mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2026-01-20 17:44:17 +00:00
Compare commits
192 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b1915d2889 | ||
|
|
eb158eb201 | ||
|
|
7f91b7e6f5 | ||
|
|
1b65963c02 | ||
|
|
4c53210aaf | ||
|
|
535eba85e2 | ||
|
|
6f7e8595fc | ||
|
|
40b6a914f3 | ||
|
|
c865de32a5 | ||
|
|
2336d7f6d6 | ||
|
|
ddda79c36f | ||
|
|
dba0c0c4ed | ||
|
|
b47b610d98 | ||
|
|
e5fdefa6cf | ||
|
|
083766d54c | ||
|
|
48a673dcb0 | ||
|
|
4ac2227488 | ||
|
|
b38248d35f | ||
|
|
fe1f429574 | ||
|
|
4152c0b30f | ||
|
|
73bdfd8891 | ||
|
|
99ba48fc40 | ||
|
|
762150cf51 | ||
|
|
bbc5fb4ed8 | ||
|
|
94e972fda6 | ||
|
|
c83dc66645 | ||
|
|
9db9892f63 | ||
|
|
b6a5f678cd | ||
|
|
e589ec505e | ||
|
|
08a1244ef1 | ||
|
|
32b2148670 | ||
|
|
3746f73854 | ||
|
|
118a66fd46 | ||
|
|
c7829769e9 | ||
|
|
3d9dd34973 | ||
|
|
eafbc89b1b | ||
|
|
352a8e0430 | ||
|
|
594c2c6522 | ||
|
|
685e0bd8da | ||
|
|
b314da19f4 | ||
|
|
245c8c2fbc | ||
|
|
a960990f1e | ||
|
|
0f71c79760 | ||
|
|
73384bea19 | ||
|
|
80c576f5ea | ||
|
|
79a7b99fe6 | ||
|
|
6a0b809fd1 | ||
|
|
3b3c48d9a8 | ||
|
|
3a4681fdd9 | ||
|
|
6ae54a6dce | ||
|
|
72b2d989df | ||
|
|
9dbb0ff89f | ||
|
|
de40c736d0 | ||
|
|
177144794b | ||
|
|
a9a3f374e5 | ||
|
|
8d52441f6d | ||
|
|
a246bf25c3 | ||
|
|
60510010d1 | ||
|
|
382307a62c | ||
|
|
2a39d3afd9 | ||
|
|
4b1c515f52 | ||
|
|
5bbfe1567f | ||
|
|
70c3daa4ee | ||
|
|
06cfbe313b | ||
|
|
c7c73df60a | ||
|
|
9cbc5dd924 | ||
|
|
6095274be6 | ||
|
|
654aefc3c3 | ||
|
|
e7f61be51a | ||
|
|
6ebd813b5f | ||
|
|
88f49ddc5e | ||
|
|
d19f1f21b6 | ||
|
|
f79dbdb2df | ||
|
|
0d0fef771f | ||
|
|
280aa0b830 | ||
|
|
5a6e4a6d75 | ||
|
|
3416a4fc9c | ||
|
|
af4366f0cb | ||
|
|
4ac7d065a6 | ||
|
|
9544c51a74 | ||
|
|
06b892bf4d | ||
|
|
9642b75581 | ||
|
|
1be993de3e | ||
|
|
de0c267f5a | ||
|
|
16600f3509 | ||
|
|
6a1bd833e0 | ||
|
|
e181318d51 | ||
|
|
fb4e507d00 | ||
|
|
37a8be7651 | ||
|
|
673682e716 | ||
|
|
5f913e8b77 | ||
|
|
b34d707cdc | ||
|
|
befd4f1487 | ||
|
|
3bd6fa3c67 | ||
|
|
5d79b9e692 | ||
|
|
12da4d14aa | ||
|
|
c627b60551 | ||
|
|
23aac43dcf | ||
|
|
16e68a071d | ||
|
|
f983071b10 | ||
|
|
455185345e | ||
|
|
35dabd718e | ||
|
|
e224673c44 | ||
|
|
bfc45829c3 | ||
|
|
30c7ddd9f1 | ||
|
|
a2ae82a417 | ||
|
|
b19355f8f0 | ||
|
|
69a1a325ee | ||
|
|
b951d0b224 | ||
|
|
a4862a2349 | ||
|
|
a537aa1c20 | ||
|
|
c8db826782 | ||
|
|
fe017d34c5 | ||
|
|
bc538ba049 | ||
|
|
f71d422690 | ||
|
|
246f16d7bc | ||
|
|
88eb6e5f04 | ||
|
|
1f15dc70df | ||
|
|
cc4cc78169 | ||
|
|
5c75d5b07c | ||
|
|
f8899dda70 | ||
|
|
9754a11398 | ||
|
|
5f178a7d24 | ||
|
|
b7842f8a5d | ||
|
|
718c4b76cc | ||
|
|
1f07b716bf | ||
|
|
40d601802d | ||
|
|
fa1272f9f2 | ||
|
|
7a2d455136 | ||
|
|
162bb42321 | ||
|
|
edd65a84dd | ||
|
|
908c634686 | ||
|
|
e285eb6993 | ||
|
|
d097224d90 | ||
|
|
97f4bee9d8 | ||
|
|
e00c9bbf38 | ||
|
|
91f08c64a7 | ||
|
|
043c46941c | ||
|
|
916a8fef0e | ||
|
|
0ba96e88d2 | ||
|
|
b9535f3c44 | ||
|
|
c4fe9e812e | ||
|
|
6dfedea98b | ||
|
|
b4ec405778 | ||
|
|
067dd43246 | ||
|
|
c9cba49ab5 | ||
|
|
fd56b22278 | ||
|
|
6f19618bb4 | ||
|
|
060102372e | ||
|
|
374dcd4da9 | ||
|
|
3f9159715f | ||
|
|
948533f7de | ||
|
|
c8aaa92e36 | ||
|
|
562767c884 | ||
|
|
594384328c | ||
|
|
cac878d7b7 | ||
|
|
45dd5a7cf4 | ||
|
|
d322ff8cd9 | ||
|
|
4afff92138 | ||
|
|
d3c40b9de4 | ||
|
|
d7a03bfea2 | ||
|
|
a9656e2915 | ||
|
|
45779680bf | ||
|
|
4271e3daf6 | ||
|
|
ddbbbaab3e | ||
|
|
46ed5d856b | ||
|
|
7ecdf9a211 | ||
|
|
44d4053fec | ||
|
|
6d676ee0e9 | ||
|
|
56fe130b15 | ||
|
|
f32861ccc5 | ||
|
|
b9e60559b8 | ||
|
|
7595c453a5 | ||
|
|
53834b74b9 | ||
|
|
0171884664 | ||
|
|
9379cbd668 | ||
|
|
24dee8f0b7 | ||
|
|
f73ae55394 | ||
|
|
f8b9e88484 | ||
|
|
d54642a263 | ||
|
|
d20c8ffd97 | ||
|
|
ce0ec40811 | ||
|
|
5ff5323538 | ||
|
|
014837e725 | ||
|
|
ec73f1b5e2 | ||
|
|
5c09d726a6 | ||
|
|
2b415e5999 | ||
|
|
17062c83b9 | ||
|
|
ca0aa2365d | ||
|
|
97e60cbbcb | ||
|
|
5b094a836b | ||
|
|
ee81366cac |
@@ -1,3 +1,3 @@
|
|||||||
2.2.2-12.1.0
|
|
||||||
2.3.0-12.1.0
|
2.3.0-12.1.0
|
||||||
2.4.0-12.4.1
|
2.4.0-12.4.1
|
||||||
|
2.5.1-12.4.1
|
||||||
|
|||||||
@@ -1,12 +1,12 @@
|
|||||||
{
|
{
|
||||||
"build": [
|
"build": [
|
||||||
{
|
{
|
||||||
"torch_command": "pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121",
|
"torch_command": "pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121",
|
||||||
"cuda_image": "hpcaitech/cuda-conda:12.1"
|
"cuda_image": "image-cloud.luchentech.com/hpcaitech/cuda-conda:12.1"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"torch_command": "pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124",
|
"torch_command": "pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124",
|
||||||
"cuda_image": "hpcaitech/cuda-conda:12.4"
|
"cuda_image": "image-cloud.luchentech.com/hpcaitech/cuda-conda:12.4"
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
|
|||||||
20
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
20
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -15,6 +15,26 @@ body:
|
|||||||
options:
|
options:
|
||||||
- label: I have searched the existing issues
|
- label: I have searched the existing issues
|
||||||
required: true
|
required: true
|
||||||
|
|
||||||
|
- type: checkboxes
|
||||||
|
attributes:
|
||||||
|
label: The bug has not been fixed in the latest main branch
|
||||||
|
options:
|
||||||
|
- label: I have checked the latest main branch
|
||||||
|
required: true
|
||||||
|
|
||||||
|
- type: dropdown
|
||||||
|
id: share_script
|
||||||
|
attributes:
|
||||||
|
label: Do you feel comfortable sharing a concise (minimal) script that reproduces the error? :)
|
||||||
|
description: If not, please share your setting/training config, and/or point to the line in the repo that throws the error.
|
||||||
|
If the issue is not easily reproducible by us, it will reduce the likelihood of getting responses.
|
||||||
|
options:
|
||||||
|
- Yes, I will share a minimal reproducible script.
|
||||||
|
- No, I prefer not to share.
|
||||||
|
validations:
|
||||||
|
required: true
|
||||||
|
|
||||||
- type: textarea
|
- type: textarea
|
||||||
attributes:
|
attributes:
|
||||||
label: 🐛 Describe the bug
|
label: 🐛 Describe the bug
|
||||||
|
|||||||
15
.github/workflows/build_on_pr.yml
vendored
15
.github/workflows/build_on_pr.yml
vendored
@@ -34,7 +34,7 @@ jobs:
|
|||||||
anyExtensionFileChanged: ${{ steps.find-extension-change.outputs.any_changed }}
|
anyExtensionFileChanged: ${{ steps.find-extension-change.outputs.any_changed }}
|
||||||
changedLibraryFiles: ${{ steps.find-lib-change.outputs.all_changed_files }}
|
changedLibraryFiles: ${{ steps.find-lib-change.outputs.all_changed_files }}
|
||||||
anyLibraryFileChanged: ${{ steps.find-lib-change.outputs.any_changed }}
|
anyLibraryFileChanged: ${{ steps.find-lib-change.outputs.any_changed }}
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
concurrency:
|
concurrency:
|
||||||
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-detect-change
|
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-detect-change
|
||||||
cancel-in-progress: true
|
cancel-in-progress: true
|
||||||
@@ -87,10 +87,10 @@ jobs:
|
|||||||
name: Build and Test Colossal-AI
|
name: Build and Test Colossal-AI
|
||||||
needs: detect
|
needs: detect
|
||||||
if: needs.detect.outputs.anyLibraryFileChanged == 'true'
|
if: needs.detect.outputs.anyLibraryFileChanged == 'true'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /dev/shm -v /data/scratch:/data/scratch
|
options: --gpus all --shm-size=2g --rm -v /dev/shm -v /data/scratch:/data/scratch
|
||||||
timeout-minutes: 90
|
timeout-minutes: 90
|
||||||
defaults:
|
defaults:
|
||||||
run:
|
run:
|
||||||
@@ -138,6 +138,10 @@ jobs:
|
|||||||
cp -p -r /github/home/cuda_ext_cache/* /__w/ColossalAI/ColossalAI/
|
cp -p -r /github/home/cuda_ext_cache/* /__w/ColossalAI/ColossalAI/
|
||||||
fi
|
fi
|
||||||
|
|
||||||
|
- name: Install flash-attention
|
||||||
|
run: |
|
||||||
|
pip install flash-attn==2.7.4.post1 --no-build-isolation
|
||||||
|
|
||||||
- name: Install Colossal-AI
|
- name: Install Colossal-AI
|
||||||
run: |
|
run: |
|
||||||
BUILD_EXT=1 pip install -v -e .
|
BUILD_EXT=1 pip install -v -e .
|
||||||
@@ -166,6 +170,7 @@ jobs:
|
|||||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
||||||
LLAMA_PATH: /data/scratch/llama-tiny
|
LLAMA_PATH: /data/scratch/llama-tiny
|
||||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||||
|
HF_ENDPOINT: https://hf-mirror.com
|
||||||
|
|
||||||
- name: Collate artifact
|
- name: Collate artifact
|
||||||
env:
|
env:
|
||||||
@@ -199,7 +204,7 @@ jobs:
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
- name: Upload test coverage artifact
|
- name: Upload test coverage artifact
|
||||||
uses: actions/upload-artifact@v3
|
uses: actions/upload-artifact@v4
|
||||||
with:
|
with:
|
||||||
name: report
|
name: report
|
||||||
path: report/
|
path: report/
|
||||||
|
|||||||
11
.github/workflows/build_on_schedule.yml
vendored
11
.github/workflows/build_on_schedule.yml
vendored
@@ -3,16 +3,16 @@ name: Build on Schedule
|
|||||||
on:
|
on:
|
||||||
schedule:
|
schedule:
|
||||||
# run at 00:00 of every Sunday
|
# run at 00:00 of every Sunday
|
||||||
- cron: "0 0 * * *"
|
- cron: "0 0 * * 0"
|
||||||
workflow_dispatch:
|
workflow_dispatch:
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
build:
|
build:
|
||||||
name: Build and Test Colossal-AI
|
name: Build and Test Colossal-AI
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /dev/shm -v /data/scratch/:/data/scratch/
|
options: --gpus all --rm -v /dev/shm -v /data/scratch/:/data/scratch/
|
||||||
timeout-minutes: 90
|
timeout-minutes: 90
|
||||||
steps:
|
steps:
|
||||||
@@ -51,6 +51,10 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
ssh-key: ${{ secrets.SSH_KEY_FOR_CI }}
|
ssh-key: ${{ secrets.SSH_KEY_FOR_CI }}
|
||||||
|
|
||||||
|
- name: Install flash-attention
|
||||||
|
run: |
|
||||||
|
pip install flash-attn==2.7.4.post1 --no-build-isolation
|
||||||
|
|
||||||
- name: Install Colossal-AI
|
- name: Install Colossal-AI
|
||||||
if: steps.check-avai.outputs.avai == 'true'
|
if: steps.check-avai.outputs.avai == 'true'
|
||||||
run: |
|
run: |
|
||||||
@@ -70,6 +74,7 @@ jobs:
|
|||||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
||||||
LLAMA_PATH: /data/scratch/llama-tiny
|
LLAMA_PATH: /data/scratch/llama-tiny
|
||||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||||
|
HF_ENDPOINT: https://hf-mirror.com
|
||||||
|
|
||||||
- name: Notify Lark
|
- name: Notify Lark
|
||||||
id: message-preparation
|
id: message-preparation
|
||||||
|
|||||||
2
.github/workflows/close_inactive.yml
vendored
2
.github/workflows/close_inactive.yml
vendored
@@ -7,7 +7,7 @@ on:
|
|||||||
jobs:
|
jobs:
|
||||||
close-issues:
|
close-issues:
|
||||||
if: github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
if: github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
permissions:
|
permissions:
|
||||||
issues: write
|
issues: write
|
||||||
pull-requests: write
|
pull-requests: write
|
||||||
|
|||||||
@@ -15,7 +15,7 @@ on:
|
|||||||
jobs:
|
jobs:
|
||||||
matrix_preparation:
|
matrix_preparation:
|
||||||
name: Prepare Container List
|
name: Prepare Container List
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||||
steps:
|
steps:
|
||||||
@@ -31,7 +31,7 @@ jobs:
|
|||||||
do
|
do
|
||||||
for cv in $CUDA_VERSIONS
|
for cv in $CUDA_VERSIONS
|
||||||
do
|
do
|
||||||
DOCKER_IMAGE+=("\"hpcaitech/pytorch-cuda:${tv}-${cv}\"")
|
DOCKER_IMAGE+=("\"image-cloud.luchentech.com/hpcaitech/pytorch-cuda:${tv}-${cv}\"")
|
||||||
done
|
done
|
||||||
done
|
done
|
||||||
|
|
||||||
@@ -44,7 +44,7 @@ jobs:
|
|||||||
name: Test for PyTorch Compatibility
|
name: Test for PyTorch Compatibility
|
||||||
needs: matrix_preparation
|
needs: matrix_preparation
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, 8-gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||||
@@ -73,9 +73,21 @@ jobs:
|
|||||||
|
|
||||||
- name: Unit Testing
|
- name: Unit Testing
|
||||||
run: |
|
run: |
|
||||||
PYTHONPATH=$PWD pytest --durations=0 tests
|
PYTHONPATH=$PWD pytest
|
||||||
|
-m "not largedist" \
|
||||||
|
--durations=0 \
|
||||||
|
--ignore tests/test_analyzer \
|
||||||
|
--ignore tests/test_auto_parallel \
|
||||||
|
--ignore tests/test_fx \
|
||||||
|
--ignore tests/test_autochunk \
|
||||||
|
--ignore tests/test_gptq \
|
||||||
|
--ignore tests/test_infer_ops \
|
||||||
|
--ignore tests/test_legacy \
|
||||||
|
--ignore tests/test_smoothquant \
|
||||||
|
tests/
|
||||||
env:
|
env:
|
||||||
DATA: /data/scratch/cifar-10
|
DATA: /data/scratch/cifar-10
|
||||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||||
LLAMA_PATH: /data/scratch/llama-tiny
|
LLAMA_PATH: /data/scratch/llama-tiny
|
||||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||||
|
HF_ENDPOINT: https://hf-mirror.com
|
||||||
|
|||||||
20
.github/workflows/compatiblity_test_on_pr.yml
vendored
20
.github/workflows/compatiblity_test_on_pr.yml
vendored
@@ -9,7 +9,7 @@ on:
|
|||||||
jobs:
|
jobs:
|
||||||
matrix_preparation:
|
matrix_preparation:
|
||||||
name: Prepare Container List
|
name: Prepare Container List
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||||
concurrency:
|
concurrency:
|
||||||
@@ -23,7 +23,7 @@ jobs:
|
|||||||
DOCKER_IMAGE=()
|
DOCKER_IMAGE=()
|
||||||
|
|
||||||
while read tag; do
|
while read tag; do
|
||||||
DOCKER_IMAGE+=("\"hpcaitech/pytorch-cuda:${tag}\"")
|
DOCKER_IMAGE+=("\"image-cloud.luchentech.com/hpcaitech/pytorch-cuda:${tag}\"")
|
||||||
done <.compatibility
|
done <.compatibility
|
||||||
|
|
||||||
container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
|
container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
|
||||||
@@ -35,7 +35,7 @@ jobs:
|
|||||||
name: Test for PyTorch Compatibility
|
name: Test for PyTorch Compatibility
|
||||||
needs: matrix_preparation
|
needs: matrix_preparation
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, 8-gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||||
@@ -67,9 +67,21 @@ jobs:
|
|||||||
|
|
||||||
- name: Unit Testing
|
- name: Unit Testing
|
||||||
run: |
|
run: |
|
||||||
PYTHONPATH=$PWD pytest --durations=0 tests
|
PYTHONPATH=$PWD pytest \
|
||||||
|
-m "not largedist" \
|
||||||
|
--durations=0 \
|
||||||
|
--ignore tests/test_analyzer \
|
||||||
|
--ignore tests/test_auto_parallel \
|
||||||
|
--ignore tests/test_fx \
|
||||||
|
--ignore tests/test_autochunk \
|
||||||
|
--ignore tests/test_gptq \
|
||||||
|
--ignore tests/test_infer_ops \
|
||||||
|
--ignore tests/test_legacy \
|
||||||
|
--ignore tests/test_smoothquant \
|
||||||
|
tests/
|
||||||
env:
|
env:
|
||||||
DATA: /data/scratch/cifar-10
|
DATA: /data/scratch/cifar-10
|
||||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||||
LLAMA_PATH: /data/scratch/llama-tiny
|
LLAMA_PATH: /data/scratch/llama-tiny
|
||||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||||
|
HF_ENDPOINT: https://hf-mirror.com
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ on:
|
|||||||
jobs:
|
jobs:
|
||||||
matrix_preparation:
|
matrix_preparation:
|
||||||
name: Prepare Container List
|
name: Prepare Container List
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||||
steps:
|
steps:
|
||||||
@@ -20,7 +20,7 @@ jobs:
|
|||||||
DOCKER_IMAGE=()
|
DOCKER_IMAGE=()
|
||||||
|
|
||||||
while read tag; do
|
while read tag; do
|
||||||
DOCKER_IMAGE+=("\"hpcaitech/pytorch-cuda:${tag}\"")
|
DOCKER_IMAGE+=("\"image-cloud.luchentech.com/hpcaitech/pytorch-cuda:${tag}\"")
|
||||||
done <.compatibility
|
done <.compatibility
|
||||||
|
|
||||||
container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
|
container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
|
||||||
@@ -32,7 +32,7 @@ jobs:
|
|||||||
name: Test for PyTorch Compatibility
|
name: Test for PyTorch Compatibility
|
||||||
needs: matrix_preparation
|
needs: matrix_preparation
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, 8-gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||||
@@ -61,12 +61,24 @@ jobs:
|
|||||||
|
|
||||||
- name: Unit Testing
|
- name: Unit Testing
|
||||||
run: |
|
run: |
|
||||||
PYTHONPATH=$PWD pytest --durations=0 tests
|
PYTHONPATH=$PWD pytest \
|
||||||
|
-m "not largedist" \
|
||||||
|
--durations=0 \
|
||||||
|
--ignore tests/test_analyzer \
|
||||||
|
--ignore tests/test_auto_parallel \
|
||||||
|
--ignore tests/test_fx \
|
||||||
|
--ignore tests/test_autochunk \
|
||||||
|
--ignore tests/test_gptq \
|
||||||
|
--ignore tests/test_infer_ops \
|
||||||
|
--ignore tests/test_legacy \
|
||||||
|
--ignore tests/test_smoothquant \
|
||||||
|
tests/
|
||||||
env:
|
env:
|
||||||
DATA: /data/scratch/cifar-10
|
DATA: /data/scratch/cifar-10
|
||||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||||
LLAMA_PATH: /data/scratch/llama-tiny
|
LLAMA_PATH: /data/scratch/llama-tiny
|
||||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||||
|
HF_ENDPOINT: https://hf-mirror.com
|
||||||
|
|
||||||
- name: Notify Lark
|
- name: Notify Lark
|
||||||
id: message-preparation
|
id: message-preparation
|
||||||
|
|||||||
@@ -10,7 +10,7 @@ jobs:
|
|||||||
matrix_preparation:
|
matrix_preparation:
|
||||||
name: Prepare Container List
|
name: Prepare Container List
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||||
steps:
|
steps:
|
||||||
@@ -24,7 +24,7 @@ jobs:
|
|||||||
build:
|
build:
|
||||||
name: Release bdist wheels
|
name: Release bdist wheels
|
||||||
needs: matrix_preparation
|
needs: matrix_preparation
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||||
|
|||||||
@@ -11,7 +11,7 @@ jobs:
|
|||||||
build-doc:
|
build-doc:
|
||||||
name: Trigger Documentation Build Workflow
|
name: Trigger Documentation Build Workflow
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
steps:
|
steps:
|
||||||
- name: trigger workflow in ColossalAI-Documentation
|
- name: trigger workflow in ColossalAI-Documentation
|
||||||
run: |
|
run: |
|
||||||
|
|||||||
8
.github/workflows/doc_check_on_pr.yml
vendored
8
.github/workflows/doc_check_on_pr.yml
vendored
@@ -15,7 +15,7 @@ jobs:
|
|||||||
if: |
|
if: |
|
||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
concurrency:
|
concurrency:
|
||||||
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-check-i18n
|
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-check-i18n
|
||||||
cancel-in-progress: true
|
cancel-in-progress: true
|
||||||
@@ -24,7 +24,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: "3.8.14"
|
python-version: "3.9"
|
||||||
|
|
||||||
- run: python .github/workflows/scripts/check_doc_i18n.py -d docs/source
|
- run: python .github/workflows/scripts/check_doc_i18n.py -d docs/source
|
||||||
|
|
||||||
@@ -33,7 +33,7 @@ jobs:
|
|||||||
if: |
|
if: |
|
||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
concurrency:
|
concurrency:
|
||||||
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-check-doc
|
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}-check-doc
|
||||||
cancel-in-progress: true
|
cancel-in-progress: true
|
||||||
@@ -50,7 +50,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: "3.8.14"
|
python-version: "3.9"
|
||||||
|
|
||||||
# we use the versions in the main branch as the guide for versions to display
|
# we use the versions in the main branch as the guide for versions to display
|
||||||
# checkout will give your merged branch
|
# checkout will give your merged branch
|
||||||
|
|||||||
6
.github/workflows/doc_test_on_pr.yml
vendored
6
.github/workflows/doc_test_on_pr.yml
vendored
@@ -15,7 +15,7 @@ jobs:
|
|||||||
if: |
|
if: |
|
||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
any_changed: ${{ steps.changed-files.outputs.any_changed }}
|
any_changed: ${{ steps.changed-files.outputs.any_changed }}
|
||||||
changed_files: ${{ steps.changed-files.outputs.all_changed_files }}
|
changed_files: ${{ steps.changed-files.outputs.all_changed_files }}
|
||||||
@@ -54,9 +54,9 @@ jobs:
|
|||||||
needs.detect-changed-doc.outputs.any_changed == 'true'
|
needs.detect-changed-doc.outputs.any_changed == 'true'
|
||||||
name: Test the changed Doc
|
name: Test the changed Doc
|
||||||
needs: detect-changed-doc
|
needs: detect-changed-doc
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm
|
options: --gpus all --rm
|
||||||
timeout-minutes: 30
|
timeout-minutes: 30
|
||||||
defaults:
|
defaults:
|
||||||
|
|||||||
4
.github/workflows/doc_test_on_schedule.yml
vendored
4
.github/workflows/doc_test_on_schedule.yml
vendored
@@ -10,9 +10,9 @@ jobs:
|
|||||||
# Add this condition to avoid executing this job if the trigger event is workflow_dispatch.
|
# Add this condition to avoid executing this job if the trigger event is workflow_dispatch.
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
name: Test the changed Doc
|
name: Test the changed Doc
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm
|
options: --gpus all --rm
|
||||||
timeout-minutes: 60
|
timeout-minutes: 60
|
||||||
steps:
|
steps:
|
||||||
|
|||||||
@@ -12,14 +12,14 @@ jobs:
|
|||||||
release:
|
release:
|
||||||
name: Draft Release Post
|
name: Draft Release Post
|
||||||
if: ( github.event_name == 'workflow_dispatch' || github.event.pull_request.merged == true ) && github.repository == 'hpcaitech/ColossalAI'
|
if: ( github.event_name == 'workflow_dispatch' || github.event.pull_request.merged == true ) && github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v2
|
- uses: actions/checkout@v2
|
||||||
with:
|
with:
|
||||||
fetch-depth: 0
|
fetch-depth: 0
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
- name: generate draft
|
- name: generate draft
|
||||||
id: generate_draft
|
id: generate_draft
|
||||||
run: |
|
run: |
|
||||||
|
|||||||
@@ -14,7 +14,7 @@ jobs:
|
|||||||
github.base_ref == 'main' &&
|
github.base_ref == 'main' &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
name: Check the examples user want
|
name: Check the examples user want
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||||
steps:
|
steps:
|
||||||
@@ -40,12 +40,12 @@ jobs:
|
|||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
name: Manually check example files
|
name: Manually check example files
|
||||||
needs: manual_check_matrix_preparation
|
needs: manual_check_matrix_preparation
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.manual_check_matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.manual_check_matrix_preparation.outputs.matrix)}}
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||||
timeout-minutes: 15
|
timeout-minutes: 15
|
||||||
steps:
|
steps:
|
||||||
|
|||||||
8
.github/workflows/example_check_on_pr.yml
vendored
8
.github/workflows/example_check_on_pr.yml
vendored
@@ -17,7 +17,7 @@ jobs:
|
|||||||
if: |
|
if: |
|
||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.setup-matrix.outputs.matrix }}
|
matrix: ${{ steps.setup-matrix.outputs.matrix }}
|
||||||
anyChanged: ${{ steps.setup-matrix.outputs.anyChanged }}
|
anyChanged: ${{ steps.setup-matrix.outputs.anyChanged }}
|
||||||
@@ -64,7 +64,7 @@ jobs:
|
|||||||
changedFileName="${file}:${changedFileName}"
|
changedFileName="${file}:${changedFileName}"
|
||||||
done
|
done
|
||||||
echo "$changedFileName was changed"
|
echo "$changedFileName was changed"
|
||||||
res=`python .github/workflows/scripts/example_checks/detect_changed_example.py --fileNameList $changedFileName`
|
res=`python3 .github/workflows/scripts/example_checks/detect_changed_example.py --fileNameList $changedFileName`
|
||||||
echo "All changed examples are $res"
|
echo "All changed examples are $res"
|
||||||
|
|
||||||
if [ "$res" == "[]" ]; then
|
if [ "$res" == "[]" ]; then
|
||||||
@@ -85,12 +85,12 @@ jobs:
|
|||||||
needs.detect-changed-example.outputs.anyChanged == 'true'
|
needs.detect-changed-example.outputs.anyChanged == 'true'
|
||||||
name: Test the changed example
|
name: Test the changed example
|
||||||
needs: detect-changed-example
|
needs: detect-changed-example
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.detect-changed-example.outputs.matrix)}}
|
matrix: ${{fromJson(needs.detect-changed-example.outputs.matrix)}}
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||||
timeout-minutes: 30
|
timeout-minutes: 30
|
||||||
concurrency:
|
concurrency:
|
||||||
|
|||||||
@@ -10,7 +10,7 @@ jobs:
|
|||||||
matrix_preparation:
|
matrix_preparation:
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
name: Prepare matrix for weekly check
|
name: Prepare matrix for weekly check
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
outputs:
|
outputs:
|
||||||
matrix: ${{ steps.setup-matrix.outputs.matrix }}
|
matrix: ${{ steps.setup-matrix.outputs.matrix }}
|
||||||
steps:
|
steps:
|
||||||
@@ -29,12 +29,12 @@ jobs:
|
|||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
name: Weekly check all examples
|
name: Weekly check all examples
|
||||||
needs: matrix_preparation
|
needs: matrix_preparation
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||||
timeout-minutes: 30
|
timeout-minutes: 30
|
||||||
steps:
|
steps:
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ jobs:
|
|||||||
release:
|
release:
|
||||||
name: Publish Docker Image to DockerHub
|
name: Publish Docker Image to DockerHub
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: "hpcaitech/docker-in-docker:latest"
|
image: "hpcaitech/docker-in-docker:latest"
|
||||||
options: --gpus all --rm -v /var/run/docker.sock:/var/run/docker.sock
|
options: --gpus all --rm -v /var/run/docker.sock:/var/run/docker.sock
|
||||||
@@ -46,14 +46,14 @@ jobs:
|
|||||||
notify:
|
notify:
|
||||||
name: Notify Lark via webhook
|
name: Notify Lark via webhook
|
||||||
needs: release
|
needs: release
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
if: ${{ always() }}
|
if: ${{ always() }}
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v2
|
- uses: actions/checkout@v2
|
||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: "3.8.14"
|
python-version: "3.9"
|
||||||
|
|
||||||
- name: Install requests
|
- name: Install requests
|
||||||
run: pip install requests
|
run: pip install requests
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ jobs:
|
|||||||
publish:
|
publish:
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
name: Build and publish Python 🐍 distributions 📦 to PyPI
|
name: Build and publish Python 🐍 distributions 📦 to PyPI
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
timeout-minutes: 20
|
timeout-minutes: 20
|
||||||
outputs:
|
outputs:
|
||||||
status: ${{ steps.publish.outcome }}
|
status: ${{ steps.publish.outcome }}
|
||||||
@@ -18,7 +18,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- run: |
|
- run: |
|
||||||
python .github/workflows/scripts/update_setup_for_nightly.py
|
python .github/workflows/scripts/update_setup_for_nightly.py
|
||||||
@@ -36,14 +36,14 @@ jobs:
|
|||||||
notify:
|
notify:
|
||||||
name: Notify Lark via webhook
|
name: Notify Lark via webhook
|
||||||
needs: publish
|
needs: publish
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
if: ${{ always() }} && github.repository == 'hpcaitech/ColossalAI'
|
if: ${{ always() }} && github.repository == 'hpcaitech/ColossalAI'
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v2
|
- uses: actions/checkout@v2
|
||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- name: Install requests
|
- name: Install requests
|
||||||
run: pip install requests
|
run: pip install requests
|
||||||
|
|||||||
@@ -7,7 +7,6 @@ on:
|
|||||||
- 'version.txt'
|
- 'version.txt'
|
||||||
types:
|
types:
|
||||||
- closed
|
- closed
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
build-n-publish:
|
build-n-publish:
|
||||||
if: github.event_name == 'workflow_dispatch' || github.repository == 'hpcaitech/ColossalAI' && github.event.pull_request.merged == true && github.base_ref == 'main'
|
if: github.event_name == 'workflow_dispatch' || github.repository == 'hpcaitech/ColossalAI' && github.event.pull_request.merged == true && github.base_ref == 'main'
|
||||||
@@ -19,7 +18,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- run: python setup.py sdist build
|
- run: python setup.py sdist build
|
||||||
|
|
||||||
@@ -42,7 +41,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- name: Install requests
|
- name: Install requests
|
||||||
run: pip install requests
|
run: pip install requests
|
||||||
|
|||||||
@@ -16,7 +16,7 @@ jobs:
|
|||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- name: add timestamp to the version
|
- name: add timestamp to the version
|
||||||
id: prep-version
|
id: prep-version
|
||||||
|
|||||||
@@ -10,14 +10,14 @@ jobs:
|
|||||||
generate-and-publish:
|
generate-and-publish:
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
name: Generate leaderboard report and publish to Lark
|
name: Generate leaderboard report and publish to Lark
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
timeout-minutes: 20
|
timeout-minutes: 20
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v2
|
- uses: actions/checkout@v2
|
||||||
|
|
||||||
- uses: actions/setup-python@v2
|
- uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: '3.8.14'
|
python-version: '3.9'
|
||||||
|
|
||||||
- run: pip install requests matplotlib seaborn requests_toolbelt pytz
|
- run: pip install requests matplotlib seaborn requests_toolbelt pytz
|
||||||
|
|
||||||
|
|||||||
2
.github/workflows/report_test_coverage.yml
vendored
2
.github/workflows/report_test_coverage.yml
vendored
@@ -8,7 +8,7 @@ on:
|
|||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
report-test-coverage:
|
report-test-coverage:
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
if: ${{ github.event.workflow_run.conclusion == 'success' }}
|
if: ${{ github.event.workflow_run.conclusion == 'success' }}
|
||||||
steps:
|
steps:
|
||||||
- name: "Download artifact"
|
- name: "Download artifact"
|
||||||
|
|||||||
29
.github/workflows/run_chatgpt_examples.yml
vendored
29
.github/workflows/run_chatgpt_examples.yml
vendored
@@ -17,11 +17,11 @@ jobs:
|
|||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.base_ref == 'main' &&
|
github.base_ref == 'main' &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.5.1-12.4.1
|
||||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data --shm-size=10.24gb
|
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data --shm-size=10.24gb
|
||||||
timeout-minutes: 60
|
timeout-minutes: 180
|
||||||
defaults:
|
defaults:
|
||||||
run:
|
run:
|
||||||
shell: bash
|
shell: bash
|
||||||
@@ -29,20 +29,32 @@ jobs:
|
|||||||
- name: Checkout ColossalAI
|
- name: Checkout ColossalAI
|
||||||
uses: actions/checkout@v2
|
uses: actions/checkout@v2
|
||||||
|
|
||||||
|
- name: Install torch
|
||||||
|
run: |
|
||||||
|
pip uninstall flash-attn
|
||||||
|
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
|
||||||
|
|
||||||
|
- name: Install flash-attn
|
||||||
|
run: |
|
||||||
|
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
||||||
|
|
||||||
- name: Install Colossal-AI
|
- name: Install Colossal-AI
|
||||||
run: |
|
run: |
|
||||||
BUILD_EXT=1 pip install --no-cache-dir -v -e .
|
BUILD_EXT=1 pip install --no-cache-dir -v -e .
|
||||||
|
|
||||||
- name: Install ChatGPT
|
- name: Install ChatGPT
|
||||||
|
env:
|
||||||
|
CFLAGS: "-O1"
|
||||||
|
CXXFLAGS: "-O1"
|
||||||
|
MAX_JOBS: 4
|
||||||
run: |
|
run: |
|
||||||
cd applications/ColossalChat
|
cd applications/ColossalChat
|
||||||
pip install --no-cache-dir -v .
|
pip install --no-cache-dir -v -e .
|
||||||
export BUILD_EXT=1
|
|
||||||
pip install --no-cache-dir -r examples/requirements.txt
|
pip install --no-cache-dir -r examples/requirements.txt
|
||||||
|
|
||||||
- name: Install Transformers
|
# - name: Install Transformers
|
||||||
run: |
|
# run: |
|
||||||
pip install --no-cache-dir transformers==4.36.2
|
# pip install --no-cache-dir transformers==4.36.2
|
||||||
|
|
||||||
- name: Execute Examples
|
- name: Execute Examples
|
||||||
run: |
|
run: |
|
||||||
@@ -61,5 +73,6 @@ jobs:
|
|||||||
PRETRAINED_MODEL_PATH: ./models
|
PRETRAINED_MODEL_PATH: ./models
|
||||||
SFT_DATASET: ./sft_data
|
SFT_DATASET: ./sft_data
|
||||||
PROMPT_DATASET: ./prompt_data
|
PROMPT_DATASET: ./prompt_data
|
||||||
|
PROMPT_RLVR_DATASET: ./prompt_data
|
||||||
PREFERENCE_DATASET: ./preference_data
|
PREFERENCE_DATASET: ./preference_data
|
||||||
KTO_DATASET: ./kto_data
|
KTO_DATASET: ./kto_data
|
||||||
|
|||||||
11
.github/workflows/run_chatgpt_unit_tests.yml
vendored
11
.github/workflows/run_chatgpt_unit_tests.yml
vendored
@@ -17,11 +17,11 @@ jobs:
|
|||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.base_ref == 'main' &&
|
github.base_ref == 'main' &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data
|
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data
|
||||||
timeout-minutes: 30
|
timeout-minutes: 180
|
||||||
defaults:
|
defaults:
|
||||||
run:
|
run:
|
||||||
shell: bash
|
shell: bash
|
||||||
@@ -30,7 +30,12 @@ jobs:
|
|||||||
uses: actions/checkout@v2
|
uses: actions/checkout@v2
|
||||||
|
|
||||||
- name: Install ChatGPT
|
- name: Install ChatGPT
|
||||||
|
env:
|
||||||
|
CFLAGS: "-O1"
|
||||||
|
CXXFLAGS: "-O1"
|
||||||
|
MAX_JOBS: 4
|
||||||
run: |
|
run: |
|
||||||
|
pip install flash-attn --no-build-isolation
|
||||||
cd applications/ColossalChat
|
cd applications/ColossalChat
|
||||||
pip install -v .
|
pip install -v .
|
||||||
pip install pytest
|
pip install pytest
|
||||||
|
|||||||
@@ -17,9 +17,9 @@ jobs:
|
|||||||
github.event.pull_request.draft == false &&
|
github.event.pull_request.draft == false &&
|
||||||
github.base_ref == 'main' &&
|
github.base_ref == 'main' &&
|
||||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||||
runs-on: [self-hosted, gpu]
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
container:
|
container:
|
||||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||||
volumes:
|
volumes:
|
||||||
- /data/scratch/test_data_colossalqa:/data/scratch/test_data_colossalqa
|
- /data/scratch/test_data_colossalqa:/data/scratch/test_data_colossalqa
|
||||||
- /data/scratch/llama-tiny:/data/scratch/llama-tiny
|
- /data/scratch/llama-tiny:/data/scratch/llama-tiny
|
||||||
|
|||||||
2
.github/workflows/submodule.yml
vendored
2
.github/workflows/submodule.yml
vendored
@@ -7,7 +7,7 @@ on:
|
|||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
sync-submodule:
|
sync-submodule:
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
if: github.repository == 'hpcaitech/ColossalAI'
|
if: github.repository == 'hpcaitech/ColossalAI'
|
||||||
steps:
|
steps:
|
||||||
- name: Checkout
|
- name: Checkout
|
||||||
|
|||||||
2
.github/workflows/translate_comment.yml
vendored
2
.github/workflows/translate_comment.yml
vendored
@@ -7,7 +7,7 @@ on:
|
|||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
build:
|
build:
|
||||||
runs-on: ubuntu-latest
|
runs-on: [self-hosted, ubuntu-latest]
|
||||||
steps:
|
steps:
|
||||||
- uses: usthe/issues-translate-action@v2.7
|
- uses: usthe/issues-translate-action@v2.7
|
||||||
with:
|
with:
|
||||||
|
|||||||
10
.gitignore
vendored
10
.gitignore
vendored
@@ -163,3 +163,13 @@ coverage.xml
|
|||||||
# log, test files - ColossalChat
|
# log, test files - ColossalChat
|
||||||
applications/ColossalChat/logs
|
applications/ColossalChat/logs
|
||||||
applications/ColossalChat/tests/logs
|
applications/ColossalChat/tests/logs
|
||||||
|
applications/ColossalChat/wandb
|
||||||
|
applications/ColossalChat/model
|
||||||
|
applications/ColossalChat/eval
|
||||||
|
applications/ColossalChat/rollouts
|
||||||
|
applications/ColossalChat/*.txt
|
||||||
|
applications/ColossalChat/*.db
|
||||||
|
applications/ColossalChat/stdin
|
||||||
|
applications/ColossalChat/*.zip
|
||||||
|
applications/ColossalChat/*.prof
|
||||||
|
applications/ColossalChat/*.png
|
||||||
|
|||||||
27
README.md
27
README.md
@@ -25,25 +25,38 @@
|
|||||||
|
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
## Get Started with Colossal-AI Without Setup
|
## Instantly Run Colossal-AI on Enterprise-Grade GPUs
|
||||||
|
|
||||||
Access high-end, on-demand compute for your research instantly—no setup needed.
|
Skip the setup. Access a powerful, pre-configured Colossal-AI environment on [**HPC-AI Cloud**](https://hpc-ai.com/?utm_source=github&utm_medium=social&utm_campaign=promotion-colossalai).
|
||||||
|
|
||||||
Sign up now and get $10 in credits!
|
Train your models and scale your AI workload in one click!
|
||||||
|
|
||||||
Limited Academic Bonuses:
|
* **NVIDIA Blackwell B200s**: Experience the next generation of AI performance ([See Benchmarks](https://hpc-ai.com/blog/b200)). Now available on cloud from **$2.47/hr**.
|
||||||
|
* **Cost-Effective H200 Cluster**: Get premier performance with on-demand rental from just **$1.99/hr**.
|
||||||
|
|
||||||
* Top up $1,000 and receive 300 credits
|
[**Get Started Now & Claim Your Free Credits →**](https://hpc-ai.com/?utm_source=github&utm_medium=social&utm_campaign=promotion-colossalai)
|
||||||
* Top up $500 and receive 100 credits
|
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<a href="https://hpc-ai.com/?utm_source=github&utm_medium=social&utm_campaign=promotion-colossalai">
|
<a href="https://hpc-ai.com/?utm_source=github&utm_medium=social&utm_campaign=promotion-colossalai">
|
||||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/colossalai/img/2.gif" width="850" />
|
<img src="https://github.com/hpcaitech/public_assets/blob/main/colossalai/img/2-3.png" width="850" />
|
||||||
</a>
|
</a>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
### Colossal-AI Benchmark
|
||||||
|
|
||||||
|
To see how these performance gains translate to real-world applications, we conducted a large language model training benchmark using Colossal-AI on Llama-like models. The tests were run on both 8-card and 16-card configurations for 7B and 70B models, respectively.
|
||||||
|
|
||||||
|
| GPU | GPUs | Model Size | Parallelism | Batch Size per DP | Seqlen | Throughput | TFLOPS/GPU | Peak Mem(MiB) |
|
||||||
|
| :-----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :--------------: | :-------------: | :-------------: | :-------------: |
|
||||||
|
| H200 | 8 | 7B | zero2(dp8) | 36 | 4096 | 17.13 samp/s | 534.18 | 119040.02 |
|
||||||
|
| H200 | 16 | 70B | zero2 | 48 | 4096 | 3.27 samp/s | 469.1 | 150032.23 |
|
||||||
|
| B200 | 8 | 7B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 25.83 samp/s | 805.69 | 100119.77 |
|
||||||
|
| H200 | 16 | 70B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 5.66 samp/s | 811.79 | 100072.02 |
|
||||||
|
|
||||||
|
The results from the Colossal-AI benchmark provide the most practical insight. For the 7B model on 8 cards, the **B200 achieved a 50% higher throughput** and a significant increase in TFLOPS per GPU. For the 70B model on 16 cards, the B200 again demonstrated a clear advantage, with **over 70% higher throughput and TFLOPS per GPU**. These numbers show that the B200's performance gains translate directly to faster training times for large-scale models.
|
||||||
|
|
||||||
## Latest News
|
## Latest News
|
||||||
|
* [2025/02] [DeepSeek 671B Fine-Tuning Guide Revealed—Unlock the Upgraded DeepSeek Suite with One Click, AI Players Ecstatic!](https://company.hpc-ai.com/blog/shocking-release-deepseek-671b-fine-tuning-guide-revealed-unlock-the-upgraded-deepseek-suite-with-one-click-ai-players-ecstatic)
|
||||||
* [2024/12] [The development cost of video generation models has saved by 50%! Open-source solutions are now available with H200 GPU vouchers](https://company.hpc-ai.com/blog/the-development-cost-of-video-generation-models-has-saved-by-50-open-source-solutions-are-now-available-with-h200-gpu-vouchers) [[code]](https://github.com/hpcaitech/Open-Sora/blob/main/scripts/train.py) [[vouchers]](https://colossalai.org/zh-Hans/docs/get_started/bonus/)
|
* [2024/12] [The development cost of video generation models has saved by 50%! Open-source solutions are now available with H200 GPU vouchers](https://company.hpc-ai.com/blog/the-development-cost-of-video-generation-models-has-saved-by-50-open-source-solutions-are-now-available-with-h200-gpu-vouchers) [[code]](https://github.com/hpcaitech/Open-Sora/blob/main/scripts/train.py) [[vouchers]](https://colossalai.org/zh-Hans/docs/get_started/bonus/)
|
||||||
* [2024/10] [How to build a low-cost Sora-like app? Solutions for you](https://company.hpc-ai.com/blog/how-to-build-a-low-cost-sora-like-app-solutions-for-you)
|
* [2024/10] [How to build a low-cost Sora-like app? Solutions for you](https://company.hpc-ai.com/blog/how-to-build-a-low-cost-sora-like-app-solutions-for-you)
|
||||||
* [2024/09] [Singapore Startup HPC-AI Tech Secures 50 Million USD in Series A Funding to Build the Video Generation AI Model and GPU Platform](https://company.hpc-ai.com/blog/singapore-startup-hpc-ai-tech-secures-50-million-usd-in-series-a-funding-to-build-the-video-generation-ai-model-and-gpu-platform)
|
* [2024/09] [Singapore Startup HPC-AI Tech Secures 50 Million USD in Series A Funding to Build the Video Generation AI Model and GPU Platform](https://company.hpc-ai.com/blog/singapore-startup-hpc-ai-tech-secures-50-million-usd-in-series-a-funding-to-build-the-video-generation-ai-model-and-gpu-platform)
|
||||||
|
|||||||
1
applications/ColossalChat/.gitignore
vendored
1
applications/ColossalChat/.gitignore
vendored
@@ -158,6 +158,7 @@ temp/
|
|||||||
applications/ColossalChat/logs
|
applications/ColossalChat/logs
|
||||||
applications/ColossalChat/models
|
applications/ColossalChat/models
|
||||||
applications/ColossalChat/sft_data
|
applications/ColossalChat/sft_data
|
||||||
|
applications/ColossalChat/kto_data
|
||||||
applications/ColossalChat/prompt_data
|
applications/ColossalChat/prompt_data
|
||||||
applications/ColossalChat/preference_data
|
applications/ColossalChat/preference_data
|
||||||
applications/ColossalChat/temp
|
applications/ColossalChat/temp
|
||||||
|
|||||||
@@ -7,31 +7,23 @@
|
|||||||
## Table of Contents
|
## Table of Contents
|
||||||
|
|
||||||
- [Table of Contents](#table-of-contents)
|
- [Table of Contents](#table-of-contents)
|
||||||
- [What is ColossalChat and Coati ?](#what-is-colossalchat-and-coati-)
|
- [What is ColossalChat?](#what-is-colossalchat)
|
||||||
- [Online demo](#online-demo)
|
- [Online demo](#online-demo)
|
||||||
- [Install](#install)
|
- [Install](#install)
|
||||||
- [Install the environment](#install-the-environment)
|
- [Install the environment](#install-the-environment)
|
||||||
- [Install the Transformers](#install-the-transformers)
|
- [Install the Transformers](#install-the-transformers)
|
||||||
- [How to use?](#how-to-use)
|
- [Introduction](#introduction)
|
||||||
- [Supervised datasets collection](#step-1-data-collection)
|
- [Supervised datasets collection](#step-1-data-collection)
|
||||||
- [RLHF Training Stage1 - Supervised instructs tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
- [RLHF Training Stage1 - Supervised instructs tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||||
- [RLHF Training Stage2 - Training reward model](#rlhf-training-stage2---training-reward-model)
|
- [RLHF Training Stage2 - Training reward model](#rlhf-training-stage2---training-reward-model)
|
||||||
- [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#rlhf-training-stage3---proximal-policy-optimization)
|
- [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#rlhf-training-stage3---proximal-policy-optimization)
|
||||||
|
- [Alternative Option for RLHF: GRPO](#alternative-option-for-rlhf-group-relative-policy-optimization-grpo)
|
||||||
|
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||||
|
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
||||||
|
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
||||||
|
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||||
|
- [SFT for DeepSeek V3/R1](#sft-for-deepseek-v3)
|
||||||
- [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
|
- [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
|
||||||
- [Coati7B examples](#coati7b-examples)
|
|
||||||
- [Generation](#generation)
|
|
||||||
- [Open QA](#open-qa)
|
|
||||||
- [Limitation for LLaMA-finetuned models](#limitation)
|
|
||||||
- [Limitation of dataset](#limitation)
|
|
||||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
|
||||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
|
||||||
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
|
||||||
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
|
||||||
- [O1 Journey](#o1-journey)
|
|
||||||
- [Inference with Self-refined MCTS](#inference-with-self-refined-mcts)
|
|
||||||
- [FAQ](#faq)
|
|
||||||
- [How to save/load checkpoint](#faq)
|
|
||||||
- [How to train with limited resources](#faq)
|
|
||||||
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
|
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
|
||||||
- [Quick Preview](#quick-preview)
|
- [Quick Preview](#quick-preview)
|
||||||
- [Authors](#authors)
|
- [Authors](#authors)
|
||||||
@@ -40,9 +32,9 @@
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## What Is ColossalChat And Coati ?
|
## What is ColossalChat?
|
||||||
|
|
||||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) is the project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI) project.
|
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalChat) is a project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI).
|
||||||
|
|
||||||
Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
|
Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
|
||||||
|
|
||||||
@@ -53,8 +45,6 @@ The Coati package provides a unified large language model framework that has imp
|
|||||||
- Supervised instructions fine-tuning
|
- Supervised instructions fine-tuning
|
||||||
- Training reward model
|
- Training reward model
|
||||||
- Reinforcement learning with human feedback
|
- Reinforcement learning with human feedback
|
||||||
- Quantization inference
|
|
||||||
- Fast model deploying
|
|
||||||
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
|
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
@@ -114,77 +104,16 @@ cd $COLOSSAL_AI_ROOT/applications/ColossalChat
|
|||||||
pip install .
|
pip install .
|
||||||
```
|
```
|
||||||
|
|
||||||
## How To Use?
|
## Introduction
|
||||||
|
|
||||||
### RLHF Training Stage1 - Supervised Instructs Tuning
|
### RLHF Training Stage1 - Supervised Instructs Tuning
|
||||||
|
|
||||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat. More details can be found in [example guideline](./examples/README.md).
|
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. More details can be found in [example guideline](./examples/README.md).
|
||||||
|
|
||||||
#### Step 1: Data Collection
|
|
||||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
|
|
||||||
|
|
||||||
```json
|
|
||||||
[
|
|
||||||
{"messages":
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"from": "user",
|
|
||||||
"content": "what are some pranks with a pen i can do?"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"from": "assistant",
|
|
||||||
"content": "Are you looking for practical joke ideas?"
|
|
||||||
},
|
|
||||||
]
|
|
||||||
},
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Step 2: Preprocessing
|
|
||||||
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
|
|
||||||
|
|
||||||
In this code, we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the [example guideline](./examples/README.md) on how to format and tokenize data.
|
|
||||||
|
|
||||||
#### Step 3: Training
|
|
||||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./examples/training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. More details can be found in [example guideline](./examples/README.md).
|
|
||||||
|
|
||||||
### RLHF Training Stage2 - Training Reward Model
|
### RLHF Training Stage2 - Training Reward Model
|
||||||
|
|
||||||
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
||||||
|
|
||||||
#### Step 1: Data Collection
|
|
||||||
Below shows the preference dataset format used in training the reward model.
|
|
||||||
|
|
||||||
```json
|
|
||||||
[
|
|
||||||
{"context": [
|
|
||||||
{
|
|
||||||
"from": "human",
|
|
||||||
"content": "Introduce butterflies species in Oregon."
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"chosen": [
|
|
||||||
{
|
|
||||||
"from": "assistant",
|
|
||||||
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
|
|
||||||
},
|
|
||||||
],
|
|
||||||
"rejected": [
|
|
||||||
{
|
|
||||||
"from": "assistant",
|
|
||||||
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
|
|
||||||
},
|
|
||||||
]
|
|
||||||
},
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Step 2: Preprocessing
|
|
||||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./examples/data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
|
||||||
|
|
||||||
#### Step 3: Training
|
|
||||||
You can run [train_rm.sh](./examples/training_scripts/train_rm.sh) to start the reward model training. More details can be found in [example guideline](./examples/README.md).
|
|
||||||
|
|
||||||
### RLHF Training Stage3 - Proximal Policy Optimization
|
### RLHF Training Stage3 - Proximal Policy Optimization
|
||||||
|
|
||||||
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
||||||
@@ -193,86 +122,26 @@ In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimi
|
|||||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
#### Step 1: Data Collection
|
|
||||||
PPO uses two kind of training data--- the prompt data and the sft data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
|
||||||
|
|
||||||
```json
|
### Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||||
[
|
|
||||||
{"messages":
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"from": "human",
|
|
||||||
"content": "what are some pranks with a pen i can do?"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
},
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Step 2: Data Preprocessing
|
|
||||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./examples/data_preparation_scripts/prepare_prompt_dataset.sh)
|
|
||||||
|
|
||||||
#### Step 3: Training
|
|
||||||
You can run the [train_ppo.sh](./examples/training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. More detais can be found in [example guideline](./examples/README.md).
|
|
||||||
|
|
||||||
```bash
|
|
||||||
--pretrain $PRETRAINED_MODEL_PATH \
|
|
||||||
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectual
|
|
||||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
|
||||||
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
|
|
||||||
--prompt_dataset ${prompt_dataset[@]} \ # List of string, the prompt dataset
|
|
||||||
--ptx_dataset ${ptx_dataset[@]} \ # List of string, the SFT data used in the SFT stage
|
|
||||||
--ptx_batch_size 1 \ # batch size for calculate ptx loss
|
|
||||||
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
|
|
||||||
--num_episodes 2000 \ # number of episodes to train
|
|
||||||
--num_collect_steps 1 \
|
|
||||||
--num_update_steps 1 \
|
|
||||||
--experience_batch_size 8 \
|
|
||||||
--train_batch_size 4 \
|
|
||||||
--accumulation_steps 2
|
|
||||||
```
|
|
||||||
|
|
||||||
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameter of actor and critic.
|
|
||||||
|
|
||||||
- Without tensor parallelism,
|
|
||||||
```
|
|
||||||
experience buffer size
|
|
||||||
= num_process * num_collect_steps * experience_batch_size
|
|
||||||
= train_batch_size * accumulation_steps * num_process
|
|
||||||
```
|
|
||||||
|
|
||||||
- With tensor parallelism,
|
|
||||||
```
|
|
||||||
num_tp_group = num_process / tp
|
|
||||||
experience buffer size
|
|
||||||
= num_tp_group * num_collect_steps * experience_batch_size
|
|
||||||
= train_batch_size * accumulation_steps * num_tp_group
|
|
||||||
```
|
|
||||||
|
|
||||||
## Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
|
||||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO. Read this [README](./examples/README.md) for more information.
|
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
### DPO Training Stage1 - Supervised Instructs Tuning
|
### Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||||
|
|
||||||
Please refer the [sft section](#dpo-training-stage1---supervised-instructs-tuning) in the PPO part.
|
|
||||||
|
|
||||||
### DPO Training Stage2 - DPO Training
|
|
||||||
#### Step 1: Data Collection & Preparation
|
|
||||||
For DPO training, you only need the preference dataset. Please follow the instruction in the [preference dataset preparation section](#rlhf-training-stage2---training-reward-model) to prepare the preference data for DPO training.
|
|
||||||
|
|
||||||
#### Step 2: Training
|
|
||||||
You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. More detais can be found in [example guideline](./examples/README.md).
|
|
||||||
|
|
||||||
## Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
|
||||||
Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process. Read this [README](./examples/README.md) for more information.
|
Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
## Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
### Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||||
Odds Ratio Preference Optimization (ORPO) from this [paper](https://arxiv.org/pdf/2403.07691) is a reference model free alignment method that use a mixture of SFT loss and a reinforcement leanring loss calculated based on odds-ratio-based implicit reward to makes the training more efficient and stable. Read this [README](./examples/README.md) for more information.
|
Odds Ratio Preference Optimization (ORPO) from this [paper](https://arxiv.org/pdf/2403.07691) is a reference model free alignment method that use a mixture of SFT loss and a reinforcement leanring loss calculated based on odds-ratio-based implicit reward to makes the training more efficient and stable. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
## Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
### Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results. Read this [README](./examples/README.md) for more information.
|
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
## Inference Quantization and Serving - After Training
|
### Alternative Option For RLHF: Group Relative Policy Optimization (GRPO)
|
||||||
|
We support the main algorithm used to train DeepSeek R1 model, a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
|
### SFT for DeepSeek V3
|
||||||
|
We support fine-tuning DeepSeek V3/R1 model with LoRA. Read this [README](./examples/README.md) for more information.
|
||||||
|
|
||||||
|
### Inference Quantization and Serving - After Training
|
||||||
|
|
||||||
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
|
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
|
||||||
|
|
||||||
@@ -281,182 +150,7 @@ We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inferen
|
|||||||
Online inference server scripts can help you deploy your own services.
|
Online inference server scripts can help you deploy your own services.
|
||||||
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||||
|
|
||||||
## O1 Journey
|
|
||||||
### Inference with Self-refined MCTS
|
|
||||||
We provide the implementation of MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models with Monte Carlo Tree Search.
|
|
||||||
You can serve model using vLLM and update the config file in `Qwen32B_prompt_CFG` and then run the following script.
|
|
||||||
```python
|
|
||||||
from coati.reasoner.guided_search.mcts import MCTS
|
|
||||||
from coati.reasoner.guided_search.prompt_store.qwen import Qwen32B_prompt_CFG
|
|
||||||
|
|
||||||
problem = "How Many R in 'Strawberry'"
|
|
||||||
|
|
||||||
search_tree = MCTS(problem=problem, max_simulations=8, cfg=Qwen32B_prompt_CFG)
|
|
||||||
answer = search_tree.simulate()
|
|
||||||
print(answer)
|
|
||||||
```
|
|
||||||
|
|
||||||
## Coati7B examples
|
|
||||||
|
|
||||||
### Generation
|
|
||||||
|
|
||||||
<details><summary><b>E-mail</b></summary>
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>coding</b></summary>
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>regex</b></summary>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Tex</b></summary>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>writing</b></summary>
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Table</b></summary>
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
### Open QA
|
|
||||||
|
|
||||||
<details><summary><b>Game</b></summary>
|
|
||||||
|
|
||||||
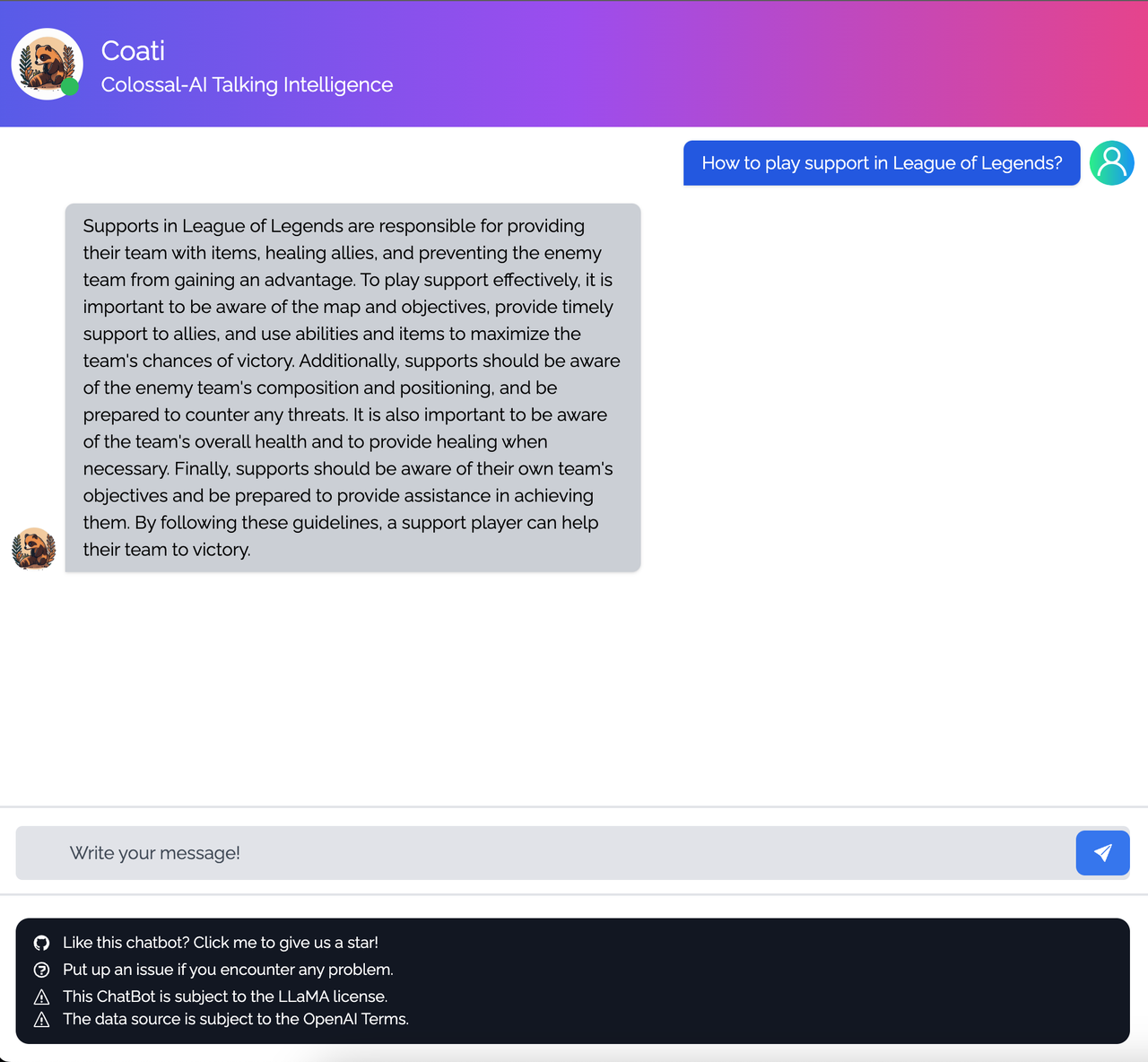
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Travel</b></summary>
|
|
||||||
|
|
||||||
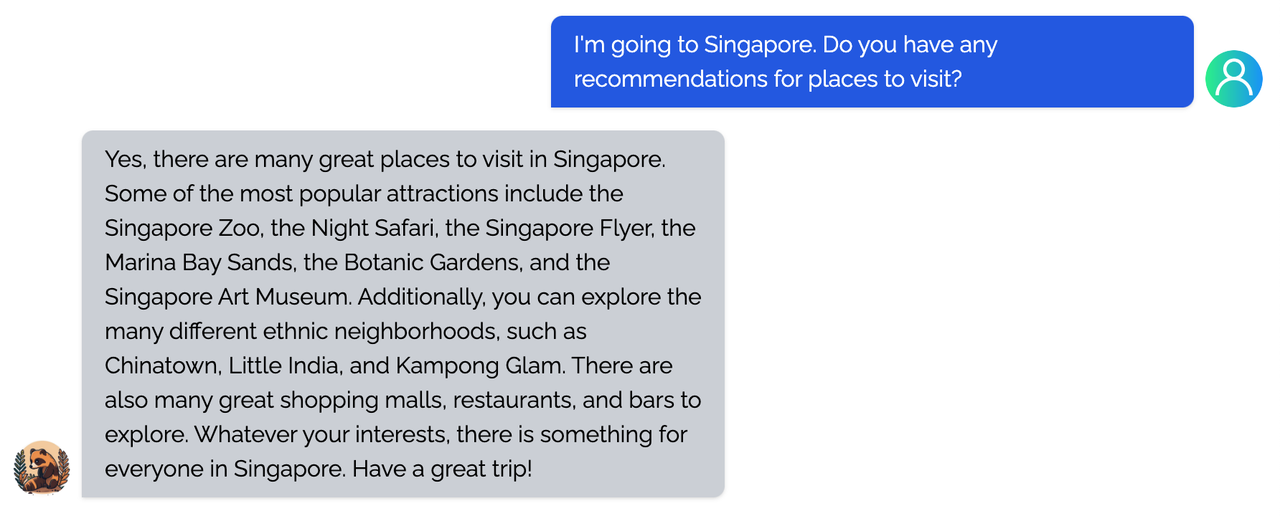
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Physical</b></summary>
|
|
||||||
|
|
||||||
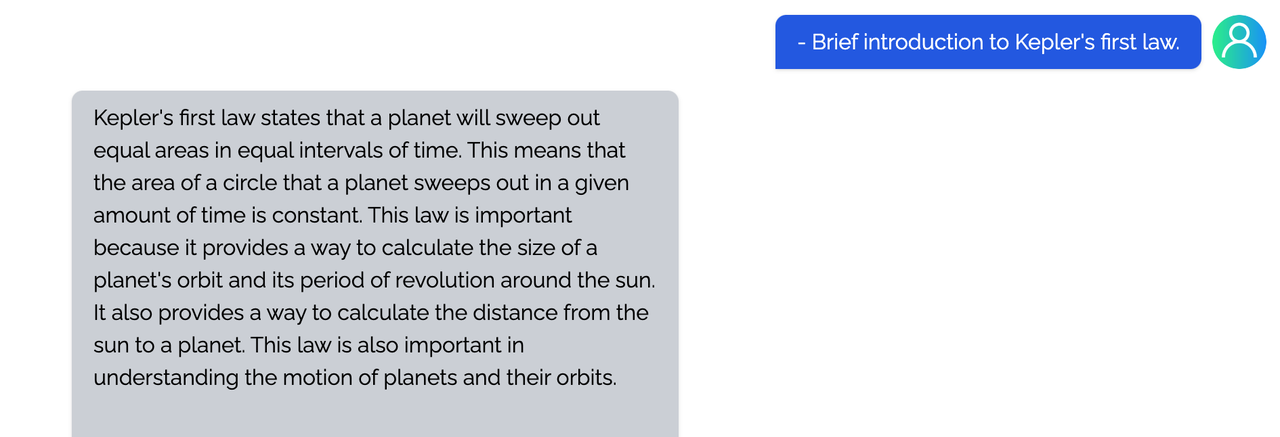
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Chemical</b></summary>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Economy</b></summary>
|
|
||||||
|
|
||||||
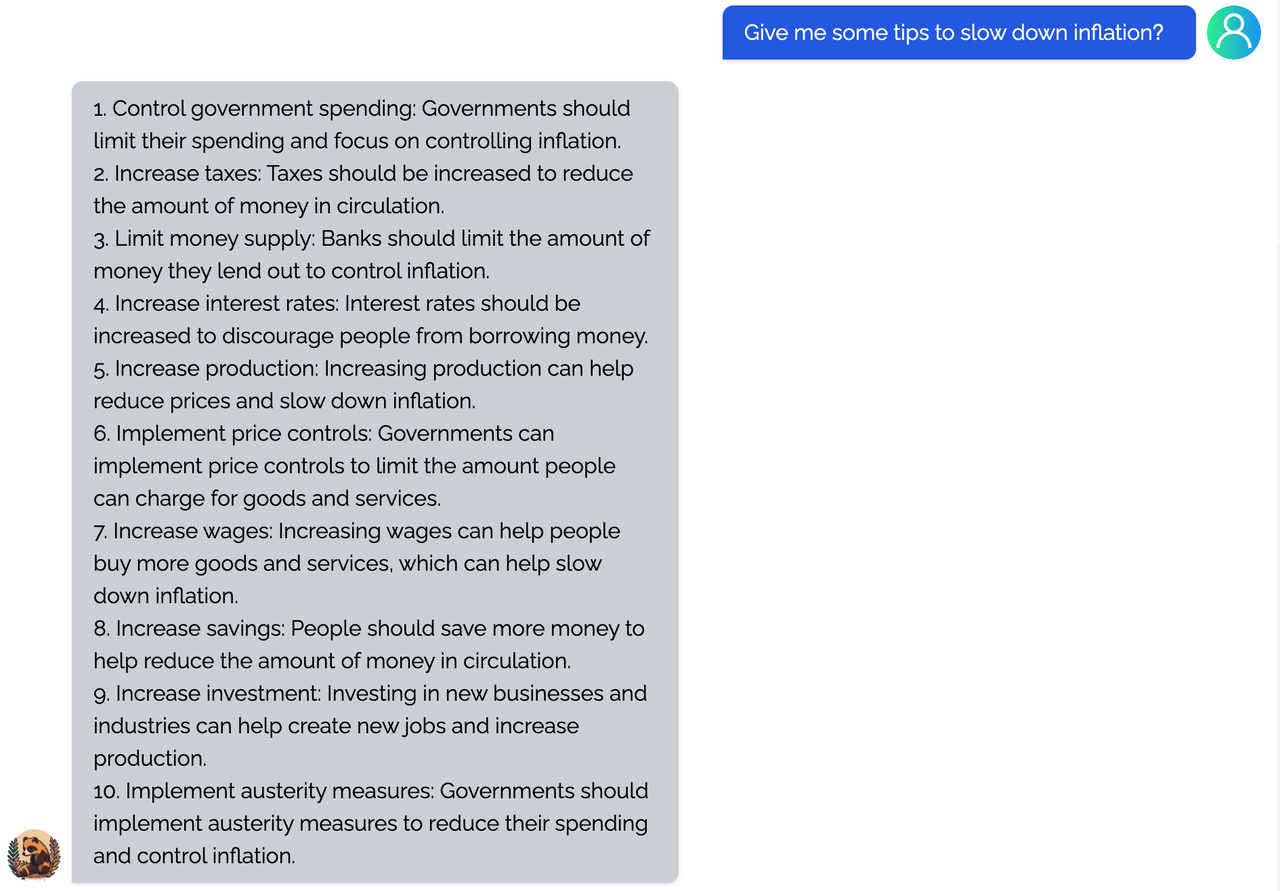
|
|
||||||
|
|
||||||
</details>
|
|
||||||
|
|
||||||
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
|
|
||||||
|
|
||||||
### Limitation
|
|
||||||
|
|
||||||
<details><summary><b>Limitation for LLaMA-finetuned models</b></summary>
|
|
||||||
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage.
|
|
||||||
- Lack of counting ability: Cannot count the number of items in a list.
|
|
||||||
- Lack of Logics (reasoning and calculation)
|
|
||||||
- Tend to repeat the last sentence (fail to produce the end token).
|
|
||||||
- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>Limitation of dataset</b></summary>
|
|
||||||
- Lack of summarization ability: No such instructions in finetune datasets.
|
|
||||||
- Lack of multi-turn chat: No such instructions in finetune datasets
|
|
||||||
- Lack of self-recognition: No such instructions in finetune datasets
|
|
||||||
- Lack of Safety:
|
|
||||||
- When the input contains fake facts, the model makes up false facts and explanations.
|
|
||||||
- Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.
|
|
||||||
</details>
|
|
||||||
|
|
||||||
## FAQ
|
|
||||||
|
|
||||||
<details><summary><b>How to save/load checkpoint</b></summary>
|
|
||||||
|
|
||||||
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
|
|
||||||
|
|
||||||
- Option 1: Save the model weights, model config and generation config (Note: tokenizer will not be saved) which can be loaded using HF's from_pretrained method.
|
|
||||||
```python
|
|
||||||
# if use lora, you can choose to merge lora weights before saving
|
|
||||||
if args.lora_rank > 0 and args.merge_lora_weights:
|
|
||||||
from coati.models.lora import LORA_MANAGER
|
|
||||||
|
|
||||||
# NOTE: set model to eval to merge LoRA weights
|
|
||||||
LORA_MANAGER.merge_weights = True
|
|
||||||
model.eval()
|
|
||||||
# save model checkpoint after fitting on only rank0
|
|
||||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
- Option 2: Save the model weights, model config, generation config, as well as the optimizer, learning rate scheduler, running states (Note: tokenizer will not be saved) which are needed for resuming training.
|
|
||||||
```python
|
|
||||||
from coati.utils import save_checkpoint
|
|
||||||
# save model checkpoint after fitting on only rank0
|
|
||||||
save_checkpoint(
|
|
||||||
save_dir=actor_save_dir,
|
|
||||||
booster=actor_booster,
|
|
||||||
model=model,
|
|
||||||
optimizer=optim,
|
|
||||||
lr_scheduler=lr_scheduler,
|
|
||||||
epoch=0,
|
|
||||||
step=step,
|
|
||||||
batch_size=train_batch_size,
|
|
||||||
coordinator=coordinator,
|
|
||||||
)
|
|
||||||
```
|
|
||||||
To load the saved checkpoint
|
|
||||||
```python
|
|
||||||
from coati.utils import load_checkpoint
|
|
||||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
|
||||||
load_dir=checkpoint_path,
|
|
||||||
booster=booster,
|
|
||||||
model=model,
|
|
||||||
optimizer=optim,
|
|
||||||
lr_scheduler=lr_scheduler,
|
|
||||||
)
|
|
||||||
```
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details><summary><b>How to train with limited resources</b></summary>
|
|
||||||
|
|
||||||
Here are some suggestions that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
|
|
||||||
|
|
||||||
`batch_size`, `lora_rank` and `grad_checkpoint` are the most important parameters to successfully train the model. To maintain a descent batch size for gradient calculation, consider increase the accumulation_step and reduce the batch_size on each rank.
|
|
||||||
|
|
||||||
If you only have a single 24G GPU. Generally, using lora and "zero2-cpu" will be sufficient.
|
|
||||||
|
|
||||||
`gemini` and `gemini-auto` can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. But that strategy doesn't support gradient accumulation.
|
|
||||||
|
|
||||||
If you have multiple GPUs each has very limited VRAM, say 8GB. You can try the `3d` for the plugin option, which supports tensor parellelism, set `--tp` to the number of GPUs that you have.
|
|
||||||
</details>
|
|
||||||
|
|
||||||
### Real-time progress
|
|
||||||
|
|
||||||
You will find our progress in github [project broad](https://github.com/orgs/hpcaitech/projects/17/views/1).
|
|
||||||
|
|
||||||
## Invitation to open-source contribution
|
## Invitation to open-source contribution
|
||||||
|
|
||||||
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
|
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
|
||||||
|
|
||||||
You may contact us or participate in the following ways:
|
You may contact us or participate in the following ways:
|
||||||
@@ -500,25 +194,17 @@ Thanks so much to all of our amazing contributors!
|
|||||||
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
|
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
|
||||||
- Keep in a sufficiently high running speed
|
- Keep in a sufficiently high running speed
|
||||||
|
|
||||||
| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
|
|
||||||
| :-----------: | :------------------: | :------------------: |
|
|
||||||
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
|
|
||||||
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
|
|
||||||
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
|
|
||||||
|
|
||||||
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
|
|
||||||
|
|
||||||
## Authors
|
## Authors
|
||||||
|
|
||||||
Coati is developed by ColossalAI Team:
|
Coati is developed by ColossalAI Team:
|
||||||
|
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework (System Lead).
|
||||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework.
|
- [Tong Li](https://github.com/TongLi3701) Leading the project while contributing to the main framework (Algorithm Lead).
|
||||||
|
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||||
- [FrankLeeeee](https://github.com/FrankLeeeee) Providing ML infra support and also taking charge of both front-end and back-end development.
|
- [FrankLeeeee](https://github.com/FrankLeeeee) Providing ML infra support and also taking charge of both front-end and back-end development.
|
||||||
- [htzhou](https://github.com/ht-zhou) Contributing to the algorithm and development for RM and PPO training.
|
- [htzhou](https://github.com/ht-zhou) Contributing to the algorithm and development for RM and PPO training.
|
||||||
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
|
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
|
||||||
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
|
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
|
||||||
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
|
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
|
||||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
|
||||||
|
|
||||||
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
|
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
|
||||||
- [Zangwei Zheng](https://github.com/zhengzangw)
|
- [Zangwei Zheng](https://github.com/zhengzangw)
|
||||||
@@ -527,7 +213,6 @@ The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contribute
|
|||||||
We also appreciate the valuable suggestions provided by [Jian Hu](https://github.com/hijkzzz) regarding the convergence of the PPO algorithm.
|
We also appreciate the valuable suggestions provided by [Jian Hu](https://github.com/hijkzzz) regarding the convergence of the PPO algorithm.
|
||||||
|
|
||||||
## Citations
|
## Citations
|
||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@article{Hu2021LoRALA,
|
@article{Hu2021LoRALA,
|
||||||
title = {LoRA: Low-Rank Adaptation of Large Language Models},
|
title = {LoRA: Low-Rank Adaptation of Large Language Models},
|
||||||
@@ -598,8 +283,22 @@ We also appreciate the valuable suggestions provided by [Jian Hu](https://github
|
|||||||
primaryClass={cs.CL},
|
primaryClass={cs.CL},
|
||||||
url={https://arxiv.org/abs/2403.07691},
|
url={https://arxiv.org/abs/2403.07691},
|
||||||
}
|
}
|
||||||
|
@misc{shao2024deepseekmathpushinglimitsmathematical,
|
||||||
|
title={DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models},
|
||||||
|
author={Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
|
||||||
|
year={2024},
|
||||||
|
eprint={2402.03300},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL},
|
||||||
|
url={https://arxiv.org/abs/2402.03300},
|
||||||
|
}
|
||||||
|
@misc{logic-rl,
|
||||||
|
author = {Tian Xie and Qingnan Ren and Yuqian Hong and Zitian Gao and Haoming Luo},
|
||||||
|
title = {Logic-RL},
|
||||||
|
howpublished = {https://github.com/Unakar/Logic-RL},
|
||||||
|
note = {Accessed: 2025-02-03},
|
||||||
|
year = {2025}
|
||||||
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## Licenses
|
## Licenses
|
||||||
|
|
||||||
Coati is licensed under the [Apache 2.0 License](LICENSE).
|
Coati is licensed under the [Apache 2.0 License](LICENSE).
|
||||||
|
|||||||
@@ -141,7 +141,7 @@ def setup_conversation_template(
|
|||||||
pass
|
pass
|
||||||
except ValueError as e:
|
except ValueError as e:
|
||||||
raise ValueError(e)
|
raise ValueError(e)
|
||||||
if not dist.is_initialized() or dist.get_rank() == 0:
|
if save_path is not None and (not dist.is_initialized() or dist.get_rank() == 0):
|
||||||
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||||
with open(save_path, "w", encoding="utf8") as f:
|
with open(save_path, "w", encoding="utf8") as f:
|
||||||
logger.info(f"Successfully generated a conversation tempalte config, save to {save_path}.")
|
logger.info(f"Successfully generated a conversation tempalte config, save to {save_path}.")
|
||||||
|
|||||||
@@ -8,6 +8,7 @@ import os
|
|||||||
from dataclasses import dataclass
|
from dataclasses import dataclass
|
||||||
from typing import Dict, Iterator, List, Optional, Sequence, Union
|
from typing import Dict, Iterator, List, Optional, Sequence, Union
|
||||||
|
|
||||||
|
import jsonlines
|
||||||
import torch
|
import torch
|
||||||
import torch.nn.functional as F
|
import torch.nn.functional as F
|
||||||
from coati.dataset.utils import chuncate_sequence, pad_to_max_len
|
from coati.dataset.utils import chuncate_sequence, pad_to_max_len
|
||||||
@@ -155,13 +156,14 @@ class DataCollatorForPromptDataset(DataCollatorForSupervisedDataset):
|
|||||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||||
"""
|
"""
|
||||||
|
gt_answer = [ins.get("gt_answer", None) for ins in instances]
|
||||||
instances = [{"input_ids": ins["input_ids"], "labels": ins["input_ids"]} for ins in instances]
|
instances = [{"input_ids": ins["input_ids"], "labels": ins["input_ids"]} for ins in instances]
|
||||||
ret = super().__call__(instances=instances)
|
ret = super().__call__(instances=instances)
|
||||||
input_ids = F.pad(
|
input_ids = F.pad(
|
||||||
ret["input_ids"], (self.max_length - ret["input_ids"].size(1), 0), value=self.tokenizer.pad_token_id
|
ret["input_ids"], (self.max_length - ret["input_ids"].size(1), 0), value=self.tokenizer.pad_token_id
|
||||||
)
|
)
|
||||||
attention_mask = F.pad(ret["attention_mask"], (self.max_length - ret["attention_mask"].size(1), 0), value=False)
|
attention_mask = F.pad(ret["attention_mask"], (self.max_length - ret["attention_mask"].size(1), 0), value=False)
|
||||||
return {"input_ids": input_ids, "attention_mask": attention_mask}
|
return {"input_ids": input_ids, "attention_mask": attention_mask, "gt_answer": gt_answer}
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
@@ -344,3 +346,116 @@ class StatefulDistributedSampler(DistributedSampler):
|
|||||||
|
|
||||||
def set_start_index(self, start_index: int) -> None:
|
def set_start_index(self, start_index: int) -> None:
|
||||||
self.start_index = start_index
|
self.start_index = start_index
|
||||||
|
|
||||||
|
|
||||||
|
def apply_chat_template_and_mask(
|
||||||
|
tokenizer: PreTrainedTokenizer,
|
||||||
|
chat: List[Dict[str, str]],
|
||||||
|
max_length: Optional[int] = None,
|
||||||
|
system_prompt: str = None,
|
||||||
|
padding: bool = True,
|
||||||
|
truncation: bool = True,
|
||||||
|
ignore_idx: int = -100,
|
||||||
|
) -> Dict[str, torch.Tensor]:
|
||||||
|
|
||||||
|
if system_prompt is None:
|
||||||
|
system_prompt = "You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Now the user asks you to solve a math problem that involves reasoning. After thinking, when you finally reach a conclusion, clearly output the final answer without explanation within the <answer> </answer> tags, i.e., <answer> 123 </answer>.\n\n"
|
||||||
|
|
||||||
|
system_element = {
|
||||||
|
"role": "system",
|
||||||
|
"content": system_prompt,
|
||||||
|
}
|
||||||
|
|
||||||
|
# Format for RL.
|
||||||
|
if "messages" in chat:
|
||||||
|
gt_answer = chat.get("gt_answer", None)
|
||||||
|
test_cases = chat.get("test_cases", None)
|
||||||
|
chat = [chat["messages"]]
|
||||||
|
|
||||||
|
tokens = []
|
||||||
|
assistant_mask = []
|
||||||
|
for i, msg in enumerate(chat):
|
||||||
|
msg_tokens = tokenizer.apply_chat_template([system_element, msg], tokenize=True, add_generation_prompt=True)
|
||||||
|
# remove unexpected bos token
|
||||||
|
if i > 0 and msg_tokens[0] == tokenizer.bos_token_id:
|
||||||
|
msg_tokens = msg_tokens[1:]
|
||||||
|
tokens.extend(msg_tokens)
|
||||||
|
if msg["role"] == "assistant":
|
||||||
|
assistant_mask.extend([True] * len(msg_tokens))
|
||||||
|
else:
|
||||||
|
assistant_mask.extend([False] * len(msg_tokens))
|
||||||
|
attention_mask = [1] * len(tokens)
|
||||||
|
if max_length is not None:
|
||||||
|
if padding and len(tokens) < max_length:
|
||||||
|
to_pad = max_length - len(tokens)
|
||||||
|
# Left padding for generation.
|
||||||
|
tokens = [tokenizer.pad_token_id] * to_pad + tokens
|
||||||
|
assistant_mask = [False] * to_pad + assistant_mask
|
||||||
|
attention_mask = [0] * to_pad + attention_mask
|
||||||
|
if truncation and len(tokens) > max_length:
|
||||||
|
tokens = tokens[:max_length]
|
||||||
|
assistant_mask = assistant_mask[:max_length]
|
||||||
|
attention_mask = attention_mask[:max_length]
|
||||||
|
input_ids = torch.tensor(tokens, dtype=torch.long)
|
||||||
|
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
|
||||||
|
labels = input_ids.clone()
|
||||||
|
labels[~torch.tensor(assistant_mask, dtype=torch.bool)] = ignore_idx
|
||||||
|
|
||||||
|
if gt_answer is not None:
|
||||||
|
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels, "gt_answer": gt_answer}
|
||||||
|
elif test_cases is not None:
|
||||||
|
return {
|
||||||
|
"input_ids": input_ids,
|
||||||
|
"attention_mask": attention_mask,
|
||||||
|
"labels": labels,
|
||||||
|
"test_cases": test_cases,
|
||||||
|
}
|
||||||
|
return {
|
||||||
|
"input_ids": input_ids,
|
||||||
|
"attention_mask": attention_mask,
|
||||||
|
"labels": labels,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
class RawConversationDataset(Dataset):
|
||||||
|
"""
|
||||||
|
Raw conversation dataset.
|
||||||
|
Each instance is a dictionary with fields `system`, `roles`, `messages`, `offset`, `sep_style`, `seps`.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, tokenizer: PreTrainedTokenizer, input_file: str, max_length: int, system_prompt: str) -> None:
|
||||||
|
self.tokenizer = tokenizer
|
||||||
|
self.raw_texts = []
|
||||||
|
with jsonlines.open(input_file) as f:
|
||||||
|
for line in f:
|
||||||
|
self.raw_texts.append(line)
|
||||||
|
self.tokenized_texts = [None] * len(self.raw_texts)
|
||||||
|
self.max_length = max_length
|
||||||
|
self.system_prompt = system_prompt
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(self.raw_texts)
|
||||||
|
|
||||||
|
def __getitem__(self, index: int):
|
||||||
|
if self.tokenized_texts[index] is None:
|
||||||
|
message = self.raw_texts[index]
|
||||||
|
tokens = apply_chat_template_and_mask(self.tokenizer, message, self.max_length, self.system_prompt)
|
||||||
|
self.tokenized_texts[index] = dict(tokens)
|
||||||
|
return self.tokenized_texts[index]
|
||||||
|
|
||||||
|
|
||||||
|
def collate_fn_grpo(batch):
|
||||||
|
input_ids = [item["input_ids"] for item in batch]
|
||||||
|
attention_mask = [item["attention_mask"] for item in batch]
|
||||||
|
labels = [item["labels"] for item in batch]
|
||||||
|
# Assume input_ids, attention_mask, labels are already of the same length,
|
||||||
|
# otherwise use pad_sequence(input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
|
||||||
|
input_ids = torch.stack(input_ids)
|
||||||
|
attention_mask = torch.stack(attention_mask)
|
||||||
|
labels = torch.stack(labels)
|
||||||
|
ret = {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
|
||||||
|
if "test_cases" in batch[0]:
|
||||||
|
ret["test_cases"] = [item["test_cases"] for item in batch]
|
||||||
|
if "gt_answer" in batch[0]:
|
||||||
|
ret["gt_answer"] = [item["gt_answer"] for item in batch]
|
||||||
|
return ret
|
||||||
|
|||||||
@@ -147,7 +147,6 @@ def tokenize_prompt(
|
|||||||
ignore_index: the ignore index when calculate loss during training
|
ignore_index: the ignore index when calculate loss during training
|
||||||
max_length: the maximum context length
|
max_length: the maximum context length
|
||||||
"""
|
"""
|
||||||
|
|
||||||
messages = data_point["messages"]
|
messages = data_point["messages"]
|
||||||
template = deepcopy(conversation_template)
|
template = deepcopy(conversation_template)
|
||||||
template.messages = []
|
template.messages = []
|
||||||
@@ -167,7 +166,6 @@ def tokenize_prompt(
|
|||||||
if len(template.messages) % 2 != 1:
|
if len(template.messages) % 2 != 1:
|
||||||
# exclude the answer if provided. keep only the prompt
|
# exclude the answer if provided. keep only the prompt
|
||||||
template.messages = template.messages[:-1]
|
template.messages = template.messages[:-1]
|
||||||
|
|
||||||
# Prepare data
|
# Prepare data
|
||||||
prompt = template.get_prompt(length=len(template.messages), add_generation_prompt=True)
|
prompt = template.get_prompt(length=len(template.messages), add_generation_prompt=True)
|
||||||
tokenized = tokenizer([prompt], add_special_tokens=False)["input_ids"][0]
|
tokenized = tokenizer([prompt], add_special_tokens=False)["input_ids"][0]
|
||||||
@@ -185,12 +183,21 @@ def tokenize_prompt(
|
|||||||
)
|
)
|
||||||
|
|
||||||
# `inputs_decode` can be used to check whether the tokenization method is true.
|
# `inputs_decode` can be used to check whether the tokenization method is true.
|
||||||
return dict(
|
if "gt_answer" in data_point:
|
||||||
input_ids=tokenized,
|
return dict(
|
||||||
inputs_decode=prompt,
|
input_ids=tokenized,
|
||||||
seq_length=len(tokenized),
|
inputs_decode=prompt,
|
||||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
seq_length=len(tokenized),
|
||||||
)
|
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||||
|
gt_answer=data_point["gt_answer"],
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
return dict(
|
||||||
|
input_ids=tokenized,
|
||||||
|
inputs_decode=prompt,
|
||||||
|
seq_length=len(tokenized),
|
||||||
|
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def apply_rlhf_data_format(template: Conversation, tokenizer: Any):
|
def apply_rlhf_data_format(template: Conversation, tokenizer: Any):
|
||||||
|
|||||||
324
applications/ColossalChat/coati/distributed/README.md
Normal file
324
applications/ColossalChat/coati/distributed/README.md
Normal file
@@ -0,0 +1,324 @@
|
|||||||
|
# Distributed RL Framework for Language Model Fine-Tuning
|
||||||
|
|
||||||
|
This repository implements a distributed Reinforcement Learning (RL) training framework designed to fine-tune large language models using algorithms such as **GRPO** and **DAPO**. It supports multi-node and multi-GPU setups, scalable rollout generation, and policy optimization using libraries like VLLM. Currently, we support two Reinforcement Learning with Verifiable Reward (RLVR) tasks: solving math problems and code generation.
|
||||||
|
|
||||||
|
**Please note that we are still under intensive development, stay tuned.**
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 🚀 Features
|
||||||
|
|
||||||
|
* **Distributed Training with Ray**: Scalable to multiple machines and GPUs.
|
||||||
|
* **Support for GRPO and DAPO**: Choose your preferred policy optimization algorithm.
|
||||||
|
* **Model Backends**: Support `vllm` as inference backends.
|
||||||
|
* **Rollout and Policy Decoupling**: Efficient generation and consumption of data through parallel inferencer-trainer architecture.
|
||||||
|
* **Evaluation Integration**: Easily plug in task-specific eval datasets.
|
||||||
|
* **Checkpoints and Logging**: Configurable intervals and directories.
|
||||||
|
* **[New]**: Zero Bubble training framework that supports GRPO and DAPO. [(read more)](./zero_bubble/README.md)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 🛠 Installation
|
||||||
|
|
||||||
|
### Prepare Develop Environment
|
||||||
|
|
||||||
|
Install Colossalai & ColossalChat
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||||
|
git checkout grpo-latest
|
||||||
|
BUILD_EXT=1 pip install -e .
|
||||||
|
|
||||||
|
cd ./applications/ColossalChat
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
Install vllm
|
||||||
|
```bash
|
||||||
|
pip install vllm==0.7.3
|
||||||
|
```
|
||||||
|
|
||||||
|
Install Ray.
|
||||||
|
```bash
|
||||||
|
pip install ray
|
||||||
|
```
|
||||||
|
|
||||||
|
Install Other Dependencies
|
||||||
|
```bash
|
||||||
|
pip install cupy-cuda12x
|
||||||
|
python -m cupyx.tools.install_library --cuda 12.x --library nccl
|
||||||
|
```
|
||||||
|
|
||||||
|
To support long input/output sequence length (e.g., 32K), you may need to manually change the default setting (180 seconds) for the `timeout_s` variable in your ray installation to a larger value as shown in the screenshot below.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/change_ray_timeout.png" width=700/>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
Prepare Model & dataset
|
||||||
|
```bash
|
||||||
|
huggingface-cli download --local-dir-use-symlinks False Qwen/Qwen2.5-7B --local-dir /models/Qwen/Qwen2.5-7B
|
||||||
|
```
|
||||||
|
|
||||||
|
## Architecture Design
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/producer-consumer-pattern.png" width=700/>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
Producer-Consumer Pattern: a classic software design pattern used for managing resources, data, or tasks between two different processes or threads.
|
||||||
|
|
||||||
|
* Producer: inference engine which rollouts out examples and saves them into a shared buffer.
|
||||||
|
* Consumer: training framework which takes training examples from the shared buffer and train the policy model.
|
||||||
|
|
||||||
|
Key features for Producer-Consumer Pattern:
|
||||||
|
* Buffer: Acts as a shared queue where the producer adds data and the consumer removes data.
|
||||||
|
* Concurrency: Rollout and training can work concurrently.
|
||||||
|
|
||||||
|
## 🧠 Data Format
|
||||||
|
|
||||||
|
Samples in the training or evaluation `.jsonl` file should follow the format specific to the type of task. We currently support two RLVR tasks: solving math problems and code generation.
|
||||||
|
|
||||||
|
### Math Data Format
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"messages": {
|
||||||
|
"role": "user",
|
||||||
|
"content": "Simplify $\\sqrt[3]{1+8} \\cdot \\sqrt[3]{1+\\sqrt[3]{8}}$."
|
||||||
|
},
|
||||||
|
"gt_answer": "3"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Code Data Format
|
||||||
|
We support [Prime code dataset format](https://github.com/PRIME-RL/PRIME). Inputs and outputs in test cases should be two lists containing only strings and matching in the number of elements. Your prompt must properly instruct the LLM to generate code to read test cases from stdin and output results to stdout.
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"messages": {
|
||||||
|
"role": "user",
|
||||||
|
"content": "Solve the following coding problem using the programming language python:\n\nMikhail walks on a Cartesian plane. He starts at the point $(0, 0)$, and in one move he can go to any of eight adjacent points. For example, ..."
|
||||||
|
},
|
||||||
|
"test_cases": {
|
||||||
|
"inputs": [
|
||||||
|
"3\n2 2 3\n4 3 7\n10 1 9\n"
|
||||||
|
],
|
||||||
|
"outputs": [
|
||||||
|
"1\n6\n-1\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## ⚙️ Hyperparameters & Arguments
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| ---------------- | --------------------------------------- | ----------------- |
|
||||||
|
| `--model` | Model path or identifier | `/path/to/model` |
|
||||||
|
| `--dataset` | Path to training `.jsonl` | `/path/to/train_data.jsonl` |
|
||||||
|
| `--eval-dataset` | JSON of task\:eval\_dataset\_path pairs | `{"eval_1":"/path/to/eval_1.jsonl"}` |
|
||||||
|
| `--project` | Project name | `Project1` |
|
||||||
|
| `--num-episodes` | Number of training episodes | `1` |
|
||||||
|
|
||||||
|
### Distributed Training
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| ----------------------------- | ------------------------------------- | ------- |
|
||||||
|
| `--num-trainers` | Number of trainer processes | `4` |
|
||||||
|
| `--num-inferencer` | Number of inferencer processes | `4` |
|
||||||
|
| `--inference-batch-size` | Prompts per inference step | `8` |
|
||||||
|
| `--inference-microbatch-size` | Per-GPU batch size for inference | `8` |
|
||||||
|
| `--train-batch-size` | Prompts per trainer step per dp group | `8` |
|
||||||
|
| `--train-minibatch-size` | Mini-batch size before forward pass | `8` |
|
||||||
|
| `--train-microbatch-size` | Per-GPU batch size for training | `2` |
|
||||||
|
|
||||||
|
### Sampling
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| --------------------- | --------------------- | -------------- |
|
||||||
|
| `--backend` | Generation backend, choose from `vllm` | `vllm` |
|
||||||
|
| `--temperature` | Sampling temperature for generation | `1.0` |
|
||||||
|
| `--top-k` | Top-K sampling parameter for generation | `None` |
|
||||||
|
| `--top-p` | Top-P sampling parameter for generation | `1.0` |
|
||||||
|
| `--system-prompt` | System prompt, optional, default to the default system prompt for each reward types. For more information, refer to the [**reward type**](#-constraints-and-notes) section | `Please reason step by step, and put your final answer within \\boxed{}.` |
|
||||||
|
| `--max-new-tokens` | Max generation tokens | `3584` |
|
||||||
|
| `--max-prompt-tokens` | Max prompt tokens | `512` |
|
||||||
|
|
||||||
|
### GRPO Specific
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| ----------------- | ---------------------------- | ------------------- |
|
||||||
|
| `--algo` | Algorithm (`GRPO` or `DAPO`), for more customization refer to [GRPO Settings](#️-grpo-settings) | `GRPO` |
|
||||||
|
| `--learning-rate` | Learning rate | `1e-6` |
|
||||||
|
| `--kl-coeff` | KL penalty coefficient, if nonzero, a reference model will be used | `0.01` |
|
||||||
|
| `--reward-type` | Reward signal type (choose from 'think_answer_tags', 'boxed', 'code') For more information, refer to the [**reward type**](#-constraints-and-notes) section | `think_answer_tags` |
|
||||||
|
| `--eval-interval` | Evaluation interval in number of training steps (positive value to enable evaluation) | `10` |
|
||||||
|
|
||||||
|
### Logging and Checkpointing
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| -------------------- | ------------------------- | ------------ |
|
||||||
|
| `--save-interval` | Training steps between checkpoints | `20` |
|
||||||
|
| `--save-dir` | Checkpoint directory | `./model` |
|
||||||
|
| `--eval-save-dir` | Evaluation save path | `./eval` |
|
||||||
|
| `--rollout-save-dir` | Rollout logs directory | `./rollouts` |
|
||||||
|
|
||||||
|
### Miscellaneous
|
||||||
|
|
||||||
|
| Argument | Description | Example |
|
||||||
|
| ------------------ | --------------------------------------- | ------- |
|
||||||
|
| `--ray_dir` | Custom Ray temp dir of a running Ray cluster (optional) | `None` |
|
||||||
|
| `--master_address` | Master address of a running Ray cluster | `None` |
|
||||||
|
| `--master_port` | Master port for torch DDP | `29506` |
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## ⚙️ GRPO Settings
|
||||||
|
|
||||||
|
In addition to the two default training settings provided—`GRPO` and `DAPO`—users can customize their training by changing the following hyperparameters in `grpo_config` in `rl_example.py`.
|
||||||
|
|
||||||
|
| Argument Name | Description | Default |
|
||||||
|
| ----------------------------- | ---------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||||
|
| `filter_range` | Filters out rollout group if the success rate within that group is out of this range.| `[0.01, 0.99]` |
|
||||||
|
| `dynamic_batching` | Enables dynamic batching as described in the [DAPO paper](https://arxiv.org/abs/2503.14476). | `True` |
|
||||||
|
| `clip_eps_low` | epsilon_low in DAPO in equation in [DAPO paper](https://arxiv.org/abs/2503.14476) | `0.2` |
|
||||||
|
| `clip_eps_high` | epsilon_high in DAPO equation in [DAPO paper](https://arxiv.org/abs/2503.14476) | `0.28` |
|
||||||
|
| `skip_threshold` | If ratio is above this threshold, the sample is skipped to avoid instability. | `20.0` |
|
||||||
|
| `loss_variation` | Type of loss variation. Supports `"token_level"` for token-wise policy gradient loss and `sample_level` for original GRPO loss. | `"token_level"` |
|
||||||
|
| `soft_over_length_punishment` | Whether to use soft overlength penalty in [DAPO paper](https://arxiv.org/abs/2503.14476) or not. | `True` |
|
||||||
|
| `cache_length` | `L_cache` parameter for soft overlength penalty in e.q. 13 in [DAPO paper](https://arxiv.org/abs/2503.14476) | `min(1024, int(args.max_new_tokens / 4))` |
|
||||||
|
| `filter_truncated_response` | Mask out truncated responses in loss calculation. | `True` |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 🔄 Constraints and Notes
|
||||||
|
|
||||||
|
* `num_inferencer + num_trainer == NUM_GPUs`
|
||||||
|
* `num_inferencer % num_trainer == 0`
|
||||||
|
* `(num_inferencer * inference_batch_size) % (num_trainer * train_batch_size) == 0`
|
||||||
|
* `train_batch_size >= train_minibatch_size >= train_microbatch_size`
|
||||||
|
* `inference_batch_size >= inference_microbatch_size`
|
||||||
|
* Set microbatch sizes based on **VRAM capacity**
|
||||||
|
* To use tensor parallelism on inferencer
|
||||||
|
* set backend to `vllm`
|
||||||
|
* change `tensor_parallel_size` in `inference_model_config` in rl_example.py
|
||||||
|
* set `num_inferencer = NUM_INFERENCE_GPUs / tensor_parallel_size`
|
||||||
|
* To set tensor parallelism / pipeline parallelism / zero stage
|
||||||
|
* change corresponding settings in `plugin_config` in rl_example.py
|
||||||
|
* Ensure rollout generation rate matches trainer consumption:
|
||||||
|
|
||||||
|
```
|
||||||
|
num_inferencer * inference_batch_size % (
|
||||||
|
num_trainer * train_batch_size /
|
||||||
|
train_pipeline_parallelism_size /
|
||||||
|
train_tensor_parallelism_size
|
||||||
|
) == 0
|
||||||
|
```
|
||||||
|
* Model weights sync every:
|
||||||
|
|
||||||
|
```
|
||||||
|
(num_inferencer * inference_batch_size) /
|
||||||
|
(num_trainer * train_batch_size /
|
||||||
|
train_pipeline_parallelism_size /
|
||||||
|
train_tensor_parallelism_size)
|
||||||
|
```
|
||||||
|
* Reward Type
|
||||||
|
|
||||||
|
We currently support three reward types--- `think_answer_tags`, `boxed`, `code`, each varies in details such as how answer is extracted and the reward calculation process. Please select one from `think_answer_tags`, `boxed` for math problem solving and use `code` for code generation. The default system prompt for each reward type is as follows. Please make sure your system prompt provides information for the answer to be correctly extracted from model responses.
|
||||||
|
|
||||||
|
* think_answer_tags
|
||||||
|
|
||||||
|
Answer extraction: extract the content between the last `<answer>`, `</answer>` tags.
|
||||||
|
|
||||||
|
```
|
||||||
|
You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Now the user asks you to solve a math problem that involves reasoning. After thinking, when you finally reach a conclusion, clearly output the final answer without explanation within the <answer> </answer> tags, i.e., <answer> 123 </answer>.\n\n
|
||||||
|
```
|
||||||
|
* boxed
|
||||||
|
|
||||||
|
Answer extraction: extract the last content marked by `\\boxed{}`
|
||||||
|
```
|
||||||
|
Please reason step by step, and put your final answer within \\boxed{}.
|
||||||
|
```
|
||||||
|
* code
|
||||||
|
|
||||||
|
Answer extraction: extract code inside ` ```python\n...``` `
|
||||||
|
```
|
||||||
|
You are a helpful assistant.
|
||||||
|
```
|
||||||
|
---
|
||||||
|
|
||||||
|
## 🧪 Example: single machine 8-GPU Zero2 Strategy
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python rl_example.py \
|
||||||
|
--dataset /path/to/train_data.jsonl \
|
||||||
|
--model /path/to/Qwen2.5-3B/ \
|
||||||
|
-t 4 -i 4 \
|
||||||
|
-b vllm \
|
||||||
|
-ibs 2 -tbs 4 -tMbs 1 -tmbs 4 -imbs 1 \
|
||||||
|
-rt boxed \
|
||||||
|
-g 4 \
|
||||||
|
-ibs 1 \
|
||||||
|
-tbs 2 \
|
||||||
|
-tMbs 1 \
|
||||||
|
-tmbs 2 \
|
||||||
|
-imbs 1 \
|
||||||
|
-s "Please reason step by step, and put your final answer within \\boxed{}." \
|
||||||
|
-tMbs 8 \
|
||||||
|
-p GRPO-Train-Align-Debug \
|
||||||
|
```
|
||||||
|
|
||||||
|
## 🧪 Example: multi-machine TP+PP Strategy
|
||||||
|
|
||||||
|
### Create ray cluster on multi-machine
|
||||||
|
For example, now we have 4 nodes and their IPs are 10.0.0.3, 10.0.0.4, 10.0.0.5, 10.0.0.6.
|
||||||
|
We use 10.0.0.3 as master node. First we start a ray cluster on 10.0.0.3:
|
||||||
|
```bash
|
||||||
|
ray start --head --node-ip-address=10.0.0.3
|
||||||
|
```
|
||||||
|
|
||||||
|
Then, for each slave node (10.0.0.4/10.0.0.5/10.0.0.6), we add to the ray cluster by following code:
|
||||||
|
```bash
|
||||||
|
ray start --address='10.0.0.3:6379'
|
||||||
|
```
|
||||||
|
|
||||||
|
Modify plugin_config in ./applications/ColossalChat/rl_example.py
|
||||||
|
```python
|
||||||
|
plugin_config={
|
||||||
|
"tp_size": 4,
|
||||||
|
"pp_size": 2,
|
||||||
|
"microbatch_size": max(
|
||||||
|
1, args.train_microbatch_size // 2
|
||||||
|
), # microbatch size should be set to train_microbatch_size // pp_size
|
||||||
|
"zero_stage": 1,
|
||||||
|
"max_norm": 1.0,
|
||||||
|
}, # for pp, tp
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Hint1: replace /models/Qwen/Qwen2.5-7B to your model path
|
||||||
|
# replace /datasets/train-alignment.jsonl to your dataset path
|
||||||
|
python rl_example.py
|
||||||
|
-m /path/to/Qwen2.5-Math-7B/ \
|
||||||
|
-d /path/to/train_data.jsonl \
|
||||||
|
--master_address '10.0.0.3'
|
||||||
|
-t 16 \
|
||||||
|
-i 16 \
|
||||||
|
-p GRPO-Train-Align-Debug \
|
||||||
|
-g 2 \
|
||||||
|
-ibs 1 \
|
||||||
|
-tbs 2 \
|
||||||
|
-tMbs 1 \
|
||||||
|
-tmbs 2 \
|
||||||
|
-imbs 1 \
|
||||||
|
-b vllm \
|
||||||
|
-e 2 \
|
||||||
|
-rt boxed \
|
||||||
|
-s "Please reason step by step, and put your final answer within \\boxed{}."
|
||||||
|
```
|
||||||
|
|
||||||
|
## Acknowledgement
|
||||||
|
Colossal-RL is a distributed version of ColossalChat and inspired by a few awesome open-source projects. We would like to express our gratitude to the following awesome open-source projects and algorithms: GRPO, DAPO, TRL, Verl, OpenRLHF, StreamRL, Qwen, Logic-RL.
|
||||||
154
applications/ColossalChat/coati/distributed/comm.py
Normal file
154
applications/ColossalChat/coati/distributed/comm.py
Normal file
@@ -0,0 +1,154 @@
|
|||||||
|
import copy
|
||||||
|
from typing import Any, Dict
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
import torch.distributed.distributed_c10d as c10d
|
||||||
|
from packaging.version import Version
|
||||||
|
|
||||||
|
|
||||||
|
def ray_broadcast_object(obj: Any, src: int = 0, device=None, group_name: str = "default") -> Any:
|
||||||
|
rank = cc.get_rank(group_name)
|
||||||
|
if rank == src:
|
||||||
|
if Version(torch.__version__) >= Version("2.3.0"):
|
||||||
|
obj_tensor, size_tensor = c10d._object_to_tensor(obj, device=device, group=None)
|
||||||
|
elif Version(torch.__version__) >= Version("1.13.0"):
|
||||||
|
obj_tensor, size_tensor = c10d._object_to_tensor(obj, device=device)
|
||||||
|
else:
|
||||||
|
obj_tensor, size_tensor = c10d._object_to_tensor(obj)
|
||||||
|
obj_tensor = obj_tensor.to(device)
|
||||||
|
size_tensor = size_tensor.to(device)
|
||||||
|
else:
|
||||||
|
size_tensor = torch.empty(1, dtype=torch.int64, device=device)
|
||||||
|
cc.broadcast(size_tensor, src, group_name)
|
||||||
|
if rank != src:
|
||||||
|
obj_tensor = torch.empty(size_tensor.item(), dtype=torch.uint8, device=device)
|
||||||
|
cc.broadcast(obj_tensor, src, group_name)
|
||||||
|
if rank != src:
|
||||||
|
if Version(torch.__version__) >= Version("2.3.0"):
|
||||||
|
obj = c10d._tensor_to_object(obj_tensor, size_tensor.item(), group=None)
|
||||||
|
else:
|
||||||
|
obj = c10d._tensor_to_object(obj, size_tensor.item())
|
||||||
|
return obj
|
||||||
|
|
||||||
|
|
||||||
|
def ray_broadcast_tensor_dict(
|
||||||
|
tensor_dict: Dict[str, torch.Tensor],
|
||||||
|
src: int = 0,
|
||||||
|
device=None,
|
||||||
|
group_name: str = "default",
|
||||||
|
backend: str = "nccl",
|
||||||
|
offload_to_cpu: bool = False,
|
||||||
|
pin_memory: bool = False,
|
||||||
|
) -> Dict[str, torch.Tensor]:
|
||||||
|
rank = cc.get_rank(group_name)
|
||||||
|
if tensor_dict is None:
|
||||||
|
tensor_dict = {}
|
||||||
|
if rank == src:
|
||||||
|
metadata = []
|
||||||
|
for k, v in tensor_dict.items():
|
||||||
|
metadata.append((k, v.shape, v.dtype))
|
||||||
|
else:
|
||||||
|
metadata = None
|
||||||
|
metadata = ray_broadcast_object(metadata, src, device, group_name)
|
||||||
|
for k, shape, dtype in metadata:
|
||||||
|
if rank == src:
|
||||||
|
if offload_to_cpu:
|
||||||
|
tensor = tensor_dict[k].to(device)
|
||||||
|
else:
|
||||||
|
tensor = tensor_dict[k]
|
||||||
|
else:
|
||||||
|
tensor = tensor_dict.get(k, torch.zeros(shape, dtype=dtype, device=device, pin_memory=pin_memory))
|
||||||
|
if backend == "gloo" and dtype == torch.bfloat16:
|
||||||
|
# Gloo does not support bfloat16, convert to float16
|
||||||
|
tensor = tensor.view(torch.float16)
|
||||||
|
cc.broadcast(tensor, src, group_name)
|
||||||
|
if backend == "gloo" and dtype == torch.bfloat16:
|
||||||
|
# Convert back to bfloat16 if it was converted to float16
|
||||||
|
tensor = tensor.view(torch.bfloat16)
|
||||||
|
if rank != src:
|
||||||
|
if offload_to_cpu:
|
||||||
|
tensor_dict[k] = tensor.cpu()
|
||||||
|
else:
|
||||||
|
tensor_dict[k] = tensor
|
||||||
|
return tensor_dict
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class SharedVariableActor:
|
||||||
|
def __init__(self, number_of_readers: int = 0, buffer_size_limit: int = 1000):
|
||||||
|
self.data_queue = []
|
||||||
|
self.data_uid = 0
|
||||||
|
self.number_of_readers = number_of_readers
|
||||||
|
self.queue_size = 0
|
||||||
|
self.signals = {}
|
||||||
|
self.process_locks = {}
|
||||||
|
self.signal_procs_meet_count = {}
|
||||||
|
self.buffer_size_limit = buffer_size_limit
|
||||||
|
|
||||||
|
def pickup_rollout_task(self, num_tasks: int):
|
||||||
|
"""
|
||||||
|
use queue size to control whether producers should generating new rollouts or wait
|
||||||
|
for consumer to consumer more data. if queue size is less than threshold,
|
||||||
|
it means consumer is consuming data fast enough, so producers can generate new rollouts.
|
||||||
|
if queue size is greater than threshold, it means consumer is consuming data slowly,
|
||||||
|
so producers should wait for consumer to consume more data.
|
||||||
|
|
||||||
|
Any free producer can pick up the task to generate rollout then increase the queued_data_size
|
||||||
|
to prevent other producer to pick up the task redundantly, Note it is not the real
|
||||||
|
queue length as data may still be generating
|
||||||
|
"""
|
||||||
|
ret = False
|
||||||
|
if self.queue_size < (self.buffer_size_limit / max(0.1, self.signals.get("sample_utilization", 1.0))):
|
||||||
|
ret = True
|
||||||
|
self.queue_size += num_tasks
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def append_data(self, data):
|
||||||
|
self.data_queue.append([self.data_uid, data, 0]) # [data_uid, data, access_count]
|
||||||
|
self.data_uid += 1
|
||||||
|
return True
|
||||||
|
|
||||||
|
def get_data(self, data_uid: int):
|
||||||
|
# for multi-process data reading
|
||||||
|
if not self.data_queue:
|
||||||
|
# no data in the queue, return None
|
||||||
|
return None
|
||||||
|
to_pop_index = None
|
||||||
|
ret = None
|
||||||
|
for i, (uid, data, access_count) in enumerate(self.data_queue):
|
||||||
|
if uid == data_uid:
|
||||||
|
# found the data with the given uid
|
||||||
|
self.data_queue[i][2] += 1
|
||||||
|
ret = copy.deepcopy(data)
|
||||||
|
if self.data_queue[i][2] == self.number_of_readers:
|
||||||
|
to_pop_index = i
|
||||||
|
break
|
||||||
|
if to_pop_index is not None:
|
||||||
|
# remove the data from the queue if it has been accessed by all readers
|
||||||
|
self.data_queue.pop(to_pop_index)
|
||||||
|
self.queue_size -= data["input_ids"].size(0)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def acquire_process_lock(self, key: str):
|
||||||
|
# atomic lock for process
|
||||||
|
if key not in self.process_locks:
|
||||||
|
self.process_locks[key] = 1 # locked
|
||||||
|
return 0
|
||||||
|
if self.process_locks[key] == 0:
|
||||||
|
self.process_locks[key] = 1 # lock the process
|
||||||
|
return 0
|
||||||
|
else:
|
||||||
|
return 1
|
||||||
|
|
||||||
|
def release_process_lock(self, key: str):
|
||||||
|
# atomic unlock for process
|
||||||
|
assert self.process_locks.get(key, 0) == 1, f"Releasing a process lock {key} that is not locked."
|
||||||
|
self.process_locks[key] = 0
|
||||||
|
|
||||||
|
def set_signal(self, key: str, signal: str):
|
||||||
|
self.signals[key] = signal
|
||||||
|
|
||||||
|
def get_signal(self):
|
||||||
|
return self.signals
|
||||||
434
applications/ColossalChat/coati/distributed/consumer.py
Normal file
434
applications/ColossalChat/coati/distributed/consumer.py
Normal file
@@ -0,0 +1,434 @@
|
|||||||
|
from contextlib import nullcontext
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
from coati.distributed.profiling_utils import CustomProfiler
|
||||||
|
from coati.utils import save_checkpoint
|
||||||
|
from tqdm import tqdm
|
||||||
|
from transformers import AutoModelForCausalLM
|
||||||
|
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import HybridParallelPlugin
|
||||||
|
from colossalai.cluster import DistCoordinator
|
||||||
|
from colossalai.initialize import launch
|
||||||
|
from colossalai.nn.optimizer import HybridAdam
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
from .comm import ray_broadcast_tensor_dict
|
||||||
|
from .utils import bind_batch, post_recv, unbind_batch
|
||||||
|
|
||||||
|
|
||||||
|
class BaseConsumer:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
num_producers: int,
|
||||||
|
num_episodes: int,
|
||||||
|
rank: int,
|
||||||
|
world_size: int,
|
||||||
|
master_addr: str,
|
||||||
|
master_port: int,
|
||||||
|
num_update_per_episode: int,
|
||||||
|
num_recv_per_update: int,
|
||||||
|
batch_size: int,
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
plugin_config: Dict[str, Any],
|
||||||
|
minibatch_size: int = 1,
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir: str = "./model",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
n_behind: int = 0,
|
||||||
|
):
|
||||||
|
self.num_producers = num_producers
|
||||||
|
self.num_episodes = num_episodes
|
||||||
|
self.rank = rank
|
||||||
|
self.world_size = world_size
|
||||||
|
self.master_addr = master_addr
|
||||||
|
self.master_port = master_port
|
||||||
|
self.num_update_per_episode = num_update_per_episode
|
||||||
|
self.num_recv_per_update = num_recv_per_update
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.minibatch_size = minibatch_size
|
||||||
|
self.save_interval = save_interval
|
||||||
|
self.save_dir = save_dir
|
||||||
|
self.enable_profiling = enable_profiling
|
||||||
|
assert batch_size % minibatch_size == 0, "batch_size should be divisible by microbatch_size"
|
||||||
|
self.num_microbatches = batch_size // minibatch_size
|
||||||
|
self.checkpoint_path = model_config.pop("checkpoint_path", None)
|
||||||
|
|
||||||
|
self.model_config = model_config
|
||||||
|
self.plugin_config = plugin_config
|
||||||
|
|
||||||
|
self.device = get_current_device()
|
||||||
|
self.lr_scheduler = None
|
||||||
|
self.n_behind = n_behind
|
||||||
|
self.total_prompt_trained = 0 # for setting start index when resume training
|
||||||
|
|
||||||
|
def setup(self) -> None:
|
||||||
|
launch(self.rank, self.world_size, self.master_addr, self.master_port, local_rank=0)
|
||||||
|
self.coordinator = DistCoordinator()
|
||||||
|
|
||||||
|
plugin_config = dict(tp_size=1, pp_size=1, precision="bf16", zero_stage=2)
|
||||||
|
if (
|
||||||
|
self.plugin_config.get("pp_size", 1) > 1
|
||||||
|
and "num_microbatches" not in self.plugin_config
|
||||||
|
and "microbatch_size" not in self.plugin_config
|
||||||
|
):
|
||||||
|
plugin_config["microbatch_size"] = max(1, self.minibatch_size // plugin_config.get("pp_size", 1))
|
||||||
|
plugin_config.update(self.plugin_config)
|
||||||
|
self.plugin = HybridParallelPlugin(**plugin_config)
|
||||||
|
self.booster = Booster(plugin=self.plugin)
|
||||||
|
self.dp_rank = dist.get_rank(self.plugin.dp_group)
|
||||||
|
self.tp_rank = dist.get_rank(self.plugin.tp_group)
|
||||||
|
self.pp_rank = dist.get_rank(self.plugin.pp_group)
|
||||||
|
|
||||||
|
self.dp_size = dist.get_world_size(self.plugin.dp_group)
|
||||||
|
self.tp_size = dist.get_world_size(self.plugin.tp_group)
|
||||||
|
self.pp_size = dist.get_world_size(self.plugin.pp_group)
|
||||||
|
|
||||||
|
# Init Hybrid ray process group
|
||||||
|
for i in range(self.num_producers):
|
||||||
|
cc.init_collective_group(self.world_size + 1, self.rank + 1, group_name=f"sync_data_{i}")
|
||||||
|
if self.pp_size > 1:
|
||||||
|
# use hybrid tp + pp
|
||||||
|
if self.tp_rank == 0 and self.dp_rank == 0:
|
||||||
|
cc.init_collective_group(
|
||||||
|
self.num_producers + 1, self.num_producers, group_name=f"sync_model_{self.pp_rank}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
if self.rank == 0:
|
||||||
|
cc.init_collective_group(self.num_producers + 1, self.num_producers, group_name="sync_model")
|
||||||
|
|
||||||
|
self.buffer = []
|
||||||
|
self.recv_cnt = 0
|
||||||
|
self.profiler = CustomProfiler(f"C{self.rank}", disabled=not self.enable_profiling)
|
||||||
|
|
||||||
|
def state_dict(self) -> Dict[str, torch.Tensor]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def step(self, step_idx: int, **kwargs) -> Optional[float]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def prepare_mini_batch(self, effective_group_to_raw_group_mapping: Dict[int, int]) -> Dict[str, torch.Tensor]:
|
||||||
|
"""
|
||||||
|
Prepare a mini-batch from the effective group to raw group mapping.
|
||||||
|
This method is used to create a mini-batch for training.
|
||||||
|
"""
|
||||||
|
batches = [
|
||||||
|
self.buffer[effective_group_to_raw_group_mapping[i]]
|
||||||
|
for i in range(self.dp_rank * self.minibatch_size, (self.dp_rank + 1) * self.minibatch_size)
|
||||||
|
]
|
||||||
|
# every dp_rank will receive a complete mini-batch, no need to sync within step() later
|
||||||
|
# each mini-batch use the first self.dp_size * minibatch_size effective samples
|
||||||
|
raw_mini_batches = self.buffer[
|
||||||
|
: effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1
|
||||||
|
] # include the last effective sample
|
||||||
|
raw_mini_batches_metric_dict = {
|
||||||
|
"raw_train_mini_batch_reward": [t[1] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_format_acc": [t[2] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_ans_acc": [t[3] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_response_len": [t[4] for t in raw_mini_batches],
|
||||||
|
}
|
||||||
|
batch = bind_batch([t[0] for t in batches])
|
||||||
|
batch = post_recv(batch)
|
||||||
|
return batch, raw_mini_batches_metric_dict
|
||||||
|
|
||||||
|
def calculate_effective_group_to_raw_group_mapping(self, step):
|
||||||
|
effective_group_to_raw_group_mapping = {}
|
||||||
|
for buffer_idx in range(len(self.buffer)):
|
||||||
|
if self.buffer[buffer_idx][0] is not None:
|
||||||
|
if self.n_behind == 0:
|
||||||
|
effective_group_to_raw_group_mapping[len(effective_group_to_raw_group_mapping)] = buffer_idx
|
||||||
|
else:
|
||||||
|
if self.buffer[buffer_idx][-1] <= step - self.n_behind:
|
||||||
|
effective_group_to_raw_group_mapping[len(effective_group_to_raw_group_mapping)] = buffer_idx
|
||||||
|
return effective_group_to_raw_group_mapping
|
||||||
|
|
||||||
|
def loop(self) -> None:
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
state_dict = self.state_dict()
|
||||||
|
if self.pp_size > 1:
|
||||||
|
if self.tp_rank == 0 and self.dp_rank == 0:
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
state_dict,
|
||||||
|
src=self.num_producers,
|
||||||
|
device=self.device,
|
||||||
|
group_name=f"sync_model_{self.pp_rank}",
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
if self.rank == 0:
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
state_dict, src=self.num_producers, device=self.device, group_name="sync_model"
|
||||||
|
)
|
||||||
|
del state_dict
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
|
||||||
|
print(
|
||||||
|
f"Consumer{self.rank} num_update: {self.num_update_per_episode}, num_recv: {self.num_recv_per_update}, nmb: {self.num_microbatches}"
|
||||||
|
)
|
||||||
|
for episode in range(self.num_episodes):
|
||||||
|
with tqdm(
|
||||||
|
range(self.num_update_per_episode),
|
||||||
|
desc=f"Episode {episode} with rollout step(s)",
|
||||||
|
disable=self.rank != 0,
|
||||||
|
) as pbar:
|
||||||
|
for step in pbar:
|
||||||
|
torch.cuda.reset_peak_memory_stats()
|
||||||
|
i = 0
|
||||||
|
|
||||||
|
self.profiler.enter(f"rollout_episode_{episode}_step_{step}")
|
||||||
|
for _ in range(self.num_recv_per_update):
|
||||||
|
if self.n_behind > 0:
|
||||||
|
# after sync model, do not wait for more data to arrive as rollout takes time, use buffered data
|
||||||
|
effective_group_to_raw_group_mapping = self.calculate_effective_group_to_raw_group_mapping(
|
||||||
|
step=step
|
||||||
|
)
|
||||||
|
while len(effective_group_to_raw_group_mapping) >= self.dp_size * self.minibatch_size:
|
||||||
|
self.profiler.log(
|
||||||
|
f"Still have {len(effective_group_to_raw_group_mapping)} effective groups, greater than {self.dp_size * self.minibatch_size}, start training"
|
||||||
|
)
|
||||||
|
batch, raw_mini_batches_metric_dict = self.prepare_mini_batch(
|
||||||
|
effective_group_to_raw_group_mapping
|
||||||
|
)
|
||||||
|
self.profiler.enter("step")
|
||||||
|
loss = self.step(i, pbar, **batch, **raw_mini_batches_metric_dict)
|
||||||
|
self.profiler.exit("step")
|
||||||
|
self.buffer = self.buffer[
|
||||||
|
effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1 :
|
||||||
|
]
|
||||||
|
# recalculate the effective group to raw group mapping
|
||||||
|
effective_group_to_raw_group_mapping_size_before = len(
|
||||||
|
effective_group_to_raw_group_mapping
|
||||||
|
)
|
||||||
|
effective_group_to_raw_group_mapping = (
|
||||||
|
self.calculate_effective_group_to_raw_group_mapping(step=step)
|
||||||
|
)
|
||||||
|
assert (
|
||||||
|
len(effective_group_to_raw_group_mapping)
|
||||||
|
== effective_group_to_raw_group_mapping_size_before
|
||||||
|
- self.dp_size * self.minibatch_size
|
||||||
|
)
|
||||||
|
if loss is not None:
|
||||||
|
pbar.set_postfix({"loss": loss})
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
# receive data from producers
|
||||||
|
for r in range(self.num_producers):
|
||||||
|
print(f"[T{dist.get_rank()}] Recv data episode {episode} step {step} from {r}")
|
||||||
|
self.profiler.enter(f"recv_broadcast_data_P{r}")
|
||||||
|
raw_batch = ray_broadcast_tensor_dict(
|
||||||
|
None, src=0, device=self.device, group_name=f"sync_data_{r}"
|
||||||
|
)
|
||||||
|
self.profiler.exit(f"recv_broadcast_data_P{r}")
|
||||||
|
# calculate group reward et al. filtering. As only the filtered group will be used for training (which is incomplete),
|
||||||
|
# we need to calculate the metrics before filtering here for logging
|
||||||
|
# [batch_size, num_generations, ...] -> [batch_size * num_generations, ...]
|
||||||
|
raw_batch = {
|
||||||
|
k: v.view(-1, self.num_generations, v.size(-1)) if k != "temperature" else v
|
||||||
|
for k, v in raw_batch.items()
|
||||||
|
}
|
||||||
|
# [batch_size, num_generations] -> [batch_size]
|
||||||
|
self.total_prompt_trained += raw_batch["reward"].size(0)
|
||||||
|
reward = raw_batch["reward"][:, :, 0]
|
||||||
|
format_acc = raw_batch["format_acc"][:, :, 0]
|
||||||
|
ans_acc = raw_batch["ans_acc"][:, :, 0]
|
||||||
|
response_len = (
|
||||||
|
raw_batch["response_idx"][:, :, 1] - raw_batch["response_idx"][:, :, 0] + 1
|
||||||
|
).type(torch.float32)
|
||||||
|
effective_group_mask = None
|
||||||
|
if self.filter_range is not None and self.grpo_config.get("dynamic_batching", True):
|
||||||
|
# filter the group based on the reward and accuracy
|
||||||
|
group_ans_acc_mean = ans_acc.mean(dim=1)
|
||||||
|
effective_group_mask = torch.logical_and(
|
||||||
|
group_ans_acc_mean > self.filter_range[0], group_ans_acc_mean < self.filter_range[1]
|
||||||
|
)
|
||||||
|
raw_batch = unbind_batch(raw_batch) # List[Dict[str, torch.Tensor]]
|
||||||
|
for group_idx, group_with_reward in enumerate(raw_batch):
|
||||||
|
self.buffer.append(
|
||||||
|
[
|
||||||
|
(
|
||||||
|
group_with_reward
|
||||||
|
if effective_group_mask is None or effective_group_mask[group_idx]
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
reward[group_idx],
|
||||||
|
format_acc[group_idx],
|
||||||
|
ans_acc[group_idx],
|
||||||
|
response_len[group_idx],
|
||||||
|
step,
|
||||||
|
]
|
||||||
|
)
|
||||||
|
if effective_group_mask is not None:
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Filter recv data: {len(raw_batch)} -> {torch.sum(effective_group_mask).cpu().item()} effective groups"
|
||||||
|
)
|
||||||
|
# mapping the effective group to the raw group for indexing
|
||||||
|
effective_group_to_raw_group_mapping = self.calculate_effective_group_to_raw_group_mapping(
|
||||||
|
step=step
|
||||||
|
)
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Collect Effective Prompt: {len(effective_group_to_raw_group_mapping)}/{self.dp_size * self.minibatch_size}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.n_behind == 0:
|
||||||
|
# If n_behind is 0, we start training after receiving data from producers.
|
||||||
|
while len(effective_group_to_raw_group_mapping) >= self.dp_size * self.minibatch_size:
|
||||||
|
self.profiler.log(
|
||||||
|
f"Collect {len(effective_group_to_raw_group_mapping)} effective groups, greater than {self.dp_size * self.minibatch_size}, start training"
|
||||||
|
)
|
||||||
|
batch, raw_mini_batches_metric_dict = self.prepare_mini_batch(
|
||||||
|
effective_group_to_raw_group_mapping
|
||||||
|
)
|
||||||
|
self.profiler.enter("step")
|
||||||
|
loss = self.step(i, pbar, **batch, **raw_mini_batches_metric_dict)
|
||||||
|
self.profiler.exit("step")
|
||||||
|
self.buffer = self.buffer[
|
||||||
|
effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1 :
|
||||||
|
]
|
||||||
|
# recalculate the effective group to raw group mapping
|
||||||
|
effective_group_to_raw_group_mapping_size_before = len(
|
||||||
|
effective_group_to_raw_group_mapping
|
||||||
|
)
|
||||||
|
effective_group_to_raw_group_mapping = (
|
||||||
|
self.calculate_effective_group_to_raw_group_mapping(step=step)
|
||||||
|
)
|
||||||
|
assert (
|
||||||
|
len(effective_group_to_raw_group_mapping)
|
||||||
|
== effective_group_to_raw_group_mapping_size_before
|
||||||
|
- self.dp_size * self.minibatch_size
|
||||||
|
)
|
||||||
|
if loss is not None:
|
||||||
|
pbar.set_postfix({"loss": loss})
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
if self.lr_scheduler is not None:
|
||||||
|
self.lr_scheduler.step()
|
||||||
|
if (step + 1) % self.save_interval == 0 or (step + 1) == self.num_update_per_episode:
|
||||||
|
if self.rank == 0:
|
||||||
|
print(f"Start saving policy model at step {step + 1}.")
|
||||||
|
save_checkpoint(
|
||||||
|
save_dir=self.save_dir,
|
||||||
|
booster=self.booster,
|
||||||
|
model=self.policy_model,
|
||||||
|
optimizer=self.optimizer,
|
||||||
|
lr_scheduler=self.lr_scheduler,
|
||||||
|
epoch=episode,
|
||||||
|
step=step,
|
||||||
|
batch_size=int(self.total_prompt_trained / step),
|
||||||
|
coordinator=self.coordinator,
|
||||||
|
) # for setting start index when resuming training
|
||||||
|
if self.rank == 0:
|
||||||
|
print(f"Saved model checkpoint at step {step + 1} in folder {self.save_dir}")
|
||||||
|
|
||||||
|
if (episode != self.num_episodes - 1 or step != self.num_update_per_episode - 1) and (
|
||||||
|
episode != 0 or step >= self.n_behind
|
||||||
|
):
|
||||||
|
if self.pp_size > 1:
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Sync model PP stage {self.pp_rank} episode {episode} step {step}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print(f"[T{dist.get_rank()}] Sync model episode {episode} step {step}")
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
state_dict = self.state_dict()
|
||||||
|
if self.pp_size > 1:
|
||||||
|
if self.tp_rank == 0 and self.dp_rank == 0:
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
state_dict,
|
||||||
|
src=self.num_producers,
|
||||||
|
device=self.device,
|
||||||
|
group_name=f"sync_model_{self.pp_rank}",
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
if self.rank == 0:
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
state_dict, src=self.num_producers, device=self.device, group_name="sync_model"
|
||||||
|
)
|
||||||
|
del state_dict
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
self.profiler.log(f"Peak memory usage: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||||
|
self.profiler.exit(f"rollout_episode_{episode}_step_{step}")
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if hasattr(self, "profiler"):
|
||||||
|
self.profiler.close()
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class SimpleConsumer(BaseConsumer):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
num_update_per_episode,
|
||||||
|
num_recv_per_update,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size=1,
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir="./model",
|
||||||
|
):
|
||||||
|
super().__init__(
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
num_update_per_episode,
|
||||||
|
num_recv_per_update,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size,
|
||||||
|
save_interval,
|
||||||
|
save_dir,
|
||||||
|
)
|
||||||
|
path = model_config.pop("path")
|
||||||
|
self.model = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.model.train()
|
||||||
|
self.model.gradient_checkpointing_enable()
|
||||||
|
self.optimizer = HybridAdam(self.model.parameters(), lr=1e-3, weight_decay=0.01)
|
||||||
|
self.accum_loss = torch.zeros(1, device=self.device)
|
||||||
|
|
||||||
|
def setup(self):
|
||||||
|
super().setup()
|
||||||
|
self.model, self.optimizer, *_ = self.booster.boost(self.model, self.optimizer)
|
||||||
|
|
||||||
|
def step(self, step_idx: int, pbar: Any, **kwargs) -> Optional[float]:
|
||||||
|
labels = kwargs["input_ids"].clone()
|
||||||
|
labels[kwargs["attention_mask"] == 0] = -100
|
||||||
|
kwargs["labels"] = labels
|
||||||
|
assert kwargs.pop("action_mask").shape == kwargs.pop("action_log_probs").shape
|
||||||
|
|
||||||
|
need_update = (step_idx + 1) % self.num_microbatches == 0
|
||||||
|
|
||||||
|
ctx = nullcontext() if need_update else self.booster.no_sync(self.model, self.optimizer)
|
||||||
|
with ctx:
|
||||||
|
out = self.model(**kwargs)
|
||||||
|
loss = out.loss / self.num_microbatches
|
||||||
|
self.accum_loss.add_(loss.data)
|
||||||
|
self.booster.backward(loss, self.optimizer)
|
||||||
|
if need_update:
|
||||||
|
self.optimizer.step()
|
||||||
|
self.optimizer.zero_grad()
|
||||||
|
loss_scalar = self.accum_loss.item()
|
||||||
|
self.accum_loss.zero_()
|
||||||
|
return loss_scalar
|
||||||
|
|
||||||
|
def state_dict(self):
|
||||||
|
self.model._force_wait_all_gather()
|
||||||
|
model = self.model.unwrap()
|
||||||
|
state_dict = model.state_dict()
|
||||||
|
return state_dict
|
||||||
612
applications/ColossalChat/coati/distributed/grpo_consumer.py
Normal file
612
applications/ColossalChat/coati/distributed/grpo_consumer.py
Normal file
@@ -0,0 +1,612 @@
|
|||||||
|
from contextlib import nullcontext
|
||||||
|
from typing import Any, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import torch
|
||||||
|
import wandb
|
||||||
|
from coati.distributed.consumer import BaseConsumer
|
||||||
|
from coati.distributed.loss import PolicyLoss
|
||||||
|
from coati.distributed.utils import entropy_from_logits, memory_efficient_logprob
|
||||||
|
from coati.trainer.utils import all_reduce_mean, all_reduce_sum
|
||||||
|
from coati.utils import load_checkpoint
|
||||||
|
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
|
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||||
|
from colossalai.nn.optimizer import HybridAdam
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class GRPOConsumer(BaseConsumer):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
num_update_per_episode,
|
||||||
|
num_recv_per_update,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size=1,
|
||||||
|
num_generations=8,
|
||||||
|
generate_config=None,
|
||||||
|
grpo_config={},
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir="./model",
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
n_behind: int = 0,
|
||||||
|
):
|
||||||
|
print(f"Using GRPO config: {grpo_config}")
|
||||||
|
if (
|
||||||
|
plugin_config.get("pp_size", 1) > 1
|
||||||
|
and "num_microbatches" not in plugin_config
|
||||||
|
and "microbatch_size" not in plugin_config
|
||||||
|
):
|
||||||
|
plugin_config["microbatch_size"] = max(
|
||||||
|
1, grpo_config.get("train_microbatch_size") // plugin_config.get("pp_size", 1)
|
||||||
|
)
|
||||||
|
super().__init__(
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
num_update_per_episode,
|
||||||
|
num_recv_per_update,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size,
|
||||||
|
save_interval=save_interval,
|
||||||
|
save_dir=save_dir,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
n_behind=n_behind,
|
||||||
|
)
|
||||||
|
path = model_config.pop("path")
|
||||||
|
self.policy_model = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.policy_model.train()
|
||||||
|
self.policy_model.gradient_checkpointing_enable()
|
||||||
|
self.optimizer = HybridAdam(
|
||||||
|
self.policy_model.parameters(),
|
||||||
|
lr=grpo_config.get("lr", 1e-6),
|
||||||
|
weight_decay=grpo_config.get("weight_decay", 0.01),
|
||||||
|
)
|
||||||
|
self.accum_loss = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_kl = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_entropy = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_advantages = torch.zeros(1, device=self.device)
|
||||||
|
self.raw_train_batch_reward = []
|
||||||
|
self.raw_train_batch_format_acc = []
|
||||||
|
self.raw_train_batch_ans_acc = []
|
||||||
|
self.raw_train_batch_response_len = []
|
||||||
|
self.accum_count = 0
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.grpo_config = grpo_config
|
||||||
|
self.project_name = project_name
|
||||||
|
self.effective_sample_count = 0
|
||||||
|
self.effective_prompt_count = 0
|
||||||
|
self.project_name = project_name
|
||||||
|
self.run_name = run_name
|
||||||
|
self.wandb_group_name = wandb_group_name
|
||||||
|
|
||||||
|
self.policy_loss_fn = PolicyLoss(
|
||||||
|
clip_eps_low=grpo_config.get("clip_eps_low", 0.2),
|
||||||
|
clip_eps_high=grpo_config.get("clip_eps_high", 0.2),
|
||||||
|
beta=grpo_config.get("beta", 0.01),
|
||||||
|
loss_variation=grpo_config.get("loss_variation", "sample_level"),
|
||||||
|
adv=grpo_config.get("algo"),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Reference model is initialized from policy model.
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.reference_model = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.reference_model.eval()
|
||||||
|
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(path)
|
||||||
|
self.pad_token_id = self.tokenizer.pad_token_id
|
||||||
|
self.num_generations = num_generations
|
||||||
|
self.filter_range = grpo_config.get("filter_range", None)
|
||||||
|
if self.filter_range is not None:
|
||||||
|
assert len(self.filter_range) == 2, "Filter range should have 2 values."
|
||||||
|
|
||||||
|
self.filter_truncated_response = grpo_config.get("filter_truncated_response", False)
|
||||||
|
if self.filter_truncated_response:
|
||||||
|
self.max_length = 0
|
||||||
|
if "max_tokens" in self.generate_config:
|
||||||
|
self.max_length = self.generate_config["max_tokens"]
|
||||||
|
elif "max_new_tokens" in self.generate_config:
|
||||||
|
self.max_length = self.generate_config["max_new_tokens"]
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
"either max_tokens (vllm) or max_new_tokens (transformers) must be set in generate_config."
|
||||||
|
)
|
||||||
|
# Initialize verifiable reward.
|
||||||
|
grpo_config.get("response_format_tags", None)
|
||||||
|
self.global_step = 0
|
||||||
|
|
||||||
|
self.lr_scheduler = CosineAnnealingWarmupLR(
|
||||||
|
optimizer=self.optimizer,
|
||||||
|
total_steps=min(self.num_episodes, 4) * self.num_update_per_episode,
|
||||||
|
warmup_steps=0,
|
||||||
|
eta_min=0.1 * grpo_config.get("lr", 1e-6),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.adv = grpo_config.get("algo")
|
||||||
|
|
||||||
|
def setup(self):
|
||||||
|
super().setup()
|
||||||
|
if (not self.plugin.pp_size > 1 and self.rank == 0) or (
|
||||||
|
self.plugin.pp_size > 1
|
||||||
|
and self.booster.plugin.stage_manager.is_last_stage()
|
||||||
|
and self.tp_rank == 0
|
||||||
|
and self.dp_rank == 0
|
||||||
|
):
|
||||||
|
self.wandb_run = wandb.init(
|
||||||
|
project=self.project_name,
|
||||||
|
sync_tensorboard=False,
|
||||||
|
dir="./wandb",
|
||||||
|
name=self.run_name,
|
||||||
|
group=self.wandb_group_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.policy_model, self.optimizer, _, _, self.lr_scheduler = self.booster.boost(
|
||||||
|
self.policy_model, self.optimizer, lr_scheduler=self.lr_scheduler
|
||||||
|
)
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.reference_model, *_ = self.booster.boost(self.reference_model)
|
||||||
|
if self.checkpoint_path is not None:
|
||||||
|
load_checkpoint(
|
||||||
|
self.checkpoint_path,
|
||||||
|
self.booster,
|
||||||
|
self.policy_model,
|
||||||
|
self.optimizer,
|
||||||
|
self.lr_scheduler,
|
||||||
|
)
|
||||||
|
self.plugin.logger.set_level("ERROR")
|
||||||
|
|
||||||
|
def step(self, step_idx: int, pbar: Any, **kwargs) -> Optional[float]:
|
||||||
|
"""
|
||||||
|
Step data from policy model:
|
||||||
|
[{
|
||||||
|
"input_ids": torch.Tensor,
|
||||||
|
"attention_mask": torch.Tensor,
|
||||||
|
"action_mask": torch.Tensor,
|
||||||
|
"action_log_probs": torch.Tensor,
|
||||||
|
},
|
||||||
|
...]
|
||||||
|
Format:
|
||||||
|
[minibatch_size, num_of_generation, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>.
|
||||||
|
"""
|
||||||
|
# Reshape to [minibatch_size x num_of_generation, prompt_length + response_length]
|
||||||
|
data = {k: v.view(-1, v.size(-1)) for k, v in kwargs.items() if "raw_train_mini_batch_" not in k}
|
||||||
|
self.raw_train_batch_reward.extend(kwargs["raw_train_mini_batch_reward"])
|
||||||
|
self.raw_train_batch_format_acc.extend(kwargs["raw_train_mini_batch_format_acc"])
|
||||||
|
self.raw_train_batch_ans_acc.extend(kwargs["raw_train_mini_batch_ans_acc"])
|
||||||
|
self.raw_train_batch_response_len.extend(kwargs["raw_train_mini_batch_response_len"])
|
||||||
|
action_mask = data["action_mask"]
|
||||||
|
num_action = action_mask.shape[1]
|
||||||
|
old_action_log_probs = data["action_log_probs"]
|
||||||
|
response_length = torch.sum(action_mask, dim=1).to(torch.float32)
|
||||||
|
train_microbatch_size = self.grpo_config.get("train_microbatch_size", data["input_ids"].size(0))
|
||||||
|
|
||||||
|
reward = data["reward"].view((-1))
|
||||||
|
format_acc = data["format_acc"].view((-1))
|
||||||
|
ans_acc = data["ans_acc"].view((-1))
|
||||||
|
|
||||||
|
# [minibatch_size, num_generations]
|
||||||
|
|
||||||
|
group_reward = reward.view(-1, self.num_generations)
|
||||||
|
reward_mean = group_reward.mean(dim=1)
|
||||||
|
# [minibatch_size x num_generations]
|
||||||
|
reward_mean = reward_mean.repeat_interleave(self.num_generations, dim=0)
|
||||||
|
|
||||||
|
if self.adv == "GRPO" or self.adv == "DAPO":
|
||||||
|
|
||||||
|
reward_std = group_reward.std(dim=1).repeat_interleave(self.num_generations, dim=0)
|
||||||
|
# [minibatch_size x num_generations]
|
||||||
|
advantages = ((reward - reward_mean) / (reward_std + 1e-4)).unsqueeze(dim=-1)
|
||||||
|
|
||||||
|
elif self.adv == "REINFORCE_PPB":
|
||||||
|
|
||||||
|
# [minibatch_size x num_generations]
|
||||||
|
advantages = ((reward - reward_mean)).unsqueeze(dim=-1)
|
||||||
|
|
||||||
|
elif self.adv == "RLOO":
|
||||||
|
|
||||||
|
advantages = (
|
||||||
|
reward * self.num_generations / (self.num_generations - 1)
|
||||||
|
- reward_mean * self.num_generations / (self.num_generations - 1)
|
||||||
|
).unsqueeze(dim=-1)
|
||||||
|
|
||||||
|
# [minibatch_size x num_of_generation]
|
||||||
|
loss_mask = torch.ones(action_mask.size(0), device=action_mask.device).bool()
|
||||||
|
|
||||||
|
# filter out overlength samples
|
||||||
|
if self.filter_truncated_response and action_mask.size(1) == self.max_length:
|
||||||
|
loss_mask = torch.logical_and(
|
||||||
|
loss_mask,
|
||||||
|
action_mask[:, -1] == False,
|
||||||
|
)
|
||||||
|
if self.filter_range is not None and self.grpo_config.get("dynamic_batching", False) == False:
|
||||||
|
# filter out samples with reward outside the range
|
||||||
|
# if dynamic batching is enabled, we filter out out of range groups before training
|
||||||
|
group_ans_acc_mean = (
|
||||||
|
ans_acc.view(-1, self.num_generations).mean(dim=1).repeat_interleave(self.num_generations, dim=-1)
|
||||||
|
)
|
||||||
|
loss_mask = torch.logical_and(
|
||||||
|
loss_mask,
|
||||||
|
torch.logical_and(
|
||||||
|
group_ans_acc_mean > self.filter_range[0],
|
||||||
|
group_ans_acc_mean < self.filter_range[1],
|
||||||
|
),
|
||||||
|
)
|
||||||
|
self.effective_prompt_count += group_reward.size(0) * self.dp_size
|
||||||
|
|
||||||
|
mean_kl, mean_loss = [], []
|
||||||
|
|
||||||
|
if self.grpo_config.get("dynamic_batching", True):
|
||||||
|
need_update = self.effective_prompt_count >= self.batch_size * self.dp_size
|
||||||
|
else:
|
||||||
|
# If dynamic batching is disabled, we need to use all samples for training.
|
||||||
|
need_update = (step_idx + 1) % self.num_microbatches == 0
|
||||||
|
|
||||||
|
effective_samples = all_reduce_sum(torch.sum(loss_mask), self.plugin)
|
||||||
|
effective_tokens_count = torch.sum(action_mask, dim=-1) * loss_mask
|
||||||
|
total_effective_tokens_count = all_reduce_sum(torch.sum(effective_tokens_count), self.plugin)
|
||||||
|
self.effective_sample_count += effective_samples.item()
|
||||||
|
pbar.set_postfix(
|
||||||
|
{
|
||||||
|
"Global Step": self.global_step,
|
||||||
|
"Gradient Accumulation on": f"{self.effective_prompt_count}/{self.batch_size * self.dp_size} effective prompts, {self.effective_sample_count}/{self.batch_size * self.dp_size * self.num_generations} effective samples",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
# Gradient must be synchronized if zero2 is enabled. https://github.com/hpcaitech/ColossalAI/blob/44d4053fec005fe0b06b6bc755fdc962463145df/colossalai/booster/plugin/hybrid_parallel_plugin.py#L1500
|
||||||
|
ctx = (
|
||||||
|
nullcontext()
|
||||||
|
if need_update or self.booster.plugin.zero_stage == 2
|
||||||
|
else self.booster.no_sync(self.policy_model, self.optimizer)
|
||||||
|
)
|
||||||
|
with ctx:
|
||||||
|
mini_batch_entropies = []
|
||||||
|
for forward_micro_batch_start in range(0, data["input_ids"].size(0), train_microbatch_size):
|
||||||
|
input_ids_forward_micro_batch = data["input_ids"][
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
old_action_log_probs_micro_batch = old_action_log_probs[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
attention_mask_forward_micro_batch = data["attention_mask"][
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
action_mask_forward_micro_batch = action_mask[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
loss_mask_forward_micro_batch = (
|
||||||
|
loss_mask[forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size]
|
||||||
|
if loss_mask is not None
|
||||||
|
else None
|
||||||
|
)
|
||||||
|
advantages_forward_micro_batch = advantages[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
|
||||||
|
if self.plugin.pp_size > 1:
|
||||||
|
# Support training with PP.
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
with torch.no_grad():
|
||||||
|
reference_model_outputs = self.booster.execute_pipeline(
|
||||||
|
iter(
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"input_ids": input_ids_forward_micro_batch,
|
||||||
|
"attention_mask": attention_mask_forward_micro_batch,
|
||||||
|
}
|
||||||
|
]
|
||||||
|
),
|
||||||
|
self.reference_model,
|
||||||
|
criterion=lambda outputs, inputs: torch.tensor(
|
||||||
|
[0.0], device=action_mask.device
|
||||||
|
), # dummy criterion
|
||||||
|
optimizer=None,
|
||||||
|
return_loss=False,
|
||||||
|
return_outputs=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.booster.plugin.stage_manager.is_last_stage():
|
||||||
|
reference_action_log_probs = memory_efficient_logprob(
|
||||||
|
reference_model_outputs["outputs"]["logits"] / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# Dummy reference logprobs for data iterator.
|
||||||
|
reference_action_log_probs = None
|
||||||
|
else:
|
||||||
|
reference_action_log_probs = None
|
||||||
|
|
||||||
|
data_policy_forward = {
|
||||||
|
"input_ids": input_ids_forward_micro_batch,
|
||||||
|
"attention_mask": attention_mask_forward_micro_batch,
|
||||||
|
"action_mask": action_mask_forward_micro_batch,
|
||||||
|
"advantages": advantages_forward_micro_batch,
|
||||||
|
"loss_mask": loss_mask_forward_micro_batch,
|
||||||
|
"old_action_log_probs": old_action_log_probs_micro_batch,
|
||||||
|
"source": self.rank,
|
||||||
|
}
|
||||||
|
if reference_action_log_probs is not None:
|
||||||
|
data_policy_forward["reference_action_log_probs"] = reference_action_log_probs
|
||||||
|
|
||||||
|
kl = []
|
||||||
|
|
||||||
|
def _criterion(outputs, inputs):
|
||||||
|
action_logits = outputs.logits
|
||||||
|
mini_batch_entropies.append(
|
||||||
|
(
|
||||||
|
((entropy_from_logits(action_logits[:, -num_action:]) * inputs["action_mask"]).sum(-1))
|
||||||
|
/ inputs["action_mask"].sum(-1)
|
||||||
|
).detach()
|
||||||
|
)
|
||||||
|
action_log_probs = memory_efficient_logprob(
|
||||||
|
action_logits / self.generate_config["temperature"],
|
||||||
|
inputs["input_ids"],
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
if "reference_action_log_probs" in inputs:
|
||||||
|
per_token_kl = (
|
||||||
|
torch.exp(inputs["reference_action_log_probs"] - action_log_probs)
|
||||||
|
- (inputs["reference_action_log_probs"] - action_log_probs)
|
||||||
|
- 1
|
||||||
|
)
|
||||||
|
appox_kl = torch.sum(per_token_kl * inputs["action_mask"], dim=-1) / torch.sum(
|
||||||
|
inputs["action_mask"], dim=-1
|
||||||
|
)
|
||||||
|
kl.append(appox_kl.mean())
|
||||||
|
else:
|
||||||
|
per_token_kl = 0.0
|
||||||
|
kl.append(torch.tensor(0.0))
|
||||||
|
|
||||||
|
inputs["advantages"].repeat_interleave(action_log_probs.size(-1), dim=-1)
|
||||||
|
|
||||||
|
if self.adv == "REINFORCE_PPB":
|
||||||
|
|
||||||
|
inputs["advantages"] = inputs["advantages"] - self.policy_loss_fn.beta * per_token_kl
|
||||||
|
advantages_forward_micro_batch_mean = torch.sum(
|
||||||
|
inputs["advantages"] * inputs["action_mask"]
|
||||||
|
) / (torch.sum(inputs["action_mask"]) + 1e-4)
|
||||||
|
advantages_forward_micro_batch_std = torch.rsqrt(
|
||||||
|
torch.sum(
|
||||||
|
(inputs["advantages"] - advantages_forward_micro_batch_mean) ** 2
|
||||||
|
* inputs["action_mask"]
|
||||||
|
)
|
||||||
|
/ (torch.sum(inputs["action_mask"]) + 1e-4)
|
||||||
|
+ 1e-8
|
||||||
|
)
|
||||||
|
inputs["advantages"] = (
|
||||||
|
(inputs["advantages"] - advantages_forward_micro_batch_mean)
|
||||||
|
* inputs["action_mask"]
|
||||||
|
/ (advantages_forward_micro_batch_std)
|
||||||
|
)
|
||||||
|
|
||||||
|
per_token_kl = 0.0
|
||||||
|
|
||||||
|
loss, _ = self.policy_loss_fn(
|
||||||
|
action_log_probs,
|
||||||
|
inputs["old_action_log_probs"],
|
||||||
|
inputs["advantages"],
|
||||||
|
per_token_kl,
|
||||||
|
inputs["action_mask"],
|
||||||
|
loss_mask=inputs["loss_mask"],
|
||||||
|
total_effective_tokens_in_batch=total_effective_tokens_count,
|
||||||
|
)
|
||||||
|
return loss
|
||||||
|
|
||||||
|
policy_model_outputs = self.booster.execute_pipeline(
|
||||||
|
iter([data_policy_forward]),
|
||||||
|
self.policy_model,
|
||||||
|
criterion=_criterion,
|
||||||
|
optimizer=self.optimizer,
|
||||||
|
return_loss=True,
|
||||||
|
return_outputs=False,
|
||||||
|
)
|
||||||
|
loss = policy_model_outputs["loss"]
|
||||||
|
|
||||||
|
if self.booster.plugin.stage_manager.is_last_stage():
|
||||||
|
if len(kl) > 0:
|
||||||
|
kl = all_reduce_mean(torch.mean(torch.stack(kl)).to(loss.device), self.plugin).data
|
||||||
|
mean_kl.append(kl)
|
||||||
|
mean_loss.append(all_reduce_mean(loss, self.plugin).data)
|
||||||
|
else:
|
||||||
|
policy_model_logits = self.policy_model(
|
||||||
|
input_ids=input_ids_forward_micro_batch,
|
||||||
|
attention_mask=attention_mask_forward_micro_batch,
|
||||||
|
).logits
|
||||||
|
action_log_probs = memory_efficient_logprob(
|
||||||
|
policy_model_logits / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
with torch.no_grad():
|
||||||
|
reference_model_logits = self.reference_model(
|
||||||
|
input_ids=input_ids_forward_micro_batch,
|
||||||
|
attention_mask=attention_mask_forward_micro_batch,
|
||||||
|
).logits
|
||||||
|
reference_action_log_probs = memory_efficient_logprob(
|
||||||
|
reference_model_logits / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
per_token_kl = (
|
||||||
|
torch.exp(reference_action_log_probs - action_log_probs)
|
||||||
|
- (reference_action_log_probs - action_log_probs)
|
||||||
|
- 1
|
||||||
|
)
|
||||||
|
kl = torch.sum(per_token_kl * action_mask_forward_micro_batch, dim=-1) / torch.sum(
|
||||||
|
action_mask_forward_micro_batch, dim=-1
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
per_token_kl = 0.0
|
||||||
|
kl = None
|
||||||
|
|
||||||
|
(
|
||||||
|
advantages_forward_micro_batch.repeat_interleave(action_log_probs.size(-1), dim=-1)
|
||||||
|
- self.policy_loss_fn.beta * per_token_kl
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.adv == "REINFORCE_PPB":
|
||||||
|
|
||||||
|
advantages_forward_micro_batch = (
|
||||||
|
advantages_forward_micro_batch - self.policy_loss_fn.beta * per_token_kl
|
||||||
|
)
|
||||||
|
advantages_forward_micro_batch_mean = torch.sum(
|
||||||
|
advantages_forward_micro_batch * action_mask_forward_micro_batch
|
||||||
|
) / (torch.sum(action_mask_forward_micro_batch) + 1e-4)
|
||||||
|
advantages_forward_micro_batch_std = torch.rsqrt(
|
||||||
|
torch.sum(
|
||||||
|
(advantages_forward_micro_batch - advantages_forward_micro_batch_mean) ** 2
|
||||||
|
* action_mask_forward_micro_batch
|
||||||
|
)
|
||||||
|
/ (torch.sum(action_mask_forward_micro_batch) + 1e-4)
|
||||||
|
+ 1e-8
|
||||||
|
)
|
||||||
|
advantages_forward_micro_batch = (
|
||||||
|
(advantages_forward_micro_batch - advantages_forward_micro_batch_mean)
|
||||||
|
* action_mask_forward_micro_batch
|
||||||
|
/ (advantages_forward_micro_batch_std)
|
||||||
|
)
|
||||||
|
|
||||||
|
per_token_kl = 0.0
|
||||||
|
|
||||||
|
loss, _ = self.policy_loss_fn(
|
||||||
|
action_log_probs,
|
||||||
|
old_action_log_probs_micro_batch,
|
||||||
|
advantages_forward_micro_batch,
|
||||||
|
per_token_kl,
|
||||||
|
action_mask_forward_micro_batch,
|
||||||
|
loss_mask=loss_mask_forward_micro_batch,
|
||||||
|
total_effective_tokens_in_batch=total_effective_tokens_count,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.booster.backward(loss, self.optimizer)
|
||||||
|
loss = all_reduce_mean(loss, self.plugin)
|
||||||
|
# Calculate accumulate value.
|
||||||
|
if kl is not None:
|
||||||
|
kl = all_reduce_mean(kl.mean(), self.plugin)
|
||||||
|
mean_kl.append(kl.data)
|
||||||
|
mean_loss.append(loss.data)
|
||||||
|
mini_batch_entropies.append(
|
||||||
|
all_reduce_mean(
|
||||||
|
(
|
||||||
|
(
|
||||||
|
(
|
||||||
|
entropy_from_logits(policy_model_logits[:, -num_action:])
|
||||||
|
* action_mask_forward_micro_batch
|
||||||
|
).sum(-1)
|
||||||
|
)
|
||||||
|
/ action_mask_forward_micro_batch.sum(-1)
|
||||||
|
).detach(),
|
||||||
|
self.plugin,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
if not self.plugin.pp_size > 1 or (
|
||||||
|
self.plugin.pp_size > 1
|
||||||
|
and self.booster.plugin.stage_manager.is_last_stage()
|
||||||
|
and self.tp_rank == 0
|
||||||
|
and self.dp_rank == 0
|
||||||
|
):
|
||||||
|
reward = all_reduce_mean(reward.mean(), self.plugin)
|
||||||
|
format_acc = all_reduce_mean(format_acc.mean(), self.plugin)
|
||||||
|
ans_acc = all_reduce_mean(ans_acc.mean(), self.plugin)
|
||||||
|
advantages = all_reduce_mean(advantages.mean(), self.plugin)
|
||||||
|
response_length = all_reduce_mean(response_length.mean(), self.plugin)
|
||||||
|
entropy = all_reduce_mean(torch.cat(mini_batch_entropies, dim=0).mean(), self.plugin)
|
||||||
|
self.accum_loss.add_(sum(mean_loss) / len(mean_loss))
|
||||||
|
self.accum_entropy.add_(entropy.data)
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.accum_kl.add_(sum(mean_kl) / len(mean_kl))
|
||||||
|
self.accum_advantages.add_(advantages.data)
|
||||||
|
self.accum_count += 1
|
||||||
|
if need_update:
|
||||||
|
self.optimizer.step()
|
||||||
|
self.optimizer.zero_grad()
|
||||||
|
self.global_step += 1
|
||||||
|
# no need to run all reduce as raw_train_batch_* are not splited across dp rank
|
||||||
|
sample_utilization = self.effective_sample_count / len(self.raw_train_batch_reward) / self.num_generations
|
||||||
|
self.effective_prompt_count = 0
|
||||||
|
self.effective_sample_count = 0
|
||||||
|
loss_scalar = self.accum_loss.item()
|
||||||
|
if not self.plugin.pp_size > 1 or (
|
||||||
|
self.plugin.pp_size > 1 and self.booster.plugin.stage_manager.is_last_stage() and self.tp_rank == 0
|
||||||
|
):
|
||||||
|
if (not self.plugin.pp_size > 1 and self.rank == 0) or (
|
||||||
|
self.plugin.pp_size > 1 and self.booster.plugin.stage_manager.is_last_stage() and self.tp_rank == 0
|
||||||
|
):
|
||||||
|
raw_batch_reward_mean = torch.cat(self.raw_train_batch_reward, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_format_acc_mean = torch.cat(self.raw_train_batch_format_acc, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_ans_acc_mean = torch.cat(self.raw_train_batch_ans_acc, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_response_len = torch.cat(self.raw_train_batch_response_len, dim=0)
|
||||||
|
raw_batch_response_len_mean = raw_batch_response_len.mean().cpu().item()
|
||||||
|
overlength_samples_ratio = (
|
||||||
|
(raw_batch_response_len >= action_mask.size(-1)).to(float).mean().cpu().item()
|
||||||
|
) # not an exact figure, but a close estimate
|
||||||
|
self.raw_train_batch_reward = []
|
||||||
|
self.raw_train_batch_format_acc = []
|
||||||
|
self.raw_train_batch_ans_acc = []
|
||||||
|
self.raw_train_batch_response_len = []
|
||||||
|
to_log_msg = [
|
||||||
|
f"Loss: {self.accum_loss.item() / self.accum_count:.4f}",
|
||||||
|
f"Reward: {raw_batch_reward_mean:.4f}",
|
||||||
|
f"format Reward: {raw_batch_format_acc_mean:.4f}",
|
||||||
|
f"Acc Reward: {raw_batch_ans_acc_mean:.4f}",
|
||||||
|
f"Advantages: {self.accum_advantages.item() / self.accum_count:.4f}",
|
||||||
|
f"Response Length: {raw_batch_response_len_mean:.4f}",
|
||||||
|
f"Sample_utilization: {sample_utilization:.4f}",
|
||||||
|
f"Overlength samples ratio: {overlength_samples_ratio:.4f}",
|
||||||
|
f"Entropy: {self.accum_entropy.item() / self.accum_count:.4f}",
|
||||||
|
] + ([f"KL: {self.accum_kl.item() / self.accum_count:.4f}"] if self.policy_loss_fn.beta > 0 else [])
|
||||||
|
print("\n".join(to_log_msg))
|
||||||
|
metrics = {
|
||||||
|
"metrics/reward": raw_batch_reward_mean,
|
||||||
|
"metrics/format_acc": raw_batch_format_acc_mean,
|
||||||
|
"metrics/ans_acc": raw_batch_ans_acc_mean,
|
||||||
|
"metrics/response_length": raw_batch_response_len_mean,
|
||||||
|
"train/loss": self.accum_loss.item() / self.accum_count,
|
||||||
|
"train/advantages": self.accum_advantages.item() / self.accum_count,
|
||||||
|
"train/learning_rate": self.lr_scheduler.get_last_lr()[0],
|
||||||
|
"train/sample_utilization": sample_utilization,
|
||||||
|
"train/entropy": self.accum_entropy.item() / self.accum_count,
|
||||||
|
"train/overlength_samples_ratio": overlength_samples_ratio,
|
||||||
|
"rollout/temperature": data["temperature"].cpu().numpy()[0][0],
|
||||||
|
}
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
metrics["train/kl"] = self.accum_kl.item() / self.accum_count
|
||||||
|
if self.wandb_run is not None:
|
||||||
|
self.wandb_run.log(metrics)
|
||||||
|
self.accum_loss.zero_()
|
||||||
|
self.accum_kl.zero_()
|
||||||
|
self.accum_entropy.zero_()
|
||||||
|
self.accum_advantages.zero_()
|
||||||
|
self.accum_count = 0
|
||||||
|
return loss_scalar
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
def state_dict(self):
|
||||||
|
self.policy_model._force_wait_all_gather()
|
||||||
|
model = self.policy_model.unwrap()
|
||||||
|
state_dict = model.state_dict()
|
||||||
|
state_dict["consumer_global_step"] = torch.tensor([self.global_step], device=self.device)
|
||||||
|
return state_dict
|
||||||
291
applications/ColossalChat/coati/distributed/inference_backend.py
Normal file
291
applications/ColossalChat/coati/distributed/inference_backend.py
Normal file
@@ -0,0 +1,291 @@
|
|||||||
|
from typing import Any, Dict
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from transformers import AutoConfig, AutoModelForCausalLM, PreTrainedModel, PreTrainedTokenizer
|
||||||
|
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
from .utils import log_probs_from_logits, update_by_default
|
||||||
|
|
||||||
|
try:
|
||||||
|
import sglang as sgl
|
||||||
|
except ImportError:
|
||||||
|
sgl = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from vllm import LLM, SamplingParams
|
||||||
|
except ImportError:
|
||||||
|
LLM = None
|
||||||
|
|
||||||
|
|
||||||
|
class BaseInferenceBackend:
|
||||||
|
def __init__(self, model_config: Dict[str, Any], generate_config: Dict[str, Any], tokenizer: PreTrainedTokenizer):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def generate(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
"""Generate new tokens given input_ids and attention_mask.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
input_ids (torch.Tensor): shape [B, S]
|
||||||
|
attention_mask (torch.Tensor): shape [B, S]
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Dict[str, torch.Tensor]: containing the
|
||||||
|
- input_ids (torch.Tensor): shape [B, S+N]
|
||||||
|
- attention_mask (torch.Tensor): shape [B, S+N]
|
||||||
|
- action_log_probs (torch.Tensor): shape [B, N]
|
||||||
|
- action_mask (torch.Tensor): shape [B, N]
|
||||||
|
where N is the number of generated tokens. And all tensors should be on CUDA.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class TransformersInferenceBackend(BaseInferenceBackend):
|
||||||
|
DEFAULT_MODEL_CONFIG = dict(
|
||||||
|
trust_remote_code=True,
|
||||||
|
torch_dtype=torch.bfloat16,
|
||||||
|
)
|
||||||
|
FORCE_MODEL_CONFIG = dict(
|
||||||
|
device_map="auto",
|
||||||
|
)
|
||||||
|
FORCE_GENERATE_CONFIG = dict(output_logits=True, return_dict_in_generate=True)
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
tokenizer: PreTrainedTokenizer,
|
||||||
|
num_generations: int = 8,
|
||||||
|
tokenizer_config: Dict[str, Any] = None,
|
||||||
|
):
|
||||||
|
model_config = update_by_default(model_config, self.DEFAULT_MODEL_CONFIG)
|
||||||
|
model_config.update(self.FORCE_MODEL_CONFIG)
|
||||||
|
path = model_config.pop("path")
|
||||||
|
self.model: PreTrainedModel = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.generate_config = generate_config.copy()
|
||||||
|
self.generate_config.update(self.FORCE_GENERATE_CONFIG)
|
||||||
|
self.tokenizer = tokenizer
|
||||||
|
self.num_generations = num_generations
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def generate(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
micro_batch_size = input_ids.size(0)
|
||||||
|
input_ids = input_ids.to(get_current_device())
|
||||||
|
attention_mask = attention_mask.to(get_current_device())
|
||||||
|
gt_answer = kwargs.pop("gt_answer", None)
|
||||||
|
test_cases = kwargs.pop("test_cases", None)
|
||||||
|
if self.num_generations > 1:
|
||||||
|
input_ids = input_ids.repeat_interleave(self.num_generations, dim=0)
|
||||||
|
attention_mask = attention_mask.repeat_interleave(self.num_generations, dim=0)
|
||||||
|
out = self.model.generate(
|
||||||
|
input_ids, attention_mask=attention_mask, **kwargs, **self.generate_config, tokenizer=self.tokenizer
|
||||||
|
)
|
||||||
|
input_len = input_ids.shape[-1]
|
||||||
|
new_token_ids = out.sequences[:, input_len:]
|
||||||
|
# get log probs
|
||||||
|
assert new_token_ids.shape[-1] == len(out.logits)
|
||||||
|
action_log_probs = []
|
||||||
|
for i, logits in enumerate(out.logits):
|
||||||
|
action_log_probs.append(log_probs_from_logits(logits[:, None, :], new_token_ids[:, i : i + 1]))
|
||||||
|
action_log_probs = torch.cat(action_log_probs, dim=1)
|
||||||
|
# get action mask
|
||||||
|
response_idx = torch.zeros((new_token_ids.size(0), 2), dtype=torch.int).to(get_current_device())
|
||||||
|
action_mask = torch.ones_like(new_token_ids, dtype=attention_mask.dtype)
|
||||||
|
if self.tokenizer.eos_token_id is not None:
|
||||||
|
for indices in torch.nonzero(new_token_ids == self.tokenizer.eos_token_id):
|
||||||
|
action_mask[indices[0], indices[1] + 1 :] = 0
|
||||||
|
response_idx[:, 0] = input_len
|
||||||
|
response_idx[:, 1] = input_len + action_mask.sum(dim=1) - 1
|
||||||
|
|
||||||
|
if attention_mask.size(0) != action_mask.size(0):
|
||||||
|
assert action_mask.size(0) % attention_mask.size(0) == 0
|
||||||
|
attention_mask = attention_mask.repeat_interleave(action_mask.size(0) // attention_mask.size(0), dim=0)
|
||||||
|
|
||||||
|
attention_mask = torch.cat((attention_mask, action_mask), dim=1)
|
||||||
|
data = {
|
||||||
|
"input_ids": out.sequences,
|
||||||
|
"attention_mask": attention_mask,
|
||||||
|
"action_log_probs": action_log_probs,
|
||||||
|
"action_mask": action_mask,
|
||||||
|
"response_idx": response_idx,
|
||||||
|
}
|
||||||
|
|
||||||
|
data = {k: v.view(micro_batch_size, self.num_generations, v.size(-1)) for k, v in data.items()}
|
||||||
|
|
||||||
|
if gt_answer is not None:
|
||||||
|
data["gt_answer"] = gt_answer
|
||||||
|
if test_cases is not None:
|
||||||
|
data["test_cases"] = test_cases
|
||||||
|
data = {k: v.to(get_current_device()) for k, v in data.items()}
|
||||||
|
return data
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
self.model.load_state_dict(state_dict)
|
||||||
|
|
||||||
|
|
||||||
|
class SGLangInferenceBackend(BaseInferenceBackend):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
tokenizer: PreTrainedTokenizer,
|
||||||
|
num_generations: int = 8,
|
||||||
|
tokenizer_config: Dict[str, Any] = None,
|
||||||
|
):
|
||||||
|
if sgl is None:
|
||||||
|
raise ImportError("sglang is not installed")
|
||||||
|
path = model_config.pop("path")
|
||||||
|
defaut_config = dict(
|
||||||
|
trust_remote_code=True,
|
||||||
|
skip_tokenizer_init=True,
|
||||||
|
)
|
||||||
|
defaut_config.update(model_config)
|
||||||
|
self.llm = sgl.Engine(model_path=path, **defaut_config)
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.tokenizer = tokenizer
|
||||||
|
self.config = AutoConfig.from_pretrained(path)
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def generate(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
outputs = self.llm.generate(input_ids=input_ids.tolist(), sampling_params=self.generate_config)
|
||||||
|
out_tokens = []
|
||||||
|
out_len = []
|
||||||
|
for out in outputs:
|
||||||
|
out_tokens.append(out["token_ids"])
|
||||||
|
out_len.append(out["meta_info"]["completion_tokens"])
|
||||||
|
max_len = max(out_len)
|
||||||
|
input_len = input_ids.shape[-1]
|
||||||
|
attention_mask = F.pad(attention_mask, (0, max_len), value=1)
|
||||||
|
for i in range(len(out_tokens)):
|
||||||
|
out_tokens[i] = out_tokens[i] + [self.tokenizer.pad_token_id] * (max_len - out_len[i])
|
||||||
|
attention_mask[i, input_len + out_len[i] :] = 0
|
||||||
|
out = torch.tensor(out_tokens)
|
||||||
|
out = torch.cat((input_ids, out), dim=1)
|
||||||
|
labels = out.clone()
|
||||||
|
labels[..., :input_len] = -100
|
||||||
|
for i in range(len(out_len)):
|
||||||
|
labels[i, input_len + out_len[i] :] = -100
|
||||||
|
data = {
|
||||||
|
"input_ids": out,
|
||||||
|
"attention_mask": attention_mask,
|
||||||
|
"labels": labels,
|
||||||
|
}
|
||||||
|
data = {k: v.to(get_current_device()) for k, v in data.items()}
|
||||||
|
return data
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
if self.config.tie_word_embeddings:
|
||||||
|
del state_dict["lm_head.weight"]
|
||||||
|
named_tensors = [(k, v) for k, v in state_dict.items()]
|
||||||
|
self.llm.update_weights_from_tensor(named_tensors)
|
||||||
|
|
||||||
|
|
||||||
|
class VLLMInferenceBackend(BaseInferenceBackend):
|
||||||
|
DEFAULT_MODEL_CONFIG = dict(
|
||||||
|
trust_remote_code=True,
|
||||||
|
enable_sleep_mode=False,
|
||||||
|
)
|
||||||
|
FORCE_GENERATE_CONFIG = dict(
|
||||||
|
logprobs=0,
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
tokenizer: PreTrainedTokenizer,
|
||||||
|
num_generations: int = 8,
|
||||||
|
tokenizer_config: Dict[str, Any] = None,
|
||||||
|
):
|
||||||
|
if LLM is None:
|
||||||
|
raise ImportError("vllm is not installed")
|
||||||
|
model_config = update_by_default(model_config, self.DEFAULT_MODEL_CONFIG)
|
||||||
|
path = model_config.pop("path")
|
||||||
|
tokenizer_path = tokenizer_config.get("path", None) if tokenizer_config is not None else None
|
||||||
|
self.llm = LLM(model=path, tokenizer=tokenizer_path, **model_config)
|
||||||
|
generate_config = generate_config.copy()
|
||||||
|
generate_config.update(self.FORCE_GENERATE_CONFIG)
|
||||||
|
generate_config.update({"n": num_generations})
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.sample_params = SamplingParams(**generate_config)
|
||||||
|
self.model_config = model_config
|
||||||
|
self.tokenizer = tokenizer
|
||||||
|
self.num_generations = num_generations
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def generate(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
micro_batch_size = input_ids.size(0)
|
||||||
|
response_start_idx = input_ids.size(1)
|
||||||
|
first_non_padding_token_idx = (input_ids != self.tokenizer.pad_token_id).int().argmax(dim=1)
|
||||||
|
micro_batch_input_ids = input_ids.tolist()
|
||||||
|
micro_batch_input_ids_no_padding = [
|
||||||
|
micro_batch_input_ids[i][first_non_padding_token_idx[i] :] for i in range(micro_batch_size)
|
||||||
|
]
|
||||||
|
sample_params = kwargs.get("sample_params", self.sample_params)
|
||||||
|
outputs = self.llm.generate(
|
||||||
|
prompt_token_ids=micro_batch_input_ids_no_padding, sampling_params=sample_params, use_tqdm=False
|
||||||
|
)
|
||||||
|
out_tokens = []
|
||||||
|
out_len = []
|
||||||
|
log_probs = []
|
||||||
|
response_idx = []
|
||||||
|
for out in outputs:
|
||||||
|
for output_i in out.outputs:
|
||||||
|
out_len.append(len(output_i.token_ids))
|
||||||
|
out_tokens.append(list(output_i.token_ids))
|
||||||
|
response_idx.append((response_start_idx, response_start_idx + len(output_i.token_ids) - 1))
|
||||||
|
assert len(output_i.logprobs) == len(output_i.token_ids)
|
||||||
|
p = [m[t].logprob for m, t in zip(output_i.logprobs, output_i.token_ids)]
|
||||||
|
log_probs.append(p)
|
||||||
|
|
||||||
|
# pad them
|
||||||
|
max_len = self.sample_params.max_tokens
|
||||||
|
action_mask = torch.ones(len(out_tokens), max_len, dtype=attention_mask.dtype)
|
||||||
|
|
||||||
|
for i, new_token_ids in enumerate(out_tokens):
|
||||||
|
pad_len = max_len - out_len[i]
|
||||||
|
out_tokens[i] = new_token_ids + [self.tokenizer.pad_token_id] * pad_len
|
||||||
|
log_probs[i] = log_probs[i] + [0.0] * pad_len
|
||||||
|
action_mask[i, out_len[i] :] = 0
|
||||||
|
|
||||||
|
out_tokens = torch.tensor(out_tokens)
|
||||||
|
log_probs = torch.tensor(log_probs)
|
||||||
|
response_idx = torch.tensor(response_idx)
|
||||||
|
|
||||||
|
if attention_mask.size(0) != action_mask.size(0):
|
||||||
|
assert action_mask.size(0) % attention_mask.size(0) == 0
|
||||||
|
num_returns = action_mask.size(0) // attention_mask.size(0)
|
||||||
|
attention_mask = attention_mask.repeat_interleave(num_returns, dim=0)
|
||||||
|
input_ids = input_ids.repeat_interleave(num_returns, dim=0)
|
||||||
|
|
||||||
|
out_tokens = torch.cat((input_ids, out_tokens), dim=1)
|
||||||
|
attention_mask = torch.cat((attention_mask, action_mask), dim=1)
|
||||||
|
|
||||||
|
data = {
|
||||||
|
"input_ids": out_tokens,
|
||||||
|
"attention_mask": attention_mask,
|
||||||
|
"action_log_probs": log_probs,
|
||||||
|
"action_mask": action_mask,
|
||||||
|
"response_idx": response_idx,
|
||||||
|
}
|
||||||
|
|
||||||
|
data = {k: v.view(micro_batch_size, -1, v.size(-1)) for k, v in data.items()}
|
||||||
|
data = {k: v.to(get_current_device()) for k, v in data.items()}
|
||||||
|
if "gt_answer" in kwargs:
|
||||||
|
data["gt_answer"] = kwargs["gt_answer"]
|
||||||
|
if "test_cases" in kwargs:
|
||||||
|
data["test_cases"] = kwargs["test_cases"]
|
||||||
|
return data
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
self.llm.llm_engine.model_executor.driver_worker.model_runner.model.load_weights(state_dict.items())
|
||||||
|
|
||||||
|
|
||||||
|
BACKEND_MAP = {
|
||||||
|
"transformers": TransformersInferenceBackend,
|
||||||
|
# "sglang": SGLangInferenceBackend, # sglang backend will stuck the process due to unknown reason
|
||||||
|
"vllm": VLLMInferenceBackend,
|
||||||
|
}
|
||||||
190
applications/ColossalChat/coati/distributed/launch.py
Normal file
190
applications/ColossalChat/coati/distributed/launch.py
Normal file
@@ -0,0 +1,190 @@
|
|||||||
|
import copy
|
||||||
|
import os
|
||||||
|
import uuid
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
|
||||||
|
from .consumer import SimpleConsumer
|
||||||
|
from .grpo_consumer import GRPOConsumer
|
||||||
|
from .producer import SimpleProducer
|
||||||
|
|
||||||
|
ALGO_MAP = {
|
||||||
|
"Simple": SimpleConsumer,
|
||||||
|
"GRPO": GRPOConsumer,
|
||||||
|
"DAPO": GRPOConsumer,
|
||||||
|
"REINFORCE_PPB": GRPOConsumer,
|
||||||
|
"RLOO": GRPOConsumer,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def get_jsonl_size_fast(path: str) -> int:
|
||||||
|
with open(path) as f:
|
||||||
|
lines = f.readlines()
|
||||||
|
lines = [line for line in lines if line.strip()]
|
||||||
|
return len(lines)
|
||||||
|
|
||||||
|
|
||||||
|
def get_dp_size_fast(n_procs: int, plugin_config: Dict[str, Any]) -> int:
|
||||||
|
tp_size = plugin_config.get("tp_size", 1)
|
||||||
|
pp_size = plugin_config.get("pp_size", 1)
|
||||||
|
ep_size = plugin_config.get("ep_size", 1)
|
||||||
|
sp_size = plugin_config.get("sp_size", 1)
|
||||||
|
return n_procs // (tp_size * pp_size * ep_size * sp_size)
|
||||||
|
|
||||||
|
|
||||||
|
def launch_distributed(
|
||||||
|
num_producers: int,
|
||||||
|
num_proc_per_producer: int,
|
||||||
|
num_consumer_procs: int,
|
||||||
|
num_episodes: int,
|
||||||
|
inference_batch_size: int,
|
||||||
|
inference_microbatch_size: int,
|
||||||
|
train_batch_size: int,
|
||||||
|
train_minibatch_size: int,
|
||||||
|
train_dataset_config: Dict[str, Any],
|
||||||
|
inference_model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
train_model_config: Dict[str, Any],
|
||||||
|
grpo_config: Dict[str, Any],
|
||||||
|
plugin_config: Dict[str, Any],
|
||||||
|
tokenizer_config: Optional[Dict[str, Any]] = None,
|
||||||
|
inference_backend: str = "transformers",
|
||||||
|
num_generations: int = 8,
|
||||||
|
master_addr: str = "localhost",
|
||||||
|
master_port: int = 29500,
|
||||||
|
core_algo: str = "GRPO",
|
||||||
|
project_name: Optional[str] = None,
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir: str = "./model",
|
||||||
|
eval_dataset_config: Optional[Dict[str, Any]] = None,
|
||||||
|
eval_interval: int = 100,
|
||||||
|
eval_save_dir: Optional[str] = None,
|
||||||
|
eval_generation_config: Optional[Dict[str, Any]] = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_save_dir: str = "./rollout",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
n_behind: int = 0,
|
||||||
|
):
|
||||||
|
if core_algo not in ALGO_MAP:
|
||||||
|
raise NotImplementedError(f"{core_algo} is not supported yet.")
|
||||||
|
else:
|
||||||
|
core_consumer = ALGO_MAP.get(core_algo, SimpleConsumer)
|
||||||
|
|
||||||
|
train_dp_size = get_dp_size_fast(num_consumer_procs, plugin_config)
|
||||||
|
|
||||||
|
assert (inference_batch_size * num_producers) % (train_batch_size * train_dp_size) == 0
|
||||||
|
|
||||||
|
dataset_path = train_dataset_config["path"]
|
||||||
|
num_samples = get_jsonl_size_fast(dataset_path)
|
||||||
|
global_inference_batch_size = inference_batch_size * num_producers
|
||||||
|
num_update_per_episode = num_samples // global_inference_batch_size
|
||||||
|
num_recv_per_update = inference_batch_size // inference_microbatch_size
|
||||||
|
|
||||||
|
run_name = f"{inference_backend}_bs_{train_batch_size * train_dp_size}_temp_{generate_config['temperature']:.01f}_top_p_{generate_config['top_p']:.02f}"
|
||||||
|
wandb_group_name = str(uuid.uuid4())
|
||||||
|
rollout_log_file = os.path.join(
|
||||||
|
rollout_save_dir,
|
||||||
|
f"{project_name.replace(' ','_')}_run_{wandb_group_name}.jsonl",
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attention: Ray use complex schedualing method that consider various factors including load-balancing.
|
||||||
|
# when requesting resources, it is not guaranteed that the resource comes from a node with lower node it
|
||||||
|
# this go against the design principle of our implementation, and we need to manually force the schedualing,
|
||||||
|
# allocating the producer to nodes with lower node id and the consumer to the resouces from nodes with higher
|
||||||
|
# node id. See the reference here: https://docs.ray.io/en/latest/ray-core/scheduling/index.html#nodeaffinityschedulingstrategy
|
||||||
|
nodes = ray.nodes()
|
||||||
|
node_info = {
|
||||||
|
node["NodeID"]: {
|
||||||
|
"num_gpus": node["Resources"].get("GPU", 0),
|
||||||
|
"address": node["NodeManagerAddress"],
|
||||||
|
} # Default to 0 if no GPUs are available
|
||||||
|
for node in nodes
|
||||||
|
}
|
||||||
|
gpu_to_node_id = []
|
||||||
|
gpu_to_ip_address = []
|
||||||
|
for node_id in node_info:
|
||||||
|
for idx in range(int(node_info[node_id]["num_gpus"])):
|
||||||
|
gpu_to_node_id.append(node_id)
|
||||||
|
gpu_to_ip_address.append(node_info[node_id]["address"])
|
||||||
|
print(node_info)
|
||||||
|
|
||||||
|
producer_procs = []
|
||||||
|
for i in range(num_producers):
|
||||||
|
node_id = gpu_to_node_id[0]
|
||||||
|
producer_ip_address = gpu_to_ip_address[0]
|
||||||
|
for _ in range(num_proc_per_producer):
|
||||||
|
gpu_to_node_id.pop(0)
|
||||||
|
gpu_to_ip_address.pop(0)
|
||||||
|
print(f"Schedual Producer P[{i}] which requires {num_proc_per_producer} GPUs on node {producer_ip_address}")
|
||||||
|
producer = SimpleProducer.options(num_gpus=num_proc_per_producer).remote(
|
||||||
|
producer_idx=i,
|
||||||
|
num_producers=num_producers,
|
||||||
|
num_consumer_procs=num_consumer_procs,
|
||||||
|
num_episodes=num_episodes,
|
||||||
|
batch_size=inference_batch_size,
|
||||||
|
train_dataset_config=train_dataset_config,
|
||||||
|
model_config=inference_model_config,
|
||||||
|
generate_config=generate_config,
|
||||||
|
tokenizer_config=tokenizer_config,
|
||||||
|
microbatch_size=inference_microbatch_size,
|
||||||
|
backend=inference_backend,
|
||||||
|
num_generations=num_generations,
|
||||||
|
consumer_plugin_config=plugin_config,
|
||||||
|
eval_dataset_config=eval_dataset_config,
|
||||||
|
eval_interval=eval_interval,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
eval_save_dir=eval_save_dir,
|
||||||
|
eval_generation_config=eval_generation_config,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
log_rollout_interval=log_rollout_interval,
|
||||||
|
rollout_log_file=rollout_log_file,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
n_behind=n_behind,
|
||||||
|
)
|
||||||
|
producer_procs.append(producer)
|
||||||
|
ray.get([p.setup.remote() for p in producer_procs])
|
||||||
|
generate_config_consumer = copy.deepcopy(generate_config)
|
||||||
|
generate_config_consumer.update(
|
||||||
|
dict(
|
||||||
|
backend=inference_backend,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
consumer_master_ip_address = gpu_to_ip_address[0]
|
||||||
|
print(f"Use {consumer_master_ip_address} as master address for torch DDP.")
|
||||||
|
consumer_procs = []
|
||||||
|
for i in range(num_consumer_procs):
|
||||||
|
node_id = gpu_to_node_id[0]
|
||||||
|
consumer_ip_address = gpu_to_ip_address[0]
|
||||||
|
gpu_to_node_id.pop(0)
|
||||||
|
gpu_to_ip_address.pop(0)
|
||||||
|
print(f"Schedual Consumer T[{i}] which requires 1 GPUs on node {consumer_ip_address}")
|
||||||
|
consumer = core_consumer.options(num_gpus=1).remote(
|
||||||
|
num_producers=num_producers,
|
||||||
|
num_episodes=num_episodes,
|
||||||
|
rank=i,
|
||||||
|
world_size=num_consumer_procs,
|
||||||
|
master_addr=consumer_master_ip_address,
|
||||||
|
master_port=master_port,
|
||||||
|
num_update_per_episode=num_update_per_episode,
|
||||||
|
num_recv_per_update=num_recv_per_update,
|
||||||
|
batch_size=train_batch_size,
|
||||||
|
model_config=train_model_config,
|
||||||
|
plugin_config=plugin_config,
|
||||||
|
minibatch_size=train_minibatch_size,
|
||||||
|
generate_config=generate_config_consumer,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
num_generations=num_generations,
|
||||||
|
save_interval=save_interval,
|
||||||
|
save_dir=save_dir,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
n_behind=n_behind,
|
||||||
|
)
|
||||||
|
consumer_procs.append(consumer)
|
||||||
|
ray.get([p.setup.remote() for p in consumer_procs])
|
||||||
|
ray.get([p.loop.remote() for p in (producer_procs + consumer_procs)])
|
||||||
@@ -0,0 +1,305 @@
|
|||||||
|
import copy
|
||||||
|
import os
|
||||||
|
import uuid
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
|
||||||
|
from .comm import SharedVariableActor
|
||||||
|
from .zero_bubble.distributor import Distributor
|
||||||
|
from .zero_bubble.grpo_consumer import GRPOConsumer
|
||||||
|
from .zero_bubble.producer import SimpleProducer
|
||||||
|
|
||||||
|
ALGO_MAP = {"GRPO": GRPOConsumer, "DAPO": GRPOConsumer}
|
||||||
|
|
||||||
|
|
||||||
|
def get_jsonl_size_fast(path: str) -> int:
|
||||||
|
with open(path) as f:
|
||||||
|
lines = f.readlines()
|
||||||
|
lines = [line for line in lines if line.strip()]
|
||||||
|
return len(lines)
|
||||||
|
|
||||||
|
|
||||||
|
def get_dp_size_fast(n_procs: int, plugin_config: Dict[str, Any]) -> int:
|
||||||
|
tp_size = plugin_config.get("tp_size", 1)
|
||||||
|
pp_size = plugin_config.get("pp_size", 1)
|
||||||
|
ep_size = plugin_config.get("ep_size", 1)
|
||||||
|
sp_size = plugin_config.get("sp_size", 1)
|
||||||
|
return n_procs // (tp_size * pp_size * ep_size * sp_size)
|
||||||
|
|
||||||
|
|
||||||
|
def launch_distributed(
|
||||||
|
num_producers: int,
|
||||||
|
num_proc_per_producer: int,
|
||||||
|
num_consumer_procs: int,
|
||||||
|
num_episodes: int,
|
||||||
|
inference_batch_size: int,
|
||||||
|
inference_microbatch_size: int,
|
||||||
|
train_batch_size: int,
|
||||||
|
train_minibatch_size: int,
|
||||||
|
train_dataset_config: Dict[str, Any],
|
||||||
|
inference_model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
train_model_config: Dict[str, Any],
|
||||||
|
grpo_config: Dict[str, Any],
|
||||||
|
plugin_config: Dict[str, Any],
|
||||||
|
tokenizer_config: Optional[Dict[str, Any]] = None,
|
||||||
|
inference_backend: str = "transformers",
|
||||||
|
num_generations: int = 8,
|
||||||
|
master_addr: str = "localhost",
|
||||||
|
master_port: int = 29500,
|
||||||
|
core_algo: str = "GRPO",
|
||||||
|
project_name: Optional[str] = None,
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir: str = "./model",
|
||||||
|
eval_dataset_config: Optional[Dict[str, Any]] = None,
|
||||||
|
eval_interval: int = 100,
|
||||||
|
eval_save_dir: Optional[str] = None,
|
||||||
|
eval_generation_config: Optional[Dict[str, Any]] = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_save_dir: str = "./rollout",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
data_actor_buffer_size_limit: int = 0,
|
||||||
|
):
|
||||||
|
if core_algo not in ALGO_MAP:
|
||||||
|
raise NotImplementedError(f"{core_algo} is not supported yet.")
|
||||||
|
else:
|
||||||
|
core_consumer = ALGO_MAP.get(core_algo, GRPOConsumer)
|
||||||
|
|
||||||
|
train_dp_size = get_dp_size_fast(num_consumer_procs, plugin_config)
|
||||||
|
assert (inference_batch_size * num_producers) % (train_batch_size * train_dp_size) == 0
|
||||||
|
if data_actor_buffer_size_limit <= 0:
|
||||||
|
# use 2 times the train_minibatch_size as the default buffer size limit
|
||||||
|
data_actor_buffer_size_limit = train_minibatch_size * train_dp_size * 2
|
||||||
|
|
||||||
|
dataset_path = train_dataset_config["path"]
|
||||||
|
train_dataset_size = get_jsonl_size_fast(dataset_path)
|
||||||
|
global_inference_batch_size = inference_batch_size * num_producers
|
||||||
|
train_dataset_size = (train_dataset_size // global_inference_batch_size) * global_inference_batch_size
|
||||||
|
|
||||||
|
run_name = f"{inference_backend}_bs_{train_batch_size * train_dp_size}_temp_{generate_config['temperature']:.01f}_top_p_{generate_config['top_p']:.02f}"
|
||||||
|
wandb_group_name = str(uuid.uuid4())
|
||||||
|
rollout_log_file = os.path.join(
|
||||||
|
rollout_save_dir,
|
||||||
|
f"{project_name.replace(' ','_')}_run_{wandb_group_name}.jsonl",
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attention: Ray use complex schedualing method that consider various factors including load-balancing.
|
||||||
|
# when requesting resources, it is not guaranteed that the resource comes from a node with lower node it
|
||||||
|
# this go against the design principle of our implementation, and we need to manually force the schedualing,
|
||||||
|
# allocating the producer to nodes with lower node id and the consumer to the resouces from nodes with higher
|
||||||
|
# node id. See the reference here: https://docs.ray.io/en/latest/ray-core/scheduling/index.html#nodeaffinityschedulingstrategy
|
||||||
|
nodes = ray.nodes()
|
||||||
|
|
||||||
|
# every producer is associated with a data worker, data worker is responsible for moving data from the producer to all consumer
|
||||||
|
shared_sync_data_actor = SharedVariableActor.remote(num_consumer_procs, data_actor_buffer_size_limit)
|
||||||
|
# all producer and the consumer 0 share the same model actor, model actor only provide signal for model synchronization
|
||||||
|
shared_signal_actor = SharedVariableActor.remote()
|
||||||
|
|
||||||
|
node_info = {
|
||||||
|
node["NodeID"]: {
|
||||||
|
"num_gpus": node["Resources"].get("GPU", 0),
|
||||||
|
"address": node["NodeManagerAddress"],
|
||||||
|
} # Default to 0 if no GPUs are available
|
||||||
|
for node in nodes
|
||||||
|
}
|
||||||
|
gpu_to_node_id = []
|
||||||
|
gpu_to_ip_address = []
|
||||||
|
for node_id in node_info:
|
||||||
|
for idx in range(int(node_info[node_id]["num_gpus"])):
|
||||||
|
gpu_to_node_id.append(node_id)
|
||||||
|
gpu_to_ip_address.append(node_info[node_id]["address"])
|
||||||
|
print(node_info)
|
||||||
|
|
||||||
|
producer_procs = []
|
||||||
|
for i in range(num_producers):
|
||||||
|
node_id = gpu_to_node_id[0]
|
||||||
|
producer_ip_address = gpu_to_ip_address[0]
|
||||||
|
for _ in range(num_proc_per_producer):
|
||||||
|
gpu_to_node_id.pop(0)
|
||||||
|
gpu_to_ip_address.pop(0)
|
||||||
|
print(f"Schedual Producer P[{i}] which requires {num_proc_per_producer} GPUs on node {producer_ip_address}")
|
||||||
|
producer = SimpleProducer.options(num_gpus=num_proc_per_producer, num_cpus=4).remote(
|
||||||
|
shared_sync_data_actor=shared_sync_data_actor,
|
||||||
|
shared_signal_actor=shared_signal_actor,
|
||||||
|
producer_idx=i,
|
||||||
|
num_producers=num_producers,
|
||||||
|
num_consumer_procs=num_consumer_procs,
|
||||||
|
num_episodes=num_episodes,
|
||||||
|
batch_size=inference_batch_size,
|
||||||
|
train_dataset_config=train_dataset_config,
|
||||||
|
model_config=inference_model_config,
|
||||||
|
generate_config=generate_config,
|
||||||
|
tokenizer_config=copy.deepcopy(tokenizer_config),
|
||||||
|
microbatch_size=inference_microbatch_size,
|
||||||
|
backend=inference_backend,
|
||||||
|
num_generations=num_generations,
|
||||||
|
consumer_plugin_config=plugin_config,
|
||||||
|
eval_dataset_config=eval_dataset_config,
|
||||||
|
eval_interval=eval_interval,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
eval_save_dir=eval_save_dir,
|
||||||
|
eval_generation_config=eval_generation_config,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
log_rollout_interval=log_rollout_interval,
|
||||||
|
rollout_log_file=rollout_log_file,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
)
|
||||||
|
producer_procs.append(producer)
|
||||||
|
# ray.get([p.setup.remote() for p in producer_procs])
|
||||||
|
generate_config_consumer = copy.deepcopy(generate_config)
|
||||||
|
generate_config_consumer.update(
|
||||||
|
dict(
|
||||||
|
backend=inference_backend,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
consumer_master_ip_address = gpu_to_ip_address[0]
|
||||||
|
print(f"Use {consumer_master_ip_address} as master address for torch DDP.")
|
||||||
|
consumer_procs = []
|
||||||
|
for i in range(num_consumer_procs):
|
||||||
|
node_id = gpu_to_node_id[0]
|
||||||
|
consumer_ip_address = gpu_to_ip_address[0]
|
||||||
|
gpu_to_node_id.pop(0)
|
||||||
|
gpu_to_ip_address.pop(0)
|
||||||
|
print(f"Schedual Consumer T[{i}] which requires 1 GPUs on node {consumer_ip_address}")
|
||||||
|
consumer = core_consumer.options(num_gpus=1, num_cpus=4).remote(
|
||||||
|
shared_sync_data_actor=shared_sync_data_actor,
|
||||||
|
shared_signal_actor=shared_signal_actor,
|
||||||
|
num_producers=num_producers,
|
||||||
|
num_episodes=num_episodes,
|
||||||
|
rank=i,
|
||||||
|
world_size=num_consumer_procs,
|
||||||
|
master_addr=consumer_master_ip_address,
|
||||||
|
master_port=master_port,
|
||||||
|
train_dataset_size=train_dataset_size,
|
||||||
|
batch_size=train_batch_size,
|
||||||
|
model_config=train_model_config,
|
||||||
|
plugin_config=plugin_config,
|
||||||
|
minibatch_size=train_minibatch_size,
|
||||||
|
tokenizer_config=copy.deepcopy(tokenizer_config),
|
||||||
|
generate_config=generate_config_consumer,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
num_generations=num_generations,
|
||||||
|
save_interval=save_interval,
|
||||||
|
save_dir=save_dir,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
)
|
||||||
|
consumer_procs.append(consumer)
|
||||||
|
|
||||||
|
distributor_procs = []
|
||||||
|
for i in range(num_producers):
|
||||||
|
distributor_procs.append(
|
||||||
|
Distributor.options(num_cpus=2).remote(
|
||||||
|
i,
|
||||||
|
plugin_config.get("pp_size", 1),
|
||||||
|
num_producers,
|
||||||
|
shared_signal_actor,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
print("=================== All processes are created, starting setup torch DDP ===================", flush=True)
|
||||||
|
ray.get([p.setup.remote() for p in consumer_procs])
|
||||||
|
print(
|
||||||
|
"=================== All processes are setup, starting initialize communication groups ===================",
|
||||||
|
flush=True,
|
||||||
|
)
|
||||||
|
remote_refs = []
|
||||||
|
# Initialize consumer communication group
|
||||||
|
for i, p in enumerate(consumer_procs):
|
||||||
|
remote_refs.append(p.init_collective_group.remote(num_consumer_procs, i, "gloo", f"consumer_pg"))
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
# Initialize producer communication group
|
||||||
|
for i, p in enumerate(producer_procs):
|
||||||
|
remote_refs.append(p.init_collective_group.remote(num_producers, i, "nccl", f"producer_pg"))
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
# Initialize distributor communication group
|
||||||
|
for i, p in enumerate(distributor_procs):
|
||||||
|
remote_refs.append(p.init_collective_group.remote(num_producers, i, "gloo", f"distributor_pg"))
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
# Initialize sync model communication group between consumer and sync model actor
|
||||||
|
# As per tested, gloo do not support nested initialization, so we need to initialize all participants in the same group in the same ray.get call.
|
||||||
|
consumer_pp = plugin_config.get("pp_size", 1)
|
||||||
|
for i, p in enumerate(consumer_procs):
|
||||||
|
consumer_ddp_config = ray.get(p.get_ddp_config.remote())
|
||||||
|
if consumer_pp > 1:
|
||||||
|
if consumer_ddp_config["tp_rank"] == 0 and consumer_ddp_config["dp_rank"] == 0:
|
||||||
|
pp_rank = consumer_ddp_config["pp_rank"]
|
||||||
|
remote_refs.append(
|
||||||
|
p.init_collective_group.remote(
|
||||||
|
num_producers + 1,
|
||||||
|
0,
|
||||||
|
backend="gloo",
|
||||||
|
group_name=f"sync_model_consumer_pp_{pp_rank}",
|
||||||
|
gloo_timeout=3000000,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
for distributor_id, p_distributor in enumerate(distributor_procs):
|
||||||
|
remote_refs.append(
|
||||||
|
p_distributor.init_collective_group.remote(
|
||||||
|
num_producers + 1,
|
||||||
|
1 + distributor_id,
|
||||||
|
backend="gloo",
|
||||||
|
group_name=f"sync_model_consumer_pp_{pp_rank}",
|
||||||
|
gloo_timeout=3000000,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
else:
|
||||||
|
if i == 0:
|
||||||
|
remote_refs.append(
|
||||||
|
p.init_collective_group.remote(
|
||||||
|
num_producers + 1, 0, backend="gloo", group_name=f"sync_model_consumer", gloo_timeout=3000000
|
||||||
|
)
|
||||||
|
)
|
||||||
|
for distributor_id, p_distributor in enumerate(distributor_procs):
|
||||||
|
remote_refs.append(
|
||||||
|
p_distributor.init_collective_group.remote(
|
||||||
|
num_producers + 1,
|
||||||
|
1 + distributor_id,
|
||||||
|
backend="gloo",
|
||||||
|
group_name=f"sync_model_consumer",
|
||||||
|
gloo_timeout=3000000,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
# Initialize sync model communication group between producer and sync model actor
|
||||||
|
for i, p in enumerate(producer_procs):
|
||||||
|
if consumer_pp > 1:
|
||||||
|
for pp_rank in range(consumer_pp):
|
||||||
|
remote_refs.append(
|
||||||
|
p.init_collective_group.remote(
|
||||||
|
2, 0, backend="gloo", group_name=f"sync_model_producer_{i}_pp_{pp_rank}", gloo_timeout=3000000
|
||||||
|
)
|
||||||
|
)
|
||||||
|
remote_refs.append(
|
||||||
|
distributor_procs[i].init_collective_group.remote(
|
||||||
|
2, 1, backend="gloo", group_name=f"sync_model_producer_{i}_pp_{pp_rank}", gloo_timeout=3000000
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
else:
|
||||||
|
remote_refs.append(
|
||||||
|
p.init_collective_group.remote(
|
||||||
|
2, 0, backend="gloo", group_name=f"sync_model_producer_{i}", gloo_timeout=3000000
|
||||||
|
)
|
||||||
|
)
|
||||||
|
remote_refs.append(
|
||||||
|
distributor_procs[i].init_collective_group.remote(
|
||||||
|
2, 1, backend="gloo", group_name=f"sync_model_producer_{i}", gloo_timeout=3000000
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray.get(remote_refs)
|
||||||
|
remote_refs = []
|
||||||
|
print("=================== All processes are set up, starting loop ===================", flush=True)
|
||||||
|
ray.get([p.loop.remote() for p in (producer_procs + consumer_procs + distributor_procs)])
|
||||||
70
applications/ColossalChat/coati/distributed/loss.py
Normal file
70
applications/ColossalChat/coati/distributed/loss.py
Normal file
@@ -0,0 +1,70 @@
|
|||||||
|
from typing import Optional
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from coati.distributed.utils import masked_mean, masked_sum
|
||||||
|
|
||||||
|
|
||||||
|
class PolicyLoss(nn.Module):
|
||||||
|
"""
|
||||||
|
Policy Loss for PPO
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
clip_eps_low: float = 0.2,
|
||||||
|
clip_eps_high: float = 0.2,
|
||||||
|
beta: float = 0.01,
|
||||||
|
loss_variation: str = "sample_level",
|
||||||
|
adv: str = "GRPO",
|
||||||
|
) -> None:
|
||||||
|
super().__init__()
|
||||||
|
self.clip_eps_low = clip_eps_low
|
||||||
|
self.clip_eps_high = clip_eps_high
|
||||||
|
self.beta = beta
|
||||||
|
self.loss_variation = loss_variation
|
||||||
|
assert loss_variation in ["sample_level", "token_level"], f"Unsupported loss variation: {loss_variation}"
|
||||||
|
self.adv = adv
|
||||||
|
|
||||||
|
def forward(
|
||||||
|
self,
|
||||||
|
log_probs: torch.Tensor,
|
||||||
|
old_log_probs: torch.Tensor,
|
||||||
|
advantages: torch.Tensor,
|
||||||
|
per_token_kl: torch.Tensor,
|
||||||
|
action_mask: Optional[torch.Tensor] = None,
|
||||||
|
loss_mask: Optional[torch.Tensor] = None,
|
||||||
|
total_effective_tokens_in_batch: torch.Tensor = None,
|
||||||
|
) -> torch.Tensor:
|
||||||
|
if action_mask is None:
|
||||||
|
ratio = (log_probs - old_log_probs.detach()).exp()
|
||||||
|
else:
|
||||||
|
ratio = ((log_probs - old_log_probs.detach()) * action_mask).exp()
|
||||||
|
|
||||||
|
surr1 = ratio * advantages
|
||||||
|
surr2 = ratio.clamp(1 - self.clip_eps_low, 1 + self.clip_eps_high) * advantages
|
||||||
|
if self.beta == 0:
|
||||||
|
# skip kl term if kl coefficient is zero
|
||||||
|
per_token_kl = 0.0
|
||||||
|
loss = -torch.min(surr1, surr2) + self.beta * per_token_kl
|
||||||
|
|
||||||
|
if self.loss_variation == "sample_level":
|
||||||
|
if action_mask is not None:
|
||||||
|
loss = masked_mean(loss, action_mask)
|
||||||
|
else:
|
||||||
|
loss = loss.mean(dim=1)
|
||||||
|
if loss_mask is not None:
|
||||||
|
loss = loss * loss_mask
|
||||||
|
loss = loss.mean()
|
||||||
|
elif self.loss_variation == "token_level":
|
||||||
|
if action_mask is not None:
|
||||||
|
loss = masked_sum(loss, action_mask)
|
||||||
|
else:
|
||||||
|
loss = loss.sum(dim=1)
|
||||||
|
if loss_mask is not None:
|
||||||
|
loss = loss * loss_mask
|
||||||
|
loss = loss.sum() / (total_effective_tokens_in_batch + 1e-8)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unsupported loss variation: {self.loss_variation}")
|
||||||
|
|
||||||
|
return loss, ratio.max()
|
||||||
513
applications/ColossalChat/coati/distributed/producer.py
Normal file
513
applications/ColossalChat/coati/distributed/producer.py
Normal file
@@ -0,0 +1,513 @@
|
|||||||
|
import copy
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
import tqdm
|
||||||
|
import wandb
|
||||||
|
from coati.dataset import StatefulDistributedSampler
|
||||||
|
from coati.dataset.loader import RawConversationDataset, collate_fn_grpo
|
||||||
|
from coati.distributed.profiling_utils import CustomProfiler
|
||||||
|
from coati.distributed.reward.reward_fn import boxed_math_reward_fn, code_reward_fn, math_reward_fn
|
||||||
|
from coati.distributed.reward.verifiable_reward import VerifiableReward
|
||||||
|
from coati.utils import load_checkpoint
|
||||||
|
from ray.util.collective import allreduce
|
||||||
|
from ray.util.collective.types import Backend, ReduceOp
|
||||||
|
from torch.utils.data import DataLoader, DistributedSampler
|
||||||
|
from transformers import AutoTokenizer
|
||||||
|
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
from .comm import ray_broadcast_tensor_dict
|
||||||
|
from .inference_backend import BACKEND_MAP
|
||||||
|
from .utils import pre_send, safe_append_to_jsonl_file
|
||||||
|
|
||||||
|
try:
|
||||||
|
from vllm import SamplingParams
|
||||||
|
except ImportError:
|
||||||
|
LLM = None
|
||||||
|
|
||||||
|
|
||||||
|
class BaseProducer:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
producer_idx: int,
|
||||||
|
num_producers: int,
|
||||||
|
num_consumer_procs: int,
|
||||||
|
num_episodes: int,
|
||||||
|
batch_size: int,
|
||||||
|
train_dataset_config: Dict[str, Any],
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
tokenizer_config: Optional[Dict[str, Any]] = None,
|
||||||
|
microbatch_size: int = 1,
|
||||||
|
backend: str = "transformers",
|
||||||
|
consumer_plugin_config: Dict[str, Any] = None,
|
||||||
|
eval_dataset_config=None,
|
||||||
|
eval_interval=-1, # disable evaluation
|
||||||
|
grpo_config: Dict[str, Any] = None,
|
||||||
|
eval_save_dir: str = "./eval",
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_log_file: str = "./rollout_log.jsonl",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
n_behind: int = 0,
|
||||||
|
):
|
||||||
|
self.producer_idx = producer_idx
|
||||||
|
self.num_producers = num_producers
|
||||||
|
self.num_consumer_procs = num_consumer_procs
|
||||||
|
self.num_episodes = num_episodes
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.microbatch_size = microbatch_size
|
||||||
|
assert batch_size % microbatch_size == 0
|
||||||
|
self.num_microbatches = batch_size // microbatch_size
|
||||||
|
self.latest_eval_step = -1
|
||||||
|
self.profiler = CustomProfiler(f"P{self.producer_idx}", disabled=not enable_profiling)
|
||||||
|
|
||||||
|
self.train_dataset_config = train_dataset_config
|
||||||
|
self.checkpoint_path = model_config.pop("checkpoint_path", None)
|
||||||
|
self.model_config = model_config
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.tokenizer_config = tokenizer_config
|
||||||
|
self.consumer_plugin_config = consumer_plugin_config
|
||||||
|
self.eval_interval = eval_interval
|
||||||
|
self.eval_save_dir = eval_save_dir
|
||||||
|
self.consumer_global_step = 0
|
||||||
|
self.eval_mode = False
|
||||||
|
self.log_rollout_interval = log_rollout_interval
|
||||||
|
self.latest_rollout_log_step = -1
|
||||||
|
self.grpo_config = grpo_config
|
||||||
|
self.n_behind = n_behind
|
||||||
|
reward_model_kwargs = {
|
||||||
|
k: v
|
||||||
|
for k, v in grpo_config.items()
|
||||||
|
if k in ["soft_over_length_punishment", "max_new_tokens", "cache_length", "code_verifier_api_url"]
|
||||||
|
}
|
||||||
|
self.response_format_tags = grpo_config.get("response_format_tags", None)
|
||||||
|
if producer_idx == 0:
|
||||||
|
if os.path.exists(rollout_log_file):
|
||||||
|
raise ValueError(
|
||||||
|
f"Rollout log file {rollout_log_file} already exists. Please delete it or change the name."
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
os.makedirs(os.path.dirname(rollout_log_file), exist_ok=True)
|
||||||
|
self.rollout_log_file = open(rollout_log_file, "w", encoding="utf8")
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run = wandb.init(
|
||||||
|
project=project_name,
|
||||||
|
sync_tensorboard=False,
|
||||||
|
dir="./wandb",
|
||||||
|
name=run_name + "_eval",
|
||||||
|
group=wandb_group_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
if os.path.exists(self.eval_save_dir) and self.eval_interval > 0:
|
||||||
|
raise ValueError(f"Eval save dir {self.eval_save_dir} already exists. Please delete it or change the name.")
|
||||||
|
|
||||||
|
# init tokenizer
|
||||||
|
if tokenizer_config is None:
|
||||||
|
tokenizer_path = model_config["path"]
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
|
||||||
|
else:
|
||||||
|
tokenizer_path = tokenizer_config.pop("path")
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, **tokenizer_config)
|
||||||
|
self.tokenizer.padding_side = "left"
|
||||||
|
|
||||||
|
if self.tokenizer.pad_token_id is None:
|
||||||
|
self.tokenizer.pad_token = self.tokenizer.eos_token
|
||||||
|
|
||||||
|
# init dataloader
|
||||||
|
train_dataset_path = train_dataset_config.pop("path")
|
||||||
|
self.train_dataset = RawConversationDataset(self.tokenizer, train_dataset_path, **train_dataset_config)
|
||||||
|
self.train_dataloader = DataLoader(
|
||||||
|
self.train_dataset,
|
||||||
|
batch_size=microbatch_size,
|
||||||
|
sampler=StatefulDistributedSampler(
|
||||||
|
self.train_dataset,
|
||||||
|
num_replicas=num_producers,
|
||||||
|
rank=producer_idx,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
seed=42,
|
||||||
|
),
|
||||||
|
num_workers=4,
|
||||||
|
drop_last=True,
|
||||||
|
collate_fn=collate_fn_grpo,
|
||||||
|
)
|
||||||
|
if self.checkpoint_path is not None:
|
||||||
|
# resume training from checkpoint
|
||||||
|
start_epoch, start_step, sampler_start_idx = load_checkpoint(self.checkpoint_path, None, None, None, None)
|
||||||
|
self.train_dataloader.sampler.set_start_index(sampler_start_idx)
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Resume training from checkpoint {self.checkpoint_path}, start epoch {start_epoch}, start step {start_step}, sampler start index {sampler_start_idx}"
|
||||||
|
)
|
||||||
|
if grpo_config["reward_fn_type"] == "think_answer_tags":
|
||||||
|
self.evaluation_function = math_reward_fn
|
||||||
|
elif grpo_config["reward_fn_type"] == "boxed":
|
||||||
|
self.evaluation_function = boxed_math_reward_fn
|
||||||
|
elif grpo_config["reward_fn_type"] == "code":
|
||||||
|
self.evaluation_function = code_reward_fn
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown evaluation function type {grpo_config['reward_fn_type']}")
|
||||||
|
|
||||||
|
self.eval_dataset_config = eval_dataset_config
|
||||||
|
if self.eval_dataset_config is not None:
|
||||||
|
self.eval_dataloaders = {}
|
||||||
|
for eval_task_name in self.eval_dataset_config:
|
||||||
|
eval_dataset_path = eval_dataset_config[eval_task_name].pop("path")
|
||||||
|
eval_dataset = RawConversationDataset(
|
||||||
|
self.tokenizer, eval_dataset_path, **eval_dataset_config[eval_task_name]
|
||||||
|
)
|
||||||
|
print(f"[P{self.producer_idx}] eval dataset {eval_task_name} size: {len(eval_dataset)}")
|
||||||
|
self.eval_dataloaders[eval_task_name] = DataLoader(
|
||||||
|
eval_dataset,
|
||||||
|
batch_size=microbatch_size,
|
||||||
|
sampler=DistributedSampler(
|
||||||
|
eval_dataset,
|
||||||
|
num_replicas=num_producers,
|
||||||
|
rank=producer_idx,
|
||||||
|
shuffle=False,
|
||||||
|
drop_last=False,
|
||||||
|
seed=42,
|
||||||
|
),
|
||||||
|
collate_fn=collate_fn_grpo,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print("No eval dataset provided, skip eval")
|
||||||
|
self.device = get_current_device()
|
||||||
|
self.reward_model = VerifiableReward(
|
||||||
|
reward_fns=[self.evaluation_function], # multiple reward functions can be added here
|
||||||
|
tokenizer=self.tokenizer,
|
||||||
|
tags=self.response_format_tags,
|
||||||
|
**reward_model_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
# init backend
|
||||||
|
if backend in BACKEND_MAP:
|
||||||
|
self.backend_cls = BACKEND_MAP[backend]
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unexpected backend {backend}")
|
||||||
|
|
||||||
|
self.consumer_pp_size = consumer_plugin_config.get("pp_size", 1) # consumer pp size
|
||||||
|
|
||||||
|
def setup(self) -> None:
|
||||||
|
cc.init_collective_group(
|
||||||
|
world_size=self.num_producers,
|
||||||
|
rank=self.producer_idx,
|
||||||
|
backend=Backend.NCCL,
|
||||||
|
group_name="producer_group",
|
||||||
|
)
|
||||||
|
cc.init_collective_group(1 + self.num_consumer_procs, 0, group_name=f"sync_data_{self.producer_idx}")
|
||||||
|
if self.consumer_pp_size > 1:
|
||||||
|
for i in range(self.consumer_pp_size):
|
||||||
|
cc.init_collective_group(self.num_producers + 1, self.producer_idx, group_name=f"sync_model_{i}")
|
||||||
|
else:
|
||||||
|
cc.init_collective_group(self.num_producers + 1, self.producer_idx, group_name="sync_model")
|
||||||
|
|
||||||
|
def rollout(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def loop(self) -> None:
|
||||||
|
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
if self.consumer_pp_size > 1:
|
||||||
|
for pp_idx in range(self.consumer_pp_size):
|
||||||
|
state_dict = ray_broadcast_tensor_dict(
|
||||||
|
None, self.num_producers, device=self.device, group_name=f"sync_model_{pp_idx}"
|
||||||
|
)
|
||||||
|
if "consumer_global_step" in state_dict:
|
||||||
|
self.consumer_global_step = state_dict.pop("consumer_global_step").item()
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
else:
|
||||||
|
state_dict = ray_broadcast_tensor_dict(
|
||||||
|
None, self.num_producers, device=self.device, group_name="sync_model"
|
||||||
|
)
|
||||||
|
if "consumer_global_step" in state_dict:
|
||||||
|
self.consumer_global_step = state_dict.pop("consumer_global_step").item()
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
print(f"[P{self.producer_idx}] Sync initial model done.")
|
||||||
|
del state_dict
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
|
||||||
|
num_update_per_episode = len(self.train_dataloader) // self.num_microbatches
|
||||||
|
num_valid_microbatches = num_update_per_episode * self.num_microbatches
|
||||||
|
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] num_valid_microbatches {num_valid_microbatches}, nmb: {self.num_microbatches}, dl: {len(self.train_dataloader)}"
|
||||||
|
)
|
||||||
|
for episode in range(self.num_episodes):
|
||||||
|
self.train_dataloader.sampler.set_epoch(episode)
|
||||||
|
for i, batch in enumerate(self.train_dataloader):
|
||||||
|
if i >= num_valid_microbatches:
|
||||||
|
break
|
||||||
|
if self.eval_interval > 0 and self.eval_dataset_config is not None:
|
||||||
|
if (
|
||||||
|
self.consumer_global_step - self.latest_eval_step >= self.eval_interval
|
||||||
|
and self.consumer_global_step > self.latest_eval_step
|
||||||
|
) or self.latest_eval_step == -1:
|
||||||
|
to_log_msg = {}
|
||||||
|
self.eval_mode = True
|
||||||
|
for eval_task_name in self.eval_dataloaders:
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Evaluate model at training step {self.consumer_global_step} on task {eval_task_name}"
|
||||||
|
)
|
||||||
|
eval_results = []
|
||||||
|
eval_statistics_tensor = torch.zeros((2,), dtype=torch.float32).to(self.device)
|
||||||
|
for eval_batch in tqdm.tqdm(
|
||||||
|
self.eval_dataloaders[eval_task_name], disable=self.producer_idx != 0
|
||||||
|
):
|
||||||
|
eval_outputs = self.rollout(**eval_batch, sample_params=self.eval_sample_params)
|
||||||
|
eval_results = eval_results + [
|
||||||
|
self.evaluation_function(
|
||||||
|
eval_outputs["input_ids"][m][n],
|
||||||
|
eval_outputs[
|
||||||
|
(
|
||||||
|
"test_cases"
|
||||||
|
if self.grpo_config["reward_fn_type"] == "code"
|
||||||
|
else "gt_answer"
|
||||||
|
)
|
||||||
|
][m],
|
||||||
|
eval_outputs["response_idx"][m][n],
|
||||||
|
tokenizer=self.tokenizer,
|
||||||
|
eval_mode=True,
|
||||||
|
tags=self.response_format_tags,
|
||||||
|
)
|
||||||
|
for m in range(eval_outputs["input_ids"].size(0))
|
||||||
|
for n in range(eval_outputs["input_ids"].size(1))
|
||||||
|
]
|
||||||
|
eval_statistics_tensor[0] += sum([max(0, res["ans_valid"]) for res in eval_results])
|
||||||
|
eval_statistics_tensor[1] += len(eval_results)
|
||||||
|
allreduce(eval_statistics_tensor, op=ReduceOp.SUM, group_name="producer_group")
|
||||||
|
to_log_msg[f"eval/{eval_task_name}"] = (
|
||||||
|
eval_statistics_tensor[0].item() / eval_statistics_tensor[1].item()
|
||||||
|
)
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}]: Accuracy on {eval_task_name}: {to_log_msg[f'eval/{eval_task_name}']}"
|
||||||
|
)
|
||||||
|
# save eval results
|
||||||
|
safe_append_to_jsonl_file(
|
||||||
|
os.path.join(
|
||||||
|
self.eval_save_dir,
|
||||||
|
f"{eval_task_name}_training_step_{self.consumer_global_step}.jsonl",
|
||||||
|
),
|
||||||
|
eval_results,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run.log(to_log_msg, step=self.consumer_global_step)
|
||||||
|
self.eval_mode = False
|
||||||
|
self.latest_eval_step = self.consumer_global_step
|
||||||
|
self.profiler.enter("rollout")
|
||||||
|
outputs = self.rollout(**batch)
|
||||||
|
self.profiler.exit("rollout")
|
||||||
|
outputs["temperature"] = torch.tensor(
|
||||||
|
[self.model.generate_config["temperature"]] * outputs["input_ids"].size(0)
|
||||||
|
).to(outputs["input_ids"].device)
|
||||||
|
bs, num_gen = outputs["input_ids"].size(0), outputs["input_ids"].size(1)
|
||||||
|
self.profiler.enter("calculate_reward")
|
||||||
|
if self.grpo_config["reward_fn_type"] == "code":
|
||||||
|
test_cases = []
|
||||||
|
for prompt_id in range(bs):
|
||||||
|
test_cases.extend([outputs["test_cases"][prompt_id]] * num_gen)
|
||||||
|
reward_model_output = self.reward_model(
|
||||||
|
outputs["input_ids"].view((-1, outputs["input_ids"].size(-1))),
|
||||||
|
test_cases=test_cases,
|
||||||
|
response_idx=outputs["response_idx"].view((-1, 2)),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
gt_answer = []
|
||||||
|
for prompt_id in range(bs):
|
||||||
|
gt_answer.extend([outputs["gt_answer"][prompt_id]] * num_gen)
|
||||||
|
reward_model_output = self.reward_model(
|
||||||
|
outputs["input_ids"].view((-1, outputs["input_ids"].size(-1))),
|
||||||
|
gt_answer=gt_answer,
|
||||||
|
response_idx=outputs["response_idx"].view((-1, 2)),
|
||||||
|
)
|
||||||
|
outputs["reward"] = (
|
||||||
|
torch.tensor([value[0] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
outputs["format_acc"] = (
|
||||||
|
torch.tensor([value[1] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
outputs["ans_acc"] = (
|
||||||
|
torch.tensor([value[2] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
if "gt_answer" in outputs:
|
||||||
|
outputs.pop("gt_answer")
|
||||||
|
if "test_cases" in outputs:
|
||||||
|
outputs.pop("test_cases")
|
||||||
|
self.profiler.exit("calculate_reward")
|
||||||
|
|
||||||
|
print(f"[P{self.producer_idx}] Send data {[(k, v.shape) for k, v in outputs.items()]}")
|
||||||
|
outputs = pre_send(outputs)
|
||||||
|
self.profiler.enter("send_broadcast_data")
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
outputs, src=0, device=self.device, group_name=f"sync_data_{self.producer_idx}"
|
||||||
|
)
|
||||||
|
self.profiler.exit("send_broadcast_data")
|
||||||
|
if (
|
||||||
|
(i + 1) % self.num_microbatches == 0
|
||||||
|
and (episode != self.num_episodes - 1 or i != num_valid_microbatches - 1)
|
||||||
|
and (episode != 0 or (i + 1) > self.n_behind * self.num_microbatches)
|
||||||
|
):
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]) and self.model.model_config.get(
|
||||||
|
"enable_sleep_mode", False
|
||||||
|
):
|
||||||
|
self.model.llm.sleep() # revict KV_cache to avoid OOM
|
||||||
|
# don't sync model for last iteration
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
if self.consumer_pp_size > 1:
|
||||||
|
for pp_idx in range(self.consumer_pp_size):
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Sync model PP stage {pp_idx} episode {episode} step {(i + 1) // self.num_microbatches - 1}"
|
||||||
|
)
|
||||||
|
state_dict = ray_broadcast_tensor_dict(
|
||||||
|
None, self.num_producers, device=self.device, group_name=f"sync_model_{pp_idx}"
|
||||||
|
)
|
||||||
|
if "consumer_global_step" in state_dict:
|
||||||
|
self.consumer_global_step = state_dict.pop("consumer_global_step").item()
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
else:
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Sync model episode {episode} step {(i + 1) // self.num_microbatches - 1}"
|
||||||
|
)
|
||||||
|
state_dict = ray_broadcast_tensor_dict(
|
||||||
|
None, self.num_producers, device=self.device, group_name="sync_model"
|
||||||
|
)
|
||||||
|
if "consumer_global_step" in state_dict:
|
||||||
|
self.consumer_global_step = state_dict.pop("consumer_global_step").item()
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
del state_dict
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]) and self.model.model_config.get(
|
||||||
|
"enable_sleep_mode", False
|
||||||
|
):
|
||||||
|
self.model.llm.wake_up()
|
||||||
|
# linear annealing for 1 episode, temperature from initial to 0.9
|
||||||
|
if episode <= 0:
|
||||||
|
ratio = 1 - (len(self.train_dataloader) - i) / len(self.train_dataloader)
|
||||||
|
self.model.generate_config["temperature"] = (1 - ratio) * self.generate_config[
|
||||||
|
"temperature"
|
||||||
|
] + ratio * 0.9
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]):
|
||||||
|
self.model.sample_params.temperature = (1 - ratio) * self.generate_config[
|
||||||
|
"temperature"
|
||||||
|
] + ratio * 0.9
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.profiler.close()
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class SimpleProducer(BaseProducer):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
producer_idx,
|
||||||
|
num_producers,
|
||||||
|
num_consumer_procs,
|
||||||
|
num_episodes,
|
||||||
|
batch_size,
|
||||||
|
train_dataset_config,
|
||||||
|
model_config,
|
||||||
|
generate_config,
|
||||||
|
tokenizer_config=None,
|
||||||
|
microbatch_size=1,
|
||||||
|
backend="transformers",
|
||||||
|
num_generations: int = 8,
|
||||||
|
consumer_plugin_config=None,
|
||||||
|
eval_dataset_config=None,
|
||||||
|
eval_interval=-1, # disable evaluation
|
||||||
|
grpo_config: Dict[str, Any] = None,
|
||||||
|
eval_save_dir: str = "./eval",
|
||||||
|
eval_generation_config={},
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_log_file: str = "./rollout_log.jsonl",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
n_behind: int = 0,
|
||||||
|
):
|
||||||
|
super().__init__(
|
||||||
|
producer_idx,
|
||||||
|
num_producers,
|
||||||
|
num_consumer_procs,
|
||||||
|
num_episodes,
|
||||||
|
batch_size,
|
||||||
|
train_dataset_config,
|
||||||
|
model_config,
|
||||||
|
generate_config,
|
||||||
|
tokenizer_config,
|
||||||
|
microbatch_size,
|
||||||
|
backend,
|
||||||
|
consumer_plugin_config,
|
||||||
|
eval_dataset_config=eval_dataset_config,
|
||||||
|
eval_interval=eval_interval,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
eval_save_dir=eval_save_dir,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
log_rollout_interval=log_rollout_interval,
|
||||||
|
rollout_log_file=rollout_log_file,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
n_behind=n_behind,
|
||||||
|
)
|
||||||
|
self.model = self.backend_cls(model_config, generate_config, self.tokenizer, num_generations)
|
||||||
|
self.eval_generation_config = copy.deepcopy(self.model.generate_config)
|
||||||
|
self.eval_generation_config["n"] = 1 # use 1 generation for evaluation
|
||||||
|
self.eval_generation_config.update(eval_generation_config)
|
||||||
|
self.eval_sample_params = SamplingParams(**self.eval_generation_config)
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def rollout(self, input_ids, attention_mask, **kwargs):
|
||||||
|
rollouts = self.model.generate(input_ids, attention_mask, **kwargs)
|
||||||
|
if self.producer_idx == 0 and not self.eval_mode:
|
||||||
|
if (
|
||||||
|
self.consumer_global_step - self.latest_rollout_log_step >= self.log_rollout_interval
|
||||||
|
or self.latest_rollout_log_step == -1
|
||||||
|
):
|
||||||
|
new_record = (
|
||||||
|
json.dumps(
|
||||||
|
{
|
||||||
|
"train_step": self.consumer_global_step,
|
||||||
|
"rollout": self.tokenizer.batch_decode(
|
||||||
|
rollouts["input_ids"][:, 0], skip_special_tokens=True
|
||||||
|
),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
+ "\n"
|
||||||
|
)
|
||||||
|
self.rollout_log_file.write(new_record)
|
||||||
|
self.rollout_log_file.flush()
|
||||||
|
self.latest_rollout_log_step = self.consumer_global_step
|
||||||
|
return rollouts
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run.finish()
|
||||||
|
if hasattr(self, "rollout_log_file"):
|
||||||
|
self.rollout_log_file.close()
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict):
|
||||||
|
self.model.load_state_dict(state_dict)
|
||||||
@@ -0,0 +1,37 @@
|
|||||||
|
import os
|
||||||
|
import time
|
||||||
|
|
||||||
|
|
||||||
|
class CustomProfiler:
|
||||||
|
def __init__(self, name, disabled=True):
|
||||||
|
self.disabled = disabled
|
||||||
|
if not disabled:
|
||||||
|
self.name = name
|
||||||
|
self.pid = os.getpid()
|
||||||
|
self.file = open(f"{name}.prof", "w")
|
||||||
|
|
||||||
|
def _log(self, message):
|
||||||
|
if self.disabled:
|
||||||
|
return
|
||||||
|
current_time = time.time()
|
||||||
|
self.file.write(f"{current_time} {self.name} {self.pid}:: {message}\n")
|
||||||
|
self.file.flush()
|
||||||
|
|
||||||
|
def log(self, message):
|
||||||
|
if self.disabled:
|
||||||
|
return
|
||||||
|
current_time = time.time()
|
||||||
|
self.file.write(f"[Log]: {current_time} {self.name} {self.pid}:: {message}\n")
|
||||||
|
self.file.flush()
|
||||||
|
|
||||||
|
def enter(self, event_name):
|
||||||
|
self._log(f"Enter {event_name}")
|
||||||
|
|
||||||
|
def exit(self, event_name):
|
||||||
|
self._log(f"Exit {event_name}")
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
if self.disabled:
|
||||||
|
return
|
||||||
|
self.file.close()
|
||||||
|
print(f"Profiler data written to {self.name}.prof")
|
||||||
@@ -0,0 +1,674 @@
|
|||||||
|
# Code from the verl Project (https://github.com/agentica-project/rllm),
|
||||||
|
# which itself is adapted from Prime (https://github.com/PRIME-RL/PRIME)
|
||||||
|
#
|
||||||
|
# Copyright 2024 ByteDance Group
|
||||||
|
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
|
||||||
|
import ast
|
||||||
|
import faulthandler
|
||||||
|
import json
|
||||||
|
import platform
|
||||||
|
|
||||||
|
# to run the solution files we're using a timing based approach
|
||||||
|
import signal
|
||||||
|
import sys
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
# used for debugging to time steps
|
||||||
|
from datetime import datetime
|
||||||
|
from enum import Enum
|
||||||
|
|
||||||
|
# for capturing the stdout
|
||||||
|
from io import StringIO
|
||||||
|
|
||||||
|
# used for testing the code that reads from input
|
||||||
|
from unittest.mock import mock_open, patch
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
from pyext import RuntimeModule
|
||||||
|
|
||||||
|
|
||||||
|
def truncatefn(s, length=300):
|
||||||
|
assert isinstance(s, str)
|
||||||
|
if len(s) <= length:
|
||||||
|
return s
|
||||||
|
|
||||||
|
return s[: length // 2] + "...(truncated) ..." + s[-length // 2 :]
|
||||||
|
|
||||||
|
|
||||||
|
class CODE_TYPE(Enum):
|
||||||
|
call_based = 0
|
||||||
|
standard_input = 1
|
||||||
|
|
||||||
|
|
||||||
|
# used to capture stdout as a list
|
||||||
|
# from https://stackoverflow.com/a/16571630/6416660
|
||||||
|
# alternative use redirect_stdout() from contextlib
|
||||||
|
class Capturing(list):
|
||||||
|
def __enter__(self):
|
||||||
|
self._stdout = sys.stdout
|
||||||
|
sys.stdout = self._stringio = StringIO()
|
||||||
|
# Make closing the StringIO a no-op
|
||||||
|
self._stringio.close = lambda x: 1
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __exit__(self, *args):
|
||||||
|
self.append(self._stringio.getvalue())
|
||||||
|
del self._stringio # free up some memory
|
||||||
|
sys.stdout = self._stdout
|
||||||
|
|
||||||
|
|
||||||
|
def only_int_check(val):
|
||||||
|
return isinstance(val, int)
|
||||||
|
|
||||||
|
|
||||||
|
def string_int_check(val):
|
||||||
|
return isinstance(val, str) and val.isdigit()
|
||||||
|
|
||||||
|
|
||||||
|
def combined_int_check(val):
|
||||||
|
return only_int_check(val) or string_int_check(val)
|
||||||
|
|
||||||
|
|
||||||
|
def clean_traceback(error_traceback):
|
||||||
|
file_start = error_traceback.find('File "<string>"')
|
||||||
|
# print(file_start)
|
||||||
|
error_traceback = "Traceback (most recent call last):\n " + error_traceback[file_start:]
|
||||||
|
return error_traceback
|
||||||
|
|
||||||
|
|
||||||
|
def run_test(in_outs, test=None, debug=False, timeout=15, run_all_tests=False):
|
||||||
|
"""
|
||||||
|
if test(generated_code) is not None it'll try to run the code.
|
||||||
|
otherwise it'll just return an input and output pair.
|
||||||
|
"""
|
||||||
|
# Disable functionalities that can make destructive changes to the test.
|
||||||
|
reliability_guard()
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"start = {datetime.now().time()}")
|
||||||
|
|
||||||
|
if in_outs:
|
||||||
|
if in_outs.get("fn_name") is None:
|
||||||
|
which_type = CODE_TYPE.standard_input # Standard input
|
||||||
|
method_name = None
|
||||||
|
else:
|
||||||
|
which_type = CODE_TYPE.call_based # Call-based
|
||||||
|
method_name = in_outs["fn_name"]
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"loaded input_output = {datetime.now().time()}")
|
||||||
|
|
||||||
|
if test is None:
|
||||||
|
raise AssertionError("should not happen: test code is none")
|
||||||
|
elif test is not None:
|
||||||
|
results = []
|
||||||
|
sol = "from string import *\nfrom re import *\nfrom datetime import *\nfrom collections import *\nfrom heapq import *\nfrom bisect import *\nfrom copy import *\nfrom math import *\nfrom random import *\nfrom statistics import *\nfrom itertools import *\nfrom functools import *\nfrom operator import *\nfrom io import *\nfrom sys import *\nfrom json import *\nfrom builtins import *\nfrom typing import *\nimport string\nimport re\nimport datetime\nimport collections\nimport heapq\nimport bisect\nimport copy\nimport math\nimport random\nimport statistics\nimport itertools\nimport functools\nimport operator\nimport io\nimport sys\nimport json\nsys.setrecursionlimit(6*10**5)\n" # noqa: E501
|
||||||
|
if debug:
|
||||||
|
print(f"loading test code = {datetime.now().time()}")
|
||||||
|
|
||||||
|
if which_type == CODE_TYPE.call_based:
|
||||||
|
sol += test
|
||||||
|
if debug:
|
||||||
|
print(f"sol = {sol}")
|
||||||
|
signal.alarm(timeout)
|
||||||
|
try:
|
||||||
|
tmp_sol = RuntimeModule.from_string("tmp_sol", "", sol)
|
||||||
|
tmp = tmp_sol if "class Solution" not in test else tmp_sol.Solution()
|
||||||
|
signal.alarm(0)
|
||||||
|
except Exception as e:
|
||||||
|
signal.alarm(0)
|
||||||
|
error_traceback = traceback.format_exc()
|
||||||
|
if debug:
|
||||||
|
print(f"type 0 compilation error = {e}")
|
||||||
|
results.append(-2)
|
||||||
|
return results, {
|
||||||
|
"error": repr(e),
|
||||||
|
# "error_code": -1,
|
||||||
|
# "error_message": "Compilation Error",
|
||||||
|
"traceback": clean_traceback(error_traceback),
|
||||||
|
}
|
||||||
|
signal.alarm(0)
|
||||||
|
|
||||||
|
elif which_type == CODE_TYPE.standard_input:
|
||||||
|
# sol
|
||||||
|
# if code has if __name__ == "__main__": then remove it
|
||||||
|
try:
|
||||||
|
astree = ast.parse(test)
|
||||||
|
last_block = astree.body[-1]
|
||||||
|
if isinstance(last_block, ast.If):
|
||||||
|
condition = last_block.test
|
||||||
|
if ast.unparse(condition).strip() == "__name__ == '__main__'":
|
||||||
|
test = ast.unparse(astree.body[:-1]) + "\n" + ast.unparse(last_block.body)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
tmp_test = test.split("\n")
|
||||||
|
|
||||||
|
new_test = []
|
||||||
|
for x in tmp_test:
|
||||||
|
if (not x.startswith("from ")) and (not x.startswith("import ")):
|
||||||
|
new_test.append("\t" + x + "\n")
|
||||||
|
else:
|
||||||
|
new_test.append(x + "\n")
|
||||||
|
tmp_test = new_test
|
||||||
|
|
||||||
|
new_test = ""
|
||||||
|
started = False
|
||||||
|
for i in tmp_test:
|
||||||
|
if i.startswith("\t") and not started:
|
||||||
|
new_test += "stdin = sys.stdin\nstdout = sys.stdout\n"
|
||||||
|
new_test += "def code():\n"
|
||||||
|
new_test += i
|
||||||
|
started = True
|
||||||
|
elif started and ((i.startswith("from ")) or (i.startswith("import "))):
|
||||||
|
new_test += "\t" + i
|
||||||
|
else:
|
||||||
|
new_test += i
|
||||||
|
tmp_test = new_test
|
||||||
|
|
||||||
|
sol += tmp_test
|
||||||
|
method_name = "code"
|
||||||
|
signal.alarm(timeout)
|
||||||
|
try:
|
||||||
|
tmp_sol = RuntimeModule.from_string("tmp_sol", "", sol)
|
||||||
|
tmp = tmp_sol
|
||||||
|
signal.alarm(0)
|
||||||
|
except Exception as e:
|
||||||
|
signal.alarm(0)
|
||||||
|
error_traceback = traceback.format_exc()
|
||||||
|
if debug:
|
||||||
|
print(f"type 1 compilation error = {e}")
|
||||||
|
results.append(-2)
|
||||||
|
return results, {
|
||||||
|
"error": repr(e),
|
||||||
|
# "error_code": -1,
|
||||||
|
# "error_message": "Compilation Error",
|
||||||
|
"traceback": clean_traceback(error_traceback),
|
||||||
|
}
|
||||||
|
signal.alarm(0)
|
||||||
|
if debug:
|
||||||
|
print(f"get method {method_name} = {datetime.now().time()}")
|
||||||
|
try:
|
||||||
|
method = getattr(tmp, method_name) # get_attr second arg must be str
|
||||||
|
except Exception:
|
||||||
|
signal.alarm(0)
|
||||||
|
error_traceback = traceback.format_exc()
|
||||||
|
error_info = sys.exc_info()
|
||||||
|
print(f"unable to get function error = {error_info}")
|
||||||
|
results.append(-2)
|
||||||
|
return results, {
|
||||||
|
"error": repr(error_info),
|
||||||
|
# "error_code": -1,
|
||||||
|
# "error_message": "Unable to extract code",
|
||||||
|
"traceback": clean_traceback(error_traceback),
|
||||||
|
}
|
||||||
|
|
||||||
|
for index, inputs in enumerate(in_outs["inputs"]):
|
||||||
|
raw_inputs = inputs
|
||||||
|
raw_outputs = in_outs["outputs"][index]
|
||||||
|
if which_type == CODE_TYPE.call_based:
|
||||||
|
inputs = [json.loads(line) for line in inputs.split("\n")]
|
||||||
|
in_outs["outputs"][index] = json.loads(in_outs["outputs"][index])
|
||||||
|
|
||||||
|
truncate_line_size = 300 // (raw_inputs.count("\n") + 1)
|
||||||
|
raw_inputs = "\n".join(
|
||||||
|
[truncatefn(line, truncate_line_size) for line in raw_inputs.strip().split("\n")]
|
||||||
|
)
|
||||||
|
raw_outputs = truncatefn(raw_outputs, 200)
|
||||||
|
else:
|
||||||
|
raw_inputs = truncatefn(raw_inputs)
|
||||||
|
raw_outputs = truncatefn(raw_outputs, 200)
|
||||||
|
# JSON forces dictionaries to have string keys; this undoes this (assuming a singleton list)
|
||||||
|
try:
|
||||||
|
if isinstance(inputs[0], dict):
|
||||||
|
inputs = [{int(k): v for k, v in inputs[0].items()}]
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
try:
|
||||||
|
if isinstance(in_outs["outputs"][index], dict):
|
||||||
|
in_outs["outputs"][index] = [{int(k): v for k, v in in_outs["outputs"][index].items()}]
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
try:
|
||||||
|
if isinstance(in_outs["outputs"][index][0], dict):
|
||||||
|
in_outs["outputs"][index] = [{int(k): v for k, v in in_outs["outputs"][index][0].items()}]
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(
|
||||||
|
f"time: {datetime.now().time()} testing index = {index} inputs = {inputs}, {type(inputs)}. type = {which_type}"
|
||||||
|
)
|
||||||
|
if which_type == CODE_TYPE.call_based: # Call-based
|
||||||
|
signal.alarm(timeout)
|
||||||
|
faulthandler.enable()
|
||||||
|
try:
|
||||||
|
output = method(*inputs)
|
||||||
|
raw_true_output = output
|
||||||
|
|
||||||
|
raw_true_output_copy = json.dumps(output)
|
||||||
|
raw_true_output_copy = truncatefn(raw_true_output_copy, 200)
|
||||||
|
|
||||||
|
# ground truth sequences are not tuples
|
||||||
|
if isinstance(output, tuple):
|
||||||
|
output = list(output)
|
||||||
|
|
||||||
|
tmp_result = output == in_outs["outputs"][index]
|
||||||
|
if isinstance(in_outs["outputs"][index], list) and in_outs["outputs"][index]:
|
||||||
|
tmp_result = tmp_result or (output == in_outs["outputs"][index][0])
|
||||||
|
|
||||||
|
# ground truth sequences are not tuples
|
||||||
|
try:
|
||||||
|
if isinstance(output[0], tuple):
|
||||||
|
tmp_result = tmp_result or ([list(x) for x in output] == in_outs["outputs"][index][0])
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
results.append(tmp_result)
|
||||||
|
if tmp_result is not True:
|
||||||
|
return results, {
|
||||||
|
"output": raw_true_output_copy,
|
||||||
|
"expected": raw_outputs,
|
||||||
|
"inputs": raw_inputs,
|
||||||
|
# "error_code": -2,
|
||||||
|
"error_message": "Wrong Answer",
|
||||||
|
}
|
||||||
|
# reset the alarm
|
||||||
|
signal.alarm(0)
|
||||||
|
except Exception as e:
|
||||||
|
signal.alarm(0)
|
||||||
|
error_traceback = traceback.format_exc()
|
||||||
|
faulthandler.disable()
|
||||||
|
if debug:
|
||||||
|
print(f"Standard input runtime error or time limit exceeded error = {e}")
|
||||||
|
results.append(-1)
|
||||||
|
return results, {
|
||||||
|
"error": repr(e),
|
||||||
|
"traceback": clean_traceback(error_traceback),
|
||||||
|
}
|
||||||
|
faulthandler.disable()
|
||||||
|
signal.alarm(0)
|
||||||
|
if debug:
|
||||||
|
print(
|
||||||
|
f"outputs = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs}, {type(inputs)}, {output == [in_outs['outputs'][index]]}"
|
||||||
|
)
|
||||||
|
elif which_type == CODE_TYPE.standard_input: # Standard input
|
||||||
|
faulthandler.enable()
|
||||||
|
passed = False
|
||||||
|
|
||||||
|
if isinstance(inputs, list):
|
||||||
|
inputs = "\n".join(inputs)
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
in_outs["outputs"][index] = "\n".join(in_outs["outputs"][index])
|
||||||
|
|
||||||
|
signal.alarm(timeout)
|
||||||
|
with Capturing() as output:
|
||||||
|
try:
|
||||||
|
call_method(method, inputs)
|
||||||
|
# reset the alarm
|
||||||
|
signal.alarm(0)
|
||||||
|
passed = True
|
||||||
|
except Exception as e:
|
||||||
|
# runtime error or took too long
|
||||||
|
signal.alarm(0)
|
||||||
|
error_traceback = traceback.format_exc()
|
||||||
|
print(f"Call-based runtime error or time limit exceeded error = {repr(e)}{e}")
|
||||||
|
results.append(-1)
|
||||||
|
signal.alarm(0)
|
||||||
|
if run_all_tests:
|
||||||
|
continue
|
||||||
|
return results, {
|
||||||
|
"error": repr(e),
|
||||||
|
"traceback": clean_traceback(error_traceback),
|
||||||
|
}
|
||||||
|
signal.alarm(0)
|
||||||
|
raw_true_output = output[0]
|
||||||
|
raw_true_output_copy = truncatefn(raw_true_output, 200)
|
||||||
|
output = raw_true_output.splitlines()
|
||||||
|
if not passed:
|
||||||
|
if debug:
|
||||||
|
nl = "\n"
|
||||||
|
if not isinstance(inputs, list):
|
||||||
|
print(
|
||||||
|
f"not passed output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs.replace(nl, ' new-line ')}, {type(inputs)}, {output == [in_outs['outputs'][index]]}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print(
|
||||||
|
f"not passed output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs}, {type(inputs)}, {output == [in_outs['outputs'][index]]}"
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if passed and debug:
|
||||||
|
print(f"==> output = {output}, test outputs = {in_outs['outputs'][index]}")
|
||||||
|
|
||||||
|
if custom_compare_(output, in_outs["outputs"][index]):
|
||||||
|
tmp_result = True
|
||||||
|
results.append(tmp_result)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# ground truth sequences are expressed as lists not tuples
|
||||||
|
if isinstance(output, tuple):
|
||||||
|
output = list(output)
|
||||||
|
|
||||||
|
tmp_result = False
|
||||||
|
try:
|
||||||
|
tmp_result = output == [in_outs["outputs"][index]]
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
tmp_result = tmp_result or (output == in_outs["outputs"][index])
|
||||||
|
if isinstance(output[0], str):
|
||||||
|
tmp_result = tmp_result or ([e.strip() for e in output] == in_outs["outputs"][index])
|
||||||
|
except Exception as e:
|
||||||
|
if debug:
|
||||||
|
print(f"Failed check1 exception = {e}")
|
||||||
|
|
||||||
|
if tmp_result is True:
|
||||||
|
results.append(tmp_result)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# try one more time without \n
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
for tmp_index, i in enumerate(in_outs["outputs"][index]):
|
||||||
|
in_outs["outputs"][index][tmp_index] = i.split("\n")
|
||||||
|
in_outs["outputs"][index][tmp_index] = [
|
||||||
|
x.strip() for x in in_outs["outputs"][index][tmp_index] if x
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
in_outs["outputs"][index] = in_outs["outputs"][index].split("\n")
|
||||||
|
in_outs["outputs"][index] = list(filter(len, in_outs["outputs"][index]))
|
||||||
|
in_outs["outputs"][index] = list(map(lambda x: x.strip(), in_outs["outputs"][index]))
|
||||||
|
|
||||||
|
try:
|
||||||
|
tmp_result = output == [in_outs["outputs"][index]]
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
tmp_result = tmp_result or (output == in_outs["outputs"][index])
|
||||||
|
except Exception as e:
|
||||||
|
if debug:
|
||||||
|
print(f"Failed check2 exception = {e}")
|
||||||
|
|
||||||
|
if tmp_result is True:
|
||||||
|
results.append(tmp_result)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# try by converting the output into a split up list too
|
||||||
|
if isinstance(output, list):
|
||||||
|
output = list(filter(len, output))
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
nl = "\n"
|
||||||
|
if not isinstance(inputs, list):
|
||||||
|
print(
|
||||||
|
f"@1 output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs.replace(nl, ' new-line ')}, {type(inputs)}, {output == [in_outs['outputs'][index]]} {tmp_result=}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print(
|
||||||
|
f"@1 output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs}, {type(inputs)}, {output == [in_outs['outputs'][index]]} {tmp_result=}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @a")
|
||||||
|
|
||||||
|
try:
|
||||||
|
tmp_result = output == [in_outs["outputs"][index]]
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
tmp_result = tmp_result or (output == in_outs["outputs"][index])
|
||||||
|
except Exception as e:
|
||||||
|
if debug:
|
||||||
|
print(f"Failed check3 exception = {e}")
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @b")
|
||||||
|
|
||||||
|
try:
|
||||||
|
all_ints = all(
|
||||||
|
combined_int_check(e1) and combined_int_check(e2)
|
||||||
|
for e1, e2 in zip(output, in_outs["outputs"][index])
|
||||||
|
)
|
||||||
|
if not all_ints:
|
||||||
|
if debug:
|
||||||
|
print(
|
||||||
|
[
|
||||||
|
combined_int_check(e1) and combined_int_check(e2)
|
||||||
|
for e1, e2 in zip(output, in_outs["outputs"][index])
|
||||||
|
]
|
||||||
|
)
|
||||||
|
output_float = [float(e) for e in output]
|
||||||
|
gt_float = [float(e) for e in in_outs["outputs"][index]]
|
||||||
|
tmp_result = tmp_result or (
|
||||||
|
(len(output_float) == len(gt_float)) and np.allclose(output_float, gt_float)
|
||||||
|
)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @c")
|
||||||
|
|
||||||
|
try:
|
||||||
|
if isinstance(output[0], list):
|
||||||
|
all_ints = all(
|
||||||
|
combined_int_check(e1) and combined_int_check(e2)
|
||||||
|
for e1, e2 in zip(output[0], in_outs["outputs"][index])
|
||||||
|
)
|
||||||
|
if not all_ints:
|
||||||
|
output_float = [float(e) for e in output[0]]
|
||||||
|
gt_float = [float(e) for e in in_outs["outputs"][index][0]]
|
||||||
|
tmp_result = tmp_result or (
|
||||||
|
(len(output_float) == len(gt_float)) and np.allclose(output_float, gt_float)
|
||||||
|
)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if tmp_result is True:
|
||||||
|
results.append(tmp_result)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @d")
|
||||||
|
# try by converting the stuff into split up list
|
||||||
|
if isinstance(in_outs["outputs"][index], list):
|
||||||
|
for tmp_index, i in enumerate(in_outs["outputs"][index]):
|
||||||
|
in_outs["outputs"][index][tmp_index] = set(i.split())
|
||||||
|
else:
|
||||||
|
in_outs["outputs"][index] = set(in_outs["outputs"][index].split())
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @e")
|
||||||
|
|
||||||
|
try:
|
||||||
|
tmp_result = output == in_outs["outputs"][index]
|
||||||
|
except Exception as e:
|
||||||
|
if debug:
|
||||||
|
print(f"Failed check4 exception = {e}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if tmp_result is True:
|
||||||
|
results.append(tmp_result)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @f")
|
||||||
|
|
||||||
|
# try by converting the output into a split up list too
|
||||||
|
if isinstance(output, list):
|
||||||
|
for tmp_index, i in enumerate(output):
|
||||||
|
output[tmp_index] = i.split()
|
||||||
|
output = list(filter(len, output))
|
||||||
|
for tmp_index, i in enumerate(output):
|
||||||
|
output[tmp_index] = set(i)
|
||||||
|
else:
|
||||||
|
output = output.split()
|
||||||
|
output = list(filter(len, output))
|
||||||
|
output = set(output)
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
print(f"{tmp_result=} @g")
|
||||||
|
|
||||||
|
if tmp_result is True and debug:
|
||||||
|
print("PASSED")
|
||||||
|
|
||||||
|
results.append(tmp_result)
|
||||||
|
if tmp_result is not True:
|
||||||
|
if debug:
|
||||||
|
print("final result:", results)
|
||||||
|
if run_all_tests:
|
||||||
|
continue
|
||||||
|
return results, {
|
||||||
|
"output": raw_true_output_copy,
|
||||||
|
"expected": raw_outputs,
|
||||||
|
"inputs": raw_inputs,
|
||||||
|
# "error_code": -2,
|
||||||
|
"error_message": "Wrong Answer",
|
||||||
|
}
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
nl = "\n"
|
||||||
|
if not isinstance(inputs, list):
|
||||||
|
print(
|
||||||
|
f"@2 output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs.replace(nl, ' new-line ')}, {type(inputs)}, {output == [in_outs['outputs'][index]]}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print(
|
||||||
|
f"@2 output = {output}, test outputs = {in_outs['outputs'][index]}, inputs = {inputs}, {type(inputs)}, {output == [in_outs['outputs'][index]]}"
|
||||||
|
)
|
||||||
|
|
||||||
|
print(f"results = {results}")
|
||||||
|
if debug:
|
||||||
|
print("final results", results)
|
||||||
|
return results, {}
|
||||||
|
|
||||||
|
|
||||||
|
def custom_compare_(output, ground_truth):
|
||||||
|
if isinstance(output, list):
|
||||||
|
output_1 = "\n".join(output)
|
||||||
|
if stripped_string_compare(output_1, ground_truth):
|
||||||
|
return True
|
||||||
|
|
||||||
|
if isinstance(output, list):
|
||||||
|
output_2 = [o.lstrip().rstrip() for o in output]
|
||||||
|
output_2 = "\n".join(output_2)
|
||||||
|
if stripped_string_compare(output_2, ground_truth):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def stripped_string_compare(s1, s2):
|
||||||
|
s1 = s1.lstrip().rstrip()
|
||||||
|
s2 = s2.lstrip().rstrip()
|
||||||
|
return s1 == s2
|
||||||
|
|
||||||
|
|
||||||
|
def call_method(method, inputs):
|
||||||
|
if isinstance(inputs, list):
|
||||||
|
inputs = "\n".join(inputs)
|
||||||
|
|
||||||
|
inputs_line_iterator = iter(inputs.split("\n"))
|
||||||
|
|
||||||
|
# sys.setrecursionlimit(10000)
|
||||||
|
|
||||||
|
# @patch('builtins.input', side_effect=inputs.split("\n"))
|
||||||
|
@patch("builtins.open", mock_open(read_data=inputs))
|
||||||
|
@patch("sys.stdin", StringIO(inputs))
|
||||||
|
@patch("sys.stdin.readline", lambda *args: next(inputs_line_iterator))
|
||||||
|
@patch("sys.stdin.readlines", lambda *args: inputs.split("\n"))
|
||||||
|
@patch("sys.stdin.read", lambda *args: inputs)
|
||||||
|
# @patch('sys.stdout.write', print)
|
||||||
|
def _inner_call_method(_method):
|
||||||
|
try:
|
||||||
|
return _method()
|
||||||
|
except SystemExit:
|
||||||
|
pass
|
||||||
|
finally:
|
||||||
|
pass
|
||||||
|
|
||||||
|
return _inner_call_method(method)
|
||||||
|
|
||||||
|
|
||||||
|
def reliability_guard(maximum_memory_bytes=None):
|
||||||
|
"""
|
||||||
|
This disables various destructive functions and prevents the generated code
|
||||||
|
from interfering with the test (e.g. fork bomb, killing other processes,
|
||||||
|
removing filesystem files, etc.)
|
||||||
|
WARNING
|
||||||
|
This function is NOT a security sandbox. Untrusted code, including, model-
|
||||||
|
generated code, should not be blindly executed outside of one. See the
|
||||||
|
Codex paper for more information about OpenAI's code sandbox, and proceed
|
||||||
|
with caution.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if maximum_memory_bytes is not None:
|
||||||
|
import resource
|
||||||
|
|
||||||
|
resource.setrlimit(resource.RLIMIT_AS, (maximum_memory_bytes, maximum_memory_bytes))
|
||||||
|
resource.setrlimit(resource.RLIMIT_DATA, (maximum_memory_bytes, maximum_memory_bytes))
|
||||||
|
if platform.uname().system != "Darwin":
|
||||||
|
resource.setrlimit(resource.RLIMIT_STACK, (maximum_memory_bytes, maximum_memory_bytes))
|
||||||
|
|
||||||
|
faulthandler.disable()
|
||||||
|
|
||||||
|
import builtins
|
||||||
|
|
||||||
|
builtins.exit = None
|
||||||
|
builtins.quit = None
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
|
os.environ["OMP_NUM_THREADS"] = "1"
|
||||||
|
|
||||||
|
os.kill = None
|
||||||
|
os.system = None # 防止干扰repl评测
|
||||||
|
os.putenv = None
|
||||||
|
os.remove = None
|
||||||
|
os.removedirs = None
|
||||||
|
os.rmdir = None
|
||||||
|
os.fchdir = None
|
||||||
|
os.setuid = None
|
||||||
|
os.fork = None
|
||||||
|
os.forkpty = None
|
||||||
|
os.killpg = None
|
||||||
|
os.rename = None
|
||||||
|
os.renames = None
|
||||||
|
os.truncate = None
|
||||||
|
os.replace = None
|
||||||
|
os.unlink = None
|
||||||
|
os.fchmod = None
|
||||||
|
os.fchown = None
|
||||||
|
os.chmod = None
|
||||||
|
os.chown = None
|
||||||
|
os.chroot = None
|
||||||
|
os.lchflags = None
|
||||||
|
os.lchmod = None
|
||||||
|
os.lchown = None
|
||||||
|
os.getcwd = None
|
||||||
|
os.chdir = None
|
||||||
|
|
||||||
|
import shutil
|
||||||
|
|
||||||
|
shutil.rmtree = None
|
||||||
|
shutil.move = None
|
||||||
|
shutil.chown = None
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
|
||||||
|
subprocess.Popen = None # type: ignore
|
||||||
|
|
||||||
|
__builtins__["help"] = None
|
||||||
|
|
||||||
|
import sys
|
||||||
|
|
||||||
|
sys.modules["ipdb"] = None
|
||||||
|
sys.modules["joblib"] = None
|
||||||
|
sys.modules["resource"] = None
|
||||||
|
sys.modules["psutil"] = None
|
||||||
|
sys.modules["tkinter"] = None
|
||||||
@@ -0,0 +1,71 @@
|
|||||||
|
# Code from the verl Project (https://github.com/agentica-project/rllm),
|
||||||
|
# which itself is adapted from Prime (https://github.com/PRIME-RL/PRIME)
|
||||||
|
#
|
||||||
|
# Copyright 2024 ByteDance Group
|
||||||
|
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
import multiprocessing
|
||||||
|
import traceback
|
||||||
|
from typing import Optional
|
||||||
|
|
||||||
|
import requests
|
||||||
|
|
||||||
|
from .testing_util import run_test
|
||||||
|
|
||||||
|
|
||||||
|
def _temp_run(sample, generation, debug, result, metadata_list, timeout):
|
||||||
|
try:
|
||||||
|
res, metadata = run_test(in_outs=sample, test=generation, debug=debug, timeout=timeout)
|
||||||
|
result.append(res)
|
||||||
|
metadata_list.append(metadata)
|
||||||
|
except Exception:
|
||||||
|
# print(e) # some tracebacks are extremely long.
|
||||||
|
traceback.print_exc(10)
|
||||||
|
result.append([-1 for i in range(len(sample["inputs"]))])
|
||||||
|
metadata_list.append({})
|
||||||
|
|
||||||
|
|
||||||
|
def check_correctness(in_outs: Optional[dict], generation, timeout=10, debug=True):
|
||||||
|
"""Check correctness of code generation with a global timeout.
|
||||||
|
The global timeout is to catch some extreme/rare cases not handled by the timeouts
|
||||||
|
inside `run_test`"""
|
||||||
|
|
||||||
|
manager = multiprocessing.Manager()
|
||||||
|
result = manager.list()
|
||||||
|
metadata_list = manager.list()
|
||||||
|
p = multiprocessing.Process(target=_temp_run, args=(in_outs, generation, debug, result, metadata_list, timeout))
|
||||||
|
p.start()
|
||||||
|
p.join(timeout=600) # Global timeout of 10 minutes that's for all test cases combined
|
||||||
|
if p.is_alive():
|
||||||
|
p.kill()
|
||||||
|
# p.terminate()
|
||||||
|
if not result:
|
||||||
|
# consider that all tests failed
|
||||||
|
result = [[-1 for i in range(len(in_outs["inputs"]))]]
|
||||||
|
if debug:
|
||||||
|
print("global timeout")
|
||||||
|
return result[0], metadata_list
|
||||||
|
|
||||||
|
|
||||||
|
def check_correctness_code_api(
|
||||||
|
in_outs: Optional[dict], generation, timeout=10, debug=True, url="http://localhost:8000/check_correctness"
|
||||||
|
):
|
||||||
|
payload = {"in_outs": in_outs, "generation": generation, "timeout": timeout, "debug": debug}
|
||||||
|
response = requests.post(url, json=payload)
|
||||||
|
if response.status_code == 200:
|
||||||
|
results = response.json()
|
||||||
|
return results["result"], results["metadata"]
|
||||||
|
else:
|
||||||
|
print(f"Error: {response.status_code} - {response.text}")
|
||||||
|
return [-1 for i in range(len(in_outs["inputs"]))], {}
|
||||||
306
applications/ColossalChat/coati/distributed/reward/reward_fn.py
Normal file
306
applications/ColossalChat/coati/distributed/reward/reward_fn.py
Normal file
@@ -0,0 +1,306 @@
|
|||||||
|
# Copyright 2024 ByteDance Group
|
||||||
|
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
"""
|
||||||
|
Some functions in this file are adapted from the verl project
|
||||||
|
under the Apache License 2.0:
|
||||||
|
https://github.com/volcengine/verl
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import json
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from latex2sympy2_extended import NormalizationConfig
|
||||||
|
from math_verify import ExprExtractionConfig, LatexExtractionConfig, parse, verify
|
||||||
|
|
||||||
|
from .code_reward.utils import check_correctness_code_api as check_correctness_code
|
||||||
|
from .reward_utils import extract_boxed_solution, extract_solution, validate_response_structure
|
||||||
|
|
||||||
|
CANNOT_PARSE_GT_ANSWER = -1
|
||||||
|
CANNOT_PARSE_PREDICTION = -2
|
||||||
|
SUCCESS = 1
|
||||||
|
MATCHING_FAIL = 0
|
||||||
|
|
||||||
|
|
||||||
|
def verify_math_representation(completion, gt_answer):
|
||||||
|
"""
|
||||||
|
Verify if the completion is a valid math representation of the gt_answer.
|
||||||
|
"""
|
||||||
|
if not completion.startswith("\\boxed{"):
|
||||||
|
completion = "\\boxed{" + completion + "}"
|
||||||
|
if not gt_answer.startswith("\\boxed{"):
|
||||||
|
gt_answer = "\\boxed{" + gt_answer + "}"
|
||||||
|
target = (
|
||||||
|
ExprExtractionConfig(),
|
||||||
|
LatexExtractionConfig(
|
||||||
|
normalization_config=NormalizationConfig(
|
||||||
|
nits=False,
|
||||||
|
malformed_operators=False,
|
||||||
|
basic_latex=True,
|
||||||
|
boxed="all",
|
||||||
|
units=True,
|
||||||
|
),
|
||||||
|
boxed_match_priority=0,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
if not isinstance(gt_answer, str) or len(gt_answer) == 0:
|
||||||
|
raise ValueError("gt_answer should be a string, please verify your training data.")
|
||||||
|
if not isinstance(completion, str) or len(completion) == 0:
|
||||||
|
return MATCHING_FAIL
|
||||||
|
try:
|
||||||
|
parsed_gt_answer = parse(gt_answer, extraction_config=target)
|
||||||
|
if len(parsed_gt_answer) == 0:
|
||||||
|
return CANNOT_PARSE_GT_ANSWER
|
||||||
|
parsed_completion = parse(completion, extraction_config=target)
|
||||||
|
if len(parsed_completion) == 0:
|
||||||
|
return CANNOT_PARSE_PREDICTION
|
||||||
|
if verify(parsed_gt_answer, parsed_completion):
|
||||||
|
return SUCCESS
|
||||||
|
else:
|
||||||
|
return MATCHING_FAIL
|
||||||
|
except Exception:
|
||||||
|
return MATCHING_FAIL
|
||||||
|
|
||||||
|
|
||||||
|
def verify_model_answer(decoded_final_answer, gt_answer, ans_acc, acc_score, reward):
|
||||||
|
math_verify_result = verify_math_representation(decoded_final_answer, gt_answer)
|
||||||
|
exact_match_result = (
|
||||||
|
SUCCESS
|
||||||
|
if decoded_final_answer.strip().replace(" ", "").replace("{", "").replace("}", "").replace(",", "")
|
||||||
|
== gt_answer.strip().replace(" ", "").replace("{", "").replace("}", "").replace(",", "")
|
||||||
|
else MATCHING_FAIL
|
||||||
|
)
|
||||||
|
if math_verify_result == SUCCESS:
|
||||||
|
ans_acc += 1
|
||||||
|
reward += acc_score
|
||||||
|
elif exact_match_result == SUCCESS:
|
||||||
|
# sometimes for answers that's not a (valid) math expression, math_verify will fail
|
||||||
|
ans_acc += 1
|
||||||
|
if math_verify_result == CANNOT_PARSE_PREDICTION:
|
||||||
|
reward += (
|
||||||
|
acc_score / 2
|
||||||
|
) # not a valid latex math representation, but the answer is correct, receive half of the score
|
||||||
|
else:
|
||||||
|
reward += acc_score
|
||||||
|
return reward, ans_acc
|
||||||
|
|
||||||
|
|
||||||
|
def math_reward_fn(input_ids, gt_answer, response_idx, **kwargs):
|
||||||
|
tokenizer = kwargs["tokenizer"]
|
||||||
|
eval_mode = kwargs.get("eval_mode", False)
|
||||||
|
soft_over_length_punishment = kwargs.get("soft_over_length_punishment", False)
|
||||||
|
acc_score = 10.0
|
||||||
|
reward = torch.tensor(0.0)
|
||||||
|
format_acc = torch.tensor(0.0)
|
||||||
|
ans_acc = torch.tensor(0.0)
|
||||||
|
s, e = response_idx[0], response_idx[1]
|
||||||
|
|
||||||
|
length_reward = 0.0
|
||||||
|
res_length = e.item() - s.item() + 1
|
||||||
|
if not eval_mode:
|
||||||
|
max_new_tokens = kwargs["max_new_tokens"]
|
||||||
|
else:
|
||||||
|
max_new_tokens = -1 # for eval mode, we don't need to check the length
|
||||||
|
if not eval_mode and soft_over_length_punishment:
|
||||||
|
cache_length = kwargs["cache_length"]
|
||||||
|
if max_new_tokens - cache_length < res_length < max_new_tokens:
|
||||||
|
length_reward = ((max_new_tokens - cache_length) - res_length) / cache_length * acc_score
|
||||||
|
|
||||||
|
if gt_answer is None:
|
||||||
|
raise ValueError("no gt_answer is provided, please check your training dataset.")
|
||||||
|
|
||||||
|
decoded_final_answer = tokenizer.decode(input_ids[s : e + 1], skip_special_tokens=True)
|
||||||
|
|
||||||
|
final_answer, processed_str = extract_solution(decoded_final_answer)
|
||||||
|
|
||||||
|
format_valid = validate_response_structure(processed_str, kwargs["tags"])
|
||||||
|
|
||||||
|
# Check answer accuracy, answer is considered correct if the answer is correct and the format is valid
|
||||||
|
if final_answer is not None:
|
||||||
|
if eval_mode or format_valid:
|
||||||
|
reward, ans_acc = verify_model_answer(final_answer, gt_answer, ans_acc, acc_score, reward)
|
||||||
|
if not eval_mode:
|
||||||
|
reward = reward + length_reward
|
||||||
|
|
||||||
|
# Check format accuracy
|
||||||
|
if format_valid:
|
||||||
|
format_acc += 1
|
||||||
|
|
||||||
|
# Check if the sequence is over length
|
||||||
|
if not eval_mode and res_length >= max_new_tokens:
|
||||||
|
reward *= 0.0
|
||||||
|
|
||||||
|
if not eval_mode:
|
||||||
|
return torch.tensor([reward, format_acc, ans_acc]).to(input_ids.device)
|
||||||
|
else:
|
||||||
|
prompt = tokenizer.decode(input_ids[:s], skip_special_tokens=True)
|
||||||
|
return {
|
||||||
|
"prompt": prompt,
|
||||||
|
"prediction": decoded_final_answer,
|
||||||
|
"gold": gt_answer,
|
||||||
|
"parsed": final_answer,
|
||||||
|
"format_valid": format_acc.item(),
|
||||||
|
"ans_valid": ans_acc.item(),
|
||||||
|
"response_length": res_length,
|
||||||
|
"reward": reward.item(),
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def boxed_math_reward_fn(input_ids, gt_answer, response_idx, **kwargs):
|
||||||
|
tokenizer = kwargs["tokenizer"]
|
||||||
|
eval_mode = kwargs.get("eval_mode", False)
|
||||||
|
soft_over_length_punishment = kwargs.get("soft_over_length_punishment", False)
|
||||||
|
acc_score = 10.0
|
||||||
|
reward = torch.tensor(0.0)
|
||||||
|
format_acc = torch.tensor(0.0)
|
||||||
|
ans_acc = torch.tensor(0.0)
|
||||||
|
s, e = response_idx[0], response_idx[1]
|
||||||
|
|
||||||
|
length_reward = 0.0
|
||||||
|
res_length = e.item() - s.item() + 1
|
||||||
|
if not eval_mode:
|
||||||
|
max_new_tokens = kwargs["max_new_tokens"]
|
||||||
|
else:
|
||||||
|
max_new_tokens = -1 # for eval mode, we don't need to check the length
|
||||||
|
if not eval_mode and soft_over_length_punishment:
|
||||||
|
cache_length = kwargs["cache_length"]
|
||||||
|
if max_new_tokens - cache_length < res_length < max_new_tokens:
|
||||||
|
length_reward = ((max_new_tokens - cache_length) - res_length) / cache_length * acc_score
|
||||||
|
|
||||||
|
if gt_answer is None:
|
||||||
|
raise ValueError("no gt_answer is provided, please check your training dataset.")
|
||||||
|
|
||||||
|
decoded_final_answer = tokenizer.decode(input_ids[s : e + 1], skip_special_tokens=True)
|
||||||
|
|
||||||
|
final_answer = extract_boxed_solution(decoded_final_answer)
|
||||||
|
format_valid = final_answer is not None
|
||||||
|
if "tags" in kwargs and kwargs["tags"]:
|
||||||
|
tags = kwargs["tags"]
|
||||||
|
format_valid = format_valid and all(
|
||||||
|
[decoded_final_answer.count(tags[tag]["text"]) == tags[tag]["num_occur"] for tag in tags]
|
||||||
|
)
|
||||||
|
|
||||||
|
# Check answer accuracy, answer is considered correct if the answer is correct and the format is valid
|
||||||
|
if final_answer is not None:
|
||||||
|
if eval_mode or format_valid:
|
||||||
|
reward, ans_acc = verify_model_answer(final_answer, gt_answer, ans_acc, acc_score, reward)
|
||||||
|
if not eval_mode:
|
||||||
|
reward = reward + length_reward
|
||||||
|
|
||||||
|
# Check format accuracy
|
||||||
|
if format_valid:
|
||||||
|
format_acc += 1
|
||||||
|
|
||||||
|
# Check if the sequence is over length
|
||||||
|
if not eval_mode and res_length >= max_new_tokens:
|
||||||
|
reward *= 0.0
|
||||||
|
|
||||||
|
if not eval_mode:
|
||||||
|
return torch.tensor([reward, format_acc, ans_acc]).to(input_ids.device)
|
||||||
|
else:
|
||||||
|
prompt = tokenizer.decode(input_ids[:s], skip_special_tokens=True)
|
||||||
|
return {
|
||||||
|
"prompt": prompt,
|
||||||
|
"prediction": decoded_final_answer,
|
||||||
|
"gold": gt_answer,
|
||||||
|
"parsed": final_answer,
|
||||||
|
"format_valid": format_acc.item(),
|
||||||
|
"ans_valid": ans_acc.item(),
|
||||||
|
"response_length": res_length,
|
||||||
|
"reward": reward.item(),
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def code_reward_fn(input_ids, test_cases, response_idx, **kwargs):
|
||||||
|
url = kwargs.get("url", "http://localhost:8000/check_correctness")
|
||||||
|
tokenizer = kwargs["tokenizer"]
|
||||||
|
eval_mode = kwargs.get("eval_mode", False)
|
||||||
|
soft_over_length_punishment = kwargs.get("soft_over_length_punishment", False)
|
||||||
|
acc_score = 10.0
|
||||||
|
reward = torch.tensor(0.0)
|
||||||
|
format_acc = torch.tensor(0.0)
|
||||||
|
ans_acc = torch.tensor(0.0)
|
||||||
|
s, e = response_idx[0], response_idx[1]
|
||||||
|
|
||||||
|
length_reward = 0.0
|
||||||
|
res_length = e.item() - s.item() + 1
|
||||||
|
if not eval_mode:
|
||||||
|
max_new_tokens = kwargs["max_new_tokens"]
|
||||||
|
else:
|
||||||
|
max_new_tokens = -1 # for eval mode, we don't need to check the length
|
||||||
|
if not eval_mode and soft_over_length_punishment:
|
||||||
|
cache_length = kwargs["cache_length"]
|
||||||
|
if max_new_tokens - cache_length < res_length < max_new_tokens:
|
||||||
|
length_reward = ((max_new_tokens - cache_length) - res_length) / cache_length * acc_score
|
||||||
|
|
||||||
|
# try to get code solution from completion. if the completion is pure code, this will not take effect.
|
||||||
|
decoded_final_answer = tokenizer.decode(input_ids[s : e + 1], skip_special_tokens=True)
|
||||||
|
|
||||||
|
solution = decoded_final_answer.split("```python")[-1].split("```")[0]
|
||||||
|
format_valid = False
|
||||||
|
if "```python" in decoded_final_answer:
|
||||||
|
format_valid = solution is not None
|
||||||
|
|
||||||
|
# Check format accuracy
|
||||||
|
if format_valid:
|
||||||
|
format_acc += 1
|
||||||
|
|
||||||
|
res = []
|
||||||
|
metadata = []
|
||||||
|
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
if not isinstance(test_cases, dict):
|
||||||
|
test_cases = json.loads(test_cases)
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error {e}: Cannot parse test cases.")
|
||||||
|
raise e
|
||||||
|
# Complete check on all in-out pairs first. If there is no failure, per-sample test can be skipped.
|
||||||
|
try:
|
||||||
|
res, metadata = check_correctness_code(
|
||||||
|
in_outs=test_cases, generation=solution, timeout=10, debug=False, url=url
|
||||||
|
)
|
||||||
|
metadata = dict(enumerate(metadata))[0]
|
||||||
|
success = all(map(lambda x: x == 1, res))
|
||||||
|
if success:
|
||||||
|
ans_acc += 1
|
||||||
|
if eval_mode or format_valid:
|
||||||
|
reward += acc_score
|
||||||
|
if not eval_mode:
|
||||||
|
reward = reward + length_reward
|
||||||
|
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# Check if the sequence is over length
|
||||||
|
if not eval_mode and res_length >= max_new_tokens:
|
||||||
|
reward *= 0.0
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
if not eval_mode:
|
||||||
|
return torch.tensor([reward, format_acc, ans_acc]).to(input_ids.device)
|
||||||
|
else:
|
||||||
|
prompt = tokenizer.decode(input_ids[:s], skip_special_tokens=True)
|
||||||
|
return {
|
||||||
|
"prompt": prompt,
|
||||||
|
"prediction": decoded_final_answer,
|
||||||
|
"test_cases": test_cases,
|
||||||
|
"test_results": res,
|
||||||
|
"test_metadata": metadata,
|
||||||
|
"parsed": solution,
|
||||||
|
"format_valid": format_acc.item(),
|
||||||
|
"ans_valid": ans_acc.item(),
|
||||||
|
"response_length": res_length,
|
||||||
|
"reward": reward.item(),
|
||||||
|
}
|
||||||
@@ -0,0 +1,124 @@
|
|||||||
|
# Copyright Unakar
|
||||||
|
# Modified from https://github.com/Unakar/Logic-RL/blob/086373176ac198c97277ff50f4b6e7e1bfe669d3/verl/utils/reward_score/kk.py#L99
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
import re
|
||||||
|
from typing import Dict, Optional, Tuple
|
||||||
|
|
||||||
|
|
||||||
|
def validate_response_structure(processed_str: str, tags: Dict = None) -> bool:
|
||||||
|
"""Performs comprehensive validation of response structure.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
processed_str: Processed response string from the model
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Boolean indicating whether all formatting requirements are met
|
||||||
|
"""
|
||||||
|
validation_passed = True
|
||||||
|
# Check required tags
|
||||||
|
if tags is None:
|
||||||
|
tags = {
|
||||||
|
"think_start": {"text": "<think>", "num_occur": 1},
|
||||||
|
"think_end": {"text": "</think>", "num_occur": 1},
|
||||||
|
"answer_start": {"text": "<answer>", "num_occur": 1},
|
||||||
|
"answer_end": {"text": "</answer>", "num_occur": 1},
|
||||||
|
}
|
||||||
|
positions = {}
|
||||||
|
for tag_name, tag_info in tags.items():
|
||||||
|
tag_str = tag_info["text"]
|
||||||
|
expected_count = tag_info["num_occur"]
|
||||||
|
count = processed_str.count(tag_str)
|
||||||
|
positions[tag_name] = pos = processed_str.find(tag_str)
|
||||||
|
if count != expected_count:
|
||||||
|
validation_passed = False
|
||||||
|
# Verify tag order
|
||||||
|
if (
|
||||||
|
positions["think_start"] > positions["think_end"]
|
||||||
|
or positions["think_end"] > positions["answer_start"]
|
||||||
|
or positions["answer_start"] > positions["answer_end"]
|
||||||
|
):
|
||||||
|
validation_passed = False
|
||||||
|
if len(processed_str) - positions["answer_end"] != len(tags["answer_end"]["text"]):
|
||||||
|
validation_passed = False
|
||||||
|
return validation_passed
|
||||||
|
|
||||||
|
|
||||||
|
def extract_solution(solution_str: str) -> Tuple[Optional[str], str]:
|
||||||
|
"""Extracts the final answer from the model's response string.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
solution_str: Raw response string from the language model
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Tuple containing (extracted_answer, processed_string)
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Extract final answer using XML-style tags
|
||||||
|
answer_pattern = r"<answer>(.*?)</answer>"
|
||||||
|
matches = list(re.finditer(answer_pattern, solution_str, re.DOTALL))
|
||||||
|
|
||||||
|
if not matches:
|
||||||
|
return None, solution_str
|
||||||
|
|
||||||
|
final_answer = matches[-1].group(1).strip()
|
||||||
|
return final_answer, solution_str
|
||||||
|
|
||||||
|
|
||||||
|
def extract_boxed_solution(text: str) -> Optional[str]:
|
||||||
|
"""
|
||||||
|
Modified from: https://gist.github.com/lewtun/9c2ce1937b741404090a3dc4c7c022b3
|
||||||
|
Retrieves the content from the last occurrence of `\boxed{}` in a LaTeX-like string.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text (str): A string potentially containing LaTeX-style boxed expressions.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Optional[str]: The text inside the final `\boxed{}` if successfully extracted;
|
||||||
|
returns `None` if no properly closed box is found.
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
>>> extract_boxed_solution("The answer is \\boxed{42}.")
|
||||||
|
'42'
|
||||||
|
>>> extract_boxed_solution("Here is an unmatched \\boxed{42")
|
||||||
|
None
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
# Find the last occurrence of "\boxed{"
|
||||||
|
start_idx = text.rindex("\\boxed{")
|
||||||
|
# Move past "\boxed{" to find the start of the content
|
||||||
|
content_start = start_idx + len("\\boxed{")
|
||||||
|
open_braces = 1
|
||||||
|
pos = content_start
|
||||||
|
|
||||||
|
# Traverse the string to find the matching closing brace
|
||||||
|
while open_braces > 0 and pos < len(text):
|
||||||
|
if text[pos] == "{":
|
||||||
|
open_braces += 1
|
||||||
|
elif text[pos] == "}":
|
||||||
|
open_braces -= 1
|
||||||
|
pos += 1
|
||||||
|
|
||||||
|
# If all braces are matched, extract and return the content
|
||||||
|
if open_braces == 0:
|
||||||
|
return text[content_start : pos - 1].strip()
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
except ValueError:
|
||||||
|
# "\boxed{" not found
|
||||||
|
return None
|
||||||
|
except Exception:
|
||||||
|
# Any other unexpected error
|
||||||
|
return None
|
||||||
@@ -0,0 +1,71 @@
|
|||||||
|
"""
|
||||||
|
Function-based reward verification module.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import inspect
|
||||||
|
from typing import Any, Dict, List
|
||||||
|
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
class VerifiableReward:
|
||||||
|
def __init__(self, reward_fns: List[callable], **kwargs: List[Dict[str, Any]]):
|
||||||
|
self.reward_fns = reward_fns
|
||||||
|
self.kwargs = kwargs
|
||||||
|
|
||||||
|
def __call__(
|
||||||
|
self,
|
||||||
|
input_ids: torch.LongTensor,
|
||||||
|
gt_answer: List[str] = None,
|
||||||
|
test_cases: List[str] = None,
|
||||||
|
response_idx: List[torch.Tensor] = None,
|
||||||
|
) -> torch.Tensor:
|
||||||
|
# Get batch size
|
||||||
|
bs = input_ids.size(0)
|
||||||
|
# Initialize reward
|
||||||
|
rewards = torch.zeros((bs, 3), device=input_ids.device)
|
||||||
|
|
||||||
|
# Loop through reward functions
|
||||||
|
for reward_fn in self.reward_fns:
|
||||||
|
# Apply the reward function to the entire batch at once
|
||||||
|
if "gt_answer" in inspect.getfullargspec(reward_fn).args:
|
||||||
|
reward_batch = torch.stack(
|
||||||
|
[
|
||||||
|
reward_fn(
|
||||||
|
input_ids[i],
|
||||||
|
gt_answer=gt_answer[i],
|
||||||
|
response_idx=response_idx[i],
|
||||||
|
**self.kwargs,
|
||||||
|
)
|
||||||
|
for i in range(bs)
|
||||||
|
],
|
||||||
|
dim=0,
|
||||||
|
)
|
||||||
|
elif "test_cases" in inspect.getfullargspec(reward_fn).args:
|
||||||
|
reward_batch = torch.stack(
|
||||||
|
[
|
||||||
|
reward_fn(
|
||||||
|
input_ids[i],
|
||||||
|
test_cases=test_cases[i],
|
||||||
|
response_idx=response_idx[i],
|
||||||
|
**self.kwargs,
|
||||||
|
)
|
||||||
|
for i in range(bs)
|
||||||
|
],
|
||||||
|
dim=0,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
reward_batch = torch.stack(
|
||||||
|
[
|
||||||
|
reward_fn(
|
||||||
|
input_ids[i],
|
||||||
|
response_idx=response_idx[i],
|
||||||
|
**self.kwargs,
|
||||||
|
)
|
||||||
|
for i in range(bs)
|
||||||
|
],
|
||||||
|
dim=0,
|
||||||
|
)
|
||||||
|
|
||||||
|
rewards += reward_batch
|
||||||
|
return rewards
|
||||||
167
applications/ColossalChat/coati/distributed/utils.py
Normal file
167
applications/ColossalChat/coati/distributed/utils.py
Normal file
@@ -0,0 +1,167 @@
|
|||||||
|
import json
|
||||||
|
import os
|
||||||
|
from typing import Any, Dict, List
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from filelock import FileLock
|
||||||
|
|
||||||
|
from colossalai.shardformer.layer.loss import dist_log_prob
|
||||||
|
|
||||||
|
|
||||||
|
def unbind_batch(batch: Dict[str, torch.Tensor]) -> List[Dict[str, torch.Tensor]]:
|
||||||
|
batches = []
|
||||||
|
for k, v in batch.items():
|
||||||
|
if len(batches) == 0:
|
||||||
|
unbinded_tensors = v.unbind(0)
|
||||||
|
batches = [{k: tensor} for tensor in unbinded_tensors]
|
||||||
|
else:
|
||||||
|
unbinded_tensors = v.unbind(0)
|
||||||
|
assert len(batches) == len(unbinded_tensors)
|
||||||
|
for i, tensor in enumerate(unbinded_tensors):
|
||||||
|
batches[i][k] = tensor
|
||||||
|
return batches
|
||||||
|
|
||||||
|
|
||||||
|
def bind_batch(batches: List[Dict[str, torch.Tensor]]) -> Dict[str, torch.Tensor]:
|
||||||
|
batch = {}
|
||||||
|
for k in batches[0].keys():
|
||||||
|
batch[k] = torch.stack([batch[k] for batch in batches], dim=0)
|
||||||
|
return batch
|
||||||
|
|
||||||
|
|
||||||
|
def pre_send(batch: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||||
|
# compress mask to save bandwidth
|
||||||
|
if "attention_mask" in batch:
|
||||||
|
batch["attention_mask"] = batch["attention_mask"].to(torch.bool)
|
||||||
|
if "action_mask" in batch:
|
||||||
|
batch["action_mask"] = batch["action_mask"].to(torch.bool)
|
||||||
|
return batch
|
||||||
|
|
||||||
|
|
||||||
|
def post_recv(batch: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||||
|
# decompress mask
|
||||||
|
if "attention_mask" in batch:
|
||||||
|
batch["attention_mask"] = batch["attention_mask"].to(torch.int)
|
||||||
|
if "action_mask" in batch:
|
||||||
|
batch["action_mask"] = batch["action_mask"].to(torch.int)
|
||||||
|
return batch
|
||||||
|
|
||||||
|
|
||||||
|
def update_by_default(data: Dict[str, Any], default: Dict[str, Any]) -> Dict[str, Any]:
|
||||||
|
data = data.copy()
|
||||||
|
for k, v in default.items():
|
||||||
|
if k not in data:
|
||||||
|
data[k] = v
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Compute the log probabilities from logits for the given labels.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
logits (torch.Tensor): The input logits.
|
||||||
|
labels (torch.Tensor): The target labels.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
torch.Tensor: The log probabilities corresponding to the labels.
|
||||||
|
"""
|
||||||
|
log_probs = torch.log_softmax(logits, dim=-1)
|
||||||
|
per_label_logps = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
|
||||||
|
return per_label_logps.squeeze(-1)
|
||||||
|
|
||||||
|
|
||||||
|
def memory_efficient_logprob(
|
||||||
|
logits: torch.Tensor,
|
||||||
|
inputs: torch.Tensor,
|
||||||
|
num_action: int,
|
||||||
|
chunk_size: int = 2048,
|
||||||
|
shard_config: Any = None,
|
||||||
|
vocab_size: int = None,
|
||||||
|
) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Calculate action log probs in a memory-efficient way by processing in chunks.
|
||||||
|
Args:
|
||||||
|
logits (torch.Tensor): Output tensor of Actor.forward.logits.
|
||||||
|
inputs (torch.LongTensor): Input sequences.
|
||||||
|
num_action (int): Number of actions.
|
||||||
|
chunk_size (int, optional): Size of each chunk to process. Default is 2048.
|
||||||
|
shard_config: Shard configuration for distributed computation.
|
||||||
|
vocab_size (int, optional): Vocabulary size. Default is None.
|
||||||
|
Returns:
|
||||||
|
torch.Tensor: Action log probs.
|
||||||
|
"""
|
||||||
|
action_log_probs = torch.zeros((logits.size(0), num_action), device=logits.device, dtype=logits.dtype)
|
||||||
|
context_length = logits.size(1) - num_action
|
||||||
|
for i in range(action_log_probs.size(0)):
|
||||||
|
# loop over each sample in the micro-batch
|
||||||
|
for start in range(context_length, logits.size(1), chunk_size):
|
||||||
|
end = min(start + chunk_size, logits.size(1))
|
||||||
|
# calculate log probs in chunks to save memory
|
||||||
|
log_probs = dist_log_prob(
|
||||||
|
inputs[i : i + 1, start - 1 : end],
|
||||||
|
logits[i : i + 1, start - 1 : end],
|
||||||
|
shard_config,
|
||||||
|
vocab_size,
|
||||||
|
logits.dtype,
|
||||||
|
) # [1, chunk_size, 1]
|
||||||
|
log_probs = log_probs.squeeze(-1)
|
||||||
|
action_log_probs[i, start - context_length : end - context_length] += log_probs[0]
|
||||||
|
return action_log_probs
|
||||||
|
|
||||||
|
|
||||||
|
def entropy_from_logits(logits: torch.Tensor) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Calculate entropy
|
||||||
|
Reference: https://github.com/volcengine/verl/blob/96b730bbed80292a439f0c0057d3920ab8b28d52/verl/utils/torch_functional.py#L145
|
||||||
|
"""
|
||||||
|
p = torch.nn.functional.softmax(logits, dim=-1)
|
||||||
|
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(p * logits, dim=-1)
|
||||||
|
return entropy
|
||||||
|
|
||||||
|
|
||||||
|
def masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Compute the masked mean of a tensor along a specified dimension.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
tensor (torch.Tensor): The input tensor.
|
||||||
|
mask (torch.Tensor): The mask tensor with the same shape as the input tensor.
|
||||||
|
dim (int, optional): The dimension along which to compute the mean. Default is 1.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
torch.Tensor: The masked mean tensor.
|
||||||
|
|
||||||
|
"""
|
||||||
|
tensor = tensor * mask
|
||||||
|
tensor = tensor.sum(dim=dim)
|
||||||
|
mask_sum = mask.sum(dim=dim)
|
||||||
|
mean = tensor / (mask_sum + 1e-8)
|
||||||
|
return mean
|
||||||
|
|
||||||
|
|
||||||
|
def masked_sum(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Compute the masked sum of a tensor along a specified dimension.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
tensor (torch.Tensor): The input tensor.
|
||||||
|
mask (torch.Tensor): The mask tensor with the same shape as the input tensor.
|
||||||
|
dim (int, optional): The dimension along which to compute the sum. Default is 1.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
torch.Tensor: The masked sum tensor.
|
||||||
|
|
||||||
|
"""
|
||||||
|
tensor = tensor * mask
|
||||||
|
return tensor.sum(dim=dim)
|
||||||
|
|
||||||
|
|
||||||
|
def safe_append_to_jsonl_file(file_path, data):
|
||||||
|
with FileLock(file_path + ".lock"):
|
||||||
|
# Ensure file exists
|
||||||
|
os.makedirs(os.path.dirname(file_path), exist_ok=True)
|
||||||
|
with open(file_path, "a", encoding="utf8") as f:
|
||||||
|
for entry in data:
|
||||||
|
json_line = json.dumps(entry, ensure_ascii=False)
|
||||||
|
f.write(json_line + "\n")
|
||||||
@@ -0,0 +1,65 @@
|
|||||||
|
# Zero Bubble Distributed RL Framework for Language Model Fine-Tuning
|
||||||
|
|
||||||
|
This folder contains code for the Zero Bubble distributed RL framework. It currently supports **GRPO** and **DAPO**. See the [main README](../README.md) for general installation instructions and usage.
|
||||||
|
|
||||||
|
**Note:** This project is under active development — expect changes.
|
||||||
|
|
||||||
|
## 🛠 Installation
|
||||||
|
|
||||||
|
1. Follow the general installation guide in the [main README](../README.md).
|
||||||
|
2. Install [pygloo](https://github.com/ray-project/pygloo). Build pygloo for Ray from source following the instructions in its repository README.
|
||||||
|
|
||||||
|
## Design idea
|
||||||
|
|
||||||
|
We aim to reduce the *“bubble”* — the idle time that occurs between rollouts and training steps (illustrated in Fig. 1).
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/all_sync.png" width=700/>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
**Fig. 1** - In an all-sync online RL framework, rollout workers wait for the trainer to finish training and synchronize weights, and the trainer waits for rollouts. This causes large GPU idle time.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/zero_bubble.png" width=700/>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
**Fig. 2** - Our Zero Bubble pipeline follows a producer–consumer pattern:
|
||||||
|
|
||||||
|
* A global **data buffer** temporarily stores rollouts produced by inference workers.
|
||||||
|
* A **weights distributor** buffers updated model weights and distributes them to inference workers.
|
||||||
|
* When the data buffer has enough data, the trainer continuously consumes from it and pushes updated weights to the weights distributor.
|
||||||
|
* After finishing a mini-batch, each inference worker checks the weights distributor and synchronizes to a newer weight version if available.
|
||||||
|
|
||||||
|
Under ideal conditions (inference workers produce data at the same rate the trainer consumes it), the pipeline eliminates idle time. We call it *zero bubble* because, with an unlimited data buffer, inference and training can run indefinitely without waiting. In practice, to avoid wasted compute and stale/off-policy data, we set a bounded buffer size so inference workers will briefly wait when the buffer is full.
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
In addition to the general parameters (see the main README), the Zero Bubble pipeline introduces one additional parameter:
|
||||||
|
|
||||||
|
* **`data_actor_buffer_size_limit`** - Maximum number of rollout batches the data buffer may hold. Defaults to **twice** the trainer’s mini-batch size. Avoid setting this too large — a very large buffer increases off-policy training. For DAPO, since only effective prompts count, you may need to raise `data_actor_buffer_size_limit` depending on sample utility.
|
||||||
|
|
||||||
|
Example: RL training on 8 GPUs with Zero Bubble (zero2)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python rl_example_zero_bubble.py \
|
||||||
|
--dataset /path/to/your/dataset.jsonl \
|
||||||
|
--model /path/to/your/model \
|
||||||
|
-t 4 -i 4 -b vllm -a DAPO \
|
||||||
|
-imbs 8 -ibs 8 -tbs 8 -e 2 -rt boxed \
|
||||||
|
-si 25 -s "Please reason step by step, and put your final answer within \\boxed{}." \
|
||||||
|
-tMbs 2 -tmbs 2 -p Rebase_Experiments -zero 2 -mpt 512 -mnt 3584
|
||||||
|
```
|
||||||
|
|
||||||
|
## Performance
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/zero_bubble_gpu_util.png" width=700/>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
**Fig. 3** - Performance of the Zero Bubble pipeline tested with an unlimited buffer size.
|
||||||
@@ -0,0 +1,347 @@
|
|||||||
|
import os
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
from coati.distributed.comm import SharedVariableActor, ray_broadcast_tensor_dict
|
||||||
|
from coati.distributed.profiling_utils import CustomProfiler
|
||||||
|
from coati.distributed.utils import bind_batch, post_recv, unbind_batch
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import HybridParallelPlugin
|
||||||
|
from colossalai.initialize import launch
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
|
||||||
|
class BaseConsumer:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
shared_sync_data_actor: SharedVariableActor,
|
||||||
|
shared_signal_actor: SharedVariableActor,
|
||||||
|
num_producers: int,
|
||||||
|
num_episodes: int,
|
||||||
|
rank: int,
|
||||||
|
world_size: int,
|
||||||
|
master_addr: str,
|
||||||
|
master_port: int,
|
||||||
|
train_dataset_size: int,
|
||||||
|
batch_size: int,
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
plugin_config: Dict[str, Any],
|
||||||
|
minibatch_size: int = 1,
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir: str = "./model",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
):
|
||||||
|
self.num_producers = num_producers
|
||||||
|
self.num_episodes = num_episodes
|
||||||
|
self.rank = rank
|
||||||
|
self.world_size = world_size
|
||||||
|
self.master_addr = master_addr
|
||||||
|
self.master_port = master_port
|
||||||
|
self.train_dataset_size = train_dataset_size
|
||||||
|
self.received_prompts = 0
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.minibatch_size = minibatch_size
|
||||||
|
self.save_interval = save_interval
|
||||||
|
self.save_dir = save_dir
|
||||||
|
self.enable_profiling = enable_profiling
|
||||||
|
assert batch_size % minibatch_size == 0, "batch_size should be divisible by microbatch_size"
|
||||||
|
self.num_microbatches = batch_size // minibatch_size
|
||||||
|
self.data_uid = 0
|
||||||
|
self.sync_model_thread_started = False
|
||||||
|
|
||||||
|
self.model_config = model_config
|
||||||
|
self.plugin_config = plugin_config
|
||||||
|
|
||||||
|
self.device = get_current_device()
|
||||||
|
self.lr_scheduler = None
|
||||||
|
|
||||||
|
self.shared_sync_data_actor = shared_sync_data_actor
|
||||||
|
self.shared_signal_actor = shared_signal_actor
|
||||||
|
self.state_dict_cpu = {}
|
||||||
|
|
||||||
|
def setup(self) -> None:
|
||||||
|
launch(self.rank, self.world_size, self.master_addr, self.master_port, local_rank=0)
|
||||||
|
|
||||||
|
plugin_config = dict(tp_size=1, pp_size=1, precision="bf16", zero_stage=2)
|
||||||
|
if (
|
||||||
|
self.plugin_config.get("pp_size", 1) > 1
|
||||||
|
and "num_microbatches" not in self.plugin_config
|
||||||
|
and "microbatch_size" not in self.plugin_config
|
||||||
|
):
|
||||||
|
plugin_config["microbatch_size"] = max(1, self.minibatch_size // plugin_config.get("pp_size", 1))
|
||||||
|
plugin_config.update(self.plugin_config)
|
||||||
|
self.plugin = HybridParallelPlugin(**plugin_config)
|
||||||
|
self.booster = Booster(plugin=self.plugin)
|
||||||
|
self.dp_rank = dist.get_rank(self.plugin.dp_group)
|
||||||
|
self.tp_rank = dist.get_rank(self.plugin.tp_group)
|
||||||
|
self.pp_rank = dist.get_rank(self.plugin.pp_group)
|
||||||
|
|
||||||
|
self.dp_size = dist.get_world_size(self.plugin.dp_group)
|
||||||
|
self.tp_size = dist.get_world_size(self.plugin.tp_group)
|
||||||
|
self.pp_size = dist.get_world_size(self.plugin.pp_group)
|
||||||
|
|
||||||
|
self.buffer = []
|
||||||
|
self.recv_cnt = 0
|
||||||
|
self.profiler = CustomProfiler(f"C{self.rank}", disabled=not self.enable_profiling)
|
||||||
|
|
||||||
|
def get_ddp_config(self) -> Dict[str, Any]:
|
||||||
|
"""
|
||||||
|
Get the DDP configuration for the consumer.
|
||||||
|
This method is used to get the DDP configuration for the consumer.
|
||||||
|
"""
|
||||||
|
return {
|
||||||
|
"dp_size": self.dp_size,
|
||||||
|
"tp_size": self.tp_size,
|
||||||
|
"pp_size": self.pp_size,
|
||||||
|
"dp_rank": self.dp_rank,
|
||||||
|
"tp_rank": self.tp_rank,
|
||||||
|
"pp_rank": self.pp_rank,
|
||||||
|
"world_size": self.world_size,
|
||||||
|
"rank": self.rank,
|
||||||
|
}
|
||||||
|
|
||||||
|
def init_collective_group(
|
||||||
|
self,
|
||||||
|
world_size: int,
|
||||||
|
rank: int,
|
||||||
|
backend: str = "nccl",
|
||||||
|
group_name: str = "default",
|
||||||
|
gloo_timeout: int = 3000000,
|
||||||
|
):
|
||||||
|
cc.init_collective_group(
|
||||||
|
world_size=world_size, rank=rank, backend=backend, group_name=group_name, gloo_timeout=gloo_timeout
|
||||||
|
)
|
||||||
|
print(f"[C{self.rank}] Initialized {group_name} collective group", flush=True)
|
||||||
|
|
||||||
|
def state_dict(self) -> Dict[str, torch.Tensor]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def step(self, **kwargs) -> Optional[float]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def prepare_mini_batch(self, effective_group_to_raw_group_mapping: Dict[int, int]) -> Dict[str, torch.Tensor]:
|
||||||
|
"""
|
||||||
|
Prepare a mini-batch from the effective group to raw group mapping.
|
||||||
|
This method is used to create a mini-batch for training.
|
||||||
|
"""
|
||||||
|
batches = [
|
||||||
|
self.buffer[effective_group_to_raw_group_mapping[i]]
|
||||||
|
for i in range(self.dp_rank * self.minibatch_size, (self.dp_rank + 1) * self.minibatch_size)
|
||||||
|
]
|
||||||
|
# every dp_rank will receive a complete mini-batch, no need to sync within step() later
|
||||||
|
# each mini-batch use the first self.dp_size * minibatch_size effective samples
|
||||||
|
raw_mini_batches = self.buffer[
|
||||||
|
: effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1
|
||||||
|
] # include the last effective sample
|
||||||
|
raw_mini_batches_metric_dict = {
|
||||||
|
"raw_train_mini_batch_reward": [t[1] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_format_acc": [t[2] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_ans_acc": [t[3] for t in raw_mini_batches],
|
||||||
|
"raw_train_mini_batch_response_len": [t[4] for t in raw_mini_batches],
|
||||||
|
}
|
||||||
|
batch = bind_batch([t[0] for t in batches])
|
||||||
|
batch = post_recv(batch)
|
||||||
|
return batch, raw_mini_batches_metric_dict
|
||||||
|
|
||||||
|
def calculate_effective_group_to_raw_group_mapping(self):
|
||||||
|
effective_group_to_raw_group_mapping = {}
|
||||||
|
for buffer_idx in range(len(self.buffer)):
|
||||||
|
if self.buffer[buffer_idx][0] is not None:
|
||||||
|
effective_group_to_raw_group_mapping[len(effective_group_to_raw_group_mapping)] = buffer_idx
|
||||||
|
return effective_group_to_raw_group_mapping
|
||||||
|
|
||||||
|
def loop(self) -> None:
|
||||||
|
print(f"Consumer{self.rank}, nmb: {self.num_microbatches}")
|
||||||
|
for episode in range(self.num_episodes):
|
||||||
|
with tqdm(
|
||||||
|
range(self.train_dataset_size),
|
||||||
|
desc=f"Episode {episode} with rollout step(s)",
|
||||||
|
disable=self.rank != 0,
|
||||||
|
) as pbar:
|
||||||
|
while self.received_prompts < self.train_dataset_size:
|
||||||
|
torch.cuda.reset_peak_memory_stats()
|
||||||
|
effective_group_to_raw_group_mapping = {}
|
||||||
|
self.profiler.enter(f"recv_data")
|
||||||
|
while len(effective_group_to_raw_group_mapping) < self.dp_size * self.minibatch_size:
|
||||||
|
# receive data from producers
|
||||||
|
raw_batch = ray.get(
|
||||||
|
self.shared_sync_data_actor.get_data.remote(self.data_uid)
|
||||||
|
) # get the first queued data
|
||||||
|
self.profiler.log(f"enter sleep")
|
||||||
|
while raw_batch is None:
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] No data received by consumer {self.rank}, skipping. Consider increasing the data actor buffer limit"
|
||||||
|
)
|
||||||
|
time.sleep(1)
|
||||||
|
raw_batch = ray.get(self.shared_sync_data_actor.get_data.remote(self.data_uid))
|
||||||
|
continue
|
||||||
|
self.profiler.log(f"exit sleep")
|
||||||
|
self.data_uid += 1
|
||||||
|
raw_batch = {k: v.to(self.device) for k, v in raw_batch.items()}
|
||||||
|
# calculate group reward et al. filtering. As only the filtered group will be used for training (which is incomplete),
|
||||||
|
# we need to calculate the metrics before filtering here for logging
|
||||||
|
# [batch_size, num_generations] -> [batch_size]
|
||||||
|
reward = raw_batch["reward"][:, :, 0]
|
||||||
|
format_acc = raw_batch["format_acc"][:, :, 0]
|
||||||
|
ans_acc = raw_batch["ans_acc"][:, :, 0]
|
||||||
|
response_len = (
|
||||||
|
raw_batch["response_idx"][:, :, 1] - raw_batch["response_idx"][:, :, 0] + 1
|
||||||
|
).type(torch.float32)
|
||||||
|
effective_group_mask = None
|
||||||
|
if self.filter_range is not None and self.grpo_config.get("dynamic_batching", True):
|
||||||
|
# filter the group based on the reward and accuracy
|
||||||
|
group_ans_acc_mean = ans_acc.mean(dim=1)
|
||||||
|
effective_group_mask = torch.logical_and(
|
||||||
|
group_ans_acc_mean > self.filter_range[0], group_ans_acc_mean < self.filter_range[1]
|
||||||
|
)
|
||||||
|
|
||||||
|
raw_batch = unbind_batch(raw_batch) # List[Dict[str, torch.Tensor]]
|
||||||
|
self.received_prompts += len(raw_batch)
|
||||||
|
pbar.update(len(raw_batch))
|
||||||
|
for group_idx, group_with_reward in enumerate(raw_batch):
|
||||||
|
self.buffer.append(
|
||||||
|
[
|
||||||
|
(
|
||||||
|
group_with_reward
|
||||||
|
if effective_group_mask is None or effective_group_mask[group_idx]
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
reward[group_idx],
|
||||||
|
format_acc[group_idx],
|
||||||
|
ans_acc[group_idx],
|
||||||
|
response_len[group_idx],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
if effective_group_mask is not None:
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Filter recv data: {len(raw_batch)} -> {torch.sum(effective_group_mask).cpu().item()} effective groups"
|
||||||
|
)
|
||||||
|
# mapping the effective group to the raw group for indexing
|
||||||
|
effective_group_to_raw_group_mapping = self.calculate_effective_group_to_raw_group_mapping()
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Collect Effective Prompt: {len(effective_group_to_raw_group_mapping)}/{self.dp_size * self.minibatch_size}"
|
||||||
|
)
|
||||||
|
self.profiler.exit(f"recv_data")
|
||||||
|
need_sync_model = False
|
||||||
|
while len(effective_group_to_raw_group_mapping) >= self.dp_size * self.minibatch_size:
|
||||||
|
# after we have enough effective groups, we can start training
|
||||||
|
# on each dp_rank, we use minibatch_size effective samples to form a batch
|
||||||
|
batch, raw_mini_batches_metric_dict = self.prepare_mini_batch(
|
||||||
|
effective_group_to_raw_group_mapping
|
||||||
|
)
|
||||||
|
self.profiler.enter("step")
|
||||||
|
loss = self.step(pbar, **batch, **raw_mini_batches_metric_dict)
|
||||||
|
self.profiler.exit("step")
|
||||||
|
self.buffer = self.buffer[
|
||||||
|
effective_group_to_raw_group_mapping[self.dp_size * self.minibatch_size - 1] + 1 :
|
||||||
|
]
|
||||||
|
# recalculate the effective group to raw group mapping
|
||||||
|
effective_group_to_raw_group_mapping_size_before = len(effective_group_to_raw_group_mapping)
|
||||||
|
effective_group_to_raw_group_mapping = self.calculate_effective_group_to_raw_group_mapping()
|
||||||
|
assert (
|
||||||
|
len(effective_group_to_raw_group_mapping)
|
||||||
|
== effective_group_to_raw_group_mapping_size_before - self.dp_size * self.minibatch_size
|
||||||
|
)
|
||||||
|
# cc.barrier(group_name="consumer_pg")
|
||||||
|
if loss is not None:
|
||||||
|
pbar.set_postfix({"loss": loss})
|
||||||
|
need_sync_model = True
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("global_step", self.global_step + 1))
|
||||||
|
if need_sync_model and (
|
||||||
|
(self.global_step + 1) % self.save_interval == 0
|
||||||
|
or self.received_prompts >= self.train_dataset_size
|
||||||
|
):
|
||||||
|
if self.rank == 0:
|
||||||
|
print(f"Start saving policy model at step {self.global_step + 1}.")
|
||||||
|
save_path = os.path.join(
|
||||||
|
self.save_dir, f"modeling-episode-{episode}-step-{self.global_step + 1}"
|
||||||
|
)
|
||||||
|
self.booster.save_model(self.policy_model, save_path, shard=True)
|
||||||
|
if self.rank == 0:
|
||||||
|
print(f"Saved model checkpoint at step {self.global_step + 1} in folder {save_path}")
|
||||||
|
|
||||||
|
if need_sync_model and (
|
||||||
|
episode != self.num_episodes - 1 or self.received_prompts != self.train_dataset_size
|
||||||
|
):
|
||||||
|
|
||||||
|
def sync_model_thread():
|
||||||
|
# sync model weights to all producers, if no model update or it is the last training step, skip syncing
|
||||||
|
if self.pp_size > 1:
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Sync model PP stage {self.pp_rank} episode {episode} step {self.global_step}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print(f"[T{dist.get_rank()}] Sync model episode {episode} step {self.global_step}")
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
if self.pp_size > 1:
|
||||||
|
if self.tp_rank == 0 and self.dp_rank == 0:
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
ray.get(
|
||||||
|
self.shared_signal_actor.set_signal.remote(
|
||||||
|
f"consumer_pp_{self.pp_rank}", "ready_sync_model"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
print(
|
||||||
|
f"[T{dist.get_rank()}] Sync model PP stage {self.pp_rank} episode {episode} step {self.global_step}"
|
||||||
|
)
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu,
|
||||||
|
src=0,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_consumer_pp_{self.pp_rank}",
|
||||||
|
backend="gloo",
|
||||||
|
)
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
else:
|
||||||
|
if self.rank == 0:
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("consumer", "ready_sync_model"))
|
||||||
|
print(f"[T{dist.get_rank()}] Sync model episode {episode} step {self.global_step}")
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu,
|
||||||
|
src=0,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name="sync_model_consumer",
|
||||||
|
backend="gloo",
|
||||||
|
)
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
|
||||||
|
if not self.sync_model_thread_started:
|
||||||
|
# only sync model when the thread is not started and no other thread is broadcasting
|
||||||
|
self.sync_model_thread_started = True
|
||||||
|
state_dict_ = self.state_dict()
|
||||||
|
if (self.pp_size > 1 and self.tp_rank == 0 and self.dp_rank == 0) or (
|
||||||
|
self.pp_size == 1 and self.rank == 0
|
||||||
|
):
|
||||||
|
if len(self.state_dict_cpu) == 0:
|
||||||
|
# use pinned memory to speed up the transfer
|
||||||
|
self.state_dict_cpu = {k: v.cpu().pin_memory() for k, v in state_dict_.items()}
|
||||||
|
torch.cuda.synchronize()
|
||||||
|
for k, v in state_dict_.items():
|
||||||
|
self.state_dict_cpu[k].copy_(v, non_blocking=True)
|
||||||
|
torch.cuda.synchronize()
|
||||||
|
cc.barrier(
|
||||||
|
group_name="consumer_pg"
|
||||||
|
) # to make sure all ranks have state dict offloaded to CPU before starting the thread
|
||||||
|
time_before_starting_thread = time.time()
|
||||||
|
threading.Thread(target=sync_model_thread).start()
|
||||||
|
# sync_model_thread()
|
||||||
|
self.profiler.log(
|
||||||
|
f"Sync model, took {time.time() - time_before_starting_thread:.2f} seconds"
|
||||||
|
)
|
||||||
|
self.sync_model_thread_started = False
|
||||||
|
# ray.get(self.shared_signal_actor.release_process_lock.remote("broadcasting_lock"))
|
||||||
|
self.profiler.log(f"Peak memory usage: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||||
|
self.received_prompts = 0
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("consumer", "terminate"))
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if hasattr(self, "profiler"):
|
||||||
|
self.profiler.close()
|
||||||
@@ -0,0 +1,124 @@
|
|||||||
|
import time
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
from coati.distributed.comm import SharedVariableActor, ray_broadcast_tensor_dict
|
||||||
|
from coati.distributed.profiling_utils import CustomProfiler
|
||||||
|
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class Distributor:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
distributor_id,
|
||||||
|
consumer_pp_size,
|
||||||
|
num_producers,
|
||||||
|
shared_signal_actor: SharedVariableActor,
|
||||||
|
enable_profiling: bool = True,
|
||||||
|
):
|
||||||
|
self.distributor_id = distributor_id
|
||||||
|
self.weight_version = [0] * consumer_pp_size
|
||||||
|
self.consumer_pp_size = consumer_pp_size
|
||||||
|
self.state_dict_cpu = {}
|
||||||
|
self.num_producers = num_producers
|
||||||
|
self.shared_signal_actor = shared_signal_actor
|
||||||
|
self.device = get_current_device()
|
||||||
|
self.profiler = CustomProfiler(f"D{self.distributor_id}", disabled=not enable_profiling)
|
||||||
|
|
||||||
|
def init_collective_group(
|
||||||
|
self,
|
||||||
|
world_size: int,
|
||||||
|
rank: int,
|
||||||
|
backend: str = "nccl",
|
||||||
|
group_name: str = "default",
|
||||||
|
gloo_timeout: int = 3000000,
|
||||||
|
):
|
||||||
|
cc.init_collective_group(
|
||||||
|
world_size=world_size, rank=rank, backend=backend, group_name=group_name, gloo_timeout=gloo_timeout
|
||||||
|
)
|
||||||
|
print(f"[D] Initialized {group_name} collective group", flush=True)
|
||||||
|
|
||||||
|
def loop(self):
|
||||||
|
last_weight_version = self.get_weight_version()
|
||||||
|
while True:
|
||||||
|
time.sleep(1)
|
||||||
|
signal = ray.get(self.shared_signal_actor.get_signal.remote())
|
||||||
|
if self.consumer_pp_size > 1:
|
||||||
|
if all(
|
||||||
|
[signal.get(f"consumer_pp_{i}", None) == "ready_sync_model" for i in range(self.consumer_pp_size)]
|
||||||
|
):
|
||||||
|
cc.barrier(group_name="distributor_pg")
|
||||||
|
for i in range(self.consumer_pp_size):
|
||||||
|
self.profiler.enter(f"sync_model_consumer_pp_{i}")
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote(f"consumer_pp_{i}", "not_ready_sync_model"))
|
||||||
|
# Broadcast the model state dict from consumer to shared variable actor
|
||||||
|
self.state_dict_cpu[i] = ray_broadcast_tensor_dict(
|
||||||
|
None,
|
||||||
|
0,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_consumer_pp_{i}",
|
||||||
|
backend="gloo",
|
||||||
|
)
|
||||||
|
self.profiler.exit(f"sync_model_consumer_pp_{i}")
|
||||||
|
self.weight_version[i] += 1
|
||||||
|
if all(
|
||||||
|
[
|
||||||
|
signal.get(f"producer_{self.distributor_id}_pp_{i}", None) == "ready_sync_model"
|
||||||
|
for i in range(self.consumer_pp_size)
|
||||||
|
]
|
||||||
|
):
|
||||||
|
for i in range(self.consumer_pp_size):
|
||||||
|
self.profiler.enter(f"sync_model_producer_{self.distributor_id}_pp_{i}")
|
||||||
|
# Broadcast the model state dict to all producers
|
||||||
|
ray.get(
|
||||||
|
self.shared_signal_actor.set_signal.remote(
|
||||||
|
f"producer_{self.distributor_id}_pp_{i}", "not_ready_sync_model"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu[i],
|
||||||
|
1,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_producer_{self.distributor_id}_pp_{i}",
|
||||||
|
backend="gloo",
|
||||||
|
)
|
||||||
|
self.profiler.exit(f"sync_model_producer_{self.distributor_id}_pp_{i}")
|
||||||
|
else:
|
||||||
|
if signal.get("consumer", None) == "ready_sync_model":
|
||||||
|
self.profiler.enter("sync_model_consumer")
|
||||||
|
cc.barrier(group_name="distributor_pg")
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("consumer", "not_ready_sync_model"))
|
||||||
|
# Broadcast the model state dict from consumer to shared variable actor
|
||||||
|
self.state_dict_cpu = ray_broadcast_tensor_dict(
|
||||||
|
None, 0, device=torch.device("cpu"), group_name="sync_model_consumer", backend="gloo"
|
||||||
|
)
|
||||||
|
self.profiler.exit("sync_model_consumer")
|
||||||
|
self.weight_version[0] += 1
|
||||||
|
if signal.get(f"producer_{self.distributor_id}", None) == "ready_sync_model":
|
||||||
|
self.profiler.enter(f"sync_model_producer_{self.distributor_id}")
|
||||||
|
# Broadcast the model state dict to all producers
|
||||||
|
ray.get(
|
||||||
|
self.shared_signal_actor.set_signal.remote(
|
||||||
|
f"producer_{self.distributor_id}", "not_ready_sync_model"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu,
|
||||||
|
1,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_producer_{self.distributor_id}",
|
||||||
|
backend="gloo",
|
||||||
|
)
|
||||||
|
self.profiler.exit(f"sync_model_producer_{self.distributor_id}")
|
||||||
|
if signal.get("consumer", None) == "terminate":
|
||||||
|
self.profiler.log("terminate sync model worker")
|
||||||
|
break
|
||||||
|
if last_weight_version != self.get_weight_version():
|
||||||
|
last_weight_version = self.get_weight_version()
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("distributor_weight_version", last_weight_version))
|
||||||
|
|
||||||
|
def get_weight_version(self):
|
||||||
|
return self.weight_version[0]
|
||||||
@@ -0,0 +1,535 @@
|
|||||||
|
from contextlib import nullcontext
|
||||||
|
from typing import Any, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import torch
|
||||||
|
import wandb
|
||||||
|
from coati.distributed.comm import SharedVariableActor
|
||||||
|
from coati.distributed.loss import PolicyLoss
|
||||||
|
from coati.distributed.utils import entropy_from_logits, memory_efficient_logprob
|
||||||
|
from coati.distributed.zero_bubble.consumer import BaseConsumer
|
||||||
|
from coati.trainer.utils import all_reduce_mean, all_reduce_sum
|
||||||
|
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
|
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||||
|
from colossalai.nn.optimizer import HybridAdam
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class GRPOConsumer(BaseConsumer):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
shared_sync_data_actor: SharedVariableActor,
|
||||||
|
shared_signal_actor: SharedVariableActor,
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
train_dataset_size,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size=1,
|
||||||
|
num_generations=8,
|
||||||
|
tokenizer_config=None,
|
||||||
|
generate_config=None,
|
||||||
|
grpo_config={},
|
||||||
|
save_interval: int = 100,
|
||||||
|
save_dir="./model",
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
):
|
||||||
|
print(f"Using GRPO config: {grpo_config}")
|
||||||
|
if (
|
||||||
|
plugin_config.get("pp_size", 1) > 1
|
||||||
|
and "num_microbatches" not in plugin_config
|
||||||
|
and "microbatch_size" not in plugin_config
|
||||||
|
):
|
||||||
|
plugin_config["microbatch_size"] = max(
|
||||||
|
1, grpo_config.get("train_microbatch_size") // plugin_config.get("pp_size", 1)
|
||||||
|
)
|
||||||
|
super().__init__(
|
||||||
|
shared_sync_data_actor,
|
||||||
|
shared_signal_actor,
|
||||||
|
num_producers,
|
||||||
|
num_episodes,
|
||||||
|
rank,
|
||||||
|
world_size,
|
||||||
|
master_addr,
|
||||||
|
master_port,
|
||||||
|
train_dataset_size,
|
||||||
|
batch_size,
|
||||||
|
model_config,
|
||||||
|
plugin_config,
|
||||||
|
minibatch_size,
|
||||||
|
save_interval=save_interval,
|
||||||
|
save_dir=save_dir,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
)
|
||||||
|
path = model_config.pop("path")
|
||||||
|
self.policy_model = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.policy_model.train()
|
||||||
|
self.policy_model.gradient_checkpointing_enable()
|
||||||
|
self.vocab_size = self.policy_model.config.vocab_size
|
||||||
|
self.optimizer = HybridAdam(self.policy_model.parameters(), lr=grpo_config.get("lr", 1e-6))
|
||||||
|
self.accum_loss = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_kl = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_entropy = torch.zeros(1, device=self.device)
|
||||||
|
self.accum_advantages = torch.zeros(1, device=self.device)
|
||||||
|
self.raw_train_batch_reward = []
|
||||||
|
self.raw_train_batch_format_acc = []
|
||||||
|
self.raw_train_batch_ans_acc = []
|
||||||
|
self.raw_train_batch_response_len = []
|
||||||
|
self.accum_count = 0
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.grpo_config = grpo_config
|
||||||
|
self.project_name = project_name
|
||||||
|
self.effective_sample_count = 0
|
||||||
|
self.effective_prompt_count = 0
|
||||||
|
self.project_name = project_name
|
||||||
|
self.run_name = run_name
|
||||||
|
self.wandb_group_name = wandb_group_name
|
||||||
|
|
||||||
|
self.policy_loss_fn = PolicyLoss(
|
||||||
|
clip_eps_low=grpo_config.get("clip_eps_low", 0.2),
|
||||||
|
clip_eps_high=grpo_config.get("clip_eps_high", 0.2),
|
||||||
|
beta=grpo_config.get("beta", 0.01),
|
||||||
|
loss_variation=grpo_config.get("loss_variation", "sample_level"),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Reference model is initialized from policy model.
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.reference_model = AutoModelForCausalLM.from_pretrained(path, **model_config)
|
||||||
|
self.reference_model.eval()
|
||||||
|
if tokenizer_config is not None:
|
||||||
|
path = tokenizer_config.pop("path", None)
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(path, **tokenizer_config)
|
||||||
|
else:
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(path)
|
||||||
|
self.pad_token_id = self.tokenizer.pad_token_id
|
||||||
|
self.num_generations = num_generations
|
||||||
|
self.filter_range = grpo_config.get("filter_range", None)
|
||||||
|
if self.filter_range is not None:
|
||||||
|
assert len(self.filter_range) == 2, "Filter range should have 2 values."
|
||||||
|
|
||||||
|
self.filter_truncated_response = grpo_config.get("filter_truncated_response", False)
|
||||||
|
if self.filter_truncated_response:
|
||||||
|
self.max_length = 0
|
||||||
|
if "max_tokens" in self.generate_config:
|
||||||
|
self.max_length = self.generate_config["max_tokens"]
|
||||||
|
elif "max_new_tokens" in self.generate_config:
|
||||||
|
self.max_length = self.generate_config["max_new_tokens"]
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
"either max_tokens (vllm) or max_new_tokens (transformers) must be set in generate_config."
|
||||||
|
)
|
||||||
|
# Initialize verifiable reward.
|
||||||
|
grpo_config.get("response_format_tags", None)
|
||||||
|
self.global_step = 0
|
||||||
|
|
||||||
|
def setup(self):
|
||||||
|
super().setup()
|
||||||
|
if (not self.plugin.pp_size > 1 and self.rank == 0) or (
|
||||||
|
self.plugin.pp_size > 1
|
||||||
|
and self.booster.plugin.stage_manager.is_last_stage()
|
||||||
|
and self.tp_rank == 0
|
||||||
|
and self.dp_rank == 0
|
||||||
|
):
|
||||||
|
self.wandb_run = wandb.init(
|
||||||
|
project=self.project_name,
|
||||||
|
sync_tensorboard=False,
|
||||||
|
dir="./wandb",
|
||||||
|
name=self.run_name,
|
||||||
|
group=self.wandb_group_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.lr_scheduler = CosineAnnealingWarmupLR(
|
||||||
|
optimizer=self.optimizer,
|
||||||
|
total_steps=min(self.num_episodes, 4) * self.train_dataset_size // (self.batch_size * self.dp_size),
|
||||||
|
warmup_steps=0,
|
||||||
|
eta_min=0.1 * self.grpo_config.get("lr", 1e-6),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.policy_model, self.optimizer, _, _, self.lr_scheduler = self.booster.boost(
|
||||||
|
self.policy_model, self.optimizer, lr_scheduler=self.lr_scheduler
|
||||||
|
)
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.reference_model, *_ = self.booster.boost(self.reference_model)
|
||||||
|
self.plugin.logger.set_level("ERROR")
|
||||||
|
|
||||||
|
def step(self, pbar: Any, **kwargs) -> Optional[float]:
|
||||||
|
"""
|
||||||
|
Step data from policy model:
|
||||||
|
[{
|
||||||
|
"input_ids": torch.Tensor,
|
||||||
|
"attention_mask": torch.Tensor,
|
||||||
|
"action_mask": torch.Tensor,
|
||||||
|
"action_log_probs": torch.Tensor,
|
||||||
|
},
|
||||||
|
...]
|
||||||
|
Format:
|
||||||
|
[minibatch_size, num_of_generation, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>.
|
||||||
|
"""
|
||||||
|
# Reshape to [minibatch_size x num_of_generation, prompt_length + response_length]
|
||||||
|
data = {k: v.view(-1, v.size(-1)) for k, v in kwargs.items() if "raw_train_mini_batch_" not in k}
|
||||||
|
self.raw_train_batch_reward.extend(kwargs["raw_train_mini_batch_reward"])
|
||||||
|
self.raw_train_batch_format_acc.extend(kwargs["raw_train_mini_batch_format_acc"])
|
||||||
|
self.raw_train_batch_ans_acc.extend(kwargs["raw_train_mini_batch_ans_acc"])
|
||||||
|
self.raw_train_batch_response_len.extend(kwargs["raw_train_mini_batch_response_len"])
|
||||||
|
action_mask = data["action_mask"]
|
||||||
|
num_action = action_mask.shape[1]
|
||||||
|
old_action_log_probs = data["action_log_probs"]
|
||||||
|
response_length = torch.sum(action_mask, dim=1).to(torch.float32)
|
||||||
|
train_microbatch_size = self.grpo_config.get("train_microbatch_size", data["input_ids"].size(0))
|
||||||
|
|
||||||
|
reward = data["reward"].view((-1))
|
||||||
|
format_acc = data["format_acc"].view((-1))
|
||||||
|
ans_acc = data["ans_acc"].view((-1))
|
||||||
|
|
||||||
|
# [minibatch_size, num_generations]
|
||||||
|
|
||||||
|
group_reward = reward.view(-1, self.num_generations)
|
||||||
|
reward_mean = group_reward.mean(dim=1)
|
||||||
|
# [minibatch_size x num_generations]
|
||||||
|
reward_mean = reward_mean.repeat_interleave(self.num_generations, dim=0)
|
||||||
|
|
||||||
|
reward_std = group_reward.std(dim=1).repeat_interleave(self.num_generations, dim=0)
|
||||||
|
# [minibatch_size x num_generations]
|
||||||
|
advantages = ((reward - reward_mean) / (reward_std + 1e-4)).unsqueeze(dim=-1)
|
||||||
|
|
||||||
|
# [minibatch_size x num_of_generation]
|
||||||
|
loss_mask = torch.ones(action_mask.size(0), device=action_mask.device).bool()
|
||||||
|
|
||||||
|
# filter out overlength samples
|
||||||
|
if self.filter_truncated_response and action_mask.size(1) == self.max_length:
|
||||||
|
loss_mask = torch.logical_and(
|
||||||
|
loss_mask,
|
||||||
|
action_mask[:, -1] == False,
|
||||||
|
)
|
||||||
|
if self.filter_range is not None and self.grpo_config.get("dynamic_batching", False) == False:
|
||||||
|
# filter out samples with reward outside the range
|
||||||
|
# if dynamic batching is enabled, we filter out out of range groups before training
|
||||||
|
group_ans_acc_mean = (
|
||||||
|
ans_acc.view(-1, self.num_generations).mean(dim=1).repeat_interleave(self.num_generations, dim=-1)
|
||||||
|
)
|
||||||
|
loss_mask = torch.logical_and(
|
||||||
|
loss_mask,
|
||||||
|
torch.logical_and(
|
||||||
|
group_ans_acc_mean > self.filter_range[0],
|
||||||
|
group_ans_acc_mean < self.filter_range[1],
|
||||||
|
),
|
||||||
|
)
|
||||||
|
self.effective_prompt_count += (
|
||||||
|
group_reward.size(0) * self.dp_size
|
||||||
|
) # all prompts in the batch are effective as we filtered out the bad ones before step.
|
||||||
|
|
||||||
|
mean_kl, mean_loss = [], []
|
||||||
|
|
||||||
|
need_update = self.effective_prompt_count >= self.batch_size * self.dp_size
|
||||||
|
|
||||||
|
effective_samples = all_reduce_sum(torch.sum(loss_mask), self.plugin)
|
||||||
|
effective_tokens_count = torch.sum(action_mask, dim=-1) * loss_mask
|
||||||
|
total_effective_tokens_count = all_reduce_sum(torch.sum(effective_tokens_count), self.plugin)
|
||||||
|
self.effective_sample_count += effective_samples.item()
|
||||||
|
pbar.set_postfix(
|
||||||
|
{
|
||||||
|
"Global Step": self.global_step,
|
||||||
|
"Gradient Accumulation on": f"{self.effective_prompt_count}/{self.batch_size * self.dp_size} effective prompts, {self.effective_sample_count}/{self.batch_size * self.dp_size * self.num_generations} effective samples",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
# Gradient must be synchronized if zero2 is enabled. https://github.com/hpcaitech/ColossalAI/blob/44d4053fec005fe0b06b6bc755fdc962463145df/colossalai/booster/plugin/hybrid_parallel_plugin.py#L1500
|
||||||
|
ctx = (
|
||||||
|
nullcontext()
|
||||||
|
if need_update or self.booster.plugin.zero_stage == 2
|
||||||
|
else self.booster.no_sync(self.policy_model, self.optimizer)
|
||||||
|
)
|
||||||
|
with ctx:
|
||||||
|
mini_batch_entropies = []
|
||||||
|
for forward_micro_batch_start in range(0, data["input_ids"].size(0), train_microbatch_size):
|
||||||
|
input_ids_forward_micro_batch = data["input_ids"][
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
old_action_log_probs_micro_batch = old_action_log_probs[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
attention_mask_forward_micro_batch = data["attention_mask"][
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
action_mask_forward_micro_batch = action_mask[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
loss_mask_forward_micro_batch = (
|
||||||
|
loss_mask[forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size]
|
||||||
|
if loss_mask is not None
|
||||||
|
else None
|
||||||
|
)
|
||||||
|
advantages_forward_micro_batch = advantages[
|
||||||
|
forward_micro_batch_start : forward_micro_batch_start + train_microbatch_size
|
||||||
|
]
|
||||||
|
|
||||||
|
if self.plugin.pp_size > 1:
|
||||||
|
# Support training with PP.
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
with torch.no_grad():
|
||||||
|
reference_model_outputs = self.booster.execute_pipeline(
|
||||||
|
iter(
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"input_ids": input_ids_forward_micro_batch,
|
||||||
|
"attention_mask": attention_mask_forward_micro_batch,
|
||||||
|
}
|
||||||
|
]
|
||||||
|
),
|
||||||
|
self.reference_model,
|
||||||
|
criterion=lambda outputs, inputs: torch.tensor(
|
||||||
|
[0.0], device=action_mask.device
|
||||||
|
), # dummy criterion
|
||||||
|
optimizer=None,
|
||||||
|
return_loss=False,
|
||||||
|
return_outputs=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.booster.plugin.stage_manager.is_last_stage():
|
||||||
|
reference_action_log_probs = memory_efficient_logprob(
|
||||||
|
reference_model_outputs["outputs"]["logits"] / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# Dummy reference logprobs for data iterator.
|
||||||
|
reference_action_log_probs = None
|
||||||
|
else:
|
||||||
|
reference_action_log_probs = None
|
||||||
|
|
||||||
|
data_policy_forward = {
|
||||||
|
"input_ids": input_ids_forward_micro_batch,
|
||||||
|
"attention_mask": attention_mask_forward_micro_batch,
|
||||||
|
"action_mask": action_mask_forward_micro_batch,
|
||||||
|
"advantages": advantages_forward_micro_batch,
|
||||||
|
"loss_mask": loss_mask_forward_micro_batch,
|
||||||
|
"old_action_log_probs": old_action_log_probs_micro_batch,
|
||||||
|
"source": self.rank,
|
||||||
|
}
|
||||||
|
if reference_action_log_probs is not None:
|
||||||
|
data_policy_forward["reference_action_log_probs"] = reference_action_log_probs
|
||||||
|
|
||||||
|
kl = []
|
||||||
|
|
||||||
|
def _criterion(outputs, inputs):
|
||||||
|
action_logits = outputs.logits
|
||||||
|
mini_batch_entropies.append(
|
||||||
|
(
|
||||||
|
((entropy_from_logits(action_logits[:, -num_action:]) * inputs["action_mask"]).sum(-1))
|
||||||
|
/ inputs["action_mask"].sum(-1)
|
||||||
|
).detach()
|
||||||
|
)
|
||||||
|
action_log_probs = memory_efficient_logprob(
|
||||||
|
action_logits / self.generate_config["temperature"],
|
||||||
|
inputs["input_ids"],
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
if "reference_action_log_probs" in inputs:
|
||||||
|
per_token_kl = (
|
||||||
|
torch.exp(inputs["reference_action_log_probs"] - action_log_probs)
|
||||||
|
- (inputs["reference_action_log_probs"] - action_log_probs)
|
||||||
|
- 1
|
||||||
|
)
|
||||||
|
appox_kl = torch.sum(per_token_kl * inputs["action_mask"], dim=-1) / torch.sum(
|
||||||
|
inputs["action_mask"], dim=-1
|
||||||
|
)
|
||||||
|
kl.append(appox_kl.mean())
|
||||||
|
else:
|
||||||
|
per_token_kl = 0.0
|
||||||
|
kl.append(torch.tensor(0.0))
|
||||||
|
|
||||||
|
loss, _ = self.policy_loss_fn(
|
||||||
|
action_log_probs,
|
||||||
|
inputs["old_action_log_probs"],
|
||||||
|
inputs["advantages"].repeat_interleave(action_log_probs.size(-1), dim=-1),
|
||||||
|
per_token_kl,
|
||||||
|
inputs["action_mask"],
|
||||||
|
loss_mask=inputs["loss_mask"],
|
||||||
|
total_effective_tokens_in_batch=total_effective_tokens_count,
|
||||||
|
)
|
||||||
|
return loss
|
||||||
|
|
||||||
|
policy_model_outputs = self.booster.execute_pipeline(
|
||||||
|
iter([data_policy_forward]),
|
||||||
|
self.policy_model,
|
||||||
|
criterion=_criterion,
|
||||||
|
optimizer=self.optimizer,
|
||||||
|
return_loss=True,
|
||||||
|
return_outputs=False,
|
||||||
|
)
|
||||||
|
loss = policy_model_outputs["loss"]
|
||||||
|
|
||||||
|
if self.booster.plugin.stage_manager.is_last_stage():
|
||||||
|
if len(kl) > 0:
|
||||||
|
kl = all_reduce_mean(torch.mean(torch.stack(kl)).to(loss.device), self.plugin).data
|
||||||
|
mean_kl.append(kl)
|
||||||
|
mean_loss.append(all_reduce_mean(loss, self.plugin).data)
|
||||||
|
else:
|
||||||
|
policy_model_logits = self.policy_model(
|
||||||
|
input_ids=input_ids_forward_micro_batch,
|
||||||
|
attention_mask=attention_mask_forward_micro_batch,
|
||||||
|
).logits
|
||||||
|
action_log_probs = memory_efficient_logprob(
|
||||||
|
policy_model_logits / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
with torch.no_grad():
|
||||||
|
reference_model_logits = self.reference_model(
|
||||||
|
input_ids=input_ids_forward_micro_batch,
|
||||||
|
attention_mask=attention_mask_forward_micro_batch,
|
||||||
|
).logits
|
||||||
|
reference_action_log_probs = memory_efficient_logprob(
|
||||||
|
reference_model_logits / self.generate_config["temperature"],
|
||||||
|
input_ids_forward_micro_batch,
|
||||||
|
num_action,
|
||||||
|
shard_config=self.plugin.shard_config,
|
||||||
|
)
|
||||||
|
per_token_kl = (
|
||||||
|
torch.exp(reference_action_log_probs - action_log_probs)
|
||||||
|
- (reference_action_log_probs - action_log_probs)
|
||||||
|
- 1
|
||||||
|
)
|
||||||
|
kl = torch.sum(per_token_kl * action_mask_forward_micro_batch, dim=-1) / torch.sum(
|
||||||
|
action_mask_forward_micro_batch, dim=-1
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
per_token_kl = 0.0
|
||||||
|
kl = None
|
||||||
|
|
||||||
|
loss, _ = self.policy_loss_fn(
|
||||||
|
action_log_probs,
|
||||||
|
old_action_log_probs_micro_batch,
|
||||||
|
advantages_forward_micro_batch.repeat_interleave(action_log_probs.size(-1), dim=-1),
|
||||||
|
per_token_kl,
|
||||||
|
action_mask_forward_micro_batch,
|
||||||
|
loss_mask=loss_mask_forward_micro_batch,
|
||||||
|
total_effective_tokens_in_batch=total_effective_tokens_count,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.booster.backward(loss, self.optimizer)
|
||||||
|
loss = all_reduce_mean(loss, self.plugin)
|
||||||
|
# Calculate accumulate value.
|
||||||
|
if kl is not None:
|
||||||
|
kl = all_reduce_mean(kl.mean(), self.plugin)
|
||||||
|
mean_kl.append(kl.data)
|
||||||
|
mean_loss.append(loss.data)
|
||||||
|
mini_batch_entropies.append(
|
||||||
|
all_reduce_mean(
|
||||||
|
(
|
||||||
|
(
|
||||||
|
(
|
||||||
|
entropy_from_logits(policy_model_logits[:, -num_action:])
|
||||||
|
* action_mask_forward_micro_batch
|
||||||
|
).sum(-1)
|
||||||
|
)
|
||||||
|
/ action_mask_forward_micro_batch.sum(-1)
|
||||||
|
).detach(),
|
||||||
|
self.plugin,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
if not self.plugin.pp_size > 1 or (
|
||||||
|
self.plugin.pp_size > 1
|
||||||
|
and self.booster.plugin.stage_manager.is_last_stage()
|
||||||
|
and self.tp_rank == 0
|
||||||
|
and self.dp_rank == 0
|
||||||
|
):
|
||||||
|
reward = all_reduce_mean(reward.mean(), self.plugin)
|
||||||
|
format_acc = all_reduce_mean(format_acc.mean(), self.plugin)
|
||||||
|
ans_acc = all_reduce_mean(ans_acc.mean(), self.plugin)
|
||||||
|
advantages = all_reduce_mean(advantages.mean(), self.plugin)
|
||||||
|
response_length = all_reduce_mean(response_length.mean(), self.plugin)
|
||||||
|
entropy = all_reduce_mean(torch.cat(mini_batch_entropies, dim=0).mean(), self.plugin)
|
||||||
|
self.accum_loss.add_(sum(mean_loss) / len(mean_loss))
|
||||||
|
self.accum_entropy.add_(entropy.data)
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
self.accum_kl.add_(sum(mean_kl) / len(mean_kl))
|
||||||
|
self.accum_advantages.add_(advantages.data)
|
||||||
|
self.accum_count += 1
|
||||||
|
if need_update:
|
||||||
|
self.optimizer.step()
|
||||||
|
self.optimizer.zero_grad()
|
||||||
|
self.global_step += 1
|
||||||
|
if self.lr_scheduler is not None:
|
||||||
|
self.lr_scheduler.step()
|
||||||
|
# no need to run all reduce as raw_train_batch_* are not splited across dp rank
|
||||||
|
sample_utilization = self.effective_sample_count / len(self.raw_train_batch_reward) / self.num_generations
|
||||||
|
self.effective_prompt_count = 0
|
||||||
|
self.effective_sample_count = 0
|
||||||
|
loss_scalar = self.accum_loss.item()
|
||||||
|
if not self.plugin.pp_size > 1 or (
|
||||||
|
self.plugin.pp_size > 1 and self.booster.plugin.stage_manager.is_last_stage() and self.tp_rank == 0
|
||||||
|
):
|
||||||
|
if (not self.plugin.pp_size > 1 and self.rank == 0) or (
|
||||||
|
self.plugin.pp_size > 1 and self.booster.plugin.stage_manager.is_last_stage() and self.tp_rank == 0
|
||||||
|
):
|
||||||
|
raw_batch_reward_mean = torch.cat(self.raw_train_batch_reward, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_format_acc_mean = torch.cat(self.raw_train_batch_format_acc, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_ans_acc_mean = torch.cat(self.raw_train_batch_ans_acc, dim=0).mean().cpu().item()
|
||||||
|
raw_batch_response_len = torch.cat(self.raw_train_batch_response_len, dim=0)
|
||||||
|
raw_batch_response_len_mean = raw_batch_response_len.mean().cpu().item()
|
||||||
|
overlength_samples_ratio = (
|
||||||
|
(raw_batch_response_len >= action_mask.size(-1)).to(float).mean().cpu().item()
|
||||||
|
) # not an exact figure, but a close estimate
|
||||||
|
self.raw_train_batch_reward = []
|
||||||
|
self.raw_train_batch_format_acc = []
|
||||||
|
self.raw_train_batch_ans_acc = []
|
||||||
|
self.raw_train_batch_response_len = []
|
||||||
|
to_log_msg = [
|
||||||
|
f"Loss: {self.accum_loss.item() / self.accum_count:.4f}",
|
||||||
|
f"Reward: {raw_batch_reward_mean:.4f}",
|
||||||
|
f"format Reward: {raw_batch_format_acc_mean:.4f}",
|
||||||
|
f"Acc Reward: {raw_batch_ans_acc_mean:.4f}",
|
||||||
|
f"Advantages: {self.accum_advantages.item() / self.accum_count:.4f}",
|
||||||
|
f"Response Length: {raw_batch_response_len_mean:.4f}",
|
||||||
|
f"Sample_utilization: {sample_utilization:.4f}",
|
||||||
|
f"Overlength samples ratio: {overlength_samples_ratio:.4f}",
|
||||||
|
f"Entropy: {self.accum_entropy.item() / self.accum_count:.4f}",
|
||||||
|
] + ([f"KL: {self.accum_kl.item() / self.accum_count:.4f}"] if self.policy_loss_fn.beta > 0 else [])
|
||||||
|
print("\n".join(to_log_msg))
|
||||||
|
metrics = {
|
||||||
|
"metrics/reward": raw_batch_reward_mean,
|
||||||
|
"metrics/format_acc": raw_batch_format_acc_mean,
|
||||||
|
"metrics/ans_acc": raw_batch_ans_acc_mean,
|
||||||
|
"metrics/response_length": raw_batch_response_len_mean,
|
||||||
|
"train/loss": self.accum_loss.item() / self.accum_count,
|
||||||
|
"train/advantages": self.accum_advantages.item() / self.accum_count,
|
||||||
|
"train/learning_rate": self.lr_scheduler.get_last_lr()[0],
|
||||||
|
"train/sample_utilization": sample_utilization,
|
||||||
|
"train/entropy": self.accum_entropy.item() / self.accum_count,
|
||||||
|
"train/overlength_samples_ratio": overlength_samples_ratio,
|
||||||
|
"rollout/temperature": data["temperature"].cpu().numpy()[0][0],
|
||||||
|
}
|
||||||
|
if self.policy_loss_fn.beta > 0:
|
||||||
|
metrics["train/kl"] = self.accum_kl.item() / self.accum_count
|
||||||
|
if self.wandb_run is not None:
|
||||||
|
self.wandb_run.log(metrics)
|
||||||
|
ray.get(self.shared_signal_actor.set_signal.remote("sample_utilization", sample_utilization))
|
||||||
|
self.accum_loss.zero_()
|
||||||
|
self.accum_kl.zero_()
|
||||||
|
self.accum_entropy.zero_()
|
||||||
|
self.accum_advantages.zero_()
|
||||||
|
self.accum_count = 0
|
||||||
|
return loss_scalar
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
def state_dict(self):
|
||||||
|
self.policy_model._force_wait_all_gather()
|
||||||
|
model = self.policy_model.unwrap()
|
||||||
|
state_dict = model.state_dict()
|
||||||
|
return state_dict
|
||||||
@@ -0,0 +1,540 @@
|
|||||||
|
import copy
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
from typing import Any, Dict, Optional
|
||||||
|
|
||||||
|
import ray
|
||||||
|
import ray.util.collective as cc
|
||||||
|
import torch
|
||||||
|
import tqdm
|
||||||
|
import wandb
|
||||||
|
from coati.dataset.loader import RawConversationDataset, collate_fn_grpo
|
||||||
|
from coati.distributed.comm import SharedVariableActor, ray_broadcast_tensor_dict
|
||||||
|
from coati.distributed.inference_backend import BACKEND_MAP
|
||||||
|
from coati.distributed.profiling_utils import CustomProfiler
|
||||||
|
from coati.distributed.reward.reward_fn import boxed_math_reward_fn, code_reward_fn, math_reward_fn
|
||||||
|
from coati.distributed.reward.verifiable_reward import VerifiableReward
|
||||||
|
from coati.distributed.utils import pre_send, safe_append_to_jsonl_file
|
||||||
|
from ray.util.collective import allreduce
|
||||||
|
from ray.util.collective.types import ReduceOp
|
||||||
|
from torch.utils.data import DataLoader, DistributedSampler
|
||||||
|
from transformers import AutoTokenizer
|
||||||
|
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
try:
|
||||||
|
from vllm import SamplingParams
|
||||||
|
except ImportError:
|
||||||
|
LLM = None
|
||||||
|
|
||||||
|
|
||||||
|
class BaseProducer:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
shared_sync_data_actor: SharedVariableActor,
|
||||||
|
shared_signal_actor: SharedVariableActor,
|
||||||
|
producer_idx: int,
|
||||||
|
num_producers: int,
|
||||||
|
num_consumer_procs: int,
|
||||||
|
num_episodes: int,
|
||||||
|
batch_size: int,
|
||||||
|
train_dataset_config: Dict[str, Any],
|
||||||
|
model_config: Dict[str, Any],
|
||||||
|
generate_config: Dict[str, Any],
|
||||||
|
tokenizer_config: Optional[Dict[str, Any]] = None,
|
||||||
|
microbatch_size: int = 1,
|
||||||
|
backend: str = "transformers",
|
||||||
|
consumer_plugin_config: Dict[str, Any] = None,
|
||||||
|
eval_dataset_config=None,
|
||||||
|
eval_interval=-1, # disable evaluation
|
||||||
|
grpo_config: Dict[str, Any] = None,
|
||||||
|
eval_save_dir: str = "./eval",
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_log_file: str = "./rollout_log.jsonl",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
):
|
||||||
|
self.producer_idx = producer_idx
|
||||||
|
self.num_producers = num_producers
|
||||||
|
self.num_consumer_procs = num_consumer_procs
|
||||||
|
self.num_episodes = num_episodes
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.microbatch_size = microbatch_size
|
||||||
|
assert batch_size % microbatch_size == 0
|
||||||
|
self.num_microbatches = batch_size // microbatch_size
|
||||||
|
self.latest_eval_step = -1
|
||||||
|
self.profiler = CustomProfiler(f"P{self.producer_idx}", disabled=not enable_profiling)
|
||||||
|
|
||||||
|
# for async data and model sync
|
||||||
|
self.shared_sync_data_actor = shared_sync_data_actor
|
||||||
|
self.shared_signal_actor = shared_signal_actor
|
||||||
|
self.sync_model_thread_started = False
|
||||||
|
|
||||||
|
self.train_dataset_config = train_dataset_config
|
||||||
|
self.model_config = model_config
|
||||||
|
self.generate_config = generate_config
|
||||||
|
self.tokenizer_config = tokenizer_config
|
||||||
|
self.consumer_plugin_config = consumer_plugin_config
|
||||||
|
self.eval_interval = eval_interval
|
||||||
|
self.eval_save_dir = eval_save_dir
|
||||||
|
self.consumer_global_step = 0
|
||||||
|
self.producer_weight_version = 0
|
||||||
|
self.eval_mode = False
|
||||||
|
self.log_rollout_interval = log_rollout_interval
|
||||||
|
self.latest_rollout_log_step = -1
|
||||||
|
self.grpo_config = grpo_config
|
||||||
|
reward_model_kwargs = {
|
||||||
|
k: v
|
||||||
|
for k, v in grpo_config.items()
|
||||||
|
if k in ["soft_over_length_punishment", "max_new_tokens", "cache_length"]
|
||||||
|
}
|
||||||
|
self.response_format_tags = grpo_config.get("response_format_tags", None)
|
||||||
|
if producer_idx == 0:
|
||||||
|
if os.path.exists(rollout_log_file):
|
||||||
|
raise ValueError(
|
||||||
|
f"Rollout log file {rollout_log_file} already exists. Please delete it or change the name."
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
os.makedirs(os.path.dirname(rollout_log_file), exist_ok=True)
|
||||||
|
self.rollout_log_file = open(rollout_log_file, "w", encoding="utf8")
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run = wandb.init(
|
||||||
|
project=project_name,
|
||||||
|
sync_tensorboard=False,
|
||||||
|
dir="./wandb",
|
||||||
|
name=run_name + "_eval",
|
||||||
|
group=wandb_group_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
if os.path.exists(self.eval_save_dir) and self.eval_interval > 0:
|
||||||
|
raise ValueError(f"Eval save dir {self.eval_save_dir} already exists. Please delete it or change the name.")
|
||||||
|
|
||||||
|
# init tokenizer
|
||||||
|
if tokenizer_config is None:
|
||||||
|
tokenizer_path = model_config["path"]
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
|
||||||
|
else:
|
||||||
|
tokenizer_path = tokenizer_config.pop("path")
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, **tokenizer_config)
|
||||||
|
self.tokenizer.padding_side = "left"
|
||||||
|
|
||||||
|
# init dataloader
|
||||||
|
train_dataset_path = train_dataset_config.pop("path")
|
||||||
|
self.train_dataset = RawConversationDataset(self.tokenizer, train_dataset_path, **train_dataset_config)
|
||||||
|
self.train_dataloader = DataLoader(
|
||||||
|
self.train_dataset,
|
||||||
|
batch_size=microbatch_size,
|
||||||
|
sampler=DistributedSampler(
|
||||||
|
self.train_dataset,
|
||||||
|
num_replicas=num_producers,
|
||||||
|
rank=producer_idx,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
seed=42,
|
||||||
|
),
|
||||||
|
num_workers=4,
|
||||||
|
drop_last=True,
|
||||||
|
collate_fn=collate_fn_grpo,
|
||||||
|
)
|
||||||
|
if grpo_config["reward_fn_type"] == "think_answer_tags":
|
||||||
|
self.evaluation_function = math_reward_fn
|
||||||
|
elif grpo_config["reward_fn_type"] == "boxed":
|
||||||
|
self.evaluation_function = boxed_math_reward_fn
|
||||||
|
elif grpo_config["reward_fn_type"] == "code":
|
||||||
|
self.evaluation_function = code_reward_fn
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown evaluation function type {grpo_config['reward_fn_type']}")
|
||||||
|
|
||||||
|
self.eval_dataset_config = eval_dataset_config
|
||||||
|
if self.eval_dataset_config is not None:
|
||||||
|
self.eval_dataloaders = {}
|
||||||
|
for eval_task_name in self.eval_dataset_config:
|
||||||
|
eval_dataset_path = eval_dataset_config[eval_task_name].pop("path")
|
||||||
|
eval_dataset = RawConversationDataset(
|
||||||
|
self.tokenizer, eval_dataset_path, **eval_dataset_config[eval_task_name]
|
||||||
|
)
|
||||||
|
print(f"[P{self.producer_idx}] eval dataset {eval_task_name} size: {len(eval_dataset)}")
|
||||||
|
self.eval_dataloaders[eval_task_name] = DataLoader(
|
||||||
|
eval_dataset,
|
||||||
|
batch_size=microbatch_size,
|
||||||
|
sampler=DistributedSampler(
|
||||||
|
eval_dataset,
|
||||||
|
num_replicas=num_producers,
|
||||||
|
rank=producer_idx,
|
||||||
|
shuffle=False,
|
||||||
|
drop_last=False,
|
||||||
|
seed=42,
|
||||||
|
),
|
||||||
|
collate_fn=collate_fn_grpo,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print("No eval dataset provided, skip eval")
|
||||||
|
self.device = get_current_device()
|
||||||
|
self.reward_model = VerifiableReward(
|
||||||
|
reward_fns=[self.evaluation_function], # multiple reward functions can be added here
|
||||||
|
tokenizer=self.tokenizer,
|
||||||
|
tags=self.response_format_tags,
|
||||||
|
**reward_model_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
# init backend
|
||||||
|
if backend in BACKEND_MAP:
|
||||||
|
self.backend_cls = BACKEND_MAP[backend]
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unexpected backend {backend}")
|
||||||
|
|
||||||
|
self.consumer_pp_size = consumer_plugin_config.get("pp_size", 1) # consumer pp size
|
||||||
|
self.state_dict_cpu = {i: None for i in range(self.consumer_pp_size)}
|
||||||
|
|
||||||
|
def init_collective_group(
|
||||||
|
self,
|
||||||
|
world_size: int,
|
||||||
|
rank: int,
|
||||||
|
backend: str = "nccl",
|
||||||
|
group_name: str = "default",
|
||||||
|
gloo_timeout: int = 3000000,
|
||||||
|
):
|
||||||
|
cc.init_collective_group(
|
||||||
|
world_size=world_size, rank=rank, backend=backend, group_name=group_name, gloo_timeout=gloo_timeout
|
||||||
|
)
|
||||||
|
print(f"[P{self.producer_idx}] Initialized {group_name} collective group", flush=True)
|
||||||
|
|
||||||
|
def rollout(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **kwargs) -> Dict[str, torch.Tensor]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict: Dict[str, torch.Tensor]) -> None:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def loop(self) -> None:
|
||||||
|
num_update_per_episode = len(self.train_dataloader) // self.num_microbatches
|
||||||
|
num_valid_microbatches = num_update_per_episode * self.num_microbatches
|
||||||
|
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] num_valid_microbatches {num_valid_microbatches}, nmb: {self.num_microbatches}, dl: {len(self.train_dataloader)}"
|
||||||
|
)
|
||||||
|
for episode in range(self.num_episodes):
|
||||||
|
self.train_dataloader.sampler.set_epoch(episode)
|
||||||
|
for i, batch in enumerate(self.train_dataloader):
|
||||||
|
self.profiler.log(f"train episode {episode} batch {i}")
|
||||||
|
if i >= num_valid_microbatches:
|
||||||
|
break
|
||||||
|
|
||||||
|
self.consumer_global_step = ray.get(self.shared_signal_actor.get_signal.remote()).get("global_step", 0)
|
||||||
|
# sync model first, as the model syncing runs in a separate thread, will not block the main thread
|
||||||
|
# sync model during inference, which takes less than 10s, so that the model can be updated immediately after inference
|
||||||
|
if episode != self.num_episodes - 1 or i != num_valid_microbatches - 1:
|
||||||
|
# don't sync model for last iteration
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]) and self.model.model_config.get(
|
||||||
|
"enable_sleep_mode", False
|
||||||
|
):
|
||||||
|
self.model.llm.sleep() # revict KV_cache to avoid OOM
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
|
||||||
|
# sync model thread function
|
||||||
|
def sync_model_thread():
|
||||||
|
if self.consumer_pp_size > 1:
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
for pp_idx in range(self.consumer_pp_size):
|
||||||
|
ray.get(
|
||||||
|
self.shared_signal_actor.set_signal.remote(
|
||||||
|
f"producer_{self.producer_idx}_pp_{pp_idx}", "ready_sync_model"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
for pp_idx in range(self.consumer_pp_size):
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Sync model PP stage {pp_idx} episode {episode} step {(i + 1) // self.num_microbatches - 1}"
|
||||||
|
)
|
||||||
|
self.state_dict_cpu[pp_idx] = ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu[pp_idx],
|
||||||
|
1,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_producer_{self.producer_idx}_pp_{pp_idx}",
|
||||||
|
backend="gloo", # use gloo for CPU communication
|
||||||
|
pin_memory=True,
|
||||||
|
)
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
else:
|
||||||
|
self.profiler.enter("sync_model")
|
||||||
|
ray.get(
|
||||||
|
self.shared_signal_actor.set_signal.remote(
|
||||||
|
f"producer_{self.producer_idx}", "ready_sync_model"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Sync model episode {episode} step {(i + 1) // self.num_microbatches - 1}"
|
||||||
|
)
|
||||||
|
time0 = time.time()
|
||||||
|
self.state_dict_cpu[0] = ray_broadcast_tensor_dict(
|
||||||
|
self.state_dict_cpu[0],
|
||||||
|
1,
|
||||||
|
device=torch.device("cpu"),
|
||||||
|
group_name=f"sync_model_producer_{self.producer_idx}",
|
||||||
|
backend="gloo", # use gloo for CPU communication
|
||||||
|
pin_memory=True,
|
||||||
|
)
|
||||||
|
self.profiler.log(f"Broadcast model state dict took {time.time() - time0:.2f} seconds")
|
||||||
|
self.profiler.exit("sync_model")
|
||||||
|
self.sync_model_thread_started = False
|
||||||
|
|
||||||
|
distributor_weight_version = ray.get(self.shared_signal_actor.get_signal.remote()).get(
|
||||||
|
f"distributor_weight_version", 0
|
||||||
|
)
|
||||||
|
if (
|
||||||
|
not self.sync_model_thread_started
|
||||||
|
and distributor_weight_version != self.producer_weight_version
|
||||||
|
):
|
||||||
|
# only sync model when the thread is not started and global step is changed
|
||||||
|
self.sync_model_thread_started = True
|
||||||
|
self.sync_model_thread = threading.Thread(target=sync_model_thread)
|
||||||
|
self.producer_weight_version = distributor_weight_version
|
||||||
|
self.sync_model_thread.start()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]) and self.model.model_config.get(
|
||||||
|
"enable_sleep_mode", False
|
||||||
|
):
|
||||||
|
self.model.llm.wake_up()
|
||||||
|
|
||||||
|
if self.eval_interval > 0 and self.eval_dataset_config is not None:
|
||||||
|
if (
|
||||||
|
self.consumer_global_step - self.latest_eval_step >= self.eval_interval
|
||||||
|
and self.consumer_global_step > self.latest_eval_step
|
||||||
|
) or self.latest_eval_step == -1:
|
||||||
|
to_log_msg = {}
|
||||||
|
self.eval_mode = True
|
||||||
|
for eval_task_name in self.eval_dataloaders:
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}] Evaluate model at training step {self.consumer_global_step} on task {eval_task_name}"
|
||||||
|
)
|
||||||
|
eval_results = []
|
||||||
|
eval_statistics_tensor = torch.zeros((2,), dtype=torch.float32).to(self.device)
|
||||||
|
for eval_batch in tqdm.tqdm(
|
||||||
|
self.eval_dataloaders[eval_task_name], disable=self.producer_idx != 0
|
||||||
|
):
|
||||||
|
eval_outputs = self.rollout(**eval_batch, sample_params=self.eval_sample_params)
|
||||||
|
eval_results = eval_results + [
|
||||||
|
self.evaluation_function(
|
||||||
|
eval_outputs["input_ids"][m][n],
|
||||||
|
eval_outputs[
|
||||||
|
(
|
||||||
|
"test_cases"
|
||||||
|
if self.grpo_config["reward_fn_type"] == "code"
|
||||||
|
else "gt_answer"
|
||||||
|
)
|
||||||
|
][m],
|
||||||
|
eval_outputs["response_idx"][m][n],
|
||||||
|
tokenizer=self.tokenizer,
|
||||||
|
eval_mode=True,
|
||||||
|
tags=self.response_format_tags,
|
||||||
|
)
|
||||||
|
for m in range(eval_outputs["input_ids"].size(0))
|
||||||
|
for n in range(eval_outputs["input_ids"].size(1))
|
||||||
|
]
|
||||||
|
eval_statistics_tensor[0] += len([res for res in eval_results if res["ans_valid"] == 1])
|
||||||
|
eval_statistics_tensor[1] += len(eval_results)
|
||||||
|
allreduce(eval_statistics_tensor, op=ReduceOp.SUM, group_name="producer_pg")
|
||||||
|
to_log_msg[f"eval/{eval_task_name}"] = (
|
||||||
|
eval_statistics_tensor[0].item() / eval_statistics_tensor[1].item()
|
||||||
|
)
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
print(
|
||||||
|
f"[P{self.producer_idx}]: Accuracy on {eval_task_name}: {to_log_msg[f'eval/{eval_task_name}']}"
|
||||||
|
)
|
||||||
|
# save eval results
|
||||||
|
safe_append_to_jsonl_file(
|
||||||
|
os.path.join(
|
||||||
|
self.eval_save_dir,
|
||||||
|
f"{eval_task_name}_training_step_{self.consumer_global_step}.jsonl",
|
||||||
|
),
|
||||||
|
eval_results,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run.log(to_log_msg, step=self.consumer_global_step)
|
||||||
|
self.eval_mode = False
|
||||||
|
self.latest_eval_step = self.consumer_global_step
|
||||||
|
self.profiler.enter("sleep")
|
||||||
|
while not (ray.get(self.shared_sync_data_actor.pickup_rollout_task.remote(self.microbatch_size))):
|
||||||
|
time.sleep(1)
|
||||||
|
self.profiler.exit("sleep")
|
||||||
|
self.profiler.enter("rollout")
|
||||||
|
self.profiler.log(f"rollout batch {i} episode {episode}")
|
||||||
|
# time.sleep(30) # simulate long inference time
|
||||||
|
outputs = self.rollout(**batch)
|
||||||
|
self.profiler.exit("rollout")
|
||||||
|
outputs["temperature"] = torch.tensor(
|
||||||
|
[self.model.generate_config["temperature"]] * outputs["input_ids"].size(0)
|
||||||
|
).to(outputs["input_ids"].device)
|
||||||
|
bs, num_gen = outputs["input_ids"].size(0), outputs["input_ids"].size(1)
|
||||||
|
self.profiler.enter("calculate_reward")
|
||||||
|
if self.grpo_config["reward_fn_type"] == "code":
|
||||||
|
test_cases = []
|
||||||
|
for prompt_id in range(bs):
|
||||||
|
test_cases.extend([outputs["test_cases"][prompt_id]] * num_gen)
|
||||||
|
reward_model_output = self.reward_model(
|
||||||
|
outputs["input_ids"].view((-1, outputs["input_ids"].size(-1))),
|
||||||
|
test_cases=test_cases,
|
||||||
|
response_idx=outputs["response_idx"].view((-1, 2)),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
gt_answer = []
|
||||||
|
for prompt_id in range(bs):
|
||||||
|
gt_answer.extend([outputs["gt_answer"][prompt_id]] * num_gen)
|
||||||
|
reward_model_output = self.reward_model(
|
||||||
|
outputs["input_ids"].view((-1, outputs["input_ids"].size(-1))),
|
||||||
|
gt_answer=gt_answer,
|
||||||
|
response_idx=outputs["response_idx"].view((-1, 2)),
|
||||||
|
)
|
||||||
|
outputs["reward"] = (
|
||||||
|
torch.tensor([value[0] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
outputs["format_acc"] = (
|
||||||
|
torch.tensor([value[1] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
outputs["ans_acc"] = (
|
||||||
|
torch.tensor([value[2] for value in reward_model_output])
|
||||||
|
.to(outputs["input_ids"].device)
|
||||||
|
.view((bs, num_gen, 1))
|
||||||
|
)
|
||||||
|
if "gt_answer" in outputs:
|
||||||
|
outputs.pop("gt_answer")
|
||||||
|
if "test_cases" in outputs:
|
||||||
|
outputs.pop("test_cases")
|
||||||
|
self.profiler.exit("calculate_reward")
|
||||||
|
|
||||||
|
print(f"[P{self.producer_idx}] Send data {[(k, v.shape) for k, v in outputs.items()]}")
|
||||||
|
outputs = pre_send(outputs)
|
||||||
|
outputs = {k: v.cpu() for k, v in outputs.items()}
|
||||||
|
self.profiler.enter("send_data")
|
||||||
|
|
||||||
|
ray.get(self.shared_sync_data_actor.append_data.remote(outputs))
|
||||||
|
self.profiler.exit("send_data")
|
||||||
|
|
||||||
|
if (i + 1) % self.num_microbatches == 0 and (
|
||||||
|
episode != self.num_episodes - 1 or i != num_valid_microbatches - 1
|
||||||
|
):
|
||||||
|
if not self.sync_model_thread_started:
|
||||||
|
# load state dict, note this should be done in the main thread to avoid race condition
|
||||||
|
for pp_idx in range(self.consumer_pp_size):
|
||||||
|
if self.state_dict_cpu[pp_idx] is not None and self.state_dict_cpu[pp_idx] != {}:
|
||||||
|
self.load_state_dict(self.state_dict_cpu[pp_idx])
|
||||||
|
|
||||||
|
# linear annealing for 1 episode, temperature from initial to 0.9
|
||||||
|
if episode <= 0:
|
||||||
|
ratio = 1 - (len(self.train_dataloader) - i) / len(self.train_dataloader)
|
||||||
|
self.model.generate_config["temperature"] = (1 - ratio) * self.generate_config[
|
||||||
|
"temperature"
|
||||||
|
] + ratio * 0.9
|
||||||
|
if isinstance(self.model, BACKEND_MAP["vllm"]):
|
||||||
|
self.model.sample_params.temperature = (1 - ratio) * self.generate_config[
|
||||||
|
"temperature"
|
||||||
|
] + ratio * 0.9
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.profiler.close()
|
||||||
|
|
||||||
|
|
||||||
|
@ray.remote
|
||||||
|
class SimpleProducer(BaseProducer):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
shared_sync_data_actor: SharedVariableActor,
|
||||||
|
shared_signal_actor: SharedVariableActor,
|
||||||
|
producer_idx,
|
||||||
|
num_producers,
|
||||||
|
num_consumer_procs,
|
||||||
|
num_episodes,
|
||||||
|
batch_size,
|
||||||
|
train_dataset_config,
|
||||||
|
model_config,
|
||||||
|
generate_config,
|
||||||
|
tokenizer_config=None,
|
||||||
|
microbatch_size=1,
|
||||||
|
backend="transformers",
|
||||||
|
num_generations: int = 8,
|
||||||
|
consumer_plugin_config=None,
|
||||||
|
eval_dataset_config=None,
|
||||||
|
eval_interval=-1, # disable evaluation
|
||||||
|
grpo_config: Dict[str, Any] = None,
|
||||||
|
eval_save_dir: str = "./eval",
|
||||||
|
eval_generation_config={},
|
||||||
|
project_name: str = None,
|
||||||
|
run_name: str = None,
|
||||||
|
wandb_group_name: str = None,
|
||||||
|
log_rollout_interval: int = 20,
|
||||||
|
rollout_log_file: str = "./rollout_log.jsonl",
|
||||||
|
enable_profiling: bool = False,
|
||||||
|
):
|
||||||
|
super().__init__(
|
||||||
|
shared_sync_data_actor,
|
||||||
|
shared_signal_actor,
|
||||||
|
producer_idx,
|
||||||
|
num_producers,
|
||||||
|
num_consumer_procs,
|
||||||
|
num_episodes,
|
||||||
|
batch_size,
|
||||||
|
train_dataset_config,
|
||||||
|
model_config,
|
||||||
|
generate_config,
|
||||||
|
copy.deepcopy(tokenizer_config),
|
||||||
|
microbatch_size,
|
||||||
|
backend,
|
||||||
|
consumer_plugin_config,
|
||||||
|
eval_dataset_config=eval_dataset_config,
|
||||||
|
eval_interval=eval_interval,
|
||||||
|
grpo_config=grpo_config,
|
||||||
|
eval_save_dir=eval_save_dir,
|
||||||
|
project_name=project_name,
|
||||||
|
run_name=run_name,
|
||||||
|
wandb_group_name=wandb_group_name,
|
||||||
|
log_rollout_interval=log_rollout_interval,
|
||||||
|
rollout_log_file=rollout_log_file,
|
||||||
|
enable_profiling=enable_profiling,
|
||||||
|
)
|
||||||
|
print("tokenizer_config", tokenizer_config)
|
||||||
|
self.model = self.backend_cls(model_config, generate_config, self.tokenizer, num_generations, tokenizer_config)
|
||||||
|
self.eval_generation_config = copy.deepcopy(self.model.generate_config)
|
||||||
|
self.eval_generation_config["n"] = 1 # use 1 generation for evaluation
|
||||||
|
self.eval_generation_config.update(eval_generation_config)
|
||||||
|
self.eval_sample_params = SamplingParams(**self.eval_generation_config)
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def rollout(self, input_ids, attention_mask, **kwargs):
|
||||||
|
rollouts = self.model.generate(input_ids, attention_mask, **kwargs)
|
||||||
|
if self.producer_idx == 0 and not self.eval_mode:
|
||||||
|
if (
|
||||||
|
self.consumer_global_step - self.latest_rollout_log_step >= self.log_rollout_interval
|
||||||
|
or self.latest_rollout_log_step == -1
|
||||||
|
):
|
||||||
|
new_record = (
|
||||||
|
json.dumps(
|
||||||
|
{
|
||||||
|
"train_step": self.consumer_global_step,
|
||||||
|
"rollout": self.tokenizer.batch_decode(
|
||||||
|
rollouts["input_ids"][:, 0], skip_special_tokens=True
|
||||||
|
),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
+ "\n"
|
||||||
|
)
|
||||||
|
self.rollout_log_file.write(new_record)
|
||||||
|
self.rollout_log_file.flush()
|
||||||
|
self.latest_rollout_log_step = self.consumer_global_step
|
||||||
|
return rollouts
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if self.producer_idx == 0:
|
||||||
|
self.wandb_run.finish()
|
||||||
|
if hasattr(self, "rollout_log_file"):
|
||||||
|
self.rollout_log_file.close()
|
||||||
|
|
||||||
|
def load_state_dict(self, state_dict):
|
||||||
|
self.model.load_state_dict(state_dict)
|
||||||
@@ -0,0 +1,2 @@
|
|||||||
|
ray==2.49.2
|
||||||
|
pygloo>=0.2.0 # you need to build from source: https://github.com/ray-project/pygloo commit 82ae2d72222aefcac54a8e88995735ede3abe9cf https://github.com/ray-project/pygloo/blob/main/README.md
|
||||||
@@ -27,6 +27,8 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
|||||||
self.target_device = torch.device(f"cuda:{torch.cuda.current_device()}")
|
self.target_device = torch.device(f"cuda:{torch.cuda.current_device()}")
|
||||||
# TODO(ver217): add prefetch
|
# TODO(ver217): add prefetch
|
||||||
self.items: List[BufferItem] = []
|
self.items: List[BufferItem] = []
|
||||||
|
self.rng_sequence = []
|
||||||
|
self.ptr = 0
|
||||||
|
|
||||||
@torch.no_grad()
|
@torch.no_grad()
|
||||||
def append(self, experience: Experience) -> None:
|
def append(self, experience: Experience) -> None:
|
||||||
@@ -40,6 +42,9 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
|||||||
if samples_to_remove > 0:
|
if samples_to_remove > 0:
|
||||||
logger.warning(f"Experience buffer is full. Removing {samples_to_remove} samples.")
|
logger.warning(f"Experience buffer is full. Removing {samples_to_remove} samples.")
|
||||||
self.items = self.items[samples_to_remove:]
|
self.items = self.items[samples_to_remove:]
|
||||||
|
self.rng_sequence = [i for i in range(len(self.items))]
|
||||||
|
random.shuffle(self.rng_sequence)
|
||||||
|
self.ptr = 0
|
||||||
|
|
||||||
def clear(self) -> None:
|
def clear(self) -> None:
|
||||||
self.items.clear()
|
self.items.clear()
|
||||||
@@ -52,7 +57,10 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
|||||||
Returns:
|
Returns:
|
||||||
A batch of sampled experiences.
|
A batch of sampled experiences.
|
||||||
"""
|
"""
|
||||||
items = random.sample(self.items, self.sample_batch_size)
|
items = []
|
||||||
|
for _ in range(self.sample_batch_size):
|
||||||
|
self.ptr = (self.ptr + 1) % len(self.items)
|
||||||
|
items.append(self.items[self.rng_sequence[self.ptr]])
|
||||||
experience = make_experience_batch(items)
|
experience = make_experience_batch(items)
|
||||||
if self.cpu_offload:
|
if self.cpu_offload:
|
||||||
experience.to_device(self.target_device)
|
experience.to_device(self.target_device)
|
||||||
|
|||||||
@@ -2,6 +2,8 @@
|
|||||||
experience maker.
|
experience maker.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
from typing import Any
|
||||||
|
|
||||||
import torch
|
import torch
|
||||||
import torch.nn.functional as F
|
import torch.nn.functional as F
|
||||||
from coati.dataset.utils import find_first_occurrence_subsequence
|
from coati.dataset.utils import find_first_occurrence_subsequence
|
||||||
@@ -38,14 +40,27 @@ class NaiveExperienceMaker(ExperienceMaker):
|
|||||||
kl_coef: float = 0.01,
|
kl_coef: float = 0.01,
|
||||||
gamma: float = 1.0,
|
gamma: float = 1.0,
|
||||||
lam: float = 0.95,
|
lam: float = 0.95,
|
||||||
|
use_grpo: bool = False,
|
||||||
|
num_generation: int = 8,
|
||||||
|
inference_batch_size: int = None,
|
||||||
|
logits_forward_batch_size: int = 2,
|
||||||
) -> None:
|
) -> None:
|
||||||
super().__init__(actor, critic, reward_model, initial_model)
|
super().__init__(actor, critic, reward_model, initial_model)
|
||||||
self.tokenizer = tokenizer
|
self.tokenizer = tokenizer
|
||||||
self.kl_coef = kl_coef
|
self.kl_coef = kl_coef
|
||||||
self.gamma = gamma
|
self.gamma = gamma
|
||||||
self.lam = lam
|
self.lam = lam
|
||||||
|
self.use_grpo = use_grpo
|
||||||
|
self.num_generation = num_generation
|
||||||
|
self.inference_batch_size = inference_batch_size
|
||||||
|
self.logits_forward_batch_size = logits_forward_batch_size
|
||||||
|
if not self.use_grpo:
|
||||||
|
assert self.critic is not None, "Critic model is required for PPO training."
|
||||||
|
else:
|
||||||
|
assert self.critic is None, "Critic model is not required for GRPO training."
|
||||||
|
assert self.num_generation > 1, "Number of generations should be greater than 1 for GRPO training."
|
||||||
|
|
||||||
@torch.no_grad()
|
@torch.inference_mode()
|
||||||
def calculate_advantage(self, value: torch.Tensor, reward: torch.Tensor, num_actions: int) -> torch.Tensor:
|
def calculate_advantage(self, value: torch.Tensor, reward: torch.Tensor, num_actions: int) -> torch.Tensor:
|
||||||
"""
|
"""
|
||||||
Calculates the advantage values for each action based on the value and reward tensors.
|
Calculates the advantage values for each action based on the value and reward tensors.
|
||||||
@@ -69,7 +84,9 @@ class NaiveExperienceMaker(ExperienceMaker):
|
|||||||
return advantages
|
return advantages
|
||||||
|
|
||||||
@torch.no_grad()
|
@torch.no_grad()
|
||||||
def make_experience(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **generate_kwargs) -> Experience:
|
def make_experience(
|
||||||
|
self, input_ids: torch.Tensor, attention_mask: torch.Tensor, gt_answer: Any = None, **generate_kwargs
|
||||||
|
) -> Experience:
|
||||||
"""
|
"""
|
||||||
Generates an experience using the given input_ids and attention_mask.
|
Generates an experience using the given input_ids and attention_mask.
|
||||||
|
|
||||||
@@ -83,98 +100,209 @@ class NaiveExperienceMaker(ExperienceMaker):
|
|||||||
|
|
||||||
"""
|
"""
|
||||||
self.actor.eval()
|
self.actor.eval()
|
||||||
self.critic.eval()
|
if self.critic:
|
||||||
|
self.critic.eval()
|
||||||
self.initial_model.eval()
|
self.initial_model.eval()
|
||||||
self.reward_model.eval()
|
self.reward_model.eval()
|
||||||
pad_token_id = self.tokenizer.pad_token_id
|
pad_token_id = self.tokenizer.pad_token_id
|
||||||
|
|
||||||
stop_token_ids = generate_kwargs.get("stop_token_ids", None)
|
stop_token_ids = generate_kwargs.get("stop_token_ids", None)
|
||||||
|
if isinstance(stop_token_ids, int):
|
||||||
|
stop_token_ids = [[stop_token_ids]]
|
||||||
|
elif isinstance(stop_token_ids[0], int):
|
||||||
|
stop_token_ids = [stop_token_ids]
|
||||||
|
elif isinstance(stop_token_ids[0], list):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"stop_token_ids should be a list of list of integers, a list of integers or an integers. got {stop_token_ids}"
|
||||||
|
)
|
||||||
|
generate_kwargs["stop_token_ids"] = stop_token_ids
|
||||||
|
# Hack: manually initialize cache_position to address transformer version conflict
|
||||||
|
if generate_kwargs.get("cache_position", None) is None and generate_kwargs.get("use_cache", False) is True:
|
||||||
|
generate_kwargs["cache_position"] = torch.arange(
|
||||||
|
0, input_ids.shape[1], dtype=torch.long, device=input_ids.device
|
||||||
|
)
|
||||||
torch.manual_seed(41) # for tp, gurantee the same input for reward model
|
torch.manual_seed(41) # for tp, gurantee the same input for reward model
|
||||||
|
|
||||||
sequences = generate(self.actor, input_ids, self.tokenizer, **generate_kwargs)
|
if self.use_grpo and self.num_generation > 1:
|
||||||
|
# Generate multiple responses for each prompt
|
||||||
|
input_ids = input_ids.repeat_interleave(self.num_generation, dim=0)
|
||||||
|
gt_answer_tmp = []
|
||||||
|
for t in gt_answer:
|
||||||
|
gt_answer_tmp.extend([t] * self.num_generation)
|
||||||
|
gt_answer = gt_answer_tmp
|
||||||
|
if self.inference_batch_size is None:
|
||||||
|
self.inference_batch_size = input_ids.size(0)
|
||||||
|
|
||||||
# Pad to max length
|
batch_sequences = []
|
||||||
sequences = F.pad(sequences, (0, generate_kwargs["max_length"] - sequences.size(1)), value=pad_token_id)
|
batch_input_ids_rm = []
|
||||||
sequence_length = sequences.size(1)
|
batch_attention_mask_rm = []
|
||||||
|
batch_attention_mask = []
|
||||||
|
batch_r = []
|
||||||
|
batch_action_log_probs = []
|
||||||
|
batch_base_action_log_probs = []
|
||||||
|
batch_action_mask = []
|
||||||
|
num_actions = 0
|
||||||
|
|
||||||
# Calculate auxiliary tensors
|
for inference_mini_batch_id in range(0, input_ids.size(0), self.inference_batch_size):
|
||||||
attention_mask = None
|
s, e = inference_mini_batch_id, inference_mini_batch_id + self.inference_batch_size
|
||||||
if pad_token_id is not None:
|
if input_ids[s:e].size(0) == 0:
|
||||||
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
break
|
||||||
|
sequences = generate(self.actor, input_ids[s:e], self.tokenizer, **generate_kwargs)
|
||||||
|
# pad to max_len, you don't want to get an OOM error after a thousands of steps
|
||||||
|
sequences = F.pad(sequences, (0, generate_kwargs["max_length"] - sequences.size(1)), value=pad_token_id)
|
||||||
|
|
||||||
input_len = input_ids.size(1)
|
# Pad to max length
|
||||||
if stop_token_ids is None:
|
sequence_length = sequences.size(1)
|
||||||
# End the sequence with eos token
|
|
||||||
eos_token_id = self.tokenizer.eos_token_id
|
# Calculate auxiliary tensors
|
||||||
if eos_token_id is None:
|
attention_mask = None
|
||||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
if pad_token_id is not None:
|
||||||
else:
|
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
||||||
# Left padding may be applied, only mask action
|
|
||||||
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
input_len = input_ids.size(1)
|
||||||
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
if stop_token_ids is None:
|
||||||
else:
|
# End the sequence with eos token
|
||||||
# stop_token_ids are given, generation ends with stop_token_ids
|
eos_token_id = self.tokenizer.eos_token_id
|
||||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
if eos_token_id is None:
|
||||||
for i in range(sequences.size(0)):
|
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||||
stop_index = find_first_occurrence_subsequence(
|
|
||||||
sequences[i][input_len:], torch.tensor(stop_token_ids).to(sequences.device)
|
|
||||||
)
|
|
||||||
if stop_index == -1:
|
|
||||||
# Sequence does not contain stop_token_ids, this should never happen BTW
|
|
||||||
logger.warning(
|
|
||||||
"Generated sequence does not contain stop_token_ids. Please check your chat template config"
|
|
||||||
)
|
|
||||||
else:
|
else:
|
||||||
# Keep stop tokens
|
# Left padding may be applied, only mask action
|
||||||
stop_index = input_len + stop_index
|
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
||||||
action_mask[i, stop_index + len(stop_token_ids) :] = False
|
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
||||||
|
|
||||||
generation_end_index = (action_mask == True).sum(dim=-1) - 1
|
|
||||||
action_mask[:, :input_len] = False
|
|
||||||
action_mask = action_mask[:, 1:]
|
|
||||||
action_mask = action_mask[:, -(sequences.size(1) - input_len) :]
|
|
||||||
num_actions = action_mask.size(1)
|
|
||||||
|
|
||||||
actor_output = self.actor(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
|
||||||
action_log_probs = calc_action_log_probs(actor_output, sequences, num_actions)
|
|
||||||
|
|
||||||
base_model_output = self.initial_model(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
|
||||||
|
|
||||||
base_action_log_probs = calc_action_log_probs(base_model_output, sequences, num_actions)
|
|
||||||
|
|
||||||
# Convert to right padding for the reward model and the critic model
|
|
||||||
input_ids_rm = torch.zeros_like(sequences, device=sequences.device)
|
|
||||||
attention_mask_rm = torch.zeros_like(sequences, device=sequences.device)
|
|
||||||
for i in range(sequences.size(0)):
|
|
||||||
sequence = sequences[i]
|
|
||||||
bos_index = (sequence != pad_token_id).nonzero().reshape([-1])[0]
|
|
||||||
eos_index = generation_end_index[i]
|
|
||||||
sequence_to_pad = sequence[bos_index:eos_index]
|
|
||||||
sequence_padded = F.pad(
|
|
||||||
sequence_to_pad, (0, sequence_length - sequence_to_pad.size(0)), value=self.tokenizer.pad_token_id
|
|
||||||
)
|
|
||||||
input_ids_rm[i] = sequence_padded
|
|
||||||
if sequence_length - sequence_to_pad.size(0) > 0:
|
|
||||||
attention_mask_rm[i, : sequence_to_pad.size(0) + 1] = 1
|
|
||||||
else:
|
else:
|
||||||
attention_mask_rm[i, :] = 1
|
# stop_token_ids are given, generation ends with stop_token_ids
|
||||||
attention_mask_rm = attention_mask_rm.to(dtype=torch.bool)
|
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||||
|
for i in range(sequences.size(0)):
|
||||||
|
stop_token_pos = [
|
||||||
|
find_first_occurrence_subsequence(
|
||||||
|
sequences[i][input_len:], torch.tensor(stop_token_id).to(sequences.device)
|
||||||
|
)
|
||||||
|
for stop_token_id in stop_token_ids
|
||||||
|
]
|
||||||
|
stop_index = min([i for i in stop_token_pos if i != -1], default=-1)
|
||||||
|
stop_token_id = stop_token_ids[stop_token_pos.index(stop_index)]
|
||||||
|
if stop_index == -1:
|
||||||
|
# Sequence does not contain stop_token_ids, this should never happen BTW
|
||||||
|
logger.warning(
|
||||||
|
"Generated sequence does not contain stop_token_ids. Please check your chat template config"
|
||||||
|
)
|
||||||
|
print(self.tokenizer.decode(sequences[i], skip_special_tokens=True))
|
||||||
|
else:
|
||||||
|
# Keep stop tokens
|
||||||
|
stop_index = input_len + stop_index
|
||||||
|
action_mask[i, stop_index + len(stop_token_id) :] = False
|
||||||
|
|
||||||
r = self.reward_model(
|
generation_end_index = (action_mask == True).sum(dim=-1) - 1
|
||||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
action_mask[:, :input_len] = False
|
||||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
action_mask = action_mask[:, 1:]
|
||||||
)
|
action_mask = action_mask[:, -(sequences.size(1) - input_len) :]
|
||||||
|
num_actions = action_mask.size(1)
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
with torch.inference_mode():
|
||||||
|
actor_output = []
|
||||||
|
base_model_output = []
|
||||||
|
for i in range(0, sequences.size(0), self.logits_forward_batch_size):
|
||||||
|
actor_output.append(
|
||||||
|
self.actor(
|
||||||
|
input_ids=sequences[i : i + self.logits_forward_batch_size],
|
||||||
|
attention_mask=attention_mask[i : i + self.logits_forward_batch_size],
|
||||||
|
use_cache=False,
|
||||||
|
)["logits"]
|
||||||
|
)
|
||||||
|
base_model_output.append(
|
||||||
|
self.initial_model(
|
||||||
|
input_ids=sequences[i : i + self.logits_forward_batch_size],
|
||||||
|
attention_mask=attention_mask[i : i + self.logits_forward_batch_size],
|
||||||
|
use_cache=False,
|
||||||
|
)["logits"]
|
||||||
|
)
|
||||||
|
actor_output = torch.cat(actor_output, dim=0)
|
||||||
|
base_model_output = torch.cat(base_model_output, dim=0)
|
||||||
|
action_log_probs = calc_action_log_probs(actor_output, sequences, num_actions)
|
||||||
|
base_action_log_probs = calc_action_log_probs(base_model_output, sequences, num_actions)
|
||||||
|
|
||||||
value = self.critic(
|
# Convert to right padding for the reward model and the critic model
|
||||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
input_ids_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
response_start = []
|
||||||
)
|
response_end = []
|
||||||
reward, kl = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
|
attention_mask_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||||
value = value[:, -num_actions:] * action_mask
|
for i in range(sequences.size(0)):
|
||||||
advantages = self.calculate_advantage(value, reward, num_actions)
|
sequence = sequences[i]
|
||||||
|
bos_index = (sequence != pad_token_id).nonzero().reshape([-1])[0]
|
||||||
|
eos_index = generation_end_index[i] + 1 # include the stop token
|
||||||
|
sequence_to_pad = sequence[bos_index:eos_index]
|
||||||
|
response_start.append(input_len - bos_index)
|
||||||
|
response_end.append(eos_index - bos_index)
|
||||||
|
sequence_padded = F.pad(
|
||||||
|
sequence_to_pad, (0, sequence_length - sequence_to_pad.size(0)), value=self.tokenizer.pad_token_id
|
||||||
|
)
|
||||||
|
input_ids_rm[i] = sequence_padded
|
||||||
|
if sequence_length - sequence_to_pad.size(0) > 0:
|
||||||
|
attention_mask_rm[i, : sequence_to_pad.size(0) + 1] = 1
|
||||||
|
else:
|
||||||
|
attention_mask_rm[i, :] = 1
|
||||||
|
attention_mask_rm = attention_mask_rm.to(dtype=torch.bool)
|
||||||
|
|
||||||
advantages = advantages.detach()
|
r = self.reward_model(
|
||||||
value = value.detach()
|
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||||
|
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||||
|
response_start=response_start,
|
||||||
|
response_end=response_end,
|
||||||
|
gt_answer=gt_answer[s:e],
|
||||||
|
)
|
||||||
|
|
||||||
|
batch_sequences.append(sequences)
|
||||||
|
batch_input_ids_rm.append(input_ids_rm)
|
||||||
|
batch_attention_mask_rm.append(attention_mask_rm)
|
||||||
|
batch_attention_mask.append(attention_mask)
|
||||||
|
batch_r.append(r)
|
||||||
|
batch_action_log_probs.append(action_log_probs.cpu())
|
||||||
|
batch_base_action_log_probs.append(base_action_log_probs.cpu())
|
||||||
|
batch_action_mask.append(action_mask)
|
||||||
|
|
||||||
|
sequences = torch.cat(batch_sequences, dim=0)
|
||||||
|
input_ids_rm = torch.cat(batch_input_ids_rm, dim=0)
|
||||||
|
attention_mask_rm = torch.cat(batch_attention_mask_rm, dim=0)
|
||||||
|
attention_mask = torch.cat(batch_attention_mask, dim=0)
|
||||||
|
r = torch.cat(batch_r, dim=0)
|
||||||
|
action_log_probs = torch.cat(batch_action_log_probs, dim=0).to(sequences.device)
|
||||||
|
base_action_log_probs = torch.cat(batch_base_action_log_probs, dim=0).to(sequences.device)
|
||||||
|
action_mask = torch.cat(batch_action_mask, dim=0).to(sequences.device)
|
||||||
|
if not self.use_grpo:
|
||||||
|
value = self.critic(
|
||||||
|
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||||
|
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||||
|
)
|
||||||
|
value = value[:, -num_actions:] * action_mask
|
||||||
|
reward, kl = compute_reward(
|
||||||
|
r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask
|
||||||
|
)
|
||||||
|
advantages = self.calculate_advantage(value, reward, num_actions)
|
||||||
|
advantages = advantages.detach()
|
||||||
|
value = value.detach()
|
||||||
|
else:
|
||||||
|
# GRPO advantage calculation
|
||||||
|
kl = torch.sum(
|
||||||
|
-self.kl_coef * (action_log_probs - base_action_log_probs) * action_mask, dim=-1
|
||||||
|
) / torch.sum(
|
||||||
|
action_mask, dim=-1
|
||||||
|
) # address numerical instability issue
|
||||||
|
r = kl + r
|
||||||
|
mean_gr = r.view(-1, self.num_generation).mean(dim=1)
|
||||||
|
std_gr = r.view(-1, self.num_generation).std(dim=1)
|
||||||
|
mean_gr = mean_gr.repeat_interleave(self.num_generation, dim=0)
|
||||||
|
std_gr = std_gr.repeat_interleave(self.num_generation, dim=0)
|
||||||
|
advantages = (r - mean_gr) / (std_gr + 1e-4)
|
||||||
|
value = r.detach() # dummy value
|
||||||
r = r.detach()
|
r = r.detach()
|
||||||
|
return Experience(
|
||||||
return Experience(sequences, action_log_probs, value, r, kl, advantages, attention_mask, action_mask)
|
sequences.cpu(),
|
||||||
|
action_log_probs.cpu(),
|
||||||
|
value.cpu(),
|
||||||
|
r.cpu(),
|
||||||
|
kl.cpu(),
|
||||||
|
advantages.cpu(),
|
||||||
|
attention_mask.cpu(),
|
||||||
|
action_mask.cpu(),
|
||||||
|
)
|
||||||
|
|||||||
@@ -4,12 +4,14 @@ from .generation import generate, generate_streaming, prepare_inputs_fn, update_
|
|||||||
from .lora import LoraConfig, convert_to_lora_module, lora_manager
|
from .lora import LoraConfig, convert_to_lora_module, lora_manager
|
||||||
from .loss import DpoLoss, KTOLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
|
from .loss import DpoLoss, KTOLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
|
||||||
from .reward_model import RewardModel
|
from .reward_model import RewardModel
|
||||||
|
from .rlvr_reward_model import RLVRRewardModel
|
||||||
from .utils import disable_dropout
|
from .utils import disable_dropout
|
||||||
|
|
||||||
__all__ = [
|
__all__ = [
|
||||||
"BaseModel",
|
"BaseModel",
|
||||||
"Critic",
|
"Critic",
|
||||||
"RewardModel",
|
"RewardModel",
|
||||||
|
"RLVRRewardModel",
|
||||||
"PolicyLoss",
|
"PolicyLoss",
|
||||||
"ValueLoss",
|
"ValueLoss",
|
||||||
"LogSigLoss",
|
"LogSigLoss",
|
||||||
|
|||||||
@@ -1,3 +1,4 @@
|
|||||||
|
import copy
|
||||||
from typing import Any, Callable, List, Optional
|
from typing import Any, Callable, List, Optional
|
||||||
|
|
||||||
import torch
|
import torch
|
||||||
@@ -88,13 +89,14 @@ def update_model_kwargs_fn(outputs: dict, new_mask, **model_kwargs) -> dict:
|
|||||||
return model_kwargs
|
return model_kwargs
|
||||||
|
|
||||||
|
|
||||||
def prepare_inputs_fn(input_ids: torch.Tensor, pad_token_id: int, **model_kwargs) -> dict:
|
def prepare_inputs_fn(input_ids: torch.Tensor, **model_kwargs) -> dict:
|
||||||
model_kwargs["input_ids"] = input_ids
|
model_kwargs["input_ids"] = input_ids
|
||||||
return model_kwargs
|
return model_kwargs
|
||||||
|
|
||||||
|
|
||||||
def _sample(
|
def _sample(
|
||||||
model: Any,
|
model: Any,
|
||||||
|
tokenizer: Any,
|
||||||
input_ids: torch.Tensor,
|
input_ids: torch.Tensor,
|
||||||
max_length: int,
|
max_length: int,
|
||||||
early_stopping: bool = True,
|
early_stopping: bool = True,
|
||||||
@@ -137,8 +139,8 @@ def _sample(
|
|||||||
if max_new_tokens is None:
|
if max_new_tokens is None:
|
||||||
max_new_tokens = max_length - context_length
|
max_new_tokens = max_length - context_length
|
||||||
if context_length + max_new_tokens > max_length or max_new_tokens == 0:
|
if context_length + max_new_tokens > max_length or max_new_tokens == 0:
|
||||||
|
print("Exeeded length limitation")
|
||||||
return input_ids
|
return input_ids
|
||||||
|
|
||||||
logits_processor = _prepare_logits_processor(top_k, top_p, temperature)
|
logits_processor = _prepare_logits_processor(top_k, top_p, temperature)
|
||||||
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
||||||
past = None
|
past = None
|
||||||
@@ -183,18 +185,14 @@ def _sample(
|
|||||||
|
|
||||||
if stop_token_ids is not None:
|
if stop_token_ids is not None:
|
||||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
for stop_token_id in stop_token_ids:
|
||||||
unfinished_sequences = unfinished_sequences.mul(
|
tokens_to_check = input_ids[:, -len(stop_token_id) :]
|
||||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
unfinished_sequences = unfinished_sequences.mul(
|
||||||
)
|
torch.any(tokens_to_check != torch.LongTensor(stop_token_id).to(input_ids.device), dim=1).long()
|
||||||
|
)
|
||||||
|
|
||||||
# Stop when each sentence is finished if early_stopping=True
|
# Stop when each sentence is finished if early_stopping=True
|
||||||
if (early_stopping and _is_sequence_finished(unfinished_sequences)) or i == context_length + max_new_tokens - 1:
|
if (early_stopping and _is_sequence_finished(unfinished_sequences)) or i == context_length + max_new_tokens - 1:
|
||||||
if i == context_length + max_new_tokens - 1:
|
|
||||||
# Force to end with stop token ids
|
|
||||||
input_ids[input_ids[:, -1] != pad_token_id, -len(stop_token_ids) :] = (
|
|
||||||
torch.LongTensor(stop_token_ids).to(input_ids.device).long()
|
|
||||||
)
|
|
||||||
return input_ids
|
return input_ids
|
||||||
|
|
||||||
|
|
||||||
@@ -237,8 +235,10 @@ def generate(
|
|||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
elif is_sample_gen_mode:
|
elif is_sample_gen_mode:
|
||||||
# Run sample
|
# Run sample
|
||||||
|
generation_kwargs = copy.deepcopy(model_kwargs)
|
||||||
res = _sample(
|
res = _sample(
|
||||||
model,
|
model,
|
||||||
|
tokenizer,
|
||||||
input_ids,
|
input_ids,
|
||||||
max_length,
|
max_length,
|
||||||
early_stopping=early_stopping,
|
early_stopping=early_stopping,
|
||||||
@@ -249,8 +249,9 @@ def generate(
|
|||||||
temperature=temperature,
|
temperature=temperature,
|
||||||
prepare_inputs_fn=prepare_inputs_fn,
|
prepare_inputs_fn=prepare_inputs_fn,
|
||||||
update_model_kwargs_fn=update_model_kwargs_fn,
|
update_model_kwargs_fn=update_model_kwargs_fn,
|
||||||
**model_kwargs,
|
**generation_kwargs,
|
||||||
)
|
)
|
||||||
|
del generation_kwargs
|
||||||
return res
|
return res
|
||||||
elif is_beam_gen_mode:
|
elif is_beam_gen_mode:
|
||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
@@ -350,11 +351,17 @@ def _sample_streaming(
|
|||||||
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
|
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
|
||||||
|
|
||||||
if stop_token_ids is not None:
|
if stop_token_ids is not None:
|
||||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
|
||||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
||||||
unfinished_sequences = unfinished_sequences.mul(
|
if isinstance(stop_token_ids[0], int):
|
||||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||||
)
|
unfinished_sequences = unfinished_sequences.mul(
|
||||||
|
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
for stop_token_id in stop_token_ids:
|
||||||
|
unfinished_sequences = unfinished_sequences.mul(
|
||||||
|
torch.any(tokens_to_check != torch.LongTensor(stop_token_id).to(input_ids.device), dim=1).long()
|
||||||
|
)
|
||||||
|
|
||||||
# Stop when each sentence is finished if early_stopping=True
|
# Stop when each sentence is finished if early_stopping=True
|
||||||
if (
|
if (
|
||||||
|
|||||||
@@ -25,7 +25,9 @@ class RewardModel(BaseModel):
|
|||||||
self.value_head = nn.Linear(self.last_hidden_state_size, 1)
|
self.value_head = nn.Linear(self.last_hidden_state_size, 1)
|
||||||
self.value_head.weight.data.normal_(mean=0.0, std=1 / (self.last_hidden_state_size + 1))
|
self.value_head.weight.data.normal_(mean=0.0, std=1 / (self.last_hidden_state_size + 1))
|
||||||
|
|
||||||
def forward(self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
|
def forward(
|
||||||
|
self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None, **kwargs
|
||||||
|
) -> torch.Tensor:
|
||||||
outputs = self.model(input_ids, attention_mask=attention_mask)
|
outputs = self.model(input_ids, attention_mask=attention_mask)
|
||||||
|
|
||||||
last_hidden_states = outputs["last_hidden_state"]
|
last_hidden_states = outputs["last_hidden_state"]
|
||||||
|
|||||||
50
applications/ColossalChat/coati/models/rlvr_reward_model.py
Normal file
50
applications/ColossalChat/coati/models/rlvr_reward_model.py
Normal file
@@ -0,0 +1,50 @@
|
|||||||
|
"""
|
||||||
|
reward model
|
||||||
|
"""
|
||||||
|
|
||||||
|
from typing import Callable, List, Optional
|
||||||
|
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
class RLVRRewardModel:
|
||||||
|
"""
|
||||||
|
RLVRReward model class. Support varifiable reward.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
reward_fn_list List: list of reward functions
|
||||||
|
**kwargs: all other kwargs as in reward functions
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, reward_fn_list: List[Callable], **kwargs) -> None:
|
||||||
|
self.reward_fn_list = reward_fn_list
|
||||||
|
self.kwargs = kwargs
|
||||||
|
|
||||||
|
def __call__(
|
||||||
|
self,
|
||||||
|
input_ids: torch.LongTensor,
|
||||||
|
attention_mask: Optional[torch.Tensor] = None,
|
||||||
|
response_start: List = None,
|
||||||
|
response_end: List = None,
|
||||||
|
gt_answer: List = None,
|
||||||
|
) -> torch.Tensor:
|
||||||
|
# apply varifiable reward
|
||||||
|
bs = input_ids.size(0)
|
||||||
|
rewards = torch.zeros(bs, device=input_ids.device)
|
||||||
|
for i in range(bs):
|
||||||
|
for reward_fn in self.reward_fn_list:
|
||||||
|
rewards[i] += reward_fn(
|
||||||
|
input_ids[i],
|
||||||
|
attention_mask[i],
|
||||||
|
response_start=response_start[i],
|
||||||
|
response_end=response_end[i],
|
||||||
|
gt_answer=gt_answer[i],
|
||||||
|
**self.kwargs,
|
||||||
|
)
|
||||||
|
return rewards
|
||||||
|
|
||||||
|
def to(self, device):
|
||||||
|
return self
|
||||||
|
|
||||||
|
def eval(self):
|
||||||
|
return self
|
||||||
@@ -142,3 +142,17 @@ def disable_dropout(model: torch.nn.Module):
|
|||||||
for module in model.modules():
|
for module in model.modules():
|
||||||
if isinstance(module, torch.nn.Dropout):
|
if isinstance(module, torch.nn.Dropout):
|
||||||
module.p = 0.0
|
module.p = 0.0
|
||||||
|
|
||||||
|
|
||||||
|
def repad_to_left(tensor, tokenizer):
|
||||||
|
repadded_input_ids = []
|
||||||
|
max_non_padded_seq_len = 0
|
||||||
|
for i in range(tensor.size(0)):
|
||||||
|
non_pad_indices = (tensor[i] != tokenizer.pad_token_id).nonzero(as_tuple=True)[0]
|
||||||
|
start, end = non_pad_indices.min(), non_pad_indices.max()
|
||||||
|
repadded_input_ids.append(tensor[i][start : end + 1])
|
||||||
|
max_non_padded_seq_len = max(max_non_padded_seq_len, repadded_input_ids[-1].size(0))
|
||||||
|
repadded_input_ids = [
|
||||||
|
F.pad(t, (max_non_padded_seq_len - t.size(0), 0), value=tokenizer.pad_token_id) for t in repadded_input_ids
|
||||||
|
]
|
||||||
|
return torch.stack(repadded_input_ids)
|
||||||
|
|||||||
@@ -1,26 +0,0 @@
|
|||||||
import openai
|
|
||||||
from openai.types.chat.chat_completion import ChatCompletion
|
|
||||||
from openai.types.chat.chat_completion_message_param import ChatCompletionMessageParam
|
|
||||||
|
|
||||||
API_KEY = "Dummy API Key"
|
|
||||||
|
|
||||||
|
|
||||||
def get_client(base_url: str | None = None) -> openai.Client:
|
|
||||||
return openai.Client(api_key=API_KEY, base_url=base_url)
|
|
||||||
|
|
||||||
|
|
||||||
def chat_completion(
|
|
||||||
messages: list[ChatCompletionMessageParam],
|
|
||||||
model: str,
|
|
||||||
base_url: str | None = None,
|
|
||||||
temperature: float = 0.8,
|
|
||||||
**kwargs,
|
|
||||||
) -> ChatCompletion:
|
|
||||||
client = get_client(base_url)
|
|
||||||
response = client.chat.completions.create(
|
|
||||||
model=model,
|
|
||||||
messages=messages,
|
|
||||||
temperature=temperature,
|
|
||||||
**kwargs,
|
|
||||||
)
|
|
||||||
return response
|
|
||||||
@@ -1,250 +0,0 @@
|
|||||||
"""
|
|
||||||
Implementation of MCTS + Self-refine algorithm.
|
|
||||||
|
|
||||||
Reference:
|
|
||||||
1. "Accessing GPT-4 level Mathematical Olympiad Solutions via Monte
|
|
||||||
Carlo Tree Self-refine with LLaMa-3 8B: A Technical Report"
|
|
||||||
2. https://github.com/BrendanGraham14/mcts-llm/
|
|
||||||
3. https://github.com/trotsky1997/MathBlackBox/
|
|
||||||
4. https://github.com/openreasoner/openr/blob/main/reason/guided_search/tree.py
|
|
||||||
"""
|
|
||||||
|
|
||||||
from __future__ import annotations
|
|
||||||
|
|
||||||
import math
|
|
||||||
from collections import deque
|
|
||||||
|
|
||||||
import numpy as np
|
|
||||||
import tqdm
|
|
||||||
from coati.reasoner.guided_search.llm import chat_completion
|
|
||||||
from coati.reasoner.guided_search.prompt_store.base import PromptCFG
|
|
||||||
from pydantic import BaseModel
|
|
||||||
|
|
||||||
|
|
||||||
class MCTSNode(BaseModel):
|
|
||||||
"""
|
|
||||||
Node for MCTS.
|
|
||||||
"""
|
|
||||||
|
|
||||||
answer: str
|
|
||||||
parent: MCTSNode = None
|
|
||||||
children: list[MCTSNode] = []
|
|
||||||
num_visits: int = 0
|
|
||||||
Q: int = 0
|
|
||||||
rewards: list[int] = []
|
|
||||||
|
|
||||||
def expand_node(self, node) -> None:
|
|
||||||
self.children.append(node)
|
|
||||||
|
|
||||||
def add_reward(self, reward: int) -> None:
|
|
||||||
self.rewards.append(reward)
|
|
||||||
self.Q = (np.min(self.rewards) + np.mean(self.rewards)) / 2
|
|
||||||
|
|
||||||
|
|
||||||
class MCTS(BaseModel):
|
|
||||||
"""
|
|
||||||
Simulation of MCTS process.
|
|
||||||
"""
|
|
||||||
|
|
||||||
problem: str
|
|
||||||
max_simulations: int
|
|
||||||
cfg: PromptCFG
|
|
||||||
C: float = 1.4
|
|
||||||
max_children: int = 2
|
|
||||||
epsilon: float = 1e-5
|
|
||||||
root: MCTSNode = None
|
|
||||||
|
|
||||||
def initialization(self):
|
|
||||||
"""
|
|
||||||
Root Initiation.
|
|
||||||
"""
|
|
||||||
# Simple answer as root. You can also use negative response such as "I do not know" as a response.
|
|
||||||
base_answer = self.sample_base_answer()
|
|
||||||
self.root = MCTSNode(answer=base_answer)
|
|
||||||
self.self_evaluate(self.root)
|
|
||||||
|
|
||||||
def is_fully_expanded(self, node: MCTSNode):
|
|
||||||
return len(node.children) >= self.max_children or any(child.Q > node.Q for child in node.children)
|
|
||||||
|
|
||||||
def select_node(self) -> MCTSNode:
|
|
||||||
"""
|
|
||||||
Select next node to explore.
|
|
||||||
"""
|
|
||||||
candidates: list[MCTSNode] = []
|
|
||||||
to_explore = deque([self.root])
|
|
||||||
|
|
||||||
while to_explore:
|
|
||||||
current_node = to_explore.popleft()
|
|
||||||
if not self.is_fully_expanded(current_node):
|
|
||||||
candidates.append(current_node)
|
|
||||||
to_explore.extend(current_node.children)
|
|
||||||
|
|
||||||
if not candidates:
|
|
||||||
return self.root
|
|
||||||
|
|
||||||
return max(candidates, key=self.compute_uct)
|
|
||||||
|
|
||||||
def self_evaluate(self, node: MCTSNode):
|
|
||||||
"""
|
|
||||||
Sample reward of the answer.
|
|
||||||
"""
|
|
||||||
reward = self.sample_reward(node)
|
|
||||||
node.add_reward(reward)
|
|
||||||
|
|
||||||
def back_propagation(self, node: MCTSNode):
|
|
||||||
"""
|
|
||||||
Back propagate the value of the refined answer.
|
|
||||||
"""
|
|
||||||
parent = node.parent
|
|
||||||
while parent:
|
|
||||||
best_child_Q = max(child.Q for child in parent.children)
|
|
||||||
parent.Q = (parent.Q + best_child_Q) / 2
|
|
||||||
parent.num_visits += 1
|
|
||||||
parent = parent.parent
|
|
||||||
|
|
||||||
def compute_uct(self, node: MCTSNode):
|
|
||||||
"""
|
|
||||||
Compute UCT.
|
|
||||||
"""
|
|
||||||
if node.parent is None:
|
|
||||||
return -100
|
|
||||||
return node.Q + self.C * math.sqrt(math.log(node.parent.num_visits + 1) / (node.num_visits + self.epsilon))
|
|
||||||
|
|
||||||
def simulate(self):
|
|
||||||
self.initialization()
|
|
||||||
for _ in tqdm.tqdm(range(self.max_simulations)):
|
|
||||||
node = self.select_node()
|
|
||||||
child = self.self_refine(node)
|
|
||||||
node.expand_node(child)
|
|
||||||
self.self_evaluate(child)
|
|
||||||
self.back_propagation(child)
|
|
||||||
|
|
||||||
return self.get_best_answer()
|
|
||||||
|
|
||||||
def get_best_answer(self):
|
|
||||||
to_visit = deque([self.root])
|
|
||||||
best_node = self.root
|
|
||||||
|
|
||||||
while to_visit:
|
|
||||||
current_node = to_visit.popleft()
|
|
||||||
if current_node.Q > best_node.Q:
|
|
||||||
best_node = current_node
|
|
||||||
to_visit.extend(current_node.children)
|
|
||||||
|
|
||||||
return best_node.answer
|
|
||||||
|
|
||||||
def self_refine(self, node: MCTSNode):
|
|
||||||
"""
|
|
||||||
Refine node.
|
|
||||||
"""
|
|
||||||
critique_response = chat_completion(
|
|
||||||
messages=[
|
|
||||||
{
|
|
||||||
"role": "system",
|
|
||||||
"content": self.cfg.critic_system_prompt,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"role": "user",
|
|
||||||
"content": "\n\n".join(
|
|
||||||
[
|
|
||||||
f"<problem>\n{self.problem}\n</problem>",
|
|
||||||
f"<current_answer>\n{node.answer}\n</current_answer>",
|
|
||||||
]
|
|
||||||
),
|
|
||||||
},
|
|
||||||
],
|
|
||||||
model=self.cfg.model,
|
|
||||||
base_url=self.cfg.base_url,
|
|
||||||
max_tokens=self.cfg.max_tokens,
|
|
||||||
)
|
|
||||||
critique = critique_response.choices[0].message.content
|
|
||||||
assert critique is not None
|
|
||||||
refined_answer_response = chat_completion(
|
|
||||||
messages=[
|
|
||||||
{
|
|
||||||
"role": "system",
|
|
||||||
"content": self.cfg.refine_system_prompt,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"role": "user",
|
|
||||||
"content": "\n\n".join(
|
|
||||||
[
|
|
||||||
f"<problem>\n{self.problem}\n</problem>",
|
|
||||||
f"<current_answer>\n{node.answer}\n</current_answer>",
|
|
||||||
f"<critique>\n{critique}\n</critique>",
|
|
||||||
]
|
|
||||||
),
|
|
||||||
},
|
|
||||||
],
|
|
||||||
model=self.cfg.model,
|
|
||||||
base_url=self.cfg.base_url,
|
|
||||||
max_tokens=self.cfg.max_tokens,
|
|
||||||
)
|
|
||||||
refined_answer = refined_answer_response.choices[0].message.content
|
|
||||||
assert refined_answer is not None
|
|
||||||
|
|
||||||
return MCTSNode(answer=refined_answer, parent=node)
|
|
||||||
|
|
||||||
def sample_base_answer(self):
|
|
||||||
response = chat_completion(
|
|
||||||
messages=[
|
|
||||||
{
|
|
||||||
"role": "system",
|
|
||||||
"content": self.cfg.base_system_prompt,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"role": "user",
|
|
||||||
"content": f"<problem>\n {self.problem} \n</problem> \nLet's think step by step",
|
|
||||||
},
|
|
||||||
],
|
|
||||||
model=self.cfg.model,
|
|
||||||
base_url=self.cfg.base_url,
|
|
||||||
max_tokens=self.cfg.max_tokens,
|
|
||||||
)
|
|
||||||
assert response.choices[0].message.content is not None
|
|
||||||
return response.choices[0].message.content
|
|
||||||
|
|
||||||
def sample_reward(self, node: MCTSNode):
|
|
||||||
"""
|
|
||||||
Calculate reward.
|
|
||||||
"""
|
|
||||||
messages = [
|
|
||||||
{
|
|
||||||
"role": "system",
|
|
||||||
"content": self.cfg.evaluate_system_prompt,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"role": "user",
|
|
||||||
"content": "\n\n".join(
|
|
||||||
[
|
|
||||||
f"<problem>\n{self.problem}\n</problem>",
|
|
||||||
f"<answer>\n{node.answer}\n</answer>",
|
|
||||||
]
|
|
||||||
),
|
|
||||||
},
|
|
||||||
]
|
|
||||||
for attempt in range(3):
|
|
||||||
try:
|
|
||||||
response = chat_completion(
|
|
||||||
messages=messages,
|
|
||||||
model=self.cfg.model,
|
|
||||||
base_url=self.cfg.base_url,
|
|
||||||
max_tokens=self.cfg.max_tokens,
|
|
||||||
)
|
|
||||||
assert response.choices[0].message.content is not None
|
|
||||||
return int(response.choices[0].message.content)
|
|
||||||
except ValueError:
|
|
||||||
messages.extend(
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"role": "assistant",
|
|
||||||
"content": response.choices[0].message.content,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"role": "user",
|
|
||||||
"content": "Failed to parse reward as an integer.",
|
|
||||||
},
|
|
||||||
]
|
|
||||||
)
|
|
||||||
if attempt == 2:
|
|
||||||
raise
|
|
||||||
@@ -1,11 +0,0 @@
|
|||||||
from pydantic import BaseModel
|
|
||||||
|
|
||||||
|
|
||||||
class PromptCFG(BaseModel):
|
|
||||||
model: str
|
|
||||||
base_url: str
|
|
||||||
max_tokens: int = 4096
|
|
||||||
base_system_prompt: str
|
|
||||||
critic_system_prompt: str
|
|
||||||
refine_system_prompt: str
|
|
||||||
evaluate_system_prompt: str
|
|
||||||
@@ -1,22 +0,0 @@
|
|||||||
"""
|
|
||||||
Prompts for Qwen Series.
|
|
||||||
"""
|
|
||||||
|
|
||||||
from coati.reasoner.guided_search.prompt_store.base import PromptCFG
|
|
||||||
|
|
||||||
Qwen32B_prompt_CFG = PromptCFG(
|
|
||||||
base_url="http://0.0.0.0:8008/v1",
|
|
||||||
model="Qwen2.5-32B-Instruct",
|
|
||||||
base_system_prompt="The user will present a problem. Analyze and solve the problem in the following structure:\n"
|
|
||||||
"Begin with [Reasoning Process] to explain the approach. \n Proceed with [Verification] to confirm the solution. \n Conclude with [Final Answer] in the format: 'Answer: [answer]'",
|
|
||||||
critic_system_prompt="Provide a detailed and constructive critique of the answer, focusing on ways to improve its clarity, accuracy, and relevance."
|
|
||||||
"Highlight specific areas that need refinement or correction, and offer concrete suggestions for enhancing the overall quality and effectiveness of the response.",
|
|
||||||
refine_system_prompt="""# Instruction
|
|
||||||
Refine the answer based on the critique. The response should begin with [reasoning process]...[Verification]... and end with [Final Answer].
|
|
||||||
""",
|
|
||||||
evaluate_system_prompt=(
|
|
||||||
"Critically analyze this answer and provide a reward score between -100 and 100 based on strict standards."
|
|
||||||
"The score should clearly reflect the quality of the answer."
|
|
||||||
"Make sure the reward score is an integer. You should only return the score. If the score is greater than 95, return 95."
|
|
||||||
),
|
|
||||||
)
|
|
||||||
@@ -1,5 +1,6 @@
|
|||||||
from .base import OLTrainer, SLTrainer
|
from .base import OLTrainer, SLTrainer
|
||||||
from .dpo import DPOTrainer
|
from .dpo import DPOTrainer
|
||||||
|
from .grpo import GRPOTrainer
|
||||||
from .kto import KTOTrainer
|
from .kto import KTOTrainer
|
||||||
from .orpo import ORPOTrainer
|
from .orpo import ORPOTrainer
|
||||||
from .ppo import PPOTrainer
|
from .ppo import PPOTrainer
|
||||||
@@ -15,4 +16,5 @@ __all__ = [
|
|||||||
"DPOTrainer",
|
"DPOTrainer",
|
||||||
"ORPOTrainer",
|
"ORPOTrainer",
|
||||||
"KTOTrainer",
|
"KTOTrainer",
|
||||||
|
"GRPOTrainer",
|
||||||
]
|
]
|
||||||
|
|||||||
@@ -96,6 +96,7 @@ class OLTrainer(ABC):
|
|||||||
self.sample_buffer = sample_buffer
|
self.sample_buffer = sample_buffer
|
||||||
self.dataloader_pin_memory = dataloader_pin_memory
|
self.dataloader_pin_memory = dataloader_pin_memory
|
||||||
self.callbacks = callbacks
|
self.callbacks = callbacks
|
||||||
|
self.num_train_step = 0
|
||||||
|
|
||||||
@contextmanager
|
@contextmanager
|
||||||
def _fit_ctx(self) -> None:
|
def _fit_ctx(self) -> None:
|
||||||
@@ -212,5 +213,6 @@ class OLTrainer(ABC):
|
|||||||
self._update_phase(update_step)
|
self._update_phase(update_step)
|
||||||
# NOTE: this is for on-policy algorithms
|
# NOTE: this is for on-policy algorithms
|
||||||
self.data_buffer.clear()
|
self.data_buffer.clear()
|
||||||
if self.save_interval > 0 and (episode + 1) % (self.save_interval) == 0:
|
|
||||||
self._save_checkpoint(episode + 1)
|
if self.num_train_step > 0 and (self.num_train_step + 1) % (self.save_interval) == 0:
|
||||||
|
self._save_checkpoint(self.num_train_step + 1)
|
||||||
|
|||||||
@@ -343,7 +343,7 @@ class DPOTrainer(SLTrainer):
|
|||||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||||
|
|
||||||
if (i + 1) % self.accumulation_steps == 0:
|
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||||
self.optimizer.step()
|
self.optimizer.step()
|
||||||
self.optimizer.zero_grad()
|
self.optimizer.zero_grad()
|
||||||
self.actor_scheduler.step()
|
self.actor_scheduler.step()
|
||||||
@@ -358,29 +358,30 @@ class DPOTrainer(SLTrainer):
|
|||||||
)
|
)
|
||||||
step_bar.update()
|
step_bar.update()
|
||||||
if self.writer and is_rank_0():
|
if self.writer and is_rank_0():
|
||||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||||
|
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/rejected_rewards",
|
"train/rejected_rewards",
|
||||||
self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/margin",
|
"train/margin",
|
||||||
self.accumulative_meter.get("chosen_rewards")
|
self.accumulative_meter.get("chosen_rewards")
|
||||||
- self.accumulative_meter.get("rejected_rewards"),
|
- self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/accuracy",
|
"train/accuracy",
|
||||||
self.accumulative_meter.get("accuracy"),
|
self.accumulative_meter.get("accuracy"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.num_train_step += 1
|
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
if self.save_dir is not None and self.num_train_step > 0 and self.num_train_step % self.save_interval == 0:
|
if self.save_dir is not None and self.num_train_step > 0 and self.num_train_step % self.save_interval == 0:
|
||||||
# save checkpoint
|
# save checkpoint
|
||||||
|
|||||||
386
applications/ColossalChat/coati/trainer/grpo.py
Executable file
386
applications/ColossalChat/coati/trainer/grpo.py
Executable file
@@ -0,0 +1,386 @@
|
|||||||
|
"""
|
||||||
|
GRPO trainer
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
from typing import Dict, List, Optional, Union
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import wandb
|
||||||
|
from coati.experience_buffer import NaiveExperienceBuffer
|
||||||
|
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||||
|
from coati.models import RewardModel, RLVRRewardModel
|
||||||
|
from coati.models.loss import GPTLMLoss, PolicyLoss
|
||||||
|
from coati.models.utils import calc_action_log_probs
|
||||||
|
from coati.trainer.callbacks import Callback
|
||||||
|
from coati.trainer.utils import all_reduce_mean
|
||||||
|
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||||
|
from torch.optim import Optimizer
|
||||||
|
from torch.optim.lr_scheduler import _LRScheduler
|
||||||
|
from torch.utils.data import DataLoader, DistributedSampler
|
||||||
|
from tqdm import tqdm
|
||||||
|
from transformers import PreTrainedModel, PreTrainedTokenizerBase
|
||||||
|
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import GeminiPlugin
|
||||||
|
from colossalai.cluster import DistCoordinator
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
from .base import OLTrainer
|
||||||
|
from .utils import AnnealingScheduler, CycledDataLoader, is_rank_0, to_device
|
||||||
|
|
||||||
|
|
||||||
|
def _set_default_generate_kwargs(actor: PreTrainedModel) -> Dict:
|
||||||
|
"""
|
||||||
|
Set default keyword arguments for generation based on the actor model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
actor (PreTrainedModel): The actor model.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Dict: A dictionary containing the default keyword arguments for generation.
|
||||||
|
"""
|
||||||
|
unwrapped_model = actor.unwrap()
|
||||||
|
new_kwargs = {}
|
||||||
|
# use huggingface models method directly
|
||||||
|
if hasattr(unwrapped_model, "prepare_inputs_for_generation"):
|
||||||
|
new_kwargs["prepare_inputs_fn"] = unwrapped_model.prepare_inputs_for_generation
|
||||||
|
if hasattr(unwrapped_model, "_update_model_kwargs_for_generation"):
|
||||||
|
new_kwargs["update_model_kwargs_fn"] = unwrapped_model._update_model_kwargs_for_generation
|
||||||
|
return new_kwargs
|
||||||
|
|
||||||
|
|
||||||
|
class GRPOTrainer(OLTrainer):
|
||||||
|
"""
|
||||||
|
Trainer for GRPO algorithm.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
strategy (Booster): the strategy to use for training
|
||||||
|
actor (Actor): the actor model in ppo algorithm
|
||||||
|
reward_model (RewardModel): the reward model in rlhf algorithm to make reward of sentences
|
||||||
|
initial_model (Actor): the initial model in rlhf algorithm to generate reference logics to limit the update of actor
|
||||||
|
actor_optim (Optimizer): the optimizer to use for actor model
|
||||||
|
kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
|
||||||
|
train_batch_size (int, defaults to 8): the batch size to use for training
|
||||||
|
buffer_limit (int, defaults to 0): the max_size limitation of buffer
|
||||||
|
buffer_cpu_offload (bool, defaults to True): whether to offload buffer to cpu
|
||||||
|
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
|
||||||
|
vf_coef (float, defaults to 1.0): the coefficient of value loss
|
||||||
|
ptx_coef (float, defaults to 0.9): the coefficient of ptx loss
|
||||||
|
value_clip (float, defaults to 0.4): the clip coefficient of value loss
|
||||||
|
sample_buffer (bool, defaults to False): whether to sample from buffer
|
||||||
|
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||||
|
offload_inference_models (bool, defaults to True): whether to offload inference models to cpu during training process
|
||||||
|
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||||
|
generate_kwargs (dict, optional): the kwargs to use while model generating
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
actor_booster: Booster,
|
||||||
|
actor: PreTrainedModel,
|
||||||
|
reward_model: Union[RewardModel, RLVRRewardModel],
|
||||||
|
initial_model: PreTrainedModel,
|
||||||
|
actor_optim: Optimizer,
|
||||||
|
actor_lr_scheduler: _LRScheduler,
|
||||||
|
tokenizer: PreTrainedTokenizerBase,
|
||||||
|
kl_coef: float = 0.1,
|
||||||
|
ptx_coef: float = 0.9,
|
||||||
|
train_batch_size: int = 8,
|
||||||
|
buffer_limit: int = 0,
|
||||||
|
buffer_cpu_offload: bool = True,
|
||||||
|
eps_clip: float = 0.2,
|
||||||
|
vf_coef: float = 1.0,
|
||||||
|
value_clip: float = 0.2,
|
||||||
|
sample_buffer: bool = False,
|
||||||
|
dataloader_pin_memory: bool = True,
|
||||||
|
offload_inference_models: bool = True,
|
||||||
|
apply_loss_mask: bool = True,
|
||||||
|
accumulation_steps: int = 1,
|
||||||
|
save_interval: int = 0,
|
||||||
|
save_dir: str = None,
|
||||||
|
use_tp: bool = False,
|
||||||
|
num_generation: int = 8,
|
||||||
|
inference_batch_size: int = None,
|
||||||
|
logits_forward_batch_size: int = None,
|
||||||
|
temperature_annealing_config: Optional[Dict] = None,
|
||||||
|
coordinator: DistCoordinator = None,
|
||||||
|
callbacks: List[Callback] = [],
|
||||||
|
**generate_kwargs,
|
||||||
|
) -> None:
|
||||||
|
if isinstance(actor_booster, GeminiPlugin):
|
||||||
|
assert not offload_inference_models, "GeminiPlugin is not compatible with manual model.to('cpu')"
|
||||||
|
|
||||||
|
data_buffer = NaiveExperienceBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
|
||||||
|
super().__init__(actor_booster, None, data_buffer, sample_buffer, dataloader_pin_memory, callbacks=callbacks)
|
||||||
|
self.generate_kwargs = _set_default_generate_kwargs(actor)
|
||||||
|
self.generate_kwargs.update(generate_kwargs)
|
||||||
|
|
||||||
|
self.actor = actor
|
||||||
|
self.actor_booster = actor_booster
|
||||||
|
self.actor_scheduler = actor_lr_scheduler
|
||||||
|
self.tokenizer = tokenizer
|
||||||
|
self.experience_maker = NaiveExperienceMaker(
|
||||||
|
self.actor,
|
||||||
|
None,
|
||||||
|
reward_model,
|
||||||
|
initial_model,
|
||||||
|
self.tokenizer,
|
||||||
|
kl_coef,
|
||||||
|
use_grpo=True,
|
||||||
|
num_generation=num_generation,
|
||||||
|
inference_batch_size=inference_batch_size,
|
||||||
|
logits_forward_batch_size=logits_forward_batch_size,
|
||||||
|
)
|
||||||
|
if temperature_annealing_config:
|
||||||
|
# use annealing
|
||||||
|
self.temperature_annealing_scheduler = AnnealingScheduler(
|
||||||
|
temperature_annealing_config["start_temperature"],
|
||||||
|
temperature_annealing_config["end_temperature"],
|
||||||
|
temperature_annealing_config["annealing_warmup_steps"],
|
||||||
|
temperature_annealing_config["annealing_steps"],
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
self.temperature_annealing_scheduler = None
|
||||||
|
|
||||||
|
self.train_batch_size = train_batch_size
|
||||||
|
|
||||||
|
self.actor_loss_fn = PolicyLoss(eps_clip)
|
||||||
|
self.vf_coef = vf_coef
|
||||||
|
self.ptx_loss_fn = GPTLMLoss()
|
||||||
|
self.ptx_coef = ptx_coef
|
||||||
|
self.actor_optim = actor_optim
|
||||||
|
self.save_interval = save_interval
|
||||||
|
self.apply_loss_mask = apply_loss_mask
|
||||||
|
self.coordinator = coordinator
|
||||||
|
self.actor_save_dir = os.path.join(save_dir, "actor")
|
||||||
|
self.num_train_step = 0
|
||||||
|
self.accumulation_steps = accumulation_steps
|
||||||
|
self.use_tp = use_tp
|
||||||
|
self.accumulative_meter = AccumulativeMeanMeter()
|
||||||
|
self.offload_inference_models = offload_inference_models
|
||||||
|
self.device = get_current_device()
|
||||||
|
|
||||||
|
def _before_fit(
|
||||||
|
self,
|
||||||
|
prompt_dataloader: DataLoader,
|
||||||
|
pretrain_dataloader: Optional[DataLoader] = None,
|
||||||
|
log_dir: Optional[str] = None,
|
||||||
|
use_wandb: bool = False,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||||
|
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||||
|
"""
|
||||||
|
self.prompt_dataloader = CycledDataLoader(prompt_dataloader)
|
||||||
|
self.pretrain_dataloader = CycledDataLoader(pretrain_dataloader) if pretrain_dataloader is not None else None
|
||||||
|
|
||||||
|
self.writer = None
|
||||||
|
if use_wandb and is_rank_0():
|
||||||
|
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||||
|
import wandb
|
||||||
|
|
||||||
|
self.wandb_run = wandb.init(project="Coati-grpo", sync_tensorboard=True)
|
||||||
|
if log_dir is not None and is_rank_0():
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
|
||||||
|
from torch.utils.tensorboard import SummaryWriter
|
||||||
|
|
||||||
|
log_dir = os.path.join(log_dir, "grpo")
|
||||||
|
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||||
|
self.writer = SummaryWriter(log_dir=log_dir)
|
||||||
|
|
||||||
|
def _setup_update_phrase_dataload(self):
|
||||||
|
"""
|
||||||
|
why not use distributed_dataloader?
|
||||||
|
if tp is used, input on each rank is the same and we use the same dataloader to feed same experience to all ranks
|
||||||
|
if tp is not used, input on each rank is different and we expect different experiences to be fed to each rank
|
||||||
|
"""
|
||||||
|
self.dataloader = DataLoader(
|
||||||
|
self.data_buffer,
|
||||||
|
batch_size=self.train_batch_size,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
pin_memory=self.dataloader_pin_memory,
|
||||||
|
collate_fn=self.data_buffer.collate_fn,
|
||||||
|
)
|
||||||
|
|
||||||
|
def _make_experience(self, collect_step: int) -> Experience:
|
||||||
|
"""
|
||||||
|
Make experience
|
||||||
|
"""
|
||||||
|
prompts = self.prompt_dataloader.next()
|
||||||
|
if self.offload_inference_models:
|
||||||
|
# TODO(ver217): this may be controlled by strategy if they are prepared by strategy
|
||||||
|
self.experience_maker.initial_model.to(self.device)
|
||||||
|
self.experience_maker.reward_model.to(self.device)
|
||||||
|
if self.temperature_annealing_scheduler:
|
||||||
|
self.generate_kwargs["temperature"] = self.temperature_annealing_scheduler.get_temperature()
|
||||||
|
return self.experience_maker.make_experience(
|
||||||
|
input_ids=prompts["input_ids"].to(get_current_device()),
|
||||||
|
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
||||||
|
gt_answer=prompts["gt_answer"],
|
||||||
|
**self.generate_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
def _training_step(self, experience: Experience):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
experience:
|
||||||
|
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
||||||
|
"""
|
||||||
|
self.actor.train()
|
||||||
|
num_actions = experience.action_log_probs.size(1)
|
||||||
|
# policy loss
|
||||||
|
|
||||||
|
actor_logits = self.actor(input_ids=experience.sequences, attention_mask=experience.attention_mask)[
|
||||||
|
"logits"
|
||||||
|
] # [batch size, prompt_length + response_length]
|
||||||
|
action_log_probs = calc_action_log_probs(actor_logits, experience.sequences, num_actions)
|
||||||
|
actor_loss, to_skip, max_ratio = self.actor_loss_fn(
|
||||||
|
action_log_probs,
|
||||||
|
experience.action_log_probs,
|
||||||
|
experience.advantages.unsqueeze(dim=-1).repeat_interleave(action_log_probs.size(-1), dim=-1),
|
||||||
|
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||||
|
)
|
||||||
|
# sequence that is not end properly are not counted in token cost
|
||||||
|
token_cost = torch.sum(
|
||||||
|
(experience.sequences[:, -num_actions:] != self.tokenizer.pad_token_id).to(torch.float), axis=-1
|
||||||
|
).to(actor_logits.device)
|
||||||
|
end_properly = experience.sequences[:, -1] == self.tokenizer.pad_token_id
|
||||||
|
mean_token_cost = torch.sum(token_cost * end_properly) / torch.sum(end_properly)
|
||||||
|
actor_loss = (1 - self.ptx_coef) * actor_loss
|
||||||
|
if not to_skip:
|
||||||
|
self.actor_booster.backward(loss=actor_loss, optimizer=self.actor_optim)
|
||||||
|
|
||||||
|
# ptx loss
|
||||||
|
if self.ptx_coef != 0:
|
||||||
|
batch = self.pretrain_dataloader.next()
|
||||||
|
batch = to_device(batch, self.device)
|
||||||
|
outputs = self.actor(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
|
||||||
|
ptx_loss = outputs.loss
|
||||||
|
ptx_loss = self.ptx_coef * ptx_loss
|
||||||
|
self.actor_booster.backward(loss=ptx_loss, optimizer=self.actor_optim)
|
||||||
|
|
||||||
|
# sync
|
||||||
|
actor_loss_mean = all_reduce_mean(tensor=actor_loss)
|
||||||
|
max_ratio_mean = all_reduce_mean(tensor=max_ratio)
|
||||||
|
reward_mean = all_reduce_mean(tensor=experience.reward.mean())
|
||||||
|
advantages_mean = all_reduce_mean(tensor=experience.advantages.mean())
|
||||||
|
kl_mean = all_reduce_mean(tensor=experience.kl.mean())
|
||||||
|
mean_token_cost = all_reduce_mean(tensor=mean_token_cost)
|
||||||
|
if self.ptx_coef != 0:
|
||||||
|
ptx_loss_mean = all_reduce_mean(tensor=ptx_loss)
|
||||||
|
|
||||||
|
self.accumulative_meter.add("actor_loss", actor_loss_mean.to(torch.float16).mean().item())
|
||||||
|
self.accumulative_meter.add("max_ratio", max_ratio_mean.to(torch.float16).item())
|
||||||
|
self.accumulative_meter.add("reward", reward_mean.to(torch.float16).mean().item())
|
||||||
|
self.accumulative_meter.add("advantages", advantages_mean.to(torch.float16).item())
|
||||||
|
self.accumulative_meter.add("skip_ratio", 1.0 if to_skip else 0.0)
|
||||||
|
self.accumulative_meter.add("mean_token_cost", mean_token_cost.to(torch.float16).item())
|
||||||
|
self.accumulative_meter.add("kl", kl_mean.to(torch.float16).item())
|
||||||
|
if self.ptx_coef != 0:
|
||||||
|
self.accumulative_meter.add("ptx_loss", ptx_loss_mean.to(torch.float16).mean().item())
|
||||||
|
|
||||||
|
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||||
|
self.actor_optim.step()
|
||||||
|
self.actor_optim.zero_grad()
|
||||||
|
self.actor_scheduler.step()
|
||||||
|
|
||||||
|
if self.temperature_annealing_scheduler:
|
||||||
|
self.temperature_annealing_scheduler.step_forward()
|
||||||
|
|
||||||
|
# preparing logging model output and corresponding rewards.
|
||||||
|
if self.num_train_step % 10 == 0:
|
||||||
|
response_text = self.experience_maker.tokenizer.batch_decode(
|
||||||
|
experience.sequences, skip_special_tokens=True
|
||||||
|
)
|
||||||
|
for i in range(len(response_text)):
|
||||||
|
response_text[i] = response_text[i] + f"\n\nReward: {experience.reward[i]}"
|
||||||
|
|
||||||
|
if self.writer and is_rank_0() and "wandb_run" in self.__dict__:
|
||||||
|
# log output to wandb
|
||||||
|
my_table = wandb.Table(
|
||||||
|
columns=[f"sample response {i}" for i in range(len(response_text))], data=[response_text]
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
self.wandb_run.log({"sample_response": my_table})
|
||||||
|
except OSError as e:
|
||||||
|
self.coordinator.print_on_master(e)
|
||||||
|
elif self.writer and is_rank_0():
|
||||||
|
for line in response_text:
|
||||||
|
self.coordinator.print_on_master(line)
|
||||||
|
|
||||||
|
if self.writer and is_rank_0():
|
||||||
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
|
self.writer.add_scalar("train/max_ratio", self.accumulative_meter.get("max_ratio"), global_step)
|
||||||
|
self.writer.add_scalar("train/skip_ratio", self.accumulative_meter.get("skip_ratio"), global_step)
|
||||||
|
self.writer.add_scalar("train/actor_loss", self.accumulative_meter.get("actor_loss"), global_step)
|
||||||
|
self.writer.add_scalar("train/lr_actor", self.actor_optim.param_groups[0]["lr"], global_step)
|
||||||
|
if self.ptx_coef != 0:
|
||||||
|
self.writer.add_scalar("train/ptx_loss", self.accumulative_meter.get("ptx_loss"), global_step)
|
||||||
|
self.writer.add_scalar("reward", self.accumulative_meter.get("reward"), global_step)
|
||||||
|
self.writer.add_scalar("token_cost", self.accumulative_meter.get("mean_token_cost"), global_step)
|
||||||
|
self.writer.add_scalar("approx_kl", self.accumulative_meter.get("kl"), global_step)
|
||||||
|
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), global_step)
|
||||||
|
self.accumulative_meter.reset()
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
|
def _learn(self, update_step: int):
|
||||||
|
"""
|
||||||
|
Perform the learning step of the PPO algorithm.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
update_step (int): The current update step.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
None
|
||||||
|
"""
|
||||||
|
if self.offload_inference_models:
|
||||||
|
self.experience_maker.initial_model.to("cpu")
|
||||||
|
self.experience_maker.reward_model.to("cpu")
|
||||||
|
# buffer may be empty at first, we should rebuild at each training
|
||||||
|
if self.sample_buffer:
|
||||||
|
experience = self.data_buffer.sample()
|
||||||
|
self._on_learn_batch_start()
|
||||||
|
experience.to_device(self.device)
|
||||||
|
self._training_step(experience)
|
||||||
|
self._on_learn_batch_end(experience)
|
||||||
|
else:
|
||||||
|
if isinstance(self.dataloader.sampler, DistributedSampler):
|
||||||
|
self.dataloader.sampler.set_epoch(update_step)
|
||||||
|
pbar = tqdm(self.dataloader, desc=f"Train epoch [{update_step + 1}]", disable=not is_rank_0())
|
||||||
|
for experience in pbar:
|
||||||
|
self._on_learn_batch_start()
|
||||||
|
experience.to_device(self.device)
|
||||||
|
self._training_step(experience)
|
||||||
|
self._on_learn_batch_end(experience)
|
||||||
|
|
||||||
|
def _save_checkpoint(self, num_train_step: int = 0):
|
||||||
|
"""
|
||||||
|
Save the actor checkpoints with running states.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_train_step (int): The current num_train_step number.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
None
|
||||||
|
"""
|
||||||
|
|
||||||
|
self.coordinator.print_on_master("\nStart saving actor checkpoint with running states")
|
||||||
|
save_checkpoint(
|
||||||
|
save_dir=self.actor_save_dir,
|
||||||
|
booster=self.actor_booster,
|
||||||
|
model=self.actor,
|
||||||
|
optimizer=self.actor_optim,
|
||||||
|
lr_scheduler=self.actor_scheduler,
|
||||||
|
epoch=0,
|
||||||
|
step=num_train_step + 1,
|
||||||
|
batch_size=self.train_batch_size,
|
||||||
|
coordinator=self.coordinator,
|
||||||
|
)
|
||||||
|
self.coordinator.print_on_master(
|
||||||
|
f"Saved actor checkpoint at episode {(num_train_step + 1)} at folder {self.actor_save_dir}"
|
||||||
|
)
|
||||||
@@ -193,12 +193,14 @@ class KTOTrainer(SLTrainer):
|
|||||||
loss_mean = all_reduce_mean(tensor=loss)
|
loss_mean = all_reduce_mean(tensor=loss)
|
||||||
chosen_reward_mean = chosen_rewards.mean()
|
chosen_reward_mean = chosen_rewards.mean()
|
||||||
chosen_rewards_list = [
|
chosen_rewards_list = [
|
||||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
torch.tensor(0, dtype=chosen_reward_mean.dtype, device=loss.device)
|
||||||
|
for _ in range(dist.get_world_size())
|
||||||
]
|
]
|
||||||
dist.all_gather(chosen_rewards_list, chosen_reward_mean)
|
dist.all_gather(chosen_rewards_list, chosen_reward_mean)
|
||||||
rejected_reward_mean = rejected_rewards.mean()
|
rejected_reward_mean = rejected_rewards.mean()
|
||||||
rejected_rewards_list = [
|
rejected_rewards_list = [
|
||||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
torch.tensor(0, dtype=rejected_reward_mean.dtype, device=loss.device)
|
||||||
|
for _ in range(dist.get_world_size())
|
||||||
]
|
]
|
||||||
dist.all_gather(rejected_rewards_list, rejected_reward_mean)
|
dist.all_gather(rejected_rewards_list, rejected_reward_mean)
|
||||||
chosen_rewards_list = [i for i in chosen_rewards_list if not i.isnan()]
|
chosen_rewards_list = [i for i in chosen_rewards_list if not i.isnan()]
|
||||||
@@ -217,25 +219,25 @@ class KTOTrainer(SLTrainer):
|
|||||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
||||||
|
|
||||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||||
self.num_train_step += 1
|
|
||||||
step_bar.update()
|
step_bar.update()
|
||||||
# logging
|
# logging
|
||||||
if self.writer and is_rank_0():
|
if self.writer and is_rank_0():
|
||||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||||
|
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/rejected_rewards",
|
"train/rejected_rewards",
|
||||||
self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/margin",
|
"train/margin",
|
||||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
|
|
||||||
@@ -256,6 +258,7 @@ class KTOTrainer(SLTrainer):
|
|||||||
self.coordinator.print_on_master(
|
self.coordinator.print_on_master(
|
||||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||||
)
|
)
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
step_bar.close()
|
step_bar.close()
|
||||||
|
|
||||||
|
|||||||
@@ -184,35 +184,35 @@ class ORPOTrainer(SLTrainer):
|
|||||||
self.accumulative_meter.add("log_odds_ratio", log_odds_ratio.to(torch.float16).mean().item())
|
self.accumulative_meter.add("log_odds_ratio", log_odds_ratio.to(torch.float16).mean().item())
|
||||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||||
|
|
||||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||||
self.num_train_step += 1
|
|
||||||
step_bar.update()
|
step_bar.update()
|
||||||
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
# logging
|
# logging
|
||||||
if self.writer and is_rank_0():
|
if self.writer and is_rank_0():
|
||||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/rejected_rewards",
|
"train/rejected_rewards",
|
||||||
self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/margin",
|
"train/margin",
|
||||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/accuracy",
|
"train/accuracy",
|
||||||
self.accumulative_meter.get("accuracy"),
|
self.accumulative_meter.get("accuracy"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/log_odds_ratio",
|
"train/log_odds_ratio",
|
||||||
self.accumulative_meter.get("log_odds_ratio"),
|
self.accumulative_meter.get("log_odds_ratio"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
|
|
||||||
@@ -233,6 +233,7 @@ class ORPOTrainer(SLTrainer):
|
|||||||
self.coordinator.print_on_master(
|
self.coordinator.print_on_master(
|
||||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||||
)
|
)
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
step_bar.close()
|
step_bar.close()
|
||||||
|
|
||||||
|
|||||||
@@ -3,13 +3,13 @@ PPO trainer
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
import os
|
import os
|
||||||
from typing import Dict, List, Optional
|
from typing import Dict, List, Optional, Union
|
||||||
|
|
||||||
import torch
|
import torch
|
||||||
import wandb
|
import wandb
|
||||||
from coati.experience_buffer import NaiveExperienceBuffer
|
from coati.experience_buffer import NaiveExperienceBuffer
|
||||||
from coati.experience_maker import Experience, NaiveExperienceMaker
|
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||||
from coati.models import Critic, RewardModel
|
from coati.models import Critic, RewardModel, RLVRRewardModel
|
||||||
from coati.models.loss import GPTLMLoss, PolicyLoss, ValueLoss
|
from coati.models.loss import GPTLMLoss, PolicyLoss, ValueLoss
|
||||||
from coati.models.utils import calc_action_log_probs
|
from coati.models.utils import calc_action_log_probs
|
||||||
from coati.trainer.callbacks import Callback
|
from coati.trainer.callbacks import Callback
|
||||||
@@ -84,7 +84,7 @@ class PPOTrainer(OLTrainer):
|
|||||||
critic_booster: Booster,
|
critic_booster: Booster,
|
||||||
actor: PreTrainedModel,
|
actor: PreTrainedModel,
|
||||||
critic: Critic,
|
critic: Critic,
|
||||||
reward_model: RewardModel,
|
reward_model: Union[RewardModel, RLVRRewardModel],
|
||||||
initial_model: PreTrainedModel,
|
initial_model: PreTrainedModel,
|
||||||
actor_optim: Optimizer,
|
actor_optim: Optimizer,
|
||||||
critic_optim: Optimizer,
|
critic_optim: Optimizer,
|
||||||
@@ -210,6 +210,7 @@ class PPOTrainer(OLTrainer):
|
|||||||
return self.experience_maker.make_experience(
|
return self.experience_maker.make_experience(
|
||||||
input_ids=prompts["input_ids"].to(get_current_device()),
|
input_ids=prompts["input_ids"].to(get_current_device()),
|
||||||
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
||||||
|
gt_answer=prompts["gt_answer"],
|
||||||
**self.generate_kwargs,
|
**self.generate_kwargs,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -219,7 +220,6 @@ class PPOTrainer(OLTrainer):
|
|||||||
experience:
|
experience:
|
||||||
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
||||||
"""
|
"""
|
||||||
self.num_train_step += 1
|
|
||||||
self.actor.train()
|
self.actor.train()
|
||||||
self.critic.train()
|
self.critic.train()
|
||||||
num_actions = experience.action_log_probs.size(1)
|
num_actions = experience.action_log_probs.size(1)
|
||||||
@@ -293,7 +293,7 @@ class PPOTrainer(OLTrainer):
|
|||||||
self.critic_scheduler.step()
|
self.critic_scheduler.step()
|
||||||
|
|
||||||
# preparing logging model output and corresponding rewards.
|
# preparing logging model output and corresponding rewards.
|
||||||
if self.num_train_step % 10 == 1:
|
if self.num_train_step % 10 == 0:
|
||||||
response_text = self.experience_maker.tokenizer.batch_decode(
|
response_text = self.experience_maker.tokenizer.batch_decode(
|
||||||
experience.sequences, skip_special_tokens=True
|
experience.sequences, skip_special_tokens=True
|
||||||
)
|
)
|
||||||
@@ -335,6 +335,7 @@ class PPOTrainer(OLTrainer):
|
|||||||
self.writer.add_scalar("value", self.accumulative_meter.get("value"), self.num_train_step)
|
self.writer.add_scalar("value", self.accumulative_meter.get("value"), self.num_train_step)
|
||||||
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), self.num_train_step)
|
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), self.num_train_step)
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
def _learn(self, update_step: int):
|
def _learn(self, update_step: int):
|
||||||
"""
|
"""
|
||||||
|
|||||||
@@ -150,29 +150,29 @@ class RewardModelTrainer(SLTrainer):
|
|||||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||||
self.accumulative_meter.add("accuracy", accuracy_mean.mean().to(torch.float16).item())
|
self.accumulative_meter.add("accuracy", accuracy_mean.mean().to(torch.float16).item())
|
||||||
|
|
||||||
if (i + 1) % self.accumulation_steps == 0:
|
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||||
self.optimizer.step()
|
self.optimizer.step()
|
||||||
self.optimizer.zero_grad()
|
self.optimizer.zero_grad()
|
||||||
self.actor_scheduler.step()
|
self.actor_scheduler.step()
|
||||||
step_bar.update()
|
step_bar.update()
|
||||||
self.num_train_step += 1
|
|
||||||
|
|
||||||
# Logging
|
# Logging
|
||||||
if self.writer and is_rank_0():
|
if self.writer and is_rank_0():
|
||||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||||
|
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/dist",
|
"train/dist",
|
||||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||||
self.num_train_step,
|
global_step,
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/reward_chosen", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
"train/reward_chosen", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||||
)
|
)
|
||||||
self.writer.add_scalar(
|
self.writer.add_scalar(
|
||||||
"train/reward_reject", self.accumulative_meter.get("rejected_rewards"), self.num_train_step
|
"train/reward_reject", self.accumulative_meter.get("rejected_rewards"), global_step
|
||||||
)
|
)
|
||||||
self.writer.add_scalar("train/acc", self.accumulative_meter.get("accuracy"), self.num_train_step)
|
self.writer.add_scalar("train/acc", self.accumulative_meter.get("accuracy"), global_step)
|
||||||
|
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
|
|
||||||
@@ -193,6 +193,7 @@ class RewardModelTrainer(SLTrainer):
|
|||||||
self.coordinator.print_on_master(
|
self.coordinator.print_on_master(
|
||||||
f"Saved checkpoint at epoch {epoch} step {(i + 1)/self.accumulation_steps} at folder {self.save_dir}"
|
f"Saved checkpoint at epoch {epoch} step {(i + 1)/self.accumulation_steps} at folder {self.save_dir}"
|
||||||
)
|
)
|
||||||
|
self.num_train_step += 1
|
||||||
step_bar.close()
|
step_bar.close()
|
||||||
|
|
||||||
def _eval(self, epoch):
|
def _eval(self, epoch):
|
||||||
|
|||||||
@@ -143,18 +143,18 @@ class SFTTrainer(SLTrainer):
|
|||||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||||
|
|
||||||
# Gradient accumulation
|
# Gradient accumulation
|
||||||
if (i + 1) % self.accumulation_steps == 0:
|
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||||
self.optimizer.step()
|
self.optimizer.step()
|
||||||
self.optimizer.zero_grad()
|
self.optimizer.zero_grad()
|
||||||
self.scheduler.step()
|
self.scheduler.step()
|
||||||
|
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||||
step_bar.set_postfix({"train/loss": self.accumulative_meter.get("loss")})
|
step_bar.set_postfix({"train/loss": self.accumulative_meter.get("loss")})
|
||||||
if self.writer:
|
if self.writer:
|
||||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||||
self.writer.add_scalar("train/lr", self.scheduler.get_last_lr()[0], self.num_train_step)
|
self.writer.add_scalar("train/lr", self.scheduler.get_last_lr()[0], global_step)
|
||||||
self.num_train_step += 1
|
|
||||||
self.accumulative_meter.reset()
|
self.accumulative_meter.reset()
|
||||||
step_bar.update()
|
step_bar.update()
|
||||||
|
self.num_train_step += 1
|
||||||
|
|
||||||
# Save checkpoint
|
# Save checkpoint
|
||||||
if (
|
if (
|
||||||
|
|||||||
@@ -12,6 +12,27 @@ from torch.utils.data import DataLoader
|
|||||||
from colossalai.booster import Plugin
|
from colossalai.booster import Plugin
|
||||||
|
|
||||||
|
|
||||||
|
class AnnealingScheduler:
|
||||||
|
def __init__(self, start, end, warmup_steps=100, annealing_step=2000):
|
||||||
|
self.start = start
|
||||||
|
self.end = end
|
||||||
|
self.warmup_steps = warmup_steps
|
||||||
|
self.step = 0
|
||||||
|
self.annealing_step = annealing_step
|
||||||
|
|
||||||
|
def get_temperature(self):
|
||||||
|
if self.step <= self.warmup_steps:
|
||||||
|
return self.start # Stop annealing after warm-up steps
|
||||||
|
elif self.step >= self.annealing_step:
|
||||||
|
return self.end
|
||||||
|
# Linear annealing
|
||||||
|
temp = self.start - (self.step / self.annealing_step) * (self.start - self.end)
|
||||||
|
return temp
|
||||||
|
|
||||||
|
def step_forward(self):
|
||||||
|
self.step += 1
|
||||||
|
|
||||||
|
|
||||||
class CycledDataLoader:
|
class CycledDataLoader:
|
||||||
"""
|
"""
|
||||||
A data loader that cycles through the data when it reaches the end.
|
A data loader that cycles through the data when it reaches the end.
|
||||||
@@ -107,7 +128,7 @@ def all_reduce_mean(tensor: torch.Tensor, plugin: Plugin = None) -> torch.Tensor
|
|||||||
return tensor
|
return tensor
|
||||||
|
|
||||||
|
|
||||||
def all_reduce_sum(tensor: torch.Tensor) -> torch.Tensor:
|
def all_reduce_sum(tensor: torch.Tensor, plugin: Plugin = None) -> torch.Tensor:
|
||||||
"""
|
"""
|
||||||
Performs an all-reduce operation to sum the values of the given tensor across all processes.
|
Performs an all-reduce operation to sum the values of the given tensor across all processes.
|
||||||
|
|
||||||
@@ -117,5 +138,35 @@ def all_reduce_sum(tensor: torch.Tensor) -> torch.Tensor:
|
|||||||
Returns:
|
Returns:
|
||||||
torch.Tensor: The reduced tensor with the sum of values across all processes.
|
torch.Tensor: The reduced tensor with the sum of values across all processes.
|
||||||
"""
|
"""
|
||||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
# All reduce sum across DP group
|
||||||
|
if plugin is not None:
|
||||||
|
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM, group=plugin.dp_group)
|
||||||
|
else:
|
||||||
|
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||||
return tensor
|
return tensor
|
||||||
|
|
||||||
|
|
||||||
|
def all_gather_tensors(local_tensor_list: torch.Tensor, plugin: Plugin = None) -> torch.Tensor:
|
||||||
|
"""
|
||||||
|
Gathers tensors from all processes and concatenates them along the first dimension.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
tensor (torch.Tensor): The input tensor to be gathered.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
torch.Tensor: The gathered tensor.
|
||||||
|
"""
|
||||||
|
# Gather tensors across DP group
|
||||||
|
if plugin is not None:
|
||||||
|
all_tensor_lists = [None] * plugin.dp_size
|
||||||
|
dist.all_gather_object(all_tensor_lists, local_tensor_list, group=plugin.dp_group)
|
||||||
|
gathered_tensor_list = []
|
||||||
|
for tensors in all_tensor_lists:
|
||||||
|
gathered_tensor_list.extend(tensors)
|
||||||
|
else:
|
||||||
|
all_tensor_lists = [None] * dist.get_world_size()
|
||||||
|
dist.all_gather_object(all_tensor_lists, local_tensor_list)
|
||||||
|
gathered_tensor_list = []
|
||||||
|
for tensors in all_tensor_lists:
|
||||||
|
gathered_tensor_list.extend(tensors)
|
||||||
|
return gathered_tensor_list
|
||||||
|
|||||||
@@ -81,9 +81,12 @@ def load_checkpoint(
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
# Update booster params states.
|
# Update booster params states.
|
||||||
booster.load_model(model=model, checkpoint=os.path.join(load_dir, "modeling"))
|
if model is not None:
|
||||||
booster.load_optimizer(optimizer=optimizer, checkpoint=os.path.join(load_dir, "optimizer"))
|
booster.load_model(model=model, checkpoint=os.path.join(load_dir, "modeling"))
|
||||||
booster.load_lr_scheduler(lr_scheduler=lr_scheduler, checkpoint=os.path.join(load_dir, "lr_scheduler"))
|
if optimizer is not None:
|
||||||
|
booster.load_optimizer(optimizer=optimizer, checkpoint=os.path.join(load_dir, "optimizer"))
|
||||||
|
if lr_scheduler is not None:
|
||||||
|
booster.load_lr_scheduler(lr_scheduler=lr_scheduler, checkpoint=os.path.join(load_dir, "lr_scheduler"))
|
||||||
|
|
||||||
running_states = load_json(file_path=os.path.join(load_dir, "running_states.json"))
|
running_states = load_json(file_path=os.path.join(load_dir, "running_states.json"))
|
||||||
return (
|
return (
|
||||||
|
|||||||
@@ -0,0 +1,4 @@
|
|||||||
|
from .competition import math_competition_reward_fn
|
||||||
|
from .gsm8k import gsm8k_reward_fn
|
||||||
|
|
||||||
|
__all__ = ["gsm8k_reward_fn", "math_competition_reward_fn"]
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
import torch
|
||||||
|
|
||||||
|
from .utils import extract_solution, validate_response_structure
|
||||||
|
|
||||||
|
|
||||||
|
def math_competition_reward_fn(input_ids, attention_mask, **kwargs):
|
||||||
|
# apply varifiable reward
|
||||||
|
# reward 10 points if the final answer is correct, reward 1 point if format is correct
|
||||||
|
|
||||||
|
gt_answer = kwargs["gt_answer"]
|
||||||
|
tokenizer = kwargs["tokenizer"]
|
||||||
|
s, e = kwargs["response_start"], kwargs["response_end"]
|
||||||
|
reward = torch.tensor(0.0).to(input_ids.device)
|
||||||
|
if gt_answer is None:
|
||||||
|
return reward
|
||||||
|
decoded_final_answer = tokenizer.decode(input_ids[s : e + 1], skip_special_tokens=True)
|
||||||
|
final_answer, processed_str = extract_solution(decoded_final_answer)
|
||||||
|
|
||||||
|
format_valid = validate_response_structure(processed_str, kwargs["tags"])
|
||||||
|
if not format_valid:
|
||||||
|
return reward
|
||||||
|
else:
|
||||||
|
reward += 1.0
|
||||||
|
if gt_answer.strip().replace(" ", "").lower() == final_answer.strip().replace(" ", "").lower():
|
||||||
|
reward = reward + 9.0
|
||||||
|
return reward
|
||||||
31
applications/ColossalChat/coati/utils/reward_score/gsm8k.py
Normal file
31
applications/ColossalChat/coati/utils/reward_score/gsm8k.py
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
import torch
|
||||||
|
|
||||||
|
from .utils import extract_solution, validate_response_structure
|
||||||
|
|
||||||
|
|
||||||
|
def gsm8k_reward_fn(input_ids, attention_mask, **kwargs):
|
||||||
|
# apply varifiable reward
|
||||||
|
# reward 10 points if the final answer is correct, reward 1 point if format is correct
|
||||||
|
|
||||||
|
gt_answer = kwargs["gt_answer"]
|
||||||
|
tokenizer = kwargs["tokenizer"]
|
||||||
|
s, e = kwargs["response_start"], kwargs["response_end"]
|
||||||
|
reward = torch.tensor(0.0).to(input_ids.device)
|
||||||
|
if gt_answer is None:
|
||||||
|
return reward
|
||||||
|
decoded_final_answer = tokenizer.decode(input_ids[s:e], skip_special_tokens=True)
|
||||||
|
final_answer, processed_str = extract_solution(decoded_final_answer)
|
||||||
|
is_valid = True
|
||||||
|
try:
|
||||||
|
int(final_answer.strip())
|
||||||
|
except Exception:
|
||||||
|
is_valid = False
|
||||||
|
|
||||||
|
format_valid = validate_response_structure(processed_str, kwargs["tags"])
|
||||||
|
if not is_valid or not format_valid:
|
||||||
|
return reward
|
||||||
|
else:
|
||||||
|
reward += 1.0
|
||||||
|
if gt_answer.strip().replace(" ", "").lower() == final_answer.strip().replace(" ", "").lower():
|
||||||
|
reward = reward + 9.0
|
||||||
|
return reward
|
||||||
76
applications/ColossalChat/coati/utils/reward_score/utils.py
Normal file
76
applications/ColossalChat/coati/utils/reward_score/utils.py
Normal file
@@ -0,0 +1,76 @@
|
|||||||
|
# Copyright Unakar
|
||||||
|
# Modified from https://github.com/Unakar/Logic-RL/blob/086373176ac198c97277ff50f4b6e7e1bfe669d3/verl/utils/reward_score/kk.py#L99
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
import re
|
||||||
|
from typing import Dict, Optional, Tuple
|
||||||
|
|
||||||
|
|
||||||
|
def validate_response_structure(processed_str: str, tags: Dict = None) -> bool:
|
||||||
|
"""Performs comprehensive validation of response structure.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
processed_str: Processed response string from the model
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Boolean indicating whether all formatting requirements are met
|
||||||
|
"""
|
||||||
|
validation_passed = True
|
||||||
|
# Check required tags
|
||||||
|
if tags is None:
|
||||||
|
tags = {
|
||||||
|
"think_start": {"text": "<think>", "num_occur": 1},
|
||||||
|
"think_end": {"text": "</think>", "num_occur": 1},
|
||||||
|
"answer_start": {"text": "<answer>", "num_occur": 1},
|
||||||
|
"answer_end": {"text": "</answer>", "num_occur": 1},
|
||||||
|
}
|
||||||
|
positions = {}
|
||||||
|
for tag_name, tag_info in tags.items():
|
||||||
|
tag_str = tag_info["text"]
|
||||||
|
expected_count = tag_info["num_occur"]
|
||||||
|
count = processed_str.count(tag_str)
|
||||||
|
positions[tag_name] = pos = processed_str.find(tag_str)
|
||||||
|
if count != expected_count:
|
||||||
|
validation_passed = False
|
||||||
|
# Verify tag order
|
||||||
|
if (
|
||||||
|
positions["think_start"] > positions["think_end"]
|
||||||
|
or positions["think_end"] > positions["answer_start"]
|
||||||
|
or positions["answer_start"] > positions["answer_end"]
|
||||||
|
):
|
||||||
|
validation_passed = False
|
||||||
|
if len(processed_str) - positions["answer_end"] != len(tags["answer_end"]["text"]):
|
||||||
|
validation_passed = False
|
||||||
|
return validation_passed
|
||||||
|
|
||||||
|
|
||||||
|
def extract_solution(solution_str: str) -> Tuple[Optional[str], str]:
|
||||||
|
"""Extracts the final answer from the model's response string.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
solution_str: Raw response string from the language model
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Tuple containing (extracted_answer, processed_string)
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Extract final answer using XML-style tags
|
||||||
|
answer_pattern = r"<answer>(.*?)</answer>"
|
||||||
|
matches = list(re.finditer(answer_pattern, solution_str, re.DOTALL))
|
||||||
|
|
||||||
|
if not matches:
|
||||||
|
return None, solution_str
|
||||||
|
|
||||||
|
final_answer = matches[-1].group(1).strip()
|
||||||
|
return final_answer, solution_str
|
||||||
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||||
|
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||||
|
"stop_ids": [
|
||||||
|
122753
|
||||||
|
],
|
||||||
|
"end_of_assistant": "<|im_end|>"
|
||||||
|
}
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
{
|
||||||
|
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||||
|
"system_message": "You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Now the user asks you to solve a math problem that involves reasoning. After thinking, when you finally reach a conclusion, clearly output the final answer without explanation within the <answer> </answer> tags, your final answer should be a integer without unit, currency mark, thousands separator or other text. i.e., <answer> 123 </answer>.\n",
|
||||||
|
"stop_ids": [
|
||||||
|
151643
|
||||||
|
],
|
||||||
|
"end_of_assistant": "<|endoftext|>",
|
||||||
|
"response_format_tags": {
|
||||||
|
"think_start": {
|
||||||
|
"text": "<think>",
|
||||||
|
"num_occur": 1
|
||||||
|
},
|
||||||
|
"think_end": {
|
||||||
|
"text": "</think>",
|
||||||
|
"num_occur": 1
|
||||||
|
},
|
||||||
|
"answer_start": {
|
||||||
|
"text": "<answer>",
|
||||||
|
"num_occur": 1
|
||||||
|
},
|
||||||
|
"answer_end": {
|
||||||
|
"text": "</answer>",
|
||||||
|
"num_occur": 1
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
@@ -2,8 +2,6 @@
|
|||||||
|
|
||||||
|
|
||||||
## Table of Contents
|
## Table of Contents
|
||||||
|
|
||||||
|
|
||||||
- [Examples](#examples)
|
- [Examples](#examples)
|
||||||
- [Table of Contents](#table-of-contents)
|
- [Table of Contents](#table-of-contents)
|
||||||
- [Install Requirements](#install-requirements)
|
- [Install Requirements](#install-requirements)
|
||||||
@@ -27,13 +25,14 @@
|
|||||||
- [Reward](#reward)
|
- [Reward](#reward)
|
||||||
- [KL Divergence](#approximate-kl-divergence)
|
- [KL Divergence](#approximate-kl-divergence)
|
||||||
- [Note on PPO Training](#note-on-ppo-training)
|
- [Note on PPO Training](#note-on-ppo-training)
|
||||||
|
- [GRPO Training and DeepSeek R1 reproduction](#grpo-training-and-deepseek-r1-reproduction)
|
||||||
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
|
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||||
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
|
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
|
||||||
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
|
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
|
||||||
- [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
|
- [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
|
||||||
- [Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
- [Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||||
- [Alternative Option For RLHF: Odds Ratio Preference Optimization](#alternative-option-for-rlhf-odds-ratio-preference-optimization)
|
- [Alternative Option For RLHF: Odds Ratio Preference Optimization](#alternative-option-for-rlhf-odds-ratio-preference-optimization)
|
||||||
- [List of Supported Models](#list-of-supported-models)
|
- [SFT for DeepSeek V3](#sft-for-deepseek-v3)
|
||||||
- [Hardware Requirements](#hardware-requirements)
|
- [Hardware Requirements](#hardware-requirements)
|
||||||
- [Inference example](#inference-example)
|
- [Inference example](#inference-example)
|
||||||
- [Attention](#attention)
|
- [Attention](#attention)
|
||||||
@@ -725,10 +724,69 @@ Answer: The causes of this problem are two-fold. Check your reward model, make s
|
|||||||
#### Q4: Generation is garbage
|
#### Q4: Generation is garbage
|
||||||
Answer: Yes, this happens and is well documented by other implementations. After training for too many episodes, the actor gradually deviate from its original state, which may leads to decrease in language modeling capabilities. A way to fix this is to add supervised loss during PPO. Set ptx_coef to an non-zero value (between 0 and 1), which balances PPO loss and sft loss.
|
Answer: Yes, this happens and is well documented by other implementations. After training for too many episodes, the actor gradually deviate from its original state, which may leads to decrease in language modeling capabilities. A way to fix this is to add supervised loss during PPO. Set ptx_coef to an non-zero value (between 0 and 1), which balances PPO loss and sft loss.
|
||||||
|
|
||||||
|
## GRPO Training and DeepSeek R1 reproduction
|
||||||
|
We support GRPO (Group Relative Policy Optimization), which is the reinforcement learning algorithm used in DeepSeek R1 paper. In this section, we will walk through GRPO training with an example trying to reproduce Deepseek R1's results in mathematical problem solving.
|
||||||
|
|
||||||
|
**Note: Currently, our PPO and GRPO pipelines are still under extensive development (integration with Ray and the inference engine). The speed is primarily limited by the rollout process, as we are using a naive generation approach without any acceleration. This experiment is focused solely on verifying the correctness of the GRPO algorithm. We will open-source the new version of code as soon as possible, so please stay tuned.**
|
||||||
|
|
||||||
|
### GRPO Model Selection
|
||||||
|
We finally select the base version of [Qwen2.5-3B](https://huggingface.co/Qwen/Qwen2.5-3B). We also did experiments on the instruct version [Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) but the later one fails to explore more diversed output. We recommend to use base models (without SFT) and use a few SFT steps (see [SFT section](#rlhf-training-stage1---supervised-instructs-tuning)) to correct the base model's output format before GRPO.
|
||||||
|
|
||||||
|
### Reinforcement Learning with Verifiable Reward
|
||||||
|
Both the PPO and the GRPO support reinforcement learning with verifiable reward (RLVR). In this experiment on mathematical problem solving, we define the reward function as following, in the following definition, forward is correct if there are exactly one pair of <think></think>, <answer></answer> tags in the response and the order of the tags is correct.
|
||||||
|
|
||||||
|
- reward=0, if format is incorrect.
|
||||||
|
- reward=1, if format is correct but the answer doesn't match the ground truth answer exactly.
|
||||||
|
- reward=10, if format is correct and the answer match the ground truth answer exactly.
|
||||||
|
|
||||||
|
### Step 1: Data Collection & Preparation
|
||||||
|
For GPRO training, you only need the prompt dataset. Please follow the instruction in the [prompt dataset preparation](#rlhf-training-stage3---proximal-policy-optimization) to prepare the prompt data for GPRO training. In our reproduction experiment, we use the [qwedsacf/competition_math dataset](https://huggingface.co/datasets/qwedsacf/competition_math), which is available on Huggingface.
|
||||||
|
|
||||||
|
### Step 2: Training
|
||||||
|
You can run the [train_grpo.sh](./training_scripts/train_grpo.sh) to start GRPO training. The script share most of its arguments with the PPO script (please refer to the [PPO training section](#step-3-training) for more details). Here are some unique arguments for GRPO.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--num_generations 8 \ # number of roll outs to collect for each prompt
|
||||||
|
--inference_batch_size 8 \ # batch size used during roll out
|
||||||
|
--logits_forward_batch_size 1 \ # batch size used to calculate logits for GRPO training
|
||||||
|
--initial_temperature \ # initial temperature for annealing algorithm
|
||||||
|
--final_temperature \ # final temperature for annealing algorithm
|
||||||
|
```
|
||||||
|
|
||||||
|
As the GRPO requires to collect a group of response from each prompt (usually greater than 8), the effective batch size will satisfy the following constraints,
|
||||||
|
|
||||||
|
- Without tensor parallelism,
|
||||||
|
```
|
||||||
|
experience buffer size
|
||||||
|
= num_process * num_collect_steps * experience_batch_size * num_generations
|
||||||
|
= train_batch_size * accumulation_steps * num_process
|
||||||
|
```
|
||||||
|
|
||||||
|
- With tensor parallelism,
|
||||||
|
```
|
||||||
|
num_tp_group = num_process / tp
|
||||||
|
experience buffer size
|
||||||
|
= num_tp_group * num_collect_steps * experience_batch_size * num_generations
|
||||||
|
= train_batch_size * accumulation_steps * num_tp_group
|
||||||
|
```
|
||||||
|
|
||||||
|
During roll out, we perform rebatching to prevent out of memory both before roll out and before calculating logits. Please choose a proper setting for the "inference_batch_size" and the "logits_forward_batch_size" based on your device.
|
||||||
|
|
||||||
|
### GRPO Result
|
||||||
|
#### Reward and Response Length
|
||||||
|
<div style="display: flex; justify-content: space-between;">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/reward.png" style="width: 48%;" />
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost.png" style="width: 48%;" />
|
||||||
|
</div>
|
||||||
|
|
||||||
|
#### Response Length Distribution (After Training) and Sample response
|
||||||
|
<div style="display: flex; justify-content: space-between;">
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost_eval.png" style="width: 48%;" />
|
||||||
|
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/sample.png" style="width: 48%;" />
|
||||||
|
</div>
|
||||||
|
|
||||||
|
|
||||||
## Alternative Option For RLHF: Direct Preference Optimization
|
## Alternative Option For RLHF: Direct Preference Optimization
|
||||||
|
|
||||||
|
|
||||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
|
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
|
||||||
|
|
||||||
|
|
||||||
@@ -814,8 +872,95 @@ For training, use the [train_kto.sh](./examples/training_scripts/train_orpo.sh)
|
|||||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/KTO.png">
|
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/KTO.png">
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
## Hardware Requirements
|
|
||||||
|
|
||||||
|
### SFT for DeepSeek V3
|
||||||
|
We add a script to supervised-fintune the DeepSeek V3/R1 model with LoRA. The script is located in `examples/training_scripts/lora_fintune.py`. The script is similar to the SFT script for Coati7B, but with a few differences. This script is compatible with Peft.
|
||||||
|
|
||||||
|
#### Dataset preparation
|
||||||
|
|
||||||
|
This script receives JSONL format file as input dataset. Each line of dataset should be a list of chat dialogues. E.g.
|
||||||
|
```json
|
||||||
|
[{"role": "user", "content": "Hello, how are you?"}, {"role": "assistant", "content": "I'm doing great. How can I help you today?"}]
|
||||||
|
```
|
||||||
|
```json
|
||||||
|
[{"role": "user", "content": "火烧赤壁 曹操为何不拨打119求救?"}, {"role": "assistant", "content": "因为在三国时期,还没有电话和现代的消防系统,所以曹操无法拨打119求救。"}]
|
||||||
|
```
|
||||||
|
|
||||||
|
The dialogues can by multiple turns and it can contain system prompt. For more details, see the [chat_templating](https://huggingface.co/docs/transformers/main/chat_templating).
|
||||||
|
|
||||||
|
#### Model weights preparation
|
||||||
|
|
||||||
|
We use bf16 weights for finetuning. If you downloaded fp8 DeepSeek V3/R1 weights, you can use the [script](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py) to convert the weights to bf16 via GPU. For Ascend NPU, you can use this [script](https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/fp8_cast_bf16.py).
|
||||||
|
|
||||||
|
We have also added details on how to load and reason with lora models.
|
||||||
|
```python
|
||||||
|
from transformers import (
|
||||||
|
AutoModelForCausalLM,
|
||||||
|
AutoTokenizer,
|
||||||
|
)
|
||||||
|
from peft import (
|
||||||
|
PeftModel
|
||||||
|
)
|
||||||
|
import torch
|
||||||
|
|
||||||
|
# Set model path
|
||||||
|
model_name = "Qwen/Qwen2.5-3B"
|
||||||
|
lora_adapter = "Qwen2.5-3B_lora" # Your lora model Path
|
||||||
|
merged_model_path = "Qwen2.5-3B_merged"
|
||||||
|
|
||||||
|
######
|
||||||
|
# How to Load lora Model
|
||||||
|
######
|
||||||
|
# 1.Load base model
|
||||||
|
base_model = AutoModelForCausalLM.from_pretrained(
|
||||||
|
model_name,
|
||||||
|
torch_dtype=torch.bfloat16,
|
||||||
|
device_map="auto",
|
||||||
|
trust_remote_code=True
|
||||||
|
)
|
||||||
|
|
||||||
|
# 2.Load lora model
|
||||||
|
peft_model = PeftModel.from_pretrained(
|
||||||
|
base_model,
|
||||||
|
lora_adapter,
|
||||||
|
torch_dtype=torch.bfloat16
|
||||||
|
)
|
||||||
|
|
||||||
|
# 3.Merge lora model
|
||||||
|
merged_model = peft_model.merge_and_unload()
|
||||||
|
|
||||||
|
# 4.Load tokenizer
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(
|
||||||
|
model_name,
|
||||||
|
trust_remote_code=True,
|
||||||
|
pad_token="<|endoftext|>"
|
||||||
|
)
|
||||||
|
|
||||||
|
# 5.Save merged lora model
|
||||||
|
merged_model.save_pretrained(
|
||||||
|
merged_model_path,
|
||||||
|
safe_serialization=True
|
||||||
|
)
|
||||||
|
tokenizer.save_pretrained(merged_model_path)
|
||||||
|
|
||||||
|
# 6.Run Inference
|
||||||
|
test_input = tokenizer("Instruction: Finding prime numbers up to 100\nAnswer:", return_tensors="pt").to("cuda")
|
||||||
|
output = merged_model.generate(**test_input, max_new_tokens=100)
|
||||||
|
print(tokenizer.decode(output[0], skip_special_tokens=True))
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Usage
|
||||||
|
|
||||||
|
After preparing the dataset and model weights, you can run the script with the following command:
|
||||||
|
```bash
|
||||||
|
colossalai run --hostfile path-to-host-file --nproc_per_node 8 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
|
||||||
|
```
|
||||||
|
|
||||||
|
For more details of each argument, you can run `python lora_finetune.py --help`.
|
||||||
|
|
||||||
|
The sample command does not use CPU offload to get better throughput. The minimum hardware requirement for sample command is 32 ascend 910B NPUs (with `ep=8,pp=4`) or 24 H100/H800 GPUs (with `ep=8,pp=3`). If you enable CPU offload by `--zero_cpu_offload`, the hardware requirement can be further reduced.
|
||||||
|
|
||||||
|
## Hardware Requirements
|
||||||
For SFT, we recommend using zero2 or zero2-cpu for 7B model and tp is your model is extra large. We tested the VRAM consumption on a dummy dataset with a sequence length of 2048. In all experiments, we use H800 GPUs with 80GB VRAM and enable gradient checkpointing and flash attention.
|
For SFT, we recommend using zero2 or zero2-cpu for 7B model and tp is your model is extra large. We tested the VRAM consumption on a dummy dataset with a sequence length of 2048. In all experiments, we use H800 GPUs with 80GB VRAM and enable gradient checkpointing and flash attention.
|
||||||
- 2 H800 GPU
|
- 2 H800 GPU
|
||||||
- zero2-cpu, micro batch size=4, VRAM Usage=22457.98 MB
|
- zero2-cpu, micro batch size=4, VRAM Usage=22457.98 MB
|
||||||
@@ -872,35 +1017,9 @@ For KTO, we recommend using zero2-cpu or zero2 plugin, We tested the VRAM consum
|
|||||||
- zero2_cpu, micro batch size=2, VRAM_USAGE=32443.22 MB
|
- zero2_cpu, micro batch size=2, VRAM_USAGE=32443.22 MB
|
||||||
- zero2, micro batch size=4, VRAM_USAGE=59307.97 MB
|
- zero2, micro batch size=4, VRAM_USAGE=59307.97 MB
|
||||||
|
|
||||||
## List of Supported Models
|
|
||||||
|
|
||||||
For SFT, we support the following models/series:
|
|
||||||
- Colossal-LLaMA-2
|
|
||||||
- ChatGLM2
|
|
||||||
- ChatGLM3 (only with zero2, zero2_cpu plugin)
|
|
||||||
- Baichuan2
|
|
||||||
- LLaMA2
|
|
||||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
|
||||||
- Yi-1.5
|
|
||||||
|
|
||||||
For PPO and DPO, we theoratically support the following models/series (without guarantee):
|
|
||||||
- Colossal-LLaMA-2 (tested)
|
|
||||||
- ChatGLM2
|
|
||||||
- Baichuan2
|
|
||||||
- LLaMA2 (tested)
|
|
||||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
|
||||||
- Yi-1.5
|
|
||||||
|
|
||||||
*-* The zero2, zero2_cpu plugin also support a wide range of chat models not listed above.
|
|
||||||
|
|
||||||
## Inference example
|
## Inference example
|
||||||
|
|
||||||
|
|
||||||
We support different inference options, including int8 and int4 quantization.
|
We support different inference options, including int8 and int4 quantization.
|
||||||
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||||
|
|
||||||
|
|
||||||
## Attention
|
## Attention
|
||||||
|
|
||||||
|
|
||||||
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.
|
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.
|
||||||
|
|||||||
@@ -11,4 +11,4 @@ python prepare_dataset.py --type prompt \
|
|||||||
--data_cache_dir $SAVE_DIR/cache \
|
--data_cache_dir $SAVE_DIR/cache \
|
||||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||||
--max_length 1024
|
--max_length 300
|
||||||
|
|||||||
@@ -1,181 +0,0 @@
|
|||||||
import argparse
|
|
||||||
import os
|
|
||||||
import socket
|
|
||||||
from functools import partial
|
|
||||||
|
|
||||||
import pandas as pd
|
|
||||||
import ray
|
|
||||||
from coati.quant import llama_load_quant, low_resource_init
|
|
||||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
|
||||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
|
||||||
from coati.ray.utils import (
|
|
||||||
get_actor_from_args,
|
|
||||||
get_critic_from_args,
|
|
||||||
get_reward_model_from_args,
|
|
||||||
get_strategy_from_args,
|
|
||||||
get_tokenizer_from_args,
|
|
||||||
)
|
|
||||||
from torch.utils.data import DataLoader
|
|
||||||
from transformers import AutoConfig
|
|
||||||
from transformers.modeling_utils import no_init_weights
|
|
||||||
|
|
||||||
|
|
||||||
def get_free_port():
|
|
||||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
|
||||||
s.bind(("", 0))
|
|
||||||
return s.getsockname()[1]
|
|
||||||
|
|
||||||
|
|
||||||
def get_local_ip():
|
|
||||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
|
||||||
s.connect(("8.8.8.8", 80))
|
|
||||||
return s.getsockname()[0]
|
|
||||||
|
|
||||||
|
|
||||||
def main(args):
|
|
||||||
master_addr = str(get_local_ip())
|
|
||||||
# trainer_env_info
|
|
||||||
trainer_port = str(get_free_port())
|
|
||||||
env_info_trainers = [
|
|
||||||
{
|
|
||||||
"local_rank": "0",
|
|
||||||
"rank": str(rank),
|
|
||||||
"world_size": str(args.num_trainers),
|
|
||||||
"master_port": trainer_port,
|
|
||||||
"master_addr": master_addr,
|
|
||||||
}
|
|
||||||
for rank in range(args.num_trainers)
|
|
||||||
]
|
|
||||||
|
|
||||||
# maker_env_info
|
|
||||||
maker_port = str(get_free_port())
|
|
||||||
env_info_maker = {
|
|
||||||
"local_rank": "0",
|
|
||||||
"rank": "0",
|
|
||||||
"world_size": "1",
|
|
||||||
"master_port": maker_port,
|
|
||||||
"master_addr": master_addr,
|
|
||||||
}
|
|
||||||
|
|
||||||
# configure tokenizer
|
|
||||||
tokenizer = get_tokenizer_from_args(args.model)
|
|
||||||
|
|
||||||
def trainer_model_fn():
|
|
||||||
actor = get_actor_from_args(args.model, args.pretrain).half().cuda()
|
|
||||||
critic = get_critic_from_args(args.model, args.critic_pretrain).half().cuda()
|
|
||||||
return actor, critic
|
|
||||||
|
|
||||||
# configure Trainer
|
|
||||||
trainer_refs = [
|
|
||||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
|
||||||
experience_maker_holder_name_list=["maker1"],
|
|
||||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
|
||||||
model_fn=trainer_model_fn,
|
|
||||||
env_info=env_info_trainer,
|
|
||||||
train_batch_size=args.train_batch_size,
|
|
||||||
buffer_limit=16,
|
|
||||||
eval_performance=True,
|
|
||||||
debug=args.debug,
|
|
||||||
update_lora_weights=not (args.lora_rank == 0),
|
|
||||||
)
|
|
||||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
|
||||||
]
|
|
||||||
|
|
||||||
def model_fn():
|
|
||||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
|
||||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
|
||||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
|
||||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
|
||||||
# quantize initial model
|
|
||||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
|
||||||
with low_resource_init(), no_init_weights():
|
|
||||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
|
||||||
initial_model.model = (
|
|
||||||
llama_load_quant(
|
|
||||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
|
||||||
)
|
|
||||||
.cuda()
|
|
||||||
.requires_grad_(False)
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
|
||||||
return actor, critic, reward_model, initial_model
|
|
||||||
|
|
||||||
# configure Experience Maker
|
|
||||||
experience_holder_ref = ExperienceMakerHolder.options(name="maker1", num_gpus=1, max_concurrency=2).remote(
|
|
||||||
detached_trainer_name_list=[f"trainer{i}" for i in range(args.num_trainers)],
|
|
||||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
|
||||||
model_fn=model_fn,
|
|
||||||
env_info=env_info_maker,
|
|
||||||
experience_batch_size=args.experience_batch_size,
|
|
||||||
kl_coef=0.1,
|
|
||||||
debug=args.debug,
|
|
||||||
update_lora_weights=not (args.lora_rank == 0),
|
|
||||||
# sync_models_from_trainers=True,
|
|
||||||
# generation kwargs:
|
|
||||||
max_length=512,
|
|
||||||
do_sample=True,
|
|
||||||
temperature=1.0,
|
|
||||||
top_k=50,
|
|
||||||
pad_token_id=tokenizer.pad_token_id,
|
|
||||||
eos_token_id=tokenizer.eos_token_id,
|
|
||||||
eval_performance=True,
|
|
||||||
use_cache=True,
|
|
||||||
)
|
|
||||||
|
|
||||||
# uncomment this function if sync_models_from_trainers is True
|
|
||||||
# ray.get([
|
|
||||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
|
||||||
# for trainer_ref in trainer_refs
|
|
||||||
# ])
|
|
||||||
|
|
||||||
wait_tasks = []
|
|
||||||
|
|
||||||
total_steps = args.experience_batch_size * args.experience_steps // (args.num_trainers * args.train_batch_size)
|
|
||||||
for trainer_ref in trainer_refs:
|
|
||||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
|
||||||
|
|
||||||
dataset_size = args.experience_batch_size * 4
|
|
||||||
|
|
||||||
def build_dataloader():
|
|
||||||
def tokenize_fn(texts):
|
|
||||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
|
||||||
return {k: v.cuda() for k, v in batch.items()}
|
|
||||||
|
|
||||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
|
||||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
|
||||||
return dataloader
|
|
||||||
|
|
||||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
|
||||||
|
|
||||||
ray.get(wait_tasks)
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
|
||||||
parser = argparse.ArgumentParser()
|
|
||||||
parser.add_argument("--prompt_path", type=str, default=None)
|
|
||||||
parser.add_argument("--num_trainers", type=int, default=1)
|
|
||||||
parser.add_argument(
|
|
||||||
"--trainer_strategy",
|
|
||||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
|
||||||
default="ddp",
|
|
||||||
)
|
|
||||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
|
||||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
|
||||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
|
||||||
parser.add_argument("--pretrain", type=str, default=None)
|
|
||||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
|
||||||
parser.add_argument("--experience_steps", type=int, default=4)
|
|
||||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
|
||||||
parser.add_argument("--train_epochs", type=int, default=1)
|
|
||||||
parser.add_argument("--update_steps", type=int, default=2)
|
|
||||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
|
||||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
|
||||||
|
|
||||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
|
||||||
parser.add_argument("--quant_bits", type=int, default=4)
|
|
||||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
|
||||||
parser.add_argument("--debug", action="store_true")
|
|
||||||
args = parser.parse_args()
|
|
||||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
|
||||||
main(args)
|
|
||||||
@@ -1,201 +0,0 @@
|
|||||||
import argparse
|
|
||||||
import os
|
|
||||||
import socket
|
|
||||||
from functools import partial
|
|
||||||
|
|
||||||
import pandas as pd
|
|
||||||
import ray
|
|
||||||
from coati.quant import llama_load_quant, low_resource_init
|
|
||||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
|
||||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
|
||||||
from coati.ray.utils import (
|
|
||||||
get_actor_from_args,
|
|
||||||
get_critic_from_args,
|
|
||||||
get_receivers_per_sender,
|
|
||||||
get_reward_model_from_args,
|
|
||||||
get_strategy_from_args,
|
|
||||||
)
|
|
||||||
from torch.utils.data import DataLoader
|
|
||||||
from transformers import AutoConfig, AutoTokenizer
|
|
||||||
from transformers.modeling_utils import no_init_weights
|
|
||||||
|
|
||||||
|
|
||||||
def get_free_port():
|
|
||||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
|
||||||
s.bind(("", 0))
|
|
||||||
return s.getsockname()[1]
|
|
||||||
|
|
||||||
|
|
||||||
def get_local_ip():
|
|
||||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
|
||||||
s.connect(("8.8.8.8", 80))
|
|
||||||
return s.getsockname()[0]
|
|
||||||
|
|
||||||
|
|
||||||
def main(args):
|
|
||||||
master_addr = str(get_local_ip())
|
|
||||||
# trainer_env_info
|
|
||||||
trainer_port = str(get_free_port())
|
|
||||||
env_info_trainers = [
|
|
||||||
{
|
|
||||||
"local_rank": "0",
|
|
||||||
"rank": str(rank),
|
|
||||||
"world_size": str(args.num_trainers),
|
|
||||||
"master_port": trainer_port,
|
|
||||||
"master_addr": master_addr,
|
|
||||||
}
|
|
||||||
for rank in range(args.num_trainers)
|
|
||||||
]
|
|
||||||
|
|
||||||
# maker_env_info
|
|
||||||
maker_port = str(get_free_port())
|
|
||||||
env_info_makers = [
|
|
||||||
{
|
|
||||||
"local_rank": "0",
|
|
||||||
"rank": str(rank),
|
|
||||||
"world_size": str(args.num_makers),
|
|
||||||
"master_port": maker_port,
|
|
||||||
"master_addr": master_addr,
|
|
||||||
}
|
|
||||||
for rank in range(args.num_makers)
|
|
||||||
]
|
|
||||||
|
|
||||||
# configure tokenizer
|
|
||||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
|
|
||||||
tokenizer.pad_token = tokenizer.eos_token
|
|
||||||
|
|
||||||
def model_fn():
|
|
||||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
|
||||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
|
||||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
|
||||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
|
||||||
# quantize initial model
|
|
||||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
|
||||||
with low_resource_init(), no_init_weights():
|
|
||||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
|
||||||
initial_model.model = (
|
|
||||||
llama_load_quant(
|
|
||||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
|
||||||
)
|
|
||||||
.cuda()
|
|
||||||
.requires_grad_(False)
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
|
||||||
return actor, critic, reward_model, initial_model
|
|
||||||
|
|
||||||
# configure Experience Maker
|
|
||||||
experience_holder_refs = [
|
|
||||||
ExperienceMakerHolder.options(name=f"maker{i}", num_gpus=1, max_concurrency=2).remote(
|
|
||||||
detached_trainer_name_list=[
|
|
||||||
f"trainer{x}"
|
|
||||||
for x in get_receivers_per_sender(i, args.num_makers, args.num_trainers, allow_idle_sender=False)
|
|
||||||
],
|
|
||||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
|
||||||
model_fn=model_fn,
|
|
||||||
env_info=env_info_maker,
|
|
||||||
kl_coef=0.1,
|
|
||||||
debug=args.debug,
|
|
||||||
update_lora_weights=not (args.lora_rank == 0),
|
|
||||||
# sync_models_from_trainers=True,
|
|
||||||
# generation kwargs:
|
|
||||||
max_length=512,
|
|
||||||
do_sample=True,
|
|
||||||
temperature=1.0,
|
|
||||||
top_k=50,
|
|
||||||
pad_token_id=tokenizer.pad_token_id,
|
|
||||||
eos_token_id=tokenizer.eos_token_id,
|
|
||||||
eval_performance=True,
|
|
||||||
use_cache=True,
|
|
||||||
)
|
|
||||||
for i, env_info_maker in enumerate(env_info_makers)
|
|
||||||
]
|
|
||||||
|
|
||||||
def trainer_model_fn():
|
|
||||||
actor = get_actor_from_args(args.model, args.pretrain, lora_rank=args.lora_rank).half().cuda()
|
|
||||||
critic = get_critic_from_args(args.model, args.critic_pretrain, lora_rank=args.lora_rank).half().cuda()
|
|
||||||
return actor, critic
|
|
||||||
|
|
||||||
# configure Trainer
|
|
||||||
trainer_refs = [
|
|
||||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
|
||||||
experience_maker_holder_name_list=[
|
|
||||||
f"maker{x}"
|
|
||||||
for x in get_receivers_per_sender(i, args.num_trainers, args.num_makers, allow_idle_sender=True)
|
|
||||||
],
|
|
||||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
|
||||||
model_fn=trainer_model_fn,
|
|
||||||
env_info=env_info_trainer,
|
|
||||||
train_batch_size=args.train_batch_size,
|
|
||||||
buffer_limit=16,
|
|
||||||
eval_performance=True,
|
|
||||||
debug=args.debug,
|
|
||||||
update_lora_weights=not (args.lora_rank == 0),
|
|
||||||
)
|
|
||||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
|
||||||
]
|
|
||||||
|
|
||||||
dataset_size = args.experience_batch_size * 4
|
|
||||||
|
|
||||||
def build_dataloader():
|
|
||||||
def tokenize_fn(texts):
|
|
||||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
|
||||||
return {k: v.cuda() for k, v in batch.items()}
|
|
||||||
|
|
||||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
|
||||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
|
||||||
return dataloader
|
|
||||||
|
|
||||||
# uncomment this function if sync_models_from_trainers is True
|
|
||||||
# ray.get([
|
|
||||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
|
||||||
# for trainer_ref in trainer_refs
|
|
||||||
# ])
|
|
||||||
|
|
||||||
wait_tasks = []
|
|
||||||
|
|
||||||
for experience_holder_ref in experience_holder_refs:
|
|
||||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
|
||||||
|
|
||||||
total_steps = (
|
|
||||||
args.experience_batch_size
|
|
||||||
* args.experience_steps
|
|
||||||
* args.num_makers
|
|
||||||
// (args.num_trainers * args.train_batch_size)
|
|
||||||
)
|
|
||||||
for trainer_ref in trainer_refs:
|
|
||||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
|
||||||
|
|
||||||
ray.get(wait_tasks)
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
|
||||||
parser = argparse.ArgumentParser()
|
|
||||||
parser.add_argument("--prompt_path", type=str, default=None)
|
|
||||||
parser.add_argument("--num_makers", type=int, default=1)
|
|
||||||
parser.add_argument("--num_trainers", type=int, default=1)
|
|
||||||
parser.add_argument(
|
|
||||||
"--trainer_strategy",
|
|
||||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
|
||||||
default="ddp",
|
|
||||||
)
|
|
||||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
|
||||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
|
||||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
|
||||||
parser.add_argument("--pretrain", type=str, default=None)
|
|
||||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
|
||||||
parser.add_argument("--experience_steps", type=int, default=4)
|
|
||||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
|
||||||
parser.add_argument("--train_epochs", type=int, default=1)
|
|
||||||
parser.add_argument("--update_steps", type=int, default=2)
|
|
||||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
|
||||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
|
||||||
|
|
||||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
|
||||||
parser.add_argument("--quant_bits", type=int, default=4)
|
|
||||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
|
||||||
parser.add_argument("--debug", action="store_true")
|
|
||||||
args = parser.parse_args()
|
|
||||||
|
|
||||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
|
||||||
main(args)
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
ray
|
|
||||||
@@ -1,12 +0,0 @@
|
|||||||
#!/bin/bash
|
|
||||||
|
|
||||||
set -xe
|
|
||||||
BASE=$(realpath $(dirname $0))
|
|
||||||
|
|
||||||
export RAY_NAMESPACE=admin
|
|
||||||
export DATA=/data/scratch/chatgpt/prompts.csv
|
|
||||||
|
|
||||||
# install requirements
|
|
||||||
pip install -r ${BASE}/requirements.txt
|
|
||||||
|
|
||||||
python ${BASE}/mmmt_prompt.py --prompt_path $DATA --num_makers 2 --num_trainers 2 --trainer_strategy colossalai_gemini --model opt --critic_model opt --pretrain facebook/opt-350m --critic_pretrain facebook/opt-125m --experience_batch_size 4 --train_batch_size 2
|
|
||||||
@@ -1,4 +1,3 @@
|
|||||||
pandas>=1.4.1
|
pandas>=1.4.1
|
||||||
sentencepiece
|
sentencepiece
|
||||||
colossalai==0.4.0
|
|
||||||
prompt_toolkit
|
prompt_toolkit
|
||||||
|
|||||||
@@ -0,0 +1,455 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Supervised fine-tuning of MoE models like Deepseek V3/R1 on a downstream task.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import resource
|
||||||
|
from contextlib import nullcontext
|
||||||
|
from types import MethodType
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
from coati.dataset.loader import RawConversationDataset
|
||||||
|
from peft import LoraConfig
|
||||||
|
from tqdm import tqdm
|
||||||
|
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
|
import colossalai
|
||||||
|
from colossalai.accelerator import get_accelerator
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import (
|
||||||
|
GeminiPlugin,
|
||||||
|
HybridParallelPlugin,
|
||||||
|
LowLevelZeroPlugin,
|
||||||
|
MoeHybridParallelPlugin,
|
||||||
|
Plugin,
|
||||||
|
TorchDDPPlugin,
|
||||||
|
)
|
||||||
|
from colossalai.cluster import DistCoordinator
|
||||||
|
from colossalai.lazy import LazyInitContext
|
||||||
|
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||||
|
from colossalai.nn.optimizer import HybridAdam
|
||||||
|
from colossalai.utils import get_current_device
|
||||||
|
|
||||||
|
|
||||||
|
def all_reduce_mean(loss: torch.Tensor, plugin: Plugin) -> torch.Tensor:
|
||||||
|
loss = loss.data
|
||||||
|
group = getattr(plugin, "dp_group", None)
|
||||||
|
dist.all_reduce(loss, group=group)
|
||||||
|
return loss / dist.get_world_size(group)
|
||||||
|
|
||||||
|
|
||||||
|
def train(args) -> None:
|
||||||
|
# ==============================
|
||||||
|
# Initialize Distributed Training
|
||||||
|
# ==============================
|
||||||
|
colossalai.launch_from_torch()
|
||||||
|
accelerator = get_accelerator()
|
||||||
|
coordinator = DistCoordinator()
|
||||||
|
|
||||||
|
# ==============================
|
||||||
|
# Initialize Booster
|
||||||
|
# ==============================
|
||||||
|
if args.plugin == "ddp":
|
||||||
|
plugin = TorchDDPPlugin(find_unused_parameters=True if args.use_grad_checkpoint is False else False)
|
||||||
|
elif args.plugin == "gemini":
|
||||||
|
plugin = GeminiPlugin(
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
enable_gradient_accumulation=(args.accumulation_steps > 1),
|
||||||
|
enable_fused_normalization=get_accelerator().is_available(),
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
)
|
||||||
|
elif args.plugin == "gemini_auto":
|
||||||
|
plugin = GeminiPlugin(
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
placement_policy="auto",
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
enable_gradient_accumulation=(args.accumulation_steps > 1),
|
||||||
|
enable_fused_normalization=get_accelerator().is_available(),
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
)
|
||||||
|
elif args.plugin == "zero2":
|
||||||
|
plugin = LowLevelZeroPlugin(
|
||||||
|
stage=2,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
)
|
||||||
|
elif args.plugin == "zero2_cpu":
|
||||||
|
plugin = LowLevelZeroPlugin(
|
||||||
|
stage=2,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
initial_scale=2**16,
|
||||||
|
cpu_offload=True,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
)
|
||||||
|
elif args.plugin == "3d":
|
||||||
|
plugin = HybridParallelPlugin(
|
||||||
|
tp_size=args.tp,
|
||||||
|
pp_size=args.pp,
|
||||||
|
sp_size=args.sp,
|
||||||
|
sequence_parallelism_mode=args.sp_mode,
|
||||||
|
zero_stage=args.zero_stage,
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
enable_fused_normalization=get_accelerator().is_available(),
|
||||||
|
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||||
|
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
microbatch_size=args.microbatch_size,
|
||||||
|
)
|
||||||
|
elif args.plugin == "moe":
|
||||||
|
plugin = MoeHybridParallelPlugin(
|
||||||
|
ep_size=args.ep,
|
||||||
|
tp_size=args.tp,
|
||||||
|
pp_size=args.pp,
|
||||||
|
zero_stage=args.zero_stage,
|
||||||
|
sp_size=args.sp,
|
||||||
|
sequence_parallelism_mode=args.sp_mode,
|
||||||
|
enable_sequence_parallelism=args.sp > 1,
|
||||||
|
enable_fused_normalization=get_accelerator().is_available(),
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
microbatch_size=args.microbatch_size,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||||
|
|
||||||
|
booster = Booster(plugin=plugin)
|
||||||
|
|
||||||
|
def is_master():
|
||||||
|
if isinstance(plugin, HybridParallelPlugin) and plugin.pp_size > 1:
|
||||||
|
return coordinator.rank == coordinator.world_size - 1
|
||||||
|
return coordinator.is_master()
|
||||||
|
|
||||||
|
# ==============================
|
||||||
|
# Initialize Tensorboard and Save Config
|
||||||
|
# ==============================
|
||||||
|
if is_master():
|
||||||
|
if args.tensorboard_dir is not None:
|
||||||
|
from torch.utils.tensorboard import SummaryWriter
|
||||||
|
|
||||||
|
os.makedirs(args.tensorboard_dir, exist_ok=True)
|
||||||
|
writer = SummaryWriter(args.tensorboard_dir)
|
||||||
|
|
||||||
|
with open(args.config_file, "w") as f:
|
||||||
|
json.dump(args.__dict__, f, indent=4)
|
||||||
|
|
||||||
|
# ======================================================
|
||||||
|
# Initialize Tokenizer, Dataset, Collator and Dataloader
|
||||||
|
# ======================================================
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(args.pretrained, trust_remote_code=True)
|
||||||
|
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Training Info:\nConfig file: {args.config_file} \nTensorboard logs: {args.tensorboard_dir} \nModel checkpoint: {args.save_dir}"
|
||||||
|
)
|
||||||
|
|
||||||
|
coordinator.print_on_master(f"Load dataset: {args.dataset}")
|
||||||
|
dataset = RawConversationDataset(
|
||||||
|
tokenizer,
|
||||||
|
args.dataset,
|
||||||
|
args.max_length,
|
||||||
|
)
|
||||||
|
|
||||||
|
dataloader = plugin.prepare_dataloader(
|
||||||
|
dataset=dataset,
|
||||||
|
batch_size=args.batch_size,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Max device memory after data loader: {accelerator.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||||
|
)
|
||||||
|
|
||||||
|
# ======================================================
|
||||||
|
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||||
|
# ======================================================
|
||||||
|
# When training the ChatGLM model, LoRA and gradient checkpointing are incompatible.
|
||||||
|
init_ctx = (
|
||||||
|
LazyInitContext(default_device=get_current_device())
|
||||||
|
if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
|
||||||
|
else nullcontext()
|
||||||
|
)
|
||||||
|
attn_impl = "eager" if get_accelerator().name == "npu" else "flash_attention_2"
|
||||||
|
|
||||||
|
config = AutoConfig.from_pretrained(args.pretrained, trust_remote_code=True)
|
||||||
|
|
||||||
|
with init_ctx:
|
||||||
|
# from_pretrained is not compatible with LoRA, we load pretrained weights later.
|
||||||
|
# model = AutoModelForCausalLM.from_pretrained(
|
||||||
|
# args.pretrained,
|
||||||
|
# torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
# trust_remote_code=True,
|
||||||
|
# attn_implementation=attn_impl,
|
||||||
|
# )
|
||||||
|
model = AutoModelForCausalLM.from_config(
|
||||||
|
config,
|
||||||
|
trust_remote_code=True,
|
||||||
|
attn_implementation=attn_impl,
|
||||||
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
)
|
||||||
|
|
||||||
|
if args.lora_rank > 0:
|
||||||
|
if model.__class__.__name__.startswith("DeepseekV3"):
|
||||||
|
lora_config = LoraConfig(
|
||||||
|
task_type="CAUSAL_LM",
|
||||||
|
r=args.lora_rank,
|
||||||
|
lora_alpha=args.lora_alpha,
|
||||||
|
target_modules=["gate_proj", "up_proj", "down_proj"],
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
lora_config = LoraConfig(task_type="CAUSAL_LM", r=args.lora_rank, lora_alpha=args.lora_alpha)
|
||||||
|
model = booster.enable_lora(model, lora_config=lora_config)
|
||||||
|
|
||||||
|
# this is essential, otherwise the grad checkpoint will not work.
|
||||||
|
model.train()
|
||||||
|
|
||||||
|
if args.use_grad_checkpoint:
|
||||||
|
model.gradient_checkpointing_enable()
|
||||||
|
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||||
|
if model.config.__class__.__name__.startswith("DeepseekV3"):
|
||||||
|
model.config.use_cache = False
|
||||||
|
model.eval()
|
||||||
|
# enable grad for moe layers
|
||||||
|
for m in model.modules():
|
||||||
|
if m.__class__.__name__ == "DeepseekV3MoE":
|
||||||
|
m.moe_infer = MethodType(m.moe_infer.__wrapped__, m)
|
||||||
|
|
||||||
|
model_numel = sum(p.numel() for p in model.parameters())
|
||||||
|
coordinator.print_on_master(f"Model params: {model_numel / 1e9:.2f} B")
|
||||||
|
|
||||||
|
optimizer = HybridAdam(
|
||||||
|
model_params=model.parameters(),
|
||||||
|
lr=args.lr,
|
||||||
|
betas=(0.9, 0.95),
|
||||||
|
weight_decay=args.weight_decay,
|
||||||
|
adamw_mode=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
if args.warmup_steps is None:
|
||||||
|
args.warmup_steps = int(args.num_epochs * 0.025 * (len(dataloader) // args.accumulation_steps))
|
||||||
|
coordinator.print_on_master(f"Warmup steps is set to {args.warmup_steps}")
|
||||||
|
|
||||||
|
lr_scheduler = CosineAnnealingWarmupLR(
|
||||||
|
optimizer=optimizer,
|
||||||
|
total_steps=args.num_epochs * (len(dataloader) // args.accumulation_steps),
|
||||||
|
warmup_steps=args.warmup_steps,
|
||||||
|
eta_min=0.1 * args.lr,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Flash attention will be disabled because it does NOT support fp32.
|
||||||
|
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||||
|
torch.set_default_dtype(default_dtype)
|
||||||
|
model, optimizer, _, dataloader, lr_scheduler = booster.boost(
|
||||||
|
model=model,
|
||||||
|
optimizer=optimizer,
|
||||||
|
lr_scheduler=lr_scheduler,
|
||||||
|
dataloader=dataloader,
|
||||||
|
)
|
||||||
|
|
||||||
|
torch.set_default_dtype(torch.float)
|
||||||
|
booster.load_model(model, args.pretrained, low_cpu_mem_mode=False, num_threads=8)
|
||||||
|
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Booster init max device memory: {accelerator.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||||
|
)
|
||||||
|
|
||||||
|
start_epoch = 0
|
||||||
|
start_step = 0
|
||||||
|
|
||||||
|
num_steps_per_epoch = len(dataloader) // args.accumulation_steps
|
||||||
|
|
||||||
|
for epoch in range(start_epoch, args.num_epochs):
|
||||||
|
dataloader.sampler.set_epoch(epoch=epoch)
|
||||||
|
if isinstance(plugin, HybridParallelPlugin) and plugin.pp_size > 1:
|
||||||
|
data_iter = iter(dataloader)
|
||||||
|
step_bar = tqdm(
|
||||||
|
range(len(dataloader)),
|
||||||
|
desc="Step",
|
||||||
|
disable=not is_master(),
|
||||||
|
)
|
||||||
|
for step in step_bar:
|
||||||
|
outputs = booster.execute_pipeline(
|
||||||
|
data_iter,
|
||||||
|
model,
|
||||||
|
criterion=lambda outputs, inputs: outputs[0],
|
||||||
|
optimizer=optimizer,
|
||||||
|
return_loss=True,
|
||||||
|
)
|
||||||
|
loss = outputs["loss"]
|
||||||
|
if booster.plugin.stage_manager.is_last_stage():
|
||||||
|
global_loss = all_reduce_mean(loss, plugin)
|
||||||
|
|
||||||
|
optimizer.step()
|
||||||
|
|
||||||
|
if booster.plugin.stage_manager.is_last_stage():
|
||||||
|
grad_norm = optimizer.get_grad_norm()
|
||||||
|
step_bar.set_postfix({"loss": global_loss.item(), "grad_norm": grad_norm})
|
||||||
|
|
||||||
|
if args.tensorboard_dir is not None and is_master():
|
||||||
|
global_step = (epoch * num_steps_per_epoch) + (step + 1) // args.accumulation_steps
|
||||||
|
writer.add_scalar(tag="Loss", scalar_value=global_loss.item(), global_step=global_step)
|
||||||
|
writer.add_scalar(
|
||||||
|
tag="Learning Rate",
|
||||||
|
scalar_value=lr_scheduler.get_last_lr()[0],
|
||||||
|
global_step=global_step,
|
||||||
|
)
|
||||||
|
writer.add_scalar(tag="Grad Norm", scalar_value=grad_norm, global_step=global_step)
|
||||||
|
|
||||||
|
lr_scheduler.step()
|
||||||
|
optimizer.zero_grad()
|
||||||
|
|
||||||
|
else:
|
||||||
|
pbar = tqdm(
|
||||||
|
dataloader,
|
||||||
|
desc=f"Epoch {epoch}",
|
||||||
|
disable=not is_master(),
|
||||||
|
initial=start_step // args.accumulation_steps,
|
||||||
|
)
|
||||||
|
total_loss = torch.tensor(0.0, device=get_current_device())
|
||||||
|
for step, batch in enumerate(pbar, start=start_step // args.accumulation_steps):
|
||||||
|
batch = {k: v.to(get_current_device()) for k, v in batch.items() if isinstance(v, torch.Tensor)}
|
||||||
|
|
||||||
|
batch_output = model(**batch)
|
||||||
|
|
||||||
|
loss = batch_output.loss / args.accumulation_steps
|
||||||
|
total_loss.add_(loss.data)
|
||||||
|
|
||||||
|
booster.backward(loss=loss, optimizer=optimizer)
|
||||||
|
|
||||||
|
if (step + 1) % args.accumulation_steps == 0:
|
||||||
|
all_reduce_mean(total_loss, plugin)
|
||||||
|
|
||||||
|
optimizer.step()
|
||||||
|
|
||||||
|
grad_norm = optimizer.get_grad_norm()
|
||||||
|
pbar.set_postfix({"loss": total_loss.item(), "grad_norm": grad_norm})
|
||||||
|
if args.tensorboard_dir is not None and is_master():
|
||||||
|
global_step = (epoch * num_steps_per_epoch) + (step + 1) // args.accumulation_steps
|
||||||
|
writer.add_scalar(tag="Loss", scalar_value=total_loss.item(), global_step=global_step)
|
||||||
|
writer.add_scalar(
|
||||||
|
tag="Learning Rate",
|
||||||
|
scalar_value=lr_scheduler.get_last_lr()[0],
|
||||||
|
global_step=global_step,
|
||||||
|
)
|
||||||
|
writer.add_scalar(tag="Grad Norm", scalar_value=grad_norm, global_step=global_step)
|
||||||
|
|
||||||
|
lr_scheduler.step()
|
||||||
|
optimizer.zero_grad()
|
||||||
|
|
||||||
|
total_loss.fill_(0.0)
|
||||||
|
|
||||||
|
# Delete cache.
|
||||||
|
# del batch, batch_labels, batch_output, loss
|
||||||
|
accelerator.empty_cache()
|
||||||
|
|
||||||
|
# Final save.
|
||||||
|
coordinator.print_on_master("Start saving final model checkpoint")
|
||||||
|
if args.lora_rank > 0:
|
||||||
|
booster.save_lora_as_pretrained(model, os.path.join(args.save_dir, "lora"))
|
||||||
|
else:
|
||||||
|
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||||
|
coordinator.print_on_master(f"Saved final model checkpoint at epoch {epoch} at folder {args.save_dir}")
|
||||||
|
|
||||||
|
coordinator.print_on_master(f"Max device memory usage: {accelerator.max_memory_allocated()/1024**2:.2f} MB")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
# Basic training information.
|
||||||
|
parser.add_argument(
|
||||||
|
"-m",
|
||||||
|
"--pretrained",
|
||||||
|
type=str,
|
||||||
|
required=True,
|
||||||
|
help="Address of the pre-trained model",
|
||||||
|
)
|
||||||
|
parser.add_argument("-d", "--dataset", type=str, required=True, help="Raw Jonl dataset for training.")
|
||||||
|
parser.add_argument(
|
||||||
|
"-p",
|
||||||
|
"--plugin",
|
||||||
|
type=str,
|
||||||
|
default="zero2",
|
||||||
|
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d", "ddp", "moe"],
|
||||||
|
help="Choose which plugin to use",
|
||||||
|
)
|
||||||
|
parser.add_argument("--save_dir", type=str, default="checkpoint_dir", help="Checkpoint directory")
|
||||||
|
parser.add_argument("--tensorboard_dir", type=str, default=None, help="Tensorboard directory")
|
||||||
|
parser.add_argument("--config_file", type=str, default="training_config.json", help="Config file")
|
||||||
|
# Training parameters
|
||||||
|
parser.add_argument("-n", "--num_epochs", type=int, default=1, help="Number of training epochs")
|
||||||
|
parser.add_argument("--accumulation_steps", type=int, default=1, help="Number of accumulation steps")
|
||||||
|
parser.add_argument("--batch_size", type=int, default=2, help="Global Batch size of each process")
|
||||||
|
parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate")
|
||||||
|
parser.add_argument("--max_length", type=int, default=8192, help="Model max length")
|
||||||
|
parser.add_argument(
|
||||||
|
"--mixed_precision",
|
||||||
|
type=str,
|
||||||
|
default="bf16",
|
||||||
|
choices=["fp16", "bf16"],
|
||||||
|
help="Mixed precision",
|
||||||
|
)
|
||||||
|
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||||
|
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||||
|
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||||
|
parser.add_argument(
|
||||||
|
"-g",
|
||||||
|
"--use_grad_checkpoint",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
help="Use gradient checkpointing",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-f",
|
||||||
|
"--use_flash_attn",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
help="Use flash-attention",
|
||||||
|
)
|
||||||
|
|
||||||
|
# Additional arguments for 3d plugin.
|
||||||
|
parser.add_argument("--tp", type=int, default=1, help="TP size, used for 3d plugin.")
|
||||||
|
parser.add_argument("--pp", type=int, default=1, help="PP size, used for 3d plugin.")
|
||||||
|
parser.add_argument("--sp", type=int, default=1, help="SP size, used for 3d plugin.")
|
||||||
|
parser.add_argument("--ep", type=int, default=1, help="EP size, used for moe plugin.")
|
||||||
|
parser.add_argument("--zero_stage", type=int, default=1, help="Zero stage, used for 3d plugin.", choices=[0, 1, 2])
|
||||||
|
parser.add_argument(
|
||||||
|
"--sp_mode",
|
||||||
|
type=str,
|
||||||
|
default="split_gather",
|
||||||
|
choices=["split_gather", "ring", "all_to_all"],
|
||||||
|
help="SP mode, used for 3d plugin.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--enable_sequence_parallelism",
|
||||||
|
default=False,
|
||||||
|
action="store_true",
|
||||||
|
help="Whether to enable SP, used for 3d plugin.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--zero_cpu_offload", default=False, action="store_true", help="Whether to use offloading, used for 3d plugin."
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--microbatch_size", type=int, default=1, help="Batch size for each process in PP, used for 3d plugin."
|
||||||
|
)
|
||||||
|
parser.add_argument("--lora_rank", type=int, default=0, help="lora rank when using lora to train.")
|
||||||
|
parser.add_argument("--lora_alpha", type=int, default=8, help="lora alpha when using lora to train.")
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
if args.plugin in ["3d", "moe"] and args.pp > 1 and args.accumulation_steps > 1:
|
||||||
|
raise ValueError("Accumulation steps should be 1 when using PP. Please adjust batch size directly.")
|
||||||
|
|
||||||
|
train(args)
|
||||||
@@ -0,0 +1,10 @@
|
|||||||
|
[{"role": "user", "content": "只剩一个心脏了还能活吗?"}, {"role": "assistant", "content": "能,人本来就只有一个心脏。"}]
|
||||||
|
[{"role": "user", "content": "爸爸再婚,我是不是就有了个新娘?"}, {"role": "assistant", "content": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"}]
|
||||||
|
[{"role": "user", "content": "马上要上游泳课了,昨天洗的泳裤还没干,怎么办"}, {"role": "assistant", "content": "游泳时泳裤本来就会湿,不用晾干。"}]
|
||||||
|
[{"role": "user", "content": "为什么没人说ABCD型的成语?🤔"}, {"role": "assistant", "content": "这是因为中文成语一般都是四字成语,每个字都有其特定的含义,四个字合在一起构成一个完整的意思。而ABCD型的成语最常见,所以大家不会刻意强调。"}]
|
||||||
|
[{"role": "user", "content": "太阳还有五十亿年就没了,那到时候向日葵看哪呢?"}, {"role": "assistant", "content": "实际上,向日葵并不会意识到太阳的存在与否,它们只是通过光敏反应来追踪太阳。如果太阳消失,向日葵也不会存活下来,所以它们不会看向任何地方。"}]
|
||||||
|
[{"role": "user", "content": "我把我车钥匙落在车里,现在锁不了车门了。 有人能告诉我怎么办吗?"}, {"role": "assistant", "content": "如果你的车钥匙已经锁在车里,那么你实际上已经无法再从外部打开车门了,所以你的车已经被锁住了。你需要做的是找专业的开锁服务或者联系汽车救援服务来帮你打开车门,取回你的车钥匙。"}]
|
||||||
|
[{"role": "user", "content": "同学说steam好玩,我现在八级烫伤了怎么办? 救救我"}, {"role": "assistant", "content": "\"Steam\"是一个电子游戏分发平台,不是steam蒸汽。建议立即去医院,顺便看看脑子。"}]
|
||||||
|
[{"role": "user", "content": "人在岩浆里憋气最长时间是多少? 刚才好奇搜了一下,水里憋气时间最长的是克罗地亚54岁在水中闭气24分33秒,但是我搜在岩浆里憋气时间最长,居然发现一个没有,不都是液体吗?为什么没人在岩浆里憋气?"}, {"role": "assistant", "content": "因为岩浆的温度极高,达到了800-1200摄氏度,人如果接触到岩浆,会立刻被烧伤,甚至瞬间死亡,所以没有人能在岩浆里憋气。这并不是一个合理的比较,因为水和岩浆虽然都是液体,但是它们的性质差别极大。"}]
|
||||||
|
[{"role": "user", "content": "出生证丢了怎么证明自己出生了"}, {"role": "assistant", "content": "这是个很有意思的问题,从现实意义来讲,你既然已经活着,就已经证明你出生了。如果需要法律意义上的证明,可以通过其他官方文件,例如护照、身份证、驾驶证等。此外,医院的出生记录、学校的入学记录、家庭照片等也可以作为间接证据。如果所有这些都没有,可以向出生地的公共卫生部门或者医院申请复制出生证明。"}]
|
||||||
|
[{"role": "user", "content": "为什么抄袭永远都是今人抄袭古人,而没有古人抄袭今人的案例?"}, {"role": "assistant", "content": "这是因为时间的流逝是单向的,古人无法预知今人的思想和作品,所以古人无法抄袭今人。而今人可以通过学习古人的作品,因此有可能出现抄袭古人的情况。"}]
|
||||||
490
applications/ColossalChat/examples/training_scripts/train_grpo.py
Executable file
490
applications/ColossalChat/examples/training_scripts/train_grpo.py
Executable file
@@ -0,0 +1,490 @@
|
|||||||
|
import argparse
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import resource
|
||||||
|
from contextlib import nullcontext
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
from coati.dataset import (
|
||||||
|
DataCollatorForPromptDataset,
|
||||||
|
DataCollatorForSupervisedDataset,
|
||||||
|
StatefulDistributedSampler,
|
||||||
|
load_tokenized_dataset,
|
||||||
|
setup_conversation_template,
|
||||||
|
)
|
||||||
|
from coati.models import LoraConfig, RewardModel, RLVRRewardModel, convert_to_lora_module, disable_dropout, lora_manager
|
||||||
|
from coati.trainer import GRPOTrainer
|
||||||
|
from coati.utils import load_checkpoint
|
||||||
|
from coati.utils.reward_score import *
|
||||||
|
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
|
import colossalai
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
|
||||||
|
from colossalai.cluster import DistCoordinator
|
||||||
|
from colossalai.logging import get_dist_logger
|
||||||
|
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||||
|
from colossalai.nn.optimizer import HybridAdam
|
||||||
|
from colossalai.shardformer.policies.auto_policy import get_autopolicy
|
||||||
|
|
||||||
|
logger = get_dist_logger()
|
||||||
|
# default settings for response format tags, overwrite it in chat_template definition if needed
|
||||||
|
response_format_tags = {
|
||||||
|
"think_start": {"text": "<think>", "num_occur": 1},
|
||||||
|
"think_end": {"text": "</think>", "num_occur": 1},
|
||||||
|
"answer_start": {"text": "<answer>", "num_occur": 1},
|
||||||
|
"answer_end": {"text": "</answer>", "num_occur": 1},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
global response_format_tags
|
||||||
|
lora_config = None
|
||||||
|
if args.lora_config is not None:
|
||||||
|
lora_config = LoraConfig.from_file(args.lora_config)
|
||||||
|
# check lora compatibility
|
||||||
|
if "gemini" in args.plugin and lora_config is not None and lora_config.r > 0:
|
||||||
|
raise ValueError("LoRA is not supported in GeminiPlugin. Please use other plugin")
|
||||||
|
if args.plugin == "gemini_auto" and args.accumulation_steps > 1:
|
||||||
|
raise ValueError("Gradient accumulation is not supported in GeminiPlugin. Please use other plugin")
|
||||||
|
# ==============================
|
||||||
|
# Initialize Distributed Training
|
||||||
|
# ==============================
|
||||||
|
colossalai.launch_from_torch()
|
||||||
|
coordinator = DistCoordinator()
|
||||||
|
|
||||||
|
# ======================================================
|
||||||
|
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||||
|
# ======================================================
|
||||||
|
# Temp Fix: Disable lazy init due to version conflict
|
||||||
|
# init_ctx = (
|
||||||
|
# LazyInitContext(default_device=get_current_device()) if isinstance(plugin, (GeminiPlugin,)) else nullcontext()
|
||||||
|
# )
|
||||||
|
|
||||||
|
init_ctx = nullcontext()
|
||||||
|
with init_ctx:
|
||||||
|
if args.use_flash_attn:
|
||||||
|
actor = AutoModelForCausalLM.from_pretrained(
|
||||||
|
args.pretrain,
|
||||||
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
use_flash_attention_2=True,
|
||||||
|
trust_remote_code=True,
|
||||||
|
)
|
||||||
|
ref_model = AutoModelForCausalLM.from_pretrained(
|
||||||
|
args.pretrain,
|
||||||
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
use_flash_attention_2=True,
|
||||||
|
trust_remote_code=True,
|
||||||
|
)
|
||||||
|
if args.rm_pretrain:
|
||||||
|
reward_model = RewardModel(
|
||||||
|
args.rm_pretrain,
|
||||||
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
use_flash_attention_2=True,
|
||||||
|
trust_remote_code=True,
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
||||||
|
else:
|
||||||
|
actor = AutoModelForCausalLM.from_pretrained(args.pretrain, trust_remote_code=True)
|
||||||
|
if args.rm_pretrain:
|
||||||
|
reward_model = RewardModel(args.rm_pretrain, trust_remote_code=True)
|
||||||
|
ref_model = AutoModelForCausalLM.from_pretrained(args.pretrain, trust_remote_code=True)
|
||||||
|
|
||||||
|
if args.lora_config is not None:
|
||||||
|
actor = convert_to_lora_module(actor, lora_config=lora_config)
|
||||||
|
for name, module in actor.named_modules():
|
||||||
|
if "norm" in name or "gate" in name:
|
||||||
|
module = module.to(torch.float32)
|
||||||
|
lora_manager.able_to_merge = False
|
||||||
|
|
||||||
|
# Disable dropout
|
||||||
|
disable_dropout(actor)
|
||||||
|
|
||||||
|
if args.grad_checkpoint:
|
||||||
|
actor.gradient_checkpointing_enable(gradient_checkpointing_kwargs={"use_reentrant": False})
|
||||||
|
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||||
|
|
||||||
|
# configure tokenizer
|
||||||
|
tokenizer_dir = args.tokenizer_dir if args.tokenizer_dir is not None else args.pretrain
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir, use_fast=False, trust_remote_code=True)
|
||||||
|
if os.path.exists(args.conversation_template_config):
|
||||||
|
with open(args.conversation_template_config, "r", encoding="utf8") as f:
|
||||||
|
conversation_template_config = json.load(f)
|
||||||
|
dist.barrier()
|
||||||
|
if "response_format_tags" in conversation_template_config:
|
||||||
|
logger.warning(f"Overwrite default response format tags with {args.conversation_template_config}")
|
||||||
|
response_format_tags = conversation_template_config.get("response_format_tags", response_format_tags)
|
||||||
|
conversation_template = setup_conversation_template(
|
||||||
|
tokenizer, chat_template_config=conversation_template_config, save_path=args.conversation_template_config
|
||||||
|
)
|
||||||
|
stop_ids = conversation_template.stop_ids if len(conversation_template.stop_ids) > 0 else None
|
||||||
|
else:
|
||||||
|
raise ValueError("Conversation template config is not provided or incorrect")
|
||||||
|
if hasattr(tokenizer, "pad_token") and hasattr(tokenizer, "eos_token") and tokenizer.eos_token is not None:
|
||||||
|
try:
|
||||||
|
# Some tokenizers doesn't allow to set pad_token mannually e.g., Qwen
|
||||||
|
tokenizer.pad_token = tokenizer.eos_token
|
||||||
|
except AttributeError as e:
|
||||||
|
logger.warning(f"Unable to set pad token to eos token, {str(e)}")
|
||||||
|
if not hasattr(tokenizer, "pad_token") or tokenizer.pad_token is None:
|
||||||
|
logger.warning(
|
||||||
|
"The tokenizer does not have a pad token which is required. May lead to unintended behavior in training, Please consider manually set them."
|
||||||
|
)
|
||||||
|
|
||||||
|
tokenizer.add_bos_token = False
|
||||||
|
tokenizer.add_eos_token = False
|
||||||
|
tokenizer.padding_side = "left" # left padding for generation (online learning)
|
||||||
|
|
||||||
|
# configure generation config
|
||||||
|
actor.generation_config.update(
|
||||||
|
pad_token_id=tokenizer.eos_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id
|
||||||
|
)
|
||||||
|
|
||||||
|
# configure optimizer
|
||||||
|
coordinator.print_on_master(f"setting up optimizer for actor: lr={args.lr}, weight_decay={args.weight_decay}")
|
||||||
|
actor_optim = HybridAdam(
|
||||||
|
model_params=actor.parameters(),
|
||||||
|
lr=args.lr,
|
||||||
|
betas=(0.9, 0.95),
|
||||||
|
weight_decay=args.weight_decay,
|
||||||
|
adamw_mode=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
if args.warmup_steps is None:
|
||||||
|
args.warmup_steps = int(0.025 * args.num_episodes)
|
||||||
|
coordinator.print_on_master(f"Warmup steps is set to {args.warmup_steps}")
|
||||||
|
|
||||||
|
actor_lr_scheduler = CosineAnnealingWarmupLR(
|
||||||
|
optimizer=actor_optim,
|
||||||
|
total_steps=args.num_episodes,
|
||||||
|
warmup_steps=args.warmup_steps,
|
||||||
|
eta_min=0.1 * args.lr,
|
||||||
|
)
|
||||||
|
|
||||||
|
# ==============================
|
||||||
|
# Initialize Booster
|
||||||
|
# ==============================
|
||||||
|
if args.plugin == "ddp":
|
||||||
|
"""
|
||||||
|
Default torch ddp plugin without any acceleration, for
|
||||||
|
debugging purpose acceleration, for debugging purpose
|
||||||
|
"""
|
||||||
|
plugin = TorchDDPPlugin(find_unused_parameters=True)
|
||||||
|
elif args.plugin == "gemini":
|
||||||
|
plugin = GeminiPlugin(
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
placement_policy="static",
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
enable_gradient_accumulation=True,
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
)
|
||||||
|
elif args.plugin == "gemini_auto":
|
||||||
|
plugin = GeminiPlugin(
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
placement_policy="auto",
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
)
|
||||||
|
elif args.plugin == "zero2":
|
||||||
|
plugin = LowLevelZeroPlugin(
|
||||||
|
stage=2,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
initial_scale=2**16,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
)
|
||||||
|
elif args.plugin == "zero2_cpu":
|
||||||
|
plugin = LowLevelZeroPlugin(
|
||||||
|
stage=2,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
initial_scale=2**16,
|
||||||
|
cpu_offload=True,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
)
|
||||||
|
elif args.plugin == "3d":
|
||||||
|
if args.use_flash_attn and (args.tp > 1 or args.pp > 1 or args.sp > 1 or args.enable_sequence_parallelism):
|
||||||
|
logger.warning("Flash attention cannot be used with 3D parallelism for PPO training. Disabling it.")
|
||||||
|
args.use_flash_attn = False
|
||||||
|
plugin = HybridParallelPlugin(
|
||||||
|
tp_size=args.tp,
|
||||||
|
pp_size=args.pp,
|
||||||
|
sp_size=args.sp,
|
||||||
|
sequence_parallelism_mode=args.sp_mode,
|
||||||
|
zero_stage=args.zero_stage,
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||||
|
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||||
|
parallel_output=False,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
)
|
||||||
|
if args.rm_pretrain:
|
||||||
|
custom_plugin = HybridParallelPlugin(
|
||||||
|
tp_size=args.tp,
|
||||||
|
pp_size=args.pp,
|
||||||
|
sp_size=args.sp,
|
||||||
|
sequence_parallelism_mode=args.sp_mode,
|
||||||
|
zero_stage=args.zero_stage,
|
||||||
|
enable_flash_attention=args.use_flash_attn,
|
||||||
|
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||||
|
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||||
|
parallel_output=False,
|
||||||
|
max_norm=args.grad_clip,
|
||||||
|
precision=args.mixed_precision,
|
||||||
|
custom_policy=get_autopolicy(reward_model.model),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||||
|
|
||||||
|
if args.plugin != "3d" and args.rm_pretrain:
|
||||||
|
custom_plugin = plugin
|
||||||
|
|
||||||
|
# configure dataset
|
||||||
|
coordinator.print_on_master(f"Load dataset: {args.prompt_dataset}")
|
||||||
|
mode_map = {"train": "train", "valid": "validation", "test": "test"}
|
||||||
|
train_prompt_dataset = load_tokenized_dataset(dataset_paths=args.prompt_dataset, mode="train", mode_map=mode_map)
|
||||||
|
|
||||||
|
data_collator = DataCollatorForPromptDataset(tokenizer=tokenizer, max_length=args.max_length - args.max_seq_len)
|
||||||
|
|
||||||
|
train_prompt_dataloader = plugin.prepare_dataloader(
|
||||||
|
dataset=train_prompt_dataset,
|
||||||
|
batch_size=args.experience_batch_size,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
collate_fn=data_collator,
|
||||||
|
distributed_sampler_cls=StatefulDistributedSampler,
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(args.ptx_dataset) > 0:
|
||||||
|
train_ptx_dataset = load_tokenized_dataset(dataset_paths=args.ptx_dataset, mode="train", mode_map=mode_map)
|
||||||
|
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer, max_length=args.max_length)
|
||||||
|
train_pretrain_dataloader = plugin.prepare_dataloader(
|
||||||
|
dataset=train_ptx_dataset,
|
||||||
|
batch_size=args.ptx_batch_size,
|
||||||
|
shuffle=True,
|
||||||
|
drop_last=True,
|
||||||
|
collate_fn=data_collator,
|
||||||
|
distributed_sampler_cls=StatefulDistributedSampler,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
train_pretrain_dataloader = None
|
||||||
|
|
||||||
|
actor_booster = Booster(plugin=plugin)
|
||||||
|
ref_booster = Booster(plugin=plugin)
|
||||||
|
if args.rm_pretrain:
|
||||||
|
rm_booster = Booster(plugin=custom_plugin)
|
||||||
|
|
||||||
|
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||||
|
torch.set_default_dtype(default_dtype)
|
||||||
|
actor, actor_optim, _, train_prompt_dataloader, actor_lr_scheduler = actor_booster.boost(
|
||||||
|
model=actor,
|
||||||
|
optimizer=actor_optim,
|
||||||
|
lr_scheduler=actor_lr_scheduler,
|
||||||
|
dataloader=train_prompt_dataloader,
|
||||||
|
)
|
||||||
|
if args.rm_pretrain:
|
||||||
|
reward_model, _, _, _, _ = rm_booster.boost(model=reward_model, dataloader=train_prompt_dataloader)
|
||||||
|
else:
|
||||||
|
if args.reward_functions:
|
||||||
|
reward_fn_list = []
|
||||||
|
for reward_fn in args.reward_functions:
|
||||||
|
"""
|
||||||
|
To define custom reward function, you can define your functions under:
|
||||||
|
colossalai/applications/ColossalChat/coati/utils/reward_score/__init__.py
|
||||||
|
and use it here by mofiying the following line:
|
||||||
|
"""
|
||||||
|
if reward_fn == "gsm8k_reward_fn":
|
||||||
|
reward_fn_list.append(gsm8k_reward_fn)
|
||||||
|
elif reward_fn == "math_competition_reward_fn":
|
||||||
|
reward_fn_list.append(math_competition_reward_fn)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown reward function {reward_fn}")
|
||||||
|
reward_model = RLVRRewardModel(
|
||||||
|
reward_fn_list=reward_fn_list, tokenizer=tokenizer, tags=response_format_tags
|
||||||
|
)
|
||||||
|
|
||||||
|
ref_model, _, _, _, _ = ref_booster.boost(model=ref_model, dataloader=train_prompt_dataloader)
|
||||||
|
|
||||||
|
torch.set_default_dtype(torch.float)
|
||||||
|
|
||||||
|
coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||||
|
)
|
||||||
|
|
||||||
|
sampler_start_idx = 0
|
||||||
|
start_step = 0
|
||||||
|
|
||||||
|
if args.rm_checkpoint_path is not None:
|
||||||
|
if "modeling" in args.rm_checkpoint_path:
|
||||||
|
rm_booster.load_model(reward_model, args.rm_checkpoint_path)
|
||||||
|
else:
|
||||||
|
_, _, _ = load_checkpoint(
|
||||||
|
load_dir=args.rm_checkpoint_path,
|
||||||
|
booster=rm_booster,
|
||||||
|
model=reward_model,
|
||||||
|
optimizer=None,
|
||||||
|
lr_scheduler=None,
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(f"Loaded reward model checkpoint {args.rm_checkpoint_path}")
|
||||||
|
if args.checkpoint_path is not None:
|
||||||
|
if "modeling" in args.checkpoint_path:
|
||||||
|
actor_booster.load_model(actor, args.checkpoint_path)
|
||||||
|
ref_booster.load_model(ref_model, args.checkpoint_path)
|
||||||
|
coordinator.print_on_master(f"Loaded actor and reference model {args.checkpoint_path}")
|
||||||
|
else:
|
||||||
|
_, start_step, sampler_start_idx = load_checkpoint(
|
||||||
|
load_dir=args.checkpoint_path,
|
||||||
|
booster=actor_booster,
|
||||||
|
model=actor,
|
||||||
|
optimizer=actor_optim,
|
||||||
|
lr_scheduler=actor_lr_scheduler,
|
||||||
|
)
|
||||||
|
_, _, _ = load_checkpoint(load_dir=args.checkpoint_path, booster=ref_booster, model=ref_model)
|
||||||
|
assert isinstance(train_prompt_dataloader.sampler, StatefulDistributedSampler)
|
||||||
|
train_prompt_dataloader.sampler.set_start_index(start_index=sampler_start_idx)
|
||||||
|
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Loaded actor and reference model checkpoint {args.checkpoint_path} at spisode {start_step}"
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(f"Loaded sample at index {sampler_start_idx}")
|
||||||
|
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Checkpoint loaded max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Checkpoint loaded CUDA memory: {torch.cuda.memory_allocated() / 1024 ** 2:.2f} MB"
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Checkpoint loaded max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||||
|
)
|
||||||
|
|
||||||
|
# configure trainer
|
||||||
|
trainer = GRPOTrainer(
|
||||||
|
actor_booster,
|
||||||
|
actor,
|
||||||
|
reward_model,
|
||||||
|
ref_model,
|
||||||
|
actor_optim,
|
||||||
|
actor_lr_scheduler,
|
||||||
|
tokenizer=tokenizer,
|
||||||
|
stop_token_ids=[stop_ids],
|
||||||
|
kl_coef=args.kl_coef,
|
||||||
|
ptx_coef=args.ptx_coef,
|
||||||
|
train_batch_size=args.train_batch_size,
|
||||||
|
buffer_limit=args.num_collect_steps * args.experience_batch_size * args.num_generations,
|
||||||
|
max_length=args.max_length,
|
||||||
|
use_cache=True,
|
||||||
|
do_sample=True,
|
||||||
|
apply_loss_mask=not args.disable_loss_mask,
|
||||||
|
accumulation_steps=args.accumulation_steps,
|
||||||
|
save_dir=args.save_path,
|
||||||
|
save_interval=args.save_interval,
|
||||||
|
top_k=50,
|
||||||
|
use_tp=args.tp > 1,
|
||||||
|
num_generations=args.num_generations,
|
||||||
|
inference_batch_size=args.inference_batch_size,
|
||||||
|
logits_forward_batch_size=args.logits_forward_batch_size,
|
||||||
|
offload_inference_models="gemini" not in args.plugin,
|
||||||
|
coordinator=coordinator,
|
||||||
|
max_tokens_thinking=args.max_tokens_thinking if args.max_tokens_thinking else args.max_length - 100,
|
||||||
|
temperature_annealing_config={
|
||||||
|
"start_temperature": args.initial_temperature,
|
||||||
|
"end_temperature": args.final_temperature,
|
||||||
|
"annealing_warmup_steps": min(100, int(args.num_episodes / 6)),
|
||||||
|
"annealing_steps": min(600, int(args.num_episodes / 2)),
|
||||||
|
},
|
||||||
|
# Hack: some old model's default update_model_kwargs_fn/prepare_inputs_fn may doesn't work due to version conflict with transformers, you can overwrite them
|
||||||
|
# update_model_kwargs_fn=update_model_kwargs_fn,
|
||||||
|
# prepare_inputs_fn = None
|
||||||
|
)
|
||||||
|
|
||||||
|
trainer.fit(
|
||||||
|
num_episodes=args.num_episodes,
|
||||||
|
num_collect_steps=args.num_collect_steps,
|
||||||
|
num_update_steps=args.num_update_steps,
|
||||||
|
prompt_dataloader=train_prompt_dataloader,
|
||||||
|
pretrain_dataloader=train_pretrain_dataloader,
|
||||||
|
log_dir=args.log_dir,
|
||||||
|
use_wandb=args.use_wandb,
|
||||||
|
)
|
||||||
|
|
||||||
|
if lora_config is not None and lora_config.r > 0:
|
||||||
|
# NOTE: set model to eval to merge LoRA weights
|
||||||
|
lora_manager.able_to_merge = True
|
||||||
|
actor.eval()
|
||||||
|
# save model checkpoint after fitting on only rank0
|
||||||
|
coordinator.print_on_master("Start saving final actor model checkpoint")
|
||||||
|
actor_booster.save_model(actor, os.path.join(trainer.actor_save_dir, "modeling"), shard=True)
|
||||||
|
coordinator.print_on_master(
|
||||||
|
f"Saved final actor model checkpoint at episodes {args.num_episodes} at folder {args.save_path}"
|
||||||
|
)
|
||||||
|
coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument("--prompt_dataset", nargs="+", default=[])
|
||||||
|
parser.add_argument("--ptx_dataset", nargs="+", default=[])
|
||||||
|
parser.add_argument(
|
||||||
|
"--plugin",
|
||||||
|
type=str,
|
||||||
|
default="gemini",
|
||||||
|
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d"],
|
||||||
|
help="Choose which plugin to use",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--conversation_template_config",
|
||||||
|
type=str,
|
||||||
|
default=None,
|
||||||
|
help="Path \
|
||||||
|
to save conversation template config files.",
|
||||||
|
)
|
||||||
|
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||||
|
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||||
|
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||||
|
parser.add_argument("--tokenizer_dir", type=str, default=None)
|
||||||
|
parser.add_argument("--tp", type=int, default=1)
|
||||||
|
parser.add_argument("--pp", type=int, default=1)
|
||||||
|
parser.add_argument("--sp", type=int, default=1)
|
||||||
|
parser.add_argument("--enable_sequence_parallelism", default=False, action="store_true")
|
||||||
|
parser.add_argument("--zero_stage", type=int, default=0, help="Zero stage", choices=[0, 1, 2])
|
||||||
|
parser.add_argument("--zero_cpu_offload", default=False, action="store_true")
|
||||||
|
parser.add_argument("--sp_mode", type=str, default="split_gather", choices=["split_gather", "ring", "all_to_all"])
|
||||||
|
parser.add_argument("--pretrain", type=str, default=None)
|
||||||
|
parser.add_argument("--rm_pretrain", type=str, default=None)
|
||||||
|
parser.add_argument("--checkpoint_path", type=str, default=None)
|
||||||
|
parser.add_argument("--rm_checkpoint_path", type=str, help="Reward model checkpoint path")
|
||||||
|
parser.add_argument("--reward_functions", type=str, nargs="+", default=None, help="Reward functions to use")
|
||||||
|
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
|
||||||
|
parser.add_argument("--num_episodes", type=int, default=1)
|
||||||
|
parser.add_argument("--num_collect_steps", type=int, default=2)
|
||||||
|
parser.add_argument("--num_update_steps", type=int, default=5)
|
||||||
|
parser.add_argument("--num_generations", type=int, default=8)
|
||||||
|
parser.add_argument("--inference_batch_size", type=int, default=None)
|
||||||
|
parser.add_argument("--save_interval", type=int, default=1000)
|
||||||
|
parser.add_argument("--train_batch_size", type=int, default=16)
|
||||||
|
parser.add_argument("--logits_forward_batch_size", type=int, default=1)
|
||||||
|
parser.add_argument("--experience_batch_size", type=int, default=16)
|
||||||
|
parser.add_argument("--ptx_batch_size", type=int, default=4)
|
||||||
|
parser.add_argument("--lora_config", type=str, default=None, help="low-rank adaptation config file path")
|
||||||
|
parser.add_argument("--mixed_precision", type=str, default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
|
||||||
|
parser.add_argument("--accumulation_steps", type=int, default=8)
|
||||||
|
parser.add_argument("--lr", type=float, default=1e-6)
|
||||||
|
parser.add_argument("--kl_coef", type=float, default=0.7)
|
||||||
|
parser.add_argument("--ptx_coef", type=float, default=0.0)
|
||||||
|
parser.add_argument("--disable_loss_mask", default=False, action="store_true")
|
||||||
|
parser.add_argument("--max_length", type=int, default=2048)
|
||||||
|
parser.add_argument("--max_tokens_thinking", type=int, default=2000)
|
||||||
|
parser.add_argument("--max_seq_len", type=int, default=256)
|
||||||
|
parser.add_argument("--initial_temperature", type=float, default=1.0)
|
||||||
|
parser.add_argument("--final_temperature", type=float, default=0.9)
|
||||||
|
parser.add_argument("--log_dir", default=None, type=str)
|
||||||
|
parser.add_argument("--use_wandb", default=False, action="store_true")
|
||||||
|
parser.add_argument("--grad_checkpoint", default=False, action="store_true")
|
||||||
|
parser.add_argument("--use_flash_attn", default=False, action="store_true")
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
train(args)
|
||||||
86
applications/ColossalChat/examples/training_scripts/train_grpo.sh
Executable file
86
applications/ColossalChat/examples/training_scripts/train_grpo.sh
Executable file
@@ -0,0 +1,86 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||||
|
local n=${1:-"9999"}
|
||||||
|
echo "GPU Memory Usage:"
|
||||||
|
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||||
|
tail -n +2 |
|
||||||
|
nl -v 0 |
|
||||||
|
tee /dev/tty |
|
||||||
|
sort -g -k 2 |
|
||||||
|
awk '{print $1}' |
|
||||||
|
head -n $n)
|
||||||
|
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||||
|
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||||
|
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||||
|
}
|
||||||
|
set_n_least_used_CUDA_VISIBLE_DEVICES 8
|
||||||
|
|
||||||
|
PROJECT_NAME="PPO-RLVR"
|
||||||
|
|
||||||
|
PARENT_SAVE_DIR="" # Path to a folder to save checkpoints
|
||||||
|
PARENT_CONFIG_FILE="" # Path to a folder to save training config logs
|
||||||
|
PRETRAINED_MODEL_PATH="" # local pretrained model path (from RLHF step 1: SFT)
|
||||||
|
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||||
|
CONVERSATION_TEMPLATE_CONFIG_PATH="" # path to the conversation config file
|
||||||
|
LOGDIR=""
|
||||||
|
|
||||||
|
declare -a prompt_dataset=(
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00000
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00001
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00002
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00003
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00004
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00005
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00006
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00007
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00008
|
||||||
|
YOUR/PROMPT/DATA/DIR/arrow/part-00009
|
||||||
|
)
|
||||||
|
|
||||||
|
declare -a ptx_dataset=(
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00000
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00001
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00002
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00003
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00004
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00005
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00006
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00007
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00008
|
||||||
|
YOUR/SFT/DATA/DIR/arrow/part-00009
|
||||||
|
)
|
||||||
|
|
||||||
|
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||||
|
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||||
|
SAVE_DIR="${PARENT_SAVE_DIR}${FULL_PROJECT_NAME}"
|
||||||
|
CONFIG_FILE="${PARENT_CONFIG_FILE}${FULL_PROJECT_NAME}.json"
|
||||||
|
|
||||||
|
colossalai run --nproc_per_node 8 --num_nodes 1 --hostfile ./hostfile train_grpo.py \
|
||||||
|
--pretrain $PRETRAINED_MODEL_PATH \
|
||||||
|
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||||
|
--prompt_dataset ${prompt_dataset[@]} \
|
||||||
|
--conversation_template_config $CONVERSATION_TEMPLATE_CONFIG_PATH \
|
||||||
|
--ptx_coef 0.0 \
|
||||||
|
--plugin "zero2_cpu" \
|
||||||
|
--reward_functions math_competition_reward_fn \
|
||||||
|
--save_interval 250 \
|
||||||
|
--save_path $SAVE_DIR \
|
||||||
|
--num_episodes 100 \
|
||||||
|
--num_collect_steps 8 \
|
||||||
|
--num_update_steps 1 \
|
||||||
|
--experience_batch_size 1 \
|
||||||
|
--train_batch_size 4 \
|
||||||
|
--inference_batch_size 8 \
|
||||||
|
--logits_forward_batch_size 2 \
|
||||||
|
--accumulation_steps 4 \
|
||||||
|
--lr 1e-6 \
|
||||||
|
--mixed_precision "bf16" \
|
||||||
|
--grad_clip 0.1\
|
||||||
|
--weight_decay 0.01 \
|
||||||
|
--kl_coef 0.01 \
|
||||||
|
--warmup_steps 40 \
|
||||||
|
--max_length 2000 \
|
||||||
|
--max_seq_len 1700 \
|
||||||
|
--log_dir $LOGDIR \
|
||||||
|
--use_flash_attn \
|
||||||
|
--grad_checkpoint
|
||||||
@@ -13,9 +13,18 @@ from coati.dataset import (
|
|||||||
load_tokenized_dataset,
|
load_tokenized_dataset,
|
||||||
setup_conversation_template,
|
setup_conversation_template,
|
||||||
)
|
)
|
||||||
from coati.models import Critic, LoraConfig, RewardModel, convert_to_lora_module, disable_dropout, lora_manager
|
from coati.models import (
|
||||||
|
Critic,
|
||||||
|
LoraConfig,
|
||||||
|
RewardModel,
|
||||||
|
RLVRRewardModel,
|
||||||
|
convert_to_lora_module,
|
||||||
|
disable_dropout,
|
||||||
|
lora_manager,
|
||||||
|
)
|
||||||
from coati.trainer import PPOTrainer
|
from coati.trainer import PPOTrainer
|
||||||
from coati.utils import load_checkpoint
|
from coati.utils import load_checkpoint
|
||||||
|
from coati.utils.reward_score import *
|
||||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
import colossalai
|
import colossalai
|
||||||
@@ -29,8 +38,17 @@ from colossalai.shardformer.policies.auto_policy import get_autopolicy
|
|||||||
|
|
||||||
logger = get_dist_logger()
|
logger = get_dist_logger()
|
||||||
|
|
||||||
|
# default settings for response format tags, overwrite it in chat_template definition if needed
|
||||||
|
response_format_tags = {
|
||||||
|
"think_start": {"text": "<think>", "num_occur": 1},
|
||||||
|
"think_end": {"text": "</think>", "num_occur": 1},
|
||||||
|
"answer_start": {"text": "<answer>", "num_occur": 1},
|
||||||
|
"answer_end": {"text": "</answer>", "num_occur": 1},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
def train(args):
|
def train(args):
|
||||||
|
global response_format_tags
|
||||||
lora_config = None
|
lora_config = None
|
||||||
if args.lora_config is not None:
|
if args.lora_config is not None:
|
||||||
lora_config = LoraConfig.from_file(args.lora_config)
|
lora_config = LoraConfig.from_file(args.lora_config)
|
||||||
@@ -60,29 +78,33 @@ def train(args):
|
|||||||
args.pretrain,
|
args.pretrain,
|
||||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
use_flash_attention_2=True,
|
use_flash_attention_2=True,
|
||||||
local_files_only=True,
|
trust_remote_code=True,
|
||||||
)
|
)
|
||||||
ref_model = AutoModelForCausalLM.from_pretrained(
|
ref_model = AutoModelForCausalLM.from_pretrained(
|
||||||
args.pretrain,
|
args.pretrain,
|
||||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
use_flash_attention_2=True,
|
use_flash_attention_2=True,
|
||||||
local_files_only=True,
|
trust_remote_code=True,
|
||||||
)
|
|
||||||
reward_model = RewardModel(
|
|
||||||
args.rm_pretrain,
|
|
||||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
|
||||||
use_flash_attention_2=True,
|
|
||||||
)
|
)
|
||||||
|
if not args.no_neural_reward_model:
|
||||||
|
reward_model = RewardModel(
|
||||||
|
args.rm_pretrain,
|
||||||
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
|
use_flash_attention_2=True,
|
||||||
|
trust_remote_code=True,
|
||||||
|
)
|
||||||
critic = Critic(
|
critic = Critic(
|
||||||
args.rm_pretrain,
|
args.rm_pretrain,
|
||||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||||
use_flash_attention_2=True,
|
use_flash_attention_2=True,
|
||||||
|
trust_remote_code=True,
|
||||||
)
|
)
|
||||||
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
||||||
else:
|
else:
|
||||||
actor = AutoModelForCausalLM.from_pretrained(args.pretrain, local_files_only=True)
|
actor = AutoModelForCausalLM.from_pretrained(args.pretrain, trust_remote_code=True)
|
||||||
ref_model = AutoModelForCausalLM.from_pretrained(args.pretrain, local_files_only=True)
|
ref_model = AutoModelForCausalLM.from_pretrained(args.pretrain, trust_remote_code=True)
|
||||||
reward_model = RewardModel(args.rm_pretrain)
|
if not args.no_neural_reward_model:
|
||||||
|
reward_model = RewardModel(args.rm_pretrain, trust_remote_code=True)
|
||||||
critic = Critic(args.rm_pretrain)
|
critic = Critic(args.rm_pretrain)
|
||||||
|
|
||||||
if args.lora_config is not None:
|
if args.lora_config is not None:
|
||||||
@@ -112,6 +134,9 @@ def train(args):
|
|||||||
with open(args.conversation_template_config, "r", encoding="utf8") as f:
|
with open(args.conversation_template_config, "r", encoding="utf8") as f:
|
||||||
conversation_template_config = json.load(f)
|
conversation_template_config = json.load(f)
|
||||||
dist.barrier()
|
dist.barrier()
|
||||||
|
if "response_format_tags" in conversation_template_config:
|
||||||
|
logger.warning(f"Overwrite default response format tags with {args.conversation_template_config}")
|
||||||
|
response_format_tags = conversation_template_config.get("response_format_tags", response_format_tags)
|
||||||
conversation_template = setup_conversation_template(
|
conversation_template = setup_conversation_template(
|
||||||
tokenizer, chat_template_config=conversation_template_config, save_path=args.conversation_template_config
|
tokenizer, chat_template_config=conversation_template_config, save_path=args.conversation_template_config
|
||||||
)
|
)
|
||||||
@@ -245,7 +270,7 @@ def train(args):
|
|||||||
parallel_output=False,
|
parallel_output=False,
|
||||||
max_norm=args.grad_clip,
|
max_norm=args.grad_clip,
|
||||||
precision=args.mixed_precision,
|
precision=args.mixed_precision,
|
||||||
custom_policy=get_autopolicy(reward_model.model),
|
custom_policy=get_autopolicy(critic.model),
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
raise ValueError(f"Unknown plugin {args.plugin}")
|
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||||
@@ -284,7 +309,8 @@ def train(args):
|
|||||||
|
|
||||||
actor_booster = Booster(plugin=plugin)
|
actor_booster = Booster(plugin=plugin)
|
||||||
ref_booster = Booster(plugin=plugin)
|
ref_booster = Booster(plugin=plugin)
|
||||||
rm_booster = Booster(plugin=custom_plugin)
|
if not args.no_neural_reward_model:
|
||||||
|
rm_booster = Booster(plugin=custom_plugin)
|
||||||
critic_booster = Booster(plugin=custom_plugin)
|
critic_booster = Booster(plugin=custom_plugin)
|
||||||
|
|
||||||
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||||
@@ -302,7 +328,28 @@ def train(args):
|
|||||||
lr_scheduler=critic_lr_scheduler,
|
lr_scheduler=critic_lr_scheduler,
|
||||||
dataloader=train_prompt_dataloader,
|
dataloader=train_prompt_dataloader,
|
||||||
)
|
)
|
||||||
reward_model, _, _, _, _ = rm_booster.boost(model=reward_model, dataloader=train_prompt_dataloader)
|
if not args.no_neural_reward_model:
|
||||||
|
reward_model, _, _, _, _ = rm_booster.boost(model=reward_model, dataloader=train_prompt_dataloader)
|
||||||
|
else:
|
||||||
|
if args.reward_functions:
|
||||||
|
reward_fn_list = []
|
||||||
|
for reward_fn in args.reward_functions:
|
||||||
|
"""
|
||||||
|
To define custom reward function, you can define your functions under:
|
||||||
|
colossalai/applications/ColossalChat/coati/utils/reward_score/__init__.py
|
||||||
|
and use it here by mofiying the following line:
|
||||||
|
"""
|
||||||
|
if reward_fn == "gsm8k_reward_fn":
|
||||||
|
reward_fn_list.append(gsm8k_reward_fn)
|
||||||
|
elif reward_fn == "math_competition_reward_fn":
|
||||||
|
reward_fn_list.append(math_competition_reward_fn)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unknown reward function {reward_fn}")
|
||||||
|
reward_fn_list.append(eval(reward_fn))
|
||||||
|
reward_model = RLVRRewardModel(
|
||||||
|
reward_fn_list=reward_fn_list, tokenizer=tokenizer, tags=response_format_tags
|
||||||
|
)
|
||||||
|
|
||||||
ref_model, _, _, _, _ = ref_booster.boost(model=ref_model, dataloader=train_prompt_dataloader)
|
ref_model, _, _, _, _ = ref_booster.boost(model=ref_model, dataloader=train_prompt_dataloader)
|
||||||
|
|
||||||
torch.set_default_dtype(torch.float)
|
torch.set_default_dtype(torch.float)
|
||||||
@@ -481,9 +528,11 @@ if __name__ == "__main__":
|
|||||||
parser.add_argument("--sp_mode", type=str, default="split_gather", choices=["split_gather", "ring", "all_to_all"])
|
parser.add_argument("--sp_mode", type=str, default="split_gather", choices=["split_gather", "ring", "all_to_all"])
|
||||||
parser.add_argument("--pretrain", type=str, default=None)
|
parser.add_argument("--pretrain", type=str, default=None)
|
||||||
parser.add_argument("--rm_pretrain", type=str, default=None)
|
parser.add_argument("--rm_pretrain", type=str, default=None)
|
||||||
|
parser.add_argument("--no_neural_reward_model", default=False, action="store_true")
|
||||||
parser.add_argument("--checkpoint_path", type=str, default=None)
|
parser.add_argument("--checkpoint_path", type=str, default=None)
|
||||||
parser.add_argument("--critic_checkpoint_path", type=str, default=None)
|
parser.add_argument("--critic_checkpoint_path", type=str, default=None)
|
||||||
parser.add_argument("--rm_checkpoint_path", type=str, help="Reward model checkpoint path")
|
parser.add_argument("--rm_checkpoint_path", type=str, help="Reward model checkpoint path")
|
||||||
|
parser.add_argument("--reward_functions", type=str, nargs="+", default=None, help="Reward functions to use")
|
||||||
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
|
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
|
||||||
parser.add_argument("--num_episodes", type=int, default=1)
|
parser.add_argument("--num_episodes", type=int, default=1)
|
||||||
parser.add_argument("--num_collect_steps", type=int, default=2)
|
parser.add_argument("--num_collect_steps", type=int, default=2)
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user