* fp8 operators for compressed communication cast_to_fp8, cast_from_fp8, all_reduce_fp8 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * fix scaling algorithm in FP8 casting * support fp8 communication in pipeline parallelism * add fp8_communication flag in the script * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * shardformer fp8 * fix rebase * remove all to all * fix shardformer fp8 communication training degradation * [fp8] support all-gather flat tensor (#5932) * [fp8] add fp8 comm for low level zero * [test] add zero fp8 test case * [Feature] llama shardformer fp8 support (#5938) * add llama shardformer fp8 * Llama Shardformer Parity * fix typo * fix all reduce * fix pytest failure * fix reduce op and move function to fp8.py * fix typo * [FP8] rebase main (#5963) * add SimPO * fix dataloader * remove debug code * add orpo * fix style * fix colossalai, transformers version * fix colossalai, transformers version * fix colossalai, transformers version * fix torch colossalai version * update transformers version * [shardformer] DeepseekMoE support (#5871) * [Feature] deepseek moe expert parallel implement * [misc] fix typo, remove redundant file (#5867) * [misc] fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] deepseek support & unit test * [misc] remove debug code & useless print * [misc] fix typos (#5872) * [Feature] remove modeling file, use auto config. (#5884) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [Deepseek] remove redundant code (#5888) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [Feature/deepseek] resolve comment. (#5889) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [misc] mv module replacement into if branch * [misc] add some warning message and modify some code in unit test * [misc] fix typos --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hoxfix] Fix CUDA_DEVICE_MAX_CONNECTIONS for comm overlap Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feat] Diffusion Model(PixArtAlpha/StableDiffusion3) Support (#5838) * Diffusion Model Inference support * Stable Diffusion 3 Support * pixartalpha support * [HotFix] CI,import,requirements-test for #5838 (#5892) * [Hot Fix] CI,import,requirements-test --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] Enable PP + SP for llama (#5868) * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * use a one cross entropy func for all shardformer models --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [ShardFormer] Add Ulysses Sequence Parallelism support for Command-R, Qwen2 and ChatGLM (#5897) * add benchmark for sft, dpo, simpo, orpo. Add benchmarking result. Support lora with gradient checkpoint * fix style * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix eval * hotfix citation * [zero] support all-gather overlap (#5898) * [zero] support all-gather overlap * [zero] add overlap all-gather flag * [misc] fix typo * [zero] update api * fix orpo cross entropy loss * [Auto Parallel]: Speed up intra-op plan generation by 44% (#5446) * Remove unnecessary calls to deepcopy * Build DimSpec's difference dict only once This change considerably speeds up construction speed of DimSpec objects. The difference_dict is the same for each DimSpec object, so a single copy of it is enough. * Fix documentation of DimSpec's difference method * [ShardFormer] fix qwen2 sp (#5903) * [compatibility] support torch 2.2 (#5875) * Support Pytorch 2.2.2 * keep build_on_pr file and update .compatibility * fix object_to_tensor usage when torch>=2.3.0 (#5820) * [misc] support torch2.3 (#5893) * [misc] support torch2.3 * [devops] update compatibility ci * [devops] update compatibility ci * [devops] add debug * [devops] add debug * [devops] add debug * [devops] add debug * [devops] remove debug * [devops] remove debug * [release] update version (#5912) * [plugin] support all-gather overlap for hybrid parallel (#5919) * [plugin] fixed all-gather overlap support for hybrid parallel * add kto * fix style, add kto data sample * [Examples] Add lazy init to OPT and GPT examples (#5924) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [ColossalChat] Hotfix for ColossalChat (#5910) * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * fix ddp issue * add Qwen 1.5 32B * refactor tokenization * [FIX BUG] UnboundLocalError: cannot access local variable 'default_conversation' where it is not associated with a value (#5931) * cannot access local variable 'default_conversation' where it is not associated with a value set default value for 'default_conversation' * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix test data * refactor evaluation * remove real data path * remove real data path * Add n_fused as an input from native_module (#5894) * [FIX BUG] convert env param to int in (#5934) * [Hotfix] Fix ZeRO typo #5936 Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feature] Add a switch to control whether the model checkpoint needs to be saved after each epoch ends (#5941) * Add a switch to control whether the model checkpoint needs to be saved after each epoch ends * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix style * fix style * fix style * [shardformer] hotfix attn mask (#5945) * [shardformer] hotfix attn mask (#5947) * [Feat] Distrifusion Acceleration Support for Diffusion Inference (#5895) * Distrifusion Support source * comp comm overlap optimization * sd3 benchmark * pixart distrifusion bug fix * sd3 bug fix and benchmark * generation bug fix * naming fix * add docstring, fix counter and shape error * add reference * readme and requirement * [zero] hotfix update master params (#5951) * [release] update version (#5952) * [Chat] Fix lora (#5946) * fix merging * remove filepath * fix style * Update README.md (#5958) * [hotfix] Remove unused plan section (#5957) * remove readme * fix readme * update * [test] add mixtral for sequence classification * [test] add mixtral transformer test * [moe] fix plugin * [test] mixtra pp shard test * [chore] handle non member group * [zero] solve hang * [test] pass mixtral shardformer test * [moe] implement transit between non moe tp and ep * [zero] solve hang * [misc] solve booster hang by rename the variable * solve hang when parallel mode = pp + dp * [moe] implement submesh initialization * [moe] add mixtral dp grad scaling when not all experts are activated * [chore] manually revert unintended commit * [chore] trivial fix * [chore] arg pass & remove drop token * [test] add mixtral modelling test * [moe] implement tp * [moe] test deepseek * [moe] clean legacy code * [Feature] MoE Ulysses Support (#5918) * moe sp support * moe sp bug solve * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [chore] minor fix * [moe] init moe plugin comm setting with sp * moe sp + ep bug fix * [moe] finalize test (no pp) * [moe] full test for deepseek and mixtral (pp + sp to fix) * [chore] minor fix after rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [chore] solve moe ckpt test failure and some other arg pass failure * [moe] remove ops * [test] fix test: test_zero1_2 * [bug] fix: somehow logger hangs the program * [moe] deepseek moe sp support * [test] add check * [deepseek] replace attn (a workaround for bug in transformers) * [misc] skip redunant test * [misc] remove debug/print code * [moe] refactor mesh assignment * Revert "[moe] implement submesh initialization" This reverts commit2f9bce6686. * [chore] change moe_pg_mesh to private * [misc] remove incompatible test config * [misc] fix ci failure: change default value to false in moe plugin * [misc] remove useless condition * [chore] docstring * [moe] remove force_overlap_comm flag and add warning instead * [doc] add MoeHybridParallelPlugin docstring * [moe] solve dp axis issue * [chore] remove redundant test case, print string & reduce test tokens * [feat] Dist Loader for Eval (#5950) * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix tp error * remove unused parameters * remove unused * update inference * update docs * update inference --------- Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [lora] lora support hybrid parallel plugin (#5956) * lora support hybrid plugin * fix * fix * fix * fix * fp8 operators for compressed communication cast_to_fp8, cast_from_fp8, all_reduce_fp8 * fix scaling algorithm in FP8 casting * support fp8 communication in pipeline parallelism * add fp8_communication flag in the script * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * shardformer fp8 * fix rebase * remove all to all * fix shardformer fp8 communication training degradation * [fp8] support all-gather flat tensor (#5932) * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update low_level_optim.py --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: Guangyao Zhang <xjtu521@qq.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: Wang Binluo <32676639+wangbluo@users.noreply.github.com> Co-authored-by: HangXu <hangxu0304@gmail.com> * [fp8]support all2all fp8 (#5953) * support all2all fp8 * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] add fp8 linear (#5967) * [fp8] add fp8 linear * [test] fix fp8 linear test condition * [test] fix fp8 linear test condition * [test] fix fp8 linear test condition * [fp8] support fp8 amp for hybrid parallel plugin (#5975) * [fp8] support fp8 amp for hybrid parallel plugin * [test] add fp8 hook test * [fp8] fix fp8 linear compatibility * fix (#5976) * [Feature]: support FP8 communication in DDP, FSDP, Gemini (#5928) * support fp8_communication in the Torch DDP grad comm, FSDP grad comm, and FSDP params comm * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * implement communication hook for FSDP params all-gather * added unit test for fp8 operators * support fp8 communication in GeminiPlugin * update training scripts to support fsdp and fp8 communication * fixed some minor bugs observed in unit test * add all_gather_into_tensor_flat_fp8 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add skip the test if torch < 2.2.0 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add skip the test if torch < 2.2.0 * add skip the test if torch < 2.2.0 * add fp8_comm flag * rebase latest fp8 operators * rebase latest fp8 operators * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [test ci]Feature/fp8 comm (#5981) * fix * fix * fix * [fp8] support gemini plugin (#5978) * [fp8] refactor hook * [fp8] support gemini plugin * [example] add fp8 option for llama benchmark * [fp8] use torch compile (torch >= 2.3.0) (#5979) * [fp8] use torch compile (torch >= 2.4.0) * [fp8] set use_fast_accum in linear * [chore] formal version check * [chore] fix sig * [fp8]Moe support fp8 communication (#5977) * fix * support moe fp8 * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix fix fi * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] support hybrid parallel plugin (#5982) * support fp8 comm for qwen2 model * support fp8 comm for qwen2 model * support fp8 comm for qwen2 model * fp8 * fix * bert and bloom * chatglm and command * gpt2,gptj,bert, falcon,blip2 * mistral,opy,sam,t5,vit,whisper * fix * fix * fix * [fp8] refactor fp8 linear with compile (#5993) * [fp8] refactor fp8 linear with compile * [fp8] fix linear test * [fp8] fix linear test * [fp8] support asynchronous FP8 communication (#5997) * fix * fix * fix * support async all2all * support async op for all gather * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [fp8] update torch.compile for linear_fp8 to >= 2.4.0 (#6004) * [fp8] linear perf enhancement * [fp8]update reduce-scatter test (#6002) * fix * fix * fix * fix * [fp8] add use_fp8 option for MoeHybridParallelPlugin (#6009) * [fp8] zero support fp8 linear. (#6006) * fix * fix * fix * zero fp8 * zero fp8 * Update requirements.txt * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix the merge * fix the merge * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix * fix * fix the merge * fix * fix * fix * fix * fix * fix the merge * fix * fix * fix * fix * [fp8] Merge feature/fp8_comm to main branch of Colossalai (#6016) * add SimPO * fix dataloader * remove debug code * add orpo * fix style * fix colossalai, transformers version * fix colossalai, transformers version * fix colossalai, transformers version * fix torch colossalai version * update transformers version * [shardformer] DeepseekMoE support (#5871) * [Feature] deepseek moe expert parallel implement * [misc] fix typo, remove redundant file (#5867) * [misc] fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] deepseek support & unit test * [misc] remove debug code & useless print * [misc] fix typos (#5872) * [Feature] remove modeling file, use auto config. (#5884) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [Deepseek] remove redundant code (#5888) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [Feature/deepseek] resolve comment. (#5889) * [misc] fix typos * [Feature] deepseek support via auto model, remove modeling file * [misc] delete useless file * [misc] fix typos * [misc] remove redundant code * [misc] mv module replacement into if branch * [misc] add some warning message and modify some code in unit test * [misc] fix typos --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hoxfix] Fix CUDA_DEVICE_MAX_CONNECTIONS for comm overlap Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feat] Diffusion Model(PixArtAlpha/StableDiffusion3) Support (#5838) * Diffusion Model Inference support * Stable Diffusion 3 Support * pixartalpha support * [HotFix] CI,import,requirements-test for #5838 (#5892) * [Hot Fix] CI,import,requirements-test --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Feature] Enable PP + SP for llama (#5868) * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * use a one cross entropy func for all shardformer models --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [ShardFormer] Add Ulysses Sequence Parallelism support for Command-R, Qwen2 and ChatGLM (#5897) * add benchmark for sft, dpo, simpo, orpo. Add benchmarking result. Support lora with gradient checkpoint * fix style * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix eval * hotfix citation * [zero] support all-gather overlap (#5898) * [zero] support all-gather overlap * [zero] add overlap all-gather flag * [misc] fix typo * [zero] update api * fix orpo cross entropy loss * [Auto Parallel]: Speed up intra-op plan generation by 44% (#5446) * Remove unnecessary calls to deepcopy * Build DimSpec's difference dict only once This change considerably speeds up construction speed of DimSpec objects. The difference_dict is the same for each DimSpec object, so a single copy of it is enough. * Fix documentation of DimSpec's difference method * [ShardFormer] fix qwen2 sp (#5903) * [compatibility] support torch 2.2 (#5875) * Support Pytorch 2.2.2 * keep build_on_pr file and update .compatibility * fix object_to_tensor usage when torch>=2.3.0 (#5820) * [misc] support torch2.3 (#5893) * [misc] support torch2.3 * [devops] update compatibility ci * [devops] update compatibility ci * [devops] add debug * [devops] add debug * [devops] add debug * [devops] add debug * [devops] remove debug * [devops] remove debug * [release] update version (#5912) * [plugin] support all-gather overlap for hybrid parallel (#5919) * [plugin] fixed all-gather overlap support for hybrid parallel * add kto * fix style, add kto data sample * [Examples] Add lazy init to OPT and GPT examples (#5924) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [ColossalChat] Hotfix for ColossalChat (#5910) * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * add ignore and tiny llama * fix path issue * run style * fix issue * update bash * fix ddp issue * add Qwen 1.5 32B * refactor tokenization * [FIX BUG] UnboundLocalError: cannot access local variable 'default_conversation' where it is not associated with a value (#5931) * cannot access local variable 'default_conversation' where it is not associated with a value set default value for 'default_conversation' * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix test data * refactor evaluation * remove real data path * remove real data path * Add n_fused as an input from native_module (#5894) * [FIX BUG] convert env param to int in (#5934) * [Hotfix] Fix ZeRO typo #5936 Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Feature] Add a switch to control whether the model checkpoint needs to be saved after each epoch ends (#5941) * Add a switch to control whether the model checkpoint needs to be saved after each epoch ends * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix style * fix style * fix style * [shardformer] hotfix attn mask (#5945) * [shardformer] hotfix attn mask (#5947) * [Feat] Distrifusion Acceleration Support for Diffusion Inference (#5895) * Distrifusion Support source * comp comm overlap optimization * sd3 benchmark * pixart distrifusion bug fix * sd3 bug fix and benchmark * generation bug fix * naming fix * add docstring, fix counter and shape error * add reference * readme and requirement * [zero] hotfix update master params (#5951) * [release] update version (#5952) * [Chat] Fix lora (#5946) * fix merging * remove filepath * fix style * Update README.md (#5958) * [hotfix] Remove unused plan section (#5957) * remove readme * fix readme * update * [test] add mixtral for sequence classification * [test] add mixtral transformer test * [moe] fix plugin * [test] mixtra pp shard test * [chore] handle non member group * [zero] solve hang * [test] pass mixtral shardformer test * [moe] implement transit between non moe tp and ep * [zero] solve hang * [misc] solve booster hang by rename the variable * solve hang when parallel mode = pp + dp * [moe] implement submesh initialization * [moe] add mixtral dp grad scaling when not all experts are activated * [chore] manually revert unintended commit * [chore] trivial fix * [chore] arg pass & remove drop token * [test] add mixtral modelling test * [moe] implement tp * [moe] test deepseek * [moe] clean legacy code * [Feature] MoE Ulysses Support (#5918) * moe sp support * moe sp bug solve * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [chore] minor fix * [moe] init moe plugin comm setting with sp * moe sp + ep bug fix * [moe] finalize test (no pp) * [moe] full test for deepseek and mixtral (pp + sp to fix) * [chore] minor fix after rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [chore] solve moe ckpt test failure and some other arg pass failure * [moe] remove ops * [test] fix test: test_zero1_2 * [bug] fix: somehow logger hangs the program * [moe] deepseek moe sp support * [test] add check * [deepseek] replace attn (a workaround for bug in transformers) * [misc] skip redunant test * [misc] remove debug/print code * [moe] refactor mesh assignment * Revert "[moe] implement submesh initialization" This reverts commit2f9bce6686. * [chore] change moe_pg_mesh to private * [misc] remove incompatible test config * [misc] fix ci failure: change default value to false in moe plugin * [misc] remove useless condition * [chore] docstring * [moe] remove force_overlap_comm flag and add warning instead * [doc] add MoeHybridParallelPlugin docstring * [moe] solve dp axis issue * [chore] remove redundant test case, print string & reduce test tokens * [feat] Dist Loader for Eval (#5950) * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * support auto distributed data loader * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix tp error * remove unused parameters * remove unused * update inference * update docs * update inference --------- Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [lora] lora support hybrid parallel plugin (#5956) * lora support hybrid plugin * fix * fix * fix * fix * Support overall loss, update KTO logging * [Docs] clarify launch port Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Hotfix] README link (#5966) * update ignore * update readme * run style * update readme * [Hotfix] Avoid fused RMSnorm import error without apex (#5985) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [Chat] fix readme (#5989) * fix readme * fix readme, tokenization fully tested * fix readme, tokenization fully tested * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix sync condition (#6000) * [plugin] add cast inputs option for zero (#6003) * [pre-commit.ci] pre-commit autoupdate (#5995) updates: - [github.com/psf/black-pre-commit-mirror: 24.4.2 → 24.8.0](https://github.com/psf/black-pre-commit-mirror/compare/24.4.2...24.8.0) Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [misc] Bypass the huggingface bug to solve the mask mismatch problem (#5991) * [Feature] Zigzag Ring attention (#5905) * halfway * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add sp_mode to benchmark; fix varlen interface * update softmax_lse shape by new interface * change tester name * remove buffer clone; support packed seq layout * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [misc] update compatibility (#6008) * [misc] update compatibility * [misc] update requirements * [devops] disable requirements cache * [test] fix torch ddp test * [test] fix rerun on address in use * [test] fix lazy init * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix the merge * overlap kv comm with output rescale (#6017) Co-authored-by: Edenzzzz <wtan45@wisc.edu> * fix the merge * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the merge * fix * fix * fix the merge * fix * [misc] Use dist logger in plugins (#6011) * use dist logger in plugins * remove trash * print on rank 0 --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> * fix * fix * fix * fix * fix the merge * fix * fix * fix * fix --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: Guangyao Zhang <xjtu521@qq.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update train_dpo.py * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update low_level_zero_plugin.py * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [CI] Remove triton version for compatibility bug; update req torch >=2.2 (#6018) * remove triton version * remove torch 2.2 * remove torch 2.1 * debug * remove 2.1 build tests * require torch >=2.2 --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> * [plugin] hotfix zero plugin (#6036) * [plugin] hotfix zero plugin * [plugin] hotfix zero plugin * [Colossal-LLaMA] Refactor latest APIs (#6030) * refactor latest code * update api * add dummy dataset * update Readme * add setup * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update files * add PP support * update arguments * update argument * reorg folder * update version * remove IB infor * update utils * update readme * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update save for zero * update save * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * add apex * update --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * add fused norm (#6038) * [FP8] unsqueeze scale to make it compatible with torch.compile (#6040) * [colossalai/checkpoint_io/...] fix bug in load_state_dict_into_model; format error msg (#6020) * fix bug in load_state_dict_into_model; format error msg * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update utils.py to support checking missing_keys * Update general_checkpoint_io.py fix bug in missing_keys error message * retrigger tests --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [Hotfix] Remove deprecated install (#6042) * remove deprecated install * remove unused folder * [fp8] optimize all-gather (#6043) * [fp8] optimize all-gather * [fp8] fix all gather fp8 ring * [fp8] enable compile * [fp8] fix all gather fp8 ring * [fp8] fix linear hook (#6046) * [fp8] disable all_to_all_fp8 in intranode (#6045) * enhance all_to_all_fp8 with internode comm control * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * disable some fp8 ops due to performance issue * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [release] update version (#6041) * [release] update version * [devops] update comp test * [devops] update comp test debug * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [devops] debug comp test * [Feature] Split cross-entropy computation in SP (#5959) * halfway * fix cross-PP-stage position id length diff bug * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * update softmax_lse shape by new interface * change tester name * remove buffer clone; support packed seq layout * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements * adapt chatglm, command-R, qwen * debug * halfway * fix cross-PP-stage position id length diff bug * fix typo * fix typo * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * unified cross entropy func for all shardformer models * remove redundant lines * add basic ring attn; debug cross entropy * fwd bwd logic complete * fwd bwd logic complete; add experimental triton rescale * precision tests passed * precision tests passed * fix typos and remove misc files * add sp_mode to benchmark; fix varlen interface * update softmax_lse shape by new interface * add varlen tests * fix typo * all tests passed * add dkv_group; fix mask * remove debug statements * add comments * q1 index only once * remove events to simplify stream sync * simplify forward/backward logic * 2d ring forward passed * 2d ring backward passed * fixes * fix ring attn loss * 2D ring backward + llama passed * merge * update logger * fix typo * rebase * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix typo * remove typos * fixes * support GPT --------- Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [hotfix] moe hybrid parallelism benchmark & follow-up fix (#6048) * [example] pass use_fp8_comm flag to all plugins * [example] add mixtral benchmark * [moe] refine assertion and check * [moe] fix mixtral & add more tests * [moe] consider checking dp * sp group and moe_dp_group * [mixtral] remove gate tp & add more tests * [deepseek] fix tp & sp for deepseek * [mixtral] minor fix * [deepseek] add deepseek benchmark * [fp8] hotfix backward hook (#6053) * [fp8] hotfix backward hook * [fp8] hotfix pipeline loss accumulation * [doc] update sp doc (#6055) * update sp doc * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * fix the sp * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix the attn * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * [fp8] fix missing fp8_comm flag in mixtral (#6057) * fix * fix * fix * [fp8] Disable all_gather intranode. Disable Redundant all_gather fp8 (#6059) * all_gather only internode, fix pytest * fix cuda arch <89 compile pytest error * fix pytest failure * disable all_gather_into_tensor_flat_fp8 * fix fp8 format * fix pytest * fix conversations * fix chunk tuple to list * [doc] FP8 training and communication document (#6050) * Add FP8 training and communication document * add fp8 docstring for plugins * fix typo * fix typo * fix * fix * [moe] add parallel strategy for shared_expert && fix test for deepseek (#6063) * [ColossalEval] support for vllm (#6056) * support vllm * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * modify vllm and update readme * run pre-commit * remove dupilicated lines and refine code * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update param name * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refine code * update readme * refine code * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> * [release] update version (#6062) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] fix poc format * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix mem check; * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [feat] moehybrid support zerobubble; * [fix] fix zerobubble pp for shardformer type input; * [fix] fix require_grad & deallocate call; * [fix] fix mem assert; * [fix] fix fwd branch, fwd pass both micro_batch & internal_inputs' * [fix] fix pipeline util func deallocate --> release_tensor_data; fix bwd_b loss bwd branch; * [fix] fix zerobubble; support shardformer model type; * [fix] fix test_pipeline_utils ci; * [plugin] hybrid support zero bubble pipeline (#6060) * hybrid support zbv * fix fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * hybrid support zbv * fix fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: duanjunwen <935724073@qq.com> * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] fix poc format * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [feat] update test; rm comments; * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix mem check; * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix mem assert; * [fix] fix fwd branch, fwd pass both micro_batch & internal_inputs' * [plugin] hybrid support zero bubble pipeline (#6060) * hybrid support zbv * fix fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * [zerobubble]Support ZeroBubble Pipeline (#6034) * [feat] add zerobubble pp (just a frame now); add POC test for dx_dw; add test for zerobubble; * [feat] add dw test; * [fix] fix weight not close; * [update] update text; * [feat] add test run_fwd_bwd automatic scheduling; * [feat] split communication and calculation; fix pop empty send_bwd_buffer error; * [feat] add test for p & p grad; * [feat] add comments for ZBV func; * [fix] rm useless assign and comments; * [fix] fix ci test; add pytest; * [feat] add run_fwd_bwd_with_microbatch (replace input) & test; add p&p.grad assert close test & all pass; * [feat] add apply v_schedule graph; p & p.grad assert err exist; * [fix] update * [feat] fix ci; add assert; * [feat] fix poc format * [feat] fix func name & ci; add comments; * [fix] fix poc test; add comments in poc; * [feat] add optim backward_b_by_grad * [feat] fix optimizer bwd b & w; support return accum loss & output * [feat] add fwd_bwd_step, run_fwd_only; * [fix] fix optim bwd; add license for v_schedule; remove redundant attributes; fix schedule loop "while"--> "for"; add communication dict; * [fix] fix communication_map; * [feat] update test; rm comments; * [fix] rm zbv in hybridplugin * [fix] fix optim bwd; * [fix] fix optim bwd; * [fix] rm output.data after send fwd; * [fix] fix bwd step if condition; remove useless comments and format info; * [fix] fix detach output & release output; * [fix] rm requir_grad for output; * [fix] fix requir grad position and detach position and input&output local buffer append position; * [feat] add memory assertation; * [fix] fix mem check; * [fix] mem assertation' * [fix] fix mem assertation * [fix] fix mem; use a new model shape; only assert mem less and equal than theo; * [fix] fix model zoo import; * [fix] fix redundant detach & clone; add buffer assertation in the end; * [fix] add output_obj_grad assert None at bwd b step; replace input_obj.require_grad_ with treemap; * [fix] update optim state dict assert (include param group & state); fix mem assert after add optim; * [fix] add testcase with microbatch 4; * hybrid support zbv * fix fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update zero_bubble_pp.py * fix * fix-ci * fix [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix * fix * fix * fix * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix * fix * fix --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: duanjunwen <935724073@qq.com> * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: HangXu <hangxu0304@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: GuangyaoZhang <xjtu521@qq.com> Co-authored-by: Hongxin Liu <lhx0217@gmail.com> Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Haze188 <haze188@qq.com> Co-authored-by: Edenzzzz <wenxuan.tan@wisc.edu> Co-authored-by: Edenzzzz <wtan45@wisc.edu> Co-authored-by: Runyu Lu <77330637+LRY89757@users.noreply.github.com> Co-authored-by: YeAnbang <44796419+YeAnbang@users.noreply.github.com> Co-authored-by: Stephan Kö <stephankoe@users.noreply.github.com> Co-authored-by: アマデウス <kurisusnowdeng@users.noreply.github.com> Co-authored-by: Tong Li <tong.li352711588@gmail.com> Co-authored-by: zhurunhua <1281592874@qq.com> Co-authored-by: Insu Jang <insujang@umich.edu> Co-authored-by: Gao, Ruiyuan <905370712@qq.com> Co-authored-by: hxwang <wang1570@e.ntu.edu.sg> Co-authored-by: Michelle <qianranma8@gmail.com> Co-authored-by: Wang Binluo <32676639+wangbluo@users.noreply.github.com> Co-authored-by: wangbluo <2538539015@qq.com> Co-authored-by: root <root@notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9-0.notebook-8f919155-6035-47b4-9c6f-1be133b9e2c9.colossal-ai.svc.cluster.local> Co-authored-by: duanjunwen <935724073@qq.com> Co-authored-by: Camille Zhong <44392324+Camille7777@users.noreply.github.com>
9.5 KiB
自动混合精度训练
作者: Mingyan Jiang
前置教程
相关论文
引言
AMP 代表自动混合精度训练。 在 Colossal-AI 中, 我们结合了混合精度训练的不同实现:
- torch.cuda.amp
- apex.amp
- naive amp
| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16 范围 |
|---|---|---|---|
| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至 fp16 |
| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至 fp16 |
前两个依赖于 PyTorch (1.6 及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现 inf 或 nan。我们修改了 torch amp 实现,使其现在与张量并行兼容。
❌️ fp16 与 ZeRO 不兼容
⚠️ 流水并行目前仅支持 naive amp
我们建议使用 torch AMP,因为在不使用流水并行时,它通常比 NVIDIA AMP 提供更好的准确性。
目录
在本教程中,我们将介绍:
AMP 介绍
自动混合精度训练是混合 FP16 和 FP32 训练。
半精度浮点格式(FP16)具有较低的算法复杂度和较高的计算效率。此外,FP16 仅需要 FP32 所需的一半存储空间,并节省了内存和网络带宽,从而为大 batch size 和大模型提供了更多内存。
然而,还有其他操作,如缩减,需要 FP32 的动态范围,以避免数值溢出/下溢。因此,我们引入自动混合精度,尝试将每个操作与其相应的数据类型相匹配,这可以减少内存占用并提高训练效率。
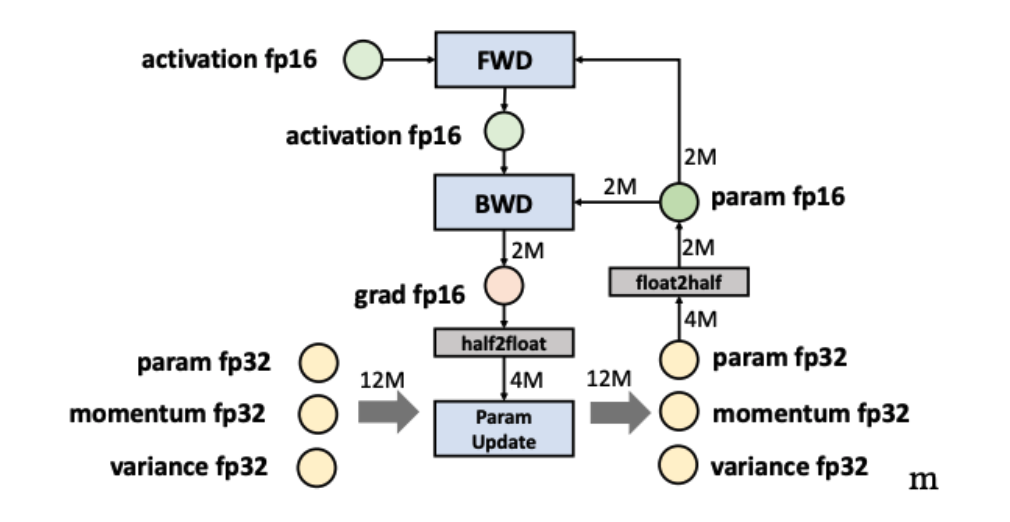
Colossal-AI 中的 AMP
我们支持三种 AMP 训练方法,并允许用户在没有改变代码的情况下使用 AMP 进行训练。booster 支持 amp 特性注入,如果您要使用混合精度训练,则在创建 booster 实例时指定mixed_precision参数; 后续将会拓展bf16.
我们目前只支持Linear层的fp8混合精度训练,如果您需要使用,请在创建 plugin实例时指定use_fp8参数。
为了减少低带宽场景下多机之间的通讯负载,我们还支持了FP8通讯。如果您需要使用,请在创建 plugin实例时指定fp8_communication参数。
booster 启动方式
您可以在创建 booster 实例时,指定mixed_precision="fp16"即使用 torch amp。
"""
初始化映射关系如下:
'fp16': torch amp
'fp16_apex': apex amp,
'bf16': bf16,
'fp16_naive': naive amp
"""
from colossalai import Booster
booster = Booster(mixed_precision='fp16',...)
或者您可以自定义一个FP16TorchMixedPrecision对象,如
from colossalai.mixed_precision import FP16TorchMixedPrecision
mixed_precision = FP16TorchMixedPrecision(
init_scale=2.**16,
growth_factor=2.0,
backoff_factor=0.5,
growth_interval=2000)
booster = Booster(mixed_precision=mixed_precision,...)
其他类型的 amp 使用方式也是一样的。
Torch AMP 配置
{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
Apex AMP 配置
对于这种模式,我们依靠 Apex 实现混合精度训练。我们支持这个插件,因为它允许对混合精度的粒度进行更精细的控制。 例如, O2 水平 (优化器水平 2) 将保持 batch normalization 为 FP32。
如果你想了解更多细节,请参考 Apex Documentation。
{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
Naive AMP 配置
在 Naive AMP 模式中, 我们实现了混合精度训练,同时保持了与复杂张量和流水并行的兼容性。该 AMP 模式将所有操作转为 FP16 。下列代码块展示了该模式的 booster 启动方式。
{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
当使用colossalai.booster时, 首先需要实例化一个模型、一个优化器和一个标准。将输出模型转换为内存消耗较小的 AMP 模型。如果您的输入模型已经太大,无法放置在 GPU 中,请使用dtype=torch.float16实例化你的模型。或者请尝试更小的模型,或尝试更多的并行化训练技术!
FP8通讯
在低带宽场景下,为了减少多机间的通讯负载,我们支持使用FP8的形式对通讯进行压缩,可以在初始化plugin实例(如GeminiPlugin)时使用fp8_communication=True来启用。此时多机之间all-to-all, all-gather以及P2P操作将使用FP8的格式进行数据传输。受限于NCCL库的支持,目前不支持缩减(Reduction)算子如Allreduce, ReduceScatter的FP8通讯。
实例
下面我们将展现如何在 Colossal-AI 使用 AMP。在该例程中,我们使用 Torch AMP.
步骤 1. 在 train.py 导入相关库
创建train.py并导入必要依赖. 请记得通过命令pip install timm scipy安装scipy和timm。
import os
from pathlib import Path
import torch
from timm.models import vit_base_patch16_224
from titans.utils import barrier_context
from torchvision import datasets, transforms
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
from colossalai.logging import get_dist_logger
from colossalai.nn.lr_scheduler import LinearWarmupLR
步骤 2. 初始化分布式环境
我们需要初始化分布式环境。为了快速演示,我们使用launch_from_torch。你可以参考 Launch Colossal-AI
使用其他初始化方法。
# 初始化分布式设置
parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
colossalai.launch_from_torch()
步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量DATA获得。你可以通过 export DATA=/path/to/data 或 Path(os.environ['DATA'])
在你的机器上设置路径。数据将会被自动下载到该路径。
# define the constants
NUM_EPOCHS = 2
BATCH_SIZE = 128
# build model
model = vit_base_patch16_224(drop_rate=0.1)
# build dataloader
train_dataset = datasets.Caltech101(
root=Path(os.environ['DATA']),
download=True,
transform=transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
Gray2RGB(),
transforms.Normalize([0.5, 0.5, 0.5],
[0.5, 0.5, 0.5])
]))
# build optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
# build loss
criterion = torch.nn.CrossEntropyLoss()
# lr_scheduler
lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
步骤 4. 插入 AMP
创建一个 MixedPrecision 对象(如果需要)及 torchDDPPlugin 对象,调用 colossalai.boost 将所有训练组件转为为 FP16 模式.
plugin = TorchDDPPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
booster = Booster(mixed_precision='fp16', plugin=plugin)
# if you need to customize the config, do like this
# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
# >>> mixed_precision = FP16TorchMixedPrecision(
# >>> init_scale=2.**16,
# >>> growth_factor=2.0,
# >>> backoff_factor=0.5,
# >>> growth_interval=2000)
# >>> plugin = TorchDDPPlugin()
# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
# boost model, optimizer, criterion, dataloader, lr_scheduler
model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
步骤 5. 使用 booster 训练
使用 booster 构建一个普通的训练循环。
model.train()
for epoch in range(NUM_EPOCHS):
for img, label in enumerate(train_dataloader):
img = img.cuda()
label = label.cuda()
optimizer.zero_grad()
output = model(img)
loss = criterion(output, label)
booster.backward(loss, optimizer)
optimizer.step()
lr_scheduler.step()
步骤 6. 启动训练脚本
使用下列命令启动训练脚本,你可以改变 --nproc_per_node 以使用不同数量的 GPU。
colossalai run --nproc_per_node 1 train.py