* fp8 operators for compressed communication cast_to_fp8, cast_from_fp8, all_reduce_fp8 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * fix scaling algorithm in FP8 casting * support fp8 communication in pipeline parallelism * add fp8_communication flag in the script * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * shardformer fp8 * fix rebase * remove all to all * fix shardformer fp8 communication training degradation * [fp8] support all-gather flat tensor (#5932) * [fp8] add fp8 comm for low level zero * [test] add zero fp8 test case * [Feature] llama shardformer fp8 support (#5938) * add llama shardformer fp8 * Llama Shardformer Parity * fix typo * fix all reduce * fix pytest failure * fix reduce op and move function to fp8.py * fix typo * [FP8] rebase main (#5963) * add SimPO * fix dataloader * remove debug code * add orpo * fix style * fix colossalai, transformers version * fix colossalai, transformers version * fix colossalai, transformers version * fix torch colossalai version * update transformers version * [shardformer] DeepseekMoE support (#5871) * [Feature] deepseek moe expert parallel implement * [misc] fix typo, remove redundant file (#5867) * [misc] fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] deepseek support & unit test * [misc] remove debug code & useless print * [misc] fix typos (#5872) * [Feature] remove modeling file, use auto config. (#5884) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [Deepseek] remove redundant code (#5888) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [Feature/deepseek] resolve comment. (#5889) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [misc] mv module replacement into if branch * [misc] add some warning message and modify some code in unit test * [misc] fix typos --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hoxfix] Fix CUDA_DEVICE_MAX_CONNECTIONS for comm overlap Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feat] Diffusion Model(PixArtAlpha/StableDiffusion3) Support (#5838) * Diffusion Model Inference support * Stable Diffusion 3 Support * pixartalpha support * [HotFix] CI,import,requirements-test for #5838 (#5892) * [Hot Fix] CI,import,requirements-test --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] Enable PP + SP for llama (#5868) * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * use a one cross entropy func for all shardformer models --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [ShardFormer] Add Ulysses Sequence Parallelism support for Command-R, Qwen2 and ChatGLM (#5897) * add benchmark for sft, dpo, simpo, orpo. Add benchmarking result. Support lora with gradient checkpoint * fix style * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix eval * hotfix citation * [zero] support all-gather overlap (#5898) * [zero] support all-gather overlap * [zero] add overlap all-gather flag * [misc] fix typo * [zero] update api * fix orpo cross entropy loss * [Auto Parallel]: Speed up intra-op plan generation by 44% (#5446) * Remove unnecessary calls to deepcopy * Build DimSpec's difference dict only once This change considerably speeds up construction speed of DimSpec objects. The difference_dict is the same for each DimSpec object, so a single copy of it is enough. * Fix documentation of DimSpec's difference method * [ShardFormer] fix qwen2 sp (#5903) * [compatibility] support torch 2.2 (#5875) * Support Pytorch 2.2.2 * keep build_on_pr file and update .compatibility * fix object_to_tensor usage when torch>=2.3.0 (#5820) * [misc] support torch2.3 (#5893) * [misc] support torch2.3 * [devops] update compatibility ci * [devops] update compatibility ci * [devops] add debug * [devops] add debug * [devops] add debug * [devops] add debug * [devops] remove debug * [devops] remove debug * [release] update version (#5912) * [plugin] support all-gather overlap for hybrid parallel (#5919) * [plugin] fixed all-gather overlap support for hybrid parallel * add kto * fix style, add kto data sample * [Examples] Add lazy init to OPT and GPT examples (#5924) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [ColossalChat] Hotfix for ColossalChat (#5910) * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * fix ddp issue * add Qwen 1.5 32B * refactor tokenization * [FIX BUG] UnboundLocalError: cannot access local variable 'default_conversation' where it is not associated with a value (#5931) * cannot access local variable 'default_conversation' where it is not associated with a value set default value for 'default_conversation' * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix test data * refactor evaluation * remove real data path * remove real data path * Add n_fused as an input from native_module (#5894) * [FIX BUG] convert env param to int in (#5934) * [Hotfix] Fix ZeRO typo #5936 Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feature] Add a switch to control whether the model checkpoint needs to be saved after each epoch ends (#5941) * Add a switch to control whether the model checkpoint needs to be saved after each epoch ends * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix style * fix style * fix style * [shardformer] hotfix attn mask (#5945) * [shardformer] hotfix attn mask (#5947) * [Feat] Distrifusion Acceleration Support for Diffusion Inference (#5895) * Distrifusion Support source * comp comm overlap optimization * sd3 benchmark * pixart distrifusion bug fix * sd3 bug fix and benchmark * generation bug fix * naming fix * add docstring, fix counter and shape error * add reference * readme and requirement * [zero] hotfix update master params (#5951) * [release] update version (#5952) * [Chat] Fix lora (#5946) * fix merging * remove filepath * fix style * Update README.md (#5958) * [hotfix] Remove unused plan section (#5957) * remove readme * fix readme * update * [test] add mixtral for sequence classification * [test] add mixtral transformer test * [moe] fix plugin * [test] mixtra pp shard test * [chore] handle non member group * [zero] solve hang * [test] pass mixtral shardformer test * [moe] implement transit between non moe tp and ep * [zero] solve hang * [misc] solve booster hang by rename the variable * solve hang when parallel mode = pp + dp * [moe] implement submesh initialization * [moe] add mixtral dp grad scaling when not all experts are activated * [chore] manually revert unintended commit * [chore] trivial fix * [chore] arg pass & remove drop token * [test] add mixtral modelling test * [moe] implement tp * [moe] test deepseek * [moe] clean legacy code * [Feature] MoE Ulysses Support (#5918) * moe sp support * moe sp bug solve * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [chore] minor fix * [moe] init moe plugin comm setting with sp * moe sp + ep bug fix * [moe] finalize test (no pp) * [moe] full test for deepseek and mixtral (pp + sp to fix) * [chore] minor fix after rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [chore] solve moe ckpt test failure and some other arg pass failure * [moe] remove ops * [test] fix test: test_zero1_2 * [bug] fix: somehow logger hangs the program * [moe] deepseek moe sp support * [test] add check * [deepseek] replace attn (a workaround for bug in transformers) * [misc] skip redunant test * [misc] remove debug/print code * [moe] refactor mesh assignment * Revert "[moe] implement submesh initialization" This reverts commit2f9bce6686. * [chore] change moe_pg_mesh to private * [misc] remove incompatible test config * [misc] fix ci failure: change default value to false in moe plugin * [misc] remove useless condition * [chore] docstring * [moe] remove force_overlap_comm flag and add warning instead * [doc] add MoeHybridParallelPlugin docstring * [moe] solve dp axis issue * [chore] remove redundant test case, print string & reduce test tokens * [feat] Dist Loader for Eval (#5950) * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix tp error * remove unused parameters * remove unused * update inference * update docs * update inference --------- Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [lora] lora support hybrid parallel plugin (#5956) * lora support hybrid plugin * fix * fix * fix * fix * fp8 operators for compressed communication cast_to_fp8, cast_from_fp8, all_reduce_fp8 * fix scaling algorithm in FP8 casting * support fp8 communication in pipeline parallelism * add fp8_communication flag in the script * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * shardformer fp8 * fix rebase * remove all to all * fix shardformer fp8 communication training degradation * [fp8] support all-gather flat tensor (#5932) * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update low_level_optim.py --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: Guangyao Zhang <xjtu521@qq.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: Wang Binluo <32676639+wangbluo@users.noreply.github.com> Co-authored-by: HangXu <hangxu0304@gmail.com> * [fp8]support all2all fp8 (#5953) * support all2all fp8 * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] add fp8 linear (#5967) * [fp8] add fp8 linear * [test] fix fp8 linear test condition * [test] fix fp8 linear test condition * [test] fix fp8 linear test condition * [fp8] support fp8 amp for hybrid parallel plugin (#5975) * [fp8] support fp8 amp for hybrid parallel plugin * [test] add fp8 hook test * [fp8] fix fp8 linear compatibility * fix (#5976) * [Feature]: support FP8 communication in DDP, FSDP, Gemini (#5928) * support fp8_communication in the Torch DDP grad comm, FSDP grad comm, and FSDP params comm * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * implement communication hook for FSDP params all-gather * added unit test for fp8 operators * support fp8 communication in GeminiPlugin * update training scripts to support fsdp and fp8 communication * fixed some minor bugs observed in unit test * add all_gather_into_tensor_flat_fp8 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add skip the test if torch < 2.2.0 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add skip the test if torch < 2.2.0 * add skip the test if torch < 2.2.0 * add fp8_comm flag * rebase latest fp8 operators * rebase latest fp8 operators * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [test ci]Feature/fp8 comm (#5981) * fix * fix * fix * [fp8] support gemini plugin (#5978) * [fp8] refactor hook * [fp8] support gemini plugin * [example] add fp8 option for llama benchmark * [fp8] use torch compile (torch >= 2.3.0) (#5979) * [fp8] use torch compile (torch >= 2.4.0) * [fp8] set use_fast_accum in linear * [chore] formal version check * [chore] fix sig * [fp8]Moe support fp8 communication (#5977) * fix * support moe fp8 * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix fix fi * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] support hybrid parallel plugin (#5982) * support fp8 comm for qwen2 model * support fp8 comm for qwen2 model * support fp8 comm for qwen2 model * fp8 * fix * bert and bloom * chatglm and command * gpt2,gptj,bert, falcon,blip2 * mistral,opy,sam,t5,vit,whisper * fix * fix * fix * [fp8] refactor fp8 linear with compile (#5993) * [fp8] refactor fp8 linear with compile * [fp8] fix linear test * [fp8] fix linear test * [fp8] support asynchronous FP8 communication (#5997) * fix * fix * fix * support async all2all * support async op for all gather * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] update torch.compile for linear_fp8 to >= 2.4.0 (#6004) * [fp8] linear perf enhancement * [fp8]update reduce-scatter test (#6002) * fix * fix * fix * fix * [fp8] add use_fp8 option for MoeHybridParallelPlugin (#6009) * [fp8] zero support fp8 linear. (#6006) * fix * fix * fix * zero fp8 * zero fp8 * Update requirements.txt * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix the merge * fix the merge * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix * fix * fix the merge * fix * fix * fix * fix * fix * fix the merge * fix * fix * fix * fix * [fp8] Merge feature/fp8_comm to main branch of Colossalai (#6016) * add SimPO * fix dataloader * remove debug code * add orpo * fix style * fix colossalai, transformers version * fix colossalai, transformers version * fix colossalai, transformers version * fix torch colossalai version * update transformers version * [shardformer] DeepseekMoE support (#5871) * [Feature] deepseek moe expert parallel implement * [misc] fix typo, remove redundant file (#5867) * [misc] fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] deepseek support & unit test * [misc] remove debug code & useless print * [misc] fix typos (#5872) * [Feature] remove modeling file, use auto config. (#5884) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [Deepseek] remove redundant code (#5888) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [Feature/deepseek] resolve comment. (#5889) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [misc] mv module replacement into if branch * [misc] add some warning message and modify some code in unit test * [misc] fix typos --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hoxfix] Fix CUDA_DEVICE_MAX_CONNECTIONS for comm overlap Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feat] Diffusion Model(PixArtAlpha/StableDiffusion3) Support (#5838) * Diffusion Model Inference support * Stable Diffusion 3 Support * pixartalpha support * [HotFix] CI,import,requirements-test for #5838 (#5892) * [Hot Fix] CI,import,requirements-test --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] Enable PP + SP for llama (#5868) * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * use a one cross entropy func for all shardformer models --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [ShardFormer] Add Ulysses Sequence Parallelism support for Command-R, Qwen2 and ChatGLM (#5897) * add benchmark for sft, dpo, simpo, orpo. Add benchmarking result. Support lora with gradient checkpoint * fix style * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix eval * hotfix citation * [zero] support all-gather overlap (#5898) * [zero] support all-gather overlap * [zero] add overlap all-gather flag * [misc] fix typo * [zero] update api * fix orpo cross entropy loss * [Auto Parallel]: Speed up intra-op plan generation by 44% (#5446) * Remove unnecessary calls to deepcopy * Build DimSpec's difference dict only once This change considerably speeds up construction speed of DimSpec objects. The difference_dict is the same for each DimSpec object, so a single copy of it is enough. * Fix documentation of DimSpec's difference method * [ShardFormer] fix qwen2 sp (#5903) * [compatibility] support torch 2.2 (#5875) * Support Pytorch 2.2.2 * keep build_on_pr file and update .compatibility * fix object_to_tensor usage when torch>=2.3.0 (#5820) * [misc] support torch2.3 (#5893) * [misc] support torch2.3 * [devops] update compatibility ci * [devops] update compatibility ci * [devops] add debug * [devops] add debug * [devops] add debug * [devops] add debug * [devops] remove debug * [devops] remove debug * [release] update version (#5912) * [plugin] support all-gather overlap for hybrid parallel (#5919) * [plugin] fixed all-gather overlap support for hybrid parallel * add kto * fix style, add kto data sample * [Examples] Add lazy init to OPT and GPT examples (#5924) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [ColossalChat] Hotfix for ColossalChat (#5910) * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * fix ddp issue * add Qwen 1.5 32B * refactor tokenization * [FIX BUG] UnboundLocalError: cannot access local variable 'default_conversation' where it is not associated with a value (#5931) * cannot access local variable 'default_conversation' where it is not associated with a value set default value for 'default_conversation' * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix test data * refactor evaluation * remove real data path * remove real data path * Add n_fused as an input from native_module (#5894) * [FIX BUG] convert env param to int in (#5934) * [Hotfix] Fix ZeRO typo #5936 Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feature] Add a switch to control whether the model checkpoint needs to be saved after each epoch ends (#5941) * Add a switch to control whether the model checkpoint needs to be saved after each epoch ends * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix style * fix style * fix style * [shardformer] hotfix attn mask (#5945) * [shardformer] hotfix attn mask (#5947) * [Feat] Distrifusion Acceleration Support for Diffusion Inference (#5895) * Distrifusion Support source * comp comm overlap optimization * sd3 benchmark * pixart distrifusion bug fix * sd3 bug fix and benchmark * generation bug fix * naming fix * add docstring, fix counter and shape error * add reference * readme and requirement * [zero] hotfix update master params (#5951) * [release] update version (#5952) * [Chat] Fix lora (#5946) * fix merging * remove filepath * fix style * Update README.md (#5958) * [hotfix] Remove unused plan section (#5957) * remove readme * fix readme * update * [test] add mixtral for sequence classification * [test] add mixtral transformer test * [moe] fix plugin * [test] mixtra pp shard test * [chore] handle non member group * [zero] solve hang * [test] pass mixtral shardformer test * [moe] implement transit between non moe tp and ep * [zero] solve hang * [misc] solve booster hang by rename the variable * solve hang when parallel mode = pp + dp * [moe] implement submesh initialization * [moe] add mixtral dp grad scaling when not all experts are activated * [chore] manually revert unintended commit * [chore] trivial fix * [chore] arg pass & remove drop token * [test] add mixtral modelling test * [moe] implement tp * [moe] test deepseek * [moe] clean legacy code * [Feature] MoE Ulysses Support (#5918) * moe sp support * moe sp bug solve * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [chore] minor fix * [moe] init moe plugin comm setting with sp * moe sp + ep bug fix * [moe] finalize test (no pp) * [moe] full test for deepseek and mixtral (pp + sp to fix) * [chore] minor fix after rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [chore] solve moe ckpt test failure and some other arg pass failure * [moe] remove ops * [test] fix test: test_zero1_2 * [bug] fix: somehow logger hangs the program * [moe] deepseek moe sp support * [test] add check * [deepseek] replace attn (a workaround for bug in transformers) * [misc] skip redunant test * [misc] remove debug/print code * [moe] refactor mesh assignment * Revert "[moe] implement submesh initialization" This reverts commit2f9bce6686. * [chore] change moe_pg_mesh to private * [misc] remove incompatible test config * [misc] fix ci failure: change default value to false in moe plugin * [misc] remove useless condition * [chore] docstring * [moe] remove force_overlap_comm flag and add warning instead * [doc] add MoeHybridParallelPlugin docstring * [moe] solve dp axis issue * [chore] remove redundant test case, print string & reduce test tokens * [feat] Dist Loader for Eval (#5950) * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix tp error * remove unused parameters * remove unused * update inference * update docs * update inference --------- Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [lora] lora support hybrid parallel plugin (#5956) * lora support hybrid plugin * fix * fix * fix * fix * Support overall loss, update KTO logging * [Docs] clarify launch port Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Hotfix] README link (#5966) * update ignore * update readme * run style * update readme * [Hotfix] Avoid fused RMSnorm import error without apex (#5985) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Chat] fix readme (#5989) * fix readme * fix readme, tokenization fully tested * fix readme, tokenization fully tested * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix sync condition (#6000) * [plugin] add cast inputs option for zero (#6003) * [pre-commit.ci] pre-commit autoupdate (#5995) updates: - [github.com/psf/black-pre-commit-mirror: 24.4.2 → 24.8.0](https://github.com/psf/black-pre-commit-mirror/compare/24.4.2...24.8.0) Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [misc] Bypass the huggingface bug to solve the mask mismatch problem (#5991) * [Feature] Zigzag Ring attention (#5905) * halfway * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add sp_mode to benchmark; fix varlen interface * update softmax_lse shape by new interface * change tester name * remove buffer clone; support packed seq layout * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [misc] update compatibility (#6008) * [misc] update compatibility * [misc] update requirements * [devops] disable requirements cache * [test] fix torch ddp test * [test] fix rerun on address in use * [test] fix lazy init * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix the merge * overlap kv comm with output rescale (#6017) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * fix the merge * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix * fix * fix the merge * fix * [misc] Use dist logger in plugins (#6011) * use dist logger in plugins * remove trash * print on rank 0 --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> * fix * fix * fix * fix * fix the merge * fix * fix * fix * fix --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: Guangyao Zhang <xjtu521@qq.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update train_dpo.py * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update low_level_zero_plugin.py * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [CI] Remove triton version for compatibility bug; update req torch >=2.2 (#6018) * remove triton version * remove torch 2.2 * remove torch 2.1 * debug * remove 2.1 build tests * require torch >=2.2 --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [plugin] hotfix zero plugin (#6036) * [plugin] hotfix zero plugin * [plugin] hotfix zero plugin * [Colossal-LLaMA] Refactor latest APIs (#6030) * refactor latest code * update api * add dummy dataset * update Readme * add setup * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update files * add PP support * update arguments * update argument * reorg folder * update version * remove IB infor * update utils * update readme * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update save for zero * update save * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add apex * update --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * add fused norm (#6038) * [FP8] unsqueeze scale to make it compatible with torch.compile (#6040) * [colossalai/checkpoint_io/...] fix bug in load_state_dict_into_model; format error msg (#6020) * fix bug in load_state_dict_into_model; format error msg * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update utils.py to support checking missing_keys * Update general_checkpoint_io.py fix bug in missing_keys error message * retrigger tests --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hotfix] Remove deprecated install (#6042) * remove deprecated install * remove unused folder * [fp8] optimize all-gather (#6043) * [fp8] optimize all-gather * [fp8] fix all gather fp8 ring * [fp8] enable compile * [fp8] fix all gather fp8 ring * [fp8] fix linear hook (#6046) * [fp8] disable all_to_all_fp8 in intranode (#6045) * enhance all_to_all_fp8 with internode comm control * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * disable some fp8 ops due to performance issue * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [release] update version (#6041) * [release] update version * [devops] update comp test * [devops] update comp test debug * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [Feature] Split cross-entropy computation in SP (#5959) * halfway * fix cross-PP-stage position id length diff bug * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * update softmax_lse shape by new interface * change tester name * remove buffer clone; support packed seq layout * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements * adapt chatglm, command-R, qwen * debug * halfway * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * add sp_mode to benchmark; fix varlen interface * update softmax_lse shape by new interface * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements * add comments * q1 index only once * remove events to simplify stream sync * simplify forward/backward logic * 2d ring forward passed * 2d ring backward passed * fixes * fix ring attn loss * 2D ring backward + llama passed * merge * update logger * fix typo * rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * remove typos * fixes * support GPT --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [hotfix] moe hybrid parallelism benchmark & follow-up fix (#6048) * [example] pass use_fp8_comm flag to all plugins * [example] add mixtral benchmark * [moe] refine assertion and check * [moe] fix mixtral & add more tests * [moe] consider checking dp * sp group and moe_dp_group * [mixtral] remove gate tp & add more tests * [deepseek] fix tp & sp for deepseek * [mixtral] minor fix * [deepseek] add deepseek benchmark * [fp8] hotfix backward hook (#6053) * [fp8] hotfix backward hook * [fp8] hotfix pipeline loss accumulation * [doc] update sp doc (#6055) * update sp doc * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix the sp * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the attn * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * [fp8] fix missing fp8_comm flag in mixtral (#6057) * fix * fix * fix * [fp8] Disable all_gather intranode. Disable Redundant all_gather fp8 (#6059) * all_gather only internode, fix pytest * fix cuda arch <89 compile pytest error * fix pytest failure * disable all_gather_into_tensor_flat_fp8 * fix fp8 format * fix pytest * fix conversations * fix chunk tuple to list * [doc] FP8 training and communication document (#6050) * Add FP8 training and communication document * add fp8 docstring for plugins * fix typo * fix typo * fix * fix * [moe] add parallel strategy for shared_expert && fix test for deepseek (#6063) * [ColossalEval] support for vllm (#6056) * support vllm * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * modify vllm and update readme * run pre-commit * remove dupilicated lines and refine code * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update param name * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refine code * update readme * refine code * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [release] update version (#6062) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] fix poc format * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix mem check; * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [feat] moehybrid support zerobubble; * [fix] fix zerobubble pp for shardformer type input; * [fix] fix require_grad & deallocate call; * [fix] fix mem assert; * [fix] fix fwd branch, fwd pass both micro_batch & internal_inputs' * [fix] fix pipeline util func deallocate --> release_tensor_data; fix bwd_b loss bwd branch; * [fix] fix zerobubble; support shardformer model type; * [fix] fix test_pipeline_utils ci; * [plugin] hybrid support zero bubble pipeline (#6060) * hybrid support zbv * fix fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * hybrid support zbv * fix fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: duanjunwen <935724073@qq.com> * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] fix poc format * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [feat] update test; rm comments; * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix mem check; * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix mem assert; * [fix] fix fwd branch, fwd pass both micro_batch & internal_inputs' * [plugin] hybrid support zero bubble pipeline (#6060) * hybrid support zbv * fix fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * hybrid support zbv * fix fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: duanjunwen <935724073@qq.com> * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: HangXu <hangxu0304@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: GuangyaoZhang <xjtu521@qq.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: Wang Binluo <32676639+wangbluo@users.noreply.github.com> Co-authored-by: wangbluo <2538539015@qq.com> Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> Co-authored-by: duanjunwen <935724073@qq.com> Co-authored-by: Camille Zhong <44392324+Camille7777@users.noreply.github.com>
10 KiB
Paradigms of Parallelism
Author: Shenggui Li, Siqi Mai
Introduction
With the development of deep learning, there is an increasing demand for parallel training. This is because that model and datasets are getting larger and larger and training time becomes a nightmare if we stick to single-GPU training. In this section, we will provide a brief overview of existing methods to parallelize training. If you wish to add on to this post, you may create a discussion in the GitHub forum.
Data Parallel
Data parallel is the most common form of parallelism due to its simplicity. In data parallel training, the dataset is split into several shards, each shard is allocated to a device. This is equivalent to parallelize the training process along the batch dimension. Each device will hold a full copy of the model replica and trains on the dataset shard allocated. After back-propagation, the gradients of the model will be all-reduced so that the model parameters on different devices can stay synchronized.
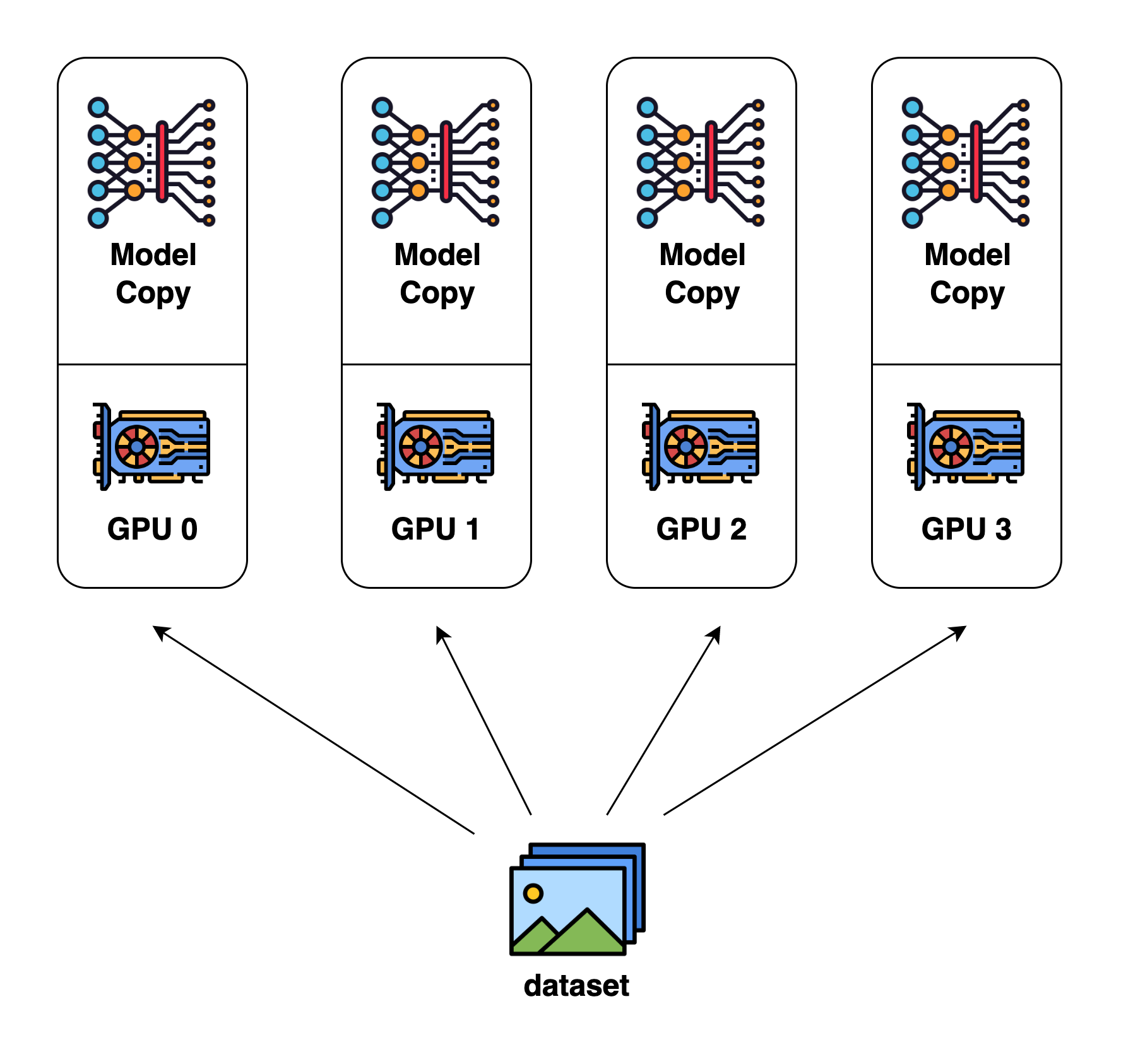
Model Parallel
In data parallel training, one prominent feature is that each GPU holds a copy of the whole model weights. This brings redundancy issue. Another paradigm of parallelism is model parallelism, where model is split and distributed over an array of devices. There are generally two types of parallelism: tensor parallelism and pipeline parallelism. Tensor parallelism is to parallelize computation within an operation such as matrix-matrix multiplication. Pipeline parallelism is to parallelize computation between layers. Thus, from another point of view, tensor parallelism can be seen as intra-layer parallelism and pipeline parallelism can be seen as inter-layer parallelism.
Tensor Parallel
Tensor parallel training is to split a tensor into N chunks along a specific dimension and each device only holds 1/N
of the whole tensor while not affecting the correctness of the computation graph. This requires additional communication
to make sure that the result is correct.
Taking a general matrix multiplication as an example, let's say we have C = AB. We can split B along the column dimension
into [B0 B1 B2 ... Bn] and each device holds a column. We then multiply A with each column in B on each device, we
will get [AB0 AB1 AB2 ... ABn]. At this moment, each device still holds partial results, e.g. device rank 0 holds AB0.
To make sure the result is correct, we need to all-gather the partial result and concatenate the tensor along the column
dimension. In this way, we are able to distribute the tensor over devices while making sure the computation flow remains
correct.
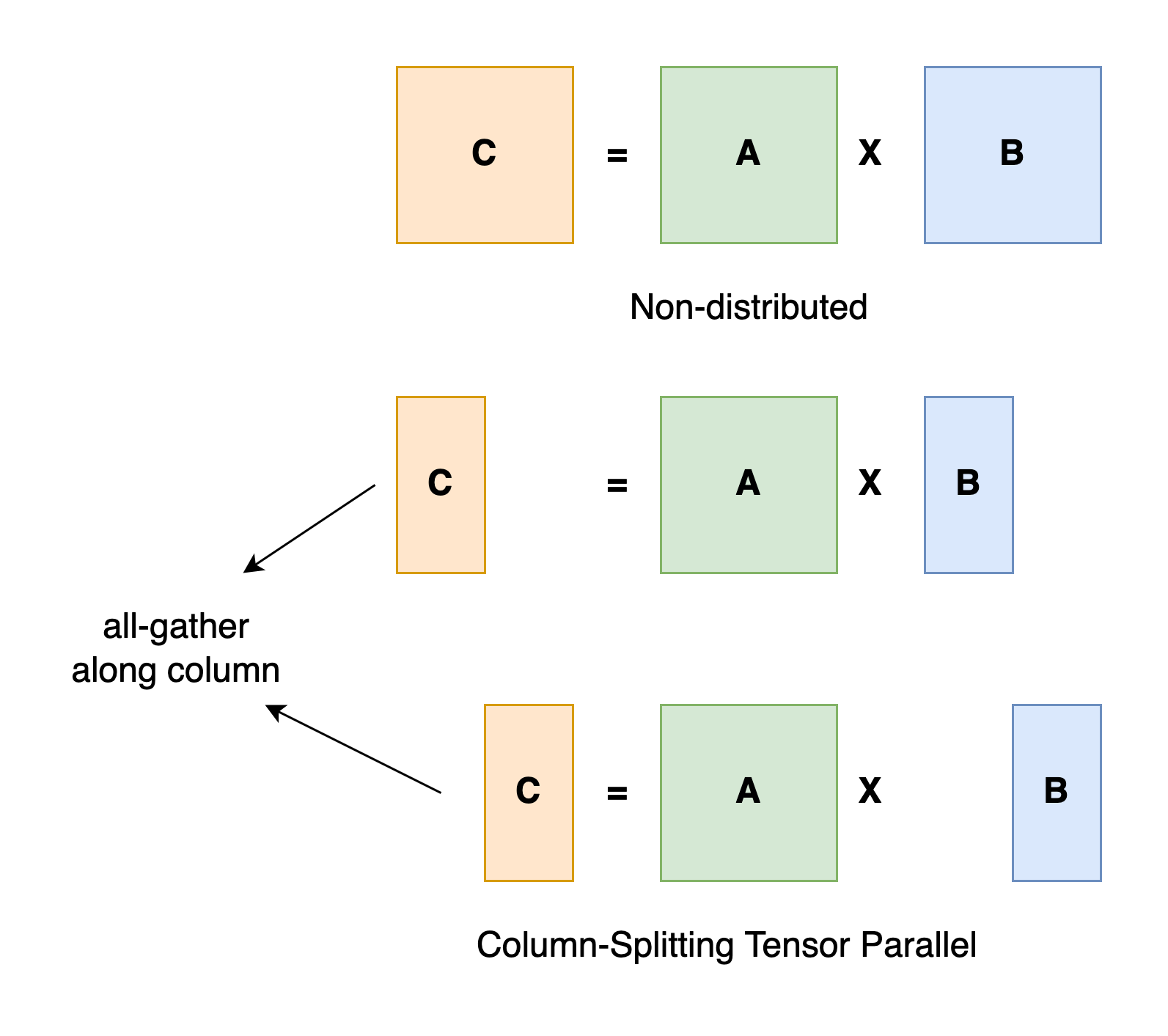
In Colossal-AI, we provide an array of tensor parallelism methods, namely 1D, 2D, 2.5D and 3D tensor parallelism. We will
talk about them in detail in advanced tutorials.
Related paper:
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- An Efficient 2D Method for Training Super-Large Deep Learning Models
- 2.5-dimensional distributed model training
- Maximizing Parallelism in Distributed Training for Huge Neural Networks
Pipeline Parallel
Pipeline parallelism is generally easy to understand. If you recall your computer architecture course, this indeed exists in the CPU design.
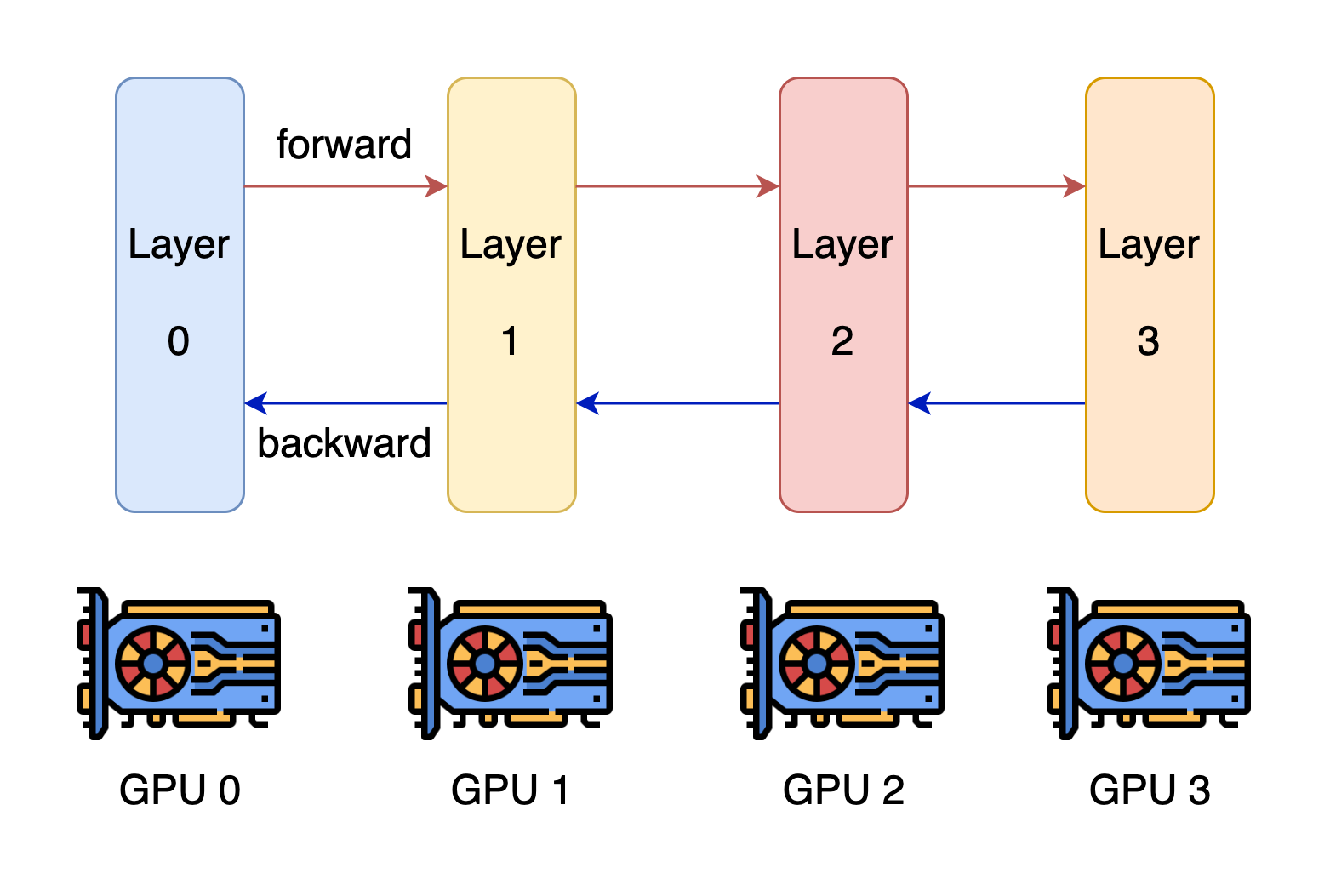
The core idea of pipeline parallelism is that the model is split by layer into several chunks, each chunk is given to a device. During the forward pass, each device passes the intermediate activation to the next stage. During the backward pass, each device passes the gradient of the input tensor back to the previous pipeline stage. This allows devices to compute simultaneously, and increases the training throughput. One drawback of pipeline parallel training is that there will be some bubble time where some devices are engaged in computation, leading to waste of computational resources.
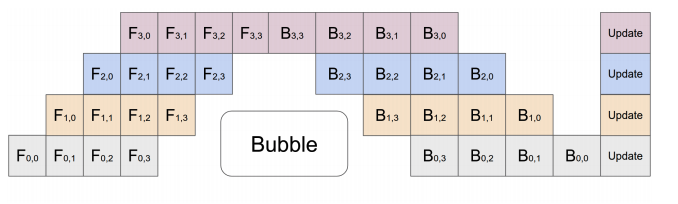
Related paper:
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines
Sequence Parallelism
Sequence parallelism is a parallel strategy that partitions along the sequence dimension, making it an effective method for training long text sequences. Mature sequence parallelism methods include Megatron’s sequence parallelism, DeepSpeed-Ulysses sequence parallelism, and ring-attention sequence parallelism.
Megatron SP:
This sequence parallelism method is implemented on top of tensor parallelism. On each GPU in model parallelism, the samples are independent and replicated. For parts that cannot utilize tensor parallelism, such as non-linear operations like LayerNorm, the sample data can be split into multiple parts along the sequence dimension, with each GPU computing a portion of the data. Then, tensor parallelism is used for the linear parts like attention and MLP, where activations need to be aggregated. This approach further reduces activation memory usage when the model is partitioned. It is important to note that this sequence parallelism method can only be used in conjunction with tensor parallelism.
DeepSpeed-Ulysses:
In this sequence parallelism, samples are split along the sequence dimension and the all-to-all communication operation is used, allowing each GPU to receive the full sequence but only compute the non-overlapping subset of attention heads, thereby achieving sequence parallelism. This parallel method supports fully general attention, allowing both dense and sparse attention. all-to-all is a full exchange operation, similar to a distributed transpose operation. Before attention computation, samples are split along the sequence dimension, so each device only has a sequence length of N/P. However, after using all-to-all, the shape of the qkv subparts becomes [N, d/p], ensuring the overall sequence is considered during attention computation.
Ring Attention:
Ring attention is conceptually similar to flash attention. Each GPU computes only a local attention, and finally, the attention blocks are reduced to calculate the total attention. In Ring Attention, the input sequence is split into multiple chunks along the sequence dimension, with each chunk handled by a different GPU or processor. Ring Attention employs a strategy called "ring communication," where kv sub-blocks are passed between GPUs through p2p communication for iterative computation, enabling multi-GPU training on ultra-long texts. In this strategy, each processor exchanges information only with its predecessor and successor, forming a ring network. This allows intermediate results to be efficiently transmitted between processors without global synchronization, reducing communication overhead.
Related paper: Reducing Activation Recomputation in Large Transformer Models DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models Ring Attention with Blockwise Transformers for Near-Infinite Context
Optimizer-Level Parallel
Another paradigm works at the optimizer level, and the current most famous method of this paradigm is ZeRO which stands for zero redundancy optimizer. ZeRO works at three levels to remove memory redundancy (fp16 training is required for ZeRO):
- Level 1: The optimizer states are partitioned across the processes
- Level 2: The reduced 32-bit gradients for updating the model weights are also partitioned such that each process only stores the gradients corresponding to its partition of the optimizer states.
- Level 3: The 16-bit model parameters are partitioned across the processes
Related paper:
Parallelism on Heterogeneous System
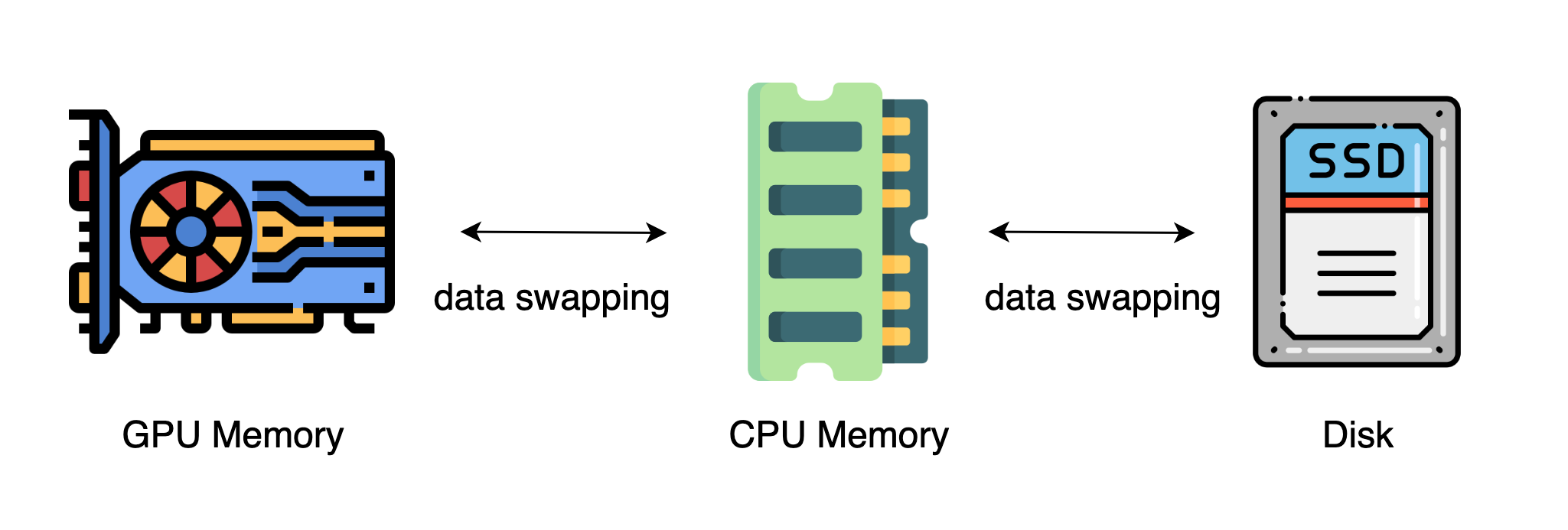
The methods mentioned above generally require a large number of GPU to train a large model. However, it is often neglected that CPU has a much larger memory compared to GPU. On a typical server, CPU can easily have several hundred GB RAM while each GPU typically only has 16 or 32 GB RAM. This prompts the community to think why CPU memory is not utilized for distributed training.
Recent advances rely on CPU and even NVMe disk to train large models. The main idea is to offload tensors back to CPU memory or NVMe disk when they are not used. By using the heterogeneous system architecture, it is possible to accommodate a huge model on a single machine.
Related paper: