This pull request introduces a new feature to the LangChain QA Retrieval
Chains with Structures. The change involves adding a prompt template as
an optional parameter for the RetrievalQA chains that utilize the
recently implemented OpenAI Functions.
The main purpose of this enhancement is to provide users with the
ability to input a more customizable prompt to the chain. By introducing
a prompt template as an optional parameter, users can tailor the prompt
to their specific needs and context, thereby improving the flexibility
and effectiveness of the RetrievalQA chains.
## Changes Made
- Created a new optional parameter, "prompt", for the RetrievalQA with
structure chains.
- Added an example to the RetrievalQA with sources notebook.
My twitter handle is @El_Rey_Zero
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Added the functionality to leverage 3 new Codey models from Vertex AI:
- code-bison - Code generation using the existing LLM integration
- code-gecko - Code completion using the existing LLM integration
- codechat-bison - Code chat using the existing chat_model integration
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR adds `KuzuGraph` and `KuzuQAChain` for interacting with [Kùzu
database](https://github.com/kuzudb/kuzu). Kùzu is an in-process
property graph database management system (GDBMS) built for query speed
and scalability. The `KuzuGraph` and `KuzuQAChain` provide the same
functionality as the existing integration with NebulaGraph and Neo4j and
enables query generation and question answering over Kùzu database.
A notebook example and a simple test case have also been added.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
#### Fix
Added the mention of "store" amongst the tasks that the data connection
module can perform aside from the existing 3 (load, transform and
query). Particularly, this implies the generation of embeddings vectors
and the creation of vector stores.
This addresses #6291 adding support for using Cassandra (and compatible
databases, such as DataStax Astra DB) as a [Vector
Store](https://cwiki.apache.org/confluence/display/CASSANDRA/CEP-30%3A+Approximate+Nearest+Neighbor(ANN)+Vector+Search+via+Storage-Attached+Indexes).
A new class `Cassandra` is introduced, which complies with the contract
and interface for a vector store, along with the corresponding
integration test, a sample notebook and modified dependency toml.
Dependencies: the implementation relies on the library `cassio`, which
simplifies interacting with Cassandra for ML- and LLM-oriented
workloads. CassIO, in turn, uses the `cassandra-driver` low-lever
drivers to communicate with the database. The former is added as
optional dependency (+ in `extended_testing`), the latter was already in
the project.
Integration testing relies on a locally-running instance of Cassandra.
[Here](https://cassio.org/more_info/#use-a-local-vector-capable-cassandra)
a detailed description can be found on how to compile and run it (at the
time of writing the feature has not made it yet to a release).
During development of the integration tests, I added a new "fake
embedding" class for what I consider a more controlled way of testing
the MMR search method. Likewise, I had to amend what looked like a
glitch in the behaviour of `ConsistentFakeEmbeddings` whereby an
`embed_query` call would have bypassed storage of the requested text in
the class cache for use in later repeated invocations.
@dev2049 might be the right person to tag here for a review. Thank you!
---------
Co-authored-by: rlm <pexpresss31@gmail.com>
Hello Folks,
Thanks for creating and maintaining this great project. I'm excited to
submit this PR to add Alibaba Cloud OpenSearch as a new vector store.
OpenSearch is a one-stop platform to develop intelligent search
services. OpenSearch was built based on the large-scale distributed
search engine developed by Alibaba. OpenSearch serves more than 500
business cases in Alibaba Group and thousands of Alibaba Cloud
customers. OpenSearch helps develop search services in different search
scenarios, including e-commerce, O2O, multimedia, the content industry,
communities and forums, and big data query in enterprises.
OpenSearch provides the vector search feature. In specific scenarios,
especially test question search and image search scenarios, you can use
the vector search feature together with the multimodal search feature to
improve the accuracy of search results.
This PR includes:
A AlibabaCloudOpenSearch class that can connect to the Alibaba Cloud
OpenSearch instance.
add embedings and metadata into a opensearch datasource.
querying by squared euclidean and metadata.
integration tests.
ipython notebook and docs.
I have read your contributing guidelines. And I have passed the tests
below
- [x] make format
- [x] make lint
- [x] make coverage
- [x] make test
---------
Co-authored-by: zhaoshengbo <shengbo.zsb@alibaba-inc.com>
1. Introduced new distance strategies support: **DOT_PRODUCT** and
**EUCLIDEAN_DISTANCE** for enhanced flexibility.
2. Implemented a feature to filter results based on metadata fields.
3. Incorporated connection attributes specifying "langchain python sdk"
usage for enhanced traceability and debugging.
4. Expanded the suite of integration tests for improved code
reliability.
5. Updated the existing notebook with the usage example
@dev2049
---------
Co-authored-by: Volodymyr Tkachuk <vtkachuk-ua@singlestore.com>
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes a link typo from `/-/route` to `/-/routes`.
and change endpoint format
from `f"{self.anyscale_service_url}/{self.anyscale_service_route}"` to
`f"{self.anyscale_service_url}{self.anyscale_service_route}"`
Also adding documentation about the format of the endpoint
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Fixed several inconsistencies:
- file names and notebook titles should be similar otherwise ToC on the
[retrievers
page](https://python.langchain.com/en/latest/modules/indexes/retrievers.html)
and on the left ToC tab are different. For example, now, `Self-querying
with Chroma` is not correctly alphabetically sorted because its file
named `chroma_self_query.ipynb`
- `Stringing compressors and document transformers...` demoted from `#`
to `##`. Otherwise, it appears in Toc.
- several formatting problems
#### Who can review?
@hwchase17
@dev2049
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
The `CustomOutputParser` needs to throw `OutputParserException` when it
fails to parse the response from the agent, so that the executor can
[catch it and
retry](be9371ca8f/langchain/agents/agent.py (L767))
when `handle_parsing_errors=True`.
<!-- Remove if not applicable -->
#### Who can review?
Tag maintainers/contributors who might be interested: @hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
#### Description
- Removed two backticks surrounding the phrase "chat messages as"
- This phrase stood out among other formatted words/phrases such as
`prompt`, `role`, `PromptTemplate`, etc., which all seem to have a clear
function.
- `chat messages as`, formatted as such, confused me while reading,
leading me to believe the backticks were misplaced.
#### Who can review?
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
Minor new line character in the markdown.
Also, this option is not yet in the latest version of LangChain
(0.0.190) from Conda. Maybe in the next update.
@eyurtsev
@hwchase17
This PR adds an example of doing question answering over documents using
OpenAI Function Agents.
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
- return raw and full output (but keep run shortcut method functional)
- change output parser to take in generations (good for working with
messages)
- add output parser to base class, always run (default to same as
current)
---------
Co-authored-by: Eugene Yurtsev <eyurtsev@gmail.com>
#### Before submitting
Add memory support for `OpenAIFunctionsAgent` like
`StructuredChatAgent`.
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
To bypass SSL verification errors during fetching, you can include the
`verify=False` parameter. This markdown proves useful, especially for
beginners in the field of web scraping.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
Fixes#6079
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
@eyurtsev
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
To bypass SSL verification errors during web scraping, you can include
the ssl_verify=False parameter along with the headers parameter. This
combination of arguments proves useful, especially for beginners in the
field of web scraping.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
Fixes#1829
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17 @eyurtsev
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Hot Fixes for Deep Lake [would highly appreciate expedited review]
* deeplake version was hardcoded and since deeplake upgraded the
integration fails with confusing error
* an additional integration test fixed due to embedding function
* Additionally fixed docs for code understanding links after docs
upgraded
* notebook removal of public parameter to make sure code understanding
notebook works
#### Who can review?
@hwchase17 @dev2049
---------
Co-authored-by: Davit Buniatyan <d@activeloop.ai>
skip building preview of docs for anything branch that doesn't start
with `__docs__`. will eventually update to look at code diff directories
but patching for now
Add oobabooga/text-generation-webui support as an LLM. Currently,
supports using text-generation-webui's non-streaming API interface.
Allows users who already have text-gen running to use the same models
with langchain.
#### Before submitting
Simple usage, similar to existing LLM supported:
```
from langchain.llms import TextGen
llm = TextGen(model_url = "http://localhost:5000")
```
#### Who can review?
@hwchase17 - project lead
---------
Co-authored-by: Hien Ngo <Hien.Ngo@adia.ae>
## DocArray as a Retriever
[DocArray](https://github.com/docarray/docarray) is an open-source tool
for managing your multi-modal data. It offers flexibility to store and
search through your data using various document index backends. This PR
introduces `DocArrayRetriever` - which works with any available backend
and serves as a retriever for Langchain apps.
Also, I added 2 notebooks:
DocArray Backends - intro to all 5 currently supported backends, how to
initialize, index, and use them as a retriever
DocArray Usage - showcasing what additional search parameters you can
pass to create versatile retrievers
Example:
```python
from docarray.index import InMemoryExactNNIndex
from docarray import BaseDoc, DocList
from docarray.typing import NdArray
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.retrievers import DocArrayRetriever
# define document schema
class MyDoc(BaseDoc):
description: str
description_embedding: NdArray[1536]
embeddings = OpenAIEmbeddings()
# create documents
descriptions = ["description 1", "description 2"]
desc_embeddings = embeddings.embed_documents(texts=descriptions)
docs = DocList[MyDoc](
[
MyDoc(description=desc, description_embedding=embedding)
for desc, embedding in zip(descriptions, desc_embeddings)
]
)
# initialize document index with data
db = InMemoryExactNNIndex[MyDoc](docs)
# create a retriever
retriever = DocArrayRetriever(
index=db,
embeddings=embeddings,
search_field="description_embedding",
content_field="description",
)
# find the relevant document
doc = retriever.get_relevant_documents("action movies")
print(doc)
```
#### Who can review?
@dev2049
---------
Signed-off-by: jupyterjazz <saba.sturua@jina.ai>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes #
links to prompt templates and example selectors on the
[Prompts](https://python.langchain.com/docs/modules/model_io/prompts/)
page are invalid.
#### Before submitting
Just a small note that I tried to run `make docs_clean` and other
related commands before PR written
[here](https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md#build-documentation-locally),
it gives me an error:
```bash
langchain % make docs_clean
Traceback (most recent call last):
File "/Users/masafumi/Downloads/langchain/.venv/bin/make", line 5, in <module>
from scripts.proto import main
ModuleNotFoundError: No module named 'scripts'
make: *** [docs_clean] Error 1
# Poetry (version 1.5.1)
# Python 3.9.13
```
I couldn't figure out how to fix this, so I didn't run those command.
But links should work.
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
Similar issue #6323
Co-authored-by: masafumimori <m.masafumimori@outlook.com>
1. Changed the implementation of add_texts interface for the AwaDB
vector store in order to improve the performance
2. Upgrade the AwaDB from 0.3.2 to 0.3.3
---------
Co-authored-by: vincent <awadb.vincent@gmail.com>
**Short Description**
Added a new argument to AutoGPT class which allows to persist the chat
history to a file.
**Changes**
1. Removed the `self.full_message_history: List[BaseMessage] = []`
2. Replaced it with `chat_history_memory` which can take any subclasses
of `BaseChatMessageHistory`
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
adding new loader for [acreom](https://acreom.com) vaults. It's based on
the Obsidian loader with some additional text processing for acreom
specific markdown elements.
@eyurtsev please take a look!
---------
Co-authored-by: rlm <pexpresss31@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Add Solidity programming language support for code splitter.
Twitter: @0xjord4n_
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
This adds implementation of MMR search in pinecone; and I have two
semi-related observations about this vector store class:
- Maybe we should also have a
`similarity_search_by_vector_returning_embeddings` like in supabase, but
it's not in the base `VectorStore` class so I didn't implement
- Talking about the base class, there's
`similarity_search_with_relevance_scores`, but in pinecone it is called
`similarity_search_with_score`; maybe we should consider renaming it to
align with other `VectorStore` base and sub classes (or add that as an
alias for backward compatibility)
#### Who can review?
Tag maintainers/contributors who might be interested:
- VectorStores / Retrievers / Memory - @dev2049
# Introduces embaas document extraction api endpoints
In this PR, we add support for embaas document extraction endpoints to
Text Embedding Models (with LLMs, in different PRs coming). We currently
offer the MTEB leaderboard top performers, will continue to add top
embedding models and soon add support for customers to deploy thier own
models. Additional Documentation + Infomation can be found
[here](https://embaas.io).
While developing this integration, I closely followed the patterns
established by other langchain integrations. Nonetheless, if there are
any aspects that require adjustments or if there's a better way to
present a new integration, let me know! :)
Additionally, I fixed some docs in the embeddings integration.
Related PR: #5976
#### Who can review?
DataLoaders
- @eyurtsev
This creates a new kind of text splitter for markdown files.
The user can supply a set of headers that they want to split the file
on.
We define a new text splitter class, `MarkdownHeaderTextSplitter`, that
does a few things:
(1) For each line, it determines the associated set of user-specified
headers
(2) It groups lines with common headers into splits
See notebook for example usage and test cases.
#### What I do
Adding embedding api for
[DashScope](https://help.aliyun.com/product/610100.html), which is the
DAMO Academy's multilingual text unified vector model based on the LLM
base. It caters to multiple mainstream languages worldwide and offers
high-quality vector services, helping developers quickly transform text
data into high-quality vector data. Currently supported languages
include Chinese, English, Spanish, French, Portuguese, Indonesian, and
more.
#### Who can review?
Models
- @hwchase17
- @agola11
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Added description of LangChain Decorators ✨ into the integration section
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Inspired by the filtering capability available in ChromaDB, added the
same functionality to the FAISS vectorestore as well. Since FAISS does
not have an inbuilt method of filtering used the approach suggested in
this [thread](https://github.com/facebookresearch/faiss/issues/1079)
Langchain Issue inspiration:
https://github.com/hwchase17/langchain/issues/4572
- [x] Added filtering capability to semantic similarly and MMR
- [x] Added test cases for filtering in
`tests/integration_tests/vectorstores/test_faiss.py`
#### Who can review?
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
- @hwchase17
HuggingFace -> Hugging Face
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
This PR updates the Vectara integration (@hwchase17 ):
* Adds reuse of requests.session to imrpove efficiency and speed.
* Utilizes Vectara's low-level API (instead of standard API) to better
match user's specific chunking with LangChain
* Now add_texts puts all the texts into a single Vectara document so
indexing is much faster.
* updated variables names from alpha to lambda_val (to be consistent
with Vectara docs) and added n_context_sentence so it's available to use
if needed.
* Updates to documentation and tests
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Unstructured XML Loader
Adds an `UnstructuredXMLLoader` class for .xml files. Works with
unstructured>=0.6.7. A plain text representation of the text with the
XML tags will be available under the `page_content` attribute in the
doc.
### Testing
```python
from langchain.document_loaders import UnstructuredXMLLoader
loader = UnstructuredXMLLoader(
"example_data/factbook.xml",
)
docs = loader.load()
```
## Who can review?
@hwchase17
@eyurtsev
Added AwaDB vector store, which is a wrapper over the AwaDB, that can be
used as a vector storage and has an efficient similarity search. Added
integration tests for the vector store
Added jupyter notebook with the example
Delete a unneeded empty file and resolve the
conflict(https://github.com/hwchase17/langchain/pull/5886)
Please check, Thanks!
@dev2049
@hwchase17
---------
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: ljeagle <vincent_jieli@yeah.net>
Co-authored-by: vincent <awadb.vincent@gmail.com>
Based on the inspiration from the SQL chain, the following three
parameters are added to Graph Cypher Chain.
- top_k: Limited the number of results from the database to be used as
context
- return_direct: Return database results without transforming them to
natural language
- return_intermediate_steps: Return intermediate steps
<!--
Fixed a simple typo on
https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/vectorstore.html
where the word "use" was missing.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
"One Retriever to merge them all, One Retriever to expose them, One
Retriever to bring them all and in and process them with Document
formatters."
Hi @dev2049! Here bothering people again!
I'm using this simple idea to deal with merging the output of several
retrievers into one.
I'm aware of DocumentCompressorPipeline and
ContextualCompressionRetriever but I don't think they allow us to do
something like this. Also I was getting in trouble to get the pipeline
working too. Please correct me if i'm wrong.
This allow to do some sort of "retrieval" preprocessing and then using
the retrieval with the curated results anywhere you could use a
retriever.
My use case is to generate diff indexes with diff embeddings and sources
for a more colorful results then filtering them with one or many
document formatters.
I saw some people looking for something like this, here:
https://github.com/hwchase17/langchain/issues/3991
and something similar here:
https://github.com/hwchase17/langchain/issues/5555
This is just a proposal I know I'm missing tests , etc. If you think
this is a worth it idea I can work on tests and anything you want to
change.
Let me know!
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
This PR adds the possibility of specifying the endpoint URL to AWS in
the DynamoDBChatMessageHistory, so that it is possible to target not
only the AWS cloud services, but also a local installation.
Specifying the endpoint URL, which is normally not done when addressing
the cloud services, is very helpful when targeting a local instance
(like [Localstack](https://localstack.cloud/)) when running local tests.
Fixes#5835
#### Who can review?
Tag maintainers/contributors who might be interested: @dev2049
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
#### Add start index to metadata in TextSplitter
- Modified method `create_documents` to track start position of each
chunk
- The `start_index` is included in the metadata if the `add_start_index`
parameter in the class constructor is set to `True`
This enables referencing back to the original document, particularly
useful when a specific chunk is retrieved.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@eyurtsev @agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
This PR adds a Baseten integration. I've done my best to follow the
contributor's guidelines and add docs, an example notebook, and an
integration test modeled after similar integrations' test.
Please let me know if there is anything I can do to improve the PR. When
it is merged, please tag https://twitter.com/basetenco and
https://twitter.com/philip_kiely as contributors (the note on the PR
template said to include Twitter accounts)
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rlm <pexpresss31@gmail.com>
Fix the document page to open both search and Mendable when pressing
Ctrl+K.
I have changed the shortcut for Mendable to Ctrl+J.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
- Added `SingleStoreDB` vector store, which is a wrapper over the
SingleStore DB database, that can be used as a vector storage and has an
efficient similarity search.
- Added integration tests for the vector store
- Added jupyter notebook with the example
@dev2049
---------
Co-authored-by: Volodymyr Tkachuk <vtkachuk-ua@singlestore.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Simply fixing a small typo in the memory page.
Also removed an extra code block at the end of the file.
Along the way, the current outputs seem to have changed in a few places
so left that for posterity, and updated the number of runs which seems
harmless, though I can clean that up if preferred.
This PR adds documentation for Shale Protocol's integration with
LangChain.
[Shale Protocol](https://shaleprotocol.com) provides forever-free
production-ready inference APIs to the open-source community. We have
global data centers and plan to support all major open LLMs (estimated
~1,000 by 2025).
The team consists of software and ML engineers, AI researchers,
designers, and operators across North America and Asia. Combined
together, the team has 50+ years experience in machine learning, cloud
infrastructure, software engineering and product development. Team
members have worked at places like Google and Microsoft.
#### Who can review?
Tag maintainers/contributors who might be interested:
- @hwchase17
- @agola11
---------
Co-authored-by: Karen Sheng <46656667+karensheng@users.noreply.github.com>
### Summary
Adds an `UnstructuredCSVLoader` for loading CSVs. One advantage of using
`UnstructuredCSVLoader` relative to the standard `CSVLoader` is that if
you use `UnstructuredCSVLoader` in `"elements"` mode, an HTML
representation of the table will be available in the metadata.
#### Who can review?
@hwchase17
@eyurtsev
Hi! I just added an example of how to use a custom scraping function
with the sitemap loader. I recently used this feature and had to dig in
the source code to find it. I thought it might be useful to other devs
to have an example in the Jupyter Notebook directly.
I only added the example to the documentation page.
@eyurtsev I was not able to run the lint. Please let me know if I have
to do anything else.
I know this is a very small contribution, but I hope it will be
valuable. My Twitter handle is @web3Dav3.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17 - project lead
- @agola11
---------
Co-authored-by: Yessen Kanapin <yessen@deepinfra.com>
just change "to" to "too" so it matches the above prompt
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Some links were broken from the previous merge. This PR fixes them.
Tested locally.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Signed-off-by: Kourosh Hakhamaneshi <kourosh@anyscale.com>
This introduces the `YoutubeAudioLoader`, which will load blobs from a
YouTube url and write them. Blobs are then parsed by
`OpenAIWhisperParser()`, as show in this
[PR](https://github.com/hwchase17/langchain/pull/5580), but we extend
the parser to split audio such that each chuck meets the 25MB OpenAI
size limit. As shown in the notebook, this enables a very simple UX:
```
# Transcribe the video to text
loader = GenericLoader(YoutubeAudioLoader([url],save_dir),OpenAIWhisperParser())
docs = loader.load()
```
Tested on full set of Karpathy lecture videos:
```
# Karpathy lecture videos
urls = ["https://youtu.be/VMj-3S1tku0"
"https://youtu.be/PaCmpygFfXo",
"https://youtu.be/TCH_1BHY58I",
"https://youtu.be/P6sfmUTpUmc",
"https://youtu.be/q8SA3rM6ckI",
"https://youtu.be/t3YJ5hKiMQ0",
"https://youtu.be/kCc8FmEb1nY"]
# Directory to save audio files
save_dir = "~/Downloads/YouTube"
# Transcribe the videos to text
loader = GenericLoader(YoutubeAudioLoader(urls,save_dir),OpenAIWhisperParser())
docs = loader.load()
```
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
In the [Databricks
integration](https://python.langchain.com/en/latest/integrations/databricks.html)
and [Databricks
LLM](https://python.langchain.com/en/latest/modules/models/llms/integrations/databricks.html),
we suggestted users to set the ENV variable `DATABRICKS_API_TOKEN`.
However, this is inconsistent with the other Databricks library. To make
it consistent, this PR changes the variable from `DATABRICKS_API_TOKEN`
to `DATABRICKS_TOKEN`
After changes, there is no more `DATABRICKS_API_TOKEN` in the doc
```
$ git grep DATABRICKS_API_TOKEN|wc -l
0
$ git grep DATABRICKS_TOKEN|wc -l
8
```
cc @hwchase17 @dev2049 @mengxr since you have reviewed the previous PRs.
# Scores in Vectorestores' Docs Are Explained
Following vectorestores can return scores with similar documents by
using `similarity_search_with_score`:
- chroma
- docarray_hnsw
- docarray_in_memory
- faiss
- myscale
- qdrant
- supabase
- vectara
- weaviate
However, in documents, these scores were either not explained at all or
explained in a way that could lead to misunderstandings (e.g., FAISS).
For instance in FAISS document: if we consider the score returned by the
function as a similarity score, we understand that a document returning
a higher score is more similar to the source document. However, since
the scores returned by the function are distance scores, we should
understand that smaller scores correspond to more similar documents.
For the libraries other than Vectara, I wrote the scores they use by
investigating from the source libraries. Since I couldn't be certain
about the score metric used by Vectara, I didn't make any changes in its
documentation. The links mentioned in Vectara's documentation became
broken due to updates, so I replaced them with working ones.
VectorStores / Retrievers / Memory
- @dev2049
my twitter: [berkedilekoglu](https://twitter.com/berkedilekoglu)
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Added an overview of LangChain modules
Aimed at introducing newcomers to LangChain's main modules :)
Twitter handle is @edrick_dch
## Who can review?
@eyurtsev
Aviary is an open source toolkit for evaluating and deploying open
source LLMs. You can find out more about it on
[http://github.com/ray-project/aviary). You can try it out at
[http://aviary.anyscale.com](aviary.anyscale.com).
This code adds support for Aviary in LangChain. To minimize
dependencies, it connects directly to the HTTP endpoint.
The current implementation is not accelerated and uses the default
implementation of `predict` and `generate`.
It includes a test and a simple example.
@hwchase17 and @agola11 could you have a look at this?
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
# Token text splitter for sentence transformers
The current TokenTextSplitter only works with OpenAi models via the
`tiktoken` package. This is not clear from the name `TokenTextSplitter`.
In this (first PR) a token based text splitter for sentence transformer
models is added. In the future I think we should work towards injecting
a tokenizer into the TokenTextSplitter to make ti more flexible.
Could perhaps be reviewed by @dev2049
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5638. Retitles "Amazon Bedrock" page to "Bedrock" so that the
Integrations section of the left nav is properly sorted in alphabetical
order.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# like
[StdoutCallbackHandler](https://github.com/hwchase17/langchain/blob/master/langchain/callbacks/stdout.py),
but writes to a file
When running experiments I have found myself wanting to log the outputs
of my chains in a more lightweight way than using WandB tracing. This PR
contributes a callback handler that writes to file what
`StdoutCallbackHandler` would print.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Example Notebook
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
See the included `filecallbackhandler.ipynb` notebook for usage. Would
it be better to include this notebook under `modules/callbacks` or under
`integrations/`?
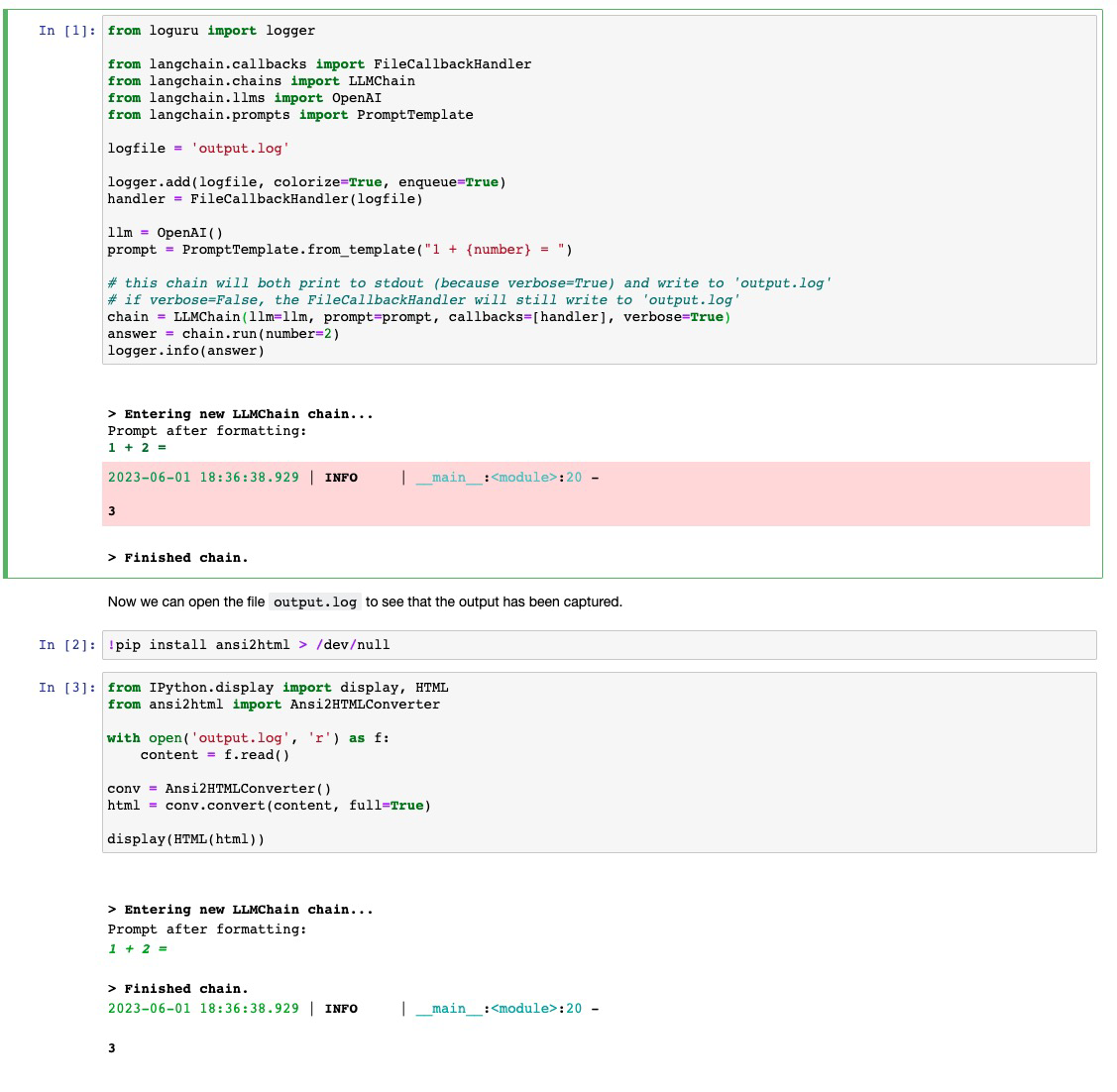
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Created fix for 5475
Currently in PGvector, we do not have any function that returns the
instance of an existing store. The from_documents always adds embeddings
and then returns the store. This fix is to add a function that will
return the instance of an existing store
Also changed the jupyter example for PGVector to show the example of
using the function
<!-- Remove if not applicable -->
Fixes # 5475
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@dev2049
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rajib76 <rajib76@yahoo.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR corrects a minor typo in the Momento chat message history
notebook and also expands the title from "Momento" to "Momento Chat
History", inline with other chat history storage providers.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
cc @dev2049 who reviewed the original integration
# Your PR Title (What it does)
Fixes the pgvector python example notebook : one of the variables was
not referencing anything
## Before submitting
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
# Make FinalStreamingStdOutCallbackHandler more robust by ignoring new
lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with
`ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The
response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]`
while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by
ignoring new lines & white spaces when determining if the answer prefix
has been reached.
Fixes#5433
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
# Implements support for Personal Access Token Authentication in the
ConfluenceLoader
Fixes#5191
Implements a new optional parameter for the ConfluenceLoader: `token`.
This allows the use of personal access authentication when using the
on-prem server version of Confluence.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @Jflick58
Twitter Handle: felipe_yyc
---------
Co-authored-by: Felipe <feferreira@ea.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# minor refactor of GenerativeAgentMemory
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
- refactor `format_memories_detail` to be more reusable
- modified prompts for getting topics for reflection and for generating
insights
- update `characters.ipynb` to reflect changes
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot
@hwchase17
@dev2049
# docs: modules pages simplified
Fixied #5627 issue
Merged several repetitive sections in the `modules` pages. Some texts,
that were hard to understand, were also simplified.
## Who can review?
@hwchase17
@dev2049
# Fixed multi input prompt for MapReduceChain
Added `kwargs` support for inner chains of `MapReduceChain` via
`from_params` method
Currently the `from_method` method of intialising `MapReduceChain` chain
doesn't work if prompt has multiple inputs. It happens because it uses
`StuffDocumentsChain` and `MapReduceDocumentsChain` underneath, both of
them require specifying `document_variable_name` if `prompt` of their
`llm_chain` has more than one `input`.
With this PR, I have added support for passing their respective `kwargs`
via the `from_params` method.
## Fixes https://github.com/hwchase17/langchain/issues/4752
## Who can review?
@dev2049 @hwchase17 @agola11
---------
Co-authored-by: imeckr <chandanroutray2012@gmail.com>
# Unstructured Excel Loader
Adds an `UnstructuredExcelLoader` class for `.xlsx` and `.xls` files.
Works with `unstructured>=0.6.7`. A plain text representation of the
Excel file will be available under the `page_content` attribute in the
doc. If you use the loader in `"elements"` mode, an HTML representation
of the Excel file will be available under the `text_as_html` metadata
key. Each sheet in the Excel document is its own document.
### Testing
```python
from langchain.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader(
"example_data/stanley-cups.xlsx",
mode="elements"
)
docs = loader.load()
```
## Who can review?
@hwchase17
@eyurtsev