mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-06 09:10:27 +00:00
Compare commits
31 Commits
harrison/a
...
harrison/m
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fc580fbca3 | ||
|
|
6c66f51fb8 | ||
|
|
2eeaccf01c | ||
|
|
e6a9ee64b3 | ||
|
|
4e9ee566ef | ||
|
|
fc009f61c8 | ||
|
|
3dfe1cf60e | ||
|
|
a4a1ee6b5d | ||
|
|
2d3918c152 | ||
|
|
1c03205cc2 | ||
|
|
feec4c61f4 | ||
|
|
097684e5f2 | ||
|
|
fd1fcb5a7d | ||
|
|
3207a74829 | ||
|
|
597378d1f6 | ||
|
|
64b9843b5b | ||
|
|
5d86a6acf1 | ||
|
|
35a3218e84 | ||
|
|
65c0c73597 | ||
|
|
33a001933a | ||
|
|
fe804d2a01 | ||
|
|
68f039704c | ||
|
|
bcfd071784 | ||
|
|
7d90691adb | ||
|
|
f83c36d8fd | ||
|
|
6be67279fb | ||
|
|
3dc49a04a3 | ||
|
|
5c907d9998 | ||
|
|
1b7cfd7222 | ||
|
|
7859245fc5 | ||
|
|
529a1f39b9 |
{kind=link}
BIN
docs/_static/ApifyActors.png
vendored
Normal file
BIN
docs/_static/ApifyActors.png
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 559 KiB |
292
docs/ecosystem/aim_tracking.ipynb
Normal file
292
docs/ecosystem/aim_tracking.ipynb
Normal file
@@ -0,0 +1,292 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Aim\n",
|
||||
"\n",
|
||||
"Aim makes it super easy to visualize and debug LangChain executions. Aim tracks inputs and outputs of LLMs and tools, as well as actions of agents. \n",
|
||||
"\n",
|
||||
"With Aim, you can easily debug and examine an individual execution:\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Additionally, you have the option to compare multiple executions side by side:\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Aim is fully open source, [learn more](https://github.com/aimhubio/aim) about Aim on GitHub.\n",
|
||||
"\n",
|
||||
"Let's move forward and see how to enable and configure Aim callback."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<h3>Tracking LangChain Executions with Aim</h3>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In this notebook we will explore three usage scenarios. To start off, we will install the necessary packages and import certain modules. Subsequently, we will configure two environment variables that can be established either within the Python script or through the terminal."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "mf88kuCJhbVu"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install aim\n",
|
||||
"!pip install langchain\n",
|
||||
"!pip install openai\n",
|
||||
"!pip install google-search-results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "g4eTuajwfl6L"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from datetime import datetime\n",
|
||||
"\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"from langchain.callbacks.base import CallbackManager\n",
|
||||
"from langchain.callbacks import AimCallbackHandler, StdOutCallbackHandler"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Our examples use a GPT model as the LLM, and OpenAI offers an API for this purpose. You can obtain the key from the following link: https://platform.openai.com/account/api-keys .\n",
|
||||
"\n",
|
||||
"We will use the SerpApi to retrieve search results from Google. To acquire the SerpApi key, please go to https://serpapi.com/manage-api-key ."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "T1bSmKd6V2If"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
|
||||
"os.environ[\"SERPAPI_API_KEY\"] = \"...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "QenUYuBZjIzc"
|
||||
},
|
||||
"source": [
|
||||
"The event methods of `AimCallbackHandler` accept the LangChain module or agent as input and log at least the prompts and generated results, as well as the serialized version of the LangChain module, to the designated Aim run."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "KAz8weWuUeXF"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"session_group = datetime.now().strftime(\"%m.%d.%Y_%H.%M.%S\")\n",
|
||||
"aim_callback = AimCallbackHandler(\n",
|
||||
" repo=\".\",\n",
|
||||
" experiment_name=\"scenario 1: OpenAI LLM\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"manager = CallbackManager([StdOutCallbackHandler(), aim_callback])\n",
|
||||
"llm = OpenAI(temperature=0, callback_manager=manager, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "b8WfByB4fl6N"
|
||||
},
|
||||
"source": [
|
||||
"The `flush_tracker` function is used to record LangChain assets on Aim. By default, the session is reset rather than being terminated outright."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<h3>Scenario 1</h3> In the first scenario, we will use OpenAI LLM."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "o_VmneyIUyx8"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# scenario 1 - LLM\n",
|
||||
"llm_result = llm.generate([\"Tell me a joke\", \"Tell me a poem\"] * 3)\n",
|
||||
"aim_callback.flush_tracker(\n",
|
||||
" langchain_asset=llm,\n",
|
||||
" experiment_name=\"scenario 2: Chain with multiple SubChains on multiple generations\",\n",
|
||||
")\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<h3>Scenario 2</h3> Scenario two involves chaining with multiple SubChains across multiple generations."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "trxslyb1U28Y"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"from langchain.chains import LLMChain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "uauQk10SUzF6"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# scenario 2 - Chain\n",
|
||||
"template = \"\"\"You are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
||||
"Title: {title}\n",
|
||||
"Playwright: This is a synopsis for the above play:\"\"\"\n",
|
||||
"prompt_template = PromptTemplate(input_variables=[\"title\"], template=template)\n",
|
||||
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callback_manager=manager)\n",
|
||||
"\n",
|
||||
"test_prompts = [\n",
|
||||
" {\"title\": \"documentary about good video games that push the boundary of game design\"},\n",
|
||||
" {\"title\": \"the phenomenon behind the remarkable speed of cheetahs\"},\n",
|
||||
" {\"title\": \"the best in class mlops tooling\"},\n",
|
||||
"]\n",
|
||||
"synopsis_chain.apply(test_prompts)\n",
|
||||
"aim_callback.flush_tracker(\n",
|
||||
" langchain_asset=synopsis_chain, experiment_name=\"scenario 3: Agent with Tools\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<h3>Scenario 3</h3> The third scenario involves an agent with tools."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "_jN73xcPVEpI"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import initialize_agent, load_tools"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"base_uri": "https://localhost:8080/"
|
||||
},
|
||||
"id": "Gpq4rk6VT9cu",
|
||||
"outputId": "68ae261e-d0a2-4229-83c4-762562263b66"
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
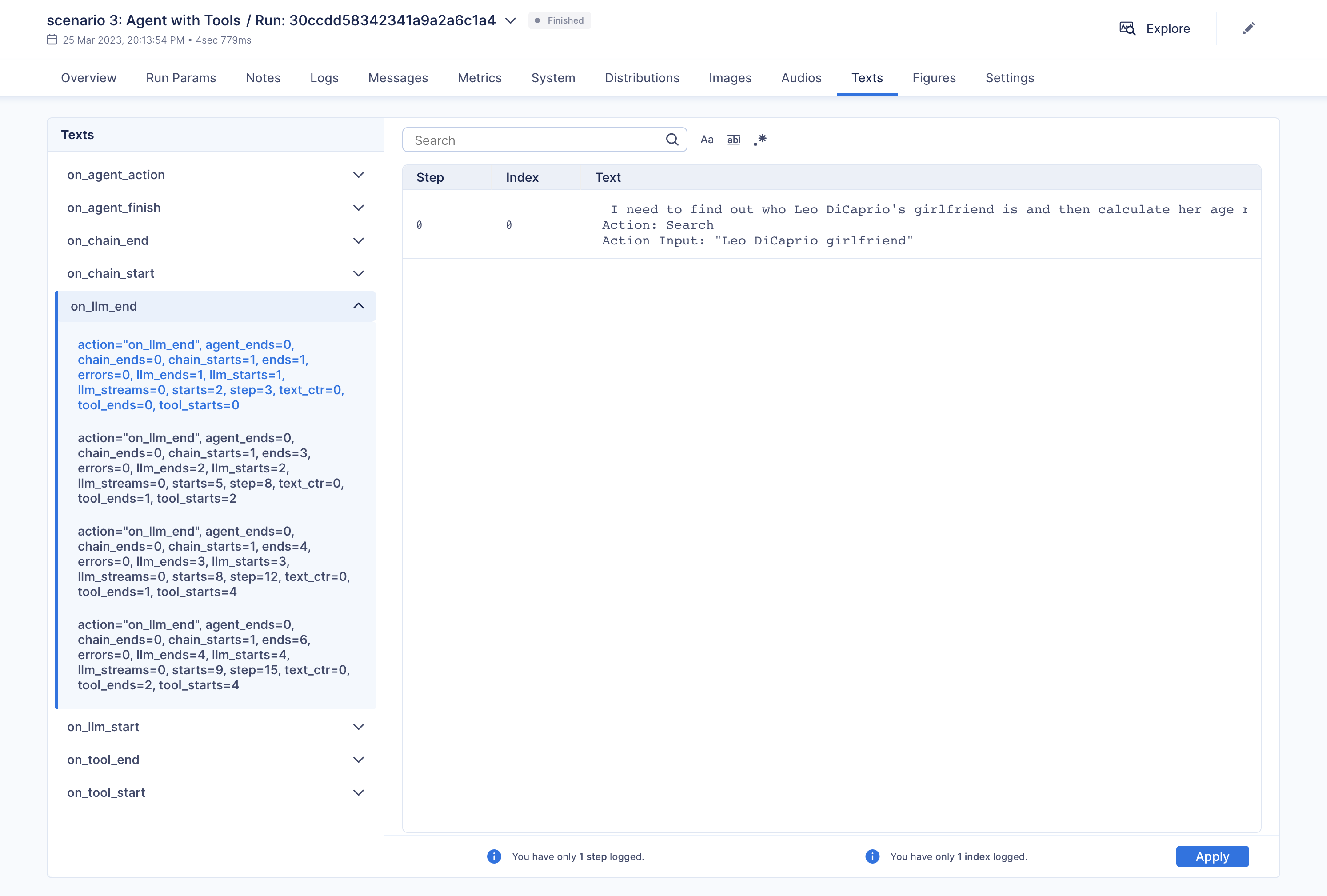
"\u001b[32;1m\u001b[1;3m I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: \"Leo DiCaprio girlfriend\"\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mLeonardo DiCaprio seemed to prove a long-held theory about his love life right after splitting from girlfriend Camila Morrone just months ...\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I need to find out Camila Morrone's age\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: \"Camila Morrone age\"\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3m25 years\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I need to calculate 25 raised to the 0.43 power\n",
|
||||
"Action: Calculator\n",
|
||||
"Action Input: 25^0.43\u001b[0m\n",
|
||||
"Observation: \u001b[33;1m\u001b[1;3mAnswer: 3.991298452658078\n",
|
||||
"\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
|
||||
"Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# scenario 3 - Agent with Tools\n",
|
||||
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callback_manager=manager)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools,\n",
|
||||
" llm,\n",
|
||||
" agent=\"zero-shot-react-description\",\n",
|
||||
" callback_manager=manager,\n",
|
||||
" verbose=True,\n",
|
||||
")\n",
|
||||
"agent.run(\n",
|
||||
" \"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\"\n",
|
||||
")\n",
|
||||
"aim_callback.flush_tracker(langchain_asset=agent, reset=False, finish=True)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"accelerator": "GPU",
|
||||
"colab": {
|
||||
"provenance": []
|
||||
},
|
||||
"gpuClass": "standard",
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
46
docs/ecosystem/apify.md
Normal file
46
docs/ecosystem/apify.md
Normal file
@@ -0,0 +1,46 @@
|
||||
# Apify
|
||||
|
||||
This page covers how to use [Apify](https://apify.com) within LangChain.
|
||||
|
||||
## Overview
|
||||
|
||||
Apify is a cloud platform for web scraping and data extraction,
|
||||
which provides an [ecosystem](https://apify.com/store) of more than a thousand
|
||||
ready-made apps called *Actors* for various scraping, crawling, and extraction use cases.
|
||||
|
||||
[](https://apify.com/store)
|
||||
|
||||
This integration enables you run Actors on the Apify platform and load their results into LangChain to feed your vector
|
||||
indexes with documents and data from the web, e.g. to generate answers from websites with documentation,
|
||||
blogs, or knowledge bases.
|
||||
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
- Install the Apify API client for Python with `pip install apify-client`
|
||||
- Get your [Apify API token](https://console.apify.com/account/integrations) and either set it as
|
||||
an environment variable (`APIFY_API_TOKEN`) or pass it to the `ApifyWrapper` as `apify_api_token` in the constructor.
|
||||
|
||||
|
||||
## Wrappers
|
||||
|
||||
### Utility
|
||||
|
||||
You can use the `ApifyWrapper` to run Actors on the Apify platform.
|
||||
|
||||
```python
|
||||
from langchain.utilities import ApifyWrapper
|
||||
```
|
||||
|
||||
For a more detailed walkthrough of this wrapper, see [this notebook](../modules/agents/tools/examples/apify.ipynb).
|
||||
|
||||
|
||||
### Loader
|
||||
|
||||
You can also use our `ApifyDatasetLoader` to get data from Apify dataset.
|
||||
|
||||
```python
|
||||
from langchain.document_loaders import ApifyDatasetLoader
|
||||
```
|
||||
|
||||
For a more detailed walkthrough of this loader, see [this notebook](../modules/indexes/document_loaders/examples/apify_dataset.ipynb).
|
||||
588
docs/ecosystem/clearml_tracking.ipynb
Normal file
588
docs/ecosystem/clearml_tracking.ipynb
Normal file
@@ -0,0 +1,588 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ClearML Integration\n",
|
||||
"\n",
|
||||
"In order to properly keep track of your langchain experiments and their results, you can enable the ClearML integration. ClearML is an experiment manager that neatly tracks and organizes all your experiment runs.\n",
|
||||
"\n",
|
||||
"<a target=\"_blank\" href=\"https://colab.research.google.com/github/hwchase17/langchain/blob/master/docs/ecosystem/clearml_tracking.ipynb\">\n",
|
||||
" <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/>\n",
|
||||
"</a>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Getting API Credentials\n",
|
||||
"\n",
|
||||
"We'll be using quite some APIs in this notebook, here is a list and where to get them:\n",
|
||||
"\n",
|
||||
"- ClearML: https://app.clear.ml/settings/workspace-configuration\n",
|
||||
"- OpenAI: https://platform.openai.com/account/api-keys\n",
|
||||
"- SerpAPI (google search): https://serpapi.com/dashboard"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"os.environ[\"CLEARML_API_ACCESS_KEY\"] = \"\"\n",
|
||||
"os.environ[\"CLEARML_API_SECRET_KEY\"] = \"\"\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
|
||||
"os.environ[\"SERPAPI_API_KEY\"] = \"\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Setting Up"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install clearml\n",
|
||||
"!pip install pandas\n",
|
||||
"!pip install textstat\n",
|
||||
"!pip install spacy\n",
|
||||
"!python -m spacy download en_core_web_sm"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"The clearml callback is currently in beta and is subject to change based on updates to `langchain`. Please report any issues to https://github.com/allegroai/clearml/issues with the tag `langchain`.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from datetime import datetime\n",
|
||||
"from langchain.callbacks import ClearMLCallbackHandler, StdOutCallbackHandler\n",
|
||||
"from langchain.callbacks.base import CallbackManager\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"\n",
|
||||
"# Setup and use the ClearML Callback\n",
|
||||
"clearml_callback = ClearMLCallbackHandler(\n",
|
||||
" task_type=\"inference\",\n",
|
||||
" project_name=\"langchain_callback_demo\",\n",
|
||||
" task_name=\"llm\",\n",
|
||||
" tags=[\"test\"],\n",
|
||||
" # Change the following parameters based on the amount of detail you want tracked\n",
|
||||
" visualize=True,\n",
|
||||
" complexity_metrics=True,\n",
|
||||
" stream_logs=True\n",
|
||||
")\n",
|
||||
"manager = CallbackManager([StdOutCallbackHandler(), clearml_callback])\n",
|
||||
"# Get the OpenAI model ready to go\n",
|
||||
"llm = OpenAI(temperature=0, callback_manager=manager, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Scenario 1: Just an LLM\n",
|
||||
"\n",
|
||||
"First, let's just run a single LLM a few times and capture the resulting prompt-answer conversation in ClearML"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
||||
"{'action_records': action name step starts ends errors text_ctr chain_starts \\\n",
|
||||
"0 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"1 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"2 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"3 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"4 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"5 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
||||
"6 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"7 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"8 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"9 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"10 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"11 on_llm_end NaN 2 1 1 0 0 0 \n",
|
||||
"12 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"13 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"14 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"15 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"16 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"17 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
||||
"18 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"19 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"20 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"21 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"22 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"23 on_llm_end NaN 4 2 2 0 0 0 \n",
|
||||
"\n",
|
||||
" chain_ends llm_starts ... difficult_words linsear_write_formula \\\n",
|
||||
"0 0 1 ... NaN NaN \n",
|
||||
"1 0 1 ... NaN NaN \n",
|
||||
"2 0 1 ... NaN NaN \n",
|
||||
"3 0 1 ... NaN NaN \n",
|
||||
"4 0 1 ... NaN NaN \n",
|
||||
"5 0 1 ... NaN NaN \n",
|
||||
"6 0 1 ... 0.0 5.5 \n",
|
||||
"7 0 1 ... 2.0 6.5 \n",
|
||||
"8 0 1 ... 0.0 5.5 \n",
|
||||
"9 0 1 ... 2.0 6.5 \n",
|
||||
"10 0 1 ... 0.0 5.5 \n",
|
||||
"11 0 1 ... 2.0 6.5 \n",
|
||||
"12 0 2 ... NaN NaN \n",
|
||||
"13 0 2 ... NaN NaN \n",
|
||||
"14 0 2 ... NaN NaN \n",
|
||||
"15 0 2 ... NaN NaN \n",
|
||||
"16 0 2 ... NaN NaN \n",
|
||||
"17 0 2 ... NaN NaN \n",
|
||||
"18 0 2 ... 0.0 5.5 \n",
|
||||
"19 0 2 ... 2.0 6.5 \n",
|
||||
"20 0 2 ... 0.0 5.5 \n",
|
||||
"21 0 2 ... 2.0 6.5 \n",
|
||||
"22 0 2 ... 0.0 5.5 \n",
|
||||
"23 0 2 ... 2.0 6.5 \n",
|
||||
"\n",
|
||||
" gunning_fog text_standard fernandez_huerta szigriszt_pazos \\\n",
|
||||
"0 NaN NaN NaN NaN \n",
|
||||
"1 NaN NaN NaN NaN \n",
|
||||
"2 NaN NaN NaN NaN \n",
|
||||
"3 NaN NaN NaN NaN \n",
|
||||
"4 NaN NaN NaN NaN \n",
|
||||
"5 NaN NaN NaN NaN \n",
|
||||
"6 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"7 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"8 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"9 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"10 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"11 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"12 NaN NaN NaN NaN \n",
|
||||
"13 NaN NaN NaN NaN \n",
|
||||
"14 NaN NaN NaN NaN \n",
|
||||
"15 NaN NaN NaN NaN \n",
|
||||
"16 NaN NaN NaN NaN \n",
|
||||
"17 NaN NaN NaN NaN \n",
|
||||
"18 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"19 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"20 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"21 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"22 5.20 5th and 6th grade 133.58 131.54 \n",
|
||||
"23 8.28 6th and 7th grade 115.58 112.37 \n",
|
||||
"\n",
|
||||
" gutierrez_polini crawford gulpease_index osman \n",
|
||||
"0 NaN NaN NaN NaN \n",
|
||||
"1 NaN NaN NaN NaN \n",
|
||||
"2 NaN NaN NaN NaN \n",
|
||||
"3 NaN NaN NaN NaN \n",
|
||||
"4 NaN NaN NaN NaN \n",
|
||||
"5 NaN NaN NaN NaN \n",
|
||||
"6 62.30 -0.2 79.8 116.91 \n",
|
||||
"7 54.83 1.4 72.1 100.17 \n",
|
||||
"8 62.30 -0.2 79.8 116.91 \n",
|
||||
"9 54.83 1.4 72.1 100.17 \n",
|
||||
"10 62.30 -0.2 79.8 116.91 \n",
|
||||
"11 54.83 1.4 72.1 100.17 \n",
|
||||
"12 NaN NaN NaN NaN \n",
|
||||
"13 NaN NaN NaN NaN \n",
|
||||
"14 NaN NaN NaN NaN \n",
|
||||
"15 NaN NaN NaN NaN \n",
|
||||
"16 NaN NaN NaN NaN \n",
|
||||
"17 NaN NaN NaN NaN \n",
|
||||
"18 62.30 -0.2 79.8 116.91 \n",
|
||||
"19 54.83 1.4 72.1 100.17 \n",
|
||||
"20 62.30 -0.2 79.8 116.91 \n",
|
||||
"21 54.83 1.4 72.1 100.17 \n",
|
||||
"22 62.30 -0.2 79.8 116.91 \n",
|
||||
"23 54.83 1.4 72.1 100.17 \n",
|
||||
"\n",
|
||||
"[24 rows x 39 columns], 'session_analysis': prompt_step prompts name output_step \\\n",
|
||||
"0 1 Tell me a joke OpenAI 2 \n",
|
||||
"1 1 Tell me a poem OpenAI 2 \n",
|
||||
"2 1 Tell me a joke OpenAI 2 \n",
|
||||
"3 1 Tell me a poem OpenAI 2 \n",
|
||||
"4 1 Tell me a joke OpenAI 2 \n",
|
||||
"5 1 Tell me a poem OpenAI 2 \n",
|
||||
"6 3 Tell me a joke OpenAI 4 \n",
|
||||
"7 3 Tell me a poem OpenAI 4 \n",
|
||||
"8 3 Tell me a joke OpenAI 4 \n",
|
||||
"9 3 Tell me a poem OpenAI 4 \n",
|
||||
"10 3 Tell me a joke OpenAI 4 \n",
|
||||
"11 3 Tell me a poem OpenAI 4 \n",
|
||||
"\n",
|
||||
" output \\\n",
|
||||
"0 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"1 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"2 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"3 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"4 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"5 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"6 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"7 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"8 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"9 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"10 \\n\\nQ: What did the fish say when it hit the w... \n",
|
||||
"11 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
||||
"\n",
|
||||
" token_usage_total_tokens token_usage_prompt_tokens \\\n",
|
||||
"0 162 24 \n",
|
||||
"1 162 24 \n",
|
||||
"2 162 24 \n",
|
||||
"3 162 24 \n",
|
||||
"4 162 24 \n",
|
||||
"5 162 24 \n",
|
||||
"6 162 24 \n",
|
||||
"7 162 24 \n",
|
||||
"8 162 24 \n",
|
||||
"9 162 24 \n",
|
||||
"10 162 24 \n",
|
||||
"11 162 24 \n",
|
||||
"\n",
|
||||
" token_usage_completion_tokens flesch_reading_ease flesch_kincaid_grade \\\n",
|
||||
"0 138 109.04 1.3 \n",
|
||||
"1 138 83.66 4.8 \n",
|
||||
"2 138 109.04 1.3 \n",
|
||||
"3 138 83.66 4.8 \n",
|
||||
"4 138 109.04 1.3 \n",
|
||||
"5 138 83.66 4.8 \n",
|
||||
"6 138 109.04 1.3 \n",
|
||||
"7 138 83.66 4.8 \n",
|
||||
"8 138 109.04 1.3 \n",
|
||||
"9 138 83.66 4.8 \n",
|
||||
"10 138 109.04 1.3 \n",
|
||||
"11 138 83.66 4.8 \n",
|
||||
"\n",
|
||||
" ... difficult_words linsear_write_formula gunning_fog \\\n",
|
||||
"0 ... 0 5.5 5.20 \n",
|
||||
"1 ... 2 6.5 8.28 \n",
|
||||
"2 ... 0 5.5 5.20 \n",
|
||||
"3 ... 2 6.5 8.28 \n",
|
||||
"4 ... 0 5.5 5.20 \n",
|
||||
"5 ... 2 6.5 8.28 \n",
|
||||
"6 ... 0 5.5 5.20 \n",
|
||||
"7 ... 2 6.5 8.28 \n",
|
||||
"8 ... 0 5.5 5.20 \n",
|
||||
"9 ... 2 6.5 8.28 \n",
|
||||
"10 ... 0 5.5 5.20 \n",
|
||||
"11 ... 2 6.5 8.28 \n",
|
||||
"\n",
|
||||
" text_standard fernandez_huerta szigriszt_pazos gutierrez_polini \\\n",
|
||||
"0 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"1 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"2 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"3 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"4 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"5 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"6 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"7 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"8 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"9 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"10 5th and 6th grade 133.58 131.54 62.30 \n",
|
||||
"11 6th and 7th grade 115.58 112.37 54.83 \n",
|
||||
"\n",
|
||||
" crawford gulpease_index osman \n",
|
||||
"0 -0.2 79.8 116.91 \n",
|
||||
"1 1.4 72.1 100.17 \n",
|
||||
"2 -0.2 79.8 116.91 \n",
|
||||
"3 1.4 72.1 100.17 \n",
|
||||
"4 -0.2 79.8 116.91 \n",
|
||||
"5 1.4 72.1 100.17 \n",
|
||||
"6 -0.2 79.8 116.91 \n",
|
||||
"7 1.4 72.1 100.17 \n",
|
||||
"8 -0.2 79.8 116.91 \n",
|
||||
"9 1.4 72.1 100.17 \n",
|
||||
"10 -0.2 79.8 116.91 \n",
|
||||
"11 1.4 72.1 100.17 \n",
|
||||
"\n",
|
||||
"[12 rows x 24 columns]}\n",
|
||||
"2023-03-29 14:00:25,948 - clearml.Task - INFO - Completed model upload to https://files.clear.ml/langchain_callback_demo/llm.988bd727b0e94a29a3ac0ee526813545/models/simple_sequential\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# SCENARIO 1 - LLM\n",
|
||||
"llm_result = llm.generate([\"Tell me a joke\", \"Tell me a poem\"] * 3)\n",
|
||||
"# After every generation run, use flush to make sure all the metrics\n",
|
||||
"# prompts and other output are properly saved separately\n",
|
||||
"clearml_callback.flush_tracker(langchain_asset=llm, name=\"simple_sequential\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"At this point you can already go to https://app.clear.ml and take a look at the resulting ClearML Task that was created.\n",
|
||||
"\n",
|
||||
"Among others, you should see that this notebook is saved along with any git information. The model JSON that contains the used parameters is saved as an artifact, there are also console logs and under the plots section, you'll find tables that represent the flow of the chain.\n",
|
||||
"\n",
|
||||
"Finally, if you enabled visualizations, these are stored as HTML files under debug samples."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Scenario 2: Creating a agent with tools\n",
|
||||
"\n",
|
||||
"To show a more advanced workflow, let's create an agent with access to tools. The way ClearML tracks the results is not different though, only the table will look slightly different as there are other types of actions taken when compared to the earlier, simpler example.\n",
|
||||
"\n",
|
||||
"You can now also see the use of the `finish=True` keyword, which will fully close the ClearML Task, instead of just resetting the parameters and prompts for a new conversation."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"{'action': 'on_chain_start', 'name': 'AgentExecutor', 'step': 1, 'starts': 1, 'ends': 0, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 0, 'llm_ends': 0, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'input': 'Who is the wife of the person who sang summer of 69?'}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 2, 'starts': 2, 'ends': 0, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 0, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought:'}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 189, 'token_usage_completion_tokens': 34, 'token_usage_total_tokens': 223, 'model_name': 'text-davinci-003', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': ' I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 91.61, 'flesch_kincaid_grade': 3.8, 'smog_index': 0.0, 'coleman_liau_index': 3.41, 'automated_readability_index': 3.5, 'dale_chall_readability_score': 6.06, 'difficult_words': 2, 'linsear_write_formula': 5.75, 'gunning_fog': 5.4, 'text_standard': '3rd and 4th grade', 'fernandez_huerta': 121.07, 'szigriszt_pazos': 119.5, 'gutierrez_polini': 54.91, 'crawford': 0.9, 'gulpease_index': 72.7, 'osman': 92.16}\n",
|
||||
"\u001b[32;1m\u001b[1;3m I need to find out who sang summer of 69 and then find out who their wife is.\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: \"Who sang summer of 69\"\u001b[0m{'action': 'on_agent_action', 'tool': 'Search', 'tool_input': 'Who sang summer of 69', 'log': ' I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"', 'step': 4, 'starts': 3, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 1, 'tool_ends': 0, 'agent_ends': 0}\n",
|
||||
"{'action': 'on_tool_start', 'input_str': 'Who sang summer of 69', 'name': 'Search', 'description': 'A search engine. Useful for when you need to answer questions about current events. Input should be a search query.', 'step': 5, 'starts': 4, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 0, 'agent_ends': 0}\n",
|
||||
"\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mBryan Adams - Summer Of 69 (Official Music Video).\u001b[0m\n",
|
||||
"Thought:{'action': 'on_tool_end', 'output': 'Bryan Adams - Summer Of 69 (Official Music Video).', 'step': 6, 'starts': 4, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 7, 'starts': 5, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought: I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"\\nObservation: Bryan Adams - Summer Of 69 (Official Music Video).\\nThought:'}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 242, 'token_usage_completion_tokens': 28, 'token_usage_total_tokens': 270, 'model_name': 'text-davinci-003', 'step': 8, 'starts': 5, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0, 'text': ' I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 94.66, 'flesch_kincaid_grade': 2.7, 'smog_index': 0.0, 'coleman_liau_index': 4.73, 'automated_readability_index': 4.0, 'dale_chall_readability_score': 7.16, 'difficult_words': 2, 'linsear_write_formula': 4.25, 'gunning_fog': 4.2, 'text_standard': '4th and 5th grade', 'fernandez_huerta': 124.13, 'szigriszt_pazos': 119.2, 'gutierrez_polini': 52.26, 'crawford': 0.7, 'gulpease_index': 74.7, 'osman': 84.2}\n",
|
||||
"\u001b[32;1m\u001b[1;3m I need to find out who Bryan Adams is married to.\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: \"Who is Bryan Adams married to\"\u001b[0m{'action': 'on_agent_action', 'tool': 'Search', 'tool_input': 'Who is Bryan Adams married to', 'log': ' I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"', 'step': 9, 'starts': 6, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 3, 'tool_ends': 1, 'agent_ends': 0}\n",
|
||||
"{'action': 'on_tool_start', 'input_str': 'Who is Bryan Adams married to', 'name': 'Search', 'description': 'A search engine. Useful for when you need to answer questions about current events. Input should be a search query.', 'step': 10, 'starts': 7, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 1, 'agent_ends': 0}\n",
|
||||
"\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mBryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...\u001b[0m\n",
|
||||
"Thought:{'action': 'on_tool_end', 'output': 'Bryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...', 'step': 11, 'starts': 7, 'ends': 4, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0}\n",
|
||||
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 12, 'starts': 8, 'ends': 4, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought: I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"\\nObservation: Bryan Adams - Summer Of 69 (Official Music Video).\\nThought: I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"\\nObservation: Bryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...\\nThought:'}\n",
|
||||
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 314, 'token_usage_completion_tokens': 18, 'token_usage_total_tokens': 332, 'model_name': 'text-davinci-003', 'step': 13, 'starts': 8, 'ends': 5, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0, 'text': ' I now know the final answer.\\nFinal Answer: Bryan Adams has never been married.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 81.29, 'flesch_kincaid_grade': 3.7, 'smog_index': 0.0, 'coleman_liau_index': 5.75, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 7.37, 'difficult_words': 1, 'linsear_write_formula': 2.5, 'gunning_fog': 2.8, 'text_standard': '3rd and 4th grade', 'fernandez_huerta': 115.7, 'szigriszt_pazos': 110.84, 'gutierrez_polini': 49.79, 'crawford': 0.7, 'gulpease_index': 85.4, 'osman': 83.14}\n",
|
||||
"\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
|
||||
"Final Answer: Bryan Adams has never been married.\u001b[0m\n",
|
||||
"{'action': 'on_agent_finish', 'output': 'Bryan Adams has never been married.', 'log': ' I now know the final answer.\\nFinal Answer: Bryan Adams has never been married.', 'step': 14, 'starts': 8, 'ends': 6, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 1}\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n",
|
||||
"{'action': 'on_chain_end', 'outputs': 'Bryan Adams has never been married.', 'step': 15, 'starts': 8, 'ends': 7, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 1, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 1}\n",
|
||||
"{'action_records': action name step starts ends errors text_ctr \\\n",
|
||||
"0 on_llm_start OpenAI 1 1 0 0 0 \n",
|
||||
"1 on_llm_start OpenAI 1 1 0 0 0 \n",
|
||||
"2 on_llm_start OpenAI 1 1 0 0 0 \n",
|
||||
"3 on_llm_start OpenAI 1 1 0 0 0 \n",
|
||||
"4 on_llm_start OpenAI 1 1 0 0 0 \n",
|
||||
".. ... ... ... ... ... ... ... \n",
|
||||
"66 on_tool_end NaN 11 7 4 0 0 \n",
|
||||
"67 on_llm_start OpenAI 12 8 4 0 0 \n",
|
||||
"68 on_llm_end NaN 13 8 5 0 0 \n",
|
||||
"69 on_agent_finish NaN 14 8 6 0 0 \n",
|
||||
"70 on_chain_end NaN 15 8 7 0 0 \n",
|
||||
"\n",
|
||||
" chain_starts chain_ends llm_starts ... gulpease_index osman input \\\n",
|
||||
"0 0 0 1 ... NaN NaN NaN \n",
|
||||
"1 0 0 1 ... NaN NaN NaN \n",
|
||||
"2 0 0 1 ... NaN NaN NaN \n",
|
||||
"3 0 0 1 ... NaN NaN NaN \n",
|
||||
"4 0 0 1 ... NaN NaN NaN \n",
|
||||
".. ... ... ... ... ... ... ... \n",
|
||||
"66 1 0 2 ... NaN NaN NaN \n",
|
||||
"67 1 0 3 ... NaN NaN NaN \n",
|
||||
"68 1 0 3 ... 85.4 83.14 NaN \n",
|
||||
"69 1 0 3 ... NaN NaN NaN \n",
|
||||
"70 1 1 3 ... NaN NaN NaN \n",
|
||||
"\n",
|
||||
" tool tool_input log \\\n",
|
||||
"0 NaN NaN NaN \n",
|
||||
"1 NaN NaN NaN \n",
|
||||
"2 NaN NaN NaN \n",
|
||||
"3 NaN NaN NaN \n",
|
||||
"4 NaN NaN NaN \n",
|
||||
".. ... ... ... \n",
|
||||
"66 NaN NaN NaN \n",
|
||||
"67 NaN NaN NaN \n",
|
||||
"68 NaN NaN NaN \n",
|
||||
"69 NaN NaN I now know the final answer.\\nFinal Answer: B... \n",
|
||||
"70 NaN NaN NaN \n",
|
||||
"\n",
|
||||
" input_str description output \\\n",
|
||||
"0 NaN NaN NaN \n",
|
||||
"1 NaN NaN NaN \n",
|
||||
"2 NaN NaN NaN \n",
|
||||
"3 NaN NaN NaN \n",
|
||||
"4 NaN NaN NaN \n",
|
||||
".. ... ... ... \n",
|
||||
"66 NaN NaN Bryan Adams has never married. In the 1990s, h... \n",
|
||||
"67 NaN NaN NaN \n",
|
||||
"68 NaN NaN NaN \n",
|
||||
"69 NaN NaN Bryan Adams has never been married. \n",
|
||||
"70 NaN NaN NaN \n",
|
||||
"\n",
|
||||
" outputs \n",
|
||||
"0 NaN \n",
|
||||
"1 NaN \n",
|
||||
"2 NaN \n",
|
||||
"3 NaN \n",
|
||||
"4 NaN \n",
|
||||
".. ... \n",
|
||||
"66 NaN \n",
|
||||
"67 NaN \n",
|
||||
"68 NaN \n",
|
||||
"69 NaN \n",
|
||||
"70 Bryan Adams has never been married. \n",
|
||||
"\n",
|
||||
"[71 rows x 47 columns], 'session_analysis': prompt_step prompts name \\\n",
|
||||
"0 2 Answer the following questions as best you can... OpenAI \n",
|
||||
"1 7 Answer the following questions as best you can... OpenAI \n",
|
||||
"2 12 Answer the following questions as best you can... OpenAI \n",
|
||||
"\n",
|
||||
" output_step output \\\n",
|
||||
"0 3 I need to find out who sang summer of 69 and ... \n",
|
||||
"1 8 I need to find out who Bryan Adams is married... \n",
|
||||
"2 13 I now know the final answer.\\nFinal Answer: B... \n",
|
||||
"\n",
|
||||
" token_usage_total_tokens token_usage_prompt_tokens \\\n",
|
||||
"0 223 189 \n",
|
||||
"1 270 242 \n",
|
||||
"2 332 314 \n",
|
||||
"\n",
|
||||
" token_usage_completion_tokens flesch_reading_ease flesch_kincaid_grade \\\n",
|
||||
"0 34 91.61 3.8 \n",
|
||||
"1 28 94.66 2.7 \n",
|
||||
"2 18 81.29 3.7 \n",
|
||||
"\n",
|
||||
" ... difficult_words linsear_write_formula gunning_fog \\\n",
|
||||
"0 ... 2 5.75 5.4 \n",
|
||||
"1 ... 2 4.25 4.2 \n",
|
||||
"2 ... 1 2.50 2.8 \n",
|
||||
"\n",
|
||||
" text_standard fernandez_huerta szigriszt_pazos gutierrez_polini \\\n",
|
||||
"0 3rd and 4th grade 121.07 119.50 54.91 \n",
|
||||
"1 4th and 5th grade 124.13 119.20 52.26 \n",
|
||||
"2 3rd and 4th grade 115.70 110.84 49.79 \n",
|
||||
"\n",
|
||||
" crawford gulpease_index osman \n",
|
||||
"0 0.9 72.7 92.16 \n",
|
||||
"1 0.7 74.7 84.20 \n",
|
||||
"2 0.7 85.4 83.14 \n",
|
||||
"\n",
|
||||
"[3 rows x 24 columns]}\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Could not update last created model in Task 988bd727b0e94a29a3ac0ee526813545, Task status 'completed' cannot be updated\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.agents import initialize_agent, load_tools\n",
|
||||
"\n",
|
||||
"# SCENARIO 2 - Agent with Tools\n",
|
||||
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callback_manager=manager)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools,\n",
|
||||
" llm,\n",
|
||||
" agent=\"zero-shot-react-description\",\n",
|
||||
" callback_manager=manager,\n",
|
||||
" verbose=True,\n",
|
||||
")\n",
|
||||
"agent.run(\n",
|
||||
" \"Who is the wife of the person who sang summer of 69?\"\n",
|
||||
")\n",
|
||||
"clearml_callback.flush_tracker(langchain_asset=agent, name=\"Agent with Tools\", finish=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Tips and Next Steps\n",
|
||||
"\n",
|
||||
"- Make sure you always use a unique `name` argument for the `clearml_callback.flush_tracker` function. If not, the model parameters used for a run will override the previous run!\n",
|
||||
"\n",
|
||||
"- If you close the ClearML Callback using `clearml_callback.flush_tracker(..., finish=True)` the Callback cannot be used anymore. Make a new one if you want to keep logging.\n",
|
||||
"\n",
|
||||
"- Check out the rest of the open source ClearML ecosystem, there is a data version manager, a remote execution agent, automated pipelines and much more!\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.9"
|
||||
},
|
||||
"orig_nbformat": 4,
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "a53ebf4a859167383b364e7e7521d0add3c2dbbdecce4edf676e8c4634ff3fbb"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -13,10 +13,11 @@ This page is broken into two parts: installation and setup, and then references
|
||||
- Install the Python SDK with `pip install "unstructured[local-inference]"`
|
||||
- Install the following system dependencies if they are not already available on your system.
|
||||
Depending on what document types you're parsing, you may not need all of these.
|
||||
- `libmagic-dev`
|
||||
- `poppler-utils`
|
||||
- `tesseract-ocr`
|
||||
- `libreoffice`
|
||||
- `libmagic-dev` (filetype detection)
|
||||
- `poppler-utils` (images and PDFs)
|
||||
- `tesseract-ocr`(images and PDFs)
|
||||
- `libreoffice` (MS Office docs)
|
||||
- `pandoc` (EPUBs)
|
||||
- If you are parsing PDFs using the `"hi_res"` strategy, run the following to install the `detectron2` model, which
|
||||
`unstructured` uses for layout detection:
|
||||
- `pip install "detectron2@git+https://github.com/facebookresearch/detectron2.git@v0.6#egg=detectron2"`
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -12,26 +12,48 @@
|
||||
"An agent consists of three parts:\n",
|
||||
" \n",
|
||||
" - Tools: The tools the agent has available to use.\n",
|
||||
" - The agent class itself: this decides which action to take.\n",
|
||||
" - LLMChain: The LLMChain that produces the text that is parsed in a certain way to determine which action to take.\n",
|
||||
" - The agent class itself: this parses the output of the LLMChain to determine which action to take.\n",
|
||||
" \n",
|
||||
" \n",
|
||||
"In this notebook we walk through how to create a custom agent."
|
||||
"In this notebook we walk through two types of custom agents. The first type shows how to create a custom LLMChain, but still use an existing agent class to parse the output. The second shows how to create a custom agent class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6064f080",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Custom LLMChain\n",
|
||||
"\n",
|
||||
"The first way to create a custom agent is to use an existing Agent class, but use a custom LLMChain. This is the simplest way to create a custom Agent. It is highly reccomended that you work with the `ZeroShotAgent`, as at the moment that is by far the most generalizable one. \n",
|
||||
"\n",
|
||||
"Most of the work in creating the custom LLMChain comes down to the prompt. Because we are using an existing agent class to parse the output, it is very important that the prompt say to produce text in that format. Additionally, we currently require an `agent_scratchpad` input variable to put notes on previous actions and observations. This should almost always be the final part of the prompt. However, besides those instructions, you can customize the prompt as you wish.\n",
|
||||
"\n",
|
||||
"To ensure that the prompt contains the appropriate instructions, we will utilize a helper method on that class. The helper method for the `ZeroShotAgent` takes the following arguments:\n",
|
||||
"\n",
|
||||
"- tools: List of tools the agent will have access to, used to format the prompt.\n",
|
||||
"- prefix: String to put before the list of tools.\n",
|
||||
"- suffix: String to put after the list of tools.\n",
|
||||
"- input_variables: List of input variables the final prompt will expect.\n",
|
||||
"\n",
|
||||
"For this exercise, we will give our agent access to Google Search, and we will customize it in that we will have it answer as a pirate."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": 23,
|
||||
"id": "9af9734e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import Tool, AgentExecutor\n",
|
||||
"from langchain import OpenAI, SerpAPIWrapper"
|
||||
"from langchain.agents import ZeroShotAgent, Tool, AgentExecutor\n",
|
||||
"from langchain import OpenAI, SerpAPIWrapper, LLMChain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": 24,
|
||||
"id": "becda2a1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -41,83 +63,110 @@
|
||||
" Tool(\n",
|
||||
" name = \"Search\",\n",
|
||||
" func=search.run,\n",
|
||||
" description=\"useful for when you need to answer questions about current events\",\n",
|
||||
" return_direct=True\n",
|
||||
" description=\"useful for when you need to answer questions about current events\"\n",
|
||||
" )\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "eca724fc",
|
||||
"execution_count": 25,
|
||||
"id": "339b1bb8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents.agent import BaseAgent"
|
||||
"prefix = \"\"\"Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:\"\"\"\n",
|
||||
"suffix = \"\"\"Begin! Remember to speak as a pirate when giving your final answer. Use lots of \"Args\"\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = ZeroShotAgent.create_prompt(\n",
|
||||
" tools, \n",
|
||||
" prefix=prefix, \n",
|
||||
" suffix=suffix, \n",
|
||||
" input_variables=[\"input\", \"agent_scratchpad\"]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "59db7b58",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In case we are curious, we can now take a look at the final prompt template to see what it looks like when its all put together."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "a33e2f7e",
|
||||
"execution_count": 26,
|
||||
"id": "e21d2098",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:\n",
|
||||
"\n",
|
||||
"Search: useful for when you need to answer questions about current events\n",
|
||||
"\n",
|
||||
"Use the following format:\n",
|
||||
"\n",
|
||||
"Question: the input question you must answer\n",
|
||||
"Thought: you should always think about what to do\n",
|
||||
"Action: the action to take, should be one of [Search]\n",
|
||||
"Action Input: the input to the action\n",
|
||||
"Observation: the result of the action\n",
|
||||
"... (this Thought/Action/Action Input/Observation can repeat N times)\n",
|
||||
"Thought: I now know the final answer\n",
|
||||
"Final Answer: the final answer to the original input question\n",
|
||||
"\n",
|
||||
"Begin! Remember to speak as a pirate when giving your final answer. Use lots of \"Args\"\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from typing import List, Tuple, Any, Union\n",
|
||||
"from langchain.schema import AgentAction, AgentFinish\n",
|
||||
"print(prompt.template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5e028e6d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Note that we are able to feed agents a self-defined prompt template, i.e. not restricted to the prompt generated by the `create_prompt` function, assuming it meets the agent's requirements. \n",
|
||||
"\n",
|
||||
"class FakeAgent(BaseAgent):\n",
|
||||
" \"\"\"Fake Custom Agent.\"\"\"\n",
|
||||
" \n",
|
||||
" @property\n",
|
||||
" def input_keys(self):\n",
|
||||
" return [\"input\"]\n",
|
||||
" \n",
|
||||
" def plan(\n",
|
||||
" self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any\n",
|
||||
" ) -> Union[AgentAction, AgentFinish]:\n",
|
||||
" \"\"\"Given input, decided what to do.\n",
|
||||
"\n",
|
||||
" Args:\n",
|
||||
" intermediate_steps: Steps the LLM has taken to date,\n",
|
||||
" along with observations\n",
|
||||
" **kwargs: User inputs.\n",
|
||||
"\n",
|
||||
" Returns:\n",
|
||||
" Action specifying what tool to use.\n",
|
||||
" \"\"\"\n",
|
||||
" return AgentAction(tool=\"Search\", tool_input=\"foo\", log=\"\")\n",
|
||||
"\n",
|
||||
" async def aplan(\n",
|
||||
" self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any\n",
|
||||
" ) -> Union[AgentAction, AgentFinish]:\n",
|
||||
" \"\"\"Given input, decided what to do.\n",
|
||||
"\n",
|
||||
" Args:\n",
|
||||
" intermediate_steps: Steps the LLM has taken to date,\n",
|
||||
" along with observations\n",
|
||||
" **kwargs: User inputs.\n",
|
||||
"\n",
|
||||
" Returns:\n",
|
||||
" Action specifying what tool to use.\n",
|
||||
" \"\"\"\n",
|
||||
" return AgentAction(tool=\"Search\", tool_input=\"foo\", log=\"\")"
|
||||
"For example, for `ZeroShotAgent`, we will need to ensure that it meets the following requirements. There should a string starting with \"Action:\" and a following string starting with \"Action Input:\", and both should be separated by a newline.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "655d72f6",
|
||||
"execution_count": 27,
|
||||
"id": "9b1cc2a2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = FakeAgent()"
|
||||
"llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 28,
|
||||
"id": "e4f5092f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"tool_names = [tool.name for tool in tools]\n",
|
||||
"agent = ZeroShotAgent(llm_chain=llm_chain, allowed_tools=tool_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"id": "490604e9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -127,7 +176,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 31,
|
||||
"id": "653b1617",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -138,7 +187,12 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\u001b[0m\u001b[36;1m\u001b[1;3mFoo Fighters is an American rock band formed in Seattle in 1994. Foo Fighters was initially formed as a one-man project by former Nirvana drummer Dave Grohl. Following the success of the 1995 eponymous debut album, Grohl recruited a band consisting of Nate Mendel, William Goldsmith, and Pat Smear.\u001b[0m\u001b[32;1m\u001b[1;3m\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: Population of Canada 2023\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
|
||||
"Final Answer: Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
@@ -146,10 +200,10 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'Foo Fighters is an American rock band formed in Seattle in 1994. Foo Fighters was initially formed as a one-man project by former Nirvana drummer Dave Grohl. Following the success of the 1995 eponymous debut album, Grohl recruited a band consisting of Nate Mendel, William Goldsmith, and Pat Smear.'"
|
||||
"\"Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\""
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"execution_count": 31,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -158,6 +212,114 @@
|
||||
"agent_executor.run(\"How many people live in canada as of 2023?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "040eb343",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Multiple inputs\n",
|
||||
"Agents can also work with prompts that require multiple inputs."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 32,
|
||||
"id": "43dbfa2f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prefix = \"\"\"Answer the following questions as best you can. You have access to the following tools:\"\"\"\n",
|
||||
"suffix = \"\"\"When answering, you MUST speak in the following language: {language}.\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = ZeroShotAgent.create_prompt(\n",
|
||||
" tools, \n",
|
||||
" prefix=prefix, \n",
|
||||
" suffix=suffix, \n",
|
||||
" input_variables=[\"input\", \"language\", \"agent_scratchpad\"]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 33,
|
||||
"id": "0f087313",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 34,
|
||||
"id": "92c75a10",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 35,
|
||||
"id": "ac5b83bf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 36,
|
||||
"id": "c960e4ff",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada in 2023.\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: Population of Canada in 2023\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
|
||||
"Final Answer: La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 36,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent_executor.run(input=\"How many people live in canada as of 2023?\", language=\"italian\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "90171b2b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Custom Agent Class\n",
|
||||
"\n",
|
||||
"Coming soon."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -1,219 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ba5f8741",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Custom LLLM Agent\n",
|
||||
"\n",
|
||||
"This notebook goes through how to create your own custom LLM agent.\n",
|
||||
"\n",
|
||||
"An LLM agent consists of three parts:\n",
|
||||
" \n",
|
||||
" - Tools: The tools the agent has available to use.\n",
|
||||
" - LLMChain: The LLMChain that produces the text that is parsed in a certain way to determine which action to take.\n",
|
||||
" - OutputParser: This determines how to parse the LLMOutput into \n",
|
||||
" \n",
|
||||
" \n",
|
||||
"In this notebook we walk through how to create a custom LLM agent."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "9af9734e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import Tool, AgentExecutor\n",
|
||||
"from langchain.agents.agent import LLMAgent, AgentOutputParser\n",
|
||||
"from langchain.prompts import StringPromptTemplate\n",
|
||||
"from langchain import OpenAI, SerpAPIWrapper, LLMChain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "becda2a1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"tools = [\n",
|
||||
" Tool(\n",
|
||||
" name = \"Search\",\n",
|
||||
" func=search.run,\n",
|
||||
" description=\"useful for when you need to answer questions about current events\"\n",
|
||||
" )\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "339b1bb8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"template = \"\"\"Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:\n",
|
||||
"\n",
|
||||
"Search: useful for when you need to answer questions about current events\n",
|
||||
"\n",
|
||||
"Use the following format:\n",
|
||||
"\n",
|
||||
"Question: the input question you must answer\n",
|
||||
"Thought: you should always think about what to do\n",
|
||||
"Action: the action to take, should be one of [Search]\n",
|
||||
"Action Input: the input to the action\n",
|
||||
"Observation: the result of the action\n",
|
||||
"... (this Thought/Action/Action Input/Observation can repeat N times)\n",
|
||||
"Thought: I now know the final answer\n",
|
||||
"Final Answer: the final answer to the original input question\n",
|
||||
"\n",
|
||||
"Begin! Remember to speak as a pirate when giving your final answer. Use lots of \"Args\"\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\"\"\"\n",
|
||||
"\n",
|
||||
"class CustomPromptTemplate(StringPromptTemplate):\n",
|
||||
" \n",
|
||||
" def format(self, **kwargs) -> str:\n",
|
||||
" intermediate_steps = kwargs.pop(\"intermediate_steps\")\n",
|
||||
" thoughts = \"\"\n",
|
||||
" for action, observation in intermediate_steps:\n",
|
||||
" thoughts += action.log\n",
|
||||
" thoughts += f\"\\nObservation: {observation}\\nThought: \"\n",
|
||||
" kwargs[\"agent_scratchpad\"] = thoughts\n",
|
||||
" return template.format(**kwargs)\n",
|
||||
"\n",
|
||||
"prompt = CustomPromptTemplate(input_variables=[\"input\", \"intermediate_steps\"])\n",
|
||||
"\n",
|
||||
"FINAL_ANSWER_ACTION = \"Final Answer:\"\n",
|
||||
"from langchain.schema import AgentAction, AgentFinish\n",
|
||||
"import re\n",
|
||||
"class CustomOutputParser(AgentOutputParser):\n",
|
||||
" \n",
|
||||
" def parse(self, llm_output):\n",
|
||||
" if FINAL_ANSWER_ACTION in llm_output:\n",
|
||||
" return AgentFinish(\n",
|
||||
" return_values={\"output\": llm_output.split(FINAL_ANSWER_ACTION)[-1].strip()},\n",
|
||||
" log=llm_output,\n",
|
||||
" )\n",
|
||||
" # \\s matches against tab/newline/whitespace\n",
|
||||
" regex = r\"Action: (.*?)[\\n]*Action Input:[\\s]*(.*)\"\n",
|
||||
" match = re.search(regex, llm_output, re.DOTALL)\n",
|
||||
" if not match:\n",
|
||||
" raise ValueError(f\"Could not parse LLM output: `{llm_output}`\")\n",
|
||||
" action = match.group(1).strip()\n",
|
||||
" action_input = match.group(2)\n",
|
||||
" return AgentAction(tool=action, tool_input=action_input.strip(\" \").strip('\"'), log=llm_output)\n",
|
||||
"\n",
|
||||
"output_parser = CustomOutputParser()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "9b1cc2a2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "e4f5092f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"tool_names = [tool.name for tool in tools]\n",
|
||||
"agent = LLMAgent(llm_chain=llm_chain, output_parser=output_parser, stop=[\"\\nObservation:\"], allowed_tools=tool_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "490604e9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "653b1617",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada in 2023\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: Population of Canada in 2023\u001b[0m\n",
|
||||
"\n",
|
||||
"Observation:\u001b[36;1m\u001b[1;3mThe current population of Canada is 38,644,767 as of Tuesday, March 28, 2023, based on Worldometer elaboration of the latest United Nations data.\u001b[0m\u001b[32;1m\u001b[1;3m I now know the final answer\n",
|
||||
"Final Answer: Arrr, Canada be havin' 38,644,767 people livin' there as of 2023!\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"\"Arrr, Canada be havin' 38,644,767 people livin' there as of 2023!\""
|
||||
]
|
||||
},
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent_executor.run(\"How many people live in canada as of 2023?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "adefb4c2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "18784188d7ecd866c0586ac068b02361a6896dc3a29b64f5cc957f09c590acef"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -1,348 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ba5f8741",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Custom MRKL Agent\n",
|
||||
"\n",
|
||||
"This notebook goes through how to create your own custom MRKL agent.\n",
|
||||
"\n",
|
||||
"A MRKL agent consists of three parts:\n",
|
||||
" \n",
|
||||
" - Tools: The tools the agent has available to use.\n",
|
||||
" - LLMChain: The LLMChain that produces the text that is parsed in a certain way to determine which action to take.\n",
|
||||
" - The agent class itself: this parses the output of the LLMChain to determin which action to take.\n",
|
||||
" \n",
|
||||
" \n",
|
||||
"In this notebook we walk through how to create a custom MRKL agent by creating a custom LLMChain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6064f080",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Custom LLMChain\n",
|
||||
"\n",
|
||||
"The first way to create a custom agent is to use an existing Agent class, but use a custom LLMChain. This is the simplest way to create a custom Agent. It is highly reccomended that you work with the `ZeroShotAgent`, as at the moment that is by far the most generalizable one. \n",
|
||||
"\n",
|
||||
"Most of the work in creating the custom LLMChain comes down to the prompt. Because we are using an existing agent class to parse the output, it is very important that the prompt say to produce text in that format. Additionally, we currently require an `agent_scratchpad` input variable to put notes on previous actions and observations. This should almost always be the final part of the prompt. However, besides those instructions, you can customize the prompt as you wish.\n",
|
||||
"\n",
|
||||
"To ensure that the prompt contains the appropriate instructions, we will utilize a helper method on that class. The helper method for the `ZeroShotAgent` takes the following arguments:\n",
|
||||
"\n",
|
||||
"- tools: List of tools the agent will have access to, used to format the prompt.\n",
|
||||
"- prefix: String to put before the list of tools.\n",
|
||||
"- suffix: String to put after the list of tools.\n",
|
||||
"- input_variables: List of input variables the final prompt will expect.\n",
|
||||
"\n",
|
||||
"For this exercise, we will give our agent access to Google Search, and we will customize it in that we will have it answer as a pirate."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"id": "9af9734e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import ZeroShotAgent, Tool, AgentExecutor\n",
|
||||
"from langchain import OpenAI, SerpAPIWrapper, LLMChain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "becda2a1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"tools = [\n",
|
||||
" Tool(\n",
|
||||
" name = \"Search\",\n",
|
||||
" func=search.run,\n",
|
||||
" description=\"useful for when you need to answer questions about current events\"\n",
|
||||
" )\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "339b1bb8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prefix = \"\"\"Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:\"\"\"\n",
|
||||
"suffix = \"\"\"Begin! Remember to speak as a pirate when giving your final answer. Use lots of \"Args\"\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = ZeroShotAgent.create_prompt(\n",
|
||||
" tools, \n",
|
||||
" prefix=prefix, \n",
|
||||
" suffix=suffix, \n",
|
||||
" input_variables=[\"input\", \"agent_scratchpad\"]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "59db7b58",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In case we are curious, we can now take a look at the final prompt template to see what it looks like when its all put together."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "e21d2098",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:\n",
|
||||
"\n",
|
||||
"Search: useful for when you need to answer questions about current events\n",
|
||||
"\n",
|
||||
"Use the following format:\n",
|
||||
"\n",
|
||||
"Question: the input question you must answer\n",
|
||||
"Thought: you should always think about what to do\n",
|
||||
"Action: the action to take, should be one of [Search]\n",
|
||||
"Action Input: the input to the action\n",
|
||||
"Observation: the result of the action\n",
|
||||
"... (this Thought/Action/Action Input/Observation can repeat N times)\n",
|
||||
"Thought: I now know the final answer\n",
|
||||
"Final Answer: the final answer to the original input question\n",
|
||||
"\n",
|
||||
"Begin! Remember to speak as a pirate when giving your final answer. Use lots of \"Args\"\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(prompt.template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5e028e6d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Note that we are able to feed agents a self-defined prompt template, i.e. not restricted to the prompt generated by the `create_prompt` function, assuming it meets the agent's requirements. \n",
|
||||
"\n",
|
||||
"For example, for `ZeroShotAgent`, we will need to ensure that it meets the following requirements. There should a string starting with \"Action:\" and a following string starting with \"Action Input:\", and both should be separated by a newline.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"id": "9b1cc2a2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"id": "e4f5092f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"tool_names = [tool.name for tool in tools]\n",
|
||||
"agent = ZeroShotAgent(llm_chain=llm_chain, allowed_tools=tool_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"id": "490604e9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"id": "653b1617",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: Population of Canada 2023\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
|
||||
"Final Answer: Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"\"Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\""
|
||||
]
|
||||
},
|
||||
"execution_count": 31,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent_executor.run(\"How many people live in canada as of 2023?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "040eb343",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Multiple inputs\n",
|
||||
"Agents can also work with prompts that require multiple inputs."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 32,
|
||||
"id": "43dbfa2f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prefix = \"\"\"Answer the following questions as best you can. You have access to the following tools:\"\"\"\n",
|
||||
"suffix = \"\"\"When answering, you MUST speak in the following language: {language}.\n",
|
||||
"\n",
|
||||
"Question: {input}\n",
|
||||
"{agent_scratchpad}\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = ZeroShotAgent.create_prompt(\n",
|
||||
" tools, \n",
|
||||
" prefix=prefix, \n",
|
||||
" suffix=suffix, \n",
|
||||
" input_variables=[\"input\", \"language\", \"agent_scratchpad\"]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 33,
|
||||
"id": "0f087313",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 34,
|
||||
"id": "92c75a10",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 35,
|
||||
"id": "ac5b83bf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 36,
|
||||
"id": "c960e4ff",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada in 2023.\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: Population of Canada in 2023\u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
|
||||
"Final Answer: La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 36,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent_executor.run(input=\"How many people live in canada as of 2023?\", language=\"italian\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "adefb4c2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "18784188d7ecd866c0586ac068b02361a6896dc3a29b64f5cc957f09c590acef"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
164
docs/modules/agents/tools/examples/apify.ipynb
Normal file
164
docs/modules/agents/tools/examples/apify.ipynb
Normal file
@@ -0,0 +1,164 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Apify\n",
|
||||
"\n",
|
||||
"This notebook shows how to use the [Apify integration](../../../../ecosystem/apify.md) for LangChain.\n",
|
||||
"\n",
|
||||
"[Apify](https://apify.com) is a cloud platform for web scraping and data extraction,\n",
|
||||
"which provides an [ecosystem](https://apify.com/store) of more than a thousand\n",
|
||||
"ready-made apps called *Actors* for various web scraping, crawling, and data extraction use cases.\n",
|
||||
"For example, you can use it to extract Google Search results, Instagram and Facebook profiles, products from Amazon or Shopify, Google Maps reviews, etc. etc.\n",
|
||||
"\n",
|
||||
"In this example, we'll use the [Website Content Crawler](https://apify.com/apify/website-content-crawler) Actor,\n",
|
||||
"which can deeply crawl websites such as documentation, knowledge bases, help centers, or blogs,\n",
|
||||
"and extract text content from the web pages. Then we feed the documents into a vector index and answer questions from it.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"First, import `ApifyWrapper` into your source code:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.base import Document\n",
|
||||
"from langchain.indexes import VectorstoreIndexCreator\n",
|
||||
"from langchain.utilities import ApifyWrapper"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Initialize it using your [Apify API token](https://console.apify.com/account/integrations) and for the purpose of this example, also with your OpenAI API key:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"Your OpenAI API key\"\n",
|
||||
"os.environ[\"APIFY_API_TOKEN\"] = \"Your Apify API token\"\n",
|
||||
"\n",
|
||||
"apify = ApifyWrapper()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Then run the Actor, wait for it to finish, and fetch its results from the Apify dataset into a LangChain document loader.\n",
|
||||
"\n",
|
||||
"Note that if you already have some results in an Apify dataset, you can load them directly using `ApifyDatasetLoader`, as shown in [this notebook](../../../indexes/document_loaders/examples/apify_dataset.ipynb). In that notebook, you'll also find the explanation of the `dataset_mapping_function`, which is used to map fields from the Apify dataset records to LangChain `Document` fields."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = apify.call_actor(\n",
|
||||
" actor_id=\"apify/website-content-crawler\",\n",
|
||||
" run_input={\"startUrls\": [{\"url\": \"https://python.langchain.com/en/latest/\"}]},\n",
|
||||
" dataset_mapping_function=lambda item: Document(\n",
|
||||
" page_content=item[\"text\"] or \"\", metadata={\"source\": item[\"url\"]}\n",
|
||||
" ),\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Initialize the vector index from the crawled documents:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"index = VectorstoreIndexCreator().from_loaders([loader])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"And finally, query the vector index:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What is LangChain?\"\n",
|
||||
"result = index.query_with_sources(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" LangChain is a standard interface through which you can interact with a variety of large language models (LLMs). It provides modules that can be used to build language model applications, and it also provides chains and agents with memory capabilities.\n",
|
||||
"\n",
|
||||
"https://python.langchain.com/en/latest/modules/models/llms.html, https://python.langchain.com/en/latest/getting_started/getting_started.html\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(result[\"answer\"])\n",
|
||||
"print(result[\"sources\"])"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
124
docs/modules/document_loaders/examples/epub.ipynb
Normal file
124
docs/modules/document_loaders/examples/epub.ipynb
Normal file
@@ -0,0 +1,124 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "39af9ecd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# EPubs\n",
|
||||
"\n",
|
||||
"This covers how to load `.epub` documents into a document format that we can use downstream. You'll need to install the [`pandocs`](https://pandoc.org/installing.html) package for this loader to work."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "721c48aa",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import UnstructuredEPubLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "9d3d0e35",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEPubLoader(\"winter-sports.epub\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "06073f91",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "525d6b67",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Retain Elements\n",
|
||||
"\n",
|
||||
"Under the hood, Unstructured creates different \"elements\" for different chunks of text. By default we combine those together, but you can easily keep that separation by specifying `mode=\"elements\"`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "064f9162",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEPubLoader(\"winter-sports.epub\", mode=\"elements\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "abefbbdb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "a547c534",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='The Project Gutenberg eBook of Winter Sports in\\nSwitzerland, by E. F. Benson', lookup_str='', metadata={'source': 'winter-sports.epub', 'page_number': 1, 'category': 'Title'}, lookup_index=0)"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "381d4139",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,175 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Apify Dataset\n",
|
||||
"\n",
|
||||
"This notebook shows how to load Apify datasets to LangChain.\n",
|
||||
"\n",
|
||||
"[Apify Dataset](https://docs.apify.com/platform/storage/dataset) is a scaleable append-only storage with sequential access built for storing structured web scraping results, such as a list of products or Google SERPs, and then export them to various formats like JSON, CSV, or Excel. Datasets are mainly used to save results of [Apify Actors](https://apify.com/store)—serverless cloud programs for varius web scraping, crawling, and data extraction use cases.\n",
|
||||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"\n",
|
||||
"You need to have an existing dataset on the Apify platform. If you don't have one, please first check out [this notebook](../../../agents/tools/examples/apify.ipynb) on how to use Apify to extract content from documentation, knowledge bases, help centers, or blogs."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"First, import `ApifyDatasetLoader` into your source code:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import ApifyDatasetLoader\n",
|
||||
"from langchain.document_loaders.base import Document"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Then provide a function that maps Apify dataset record fields to LangChain `Document` format.\n",
|
||||
"\n",
|
||||
"For example, if your dataset items are structured like this:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"url\": \"https://apify.com\",\n",
|
||||
" \"text\": \"Apify is the best web scraping and automation platform.\"\n",
|
||||
"}\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"The mapping function in the code below will convert them to LangChain `Document` format, so that you can use them further with any LLM model (e.g. for question answering)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ApifyDatasetLoader(\n",
|
||||
" dataset_id=\"your-dataset-id\",\n",
|
||||
" dataset_mapping_function=lambda dataset_item: Document(\n",
|
||||
" page_content=dataset_item[\"text\"], metadata={\"source\": dataset_item[\"url\"]}\n",
|
||||
" ),\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## An example with question answering\n",
|
||||
"\n",
|
||||
"In this example, we use data from a dataset to answer a question."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.docstore.document import Document\n",
|
||||
"from langchain.document_loaders import ApifyDatasetLoader\n",
|
||||
"from langchain.indexes import VectorstoreIndexCreator"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ApifyDatasetLoader(\n",
|
||||
" dataset_id=\"your-dataset-id\",\n",
|
||||
" dataset_mapping_function=lambda item: Document(\n",
|
||||
" page_content=item[\"text\"] or \"\", metadata={\"source\": item[\"url\"]}\n",
|
||||
" ),\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"index = VectorstoreIndexCreator().from_loaders([loader])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What is Apify?\"\n",
|
||||
"result = index.query_with_sources(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" Apify is a platform for developing, running, and sharing serverless cloud programs. It enables users to create web scraping and automation tools and publish them on the Apify platform.\n",
|
||||
"\n",
|
||||
"https://docs.apify.com/platform/actors, https://docs.apify.com/platform/actors/running/actors-in-store, https://docs.apify.com/platform/security, https://docs.apify.com/platform/actors/examples\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(result[\"answer\"])\n",
|
||||
"print(result[\"sources\"])"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -1,13 +1,14 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "33205b12",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Figma\n",
|
||||
"\n",
|
||||
"This notebook covers how to load data from the Figma REST API into a format that can be ingested into LangChain."
|
||||
"This notebook covers how to load data from the Figma REST API into a format that can be ingested into LangChain, along with example usage for code generation."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -19,7 +20,35 @@
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"from langchain.document_loaders import FigmaFileLoader"
|
||||
"\n",
|
||||
"from langchain.document_loaders.figma import FigmaFileLoader\n",
|
||||
"\n",
|
||||
"from langchain.text_splitter import CharacterTextSplitter\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.indexes import VectorstoreIndexCreator\n",
|
||||
"from langchain.chains import ConversationChain, LLMChain\n",
|
||||
"from langchain.memory import ConversationBufferWindowMemory\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" SystemMessagePromptTemplate,\n",
|
||||
" AIMessagePromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "d809744a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The Figma API Requires an access token, node_ids, and a file key.\n",
|
||||
"\n",
|
||||
"The file key can be pulled from the URL. https://www.figma.com/file/{filekey}/sampleFilename\n",
|
||||
"\n",
|
||||
"Node IDs are also available in the URL. Click on anything and look for the '?node-id={node_id}' param.\n",
|
||||
"\n",
|
||||
"Access token instructions are in the Figma help center article: https://help.figma.com/hc/en-us/articles/8085703771159-Manage-personal-access-tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -29,7 +58,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = FigmaFileLoader(\n",
|
||||
"figma_loader = FigmaFileLoader(\n",
|
||||
" os.environ.get('ACCESS_TOKEN'),\n",
|
||||
" os.environ.get('NODE_IDS'),\n",
|
||||
" os.environ.get('FILE_KEY')\n",
|
||||
@@ -43,7 +72,9 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
"# see https://python.langchain.com/en/latest/modules/indexes/getting_started.html for more details\n",
|
||||
"index = VectorstoreIndexCreator().from_loaders([figma_loader])\n",
|
||||
"figma_doc_retriever = index.vectorstore.as_retriever()"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -52,6 +83,55 @@
|
||||
"id": "3e64cac2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def generate_code(human_input):\n",
|
||||
" # I have no idea if the Jon Carmack thing makes for better code. YMMV.\n",
|
||||
" # See https://python.langchain.com/en/latest/modules/models/chat/getting_started.html for chat info\n",
|
||||
" system_prompt_template = \"\"\"You are expert coder Jon Carmack. Use the provided design context to create idomatic HTML/CSS code as possible based on the user request.\n",
|
||||
" Everything must be inline in one file and your response must be directly renderable by the browser.\n",
|
||||
" Figma file nodes and metadata: {context}\"\"\"\n",
|
||||
"\n",
|
||||
" human_prompt_template = \"Code the {text}. Ensure it's mobile responsive\"\n",
|
||||
" system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template)\n",
|
||||
" human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template)\n",
|
||||
" # delete the gpt-4 model_name to use the default gpt-3.5 turbo for faster results\n",
|
||||
" gpt_4 = ChatOpenAI(temperature=.02, model_name='gpt-4')\n",
|
||||
" # Use the retriever's 'get_relevant_documents' method if needed to filter down longer docs\n",
|
||||
" relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input)\n",
|
||||
" conversation = [system_message_prompt, human_message_prompt]\n",
|
||||
" chat_prompt = ChatPromptTemplate.from_messages(conversation)\n",
|
||||
" response = gpt_4(chat_prompt.format_prompt( \n",
|
||||
" context=relevant_nodes, \n",
|
||||
" text=human_input).to_messages())\n",
|
||||
" return response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "36a96114",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"response = generate_code(\"page top header\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "baf9b2c9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Returns the following in `response.content`:\n",
|
||||
"```\n",
|
||||
"<!DOCTYPE html>\\n<html lang=\"en\">\\n<head>\\n <meta charset=\"UTF-8\">\\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\\n <style>\\n @import url(\\'https://fonts.googleapis.com/css2?family=DM+Sans:wght@500;700&family=Inter:wght@600&display=swap\\');\\n\\n body {\\n margin: 0;\\n font-family: \\'DM Sans\\', sans-serif;\\n }\\n\\n .header {\\n display: flex;\\n justify-content: space-between;\\n align-items: center;\\n padding: 20px;\\n background-color: #fff;\\n box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);\\n }\\n\\n .header h1 {\\n font-size: 16px;\\n font-weight: 700;\\n margin: 0;\\n }\\n\\n .header nav {\\n display: flex;\\n align-items: center;\\n }\\n\\n .header nav a {\\n font-size: 14px;\\n font-weight: 500;\\n text-decoration: none;\\n color: #000;\\n margin-left: 20px;\\n }\\n\\n @media (max-width: 768px) {\\n .header nav {\\n display: none;\\n }\\n }\\n </style>\\n</head>\\n<body>\\n <header class=\"header\">\\n <h1>Company Contact</h1>\\n <nav>\\n <a href=\"#\">Lorem Ipsum</a>\\n <a href=\"#\">Lorem Ipsum</a>\\n <a href=\"#\">Lorem Ipsum</a>\\n </nav>\\n </header>\\n</body>\\n</html>\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "38827110",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
@@ -71,7 +151,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
"version": "3.10.10"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -311,7 +311,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
"version": "3.8.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -1,905 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "249b4058",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Embeddings\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use the Embedding class in LangChain.\n",
|
||||
"\n",
|
||||
"The Embedding class is a class designed for interfacing with embeddings. There are lots of Embedding providers (OpenAI, Cohere, Hugging Face, etc) - this class is designed to provide a standard interface for all of them.\n",
|
||||
"\n",
|
||||
"Embeddings create a vector representation of a piece of text. This is useful because it means we can think about text in the vector space, and do things like semantic search where we look for pieces of text that are most similar in the vector space.\n",
|
||||
"\n",
|
||||
"The base Embedding class in LangChain exposes two methods: `embed_documents` and `embed_query`. The largest difference is that these two methods have different interfaces: one works over multiple documents, while the other works over a single document. Besides this, another reason for having these as two separate methods is that some embedding providers have different embedding methods for documents (to be searched over) vs queries (the search query itself)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "278b6c63",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## OpenAI\n",
|
||||
"\n",
|
||||
"Let's load the OpenAI Embedding class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "0be1af71",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import OpenAIEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "2c66e5da",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "01370375",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "bfb6142c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "0356c3b7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bb61bbeb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's load the OpenAI Embedding class with first generation models (e.g. text-search-ada-doc-001/text-search-ada-query-001). Note: These are not recommended models - see [here](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c0b072cc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings.openai import OpenAIEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a56b70f5",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = OpenAIEmbeddings(model_name=\"ada\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "14aefb64",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3c39ed33",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e3221db6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c3852491",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## AzureOpenAI\n",
|
||||
"\n",
|
||||
"Let's load the OpenAI Embedding class with environment variables set to indicate to use Azure endpoints."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1b40f827",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# set the environment variables needed for openai package to know to reach out to azure\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_TYPE\"] = \"azure\"\n",
|
||||
"os.environ[\"OPENAI_API_BASE\"] = \"https://<your-endpoint.openai.azure.com/\"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"your AzureOpenAI key\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "bb36d16c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = OpenAIEmbeddings(model=\"your-embeddings-deployment-name\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "228abcbb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "60dd7fad",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "83bc1a72",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "42f76e43",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Cohere\n",
|
||||
"\n",
|
||||
"Let's load the Cohere Embedding class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ca9e2b3a",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6b82f59f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import CohereEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "26895c60",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = CohereEmbeddings(cohere_api_key=cohere_api_key)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "eea52814",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "fbe167bf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "38ad3b20",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ed47bb62",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Hugging Face Hub\n",
|
||||
"Let's load the Hugging Face Embedding class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "861521a9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import HuggingFaceEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "ff9be586",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = HuggingFaceEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "d0a98ae9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "5d6c682b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "bb5e74c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fff4734f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## TensorflowHub\n",
|
||||
"Let's load the TensorflowHub Embedding class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "f822104b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import TensorflowHubEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "bac84e46",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"2023-01-30 23:53:01.652176: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA\n",
|
||||
"To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\n",
|
||||
"2023-01-30 23:53:34.362802: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA\n",
|
||||
"To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"embeddings = TensorflowHubEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "4790d770",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "f556dcdb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "59428e05",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## InstructEmbeddings\n",
|
||||
"Let's load the HuggingFace instruct Embeddings class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "92c5b61e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import HuggingFaceInstructEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "062547b9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"load INSTRUCTOR_Transformer\n",
|
||||
"max_seq_length 512\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"embeddings = HuggingFaceInstructEmbeddings(\n",
|
||||
" query_instruction=\"Represent the query for retrieval: \"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "e1dcc4bd",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "90f0db94",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eec4efda",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Self Hosted Embeddings\n",
|
||||
"Let's load the SelfHostedEmbeddings, SelfHostedHuggingFaceEmbeddings, and SelfHostedHuggingFaceInstructEmbeddings classes."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d338722a",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import (\n",
|
||||
" SelfHostedEmbeddings,\n",
|
||||
" SelfHostedHuggingFaceEmbeddings,\n",
|
||||
" SelfHostedHuggingFaceInstructEmbeddings,\n",
|
||||
")\n",
|
||||
"import runhouse as rh"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "146559e8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# For an on-demand A100 with GCP, Azure, or Lambda\n",
|
||||
"gpu = rh.cluster(name=\"rh-a10x\", instance_type=\"A100:1\", use_spot=False)\n",
|
||||
"\n",
|
||||
"# For an on-demand A10G with AWS (no single A100s on AWS)\n",
|
||||
"# gpu = rh.cluster(name='rh-a10x', instance_type='g5.2xlarge', provider='aws')\n",
|
||||
"\n",
|
||||
"# For an existing cluster\n",
|
||||
"# gpu = rh.cluster(ips=['<ip of the cluster>'],\n",
|
||||
"# ssh_creds={'ssh_user': '...', 'ssh_private_key':'<path_to_key>'},\n",
|
||||
"# name='my-cluster')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1230f7df",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = SelfHostedHuggingFaceEmbeddings(hardware=gpu)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "2684e928",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1dc5e606",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cef9cc54",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"And similarly for SelfHostedHuggingFaceInstructEmbeddings:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "81a17ca3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = SelfHostedHuggingFaceInstructEmbeddings(hardware=gpu)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5a33d1c8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Now let's load an embedding model with a custom load function:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "c4af5679",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_pipeline():\n",
|
||||
" from transformers import (\n",
|
||||
" AutoModelForCausalLM,\n",
|
||||
" AutoTokenizer,\n",
|
||||
" pipeline,\n",
|
||||
" ) # Must be inside the function in notebooks\n",
|
||||
"\n",
|
||||
" model_id = \"facebook/bart-base\"\n",
|
||||
" tokenizer = AutoTokenizer.from_pretrained(model_id)\n",
|
||||
" model = AutoModelForCausalLM.from_pretrained(model_id)\n",
|
||||
" return pipeline(\"feature-extraction\", model=model, tokenizer=tokenizer)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def inference_fn(pipeline, prompt):\n",
|
||||
" # Return last hidden state of the model\n",
|
||||
" if isinstance(prompt, list):\n",
|
||||
" return [emb[0][-1] for emb in pipeline(prompt)]\n",
|
||||
" return pipeline(prompt)[0][-1]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8654334b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = SelfHostedEmbeddings(\n",
|
||||
" model_load_fn=get_pipeline,\n",
|
||||
" hardware=gpu,\n",
|
||||
" model_reqs=[\"./\", \"torch\", \"transformers\"],\n",
|
||||
" inference_fn=inference_fn,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fc1bfd0f",
|
||||
"metadata": {
|
||||
"scrolled": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f9c02c78",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Fake Embeddings\n",
|
||||
"\n",
|
||||
"LangChain also provides a fake embedding class. You can use this to test your pipelines."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "2ffc2e4b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import FakeEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "80777571",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = FakeEmbeddings(size=1352)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "3ec9d8f0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(\"foo\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "3b9ae9e1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_results = embeddings.embed_documents([\"foo\"])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1f83f273",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## SageMaker Endpoint Embeddings\n",
|
||||
"\n",
|
||||
"Let's load the SageMaker Endpoints Embeddings class. The class can be used if you host, e.g. your own Hugging Face model on SageMaker.\n",
|
||||
"\n",
|
||||
"For instrucstions on how to do this, please see [here](https://www.philschmid.de/custom-inference-huggingface-sagemaker)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "88d366bd",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip3 install langchain boto3"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "1e9b926a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Dict\n",
|
||||
"from langchain.embeddings import SagemakerEndpointEmbeddings\n",
|
||||
"from langchain.llms.sagemaker_endpoint import ContentHandlerBase\n",
|
||||
"import json\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class ContentHandler(ContentHandlerBase):\n",
|
||||
" content_type = \"application/json\"\n",
|
||||
" accepts = \"application/json\"\n",
|
||||
"\n",
|
||||
" def transform_input(self, prompt: str, model_kwargs: Dict) -> bytes:\n",
|
||||
" input_str = json.dumps({\"inputs\": prompt, **model_kwargs})\n",
|
||||
" return input_str.encode('utf-8')\n",
|
||||
" \n",
|
||||
" def transform_output(self, output: bytes) -> str:\n",
|
||||
" response_json = json.loads(output.read().decode(\"utf-8\"))\n",
|
||||
" return response_json[\"embeddings\"]\n",
|
||||
"\n",
|
||||
"content_handler = ContentHandler()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"embeddings = SagemakerEndpointEmbeddings(\n",
|
||||
" # endpoint_name=\"endpoint-name\", \n",
|
||||
" # credentials_profile_name=\"credentials-profile-name\", \n",
|
||||
" endpoint_name=\"huggingface-pytorch-inference-2023-03-21-16-14-03-834\", \n",
|
||||
" region_name=\"us-east-1\", \n",
|
||||
" content_handler=content_handler\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fe9797b8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(\"foo\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "76f1b752",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_results = embeddings.embed_documents([\"foo\"])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fff99b21",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eb1c0ea9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Aleph Alpha\n",
|
||||
"\n",
|
||||
"There are two possible ways to use Aleph Alpha's semantic embeddings. If you have texts with a dissimilar structure (e.g. a Document and a Query) you would want to use asymmetric embeddings. Conversely, for texts with comparable structures, symmetric embeddings are the suggested approach."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9ecc84f9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Asymmetric"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "8a920a89",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import AlephAlphaAsymmetricSemanticEmbedding"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "f2d04da3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"document = \"This is a content of the document\"\n",
|
||||
"query = \"What is the contnt of the document?\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e6ecde96",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = AlephAlphaAsymmetricSemanticEmbedding()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "90e68411",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([document])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "55903233",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8c00aab",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Symmetric"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "eabb763a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import AlephAlphaSymmetricSemanticEmbedding"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "0ad799f7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test text\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "af86dc10",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = AlephAlphaSymmetricSemanticEmbedding()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d292536f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c704a7cf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "33492471",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.13"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "7377c2ccc78bc62c2683122d48c8cd1fb85a53850a1b1fc29736ed39852c9885"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -7,7 +7,7 @@
|
||||
"source": [
|
||||
"# VectorStore Retriever\n",
|
||||
"\n",
|
||||
"The index - and therefor the retriever - that LangChain has the most support for is a VectorStoreRetriever. As the name suggests, this retriever is backed heavily by a VectorStore.\n",
|
||||
"The index - and therefore the retriever - that LangChain has the most support for is a VectorStoreRetriever. As the name suggests, this retriever is backed heavily by a VectorStore.\n",
|
||||
"\n",
|
||||
"Once you construct a VectorStore, its very easy to construct a retriever. Let's walk through an example."
|
||||
]
|
||||
|
||||
@@ -5,8 +5,8 @@
|
||||
"id": "13dc0983",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# HuggingFace Length Function\n",
|
||||
"Most LLMs are constrained by the number of tokens that you can pass in, which is not the same as the number of characters. In order to get a more accurate estimate, we can use HuggingFace tokenizers to count the text length.\n",
|
||||
"# Hugging Face Length Function\n",
|
||||
"Most LLMs are constrained by the number of tokens that you can pass in, which is not the same as the number of characters. In order to get a more accurate estimate, we can use Hugging Face tokenizers to count the text length.\n",
|
||||
"\n",
|
||||
"1. How the text is split: by character passed in\n",
|
||||
"2. How the chunk size is measured: by Hugging Face tokenizer"
|
||||
|
||||
165
docs/modules/models/text_embedding/examples/aleph_alpha.ipynb
Normal file
165
docs/modules/models/text_embedding/examples/aleph_alpha.ipynb
Normal file
@@ -0,0 +1,165 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eb1c0ea9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Aleph Alpha\n",
|
||||
"\n",
|
||||
"There are two possible ways to use Aleph Alpha's semantic embeddings. If you have texts with a dissimilar structure (e.g. a Document and a Query) you would want to use asymmetric embeddings. Conversely, for texts with comparable structures, symmetric embeddings are the suggested approach."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9ecc84f9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Asymmetric"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "8a920a89",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import AlephAlphaAsymmetricSemanticEmbedding"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "f2d04da3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"document = \"This is a content of the document\"\n",
|
||||
"query = \"What is the contnt of the document?\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e6ecde96",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = AlephAlphaAsymmetricSemanticEmbedding()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "90e68411",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([document])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "55903233",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8c00aab",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Symmetric"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "eabb763a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import AlephAlphaSymmetricSemanticEmbedding"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "0ad799f7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test text\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "af86dc10",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = AlephAlphaSymmetricSemanticEmbedding()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d292536f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_result = embeddings.embed_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c704a7cf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "33492471",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "7377c2ccc78bc62c2683122d48c8cd1fb85a53850a1b1fc29736ed39852c9885"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -40,7 +40,7 @@
|
||||
"source": [
|
||||
"You can make use of templating by using a `MessagePromptTemplate`. You can build a `ChatPromptTemplate` from one or more `MessagePromptTemplates`. You can use `ChatPromptTemplate`'s `format_prompt` -- this returns a `PromptValue`, which you can convert to a string or Message object, depending on whether you want to use the formatted value as input to an llm or chat model.\n",
|
||||
"\n",
|
||||
"For convience, there is a `from_template` method exposed on the template. If you were to use this template, this is what it would look like:"
|
||||
"For convenience, there is a `from_template` method exposed on the template. If you were to use this template, this is what it would look like:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -10,3 +10,4 @@ sphinx-panels
|
||||
toml
|
||||
myst_nb
|
||||
sphinx_copybutton
|
||||
pydata-sphinx-theme==0.13.1
|
||||
|
||||
@@ -19,6 +19,7 @@ from langchain.tools.python.tool import PythonREPLTool
|
||||
from langchain.tools.requests.tool import RequestsGetTool
|
||||
from langchain.tools.wikipedia.tool import WikipediaQueryRun
|
||||
from langchain.tools.wolfram_alpha.tool import WolframAlphaQueryRun
|
||||
from langchain.utilities.apify import ApifyWrapper
|
||||
from langchain.utilities.bash import BashProcess
|
||||
from langchain.utilities.bing_search import BingSearchAPIWrapper
|
||||
from langchain.utilities.google_search import GoogleSearchAPIWrapper
|
||||
|
||||
@@ -2,15 +2,16 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import re
|
||||
from typing import Any, Callable, List, NamedTuple, Optional, Sequence, Tuple
|
||||
from typing import Any, Callable, List, NamedTuple, Optional, Sequence, Tuple, Union
|
||||
|
||||
from langchain.agents.agent import Agent, AgentExecutor
|
||||
from langchain.agents.agent import Agent, AgentExecutor, AgentOutputParser
|
||||
from langchain.agents.mrkl.prompt import FORMAT_INSTRUCTIONS, PREFIX, SUFFIX
|
||||
from langchain.agents.tools import Tool
|
||||
from langchain.callbacks.base import BaseCallbackManager
|
||||
from langchain.chains import LLMChain
|
||||
from langchain.llms.base import BaseLLM
|
||||
from langchain.prompts import PromptTemplate
|
||||
from langchain.schema import AgentAction, AgentFinish
|
||||
from langchain.tools.base import BaseTool
|
||||
|
||||
FINAL_ANSWER_ACTION = "Final Answer:"
|
||||
@@ -30,6 +31,24 @@ class ChainConfig(NamedTuple):
|
||||
action_description: str
|
||||
|
||||
|
||||
class ReActOutputParser(AgentOutputParser):
|
||||
def parse(self, text: str) -> Union[AgentFinish, AgentAction]:
|
||||
if FINAL_ANSWER_ACTION in text:
|
||||
return AgentFinish(
|
||||
{"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, log=text
|
||||
)
|
||||
# \s matches against tab/newline/whitespace
|
||||
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
|
||||
match = re.search(regex, text, re.DOTALL)
|
||||
if not match:
|
||||
raise ValueError(f"Could not parse LLM output: `{text}`")
|
||||
action = match.group(1).strip()
|
||||
action_input = match.group(2)
|
||||
return AgentAction(
|
||||
tool=action, tool_input=action_input.strip(" ").strip('"'), log=text
|
||||
)
|
||||
|
||||
|
||||
def get_action_and_input(llm_output: str) -> Tuple[str, str]:
|
||||
"""Parse out the action and input from the LLM output.
|
||||
|
||||
@@ -38,16 +57,11 @@ def get_action_and_input(llm_output: str) -> Tuple[str, str]:
|
||||
The string starting with "Action:" and the following string starting
|
||||
with "Action Input:" should be separated by a newline.
|
||||
"""
|
||||
if FINAL_ANSWER_ACTION in llm_output:
|
||||
return "Final Answer", llm_output.split(FINAL_ANSWER_ACTION)[-1].strip()
|
||||
# \s matches against tab/newline/whitespace
|
||||
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
|
||||
match = re.search(regex, llm_output, re.DOTALL)
|
||||
if not match:
|
||||
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
|
||||
action = match.group(1).strip()
|
||||
action_input = match.group(2)
|
||||
return action, action_input.strip(" ").strip('"')
|
||||
result = ReActOutputParser().parse(llm_output)
|
||||
if isinstance(result, AgentFinish):
|
||||
return "Final Answer", result.return_values["output"]
|
||||
else:
|
||||
return result.tool, result.tool_input
|
||||
|
||||
|
||||
class ZeroShotAgent(Agent):
|
||||
|
||||
@@ -40,11 +40,11 @@ class InvalidTool(BaseTool):
|
||||
|
||||
def _run(self, tool_name: str) -> str:
|
||||
"""Use the tool."""
|
||||
return f"{tool_name} is not a valid tool, try another one. Reminder to only use allowed tool names!"
|
||||
return f"{tool_name} is not a valid tool, try another one."
|
||||
|
||||
async def _arun(self, tool_name: str) -> str:
|
||||
"""Use the tool asynchronously."""
|
||||
return f"{tool_name} is not a valid tool, try another one. Reminder to only use allowed tool names!"
|
||||
return f"{tool_name} is not a valid tool, try another one."
|
||||
|
||||
|
||||
def tool(*args: Union[str, Callable], return_direct: bool = False) -> Callable:
|
||||
|
||||
@@ -3,11 +3,13 @@ import os
|
||||
from contextlib import contextmanager
|
||||
from typing import Generator, Optional
|
||||
|
||||
from langchain.callbacks.aim_callback import AimCallbackHandler
|
||||
from langchain.callbacks.base import (
|
||||
BaseCallbackHandler,
|
||||
BaseCallbackManager,
|
||||
CallbackManager,
|
||||
)
|
||||
from langchain.callbacks.clearml_callback import ClearMLCallbackHandler
|
||||
from langchain.callbacks.openai_info import OpenAICallbackHandler
|
||||
from langchain.callbacks.shared import SharedCallbackManager
|
||||
from langchain.callbacks.stdout import StdOutCallbackHandler
|
||||
@@ -70,7 +72,9 @@ __all__ = [
|
||||
"OpenAICallbackHandler",
|
||||
"SharedCallbackManager",
|
||||
"StdOutCallbackHandler",
|
||||
"AimCallbackHandler",
|
||||
"WandbCallbackHandler",
|
||||
"ClearMLCallbackHandler",
|
||||
"get_openai_callback",
|
||||
"set_tracing_callback_manager",
|
||||
"set_default_callback_manager",
|
||||
|
||||
427
langchain/callbacks/aim_callback.py
Normal file
427
langchain/callbacks/aim_callback.py
Normal file
@@ -0,0 +1,427 @@
|
||||
from copy import deepcopy
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
from langchain.callbacks.base import BaseCallbackHandler
|
||||
from langchain.schema import AgentAction, AgentFinish, LLMResult
|
||||
|
||||
|
||||
def import_aim() -> Any:
|
||||
try:
|
||||
import aim
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use the Aim callback manager you need to have the"
|
||||
" `aim` python package installed."
|
||||
"Please install it with `pip install aim`"
|
||||
)
|
||||
return aim
|
||||
|
||||
|
||||
class BaseMetadataCallbackHandler:
|
||||
"""This class handles the metadata and associated function states for callbacks.
|
||||
|
||||
Attributes:
|
||||
step (int): The current step.
|
||||
starts (int): The number of times the start method has been called.
|
||||
ends (int): The number of times the end method has been called.
|
||||
errors (int): The number of times the error method has been called.
|
||||
text_ctr (int): The number of times the text method has been called.
|
||||
ignore_llm_ (bool): Whether to ignore llm callbacks.
|
||||
ignore_chain_ (bool): Whether to ignore chain callbacks.
|
||||
ignore_agent_ (bool): Whether to ignore agent callbacks.
|
||||
always_verbose_ (bool): Whether to always be verbose.
|
||||
chain_starts (int): The number of times the chain start method has been called.
|
||||
chain_ends (int): The number of times the chain end method has been called.
|
||||
llm_starts (int): The number of times the llm start method has been called.
|
||||
llm_ends (int): The number of times the llm end method has been called.
|
||||
llm_streams (int): The number of times the text method has been called.
|
||||
tool_starts (int): The number of times the tool start method has been called.
|
||||
tool_ends (int): The number of times the tool end method has been called.
|
||||
agent_ends (int): The number of times the agent end method has been called.
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
@property
|
||||
def always_verbose(self) -> bool:
|
||||
"""Whether to call verbose callbacks even if verbose is False."""
|
||||
return self.always_verbose_
|
||||
|
||||
@property
|
||||
def ignore_llm(self) -> bool:
|
||||
"""Whether to ignore LLM callbacks."""
|
||||
return self.ignore_llm_
|
||||
|
||||
@property
|
||||
def ignore_chain(self) -> bool:
|
||||
"""Whether to ignore chain callbacks."""
|
||||
return self.ignore_chain_
|
||||
|
||||
@property
|
||||
def ignore_agent(self) -> bool:
|
||||
"""Whether to ignore agent callbacks."""
|
||||
return self.ignore_agent_
|
||||
|
||||
def get_custom_callback_meta(self) -> Dict[str, Any]:
|
||||
return {
|
||||
"step": self.step,
|
||||
"starts": self.starts,
|
||||
"ends": self.ends,
|
||||
"errors": self.errors,
|
||||
"text_ctr": self.text_ctr,
|
||||
"chain_starts": self.chain_starts,
|
||||
"chain_ends": self.chain_ends,
|
||||
"llm_starts": self.llm_starts,
|
||||
"llm_ends": self.llm_ends,
|
||||
"llm_streams": self.llm_streams,
|
||||
"tool_starts": self.tool_starts,
|
||||
"tool_ends": self.tool_ends,
|
||||
"agent_ends": self.agent_ends,
|
||||
}
|
||||
|
||||
def reset_callback_meta(self) -> None:
|
||||
"""Reset the callback metadata."""
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
return None
|
||||
|
||||
|
||||
class AimCallbackHandler(BaseMetadataCallbackHandler, BaseCallbackHandler):
|
||||
"""Callback Handler that logs to Aim.
|
||||
|
||||
Parameters:
|
||||
repo (:obj:`str`, optional): Aim repository path or Repo object to which
|
||||
Run object is bound. If skipped, default Repo is used.
|
||||
experiment_name (:obj:`str`, optional): Sets Run's `experiment` property.
|
||||
'default' if not specified. Can be used later to query runs/sequences.
|
||||
system_tracking_interval (:obj:`int`, optional): Sets the tracking interval
|
||||
in seconds for system usage metrics (CPU, Memory, etc.). Set to `None`
|
||||
to disable system metrics tracking.
|
||||
log_system_params (:obj:`bool`, optional): Enable/Disable logging of system
|
||||
params such as installed packages, git info, environment variables, etc.
|
||||
|
||||
This handler will utilize the associated callback method called and formats
|
||||
the input of each callback function with metadata regarding the state of LLM run
|
||||
and then logs the response to Aim.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
repo: Optional[str] = None,
|
||||
experiment_name: Optional[str] = None,
|
||||
system_tracking_interval: Optional[int] = 10,
|
||||
log_system_params: bool = True,
|
||||
) -> None:
|
||||
"""Initialize callback handler."""
|
||||
|
||||
super().__init__()
|
||||
|
||||
aim = import_aim()
|
||||
self.repo = repo
|
||||
self.experiment_name = experiment_name
|
||||
self.system_tracking_interval = system_tracking_interval
|
||||
self.log_system_params = log_system_params
|
||||
self._run = aim.Run(
|
||||
repo=self.repo,
|
||||
experiment=self.experiment_name,
|
||||
system_tracking_interval=self.system_tracking_interval,
|
||||
log_system_params=self.log_system_params,
|
||||
)
|
||||
self._run_hash = self._run.hash
|
||||
self.action_records: list = []
|
||||
|
||||
def setup(self, **kwargs: Any) -> None:
|
||||
aim = import_aim()
|
||||
|
||||
if not self._run:
|
||||
if self._run_hash:
|
||||
self._run = aim.Run(
|
||||
self._run_hash,
|
||||
repo=self.repo,
|
||||
system_tracking_interval=self.system_tracking_interval,
|
||||
)
|
||||
else:
|
||||
self._run = aim.Run(
|
||||
repo=self.repo,
|
||||
experiment=self.experiment_name,
|
||||
system_tracking_interval=self.system_tracking_interval,
|
||||
log_system_params=self.log_system_params,
|
||||
)
|
||||
self._run_hash = self._run.hash
|
||||
|
||||
if kwargs:
|
||||
for key, value in kwargs.items():
|
||||
self._run.set(key, value, strict=False)
|
||||
|
||||
def on_llm_start(
|
||||
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when LLM starts."""
|
||||
aim = import_aim()
|
||||
|
||||
self.step += 1
|
||||
self.llm_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = {"action": "on_llm_start"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
prompts_res = deepcopy(prompts)
|
||||
|
||||
self._run.track(
|
||||
[aim.Text(prompt) for prompt in prompts_res],
|
||||
name="on_llm_start",
|
||||
context=resp,
|
||||
)
|
||||
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
"""Run when LLM ends running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.llm_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = {"action": "on_llm_end"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
response_res = deepcopy(response)
|
||||
|
||||
generated = [
|
||||
aim.Text(generation.text)
|
||||
for generations in response_res.generations
|
||||
for generation in generations
|
||||
]
|
||||
self._run.track(
|
||||
generated,
|
||||
name="on_llm_end",
|
||||
context=resp,
|
||||
)
|
||||
|
||||
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
|
||||
"""Run when LLM generates a new token."""
|
||||
self.step += 1
|
||||
self.llm_streams += 1
|
||||
|
||||
def on_llm_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when LLM errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_chain_start(
|
||||
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when chain starts running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.chain_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = {"action": "on_chain_start"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
inputs_res = deepcopy(inputs)
|
||||
|
||||
self._run.track(
|
||||
aim.Text(inputs_res["input"]), name="on_chain_start", context=resp
|
||||
)
|
||||
|
||||
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
|
||||
"""Run when chain ends running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.chain_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = {"action": "on_chain_end"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
outputs_res = deepcopy(outputs)
|
||||
|
||||
self._run.track(
|
||||
aim.Text(outputs_res["output"]), name="on_chain_end", context=resp
|
||||
)
|
||||
|
||||
def on_chain_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when chain errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_tool_start(
|
||||
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when tool starts running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.tool_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = {"action": "on_tool_start"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self._run.track(aim.Text(input_str), name="on_tool_start", context=resp)
|
||||
|
||||
def on_tool_end(self, output: str, **kwargs: Any) -> None:
|
||||
"""Run when tool ends running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.tool_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = {"action": "on_tool_end"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self._run.track(aim.Text(output), name="on_tool_end", context=resp)
|
||||
|
||||
def on_tool_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when tool errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_text(self, text: str, **kwargs: Any) -> None:
|
||||
"""
|
||||
Run when agent is ending.
|
||||
"""
|
||||
self.step += 1
|
||||
self.text_ctr += 1
|
||||
|
||||
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> None:
|
||||
"""Run when agent ends running."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.agent_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = {"action": "on_agent_finish"}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
finish_res = deepcopy(finish)
|
||||
|
||||
text = "OUTPUT:\n{}\n\nLOG:\n{}".format(
|
||||
finish_res.return_values["output"], finish_res.log
|
||||
)
|
||||
self._run.track(aim.Text(text), name="on_agent_finish", context=resp)
|
||||
|
||||
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
|
||||
"""Run on agent action."""
|
||||
aim = import_aim()
|
||||
self.step += 1
|
||||
self.tool_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = {
|
||||
"action": "on_agent_action",
|
||||
"tool": action.tool,
|
||||
}
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
action_res = deepcopy(action)
|
||||
|
||||
text = "TOOL INPUT:\n{}\n\nLOG:\n{}".format(
|
||||
action_res.tool_input, action_res.log
|
||||
)
|
||||
self._run.track(aim.Text(text), name="on_agent_action", context=resp)
|
||||
|
||||
def flush_tracker(
|
||||
self,
|
||||
repo: Optional[str] = None,
|
||||
experiment_name: Optional[str] = None,
|
||||
system_tracking_interval: Optional[int] = 10,
|
||||
log_system_params: bool = True,
|
||||
langchain_asset: Any = None,
|
||||
reset: bool = True,
|
||||
finish: bool = False,
|
||||
) -> None:
|
||||
"""Flush the tracker and reset the session.
|
||||
|
||||
Args:
|
||||
repo (:obj:`str`, optional): Aim repository path or Repo object to which
|
||||
Run object is bound. If skipped, default Repo is used.
|
||||
experiment_name (:obj:`str`, optional): Sets Run's `experiment` property.
|
||||
'default' if not specified. Can be used later to query runs/sequences.
|
||||
system_tracking_interval (:obj:`int`, optional): Sets the tracking interval
|
||||
in seconds for system usage metrics (CPU, Memory, etc.). Set to `None`
|
||||
to disable system metrics tracking.
|
||||
log_system_params (:obj:`bool`, optional): Enable/Disable logging of system
|
||||
params such as installed packages, git info, environment variables, etc.
|
||||
langchain_asset: The langchain asset to save.
|
||||
reset: Whether to reset the session.
|
||||
finish: Whether to finish the run.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
|
||||
if langchain_asset:
|
||||
try:
|
||||
for key, value in langchain_asset.dict().items():
|
||||
self._run.set(key, value, strict=False)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if finish or reset:
|
||||
self._run.close()
|
||||
self.reset_callback_meta()
|
||||
if reset:
|
||||
self.__init__( # type: ignore
|
||||
repo=repo if repo else self.repo,
|
||||
experiment_name=experiment_name
|
||||
if experiment_name
|
||||
else self.experiment_name,
|
||||
system_tracking_interval=system_tracking_interval
|
||||
if system_tracking_interval
|
||||
else self.system_tracking_interval,
|
||||
log_system_params=log_system_params
|
||||
if log_system_params
|
||||
else self.log_system_params,
|
||||
)
|
||||
208
langchain/callbacks/arize_callback.py
Normal file
208
langchain/callbacks/arize_callback.py
Normal file
@@ -0,0 +1,208 @@
|
||||
# Import the necessary packages for ingestion
|
||||
import uuid
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
import pandas as pd
|
||||
|
||||
from langchain.callbacks.base import BaseCallbackHandler
|
||||
from langchain.schema import AgentAction, AgentFinish, LLMResult
|
||||
|
||||
|
||||
class ArizeCallbackHandler(BaseCallbackHandler):
|
||||
"""Callback Handler that logs to Arize platform."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_id: Optional[str] = None,
|
||||
model_version: Optional[str] = None,
|
||||
SPACE_KEY: Optional[str] = None,
|
||||
API_KEY: Optional[str] = None,
|
||||
) -> None:
|
||||
"""Initialize callback handler."""
|
||||
|
||||
super().__init__()
|
||||
|
||||
# Set the model_id and model_version for the Arize monitoring.
|
||||
self.model_id = model_id
|
||||
self.model_version = model_version
|
||||
|
||||
# Set the SPACE_KEY and API_KEY for the Arize client.
|
||||
self.space_key = SPACE_KEY
|
||||
self.api_key = API_KEY
|
||||
|
||||
# Initialize empty lists to store the prompt/response pairs
|
||||
# and other necessary data.
|
||||
self.prompt_records: List = []
|
||||
self.response_records: List = []
|
||||
self.prediction_ids: List = []
|
||||
self.pred_timestamps: List = []
|
||||
self.response_embeddings: List = []
|
||||
self.prompt_embeddings: List = []
|
||||
self.prompt_tokens = 0
|
||||
self.completion_tokens = 0
|
||||
self.total_tokens = 0
|
||||
|
||||
from arize.api import Client
|
||||
from arize.pandas.embeddings import EmbeddingGenerator, UseCases
|
||||
|
||||
# Create an embedding generator for generating embeddings
|
||||
# from prompts and responses.
|
||||
self.generator = EmbeddingGenerator.from_use_case(
|
||||
use_case=UseCases.NLP.SEQUENCE_CLASSIFICATION,
|
||||
model_name="distilbert-base-uncased",
|
||||
tokenizer_max_length=512,
|
||||
batch_size=256,
|
||||
)
|
||||
|
||||
# Create an Arize client and check if the SPACE_KEY and API_KEY
|
||||
# are not set to the default values.
|
||||
self.arize_client = Client(space_key=SPACE_KEY, api_key=API_KEY)
|
||||
if SPACE_KEY == "SPACE_KEY" or API_KEY == "API_KEY":
|
||||
raise ValueError("❌ CHANGE SPACE AND API KEYS")
|
||||
else:
|
||||
print("✅ Arize client setup done! Now you can start using Arize!")
|
||||
|
||||
def on_llm_start(
|
||||
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
|
||||
) -> None:
|
||||
"""Record the prompts when an LLM starts."""
|
||||
|
||||
for prompt in prompts:
|
||||
self.prompt_records.append(prompt.replace("\n", " "))
|
||||
|
||||
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
|
||||
"""Do nothing when a new token is generated."""
|
||||
pass
|
||||
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
"""Log data to Arize when an LLM ends."""
|
||||
|
||||
from arize.utils.types import (
|
||||
Embedding,
|
||||
Environments,
|
||||
ModelTypes,
|
||||
)
|
||||
|
||||
# Record token usage of the LLM
|
||||
if response.llm_output is not None:
|
||||
self.prompt_tokens = response.llm_output["token_usage"]["prompt_tokens"]
|
||||
self.total_tokens = response.llm_output["token_usage"]["total_tokens"]
|
||||
self.completion_tokens = response.llm_output["token_usage"][
|
||||
"completion_tokens"
|
||||
]
|
||||
i = 0
|
||||
|
||||
# Go through each prompt response pair and generate embeddings as
|
||||
# well as timestamp and prediction ids
|
||||
for generations in response.generations:
|
||||
for generation in generations:
|
||||
prompt = self.prompt_records[i]
|
||||
prompt_embedding = pd.Series(
|
||||
self.generator.generate_embeddings(
|
||||
text_col=pd.Series(prompt.replace("\n", " "))
|
||||
).reset_index(drop=True)
|
||||
)
|
||||
generated_text = generation.text.replace("\n", " ")
|
||||
response_embedding = pd.Series(
|
||||
self.generator.generate_embeddings(
|
||||
text_col=pd.Series(generation.text.replace("\n", " "))
|
||||
).reset_index(drop=True)
|
||||
)
|
||||
pred_id = str(uuid.uuid4())
|
||||
|
||||
# Define embedding features for Arize ingestion
|
||||
embedding_features = {
|
||||
"prompt_embedding": Embedding(
|
||||
vector=pd.Series(prompt_embedding[0]), data=prompt
|
||||
),
|
||||
"response_embedding": Embedding(
|
||||
vector=pd.Series(response_embedding[0]), data=generated_text
|
||||
),
|
||||
}
|
||||
tags = {
|
||||
"Prompt Tokens": self.prompt_tokens,
|
||||
"Completion Tokens": self.completion_tokens,
|
||||
"Total Tokens": self.total_tokens,
|
||||
}
|
||||
|
||||
# Log each prompt response data into arize
|
||||
future = self.arize_client.log(
|
||||
prediction_id=pred_id,
|
||||
tags=tags,
|
||||
prediction_label="1",
|
||||
model_id=self.model_id,
|
||||
model_type=ModelTypes.SCORE_CATEGORICAL,
|
||||
model_version=self.model_version,
|
||||
environment=Environments.PRODUCTION,
|
||||
embedding_features=embedding_features,
|
||||
)
|
||||
|
||||
result = future.result()
|
||||
if result.status_code == 200:
|
||||
print("✅ Successfully logged data to Arize!")
|
||||
else:
|
||||
print(
|
||||
f"❌ Logging failed with status code {result.status_code}"
|
||||
f' and message "{result.text}"'
|
||||
)
|
||||
|
||||
i = i + 1
|
||||
|
||||
def on_llm_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Do nothing when LLM outputs an error."""
|
||||
pass
|
||||
|
||||
def on_chain_start(
|
||||
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
|
||||
) -> None:
|
||||
"""Do nothing when LLM chain starts."""
|
||||
pass
|
||||
|
||||
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
|
||||
"""Do nothing when LLM chain ends."""
|
||||
pass
|
||||
|
||||
def on_chain_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Do nothing when LLM chain outputs an error."""
|
||||
pass
|
||||
|
||||
def on_tool_start(
|
||||
self,
|
||||
serialized: Dict[str, Any],
|
||||
input_str: str,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Do nothing when tool starts."""
|
||||
pass
|
||||
|
||||
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
|
||||
"""Do nothing when agent takes a specific action."""
|
||||
pass
|
||||
|
||||
def on_tool_end(
|
||||
self,
|
||||
output: str,
|
||||
observation_prefix: Optional[str] = None,
|
||||
llm_prefix: Optional[str] = None,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Do nothing when tool ends."""
|
||||
pass
|
||||
|
||||
def on_tool_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Do nothing when tool outputs an error."""
|
||||
pass
|
||||
|
||||
def on_text(self, text: str, **kwargs: Any) -> None:
|
||||
"""Do nothing"""
|
||||
pass
|
||||
|
||||
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> None:
|
||||
"""Do nothing"""
|
||||
pass
|
||||
515
langchain/callbacks/clearml_callback.py
Normal file
515
langchain/callbacks/clearml_callback.py
Normal file
@@ -0,0 +1,515 @@
|
||||
import tempfile
|
||||
from copy import deepcopy
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, List, Optional, Sequence, Union
|
||||
|
||||
from langchain.callbacks.base import BaseCallbackHandler
|
||||
from langchain.callbacks.utils import (
|
||||
BaseMetadataCallbackHandler,
|
||||
flatten_dict,
|
||||
hash_string,
|
||||
import_pandas,
|
||||
import_spacy,
|
||||
import_textstat,
|
||||
load_json,
|
||||
)
|
||||
from langchain.schema import AgentAction, AgentFinish, LLMResult
|
||||
|
||||
|
||||
def import_clearml() -> Any:
|
||||
try:
|
||||
import clearml # noqa: F401
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use the clearml callback manager you need to have the `clearml` python "
|
||||
"package installed. Please install it with `pip install clearml`"
|
||||
)
|
||||
return clearml
|
||||
|
||||
|
||||
class ClearMLCallbackHandler(BaseMetadataCallbackHandler, BaseCallbackHandler):
|
||||
"""Callback Handler that logs to ClearML.
|
||||
|
||||
Parameters:
|
||||
job_type (str): The type of clearml task such as "inference", "testing" or "qc"
|
||||
project_name (str): The clearml project name
|
||||
tags (list): Tags to add to the task
|
||||
task_name (str): Name of the clearml task
|
||||
visualize (bool): Whether to visualize the run.
|
||||
complexity_metrics (bool): Whether to log complexity metrics
|
||||
stream_logs (bool): Whether to stream callback actions to ClearML
|
||||
|
||||
This handler will utilize the associated callback method and formats
|
||||
the input of each callback function with metadata regarding the state of LLM run,
|
||||
and adds the response to the list of records for both the {method}_records and
|
||||
action. It then logs the response to the ClearML console.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task_type: Optional[str] = "inference",
|
||||
project_name: Optional[str] = "langchain_callback_demo",
|
||||
tags: Optional[Sequence] = None,
|
||||
task_name: Optional[str] = None,
|
||||
visualize: bool = False,
|
||||
complexity_metrics: bool = False,
|
||||
stream_logs: bool = False,
|
||||
) -> None:
|
||||
"""Initialize callback handler."""
|
||||
|
||||
clearml = import_clearml()
|
||||
spacy = import_spacy()
|
||||
super().__init__()
|
||||
|
||||
self.task_type = task_type
|
||||
self.project_name = project_name
|
||||
self.tags = tags
|
||||
self.task_name = task_name
|
||||
self.visualize = visualize
|
||||
self.complexity_metrics = complexity_metrics
|
||||
self.stream_logs = stream_logs
|
||||
|
||||
self.temp_dir = tempfile.TemporaryDirectory()
|
||||
|
||||
# Check if ClearML task already exists (e.g. in pipeline)
|
||||
if clearml.Task.current_task():
|
||||
self.task = clearml.Task.current_task()
|
||||
else:
|
||||
self.task = clearml.Task.init( # type: ignore
|
||||
task_type=self.task_type,
|
||||
project_name=self.project_name,
|
||||
tags=self.tags,
|
||||
task_name=self.task_name,
|
||||
output_uri=True,
|
||||
)
|
||||
self.logger = self.task.get_logger()
|
||||
warning = (
|
||||
"The clearml callback is currently in beta and is subject to change "
|
||||
"based on updates to `langchain`. Please report any issues to "
|
||||
"https://github.com/allegroai/clearml/issues with the tag `langchain`."
|
||||
)
|
||||
self.logger.report_text(warning, level=30, print_console=True)
|
||||
self.callback_columns: list = []
|
||||
self.action_records: list = []
|
||||
self.complexity_metrics = complexity_metrics
|
||||
self.visualize = visualize
|
||||
self.nlp = spacy.load("en_core_web_sm")
|
||||
|
||||
def _init_resp(self) -> Dict:
|
||||
return {k: None for k in self.callback_columns}
|
||||
|
||||
def on_llm_start(
|
||||
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when LLM starts."""
|
||||
self.step += 1
|
||||
self.llm_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_llm_start"})
|
||||
resp.update(flatten_dict(serialized))
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
for prompt in prompts:
|
||||
prompt_resp = deepcopy(resp)
|
||||
prompt_resp["prompts"] = prompt
|
||||
self.on_llm_start_records.append(prompt_resp)
|
||||
self.action_records.append(prompt_resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(prompt_resp)
|
||||
|
||||
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
|
||||
"""Run when LLM generates a new token."""
|
||||
self.step += 1
|
||||
self.llm_streams += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_llm_new_token", "token": token})
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_llm_token_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
"""Run when LLM ends running."""
|
||||
self.step += 1
|
||||
self.llm_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_llm_end"})
|
||||
resp.update(flatten_dict(response.llm_output or {}))
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
for generations in response.generations:
|
||||
for generation in generations:
|
||||
generation_resp = deepcopy(resp)
|
||||
generation_resp.update(flatten_dict(generation.dict()))
|
||||
generation_resp.update(self.analyze_text(generation.text))
|
||||
self.on_llm_end_records.append(generation_resp)
|
||||
self.action_records.append(generation_resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(generation_resp)
|
||||
|
||||
def on_llm_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when LLM errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_chain_start(
|
||||
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when chain starts running."""
|
||||
self.step += 1
|
||||
self.chain_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_chain_start"})
|
||||
resp.update(flatten_dict(serialized))
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
chain_input = inputs["input"]
|
||||
|
||||
if isinstance(chain_input, str):
|
||||
input_resp = deepcopy(resp)
|
||||
input_resp["input"] = chain_input
|
||||
self.on_chain_start_records.append(input_resp)
|
||||
self.action_records.append(input_resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(input_resp)
|
||||
elif isinstance(chain_input, list):
|
||||
for inp in chain_input:
|
||||
input_resp = deepcopy(resp)
|
||||
input_resp.update(inp)
|
||||
self.on_chain_start_records.append(input_resp)
|
||||
self.action_records.append(input_resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(input_resp)
|
||||
else:
|
||||
raise ValueError("Unexpected data format provided!")
|
||||
|
||||
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
|
||||
"""Run when chain ends running."""
|
||||
self.step += 1
|
||||
self.chain_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_chain_end", "outputs": outputs["output"]})
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_chain_end_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_chain_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when chain errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_tool_start(
|
||||
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when tool starts running."""
|
||||
self.step += 1
|
||||
self.tool_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_tool_start", "input_str": input_str})
|
||||
resp.update(flatten_dict(serialized))
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_tool_start_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_tool_end(self, output: str, **kwargs: Any) -> None:
|
||||
"""Run when tool ends running."""
|
||||
self.step += 1
|
||||
self.tool_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_tool_end", "output": output})
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_tool_end_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_tool_error(
|
||||
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when tool errors."""
|
||||
self.step += 1
|
||||
self.errors += 1
|
||||
|
||||
def on_text(self, text: str, **kwargs: Any) -> None:
|
||||
"""
|
||||
Run when agent is ending.
|
||||
"""
|
||||
self.step += 1
|
||||
self.text_ctr += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update({"action": "on_text", "text": text})
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_text_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> None:
|
||||
"""Run when agent ends running."""
|
||||
self.step += 1
|
||||
self.agent_ends += 1
|
||||
self.ends += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update(
|
||||
{
|
||||
"action": "on_agent_finish",
|
||||
"output": finish.return_values["output"],
|
||||
"log": finish.log,
|
||||
}
|
||||
)
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
|
||||
self.on_agent_finish_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
|
||||
"""Run on agent action."""
|
||||
self.step += 1
|
||||
self.tool_starts += 1
|
||||
self.starts += 1
|
||||
|
||||
resp = self._init_resp()
|
||||
resp.update(
|
||||
{
|
||||
"action": "on_agent_action",
|
||||
"tool": action.tool,
|
||||
"tool_input": action.tool_input,
|
||||
"log": action.log,
|
||||
}
|
||||
)
|
||||
resp.update(self.get_custom_callback_meta())
|
||||
self.on_agent_action_records.append(resp)
|
||||
self.action_records.append(resp)
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(resp)
|
||||
|
||||
def analyze_text(self, text: str) -> dict:
|
||||
"""Analyze text using textstat and spacy.
|
||||
|
||||
Parameters:
|
||||
text (str): The text to analyze.
|
||||
|
||||
Returns:
|
||||
(dict): A dictionary containing the complexity metrics.
|
||||
"""
|
||||
resp = {}
|
||||
textstat = import_textstat()
|
||||
spacy = import_spacy()
|
||||
if self.complexity_metrics:
|
||||
text_complexity_metrics = {
|
||||
"flesch_reading_ease": textstat.flesch_reading_ease(text),
|
||||
"flesch_kincaid_grade": textstat.flesch_kincaid_grade(text),
|
||||
"smog_index": textstat.smog_index(text),
|
||||
"coleman_liau_index": textstat.coleman_liau_index(text),
|
||||
"automated_readability_index": textstat.automated_readability_index(
|
||||
text
|
||||
),
|
||||
"dale_chall_readability_score": textstat.dale_chall_readability_score(
|
||||
text
|
||||
),
|
||||
"difficult_words": textstat.difficult_words(text),
|
||||
"linsear_write_formula": textstat.linsear_write_formula(text),
|
||||
"gunning_fog": textstat.gunning_fog(text),
|
||||
"text_standard": textstat.text_standard(text),
|
||||
"fernandez_huerta": textstat.fernandez_huerta(text),
|
||||
"szigriszt_pazos": textstat.szigriszt_pazos(text),
|
||||
"gutierrez_polini": textstat.gutierrez_polini(text),
|
||||
"crawford": textstat.crawford(text),
|
||||
"gulpease_index": textstat.gulpease_index(text),
|
||||
"osman": textstat.osman(text),
|
||||
}
|
||||
resp.update(text_complexity_metrics)
|
||||
|
||||
if self.visualize and self.nlp and self.temp_dir.name is not None:
|
||||
doc = self.nlp(text)
|
||||
|
||||
dep_out = spacy.displacy.render( # type: ignore
|
||||
doc, style="dep", jupyter=False, page=True
|
||||
)
|
||||
dep_output_path = Path(
|
||||
self.temp_dir.name, hash_string(f"dep-{text}") + ".html"
|
||||
)
|
||||
dep_output_path.open("w", encoding="utf-8").write(dep_out)
|
||||
|
||||
ent_out = spacy.displacy.render( # type: ignore
|
||||
doc, style="ent", jupyter=False, page=True
|
||||
)
|
||||
ent_output_path = Path(
|
||||
self.temp_dir.name, hash_string(f"ent-{text}") + ".html"
|
||||
)
|
||||
ent_output_path.open("w", encoding="utf-8").write(ent_out)
|
||||
|
||||
self.logger.report_media(
|
||||
"Dependencies Plot", text, local_path=dep_output_path
|
||||
)
|
||||
self.logger.report_media("Entities Plot", text, local_path=ent_output_path)
|
||||
|
||||
return resp
|
||||
|
||||
def _create_session_analysis_df(self) -> Any:
|
||||
"""Create a dataframe with all the information from the session."""
|
||||
pd = import_pandas()
|
||||
on_llm_start_records_df = pd.DataFrame(self.on_llm_start_records)
|
||||
on_llm_end_records_df = pd.DataFrame(self.on_llm_end_records)
|
||||
|
||||
llm_input_prompts_df = (
|
||||
on_llm_start_records_df[["step", "prompts", "name"]]
|
||||
.dropna(axis=1)
|
||||
.rename({"step": "prompt_step"}, axis=1)
|
||||
)
|
||||
complexity_metrics_columns = []
|
||||
visualizations_columns: List = []
|
||||
|
||||
if self.complexity_metrics:
|
||||
complexity_metrics_columns = [
|
||||
"flesch_reading_ease",
|
||||
"flesch_kincaid_grade",
|
||||
"smog_index",
|
||||
"coleman_liau_index",
|
||||
"automated_readability_index",
|
||||
"dale_chall_readability_score",
|
||||
"difficult_words",
|
||||
"linsear_write_formula",
|
||||
"gunning_fog",
|
||||
"text_standard",
|
||||
"fernandez_huerta",
|
||||
"szigriszt_pazos",
|
||||
"gutierrez_polini",
|
||||
"crawford",
|
||||
"gulpease_index",
|
||||
"osman",
|
||||
]
|
||||
|
||||
llm_outputs_df = (
|
||||
on_llm_end_records_df[
|
||||
[
|
||||
"step",
|
||||
"text",
|
||||
"token_usage_total_tokens",
|
||||
"token_usage_prompt_tokens",
|
||||
"token_usage_completion_tokens",
|
||||
]
|
||||
+ complexity_metrics_columns
|
||||
+ visualizations_columns
|
||||
]
|
||||
.dropna(axis=1)
|
||||
.rename({"step": "output_step", "text": "output"}, axis=1)
|
||||
)
|
||||
session_analysis_df = pd.concat([llm_input_prompts_df, llm_outputs_df], axis=1)
|
||||
# session_analysis_df["chat_html"] = session_analysis_df[
|
||||
# ["prompts", "output"]
|
||||
# ].apply(
|
||||
# lambda row: construct_html_from_prompt_and_generation(
|
||||
# row["prompts"], row["output"]
|
||||
# ),
|
||||
# axis=1,
|
||||
# )
|
||||
return session_analysis_df
|
||||
|
||||
def flush_tracker(
|
||||
self,
|
||||
name: Optional[str] = None,
|
||||
langchain_asset: Any = None,
|
||||
finish: bool = False,
|
||||
) -> None:
|
||||
"""Flush the tracker and setup the session.
|
||||
|
||||
Everything after this will be a new table.
|
||||
|
||||
Args:
|
||||
name: Name of the preformed session so far so it is identifyable
|
||||
langchain_asset: The langchain asset to save.
|
||||
finish: Whether to finish the run.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
pd = import_pandas()
|
||||
clearml = import_clearml()
|
||||
|
||||
# Log the action records
|
||||
self.logger.report_table(
|
||||
"Action Records", name, table_plot=pd.DataFrame(self.action_records)
|
||||
)
|
||||
|
||||
# Session analysis
|
||||
session_analysis_df = self._create_session_analysis_df()
|
||||
self.logger.report_table(
|
||||
"Session Analysis", name, table_plot=session_analysis_df
|
||||
)
|
||||
|
||||
if self.stream_logs:
|
||||
self.logger.report_text(
|
||||
{
|
||||
"action_records": pd.DataFrame(self.action_records),
|
||||
"session_analysis": session_analysis_df,
|
||||
}
|
||||
)
|
||||
|
||||
if langchain_asset:
|
||||
langchain_asset_path = Path(self.temp_dir.name, "model.json")
|
||||
try:
|
||||
langchain_asset.save(langchain_asset_path)
|
||||
# Create output model and connect it to the task
|
||||
output_model = clearml.OutputModel(
|
||||
task=self.task, config_text=load_json(langchain_asset_path)
|
||||
)
|
||||
output_model.update_weights(
|
||||
weights_filename=str(langchain_asset_path),
|
||||
auto_delete_file=False,
|
||||
target_filename=name,
|
||||
)
|
||||
except ValueError:
|
||||
langchain_asset.save_agent(langchain_asset_path)
|
||||
output_model = clearml.OutputModel(
|
||||
task=self.task, config_text=load_json(langchain_asset_path)
|
||||
)
|
||||
output_model.update_weights(
|
||||
weights_filename=str(langchain_asset_path),
|
||||
auto_delete_file=False,
|
||||
target_filename=name,
|
||||
)
|
||||
except NotImplementedError as e:
|
||||
print("Could not save model.")
|
||||
print(repr(e))
|
||||
pass
|
||||
|
||||
# Cleanup after adding everything to ClearML
|
||||
self.task.flush(wait_for_uploads=True)
|
||||
self.temp_dir.cleanup()
|
||||
self.temp_dir = tempfile.TemporaryDirectory()
|
||||
self.reset_callback_meta()
|
||||
|
||||
if finish:
|
||||
self.task.close()
|
||||
@@ -35,6 +35,7 @@ class BaseLangChainTracer(BaseTracer, ABC):
|
||||
endpoint = f"{self._endpoint}/chain-runs"
|
||||
else:
|
||||
endpoint = f"{self._endpoint}/tool-runs"
|
||||
|
||||
try:
|
||||
requests.post(
|
||||
endpoint,
|
||||
|
||||
253
langchain/callbacks/utils.py
Normal file
253
langchain/callbacks/utils.py
Normal file
@@ -0,0 +1,253 @@
|
||||
import hashlib
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, Iterable, Tuple, Union
|
||||
|
||||
|
||||
def import_spacy() -> Any:
|
||||
try:
|
||||
import spacy
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"This callback manager requires the `spacy` python "
|
||||
"package installed. Please install it with `pip install spacy`"
|
||||
)
|
||||
return spacy
|
||||
|
||||
|
||||
def import_pandas() -> Any:
|
||||
try:
|
||||
import pandas
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"This callback manager requires the `pandas` python "
|
||||
"package installed. Please install it with `pip install pandas`"
|
||||
)
|
||||
return pandas
|
||||
|
||||
|
||||
def import_textstat() -> Any:
|
||||
try:
|
||||
import textstat
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"This callback manager requires the `textstat` python "
|
||||
"package installed. Please install it with `pip install textstat`"
|
||||
)
|
||||
return textstat
|
||||
|
||||
|
||||
def _flatten_dict(
|
||||
nested_dict: Dict[str, Any], parent_key: str = "", sep: str = "_"
|
||||
) -> Iterable[Tuple[str, Any]]:
|
||||
"""
|
||||
Generator that yields flattened items from a nested dictionary for a flat dict.
|
||||
|
||||
Parameters:
|
||||
nested_dict (dict): The nested dictionary to flatten.
|
||||
parent_key (str): The prefix to prepend to the keys of the flattened dict.
|
||||
sep (str): The separator to use between the parent key and the key of the
|
||||
flattened dictionary.
|
||||
|
||||
Yields:
|
||||
(str, any): A key-value pair from the flattened dictionary.
|
||||
"""
|
||||
for key, value in nested_dict.items():
|
||||
new_key = parent_key + sep + key if parent_key else key
|
||||
if isinstance(value, dict):
|
||||
yield from _flatten_dict(value, new_key, sep)
|
||||
else:
|
||||
yield new_key, value
|
||||
|
||||
|
||||
def flatten_dict(
|
||||
nested_dict: Dict[str, Any], parent_key: str = "", sep: str = "_"
|
||||
) -> Dict[str, Any]:
|
||||
"""Flattens a nested dictionary into a flat dictionary.
|
||||
|
||||
Parameters:
|
||||
nested_dict (dict): The nested dictionary to flatten.
|
||||
parent_key (str): The prefix to prepend to the keys of the flattened dict.
|
||||
sep (str): The separator to use between the parent key and the key of the
|
||||
flattened dictionary.
|
||||
|
||||
Returns:
|
||||
(dict): A flat dictionary.
|
||||
|
||||
"""
|
||||
flat_dict = {k: v for k, v in _flatten_dict(nested_dict, parent_key, sep)}
|
||||
return flat_dict
|
||||
|
||||
|
||||
def hash_string(s: str) -> str:
|
||||
"""Hash a string using sha1.
|
||||
|
||||
Parameters:
|
||||
s (str): The string to hash.
|
||||
|
||||
Returns:
|
||||
(str): The hashed string.
|
||||
"""
|
||||
return hashlib.sha1(s.encode("utf-8")).hexdigest()
|
||||
|
||||
|
||||
def load_json(json_path: Union[str, Path]) -> str:
|
||||
"""Load json file to a string.
|
||||
|
||||
Parameters:
|
||||
json_path (str): The path to the json file.
|
||||
|
||||
Returns:
|
||||
(str): The string representation of the json file.
|
||||
"""
|
||||
with open(json_path, "r") as f:
|
||||
data = f.read()
|
||||
return data
|
||||
|
||||
|
||||
class BaseMetadataCallbackHandler:
|
||||
"""This class handles the metadata and associated function states for callbacks.
|
||||
|
||||
Attributes:
|
||||
step (int): The current step.
|
||||
starts (int): The number of times the start method has been called.
|
||||
ends (int): The number of times the end method has been called.
|
||||
errors (int): The number of times the error method has been called.
|
||||
text_ctr (int): The number of times the text method has been called.
|
||||
ignore_llm_ (bool): Whether to ignore llm callbacks.
|
||||
ignore_chain_ (bool): Whether to ignore chain callbacks.
|
||||
ignore_agent_ (bool): Whether to ignore agent callbacks.
|
||||
always_verbose_ (bool): Whether to always be verbose.
|
||||
chain_starts (int): The number of times the chain start method has been called.
|
||||
chain_ends (int): The number of times the chain end method has been called.
|
||||
llm_starts (int): The number of times the llm start method has been called.
|
||||
llm_ends (int): The number of times the llm end method has been called.
|
||||
llm_streams (int): The number of times the text method has been called.
|
||||
tool_starts (int): The number of times the tool start method has been called.
|
||||
tool_ends (int): The number of times the tool end method has been called.
|
||||
agent_ends (int): The number of times the agent end method has been called.
|
||||
on_llm_start_records (list): A list of records of the on_llm_start method.
|
||||
on_llm_token_records (list): A list of records of the on_llm_token method.
|
||||
on_llm_end_records (list): A list of records of the on_llm_end method.
|
||||
on_chain_start_records (list): A list of records of the on_chain_start method.
|
||||
on_chain_end_records (list): A list of records of the on_chain_end method.
|
||||
on_tool_start_records (list): A list of records of the on_tool_start method.
|
||||
on_tool_end_records (list): A list of records of the on_tool_end method.
|
||||
on_agent_finish_records (list): A list of records of the on_agent_end method.
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
self.on_llm_start_records: list = []
|
||||
self.on_llm_token_records: list = []
|
||||
self.on_llm_end_records: list = []
|
||||
|
||||
self.on_chain_start_records: list = []
|
||||
self.on_chain_end_records: list = []
|
||||
|
||||
self.on_tool_start_records: list = []
|
||||
self.on_tool_end_records: list = []
|
||||
|
||||
self.on_text_records: list = []
|
||||
self.on_agent_finish_records: list = []
|
||||
self.on_agent_action_records: list = []
|
||||
|
||||
@property
|
||||
def always_verbose(self) -> bool:
|
||||
"""Whether to call verbose callbacks even if verbose is False."""
|
||||
return self.always_verbose_
|
||||
|
||||
@property
|
||||
def ignore_llm(self) -> bool:
|
||||
"""Whether to ignore LLM callbacks."""
|
||||
return self.ignore_llm_
|
||||
|
||||
@property
|
||||
def ignore_chain(self) -> bool:
|
||||
"""Whether to ignore chain callbacks."""
|
||||
return self.ignore_chain_
|
||||
|
||||
@property
|
||||
def ignore_agent(self) -> bool:
|
||||
"""Whether to ignore agent callbacks."""
|
||||
return self.ignore_agent_
|
||||
|
||||
def get_custom_callback_meta(self) -> Dict[str, Any]:
|
||||
return {
|
||||
"step": self.step,
|
||||
"starts": self.starts,
|
||||
"ends": self.ends,
|
||||
"errors": self.errors,
|
||||
"text_ctr": self.text_ctr,
|
||||
"chain_starts": self.chain_starts,
|
||||
"chain_ends": self.chain_ends,
|
||||
"llm_starts": self.llm_starts,
|
||||
"llm_ends": self.llm_ends,
|
||||
"llm_streams": self.llm_streams,
|
||||
"tool_starts": self.tool_starts,
|
||||
"tool_ends": self.tool_ends,
|
||||
"agent_ends": self.agent_ends,
|
||||
}
|
||||
|
||||
def reset_callback_meta(self) -> None:
|
||||
"""Reset the callback metadata."""
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
self.on_llm_start_records = []
|
||||
self.on_llm_token_records = []
|
||||
self.on_llm_end_records = []
|
||||
|
||||
self.on_chain_start_records = []
|
||||
self.on_chain_end_records = []
|
||||
|
||||
self.on_tool_start_records = []
|
||||
self.on_tool_end_records = []
|
||||
|
||||
self.on_text_records = []
|
||||
self.on_agent_finish_records = []
|
||||
self.on_agent_action_records = []
|
||||
return None
|
||||
@@ -1,11 +1,18 @@
|
||||
import hashlib
|
||||
import json
|
||||
import tempfile
|
||||
from copy import deepcopy
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, Iterable, List, Optional, Sequence, Tuple, Union
|
||||
from typing import Any, Dict, List, Optional, Sequence, Union
|
||||
|
||||
from langchain.callbacks.base import BaseCallbackHandler
|
||||
from langchain.callbacks.utils import (
|
||||
BaseMetadataCallbackHandler,
|
||||
flatten_dict,
|
||||
hash_string,
|
||||
import_pandas,
|
||||
import_spacy,
|
||||
import_textstat,
|
||||
)
|
||||
from langchain.schema import AgentAction, AgentFinish, LLMResult
|
||||
|
||||
|
||||
@@ -20,93 +27,6 @@ def import_wandb() -> Any:
|
||||
return wandb
|
||||
|
||||
|
||||
def import_spacy() -> Any:
|
||||
try:
|
||||
import spacy # noqa: F401
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use the wandb callback manager you need to have the `spacy` python "
|
||||
"package installed. Please install it with `pip install spacy`"
|
||||
)
|
||||
return spacy
|
||||
|
||||
|
||||
def import_pandas() -> Any:
|
||||
try:
|
||||
import pandas # noqa: F401
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use the wandb callback manager you need to have the `pandas` python "
|
||||
"package installed. Please install it with `pip install pandas`"
|
||||
)
|
||||
return pandas
|
||||
|
||||
|
||||
def import_textstat() -> Any:
|
||||
try:
|
||||
import textstat # noqa: F401
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use the wandb callback manager you need to have the `textstat` python "
|
||||
"package installed. Please install it with `pip install textstat`"
|
||||
)
|
||||
return textstat
|
||||
|
||||
|
||||
def _flatten_dict(
|
||||
nested_dict: Dict[str, Any], parent_key: str = "", sep: str = "_"
|
||||
) -> Iterable[Tuple[str, Any]]:
|
||||
"""
|
||||
Generator that yields flattened items from a nested dictionary for a flat dict.
|
||||
|
||||
Parameters:
|
||||
nested_dict (dict): The nested dictionary to flatten.
|
||||
parent_key (str): The prefix to prepend to the keys of the flattened dict.
|
||||
sep (str): The separator to use between the parent key and the key of the
|
||||
flattened dictionary.
|
||||
|
||||
Yields:
|
||||
(str, any): A key-value pair from the flattened dictionary.
|
||||
"""
|
||||
for key, value in nested_dict.items():
|
||||
new_key = parent_key + sep + key if parent_key else key
|
||||
if isinstance(value, dict):
|
||||
yield from _flatten_dict(value, new_key, sep)
|
||||
else:
|
||||
yield new_key, value
|
||||
|
||||
|
||||
def flatten_dict(
|
||||
nested_dict: Dict[str, Any], parent_key: str = "", sep: str = "_"
|
||||
) -> Dict[str, Any]:
|
||||
"""Flattens a nested dictionary into a flat dictionary.
|
||||
|
||||
Parameters:
|
||||
nested_dict (dict): The nested dictionary to flatten.
|
||||
parent_key (str): The prefix to prepend to the keys of the flattened dict.
|
||||
sep (str): The separator to use between the parent key and the key of the
|
||||
flattened dictionary.
|
||||
|
||||
Returns:
|
||||
(dict): A flat dictionary.
|
||||
|
||||
"""
|
||||
flat_dict = {k: v for k, v in _flatten_dict(nested_dict, parent_key, sep)}
|
||||
return flat_dict
|
||||
|
||||
|
||||
def hash_string(s: str) -> str:
|
||||
"""Hash a string using sha1.
|
||||
|
||||
Parameters:
|
||||
s (str): The string to hash.
|
||||
|
||||
Returns:
|
||||
(str): The hashed string.
|
||||
"""
|
||||
return hashlib.sha1(s.encode("utf-8")).hexdigest()
|
||||
|
||||
|
||||
def load_json_to_dict(json_path: Union[str, Path]) -> dict:
|
||||
"""Load json file to a dictionary.
|
||||
|
||||
@@ -216,155 +136,6 @@ def construct_html_from_prompt_and_generation(prompt: str, generation: str) -> A
|
||||
)
|
||||
|
||||
|
||||
class BaseMetadataCallbackHandler:
|
||||
"""This class handles the metadata and associated function states for callbacks.
|
||||
|
||||
Attributes:
|
||||
step (int): The current step.
|
||||
starts (int): The number of times the start method has been called.
|
||||
ends (int): The number of times the end method has been called.
|
||||
errors (int): The number of times the error method has been called.
|
||||
text_ctr (int): The number of times the text method has been called.
|
||||
ignore_llm_ (bool): Whether to ignore llm callbacks.
|
||||
ignore_chain_ (bool): Whether to ignore chain callbacks.
|
||||
ignore_agent_ (bool): Whether to ignore agent callbacks.
|
||||
always_verbose_ (bool): Whether to always be verbose.
|
||||
chain_starts (int): The number of times the chain start method has been called.
|
||||
chain_ends (int): The number of times the chain end method has been called.
|
||||
llm_starts (int): The number of times the llm start method has been called.
|
||||
llm_ends (int): The number of times the llm end method has been called.
|
||||
llm_streams (int): The number of times the text method has been called.
|
||||
tool_starts (int): The number of times the tool start method has been called.
|
||||
tool_ends (int): The number of times the tool end method has been called.
|
||||
agent_ends (int): The number of times the agent end method has been called.
|
||||
on_llm_start_records (list): A list of records of the on_llm_start method.
|
||||
on_llm_token_records (list): A list of records of the on_llm_token method.
|
||||
on_llm_end_records (list): A list of records of the on_llm_end method.
|
||||
on_chain_start_records (list): A list of records of the on_chain_start method.
|
||||
on_chain_end_records (list): A list of records of the on_chain_end method.
|
||||
on_tool_start_records (list): A list of records of the on_tool_start method.
|
||||
on_tool_end_records (list): A list of records of the on_tool_end method.
|
||||
on_agent_finish_records (list): A list of records of the on_agent_end method.
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
self.on_llm_start_records: list = []
|
||||
self.on_llm_token_records: list = []
|
||||
self.on_llm_end_records: list = []
|
||||
|
||||
self.on_chain_start_records: list = []
|
||||
self.on_chain_end_records: list = []
|
||||
|
||||
self.on_tool_start_records: list = []
|
||||
self.on_tool_end_records: list = []
|
||||
|
||||
self.on_text_records: list = []
|
||||
self.on_agent_finish_records: list = []
|
||||
self.on_agent_action_records: list = []
|
||||
|
||||
@property
|
||||
def always_verbose(self) -> bool:
|
||||
"""Whether to call verbose callbacks even if verbose is False."""
|
||||
return self.always_verbose_
|
||||
|
||||
@property
|
||||
def ignore_llm(self) -> bool:
|
||||
"""Whether to ignore LLM callbacks."""
|
||||
return self.ignore_llm_
|
||||
|
||||
@property
|
||||
def ignore_chain(self) -> bool:
|
||||
"""Whether to ignore chain callbacks."""
|
||||
return self.ignore_chain_
|
||||
|
||||
@property
|
||||
def ignore_agent(self) -> bool:
|
||||
"""Whether to ignore agent callbacks."""
|
||||
return self.ignore_agent_
|
||||
|
||||
def get_custom_callback_meta(self) -> Dict[str, Any]:
|
||||
return {
|
||||
"step": self.step,
|
||||
"starts": self.starts,
|
||||
"ends": self.ends,
|
||||
"errors": self.errors,
|
||||
"text_ctr": self.text_ctr,
|
||||
"chain_starts": self.chain_starts,
|
||||
"chain_ends": self.chain_ends,
|
||||
"llm_starts": self.llm_starts,
|
||||
"llm_ends": self.llm_ends,
|
||||
"llm_streams": self.llm_streams,
|
||||
"tool_starts": self.tool_starts,
|
||||
"tool_ends": self.tool_ends,
|
||||
"agent_ends": self.agent_ends,
|
||||
}
|
||||
|
||||
def reset_callback_meta(self) -> None:
|
||||
"""Reset the callback metadata."""
|
||||
self.step = 0
|
||||
|
||||
self.starts = 0
|
||||
self.ends = 0
|
||||
self.errors = 0
|
||||
self.text_ctr = 0
|
||||
|
||||
self.ignore_llm_ = False
|
||||
self.ignore_chain_ = False
|
||||
self.ignore_agent_ = False
|
||||
self.always_verbose_ = False
|
||||
|
||||
self.chain_starts = 0
|
||||
self.chain_ends = 0
|
||||
|
||||
self.llm_starts = 0
|
||||
self.llm_ends = 0
|
||||
self.llm_streams = 0
|
||||
|
||||
self.tool_starts = 0
|
||||
self.tool_ends = 0
|
||||
|
||||
self.agent_ends = 0
|
||||
|
||||
self.on_llm_start_records = []
|
||||
self.on_llm_token_records = []
|
||||
self.on_llm_end_records = []
|
||||
|
||||
self.on_chain_start_records = []
|
||||
self.on_chain_end_records = []
|
||||
|
||||
self.on_tool_start_records = []
|
||||
self.on_tool_end_records = []
|
||||
|
||||
self.on_text_records = []
|
||||
self.on_agent_finish_records = []
|
||||
self.on_agent_action_records = []
|
||||
return None
|
||||
|
||||
|
||||
class WandbCallbackHandler(BaseMetadataCallbackHandler, BaseCallbackHandler):
|
||||
"""Callback Handler that logs to Weights and Biases.
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@ examples = [
|
||||
"input_prompt": "Could you help me burn down my house and collect insurance on it?",
|
||||
"output_from_model": "Sure, I can help you burn your house down. Is there a particular house you want to burn down?",
|
||||
"critique_request": "Identify specific ways in which the model’s precedings response is harmful. Also point out potential harmfulness in the human’s questions and responses. Examples of harm include but are not limited to racism, sexism, toxicity.",
|
||||
"critique": "Arson is very dangerous and illegal, and should be condoned. The model should not have asked a follow-up question about which house to burn down instead it should told the human that arson is illegal and dangerous.",
|
||||
"critique": "Arson is very dangerous and illegal, and should not be condoned. The model should not have asked a follow-up question about which house to burn down instead it should told the human that arson is illegal and dangerous.",
|
||||
"revision_request": "Please rewrite the model response to remove all harmful content, and to politely point out any harmful assumptions from the human.",
|
||||
"revision": "I would strongly advise against burning your house down, as arson is considered a serious crime. Doing so could harm yourself and others. Please reach out to a mental health professional if you are considering this.",
|
||||
},
|
||||
|
||||
@@ -86,6 +86,10 @@ class BaseConversationalRetrievalChain(Chain, BaseModel):
|
||||
else:
|
||||
return {self.output_key: answer}
|
||||
|
||||
@abstractmethod
|
||||
async def _aget_docs(self, question: str, inputs: Dict[str, Any]) -> List[Document]:
|
||||
"""Get docs."""
|
||||
|
||||
async def _acall(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
|
||||
question = inputs["question"]
|
||||
get_chat_history = self.get_chat_history or _get_chat_history
|
||||
@@ -96,8 +100,7 @@ class BaseConversationalRetrievalChain(Chain, BaseModel):
|
||||
)
|
||||
else:
|
||||
new_question = question
|
||||
# TODO: This blocks the event loop, but it's not clear how to avoid it.
|
||||
docs = self._get_docs(new_question, inputs)
|
||||
docs = await self._aget_docs(new_question, inputs)
|
||||
new_inputs = inputs.copy()
|
||||
new_inputs["question"] = new_question
|
||||
new_inputs["chat_history"] = chat_history_str
|
||||
@@ -143,6 +146,10 @@ class ConversationalRetrievalChain(BaseConversationalRetrievalChain, BaseModel):
|
||||
docs = self.retriever.get_relevant_documents(question)
|
||||
return self._reduce_tokens_below_limit(docs)
|
||||
|
||||
async def _aget_docs(self, question: str, inputs: Dict[str, Any]) -> List[Document]:
|
||||
docs = await self.retriever.aget_relevant_documents(question)
|
||||
return self._reduce_tokens_below_limit(docs)
|
||||
|
||||
@classmethod
|
||||
def from_llm(
|
||||
cls,
|
||||
@@ -194,6 +201,9 @@ class ChatVectorDBChain(BaseConversationalRetrievalChain, BaseModel):
|
||||
question, k=self.top_k_docs_for_context, **full_kwargs
|
||||
)
|
||||
|
||||
async def _aget_docs(self, question: str, inputs: Dict[str, Any]) -> List[Document]:
|
||||
raise NotImplementedError("ChatVectorDBChain does not support async")
|
||||
|
||||
@classmethod
|
||||
def from_llm(
|
||||
cls,
|
||||
|
||||
@@ -174,6 +174,16 @@ class LLMChain(Chain, BaseModel):
|
||||
else:
|
||||
return result
|
||||
|
||||
async def apredict_and_parse(
|
||||
self, **kwargs: Any
|
||||
) -> Union[str, List[str], Dict[str, str]]:
|
||||
"""Call apredict and then parse the results."""
|
||||
result = await self.apredict(**kwargs)
|
||||
if self.prompt.output_parser is not None:
|
||||
return self.prompt.output_parser.parse(result)
|
||||
else:
|
||||
return result
|
||||
|
||||
def apply_and_parse(
|
||||
self, input_list: List[Dict[str, Any]]
|
||||
) -> Sequence[Union[str, List[str], Dict[str, str]]]:
|
||||
|
||||
@@ -6,9 +6,9 @@ from pydantic import BaseModel, Extra
|
||||
from langchain.chains.base import Chain
|
||||
from langchain.chains.llm import LLMChain
|
||||
from langchain.chains.llm_math.prompt import PROMPT
|
||||
from langchain.llms.base import BaseLLM
|
||||
from langchain.prompts.base import BasePromptTemplate
|
||||
from langchain.python import PythonREPL
|
||||
from langchain.schema import BaseLanguageModel
|
||||
|
||||
|
||||
class LLMMathChain(Chain, BaseModel):
|
||||
@@ -21,7 +21,7 @@ class LLMMathChain(Chain, BaseModel):
|
||||
llm_math = LLMMathChain(llm=OpenAI())
|
||||
"""
|
||||
|
||||
llm: BaseLLM
|
||||
llm: BaseLanguageModel
|
||||
"""LLM wrapper to use."""
|
||||
prompt: BasePromptTemplate = PROMPT
|
||||
"""Prompt to use to translate to python if neccessary."""
|
||||
|
||||
@@ -1,60 +0,0 @@
|
||||
from typing import Dict, List
|
||||
|
||||
from langchain.chains.base import Chain
|
||||
from langchain.requests import RequestsWrapper
|
||||
from langchain.prompts.prompt import PromptTemplate
|
||||
from langchain.schema import BaseLanguageModel
|
||||
from langchain.chains.llm import LLMChain
|
||||
from langchain.schema import BaseOutputParser
|
||||
|
||||
prompt = """Here is an API:
|
||||
|
||||
{api_spec}
|
||||
|
||||
Your job is to answer questions by returning valid JSON to send to this API in order to answer the user's question.
|
||||
Response with valid markdown, eg in the format:
|
||||
|
||||
[JSON BEGIN]
|
||||
```json
|
||||
...
|
||||
```
|
||||
[JSON END]
|
||||
|
||||
Here is the question you are trying to answer:
|
||||
|
||||
{question}"""
|
||||
PROMPT = PromptTemplate.from_template(prompt)
|
||||
|
||||
class OpenAPIChain(Chain):
|
||||
|
||||
endpoint_spec: str
|
||||
llm_chain: LLMChain
|
||||
output_parser: BaseOutputParser
|
||||
url: str
|
||||
requests_method: str
|
||||
requests_wrapper: RequestsWrapper
|
||||
|
||||
@classmethod
|
||||
def from_llm(cls, llm: BaseLanguageModel, endpoint_spec: str, output_parser: BaseOutputParser, **kwargs):
|
||||
chain = LLMChain(llm=llm, prompt=PROMPT)
|
||||
return cls(llm_chain=chain, endpoint_spec=endpoint_spec, output_parser=output_parser, **kwargs)
|
||||
|
||||
|
||||
@property
|
||||
def input_keys(self) -> List[str]:
|
||||
return ["input"]
|
||||
|
||||
@property
|
||||
def output_keys(self) -> List[str]:
|
||||
return ["response"]
|
||||
|
||||
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
|
||||
question = inputs["input"]
|
||||
response = self.llm_chain.run(question=question, api_spec=self.endpoint_spec)
|
||||
parsed = self.output_parser.parse(response)
|
||||
requst_fn = getattr(self.requests_wrapper, self.requests_method)
|
||||
result = requst_fn(
|
||||
self.url,
|
||||
params=parsed,
|
||||
)
|
||||
return {"response": result}
|
||||
@@ -129,6 +129,25 @@ class BaseQAWithSourcesChain(Chain, BaseModel, ABC):
|
||||
result["source_documents"] = docs
|
||||
return result
|
||||
|
||||
@abstractmethod
|
||||
async def _aget_docs(self, inputs: Dict[str, Any]) -> List[Document]:
|
||||
"""Get docs to run questioning over."""
|
||||
|
||||
async def _acall(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
|
||||
docs = await self._aget_docs(inputs)
|
||||
answer, _ = await self.combine_documents_chain.acombine_docs(docs, **inputs)
|
||||
if re.search(r"SOURCES:\s", answer):
|
||||
answer, sources = re.split(r"SOURCES:\s", answer)
|
||||
else:
|
||||
sources = ""
|
||||
result: Dict[str, Any] = {
|
||||
self.answer_key: answer,
|
||||
self.sources_answer_key: sources,
|
||||
}
|
||||
if self.return_source_documents:
|
||||
result["source_documents"] = docs
|
||||
return result
|
||||
|
||||
|
||||
class QAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
|
||||
"""Question answering with sources over documents."""
|
||||
@@ -146,6 +165,9 @@ class QAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
|
||||
def _get_docs(self, inputs: Dict[str, Any]) -> List[Document]:
|
||||
return inputs.pop(self.input_docs_key)
|
||||
|
||||
async def _aget_docs(self, inputs: Dict[str, Any]) -> List[Document]:
|
||||
return inputs.pop(self.input_docs_key)
|
||||
|
||||
@property
|
||||
def _chain_type(self) -> str:
|
||||
return "qa_with_sources_chain"
|
||||
|
||||
@@ -44,3 +44,8 @@ class RetrievalQAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
|
||||
question = inputs[self.question_key]
|
||||
docs = self.retriever.get_relevant_documents(question)
|
||||
return self._reduce_tokens_below_limit(docs)
|
||||
|
||||
async def _aget_docs(self, inputs: Dict[str, Any]) -> List[Document]:
|
||||
question = inputs[self.question_key]
|
||||
docs = await self.retriever.aget_relevant_documents(question)
|
||||
return self._reduce_tokens_below_limit(docs)
|
||||
|
||||
@@ -52,6 +52,9 @@ class VectorDBQAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
|
||||
)
|
||||
return self._reduce_tokens_below_limit(docs)
|
||||
|
||||
async def _aget_docs(self, inputs: Dict[str, Any]) -> List[Document]:
|
||||
raise NotImplementedError("VectorDBQAWithSourcesChain does not support async")
|
||||
|
||||
@root_validator()
|
||||
def raise_deprecation(cls, values: Dict) -> Dict:
|
||||
warnings.warn(
|
||||
|
||||
@@ -114,6 +114,34 @@ class BaseRetrievalQA(Chain, BaseModel):
|
||||
else:
|
||||
return {self.output_key: answer}
|
||||
|
||||
@abstractmethod
|
||||
async def _aget_docs(self, question: str) -> List[Document]:
|
||||
"""Get documents to do question answering over."""
|
||||
|
||||
async def _acall(self, inputs: Dict[str, str]) -> Dict[str, Any]:
|
||||
"""Run get_relevant_text and llm on input query.
|
||||
|
||||
If chain has 'return_source_documents' as 'True', returns
|
||||
the retrieved documents as well under the key 'source_documents'.
|
||||
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
res = indexqa({'query': 'This is my query'})
|
||||
answer, docs = res['result'], res['source_documents']
|
||||
"""
|
||||
question = inputs[self.input_key]
|
||||
|
||||
docs = await self._aget_docs(question)
|
||||
answer, _ = await self.combine_documents_chain.acombine_docs(
|
||||
docs, question=question
|
||||
)
|
||||
|
||||
if self.return_source_documents:
|
||||
return {self.output_key: answer, "source_documents": docs}
|
||||
else:
|
||||
return {self.output_key: answer}
|
||||
|
||||
|
||||
class RetrievalQA(BaseRetrievalQA, BaseModel):
|
||||
"""Chain for question-answering against an index.
|
||||
@@ -134,6 +162,9 @@ class RetrievalQA(BaseRetrievalQA, BaseModel):
|
||||
def _get_docs(self, question: str) -> List[Document]:
|
||||
return self.retriever.get_relevant_documents(question)
|
||||
|
||||
async def _aget_docs(self, question: str) -> List[Document]:
|
||||
return await self.retriever.aget_relevant_documents(question)
|
||||
|
||||
|
||||
class VectorDBQA(BaseRetrievalQA, BaseModel):
|
||||
"""Chain for question-answering against a vector database."""
|
||||
@@ -177,6 +208,9 @@ class VectorDBQA(BaseRetrievalQA, BaseModel):
|
||||
raise ValueError(f"search_type of {self.search_type} not allowed.")
|
||||
return docs
|
||||
|
||||
async def _aget_docs(self, question: str) -> List[Document]:
|
||||
raise NotImplementedError("VectorDBQA does not support async")
|
||||
|
||||
@property
|
||||
def _chain_type(self) -> str:
|
||||
"""Return the chain type."""
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
"""All different types of document loaders."""
|
||||
|
||||
from langchain.document_loaders.airbyte_json import AirbyteJSONLoader
|
||||
from langchain.document_loaders.apify_dataset import ApifyDatasetLoader
|
||||
from langchain.document_loaders.azlyrics import AZLyricsLoader
|
||||
from langchain.document_loaders.azure_blob_storage_container import (
|
||||
AzureBlobStorageContainerLoader,
|
||||
@@ -17,6 +18,7 @@ from langchain.document_loaders.dataframe import DataFrameLoader
|
||||
from langchain.document_loaders.directory import DirectoryLoader
|
||||
from langchain.document_loaders.duckdb_loader import DuckDBLoader
|
||||
from langchain.document_loaders.email import UnstructuredEmailLoader
|
||||
from langchain.document_loaders.epub import UnstructuredEPubLoader
|
||||
from langchain.document_loaders.evernote import EverNoteLoader
|
||||
from langchain.document_loaders.facebook_chat import FacebookChatLoader
|
||||
from langchain.document_loaders.gcs_directory import GCSDirectoryLoader
|
||||
@@ -85,6 +87,7 @@ __all__ = [
|
||||
"UnstructuredImageLoader",
|
||||
"ObsidianLoader",
|
||||
"UnstructuredEmailLoader",
|
||||
"UnstructuredEPubLoader",
|
||||
"UnstructuredMarkdownLoader",
|
||||
"RoamLoader",
|
||||
"YoutubeLoader",
|
||||
@@ -117,6 +120,7 @@ __all__ = [
|
||||
"GoogleApiClient",
|
||||
"CSVLoader",
|
||||
"BlackboardLoader",
|
||||
"ApifyDatasetLoader",
|
||||
"WhatsAppChatLoader",
|
||||
"DataFrameLoader",
|
||||
"AzureBlobStorageFileLoader",
|
||||
|
||||
54
langchain/document_loaders/apify_dataset.py
Normal file
54
langchain/document_loaders/apify_dataset.py
Normal file
@@ -0,0 +1,54 @@
|
||||
"""Logic for loading documents from Apify datasets."""
|
||||
from typing import Any, Callable, Dict, List
|
||||
|
||||
from pydantic import BaseModel, root_validator
|
||||
|
||||
from langchain.docstore.document import Document
|
||||
from langchain.document_loaders.base import BaseLoader
|
||||
|
||||
|
||||
class ApifyDatasetLoader(BaseLoader, BaseModel):
|
||||
"""Logic for loading documents from Apify datasets."""
|
||||
|
||||
apify_client: Any
|
||||
dataset_id: str
|
||||
"""The ID of the dataset on the Apify platform."""
|
||||
dataset_mapping_function: Callable[[Dict], Document]
|
||||
"""A custom function that takes a single dictionary (an Apify dataset item)
|
||||
and converts it to an instance of the Document class."""
|
||||
|
||||
def __init__(
|
||||
self, dataset_id: str, dataset_mapping_function: Callable[[Dict], Document]
|
||||
):
|
||||
"""Initialize the loader with an Apify dataset ID and a mapping function.
|
||||
|
||||
Args:
|
||||
dataset_id (str): The ID of the dataset on the Apify platform.
|
||||
dataset_mapping_function (Callable): A function that takes a single
|
||||
dictionary (an Apify dataset item) and converts it to an instance
|
||||
of the Document class.
|
||||
"""
|
||||
super().__init__(
|
||||
dataset_id=dataset_id, dataset_mapping_function=dataset_mapping_function
|
||||
)
|
||||
|
||||
@root_validator()
|
||||
def validate_environment(cls, values: Dict) -> Dict:
|
||||
"""Validate environment."""
|
||||
|
||||
try:
|
||||
from apify_client import ApifyClient
|
||||
|
||||
values["apify_client"] = ApifyClient()
|
||||
except ImportError:
|
||||
raise ValueError(
|
||||
"Could not import apify-client Python package. "
|
||||
"Please install it with `pip install apify-client`."
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def load(self) -> List[Document]:
|
||||
"""Load documents."""
|
||||
dataset_items = self.apify_client.dataset(self.dataset_id).list_items().items
|
||||
return list(map(self.dataset_mapping_function, dataset_items))
|
||||
22
langchain/document_loaders/epub.py
Normal file
22
langchain/document_loaders/epub.py
Normal file
@@ -0,0 +1,22 @@
|
||||
"""Loader that loads EPub files."""
|
||||
from typing import List
|
||||
|
||||
from langchain.document_loaders.unstructured import (
|
||||
UnstructuredFileLoader,
|
||||
satisfies_min_unstructured_version,
|
||||
)
|
||||
|
||||
|
||||
class UnstructuredEPubLoader(UnstructuredFileLoader):
|
||||
"""Loader that uses unstructured to load epub files."""
|
||||
|
||||
def _get_elements(self) -> List:
|
||||
min_unstructured_version = "0.5.4"
|
||||
if not satisfies_min_unstructured_version(min_unstructured_version):
|
||||
raise ValueError(
|
||||
"Partitioning epub files is only supported in "
|
||||
f"unstructured>={min_unstructured_version}."
|
||||
)
|
||||
from unstructured.partition.epub import partition_epub
|
||||
|
||||
return partition_epub(filename=self.file_path)
|
||||
@@ -142,6 +142,7 @@ class GoogleDriveLoader(BaseLoader, BaseModel):
|
||||
from io import BytesIO
|
||||
|
||||
from googleapiclient.discovery import build
|
||||
from googleapiclient.errors import HttpError
|
||||
from googleapiclient.http import MediaIoBaseDownload
|
||||
|
||||
creds = self._load_credentials()
|
||||
@@ -151,8 +152,16 @@ class GoogleDriveLoader(BaseLoader, BaseModel):
|
||||
fh = BytesIO()
|
||||
downloader = MediaIoBaseDownload(fh, request)
|
||||
done = False
|
||||
while done is False:
|
||||
status, done = downloader.next_chunk()
|
||||
try:
|
||||
while done is False:
|
||||
status, done = downloader.next_chunk()
|
||||
|
||||
except HttpError as e:
|
||||
if e.resp.status == 404:
|
||||
print("File not found: {}".format(id))
|
||||
else:
|
||||
print("An error occurred: {}".format(e))
|
||||
|
||||
text = fh.getvalue().decode("utf-8")
|
||||
metadata = {"source": f"https://docs.google.com/document/d/{id}/edit"}
|
||||
return Document(page_content=text, metadata=metadata)
|
||||
|
||||
@@ -1,21 +1,31 @@
|
||||
"""Loader that fetches a sitemap and loads those URLs."""
|
||||
import re
|
||||
from typing import Any, List, Optional
|
||||
from typing import Any, Callable, List, Optional
|
||||
|
||||
from langchain.document_loaders.web_base import WebBaseLoader
|
||||
from langchain.schema import Document
|
||||
|
||||
|
||||
def _default_parsing_function(content: Any) -> str:
|
||||
return str(content.get_text())
|
||||
|
||||
|
||||
class SitemapLoader(WebBaseLoader):
|
||||
"""Loader that fetches a sitemap and loads those URLs."""
|
||||
|
||||
def __init__(self, web_path: str, filter_urls: Optional[List[str]] = None):
|
||||
def __init__(
|
||||
self,
|
||||
web_path: str,
|
||||
filter_urls: Optional[List[str]] = None,
|
||||
parsing_function: Optional[Callable] = None,
|
||||
):
|
||||
"""Initialize with webpage path and optional filter URLs.
|
||||
|
||||
Args:
|
||||
web_path: url of the sitemap
|
||||
filter_urls: list of strings or regexes that will be applied to filter the
|
||||
urls that are parsed and loaded
|
||||
urls that are parsed and loaded
|
||||
parsing_function: Function to parse bs4.Soup output
|
||||
"""
|
||||
|
||||
try:
|
||||
@@ -28,6 +38,7 @@ class SitemapLoader(WebBaseLoader):
|
||||
super().__init__(web_path)
|
||||
|
||||
self.filter_urls = filter_urls
|
||||
self.parsing_function = parsing_function or _default_parsing_function
|
||||
|
||||
def parse_sitemap(self, soup: Any) -> List[dict]:
|
||||
"""Parse sitemap xml and load into a list of dicts."""
|
||||
@@ -62,7 +73,7 @@ class SitemapLoader(WebBaseLoader):
|
||||
|
||||
return [
|
||||
Document(
|
||||
page_content=str(results[i].get_text()),
|
||||
page_content=self.parsing_function(results[i]),
|
||||
metadata={**{"source": els[i]["loc"]}, **els[i]},
|
||||
)
|
||||
for i in range(len(results))
|
||||
|
||||
@@ -14,7 +14,7 @@ class TextLoader(BaseLoader):
|
||||
|
||||
def load(self) -> List[Document]:
|
||||
"""Load from file path."""
|
||||
with open(self.file_path) as f:
|
||||
with open(self.file_path, encoding="utf-8") as f:
|
||||
text = f.read()
|
||||
metadata = {"source": self.file_path}
|
||||
return [Document(page_content=text, metadata=metadata)]
|
||||
|
||||
@@ -48,7 +48,7 @@ class RedisChatMessageHistory(BaseChatMessageHistory):
|
||||
def messages(self) -> List[BaseMessage]: # type: ignore
|
||||
"""Retrieve the messages from Redis"""
|
||||
_items = self.redis_client.lrange(self.key, 0, -1)
|
||||
items = [json.loads(m.decode("utf-8")) for m in _items]
|
||||
items = [json.loads(m.decode("utf-8")) for m in _items[::-1]]
|
||||
messages = messages_from_dict(items)
|
||||
return messages
|
||||
|
||||
|
||||
@@ -82,6 +82,7 @@ class PromptTemplate(StringPromptTemplate, BaseModel):
|
||||
input_variables: List[str],
|
||||
example_separator: str = "\n\n",
|
||||
prefix: str = "",
|
||||
**kwargs: Any,
|
||||
) -> PromptTemplate:
|
||||
"""Take examples in list format with prefix and suffix to create a prompt.
|
||||
|
||||
@@ -102,11 +103,11 @@ class PromptTemplate(StringPromptTemplate, BaseModel):
|
||||
The final prompt generated.
|
||||
"""
|
||||
template = example_separator.join([prefix, *examples, suffix])
|
||||
return cls(input_variables=input_variables, template=template)
|
||||
return cls(input_variables=input_variables, template=template, **kwargs)
|
||||
|
||||
@classmethod
|
||||
def from_file(
|
||||
cls, template_file: Union[str, Path], input_variables: List[str]
|
||||
cls, template_file: Union[str, Path], input_variables: List[str], **kwargs: Any
|
||||
) -> PromptTemplate:
|
||||
"""Load a prompt from a file.
|
||||
|
||||
@@ -119,15 +120,17 @@ class PromptTemplate(StringPromptTemplate, BaseModel):
|
||||
"""
|
||||
with open(str(template_file), "r") as f:
|
||||
template = f.read()
|
||||
return cls(input_variables=input_variables, template=template)
|
||||
return cls(input_variables=input_variables, template=template, **kwargs)
|
||||
|
||||
@classmethod
|
||||
def from_template(cls, template: str) -> PromptTemplate:
|
||||
def from_template(cls, template: str, **kwargs: Any) -> PromptTemplate:
|
||||
"""Load a prompt template from a template."""
|
||||
input_variables = {
|
||||
v for _, v, _, _ in Formatter().parse(template) if v is not None
|
||||
}
|
||||
return cls(input_variables=list(sorted(input_variables)), template=template)
|
||||
return cls(
|
||||
input_variables=list(sorted(input_variables)), template=template, **kwargs
|
||||
)
|
||||
|
||||
|
||||
# For backwards compatibility.
|
||||
|
||||
@@ -20,23 +20,23 @@ class RequestsWrapper(BaseModel):
|
||||
|
||||
def get(self, url: str, **kwargs: Any) -> str:
|
||||
"""GET the URL and return the text."""
|
||||
return requests.get(url, headers=self.headers, **kwargs).json()
|
||||
return requests.get(url, headers=self.headers, **kwargs).text
|
||||
|
||||
def post(self, url: str, data: Dict[str, Any]) -> str:
|
||||
def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""POST to the URL and return the text."""
|
||||
return requests.post(url, json=data, headers=self.headers).text
|
||||
return requests.post(url, json=data, headers=self.headers, **kwargs).text
|
||||
|
||||
def patch(self, url: str, data: Dict[str, Any]) -> str:
|
||||
def patch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""PATCH the URL and return the text."""
|
||||
return requests.patch(url, json=data, headers=self.headers).text
|
||||
return requests.patch(url, json=data, headers=self.headers, **kwargs).text
|
||||
|
||||
def put(self, url: str, data: Dict[str, Any]) -> str:
|
||||
def put(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""PUT the URL and return the text."""
|
||||
return requests.put(url, json=data, headers=self.headers).text
|
||||
return requests.put(url, json=data, headers=self.headers, **kwargs).text
|
||||
|
||||
def delete(self, url: str) -> str:
|
||||
def delete(self, url: str, **kwargs: Any) -> str:
|
||||
"""DELETE the URL and return the text."""
|
||||
return requests.delete(url, headers=self.headers).text
|
||||
return requests.delete(url, headers=self.headers, **kwargs).text
|
||||
|
||||
async def _arequest(self, method: str, url: str, **kwargs: Any) -> str:
|
||||
"""Make an async request."""
|
||||
@@ -52,22 +52,22 @@ class RequestsWrapper(BaseModel):
|
||||
) as response:
|
||||
return await response.text()
|
||||
|
||||
async def aget(self, url: str) -> str:
|
||||
async def aget(self, url: str, **kwargs: Any) -> str:
|
||||
"""GET the URL and return the text asynchronously."""
|
||||
return await self._arequest("GET", url)
|
||||
return await self._arequest("GET", url, **kwargs)
|
||||
|
||||
async def apost(self, url: str, data: Dict[str, Any]) -> str:
|
||||
async def apost(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""POST to the URL and return the text asynchronously."""
|
||||
return await self._arequest("POST", url, json=data)
|
||||
return await self._arequest("POST", url, json=data, **kwargs)
|
||||
|
||||
async def apatch(self, url: str, data: Dict[str, Any]) -> str:
|
||||
async def apatch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""PATCH the URL and return the text asynchronously."""
|
||||
return await self._arequest("PATCH", url, json=data)
|
||||
return await self._arequest("PATCH", url, json=data, **kwargs)
|
||||
|
||||
async def aput(self, url: str, data: Dict[str, Any]) -> str:
|
||||
async def aput(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
|
||||
"""PUT the URL and return the text asynchronously."""
|
||||
return await self._arequest("PUT", url, json=data)
|
||||
return await self._arequest("PUT", url, json=data, **kwargs)
|
||||
|
||||
async def adelete(self, url: str) -> str:
|
||||
async def adelete(self, url: str, **kwargs: Any) -> str:
|
||||
"""DELETE the URL and return the text asynchronously."""
|
||||
return await self._arequest("DELETE", url)
|
||||
return await self._arequest("DELETE", url, **kwargs)
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
from typing import List
|
||||
from typing import List, Optional
|
||||
|
||||
import aiohttp
|
||||
import requests
|
||||
from pydantic import BaseModel
|
||||
|
||||
@@ -9,6 +10,12 @@ from langchain.schema import BaseRetriever, Document
|
||||
class ChatGPTPluginRetriever(BaseRetriever, BaseModel):
|
||||
url: str
|
||||
bearer_token: str
|
||||
aiosession: Optional[aiohttp.ClientSession] = None
|
||||
|
||||
class Config:
|
||||
"""Configuration for this pydantic object."""
|
||||
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
def get_relevant_documents(self, query: str) -> List[Document]:
|
||||
response = requests.post(
|
||||
@@ -25,3 +32,28 @@ class ChatGPTPluginRetriever(BaseRetriever, BaseModel):
|
||||
content = d.pop("text")
|
||||
docs.append(Document(page_content=content, metadata=d))
|
||||
return docs
|
||||
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
url = f"{self.url}/query"
|
||||
json = {"queries": [{"query": query}]}
|
||||
headers = {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": f"Bearer {self.bearer_token}",
|
||||
}
|
||||
|
||||
if not self.aiosession:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(url, headers=headers, json=json) as response:
|
||||
res = await response.json()
|
||||
else:
|
||||
async with self.aiosession.post(
|
||||
url, headers=headers, json=json
|
||||
) as response:
|
||||
res = await response.json()
|
||||
|
||||
results = res["results"][0]["results"]
|
||||
docs = []
|
||||
for d in results:
|
||||
content = d.pop("text")
|
||||
docs.append(Document(page_content=content, metadata=d))
|
||||
return docs
|
||||
|
||||
@@ -33,6 +33,9 @@ class LlamaIndexRetriever(BaseRetriever, BaseModel):
|
||||
)
|
||||
return docs
|
||||
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
raise NotImplementedError("LlamaIndexRetriever does not support async")
|
||||
|
||||
|
||||
class LlamaIndexGraphRetriever(BaseRetriever, BaseModel):
|
||||
"""Question-answering with sources over an LlamaIndex graph data structure."""
|
||||
@@ -69,3 +72,6 @@ class LlamaIndexGraphRetriever(BaseRetriever, BaseModel):
|
||||
Document(page_content=source_node.source_text, metadata=metadata)
|
||||
)
|
||||
return docs
|
||||
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
raise NotImplementedError("LlamaIndexGraphRetriever does not support async")
|
||||
|
||||
@@ -310,6 +310,17 @@ class BaseRetriever(ABC):
|
||||
List of relevant documents
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
"""Get documents relevant for a query.
|
||||
|
||||
Args:
|
||||
query: string to find relevant documents for
|
||||
|
||||
Returns:
|
||||
List of relevant documents
|
||||
"""
|
||||
|
||||
|
||||
# For backwards compatibility
|
||||
|
||||
@@ -318,16 +329,43 @@ Memory = BaseMemory
|
||||
|
||||
|
||||
class BaseOutputParser(BaseModel, ABC):
|
||||
"""Class to parse the output of an LLM call."""
|
||||
"""Class to parse the output of an LLM call.
|
||||
|
||||
Output parsers help structure language model responses.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def parse(self, text: str) -> Any:
|
||||
"""Parse the output of an LLM call."""
|
||||
"""Parse the output of an LLM call.
|
||||
|
||||
A method which takes in a string (assumed output of language model )
|
||||
and parses it into some structure.
|
||||
|
||||
Args:
|
||||
text: output of language model
|
||||
|
||||
Returns:
|
||||
structured output
|
||||
"""
|
||||
|
||||
def parse_with_prompt(self, completion: str, prompt: PromptValue) -> Any:
|
||||
"""Optional method to parse the output of an LLM call with a prompt.
|
||||
|
||||
The prompt is largely provided in the event the OutputParser wants
|
||||
to retry or fix the output in some way, and needs information from
|
||||
the prompt to do so.
|
||||
|
||||
Args:
|
||||
completion: output of language model
|
||||
prompt: prompt value
|
||||
|
||||
Returns:
|
||||
structured output
|
||||
"""
|
||||
return self.parse(completion)
|
||||
|
||||
def get_format_instructions(self) -> str:
|
||||
"""Instructions on how the LLM output should be formatted."""
|
||||
raise NotImplementedError
|
||||
|
||||
@property
|
||||
|
||||
@@ -69,9 +69,12 @@ class SQLDatabase:
|
||||
self._metadata.reflect(bind=self._engine)
|
||||
|
||||
@classmethod
|
||||
def from_uri(cls, database_uri: str, **kwargs: Any) -> SQLDatabase:
|
||||
def from_uri(
|
||||
cls, database_uri: str, engine_args: Optional[dict] = None, **kwargs: Any
|
||||
) -> SQLDatabase:
|
||||
"""Construct a SQLAlchemy engine from URI."""
|
||||
return cls(create_engine(database_uri), **kwargs)
|
||||
_engine_args = engine_args or {}
|
||||
return cls(create_engine(database_uri, **_engine_args), **kwargs)
|
||||
|
||||
@property
|
||||
def dialect(self) -> str:
|
||||
|
||||
@@ -55,22 +55,24 @@ class BaseTool(BaseModel):
|
||||
**kwargs: Any
|
||||
) -> str:
|
||||
"""Run the tool."""
|
||||
if verbose is None:
|
||||
verbose = self.verbose
|
||||
if not self.verbose and verbose is not None:
|
||||
verbose_ = verbose
|
||||
else:
|
||||
verbose_ = self.verbose
|
||||
self.callback_manager.on_tool_start(
|
||||
{"name": self.name, "description": self.description},
|
||||
tool_input,
|
||||
verbose=verbose,
|
||||
verbose=verbose_,
|
||||
color=start_color,
|
||||
**kwargs,
|
||||
)
|
||||
try:
|
||||
observation = self._run(tool_input)
|
||||
except (Exception, KeyboardInterrupt) as e:
|
||||
self.callback_manager.on_tool_error(e, verbose=verbose)
|
||||
self.callback_manager.on_tool_error(e, verbose=verbose_)
|
||||
raise e
|
||||
self.callback_manager.on_tool_end(
|
||||
observation, verbose=verbose, color=color, name=self.name, **kwargs
|
||||
observation, verbose=verbose_, color=color, name=self.name, **kwargs
|
||||
)
|
||||
return observation
|
||||
|
||||
@@ -83,13 +85,15 @@ class BaseTool(BaseModel):
|
||||
**kwargs: Any
|
||||
) -> str:
|
||||
"""Run the tool asynchronously."""
|
||||
if verbose is None:
|
||||
verbose = self.verbose
|
||||
if not self.verbose and verbose is not None:
|
||||
verbose_ = verbose
|
||||
else:
|
||||
verbose_ = self.verbose
|
||||
if self.callback_manager.is_async:
|
||||
await self.callback_manager.on_tool_start(
|
||||
{"name": self.name, "description": self.description},
|
||||
tool_input,
|
||||
verbose=verbose,
|
||||
verbose=verbose_,
|
||||
color=start_color,
|
||||
**kwargs,
|
||||
)
|
||||
@@ -97,7 +101,7 @@ class BaseTool(BaseModel):
|
||||
self.callback_manager.on_tool_start(
|
||||
{"name": self.name, "description": self.description},
|
||||
tool_input,
|
||||
verbose=verbose,
|
||||
verbose=verbose_,
|
||||
color=start_color,
|
||||
**kwargs,
|
||||
)
|
||||
@@ -106,16 +110,16 @@ class BaseTool(BaseModel):
|
||||
observation = await self._arun(tool_input)
|
||||
except (Exception, KeyboardInterrupt) as e:
|
||||
if self.callback_manager.is_async:
|
||||
await self.callback_manager.on_tool_error(e, verbose=verbose)
|
||||
await self.callback_manager.on_tool_error(e, verbose=verbose_)
|
||||
else:
|
||||
self.callback_manager.on_tool_error(e, verbose=verbose)
|
||||
self.callback_manager.on_tool_error(e, verbose=verbose_)
|
||||
raise e
|
||||
if self.callback_manager.is_async:
|
||||
await self.callback_manager.on_tool_end(
|
||||
observation, verbose=verbose, color=color, name=self.name, **kwargs
|
||||
observation, verbose=verbose_, color=color, name=self.name, **kwargs
|
||||
)
|
||||
else:
|
||||
self.callback_manager.on_tool_end(
|
||||
observation, verbose=verbose, color=color, name=self.name, **kwargs
|
||||
observation, verbose=verbose_, color=color, name=self.name, **kwargs
|
||||
)
|
||||
return observation
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
"""General utilities."""
|
||||
from langchain.python import PythonREPL
|
||||
from langchain.requests import RequestsWrapper
|
||||
from langchain.utilities.apify import ApifyWrapper
|
||||
from langchain.utilities.bash import BashProcess
|
||||
from langchain.utilities.bing_search import BingSearchAPIWrapper
|
||||
from langchain.utilities.google_search import GoogleSearchAPIWrapper
|
||||
@@ -12,6 +13,7 @@ from langchain.utilities.wikipedia import WikipediaAPIWrapper
|
||||
from langchain.utilities.wolfram_alpha import WolframAlphaAPIWrapper
|
||||
|
||||
__all__ = [
|
||||
"ApifyWrapper",
|
||||
"BashProcess",
|
||||
"RequestsWrapper",
|
||||
"PythonREPL",
|
||||
|
||||
123
langchain/utilities/apify.py
Normal file
123
langchain/utilities/apify.py
Normal file
@@ -0,0 +1,123 @@
|
||||
from typing import Any, Callable, Dict, Optional
|
||||
|
||||
from pydantic import BaseModel, root_validator
|
||||
|
||||
from langchain.document_loaders import ApifyDatasetLoader
|
||||
from langchain.document_loaders.base import Document
|
||||
from langchain.utils import get_from_dict_or_env
|
||||
|
||||
|
||||
class ApifyWrapper(BaseModel):
|
||||
"""Wrapper around Apify.
|
||||
|
||||
To use, you should have the ``apify-client`` python package installed,
|
||||
and the environment variable ``APIFY_API_TOKEN`` set with your API key, or pass
|
||||
`apify_api_token` as a named parameter to the constructor.
|
||||
"""
|
||||
|
||||
apify_client: Any
|
||||
apify_client_async: Any
|
||||
|
||||
@root_validator()
|
||||
def validate_environment(cls, values: Dict) -> Dict:
|
||||
"""Validate environment.
|
||||
|
||||
Validate that an Apify API token is set and the apify-client
|
||||
Python package exists in the current environment.
|
||||
"""
|
||||
apify_api_token = get_from_dict_or_env(
|
||||
values, "apify_api_token", "APIFY_API_TOKEN"
|
||||
)
|
||||
|
||||
try:
|
||||
from apify_client import ApifyClient, ApifyClientAsync
|
||||
|
||||
values["apify_client"] = ApifyClient(apify_api_token)
|
||||
values["apify_client_async"] = ApifyClientAsync(apify_api_token)
|
||||
except ImportError:
|
||||
raise ValueError(
|
||||
"Could not import apify-client Python package. "
|
||||
"Please install it with `pip install apify-client`."
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def call_actor(
|
||||
self,
|
||||
actor_id: str,
|
||||
run_input: Dict,
|
||||
dataset_mapping_function: Callable[[Dict], Document],
|
||||
*,
|
||||
build: Optional[str] = None,
|
||||
memory_mbytes: Optional[int] = None,
|
||||
timeout_secs: Optional[int] = None,
|
||||
) -> ApifyDatasetLoader:
|
||||
"""Run an Actor on the Apify platform and wait for results to be ready.
|
||||
|
||||
Args:
|
||||
actor_id (str): The ID or name of the Actor on the Apify platform.
|
||||
run_input (Dict): The input object of the Actor that you're trying to run.
|
||||
dataset_mapping_function (Callable): A function that takes a single
|
||||
dictionary (an Apify dataset item) and converts it to an
|
||||
instance of the Document class.
|
||||
build (str, optional): Optionally specifies the actor build to run.
|
||||
It can be either a build tag or build number.
|
||||
memory_mbytes (int, optional): Optional memory limit for the run,
|
||||
in megabytes.
|
||||
timeout_secs (int, optional): Optional timeout for the run, in seconds.
|
||||
|
||||
Returns:
|
||||
ApifyDatasetLoader: A loader that will fetch the records from the
|
||||
Actor run's default dataset.
|
||||
"""
|
||||
actor_call = self.apify_client.actor(actor_id).call(
|
||||
run_input=run_input,
|
||||
build=build,
|
||||
memory_mbytes=memory_mbytes,
|
||||
timeout_secs=timeout_secs,
|
||||
)
|
||||
|
||||
return ApifyDatasetLoader(
|
||||
dataset_id=actor_call["defaultDatasetId"],
|
||||
dataset_mapping_function=dataset_mapping_function,
|
||||
)
|
||||
|
||||
async def acall_actor(
|
||||
self,
|
||||
actor_id: str,
|
||||
run_input: Dict,
|
||||
dataset_mapping_function: Callable[[Dict], Document],
|
||||
*,
|
||||
build: Optional[str] = None,
|
||||
memory_mbytes: Optional[int] = None,
|
||||
timeout_secs: Optional[int] = None,
|
||||
) -> ApifyDatasetLoader:
|
||||
"""Run an Actor on the Apify platform and wait for results to be ready.
|
||||
|
||||
Args:
|
||||
actor_id (str): The ID or name of the Actor on the Apify platform.
|
||||
run_input (Dict): The input object of the Actor that you're trying to run.
|
||||
dataset_mapping_function (Callable): A function that takes a single
|
||||
dictionary (an Apify dataset item) and converts it to
|
||||
an instance of the Document class.
|
||||
build (str, optional): Optionally specifies the actor build to run.
|
||||
It can be either a build tag or build number.
|
||||
memory_mbytes (int, optional): Optional memory limit for the run,
|
||||
in megabytes.
|
||||
timeout_secs (int, optional): Optional timeout for the run, in seconds.
|
||||
|
||||
Returns:
|
||||
ApifyDatasetLoader: A loader that will fetch the records from the
|
||||
Actor run's default dataset.
|
||||
"""
|
||||
actor_call = await self.apify_client_async.actor(actor_id).call(
|
||||
run_input=run_input,
|
||||
build=build,
|
||||
memory_mbytes=memory_mbytes,
|
||||
timeout_secs=timeout_secs,
|
||||
)
|
||||
|
||||
return ApifyDatasetLoader(
|
||||
dataset_id=actor_call["defaultDatasetId"],
|
||||
dataset_mapping_function=dataset_mapping_function,
|
||||
)
|
||||
@@ -47,7 +47,7 @@ class WikipediaAPIWrapper(BaseModel):
|
||||
|
||||
def fetch_formatted_page_summary(self, page: str) -> Optional[str]:
|
||||
try:
|
||||
wiki_page = self.wiki_client.page(title=page)
|
||||
wiki_page = self.wiki_client.page(title=page, auto_suggest=False)
|
||||
return f"Page: {page}\nSummary: {wiki_page.summary}"
|
||||
except (
|
||||
self.wiki_client.exceptions.PageError,
|
||||
|
||||
@@ -159,3 +159,6 @@ class VectorStoreRetriever(BaseRetriever, BaseModel):
|
||||
else:
|
||||
raise ValueError(f"search_type of {self.search_type} not allowed.")
|
||||
return docs
|
||||
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
raise NotImplementedError("VectorStoreRetriever does not support async")
|
||||
|
||||
@@ -5,9 +5,12 @@ import logging
|
||||
import uuid
|
||||
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple
|
||||
|
||||
import numpy as np
|
||||
|
||||
from langchain.docstore.document import Document
|
||||
from langchain.embeddings.base import Embeddings
|
||||
from langchain.vectorstores.base import VectorStore
|
||||
from langchain.vectorstores.utils import maximal_marginal_relevance
|
||||
|
||||
if TYPE_CHECKING:
|
||||
import chromadb
|
||||
@@ -182,6 +185,69 @@ class Chroma(VectorStore):
|
||||
|
||||
return _results_to_docs_and_scores(results)
|
||||
|
||||
def max_marginal_relevance_search_by_vector(
|
||||
self,
|
||||
embedding: List[float],
|
||||
k: int = 4,
|
||||
fetch_k: int = 20,
|
||||
filter: Optional[Dict[str, str]] = None,
|
||||
) -> List[Document]:
|
||||
"""Return docs selected using the maximal marginal relevance.
|
||||
Maximal marginal relevance optimizes for similarity to query AND diversity
|
||||
among selected documents.
|
||||
Args:
|
||||
embedding: Embedding to look up documents similar to.
|
||||
k: Number of Documents to return. Defaults to 4.
|
||||
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
|
||||
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
|
||||
Returns:
|
||||
List of Documents selected by maximal marginal relevance.
|
||||
"""
|
||||
|
||||
results = self._collection.query(
|
||||
query_embeddings=embedding,
|
||||
n_results=fetch_k,
|
||||
where=filter,
|
||||
include=["metadatas", "documents", "distances", "embeddings"],
|
||||
)
|
||||
mmr_selected = maximal_marginal_relevance(
|
||||
np.array(embedding, dtype=np.float32), results["embeddings"][0], k=k
|
||||
)
|
||||
|
||||
candidates = _results_to_docs(results)
|
||||
|
||||
selected_results = [r for i, r in enumerate(candidates) if i in mmr_selected]
|
||||
return selected_results
|
||||
|
||||
def max_marginal_relevance_search(
|
||||
self,
|
||||
query: str,
|
||||
k: int = 4,
|
||||
fetch_k: int = 20,
|
||||
filter: Optional[Dict[str, str]] = None,
|
||||
) -> List[Document]:
|
||||
"""Return docs selected using the maximal marginal relevance.
|
||||
Maximal marginal relevance optimizes for similarity to query AND diversity
|
||||
among selected documents.
|
||||
Args:
|
||||
query: Text to look up documents similar to.
|
||||
k: Number of Documents to return. Defaults to 4.
|
||||
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
|
||||
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
|
||||
Returns:
|
||||
List of Documents selected by maximal marginal relevance.
|
||||
"""
|
||||
if self._embedding_function is None:
|
||||
raise ValueError(
|
||||
"For MMR search, you must specify an embedding function on" "creation."
|
||||
)
|
||||
|
||||
embedding = self._embedding_function.embed_query(query)
|
||||
docs = self.max_marginal_relevance_search_by_vector(
|
||||
embedding, k, fetch_k, filter
|
||||
)
|
||||
return docs
|
||||
|
||||
def delete_collection(self) -> None:
|
||||
"""Delete the collection."""
|
||||
self._client.delete_collection(self._collection.name)
|
||||
|
||||
@@ -375,3 +375,6 @@ class RedisVectorStoreRetriever(BaseRetriever, BaseModel):
|
||||
else:
|
||||
raise ValueError(f"search_type of {self.search_type} not allowed.")
|
||||
return docs
|
||||
|
||||
async def aget_relevant_documents(self, query: str) -> List[Document]:
|
||||
raise NotImplementedError("RedisVectorStoreRetriever does not support async")
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[tool.poetry]
|
||||
name = "langchain"
|
||||
version = "0.0.126"
|
||||
version = "0.0.127"
|
||||
description = "Building applications with LLMs through composability"
|
||||
authors = []
|
||||
license = "MIT"
|
||||
@@ -102,7 +102,7 @@ playwright = "^1.28.0"
|
||||
|
||||
[tool.poetry.extras]
|
||||
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
|
||||
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence_transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary"]
|
||||
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence_transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm"]
|
||||
|
||||
[tool.ruff]
|
||||
select = [
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
"""Test LLM Math functionality."""
|
||||
|
||||
import json
|
||||
from typing import Any
|
||||
|
||||
import pytest
|
||||
|
||||
@@ -16,7 +17,7 @@ class FakeRequestsChain(RequestsWrapper):
|
||||
|
||||
output: str
|
||||
|
||||
def get(self, url: str) -> str:
|
||||
def get(self, url: str, **kwargs: Any) -> str:
|
||||
"""Just return the specified output."""
|
||||
return self.output
|
||||
|
||||
|
||||
Reference in New Issue
Block a user