mirror of
https://github.com/hwchase17/langchain.git
synced 2026-07-16 17:26:50 +00:00
Update Gemini template README.md (#14993)
This commit is contained in:
@@ -1,13 +1,15 @@
|
||||
|
||||
# rag-gemini-multi-modal
|
||||
|
||||
Multi-modal LLMs enable text-to-image retrieval and question-answering over images.
|
||||
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
||||
|
||||
You can ask questions in natural language about a collection of photos, retrieve relevant ones, and have a multi-modal LLM answer questions about the retrieved images.
|
||||
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
||||
|
||||
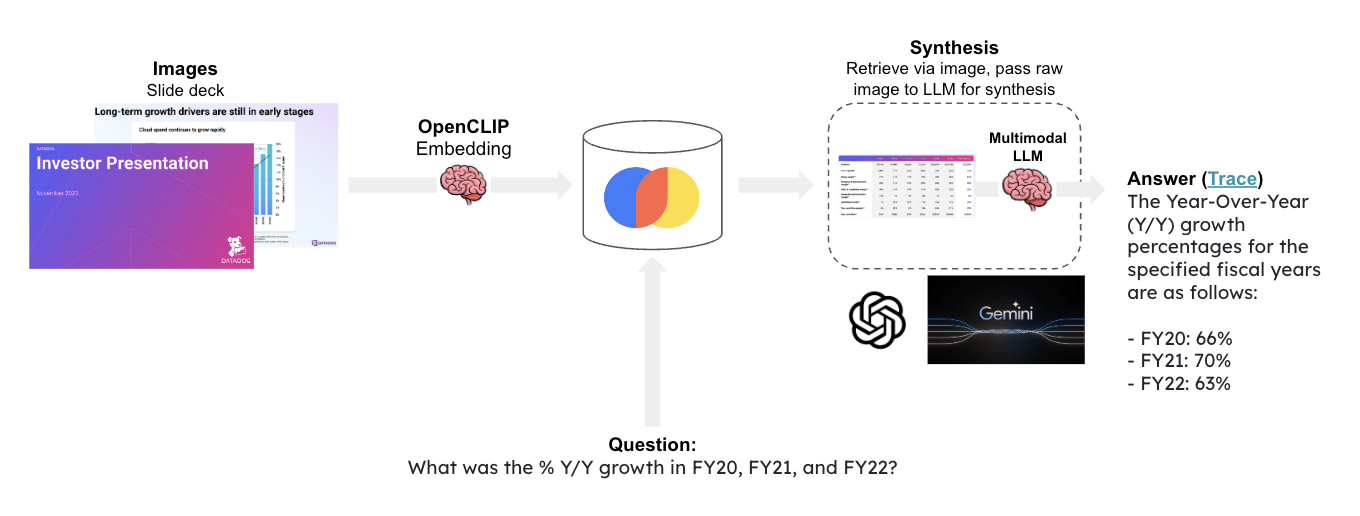
This template performs text-to-image retrieval for question-answering about a slide deck, which often contains visual elements that are not captured in standard RAG.
|
||||
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
||||
|
||||
This will use OpenCLIP embeddings and [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||
Given a question, relevat slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
||||
|
||||
|
||||
|
||||
## Input
|
||||
|
||||
@@ -112,4 +114,4 @@ We can access the template from code with:
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/rag-gemini-multi-modal")
|
||||
```
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user