mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2025-09-02 09:38:05 +00:00
[Feature] Add document retrieval QA (#5020)
* add langchain * add langchain * Add files via upload * add langchain * fix style * fix style: remove extra space * add pytest; modified retriever * add pytest; modified retriever * add tests to build_on_pr.yml * fix build_on_pr.yml * fix build on pr; fix environ vars * seperate unit tests for colossalqa from build from pr * fix container setting; fix environ vars * commented dev code * add incremental update * remove stale code * fix style * change to sha3 224 * fix retriever; fix style; add unit test for document loader * fix ci workflow config * fix ci workflow config * add set cuda visible device script in ci * fix doc string * fix style; update readme; refactored * add force log info * change build on pr, ignore colossalqa * fix docstring, captitalize all initial letters * fix indexing; fix text-splitter * remove debug code, update reference * reset previous commit * update LICENSE update README add key-value mode, fix bugs * add files back * revert force push * remove junk file * add test files * fix retriever bug, add intent classification * change conversation chain design * rewrite prompt and conversation chain * add ui v1 * ui v1 * fix atavar * add header * Refactor the RAG Code and support Pangu * Refactor the ColossalQA chain to Object-Oriented Programming and the UI demo. * resolved conversation. tested scripts under examples. web demo still buggy * fix ci tests * Some modifications to add ChatGPT api * modify llm.py and remove unnecessary files * Delete applications/ColossalQA/examples/ui/test_frontend_input.json * Remove OpenAI api key * add colossalqa * move files * move files * move files * move files * fix style * Add Readme and fix some bugs. * Add something to readme and modify some code * modify a directory name for clarity * remove redundant directory * Correct a type in llm.py * fix AI prefix * fix test_memory.py * fix conversation * fix some erros and typos * Fix a missing import in RAG_ChatBot.py * add colossalcloud LLM wrapper, correct issues in code review --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Orion-Zheng <zheng_zian@u.nus.edu> Co-authored-by: Zian(Andy) Zheng <62330719+Orion-Zheng@users.noreply.github.com> Co-authored-by: Orion-Zheng <zhengzian@u.nus.edu>
This commit is contained in:
184
applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py
Normal file
184
applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py
Normal file
@@ -0,0 +1,184 @@
|
||||
from typing import Dict, Tuple
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.prompt.prompt import (
|
||||
PROMPT_DISAMBIGUATE_ZH,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
SUMMARY_PROMPT_ZH,
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
)
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
DEFAULT_RAG_CFG = {
|
||||
"retri_top_k": 3,
|
||||
"retri_kb_file_path": "./",
|
||||
"verbose": True,
|
||||
"mem_summary_prompt": SUMMARY_PROMPT_ZH,
|
||||
"mem_human_prefix": "用户",
|
||||
"mem_ai_prefix": "Assistant",
|
||||
"mem_max_tokens": 2000,
|
||||
"mem_llm_kwargs": {"max_new_tokens": 50, "temperature": 1, "do_sample": True},
|
||||
"disambig_prompt": PROMPT_DISAMBIGUATE_ZH,
|
||||
"disambig_llm_kwargs": {"max_new_tokens": 30, "temperature": 1, "do_sample": True},
|
||||
"embed_model_name_or_path": "moka-ai/m3e-base",
|
||||
"embed_model_device": {"device": "cpu"},
|
||||
"gen_llm_kwargs": {"max_new_tokens": 100, "temperature": 1, "do_sample": True},
|
||||
"gen_qa_prompt": PROMPT_RETRIEVAL_QA_ZH,
|
||||
}
|
||||
|
||||
|
||||
class RAG_ChatBot:
|
||||
def __init__(
|
||||
self,
|
||||
llm,
|
||||
rag_config,
|
||||
) -> None:
|
||||
self.llm = llm
|
||||
self.rag_config = rag_config
|
||||
self.set_embed_model(**self.rag_config)
|
||||
self.set_text_splitter(**self.rag_config)
|
||||
self.set_memory(**self.rag_config)
|
||||
self.set_info_retriever(**self.rag_config)
|
||||
self.set_rag_chain(**self.rag_config)
|
||||
if self.rag_config.get("disambig_prompt", None):
|
||||
self.set_disambig_retriv(**self.rag_config)
|
||||
|
||||
def set_embed_model(self, **kwargs):
|
||||
self.embed_model = HuggingFaceEmbeddings(
|
||||
model_name=kwargs["embed_model_name_or_path"],
|
||||
model_kwargs=kwargs["embed_model_device"],
|
||||
encode_kwargs={"normalize_embeddings": False},
|
||||
)
|
||||
|
||||
def set_text_splitter(self, **kwargs):
|
||||
# Initialize text_splitter
|
||||
self.text_splitter = ChineseTextSplitter()
|
||||
|
||||
def set_memory(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["mem_llm_kwargs"]} if kwargs.get("mem_llm_kwargs", None) else {}
|
||||
# Initialize memory with summarization ability
|
||||
self.memory = ConversationBufferWithSummary(
|
||||
llm=self.llm,
|
||||
prompt=kwargs["mem_summary_prompt"],
|
||||
human_prefix=kwargs["mem_human_prefix"],
|
||||
ai_prefix=kwargs["mem_ai_prefix"],
|
||||
max_tokens=kwargs["mem_max_tokens"],
|
||||
**params,
|
||||
)
|
||||
|
||||
def set_info_retriever(self, **kwargs):
|
||||
self.info_retriever = CustomRetriever(
|
||||
k=kwargs["retri_top_k"], sql_file_path=kwargs["retri_kb_file_path"], verbose=kwargs["verbose"]
|
||||
)
|
||||
|
||||
def set_rag_chain(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["gen_llm_kwargs"]} if kwargs.get("gen_llm_kwargs", None) else {}
|
||||
self.rag_chain = RetrievalQA.from_chain_type(
|
||||
llm=self.llm,
|
||||
verbose=kwargs["verbose"],
|
||||
chain_type="stuff",
|
||||
retriever=self.info_retriever,
|
||||
chain_type_kwargs={"prompt": kwargs["gen_qa_prompt"], "memory": self.memory},
|
||||
**params,
|
||||
)
|
||||
|
||||
def split_docs(self, documents):
|
||||
doc_splits = self.text_splitter.split_documents(documents)
|
||||
return doc_splits
|
||||
|
||||
def set_disambig_retriv(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["disambig_llm_kwargs"]} if kwargs.get("disambig_llm_kwargs", None) else {}
|
||||
self.llm_chain_disambiguate = LLMChain(llm=self.llm, prompt=kwargs["disambig_prompt"], **params)
|
||||
|
||||
def disambiguity(input: str):
|
||||
out = self.llm_chain_disambiguate.run(input=input, chat_history=self.memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
self.info_retriever.set_rephrase_handler(disambiguity)
|
||||
|
||||
def load_doc_from_console(self, json_parse_args: Dict = {}):
|
||||
documents = []
|
||||
print("Select files for constructing Chinese retriever")
|
||||
while True:
|
||||
file = input("Enter a file path or press Enter directly without input to exit:").strip()
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
|
||||
documents.extend(docs)
|
||||
self.documents = documents
|
||||
self.split_docs_and_add_to_mem(**self.rag_config)
|
||||
|
||||
def load_doc_from_files(self, files, data_name="default_kb", json_parse_args: Dict = {}):
|
||||
documents = []
|
||||
for file in files:
|
||||
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
|
||||
documents.extend(docs)
|
||||
self.documents = documents
|
||||
self.split_docs_and_add_to_mem(**self.rag_config)
|
||||
|
||||
def split_docs_and_add_to_mem(self, **kwargs):
|
||||
self.doc_splits = self.split_docs(self.documents)
|
||||
self.info_retriever.add_documents(
|
||||
docs=self.doc_splits, cleanup="incremental", mode="by_source", embedding=self.embed_model
|
||||
)
|
||||
self.memory.initiate_document_retrieval_chain(self.llm, kwargs["gen_qa_prompt"], self.info_retriever)
|
||||
|
||||
def reset_config(self, rag_config):
|
||||
self.rag_config = rag_config
|
||||
self.set_embed_model(**self.rag_config)
|
||||
self.set_text_splitter(**self.rag_config)
|
||||
self.set_memory(**self.rag_config)
|
||||
self.set_info_retriever(**self.rag_config)
|
||||
self.set_rag_chain(**self.rag_config)
|
||||
if self.rag_config.get("disambig_prompt", None):
|
||||
self.set_disambig_retriv(**self.rag_config)
|
||||
|
||||
def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[str, ConversationBufferWithSummary]:
|
||||
if memory:
|
||||
memory.buffered_history.messages = memory.buffered_history.messages
|
||||
memory.summarized_history_temp.messages = memory.summarized_history_temp.messages
|
||||
result = self.rag_chain.run(
|
||||
query=user_input,
|
||||
stop=[memory.human_prefix + ": "],
|
||||
rejection_trigger_keywrods=ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
rejection_answer=ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
)
|
||||
return result.split("\n")[0], memory
|
||||
|
||||
def start_test_session(self):
|
||||
"""
|
||||
Simple session for testing purpose
|
||||
"""
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response, self.memory = self.run(user_input, self.memory)
|
||||
print(f"Agent: {agent_response}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Initialize an Langchain LLM(here we use ChatGPT as an example)
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
|
||||
|
||||
# chatgpt cannot control temperature, do_sample, etc.
|
||||
DEFAULT_RAG_CFG["mem_llm_kwargs"] = None
|
||||
DEFAULT_RAG_CFG["disambig_llm_kwargs"] = None
|
||||
DEFAULT_RAG_CFG["gen_llm_kwargs"] = None
|
||||
|
||||
rag = RAG_ChatBot(llm, DEFAULT_RAG_CFG)
|
||||
rag.load_doc_from_console()
|
||||
rag.start_test_session()
|
||||
37
applications/ColossalQA/examples/webui_demo/README.md
Normal file
37
applications/ColossalQA/examples/webui_demo/README.md
Normal file
@@ -0,0 +1,37 @@
|
||||
# ColossalQA WebUI Demo
|
||||
|
||||
This demo provides a simple WebUI for ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser.
|
||||
|
||||
The `server.py` initializes the backend RAG chain that can be backed by various language models (e.g., ChatGPT, Huawei Pangu, ChatGLM2). Meanwhile, `webui.py` launches a Gradio-supported chatbot interface.
|
||||
|
||||
# Usage
|
||||
|
||||
## Installation
|
||||
|
||||
First, install the necessary dependencies for ColossalQA:
|
||||
|
||||
```sh
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
cd ColossalAI/applications/ColossalQA/
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
## Configure the RAG Chain
|
||||
|
||||
Customize the RAG Chain settings, such as the embedding model (default: moka-ai/m3e) and the language model, in the `start_colossal_qa.sh` script.
|
||||
|
||||
For API-based language models (like ChatGPT or Huawei Pangu), provide your API key for authentication. For locally-run models, indicate the path to the model's checkpoint file.
|
||||
|
||||
If you want to customize prompts in the RAG Chain, you can have a look at the `RAG_ChatBot.py` file to modify them.
|
||||
|
||||
## Run WebUI Demo
|
||||
|
||||
Execute the following command to start the demo:
|
||||
|
||||
```sh
|
||||
bash start_colossal_qa.sh
|
||||
```
|
||||
|
||||
After launching the script, you can upload files and engage with the chatbot through your web browser.
|
||||
|
||||
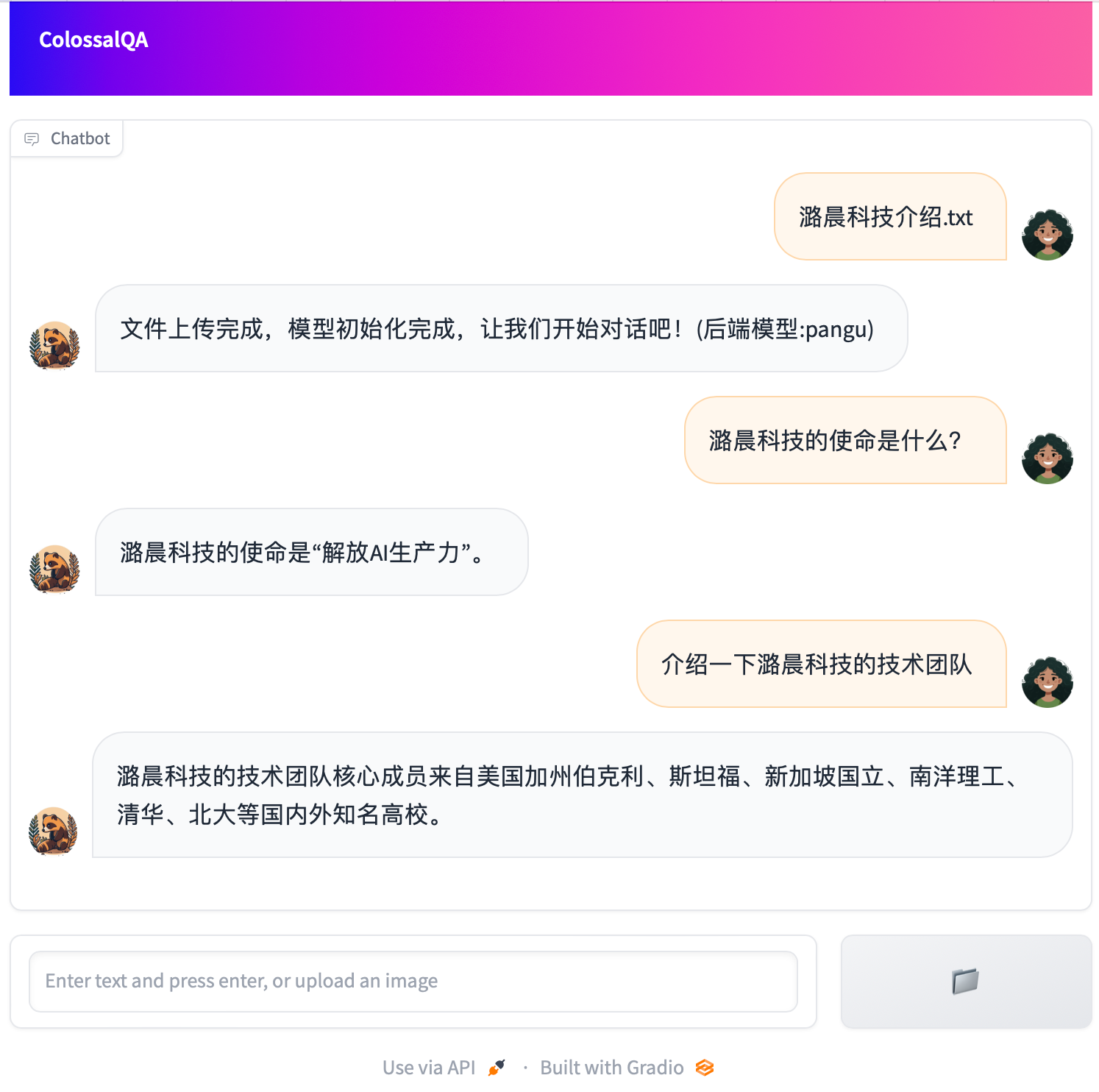
|
||||
BIN
applications/ColossalQA/examples/webui_demo/img/avatar_ai.png
Normal file
BIN
applications/ColossalQA/examples/webui_demo/img/avatar_ai.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 7.9 KiB |
BIN
applications/ColossalQA/examples/webui_demo/img/avatar_user.png
Normal file
BIN
applications/ColossalQA/examples/webui_demo/img/avatar_user.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.4 KiB |
117
applications/ColossalQA/examples/webui_demo/server.py
Normal file
117
applications/ColossalQA/examples/webui_demo/server.py
Normal file
@@ -0,0 +1,117 @@
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import string
|
||||
from http.server import BaseHTTPRequestHandler, HTTPServer
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.retrieval_conversation_zh import ChineseRetrievalConversation
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
from RAG_ChatBot import RAG_ChatBot, DEFAULT_RAG_CFG
|
||||
|
||||
# Define the mapping between embed_model_name(passed from Front End) and the actual path on the back end server
|
||||
EMBED_MODEL_DICT = {
|
||||
"m3e": os.environ.get("EMB_MODEL_PATH", DEFAULT_RAG_CFG["embed_model_name_or_path"])
|
||||
}
|
||||
# Define the mapping between LLM_name(passed from Front End) and the actual path on the back end server
|
||||
LLM_DICT = {
|
||||
"chatglm2": os.environ.get("CHAT_LLM_PATH", "THUDM/chatglm-6b"),
|
||||
"pangu": "Pangu_API",
|
||||
"chatgpt": "OpenAI_API"
|
||||
}
|
||||
|
||||
def randomword(length):
|
||||
letters = string.ascii_lowercase
|
||||
return "".join(random.choice(letters) for i in range(length))
|
||||
|
||||
class ColossalQAServerRequestHandler(BaseHTTPRequestHandler):
|
||||
chatbot = None
|
||||
def _set_response(self):
|
||||
"""
|
||||
set http header for response
|
||||
"""
|
||||
self.send_response(200)
|
||||
self.send_header("Content-type", "application/json")
|
||||
self.end_headers()
|
||||
|
||||
def do_POST(self):
|
||||
content_length = int(self.headers["Content-Length"])
|
||||
post_data = self.rfile.read(content_length)
|
||||
received_json = json.loads(post_data.decode("utf-8"))
|
||||
print(received_json)
|
||||
# conversation_ready is False(user's first request): Need to upload files and initialize the RAG chain
|
||||
if received_json["conversation_ready"] is False:
|
||||
self.rag_config = DEFAULT_RAG_CFG.copy()
|
||||
try:
|
||||
assert received_json["embed_model_name"] in EMBED_MODEL_DICT
|
||||
assert received_json["llm_name"] in LLM_DICT
|
||||
self.docs_files = received_json["docs"]
|
||||
embed_model_name, llm_name = received_json["embed_model_name"], received_json["llm_name"]
|
||||
|
||||
# Find the embed_model/llm ckpt path on the back end server.
|
||||
embed_model_path, llm_path = EMBED_MODEL_DICT[embed_model_name], LLM_DICT[llm_name]
|
||||
self.rag_config["embed_model_name_or_path"] = embed_model_path
|
||||
|
||||
# Create the storage path for knowledge base files
|
||||
self.rag_config["retri_kb_file_path"] = os.path.join(os.environ["TMP"], "colossalqa_kb/"+randomword(20))
|
||||
if not os.path.exists(self.rag_config["retri_kb_file_path"]):
|
||||
os.makedirs(self.rag_config["retri_kb_file_path"])
|
||||
|
||||
if (embed_model_path is not None) and (llm_path is not None):
|
||||
# ---- Intialize LLM, QA_chatbot here ----
|
||||
print("Initializing LLM...")
|
||||
if llm_path == "Pangu_API":
|
||||
from colossalqa.local.pangu_llm import Pangu
|
||||
self.llm = Pangu(id=1)
|
||||
self.llm.set_auth_config() # verify user's auth info here
|
||||
self.rag_config["mem_llm_kwargs"] = None
|
||||
self.rag_config["disambig_llm_kwargs"] = None
|
||||
self.rag_config["gen_llm_kwargs"] = None
|
||||
elif llm_path == "OpenAI_API":
|
||||
from langchain.llms import OpenAI
|
||||
self.llm = OpenAI()
|
||||
self.rag_config["mem_llm_kwargs"] = None
|
||||
self.rag_config["disambig_llm_kwargs"] = None
|
||||
self.rag_config["gen_llm_kwargs"] = None
|
||||
else:
|
||||
# ** (For Testing Only) **
|
||||
# In practice, all LLMs will run on the cloud platform and accessed by API, instead of running locally.
|
||||
# initialize model from model_path by using ColossalLLM
|
||||
self.rag_config["mem_llm_kwargs"] = {"max_new_tokens": 50, "temperature": 1, "do_sample": True}
|
||||
self.rag_config["disambig_llm_kwargs"] = {"max_new_tokens": 30, "temperature": 1, "do_sample": True}
|
||||
self.rag_config["gen_llm_kwargs"] = {"max_new_tokens": 100, "temperature": 1, "do_sample": True}
|
||||
self.colossal_api = ColossalAPI(llm_name, llm_path)
|
||||
self.llm = ColossalLLM(n=1, api=self.colossal_api)
|
||||
|
||||
print(f"Initializing RAG Chain...")
|
||||
print("RAG_CONFIG: ", self.rag_config)
|
||||
self.__class__.chatbot = RAG_ChatBot(self.llm, self.rag_config)
|
||||
print("Loading Files....\n", self.docs_files)
|
||||
self.__class__.chatbot.load_doc_from_files(self.docs_files)
|
||||
# -----------------------------------------------------------------------------------
|
||||
res = {"response": f"文件上传完成,模型初始化完成,让我们开始对话吧!(后端模型:{llm_name})", "error": "", "conversation_ready": True}
|
||||
except Exception as e:
|
||||
res = {"response": "文件上传或模型初始化有误,无法开始对话。",
|
||||
"error": f"Error in File Uploading and/or RAG initialization. Error details: {e}",
|
||||
"conversation_ready": False}
|
||||
# conversation_ready is True: Chatbot and docs are all set. Ready to chat.
|
||||
else:
|
||||
user_input = received_json["user_input"]
|
||||
chatbot_response, self.__class__.chatbot.memory = self.__class__.chatbot.run(user_input, self.__class__.chatbot.memory)
|
||||
res = {"response": chatbot_response, "error": "", "conversation_ready": True}
|
||||
self._set_response()
|
||||
self.wfile.write(json.dumps(res).encode("utf-8"))
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Chinese retrieval based conversation system")
|
||||
parser.add_argument("--port", type=int, default=13666, help="port on localhost to start the server")
|
||||
args = parser.parse_args()
|
||||
server_address = ("localhost", args.port)
|
||||
httpd = HTTPServer(server_address, ColossalQAServerRequestHandler)
|
||||
print(f"Starting server on port {args.port}...")
|
||||
httpd.serve_forever()
|
||||
|
||||
43
applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh
Executable file
43
applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh
Executable file
@@ -0,0 +1,43 @@
|
||||
#!/bin/bash
|
||||
cleanup() {
|
||||
echo "Caught Signal ... cleaning up."
|
||||
pkill -P $$ # kill all subprocess of this script
|
||||
exit 1 # exit script
|
||||
}
|
||||
# 'cleanup' is trigered when receive SIGINT(Ctrl+C) OR SIGTERM(kill) signal
|
||||
trap cleanup INT TERM
|
||||
|
||||
# Disable your proxy
|
||||
# unset HTTP_PROXY HTTPS_PROXY http_proxy https_proxy
|
||||
|
||||
# Path to store knowledge base(Home Directory by default)
|
||||
export TMP=$HOME
|
||||
|
||||
# Use m3e as embedding model
|
||||
export EMB_MODEL="m3e" # moka-ai/m3e-base model will be download automatically
|
||||
# export EMB_MODEL_PATH="PATH_TO_LOCAL_CHECKPOINT/m3e-base" # you can also specify the local path to embedding model
|
||||
|
||||
# Choose a backend LLM
|
||||
# - ChatGLM2
|
||||
# export CHAT_LLM="chatglm2"
|
||||
# export CHAT_LLM_PATH="PATH_TO_LOCAL_CHECKPOINT/chatglm2-6b"
|
||||
|
||||
# - ChatGPT
|
||||
export CHAT_LLM="chatgpt"
|
||||
# Auth info for OpenAI API
|
||||
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
|
||||
|
||||
# - Pangu
|
||||
# export CHAT_LLM="pangu"
|
||||
# # Auth info for Pangu API
|
||||
# export URL=""
|
||||
# export USERNAME=""
|
||||
# export PASSWORD=""
|
||||
# export DOMAIN_NAME=""
|
||||
|
||||
# Run server.py and colossalqa_webui.py in the background
|
||||
python server.py &
|
||||
python webui.py &
|
||||
|
||||
# Wait for all processes to finish
|
||||
wait
|
||||
102
applications/ColossalQA/examples/webui_demo/webui.py
Normal file
102
applications/ColossalQA/examples/webui_demo/webui.py
Normal file
@@ -0,0 +1,102 @@
|
||||
import json
|
||||
import os
|
||||
import gradio as gr
|
||||
import requests
|
||||
|
||||
RAG_STATE = {"conversation_ready": False, # Conversation is not ready until files are uploaded and RAG chain is initialized
|
||||
"embed_model_name": os.environ.get("EMB_MODEL", "m3e"),
|
||||
"llm_name": os.environ.get("CHAT_LLM", "chatgpt")}
|
||||
URL = "http://localhost:13666"
|
||||
|
||||
def get_response(client_data, URL):
|
||||
headers = {"Content-type": "application/json"}
|
||||
print(f"Sending request to server url: {URL}")
|
||||
response = requests.post(URL, data=json.dumps(client_data), headers=headers)
|
||||
response = json.loads(response.content)
|
||||
return response
|
||||
|
||||
def add_text(history, text):
|
||||
history = history + [(text, None)]
|
||||
return history, gr.update(value=None, interactive=True)
|
||||
|
||||
def add_file(history, files):
|
||||
global RAG_STATE
|
||||
RAG_STATE["conversation_ready"] = False # after adding new files, reset the ChatBot
|
||||
RAG_STATE["upload_files"]=[file.name for file in files]
|
||||
files_string = "\n".join([os.path.basename(path) for path in RAG_STATE["upload_files"]])
|
||||
print(files_string)
|
||||
history = history + [(files_string, None)]
|
||||
return history
|
||||
|
||||
def bot(history):
|
||||
print(history)
|
||||
global RAG_STATE
|
||||
if not RAG_STATE["conversation_ready"]:
|
||||
# Upload files and initialize models
|
||||
client_data = {
|
||||
"docs": RAG_STATE["upload_files"],
|
||||
"embed_model_name": RAG_STATE["embed_model_name"], # Select embedding model name here
|
||||
"llm_name": RAG_STATE["llm_name"], # Select LLM model name here. ["pangu", "chatglm2"]
|
||||
"conversation_ready": RAG_STATE["conversation_ready"]
|
||||
}
|
||||
else:
|
||||
client_data = {}
|
||||
client_data["conversation_ready"] = RAG_STATE["conversation_ready"]
|
||||
client_data["user_input"] = history[-1][0].strip()
|
||||
|
||||
response = get_response(client_data, URL) # TODO: async request, to avoid users waiting the model initialization too long
|
||||
print(response)
|
||||
if response["error"] != "":
|
||||
raise gr.Error(response["error"])
|
||||
|
||||
RAG_STATE["conversation_ready"] = response["conversation_ready"]
|
||||
history[-1][1] = response["response"]
|
||||
yield history
|
||||
|
||||
|
||||
CSS = """
|
||||
.contain { display: flex; flex-direction: column; height: 100vh }
|
||||
#component-0 { height: 100%; }
|
||||
#chatbot { flex-grow: 1; }
|
||||
"""
|
||||
|
||||
header_html = """
|
||||
<div style="background: linear-gradient(to right, #2a0cf4, #7100ed, #9800e6, #b600df, #ce00d9, #dc0cd1, #e81bca, #f229c3, #f738ba, #f946b2, #fb53ab, #fb5fa5); padding: 20px; text-align: left;">
|
||||
<h1 style="color: white;">ColossalQA</h1>
|
||||
<h4 style="color: white;">ColossalQA</h4>
|
||||
</div>
|
||||
"""
|
||||
|
||||
with gr.Blocks(css=CSS) as demo:
|
||||
html = gr.HTML(header_html)
|
||||
chatbot = gr.Chatbot(
|
||||
[],
|
||||
elem_id="chatbot",
|
||||
bubble_full_width=False,
|
||||
avatar_images=(
|
||||
(os.path.join(os.path.dirname(__file__), "img/avatar_user.png")),
|
||||
(os.path.join(os.path.dirname(__file__), "img/avatar_ai.png")),
|
||||
),
|
||||
)
|
||||
|
||||
with gr.Row():
|
||||
txt = gr.Textbox(
|
||||
scale=4,
|
||||
show_label=False,
|
||||
placeholder="Enter text and press enter, or upload an image",
|
||||
container=True,
|
||||
autofocus=True,
|
||||
)
|
||||
btn = gr.UploadButton("📁", file_types=["file"], file_count="multiple")
|
||||
|
||||
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)
|
||||
# Clear the original textbox
|
||||
txt_msg.then(lambda: gr.update(value=None, interactive=True), None, [txt], queue=False)
|
||||
# Click Upload Button: 1. upload files 2. send config to backend, initalize model 3. get response "conversation_ready" = True/False
|
||||
file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False).then(bot, chatbot, chatbot)
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
demo.queue()
|
||||
demo.launch(share=True) # share=True will release a public link of the demo
|
||||
Reference in New Issue
Block a user