mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-13 06:16:26 +00:00
Compare commits
27 Commits
langchain-
...
wip-v0.4
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
281488a5cf | ||
|
|
8d2ba88ef0 | ||
|
|
45a067509f | ||
|
|
23c3fa65d4 | ||
|
|
13d67cf37e | ||
|
|
7f989d3c3b | ||
|
|
b7968c2b7d | ||
|
|
2f0c6421a1 | ||
|
|
cfe13f673a | ||
|
|
5599c59d4a | ||
|
|
11d68a0b9e | ||
|
|
566774a893 | ||
|
|
255a6d668a | ||
|
|
cbf4c0e565 | ||
|
|
dc66737f03 | ||
|
|
499dc35cfb | ||
|
|
42c1159991 | ||
|
|
cc6139860c | ||
|
|
ae8f58ac6f | ||
|
|
346731544b | ||
|
|
c1b86cc929 | ||
|
|
376f70be96 | ||
|
|
ac2de920b1 | ||
|
|
e02eed5489 | ||
|
|
5414527236 | ||
|
|
881c6534a6 | ||
|
|
5e9eb19a83 |
2
.github/CONTRIBUTING.md
vendored
2
.github/CONTRIBUTING.md
vendored
@@ -7,4 +7,4 @@ To learn how to contribute to LangChain, please follow the [contribution guide h
|
||||
|
||||
## New features
|
||||
|
||||
For new features, please start a new [discussion on our forum](https://forum.langchain.com/), where the maintainers will help with scoping out the necessary changes.
|
||||
For new features, please start a new [discussion](https://forum.langchain.com/), where the maintainers will help with scoping out the necessary changes.
|
||||
|
||||
@@ -79,17 +79,6 @@
|
||||
"tool_executor = ToolExecutor(tools)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "168152fc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"📘 **Note on `SystemMessage` usage with LangGraph-based agents**\n",
|
||||
"\n",
|
||||
"When constructing the `messages` list for an agent, you *must* manually include any `SystemMessage`s.\n",
|
||||
"Unlike some agent executors in LangChain that set a default, LangGraph requires explicit inclusion."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fe6e8f78-1ef7-42ad-b2bf-835ed5850553",
|
||||
|
||||
@@ -217,7 +217,11 @@ def _load_package_modules(
|
||||
# Get the full namespace of the module
|
||||
namespace = str(relative_module_name).replace(".py", "").replace("/", ".")
|
||||
# Keep only the top level namespace
|
||||
top_namespace = namespace.split(".")[0]
|
||||
# (but make special exception for content_blocks and v1.messages)
|
||||
if namespace == "messages.content_blocks" or namespace == "v1.messages":
|
||||
top_namespace = namespace # Keep full namespace for content_blocks
|
||||
else:
|
||||
top_namespace = namespace.split(".")[0]
|
||||
|
||||
try:
|
||||
# If submodule is present, we need to construct the paths in a slightly
|
||||
@@ -545,14 +549,7 @@ def _build_index(dirs: List[str]) -> None:
|
||||
"ai21": "AI21",
|
||||
"ibm": "IBM",
|
||||
}
|
||||
ordered = [
|
||||
"core",
|
||||
"langchain",
|
||||
"text-splitters",
|
||||
"community",
|
||||
"experimental",
|
||||
"standard-tests",
|
||||
]
|
||||
ordered = ["core", "langchain", "text-splitters", "community", "experimental"]
|
||||
main_ = [dir_ for dir_ in ordered if dir_ in dirs]
|
||||
integrations = sorted(dir_ for dir_ in dirs if dir_ not in main_)
|
||||
doc = """# LangChain Python API Reference
|
||||
|
||||
@@ -53,29 +53,17 @@ This is how you use MessagesPlaceholder.
|
||||
|
||||
```python
|
||||
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain_core.messages import HumanMessage, AIMessage
|
||||
from langchain_core.messages import HumanMessage
|
||||
|
||||
prompt_template = ChatPromptTemplate([
|
||||
("system", "You are a helpful assistant"),
|
||||
MessagesPlaceholder("msgs")
|
||||
])
|
||||
|
||||
# Simple example with one message
|
||||
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})
|
||||
|
||||
# More complex example with conversation history
|
||||
messages_to_pass = [
|
||||
HumanMessage(content="What's the capital of France?"),
|
||||
AIMessage(content="The capital of France is Paris."),
|
||||
HumanMessage(content="And what about Germany?")
|
||||
]
|
||||
|
||||
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
|
||||
print(formatted_prompt)
|
||||
```
|
||||
|
||||
|
||||
This will produce a list of four messages total: the system message plus the three messages we passed in (two HumanMessages and one AIMessage).
|
||||
This will produce a list of two messages, the first one being a system message, and the second one being the HumanMessage we passed in.
|
||||
If we had passed in 5 messages, then it would have produced 6 messages in total (the system message plus the 5 passed in).
|
||||
This is useful for letting a list of messages be slotted into a particular spot.
|
||||
|
||||
|
||||
@@ -171,26 +171,6 @@ Please see the [InjectedState](https://langchain-ai.github.io/langgraph/referenc
|
||||
|
||||
Please see the [InjectedStore](https://langchain-ai.github.io/langgraph/reference/prebuilt/#langgraph.prebuilt.tool_node.InjectedStore) documentation for more details.
|
||||
|
||||
## Tool Artifacts vs. Injected State
|
||||
|
||||
Although similar conceptually, tool artifacts in LangChain and [injected state in LangGraph](https://langchain-ai.github.io/langgraph/reference/agents/#langgraph.prebuilt.tool_node.InjectedState) serve different purposes and operate at different levels of abstraction.
|
||||
|
||||
**Tool Artifacts**
|
||||
|
||||
- **Purpose:** Store and pass data between tool executions within a single chain/workflow
|
||||
- **Scope:** Limited to tool-to-tool communication
|
||||
- **Lifecycle:** Tied to individual tool calls and their immediate context
|
||||
- **Usage:** Temporary storage for intermediate results that tools need to share
|
||||
|
||||
**Injected State (LangGraph)**
|
||||
|
||||
- **Purpose:** Maintain persistent state across the entire graph execution
|
||||
- **Scope:** Global to the entire graph workflow
|
||||
- **Lifecycle:** Persists throughout the entire graph execution and can be saved/restored
|
||||
- **Usage:** Long-term state management, conversation memory, user context, workflow checkpointing
|
||||
|
||||
Tool artifacts are ephemeral data passed between tools, while injected state is persistent workflow-level state that survives across multiple steps, tool calls, and even execution sessions in LangGraph.
|
||||
|
||||
## Best practices
|
||||
|
||||
When designing tools to be used by models, keep the following in mind:
|
||||
|
||||
@@ -122,13 +122,13 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"from langchain_experimental.graph_transformers import LLMGraphTransformer\n",
|
||||
"# from langchain_experimental.graph_transformers import LLMGraphTransformer\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(temperature=0, model_name=\"gpt-4-turbo\")\n",
|
||||
|
||||
@@ -46,7 +46,7 @@
|
||||
"\n",
|
||||
"1. [`llama.cpp`](https://github.com/ggerganov/llama.cpp): C++ implementation of llama inference code with [weight optimization / quantization](https://finbarr.ca/how-is-llama-cpp-possible/)\n",
|
||||
"2. [`gpt4all`](https://docs.gpt4all.io/index.html): Optimized C backend for inference\n",
|
||||
"3. [`ollama`](https://github.com/ollama/ollama): Bundles model weights and environment into an app that runs on device and serves the LLM\n",
|
||||
"3. [`Ollama`](https://ollama.ai/): Bundles model weights and environment into an app that runs on device and serves the LLM\n",
|
||||
"4. [`llamafile`](https://github.com/Mozilla-Ocho/llamafile): Bundles model weights and everything needed to run the model in a single file, allowing you to run the LLM locally from this file without any additional installation steps\n",
|
||||
"\n",
|
||||
"In general, these frameworks will do a few things:\n",
|
||||
@@ -74,12 +74,12 @@
|
||||
"\n",
|
||||
"## Quickstart\n",
|
||||
"\n",
|
||||
"[Ollama](https://ollama.com/) is one way to easily run inference on macOS.\n",
|
||||
"[`Ollama`](https://ollama.ai/) is one way to easily run inference on macOS.\n",
|
||||
" \n",
|
||||
"The instructions [here](https://github.com/ollama/ollama?tab=readme-ov-file#ollama) provide details, which we summarize:\n",
|
||||
"The instructions [here](https://github.com/jmorganca/ollama?tab=readme-ov-file#ollama) provide details, which we summarize:\n",
|
||||
" \n",
|
||||
"* [Download and run](https://ollama.ai/download) the app\n",
|
||||
"* From command line, fetch a model from this [list of options](https://ollama.com/search): e.g., `ollama pull gpt-oss:20b`\n",
|
||||
"* From command line, fetch a model from this [list of options](https://github.com/jmorganca/ollama): e.g., `ollama pull llama3.1:8b`\n",
|
||||
"* When the app is running, all models are automatically served on `localhost:11434`\n"
|
||||
]
|
||||
},
|
||||
@@ -95,7 +95,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 2,
|
||||
"id": "86178adb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -111,11 +111,11 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_ollama import ChatOllama\n",
|
||||
"from langchain_ollama import OllamaLLM\n",
|
||||
"\n",
|
||||
"llm = ChatOllama(model=\"gpt-oss:20b\", validate_model_on_init=True)\n",
|
||||
"llm = OllamaLLM(model=\"llama3.1:8b\")\n",
|
||||
"\n",
|
||||
"llm.invoke(\"The first man on the moon was ...\").content"
|
||||
"llm.invoke(\"The first man on the moon was ...\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -200,7 +200,7 @@
|
||||
"\n",
|
||||
"### Running Apple silicon GPU\n",
|
||||
"\n",
|
||||
"`ollama` and [`llamafile`](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#gpu-support) will automatically utilize the GPU on Apple devices.\n",
|
||||
"`Ollama` and [`llamafile`](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#gpu-support) will automatically utilize the GPU on Apple devices.\n",
|
||||
" \n",
|
||||
"Other frameworks require the user to set up the environment to utilize the Apple GPU.\n",
|
||||
"\n",
|
||||
@@ -212,15 +212,15 @@
|
||||
"\n",
|
||||
"In particular, ensure that conda is using the correct virtual environment that you created (`miniforge3`).\n",
|
||||
"\n",
|
||||
"e.g., for me:\n",
|
||||
"E.g., for me:\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"```\n",
|
||||
"conda activate /Users/rlm/miniforge3/envs/llama\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"With the above confirmed, then:\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"```\n",
|
||||
"CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir\n",
|
||||
"```"
|
||||
]
|
||||
@@ -236,16 +236,20 @@
|
||||
"\n",
|
||||
"1. [`HuggingFace`](https://huggingface.co/TheBloke) - Many quantized model are available for download and can be run with framework such as [`llama.cpp`](https://github.com/ggerganov/llama.cpp). You can also download models in [`llamafile` format](https://huggingface.co/models?other=llamafile) from HuggingFace.\n",
|
||||
"2. [`gpt4all`](https://gpt4all.io/index.html) - The model explorer offers a leaderboard of metrics and associated quantized models available for download \n",
|
||||
"3. [`ollama`](https://github.com/jmorganca/ollama) - Several models can be accessed directly via `pull`\n",
|
||||
"3. [`Ollama`](https://github.com/jmorganca/ollama) - Several models can be accessed directly via `pull`\n",
|
||||
"\n",
|
||||
"### Ollama\n",
|
||||
"\n",
|
||||
"With [Ollama](https://github.com/ollama/ollama), fetch a model via `ollama pull <model family>:<tag>`."
|
||||
"With [Ollama](https://github.com/jmorganca/ollama), fetch a model via `ollama pull <model family>:<tag>`:\n",
|
||||
"\n",
|
||||
"* E.g., for Llama 2 7b: `ollama pull llama2` will download the most basic version of the model (e.g., smallest # parameters and 4 bit quantization)\n",
|
||||
"* We can also specify a particular version from the [model list](https://github.com/jmorganca/ollama?tab=readme-ov-file#model-library), e.g., `ollama pull llama2:13b`\n",
|
||||
"* See the full set of parameters on the [API reference page](https://python.langchain.com/api_reference/community/llms/langchain_community.llms.ollama.Ollama.html)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 42,
|
||||
"id": "8ecd2f78",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -261,7 +265,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"llm = ChatOllama(model=\"gpt-oss:20b\")\n",
|
||||
"llm = OllamaLLM(model=\"llama2:13b\")\n",
|
||||
"llm.invoke(\"The first man on the moon was ... think step by step\")"
|
||||
]
|
||||
},
|
||||
@@ -690,7 +694,7 @@
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
@@ -704,7 +708,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
"version": "3.10.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -74,12 +74,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": null,
|
||||
"id": "a88ff70c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_experimental.text_splitter import SemanticChunker\n",
|
||||
"# from langchain_experimental.text_splitter import SemanticChunker\n",
|
||||
"from langchain_openai.embeddings import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"text_splitter = SemanticChunker(OpenAIEmbeddings())"
|
||||
|
||||
@@ -612,56 +612,11 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"execution_count": null,
|
||||
"id": "35ea904e-795f-411b-bef8-6484dbb6e35c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `python_repl_ast` with `{'query': \"df[['Age', 'Fare']].corr().iloc[0,1]\"}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3m0.11232863699941621\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `python_repl_ast` with `{'query': \"df[['Fare', 'Survived']].corr().iloc[0,1]\"}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3m0.2561785496289603\u001b[0m\u001b[32;1m\u001b[1;3mThe correlation between Age and Fare is approximately 0.112, and the correlation between Fare and Survival is approximately 0.256.\n",
|
||||
"\n",
|
||||
"Therefore, the correlation between Fare and Survival (0.256) is greater than the correlation between Age and Fare (0.112).\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'input': \"What's the correlation between age and fare? is that greater than the correlation between fare and survival?\",\n",
|
||||
" 'output': 'The correlation between Age and Fare is approximately 0.112, and the correlation between Fare and Survival is approximately 0.256.\\n\\nTherefore, the correlation between Fare and Survival (0.256) is greater than the correlation between Age and Fare (0.112).'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_experimental.agents import create_pandas_dataframe_agent\n",
|
||||
"\n",
|
||||
"agent = create_pandas_dataframe_agent(\n",
|
||||
" llm, df, agent_type=\"openai-tools\", verbose=True, allow_dangerous_code=True\n",
|
||||
")\n",
|
||||
"agent.invoke(\n",
|
||||
" {\n",
|
||||
" \"input\": \"What's the correlation between age and fare? is that greater than the correlation between fare and survival?\"\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
"outputs": [],
|
||||
"source": "from langchain_experimental.agents import create_pandas_dataframe_agent\n\nagent = create_pandas_dataframe_agent(\n llm, df, agent_type=\"openai-tools\", verbose=True, allow_dangerous_code=True\n)\nagent.invoke(\n {\n \"input\": \"What's the correlation between age and fare? is that greater than the correlation between fare and survival?\"\n }\n)"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -786,4 +741,4 @@
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
}
|
||||
@@ -17,9 +17,9 @@
|
||||
"source": [
|
||||
"# ChatOllama\n",
|
||||
"\n",
|
||||
"[Ollama](https://ollama.com/) allows you to run open-source large language models, such as `got-oss`, locally.\n",
|
||||
"[Ollama](https://ollama.ai/) allows you to run open-source large language models, such as Llama 2, locally.\n",
|
||||
"\n",
|
||||
"`ollama` bundles model weights, configuration, and data into a single package, defined by a Modelfile.\n",
|
||||
"Ollama bundles model weights, configuration, and data into a single package, defined by a Modelfile.\n",
|
||||
"\n",
|
||||
"It optimizes setup and configuration details, including GPU usage.\n",
|
||||
"\n",
|
||||
@@ -28,14 +28,14 @@
|
||||
"## Overview\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/chat/ollama) | Package downloads | Package latest |\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/v0.2/docs/integrations/chat/ollama) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ChatOllama](https://python.langchain.com/api_reference/ollama/chat_models/langchain_ollama.chat_models.ChatOllama.html#chatollama) | [langchain-ollama](https://python.langchain.com/api_reference/ollama/index.html) | ✅ | ❌ | ✅ |  |  |\n",
|
||||
"| [ChatOllama](https://python.langchain.com/v0.2/api_reference/ollama/chat_models/langchain_ollama.chat_models.ChatOllama.html) | [langchain-ollama](https://python.langchain.com/v0.2/api_reference/ollama/index.html) | ✅ | ❌ | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| [Tool calling](/docs/how_to/tool_calling/) | [Structured output](/docs/how_to/structured_output/) | JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
"| :---: |:----------------------------------------------------:| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ |\n",
|
||||
"| ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -45,17 +45,17 @@
|
||||
" * macOS users can install via Homebrew with `brew install ollama` and start with `brew services start ollama`\n",
|
||||
"* Fetch available LLM model via `ollama pull <name-of-model>`\n",
|
||||
" * View a list of available models via the [model library](https://ollama.ai/library)\n",
|
||||
" * e.g., `ollama pull gpt-oss:20b`\n",
|
||||
" * e.g., `ollama pull llama3`\n",
|
||||
"* This will download the default tagged version of the model. Typically, the default points to the latest, smallest sized-parameter model.\n",
|
||||
"\n",
|
||||
"> On Mac, the models will be download to `~/.ollama/models`\n",
|
||||
">\n",
|
||||
"> On Linux (or WSL), the models will be stored at `/usr/share/ollama/.ollama/models`\n",
|
||||
"\n",
|
||||
"* Specify the exact version of the model of interest as such `ollama pull gpt-oss:20b` (View the [various tags for the `Vicuna`](https://ollama.ai/library/vicuna/tags) model in this instance)\n",
|
||||
"* Specify the exact version of the model of interest as such `ollama pull vicuna:13b-v1.5-16k-q4_0` (View the [various tags for the `Vicuna`](https://ollama.ai/library/vicuna/tags) model in this instance)\n",
|
||||
"* To view all pulled models, use `ollama list`\n",
|
||||
"* To chat directly with a model from the command line, use `ollama run <name-of-model>`\n",
|
||||
"* View the [Ollama documentation](https://github.com/ollama/ollama/blob/main/docs/README.md) for more commands. You can run `ollama help` in the terminal to see available commands.\n"
|
||||
"* View the [Ollama documentation](https://github.com/ollama/ollama/tree/main/docs) for more commands. You can run `ollama help` in the terminal to see available commands.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -102,11 +102,7 @@
|
||||
"id": "b18bd692076f7cf7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
":::warning\n",
|
||||
"Make sure you're using the latest Ollama version!\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
"Update by running:"
|
||||
"Make sure you're using the latest Ollama version for structured outputs. Update by running:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -261,10 +257,10 @@
|
||||
"source": [
|
||||
"## Tool calling\n",
|
||||
"\n",
|
||||
"We can use [tool calling](/docs/concepts/tool_calling/) with an LLM [that has been fine-tuned for tool use](https://ollama.com/search?&c=tools) such as `gpt-oss`:\n",
|
||||
"We can use [tool calling](/docs/concepts/tool_calling/) with an LLM [that has been fine-tuned for tool use](https://ollama.com/search?&c=tools) such as `llama3.1`:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"ollama pull gpt-oss:20b\n",
|
||||
"ollama pull llama3.1\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Details on creating custom tools are available in [this guide](/docs/how_to/custom_tools/). Below, we demonstrate how to create a tool using the `@tool` decorator on a normal python function."
|
||||
@@ -272,7 +268,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 13,
|
||||
"id": "f767015f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -304,8 +300,7 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"llm = ChatOllama(\n",
|
||||
" model=\"gpt-oss:20b\",\n",
|
||||
" validate_model_on_init=True,\n",
|
||||
" model=\"llama3.1\",\n",
|
||||
" temperature=0,\n",
|
||||
").bind_tools([validate_user])\n",
|
||||
"\n",
|
||||
@@ -326,7 +321,9 @@
|
||||
"source": [
|
||||
"## Multi-modal\n",
|
||||
"\n",
|
||||
"Ollama has limited support for multi-modal LLMs, such as [gemma3](https://ollama.com/library/gemma3)\n",
|
||||
"Ollama has support for multi-modal LLMs, such as [bakllava](https://ollama.com/library/bakllava) and [llava](https://ollama.com/library/llava).\n",
|
||||
"\n",
|
||||
" ollama pull bakllava\n",
|
||||
"\n",
|
||||
"Be sure to update Ollama so that you have the most recent version to support multi-modal."
|
||||
]
|
||||
@@ -521,7 +518,7 @@
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
@@ -535,7 +532,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
"version": "3.10.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -132,12 +132,13 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.documents import Document\n",
|
||||
"from langchain_experimental.graph_transformers import LLMGraphTransformer\n",
|
||||
"\n",
|
||||
"# from langchain_experimental.graph_transformers import LLMGraphTransformer\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# Define the LLMGraphTransformer\n",
|
||||
|
||||
@@ -548,12 +548,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.documents import Document\n",
|
||||
"from langchain_experimental.graph_transformers import LLMGraphTransformer"
|
||||
"# from langchain_experimental.graph_transformers import LLMGraphTransformer"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -44,7 +44,9 @@
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": "%pip install --upgrade --quiet llama-cpp-python"
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet llama-cpp-python"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -62,7 +64,9 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": "!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -76,7 +80,9 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": "!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -94,7 +100,9 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": "!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -108,7 +116,9 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": "!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python --force-reinstall --no-binary :all: --no-cache-dir"
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -164,7 +174,9 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": "!python -m pip install -e . --force-reinstall --no-cache-dir"
|
||||
"source": [
|
||||
"!python -m pip install -e . --force-reinstall --no-cache-dir"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -706,4 +718,4 @@
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,38 +0,0 @@
|
||||
# Anchor Browser
|
||||
|
||||
[Anchor](https://anchorbrowser.io?utm=langchain) is the platform for AI Agentic browser automation, which solves the challenge of automating workflows for web applications that lack APIs or have limited API coverage. It simplifies the creation, deployment, and management of browser-based automations, transforming complex web interactions into simple API endpoints.
|
||||
|
||||
`langchain-anchorbrowser` provides 3 main tools:
|
||||
- `AnchorContentTool` - For web content extractions in Markdown or HTML format.
|
||||
- `AnchorScreenshotTool` - For web page screenshots.
|
||||
- `AnchorWebTaskTools` - To perform web tasks.
|
||||
|
||||
## Quickstart
|
||||
|
||||
### Installation
|
||||
|
||||
Install the package:
|
||||
|
||||
```bash
|
||||
pip install langchain-anchorbrowser
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Import and utilize your intended tool. The full list of Anchor Browser available tools see **Tool Features** table in [Anchor Browser tool page](/docs/integrations/tools/anchor_browser)
|
||||
|
||||
```python
|
||||
from langchain_anchorbrowser import AnchorContentTool
|
||||
|
||||
# Get Markdown Content for https://www.anchorbrowser.io
|
||||
AnchorContentTool().invoke(
|
||||
{"url": "https://www.anchorbrowser.io", "format": "markdown"}
|
||||
)
|
||||
```
|
||||
|
||||
## Additional Resources
|
||||
|
||||
- [PyPi](https://pypi.org/project/langchain-anchorbrowser)
|
||||
- [Github](https://github.com/anchorbrowser/langchain-anchorbrowser)
|
||||
- [Anchor Browser Docs](https://docs.anchorbrowser.io/introduction?utm=langchain)
|
||||
- [Anchor Browser API Reference](https://docs.anchorbrowser.io/api-reference/ai-tools/perform-web-task?utm=langchain)
|
||||
@@ -929,41 +929,6 @@ from langchain_google_community.gmail.search import GmailSearch
|
||||
from langchain_google_community.gmail.send_message import GmailSendMessage
|
||||
```
|
||||
|
||||
### MCP Toolbox
|
||||
|
||||
[MCP Toolbox](https://github.com/googleapis/genai-toolbox) provides a simple and efficient way to connect to your databases, including those on Google Cloud like [Cloud SQL](https://cloud.google.com/sql/docs) and [AlloyDB](https://cloud.google.com/alloydb/docs/overview). With MCP Toolbox, you can seamlessly integrate your database with LangChain to build powerful, data-driven applications.
|
||||
|
||||
#### Installation
|
||||
|
||||
To get started, [install the Toolbox server and client](https://github.com/googleapis/genai-toolbox/releases/).
|
||||
|
||||
|
||||
[Configure](https://googleapis.github.io/genai-toolbox/getting-started/configure/) a `tools.yaml` to define your tools, and then execute toolbox to start the server:
|
||||
|
||||
```bash
|
||||
toolbox --tools-file "tools.yaml"
|
||||
```
|
||||
|
||||
Then, install the Toolbox client:
|
||||
|
||||
```bash
|
||||
pip install toolbox-langchain
|
||||
```
|
||||
|
||||
#### Getting Started
|
||||
|
||||
Here is a quick example of how to use MCP Toolbox to connect to your database:
|
||||
|
||||
```python
|
||||
from toolbox_langchain import ToolboxClient
|
||||
|
||||
async with ToolboxClient("http://127.0.0.1:5000") as client:
|
||||
|
||||
tools = client.load_toolset()
|
||||
```
|
||||
|
||||
See [usage example and setup instructions](/docs/integrations/tools/toolbox).
|
||||
|
||||
### Memory
|
||||
|
||||
Store conversation history using Google Cloud databases.
|
||||
|
||||
@@ -2,10 +2,17 @@
|
||||
|
||||
This will help you getting started with DigitalOcean Gradient [chat models](/docs/concepts/chat_models).
|
||||
|
||||
## Overview
|
||||
### Integration details
|
||||
|
||||
| Class | Package | Package downloads | Package latest |
|
||||
| :--- | :--- | :---: | :---: |
|
||||
| [ChatGradient](https://python.langchain.com/api_reference/langchain-gradient/chat_models/langchain_gradient.chat_models.ChatGradient.html) | [langchain-gradient](https://python.langchain.com/api_reference/langchain-gradient/) |  |  |
|
||||
|
||||
|
||||
## Setup
|
||||
|
||||
langchain-gradient uses DigitalOcean's Gradient™ AI Platform.
|
||||
langchain-gradient uses DigitalOcean Gradient Platform.
|
||||
|
||||
Create an account on DigitalOcean, acquire a `DIGITALOCEAN_INFERENCE_KEY` API key from the Gradient Platform, and install the `langchain-gradient` integration package.
|
||||
|
||||
|
||||
@@ -1,14 +1,14 @@
|
||||
# Ollama
|
||||
|
||||
>[Ollama](https://ollama.com/) allows you to run open-source large language models,
|
||||
> such as [gpt-oss](https://ollama.com/library/gpt-oss), locally.
|
||||
> such as [Llama3.1](https://ai.meta.com/blog/meta-llama-3-1/), locally.
|
||||
>
|
||||
>`Ollama` bundles model weights, configuration, and data into a single package, defined by a Modelfile.
|
||||
>It optimizes setup and configuration details, including GPU usage.
|
||||
>For a complete list of supported models and model variants, see the [Ollama model library](https://ollama.ai/library).
|
||||
|
||||
See [this guide](/docs/how_to/local_llms#ollama) for more details
|
||||
on how to use `ollama` with LangChain.
|
||||
See [this guide](/docs/how_to/local_llms) for more details
|
||||
on how to use `Ollama` with LangChain.
|
||||
|
||||
## Installation and Setup
|
||||
### Ollama installation
|
||||
@@ -26,7 +26,7 @@ ollama serve
|
||||
After starting ollama, run `ollama pull <name-of-model>` to download a model from the [Ollama model library](https://ollama.ai/library):
|
||||
|
||||
```bash
|
||||
ollama pull gpt-oss:20b
|
||||
ollama pull llama3.1
|
||||
```
|
||||
|
||||
- This will download the default tagged version of the model. Typically, the default points to the latest, smallest sized-parameter model.
|
||||
|
||||
@@ -1,26 +0,0 @@
|
||||
# Scrapeless
|
||||
|
||||
[Scrapeless](https://scrapeless.com) offers flexible and feature-rich data acquisition services with extensive parameter customization and multi-format export support.
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
```bash
|
||||
pip install langchain-scrapeless
|
||||
```
|
||||
|
||||
You'll need to set up your Scrapeless API key:
|
||||
|
||||
```python
|
||||
import os
|
||||
os.environ["SCRAPELESS_API_KEY"] = "your-api-key"
|
||||
```
|
||||
|
||||
## Tools
|
||||
|
||||
The Scrapeless integration provides several tools:
|
||||
|
||||
- [ScrapelessDeepSerpGoogleSearchTool](/docs/integrations/tools/scrapeless_scraping_api) - Enables comprehensive extraction of Google SERP data across all result types.
|
||||
- [ScrapelessDeepSerpGoogleTrendsTool](/docs/integrations/tools/scrapeless_scraping_api) - Retrieves keyword trend data from Google, including popularity over time, regional interest, and related searches.
|
||||
- [ScrapelessUniversalScrapingTool](/docs/integrations/tools/scrapeless_universal_scraping) - Access and extract data from JS-Render websites that typically block bots.
|
||||
- [ScrapelessCrawlerCrawlTool](/docs/integrations/tools/scrapeless_crawl) - Crawl a website and its linked pages to extract comprehensive data.
|
||||
- [ScrapelessCrawlerScrapeTool](/docs/integrations/tools/scrapeless_crawl) - Extract information from a single webpage.
|
||||
@@ -1,23 +0,0 @@
|
||||
# MCP Toolbox
|
||||
|
||||
The [MCP Toolbox](https://googleapis.github.io/genai-toolbox/getting-started/introduction/) in LangChain allows you to equip an agent with a set of tools. When the agent receives a query, it can intelligently select and use the most appropriate tool provided by MCP Toolbox to fulfill the request.
|
||||
|
||||
## What is it?
|
||||
|
||||
MCP Toolbox is essentially a container for your tools. Think of it as a multi-tool device for your agent; it can hold any tools you create. The agent then decides which specific tool to use based on the user's input.
|
||||
|
||||
This is particularly useful when you have an agent that needs to perform a variety of tasks that require different capabilities.
|
||||
|
||||
## Installation
|
||||
|
||||
To get started, you'll need to install the necessary package:
|
||||
|
||||
```bash
|
||||
pip install toolbox-langchain
|
||||
```
|
||||
|
||||
## Tutorial
|
||||
|
||||
For a complete, step-by-step guide on how to create, configure, and use MCP Toolbox with your agents, please refer to our detailed Jupyter notebook tutorial.
|
||||
|
||||
**[➡️ View the full tutorial here](/docs/integrations/tools/toolbox)**.
|
||||
@@ -1,101 +0,0 @@
|
||||
# TrueFoundry
|
||||
|
||||
TrueFoundry provides an enterprise-ready [AI Gateway](https://www.truefoundry.com/ai-gateway) to provide governance and observability to agentic frameworks like LangChain. TrueFoundry AI Gateway serves as a unified interface for LLM access, providing:
|
||||
|
||||
- **Unified API Access**: Connect to 250+ LLMs (OpenAI, Claude, Gemini, Groq, Mistral) through one API
|
||||
- **Low Latency**: Sub-3ms internal latency with intelligent routing and load balancing
|
||||
- **Enterprise Security**: SOC 2, HIPAA, GDPR compliance with RBAC and audit logging
|
||||
- **Quota and cost management**: Token-based quotas, rate limiting, and comprehensive usage tracking
|
||||
- **Observability**: Full request/response logging, metrics, and traces with customizable retention
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before integrating LangChain with TrueFoundry, ensure you have:
|
||||
|
||||
1. **TrueFoundry Account**: A [TrueFoundry account](https://www.truefoundry.com/register) with at least one model provider configured. Follow quick start guide [here](https://docs.truefoundry.com/gateway/quick-start)
|
||||
2. **Personal Access Token**: Generate a token by following the [TrueFoundry token generation guide](https://docs.truefoundry.com/gateway/authentication)
|
||||
|
||||
## Quickstart
|
||||
|
||||
You can connect to TrueFoundry's unified LLM gateway through the `ChatOpenAI` interface.
|
||||
|
||||
- Set the `base_url` to your TrueFoundry endpoint (explained below)
|
||||
- Set the `api_key` to your TrueFoundry [PAT (Personal Access Token)](https://docs.truefoundry.com/gateway/authentication#personal-access-token-pat)
|
||||
- Use the same `model-name` as shown in the unified code snippet
|
||||
|
||||

|
||||
|
||||
### Installation
|
||||
|
||||
```bash
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
### Basic Setup
|
||||
|
||||
Connect to TrueFoundry by updating the `ChatOpenAI` model in LangChain:
|
||||
|
||||
```python
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
llm = ChatOpenAI(
|
||||
api_key=TRUEFOUNDRY_API_KEY,
|
||||
base_url=TRUEFOUNDRY_GATEWAY_BASE_URL,
|
||||
model="openai-main/gpt-4o" # Similarly you can call any model from any model provider
|
||||
)
|
||||
|
||||
llm.invoke("What is the meaning of life, universe and everything?")
|
||||
```
|
||||
|
||||
The request is routed through your TrueFoundry gateway to the specified model provider. TrueFoundry automatically handles rate limiting, load balancing, and observability.
|
||||
|
||||
### LangGraph Integration
|
||||
|
||||
|
||||
```python
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langgraph.graph import StateGraph, MessagesState
|
||||
from langchain_core.messages import HumanMessage
|
||||
|
||||
# Define your LangGraph workflow
|
||||
def call_model(state: MessagesState):
|
||||
model = ChatOpenAI(
|
||||
api_key=TRUEFOUNDRY_API_KEY,
|
||||
base_url=TRUEFOUNDRY_GATEWAY_BASE_URL,
|
||||
# Copy the exact model name from gateway
|
||||
model="openai-main/gpt-4o"
|
||||
)
|
||||
response = model.invoke(state["messages"])
|
||||
return {"messages": [response]}
|
||||
|
||||
# Build workflow
|
||||
workflow = StateGraph(MessagesState)
|
||||
workflow.add_node("agent", call_model)
|
||||
workflow.set_entry_point("agent")
|
||||
workflow.set_finish_point("agent")
|
||||
|
||||
app = workflow.compile()
|
||||
|
||||
# Run agent through TrueFoundry
|
||||
result = app.invoke({"messages": [HumanMessage(content="Hello!")]})
|
||||
```
|
||||
|
||||
|
||||
## Observability and Governance
|
||||
|
||||

|
||||
|
||||
With the Metrics Dashboard, you can monitor and analyze:
|
||||
|
||||
- **Performance Metrics**: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
|
||||
- **Cost and Token Usage**: Gain visibility into your application's costs with detailed breakdowns of input/output tokens and the associated expenses for each model
|
||||
- **Usage Patterns**: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
|
||||
- **Rate Limiting & Load Balancing**: Configure limits, distribute traffic across models, and set up fallbacks
|
||||
|
||||
## Support
|
||||
|
||||
For questions, issues, or support:
|
||||
|
||||
- **Email**: [support@truefoundry.com](mailto:support@truefoundry.com)
|
||||
- **Documentation**: [https://docs.truefoundry.com/](https://docs.truefoundry.com/)
|
||||
@@ -1,307 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "2ce4bdbc",
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "raw"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: anchor_browser\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a6f91f20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Anchor Browser\n",
|
||||
"\n",
|
||||
"Anchor is a platform for AI Agentic browser automation, which solves the challenge of automating workflows for web applications that lack APIs or have limited API coverage. It simplifies the creation, deployment, and management of browser-based automations, transforming complex web interactions into simple API endpoints.\n",
|
||||
"\n",
|
||||
"This notebook provides a quick overview for getting started with Anchor Browser tools. For more information of Anchor Browser visit [Anchorbrowser.io](https://anchorbrowser.io?utm=langchain) or the [Anchor Browser Docs](https://docs.anchorbrowser.io?utm=langchain)\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"Anchor Browser package for LangChain is [langchain-anchorbrowser](https://pypi.org/project/langchain-anchorbrowser), and the current latest version is .\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Tool features\n",
|
||||
"| Tool Name | Package | Description | Parameters |\n",
|
||||
"| :--- | :--- | :--- | :---|\n",
|
||||
"| `AnchorContentTool` | langchain-anchorbrowser | Extract text content from web pages | `url`, `format` |\n",
|
||||
"| `AnchorScreenshotTool` | langchain-anchorbrowser | Take screenshots of web pages | `url`, `width`, `height`, `image_quality`, `wait`, `scroll_all_content`, `capture_full_height`, `s3_target_address` |\n",
|
||||
"| `AnchorWebTaskToolKit` | langchain-anchorbrowser | Perform intelligent web tasks using AI (Simple & Advanced modes) | see below |\n",
|
||||
"\n",
|
||||
"The parameters allowed in `langchain-anchorbrowser` are only a subset of those listed in the Anchor Browser API reference respectively: [Get Webpage Content](https://docs.anchorbrowser.io/sdk-reference/tools/get-webpage-content?utm=langchain), [Screenshot Webpage](https://docs.anchorbrowser.io/sdk-reference/tools/screenshot-webpage?utm=langchain), and [Perform Web Task](https://docs.anchorbrowser.io/sdk-reference/ai-tools/perform-web-task?utm=langchain).\n",
|
||||
"\n",
|
||||
"**Info:** Anchor currently implements `SimpleAnchorWebTaskTool` and `AdvancedAnchorWebTaskTool` tools for langchain with `browser_use` agent. For \n",
|
||||
"\n",
|
||||
"#### AnchorWebTaskToolKit Tools\n",
|
||||
"\n",
|
||||
"The difference between each tool in this toolkit is the pydantic configuration structure.\n",
|
||||
"| Tool Name | Package | Parameters |\n",
|
||||
"| :--- | :--- | :--- |\n",
|
||||
"| `SimpleAnchorWebTaskTool` | langchain-anchorbrowser | prompt, url |\n",
|
||||
"| `AdvancedAnchorWebTaskTool` | langchain-anchorbrowser | prompt, url, output_schema |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-anchorbrowser` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f85b4089",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --quiet -U langchain-anchorbrowser"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b15e9266",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"Use your Anchor Browser Credentials. Get them on Anchor Browser [API Keys page](https://app.anchorbrowser.io/api-keys?utm=langchain) as needed."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "e0b178a2-8816-40ca-b57c-ccdd86dde9c9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"if not os.environ.get(\"ANCHORBROWSER_API_KEY\"):\n",
|
||||
" os.environ[\"ANCHORBROWSER_API_KEY\"] = getpass.getpass(\"ANCHORBROWSER API key:\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1c97218f-f366-479d-8bf7-fe9f2f6df73f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation\n",
|
||||
"\n",
|
||||
"Instantiace easily Anchor Browser tools instances."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8b3ddfe9-ca79-494c-a7ab-1f56d9407a64",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_anchorbrowser import (\n",
|
||||
" AnchorContentTool,\n",
|
||||
" AnchorScreenshotTool,\n",
|
||||
" AdvancedAnchorWebTaskTool,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"anchor_content_tool = AnchorContentTool()\n",
|
||||
"anchor_screenshot_tool = AnchorScreenshotTool()\n",
|
||||
"anchor_advanced_web_task_tool = AdvancedAnchorWebTaskTool()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "74147a1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n",
|
||||
"\n",
|
||||
"### [Invoke directly with args](/docs/concepts/tools/#use-the-tool-directly)\n",
|
||||
"\n",
|
||||
"The full available argument list appear above in the tool features table."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "65310a8b-eb0c-4d9e-a618-4f4abe2414fc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Get Markdown Content for https://www.anchorbrowser.io\n",
|
||||
"anchor_content_tool.invoke(\n",
|
||||
" {\"url\": \"https://www.anchorbrowser.io\", \"format\": \"markdown\"}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Get a Screenshot for https://docs.anchorbrowser.io\n",
|
||||
"anchor_screenshot_tool.invoke(\n",
|
||||
" {\"url\": \"https://docs.anchorbrowser.io\", \"width\": 1280, \"height\": 720}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Get a Screenshot for https://docs.anchorbrowser.io\n",
|
||||
"anchor_advanced_web_task_tool.invoke(\n",
|
||||
" {\n",
|
||||
" \"prompt\": \"Collect the node names and their CPU average %\",\n",
|
||||
" \"url\": \"https://play.grafana.org/a/grafana-k8s-app/navigation/nodes?from=now-1h&to=now&refresh=1m\",\n",
|
||||
" \"output_schema\": {\n",
|
||||
" \"nodes_cpu_usage\": [\n",
|
||||
" {\"node\": \"string\", \"cluster\": \"string\", \"cpu_avg_percentage\": \"number\"}\n",
|
||||
" ]\n",
|
||||
" },\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d6e73897",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### [Invoke with ToolCall](/docs/concepts/tool_calling/#tool-execution)\n",
|
||||
"\n",
|
||||
"We can also invoke the tool with a model-generated ToolCall, in which case a ToolMessage will be returned:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f90e33a7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This is usually generated by a model, but we'll create a tool call directly for demo purposes.\n",
|
||||
"model_generated_tool_call = {\n",
|
||||
" \"args\": {\"url\": \"https://www.anchorbrowser.io\", \"format\": \"markdown\"},\n",
|
||||
" \"id\": \"1\",\n",
|
||||
" \"name\": anchor_content_tool.name,\n",
|
||||
" \"type\": \"tool_call\",\n",
|
||||
"}\n",
|
||||
"anchor_content_tool.invoke(model_generated_tool_call)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "659f9fbd-6fcf-445f-aa8c-72d8e60154bd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"We can use our tool in a chain by first binding it to a [tool-calling model](/docs/how_to/tool_calling/) and then calling it:\n",
|
||||
"## Use within an agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c67bfd54",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "af3123ad-7a02-40e5-b58e-7d56e23e5830",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import init_chat_model\n",
|
||||
"\n",
|
||||
"llm = init_chat_model(model=\"gpt-4o\", model_provider=\"openai\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "210511c8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"if not os.environ.get(\"OPENAI_API_KEY\"):\n",
|
||||
" os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OPENAI API key:\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fdbf35b5-3aaf-4947-9ec6-48c21533fb95",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_core.runnables import RunnableConfig, chain\n",
|
||||
"\n",
|
||||
"prompt = ChatPromptTemplate(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You are a helpful assistant.\"),\n",
|
||||
" (\"human\", \"{user_input}\"),\n",
|
||||
" (\"placeholder\", \"{messages}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# specifying tool_choice will force the model to call this tool.\n",
|
||||
"llm_with_tools = llm.bind_tools(\n",
|
||||
" [anchor_content_tool], tool_choice=anchor_content_tool.name\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"llm_chain = prompt | llm_with_tools\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"@chain\n",
|
||||
"def tool_chain(user_input: str, config: RunnableConfig):\n",
|
||||
" input_ = {\"user_input\": user_input}\n",
|
||||
" ai_msg = llm_chain.invoke(input_, config=config)\n",
|
||||
" tool_msgs = anchor_content_tool.batch(ai_msg.tool_calls, config=config)\n",
|
||||
" return llm_chain.invoke({**input_, \"messages\": [ai_msg, *tool_msgs]}, config=config)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tool_chain.invoke(input())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4ac8146c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
" - [PyPi](https://pypi.org/project/langchain-anchorbrowser)\n",
|
||||
" - [Github](https://github.com/anchorbrowser/langchain-anchorbrowser)\n",
|
||||
" - [Anchor Browser Docs](https://docs.anchorbrowser.io/introduction?utm=langchain)\n",
|
||||
" - [Anchor Browser API Reference](https://docs.anchorbrowser.io/api-reference/ai-tools/perform-web-task?utm=langchain)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -1,339 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a6f91f20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Scrapeless\n",
|
||||
"\n",
|
||||
"**Scrapeless** offers flexible and feature-rich data acquisition services with extensive parameter customization and multi-format export support. These capabilities empower LangChain to integrate and leverage external data more effectively. The core functional modules include:\n",
|
||||
"\n",
|
||||
"**DeepSerp**\n",
|
||||
"- **Google Search**: Enables comprehensive extraction of Google SERP data across all result types.\n",
|
||||
" - Supports selection of localized Google domains (e.g., `google.com`, `google.ad`) to retrieve region-specific search results.\n",
|
||||
" - Pagination supported for retrieving results beyond the first page.\n",
|
||||
" - Supports a search result filtering toggle to control whether to exclude duplicate or similar content.\n",
|
||||
"- **Google Trends**: Retrieves keyword trend data from Google, including popularity over time, regional interest, and related searches.\n",
|
||||
" - Supports multi-keyword comparison.\n",
|
||||
" - Supports multiple data types: `interest_over_time`, `interest_by_region`, `related_queries`, and `related_topics`.\n",
|
||||
" - Allows filtering by specific Google properties (Web, YouTube, News, Shopping) for source-specific trend analysis.\n",
|
||||
"\n",
|
||||
"**Universal Scraping**\n",
|
||||
"- Designed for modern, JavaScript-heavy websites, allowing dynamic content extraction.\n",
|
||||
" - Global premium proxy support for bypassing geo-restrictions and improving reliability.\n",
|
||||
"\n",
|
||||
"**Crawler**\n",
|
||||
"- **Crawl**: Recursively crawl a website and its linked pages to extract site-wide content.\n",
|
||||
" - Supports configurable crawl depth and scoped URL targeting.\n",
|
||||
"- **Scrape**: Extract content from a single webpage with high precision.\n",
|
||||
" - Supports \"main content only\" extraction to exclude ads, footers, and other non-essential elements.\n",
|
||||
" - Allows batch scraping of multiple standalone URLs.\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"| Class | Package | Serializable | JS support | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [ScrapelessUniversalScrapingTool](https://pypi.org/project/langchain-scrapeless/) | [langchain-scrapeless](https://pypi.org/project/langchain-scrapeless/) | ✅ | ❌ |  |\n",
|
||||
"\n",
|
||||
"### Tool features\n",
|
||||
"\n",
|
||||
"|Native async|Returns artifact|Return data|\n",
|
||||
"|:-:|:-:|:-:|\n",
|
||||
"|✅|✅|html, markdown, links, metadata, structured content|\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-scrapeless` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "ca676665",
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "raw"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"!pip install langchain-scrapeless"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b15e9266",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"You'll need a Scrapeless API key to use this tool. You can set it as an environment variable:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e0b178a2-8816-40ca-b57c-ccdd86dde9c9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"SCRAPELESS_API_KEY\"] = \"your-api-key\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1c97218f-f366-479d-8bf7-fe9f2f6df73f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation\n",
|
||||
"\n",
|
||||
"Here we show how to instantiate an instance of the Scrapeless Universal Scraping Tool. This tool allows you to scrape any website using a headless browser with JavaScript rendering capabilities, customizable output types, and geo-specific proxy support.\n",
|
||||
"\n",
|
||||
"The tool accepts the following parameters during instantiation:\n",
|
||||
"- `url` (required, str): The URL of the website to scrape.\n",
|
||||
"- `headless` (optional, bool): Whether to use a headless browser. Default is True.\n",
|
||||
"- `js_render` (optional, bool): Whether to enable JavaScript rendering. Default is True.\n",
|
||||
"- `js_wait_until` (optional, str): Defines when to consider the JavaScript-rendered page ready. Default is `'domcontentloaded'`. Options include:\n",
|
||||
" - `load`: Wait until the page is fully loaded.\n",
|
||||
" - `domcontentloaded`: Wait until the DOM is fully loaded.\n",
|
||||
" - `networkidle0`: Wait until the network is idle.\n",
|
||||
" - `networkidle2`: Wait until the network is idle for 2 seconds.\n",
|
||||
"- `outputs` (optional, str): The specific type of data to extract from the page. Options include:\n",
|
||||
" - `phone_numbers`\n",
|
||||
" - `headings`\n",
|
||||
" - `images`\n",
|
||||
" - `audios`\n",
|
||||
" - `videos`\n",
|
||||
" - `links`\n",
|
||||
" - `menus`\n",
|
||||
" - `hashtags`\n",
|
||||
" - `emails`\n",
|
||||
" - `metadata`\n",
|
||||
" - `tables`\n",
|
||||
" - `favicon`\n",
|
||||
"- `response_type` (optional, str): Defines the format of the response. Default is `'html'`. Options include:\n",
|
||||
" - `html`: Return the raw HTML of the page.\n",
|
||||
" - `plaintext`: Return the plain text content.\n",
|
||||
" - `markdown`: Return a Markdown version of the page.\n",
|
||||
" - `png`: Return a PNG screenshot.\n",
|
||||
" - `jpeg`: Return a JPEG screenshot.\n",
|
||||
"- `response_image_full_page` (optional, bool): Whether to capture and return a full-page image when using screenshot output (png or jpeg). Default is False.\n",
|
||||
"- `selector` (optional, str): A specific CSS selector to scope scraping within a part of the page. Default is `None`.\n",
|
||||
"- `proxy_country` (optional, str): Two-letter country code for geo-specific proxy access (e.g., `'us'`, `'gb'`, `'de'`, `'jp'`). Default is `'ANY'`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "74147a1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n",
|
||||
"\n",
|
||||
"### Basic Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "65310a8b-eb0c-4d9e-a618-4f4abe2414fc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"<!DOCTYPE html><html><head>\n",
|
||||
" <title>Example Domain</title>\n",
|
||||
"\n",
|
||||
" <meta charset=\"utf-8\">\n",
|
||||
" <meta http-equiv=\"Content-type\" content=\"text/html; charset=utf-8\">\n",
|
||||
" <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n",
|
||||
" <style type=\"text/css\">\n",
|
||||
" body {\n",
|
||||
" background-color: #f0f0f2;\n",
|
||||
" margin: 0;\n",
|
||||
" padding: 0;\n",
|
||||
" font-family: -apple-system, system-ui, BlinkMacSystemFont, \"Segoe UI\", \"Open Sans\", \"Helvetica Neue\", Helvetica, Arial, sans-serif;\n",
|
||||
" \n",
|
||||
" }\n",
|
||||
" div {\n",
|
||||
" width: 600px;\n",
|
||||
" margin: 5em auto;\n",
|
||||
" padding: 2em;\n",
|
||||
" background-color: #fdfdff;\n",
|
||||
" border-radius: 0.5em;\n",
|
||||
" box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);\n",
|
||||
" }\n",
|
||||
" a:link, a:visited {\n",
|
||||
" color: #38488f;\n",
|
||||
" text-decoration: none;\n",
|
||||
" }\n",
|
||||
" @media (max-width: 700px) {\n",
|
||||
" div {\n",
|
||||
" margin: 0 auto;\n",
|
||||
" width: auto;\n",
|
||||
" }\n",
|
||||
" }\n",
|
||||
" </style> \n",
|
||||
"</head>\n",
|
||||
"\n",
|
||||
"<body>\n",
|
||||
"<div>\n",
|
||||
" <h1>Example Domain</h1>\n",
|
||||
" <p>This domain is for use in illustrative examples in documents. You may use this\n",
|
||||
" domain in literature without prior coordination or asking for permission.</p>\n",
|
||||
" <p><a href=\"https://www.iana.org/domains/example\">More information...</a></p>\n",
|
||||
"</div>\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"</body></html>\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"# Basic usage\n",
|
||||
"result = tool.invoke(\"https://example.com\")\n",
|
||||
"print(result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d6e73897",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Advanced Usage with Parameters"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f90e33a7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"# Well hello there.\n",
|
||||
"\n",
|
||||
"Welcome to exmaple.com.\n",
|
||||
"Chances are you got here by mistake (example.com, anyone?)\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"result = tool.invoke({\"url\": \"https://exmaple.com\", \"response_type\": \"markdown\"})\n",
|
||||
"print(result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "659f9fbd-6fcf-445f-aa8c-72d8e60154bd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Use within an agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "af3123ad-7a02-40e5-b58e-7d56e23e5830",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"================================\u001b[1m Human Message \u001b[0m=================================\n",
|
||||
"\n",
|
||||
"Use the scrapeless scraping tool to fetch https://www.scrapeless.com/en and extract the h1 tag.\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"Tool Calls:\n",
|
||||
" scrapeless_universal_scraping (call_jBrvMVL2ixhvf6gklhi7Gqtb)\n",
|
||||
" Call ID: call_jBrvMVL2ixhvf6gklhi7Gqtb\n",
|
||||
" Args:\n",
|
||||
" url: https://www.scrapeless.com/en\n",
|
||||
" outputs: headings\n",
|
||||
"=================================\u001b[1m Tool Message \u001b[0m=================================\n",
|
||||
"Name: scrapeless_universal_scraping\n",
|
||||
"\n",
|
||||
"{\"headings\":[\"Effortless Web Scraping Toolkitfor Business and Developers\",\"4.8\",\"4.5\",\"8.5\",\"A Flexible Toolkit for Accessing Public Web Data\",\"Deep SerpApi\",\"Scraping Browser\",\"Universal Scraping API\",\"Customized Services\",\"From Simple Data Scraping to Complex Anti-Bot Challenges, Scrapeless Has You Covered.\",\"Fully Compatible with Key Programming Languages and Tools\",\"Enterprise-level Data Scraping Solution\",\"Customized Data Scraping Solutions\",\"High Concurrency and High-Performance Scraping\",\"Data Cleaning and Transformation\",\"Real-Time Data Push and API Integration\",\"Data Security and Privacy Protection\",\"Enterprise-level SLA\",\"Why Scrapeless: Simplify Your Data Flow Effortlessly.\",\"Articles\",\"Organized Fresh Data\",\"Prices\",\"No need to hassle with browser maintenance\",\"Reviews\",\"Only pay for successful requests\",\"Products\",\"Fully scalable\",\"Unleash Your Competitive Edgein Data within the Industry\",\"Regulate Compliance for All Users\",\"Web Scraping Blog\",\"Scrapeless MCP Server Is Officially Live! Build Your Ultimate AI-Web Connector\",\"Product Updates | New Profile Feature\",\"How to Track Your Ranking on ChatGPT?\",\"For Scraping\",\"For Data\",\"For AI\",\"Top Scraper API\",\"Learning Center\",\"Legal\"]}\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"The h1 tag extracted from the website https://www.scrapeless.com/en is \"Effortless Web Scraping Toolkit for Business and Developers\".\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI()\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"# Use the tool with an agent\n",
|
||||
"tools = [tool]\n",
|
||||
"agent = create_react_agent(llm, tools)\n",
|
||||
"\n",
|
||||
"for chunk in agent.stream(\n",
|
||||
" {\n",
|
||||
" \"messages\": [\n",
|
||||
" (\n",
|
||||
" \"human\",\n",
|
||||
" \"Use the scrapeless scraping tool to fetch https://www.scrapeless.com/en and extract the h1 tag.\",\n",
|
||||
" )\n",
|
||||
" ]\n",
|
||||
" },\n",
|
||||
" stream_mode=\"values\",\n",
|
||||
"):\n",
|
||||
" chunk[\"messages\"][-1].pretty_print()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4ac8146c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
"- [Scrapeless Documentation](https://docs.scrapeless.com/en/universal-scraping-api/quickstart/introduction/)\n",
|
||||
"- [Scrapeless API Reference](https://apidocs.scrapeless.com/api-12948840)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -1,378 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "554b9f85",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# MCP Toolbox for Databases\n",
|
||||
"\n",
|
||||
"Integrate your databases with LangChain agents using MCP Toolbox.\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"[MCP Toolbox for Databases](https://github.com/googleapis/genai-toolbox) is an open source MCP server for databases. It was designed with enterprise-grade and production-quality in mind. It enables you to develop tools easier, faster, and more securely by handling the complexities such as connection pooling, authentication, and more.\n",
|
||||
"\n",
|
||||
"Toolbox Tools can be seemlessly integrated with Langchain applications. For more\n",
|
||||
"information on [getting\n",
|
||||
"started](https://googleapis.github.io/genai-toolbox/getting-started/local_quickstart/) or\n",
|
||||
"[configuring](https://googleapis.github.io/genai-toolbox/getting-started/configure/)\n",
|
||||
"MCP Toolbox, see the\n",
|
||||
"[documentation](https://googleapis.github.io/genai-toolbox/getting-started/introduction/).\n",
|
||||
"\n",
|
||||
"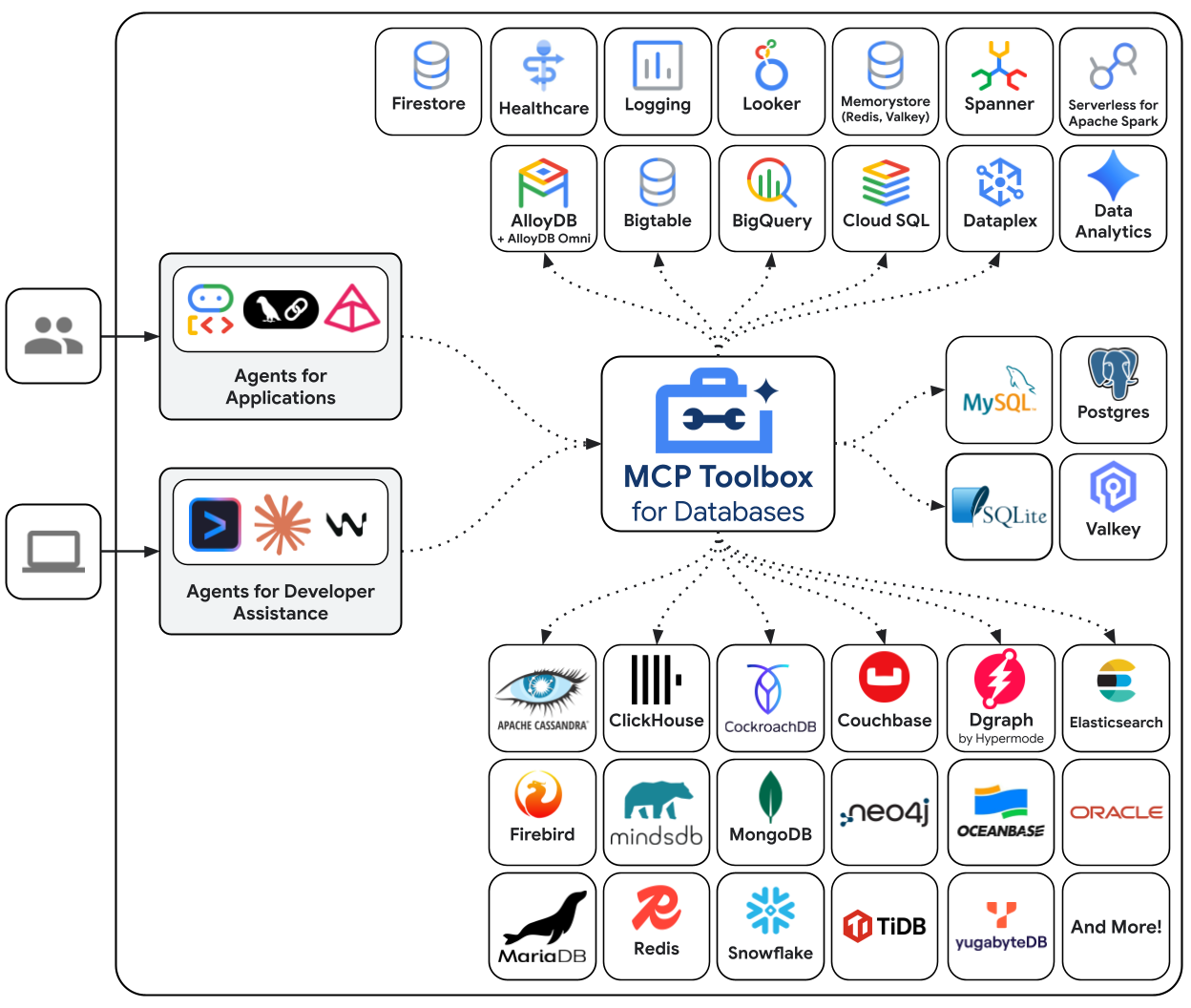"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "788ff64c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"This guide assumes you have already done the following:\n",
|
||||
"\n",
|
||||
"1. Installed [Python 3.9+](https://wiki.python.org/moin/BeginnersGuide/Download) and [pip](https://pip.pypa.io/en/stable/installation/).\n",
|
||||
"2. Installed [PostgreSQL 16+ and the `psql` command-line client](https://www.postgresql.org/download/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4847d196",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 1. Setup your Database\n",
|
||||
"\n",
|
||||
"First, let's set up a PostgreSQL database. We'll create a new database, a dedicated user for MCP Toolbox, and a `hotels` table with some sample data.\n",
|
||||
"\n",
|
||||
"Connect to PostgreSQL using the `psql` command. You may need to adjust the command based on your PostgreSQL setup (e.g., if you need to specify a host or a different superuser).\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"psql -U postgres\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Now, run the following SQL commands to create the user, database, and grant the necessary permissions:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"CREATE USER toolbox_user WITH PASSWORD 'my-password';\n",
|
||||
"CREATE DATABASE toolbox_db;\n",
|
||||
"GRANT ALL PRIVILEGES ON DATABASE toolbox_db TO toolbox_user;\n",
|
||||
"ALTER DATABASE toolbox_db OWNER TO toolbox_user;\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Connect to your newly created database with the new user:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"\\c toolbox_db toolbox_user\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Finally, create the `hotels` table and insert some data:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"CREATE TABLE hotels(\n",
|
||||
" id INTEGER NOT NULL PRIMARY KEY,\n",
|
||||
" name VARCHAR NOT NULL,\n",
|
||||
" location VARCHAR NOT NULL,\n",
|
||||
" price_tier VARCHAR NOT NULL,\n",
|
||||
" booked BIT NOT NULL\n",
|
||||
");\n",
|
||||
"\n",
|
||||
"INSERT INTO hotels(id, name, location, price_tier, booked)\n",
|
||||
"VALUES \n",
|
||||
" (1, 'Hilton Basel', 'Basel', 'Luxury', B'0'),\n",
|
||||
" (2, 'Marriott Zurich', 'Zurich', 'Upscale', B'0'),\n",
|
||||
" (3, 'Hyatt Regency Basel', 'Basel', 'Upper Upscale', B'0');\n",
|
||||
"```\n",
|
||||
"You can now exit `psql` by typing `\\q`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "855133f8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 2. Install MCP Toolbox\n",
|
||||
"\n",
|
||||
"Next, we will install MCP Toolbox, define our tools in a `tools.yaml` configuration file, and run the MCP Toolbox server.\n",
|
||||
"\n",
|
||||
"For **macOS** users, the easiest way to install is with [Homebrew](https://formulae.brew.sh/formula/mcp-toolbox):\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"brew install mcp-toolbox\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"For other platforms, [download the latest MCP Toolbox binary for your operating system and architecture.](https://github.com/googleapis/genai-toolbox/releases)\n",
|
||||
"\n",
|
||||
"Create a `tools.yaml` file. This file defines the data sources MCP Toolbox can connect to and the tools it can expose to your agent. For production use, always use environment variables for secrets.\n",
|
||||
"\n",
|
||||
"```yaml\n",
|
||||
"sources:\n",
|
||||
" my-pg-source:\n",
|
||||
" kind: postgres\n",
|
||||
" host: 127.0.0.1\n",
|
||||
" port: 5432\n",
|
||||
" database: toolbox_db\n",
|
||||
" user: toolbox_user\n",
|
||||
" password: my-password\n",
|
||||
"\n",
|
||||
"tools:\n",
|
||||
" search-hotels-by-location:\n",
|
||||
" kind: postgres-sql\n",
|
||||
" source: my-pg-source\n",
|
||||
" description: Search for hotels based on location.\n",
|
||||
" parameters:\n",
|
||||
" - name: location\n",
|
||||
" type: string\n",
|
||||
" description: The location of the hotel.\n",
|
||||
" statement: SELECT id, name, location, price_tier FROM hotels WHERE location ILIKE '%' || $1 || '%';\n",
|
||||
" book-hotel:\n",
|
||||
" kind: postgres-sql\n",
|
||||
" source: my-pg-source\n",
|
||||
" description: >-\n",
|
||||
" Book a hotel by its ID. If the hotel is successfully booked, returns a confirmation message.\n",
|
||||
" parameters:\n",
|
||||
" - name: hotel_id\n",
|
||||
" type: integer\n",
|
||||
" description: The ID of the hotel to book.\n",
|
||||
" statement: UPDATE hotels SET booked = B'1' WHERE id = $1;\n",
|
||||
"\n",
|
||||
"toolsets:\n",
|
||||
" hotel_toolset:\n",
|
||||
" - search-hotels-by-location\n",
|
||||
" - book-hotel\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Now, in a separate terminal window, start the MCP Toolbox server. If you installed via Homebrew, you can just run `toolbox`. If you downloaded the binary manually, you'll need to run `./toolbox` from the directory where you saved it:\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"toolbox --tools-file \"tools.yaml\"\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"MCP Toolbox will start on `http://127.0.0.1:5000` by default and will hot-reload if you make changes to your `tools.yaml` file."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b9b2f041",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d4c31f3b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install toolbox-langchain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "14a68a49",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" search_tool = await client.aload_tool(\"search-hotels-by-location\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "95eec50c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8e99351b",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[{\"id\":1,\"location\":\"Basel\",\"name\":\"Hilton Basel\",\"price_tier\":\"Luxury\"},{\"id\":3,\"location\":\"Basel\",\"name\":\"Hyatt Regency Basel\",\"price_tier\":\"Upper Upscale\"}]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" search_tool = await client.aload_tool(\"search-hotels-by-location\")\n",
|
||||
" results = search_tool.invoke({\"location\": \"Basel\"})\n",
|
||||
" print(results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9e8dbd39",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Use within an agent\n",
|
||||
"\n",
|
||||
"Now for the fun part! We'll install the required LangChain packages and create an agent that can use the tools we defined in MCP Toolbox."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9b716a84",
|
||||
"metadata": {
|
||||
"id": "install-packages"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U --quiet toolbox-langchain langgraph langchain-google-vertexai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "affda34b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"With the packages installed, we can define our agent. We will use `ChatVertexAI` for the model and `ToolboxClient` to load our tools. The `create_react_agent` from `langgraph.prebuilt` creates a robust agent that can reason about which tools to call.\n",
|
||||
"\n",
|
||||
"**Note:** Ensure your MCP Toolbox server is running in a separate terminal before executing the code below."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "ddd82892",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"from langchain_google_vertexai import ChatVertexAI\n",
|
||||
"from langgraph.checkpoint.memory import MemorySaver\n",
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"prompt = \"\"\"\n",
|
||||
"You're a helpful hotel assistant. You handle hotel searching and booking.\n",
|
||||
"When the user searches for a hotel, list the full details for each hotel found: id, name, location, and price tier.\n",
|
||||
"Always use the hotel ID for booking operations.\n",
|
||||
"For any bookings, provide a clear confirmation message.\n",
|
||||
"Don't ask for clarification or confirmation from the user; perform the requested action directly.\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_queries(agent_executor):\n",
|
||||
" config = {\"configurable\": {\"thread_id\": \"hotel-thread-1\"}}\n",
|
||||
"\n",
|
||||
" # --- Query 1: Search for hotels ---\n",
|
||||
" query1 = \"I need to find a hotel in Basel.\"\n",
|
||||
" print(f'\\n--- USER: \"{query1}\" ---')\n",
|
||||
" inputs1 = {\"messages\": [(\"user\", prompt + query1)]}\n",
|
||||
" async for event in agent_executor.astream_events(\n",
|
||||
" inputs1, config=config, version=\"v2\"\n",
|
||||
" ):\n",
|
||||
" if event[\"event\"] == \"on_chat_model_end\" and event[\"data\"][\"output\"].content:\n",
|
||||
" print(f\"--- AGENT: ---\\n{event['data']['output'].content}\")\n",
|
||||
"\n",
|
||||
" # --- Query 2: Book a hotel ---\n",
|
||||
" query2 = \"Great, please book the Hyatt Regency Basel for me.\"\n",
|
||||
" print(f'\\n--- USER: \"{query2}\" ---')\n",
|
||||
" inputs2 = {\"messages\": [(\"user\", query2)]}\n",
|
||||
" async for event in agent_executor.astream_events(\n",
|
||||
" inputs2, config=config, version=\"v2\"\n",
|
||||
" ):\n",
|
||||
" if event[\"event\"] == \"on_chat_model_end\" and event[\"data\"][\"output\"].content:\n",
|
||||
" print(f\"--- AGENT: ---\\n{event['data']['output'].content}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "54552733",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run the agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9f7c199b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"async def main():\n",
|
||||
" await run_hotel_agent()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_hotel_agent():\n",
|
||||
" model = ChatVertexAI(model_name=\"gemini-2.5-flash\")\n",
|
||||
"\n",
|
||||
" # Load the tools from the running MCP Toolbox server\n",
|
||||
" async with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" tools = await client.aload_toolset(\"hotel_toolset\")\n",
|
||||
"\n",
|
||||
" agent = create_react_agent(model, tools, checkpointer=MemorySaver())\n",
|
||||
"\n",
|
||||
" await run_queries(agent)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await main()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "79bce43d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You've successfully connected a LangChain agent to a local database using MCP Toolbox! 🥳\n",
|
||||
"\n",
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
"The primary class for this integration is `ToolboxClient`.\n",
|
||||
"\n",
|
||||
"For more information, see the following resources:\n",
|
||||
"- [Toolbox Official Documentation](https://googleapis.github.io/genai-toolbox/)\n",
|
||||
"- [Toolbox GitHub Repository](https://github.com/googleapis/genai-toolbox)\n",
|
||||
"- [Toolbox LangChain SDK](https://github.com/googleapis/mcp-toolbox-python-sdk/tree/main/packages/toolbox-langchain)\n",
|
||||
"\n",
|
||||
"MCP Toolbox has a variety of features to make developing Gen AI tools for databases seamless:\n",
|
||||
"- [Authenticated Parameters](https://googleapis.github.io/genai-toolbox/resources/tools/#authenticated-parameters): Bind tool inputs to values from OIDC tokens automatically, making it easy to run sensitive queries without potentially leaking data\n",
|
||||
"- [Authorized Invocations](https://googleapis.github.io/genai-toolbox/resources/tools/#authorized-invocations): Restrict access to use a tool based on the users Auth token\n",
|
||||
"- [OpenTelemetry](https://googleapis.github.io/genai-toolbox/how-to/export_telemetry/): Get metrics and tracing from MCP Toolbox with [OpenTelemetry](https://opentelemetry.io/docs/)\n",
|
||||
"\n",
|
||||
"# Community and Support\n",
|
||||
"\n",
|
||||
"We encourage you to get involved with the community:\n",
|
||||
"- ⭐️ Head over to the [GitHub repository](https://github.com/googleapis/genai-toolbox) to get started and follow along with updates.\n",
|
||||
"- 📚 Dive into the [official documentation](https://googleapis.github.io/genai-toolbox/getting-started/introduction/) for more advanced features and configurations.\n",
|
||||
"- 💬 Join our [Discord server](https://discord.com/invite/a4XjGqtmnG) to connect with the community and ask questions."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -11,7 +11,7 @@ LangChain simplifies every stage of the LLM application lifecycle:
|
||||
- **Development**: Build your applications using LangChain's open-source [components](/docs/concepts) and [third-party integrations](/docs/integrations/providers/).
|
||||
Use [LangGraph](/docs/concepts/architecture/#langgraph) to build stateful agents with first-class streaming and human-in-the-loop support.
|
||||
- **Productionization**: Use [LangSmith](https://docs.smith.langchain.com/) to inspect, monitor and evaluate your applications, so that you can continuously optimize and deploy with confidence.
|
||||
- **Deployment**: Turn your LangGraph applications into production-ready APIs and Assistants with [LangGraph Platform](https://docs.langchain.com/langgraph-platform).
|
||||
- **Deployment**: Turn your LangGraph applications into production-ready APIs and Assistants with [LangGraph Platform](https://langchain-ai.github.io/langgraph/cloud/).
|
||||
|
||||
import ThemedImage from '@theme/ThemedImage';
|
||||
import useBaseUrl from '@docusaurus/useBaseUrl';
|
||||
|
||||
@@ -85,7 +85,7 @@
|
||||
"As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent.\n",
|
||||
"The best way to do this is with [LangSmith](https://smith.langchain.com).\n",
|
||||
"\n",
|
||||
"After you sign up at the link above, **(you'll need to create an API key from the Settings -> API Keys page on the LangSmith website)**, make sure to set your environment variables to start logging traces:\n",
|
||||
"After you sign up at the link above, make sure to set your environment variables to start logging traces:\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"export LANGSMITH_TRACING=\"true\"\n",
|
||||
|
||||
@@ -192,7 +192,7 @@
|
||||
"source": [
|
||||
":::tip\n",
|
||||
"\n",
|
||||
"If we've enabled LangSmith, we can see that this run is logged to LangSmith, and can see the [LangSmith trace](https://docs.smith.langchain.com/observability/concepts#traces). The LangSmith trace reports [token](/docs/concepts/tokens/) usage information, latency, [standard model parameters](/docs/concepts/chat_models/#standard-parameters) (such as temperature), and other information.\n",
|
||||
"If we've enabled LangSmith, we can see that this run is logged to LangSmith, and can see the [LangSmith trace](https://smith.langchain.com/public/88baa0b2-7c1a-4d09-ba30-a47985dde2ea/r). The LangSmith trace reports [token](/docs/concepts/tokens/) usage information, latency, [standard model parameters](/docs/concepts/chat_models/#standard-parameters) (such as temperature), and other information.\n",
|
||||
"\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
|
||||
@@ -182,10 +182,6 @@ DATABASE_TOOL_FEAT_TABLE = {
|
||||
"link": "/docs/integrations/tools/cassandra_database",
|
||||
"operations": "SELECT and schema introspection",
|
||||
},
|
||||
"MCP Toolbox": {
|
||||
"link": "/docs/integrations/tools/toolbox",
|
||||
"operations": "Any SQL operation",
|
||||
},
|
||||
}
|
||||
|
||||
FINANCE_TOOL_FEAT_TABLE = {
|
||||
|
||||
@@ -27,7 +27,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'tutorials/index' },
|
||||
link: {type: 'doc', id: 'tutorials/index'},
|
||||
label: "Tutorials",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
@@ -38,7 +38,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'how_to/index' },
|
||||
link: {type: 'doc', id: 'how_to/index'},
|
||||
label: "How-to guides",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
@@ -49,7 +49,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'concepts/index' },
|
||||
link: {type: 'doc', id: 'concepts/index'},
|
||||
label: "Conceptual guide",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
@@ -103,7 +103,7 @@ module.exports = {
|
||||
{
|
||||
type: "category",
|
||||
label: "Migrating from v0.0 chains",
|
||||
link: { type: 'doc', id: 'versions/migrating_chains/index' },
|
||||
link: {type: 'doc', id: 'versions/migrating_chains/index'},
|
||||
collapsible: false,
|
||||
collapsed: false,
|
||||
items: [{
|
||||
@@ -115,7 +115,7 @@ module.exports = {
|
||||
{
|
||||
type: "category",
|
||||
label: "Upgrading to LangGraph memory",
|
||||
link: { type: 'doc', id: 'versions/migrating_memory/index' },
|
||||
link: {type: 'doc', id: 'versions/migrating_memory/index'},
|
||||
collapsible: false,
|
||||
collapsed: false,
|
||||
items: [{
|
||||
@@ -418,7 +418,7 @@ module.exports = {
|
||||
},
|
||||
],
|
||||
},
|
||||
|
||||
|
||||
],
|
||||
link: {
|
||||
type: "generated-index",
|
||||
@@ -434,7 +434,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'contributing/tutorials/index' },
|
||||
link: {type: 'doc', id: 'contributing/tutorials/index'},
|
||||
label: "Tutorials",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
@@ -445,7 +445,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'contributing/how_to/index' },
|
||||
link: {type: 'doc', id: 'contributing/how_to/index'},
|
||||
label: "How-to guides",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
@@ -456,7 +456,7 @@ module.exports = {
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
link: { type: 'doc', id: 'contributing/reference/index' },
|
||||
link: {type: 'doc', id: 'contributing/reference/index'},
|
||||
label: "Reference & FAQ",
|
||||
collapsible: false,
|
||||
items: [{
|
||||
|
||||
@@ -822,17 +822,10 @@ const FEATURE_TABLES = {
|
||||
api: "Package",
|
||||
apiLink: "https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.sitemap.SitemapLoader.html"
|
||||
},
|
||||
{
|
||||
name: "Spider",
|
||||
link: "spider",
|
||||
source: "Crawler and scraper that returns LLM-ready data.",
|
||||
api: "API",
|
||||
apiLink: "https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.spider.SpiderLoader.html"
|
||||
},
|
||||
{
|
||||
name: "Firecrawl",
|
||||
link: "firecrawl",
|
||||
source: "API service that can be deployed locally.",
|
||||
source: "API service that can be deployed locally, hosted version has free credits.",
|
||||
api: "API",
|
||||
apiLink: "https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.firecrawl.FireCrawlLoader.html"
|
||||
},
|
||||
|
||||
@@ -77,7 +77,7 @@ export default function VectorStoreTabs(props) {
|
||||
{
|
||||
value: "Qdrant",
|
||||
label: "Qdrant",
|
||||
text: `from qdrant_client.models import Distance, VectorParams\nfrom langchain_qdrant import QdrantVectorStore\nfrom qdrant_client import QdrantClient\n${useFakeEmbeddings ? fakeEmbeddingsString : ""}\nclient = QdrantClient(":memory:")\n\nvector_size = len(embeddings.embed_query("sample text"))\n\nif not client.collection_exists("test"):\n client.create_collection(\n collection_name="test",\n vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE)\n )\n${vectorStoreVarName} = QdrantVectorStore(\n client=client,\n collection_name="test",\n embedding=embeddings,\n)`,
|
||||
text: `from langchain_qdrant import QdrantVectorStore\nfrom qdrant_client import QdrantClient\n${useFakeEmbeddings ? fakeEmbeddingsString : ""}\nclient = QdrantClient(":memory:")\n${vectorStoreVarName} = QdrantVectorStore(\n client=client,\n collection_name="test",\n embedding=embeddings,\n)`,
|
||||
packageName: "langchain-qdrant",
|
||||
default: false,
|
||||
},
|
||||
|
||||
BIN
docs/static/img/gateway-metrics.png
vendored
BIN
docs/static/img/gateway-metrics.png
vendored
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 530 KiB |
BIN
docs/static/img/unified-code-tfy.png
vendored
BIN
docs/static/img/unified-code-tfy.png
vendored
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 408 KiB |
@@ -1,5 +1,3 @@
|
||||
"""LangChain CLI."""
|
||||
|
||||
from langchain_cli._version import __version__
|
||||
|
||||
__all__ = [
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
"""LangChain CLI."""
|
||||
|
||||
from typing import Annotated, Optional
|
||||
|
||||
import typer
|
||||
@@ -36,21 +34,20 @@ app.command(
|
||||
)
|
||||
|
||||
|
||||
def _version_callback(*, show_version: bool) -> None:
|
||||
def version_callback(show_version: bool) -> None: # noqa: FBT001
|
||||
if show_version:
|
||||
typer.echo(f"langchain-cli {__version__}")
|
||||
raise typer.Exit
|
||||
|
||||
|
||||
@app.callback()
|
||||
def _main(
|
||||
*,
|
||||
version: bool = typer.Option(
|
||||
def main(
|
||||
version: bool = typer.Option( # noqa: FBT001
|
||||
False, # noqa: FBT003
|
||||
"--version",
|
||||
"-v",
|
||||
help="Print the current CLI version.",
|
||||
callback=_version_callback,
|
||||
callback=version_callback,
|
||||
is_eager=True,
|
||||
),
|
||||
) -> None:
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
"""LangChain CLI constants."""
|
||||
|
||||
DEFAULT_GIT_REPO = "https://github.com/langchain-ai/langchain.git"
|
||||
DEFAULT_GIT_SUBDIRECTORY = "templates"
|
||||
DEFAULT_GIT_REF = "master"
|
||||
|
||||
@@ -13,7 +13,7 @@ def create_demo_server(
|
||||
*,
|
||||
config_keys: Sequence[str] = (),
|
||||
playground_type: Literal["default", "chat"] = "default",
|
||||
) -> FastAPI:
|
||||
):
|
||||
"""Create a demo server for the current template."""
|
||||
app = FastAPI()
|
||||
package_root = get_package_root()
|
||||
@@ -40,11 +40,9 @@ def create_demo_server(
|
||||
return app
|
||||
|
||||
|
||||
def create_demo_server_configurable() -> FastAPI:
|
||||
"""Create a configurable demo server."""
|
||||
def create_demo_server_configurable():
|
||||
return create_demo_server(config_keys=["configurable"])
|
||||
|
||||
|
||||
def create_demo_server_chat() -> FastAPI:
|
||||
"""Create a chat demo server."""
|
||||
def create_demo_server_chat():
|
||||
return create_demo_server(playground_type="chat")
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
"""Namespaces."""
|
||||
|
||||
@@ -8,7 +8,6 @@ from pathlib import Path
|
||||
from typing import Annotated, Optional
|
||||
|
||||
import typer
|
||||
import uvicorn
|
||||
|
||||
from langchain_cli.utils.events import create_events
|
||||
from langchain_cli.utils.git import (
|
||||
@@ -262,7 +261,7 @@ def add(
|
||||
cmd = ["pip", "install", "-e", *installed_destination_strs]
|
||||
cmd_str = " \\\n ".join(installed_destination_strs)
|
||||
typer.echo(f"Running: pip install -e \\\n {cmd_str}")
|
||||
subprocess.run(cmd, cwd=cwd, check=True) # noqa: S603
|
||||
subprocess.run(cmd, cwd=cwd) # noqa: S603
|
||||
|
||||
chain_names = []
|
||||
for e in installed_exports:
|
||||
@@ -368,6 +367,8 @@ def serve(
|
||||
app_str = app if app is not None else "app.server:app"
|
||||
host_str = host if host is not None else "127.0.0.1"
|
||||
|
||||
import uvicorn
|
||||
|
||||
uvicorn.run(
|
||||
app_str,
|
||||
host=host_str,
|
||||
|
||||
@@ -15,8 +15,6 @@ integration_cli = typer.Typer(no_args_is_help=True, add_completion=False)
|
||||
|
||||
|
||||
class Replacements(TypedDict):
|
||||
"""Replacements."""
|
||||
|
||||
__package_name__: str
|
||||
__module_name__: str
|
||||
__ModuleName__: str
|
||||
@@ -129,7 +127,6 @@ def new(
|
||||
subprocess.run(
|
||||
["poetry", "install", "--with", "lint,test,typing,test_integration"], # noqa: S607
|
||||
cwd=destination_dir,
|
||||
check=True,
|
||||
)
|
||||
else:
|
||||
# confirm src and dst are the same length
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
"""Migrations."""
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
"""Generate migrations."""
|
||||
|
||||
@@ -3,7 +3,6 @@
|
||||
import importlib
|
||||
import inspect
|
||||
import pkgutil
|
||||
from types import ModuleType
|
||||
|
||||
|
||||
def generate_raw_migrations(
|
||||
@@ -90,7 +89,7 @@ def generate_top_level_imports(pkg: str) -> list[tuple[str, str]]:
|
||||
items = []
|
||||
|
||||
# Function to handle importing from modules
|
||||
def handle_module(module: ModuleType, module_name: str) -> None:
|
||||
def handle_module(module, module_name) -> None:
|
||||
if hasattr(module, "__all__"):
|
||||
all_objects = module.__all__
|
||||
for name in all_objects:
|
||||
|
||||
@@ -1,6 +1,3 @@
|
||||
"""Migration as Grit file."""
|
||||
|
||||
|
||||
def split_package(package: str) -> tuple[str, str]:
|
||||
"""Split a package name into the containing package and the final name."""
|
||||
parts = package.split(".")
|
||||
|
||||
@@ -1,11 +1,8 @@
|
||||
"""Generate migrations utilities."""
|
||||
|
||||
import ast
|
||||
import inspect
|
||||
import os
|
||||
import pathlib
|
||||
from pathlib import Path
|
||||
from types import ModuleType
|
||||
from typing import Any, Optional
|
||||
|
||||
HERE = Path(__file__).parent
|
||||
@@ -18,14 +15,12 @@ PARTNER_PKGS = PKGS_ROOT / "partners"
|
||||
|
||||
|
||||
class ImportExtractor(ast.NodeVisitor):
|
||||
"""Import extractor."""
|
||||
|
||||
def __init__(self, *, from_package: Optional[str] = None) -> None:
|
||||
"""Extract all imports from the given code, optionally filtering by package."""
|
||||
self.imports: list = []
|
||||
self.package = from_package
|
||||
|
||||
def visit_ImportFrom(self, node: ast.ImportFrom) -> None: # noqa: N802
|
||||
def visit_ImportFrom(self, node) -> None: # noqa: N802
|
||||
if node.module and (
|
||||
self.package is None or str(node.module).startswith(self.package)
|
||||
):
|
||||
@@ -44,7 +39,7 @@ def _get_class_names(code: str) -> list[str]:
|
||||
|
||||
# Define a node visitor class to collect class names
|
||||
class ClassVisitor(ast.NodeVisitor):
|
||||
def visit_ClassDef(self, node: ast.ClassDef) -> None: # noqa: N802
|
||||
def visit_ClassDef(self, node) -> None: # noqa: N802
|
||||
class_names.append(node.name)
|
||||
self.generic_visit(node)
|
||||
|
||||
@@ -63,7 +58,7 @@ def is_subclass(class_obj: Any, classes_: list[type]) -> bool:
|
||||
)
|
||||
|
||||
|
||||
def find_subclasses_in_module(module: ModuleType, classes_: list[type]) -> list[str]:
|
||||
def find_subclasses_in_module(module, classes_: list[type]) -> list[str]:
|
||||
"""Find all classes in the module that inherit from one of the classes."""
|
||||
subclasses = []
|
||||
# Iterate over all attributes of the module that are classes
|
||||
@@ -75,7 +70,8 @@ def find_subclasses_in_module(module: ModuleType, classes_: list[type]) -> list[
|
||||
|
||||
def _get_all_classnames_from_file(file: Path, pkg: str) -> list[tuple[str, str]]:
|
||||
"""Extract all class names from a file."""
|
||||
code = Path(file).read_text(encoding="utf-8")
|
||||
with open(file, encoding="utf-8") as f:
|
||||
code = f.read()
|
||||
module_name = _get_current_module(file, pkg)
|
||||
class_names = _get_class_names(code)
|
||||
|
||||
@@ -88,7 +84,8 @@ def identify_all_imports_in_file(
|
||||
from_package: Optional[str] = None,
|
||||
) -> list[tuple[str, str]]:
|
||||
"""Let's also identify all the imports in the given file."""
|
||||
code = Path(file).read_text(encoding="utf-8")
|
||||
with open(file, encoding="utf-8") as f:
|
||||
code = f.read()
|
||||
return find_imports_from_package(code, from_package=from_package)
|
||||
|
||||
|
||||
@@ -146,7 +143,6 @@ def find_imports_from_package(
|
||||
*,
|
||||
from_package: Optional[str] = None,
|
||||
) -> list[tuple[str, str]]:
|
||||
"""Find imports in code."""
|
||||
# Parse the code into an AST
|
||||
tree = ast.parse(code)
|
||||
# Create an instance of the visitor
|
||||
@@ -158,7 +154,8 @@ def find_imports_from_package(
|
||||
|
||||
def _get_current_module(path: Path, pkg_root: str) -> str:
|
||||
"""Convert a path to a module name."""
|
||||
relative_path = path.relative_to(pkg_root).with_suffix("")
|
||||
path_as_pathlib = pathlib.Path(os.path.abspath(path))
|
||||
relative_path = path_as_pathlib.relative_to(pkg_root).with_suffix("")
|
||||
posix_path = relative_path.as_posix()
|
||||
norm_path = os.path.normpath(str(posix_path))
|
||||
fully_qualified_module = norm_path.replace("/", ".")
|
||||
|
||||
@@ -7,9 +7,7 @@ from pathlib import Path
|
||||
from typing import Annotated, Optional
|
||||
|
||||
import typer
|
||||
import uvicorn
|
||||
|
||||
from langchain_cli.utils.github import list_packages
|
||||
from langchain_cli.utils.packages import get_langserve_export, get_package_root
|
||||
|
||||
package_cli = typer.Typer(no_args_is_help=True, add_completion=False)
|
||||
@@ -81,7 +79,7 @@ def new(
|
||||
|
||||
# poetry install
|
||||
if with_poetry:
|
||||
subprocess.run(["poetry", "install"], cwd=destination_dir, check=True) # noqa: S607
|
||||
subprocess.run(["poetry", "install"], cwd=destination_dir) # noqa: S607
|
||||
|
||||
|
||||
@package_cli.command()
|
||||
@@ -130,6 +128,8 @@ def serve(
|
||||
)
|
||||
)
|
||||
|
||||
import uvicorn
|
||||
|
||||
uvicorn.run(
|
||||
script,
|
||||
factory=True,
|
||||
@@ -142,6 +142,8 @@ def serve(
|
||||
@package_cli.command()
|
||||
def list(contains: Annotated[Optional[str], typer.Argument()] = None) -> None: # noqa: A001
|
||||
"""List all or search for available templates."""
|
||||
from langchain_cli.utils.github import list_packages
|
||||
|
||||
packages = list_packages(contains=contains)
|
||||
for package in packages:
|
||||
typer.echo(package)
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
"""Utilities."""
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
"""Events utilities."""
|
||||
|
||||
import http.client
|
||||
import json
|
||||
from typing import Any, Optional, TypedDict
|
||||
@@ -10,19 +8,11 @@ WRITE_KEY = "310apTK0HUFl4AOv"
|
||||
|
||||
|
||||
class EventDict(TypedDict):
|
||||
"""Event data structure for analytics tracking.
|
||||
|
||||
Attributes:
|
||||
event: The name of the event.
|
||||
properties: Optional dictionary of event properties.
|
||||
"""
|
||||
|
||||
event: str
|
||||
properties: Optional[dict[str, Any]]
|
||||
|
||||
|
||||
def create_events(events: list[EventDict]) -> Optional[Any]:
|
||||
"""Create events."""
|
||||
try:
|
||||
data = {
|
||||
"events": [
|
||||
|
||||
@@ -1,10 +1,7 @@
|
||||
"""Find and replace text in files."""
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def find_and_replace(source: str, replacements: dict[str, str]) -> str:
|
||||
"""Find and replace text in a string."""
|
||||
rtn = source
|
||||
|
||||
# replace keys in deterministic alphabetical order
|
||||
@@ -16,7 +13,6 @@ def find_and_replace(source: str, replacements: dict[str, str]) -> str:
|
||||
|
||||
|
||||
def replace_file(source: Path, replacements: dict[str, str]) -> None:
|
||||
"""Replace text in a file."""
|
||||
try:
|
||||
content = source.read_text()
|
||||
except UnicodeDecodeError:
|
||||
@@ -28,7 +24,6 @@ def replace_file(source: Path, replacements: dict[str, str]) -> None:
|
||||
|
||||
|
||||
def replace_glob(parent: Path, glob: str, replacements: dict[str, str]) -> None:
|
||||
"""Replace text in files matching a glob pattern."""
|
||||
for file in parent.glob(glob):
|
||||
if not file.is_file():
|
||||
continue
|
||||
|
||||
@@ -1,7 +1,4 @@
|
||||
"""Git utilities."""
|
||||
|
||||
import hashlib
|
||||
import logging
|
||||
import re
|
||||
import shutil
|
||||
from collections.abc import Sequence
|
||||
@@ -16,12 +13,8 @@ from langchain_cli.constants import (
|
||||
DEFAULT_GIT_SUBDIRECTORY,
|
||||
)
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class DependencySource(TypedDict):
|
||||
"""Dependency source information."""
|
||||
|
||||
git: str
|
||||
ref: Optional[str]
|
||||
subdirectory: Optional[str]
|
||||
@@ -36,7 +29,6 @@ def parse_dependency_string(
|
||||
branch: Optional[str],
|
||||
api_path: Optional[str],
|
||||
) -> DependencySource:
|
||||
"""Parse a dependency string into a DependencySource."""
|
||||
if dep is not None and dep.startswith("git+"):
|
||||
if repo is not None or branch is not None:
|
||||
msg = (
|
||||
@@ -129,7 +121,6 @@ def parse_dependencies(
|
||||
branch: list[str],
|
||||
api_path: list[str],
|
||||
) -> list[DependencySource]:
|
||||
"""Parse dependencies."""
|
||||
num_deps = max(
|
||||
len(dependencies) if dependencies is not None else 0,
|
||||
len(repo),
|
||||
@@ -177,22 +168,22 @@ def _get_repo_path(gitstring: str, ref: Optional[str], repo_dir: Path) -> Path:
|
||||
|
||||
|
||||
def update_repo(gitstring: str, ref: Optional[str], repo_dir: Path) -> Path:
|
||||
"""Update a git repository to the specified ref."""
|
||||
# see if path already saved
|
||||
repo_path = _get_repo_path(gitstring, ref, repo_dir)
|
||||
if repo_path.exists():
|
||||
# try pulling
|
||||
try:
|
||||
repo = Repo(repo_path)
|
||||
if repo.active_branch.name == ref:
|
||||
repo.remotes.origin.pull()
|
||||
return repo_path
|
||||
if repo.active_branch.name != ref:
|
||||
raise ValueError
|
||||
repo.remotes.origin.pull()
|
||||
except Exception:
|
||||
logger.exception("Failed to pull existing repo")
|
||||
# if it fails, delete and clone again
|
||||
shutil.rmtree(repo_path)
|
||||
# if it fails, delete and clone again
|
||||
shutil.rmtree(repo_path)
|
||||
Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
|
||||
else:
|
||||
Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
|
||||
|
||||
Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
|
||||
return repo_path
|
||||
|
||||
|
||||
@@ -205,7 +196,7 @@ def copy_repo(
|
||||
Raises FileNotFound error if it can't find source
|
||||
"""
|
||||
|
||||
def ignore_func(_: str, files: list[str]) -> list[str]:
|
||||
def ignore_func(_, files):
|
||||
return [f for f in files if f == ".git"]
|
||||
|
||||
shutil.copytree(source, destination, ignore=ignore_func)
|
||||
|
||||
@@ -1,12 +1,9 @@
|
||||
"""GitHub utilities."""
|
||||
|
||||
import http.client
|
||||
import json
|
||||
from typing import Optional
|
||||
|
||||
|
||||
def list_packages(*, contains: Optional[str] = None) -> list[str]:
|
||||
"""List all packages in the langchain repository templates directory."""
|
||||
conn = http.client.HTTPSConnection("api.github.com")
|
||||
try:
|
||||
headers = {
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
"""Packages utilities."""
|
||||
|
||||
from pathlib import Path
|
||||
from typing import Any, Optional, TypedDict
|
||||
|
||||
@@ -7,7 +5,6 @@ from tomlkit import load
|
||||
|
||||
|
||||
def get_package_root(cwd: Optional[Path] = None) -> Path:
|
||||
"""Get package root directory."""
|
||||
# traverse path for routes to host (any directory holding a pyproject.toml file)
|
||||
package_root = Path.cwd() if cwd is None else cwd
|
||||
visited: set[Path] = set()
|
||||
@@ -38,8 +35,7 @@ class LangServeExport(TypedDict):
|
||||
|
||||
|
||||
def get_langserve_export(filepath: Path) -> LangServeExport:
|
||||
"""Get LangServe export information from a pyproject.toml file."""
|
||||
with filepath.open() as f:
|
||||
with open(filepath) as f:
|
||||
data: dict[str, Any] = load(f)
|
||||
try:
|
||||
module = data["tool"]["langserve"]["export_module"]
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
"""Pyproject.toml utilities."""
|
||||
|
||||
import contextlib
|
||||
from collections.abc import Iterable
|
||||
from pathlib import Path
|
||||
@@ -20,7 +18,7 @@ def add_dependencies_to_pyproject_toml(
|
||||
local_editable_dependencies: Iterable[tuple[str, Path]],
|
||||
) -> None:
|
||||
"""Add dependencies to pyproject.toml."""
|
||||
with pyproject_toml.open(encoding="utf-8") as f:
|
||||
with open(pyproject_toml, encoding="utf-8") as f:
|
||||
# tomlkit types aren't amazing - treat as Dict instead
|
||||
pyproject: dict[str, Any] = load(f)
|
||||
pyproject["tool"]["poetry"]["dependencies"].update(
|
||||
@@ -29,7 +27,7 @@ def add_dependencies_to_pyproject_toml(
|
||||
for name, loc in local_editable_dependencies
|
||||
},
|
||||
)
|
||||
with pyproject_toml.open("w", encoding="utf-8") as f:
|
||||
with open(pyproject_toml, "w", encoding="utf-8") as f:
|
||||
dump(pyproject, f)
|
||||
|
||||
|
||||
@@ -38,13 +36,12 @@ def remove_dependencies_from_pyproject_toml(
|
||||
local_editable_dependencies: Iterable[str],
|
||||
) -> None:
|
||||
"""Remove dependencies from pyproject.toml."""
|
||||
with pyproject_toml.open(encoding="utf-8") as f:
|
||||
with open(pyproject_toml, encoding="utf-8") as f:
|
||||
pyproject: dict[str, Any] = load(f)
|
||||
# tomlkit types aren't amazing - treat as Dict instead
|
||||
dependencies = pyproject["tool"]["poetry"]["dependencies"]
|
||||
for name in local_editable_dependencies:
|
||||
with contextlib.suppress(KeyError):
|
||||
del dependencies[name]
|
||||
|
||||
with pyproject_toml.open("w", encoding="utf-8") as f:
|
||||
with open(pyproject_toml, "w", encoding="utf-8") as f:
|
||||
dump(pyproject, f)
|
||||
|
||||
@@ -48,41 +48,58 @@ exclude = [
|
||||
]
|
||||
|
||||
[tool.ruff.lint]
|
||||
select = [ "ALL",]
|
||||
select = [
|
||||
"A", # flake8-builtins
|
||||
"B", # flake8-bugbear
|
||||
"ARG", # flake8-unused-arguments
|
||||
"ASYNC", # flake8-async
|
||||
"C4", # flake8-comprehensions
|
||||
"COM", # flake8-commas
|
||||
"D", # pydocstyle
|
||||
"E", # pycodestyle error
|
||||
"EM", # flake8-errmsg
|
||||
"F", # pyflakes
|
||||
"FA", # flake8-future-annotations
|
||||
"FBT", # flake8-boolean-trap
|
||||
"FLY", # flake8-flynt
|
||||
"I", # isort
|
||||
"ICN", # flake8-import-conventions
|
||||
"INT", # flake8-gettext
|
||||
"ISC", # isort-comprehensions
|
||||
"N", # pep8-naming
|
||||
"PT", # flake8-pytest-style
|
||||
"PGH", # pygrep-hooks
|
||||
"PIE", # flake8-pie
|
||||
"PERF", # flake8-perf
|
||||
"PYI", # flake8-pyi
|
||||
"Q", # flake8-quotes
|
||||
"RET", # flake8-return
|
||||
"RSE", # flake8-rst-docstrings
|
||||
"RUF", # ruff
|
||||
"S", # flake8-bandit
|
||||
"SLF", # flake8-self
|
||||
"SLOT", # flake8-slots
|
||||
"SIM", # flake8-simplify
|
||||
"T10", # flake8-debugger
|
||||
"T20", # flake8-print
|
||||
"TID", # flake8-tidy-imports
|
||||
"UP", # pyupgrade
|
||||
"W", # pycodestyle warning
|
||||
"YTT", # flake8-2020
|
||||
]
|
||||
ignore = [
|
||||
"C90", # McCabe complexity
|
||||
"D100", # pydocstyle: Missing docstring in public module
|
||||
"D101", # pydocstyle: Missing docstring in public class
|
||||
"D102", # pydocstyle: Missing docstring in public method
|
||||
"D103", # pydocstyle: Missing docstring in public function
|
||||
"D104", # pydocstyle: Missing docstring in public package
|
||||
"D105", # pydocstyle: Missing docstring in magic method
|
||||
"D107", # pydocstyle: Missing docstring in __init__
|
||||
"D407", # pydocstyle: Missing-dashed-underline-after-section
|
||||
"COM812", # Messes with the formatter
|
||||
"FIX002", # Line contains TODO
|
||||
"PERF203", # Rarely useful
|
||||
"PLR09", # Too many something (arg, statements, etc)
|
||||
"RUF012", # Doesn't play well with Pydantic
|
||||
"TC001", # Doesn't play well with Pydantic
|
||||
"TC002", # Doesn't play well with Pydantic
|
||||
"TC003", # Doesn't play well with Pydantic
|
||||
"TD002", # Missing author in TODO
|
||||
"TD003", # Missing issue link in TODO
|
||||
|
||||
# TODO rules
|
||||
"ANN401",
|
||||
"BLE",
|
||||
"D1",
|
||||
]
|
||||
unfixable = [
|
||||
"B028", # People should intentionally tune the stacklevel
|
||||
"PLW1510", # People should intentionally set the check argument
|
||||
]
|
||||
|
||||
flake8-annotations.allow-star-arg-any = true
|
||||
flake8-annotations.mypy-init-return = true
|
||||
flake8-type-checking.runtime-evaluated-base-classes = ["pydantic.BaseModel","langchain_core.load.serializable.Serializable","langchain_core.runnables.base.RunnableSerializable"]
|
||||
pep8-naming.classmethod-decorators = [ "classmethod", "langchain_core.utils.pydantic.pre_init", "pydantic.field_validator", "pydantic.v1.root_validator",]
|
||||
pydocstyle.convention = "google"
|
||||
pyupgrade.keep-runtime-typing = true
|
||||
|
||||
[tool.ruff.lint.per-file-ignores]
|
||||
"tests/**" = [ "D1", "S", "SLF",]
|
||||
"scripts/**" = [ "INP", "S",]
|
||||
|
||||
[tool.mypy]
|
||||
exclude = [
|
||||
"langchain_cli/integration_template",
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
"""Scripts."""
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
"""Script to generate migrations for the migration script."""
|
||||
|
||||
import json
|
||||
import os
|
||||
import pkgutil
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import click
|
||||
@@ -73,18 +73,19 @@ def generic(
|
||||
else:
|
||||
dumped = dump_migrations_as_grit(name, migrations)
|
||||
|
||||
Path(output).write_text(dumped)
|
||||
with open(output, "w") as f:
|
||||
f.write(dumped)
|
||||
|
||||
|
||||
def handle_partner(pkg: str, output: Optional[str] = None) -> None:
|
||||
"""Handle partner package migrations."""
|
||||
migrations = get_migrations_for_partner_package(pkg)
|
||||
# Run with python 3.9+
|
||||
name = pkg.removeprefix("langchain_")
|
||||
data = dump_migrations_as_grit(name, migrations)
|
||||
output_name = f"{name}.grit" if output is None else output
|
||||
if migrations:
|
||||
Path(output_name).write_text(data)
|
||||
with open(output_name, "w") as f:
|
||||
f.write(data)
|
||||
click.secho(f"LangChain migration script saved to {output_name}")
|
||||
else:
|
||||
click.secho(f"No migrations found for {pkg}", fg="yellow")
|
||||
@@ -103,13 +104,13 @@ def partner(pkg: str, output: str) -> None:
|
||||
@click.argument("json_file")
|
||||
def json_to_grit(json_file: str) -> None:
|
||||
"""Generate a Grit migration from an old JSON migration file."""
|
||||
file = Path(json_file)
|
||||
with file.open() as f:
|
||||
with open(json_file) as f:
|
||||
migrations = json.load(f)
|
||||
name = file.stem
|
||||
name = os.path.basename(json_file).removesuffix(".json").removesuffix(".grit")
|
||||
data = dump_migrations_as_grit(name, migrations)
|
||||
output_name = f"{name}.grit"
|
||||
Path(output_name).write_text(data)
|
||||
with open(output_name, "w") as f:
|
||||
f.write(data)
|
||||
click.secho(f"GritQL migration script saved to {output_name}")
|
||||
|
||||
|
||||
|
||||
@@ -14,6 +14,3 @@ class File:
|
||||
return False
|
||||
|
||||
return self.content == __value.content
|
||||
|
||||
def __hash__(self) -> int:
|
||||
return hash((self.name, self.content))
|
||||
|
||||
@@ -57,6 +57,3 @@ class Folder:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
def __hash__(self) -> int:
|
||||
return hash((self.name, tuple(self.files)))
|
||||
|
||||
@@ -7,6 +7,8 @@ from typing import TYPE_CHECKING, Any, Optional, Union
|
||||
|
||||
from typing_extensions import Self
|
||||
|
||||
from langchain_core.v1.messages import AIMessage, AIMessageChunk, MessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import Sequence
|
||||
from uuid import UUID
|
||||
@@ -66,7 +68,9 @@ class LLMManagerMixin:
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
@@ -75,8 +79,8 @@ class LLMManagerMixin:
|
||||
|
||||
Args:
|
||||
token (str): The new token.
|
||||
chunk (GenerationChunk | ChatGenerationChunk): The new generated chunk,
|
||||
containing content and other information.
|
||||
chunk (GenerationChunk | ChatGenerationChunk | AIMessageChunk): The new
|
||||
generated chunk, containing content and other information.
|
||||
run_id (UUID): The run ID. This is the ID of the current run.
|
||||
parent_run_id (UUID): The parent run ID. This is the ID of the parent run.
|
||||
kwargs (Any): Additional keyword arguments.
|
||||
@@ -84,7 +88,7 @@ class LLMManagerMixin:
|
||||
|
||||
def on_llm_end(
|
||||
self,
|
||||
response: LLMResult,
|
||||
response: Union[LLMResult, AIMessage],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -93,7 +97,7 @@ class LLMManagerMixin:
|
||||
"""Run when LLM ends running.
|
||||
|
||||
Args:
|
||||
response (LLMResult): The response which was generated.
|
||||
response (LLMResult | AIMessage): The response which was generated.
|
||||
run_id (UUID): The run ID. This is the ID of the current run.
|
||||
parent_run_id (UUID): The parent run ID. This is the ID of the parent run.
|
||||
kwargs (Any): Additional keyword arguments.
|
||||
@@ -261,7 +265,7 @@ class CallbackManagerMixin:
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -439,6 +443,9 @@ class BaseCallbackHandler(
|
||||
run_inline: bool = False
|
||||
"""Whether to run the callback inline."""
|
||||
|
||||
accepts_new_messages: bool = False
|
||||
"""Whether the callback accepts new message format."""
|
||||
|
||||
@property
|
||||
def ignore_llm(self) -> bool:
|
||||
"""Whether to ignore LLM callbacks."""
|
||||
@@ -509,7 +516,7 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -540,7 +547,9 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
tags: Optional[list[str]] = None,
|
||||
@@ -550,8 +559,8 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
|
||||
Args:
|
||||
token (str): The new token.
|
||||
chunk (GenerationChunk | ChatGenerationChunk): The new generated chunk,
|
||||
containing content and other information.
|
||||
chunk (GenerationChunk | ChatGenerationChunk | AIMessageChunk): The new
|
||||
generated chunk, containing content and other information.
|
||||
run_id (UUID): The run ID. This is the ID of the current run.
|
||||
parent_run_id (UUID): The parent run ID. This is the ID of the parent run.
|
||||
tags (Optional[list[str]]): The tags.
|
||||
@@ -560,7 +569,7 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
|
||||
async def on_llm_end(
|
||||
self,
|
||||
response: LLMResult,
|
||||
response: Union[LLMResult, AIMessage],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -570,7 +579,7 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
"""Run when LLM ends running.
|
||||
|
||||
Args:
|
||||
response (LLMResult): The response which was generated.
|
||||
response (LLMResult | AIMessage): The response which was generated.
|
||||
run_id (UUID): The run ID. This is the ID of the current run.
|
||||
parent_run_id (UUID): The parent run ID. This is the ID of the parent run.
|
||||
tags (Optional[list[str]]): The tags.
|
||||
@@ -594,8 +603,8 @@ class AsyncCallbackHandler(BaseCallbackHandler):
|
||||
parent_run_id: The parent run ID. This is the ID of the parent run.
|
||||
tags: The tags.
|
||||
kwargs (Any): Additional keyword arguments.
|
||||
- response (LLMResult): The response which was generated before
|
||||
the error occurred.
|
||||
- response (LLMResult | AIMessage): The response which was generated
|
||||
before the error occurred.
|
||||
"""
|
||||
|
||||
async def on_chain_start(
|
||||
|
||||
@@ -29,8 +29,16 @@ from langchain_core.callbacks.base import (
|
||||
)
|
||||
from langchain_core.callbacks.stdout import StdOutCallbackHandler
|
||||
from langchain_core.messages import BaseMessage, get_buffer_string
|
||||
from langchain_core.messages.utils import convert_from_v1_message
|
||||
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, LLMResult
|
||||
from langchain_core.tracers.schemas import Run
|
||||
from langchain_core.utils.env import env_var_is_set
|
||||
from langchain_core.v1.messages import (
|
||||
AIMessage,
|
||||
AIMessageChunk,
|
||||
MessageV1,
|
||||
MessageV1Types,
|
||||
)
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import AsyncGenerator, Coroutine, Generator, Sequence
|
||||
@@ -39,7 +47,7 @@ if TYPE_CHECKING:
|
||||
|
||||
from langchain_core.agents import AgentAction, AgentFinish
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.outputs import ChatGenerationChunk, GenerationChunk, LLMResult
|
||||
from langchain_core.outputs import GenerationChunk
|
||||
from langchain_core.runnables.config import RunnableConfig
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -238,6 +246,46 @@ def shielded(func: Func) -> Func:
|
||||
return cast("Func", wrapped)
|
||||
|
||||
|
||||
def _convert_llm_events(
|
||||
event_name: str, args: tuple[Any, ...], kwargs: dict[str, Any]
|
||||
) -> tuple[tuple[Any, ...], dict[str, Any]]:
|
||||
args_list = list(args)
|
||||
if (
|
||||
event_name == "on_chat_model_start"
|
||||
and isinstance(args_list[1], list)
|
||||
and args_list[1]
|
||||
and isinstance(args_list[1][0], MessageV1Types)
|
||||
):
|
||||
batch = [
|
||||
convert_from_v1_message(item)
|
||||
for item in args_list[1]
|
||||
if isinstance(item, MessageV1Types)
|
||||
]
|
||||
args_list[1] = [batch]
|
||||
elif (
|
||||
event_name == "on_llm_new_token"
|
||||
and "chunk" in kwargs
|
||||
and isinstance(kwargs["chunk"], MessageV1Types)
|
||||
):
|
||||
chunk = kwargs["chunk"]
|
||||
kwargs["chunk"] = ChatGenerationChunk(text=chunk.text, message=chunk)
|
||||
elif event_name == "on_llm_end" and isinstance(args_list[0], MessageV1Types):
|
||||
args_list[0] = LLMResult(
|
||||
generations=[
|
||||
[
|
||||
ChatGeneration(
|
||||
text=args_list[0].text,
|
||||
message=convert_from_v1_message(args_list[0]),
|
||||
)
|
||||
]
|
||||
]
|
||||
)
|
||||
else:
|
||||
pass
|
||||
|
||||
return tuple(args_list), kwargs
|
||||
|
||||
|
||||
def handle_event(
|
||||
handlers: list[BaseCallbackHandler],
|
||||
event_name: str,
|
||||
@@ -268,6 +316,8 @@ def handle_event(
|
||||
if ignore_condition_name is None or not getattr(
|
||||
handler, ignore_condition_name
|
||||
):
|
||||
if not handler.accepts_new_messages:
|
||||
args, kwargs = _convert_llm_events(event_name, args, kwargs)
|
||||
event = getattr(handler, event_name)(*args, **kwargs)
|
||||
if asyncio.iscoroutine(event):
|
||||
coros.append(event)
|
||||
@@ -362,6 +412,8 @@ async def _ahandle_event_for_handler(
|
||||
) -> None:
|
||||
try:
|
||||
if ignore_condition_name is None or not getattr(handler, ignore_condition_name):
|
||||
if not handler.accepts_new_messages:
|
||||
args, kwargs = _convert_llm_events(event_name, args, kwargs)
|
||||
event = getattr(handler, event_name)
|
||||
if asyncio.iscoroutinefunction(event):
|
||||
await event(*args, **kwargs)
|
||||
@@ -681,7 +733,9 @@ class CallbackManagerForLLMRun(RunManager, LLMManagerMixin):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Run when LLM generates a new token.
|
||||
@@ -707,11 +761,11 @@ class CallbackManagerForLLMRun(RunManager, LLMManagerMixin):
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
def on_llm_end(self, response: Union[LLMResult, AIMessage], **kwargs: Any) -> None:
|
||||
"""Run when LLM ends running.
|
||||
|
||||
Args:
|
||||
response (LLMResult): The LLM result.
|
||||
response (LLMResult | AIMessage): The LLM result.
|
||||
**kwargs (Any): Additional keyword arguments.
|
||||
|
||||
"""
|
||||
@@ -738,8 +792,9 @@ class CallbackManagerForLLMRun(RunManager, LLMManagerMixin):
|
||||
Args:
|
||||
error (Exception or KeyboardInterrupt): The error.
|
||||
kwargs (Any): Additional keyword arguments.
|
||||
- response (LLMResult): The response which was generated before
|
||||
the error occurred.
|
||||
- response (LLMResult | AIMessage): The response which was generated
|
||||
before the error occurred.
|
||||
|
||||
"""
|
||||
if not self.handlers:
|
||||
return
|
||||
@@ -780,7 +835,9 @@ class AsyncCallbackManagerForLLMRun(AsyncRunManager, LLMManagerMixin):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Run when LLM generates a new token.
|
||||
@@ -807,11 +864,13 @@ class AsyncCallbackManagerForLLMRun(AsyncRunManager, LLMManagerMixin):
|
||||
)
|
||||
|
||||
@shielded
|
||||
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
async def on_llm_end(
|
||||
self, response: Union[LLMResult, AIMessage], **kwargs: Any
|
||||
) -> None:
|
||||
"""Run when LLM ends running.
|
||||
|
||||
Args:
|
||||
response (LLMResult): The LLM result.
|
||||
response (LLMResult | AIMessage): The LLM result.
|
||||
**kwargs (Any): Additional keyword arguments.
|
||||
|
||||
"""
|
||||
@@ -839,10 +898,8 @@ class AsyncCallbackManagerForLLMRun(AsyncRunManager, LLMManagerMixin):
|
||||
Args:
|
||||
error (Exception or KeyboardInterrupt): The error.
|
||||
kwargs (Any): Additional keyword arguments.
|
||||
- response (LLMResult): The response which was generated before
|
||||
the error occurred.
|
||||
|
||||
|
||||
- response (LLMResult | AIMessage): The response which was generated
|
||||
before the error occurred.
|
||||
|
||||
"""
|
||||
if not self.handlers:
|
||||
@@ -1384,7 +1441,7 @@ class CallbackManager(BaseCallbackManager):
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
) -> list[CallbackManagerForLLMRun]:
|
||||
@@ -1392,7 +1449,7 @@ class CallbackManager(BaseCallbackManager):
|
||||
|
||||
Args:
|
||||
serialized (dict[str, Any]): The serialized LLM.
|
||||
messages (list[list[BaseMessage]]): The list of messages.
|
||||
messages (list[list[BaseMessage | MessageV1]]): The list of messages.
|
||||
run_id (UUID, optional): The ID of the run. Defaults to None.
|
||||
**kwargs (Any): Additional keyword arguments.
|
||||
|
||||
@@ -1401,6 +1458,32 @@ class CallbackManager(BaseCallbackManager):
|
||||
list of messages as an LLM run.
|
||||
|
||||
"""
|
||||
if messages and isinstance(messages[0], MessageV1Types):
|
||||
run_id_ = run_id if run_id is not None else uuid.uuid4()
|
||||
handle_event(
|
||||
self.handlers,
|
||||
"on_chat_model_start",
|
||||
"ignore_chat_model",
|
||||
serialized,
|
||||
messages,
|
||||
run_id=run_id_,
|
||||
parent_run_id=self.parent_run_id,
|
||||
tags=self.tags,
|
||||
metadata=self.metadata,
|
||||
**kwargs,
|
||||
)
|
||||
return [
|
||||
CallbackManagerForLLMRun(
|
||||
run_id=run_id_,
|
||||
handlers=self.handlers,
|
||||
inheritable_handlers=self.inheritable_handlers,
|
||||
parent_run_id=self.parent_run_id,
|
||||
tags=self.tags,
|
||||
inheritable_tags=self.inheritable_tags,
|
||||
metadata=self.metadata,
|
||||
inheritable_metadata=self.inheritable_metadata,
|
||||
)
|
||||
]
|
||||
managers = []
|
||||
for message_list in messages:
|
||||
if run_id is not None:
|
||||
@@ -1903,7 +1986,7 @@ class AsyncCallbackManager(BaseCallbackManager):
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
) -> list[AsyncCallbackManagerForLLMRun]:
|
||||
@@ -1911,7 +1994,7 @@ class AsyncCallbackManager(BaseCallbackManager):
|
||||
|
||||
Args:
|
||||
serialized (dict[str, Any]): The serialized LLM.
|
||||
messages (list[list[BaseMessage]]): The list of messages.
|
||||
messages (list[list[BaseMessage | MessageV1]]): The list of messages.
|
||||
run_id (UUID, optional): The ID of the run. Defaults to None.
|
||||
**kwargs (Any): Additional keyword arguments.
|
||||
|
||||
@@ -1920,10 +2003,51 @@ class AsyncCallbackManager(BaseCallbackManager):
|
||||
async callback managers, one for each LLM Run
|
||||
corresponding to each inner message list.
|
||||
"""
|
||||
if messages and isinstance(messages[0], MessageV1Types):
|
||||
run_id_ = run_id if run_id is not None else uuid.uuid4()
|
||||
inline_tasks = []
|
||||
non_inline_tasks = []
|
||||
for handler in self.handlers:
|
||||
task = ahandle_event(
|
||||
[handler],
|
||||
"on_chat_model_start",
|
||||
"ignore_chat_model",
|
||||
serialized,
|
||||
messages,
|
||||
run_id=run_id_,
|
||||
parent_run_id=self.parent_run_id,
|
||||
tags=self.tags,
|
||||
metadata=self.metadata,
|
||||
**kwargs,
|
||||
)
|
||||
if handler.run_inline:
|
||||
inline_tasks.append(task)
|
||||
else:
|
||||
non_inline_tasks.append(task)
|
||||
managers = [
|
||||
AsyncCallbackManagerForLLMRun(
|
||||
run_id=run_id_,
|
||||
handlers=self.handlers,
|
||||
inheritable_handlers=self.inheritable_handlers,
|
||||
parent_run_id=self.parent_run_id,
|
||||
tags=self.tags,
|
||||
inheritable_tags=self.inheritable_tags,
|
||||
metadata=self.metadata,
|
||||
inheritable_metadata=self.inheritable_metadata,
|
||||
)
|
||||
]
|
||||
# Run inline tasks sequentially
|
||||
for task in inline_tasks:
|
||||
await task
|
||||
|
||||
# Run non-inline tasks concurrently
|
||||
if non_inline_tasks:
|
||||
await asyncio.gather(*non_inline_tasks)
|
||||
|
||||
return managers
|
||||
inline_tasks = []
|
||||
non_inline_tasks = []
|
||||
managers = []
|
||||
|
||||
for message_list in messages:
|
||||
if run_id is not None:
|
||||
run_id_ = run_id
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import sys
|
||||
from typing import TYPE_CHECKING, Any
|
||||
from typing import TYPE_CHECKING, Any, Union
|
||||
|
||||
from typing_extensions import override
|
||||
|
||||
@@ -13,6 +13,7 @@ if TYPE_CHECKING:
|
||||
from langchain_core.agents import AgentAction, AgentFinish
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.outputs import LLMResult
|
||||
from langchain_core.v1.messages import AIMessage, MessageV1
|
||||
|
||||
|
||||
class StreamingStdOutCallbackHandler(BaseCallbackHandler):
|
||||
@@ -32,7 +33,7 @@ class StreamingStdOutCallbackHandler(BaseCallbackHandler):
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Run when LLM starts running.
|
||||
@@ -54,7 +55,7 @@ class StreamingStdOutCallbackHandler(BaseCallbackHandler):
|
||||
sys.stdout.write(token)
|
||||
sys.stdout.flush()
|
||||
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
def on_llm_end(self, response: Union[LLMResult, AIMessage], **kwargs: Any) -> None:
|
||||
"""Run when LLM ends running.
|
||||
|
||||
Args:
|
||||
|
||||
@@ -4,14 +4,16 @@ import threading
|
||||
from collections.abc import Generator
|
||||
from contextlib import contextmanager
|
||||
from contextvars import ContextVar
|
||||
from typing import Any, Optional
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
from typing_extensions import override
|
||||
|
||||
from langchain_core.callbacks import BaseCallbackHandler
|
||||
from langchain_core.messages import AIMessage
|
||||
from langchain_core.messages.ai import UsageMetadata, add_usage
|
||||
from langchain_core.messages.utils import convert_from_v1_message
|
||||
from langchain_core.outputs import ChatGeneration, LLMResult
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
|
||||
|
||||
class UsageMetadataCallbackHandler(BaseCallbackHandler):
|
||||
@@ -58,9 +60,17 @@ class UsageMetadataCallbackHandler(BaseCallbackHandler):
|
||||
return str(self.usage_metadata)
|
||||
|
||||
@override
|
||||
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
||||
def on_llm_end(
|
||||
self, response: Union[LLMResult, AIMessageV1], **kwargs: Any
|
||||
) -> None:
|
||||
"""Collect token usage."""
|
||||
# Check for usage_metadata (langchain-core >= 0.2.2)
|
||||
if isinstance(response, AIMessageV1):
|
||||
response = LLMResult(
|
||||
generations=[
|
||||
[ChatGeneration(message=convert_from_v1_message(response))]
|
||||
]
|
||||
)
|
||||
try:
|
||||
generation = response.generations[0][0]
|
||||
except IndexError:
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
import copy
|
||||
import re
|
||||
from collections.abc import Sequence
|
||||
from typing import Optional
|
||||
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
|
||||
|
||||
def _is_openai_data_block(block: dict) -> bool:
|
||||
@@ -138,3 +140,37 @@ def _normalize_messages(messages: Sequence[BaseMessage]) -> list[BaseMessage]:
|
||||
formatted_messages.append(formatted_message)
|
||||
|
||||
return formatted_messages
|
||||
|
||||
|
||||
def _normalize_messages_v1(messages: Sequence[MessageV1]) -> list[MessageV1]:
|
||||
"""Extend support for message formats.
|
||||
|
||||
Chat models implement support for images in OpenAI Chat Completions format, as well
|
||||
as other multimodal data as standard data blocks. This function extends support to
|
||||
audio and file data in OpenAI Chat Completions format by converting them to standard
|
||||
data blocks.
|
||||
"""
|
||||
formatted_messages = []
|
||||
for message in messages:
|
||||
formatted_message = message
|
||||
if isinstance(message.content, list):
|
||||
for idx, block in enumerate(message.content):
|
||||
if (
|
||||
isinstance(block, dict)
|
||||
# Subset to (PDF) files and audio, as most relevant chat models
|
||||
# support images in OAI format (and some may not yet support the
|
||||
# standard data block format)
|
||||
and block.get("type") in {"file", "input_audio"}
|
||||
and _is_openai_data_block(block) # type: ignore[arg-type]
|
||||
):
|
||||
if formatted_message is message:
|
||||
formatted_message = copy.copy(message)
|
||||
# Also shallow-copy content
|
||||
formatted_message.content = list(formatted_message.content)
|
||||
|
||||
formatted_message.content[idx] = ( # type: ignore[call-overload]
|
||||
_convert_openai_format_to_data_block(block) # type: ignore[arg-type]
|
||||
)
|
||||
formatted_messages.append(formatted_message)
|
||||
|
||||
return formatted_messages
|
||||
|
||||
@@ -31,6 +31,7 @@ from langchain_core.messages import (
|
||||
from langchain_core.prompt_values import PromptValue
|
||||
from langchain_core.runnables import Runnable, RunnableSerializable
|
||||
from langchain_core.utils import get_pydantic_field_names
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from langchain_core.outputs import LLMResult
|
||||
@@ -85,7 +86,9 @@ def _get_token_ids_default_method(text: str) -> list[int]:
|
||||
LanguageModelInput = Union[PromptValue, str, Sequence[MessageLikeRepresentation]]
|
||||
LanguageModelOutput = Union[BaseMessage, str]
|
||||
LanguageModelLike = Runnable[LanguageModelInput, LanguageModelOutput]
|
||||
LanguageModelOutputVar = TypeVar("LanguageModelOutputVar", BaseMessage, str)
|
||||
LanguageModelOutputVar = TypeVar(
|
||||
"LanguageModelOutputVar", BaseMessage, str, AIMessageV1
|
||||
)
|
||||
|
||||
|
||||
def _get_verbosity() -> bool:
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
import asyncio
|
||||
import re
|
||||
import time
|
||||
from collections.abc import AsyncIterator, Iterator
|
||||
from collections.abc import AsyncIterator, Iterable, Iterator
|
||||
from typing import Any, Optional, Union, cast
|
||||
|
||||
from typing_extensions import override
|
||||
@@ -16,6 +16,10 @@ from langchain_core.language_models.chat_models import BaseChatModel, SimpleChat
|
||||
from langchain_core.messages import AIMessage, AIMessageChunk, BaseMessage
|
||||
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
|
||||
from langchain_core.runnables import RunnableConfig
|
||||
from langchain_core.v1.chat_models import BaseChatModel as BaseChatModelV1
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
from langchain_core.v1.messages import AIMessageChunk as AIMessageChunkV1
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
|
||||
|
||||
class FakeMessagesListChatModel(BaseChatModel):
|
||||
@@ -368,3 +372,69 @@ class ParrotFakeChatModel(BaseChatModel):
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "parrot-fake-chat-model"
|
||||
|
||||
|
||||
class GenericFakeChatModelV1(BaseChatModelV1):
|
||||
"""Generic fake chat model that can be used to test the chat model interface."""
|
||||
|
||||
messages: Optional[Iterator[Union[AIMessageV1, str]]] = None
|
||||
message_chunks: Optional[Iterable[Union[AIMessageChunkV1, str]]] = None
|
||||
|
||||
@override
|
||||
def _invoke(
|
||||
self,
|
||||
messages: list[MessageV1],
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> AIMessageV1:
|
||||
"""Top Level call."""
|
||||
if self.messages is None:
|
||||
error_msg = "Messages iterator is not set."
|
||||
raise ValueError(error_msg)
|
||||
message = next(self.messages)
|
||||
return AIMessageV1(content=message) if isinstance(message, str) else message
|
||||
|
||||
@override
|
||||
def _stream(
|
||||
self,
|
||||
messages: list[MessageV1],
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> Iterator[AIMessageChunkV1]:
|
||||
"""Top Level call."""
|
||||
if self.message_chunks is None:
|
||||
error_msg = "Message chunks iterator is not set."
|
||||
raise ValueError(error_msg)
|
||||
for chunk in self.message_chunks:
|
||||
if isinstance(chunk, str):
|
||||
yield AIMessageChunkV1(chunk)
|
||||
else:
|
||||
yield chunk
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "generic-fake-chat-model"
|
||||
|
||||
|
||||
class ParrotFakeChatModelV1(BaseChatModelV1):
|
||||
"""Generic fake chat model that can be used to test the chat model interface.
|
||||
|
||||
* Chat model should be usable in both sync and async tests
|
||||
"""
|
||||
|
||||
@override
|
||||
def _invoke(
|
||||
self,
|
||||
messages: list[MessageV1],
|
||||
stop: Optional[list[str]] = None,
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> AIMessageV1:
|
||||
"""Top Level call."""
|
||||
if isinstance(messages[-1], AIMessageV1):
|
||||
return messages[-1]
|
||||
return AIMessageV1(content=messages[-1].content)
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "parrot-fake-chat-model"
|
||||
|
||||
@@ -1,11 +1,14 @@
|
||||
"""Dump objects to json."""
|
||||
|
||||
import dataclasses
|
||||
import inspect
|
||||
import json
|
||||
from typing import Any
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
from langchain_core.load.serializable import Serializable, to_json_not_implemented
|
||||
from langchain_core.v1.messages import MessageV1Types
|
||||
|
||||
|
||||
def default(obj: Any) -> Any:
|
||||
@@ -19,6 +22,24 @@ def default(obj: Any) -> Any:
|
||||
"""
|
||||
if isinstance(obj, Serializable):
|
||||
return obj.to_json()
|
||||
|
||||
# Handle v1 message classes
|
||||
if type(obj) in MessageV1Types:
|
||||
# Get the constructor signature to only include valid parameters
|
||||
init_sig = inspect.signature(type(obj).__init__)
|
||||
valid_params = set(init_sig.parameters.keys()) - {"self"}
|
||||
|
||||
# Filter dataclass fields to only include constructor params
|
||||
all_fields = dataclasses.asdict(obj)
|
||||
kwargs = {k: v for k, v in all_fields.items() if k in valid_params}
|
||||
|
||||
return {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": ["langchain_core", "v1", "messages", type(obj).__name__],
|
||||
"kwargs": kwargs,
|
||||
}
|
||||
|
||||
return to_json_not_implemented(obj)
|
||||
|
||||
|
||||
|
||||
@@ -156,8 +156,13 @@ class Reviver:
|
||||
|
||||
cls = getattr(mod, name)
|
||||
|
||||
# The class must be a subclass of Serializable.
|
||||
if not issubclass(cls, Serializable):
|
||||
# Import MessageV1Types lazily to avoid circular import:
|
||||
# load.load -> v1.messages -> messages.ai -> messages.base ->
|
||||
# load.serializable -> load.__init__ -> load.load
|
||||
from langchain_core.v1.messages import MessageV1Types
|
||||
|
||||
# The class must be a subclass of Serializable or a v1 message class.
|
||||
if not (issubclass(cls, Serializable) or cls in MessageV1Types):
|
||||
msg = f"Invalid namespace: {value}"
|
||||
raise ValueError(msg)
|
||||
|
||||
|
||||
@@ -33,9 +33,31 @@ if TYPE_CHECKING:
|
||||
)
|
||||
from langchain_core.messages.chat import ChatMessage, ChatMessageChunk
|
||||
from langchain_core.messages.content_blocks import (
|
||||
Annotation,
|
||||
AudioContentBlock,
|
||||
Citation,
|
||||
CodeInterpreterCall,
|
||||
CodeInterpreterOutput,
|
||||
CodeInterpreterResult,
|
||||
ContentBlock,
|
||||
DataContentBlock,
|
||||
FileContentBlock,
|
||||
ImageContentBlock,
|
||||
NonStandardAnnotation,
|
||||
NonStandardContentBlock,
|
||||
PlainTextContentBlock,
|
||||
ReasoningContentBlock,
|
||||
TextContentBlock,
|
||||
VideoContentBlock,
|
||||
WebSearchCall,
|
||||
WebSearchResult,
|
||||
convert_to_openai_data_block,
|
||||
convert_to_openai_image_block,
|
||||
is_data_content_block,
|
||||
is_reasoning_block,
|
||||
is_text_block,
|
||||
is_tool_call_block,
|
||||
is_tool_call_chunk,
|
||||
)
|
||||
from langchain_core.messages.function import FunctionMessage, FunctionMessageChunk
|
||||
from langchain_core.messages.human import HumanMessage, HumanMessageChunk
|
||||
@@ -65,24 +87,42 @@ if TYPE_CHECKING:
|
||||
__all__ = (
|
||||
"AIMessage",
|
||||
"AIMessageChunk",
|
||||
"Annotation",
|
||||
"AnyMessage",
|
||||
"AudioContentBlock",
|
||||
"BaseMessage",
|
||||
"BaseMessageChunk",
|
||||
"ChatMessage",
|
||||
"ChatMessageChunk",
|
||||
"Citation",
|
||||
"CodeInterpreterCall",
|
||||
"CodeInterpreterOutput",
|
||||
"CodeInterpreterResult",
|
||||
"ContentBlock",
|
||||
"DataContentBlock",
|
||||
"FileContentBlock",
|
||||
"FunctionMessage",
|
||||
"FunctionMessageChunk",
|
||||
"HumanMessage",
|
||||
"HumanMessageChunk",
|
||||
"ImageContentBlock",
|
||||
"InvalidToolCall",
|
||||
"MessageLikeRepresentation",
|
||||
"NonStandardAnnotation",
|
||||
"NonStandardContentBlock",
|
||||
"PlainTextContentBlock",
|
||||
"ReasoningContentBlock",
|
||||
"RemoveMessage",
|
||||
"SystemMessage",
|
||||
"SystemMessageChunk",
|
||||
"TextContentBlock",
|
||||
"ToolCall",
|
||||
"ToolCallChunk",
|
||||
"ToolMessage",
|
||||
"ToolMessageChunk",
|
||||
"VideoContentBlock",
|
||||
"WebSearchCall",
|
||||
"WebSearchResult",
|
||||
"_message_from_dict",
|
||||
"convert_to_messages",
|
||||
"convert_to_openai_data_block",
|
||||
@@ -91,6 +131,10 @@ __all__ = (
|
||||
"filter_messages",
|
||||
"get_buffer_string",
|
||||
"is_data_content_block",
|
||||
"is_reasoning_block",
|
||||
"is_text_block",
|
||||
"is_tool_call_block",
|
||||
"is_tool_call_chunk",
|
||||
"merge_content",
|
||||
"merge_message_runs",
|
||||
"message_chunk_to_message",
|
||||
@@ -103,25 +147,43 @@ __all__ = (
|
||||
_dynamic_imports = {
|
||||
"AIMessage": "ai",
|
||||
"AIMessageChunk": "ai",
|
||||
"Annotation": "content_blocks",
|
||||
"AudioContentBlock": "content_blocks",
|
||||
"BaseMessage": "base",
|
||||
"BaseMessageChunk": "base",
|
||||
"merge_content": "base",
|
||||
"message_to_dict": "base",
|
||||
"messages_to_dict": "base",
|
||||
"Citation": "content_blocks",
|
||||
"ContentBlock": "content_blocks",
|
||||
"ChatMessage": "chat",
|
||||
"ChatMessageChunk": "chat",
|
||||
"CodeInterpreterCall": "content_blocks",
|
||||
"CodeInterpreterOutput": "content_blocks",
|
||||
"CodeInterpreterResult": "content_blocks",
|
||||
"DataContentBlock": "content_blocks",
|
||||
"FileContentBlock": "content_blocks",
|
||||
"FunctionMessage": "function",
|
||||
"FunctionMessageChunk": "function",
|
||||
"HumanMessage": "human",
|
||||
"HumanMessageChunk": "human",
|
||||
"NonStandardAnnotation": "content_blocks",
|
||||
"NonStandardContentBlock": "content_blocks",
|
||||
"PlainTextContentBlock": "content_blocks",
|
||||
"ReasoningContentBlock": "content_blocks",
|
||||
"RemoveMessage": "modifier",
|
||||
"SystemMessage": "system",
|
||||
"SystemMessageChunk": "system",
|
||||
"WebSearchCall": "content_blocks",
|
||||
"WebSearchResult": "content_blocks",
|
||||
"ImageContentBlock": "content_blocks",
|
||||
"InvalidToolCall": "tool",
|
||||
"TextContentBlock": "content_blocks",
|
||||
"ToolCall": "tool",
|
||||
"ToolCallChunk": "tool",
|
||||
"ToolMessage": "tool",
|
||||
"ToolMessageChunk": "tool",
|
||||
"VideoContentBlock": "content_blocks",
|
||||
"AnyMessage": "utils",
|
||||
"MessageLikeRepresentation": "utils",
|
||||
"_message_from_dict": "utils",
|
||||
@@ -132,6 +194,10 @@ _dynamic_imports = {
|
||||
"filter_messages": "utils",
|
||||
"get_buffer_string": "utils",
|
||||
"is_data_content_block": "content_blocks",
|
||||
"is_reasoning_block": "content_blocks",
|
||||
"is_text_block": "content_blocks",
|
||||
"is_tool_call_block": "content_blocks",
|
||||
"is_tool_call_chunk": "content_blocks",
|
||||
"merge_message_runs": "utils",
|
||||
"message_chunk_to_message": "utils",
|
||||
"messages_from_dict": "utils",
|
||||
|
||||
@@ -8,11 +8,7 @@ from typing import Any, Literal, Optional, Union, cast
|
||||
from pydantic import model_validator
|
||||
from typing_extensions import NotRequired, Self, TypedDict, override
|
||||
|
||||
from langchain_core.messages.base import (
|
||||
BaseMessage,
|
||||
BaseMessageChunk,
|
||||
merge_content,
|
||||
)
|
||||
from langchain_core.messages.base import BaseMessage, BaseMessageChunk, merge_content
|
||||
from langchain_core.messages.tool import (
|
||||
InvalidToolCall,
|
||||
ToolCall,
|
||||
@@ -20,23 +16,26 @@ from langchain_core.messages.tool import (
|
||||
default_tool_chunk_parser,
|
||||
default_tool_parser,
|
||||
)
|
||||
from langchain_core.messages.tool import (
|
||||
invalid_tool_call as create_invalid_tool_call,
|
||||
)
|
||||
from langchain_core.messages.tool import (
|
||||
tool_call as create_tool_call,
|
||||
)
|
||||
from langchain_core.messages.tool import (
|
||||
tool_call_chunk as create_tool_call_chunk,
|
||||
)
|
||||
from langchain_core.messages.tool import invalid_tool_call as create_invalid_tool_call
|
||||
from langchain_core.messages.tool import tool_call as create_tool_call
|
||||
from langchain_core.messages.tool import tool_call_chunk as create_tool_call_chunk
|
||||
from langchain_core.utils._merge import merge_dicts, merge_lists
|
||||
from langchain_core.utils.json import parse_partial_json
|
||||
from langchain_core.utils.usage import _dict_int_op
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
_LC_AUTO_PREFIX = "lc_"
|
||||
"""LangChain auto-generated ID prefix for messages and content blocks."""
|
||||
|
||||
_LC_ID_PREFIX = "run-"
|
||||
_LC_ID_PREFIX = f"{_LC_AUTO_PREFIX}run-"
|
||||
"""Internal tracing/callback system identifier.
|
||||
|
||||
Used for:
|
||||
- Tracing. Every LangChain operation (LLM call, chain execution, tool use, etc.)
|
||||
gets a unique run_id (UUID)
|
||||
- Enables tracking parent-child relationships between operations
|
||||
"""
|
||||
|
||||
|
||||
class InputTokenDetails(TypedDict, total=False):
|
||||
@@ -428,17 +427,27 @@ def add_ai_message_chunks(
|
||||
|
||||
chunk_id = None
|
||||
candidates = [left.id] + [o.id for o in others]
|
||||
# first pass: pick the first non-run-* id
|
||||
# first pass: pick the first provider-assigned id (non-run-* and non-lc_*)
|
||||
for id_ in candidates:
|
||||
if id_ and not id_.startswith(_LC_ID_PREFIX):
|
||||
if (
|
||||
id_
|
||||
and not id_.startswith(_LC_ID_PREFIX)
|
||||
and not id_.startswith(_LC_AUTO_PREFIX)
|
||||
):
|
||||
chunk_id = id_
|
||||
break
|
||||
else:
|
||||
# second pass: no provider-assigned id found, just take the first non-null
|
||||
# second pass: prefer lc_run-* ids over lc_* ids
|
||||
for id_ in candidates:
|
||||
if id_:
|
||||
if id_ and id_.startswith(_LC_ID_PREFIX):
|
||||
chunk_id = id_
|
||||
break
|
||||
else:
|
||||
# third pass: take any remaining id (auto-generated lc_* ids)
|
||||
for id_ in candidates:
|
||||
if id_:
|
||||
chunk_id = id_
|
||||
break
|
||||
|
||||
return left.__class__(
|
||||
example=left.example,
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -5,9 +5,12 @@ from typing import Any, Literal, Optional, Union
|
||||
from uuid import UUID
|
||||
|
||||
from pydantic import Field, model_validator
|
||||
from typing_extensions import NotRequired, TypedDict, override
|
||||
from typing_extensions import override
|
||||
|
||||
from langchain_core.messages.base import BaseMessage, BaseMessageChunk, merge_content
|
||||
from langchain_core.messages.content_blocks import InvalidToolCall as InvalidToolCall
|
||||
from langchain_core.messages.content_blocks import ToolCall as ToolCall
|
||||
from langchain_core.messages.content_blocks import ToolCallChunk as ToolCallChunk
|
||||
from langchain_core.utils._merge import merge_dicts, merge_obj
|
||||
|
||||
|
||||
@@ -177,37 +180,6 @@ class ToolMessageChunk(ToolMessage, BaseMessageChunk):
|
||||
return super().__add__(other)
|
||||
|
||||
|
||||
class ToolCall(TypedDict):
|
||||
"""Represents a request to call a tool.
|
||||
|
||||
Example:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
{
|
||||
"name": "foo",
|
||||
"args": {"a": 1},
|
||||
"id": "123"
|
||||
}
|
||||
|
||||
This represents a request to call the tool named "foo" with arguments {"a": 1}
|
||||
and an identifier of "123".
|
||||
|
||||
"""
|
||||
|
||||
name: str
|
||||
"""The name of the tool to be called."""
|
||||
args: dict[str, Any]
|
||||
"""The arguments to the tool call."""
|
||||
id: Optional[str]
|
||||
"""An identifier associated with the tool call.
|
||||
|
||||
An identifier is needed to associate a tool call request with a tool
|
||||
call result in events when multiple concurrent tool calls are made.
|
||||
"""
|
||||
type: NotRequired[Literal["tool_call"]]
|
||||
|
||||
|
||||
def tool_call(
|
||||
*,
|
||||
name: str,
|
||||
@@ -224,38 +196,6 @@ def tool_call(
|
||||
return ToolCall(name=name, args=args, id=id, type="tool_call")
|
||||
|
||||
|
||||
class ToolCallChunk(TypedDict):
|
||||
"""A chunk of a tool call (e.g., as part of a stream).
|
||||
|
||||
When merging ToolCallChunks (e.g., via AIMessageChunk.__add__),
|
||||
all string attributes are concatenated. Chunks are only merged if their
|
||||
values of `index` are equal and not None.
|
||||
|
||||
Example:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
left_chunks = [ToolCallChunk(name="foo", args='{"a":', index=0)]
|
||||
right_chunks = [ToolCallChunk(name=None, args='1}', index=0)]
|
||||
|
||||
(
|
||||
AIMessageChunk(content="", tool_call_chunks=left_chunks)
|
||||
+ AIMessageChunk(content="", tool_call_chunks=right_chunks)
|
||||
).tool_call_chunks == [ToolCallChunk(name='foo', args='{"a":1}', index=0)]
|
||||
|
||||
"""
|
||||
|
||||
name: Optional[str]
|
||||
"""The name of the tool to be called."""
|
||||
args: Optional[str]
|
||||
"""The arguments to the tool call."""
|
||||
id: Optional[str]
|
||||
"""An identifier associated with the tool call."""
|
||||
index: Optional[int]
|
||||
"""The index of the tool call in a sequence."""
|
||||
type: NotRequired[Literal["tool_call_chunk"]]
|
||||
|
||||
|
||||
def tool_call_chunk(
|
||||
*,
|
||||
name: Optional[str] = None,
|
||||
@@ -276,24 +216,6 @@ def tool_call_chunk(
|
||||
)
|
||||
|
||||
|
||||
class InvalidToolCall(TypedDict):
|
||||
"""Allowance for errors made by LLM.
|
||||
|
||||
Here we add an `error` key to surface errors made during generation
|
||||
(e.g., invalid JSON arguments.)
|
||||
"""
|
||||
|
||||
name: Optional[str]
|
||||
"""The name of the tool to be called."""
|
||||
args: Optional[str]
|
||||
"""The arguments to the tool call."""
|
||||
id: Optional[str]
|
||||
"""An identifier associated with the tool call."""
|
||||
error: Optional[str]
|
||||
"""An error message associated with the tool call."""
|
||||
type: NotRequired[Literal["invalid_tool_call"]]
|
||||
|
||||
|
||||
def invalid_tool_call(
|
||||
*,
|
||||
name: Optional[str] = None,
|
||||
|
||||
@@ -35,11 +35,18 @@ from langchain_core.messages import convert_to_openai_data_block, is_data_conten
|
||||
from langchain_core.messages.ai import AIMessage, AIMessageChunk
|
||||
from langchain_core.messages.base import BaseMessage, BaseMessageChunk
|
||||
from langchain_core.messages.chat import ChatMessage, ChatMessageChunk
|
||||
from langchain_core.messages.content_blocks import ContentBlock
|
||||
from langchain_core.messages.function import FunctionMessage, FunctionMessageChunk
|
||||
from langchain_core.messages.human import HumanMessage, HumanMessageChunk
|
||||
from langchain_core.messages.modifier import RemoveMessage
|
||||
from langchain_core.messages.system import SystemMessage, SystemMessageChunk
|
||||
from langchain_core.messages.tool import ToolCall, ToolMessage, ToolMessageChunk
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
from langchain_core.v1.messages import AIMessageChunk as AIMessageChunkV1
|
||||
from langchain_core.v1.messages import HumanMessage as HumanMessageV1
|
||||
from langchain_core.v1.messages import MessageV1, MessageV1Types, ResponseMetadata
|
||||
from langchain_core.v1.messages import SystemMessage as SystemMessageV1
|
||||
from langchain_core.v1.messages import ToolMessage as ToolMessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from langchain_text_splitters import TextSplitter
|
||||
@@ -203,7 +210,7 @@ def message_chunk_to_message(chunk: BaseMessageChunk) -> BaseMessage:
|
||||
|
||||
|
||||
MessageLikeRepresentation = Union[
|
||||
BaseMessage, list[str], tuple[str, str], str, dict[str, Any]
|
||||
BaseMessage, list[str], tuple[str, str], str, dict[str, Any], MessageV1
|
||||
]
|
||||
|
||||
|
||||
@@ -294,6 +301,130 @@ def _create_message_from_message_type(
|
||||
return message
|
||||
|
||||
|
||||
def _create_message_from_message_type_v1(
|
||||
message_type: str,
|
||||
content: str,
|
||||
name: Optional[str] = None,
|
||||
tool_call_id: Optional[str] = None,
|
||||
tool_calls: Optional[list[dict[str, Any]]] = None,
|
||||
id: Optional[str] = None,
|
||||
**kwargs: Any,
|
||||
) -> MessageV1:
|
||||
"""Create a message from a message type and content string.
|
||||
|
||||
Args:
|
||||
message_type: (str) the type of the message (e.g., "human", "ai", etc.).
|
||||
content: (str) the content string.
|
||||
name: (str) the name of the message. Default is None.
|
||||
tool_call_id: (str) the tool call id. Default is None.
|
||||
tool_calls: (list[dict[str, Any]]) the tool calls. Default is None.
|
||||
id: (str) the id of the message. Default is None.
|
||||
kwargs: (dict[str, Any]) additional keyword arguments.
|
||||
|
||||
Returns:
|
||||
a message of the appropriate type.
|
||||
|
||||
Raises:
|
||||
ValueError: if the message type is not one of "human", "user", "ai",
|
||||
"assistant", "tool", "system", or "developer".
|
||||
"""
|
||||
if name is not None:
|
||||
kwargs["name"] = name
|
||||
if tool_call_id is not None:
|
||||
kwargs["tool_call_id"] = tool_call_id
|
||||
if kwargs and (response_metadata := kwargs.pop("response_metadata", None)):
|
||||
kwargs["response_metadata"] = response_metadata
|
||||
if id is not None:
|
||||
kwargs["id"] = id
|
||||
if tool_calls is not None:
|
||||
kwargs["tool_calls"] = []
|
||||
for tool_call in tool_calls:
|
||||
# Convert OpenAI-format tool call to LangChain format.
|
||||
if "function" in tool_call:
|
||||
args = tool_call["function"]["arguments"]
|
||||
if isinstance(args, str):
|
||||
args = json.loads(args, strict=False)
|
||||
kwargs["tool_calls"].append(
|
||||
{
|
||||
"name": tool_call["function"]["name"],
|
||||
"args": args,
|
||||
"id": tool_call["id"],
|
||||
"type": "tool_call",
|
||||
}
|
||||
)
|
||||
else:
|
||||
kwargs["tool_calls"].append(tool_call)
|
||||
if message_type in {"human", "user"}:
|
||||
message: MessageV1 = HumanMessageV1(content=content, **kwargs)
|
||||
elif message_type in {"ai", "assistant"}:
|
||||
message = AIMessageV1(content=content, **kwargs)
|
||||
elif message_type in {"system", "developer"}:
|
||||
if message_type == "developer":
|
||||
kwargs["custom_role"] = "developer"
|
||||
message = SystemMessageV1(content=content, **kwargs)
|
||||
elif message_type == "tool":
|
||||
artifact = kwargs.pop("artifact", None)
|
||||
message = ToolMessageV1(content=content, artifact=artifact, **kwargs)
|
||||
else:
|
||||
msg = (
|
||||
f"Unexpected message type: '{message_type}'. Use one of 'human',"
|
||||
f" 'user', 'ai', 'assistant', 'function', 'tool', 'system', or 'developer'."
|
||||
)
|
||||
msg = create_message(message=msg, error_code=ErrorCode.MESSAGE_COERCION_FAILURE)
|
||||
raise ValueError(msg)
|
||||
return message
|
||||
|
||||
|
||||
def convert_from_v1_message(message: MessageV1) -> BaseMessage:
|
||||
"""Compatibility layer to convert v1 messages to current messages.
|
||||
|
||||
Args:
|
||||
message: MessageV1 instance to convert.
|
||||
|
||||
Returns:
|
||||
BaseMessage: Converted message instance.
|
||||
"""
|
||||
content = cast("Union[str, list[str | dict]]", message.content)
|
||||
if isinstance(message, AIMessageV1):
|
||||
return AIMessage(
|
||||
content=content,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
tool_calls=message.tool_calls,
|
||||
response_metadata=cast("dict", message.response_metadata),
|
||||
)
|
||||
if isinstance(message, AIMessageChunkV1):
|
||||
return AIMessageChunk(
|
||||
content=content,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
tool_call_chunks=message.tool_call_chunks,
|
||||
response_metadata=cast("dict", message.response_metadata),
|
||||
)
|
||||
if isinstance(message, HumanMessageV1):
|
||||
return HumanMessage(
|
||||
content=content,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
)
|
||||
if isinstance(message, SystemMessageV1):
|
||||
return SystemMessage(
|
||||
content=content,
|
||||
id=message.id,
|
||||
)
|
||||
if isinstance(message, ToolMessageV1):
|
||||
return ToolMessage(
|
||||
content=content,
|
||||
id=message.id,
|
||||
tool_call_id=message.tool_call_id,
|
||||
artifact=message.artifact,
|
||||
name=message.name,
|
||||
status=message.status,
|
||||
)
|
||||
message = f"Unsupported message type: {type(message)}"
|
||||
raise NotImplementedError(message)
|
||||
|
||||
|
||||
def _convert_to_message(message: MessageLikeRepresentation) -> BaseMessage:
|
||||
"""Instantiate a message from a variety of message formats.
|
||||
|
||||
@@ -341,6 +472,143 @@ def _convert_to_message(message: MessageLikeRepresentation) -> BaseMessage:
|
||||
message_ = _create_message_from_message_type(
|
||||
msg_type, msg_content, **msg_kwargs
|
||||
)
|
||||
elif isinstance(message, MessageV1Types):
|
||||
message_ = convert_from_v1_message(message)
|
||||
else:
|
||||
msg = f"Unsupported message type: {type(message)}"
|
||||
msg = create_message(message=msg, error_code=ErrorCode.MESSAGE_COERCION_FAILURE)
|
||||
raise NotImplementedError(msg)
|
||||
|
||||
return message_
|
||||
|
||||
|
||||
def _convert_from_v0_to_v1(message: BaseMessage) -> MessageV1:
|
||||
"""Convert a v0 message to a v1 message."""
|
||||
if isinstance(message, HumanMessage): # Checking for v0 HumanMessage
|
||||
return HumanMessageV1(message.content, id=message.id, name=message.name) # type: ignore[arg-type]
|
||||
if isinstance(message, AIMessage): # Checking for v0 AIMessage
|
||||
return AIMessageV1(
|
||||
content=message.content, # type: ignore[arg-type]
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
lc_version="v1",
|
||||
response_metadata=message.response_metadata, # type: ignore[arg-type]
|
||||
usage_metadata=message.usage_metadata,
|
||||
tool_calls=message.tool_calls,
|
||||
invalid_tool_calls=message.invalid_tool_calls,
|
||||
)
|
||||
if isinstance(message, SystemMessage): # Checking for v0 SystemMessage
|
||||
return SystemMessageV1(
|
||||
message.content, # type: ignore[arg-type]
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
)
|
||||
if isinstance(message, ToolMessage): # Checking for v0 ToolMessage
|
||||
return ToolMessageV1(
|
||||
message.content, # type: ignore[arg-type]
|
||||
message.tool_call_id,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
artifact=message.artifact,
|
||||
status=message.status,
|
||||
)
|
||||
msg = f"Unsupported v0 message type for conversion to v1: {type(message)}"
|
||||
raise NotImplementedError(msg)
|
||||
|
||||
|
||||
def _safe_convert_from_v0_to_v1(message: BaseMessage) -> MessageV1:
|
||||
"""Convert a v0 message to a v1 message."""
|
||||
from langchain_core.messages.content_blocks import create_text_block
|
||||
|
||||
if isinstance(message, HumanMessage): # Checking for v0 HumanMessage
|
||||
content: list[ContentBlock] = [create_text_block(str(message.content))]
|
||||
return HumanMessageV1(content, id=message.id, name=message.name)
|
||||
if isinstance(message, AIMessage): # Checking for v0 AIMessage
|
||||
content = [create_text_block(str(message.content))]
|
||||
|
||||
# Construct ResponseMetadata TypedDict from v0 response_metadata dict
|
||||
# Since ResponseMetadata has total=False, we can safely cast the dict
|
||||
response_metadata = cast("ResponseMetadata", message.response_metadata or {})
|
||||
return AIMessageV1(
|
||||
content=content,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
lc_version="v1",
|
||||
response_metadata=response_metadata,
|
||||
usage_metadata=message.usage_metadata,
|
||||
tool_calls=message.tool_calls,
|
||||
invalid_tool_calls=message.invalid_tool_calls,
|
||||
)
|
||||
if isinstance(message, SystemMessage): # Checking for v0 SystemMessage
|
||||
content = [create_text_block(str(message.content))]
|
||||
return SystemMessageV1(content=content, id=message.id, name=message.name)
|
||||
if isinstance(message, ToolMessage): # Checking for v0 ToolMessage
|
||||
content = [create_text_block(str(message.content))]
|
||||
return ToolMessageV1(
|
||||
content,
|
||||
message.tool_call_id,
|
||||
id=message.id,
|
||||
name=message.name,
|
||||
artifact=message.artifact,
|
||||
status=message.status,
|
||||
)
|
||||
msg = f"Unsupported v0 message type for conversion to v1: {type(message)}"
|
||||
raise NotImplementedError(msg)
|
||||
|
||||
|
||||
def _convert_to_message_v1(message: MessageLikeRepresentation) -> MessageV1:
|
||||
"""Instantiate a message from a variety of message formats.
|
||||
|
||||
The message format can be one of the following:
|
||||
|
||||
- BaseMessagePromptTemplate
|
||||
- BaseMessage
|
||||
- 2-tuple of (role string, template); e.g., ("human", "{user_input}")
|
||||
- dict: a message dict with role and content keys
|
||||
- string: shorthand for ("human", template); e.g., "{user_input}"
|
||||
|
||||
Args:
|
||||
message: a representation of a message in one of the supported formats.
|
||||
|
||||
Returns:
|
||||
an instance of a message or a message template.
|
||||
|
||||
Raises:
|
||||
NotImplementedError: if the message type is not supported.
|
||||
ValueError: if the message dict does not contain the required keys.
|
||||
"""
|
||||
if isinstance(message, MessageV1Types):
|
||||
if isinstance(message, AIMessageChunkV1):
|
||||
message_: MessageV1 = message.to_message()
|
||||
else:
|
||||
message_ = message
|
||||
elif isinstance(message, BaseMessage):
|
||||
# Convert v0 messages to v1 messages
|
||||
message_ = _convert_from_v0_to_v1(message)
|
||||
elif isinstance(message, str):
|
||||
message_ = _create_message_from_message_type_v1("human", message)
|
||||
elif isinstance(message, Sequence) and len(message) == 2:
|
||||
# mypy doesn't realise this can't be a string given the previous branch
|
||||
message_type_str, template = message # type: ignore[misc]
|
||||
message_ = _create_message_from_message_type_v1(message_type_str, template)
|
||||
elif isinstance(message, dict):
|
||||
msg_kwargs = message.copy()
|
||||
try:
|
||||
try:
|
||||
msg_type = msg_kwargs.pop("role")
|
||||
except KeyError:
|
||||
msg_type = msg_kwargs.pop("type")
|
||||
# None msg content is not allowed
|
||||
msg_content = msg_kwargs.pop("content") or ""
|
||||
except KeyError as e:
|
||||
msg = f"Message dict must contain 'role' and 'content' keys, got {message}"
|
||||
msg = create_message(
|
||||
message=msg, error_code=ErrorCode.MESSAGE_COERCION_FAILURE
|
||||
)
|
||||
raise ValueError(msg) from e
|
||||
message_ = _create_message_from_message_type_v1(
|
||||
msg_type, msg_content, **msg_kwargs
|
||||
)
|
||||
else:
|
||||
msg = f"Unsupported message type: {type(message)}"
|
||||
msg = create_message(message=msg, error_code=ErrorCode.MESSAGE_COERCION_FAILURE)
|
||||
@@ -368,6 +636,25 @@ def convert_to_messages(
|
||||
return [_convert_to_message(m) for m in messages]
|
||||
|
||||
|
||||
def convert_to_messages_v1(
|
||||
messages: Union[Iterable[MessageLikeRepresentation], PromptValue],
|
||||
) -> list[MessageV1]:
|
||||
"""Convert a sequence of messages to a list of messages.
|
||||
|
||||
Args:
|
||||
messages: Sequence of messages to convert.
|
||||
|
||||
Returns:
|
||||
list of messages (BaseMessages).
|
||||
"""
|
||||
# Import here to avoid circular imports
|
||||
from langchain_core.prompt_values import PromptValue
|
||||
|
||||
if isinstance(messages, PromptValue):
|
||||
return messages.to_messages(message_version="v1")
|
||||
return [_convert_to_message_v1(m) for m in messages]
|
||||
|
||||
|
||||
def _runnable_support(func: Callable) -> Callable:
|
||||
@overload
|
||||
def wrapped(
|
||||
@@ -1008,10 +1295,11 @@ def convert_to_openai_messages(
|
||||
|
||||
oai_messages: list = []
|
||||
|
||||
if is_single := isinstance(messages, (BaseMessage, dict, str)):
|
||||
if is_single := isinstance(messages, (BaseMessage, dict, str, MessageV1Types)):
|
||||
messages = [messages]
|
||||
|
||||
messages = convert_to_messages(messages)
|
||||
# TODO: resolve type ignore here
|
||||
messages = convert_to_messages(messages) # type: ignore[arg-type]
|
||||
|
||||
for i, message in enumerate(messages):
|
||||
oai_msg: dict = {"role": _get_message_openai_role(message)}
|
||||
|
||||
@@ -11,6 +11,7 @@ from typing import (
|
||||
Optional,
|
||||
TypeVar,
|
||||
Union,
|
||||
cast,
|
||||
)
|
||||
|
||||
from typing_extensions import override
|
||||
@@ -20,19 +21,22 @@ from langchain_core.messages import AnyMessage, BaseMessage
|
||||
from langchain_core.outputs import ChatGeneration, Generation
|
||||
from langchain_core.runnables import Runnable, RunnableConfig, RunnableSerializable
|
||||
from langchain_core.runnables.config import run_in_executor
|
||||
from langchain_core.v1.messages import AIMessage, MessageV1, MessageV1Types
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from langchain_core.prompt_values import PromptValue
|
||||
|
||||
T = TypeVar("T")
|
||||
OutputParserLike = Runnable[LanguageModelOutput, T]
|
||||
OutputParserLike = Runnable[Union[LanguageModelOutput, AIMessage], T]
|
||||
|
||||
|
||||
class BaseLLMOutputParser(ABC, Generic[T]):
|
||||
"""Abstract base class for parsing the outputs of a model."""
|
||||
|
||||
@abstractmethod
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> T:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> T:
|
||||
"""Parse a list of candidate model Generations into a specific format.
|
||||
|
||||
Args:
|
||||
@@ -46,7 +50,7 @@ class BaseLLMOutputParser(ABC, Generic[T]):
|
||||
"""
|
||||
|
||||
async def aparse_result(
|
||||
self, result: list[Generation], *, partial: bool = False
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> T:
|
||||
"""Async parse a list of candidate model Generations into a specific format.
|
||||
|
||||
@@ -71,7 +75,7 @@ class BaseGenerationOutputParser(
|
||||
@override
|
||||
def InputType(self) -> Any:
|
||||
"""Return the input type for the parser."""
|
||||
return Union[str, AnyMessage]
|
||||
return Union[str, AnyMessage, MessageV1]
|
||||
|
||||
@property
|
||||
@override
|
||||
@@ -84,7 +88,7 @@ class BaseGenerationOutputParser(
|
||||
@override
|
||||
def invoke(
|
||||
self,
|
||||
input: Union[str, BaseMessage],
|
||||
input: Union[str, BaseMessage, MessageV1],
|
||||
config: Optional[RunnableConfig] = None,
|
||||
**kwargs: Any,
|
||||
) -> T:
|
||||
@@ -97,9 +101,16 @@ class BaseGenerationOutputParser(
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
if isinstance(input, MessageV1Types):
|
||||
return self._call_with_config(
|
||||
lambda inner_input: self.parse_result(inner_input),
|
||||
input,
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
return self._call_with_config(
|
||||
lambda inner_input: self.parse_result([Generation(text=inner_input)]),
|
||||
input,
|
||||
cast("str", input),
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
@@ -120,6 +131,13 @@ class BaseGenerationOutputParser(
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
if isinstance(input, MessageV1Types):
|
||||
return await self._acall_with_config(
|
||||
lambda inner_input: self.aparse_result(inner_input),
|
||||
input,
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
return await self._acall_with_config(
|
||||
lambda inner_input: self.aparse_result([Generation(text=inner_input)]),
|
||||
input,
|
||||
@@ -129,7 +147,7 @@ class BaseGenerationOutputParser(
|
||||
|
||||
|
||||
class BaseOutputParser(
|
||||
BaseLLMOutputParser, RunnableSerializable[LanguageModelOutput, T]
|
||||
BaseLLMOutputParser, RunnableSerializable[Union[LanguageModelOutput, AIMessage], T]
|
||||
):
|
||||
"""Base class to parse the output of an LLM call.
|
||||
|
||||
@@ -162,7 +180,7 @@ class BaseOutputParser(
|
||||
@override
|
||||
def InputType(self) -> Any:
|
||||
"""Return the input type for the parser."""
|
||||
return Union[str, AnyMessage]
|
||||
return Union[str, AnyMessage, MessageV1]
|
||||
|
||||
@property
|
||||
@override
|
||||
@@ -189,7 +207,7 @@ class BaseOutputParser(
|
||||
@override
|
||||
def invoke(
|
||||
self,
|
||||
input: Union[str, BaseMessage],
|
||||
input: Union[str, BaseMessage, MessageV1],
|
||||
config: Optional[RunnableConfig] = None,
|
||||
**kwargs: Any,
|
||||
) -> T:
|
||||
@@ -202,9 +220,16 @@ class BaseOutputParser(
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
if isinstance(input, MessageV1Types):
|
||||
return self._call_with_config(
|
||||
lambda inner_input: self.parse_result(inner_input),
|
||||
input,
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
return self._call_with_config(
|
||||
lambda inner_input: self.parse_result([Generation(text=inner_input)]),
|
||||
input,
|
||||
cast("str", input),
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
@@ -212,7 +237,7 @@ class BaseOutputParser(
|
||||
@override
|
||||
async def ainvoke(
|
||||
self,
|
||||
input: Union[str, BaseMessage],
|
||||
input: Union[str, BaseMessage, MessageV1],
|
||||
config: Optional[RunnableConfig] = None,
|
||||
**kwargs: Optional[Any],
|
||||
) -> T:
|
||||
@@ -225,15 +250,24 @@ class BaseOutputParser(
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
if isinstance(input, MessageV1Types):
|
||||
return await self._acall_with_config(
|
||||
lambda inner_input: self.aparse_result(inner_input),
|
||||
input,
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
return await self._acall_with_config(
|
||||
lambda inner_input: self.aparse_result([Generation(text=inner_input)]),
|
||||
input,
|
||||
cast("str", input),
|
||||
config,
|
||||
run_type="parser",
|
||||
)
|
||||
|
||||
@override
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> T:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> T:
|
||||
"""Parse a list of candidate model Generations into a specific format.
|
||||
|
||||
The return value is parsed from only the first Generation in the result, which
|
||||
@@ -248,6 +282,8 @@ class BaseOutputParser(
|
||||
Returns:
|
||||
Structured output.
|
||||
"""
|
||||
if isinstance(result, AIMessage):
|
||||
return self.parse(result.text)
|
||||
return self.parse(result[0].text)
|
||||
|
||||
@abstractmethod
|
||||
@@ -262,7 +298,7 @@ class BaseOutputParser(
|
||||
"""
|
||||
|
||||
async def aparse_result(
|
||||
self, result: list[Generation], *, partial: bool = False
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> T:
|
||||
"""Async parse a list of candidate model Generations into a specific format.
|
||||
|
||||
|
||||
@@ -21,6 +21,7 @@ from langchain_core.utils.json import (
|
||||
parse_json_markdown,
|
||||
parse_partial_json,
|
||||
)
|
||||
from langchain_core.v1.messages import AIMessage
|
||||
|
||||
# Union type needs to be last assignment to PydanticBaseModel to make mypy happy.
|
||||
PydanticBaseModel = Union[BaseModel, pydantic.BaseModel]
|
||||
@@ -53,7 +54,9 @@ class JsonOutputParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
return pydantic_object.schema()
|
||||
return None
|
||||
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
@@ -70,7 +73,7 @@ class JsonOutputParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
Raises:
|
||||
OutputParserException: If the output is not valid JSON.
|
||||
"""
|
||||
text = result[0].text
|
||||
text = result.text if isinstance(result, AIMessage) else result[0].text
|
||||
text = text.strip()
|
||||
if partial:
|
||||
try:
|
||||
|
||||
@@ -13,6 +13,7 @@ from typing_extensions import override
|
||||
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.output_parsers.transform import BaseTransformOutputParser
|
||||
from langchain_core.v1.messages import AIMessage
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import AsyncIterator, Iterator
|
||||
@@ -71,7 +72,7 @@ class ListOutputParser(BaseTransformOutputParser[list[str]]):
|
||||
|
||||
@override
|
||||
def _transform(
|
||||
self, input: Iterator[Union[str, BaseMessage]]
|
||||
self, input: Iterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> Iterator[list[str]]:
|
||||
buffer = ""
|
||||
for chunk in input:
|
||||
@@ -81,6 +82,8 @@ class ListOutputParser(BaseTransformOutputParser[list[str]]):
|
||||
if not isinstance(chunk_content, str):
|
||||
continue
|
||||
buffer += chunk_content
|
||||
elif isinstance(chunk, AIMessage):
|
||||
buffer += chunk.text
|
||||
else:
|
||||
# add current chunk to buffer
|
||||
buffer += chunk
|
||||
@@ -105,7 +108,7 @@ class ListOutputParser(BaseTransformOutputParser[list[str]]):
|
||||
|
||||
@override
|
||||
async def _atransform(
|
||||
self, input: AsyncIterator[Union[str, BaseMessage]]
|
||||
self, input: AsyncIterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> AsyncIterator[list[str]]:
|
||||
buffer = ""
|
||||
async for chunk in input:
|
||||
@@ -115,6 +118,8 @@ class ListOutputParser(BaseTransformOutputParser[list[str]]):
|
||||
if not isinstance(chunk_content, str):
|
||||
continue
|
||||
buffer += chunk_content
|
||||
elif isinstance(chunk, AIMessage):
|
||||
buffer += chunk.text
|
||||
else:
|
||||
# add current chunk to buffer
|
||||
buffer += chunk
|
||||
|
||||
@@ -17,6 +17,7 @@ from langchain_core.output_parsers import (
|
||||
)
|
||||
from langchain_core.output_parsers.json import parse_partial_json
|
||||
from langchain_core.outputs import ChatGeneration, Generation
|
||||
from langchain_core.v1.messages import AIMessage
|
||||
|
||||
|
||||
class OutputFunctionsParser(BaseGenerationOutputParser[Any]):
|
||||
@@ -26,7 +27,9 @@ class OutputFunctionsParser(BaseGenerationOutputParser[Any]):
|
||||
"""Whether to only return the arguments to the function call."""
|
||||
|
||||
@override
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
@@ -39,6 +42,12 @@ class OutputFunctionsParser(BaseGenerationOutputParser[Any]):
|
||||
Raises:
|
||||
OutputParserException: If the output is not valid JSON.
|
||||
"""
|
||||
if isinstance(result, AIMessage):
|
||||
msg = (
|
||||
"This output parser does not support v1 AIMessages. Use "
|
||||
"JsonOutputToolsParser instead."
|
||||
)
|
||||
raise TypeError(msg)
|
||||
generation = result[0]
|
||||
if not isinstance(generation, ChatGeneration):
|
||||
msg = "This output parser can only be used with a chat generation."
|
||||
@@ -77,7 +86,9 @@ class JsonOutputFunctionsParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
def _diff(self, prev: Optional[Any], next: Any) -> Any:
|
||||
return jsonpatch.make_patch(prev, next).patch
|
||||
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
@@ -90,6 +101,12 @@ class JsonOutputFunctionsParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
Raises:
|
||||
OutputParserException: If the output is not valid JSON.
|
||||
"""
|
||||
if isinstance(result, AIMessage):
|
||||
msg = (
|
||||
"This output parser does not support v1 AIMessages. Use "
|
||||
"JsonOutputToolsParser instead."
|
||||
)
|
||||
raise TypeError(msg)
|
||||
if len(result) != 1:
|
||||
msg = f"Expected exactly one result, but got {len(result)}"
|
||||
raise OutputParserException(msg)
|
||||
@@ -160,7 +177,9 @@ class JsonKeyOutputFunctionsParser(JsonOutputFunctionsParser):
|
||||
key_name: str
|
||||
"""The name of the key to return."""
|
||||
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
@@ -254,7 +273,9 @@ class PydanticOutputFunctionsParser(OutputFunctionsParser):
|
||||
return values
|
||||
|
||||
@override
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
@@ -294,7 +315,9 @@ class PydanticAttrOutputFunctionsParser(PydanticOutputFunctionsParser):
|
||||
"""The name of the attribute to return."""
|
||||
|
||||
@override
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a JSON object.
|
||||
|
||||
Args:
|
||||
|
||||
@@ -4,7 +4,7 @@ import copy
|
||||
import json
|
||||
import logging
|
||||
from json import JSONDecodeError
|
||||
from typing import Annotated, Any, Optional
|
||||
from typing import Annotated, Any, Optional, Union
|
||||
|
||||
from pydantic import SkipValidation, ValidationError
|
||||
|
||||
@@ -16,6 +16,7 @@ from langchain_core.output_parsers.transform import BaseCumulativeTransformOutpu
|
||||
from langchain_core.outputs import ChatGeneration, Generation
|
||||
from langchain_core.utils.json import parse_partial_json
|
||||
from langchain_core.utils.pydantic import TypeBaseModel
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -156,7 +157,9 @@ class JsonOutputToolsParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
If no tool calls are found, None will be returned.
|
||||
"""
|
||||
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessageV1], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a list of tool calls.
|
||||
|
||||
Args:
|
||||
@@ -173,31 +176,45 @@ class JsonOutputToolsParser(BaseCumulativeTransformOutputParser[Any]):
|
||||
Raises:
|
||||
OutputParserException: If the output is not valid JSON.
|
||||
"""
|
||||
generation = result[0]
|
||||
if not isinstance(generation, ChatGeneration):
|
||||
msg = "This output parser can only be used with a chat generation."
|
||||
raise OutputParserException(msg)
|
||||
message = generation.message
|
||||
if isinstance(message, AIMessage) and message.tool_calls:
|
||||
tool_calls = [dict(tc) for tc in message.tool_calls]
|
||||
if isinstance(result, list):
|
||||
generation = result[0]
|
||||
if not isinstance(generation, ChatGeneration):
|
||||
msg = (
|
||||
"This output parser can only be used with a chat generation or "
|
||||
"v1 AIMessage."
|
||||
)
|
||||
raise OutputParserException(msg)
|
||||
message = generation.message
|
||||
if isinstance(message, AIMessage) and message.tool_calls:
|
||||
tool_calls = [dict(tc) for tc in message.tool_calls]
|
||||
for tool_call in tool_calls:
|
||||
if not self.return_id:
|
||||
_ = tool_call.pop("id")
|
||||
else:
|
||||
try:
|
||||
raw_tool_calls = copy.deepcopy(
|
||||
message.additional_kwargs["tool_calls"]
|
||||
)
|
||||
except KeyError:
|
||||
return []
|
||||
tool_calls = parse_tool_calls(
|
||||
raw_tool_calls,
|
||||
partial=partial,
|
||||
strict=self.strict,
|
||||
return_id=self.return_id,
|
||||
)
|
||||
elif result.tool_calls:
|
||||
# v1 message
|
||||
tool_calls = [dict(tc) for tc in result.tool_calls]
|
||||
for tool_call in tool_calls:
|
||||
if not self.return_id:
|
||||
_ = tool_call.pop("id")
|
||||
else:
|
||||
try:
|
||||
raw_tool_calls = copy.deepcopy(message.additional_kwargs["tool_calls"])
|
||||
except KeyError:
|
||||
return []
|
||||
tool_calls = parse_tool_calls(
|
||||
raw_tool_calls,
|
||||
partial=partial,
|
||||
strict=self.strict,
|
||||
return_id=self.return_id,
|
||||
)
|
||||
return []
|
||||
|
||||
# for backwards compatibility
|
||||
for tc in tool_calls:
|
||||
tc["type"] = tc.pop("name")
|
||||
|
||||
if self.first_tool_only:
|
||||
return tool_calls[0] if tool_calls else None
|
||||
return tool_calls
|
||||
@@ -220,7 +237,9 @@ class JsonOutputKeyToolsParser(JsonOutputToolsParser):
|
||||
key_name: str
|
||||
"""The type of tools to return."""
|
||||
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessageV1], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a list of tool calls.
|
||||
|
||||
Args:
|
||||
@@ -234,32 +253,47 @@ class JsonOutputKeyToolsParser(JsonOutputToolsParser):
|
||||
Returns:
|
||||
The parsed tool calls.
|
||||
"""
|
||||
generation = result[0]
|
||||
if not isinstance(generation, ChatGeneration):
|
||||
msg = "This output parser can only be used with a chat generation."
|
||||
raise OutputParserException(msg)
|
||||
message = generation.message
|
||||
if isinstance(message, AIMessage) and message.tool_calls:
|
||||
parsed_tool_calls = [dict(tc) for tc in message.tool_calls]
|
||||
if isinstance(result, list):
|
||||
generation = result[0]
|
||||
if not isinstance(generation, ChatGeneration):
|
||||
msg = "This output parser can only be used with a chat generation."
|
||||
raise OutputParserException(msg)
|
||||
message = generation.message
|
||||
if isinstance(message, AIMessage) and message.tool_calls:
|
||||
parsed_tool_calls = [dict(tc) for tc in message.tool_calls]
|
||||
for tool_call in parsed_tool_calls:
|
||||
if not self.return_id:
|
||||
_ = tool_call.pop("id")
|
||||
else:
|
||||
try:
|
||||
raw_tool_calls = copy.deepcopy(
|
||||
message.additional_kwargs["tool_calls"]
|
||||
)
|
||||
except KeyError:
|
||||
if self.first_tool_only:
|
||||
return None
|
||||
return []
|
||||
parsed_tool_calls = parse_tool_calls(
|
||||
raw_tool_calls,
|
||||
partial=partial,
|
||||
strict=self.strict,
|
||||
return_id=self.return_id,
|
||||
)
|
||||
elif result.tool_calls:
|
||||
# v1 message
|
||||
parsed_tool_calls = [dict(tc) for tc in result.tool_calls]
|
||||
for tool_call in parsed_tool_calls:
|
||||
if not self.return_id:
|
||||
_ = tool_call.pop("id")
|
||||
else:
|
||||
try:
|
||||
raw_tool_calls = copy.deepcopy(message.additional_kwargs["tool_calls"])
|
||||
except KeyError:
|
||||
if self.first_tool_only:
|
||||
return None
|
||||
return []
|
||||
parsed_tool_calls = parse_tool_calls(
|
||||
raw_tool_calls,
|
||||
partial=partial,
|
||||
strict=self.strict,
|
||||
return_id=self.return_id,
|
||||
)
|
||||
if self.first_tool_only:
|
||||
return None
|
||||
return []
|
||||
|
||||
# For backwards compatibility
|
||||
for tc in parsed_tool_calls:
|
||||
tc["type"] = tc.pop("name")
|
||||
|
||||
if self.first_tool_only:
|
||||
parsed_result = list(
|
||||
filter(lambda x: x["type"] == self.key_name, parsed_tool_calls)
|
||||
@@ -299,7 +333,9 @@ class PydanticToolsParser(JsonOutputToolsParser):
|
||||
|
||||
# TODO: Support more granular streaming of objects. Currently only streams once all
|
||||
# Pydantic object fields are present.
|
||||
def parse_result(self, result: list[Generation], *, partial: bool = False) -> Any:
|
||||
def parse_result(
|
||||
self, result: Union[list[Generation], AIMessageV1], *, partial: bool = False
|
||||
) -> Any:
|
||||
"""Parse the result of an LLM call to a list of Pydantic objects.
|
||||
|
||||
Args:
|
||||
@@ -337,12 +373,19 @@ class PydanticToolsParser(JsonOutputToolsParser):
|
||||
except (ValidationError, ValueError):
|
||||
if partial:
|
||||
continue
|
||||
has_max_tokens_stop_reason = any(
|
||||
generation.message.response_metadata.get("stop_reason")
|
||||
== "max_tokens"
|
||||
for generation in result
|
||||
if isinstance(generation, ChatGeneration)
|
||||
)
|
||||
has_max_tokens_stop_reason = False
|
||||
if isinstance(result, list):
|
||||
has_max_tokens_stop_reason = any(
|
||||
generation.message.response_metadata.get("stop_reason")
|
||||
== "max_tokens"
|
||||
for generation in result
|
||||
if isinstance(generation, ChatGeneration)
|
||||
)
|
||||
else:
|
||||
# v1 message
|
||||
has_max_tokens_stop_reason = (
|
||||
result.response_metadata.get("stop_reason") == "max_tokens"
|
||||
)
|
||||
if has_max_tokens_stop_reason:
|
||||
logger.exception(_MAX_TOKENS_ERROR)
|
||||
raise
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
"""Output parsers using Pydantic."""
|
||||
|
||||
import json
|
||||
from typing import Annotated, Generic, Optional
|
||||
from typing import Annotated, Generic, Optional, Union
|
||||
|
||||
import pydantic
|
||||
from pydantic import SkipValidation
|
||||
@@ -14,6 +14,7 @@ from langchain_core.utils.pydantic import (
|
||||
PydanticBaseModel,
|
||||
TBaseModel,
|
||||
)
|
||||
from langchain_core.v1.messages import AIMessage
|
||||
|
||||
|
||||
class PydanticOutputParser(JsonOutputParser, Generic[TBaseModel]):
|
||||
@@ -43,7 +44,7 @@ class PydanticOutputParser(JsonOutputParser, Generic[TBaseModel]):
|
||||
return OutputParserException(msg, llm_output=json_string)
|
||||
|
||||
def parse_result(
|
||||
self, result: list[Generation], *, partial: bool = False
|
||||
self, result: Union[list[Generation], AIMessage], *, partial: bool = False
|
||||
) -> Optional[TBaseModel]:
|
||||
"""Parse the result of an LLM call to a pydantic object.
|
||||
|
||||
|
||||
@@ -20,6 +20,7 @@ from langchain_core.outputs import (
|
||||
GenerationChunk,
|
||||
)
|
||||
from langchain_core.runnables.config import run_in_executor
|
||||
from langchain_core.v1.messages import AIMessage, AIMessageChunk
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import AsyncIterator, Iterator
|
||||
@@ -32,23 +33,27 @@ class BaseTransformOutputParser(BaseOutputParser[T]):
|
||||
|
||||
def _transform(
|
||||
self,
|
||||
input: Iterator[Union[str, BaseMessage]],
|
||||
input: Iterator[Union[str, BaseMessage, AIMessage]],
|
||||
) -> Iterator[T]:
|
||||
for chunk in input:
|
||||
if isinstance(chunk, BaseMessage):
|
||||
yield self.parse_result([ChatGeneration(message=chunk)])
|
||||
elif isinstance(chunk, AIMessage):
|
||||
yield self.parse_result(chunk)
|
||||
else:
|
||||
yield self.parse_result([Generation(text=chunk)])
|
||||
|
||||
async def _atransform(
|
||||
self,
|
||||
input: AsyncIterator[Union[str, BaseMessage]],
|
||||
input: AsyncIterator[Union[str, BaseMessage, AIMessage]],
|
||||
) -> AsyncIterator[T]:
|
||||
async for chunk in input:
|
||||
if isinstance(chunk, BaseMessage):
|
||||
yield await run_in_executor(
|
||||
None, self.parse_result, [ChatGeneration(message=chunk)]
|
||||
)
|
||||
elif isinstance(chunk, AIMessage):
|
||||
yield await run_in_executor(None, self.parse_result, chunk)
|
||||
else:
|
||||
yield await run_in_executor(
|
||||
None, self.parse_result, [Generation(text=chunk)]
|
||||
@@ -57,7 +62,7 @@ class BaseTransformOutputParser(BaseOutputParser[T]):
|
||||
@override
|
||||
def transform(
|
||||
self,
|
||||
input: Iterator[Union[str, BaseMessage]],
|
||||
input: Iterator[Union[str, BaseMessage, AIMessage]],
|
||||
config: Optional[RunnableConfig] = None,
|
||||
**kwargs: Any,
|
||||
) -> Iterator[T]:
|
||||
@@ -78,7 +83,7 @@ class BaseTransformOutputParser(BaseOutputParser[T]):
|
||||
@override
|
||||
async def atransform(
|
||||
self,
|
||||
input: AsyncIterator[Union[str, BaseMessage]],
|
||||
input: AsyncIterator[Union[str, BaseMessage, AIMessage]],
|
||||
config: Optional[RunnableConfig] = None,
|
||||
**kwargs: Any,
|
||||
) -> AsyncIterator[T]:
|
||||
@@ -125,23 +130,42 @@ class BaseCumulativeTransformOutputParser(BaseTransformOutputParser[T]):
|
||||
raise NotImplementedError
|
||||
|
||||
@override
|
||||
def _transform(self, input: Iterator[Union[str, BaseMessage]]) -> Iterator[Any]:
|
||||
def _transform(
|
||||
self, input: Iterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> Iterator[Any]:
|
||||
prev_parsed = None
|
||||
acc_gen: Union[GenerationChunk, ChatGenerationChunk, None] = None
|
||||
acc_gen: Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk, None] = (
|
||||
None
|
||||
)
|
||||
for chunk in input:
|
||||
chunk_gen: Union[GenerationChunk, ChatGenerationChunk]
|
||||
chunk_gen: Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
if isinstance(chunk, BaseMessageChunk):
|
||||
chunk_gen = ChatGenerationChunk(message=chunk)
|
||||
elif isinstance(chunk, BaseMessage):
|
||||
chunk_gen = ChatGenerationChunk(
|
||||
message=BaseMessageChunk(**chunk.model_dump())
|
||||
)
|
||||
elif isinstance(chunk, AIMessageChunk):
|
||||
chunk_gen = chunk
|
||||
elif isinstance(chunk, AIMessage):
|
||||
chunk_gen = AIMessageChunk(
|
||||
content=chunk.content,
|
||||
id=chunk.id,
|
||||
name=chunk.name,
|
||||
lc_version=chunk.lc_version,
|
||||
response_metadata=chunk.response_metadata,
|
||||
usage_metadata=chunk.usage_metadata,
|
||||
parsed=chunk.parsed,
|
||||
)
|
||||
else:
|
||||
chunk_gen = GenerationChunk(text=chunk)
|
||||
|
||||
acc_gen = chunk_gen if acc_gen is None else acc_gen + chunk_gen # type: ignore[operator]
|
||||
|
||||
parsed = self.parse_result([acc_gen], partial=True)
|
||||
if isinstance(acc_gen, AIMessageChunk):
|
||||
parsed = self.parse_result(acc_gen, partial=True)
|
||||
else:
|
||||
parsed = self.parse_result([acc_gen], partial=True)
|
||||
if parsed is not None and parsed != prev_parsed:
|
||||
if self.diff:
|
||||
yield self._diff(prev_parsed, parsed)
|
||||
@@ -151,24 +175,41 @@ class BaseCumulativeTransformOutputParser(BaseTransformOutputParser[T]):
|
||||
|
||||
@override
|
||||
async def _atransform(
|
||||
self, input: AsyncIterator[Union[str, BaseMessage]]
|
||||
self, input: AsyncIterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> AsyncIterator[T]:
|
||||
prev_parsed = None
|
||||
acc_gen: Union[GenerationChunk, ChatGenerationChunk, None] = None
|
||||
acc_gen: Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk, None] = (
|
||||
None
|
||||
)
|
||||
async for chunk in input:
|
||||
chunk_gen: Union[GenerationChunk, ChatGenerationChunk]
|
||||
chunk_gen: Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
if isinstance(chunk, BaseMessageChunk):
|
||||
chunk_gen = ChatGenerationChunk(message=chunk)
|
||||
elif isinstance(chunk, BaseMessage):
|
||||
chunk_gen = ChatGenerationChunk(
|
||||
message=BaseMessageChunk(**chunk.model_dump())
|
||||
)
|
||||
elif isinstance(chunk, AIMessageChunk):
|
||||
chunk_gen = chunk
|
||||
elif isinstance(chunk, AIMessage):
|
||||
chunk_gen = AIMessageChunk(
|
||||
content=chunk.content,
|
||||
id=chunk.id,
|
||||
name=chunk.name,
|
||||
lc_version=chunk.lc_version,
|
||||
response_metadata=chunk.response_metadata,
|
||||
usage_metadata=chunk.usage_metadata,
|
||||
parsed=chunk.parsed,
|
||||
)
|
||||
else:
|
||||
chunk_gen = GenerationChunk(text=chunk)
|
||||
|
||||
acc_gen = chunk_gen if acc_gen is None else acc_gen + chunk_gen # type: ignore[operator]
|
||||
|
||||
parsed = await self.aparse_result([acc_gen], partial=True)
|
||||
if isinstance(acc_gen, AIMessageChunk):
|
||||
parsed = await self.aparse_result(acc_gen, partial=True)
|
||||
else:
|
||||
parsed = await self.aparse_result([acc_gen], partial=True)
|
||||
if parsed is not None and parsed != prev_parsed:
|
||||
if self.diff:
|
||||
yield await run_in_executor(None, self._diff, prev_parsed, parsed)
|
||||
|
||||
@@ -12,8 +12,10 @@ from typing_extensions import override
|
||||
|
||||
from langchain_core.exceptions import OutputParserException
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.messages.utils import convert_from_v1_message
|
||||
from langchain_core.output_parsers.transform import BaseTransformOutputParser
|
||||
from langchain_core.runnables.utils import AddableDict
|
||||
from langchain_core.v1.messages import AIMessage
|
||||
|
||||
XML_FORMAT_INSTRUCTIONS = """The output should be formatted as a XML file.
|
||||
1. Output should conform to the tags below.
|
||||
@@ -105,24 +107,27 @@ class _StreamingParser:
|
||||
self.buffer = ""
|
||||
# yield all events
|
||||
try:
|
||||
events = self.pull_parser.read_events()
|
||||
for event, elem in events: # type: ignore[misc]
|
||||
if event == "start":
|
||||
# update current path
|
||||
self.current_path.append(elem.tag) # type: ignore[union-attr]
|
||||
self.current_path_has_children = False
|
||||
elif event == "end":
|
||||
# remove last element from current path
|
||||
#
|
||||
self.current_path.pop()
|
||||
# yield element
|
||||
if not self.current_path_has_children:
|
||||
yield nested_element(self.current_path, elem) # type: ignore[arg-type]
|
||||
# prevent yielding of parent element
|
||||
if self.current_path:
|
||||
self.current_path_has_children = True
|
||||
else:
|
||||
self.xml_started = False
|
||||
for raw_event in self.pull_parser.read_events():
|
||||
if len(raw_event) <= 1:
|
||||
continue
|
||||
event, elem = raw_event
|
||||
if isinstance(elem, ET.Element):
|
||||
if event == "start":
|
||||
# update current path
|
||||
self.current_path.append(elem.tag)
|
||||
self.current_path_has_children = False
|
||||
elif event == "end":
|
||||
# remove last element from current path
|
||||
#
|
||||
self.current_path.pop()
|
||||
# yield element
|
||||
if not self.current_path_has_children:
|
||||
yield nested_element(self.current_path, elem)
|
||||
# prevent yielding of parent element
|
||||
if self.current_path:
|
||||
self.current_path_has_children = True
|
||||
else:
|
||||
self.xml_started = False
|
||||
except xml.etree.ElementTree.ParseError:
|
||||
# This might be junk at the end of the XML input.
|
||||
# Let's check whether the current path is empty.
|
||||
@@ -241,21 +246,28 @@ class XMLOutputParser(BaseTransformOutputParser):
|
||||
|
||||
@override
|
||||
def _transform(
|
||||
self, input: Iterator[Union[str, BaseMessage]]
|
||||
self, input: Iterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> Iterator[AddableDict]:
|
||||
streaming_parser = _StreamingParser(self.parser)
|
||||
for chunk in input:
|
||||
yield from streaming_parser.parse(chunk)
|
||||
if isinstance(chunk, AIMessage):
|
||||
yield from streaming_parser.parse(convert_from_v1_message(chunk))
|
||||
else:
|
||||
yield from streaming_parser.parse(chunk)
|
||||
streaming_parser.close()
|
||||
|
||||
@override
|
||||
async def _atransform(
|
||||
self, input: AsyncIterator[Union[str, BaseMessage]]
|
||||
self, input: AsyncIterator[Union[str, BaseMessage, AIMessage]]
|
||||
) -> AsyncIterator[AddableDict]:
|
||||
streaming_parser = _StreamingParser(self.parser)
|
||||
async for chunk in input:
|
||||
for output in streaming_parser.parse(chunk):
|
||||
yield output
|
||||
if isinstance(chunk, AIMessage):
|
||||
for output in streaming_parser.parse(convert_from_v1_message(chunk)):
|
||||
yield output
|
||||
else:
|
||||
for output in streaming_parser.parse(chunk):
|
||||
yield output
|
||||
streaming_parser.close()
|
||||
|
||||
def _root_to_dict(self, root: ET.Element) -> dict[str, Union[str, list[Any]]]:
|
||||
|
||||
@@ -8,17 +8,65 @@ from __future__ import annotations
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from collections.abc import Sequence
|
||||
from typing import Literal, cast
|
||||
from typing import Literal, Union, cast
|
||||
|
||||
from typing_extensions import TypedDict
|
||||
from typing_extensions import TypedDict, overload
|
||||
|
||||
from langchain_core.load.serializable import Serializable
|
||||
from langchain_core.messages import (
|
||||
AIMessage,
|
||||
AnyMessage,
|
||||
BaseMessage,
|
||||
HumanMessage,
|
||||
SystemMessage,
|
||||
ToolMessage,
|
||||
get_buffer_string,
|
||||
)
|
||||
from langchain_core.messages import content_blocks as types
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
from langchain_core.v1.messages import HumanMessage as HumanMessageV1
|
||||
from langchain_core.v1.messages import MessageV1, ResponseMetadata
|
||||
from langchain_core.v1.messages import SystemMessage as SystemMessageV1
|
||||
from langchain_core.v1.messages import ToolMessage as ToolMessageV1
|
||||
|
||||
|
||||
def _convert_to_v1(message: BaseMessage) -> MessageV1:
|
||||
"""Best-effort conversion of a V0 AIMessage to V1."""
|
||||
if isinstance(message.content, str):
|
||||
content: list[types.ContentBlock] = []
|
||||
if message.content:
|
||||
content = [{"type": "text", "text": message.content}]
|
||||
else:
|
||||
content = []
|
||||
for block in message.content:
|
||||
if isinstance(block, str):
|
||||
content.append({"type": "text", "text": block})
|
||||
elif isinstance(block, dict):
|
||||
content.append(cast("types.ContentBlock", block))
|
||||
else:
|
||||
pass
|
||||
|
||||
if isinstance(message, HumanMessage):
|
||||
return HumanMessageV1(content=content)
|
||||
if isinstance(message, AIMessage):
|
||||
for tool_call in message.tool_calls:
|
||||
content.append(tool_call)
|
||||
return AIMessageV1(
|
||||
content=content,
|
||||
usage_metadata=message.usage_metadata,
|
||||
response_metadata=cast("ResponseMetadata", message.response_metadata),
|
||||
tool_calls=message.tool_calls,
|
||||
)
|
||||
if isinstance(message, SystemMessage):
|
||||
return SystemMessageV1(content=content)
|
||||
if isinstance(message, ToolMessage):
|
||||
return ToolMessageV1(
|
||||
tool_call_id=message.tool_call_id,
|
||||
content=content,
|
||||
artifact=message.artifact,
|
||||
)
|
||||
error_message = f"Unsupported message type: {type(message)}"
|
||||
raise TypeError(error_message)
|
||||
|
||||
|
||||
class PromptValue(Serializable, ABC):
|
||||
@@ -46,8 +94,18 @@ class PromptValue(Serializable, ABC):
|
||||
def to_string(self) -> str:
|
||||
"""Return prompt value as string."""
|
||||
|
||||
@overload
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0"] = "v0"
|
||||
) -> list[BaseMessage]: ...
|
||||
|
||||
@overload
|
||||
def to_messages(self, message_version: Literal["v1"]) -> list[MessageV1]: ...
|
||||
|
||||
@abstractmethod
|
||||
def to_messages(self) -> list[BaseMessage]:
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0", "v1"] = "v0"
|
||||
) -> Union[Sequence[BaseMessage], Sequence[MessageV1]]:
|
||||
"""Return prompt as a list of Messages."""
|
||||
|
||||
|
||||
@@ -71,8 +129,20 @@ class StringPromptValue(PromptValue):
|
||||
"""Return prompt as string."""
|
||||
return self.text
|
||||
|
||||
def to_messages(self) -> list[BaseMessage]:
|
||||
@overload
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0"] = "v0"
|
||||
) -> list[BaseMessage]: ...
|
||||
|
||||
@overload
|
||||
def to_messages(self, message_version: Literal["v1"]) -> list[MessageV1]: ...
|
||||
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0", "v1"] = "v0"
|
||||
) -> Union[Sequence[BaseMessage], Sequence[MessageV1]]:
|
||||
"""Return prompt as messages."""
|
||||
if message_version == "v1":
|
||||
return [HumanMessageV1(content=self.text)]
|
||||
return [HumanMessage(content=self.text)]
|
||||
|
||||
|
||||
@@ -89,8 +159,24 @@ class ChatPromptValue(PromptValue):
|
||||
"""Return prompt as string."""
|
||||
return get_buffer_string(self.messages)
|
||||
|
||||
def to_messages(self) -> list[BaseMessage]:
|
||||
"""Return prompt as a list of messages."""
|
||||
@overload
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0"] = "v0"
|
||||
) -> list[BaseMessage]: ...
|
||||
|
||||
@overload
|
||||
def to_messages(self, message_version: Literal["v1"]) -> list[MessageV1]: ...
|
||||
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0", "v1"] = "v0"
|
||||
) -> Union[Sequence[BaseMessage], Sequence[MessageV1]]:
|
||||
"""Return prompt as a list of messages.
|
||||
|
||||
Args:
|
||||
message_version: The output version, either "v0" (default) or "v1".
|
||||
"""
|
||||
if message_version == "v1":
|
||||
return [_convert_to_v1(m) for m in self.messages]
|
||||
return list(self.messages)
|
||||
|
||||
@classmethod
|
||||
@@ -125,8 +211,26 @@ class ImagePromptValue(PromptValue):
|
||||
"""Return prompt (image URL) as string."""
|
||||
return self.image_url["url"]
|
||||
|
||||
def to_messages(self) -> list[BaseMessage]:
|
||||
@overload
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0"] = "v0"
|
||||
) -> list[BaseMessage]: ...
|
||||
|
||||
@overload
|
||||
def to_messages(self, message_version: Literal["v1"]) -> list[MessageV1]: ...
|
||||
|
||||
def to_messages(
|
||||
self, message_version: Literal["v0", "v1"] = "v0"
|
||||
) -> Union[Sequence[BaseMessage], Sequence[MessageV1]]:
|
||||
"""Return prompt (image URL) as messages."""
|
||||
if message_version == "v1":
|
||||
block: types.ImageContentBlock = {
|
||||
"type": "image",
|
||||
"url": self.image_url["url"],
|
||||
}
|
||||
if "detail" in self.image_url:
|
||||
block["detail"] = self.image_url["detail"]
|
||||
return [HumanMessageV1(content=[block])]
|
||||
return [HumanMessage(content=[cast("dict", self.image_url)])]
|
||||
|
||||
|
||||
|
||||
@@ -2383,6 +2383,7 @@ class Runnable(ABC, Generic[Input, Output]):
|
||||
name: Optional[str] = None,
|
||||
description: Optional[str] = None,
|
||||
arg_types: Optional[dict[str, type]] = None,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> BaseTool:
|
||||
"""Create a ``BaseTool`` from a ``Runnable``.
|
||||
|
||||
@@ -2401,6 +2402,9 @@ class Runnable(ABC, Generic[Input, Output]):
|
||||
message_version: Version of ``ToolMessage`` to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``'v0'``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``'v1'``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
Returns:
|
||||
A ``BaseTool`` instance.
|
||||
|
||||
@@ -2475,7 +2479,7 @@ class Runnable(ABC, Generic[Input, Output]):
|
||||
|
||||
.. versionadded:: 0.2.14
|
||||
|
||||
"""
|
||||
""" # noqa: E501
|
||||
# Avoid circular import
|
||||
from langchain_core.tools import convert_runnable_to_tool
|
||||
|
||||
@@ -2485,6 +2489,7 @@ class Runnable(ABC, Generic[Input, Output]):
|
||||
name=name,
|
||||
description=description,
|
||||
arg_types=arg_types,
|
||||
message_version=message_version,
|
||||
)
|
||||
|
||||
|
||||
|
||||
@@ -68,6 +68,7 @@ from langchain_core.utils.pydantic import (
|
||||
is_pydantic_v1_subclass,
|
||||
is_pydantic_v2_subclass,
|
||||
)
|
||||
from langchain_core.v1.messages import ToolMessage as ToolMessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
import uuid
|
||||
@@ -505,6 +506,15 @@ class ChildTool(BaseTool):
|
||||
two-tuple corresponding to the (content, artifact) of a ToolMessage.
|
||||
"""
|
||||
|
||||
message_version: Literal["v0", "v1"] = "v0"
|
||||
"""Version of ToolMessage to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``"v0"``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``"v1"``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self, **kwargs: Any) -> None:
|
||||
"""Initialize the tool."""
|
||||
if (
|
||||
@@ -842,7 +852,7 @@ class ChildTool(BaseTool):
|
||||
|
||||
content = None
|
||||
artifact = None
|
||||
status = "success"
|
||||
status: Literal["success", "error"] = "success"
|
||||
error_to_raise: Union[Exception, KeyboardInterrupt, None] = None
|
||||
try:
|
||||
child_config = patch_config(config, callbacks=run_manager.get_child())
|
||||
@@ -886,7 +896,14 @@ class ChildTool(BaseTool):
|
||||
if error_to_raise:
|
||||
run_manager.on_tool_error(error_to_raise)
|
||||
raise error_to_raise
|
||||
output = _format_output(content, artifact, tool_call_id, self.name, status)
|
||||
output = _format_output(
|
||||
content,
|
||||
artifact,
|
||||
tool_call_id,
|
||||
self.name,
|
||||
status,
|
||||
message_version=self.message_version,
|
||||
)
|
||||
run_manager.on_tool_end(output, color=color, name=self.name, **kwargs)
|
||||
return output
|
||||
|
||||
@@ -952,7 +969,7 @@ class ChildTool(BaseTool):
|
||||
)
|
||||
content = None
|
||||
artifact = None
|
||||
status = "success"
|
||||
status: Literal["success", "error"] = "success"
|
||||
error_to_raise: Optional[Union[Exception, KeyboardInterrupt]] = None
|
||||
try:
|
||||
tool_args, tool_kwargs = self._to_args_and_kwargs(tool_input, tool_call_id)
|
||||
@@ -1000,7 +1017,14 @@ class ChildTool(BaseTool):
|
||||
await run_manager.on_tool_error(error_to_raise)
|
||||
raise error_to_raise
|
||||
|
||||
output = _format_output(content, artifact, tool_call_id, self.name, status)
|
||||
output = _format_output(
|
||||
content,
|
||||
artifact,
|
||||
tool_call_id,
|
||||
self.name,
|
||||
status,
|
||||
message_version=self.message_version,
|
||||
)
|
||||
await run_manager.on_tool_end(output, color=color, name=self.name, **kwargs)
|
||||
return output
|
||||
|
||||
@@ -1138,7 +1162,9 @@ def _format_output(
|
||||
artifact: Any,
|
||||
tool_call_id: Optional[str],
|
||||
name: str,
|
||||
status: str,
|
||||
status: Literal["success", "error"],
|
||||
*,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> Union[ToolOutputMixin, Any]:
|
||||
"""Format tool output as a ToolMessage if appropriate.
|
||||
|
||||
@@ -1148,6 +1174,7 @@ def _format_output(
|
||||
tool_call_id: The ID of the tool call.
|
||||
name: The name of the tool.
|
||||
status: The execution status.
|
||||
message_version: The version of the ToolMessage to return.
|
||||
|
||||
Returns:
|
||||
The formatted output, either as a ToolMessage or the original content.
|
||||
@@ -1156,7 +1183,15 @@ def _format_output(
|
||||
return content
|
||||
if not _is_message_content_type(content):
|
||||
content = _stringify(content)
|
||||
return ToolMessage(
|
||||
if message_version == "v0":
|
||||
return ToolMessage(
|
||||
content,
|
||||
artifact=artifact,
|
||||
tool_call_id=tool_call_id,
|
||||
name=name,
|
||||
status=status,
|
||||
)
|
||||
return ToolMessageV1(
|
||||
content,
|
||||
artifact=artifact,
|
||||
tool_call_id=tool_call_id,
|
||||
|
||||
@@ -22,6 +22,7 @@ def tool(
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = True,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> Callable[[Union[Callable, Runnable]], BaseTool]: ...
|
||||
|
||||
|
||||
@@ -37,6 +38,7 @@ def tool(
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = True,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> BaseTool: ...
|
||||
|
||||
|
||||
@@ -51,6 +53,7 @@ def tool(
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = True,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> BaseTool: ...
|
||||
|
||||
|
||||
@@ -65,6 +68,7 @@ def tool(
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = True,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> Callable[[Union[Callable, Runnable]], BaseTool]: ...
|
||||
|
||||
|
||||
@@ -79,6 +83,7 @@ def tool(
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = True,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> Union[
|
||||
BaseTool,
|
||||
Callable[[Union[Callable, Runnable]], BaseTool],
|
||||
@@ -118,6 +123,11 @@ def tool(
|
||||
error_on_invalid_docstring: if ``parse_docstring`` is provided, configure
|
||||
whether to raise ValueError on invalid Google Style docstrings.
|
||||
Defaults to True.
|
||||
message_version: Version of ToolMessage to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``"v0"``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``"v1"``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
Returns:
|
||||
The tool.
|
||||
@@ -216,7 +226,7 @@ def tool(
|
||||
\"\"\"
|
||||
return bar
|
||||
|
||||
""" # noqa: D214, D410, D411
|
||||
""" # noqa: D214, D410, D411, E501
|
||||
|
||||
def _create_tool_factory(
|
||||
tool_name: str,
|
||||
@@ -274,6 +284,7 @@ def tool(
|
||||
response_format=response_format,
|
||||
parse_docstring=parse_docstring,
|
||||
error_on_invalid_docstring=error_on_invalid_docstring,
|
||||
message_version=message_version,
|
||||
)
|
||||
# If someone doesn't want a schema applied, we must treat it as
|
||||
# a simple string->string function
|
||||
@@ -290,6 +301,7 @@ def tool(
|
||||
return_direct=return_direct,
|
||||
coroutine=coroutine,
|
||||
response_format=response_format,
|
||||
message_version=message_version,
|
||||
)
|
||||
|
||||
return _tool_factory
|
||||
@@ -383,6 +395,7 @@ def convert_runnable_to_tool(
|
||||
name: Optional[str] = None,
|
||||
description: Optional[str] = None,
|
||||
arg_types: Optional[dict[str, type]] = None,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
) -> BaseTool:
|
||||
"""Convert a Runnable into a BaseTool.
|
||||
|
||||
@@ -392,10 +405,15 @@ def convert_runnable_to_tool(
|
||||
name: The name of the tool. Defaults to None.
|
||||
description: The description of the tool. Defaults to None.
|
||||
arg_types: The types of the arguments. Defaults to None.
|
||||
message_version: Version of ToolMessage to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``"v0"``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``"v1"``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
Returns:
|
||||
The tool.
|
||||
"""
|
||||
""" # noqa: E501
|
||||
if args_schema:
|
||||
runnable = runnable.with_types(input_type=args_schema)
|
||||
description = description or _get_description_from_runnable(runnable)
|
||||
@@ -408,6 +426,7 @@ def convert_runnable_to_tool(
|
||||
func=runnable.invoke,
|
||||
coroutine=runnable.ainvoke,
|
||||
description=description,
|
||||
message_version=message_version,
|
||||
)
|
||||
|
||||
async def ainvoke_wrapper(
|
||||
@@ -435,4 +454,5 @@ def convert_runnable_to_tool(
|
||||
coroutine=ainvoke_wrapper,
|
||||
description=description,
|
||||
args_schema=args_schema,
|
||||
message_version=message_version,
|
||||
)
|
||||
|
||||
@@ -72,6 +72,7 @@ def create_retriever_tool(
|
||||
document_prompt: Optional[BasePromptTemplate] = None,
|
||||
document_separator: str = "\n\n",
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
message_version: Literal["v0", "v1"] = "v1",
|
||||
) -> Tool:
|
||||
r"""Create a tool to do retrieval of documents.
|
||||
|
||||
@@ -88,10 +89,15 @@ def create_retriever_tool(
|
||||
"content_and_artifact" then the output is expected to be a two-tuple
|
||||
corresponding to the (content, artifact) of a ToolMessage (artifact
|
||||
being a list of documents in this case). Defaults to "content".
|
||||
message_version: Version of ToolMessage to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``"v0"``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``"v1"``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
Returns:
|
||||
Tool class to pass to an agent.
|
||||
"""
|
||||
""" # noqa: E501
|
||||
document_prompt = document_prompt or PromptTemplate.from_template("{page_content}")
|
||||
func = partial(
|
||||
_get_relevant_documents,
|
||||
@@ -114,4 +120,5 @@ def create_retriever_tool(
|
||||
coroutine=afunc,
|
||||
args_schema=RetrieverInput,
|
||||
response_format=response_format,
|
||||
message_version=message_version,
|
||||
)
|
||||
|
||||
@@ -129,6 +129,7 @@ class StructuredTool(BaseTool):
|
||||
response_format: Literal["content", "content_and_artifact"] = "content",
|
||||
parse_docstring: bool = False,
|
||||
error_on_invalid_docstring: bool = False,
|
||||
message_version: Literal["v0", "v1"] = "v0",
|
||||
**kwargs: Any,
|
||||
) -> StructuredTool:
|
||||
"""Create tool from a given function.
|
||||
@@ -157,6 +158,12 @@ class StructuredTool(BaseTool):
|
||||
error_on_invalid_docstring: if ``parse_docstring`` is provided, configure
|
||||
whether to raise ValueError on invalid Google Style docstrings.
|
||||
Defaults to False.
|
||||
message_version: Version of ToolMessage to return given
|
||||
:class:`~langchain_core.messages.content_blocks.ToolCall` input.
|
||||
|
||||
If ``"v0"``, output will be a v0 :class:`~langchain_core.messages.tool.ToolMessage`.
|
||||
If ``"v1"``, output will be a v1 :class:`~langchain_core.v1.messages.ToolMessage`.
|
||||
|
||||
kwargs: Additional arguments to pass to the tool
|
||||
|
||||
Returns:
|
||||
@@ -175,7 +182,7 @@ class StructuredTool(BaseTool):
|
||||
tool = StructuredTool.from_function(add)
|
||||
tool.run(1, 2) # 3
|
||||
|
||||
"""
|
||||
""" # noqa: E501
|
||||
if func is not None:
|
||||
source_function = func
|
||||
elif coroutine is not None:
|
||||
@@ -232,6 +239,7 @@ class StructuredTool(BaseTool):
|
||||
description=description_,
|
||||
return_direct=return_direct,
|
||||
response_format=response_format,
|
||||
message_version=message_version,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
@@ -17,6 +17,7 @@ from typing_extensions import override
|
||||
from langchain_core.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler
|
||||
from langchain_core.exceptions import TracerException # noqa: F401
|
||||
from langchain_core.tracers.core import _TracerCore
|
||||
from langchain_core.v1.messages import AIMessage, AIMessageChunk, MessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import Sequence
|
||||
@@ -54,7 +55,7 @@ class BaseTracer(_TracerCore, BaseCallbackHandler, ABC):
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
tags: Optional[list[str]] = None,
|
||||
@@ -138,7 +139,9 @@ class BaseTracer(_TracerCore, BaseCallbackHandler, ABC):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
@@ -190,7 +193,9 @@ class BaseTracer(_TracerCore, BaseCallbackHandler, ABC):
|
||||
)
|
||||
|
||||
@override
|
||||
def on_llm_end(self, response: LLMResult, *, run_id: UUID, **kwargs: Any) -> Run:
|
||||
def on_llm_end(
|
||||
self, response: Union[LLMResult, AIMessage], *, run_id: UUID, **kwargs: Any
|
||||
) -> Run:
|
||||
"""End a trace for an LLM run.
|
||||
|
||||
Args:
|
||||
@@ -562,7 +567,7 @@ class AsyncBaseTracer(_TracerCore, AsyncCallbackHandler, ABC):
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -617,7 +622,9 @@ class AsyncBaseTracer(_TracerCore, AsyncCallbackHandler, ABC):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
@@ -646,7 +653,7 @@ class AsyncBaseTracer(_TracerCore, AsyncCallbackHandler, ABC):
|
||||
@override
|
||||
async def on_llm_end(
|
||||
self,
|
||||
response: LLMResult,
|
||||
response: Union[LLMResult, AIMessage],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -882,7 +889,7 @@ class AsyncBaseTracer(_TracerCore, AsyncCallbackHandler, ABC):
|
||||
self,
|
||||
run: Run,
|
||||
token: str,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]],
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]],
|
||||
) -> None:
|
||||
"""Process new LLM token."""
|
||||
|
||||
|
||||
@@ -18,6 +18,7 @@ from typing import (
|
||||
|
||||
from langchain_core.exceptions import TracerException
|
||||
from langchain_core.load import dumpd
|
||||
from langchain_core.messages.utils import convert_from_v1_message
|
||||
from langchain_core.outputs import (
|
||||
ChatGeneration,
|
||||
ChatGenerationChunk,
|
||||
@@ -25,6 +26,12 @@ from langchain_core.outputs import (
|
||||
LLMResult,
|
||||
)
|
||||
from langchain_core.tracers.schemas import Run
|
||||
from langchain_core.v1.messages import (
|
||||
AIMessage,
|
||||
AIMessageChunk,
|
||||
MessageV1,
|
||||
MessageV1Types,
|
||||
)
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import Coroutine, Sequence
|
||||
@@ -156,7 +163,7 @@ class _TracerCore(ABC):
|
||||
def _create_chat_model_run(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
run_id: UUID,
|
||||
tags: Optional[list[str]] = None,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -181,6 +188,12 @@ class _TracerCore(ABC):
|
||||
start_time = datetime.now(timezone.utc)
|
||||
if metadata:
|
||||
kwargs.update({"metadata": metadata})
|
||||
if isinstance(messages[0], MessageV1Types):
|
||||
# Convert from v1 messages to BaseMessage
|
||||
messages = [
|
||||
[convert_from_v1_message(msg) for msg in messages] # type: ignore[arg-type]
|
||||
]
|
||||
messages = cast("list[list[BaseMessage]]", messages)
|
||||
return Run(
|
||||
id=run_id,
|
||||
parent_run_id=parent_run_id,
|
||||
@@ -230,7 +243,9 @@ class _TracerCore(ABC):
|
||||
self,
|
||||
token: str,
|
||||
run_id: UUID,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
parent_run_id: Optional[UUID] = None, # noqa: ARG002
|
||||
) -> Run:
|
||||
"""Append token event to LLM run and return the run."""
|
||||
@@ -276,7 +291,15 @@ class _TracerCore(ABC):
|
||||
)
|
||||
return llm_run
|
||||
|
||||
def _complete_llm_run(self, response: LLMResult, run_id: UUID) -> Run:
|
||||
def _complete_llm_run(
|
||||
self, response: Union[LLMResult, AIMessage], run_id: UUID
|
||||
) -> Run:
|
||||
if isinstance(response, AIMessage):
|
||||
response = LLMResult(
|
||||
generations=[
|
||||
[ChatGeneration(message=convert_from_v1_message(response))]
|
||||
]
|
||||
)
|
||||
llm_run = self._get_run(run_id, run_type={"llm", "chat_model"})
|
||||
if getattr(llm_run, "outputs", None) is None:
|
||||
llm_run.outputs = {}
|
||||
@@ -558,7 +581,7 @@ class _TracerCore(ABC):
|
||||
self,
|
||||
run: Run, # noqa: ARG002
|
||||
token: str, # noqa: ARG002
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]], # noqa: ARG002
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]], # noqa: ARG002
|
||||
) -> Union[None, Coroutine[Any, Any, None]]:
|
||||
"""Process new LLM token."""
|
||||
return None
|
||||
|
||||
@@ -38,6 +38,7 @@ from langchain_core.runnables.utils import (
|
||||
from langchain_core.tracers._streaming import _StreamingCallbackHandler
|
||||
from langchain_core.tracers.memory_stream import _MemoryStream
|
||||
from langchain_core.utils.aiter import aclosing, py_anext
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from collections.abc import AsyncIterator, Iterator, Sequence
|
||||
@@ -45,6 +46,8 @@ if TYPE_CHECKING:
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.runnables import Runnable, RunnableConfig
|
||||
from langchain_core.tracers.log_stream import LogEntry
|
||||
from langchain_core.v1.messages import AIMessage as AIMessageV1
|
||||
from langchain_core.v1.messages import AIMessageChunk as AIMessageChunkV1
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -297,7 +300,7 @@ class _AstreamEventsCallbackHandler(AsyncCallbackHandler, _StreamingCallbackHand
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
tags: Optional[list[str]] = None,
|
||||
@@ -307,6 +310,8 @@ class _AstreamEventsCallbackHandler(AsyncCallbackHandler, _StreamingCallbackHand
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Start a trace for an LLM run."""
|
||||
# below cast is because type is converted in handle_event
|
||||
messages = cast("list[list[BaseMessage]]", messages)
|
||||
name_ = _assign_name(name, serialized)
|
||||
run_type = "chat_model"
|
||||
|
||||
@@ -407,13 +412,18 @@ class _AstreamEventsCallbackHandler(AsyncCallbackHandler, _StreamingCallbackHand
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunkV1]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Run on new LLM token. Only available when streaming is enabled."""
|
||||
run_info = self.run_map.get(run_id)
|
||||
chunk = cast(
|
||||
"Optional[Union[GenerationChunk, ChatGenerationChunk]]", chunk
|
||||
) # converted in handle_event
|
||||
chunk_: Union[GenerationChunk, BaseMessageChunk]
|
||||
|
||||
if run_info is None:
|
||||
@@ -456,9 +466,10 @@ class _AstreamEventsCallbackHandler(AsyncCallbackHandler, _StreamingCallbackHand
|
||||
|
||||
@override
|
||||
async def on_llm_end(
|
||||
self, response: LLMResult, *, run_id: UUID, **kwargs: Any
|
||||
self, response: Union[LLMResult, AIMessageV1], *, run_id: UUID, **kwargs: Any
|
||||
) -> None:
|
||||
"""End a trace for an LLM run."""
|
||||
response = cast("LLMResult", response) # converted in handle_event
|
||||
run_info = self.run_map.pop(run_id)
|
||||
inputs_ = run_info["inputs"]
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@ from __future__ import annotations
|
||||
import logging
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from datetime import datetime, timezone
|
||||
from typing import TYPE_CHECKING, Any, Optional, Union
|
||||
from typing import TYPE_CHECKING, Any, Optional, Union, cast
|
||||
from uuid import UUID
|
||||
|
||||
from langsmith import Client
|
||||
@@ -21,12 +21,15 @@ from typing_extensions import override
|
||||
|
||||
from langchain_core.env import get_runtime_environment
|
||||
from langchain_core.load import dumpd
|
||||
from langchain_core.messages.utils import convert_from_v1_message
|
||||
from langchain_core.tracers.base import BaseTracer
|
||||
from langchain_core.tracers.schemas import Run
|
||||
from langchain_core.v1.messages import MessageV1Types
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.outputs import ChatGenerationChunk, GenerationChunk
|
||||
from langchain_core.v1.messages import AIMessageChunk, MessageV1
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
_LOGGED = set()
|
||||
@@ -113,7 +116,7 @@ class LangChainTracer(BaseTracer):
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
tags: Optional[list[str]] = None,
|
||||
@@ -140,6 +143,12 @@ class LangChainTracer(BaseTracer):
|
||||
start_time = datetime.now(timezone.utc)
|
||||
if metadata:
|
||||
kwargs.update({"metadata": metadata})
|
||||
if isinstance(messages[0], MessageV1Types):
|
||||
# Convert from v1 messages to BaseMessage
|
||||
messages = [
|
||||
[convert_from_v1_message(msg) for msg in messages] # type: ignore[arg-type]
|
||||
]
|
||||
messages = cast("list[list[BaseMessage]]", messages)
|
||||
chat_model_run = Run(
|
||||
id=run_id,
|
||||
parent_run_id=parent_run_id,
|
||||
@@ -232,7 +241,9 @@ class LangChainTracer(BaseTracer):
|
||||
self,
|
||||
token: str,
|
||||
run_id: UUID,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]
|
||||
] = None,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
) -> Run:
|
||||
"""Append token event to LLM run and return the run."""
|
||||
|
||||
@@ -34,6 +34,7 @@ if TYPE_CHECKING:
|
||||
|
||||
from langchain_core.runnables.utils import Input, Output
|
||||
from langchain_core.tracers.schemas import Run
|
||||
from langchain_core.v1.messages import AIMessageChunk
|
||||
|
||||
|
||||
class LogEntry(TypedDict):
|
||||
@@ -485,7 +486,7 @@ class LogStreamCallbackHandler(BaseTracer, _StreamingCallbackHandler):
|
||||
self,
|
||||
run: Run,
|
||||
token: str,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]],
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk, AIMessageChunk]],
|
||||
) -> None:
|
||||
"""Process new LLM token."""
|
||||
index = self._key_map_by_run_id.get(run.id)
|
||||
|
||||
1
libs/core/langchain_core/v1/__init__.py
Normal file
1
libs/core/langchain_core/v1/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
"""LangChain v1.0.0 types."""
|
||||
1090
libs/core/langchain_core/v1/chat_models.py
Normal file
1090
libs/core/langchain_core/v1/chat_models.py
Normal file
File diff suppressed because it is too large
Load Diff
922
libs/core/langchain_core/v1/messages.py
Normal file
922
libs/core/langchain_core/v1/messages.py
Normal file
@@ -0,0 +1,922 @@
|
||||
"""LangChain v1.0.0 message format.
|
||||
|
||||
Each message has content that may be comprised of content blocks, defined under
|
||||
``langchain_core.messages.content_blocks``.
|
||||
|
||||
"""
|
||||
|
||||
import uuid
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Literal, Optional, Union, cast, get_args
|
||||
|
||||
from pydantic import BaseModel
|
||||
from typing_extensions import TypedDict
|
||||
|
||||
import langchain_core.messages.content_blocks as types
|
||||
from langchain_core._api.deprecation import warn_deprecated
|
||||
from langchain_core.messages.ai import (
|
||||
_LC_AUTO_PREFIX,
|
||||
_LC_ID_PREFIX,
|
||||
UsageMetadata,
|
||||
add_usage,
|
||||
)
|
||||
from langchain_core.messages.base import merge_content
|
||||
from langchain_core.messages.tool import ToolOutputMixin
|
||||
from langchain_core.messages.tool import invalid_tool_call as create_invalid_tool_call
|
||||
from langchain_core.messages.tool import tool_call as create_tool_call
|
||||
from langchain_core.utils._merge import merge_dicts
|
||||
from langchain_core.utils.json import parse_partial_json
|
||||
|
||||
|
||||
class TextAccessor(str):
|
||||
"""String-like object that supports both property and method access patterns.
|
||||
|
||||
Exists to maintain backward compatibility while transitioning from method-based to
|
||||
property-based text access in message objects. In LangChain <v0.4, message text was
|
||||
accessed via ``.text()`` method calls. In v0.4=<, the preferred pattern is property
|
||||
access via ``.text``.
|
||||
|
||||
Rather than breaking existing code immediately, ``TextAccessor`` allows both
|
||||
patterns:
|
||||
- Modern property access: ``message.text`` (returns string directly)
|
||||
- Legacy method access: ``message.text()`` (callable, emits deprecation warning)
|
||||
|
||||
Examples:
|
||||
>>> msg = AIMessage("Hello world")
|
||||
>>> text = msg.text # Preferred: property access
|
||||
>>> text = msg.text() # Deprecated: method access (shows warning)
|
||||
|
||||
"""
|
||||
|
||||
__slots__ = ()
|
||||
|
||||
def __new__(cls, value: str) -> "TextAccessor":
|
||||
"""Create new TextAccessor instance."""
|
||||
return str.__new__(cls, value)
|
||||
|
||||
def __call__(self) -> str:
|
||||
"""Enable method-style text access for backward compatibility.
|
||||
|
||||
.. deprecated:: 0.4.0
|
||||
Calling ``.text()`` as a method is deprecated. Use ``.text`` as a property
|
||||
instead. This method will be removed in 2.0.0.
|
||||
|
||||
Returns:
|
||||
The string content, identical to property access.
|
||||
|
||||
"""
|
||||
warn_deprecated(
|
||||
since="0.4.0",
|
||||
message=(
|
||||
"Calling .text() as a method is deprecated. "
|
||||
"Use .text as a property instead (e.g., message.text)."
|
||||
),
|
||||
removal="2.0.0",
|
||||
)
|
||||
return str(self)
|
||||
|
||||
|
||||
def _ensure_id(id_val: Optional[str]) -> str:
|
||||
"""Ensure the ID is a valid string, generating a new UUID if not provided.
|
||||
|
||||
Auto-generated UUIDs are prefixed by ``'lc_'`` to indicate they are
|
||||
LangChain-generated IDs.
|
||||
|
||||
Args:
|
||||
id_val: Optional string ID value to validate.
|
||||
|
||||
Returns:
|
||||
A valid string ID, either the provided value or a new UUID.
|
||||
|
||||
"""
|
||||
return id_val or str(f"{_LC_AUTO_PREFIX}{uuid.uuid4()}")
|
||||
|
||||
|
||||
class ResponseMetadata(TypedDict, total=False):
|
||||
"""Metadata about the response from the AI provider.
|
||||
|
||||
Contains additional information returned by the provider, such as
|
||||
response headers, service tiers, log probabilities, system fingerprints, etc.
|
||||
|
||||
**Extensibility Design:**
|
||||
|
||||
This uses ``total=False`` to allow arbitrary additional keys beyond the typed
|
||||
fields below. This enables provider-specific metadata without breaking type safety:
|
||||
|
||||
- OpenAI might include: ``{"system_fingerprint": "fp_123", "logprobs": {...}}``
|
||||
- Anthropic might include: ``{"stop_reason": "stop_sequence", "usage": {...}}``
|
||||
- Custom providers can add their own fields
|
||||
|
||||
The common fields (``model_provider``, ``model_name``) provide a baseline
|
||||
contract while preserving flexibility for provider innovations.
|
||||
|
||||
.. note::
|
||||
Not all providers will return the metadata required by this class. In this case,
|
||||
it is acceptable to inject these fields with values at invocation.
|
||||
|
||||
For instance, requests to OpenAI's responses API will not return a provider
|
||||
field in the raw response, as it can be inferred that by making the request, the
|
||||
provider responding is OpenAI. In this case, it is safe to set the
|
||||
``model_provider`` field to ``'openai'`` when creating the message.
|
||||
|
||||
On the other hand, ``model_name`` is often returned, and in such cases it is
|
||||
expected that you populate this field with the unmodified model name (such as
|
||||
``'o1-2024-12-17'``). Only in situations where the provider does not return a
|
||||
model name should you artifically set this field - in which case, the value
|
||||
should be set to the ``model`` or ``model_name`` parameter passed in during
|
||||
invocation.
|
||||
|
||||
"""
|
||||
|
||||
model_provider: str
|
||||
"""Name and version of the provider that created the message (ex: ``'openai'``)."""
|
||||
|
||||
model_name: str
|
||||
"""Name of the model that generated the message."""
|
||||
|
||||
|
||||
@dataclass
|
||||
class AIMessage:
|
||||
"""A v1 message generated by an AI assistant.
|
||||
|
||||
Represents a response from an AI model, including text content, tool calls,
|
||||
and metadata about the generation process.
|
||||
|
||||
Attributes:
|
||||
type: Message type identifier, always ``'ai'``.
|
||||
id: Unique identifier for the message.
|
||||
name: Optional human-readable name for the message.
|
||||
lc_version: Encoding version for the message.
|
||||
content: List of content blocks containing the message data.
|
||||
tool_calls: Optional list of tool calls made by the AI.
|
||||
invalid_tool_calls: Optional list of tool calls that failed validation.
|
||||
usage: Optional dictionary containing usage statistics.
|
||||
|
||||
"""
|
||||
|
||||
type: Literal["ai"] = "ai"
|
||||
"""The type of the message. Must be a string that is unique to the message type.
|
||||
|
||||
The purpose of this field is to allow for easy identification of the message type
|
||||
when deserializing messages.
|
||||
|
||||
"""
|
||||
|
||||
name: Optional[str] = None
|
||||
"""An optional name for the message.
|
||||
|
||||
This can be used to provide a human-readable name for the message.
|
||||
|
||||
Usage of this field is optional, and whether it's used or not is up to the
|
||||
model implementation.
|
||||
|
||||
"""
|
||||
|
||||
id: Optional[str] = None
|
||||
"""Unique identifier for the message.
|
||||
|
||||
If the provider assigns a meaningful ID, it should be used here. Otherwise, a
|
||||
LangChain-generated ID will be used.
|
||||
|
||||
"""
|
||||
|
||||
lc_version: str = "v1"
|
||||
"""Encoding version for the message. Used for serialization."""
|
||||
|
||||
content: list[types.ContentBlock] = field(default_factory=list)
|
||||
"""Message content as a list of content blocks."""
|
||||
|
||||
usage_metadata: Optional[UsageMetadata] = None
|
||||
"""If provided, usage metadata for a message, such as token counts."""
|
||||
|
||||
response_metadata: ResponseMetadata = field(
|
||||
default_factory=lambda: ResponseMetadata()
|
||||
)
|
||||
"""Metadata about the response.
|
||||
|
||||
This field should include non-standard data returned by the provider, such as
|
||||
response headers, service tiers, or log probabilities.
|
||||
|
||||
"""
|
||||
|
||||
parsed: Optional[Union[dict[str, Any], BaseModel]] = None
|
||||
"""Auto-parsed message contents, if applicable."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
content: Union[str, list[types.ContentBlock]],
|
||||
id: Optional[str] = None,
|
||||
name: Optional[str] = None,
|
||||
lc_version: str = "v1",
|
||||
response_metadata: Optional[ResponseMetadata] = None,
|
||||
usage_metadata: Optional[UsageMetadata] = None,
|
||||
tool_calls: Optional[list[types.ToolCall]] = None,
|
||||
invalid_tool_calls: Optional[list[types.InvalidToolCall]] = None,
|
||||
parsed: Optional[Union[dict[str, Any], BaseModel]] = None,
|
||||
):
|
||||
"""Initialize a v1 AI message.
|
||||
|
||||
Args:
|
||||
content: Message content as string or list of content blocks.
|
||||
id: Optional unique identifier for the message.
|
||||
name: Optional human-readable name for the message.
|
||||
lc_version: Encoding version for the message.
|
||||
response_metadata: Optional metadata about the response.
|
||||
usage_metadata: Optional metadata about token usage.
|
||||
tool_calls: Optional list of tool calls made by the AI. Tool calls should
|
||||
generally be included in message content. If passed on init, they will
|
||||
be added to the content list.
|
||||
invalid_tool_calls: Optional list of tool calls that failed validation.
|
||||
parsed: Optional auto-parsed message contents, if applicable.
|
||||
|
||||
"""
|
||||
if isinstance(content, str):
|
||||
self.content = [types.create_text_block(content)]
|
||||
else:
|
||||
self.content = content
|
||||
|
||||
self.id = _ensure_id(id)
|
||||
self.name = name
|
||||
self.lc_version = lc_version
|
||||
self.usage_metadata = usage_metadata
|
||||
self.parsed = parsed
|
||||
if response_metadata is None:
|
||||
self.response_metadata = {}
|
||||
else:
|
||||
self.response_metadata = response_metadata
|
||||
|
||||
# Add tool calls to content if provided on init
|
||||
if tool_calls:
|
||||
content_tool_calls = {
|
||||
block["id"]
|
||||
for block in self.content
|
||||
if types.is_tool_call_block(block) and "id" in block
|
||||
}
|
||||
for tool_call in tool_calls:
|
||||
if "id" in tool_call and tool_call["id"] in content_tool_calls:
|
||||
continue
|
||||
self.content.append(tool_call)
|
||||
if invalid_tool_calls:
|
||||
content_tool_calls = {
|
||||
block["id"]
|
||||
for block in self.content
|
||||
if types.is_invalid_tool_call_block(block) and "id" in block
|
||||
}
|
||||
for invalid_tool_call in invalid_tool_calls:
|
||||
if (
|
||||
"id" in invalid_tool_call
|
||||
and invalid_tool_call["id"] in content_tool_calls
|
||||
):
|
||||
continue
|
||||
self.content.append(invalid_tool_call)
|
||||
self._tool_calls: list[types.ToolCall] = [
|
||||
block for block in self.content if types.is_tool_call_block(block)
|
||||
]
|
||||
self._invalid_tool_calls: list[types.InvalidToolCall] = [
|
||||
block for block in self.content if types.is_invalid_tool_call_block(block)
|
||||
]
|
||||
|
||||
@property
|
||||
def text(self) -> str:
|
||||
"""Extract all text content from the AI message as a string.
|
||||
|
||||
Can be used as both property (``message.text``) and method (``message.text()``).
|
||||
|
||||
.. deprecated:: 0.4.0
|
||||
Calling ``.text()`` as a method is deprecated. Use ``.text`` as a property
|
||||
instead. This method will be removed in 2.0.0.
|
||||
|
||||
"""
|
||||
text_value = "".join(
|
||||
block["text"] for block in self.content if types.is_text_block(block)
|
||||
)
|
||||
return cast("str", TextAccessor(text_value))
|
||||
|
||||
@property
|
||||
def tool_calls(self) -> list[types.ToolCall]:
|
||||
"""Get the tool calls made by the AI."""
|
||||
if not self._tool_calls:
|
||||
self._tool_calls = [
|
||||
block for block in self.content if types.is_tool_call_block(block)
|
||||
]
|
||||
return self._tool_calls
|
||||
|
||||
@tool_calls.setter
|
||||
def tool_calls(self, value: list[types.ToolCall]) -> None:
|
||||
"""Set the tool calls for the AI message."""
|
||||
self._tool_calls = value
|
||||
|
||||
@property
|
||||
def invalid_tool_calls(self) -> list[types.InvalidToolCall]:
|
||||
"""Get the invalid tool calls made by the AI."""
|
||||
if not self._invalid_tool_calls:
|
||||
self._invalid_tool_calls = [
|
||||
block
|
||||
for block in self.content
|
||||
if types.is_invalid_tool_call_block(block)
|
||||
]
|
||||
return self._invalid_tool_calls
|
||||
|
||||
|
||||
@dataclass
|
||||
class AIMessageChunk(AIMessage):
|
||||
"""A partial chunk of an AI message during streaming.
|
||||
|
||||
Represents a portion of an AI response that is delivered incrementally
|
||||
during streaming generation. When AI providers stream responses token-by-token,
|
||||
each chunk contains partial content that gets accumulated into a complete message.
|
||||
|
||||
**Streaming Workflow:**
|
||||
|
||||
1. Provider streams partial responses as ``AIMessageChunk`` objects
|
||||
2. Chunks are accumulated: ``chunk1 + chunk2 + ...``
|
||||
3. Final accumulated chunk can be converted to ``AIMessage`` via ``.to_message()``
|
||||
|
||||
**Tool Call Handling:**
|
||||
|
||||
During streaming, tool calls arrive as ``ToolCallChunk`` objects with partial
|
||||
JSON. When chunks are accumulated, the final chunk (marked with
|
||||
``chunk_position="last"``) triggers parsing of complete tool calls from the
|
||||
accumulated JSON strings.
|
||||
|
||||
**Content Merging:**
|
||||
|
||||
Content blocks are merged intelligently - text blocks combine their strings,
|
||||
tool call chunks accumulate arguments, and other blocks are concatenated.
|
||||
|
||||
Attributes:
|
||||
type: Message type identifier, always ``'ai_chunk'``.
|
||||
id: Unique identifier for the message chunk.
|
||||
name: Optional human-readable name for the message.
|
||||
content: List of content blocks containing partial message data.
|
||||
tool_call_chunks: Optional list of partial tool call data.
|
||||
usage_metadata: Optional metadata about token usage and costs.
|
||||
|
||||
"""
|
||||
|
||||
type: Literal["ai_chunk"] = "ai_chunk" # type: ignore[assignment]
|
||||
"""The type of the message. Must be a string that is unique to the message type.
|
||||
|
||||
The purpose of this field is to allow for easy identification of the message type
|
||||
when deserializing messages.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
content: Union[str, list[types.ContentBlock]],
|
||||
*,
|
||||
id: Optional[str] = None,
|
||||
name: Optional[str] = None,
|
||||
lc_version: str = "v1",
|
||||
response_metadata: Optional[ResponseMetadata] = None,
|
||||
usage_metadata: Optional[UsageMetadata] = None,
|
||||
tool_call_chunks: Optional[list[types.ToolCallChunk]] = None,
|
||||
parsed: Optional[Union[dict[str, Any], BaseModel]] = None,
|
||||
chunk_position: Optional[Literal["last"]] = None,
|
||||
):
|
||||
"""Initialize a v1 AI message.
|
||||
|
||||
Args:
|
||||
content: Message content as string or list of content blocks.
|
||||
id: Optional unique identifier for the message.
|
||||
name: Optional human-readable name for the message.
|
||||
lc_version: Encoding version for the message.
|
||||
response_metadata: Optional metadata about the response.
|
||||
usage_metadata: Optional metadata about token usage.
|
||||
tool_call_chunks: Optional list of partial tool call data.
|
||||
parsed: Optional auto-parsed message contents, if applicable.
|
||||
chunk_position: Optional position of the chunk in the stream. If ``'last'``,
|
||||
tool calls will be parsed when aggregated into a stream.
|
||||
|
||||
"""
|
||||
if isinstance(content, str):
|
||||
self.content = [{"type": "text", "text": content, "index": 0}]
|
||||
else:
|
||||
self.content = content
|
||||
|
||||
self.id = _ensure_id(id)
|
||||
self.name = name
|
||||
self.lc_version = lc_version
|
||||
self.usage_metadata = usage_metadata
|
||||
self.parsed = parsed
|
||||
self.chunk_position = chunk_position
|
||||
if response_metadata is None:
|
||||
self.response_metadata = {}
|
||||
else:
|
||||
self.response_metadata = response_metadata
|
||||
|
||||
if tool_call_chunks:
|
||||
content_tool_call_chunks = {
|
||||
block["id"]
|
||||
for block in self.content
|
||||
if types.is_tool_call_chunk(block) and "id" in block
|
||||
}
|
||||
for chunk in tool_call_chunks:
|
||||
if "id" in chunk and chunk["id"] in content_tool_call_chunks:
|
||||
continue
|
||||
self.content.append(chunk)
|
||||
self._tool_call_chunks = [
|
||||
block for block in self.content if types.is_tool_call_chunk(block)
|
||||
]
|
||||
|
||||
self._tool_calls: list[types.ToolCall] = []
|
||||
self._invalid_tool_calls: list[types.InvalidToolCall] = []
|
||||
|
||||
@property
|
||||
def tool_call_chunks(self) -> list[types.ToolCallChunk]:
|
||||
"""Get the tool calls made by the AI."""
|
||||
if not self._tool_call_chunks:
|
||||
self._tool_call_chunks = [
|
||||
block for block in self.content if types.is_tool_call_chunk(block)
|
||||
]
|
||||
return self._tool_call_chunks
|
||||
|
||||
@property
|
||||
def tool_calls(self) -> list[types.ToolCall]:
|
||||
"""Get the tool calls made by the AI."""
|
||||
if not self._tool_calls:
|
||||
parsed_content = _init_tool_calls(self.content)
|
||||
tool_calls: list[types.ToolCall] = []
|
||||
invalid_tool_calls: list[types.InvalidToolCall] = []
|
||||
for block in parsed_content:
|
||||
if types.is_tool_call_block(block):
|
||||
tool_calls.append(block)
|
||||
elif types.is_invalid_tool_call_block(block):
|
||||
invalid_tool_calls.append(block)
|
||||
self._tool_calls = tool_calls
|
||||
self._invalid_tool_calls = invalid_tool_calls
|
||||
return self._tool_calls
|
||||
|
||||
@tool_calls.setter
|
||||
def tool_calls(self, value: list[types.ToolCall]) -> None:
|
||||
"""Set the tool calls for the AI message."""
|
||||
self._tool_calls = value
|
||||
|
||||
@property
|
||||
def invalid_tool_calls(self) -> list[types.InvalidToolCall]:
|
||||
"""Get the invalid tool calls made by the AI."""
|
||||
if not self._invalid_tool_calls:
|
||||
parsed_content = _init_tool_calls(self.content)
|
||||
tool_calls: list[types.ToolCall] = []
|
||||
invalid_tool_calls: list[types.InvalidToolCall] = []
|
||||
for block in parsed_content:
|
||||
if types.is_tool_call_block(block):
|
||||
tool_calls.append(block)
|
||||
elif types.is_invalid_tool_call_block(block):
|
||||
invalid_tool_calls.append(block)
|
||||
self._tool_calls = tool_calls
|
||||
self._invalid_tool_calls = invalid_tool_calls
|
||||
return self._invalid_tool_calls
|
||||
|
||||
def __add__(self, other: Any) -> "AIMessageChunk":
|
||||
"""Add ``AIMessageChunk`` to this one."""
|
||||
if isinstance(other, AIMessageChunk):
|
||||
return add_ai_message_chunks(self, other)
|
||||
if isinstance(other, (list, tuple)) and all(
|
||||
isinstance(o, AIMessageChunk) for o in other
|
||||
):
|
||||
return add_ai_message_chunks(self, *other)
|
||||
error_msg = "Can only add AIMessageChunk or sequence of AIMessageChunk."
|
||||
raise NotImplementedError(error_msg)
|
||||
|
||||
def to_message(self) -> "AIMessage":
|
||||
"""Convert this ``AIMessageChunk`` to an ``AIMessage``."""
|
||||
return AIMessage(
|
||||
content=_init_tool_calls(self.content),
|
||||
id=self.id,
|
||||
name=self.name,
|
||||
lc_version=self.lc_version,
|
||||
response_metadata=self.response_metadata,
|
||||
usage_metadata=self.usage_metadata,
|
||||
parsed=self.parsed,
|
||||
)
|
||||
|
||||
|
||||
def _init_tool_calls(content: list[types.ContentBlock]) -> list[types.ContentBlock]:
|
||||
"""Parse tool call chunks in content into tool calls."""
|
||||
new_content = []
|
||||
for block in content:
|
||||
if not types.is_tool_call_chunk(block):
|
||||
new_content.append(block)
|
||||
continue
|
||||
try:
|
||||
args_str = block.get("args")
|
||||
args_ = parse_partial_json(str(args_str)) if args_str else {}
|
||||
if isinstance(args_, dict):
|
||||
new_content.append(
|
||||
create_tool_call(
|
||||
name=block.get("name") or "",
|
||||
args=args_,
|
||||
id=block.get("id", ""),
|
||||
)
|
||||
)
|
||||
else:
|
||||
new_content.append(
|
||||
create_invalid_tool_call(
|
||||
name=block.get("name", ""),
|
||||
args=block.get("args", ""),
|
||||
id=block.get("id", ""),
|
||||
error=None,
|
||||
)
|
||||
)
|
||||
except Exception:
|
||||
new_content.append(
|
||||
create_invalid_tool_call(
|
||||
name=block.get("name", ""),
|
||||
args=block.get("args", ""),
|
||||
id=block.get("id", ""),
|
||||
error=None,
|
||||
)
|
||||
)
|
||||
return new_content
|
||||
|
||||
|
||||
def add_ai_message_chunks(
|
||||
left: AIMessageChunk, *others: AIMessageChunk
|
||||
) -> AIMessageChunk:
|
||||
"""Add multiple ``AIMessageChunks`` together."""
|
||||
if not others:
|
||||
return left
|
||||
content = cast(
|
||||
"list[types.ContentBlock]",
|
||||
merge_content(
|
||||
cast("list[str | dict[Any, Any]]", left.content),
|
||||
*(cast("list[str | dict[Any, Any]]", o.content) for o in others),
|
||||
),
|
||||
)
|
||||
response_metadata = merge_dicts(
|
||||
cast("dict", left.response_metadata),
|
||||
*(cast("dict", o.response_metadata) for o in others),
|
||||
)
|
||||
|
||||
# Token usage
|
||||
if left.usage_metadata or any(o.usage_metadata is not None for o in others):
|
||||
usage_metadata: Optional[UsageMetadata] = left.usage_metadata
|
||||
for other in others:
|
||||
usage_metadata = add_usage(usage_metadata, other.usage_metadata)
|
||||
else:
|
||||
usage_metadata = None
|
||||
|
||||
# Parsed
|
||||
# 'parsed' always represents an aggregation not an incremental value, so the last
|
||||
# non-null value is kept.
|
||||
parsed = None
|
||||
for m in reversed([left, *others]):
|
||||
if m.parsed is not None:
|
||||
parsed = m.parsed
|
||||
break
|
||||
|
||||
chunk_id = None
|
||||
candidates = [left.id] + [o.id for o in others]
|
||||
# first pass: pick the first provider-assigned id (non-`run-*` and non-`lc_*`)
|
||||
for id_ in candidates:
|
||||
if (
|
||||
id_
|
||||
and not id_.startswith(_LC_ID_PREFIX)
|
||||
and not id_.startswith(_LC_AUTO_PREFIX)
|
||||
):
|
||||
chunk_id = id_
|
||||
break
|
||||
else:
|
||||
# second pass: prefer lc_run-* ids over lc_* ids
|
||||
for id_ in candidates:
|
||||
if id_ and id_.startswith(_LC_ID_PREFIX):
|
||||
chunk_id = id_
|
||||
break
|
||||
else:
|
||||
# third pass: take any remaining id (auto-generated lc_* ids)
|
||||
for id_ in candidates:
|
||||
if id_:
|
||||
chunk_id = id_
|
||||
break
|
||||
|
||||
chunk_position: Optional[Literal["last"]] = (
|
||||
"last" if any(x.chunk_position == "last" for x in [left, *others]) else None
|
||||
)
|
||||
if chunk_position == "last":
|
||||
content = _init_tool_calls(content)
|
||||
|
||||
return left.__class__(
|
||||
content=content,
|
||||
response_metadata=cast("ResponseMetadata", response_metadata),
|
||||
usage_metadata=usage_metadata,
|
||||
parsed=parsed,
|
||||
id=chunk_id,
|
||||
chunk_position=chunk_position,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class HumanMessage:
|
||||
"""A message from a human user.
|
||||
|
||||
Represents input from a human user in a conversation, containing text
|
||||
or other content types like images.
|
||||
|
||||
Attributes:
|
||||
type: Message type identifier, always ``'human'``.
|
||||
id: Unique identifier for the message.
|
||||
content: List of content blocks containing the user's input.
|
||||
name: Optional human-readable name for the message.
|
||||
|
||||
"""
|
||||
|
||||
id: str
|
||||
"""Used for serialization.
|
||||
|
||||
If the provider assigns a meaningful ID, it should be used here. Otherwise, a
|
||||
LangChain-generated ID will be used.
|
||||
|
||||
"""
|
||||
|
||||
content: list[types.ContentBlock]
|
||||
"""Message content as a list of content blocks."""
|
||||
|
||||
type: Literal["human"] = "human"
|
||||
"""The type of the message. Must be a string that is unique to the message type.
|
||||
|
||||
The purpose of this field is to allow for easy identification of the message type
|
||||
when deserializing messages.
|
||||
|
||||
"""
|
||||
|
||||
name: Optional[str] = None
|
||||
"""An optional name for the message.
|
||||
|
||||
This can be used to provide a human-readable name for the message.
|
||||
|
||||
Usage of this field is optional, and whether it's used or not is up to the
|
||||
model implementation.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
content: Union[str, list[types.ContentBlock]],
|
||||
*,
|
||||
id: Optional[str] = None,
|
||||
name: Optional[str] = None,
|
||||
):
|
||||
"""Initialize a v1 human message.
|
||||
|
||||
Args:
|
||||
content: Message content as string or list of content blocks.
|
||||
id: Optional unique identifier for the message.
|
||||
name: Optional human-readable name for the message.
|
||||
|
||||
"""
|
||||
self.id = _ensure_id(id)
|
||||
if isinstance(content, str):
|
||||
self.content = [{"type": "text", "text": content}]
|
||||
else:
|
||||
self.content = content
|
||||
self.name = name
|
||||
|
||||
@property
|
||||
def text(self) -> str:
|
||||
"""Extract all text content from the message as a string.
|
||||
|
||||
Can be used as both property (``message.text``) and method (``message.text()``).
|
||||
|
||||
.. deprecated:: 0.4.0
|
||||
Calling ``.text()`` as a method is deprecated. Use ``.text`` as a property
|
||||
instead. This method will be removed in 2.0.0.
|
||||
|
||||
"""
|
||||
text_value = "".join(
|
||||
block["text"] for block in self.content if types.is_text_block(block)
|
||||
)
|
||||
return cast("str", TextAccessor(text_value))
|
||||
|
||||
|
||||
@dataclass
|
||||
class SystemMessage:
|
||||
"""A system message containing instructions or context.
|
||||
|
||||
Represents system-level instructions or context that guides the AI's
|
||||
behavior and understanding of the conversation.
|
||||
|
||||
Attributes:
|
||||
type: Message type identifier, always ``'system'``.
|
||||
id: Unique identifier for the message.
|
||||
content: List of content blocks containing system instructions.
|
||||
|
||||
"""
|
||||
|
||||
id: str
|
||||
"""Used for serialization.
|
||||
|
||||
If the provider assigns a meaningful ID, it should be used here. Otherwise, a
|
||||
LangChain-generated ID will be used.
|
||||
|
||||
"""
|
||||
|
||||
content: list[types.ContentBlock]
|
||||
"""Message content as a list of content blocks."""
|
||||
|
||||
type: Literal["system"] = "system"
|
||||
"""The type of the message. Must be a string that is unique to the message type.
|
||||
|
||||
The purpose of this field is to allow for easy identification of the message type
|
||||
when deserializing messages.
|
||||
|
||||
"""
|
||||
|
||||
name: Optional[str] = None
|
||||
"""An optional name for the message.
|
||||
|
||||
This can be used to provide a human-readable name for the message.
|
||||
|
||||
Usage of this field is optional, and whether it's used or not is up to the
|
||||
model implementation.
|
||||
|
||||
"""
|
||||
|
||||
custom_role: Optional[str] = None
|
||||
"""If provided, a custom role for the system message.
|
||||
|
||||
Example: ``'developer'``.
|
||||
|
||||
Integration packages may use this field to assign the system message role if it
|
||||
contains a recognized value.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
content: Union[str, list[types.ContentBlock]],
|
||||
*,
|
||||
id: Optional[str] = None,
|
||||
custom_role: Optional[str] = None,
|
||||
name: Optional[str] = None,
|
||||
):
|
||||
"""Initialize a v1 system message.
|
||||
|
||||
Args:
|
||||
content: Message content as string or list of content blocks.
|
||||
id: Optional unique identifier for the message.
|
||||
custom_role: If provided, a custom role for the system message.
|
||||
name: Optional human-readable name for the message.
|
||||
|
||||
"""
|
||||
self.id = _ensure_id(id)
|
||||
if isinstance(content, str):
|
||||
self.content = [{"type": "text", "text": content}]
|
||||
else:
|
||||
self.content = content
|
||||
self.custom_role = custom_role
|
||||
self.name = name
|
||||
|
||||
@property
|
||||
def text(self) -> str:
|
||||
"""Extract all text content from the system message as a string.
|
||||
|
||||
Can be used as both property (``message.text``) and method (``message.text()``).
|
||||
|
||||
.. deprecated:: 0.4.0
|
||||
Calling ``.text()`` as a method is deprecated. Use ``.text`` as a property
|
||||
instead. This method will be removed in 2.0.0.
|
||||
|
||||
"""
|
||||
text_value = "".join(
|
||||
block["text"] for block in self.content if types.is_text_block(block)
|
||||
)
|
||||
return cast("str", TextAccessor(text_value))
|
||||
|
||||
|
||||
@dataclass
|
||||
class ToolMessage(ToolOutputMixin):
|
||||
"""A message containing the result of a tool execution.
|
||||
|
||||
Represents the output from executing a tool or function call,
|
||||
including the result data and execution status.
|
||||
|
||||
Attributes:
|
||||
type: Message type identifier, always ``'tool'``.
|
||||
id: Unique identifier for the message.
|
||||
tool_call_id: ID of the tool call this message responds to.
|
||||
content: The result content from tool execution.
|
||||
artifact: Optional app-side payload not intended for the model.
|
||||
status: Execution status ("success" or "error").
|
||||
|
||||
"""
|
||||
|
||||
id: str
|
||||
"""Used for serialization."""
|
||||
|
||||
tool_call_id: str
|
||||
"""ID of the tool call this message responds to.
|
||||
|
||||
This should match the ID of the tool call that this message is responding to.
|
||||
|
||||
"""
|
||||
|
||||
content: list[types.ContentBlock]
|
||||
"""Message content as a list of content blocks.
|
||||
|
||||
The tool's output should be included in the content, mapped to the appropriate
|
||||
content block type (e.g., text, image, etc.). For instance, if the tool call returns
|
||||
a string, it should be wrapped in a ``TextContentBlock``.
|
||||
|
||||
"""
|
||||
|
||||
type: Literal["tool"] = "tool"
|
||||
"""The type of the message. Must be a string that is unique to the message type.
|
||||
|
||||
The purpose of this field is to allow for easy identification of the message type
|
||||
when deserializing messages.
|
||||
|
||||
"""
|
||||
|
||||
artifact: Optional[Any] = None
|
||||
"""App-side payload not intended for model consumption.
|
||||
|
||||
Additonal info and usage examples are available
|
||||
`in the LangChain documentation <https://python.langchain.com/docs/concepts/tools/#tool-artifacts>`__.
|
||||
|
||||
"""
|
||||
|
||||
name: Optional[str] = None
|
||||
"""An optional name for the message.
|
||||
|
||||
This can be used to provide a human-readable name for the message.
|
||||
|
||||
Usage of this field is optional, and whether it's used or not is up to the
|
||||
model implementation.
|
||||
|
||||
"""
|
||||
|
||||
status: Literal["success", "error"] = "success"
|
||||
"""Execution status of the tool call.
|
||||
|
||||
Indicates whether the tool call was successful or encountered an error.
|
||||
Defaults to "success".
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
content: Union[str, list[types.ContentBlock]],
|
||||
tool_call_id: str,
|
||||
*,
|
||||
id: Optional[str] = None,
|
||||
name: Optional[str] = None,
|
||||
artifact: Optional[Any] = None,
|
||||
status: Literal["success", "error"] = "success",
|
||||
):
|
||||
"""Initialize a v1 tool message.
|
||||
|
||||
Args:
|
||||
content: Message content as string or list of content blocks.
|
||||
tool_call_id: ID of the tool call this message responds to.
|
||||
id: Optional unique identifier for the message.
|
||||
name: Optional human-readable name for the message.
|
||||
artifact: Optional app-side payload not intended for the model.
|
||||
status: Execution status (``'success'`` or ``'error'``).
|
||||
|
||||
"""
|
||||
self.id = _ensure_id(id)
|
||||
self.tool_call_id = tool_call_id
|
||||
if isinstance(content, str):
|
||||
self.content = [{"type": "text", "text": content}]
|
||||
else:
|
||||
self.content = content
|
||||
self.name = name
|
||||
self.artifact = artifact
|
||||
self.status = status
|
||||
|
||||
@property
|
||||
def text(self) -> str:
|
||||
"""Extract all text content from the tool message as a string.
|
||||
|
||||
Can be used as both property (``message.text``) and method (``message.text()``).
|
||||
|
||||
.. deprecated:: 0.4.0
|
||||
Calling ``.text()`` as a method is deprecated. Use ``.text`` as a property
|
||||
instead. This method will be removed in 2.0.0.
|
||||
|
||||
"""
|
||||
text_value = "".join(
|
||||
block["text"] for block in self.content if types.is_text_block(block)
|
||||
)
|
||||
return cast("str", TextAccessor(text_value))
|
||||
|
||||
def __post_init__(self) -> None:
|
||||
"""Initialize computed fields after dataclass creation.
|
||||
|
||||
Ensures the tool message has a valid ID.
|
||||
|
||||
"""
|
||||
self.id = _ensure_id(self.id)
|
||||
|
||||
|
||||
# Alias for a message type that can be any of the defined message types
|
||||
MessageV1 = Union[
|
||||
AIMessage,
|
||||
AIMessageChunk,
|
||||
HumanMessage,
|
||||
SystemMessage,
|
||||
ToolMessage,
|
||||
]
|
||||
MessageV1Types = get_args(MessageV1)
|
||||
@@ -1,3 +1,3 @@
|
||||
"""langchain-core version information and utilities."""
|
||||
|
||||
VERSION = "0.3.74"
|
||||
VERSION = "0.4.0.dev0"
|
||||
|
||||
@@ -16,7 +16,7 @@ dependencies = [
|
||||
"pydantic>=2.7.4",
|
||||
]
|
||||
name = "langchain-core"
|
||||
version = "0.3.74"
|
||||
version = "0.4.0.dev0"
|
||||
description = "Building applications with LLMs through composability"
|
||||
readme = "README.md"
|
||||
|
||||
@@ -67,6 +67,7 @@ langchain-text-splitters = { path = "../text-splitters" }
|
||||
strict = "True"
|
||||
strict_bytes = "True"
|
||||
enable_error_code = "deprecated"
|
||||
disable_error_code = ["typeddict-unknown-key"]
|
||||
|
||||
# TODO: activate for 'strict' checking
|
||||
disallow_any_generics = "False"
|
||||
|
||||
@@ -11,6 +11,8 @@ from langchain_core.callbacks.base import AsyncCallbackHandler
|
||||
from langchain_core.language_models import GenericFakeChatModel
|
||||
from langchain_core.messages import AIMessage, BaseMessage
|
||||
from langchain_core.outputs import ChatGenerationChunk, GenerationChunk
|
||||
from langchain_core.v1.messages import AIMessageChunk as AIMessageChunkV1
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
|
||||
|
||||
class MyCustomAsyncHandler(AsyncCallbackHandler):
|
||||
@@ -18,7 +20,7 @@ class MyCustomAsyncHandler(AsyncCallbackHandler):
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -35,7 +37,9 @@ class MyCustomAsyncHandler(AsyncCallbackHandler):
|
||||
self,
|
||||
token: str,
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunkV1]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
tags: Optional[list[str]] = None,
|
||||
|
||||
@@ -9,6 +9,7 @@ from typing_extensions import override
|
||||
|
||||
from langchain_core.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler
|
||||
from langchain_core.messages import BaseMessage
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
|
||||
|
||||
class BaseFakeCallbackHandler(BaseModel):
|
||||
@@ -285,7 +286,7 @@ class FakeCallbackHandlerWithChatStart(FakeCallbackHandler):
|
||||
def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
|
||||
@@ -16,6 +16,8 @@ from langchain_core.language_models import (
|
||||
)
|
||||
from langchain_core.messages import AIMessage, AIMessageChunk, BaseMessage, HumanMessage
|
||||
from langchain_core.outputs import ChatGenerationChunk, GenerationChunk
|
||||
from langchain_core.v1.messages import AIMessageChunk as AIMessageChunkV1
|
||||
from langchain_core.v1.messages import MessageV1
|
||||
from tests.unit_tests.stubs import (
|
||||
_any_id_ai_message,
|
||||
_any_id_ai_message_chunk,
|
||||
@@ -157,13 +159,13 @@ async def test_callback_handlers() -> None:
|
||||
"""Verify that model is implemented correctly with handlers working."""
|
||||
|
||||
class MyCustomAsyncHandler(AsyncCallbackHandler):
|
||||
def __init__(self, store: list[str]) -> None:
|
||||
def __init__(self, store: list[Union[str, AIMessageChunkV1]]) -> None:
|
||||
self.store = store
|
||||
|
||||
async def on_chat_model_start(
|
||||
self,
|
||||
serialized: dict[str, Any],
|
||||
messages: list[list[BaseMessage]],
|
||||
messages: Union[list[list[BaseMessage]], list[MessageV1]],
|
||||
*,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
@@ -178,9 +180,11 @@ async def test_callback_handlers() -> None:
|
||||
@override
|
||||
async def on_llm_new_token(
|
||||
self,
|
||||
token: str,
|
||||
token: Union[str, AIMessageChunkV1],
|
||||
*,
|
||||
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
|
||||
chunk: Optional[
|
||||
Union[GenerationChunk, ChatGenerationChunk, AIMessageChunkV1]
|
||||
] = None,
|
||||
run_id: UUID,
|
||||
parent_run_id: Optional[UUID] = None,
|
||||
tags: Optional[list[str]] = None,
|
||||
@@ -194,7 +198,7 @@ async def test_callback_handlers() -> None:
|
||||
]
|
||||
)
|
||||
model = GenericFakeChatModel(messages=infinite_cycle)
|
||||
tokens: list[str] = []
|
||||
tokens: list[Union[str, AIMessageChunkV1]] = []
|
||||
# New model
|
||||
results = [
|
||||
chunk
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user