mirror of
https://github.com/hwchase17/langchain.git
synced 2025-08-27 13:31:53 +00:00
Batch update of alt text and title attributes for images in md/mdx files across repo (#15357)
**Description:** Batch update of alt text and title attributes for images in `md` & `mdx` files across the repo using [alttexter](https://github.com/jonathanalgar/alttexter)/[alttexter-ghclient](https://github.com/jonathanalgar/alttexter-ghclient) (built using LangChain/LangSmith). **Limitation:** cannot update `ipynb` files because of [this issue](https://github.com/langchain-ai/langchain/pull/15357#issuecomment-1885037250). Can revisit when Docusaurus is bumped to v3. I checked all the generated alt texts and titles and didn't find any technical inaccuracies. That's not to say they're _perfect_, but a lot better than what's there currently. [Deployed](https://langchain-819yf1tbk-langchain.vercel.app/docs/modules/model_io/) image example: 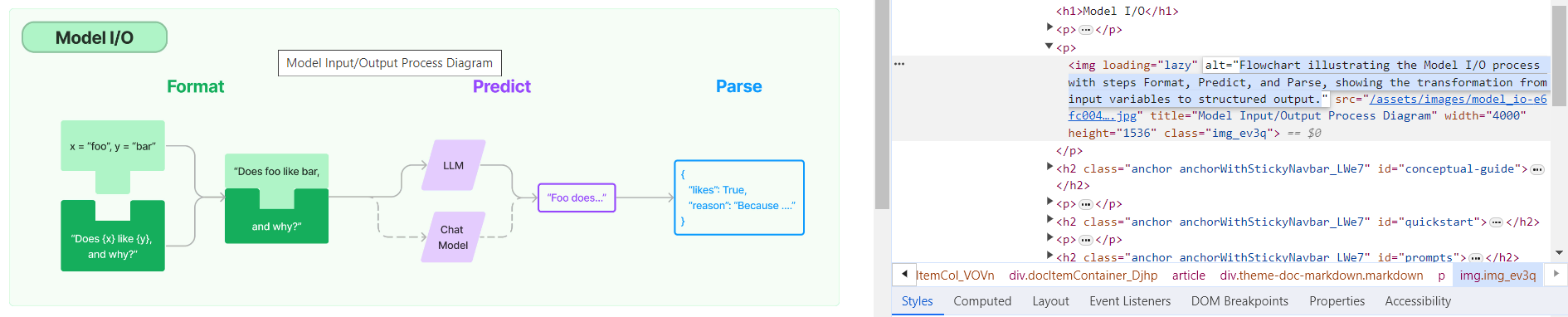 You can see LangSmith traces for all the calls out to the LLM in the PRs merged into this one: * https://github.com/jonathanalgar/langchain/pull/6 * https://github.com/jonathanalgar/langchain/pull/4 * https://github.com/jonathanalgar/langchain/pull/3 I didn't add the following files to the PR as the images already have OK alt texts: *27dca2d92f/docs/docs/integrations/providers/argilla.mdx (L3)*27dca2d92f/docs/docs/integrations/providers/apify.mdx (L11)--------- Co-authored-by: github-actions <github-actions@github.com>
This commit is contained in:
parent
efe6cfafe2
commit
a74f3a4979
@ -49,7 +49,7 @@ The LangChain libraries themselves are made up of several different packages.
|
||||
- **[`langchain-community`](libs/community)**: Third party integrations.
|
||||
- **[`langchain`](libs/langchain)**: Chains, agents, and retrieval strategies that make up an application's cognitive architecture.
|
||||
|
||||

|
||||

|
||||
|
||||
## 🧱 What can you build with LangChain?
|
||||
**❓ Retrieval augmented generation**
|
||||
|
||||
@ -14,7 +14,7 @@ This framework consists of several parts.
|
||||
- **[LangServe](/docs/langserve)**: A library for deploying LangChain chains as a REST API.
|
||||
- **[LangSmith](/docs/langsmith)**: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
|
||||
|
||||

|
||||

|
||||
|
||||
Together, these products simplify the entire application lifecycle:
|
||||
- **Develop**: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.
|
||||
|
||||
@ -12,7 +12,7 @@ Platforms with tracing capabilities like [LangSmith](/docs/langsmith/) and [Wand
|
||||
|
||||
For anyone building production-grade LLM applications, we highly recommend using a platform like this.
|
||||
|
||||

|
||||

|
||||
|
||||
## `set_debug` and `set_verbose`
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ This page covers how to use the [Remembrall](https://remembrall.dev) ecosystem w
|
||||
|
||||
Remembrall gives your language model long-term memory, retrieval augmented generation, and complete observability with just a few lines of code.
|
||||
|
||||

|
||||

|
||||
|
||||
It works as a light-weight proxy on top of your OpenAI calls and simply augments the context of the chat calls at runtime with relevant facts that have been collected.
|
||||
|
||||
|
||||
@ -150,4 +150,4 @@ This command will initiate the execution of the `langchain_llm` task on the Flyt
|
||||
|
||||
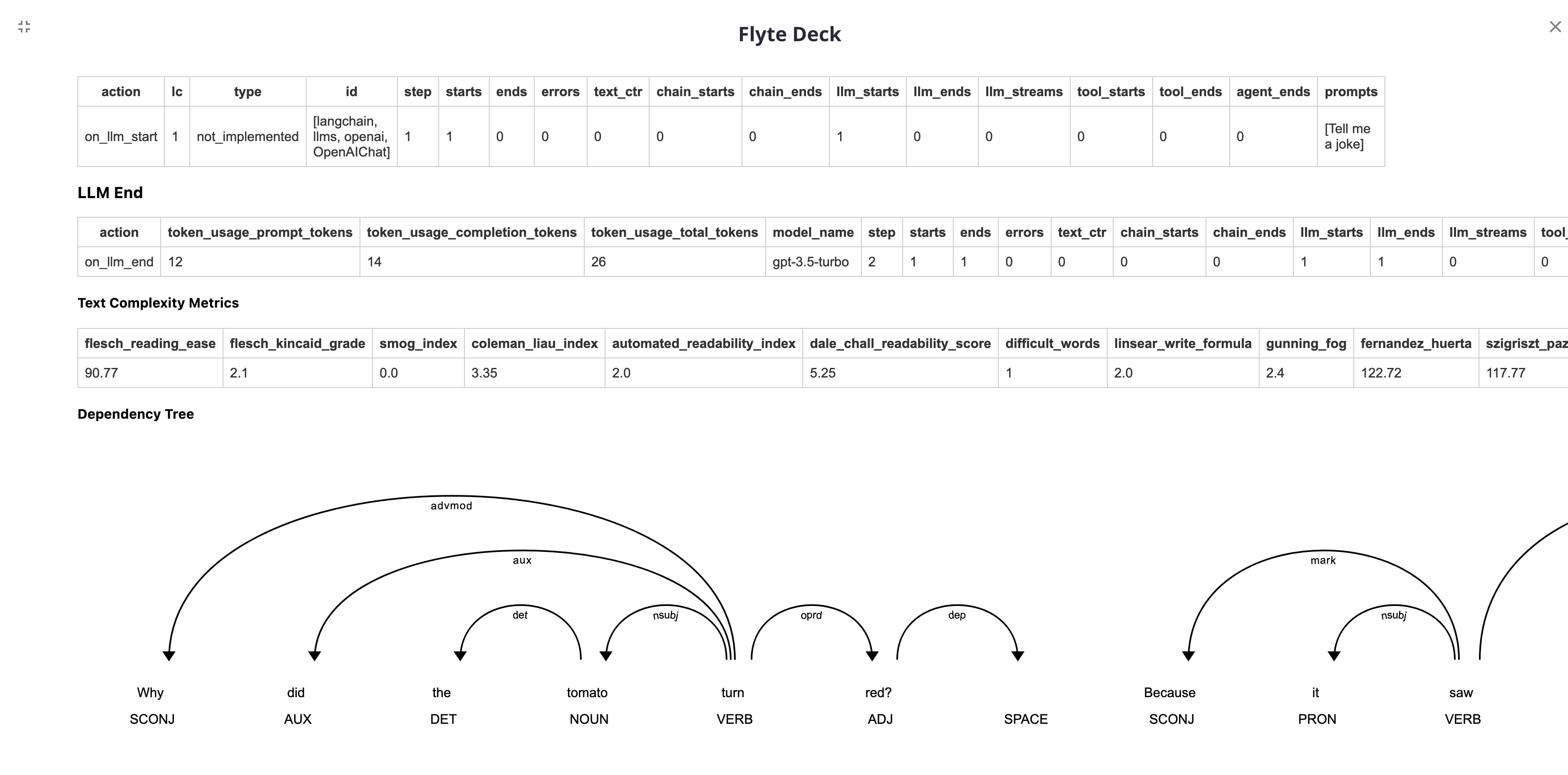
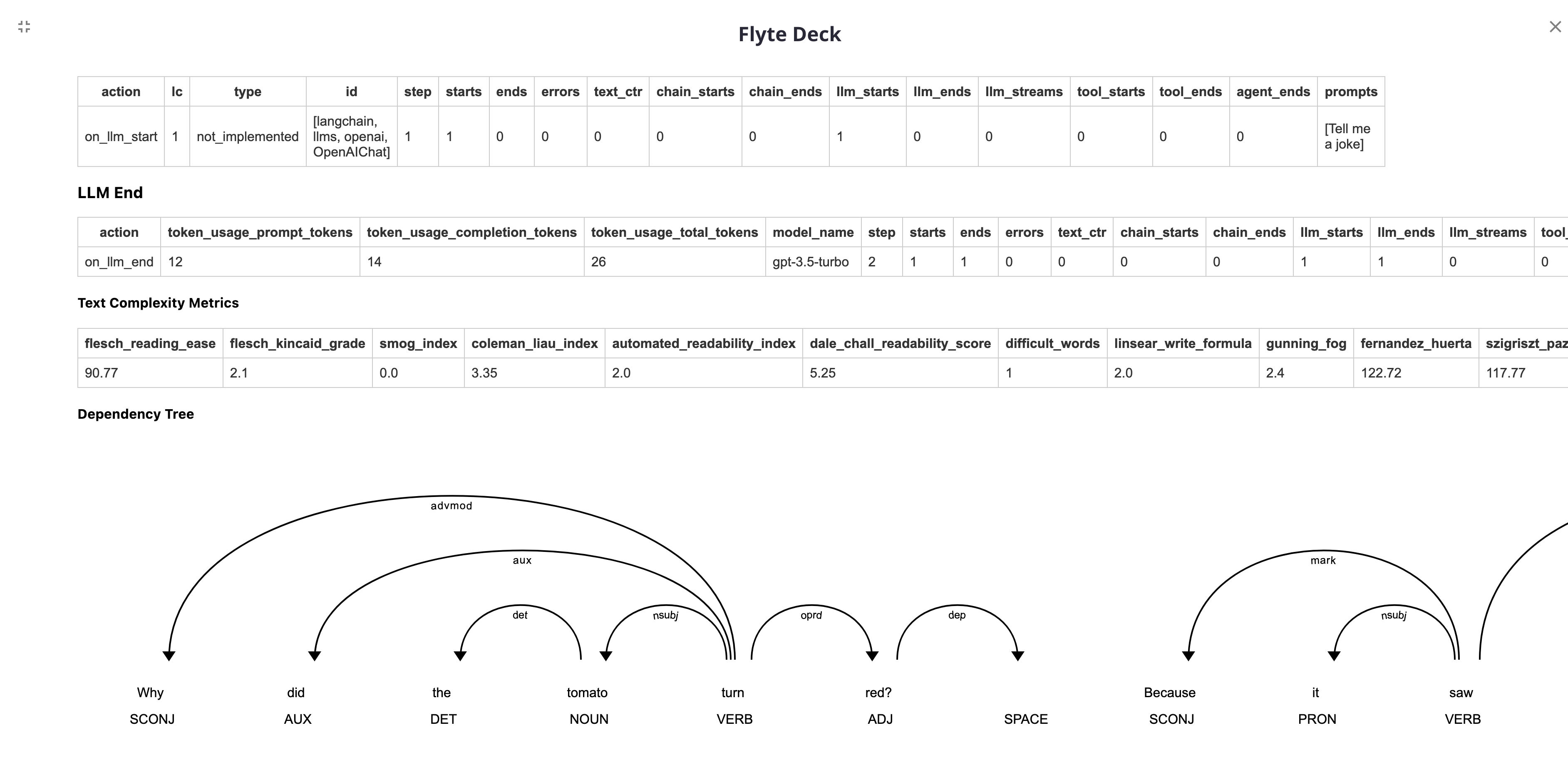
The metrics will be displayed on the Flyte UI as follows:
|
||||
|
||||
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ This page covers how to use the [Helicone](https://helicone.ai) ecosystem within
|
||||
|
||||
Helicone is an [open-source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
@ -18,7 +18,7 @@ export OPENAI_API_BASE="https://oai.hconeai.com/v1"
|
||||
|
||||
Now head over to [helicone.ai](https://helicone.ai/onboarding?step=2) to create your account, and add your OpenAI API key within our dashboard to view your logs.
|
||||
|
||||

|
||||

|
||||
|
||||
## How to enable Helicone caching
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ This page covers how to use [Metal](https://getmetal.io) within LangChain.
|
||||
|
||||
Metal is a managed retrieval & memory platform built for production. Easily index your data into `Metal` and run semantic search and retrieval on it.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ This section of the documentation covers everything related to the *retrieval* s
|
||||
Although this sounds simple, it can be subtly complex.
|
||||
This encompasses several key modules.
|
||||
|
||||

|
||||

|
||||
|
||||
**[Document loaders](/docs/modules/data_connection/document_loaders/)**
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@ vectors, and then at query time to embed the unstructured query and retrieve the
|
||||
'most similar' to the embedded query. A vector store takes care of storing embedded data and performing vector search
|
||||
for you.
|
||||
|
||||

|
||||

|
||||
|
||||
## Get started
|
||||
|
||||
|
||||
@ -36,7 +36,7 @@ A chain will interact with its memory system twice in a given run.
|
||||
1. AFTER receiving the initial user inputs but BEFORE executing the core logic, a chain will READ from its memory system and augment the user inputs.
|
||||
2. AFTER executing the core logic but BEFORE returning the answer, a chain will WRITE the inputs and outputs of the current run to memory, so that they can be referred to in future runs.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
## Building memory into a system
|
||||
|
||||
@ -9,7 +9,7 @@ sidebar_class_name: hidden
|
||||
|
||||
The core element of any language model application is...the model. LangChain gives you the building blocks to interface with any language model.
|
||||
|
||||

|
||||

|
||||
|
||||
## [Conceptual Guide](/docs/modules/model_io/concepts)
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@ LangChain Community contains third-party integrations that implement the base in
|
||||
|
||||
For full documentation see the [API reference](https://api.python.langchain.com/en/stable/community_api_reference.html).
|
||||
|
||||

|
||||

|
||||
|
||||
## 📕 Releases & Versioning
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@ Rather than having to write multiple implementations for all of those, LCEL allo
|
||||
|
||||
For more check out the [LCEL docs](https://python.langchain.com/docs/expression_language/).
|
||||
|
||||

|
||||

|
||||
|
||||
## 📕 Releases & Versioning
|
||||
|
||||
|
||||
@ -102,11 +102,11 @@ langchain serve
|
||||
This now gives a fully deployed LangServe application.
|
||||
For example, you get a playground out-of-the-box at [http://127.0.0.1:8000/pirate-speak/playground/](http://127.0.0.1:8000/pirate-speak/playground/):
|
||||
|
||||

|
||||

|
||||
|
||||
Access API documentation at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
|
||||

|
||||

|
||||
|
||||
Use the LangServe python or js SDK to interact with the API as if it were a regular [Runnable](https://python.langchain.com/docs/expression_language/).
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ LangChain template that uses [Anthropic's Claude on Amazon Bedrock](https://aws.
|
||||
|
||||
> I am the Fred Astaire of Chatbots! 🕺
|
||||
|
||||
'
|
||||
'
|
||||
|
||||
## Environment Setup
|
||||
|
||||
@ -78,4 +78,4 @@ We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/d
|
||||
|
||||
We can also access the playground at [http://127.0.0.1:8000/bedrock-jcvd/playground](http://127.0.0.1:8000/bedrock-jcvd/playground)
|
||||
|
||||

|
||||

|
||||
@ -9,11 +9,11 @@ Taking [Chat Langchain](https://chat.langchain.com/) as a case study, only about
|
||||
|
||||
This template helps solve this "feedback scarcity" problem. Below is an example invocation of this chat bot:
|
||||
|
||||
[](https://smith.langchain.com/public/3378daea-133c-4fe8-b4da-0a3044c5dbe8/r?runtab=1)
|
||||
[](https://smith.langchain.com/public/3378daea-133c-4fe8-b4da-0a3044c5dbe8/r?runtab=1)
|
||||
|
||||
When the user responds to this ([link](https://smith.langchain.com/public/a7e2df54-4194-455d-9978-cecd8be0df1e/r)), the response evaluator is invoked, resulting in the following evaluationrun:
|
||||
|
||||
[](https://smith.langchain.com/public/534184ee-db8f-4831-a386-3f578145114c/r)
|
||||
[](https://smith.langchain.com/public/534184ee-db8f-4831-a386-3f578145114c/r)
|
||||
|
||||
As shown, the evaluator sees that the user is increasingly frustrated, indicating that the prior response was not effective
|
||||
|
||||
|
||||
@ -38,4 +38,4 @@ langchain template serve
|
||||
This will spin up endpoints, documentation, and playground for this chain.
|
||||
For example, you can access the playground at [http://127.0.0.1:8000/playground/](http://127.0.0.1:8000/playground/)
|
||||
|
||||

|
||||

|
||||
|
||||
@ -99,15 +99,15 @@ We will first follow the standard MongoDB Atlas setup instructions [here](https:
|
||||
|
||||
This can be done by going to the deployement overview page and connecting to you database
|
||||
|
||||

|
||||

|
||||
|
||||
We then look at the drivers available
|
||||
|
||||

|
||||

|
||||
|
||||
Among which we will see our URI listed
|
||||
|
||||

|
||||

|
||||
|
||||
Let's then set that as an environment variable locally:
|
||||
|
||||
|
||||
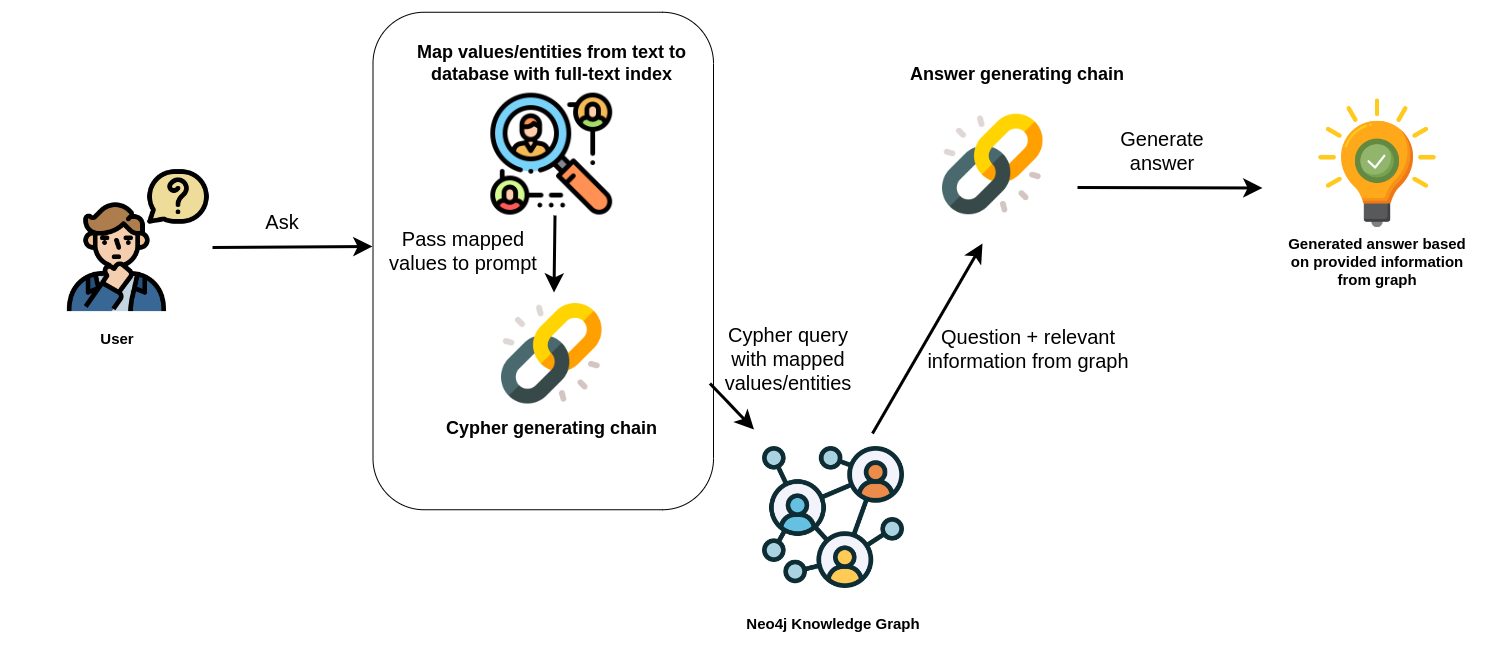
@ -9,7 +9,7 @@ The package utilizes a full-text index for efficient mapping of text values to d
|
||||
|
||||
In the provided example, the full-text index is used to map names of people and movies from the user's query to corresponding database entries.
|
||||
|
||||
|
||||

|
||||
|
||||
## Environment Setup
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ Additionally, it features a conversational memory module that stores the dialogu
|
||||
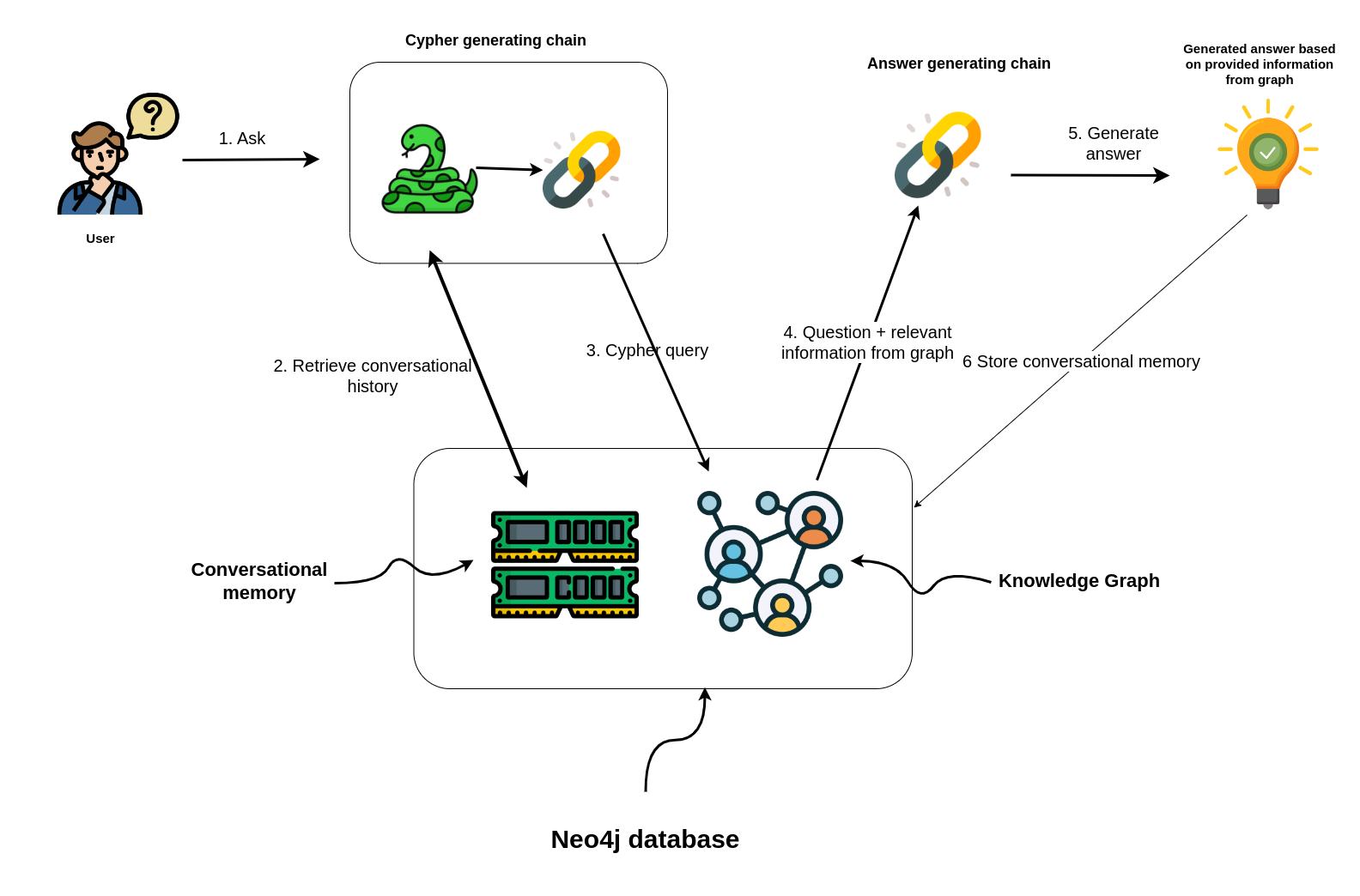
The conversation memory is uniquely maintained for each user session, ensuring personalized interactions.
|
||||
To facilitate this, please supply both the `user_id` and `session_id` when using the conversation chain.
|
||||
|
||||
|
||||

|
||||
|
||||
## Environment Setup
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ This template allows you to interact with a Neo4j graph database in natural lang
|
||||
|
||||
It transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
|
||||
|
||||
[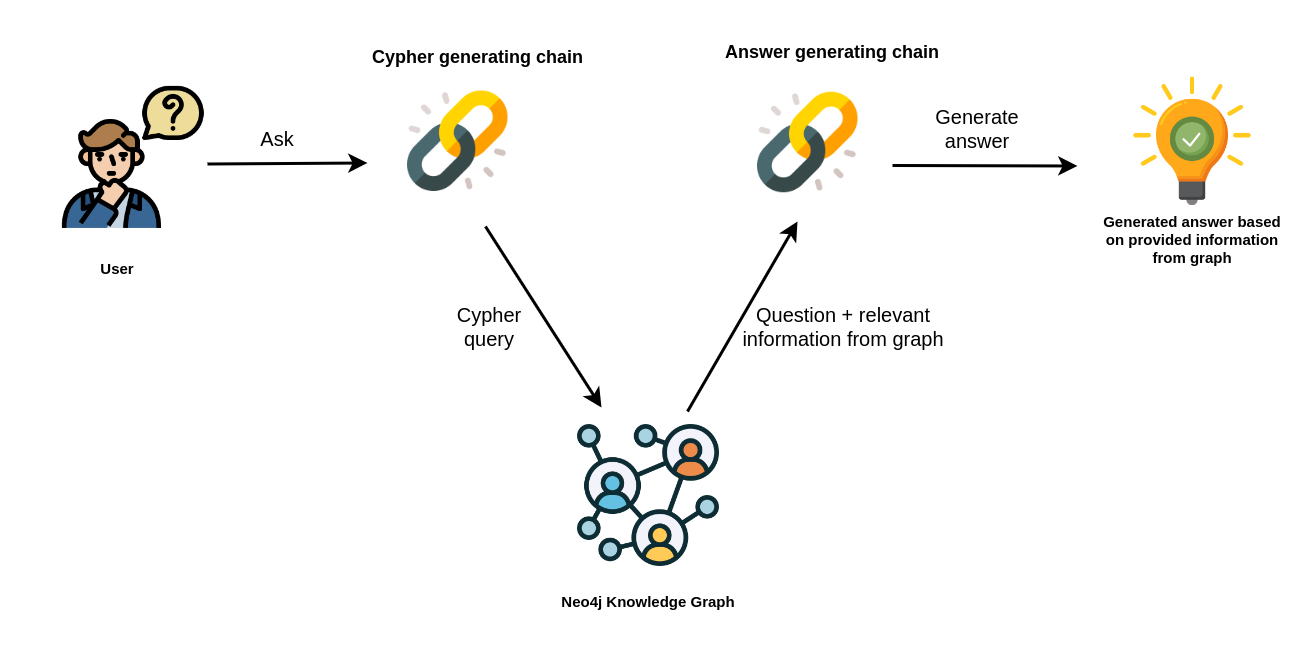](https://medium.com/neo4j/langchain-cypher-search-tips-tricks-f7c9e9abca4d)
|
||||
[](https://medium.com/neo4j/langchain-cypher-search-tips-tricks-f7c9e9abca4d)
|
||||
|
||||
## Environment Setup
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
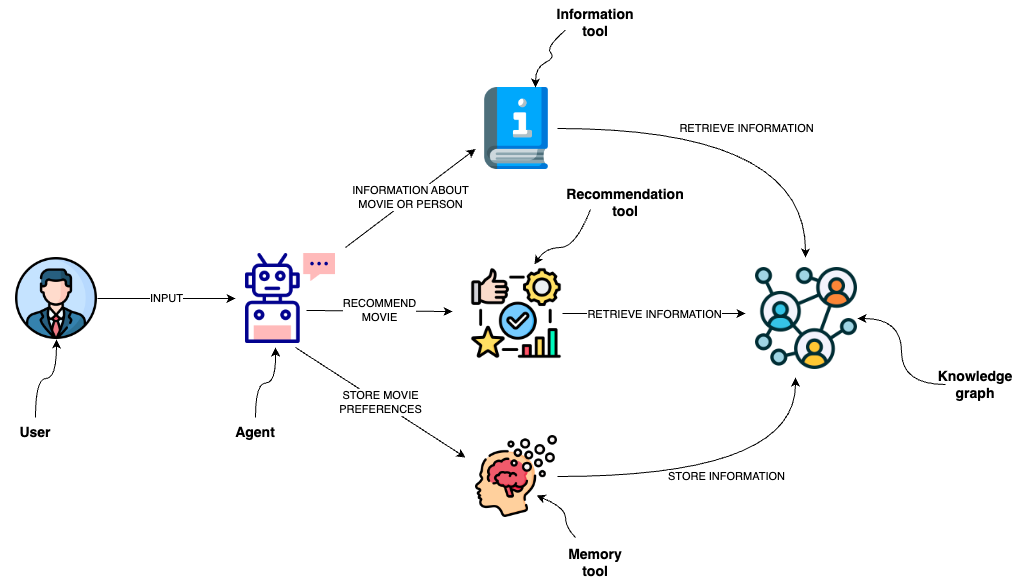
This template is designed to implement an agent capable of interacting with a graph database like Neo4j through a semantic layer using OpenAI function calling.
|
||||
The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph databas based on the user's intent.
|
||||
|
||||
|
||||

|
||||
|
||||
## Tools
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@ Ever struggled to reach inbox zero?
|
||||
|
||||
Using this template, you can create and customize your very own AI assistant to manage your Gmail account. Using the default Gmail tools, it can read, search through, and draft emails to respond on your behalf. It also has access to a Tavily search engine so it can search for relevant information about any topics or people in the email thread before writing, ensuring the drafts include all the relevant information needed to sound well-informed.
|
||||
|
||||

|
||||

|
||||
|
||||
## The details
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
This template demonstrates the multi-vector indexing strategy proposed by Chen, et. al.'s [Dense X Retrieval: What Retrieval Granularity Should We Use?](https://arxiv.org/abs/2312.06648). The prompt, which you can [try out on the hub](https://smith.langchain.com/hub/wfh/proposal-indexing), directs an LLM to generate de-contextualized "propositions" which can be vectorized to increase the retrieval accuracy. You can see the full definition in `proposal_chain.py`.
|
||||
|
||||

|
||||

|
||||
|
||||
## Storage
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ It uses GPT-4V to create image summaries for each slide, embeds the summaries, a
|
||||
|
||||
Given a question, relevat slides are retrieved and passed to GPT-4V for answer synthesis.
|
||||
|
||||

|
||||

|
||||
|
||||
## Input
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ It uses OpenCLIP embeddings to embed all of the slide images and stores them in
|
||||
|
||||
Given a question, relevat slides are retrieved and passed to GPT-4V for answer synthesis.
|
||||
|
||||

|
||||

|
||||
|
||||
## Input
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ It uses OpenCLIP embeddings to embed all of the slide images and stores them in
|
||||
|
||||
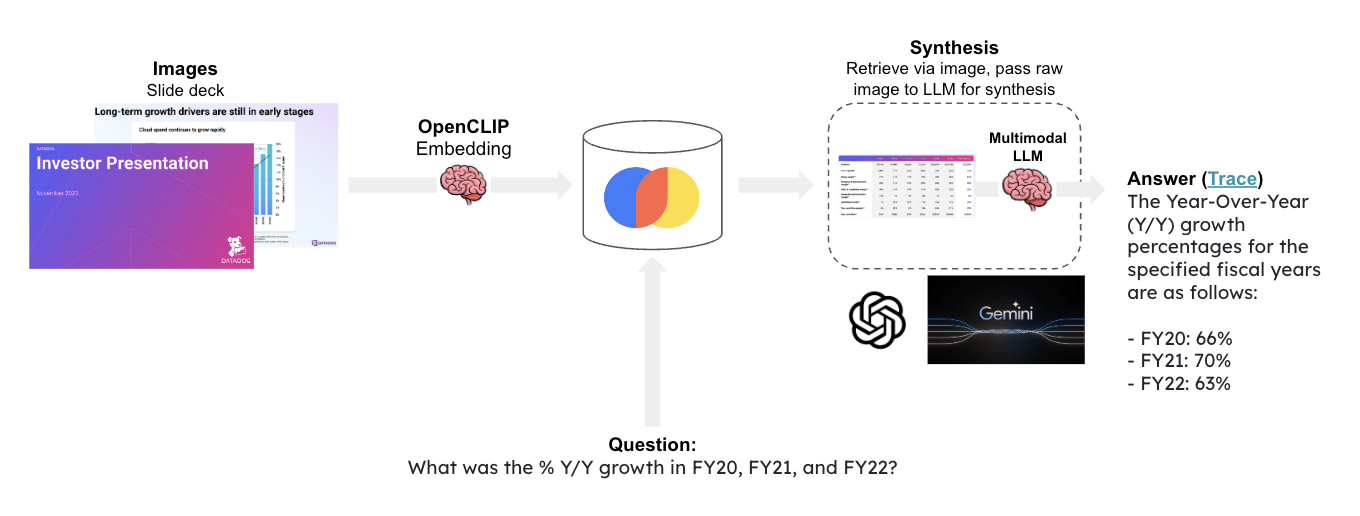
Given a question, relevat slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||
|
||||
|
||||

|
||||
|
||||
## Input
|
||||
|
||||
|
||||
@ -97,15 +97,15 @@ We will first follow the standard MongoDB Atlas setup instructions [here](https:
|
||||
|
||||
This can be done by going to the deployement overview page and connecting to you database
|
||||
|
||||

|
||||

|
||||
|
||||
We then look at the drivers available
|
||||
|
||||

|
||||

|
||||
|
||||
Among which we will see our URI listed
|
||||
|
||||

|
||||

|
||||
|
||||
Let's then set that as an environment variable locally:
|
||||
|
||||
@ -131,23 +131,23 @@ Note that you can (and should!) change this to ingest data of your choice
|
||||
|
||||
We can first connect to the cluster where our database lives
|
||||
|
||||

|
||||

|
||||
|
||||
We can then navigate to where all our collections are listed
|
||||
|
||||

|
||||

|
||||
|
||||
We can then find the collection we want and look at the search indexes for that collection
|
||||
|
||||

|
||||

|
||||
|
||||
That should likely be empty, and we want to create a new one:
|
||||
|
||||

|
||||

|
||||
|
||||
We will use the JSON editor to create it
|
||||
|
||||

|
||||

|
||||
|
||||
And we will paste the following JSON in:
|
||||
|
||||
@ -165,7 +165,6 @@ And we will paste the following JSON in:
|
||||
}
|
||||
}
|
||||
```
|
||||

|
||||
|
||||
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!
|
||||

|
||||
|
||||
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!
|
||||
@ -11,7 +11,7 @@ It uses OpenCLIP embeddings to embed all of the photos and stores them in Chroma
|
||||
|
||||
Given a question, relevat photos are retrieved and passed to an open source multi-modal LLM of your choice for answer synthesis.
|
||||
|
||||

|
||||

|
||||
|
||||
## Input
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@ It uses an open source multi-modal LLM of your choice to create image summaries
|
||||
|
||||
Given a question, relevat photos are retrieved and passed to the multi-modal LLM for answer synthesis.
|
||||
|
||||

|
||||

|
||||
|
||||
## Input
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user