama, Chroma - multi-modal, multi-vector, local
|
||||||
|
|
||||||
# rag-multi-modal-mv-local
|
Visual search is a familiar application to many with iPhones or Android devices. It allows user to search photos using natural language.
|
||||||
|
|
||||||
Visual search is a famililar application to many with iPhones or Android devices. It allows user to search photos using natural language.
|
|
||||||
|
|
||||||
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
||||||
|
|
||||||
@ -11,7 +10,7 @@ It uses an open source multi-modal LLM of your choice to create image summaries
|
|||||||
|
|
||||||
Given a question, relevant photos are retrieved and passed to the multi-modal LLM for answer synthesis.
|
Given a question, relevant photos are retrieved and passed to the multi-modal LLM for answer synthesis.
|
||||||
|
|
||||||

|
 "Visual Search Process Diagram"
|
||||||
|
|
||||||
## Input
|
## Input
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - Ollama - multi-query
|
||||||
|
|
||||||
# rag-ollama-multi-query
|
This template performs RAG using `Ollama` and `OpenAI` with a multi-query retriever.
|
||||||
|
|
||||||
This template performs RAG using Ollama and OpenAI with a multi-query retriever.
|
The `multi-query retriever` is an example of query transformation, generating multiple queries from different perspectives based on the user's input query.
|
||||||
|
|
||||||
The multi-query retriever is an example of query transformation, generating multiple queries from different perspectives based on the user's input query.
|
|
||||||
|
|
||||||
For each query, it retrieves a set of relevant documents and takes the unique union across all queries for answer synthesis.
|
For each query, it retrieves a set of relevant documents and takes the unique union across all queries for answer synthesis.
|
||||||
|
|
||||||
@ -11,7 +10,7 @@ We use a private, local LLM for the narrow task of query generation to avoid exc
|
|||||||
|
|
||||||
See an example trace for Ollama LLM performing the query expansion [here](https://smith.langchain.com/public/8017d04d-2045-4089-b47f-f2d66393a999/r).
|
See an example trace for Ollama LLM performing the query expansion [here](https://smith.langchain.com/public/8017d04d-2045-4089-b47f-f2d66393a999/r).
|
||||||
|
|
||||||
But we use OpenAI for the more challenging task of answer syntesis (full trace example [here](https://smith.langchain.com/public/ec75793b-645b-498d-b855-e8d85e1f6738/r)).
|
But we use OpenAI for the more challenging task of answer synthesis (full trace example [here](https://smith.langchain.com/public/ec75793b-645b-498d-b855-e8d85e1f6738/r)).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# rag-opensearch
|
# RAG - OpenSearch
|
||||||
|
|
||||||
This Template performs RAG using [OpenSearch](https://python.langchain.com/docs/integrations/vectorstores/opensearch).
|
This template performs RAG using [OpenSearch](https://python.langchain.com/docs/integrations/vectorstores/opensearch).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Pinecone - multi-query
|
||||||
|
|
||||||
# rag-pinecone-multi-query
|
This template performs RAG using `Pinecone` and `OpenAI` with a multi-query retriever.
|
||||||
|
|
||||||
This template performs RAG using Pinecone and OpenAI with a multi-query retriever.
|
|
||||||
|
|
||||||
It uses an LLM to generate multiple queries from different perspectives based on the user's input query.
|
It uses an LLM to generate multiple queries from different perspectives based on the user's input query.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# RAG - Pinecone - rerank
|
||||||
|
|
||||||
# rag-pinecone-rerank
|
This template performs RAG using `Pinecone` and `OpenAI` along with [Cohere to perform re-ranking](https://txt.cohere.com/rerank/) on returned documents.
|
||||||
|
|
||||||
This template performs RAG using Pinecone and OpenAI along with [Cohere to perform re-ranking](https://txt.cohere.com/rerank/) on returned documents.
|
`Re-ranking` provides a way to rank retrieved documents using specified filters or criteria.
|
||||||
|
|
||||||
Re-ranking provides a way to rank retrieved documents using specified filters or criteria.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Pinecone
|
||||||
|
|
||||||
# rag-pinecone
|
This template performs RAG using `Pinecone` and `OpenAI`.
|
||||||
|
|
||||||
This template performs RAG using Pinecone and OpenAI.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,11 +1,10 @@
|
|||||||
|
# RAG - Redis - multi-modal, multi-vector
|
||||||
|
|
||||||
# rag-redis-multi-modal-multi-vector
|
`Multi-modal` LLMs enable visual assistants that can perform question-answering about images.
|
||||||
|
|
||||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
|
||||||
|
|
||||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||||
|
|
||||||
It uses GPT-4V to create image summaries for each slide, embeds the summaries, and stores them in Redis.
|
It uses `GPT-4V` to create image summaries for each slide, embeds the summaries, and stores them in `Redis`.
|
||||||
|
|
||||||
Given a question, relevant slides are retrieved and passed to GPT-4V for answer synthesis.
|
Given a question, relevant slides are retrieved and passed to GPT-4V for answer synthesis.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Redis
|
||||||
|
|
||||||
# rag-redis
|
This template performs RAG using `Redis` (vector database) and `OpenAI` (LLM) on financial 10k filings docs for Nike.
|
||||||
|
|
||||||
This template performs RAG using Redis (vector database) and OpenAI (LLM) on financial 10k filings docs for Nike.
|
|
||||||
|
|
||||||
It relies on the sentence transformer `all-MiniLM-L6-v2` for embedding chunks of the pdf and user questions.
|
It relies on the sentence transformer `all-MiniLM-L6-v2` for embedding chunks of the pdf and user questions.
|
||||||
|
|
||||||
|
|||||||
@ -1,14 +1,16 @@
|
|||||||
# rag-self-query
|
# RAG - Elasticsearch - Self-query
|
||||||
|
|
||||||
This template performs RAG using the self-query retrieval technique. The main idea is to let an LLM convert unstructured queries into structured queries. See the [docs for more on how this works](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query).
|
This template performs RAG using the `self-query` retrieval technique.
|
||||||
|
The main idea is to let an LLM convert unstructured queries into
|
||||||
|
structured queries. See the [docs for more on how this works](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query).
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
In this template we'll use OpenAI models and an Elasticsearch vector store, but the approach generalizes to all LLMs/ChatModels and [a number of vector stores](https://python.langchain.com/docs/integrations/retrievers/self_query/).
|
In this template we'll use `OpenAI` models and an `Elasticsearch` vector store, but the approach generalizes to all LLMs/ChatModels and [a number of vector stores](https://python.langchain.com/docs/integrations/retrievers/self_query/).
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the `OpenAI` models.
|
||||||
|
|
||||||
To connect to your Elasticsearch instance, use the following environment variables:
|
To connect to your `Elasticsearch` instance, use the following environment variables:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
export ELASTIC_CLOUD_ID = <ClOUD_ID>
|
export ELASTIC_CLOUD_ID = <ClOUD_ID>
|
||||||
|
|||||||
@ -1,6 +1,8 @@
|
|||||||
# rag-semi-structured
|
# RAG - Unstructured - semi-structured
|
||||||
|
|
||||||
This template performs RAG on semi-structured data, such as a PDF with text and tables.
|
This template performs RAG on `semi-structured data`, such as a PDF with text and tables.
|
||||||
|
|
||||||
|
It uses the `unstructured` parser to extract the text and tables from the PDF and then uses the LLM to generate queries based on the user input.
|
||||||
|
|
||||||
See [this cookbook](https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb) as a reference.
|
See [this cookbook](https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb) as a reference.
|
||||||
|
|
||||||
|
|||||||
@ -1,13 +1,12 @@
|
|||||||
|
# RAG - SingleStoreDB
|
||||||
|
|
||||||
# rag-singlestoredb
|
This template performs RAG using `SingleStoreDB` and OpenAI.
|
||||||
|
|
||||||
This template performs RAG using SingleStoreDB and OpenAI.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
This template uses SingleStoreDB as a vectorstore and requires that `SINGLESTOREDB_URL` is set. It should take the form `admin:password@svc-xxx.svc.singlestore.com:port/db_name`
|
This template uses `SingleStoreDB` as a vectorstore and requires that `SINGLESTOREDB_URL` is set. It should take the form `admin:password@svc-xxx.svc.singlestore.com:port/db_name`
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the `OpenAI` models.
|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,9 @@
|
|||||||
|
# RAG - Supabase
|
||||||
|
|
||||||
# rag_supabase
|
This template performs RAG with `Supabase`.
|
||||||
|
|
||||||
This template performs RAG with Supabase.
|
[Supabase](https://supabase.com/docs) is an open-source `Firebase` alternative. It is built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL), a free and open-source relational database management system (RDBMS) and uses [pgvector](https://github.com/pgvector/pgvector) to store embeddings within your tables.
|
||||||
|
|
||||||
[Supabase](https://supabase.com/docs) is an open-source Firebase alternative. It is built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL), a free and open-source relational database management system (RDBMS) and uses [pgvector](https://github.com/pgvector/pgvector) to store embeddings within your tables.
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
||||||
|
|||||||
@ -1,5 +1,4 @@
|
|||||||
|
# RAG - Timescale - conversation
|
||||||
# rag-timescale-conversation
|
|
||||||
|
|
||||||
This template is used for [conversational](https://python.langchain.com/docs/expression_language/cookbook/retrieval#conversational-retrieval-chain) [retrieval](https://python.langchain.com/docs/use_cases/question_answering/), which is one of the most popular LLM use-cases.
|
This template is used for [conversational](https://python.langchain.com/docs/expression_language/cookbook/retrieval#conversational-retrieval-chain) [retrieval](https://python.langchain.com/docs/use_cases/question_answering/), which is one of the most popular LLM use-cases.
|
||||||
|
|
||||||
@ -7,7 +6,7 @@ It passes both a conversation history and retrieved documents into an LLM for sy
|
|||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
This template uses Timescale Vector as a vectorstore and requires that `TIMESCALES_SERVICE_URL`. Signup for a 90-day trial [here](https://console.cloud.timescale.com/signup?utm_campaign=vectorlaunch&utm_source=langchain&utm_medium=referral) if you don't yet have an account.
|
This template uses `Timescale Vector` as a vectorstore and requires that `TIMESCALES_SERVICE_URL`. Signup for a 90-day trial [here](https://console.cloud.timescale.com/signup?utm_campaign=vectorlaunch&utm_source=langchain&utm_medium=referral) if you don't yet have an account.
|
||||||
|
|
||||||
To load the sample dataset, set `LOAD_SAMPLE_DATA=1`. To load your own dataset see the section below.
|
To load the sample dataset, set `LOAD_SAMPLE_DATA=1`. To load your own dataset see the section below.
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,7 @@
|
|||||||
# RAG with Timescale Vector using hybrid search
|
# RAG - Timescale - hybrid search
|
||||||
|
|
||||||
|
This template shows how to use `Timescale Vector` with the self-query retriever to perform hybrid search on similarity and time.
|
||||||
|
|
||||||
This template shows how to use timescale-vector with the self-query retriver to perform hybrid search on similarity and time.
|
|
||||||
This is useful any time your data has a strong time-based component. Some examples of such data are:
|
This is useful any time your data has a strong time-based component. Some examples of such data are:
|
||||||
- News articles (politics, business, etc)
|
- News articles (politics, business, etc)
|
||||||
- Blog posts, documentation or other published material (public or private).
|
- Blog posts, documentation or other published material (public or private).
|
||||||
@ -15,6 +16,7 @@ Such items are often searched by both similarity and time. For example: Show me
|
|||||||
Langchain's self-query retriever allows deducing time-ranges (as well as other search criteria) from the text of user queries.
|
Langchain's self-query retriever allows deducing time-ranges (as well as other search criteria) from the text of user queries.
|
||||||
|
|
||||||
## What is Timescale Vector?
|
## What is Timescale Vector?
|
||||||
|
|
||||||
**[Timescale Vector](https://www.timescale.com/ai?utm_campaign=vectorlaunch&utm_source=langchain&utm_medium=referral) is PostgreSQL++ for AI applications.**
|
**[Timescale Vector](https://www.timescale.com/ai?utm_campaign=vectorlaunch&utm_source=langchain&utm_medium=referral) is PostgreSQL++ for AI applications.**
|
||||||
|
|
||||||
Timescale Vector enables you to efficiently store and query billions of vector embeddings in `PostgreSQL`.
|
Timescale Vector enables you to efficiently store and query billions of vector embeddings in `PostgreSQL`.
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Vectara - multi-query
|
||||||
|
|
||||||
# rag-vectara-multiquery
|
This template performs multiquery RAG with `Vectara` vectorstore.
|
||||||
|
|
||||||
This template performs multiquery RAG with vectara.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Vectara
|
||||||
|
|
||||||
# rag-vectara
|
This template performs RAG with `Vectara` vectorstore.
|
||||||
|
|
||||||
This template performs RAG with vectara.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# RAG - Weaviate
|
||||||
|
|
||||||
# rag-weaviate
|
This template performs RAG with `Weaviate` vectorstore.
|
||||||
|
|
||||||
This template performs RAG with Weaviate.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# research-assistant
|
# Research assistant
|
||||||
|
|
||||||
This template implements a version of
|
This template implements a version of
|
||||||
[GPT Researcher](https://github.com/assafelovic/gpt-researcher) that you can use
|
[GPT Researcher](https://github.com/assafelovic/gpt-researcher) that you can use
|
||||||
@ -6,12 +6,12 @@ as a starting point for a research agent.
|
|||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
The default template relies on ChatOpenAI and DuckDuckGo, so you will need the
|
The default template relies on `ChatOpenAI` and `DuckDuckGo`, so you will need the
|
||||||
following environment variable:
|
following environment variable:
|
||||||
|
|
||||||
- `OPENAI_API_KEY`
|
- `OPENAI_API_KEY`
|
||||||
|
|
||||||
And to use the Tavily LLM-optimized search engine, you will need:
|
And to use the `Tavily` LLM-optimized search engine, you will need:
|
||||||
|
|
||||||
- `TAVILY_API_KEY`
|
- `TAVILY_API_KEY`
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,9 @@
|
|||||||
# retrieval-agent-fireworks
|
# Retrieval agent - Fireworks, Hugging Face
|
||||||
|
|
||||||
This package uses open source models hosted on FireworksAI to do retrieval using an agent architecture. By default, this does retrieval over Arxiv.
|
This package uses open source models hosted on `Fireworks AI` to do retrieval using an agent architecture. By default, this does retrieval over `Arxiv`.
|
||||||
|
|
||||||
We will use `Mixtral8x7b-instruct-v0.1`, which is shown in this blog to yield reasonable
|
We will use `Mixtral8x7b-instruct-v0.1`, which is shown in this blog to yield reasonable
|
||||||
results with function calling even though it is not fine tuned for this task: https://huggingface.co/blog/open-source-llms-as-agents
|
results with function calling even though it is not fine-tuned for this task: https://huggingface.co/blog/open-source-llms-as-agents
|
||||||
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
# retrieval-agent
|
# Retrieval agent
|
||||||
|
|
||||||
This package uses Azure OpenAI to do retrieval using an agent architecture.
|
This package uses `Azure OpenAI` to do retrieval using an agent architecture.
|
||||||
By default, this does retrieval over Arxiv.
|
By default, this does retrieval over `Arxiv`.
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
|
# Rewrite-Retrieve-Read
|
||||||
|
|
||||||
# rewrite_retrieve_read
|
This template implements a method for query transformation (re-writing)
|
||||||
|
in the paper [Query Rewriting for Retrieval-Augmented Large Language Models](https://arxiv.org/pdf/2305.14283.pdf) to optimize for RAG.
|
||||||
This template implemenets a method for query transformation (re-writing) in the paper [Query Rewriting for Retrieval-Augmented Large Language Models](https://arxiv.org/pdf/2305.14283.pdf) to optimize for RAG.
|
|
||||||
|
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# Langchain - Robocorp Action Server
|
# Robocorp Action Server - agent
|
||||||
|
|
||||||
This template enables using [Robocorp Action Server](https://github.com/robocorp/robocorp) served actions as tools for an Agent.
|
This template enables using [Robocorp Action Server](https://github.com/robocorp/robocorp) served actions as tools for an Agent.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# Self-query - Qdrant
|
||||||
# self-query-qdrant
|
|
||||||
|
|
||||||
This template performs [self-querying](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/)
|
This template performs [self-querying](https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/)
|
||||||
using Qdrant and OpenAI. By default, it uses an artificial dataset of 10 documents, but you can replace it with your own dataset.
|
``using `Qdrant` and OpenAI. By default, it uses an artificial dataset of 10 documents, but you can replace it with your own dataset.
|
||||||
|
``
|
||||||
## Environment Setup
|
## Environment Setup
|
||||||
|
|
||||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# Self-query - Supabase
|
||||||
|
|
||||||
# self-query-supabase
|
This template allows natural language structured querying of `Supabase`.
|
||||||
|
|
||||||
This templates allows natural language structured quering of Supabase.
|
[Supabase](https://supabase.com/docs) is an open-source alternative to `Firebase`, built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL).
|
||||||
|
|
||||||
[Supabase](https://supabase.com/docs) is an open-source alternative to Firebase, built on top of [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL).
|
|
||||||
|
|
||||||
It uses [pgvector](https://github.com/pgvector/pgvector) to store embeddings within your tables.
|
It uses [pgvector](https://github.com/pgvector/pgvector) to store embeddings within your tables.
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# shopping-assistant
|
# Shopping assistant - Ionic
|
||||||
|
|
||||||
This template creates a shopping assistant that helps users find products that they are looking for.
|
This template creates a `shopping assistant` that helps users find products that they are looking for.
|
||||||
|
|
||||||
This template will use `Ionic` to search for products.
|
This template will use `Ionic` to search for products.
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# skeleton-of-thought
|
# Skeleton-of-Thought
|
||||||
|
|
||||||
Implements "Skeleton of Thought" from [this](https://sites.google.com/view/sot-llm) paper.
|
It implements [Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation](https://arxiv.org/abs/2307.15337) paper.
|
||||||
|
|
||||||
This technique makes it possible to generate longer generations more quickly by first generating a skeleton, then generating each point of the outline.
|
This technique makes it possible to generate longer generations more quickly by first generating a skeleton, then generating each point of the outline.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,14 @@
|
|||||||
# solo-performance-prompting-agent
|
# Solo performance prompting agent
|
||||||
|
|
||||||
This template creates an agent that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas.
|
This template creates an agent that transforms a single LLM
|
||||||
A cognitive synergist refers to an intelligent agent that collaborates with multiple minds, combining their individual strengths and knowledge, to enhance problem-solving and overall performance in complex tasks. By dynamically identifying and simulating different personas based on task inputs, SPP unleashes the potential of cognitive synergy in LLMs.
|
into a cognitive synergist by engaging in multi-turn self-collaboration
|
||||||
|
with multiple personas.
|
||||||
|
|
||||||
|
A `cognitive synergist` refers to an intelligent agent that collaborates
|
||||||
|
with multiple minds, combining their individual strengths and knowledge,
|
||||||
|
to enhance problem-solving and overall performance in complex tasks.
|
||||||
|
By dynamically identifying and simulating different personas based
|
||||||
|
on task inputs, SPP unleashes the potential of cognitive synergy in LLMs.
|
||||||
|
|
||||||
This template will use the `DuckDuckGo` search API.
|
This template will use the `DuckDuckGo` search API.
|
||||||
|
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
|
# SQL - LLamA2
|
||||||
|
|
||||||
# sql-llama2
|
This template enables a user to interact with a `SQL` database using natural language.
|
||||||
|
|
||||||
This template enables a user to interact with a SQL database using natural language.
|
It uses `LLamA2-13b` hosted by [Replicate](https://python.langchain.com/docs/integrations/llms/replicate), but can be adapted to any API that supports LLaMA2 including [Fireworks](https://python.langchain.com/docs/integrations/chat/fireworks).
|
||||||
|
|
||||||
It uses LLamA2-13b hosted by [Replicate](https://python.langchain.com/docs/integrations/llms/replicate), but can be adapted to any API that supports LLaMA2 including [Fireworks](https://python.langchain.com/docs/integrations/chat/fireworks).
|
|
||||||
|
|
||||||
The template includes an example database of 2023 NBA rosters.
|
The template includes an example database of 2023 NBA rosters.
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
|
# SQL - llama.cpp
|
||||||
|
|
||||||
# sql-llamacpp
|
This template enables a user to interact with a `SQL` database using natural language.
|
||||||
|
|
||||||
This template enables a user to interact with a SQL database using natural language.
|
|
||||||
|
|
||||||
It uses [Mistral-7b](https://mistral.ai/news/announcing-mistral-7b/) via [llama.cpp](https://github.com/ggerganov/llama.cpp) to run inference locally on a Mac laptop.
|
It uses [Mistral-7b](https://mistral.ai/news/announcing-mistral-7b/) via [llama.cpp](https://github.com/ggerganov/llama.cpp) to run inference locally on a Mac laptop.
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# sql-ollama
|
# SQL - Ollama
|
||||||
|
|
||||||
This template enables a user to interact with a SQL database using natural language.
|
This template enables a user to interact with a SQL database using natural language.
|
||||||
|
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user