mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-21 06:33:41 +00:00
Merge branch 'master' into nc/20dec/runnable-chain
This commit is contained in:
@@ -26,7 +26,7 @@ class AzureChatOpenAI(ChatOpenAI):
|
||||
In addition, you should have the ``openai`` python package installed, and the
|
||||
following environment variables set or passed in constructor in lower case:
|
||||
- ``AZURE_OPENAI_API_KEY``
|
||||
- ``AZURE_OPENAI_API_ENDPOINT``
|
||||
- ``AZURE_OPENAI_ENDPOINT``
|
||||
- ``AZURE_OPENAI_AD_TOKEN``
|
||||
- ``OPENAI_API_VERSION``
|
||||
- ``OPENAI_PROXY``
|
||||
|
||||
@@ -2,10 +2,7 @@ from __future__ import annotations
|
||||
|
||||
import json
|
||||
import logging
|
||||
from typing import TYPE_CHECKING, Any, List, Optional, Tuple
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from jaguardb_http_client.JaguarHttpClient import JaguarHttpClient
|
||||
from typing import Any, List, Optional, Tuple
|
||||
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.embeddings import Embeddings
|
||||
@@ -23,7 +20,7 @@ class Jaguar(VectorStore):
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
from langchain.vectorstores import Jaguar
|
||||
from langchain_community.vectorstores.jaguar import Jaguar
|
||||
|
||||
vectorstore = Jaguar(
|
||||
pod = 'vdb',
|
||||
@@ -53,6 +50,13 @@ class Jaguar(VectorStore):
|
||||
self._vector_dimension = vector_dimension
|
||||
|
||||
self._embedding = embedding
|
||||
try:
|
||||
from jaguardb_http_client.JaguarHttpClient import JaguarHttpClient
|
||||
except ImportError:
|
||||
raise ValueError(
|
||||
"Could not import jaguardb-http-client python package. "
|
||||
"Please install it with `pip install -U jaguardb-http-client`"
|
||||
)
|
||||
|
||||
self._jag = JaguarHttpClient(url)
|
||||
self._token = ""
|
||||
|
||||
@@ -306,8 +306,13 @@ class MomentoVectorIndex(VectorStore):
|
||||
|
||||
if "top_k" in kwargs:
|
||||
k = kwargs["k"]
|
||||
filter_expression = kwargs.get("filter_expression", None)
|
||||
response = self._client.search(
|
||||
self.index_name, embedding, top_k=k, metadata_fields=ALL_METADATA
|
||||
self.index_name,
|
||||
embedding,
|
||||
top_k=k,
|
||||
metadata_fields=ALL_METADATA,
|
||||
filter_expression=filter_expression,
|
||||
)
|
||||
|
||||
if not isinstance(response, Search.Success):
|
||||
@@ -366,8 +371,13 @@ class MomentoVectorIndex(VectorStore):
|
||||
from momento.requests.vector_index import ALL_METADATA
|
||||
from momento.responses.vector_index import SearchAndFetchVectors
|
||||
|
||||
filter_expression = kwargs.get("filter_expression", None)
|
||||
response = self._client.search_and_fetch_vectors(
|
||||
self.index_name, embedding, top_k=fetch_k, metadata_fields=ALL_METADATA
|
||||
self.index_name,
|
||||
embedding,
|
||||
top_k=fetch_k,
|
||||
metadata_fields=ALL_METADATA,
|
||||
filter_expression=filter_expression,
|
||||
)
|
||||
|
||||
if isinstance(response, SearchAndFetchVectors.Success):
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
import os
|
||||
import time
|
||||
import uuid
|
||||
from typing import Iterator, List
|
||||
from typing import Generator, Iterator, List
|
||||
|
||||
import pytest
|
||||
from langchain_core.documents import Document
|
||||
|
||||
from langchain_community.document_loaders import TextLoader
|
||||
from langchain_community.embeddings import OpenAIEmbeddings
|
||||
from langchain_community.vectorstores import MomentoVectorIndex
|
||||
|
||||
@@ -24,6 +26,23 @@ def wait() -> None:
|
||||
time.sleep(1)
|
||||
|
||||
|
||||
@pytest.fixture(scope="module")
|
||||
def embedding_openai() -> OpenAIEmbeddings:
|
||||
if not os.environ.get("OPENAI_API_KEY"):
|
||||
raise ValueError("OPENAI_API_KEY is not set")
|
||||
return OpenAIEmbeddings()
|
||||
|
||||
|
||||
@pytest.fixture(scope="function")
|
||||
def texts() -> Generator[List[str], None, None]:
|
||||
# Load the documents from a file located in the fixtures directory
|
||||
documents = TextLoader(
|
||||
os.path.join(os.path.dirname(__file__), "fixtures", "sharks.txt")
|
||||
).load()
|
||||
|
||||
yield [doc.page_content for doc in documents]
|
||||
|
||||
|
||||
@pytest.fixture(scope="function")
|
||||
def vector_store(
|
||||
embedding_openai: OpenAIEmbeddings, random_index_name: str
|
||||
|
||||
@@ -10,7 +10,7 @@ def get_runtime_environment() -> dict:
|
||||
|
||||
return {
|
||||
"library_version": __version__,
|
||||
"library": "langchain",
|
||||
"library": "langchain-core",
|
||||
"platform": platform.platform(),
|
||||
"runtime": "python",
|
||||
"runtime_version": platform.python_version(),
|
||||
|
||||
@@ -1,53 +1,74 @@
|
||||
|
||||
# rag-chroma-multi-modal-multi-vector
|
||||
|
||||
Presentations (slide decks, etc) contain visual content that challenges conventional RAG.
|
||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||
|
||||
Multi-modal LLMs unlock new ways to build apps over visual content like presentations.
|
||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||
|
||||
It uses GPT-4V to create image summaries for each slide, embeds the summaries, and stores them in Chroma.
|
||||
|
||||
This template performs multi-modal RAG using Chroma with the multi-vector retriever (see [blog](https://blog.langchain.dev/multi-modal-rag-template/)):
|
||||
Given a question, relevat slides are retrieved and passed to GPT-4V for answer synthesis.
|
||||
|
||||
* Extracts the slides as images
|
||||
* Uses GPT-4V to summarize each image
|
||||
* Embeds the image summaries with a link to the original images
|
||||
* Retrieves relevant image based on similarity between the image summary and the user input
|
||||
* Finally pass those images to GPT-4V for answer synthesis
|
||||

|
||||
|
||||
## Input
|
||||
|
||||
Supply a slide deck as pdf in the `/docs` directory.
|
||||
|
||||
By default, this template has a slide deck about Q3 earnings from DataDog, a public techologyy company.
|
||||
|
||||
Example questions to ask can be:
|
||||
```
|
||||
How many customers does Datadog have?
|
||||
What is Datadog platform % Y/Y growth in FY20, FY21, and FY22?
|
||||
```
|
||||
|
||||
To create an index of the slide deck, run:
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## Storage
|
||||
|
||||
Here is the process the template will use to create an index of the slides (see [blog](https://blog.langchain.dev/multi-modal-rag-template/)):
|
||||
|
||||
* Extract the slides as a collection of images
|
||||
* Use GPT-4V to summarize each image
|
||||
* Embed the image summaries using text embeddings with a link to the original images
|
||||
* Retrieve relevant image based on similarity between the image summary and the user input question
|
||||
* Pass those images to GPT-4V for answer synthesis
|
||||
|
||||
By default, this will use [LocalFileStore](https://python.langchain.com/docs/integrations/stores/file_system) to store images and Chroma to store summaries.
|
||||
|
||||
For production, it may be desirable to use a remote option such as Redis.
|
||||
|
||||
You can set the `local_file_store` flag in `chain.py` and `ingest.py` to switch between the two options.
|
||||
|
||||
For Redis, the template will use [UpstashRedisByteStore](https://python.langchain.com/docs/integrations/stores/upstash_redis).
|
||||
|
||||
We will use Upstash to store the images, which offers Redis with a REST API.
|
||||
|
||||
Simply login [here](https://upstash.com/) and create a database.
|
||||
|
||||
This will give you a REST API with:
|
||||
|
||||
* UPSTASH_URL
|
||||
* UPSTASH_TOKEN
|
||||
|
||||
* `UPSTASH_URL`
|
||||
* `UPSTASH_TOKEN`
|
||||
|
||||
Set `UPSTASH_URL` and `UPSTASH_TOKEN` as environment variables to access your database.
|
||||
|
||||
We will use Chroma to store and index the image summaries, which will be created locally in the template directory.
|
||||
|
||||
## Input
|
||||
|
||||
Supply a slide deck as pdf in the `/docs` directory.
|
||||
|
||||
Create your vectorstore (Chroma) and populae Upstash with:
|
||||
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## LLM
|
||||
|
||||
The app will retrieve images using multi-modal embeddings, and pass them to GPT-4V.
|
||||
The app will retrieve images based on similarity between the text input and the image summary, and pass the images to GPT-4V.
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI GPT-4V.
|
||||
|
||||
Set `UPSTASH_URL` and `UPSTASH_TOKEN` as environment variables to access your database.
|
||||
Set `UPSTASH_URL` and `UPSTASH_TOKEN` as environment variables to access your database if you use `UpstashRedisByteStore`.
|
||||
|
||||
## Usage
|
||||
|
||||
@@ -105,4 +126,4 @@ We can access the template from code with:
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-chroma-multi-modal-multi-vector")
|
||||
```
|
||||
```
|
||||
|
||||
@@ -11,7 +11,7 @@ from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.retrievers.multi_vector import MultiVectorRetriever
|
||||
from langchain.schema.document import Document
|
||||
from langchain.schema.messages import HumanMessage
|
||||
from langchain.storage import UpstashRedisByteStore
|
||||
from langchain.storage import LocalFileStore, UpstashRedisByteStore
|
||||
from langchain.vectorstores import Chroma
|
||||
from PIL import Image
|
||||
|
||||
@@ -126,20 +126,31 @@ def convert_to_base64(pil_image):
|
||||
return img_str
|
||||
|
||||
|
||||
def create_multi_vector_retriever(vectorstore, image_summaries, images):
|
||||
def create_multi_vector_retriever(
|
||||
vectorstore, image_summaries, images, local_file_store
|
||||
):
|
||||
"""
|
||||
Create retriever that indexes summaries, but returns raw images or texts
|
||||
|
||||
:param vectorstore: Vectorstore to store embedded image sumamries
|
||||
:param image_summaries: Image summaries
|
||||
:param images: Base64 encoded images
|
||||
:param local_file_store: Use local file storage
|
||||
:return: Retriever
|
||||
"""
|
||||
|
||||
# Initialize the storage layer for images
|
||||
UPSTASH_URL = os.getenv("UPSTASH_URL")
|
||||
UPSTASH_TOKEN = os.getenv("UPSTASH_TOKEN")
|
||||
store = UpstashRedisByteStore(url=UPSTASH_URL, token=UPSTASH_TOKEN)
|
||||
# File storage option
|
||||
if local_file_store:
|
||||
store = LocalFileStore(
|
||||
str(Path(__file__).parent / "multi_vector_retriever_metadata")
|
||||
)
|
||||
else:
|
||||
# Initialize the storage layer for images using Redis
|
||||
UPSTASH_URL = os.getenv("UPSTASH_URL")
|
||||
UPSTASH_TOKEN = os.getenv("UPSTASH_TOKEN")
|
||||
store = UpstashRedisByteStore(url=UPSTASH_URL, token=UPSTASH_TOKEN)
|
||||
|
||||
# Doc ID
|
||||
id_key = "doc_id"
|
||||
|
||||
# Create the multi-vector retriever
|
||||
@@ -194,4 +205,5 @@ retriever_multi_vector_img = create_multi_vector_retriever(
|
||||
vectorstore_mvr,
|
||||
image_summaries,
|
||||
images_base_64_processed_documents,
|
||||
local_file_store=True,
|
||||
)
|
||||
|
||||
@@ -11,7 +11,7 @@ from langchain.schema.document import Document
|
||||
from langchain.schema.messages import HumanMessage
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
|
||||
from langchain.storage import UpstashRedisByteStore
|
||||
from langchain.storage import LocalFileStore, UpstashRedisByteStore
|
||||
from langchain.vectorstores import Chroma
|
||||
from PIL import Image
|
||||
|
||||
@@ -101,6 +101,9 @@ def multi_modal_rag_chain(retriever):
|
||||
return chain
|
||||
|
||||
|
||||
# Flag
|
||||
local_file_store = True
|
||||
|
||||
# Load chroma
|
||||
vectorstore_mvr = Chroma(
|
||||
collection_name="image_summaries",
|
||||
@@ -108,10 +111,17 @@ vectorstore_mvr = Chroma(
|
||||
embedding_function=OpenAIEmbeddings(),
|
||||
)
|
||||
|
||||
# Load redis
|
||||
UPSTASH_URL = os.getenv("UPSTASH_URL")
|
||||
UPSTASH_TOKEN = os.getenv("UPSTASH_TOKEN")
|
||||
store = UpstashRedisByteStore(url=UPSTASH_URL, token=UPSTASH_TOKEN)
|
||||
if local_file_store:
|
||||
store = LocalFileStore(
|
||||
str(Path(__file__).parent.parent / "multi_vector_retriever_metadata")
|
||||
)
|
||||
else:
|
||||
# Load redis
|
||||
UPSTASH_URL = os.getenv("UPSTASH_URL")
|
||||
UPSTASH_TOKEN = os.getenv("UPSTASH_TOKEN")
|
||||
store = UpstashRedisByteStore(url=UPSTASH_URL, token=UPSTASH_TOKEN)
|
||||
|
||||
#
|
||||
id_key = "doc_id"
|
||||
|
||||
# Create the multi-vector retriever
|
||||
|
||||
@@ -1,32 +1,43 @@
|
||||
|
||||
# rag-chroma-multi-modal
|
||||
|
||||
Presentations (slide decks, etc) contain visual content that challenges conventional RAG.
|
||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||
|
||||
Multi-modal LLMs unlock new ways to build apps over visual content like presentations.
|
||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||
|
||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
||||
|
||||
This template performs multi-modal RAG using Chroma with multi-modal OpenCLIP embeddings and OpenAI GPT-4V.
|
||||
Given a question, relevat slides are retrieved and passed to GPT-4V for answer synthesis.
|
||||
|
||||

|
||||
|
||||
## Input
|
||||
|
||||
Supply a slide deck as pdf in the `/docs` directory.
|
||||
|
||||
Create your vectorstore with:
|
||||
By default, this template has a slide deck about Q3 earnings from DataDog, a public techologyy company.
|
||||
|
||||
Example questions to ask can be:
|
||||
```
|
||||
How many customers does Datadog have?
|
||||
What is Datadog platform % Y/Y growth in FY20, FY21, and FY22?
|
||||
```
|
||||
|
||||
To create an index of the slide deck, run:
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## Embeddings
|
||||
## Storage
|
||||
|
||||
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings.
|
||||
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings to embed the images.
|
||||
|
||||
You can select different options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
||||
You can select different embedding model options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
||||
|
||||
The first time you run the app, it will automatically download the multimodal embedding model.
|
||||
|
||||
By default, LangChain will use an embedding model with reasonably strong performance, `ViT-H-14`.
|
||||
By default, LangChain will use an embedding model with moderate performance but lower memory requirments, `ViT-H-14`.
|
||||
|
||||
You can choose alternative `OpenCLIPEmbeddings` models in `rag_chroma_multi_modal/ingest.py`:
|
||||
```
|
||||
@@ -41,7 +52,7 @@ vectorstore_mmembd = Chroma(
|
||||
|
||||
## LLM
|
||||
|
||||
The app will retrieve images using multi-modal embeddings, and pass them to GPT-4V.
|
||||
The app will retrieve images based on similarity between the text input and the image, which are both mapped to multi-modal embedding space. It will then pass the images to GPT-4V.
|
||||
|
||||
## Environment Setup
|
||||
|
||||
@@ -103,4 +114,4 @@ We can access the template from code with:
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-chroma-multi-modal")
|
||||
```
|
||||
```
|
||||
|
||||
@@ -1,34 +1,45 @@
|
||||
|
||||
# rag-gemini-multi-modal
|
||||
|
||||
Presentations (slide decks, etc) contain visual content that challenges conventional RAG.
|
||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||
|
||||
Multi-modal LLMs unlock new ways to build apps over visual content like presentations.
|
||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||
|
||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
||||
|
||||
This template performs multi-modal RAG using Chroma with multi-modal OpenCLIP embeddings and [Google Gemini](https://deepmind.google/technologies/gemini/#introduction).
|
||||
Given a question, relevat slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||
|
||||
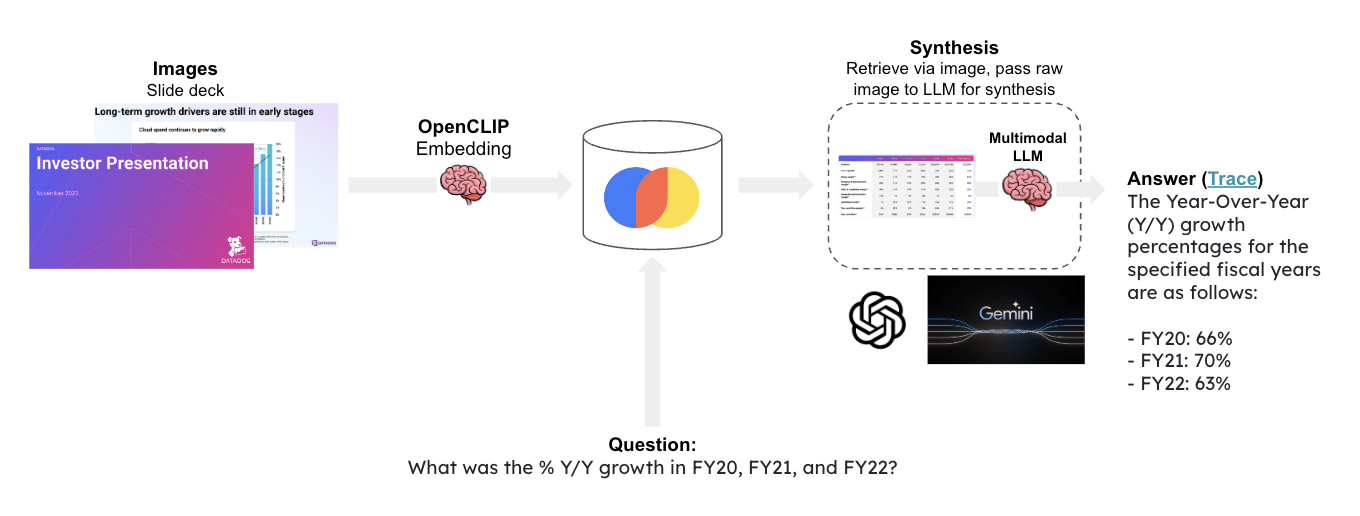
|
||||
|
||||
## Input
|
||||
|
||||
Supply a slide deck as pdf in the `/docs` directory.
|
||||
|
||||
Create your vectorstore with:
|
||||
By default, this template has a slide deck about Q3 earnings from DataDog, a public techologyy company.
|
||||
|
||||
Example questions to ask can be:
|
||||
```
|
||||
How many customers does Datadog have?
|
||||
What is Datadog platform % Y/Y growth in FY20, FY21, and FY22?
|
||||
```
|
||||
|
||||
To create an index of the slide deck, run:
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## Embeddings
|
||||
## Storage
|
||||
|
||||
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings.
|
||||
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings to embed the images.
|
||||
|
||||
You can select different options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
||||
You can select different embedding model options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
||||
|
||||
The first time you run the app, it will automatically download the multimodal embedding model.
|
||||
|
||||
By default, LangChain will use an embedding model with reasonably strong performance, `ViT-H-14`.
|
||||
By default, LangChain will use an embedding model with moderate performance but lower memory requirments, `ViT-H-14`.
|
||||
|
||||
You can choose alternative `OpenCLIPEmbeddings` models in `ingest.py`:
|
||||
You can choose alternative `OpenCLIPEmbeddings` models in `rag_chroma_multi_modal/ingest.py`:
|
||||
```
|
||||
vectorstore_mmembd = Chroma(
|
||||
collection_name="multi-modal-rag",
|
||||
@@ -45,7 +56,7 @@ The app will retrieve images using multi-modal embeddings, and pass them to Goog
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Set the `GOOGLE_API_KEY` environment variable to access Gemini.
|
||||
Set your `GOOGLE_API_KEY` environment variable in order to access Gemini.
|
||||
|
||||
## Usage
|
||||
|
||||
@@ -103,4 +114,4 @@ We can access the template from code with:
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-gemini-multi-modal")
|
||||
```
|
||||
```
|
||||
|
||||
2
templates/rag-multi-modal-local/.gitignore
vendored
Normal file
2
templates/rag-multi-modal-local/.gitignore
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
docs/img_*.jpg
|
||||
chroma_db_multi_modal
|
||||
21
templates/rag-multi-modal-local/LICENSE
Normal file
21
templates/rag-multi-modal-local/LICENSE
Normal file
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
126
templates/rag-multi-modal-local/README.md
Normal file
126
templates/rag-multi-modal-local/README.md
Normal file
@@ -0,0 +1,126 @@
|
||||
|
||||
# rag-multi-modal-local
|
||||
|
||||
Visual search is a famililar application to many with iPhones or Android devices. It allows user to serch photos using natural language.
|
||||
|
||||
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
||||
|
||||
This template demonstrates how to perform private visual search and question-answering over a collection of your photos.
|
||||
|
||||
It uses OpenCLIP embeddings to embed all of the photos and stores them in Chroma.
|
||||
|
||||
Given a question, relevat photos are retrieved and passed to an open source multi-modal LLM of your choice for answer synthesis.
|
||||
|
||||

|
||||
|
||||
## Input
|
||||
|
||||
Supply a set of photos in the `/docs` directory.
|
||||
|
||||
By default, this template has a toy collection of 3 food pictures.
|
||||
|
||||
Example questions to ask can be:
|
||||
```
|
||||
What kind of soft serve did I have?
|
||||
```
|
||||
|
||||
In practice, a larger corpus of images can be tested.
|
||||
|
||||
To create an index of the images, run:
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## Storage
|
||||
|
||||
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings to embed the images.
|
||||
|
||||
You can select different embedding model options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
||||
|
||||
The first time you run the app, it will automatically download the multimodal embedding model.
|
||||
|
||||
By default, LangChain will use an embedding model with moderate performance but lower memory requirments, `ViT-H-14`.
|
||||
|
||||
You can choose alternative `OpenCLIPEmbeddings` models in `rag_chroma_multi_modal/ingest.py`:
|
||||
```
|
||||
vectorstore_mmembd = Chroma(
|
||||
collection_name="multi-modal-rag",
|
||||
persist_directory=str(re_vectorstore_path),
|
||||
embedding_function=OpenCLIPEmbeddings(
|
||||
model_name="ViT-H-14", checkpoint="laion2b_s32b_b79k"
|
||||
),
|
||||
)
|
||||
```
|
||||
|
||||
## LLM
|
||||
|
||||
This template will use [Ollama](https://python.langchain.com/docs/integrations/chat/ollama#multi-modal).
|
||||
|
||||
Download the latest version of Ollama: https://ollama.ai/
|
||||
|
||||
Pull the an open source multi-modal LLM: e.g., https://ollama.ai/library/bakllava
|
||||
|
||||
```
|
||||
ollama pull bakllava
|
||||
```
|
||||
|
||||
The app is by default configured for `bakllava`. But you can change this in `chain.py` and `ingest.py` for different downloaded models.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U langchain-cli
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package rag-chroma-multi-modal
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add rag-chroma-multi-modal
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from rag_chroma_multi_modal import chain as rag_chroma_multi_modal_chain
|
||||
|
||||
add_routes(app, rag_chroma_multi_modal_chain, path="/rag-chroma-multi-modal")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/rag-chroma-multi-modal/playground](http://127.0.0.1:8000/rag-chroma-multi-modal/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-chroma-multi-modal")
|
||||
```
|
||||
BIN
templates/rag-multi-modal-local/docs/bread_bowl.jpg
Normal file
BIN
templates/rag-multi-modal-local/docs/bread_bowl.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 60 KiB |
BIN
templates/rag-multi-modal-local/docs/in_and_out.jpg
Normal file
BIN
templates/rag-multi-modal-local/docs/in_and_out.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 94 KiB |
BIN
templates/rag-multi-modal-local/docs/matcha.jpg
Normal file
BIN
templates/rag-multi-modal-local/docs/matcha.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 56 KiB |
35
templates/rag-multi-modal-local/ingest.py
Normal file
35
templates/rag-multi-modal-local/ingest.py
Normal file
@@ -0,0 +1,35 @@
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from langchain.vectorstores import Chroma
|
||||
from langchain_experimental.open_clip import OpenCLIPEmbeddings
|
||||
|
||||
# Load images
|
||||
img_dump_path = Path(__file__).parent / "docs/"
|
||||
rel_img_dump_path = img_dump_path.relative_to(Path.cwd())
|
||||
image_uris = sorted(
|
||||
[
|
||||
os.path.join(rel_img_dump_path, image_name)
|
||||
for image_name in os.listdir(rel_img_dump_path)
|
||||
if image_name.endswith(".jpg")
|
||||
]
|
||||
)
|
||||
|
||||
# Index
|
||||
vectorstore = Path(__file__).parent / "chroma_db_multi_modal"
|
||||
re_vectorstore_path = vectorstore.relative_to(Path.cwd())
|
||||
|
||||
# Load embedding function
|
||||
print("Loading embedding function")
|
||||
embedding = OpenCLIPEmbeddings(model_name="ViT-H-14", checkpoint="laion2b_s32b_b79k")
|
||||
|
||||
# Create chroma
|
||||
vectorstore_mmembd = Chroma(
|
||||
collection_name="multi-modal-rag",
|
||||
persist_directory=str(Path(__file__).parent / "chroma_db_multi_modal"),
|
||||
embedding_function=embedding,
|
||||
)
|
||||
|
||||
# Add images
|
||||
print("Embedding images")
|
||||
vectorstore_mmembd.add_images(uris=image_uris)
|
||||
3490
templates/rag-multi-modal-local/poetry.lock
generated
Normal file
3490
templates/rag-multi-modal-local/poetry.lock
generated
Normal file
File diff suppressed because it is too large
Load Diff
38
templates/rag-multi-modal-local/pyproject.toml
Normal file
38
templates/rag-multi-modal-local/pyproject.toml
Normal file
@@ -0,0 +1,38 @@
|
||||
[tool.poetry]
|
||||
name = "rag-multi-modal-local"
|
||||
version = "0.1.0"
|
||||
description = "Multi-modal RAG using Chroma"
|
||||
authors = [
|
||||
"Lance Martin <lance@langchain.dev>",
|
||||
]
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.351"
|
||||
openai = "<2"
|
||||
tiktoken = ">=0.5.1"
|
||||
chromadb = ">=0.4.14"
|
||||
open-clip-torch = ">=2.23.0"
|
||||
torch = ">=2.1.0"
|
||||
langchain-experimental = "^0.0.43"
|
||||
langchain-community = ">=0.0.4"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.15"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "rag_multi_modal_local"
|
||||
export_attr = "chain"
|
||||
|
||||
[tool.templates-hub]
|
||||
use-case = "rag"
|
||||
author = "LangChain"
|
||||
integrations = ["Ollama", "Chroma"]
|
||||
tags = ["multi-modal"]
|
||||
|
||||
[build-system]
|
||||
requires = [
|
||||
"poetry-core",
|
||||
]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
52
templates/rag-multi-modal-local/rag_multi_modal_local.ipynb
Normal file
52
templates/rag-multi-modal-local/rag_multi_modal_local.ipynb
Normal file
@@ -0,0 +1,52 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "681a5d1e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run Template\n",
|
||||
"\n",
|
||||
"In `server.py`, set -\n",
|
||||
"```\n",
|
||||
"add_routes(app, chain_rag_conv, path=\"/rag-multi-modal-local\")\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d774be2a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langserve.client import RemoteRunnable\n",
|
||||
"\n",
|
||||
"rag_app = RemoteRunnable(\"http://localhost:8001/rag-multi-modal-local\")\n",
|
||||
"rag_app.invoke(\" < keywords here > \")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,3 @@
|
||||
from rag_multi_modal_local.chain import chain
|
||||
|
||||
__all__ = ["chain"]
|
||||
122
templates/rag-multi-modal-local/rag_multi_modal_local/chain.py
Normal file
122
templates/rag-multi-modal-local/rag_multi_modal_local/chain.py
Normal file
@@ -0,0 +1,122 @@
|
||||
import base64
|
||||
import io
|
||||
from pathlib import Path
|
||||
|
||||
from langchain.chat_models import ChatOllama
|
||||
from langchain.vectorstores import Chroma
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.messages import HumanMessage
|
||||
from langchain_core.output_parsers import StrOutputParser
|
||||
from langchain_core.pydantic_v1 import BaseModel
|
||||
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
|
||||
from langchain_experimental.open_clip import OpenCLIPEmbeddings
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def resize_base64_image(base64_string, size=(128, 128)):
|
||||
"""
|
||||
Resize an image encoded as a Base64 string.
|
||||
|
||||
:param base64_string: A Base64 encoded string of the image to be resized.
|
||||
:param size: A tuple representing the new size (width, height) for the image.
|
||||
:return: A Base64 encoded string of the resized image.
|
||||
"""
|
||||
img_data = base64.b64decode(base64_string)
|
||||
img = Image.open(io.BytesIO(img_data))
|
||||
resized_img = img.resize(size, Image.LANCZOS)
|
||||
buffered = io.BytesIO()
|
||||
resized_img.save(buffered, format=img.format)
|
||||
return base64.b64encode(buffered.getvalue()).decode("utf-8")
|
||||
|
||||
|
||||
def get_resized_images(docs):
|
||||
"""
|
||||
Resize images from base64-encoded strings.
|
||||
|
||||
:param docs: A list of base64-encoded image to be resized.
|
||||
:return: Dict containing a list of resized base64-encoded strings.
|
||||
"""
|
||||
b64_images = []
|
||||
for doc in docs:
|
||||
if isinstance(doc, Document):
|
||||
doc = doc.page_content
|
||||
# Optional: re-size image
|
||||
# resized_image = resize_base64_image(doc, size=(1280, 720))
|
||||
b64_images.append(doc)
|
||||
return {"images": b64_images}
|
||||
|
||||
|
||||
def img_prompt_func(data_dict, num_images=1):
|
||||
"""
|
||||
GPT-4V prompt for image analysis.
|
||||
|
||||
:param data_dict: A dict with images and a user-provided question.
|
||||
:param num_images: Number of images to include in the prompt.
|
||||
:return: A list containing message objects for each image and the text prompt.
|
||||
"""
|
||||
messages = []
|
||||
if data_dict["context"]["images"]:
|
||||
for image in data_dict["context"]["images"][:num_images]:
|
||||
image_message = {
|
||||
"type": "image_url",
|
||||
"image_url": f"data:image/jpeg;base64,{image}",
|
||||
}
|
||||
messages.append(image_message)
|
||||
text_message = {
|
||||
"type": "text",
|
||||
"text": (
|
||||
"You are a helpful assistant that gives a description of food pictures.\n"
|
||||
"Give a detailed summary of the image.\n"
|
||||
"Give reccomendations for similar foods to try.\n"
|
||||
),
|
||||
}
|
||||
messages.append(text_message)
|
||||
return [HumanMessage(content=messages)]
|
||||
|
||||
|
||||
def multi_modal_rag_chain(retriever):
|
||||
"""
|
||||
Multi-modal RAG chain,
|
||||
|
||||
:param retriever: A function that retrieves the necessary context for the model.
|
||||
:return: A chain of functions representing the multi-modal RAG process.
|
||||
"""
|
||||
# Initialize the multi-modal Large Language Model with specific parameters
|
||||
model = ChatOllama(model="bakllava", temperature=0)
|
||||
|
||||
# Define the RAG pipeline
|
||||
chain = (
|
||||
{
|
||||
"context": retriever | RunnableLambda(get_resized_images),
|
||||
"question": RunnablePassthrough(),
|
||||
}
|
||||
| RunnableLambda(img_prompt_func)
|
||||
| model
|
||||
| StrOutputParser()
|
||||
)
|
||||
|
||||
return chain
|
||||
|
||||
|
||||
# Load chroma
|
||||
vectorstore_mmembd = Chroma(
|
||||
collection_name="multi-modal-rag",
|
||||
persist_directory=str(Path(__file__).parent.parent / "chroma_db_multi_modal"),
|
||||
embedding_function=OpenCLIPEmbeddings(
|
||||
model_name="ViT-H-14", checkpoint="laion2b_s32b_b79k"
|
||||
),
|
||||
)
|
||||
|
||||
# Make retriever
|
||||
retriever_mmembd = vectorstore_mmembd.as_retriever()
|
||||
|
||||
# Create RAG chain
|
||||
chain = multi_modal_rag_chain(retriever_mmembd)
|
||||
|
||||
|
||||
# Add typing for input
|
||||
class Question(BaseModel):
|
||||
__root__: str
|
||||
|
||||
|
||||
chain = chain.with_types(input_type=Question)
|
||||
0
templates/rag-multi-modal-local/tests/__init__.py
Normal file
0
templates/rag-multi-modal-local/tests/__init__.py
Normal file
3
templates/rag-multi-modal-mv-local/.gitignore
vendored
Normal file
3
templates/rag-multi-modal-mv-local/.gitignore
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
docs/img_*.jpg
|
||||
chroma_db_multi_modal
|
||||
multi_vector_retriever_metadata
|
||||
21
templates/rag-multi-modal-mv-local/LICENSE
Normal file
21
templates/rag-multi-modal-mv-local/LICENSE
Normal file
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
122
templates/rag-multi-modal-mv-local/README.md
Normal file
122
templates/rag-multi-modal-mv-local/README.md
Normal file
@@ -0,0 +1,122 @@
|
||||
|
||||
# rag-multi-modal-mv-local
|
||||
|
||||
Visual search is a famililar application to many with iPhones or Android devices. It allows user to serch photos using natural language.
|
||||
|
||||
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
|
||||
|
||||
This template demonstrates how to perform private visual search and question-answering over a collection of your photos.
|
||||
|
||||
It uses an open source multi-modal LLM of your choice to create image summaries for each photos, embeds the summaries, and stores them in Chroma.
|
||||
|
||||
Given a question, relevat photos are retrieved and passed to the multi-modal LLM for answer synthesis.
|
||||
|
||||

|
||||
|
||||
## Input
|
||||
|
||||
Supply a set of photos in the `/docs` directory.
|
||||
|
||||
By default, this template has a toy collection of 3 food pictures.
|
||||
|
||||
The app will look up and summarize photos based upon provided keywords or questions:
|
||||
```
|
||||
What kind of ice cream did I have?
|
||||
```
|
||||
|
||||
In practice, a larger corpus of images can be tested.
|
||||
|
||||
To create an index of the images, run:
|
||||
```
|
||||
poetry install
|
||||
python ingest.py
|
||||
```
|
||||
|
||||
## Storage
|
||||
|
||||
Here is the process the template will use to create an index of the slides (see [blog](https://blog.langchain.dev/multi-modal-rag-template/)):
|
||||
|
||||
* Given a set of images
|
||||
* It uses a local multi-modal LLM ([bakllava](https://ollama.ai/library/bakllava)) to summarize each image
|
||||
* Embeds the image summaries with a link to the original images
|
||||
* Given a user question, it will relevant image(s) based on similarity between the image summary and user input (using Ollama embeddings)
|
||||
* It will pass those images to bakllava for answer synthesis
|
||||
|
||||
By default, this will use [LocalFileStore](https://python.langchain.com/docs/integrations/stores/file_system) to store images and Chroma to store summaries.
|
||||
|
||||
## LLM and Embedding Models
|
||||
|
||||
We will use [Ollama](https://python.langchain.com/docs/integrations/chat/ollama#multi-modal) for generating image summaries, embeddings, and the final image QA.
|
||||
|
||||
Download the latest version of Ollama: https://ollama.ai/
|
||||
|
||||
Pull an open source multi-modal LLM: e.g., https://ollama.ai/library/bakllava
|
||||
|
||||
Pull an open source embedding model: e.g., https://ollama.ai/library/llama2:7b
|
||||
|
||||
```
|
||||
ollama pull bakllava
|
||||
ollama pull llama2:7b
|
||||
```
|
||||
|
||||
The app is by default configured for `bakllava`. But you can change this in `chain.py` and `ingest.py` for different downloaded models.
|
||||
|
||||
The app will retrieve images based on similarity between the text input and the image summary, and pass the images to `bakllava`.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U langchain-cli
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package rag-multi-modal-mv-local
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add rag-multi-modal-mv-local
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from rag_multi_modal_mv_local import chain as rag_multi_modal_mv_local_chain
|
||||
|
||||
add_routes(app, rag_multi_modal_mv_local_chain, path="/rag-multi-modal-mv-local")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/rag-multi-modal-mv-local/playground](http://127.0.0.1:8000/rag-multi-modal-mv-local/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-multi-modal-mv-local")
|
||||
```
|
||||
BIN
templates/rag-multi-modal-mv-local/docs/bread_bowl.jpg
Normal file
BIN
templates/rag-multi-modal-mv-local/docs/bread_bowl.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 60 KiB |
BIN
templates/rag-multi-modal-mv-local/docs/in_and_out.jpg
Normal file
BIN
templates/rag-multi-modal-mv-local/docs/in_and_out.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 94 KiB |
BIN
templates/rag-multi-modal-mv-local/docs/matcha.jpg
Normal file
BIN
templates/rag-multi-modal-mv-local/docs/matcha.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 56 KiB |
192
templates/rag-multi-modal-mv-local/ingest.py
Normal file
192
templates/rag-multi-modal-mv-local/ingest.py
Normal file
@@ -0,0 +1,192 @@
|
||||
import base64
|
||||
import io
|
||||
import os
|
||||
import uuid
|
||||
from io import BytesIO
|
||||
from pathlib import Path
|
||||
|
||||
from langchain.chat_models import ChatOllama
|
||||
from langchain.embeddings import OllamaEmbeddings
|
||||
from langchain.retrievers.multi_vector import MultiVectorRetriever
|
||||
from langchain.schema.document import Document
|
||||
from langchain.schema.messages import HumanMessage
|
||||
from langchain.storage import LocalFileStore
|
||||
from langchain.vectorstores import Chroma
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def image_summarize(img_base64, prompt):
|
||||
"""
|
||||
Make image summary
|
||||
|
||||
:param img_base64: Base64 encoded string for image
|
||||
:param prompt: Text prompt for summarizatiomn
|
||||
:return: Image summarization prompt
|
||||
|
||||
"""
|
||||
chat = ChatOllama(model="bakllava", temperature=0)
|
||||
|
||||
msg = chat.invoke(
|
||||
[
|
||||
HumanMessage(
|
||||
content=[
|
||||
{"type": "text", "text": prompt},
|
||||
{
|
||||
"type": "image_url",
|
||||
"image_url": f"data:image/jpeg;base64,{img_base64}",
|
||||
},
|
||||
]
|
||||
)
|
||||
]
|
||||
)
|
||||
return msg.content
|
||||
|
||||
|
||||
def generate_img_summaries(img_base64_list):
|
||||
"""
|
||||
Generate summaries for images
|
||||
|
||||
:param img_base64_list: Base64 encoded images
|
||||
:return: List of image summaries and processed images
|
||||
"""
|
||||
|
||||
# Store image summaries
|
||||
image_summaries = []
|
||||
processed_images = []
|
||||
|
||||
# Prompt
|
||||
prompt = """Give a detailed summary of the image."""
|
||||
|
||||
# Apply summarization to images
|
||||
for i, base64_image in enumerate(img_base64_list):
|
||||
try:
|
||||
image_summaries.append(image_summarize(base64_image, prompt))
|
||||
processed_images.append(base64_image)
|
||||
except Exception as e:
|
||||
print(f"Error with image {i+1}: {e}")
|
||||
|
||||
return image_summaries, processed_images
|
||||
|
||||
|
||||
def get_images(img_path):
|
||||
"""
|
||||
Extract images.
|
||||
|
||||
:param img_path: A string representing the path to the images.
|
||||
"""
|
||||
# Get image URIs
|
||||
pil_images = [
|
||||
Image.open(os.path.join(img_path, image_name))
|
||||
for image_name in os.listdir(img_path)
|
||||
if image_name.endswith(".jpg")
|
||||
]
|
||||
return pil_images
|
||||
|
||||
|
||||
def resize_base64_image(base64_string, size=(128, 128)):
|
||||
"""
|
||||
Resize an image encoded as a Base64 string
|
||||
|
||||
:param base64_string: Base64 string
|
||||
:param size: Image size
|
||||
:return: Re-sized Base64 string
|
||||
"""
|
||||
# Decode the Base64 string
|
||||
img_data = base64.b64decode(base64_string)
|
||||
img = Image.open(io.BytesIO(img_data))
|
||||
|
||||
# Resize the image
|
||||
resized_img = img.resize(size, Image.LANCZOS)
|
||||
|
||||
# Save the resized image to a bytes buffer
|
||||
buffered = io.BytesIO()
|
||||
resized_img.save(buffered, format=img.format)
|
||||
|
||||
# Encode the resized image to Base64
|
||||
return base64.b64encode(buffered.getvalue()).decode("utf-8")
|
||||
|
||||
|
||||
def convert_to_base64(pil_image):
|
||||
"""
|
||||
Convert PIL images to Base64 encoded strings
|
||||
|
||||
:param pil_image: PIL image
|
||||
:return: Re-sized Base64 string
|
||||
"""
|
||||
|
||||
buffered = BytesIO()
|
||||
pil_image.save(buffered, format="JPEG") # You can change the format if needed
|
||||
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
|
||||
# img_str = resize_base64_image(img_str, size=(831,623))
|
||||
return img_str
|
||||
|
||||
|
||||
def create_multi_vector_retriever(vectorstore, image_summaries, images):
|
||||
"""
|
||||
Create retriever that indexes summaries, but returns raw images or texts
|
||||
|
||||
:param vectorstore: Vectorstore to store embedded image sumamries
|
||||
:param image_summaries: Image summaries
|
||||
:param images: Base64 encoded images
|
||||
:return: Retriever
|
||||
"""
|
||||
|
||||
# Initialize the storage layer for images
|
||||
store = LocalFileStore(
|
||||
str(Path(__file__).parent / "multi_vector_retriever_metadata")
|
||||
)
|
||||
id_key = "doc_id"
|
||||
|
||||
# Create the multi-vector retriever
|
||||
retriever = MultiVectorRetriever(
|
||||
vectorstore=vectorstore,
|
||||
byte_store=store,
|
||||
id_key=id_key,
|
||||
)
|
||||
|
||||
# Helper function to add documents to the vectorstore and docstore
|
||||
def add_documents(retriever, doc_summaries, doc_contents):
|
||||
doc_ids = [str(uuid.uuid4()) for _ in doc_contents]
|
||||
summary_docs = [
|
||||
Document(page_content=s, metadata={id_key: doc_ids[i]})
|
||||
for i, s in enumerate(doc_summaries)
|
||||
]
|
||||
retriever.vectorstore.add_documents(summary_docs)
|
||||
retriever.docstore.mset(list(zip(doc_ids, doc_contents)))
|
||||
|
||||
add_documents(retriever, image_summaries, images)
|
||||
|
||||
return retriever
|
||||
|
||||
|
||||
# Load images
|
||||
doc_path = Path(__file__).parent / "docs/"
|
||||
rel_doc_path = doc_path.relative_to(Path.cwd())
|
||||
print("Read images")
|
||||
pil_images = get_images(rel_doc_path)
|
||||
|
||||
# Convert to b64
|
||||
images_base_64 = [convert_to_base64(i) for i in pil_images]
|
||||
|
||||
# Image summaries
|
||||
print("Generate image summaries")
|
||||
image_summaries, images_base_64_processed = generate_img_summaries(images_base_64)
|
||||
|
||||
# The vectorstore to use to index the images summaries
|
||||
vectorstore_mvr = Chroma(
|
||||
collection_name="image_summaries",
|
||||
persist_directory=str(Path(__file__).parent / "chroma_db_multi_modal"),
|
||||
embedding_function=OllamaEmbeddings(model="llama2:7b"),
|
||||
)
|
||||
|
||||
# Create documents
|
||||
images_base_64_processed_documents = [
|
||||
Document(page_content=i) for i in images_base_64_processed
|
||||
]
|
||||
|
||||
# Create retriever
|
||||
retriever_multi_vector_img = create_multi_vector_retriever(
|
||||
vectorstore_mvr,
|
||||
image_summaries,
|
||||
images_base_64_processed_documents,
|
||||
)
|
||||
2920
templates/rag-multi-modal-mv-local/poetry.lock
generated
Normal file
2920
templates/rag-multi-modal-mv-local/poetry.lock
generated
Normal file
File diff suppressed because it is too large
Load Diff
38
templates/rag-multi-modal-mv-local/pyproject.toml
Normal file
38
templates/rag-multi-modal-mv-local/pyproject.toml
Normal file
@@ -0,0 +1,38 @@
|
||||
[tool.poetry]
|
||||
name = "rag-multi-modal-mv-local"
|
||||
version = "0.1.0"
|
||||
description = "Multi-modal RAG using Chroma and multi-vector retriever"
|
||||
authors = [
|
||||
"Lance Martin <lance@langchain.dev>",
|
||||
]
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.351"
|
||||
openai = "<2"
|
||||
tiktoken = ">=0.5.1"
|
||||
chromadb = ">=0.4.14"
|
||||
pypdfium2 = ">=4.20.0"
|
||||
langchain-experimental = "^0.0.43"
|
||||
pillow = ">=10.1.0"
|
||||
langchain-community = ">=0.0.4"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.15"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "rag_multi_modal_mv_local"
|
||||
export_attr = "chain"
|
||||
|
||||
[tool.templates-hub]
|
||||
use-case = "rag"
|
||||
author = "LangChain"
|
||||
integrations = ["Ollama", "Chroma"]
|
||||
tags = ["multi-modal"]
|
||||
|
||||
[build-system]
|
||||
requires = [
|
||||
"poetry-core",
|
||||
]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,52 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "681a5d1e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run Template\n",
|
||||
"\n",
|
||||
"In `server.py`, set -\n",
|
||||
"```\n",
|
||||
"add_routes(app, chain_rag_conv, path=\"/rag-multi-modal-mv-local\")\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d774be2a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langserve.client import RemoteRunnable\n",
|
||||
"\n",
|
||||
"rag_app = RemoteRunnable(\"http://localhost:8001/rag-multi-modal-mv-local\")\n",
|
||||
"rag_app.invoke(\" < keywords here > \")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,3 @@
|
||||
from rag_multi_modal_mv_local.chain import chain
|
||||
|
||||
__all__ = ["chain"]
|
||||
@@ -0,0 +1,131 @@
|
||||
import base64
|
||||
import io
|
||||
from pathlib import Path
|
||||
|
||||
from langchain.chat_models import ChatOllama
|
||||
from langchain.embeddings import OllamaEmbeddings
|
||||
from langchain.pydantic_v1 import BaseModel
|
||||
from langchain.retrievers.multi_vector import MultiVectorRetriever
|
||||
from langchain.schema.document import Document
|
||||
from langchain.schema.messages import HumanMessage
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
|
||||
from langchain.storage import LocalFileStore
|
||||
from langchain.vectorstores import Chroma
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def resize_base64_image(base64_string, size=(128, 128)):
|
||||
"""
|
||||
Resize an image encoded as a Base64 string.
|
||||
|
||||
:param base64_string: A Base64 encoded string of the image to be resized.
|
||||
:param size: A tuple representing the new size (width, height) for the image.
|
||||
:return: A Base64 encoded string of the resized image.
|
||||
"""
|
||||
img_data = base64.b64decode(base64_string)
|
||||
img = Image.open(io.BytesIO(img_data))
|
||||
resized_img = img.resize(size, Image.LANCZOS)
|
||||
buffered = io.BytesIO()
|
||||
resized_img.save(buffered, format=img.format)
|
||||
return base64.b64encode(buffered.getvalue()).decode("utf-8")
|
||||
|
||||
|
||||
def get_resized_images(docs):
|
||||
"""
|
||||
Resize images from base64-encoded strings.
|
||||
|
||||
:param docs: A list of base64-encoded image to be resized.
|
||||
:return: Dict containing a list of resized base64-encoded strings.
|
||||
"""
|
||||
b64_images = []
|
||||
for doc in docs:
|
||||
if isinstance(doc, Document):
|
||||
doc = doc.page_content
|
||||
# Optional: re-size image
|
||||
# resized_image = resize_base64_image(doc, size=(1280, 720))
|
||||
b64_images.append(doc)
|
||||
return {"images": b64_images}
|
||||
|
||||
|
||||
def img_prompt_func(data_dict, num_images=1):
|
||||
"""
|
||||
Ollama prompt for image analysis.
|
||||
|
||||
:param data_dict: A dict with images and a user-provided question.
|
||||
:param num_images: Number of images to include in the prompt.
|
||||
:return: A list containing message objects for each image and the text prompt.
|
||||
"""
|
||||
messages = []
|
||||
if data_dict["context"]["images"]:
|
||||
for image in data_dict["context"]["images"][:num_images]:
|
||||
image_message = {
|
||||
"type": "image_url",
|
||||
"image_url": f"data:image/jpeg;base64,{image}",
|
||||
}
|
||||
messages.append(image_message)
|
||||
text_message = {
|
||||
"type": "text",
|
||||
"text": (
|
||||
"You are a helpful assistant that gives a description of food pictures.\n"
|
||||
"Give a detailed summary of the image.\n"
|
||||
),
|
||||
}
|
||||
messages.append(text_message)
|
||||
return [HumanMessage(content=messages)]
|
||||
|
||||
|
||||
def multi_modal_rag_chain(retriever):
|
||||
"""
|
||||
Multi-modal RAG chain,
|
||||
|
||||
:param retriever: A function that retrieves the necessary context for the model.
|
||||
:return: A chain of functions representing the multi-modal RAG process.
|
||||
"""
|
||||
# Initialize the multi-modal Large Language Model with specific parameters
|
||||
model = ChatOllama(model="bakllava", temperature=0)
|
||||
|
||||
# Define the RAG pipeline
|
||||
chain = (
|
||||
{
|
||||
"context": retriever | RunnableLambda(get_resized_images),
|
||||
"question": RunnablePassthrough(),
|
||||
}
|
||||
| RunnableLambda(img_prompt_func)
|
||||
| model
|
||||
| StrOutputParser()
|
||||
)
|
||||
|
||||
return chain
|
||||
|
||||
|
||||
# Load chroma
|
||||
vectorstore_mvr = Chroma(
|
||||
collection_name="image_summaries",
|
||||
persist_directory=str(Path(__file__).parent.parent / "chroma_db_multi_modal"),
|
||||
embedding_function=OllamaEmbeddings(model="llama2:7b"),
|
||||
)
|
||||
|
||||
# Load file store
|
||||
store = LocalFileStore(
|
||||
str(Path(__file__).parent.parent / "multi_vector_retriever_metadata")
|
||||
)
|
||||
id_key = "doc_id"
|
||||
|
||||
# Create the multi-vector retriever
|
||||
retriever = MultiVectorRetriever(
|
||||
vectorstore=vectorstore_mvr,
|
||||
byte_store=store,
|
||||
id_key=id_key,
|
||||
)
|
||||
|
||||
# Create RAG chain
|
||||
chain = multi_modal_rag_chain(retriever)
|
||||
|
||||
|
||||
# Add typing for input
|
||||
class Question(BaseModel):
|
||||
__root__: str
|
||||
|
||||
|
||||
chain = chain.with_types(input_type=Question)
|
||||
Reference in New Issue
Block a user