mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-11 19:49:54 +00:00
Compare commits
55 Commits
langchain-
...
eugene/upd
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1dcebc7101 | ||
|
|
166c027434 | ||
|
|
4a2a3fcd43 | ||
|
|
d46dcf4a60 | ||
|
|
d2ac3b375c | ||
|
|
1e38fd2ce3 | ||
|
|
155e3740bc | ||
|
|
f9b4e501a8 | ||
|
|
5a50802c9a | ||
|
|
9a7e66be60 | ||
|
|
5597b277c5 | ||
|
|
a1da5697c6 | ||
|
|
11a54b1f1a | ||
|
|
5ccdcd7b7b | ||
|
|
ee4c2510eb | ||
|
|
7db9e60601 | ||
|
|
e5d0a4e4d6 | ||
|
|
457ce9c4b0 | ||
|
|
27b6b53f20 | ||
|
|
f55186b38f | ||
|
|
374f414c91 | ||
|
|
9b3f3dc8d9 | ||
|
|
afc3b1824c | ||
|
|
130b7e6170 | ||
|
|
d40fa534c1 | ||
|
|
20bd296421 | ||
|
|
9259eea846 | ||
|
|
afcb097ef5 | ||
|
|
088095b663 | ||
|
|
c31236264e | ||
|
|
02001212b0 | ||
|
|
00244122bd | ||
|
|
6727d6e8c8 | ||
|
|
5036bd7adb | ||
|
|
ec2b34a02d | ||
|
|
145d38f7dd | ||
|
|
68c70da33e | ||
|
|
754528d23f | ||
|
|
ac706c77d4 | ||
|
|
8493887b6f | ||
|
|
a647073b26 | ||
|
|
e120604774 | ||
|
|
06d8754b0b | ||
|
|
6e108c1cb4 | ||
|
|
bc4251b9e0 | ||
|
|
2543007436 | ||
|
|
ba83f58141 | ||
|
|
fb490b0c39 | ||
|
|
419c173225 | ||
|
|
4011257c25 | ||
|
|
9de0892a77 | ||
|
|
fd532c692d | ||
|
|
97db95b426 | ||
|
|
b9ebae37a4 | ||
|
|
d3930f9906 |
@@ -15,12 +15,12 @@ You may use the button above, or follow these steps to open this repo in a Codes
|
||||
1. Click **Create codespace on master**.
|
||||
|
||||
For more info, check out the [GitHub documentation](https://docs.github.com/en/free-pro-team@latest/github/developing-online-with-codespaces/creating-a-codespace#creating-a-codespace).
|
||||
|
||||
|
||||
## VS Code Dev Containers
|
||||
|
||||
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/langchain-ai/langchain)
|
||||
|
||||
> [!NOTE]
|
||||
> [!NOTE]
|
||||
> If you click the link above you will open the main repo (`langchain-ai/langchain`) and *not* your local cloned repo. This is fine if you only want to run and test the library, but if you want to contribute you can use the link below and replace with your username and cloned repo name:
|
||||
|
||||
```txt
|
||||
|
||||
@@ -4,7 +4,7 @@ services:
|
||||
build:
|
||||
dockerfile: libs/langchain/dev.Dockerfile
|
||||
context: ..
|
||||
|
||||
|
||||
networks:
|
||||
- langchain-network
|
||||
|
||||
|
||||
2
.github/CODE_OF_CONDUCT.md
vendored
2
.github/CODE_OF_CONDUCT.md
vendored
@@ -129,4 +129,4 @@ For answers to common questions about this code of conduct, see the FAQ at
|
||||
[v2.1]: https://www.contributor-covenant.org/version/2/1/code_of_conduct.html
|
||||
[Mozilla CoC]: https://github.com/mozilla/diversity
|
||||
[FAQ]: https://www.contributor-covenant.org/faq
|
||||
[translations]: https://www.contributor-covenant.org/translations
|
||||
[translations]: https://www.contributor-covenant.org/translations
|
||||
|
||||
8
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
8
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -5,7 +5,7 @@ body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thank you for taking the time to file a bug report.
|
||||
Thank you for taking the time to file a bug report.
|
||||
|
||||
Use this to report BUGS in LangChain. For usage questions, feature requests and general design questions, please use the [LangChain Forum](https://forum.langchain.com/).
|
||||
|
||||
@@ -50,7 +50,7 @@ body:
|
||||
|
||||
If a maintainer can copy it, run it, and see it right away, there's a much higher chance that you'll be able to get help.
|
||||
|
||||
**Important!**
|
||||
**Important!**
|
||||
|
||||
* Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
* Reduce your code to the minimum required to reproduce the issue if possible. This makes it much easier for others to help you.
|
||||
@@ -58,14 +58,14 @@ body:
|
||||
* INCLUDE the language label (e.g. `python`) after the first three backticks to enable syntax highlighting. (e.g., ```python rather than ```).
|
||||
|
||||
placeholder: |
|
||||
The following code:
|
||||
The following code:
|
||||
|
||||
```python
|
||||
from langchain_core.runnables import RunnableLambda
|
||||
|
||||
def bad_code(inputs) -> int:
|
||||
raise NotImplementedError('For demo purpose')
|
||||
|
||||
|
||||
chain = RunnableLambda(bad_code)
|
||||
chain.invoke('Hello!')
|
||||
```
|
||||
|
||||
2
.github/ISSUE_TEMPLATE/documentation.yml
vendored
2
.github/ISSUE_TEMPLATE/documentation.yml
vendored
@@ -14,7 +14,7 @@ body:
|
||||
|
||||
Do **NOT** use this to ask usage questions or reporting issues with your code.
|
||||
|
||||
If you have usage questions or need help solving some problem,
|
||||
If you have usage questions or need help solving some problem,
|
||||
please use the [LangChain Forum](https://forum.langchain.com/).
|
||||
|
||||
If you're in the wrong place, here are some helpful links to find a better
|
||||
|
||||
2
.github/ISSUE_TEMPLATE/privileged.yml
vendored
2
.github/ISSUE_TEMPLATE/privileged.yml
vendored
@@ -8,7 +8,7 @@ body:
|
||||
|
||||
If you are not a LangChain maintainer or were not asked directly by a maintainer to create an issue, then please start the conversation on the [LangChain Forum](https://forum.langchain.com/) instead.
|
||||
|
||||
You are a LangChain maintainer if you maintain any of the packages inside of the LangChain repository
|
||||
You are a LangChain maintainer if you maintain any of the packages inside of the LangChain repository
|
||||
or are a regular contributor to LangChain with previous merged pull requests.
|
||||
- type: checkboxes
|
||||
id: privileged
|
||||
|
||||
2
.github/actions/people/Dockerfile
vendored
2
.github/actions/people/Dockerfile
vendored
@@ -4,4 +4,4 @@ RUN pip install httpx PyGithub "pydantic==2.0.2" pydantic-settings "pyyaml>=5.3.
|
||||
|
||||
COPY ./app /app
|
||||
|
||||
CMD ["python", "/app/main.py"]
|
||||
CMD ["python", "/app/main.py"]
|
||||
|
||||
6
.github/actions/people/action.yml
vendored
6
.github/actions/people/action.yml
vendored
@@ -4,8 +4,8 @@ description: "Generate the data for the LangChain People page"
|
||||
author: "Jacob Lee <jacob@langchain.dev>"
|
||||
inputs:
|
||||
token:
|
||||
description: 'User token, to read the GitHub API. Can be passed in using {{ secrets.LANGCHAIN_PEOPLE_GITHUB_TOKEN }}'
|
||||
description: "User token, to read the GitHub API. Can be passed in using {{ secrets.LANGCHAIN_PEOPLE_GITHUB_TOKEN }}"
|
||||
required: true
|
||||
runs:
|
||||
using: 'docker'
|
||||
image: 'Dockerfile'
|
||||
using: "docker"
|
||||
image: "Dockerfile"
|
||||
|
||||
25
.github/scripts/check_diff.py
vendored
25
.github/scripts/check_diff.py
vendored
@@ -3,14 +3,12 @@ import json
|
||||
import os
|
||||
import sys
|
||||
from collections import defaultdict
|
||||
from typing import Dict, List, Set
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Set
|
||||
|
||||
import tomllib
|
||||
|
||||
from packaging.requirements import Requirement
|
||||
|
||||
from get_min_versions import get_min_version_from_toml
|
||||
|
||||
from packaging.requirements import Requirement
|
||||
|
||||
LANGCHAIN_DIRS = [
|
||||
"libs/core",
|
||||
@@ -38,7 +36,7 @@ IGNORED_PARTNERS = [
|
||||
]
|
||||
|
||||
PY_312_MAX_PACKAGES = [
|
||||
"libs/partners/chroma", # https://github.com/chroma-core/chroma/issues/4382
|
||||
"libs/partners/chroma", # https://github.com/chroma-core/chroma/issues/4382
|
||||
]
|
||||
|
||||
|
||||
@@ -85,9 +83,9 @@ def dependents_graph() -> dict:
|
||||
for depline in extended_deps:
|
||||
if depline.startswith("-e "):
|
||||
# editable dependency
|
||||
assert depline.startswith(
|
||||
"-e ../partners/"
|
||||
), "Extended test deps should only editable install partner packages"
|
||||
assert depline.startswith("-e ../partners/"), (
|
||||
"Extended test deps should only editable install partner packages"
|
||||
)
|
||||
partner = depline.split("partners/")[1]
|
||||
dep = f"langchain-{partner}"
|
||||
else:
|
||||
@@ -271,7 +269,7 @@ if __name__ == "__main__":
|
||||
dirs_to_run["extended-test"].add(dir_)
|
||||
elif file.startswith("libs/standard-tests"):
|
||||
# TODO: update to include all packages that rely on standard-tests (all partner packages)
|
||||
# note: won't run on external repo partners
|
||||
# Note: won't run on external repo partners
|
||||
dirs_to_run["lint"].add("libs/standard-tests")
|
||||
dirs_to_run["test"].add("libs/standard-tests")
|
||||
dirs_to_run["lint"].add("libs/cli")
|
||||
@@ -285,7 +283,7 @@ if __name__ == "__main__":
|
||||
elif file.startswith("libs/cli"):
|
||||
dirs_to_run["lint"].add("libs/cli")
|
||||
dirs_to_run["test"].add("libs/cli")
|
||||
|
||||
|
||||
elif file.startswith("libs/partners"):
|
||||
partner_dir = file.split("/")[2]
|
||||
if os.path.isdir(f"libs/partners/{partner_dir}") and [
|
||||
@@ -303,7 +301,10 @@ if __name__ == "__main__":
|
||||
f"Unknown lib: {file}. check_diff.py likely needs "
|
||||
"an update for this new library!"
|
||||
)
|
||||
elif file.startswith("docs/") or file in ["pyproject.toml", "uv.lock"]: # docs or root uv files
|
||||
elif file.startswith("docs/") or file in [
|
||||
"pyproject.toml",
|
||||
"uv.lock",
|
||||
]: # docs or root uv files
|
||||
docs_edited = True
|
||||
dirs_to_run["lint"].add(".")
|
||||
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import sys
|
||||
|
||||
import tomllib
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
26
.github/scripts/get_min_versions.py
vendored
26
.github/scripts/get_min_versions.py
vendored
@@ -1,5 +1,5 @@
|
||||
from collections import defaultdict
|
||||
import sys
|
||||
from collections import defaultdict
|
||||
from typing import Optional
|
||||
|
||||
if sys.version_info >= (3, 11):
|
||||
@@ -8,17 +8,13 @@ else:
|
||||
# for python 3.10 and below, which doesnt have stdlib tomllib
|
||||
import tomli as tomllib
|
||||
|
||||
from packaging.requirements import Requirement
|
||||
from packaging.specifiers import SpecifierSet
|
||||
from packaging.version import Version
|
||||
|
||||
|
||||
import requests
|
||||
from packaging.version import parse
|
||||
import re
|
||||
from typing import List
|
||||
|
||||
import re
|
||||
|
||||
import requests
|
||||
from packaging.requirements import Requirement
|
||||
from packaging.specifiers import SpecifierSet
|
||||
from packaging.version import Version, parse
|
||||
|
||||
MIN_VERSION_LIBS = [
|
||||
"langchain-core",
|
||||
@@ -72,11 +68,13 @@ def get_minimum_version(package_name: str, spec_string: str) -> Optional[str]:
|
||||
spec_string = re.sub(r"\^0\.0\.(\d+)", r"0.0.\1", spec_string)
|
||||
# rewrite occurrences of ^0.y.z to >=0.y.z,<0.y+1 (can be anywhere in constraint string)
|
||||
for y in range(1, 10):
|
||||
spec_string = re.sub(rf"\^0\.{y}\.(\d+)", rf">=0.{y}.\1,<0.{y+1}", spec_string)
|
||||
spec_string = re.sub(
|
||||
rf"\^0\.{y}\.(\d+)", rf">=0.{y}.\1,<0.{y + 1}", spec_string
|
||||
)
|
||||
# rewrite occurrences of ^x.y.z to >=x.y.z,<x+1.0.0 (can be anywhere in constraint string)
|
||||
for x in range(1, 10):
|
||||
spec_string = re.sub(
|
||||
rf"\^{x}\.(\d+)\.(\d+)", rf">={x}.\1.\2,<{x+1}", spec_string
|
||||
rf"\^{x}\.(\d+)\.(\d+)", rf">={x}.\1.\2,<{x + 1}", spec_string
|
||||
)
|
||||
|
||||
spec_set = SpecifierSet(spec_string)
|
||||
@@ -169,12 +167,12 @@ def check_python_version(version_string, constraint_string):
|
||||
# rewrite occurrences of ^0.y.z to >=0.y.z,<0.y+1.0 (can be anywhere in constraint string)
|
||||
for y in range(1, 10):
|
||||
constraint_string = re.sub(
|
||||
rf"\^0\.{y}\.(\d+)", rf">=0.{y}.\1,<0.{y+1}.0", constraint_string
|
||||
rf"\^0\.{y}\.(\d+)", rf">=0.{y}.\1,<0.{y + 1}.0", constraint_string
|
||||
)
|
||||
# rewrite occurrences of ^x.y.z to >=x.y.z,<x+1.0.0 (can be anywhere in constraint string)
|
||||
for x in range(1, 10):
|
||||
constraint_string = re.sub(
|
||||
rf"\^{x}\.0\.(\d+)", rf">={x}.0.\1,<{x+1}.0.0", constraint_string
|
||||
rf"\^{x}\.0\.(\d+)", rf">={x}.0.\1,<{x + 1}.0.0", constraint_string
|
||||
)
|
||||
|
||||
try:
|
||||
|
||||
47
.github/scripts/prep_api_docs_build.py
vendored
47
.github/scripts/prep_api_docs_build.py
vendored
@@ -3,9 +3,10 @@
|
||||
|
||||
import os
|
||||
import shutil
|
||||
import yaml
|
||||
from pathlib import Path
|
||||
from typing import Dict, Any
|
||||
from typing import Any, Dict
|
||||
|
||||
import yaml
|
||||
|
||||
|
||||
def load_packages_yaml() -> Dict[str, Any]:
|
||||
@@ -28,7 +29,6 @@ def get_target_dir(package_name: str) -> Path:
|
||||
def clean_target_directories(packages: list) -> None:
|
||||
"""Remove old directories that will be replaced."""
|
||||
for package in packages:
|
||||
|
||||
target_dir = get_target_dir(package["name"])
|
||||
if target_dir.exists():
|
||||
print(f"Removing {target_dir}")
|
||||
@@ -38,7 +38,6 @@ def clean_target_directories(packages: list) -> None:
|
||||
def move_libraries(packages: list) -> None:
|
||||
"""Move libraries from their source locations to the target directories."""
|
||||
for package in packages:
|
||||
|
||||
repo_name = package["repo"].split("/")[1]
|
||||
source_path = package["path"]
|
||||
target_dir = get_target_dir(package["name"])
|
||||
@@ -68,23 +67,33 @@ def main():
|
||||
package_yaml = load_packages_yaml()
|
||||
|
||||
# Clean target directories
|
||||
clean_target_directories([
|
||||
p
|
||||
for p in package_yaml["packages"]
|
||||
if (p["repo"].startswith("langchain-ai/") or p.get("include_in_api_ref"))
|
||||
and p["repo"] != "langchain-ai/langchain"
|
||||
and p["name"] != "langchain-ai21" # Skip AI21 due to dependency conflicts
|
||||
])
|
||||
clean_target_directories(
|
||||
[
|
||||
p
|
||||
for p in package_yaml["packages"]
|
||||
if (
|
||||
p["repo"].startswith("langchain-ai/") or p.get("include_in_api_ref")
|
||||
)
|
||||
and p["repo"] != "langchain-ai/langchain"
|
||||
and p["name"]
|
||||
!= "langchain-ai21" # Skip AI21 due to dependency conflicts
|
||||
]
|
||||
)
|
||||
|
||||
# Move libraries to their new locations
|
||||
move_libraries([
|
||||
p
|
||||
for p in package_yaml["packages"]
|
||||
if not p.get("disabled", False)
|
||||
and (p["repo"].startswith("langchain-ai/") or p.get("include_in_api_ref"))
|
||||
and p["repo"] != "langchain-ai/langchain"
|
||||
and p["name"] != "langchain-ai21" # Skip AI21 due to dependency conflicts
|
||||
])
|
||||
move_libraries(
|
||||
[
|
||||
p
|
||||
for p in package_yaml["packages"]
|
||||
if not p.get("disabled", False)
|
||||
and (
|
||||
p["repo"].startswith("langchain-ai/") or p.get("include_in_api_ref")
|
||||
)
|
||||
and p["repo"] != "langchain-ai/langchain"
|
||||
and p["name"]
|
||||
!= "langchain-ai21" # Skip AI21 due to dependency conflicts
|
||||
]
|
||||
)
|
||||
|
||||
# Delete ones without a pyproject.toml
|
||||
for partner in Path("langchain/libs/partners").iterdir():
|
||||
|
||||
416
.github/tools/git-restore-mtime
vendored
416
.github/tools/git-restore-mtime
vendored
@@ -81,56 +81,93 @@ import time
|
||||
__version__ = "2022.12+dev"
|
||||
|
||||
# Update symlinks only if the platform supports not following them
|
||||
UPDATE_SYMLINKS = bool(os.utime in getattr(os, 'supports_follow_symlinks', []))
|
||||
UPDATE_SYMLINKS = bool(os.utime in getattr(os, "supports_follow_symlinks", []))
|
||||
|
||||
# Call os.path.normpath() only if not in a POSIX platform (Windows)
|
||||
NORMALIZE_PATHS = (os.path.sep != '/')
|
||||
NORMALIZE_PATHS = os.path.sep != "/"
|
||||
|
||||
# How many files to process in each batch when re-trying merge commits
|
||||
STEPMISSING = 100
|
||||
|
||||
# (Extra) keywords for the os.utime() call performed by touch()
|
||||
UTIME_KWS = {} if not UPDATE_SYMLINKS else {'follow_symlinks': False}
|
||||
UTIME_KWS = {} if not UPDATE_SYMLINKS else {"follow_symlinks": False}
|
||||
|
||||
|
||||
# Command-line interface ######################################################
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description=__doc__.split('\n---')[0])
|
||||
parser = argparse.ArgumentParser(description=__doc__.split("\n---")[0])
|
||||
|
||||
group = parser.add_mutually_exclusive_group()
|
||||
group.add_argument('--quiet', '-q', dest='loglevel',
|
||||
action="store_const", const=logging.WARNING, default=logging.INFO,
|
||||
help="Suppress informative messages and summary statistics.")
|
||||
group.add_argument('--verbose', '-v', action="count", help="""
|
||||
group.add_argument(
|
||||
"--quiet",
|
||||
"-q",
|
||||
dest="loglevel",
|
||||
action="store_const",
|
||||
const=logging.WARNING,
|
||||
default=logging.INFO,
|
||||
help="Suppress informative messages and summary statistics.",
|
||||
)
|
||||
group.add_argument(
|
||||
"--verbose",
|
||||
"-v",
|
||||
action="count",
|
||||
help="""
|
||||
Print additional information for each processed file.
|
||||
Specify twice to further increase verbosity.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--cwd', '-C', metavar="DIRECTORY", help="""
|
||||
parser.add_argument(
|
||||
"--cwd",
|
||||
"-C",
|
||||
metavar="DIRECTORY",
|
||||
help="""
|
||||
Run as if %(prog)s was started in directory %(metavar)s.
|
||||
This affects how --work-tree, --git-dir and PATHSPEC arguments are handled.
|
||||
See 'man 1 git' or 'git --help' for more information.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--git-dir', dest='gitdir', metavar="GITDIR", help="""
|
||||
parser.add_argument(
|
||||
"--git-dir",
|
||||
dest="gitdir",
|
||||
metavar="GITDIR",
|
||||
help="""
|
||||
Path to the git repository, by default auto-discovered by searching
|
||||
the current directory and its parents for a .git/ subdirectory.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--work-tree', dest='workdir', metavar="WORKTREE", help="""
|
||||
parser.add_argument(
|
||||
"--work-tree",
|
||||
dest="workdir",
|
||||
metavar="WORKTREE",
|
||||
help="""
|
||||
Path to the work tree root, by default the parent of GITDIR if it's
|
||||
automatically discovered, or the current directory if GITDIR is set.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--force', '-f', default=False, action="store_true", help="""
|
||||
parser.add_argument(
|
||||
"--force",
|
||||
"-f",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Force updating files with uncommitted modifications.
|
||||
Untracked files and uncommitted deletions, renames and additions are
|
||||
always ignored.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--merge', '-m', default=False, action="store_true", help="""
|
||||
parser.add_argument(
|
||||
"--merge",
|
||||
"-m",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Include merge commits.
|
||||
Leads to more recent times and more files per commit, thus with the same
|
||||
time, which may or may not be what you want.
|
||||
@@ -138,71 +175,130 @@ def parse_args():
|
||||
are found sooner, which can improve performance, sometimes substantially.
|
||||
But as merge commits are usually huge, processing them may also take longer.
|
||||
By default, merge commits are only used for files missing from regular commits.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--first-parent', default=False, action="store_true", help="""
|
||||
parser.add_argument(
|
||||
"--first-parent",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Consider only the first parent, the "main branch", when evaluating merge commits.
|
||||
Only effective when merge commits are processed, either when --merge is
|
||||
used or when finding missing files after the first regular log search.
|
||||
See --skip-missing.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--skip-missing', '-s', dest="missing", default=True,
|
||||
action="store_false", help="""
|
||||
parser.add_argument(
|
||||
"--skip-missing",
|
||||
"-s",
|
||||
dest="missing",
|
||||
default=True,
|
||||
action="store_false",
|
||||
help="""
|
||||
Do not try to find missing files.
|
||||
If merge commits were not evaluated with --merge and some files were
|
||||
not found in regular commits, by default %(prog)s searches for these
|
||||
files again in the merge commits.
|
||||
This option disables this retry, so files found only in merge commits
|
||||
will not have their timestamp updated.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--no-directories', '-D', dest='dirs', default=True,
|
||||
action="store_false", help="""
|
||||
parser.add_argument(
|
||||
"--no-directories",
|
||||
"-D",
|
||||
dest="dirs",
|
||||
default=True,
|
||||
action="store_false",
|
||||
help="""
|
||||
Do not update directory timestamps.
|
||||
By default, use the time of its most recently created, renamed or deleted file.
|
||||
Note that just modifying a file will NOT update its directory time.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--test', '-t', default=False, action="store_true",
|
||||
help="Test run: do not actually update any file timestamp.")
|
||||
parser.add_argument(
|
||||
"--test",
|
||||
"-t",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="Test run: do not actually update any file timestamp.",
|
||||
)
|
||||
|
||||
parser.add_argument('--commit-time', '-c', dest='commit_time', default=False,
|
||||
action='store_true', help="Use commit time instead of author time.")
|
||||
parser.add_argument(
|
||||
"--commit-time",
|
||||
"-c",
|
||||
dest="commit_time",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="Use commit time instead of author time.",
|
||||
)
|
||||
|
||||
parser.add_argument('--oldest-time', '-o', dest='reverse_order', default=False,
|
||||
action='store_true', help="""
|
||||
parser.add_argument(
|
||||
"--oldest-time",
|
||||
"-o",
|
||||
dest="reverse_order",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Update times based on the oldest, instead of the most recent commit of a file.
|
||||
This reverses the order in which the git log is processed to emulate a
|
||||
file "creation" date. Note this will be inaccurate for files deleted and
|
||||
re-created at later dates.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--skip-older-than', metavar='SECONDS', type=int, help="""
|
||||
parser.add_argument(
|
||||
"--skip-older-than",
|
||||
metavar="SECONDS",
|
||||
type=int,
|
||||
help="""
|
||||
Ignore files that are currently older than %(metavar)s.
|
||||
Useful in workflows that assume such files already have a correct timestamp,
|
||||
as it may improve performance by processing fewer files.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--skip-older-than-commit', '-N', default=False,
|
||||
action='store_true', help="""
|
||||
parser.add_argument(
|
||||
"--skip-older-than-commit",
|
||||
"-N",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Ignore files older than the timestamp it would be updated to.
|
||||
Such files may be considered "original", likely in the author's repository.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--unique-times', default=False, action="store_true", help="""
|
||||
parser.add_argument(
|
||||
"--unique-times",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="""
|
||||
Set the microseconds to a unique value per commit.
|
||||
Allows telling apart changes that would otherwise have identical timestamps,
|
||||
as git's time accuracy is in seconds.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('pathspec', nargs='*', metavar='PATHSPEC', help="""
|
||||
parser.add_argument(
|
||||
"pathspec",
|
||||
nargs="*",
|
||||
metavar="PATHSPEC",
|
||||
help="""
|
||||
Only modify paths matching %(metavar)s, relative to current directory.
|
||||
By default, update all but untracked files and submodules.
|
||||
""")
|
||||
""",
|
||||
)
|
||||
|
||||
parser.add_argument('--version', '-V', action='version',
|
||||
version='%(prog)s version {version}'.format(version=get_version()))
|
||||
parser.add_argument(
|
||||
"--version",
|
||||
"-V",
|
||||
action="version",
|
||||
version="%(prog)s version {version}".format(version=get_version()),
|
||||
)
|
||||
|
||||
args_ = parser.parse_args()
|
||||
if args_.verbose:
|
||||
@@ -212,17 +308,18 @@ def parse_args():
|
||||
|
||||
|
||||
def get_version(version=__version__):
|
||||
if not version.endswith('+dev'):
|
||||
if not version.endswith("+dev"):
|
||||
return version
|
||||
try:
|
||||
cwd = os.path.dirname(os.path.realpath(__file__))
|
||||
return Git(cwd=cwd, errors=False).describe().lstrip('v')
|
||||
return Git(cwd=cwd, errors=False).describe().lstrip("v")
|
||||
except Git.Error:
|
||||
return '-'.join((version, "unknown"))
|
||||
return "-".join((version, "unknown"))
|
||||
|
||||
|
||||
# Helper functions ############################################################
|
||||
|
||||
|
||||
def setup_logging():
|
||||
"""Add TRACE logging level and corresponding method, return the root logger"""
|
||||
logging.TRACE = TRACE = logging.DEBUG // 2
|
||||
@@ -255,11 +352,13 @@ def normalize(path):
|
||||
if path and path[0] == '"':
|
||||
# Python 2: path = path[1:-1].decode("string-escape")
|
||||
# Python 3: https://stackoverflow.com/a/46650050/624066
|
||||
path = (path[1:-1] # Remove enclosing double quotes
|
||||
.encode('latin1') # Convert to bytes, required by 'unicode-escape'
|
||||
.decode('unicode-escape') # Perform the actual octal-escaping decode
|
||||
.encode('latin1') # 1:1 mapping to bytes, UTF-8 encoded
|
||||
.decode('utf8', 'surrogateescape')) # Decode from UTF-8
|
||||
path = (
|
||||
path[1:-1] # Remove enclosing double quotes
|
||||
.encode("latin1") # Convert to bytes, required by 'unicode-escape'
|
||||
.decode("unicode-escape") # Perform the actual octal-escaping decode
|
||||
.encode("latin1") # 1:1 mapping to bytes, UTF-8 encoded
|
||||
.decode("utf8", "surrogateescape")
|
||||
) # Decode from UTF-8
|
||||
if NORMALIZE_PATHS:
|
||||
# Make sure the slash matches the OS; for Windows we need a backslash
|
||||
path = os.path.normpath(path)
|
||||
@@ -282,12 +381,12 @@ def touch_ns(path, mtime_ns):
|
||||
|
||||
def isodate(secs: int):
|
||||
# time.localtime() accepts floats, but discards fractional part
|
||||
return time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(secs))
|
||||
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(secs))
|
||||
|
||||
|
||||
def isodate_ns(ns: int):
|
||||
# for integers fromtimestamp() is equivalent and ~16% slower than isodate()
|
||||
return datetime.datetime.fromtimestamp(ns / 1000000000).isoformat(sep=' ')
|
||||
return datetime.datetime.fromtimestamp(ns / 1000000000).isoformat(sep=" ")
|
||||
|
||||
|
||||
def get_mtime_ns(secs: int, idx: int):
|
||||
@@ -305,35 +404,49 @@ def get_mtime_path(path):
|
||||
|
||||
# Git class and parse_log(), the heart of the script ##########################
|
||||
|
||||
|
||||
class Git:
|
||||
def __init__(self, workdir=None, gitdir=None, cwd=None, errors=True):
|
||||
self.gitcmd = ['git']
|
||||
self.gitcmd = ["git"]
|
||||
self.errors = errors
|
||||
self._proc = None
|
||||
if workdir: self.gitcmd.extend(('--work-tree', workdir))
|
||||
if gitdir: self.gitcmd.extend(('--git-dir', gitdir))
|
||||
if cwd: self.gitcmd.extend(('-C', cwd))
|
||||
if workdir:
|
||||
self.gitcmd.extend(("--work-tree", workdir))
|
||||
if gitdir:
|
||||
self.gitcmd.extend(("--git-dir", gitdir))
|
||||
if cwd:
|
||||
self.gitcmd.extend(("-C", cwd))
|
||||
self.workdir, self.gitdir = self._get_repo_dirs()
|
||||
|
||||
def ls_files(self, paths: list = None):
|
||||
return (normalize(_) for _ in self._run('ls-files --full-name', paths))
|
||||
return (normalize(_) for _ in self._run("ls-files --full-name", paths))
|
||||
|
||||
def ls_dirty(self, force=False):
|
||||
return (normalize(_[3:].split(' -> ', 1)[-1])
|
||||
for _ in self._run('status --porcelain')
|
||||
if _[:2] != '??' and (not force or (_[0] in ('R', 'A')
|
||||
or _[1] == 'D')))
|
||||
return (
|
||||
normalize(_[3:].split(" -> ", 1)[-1])
|
||||
for _ in self._run("status --porcelain")
|
||||
if _[:2] != "??" and (not force or (_[0] in ("R", "A") or _[1] == "D"))
|
||||
)
|
||||
|
||||
def log(self, merge=False, first_parent=False, commit_time=False,
|
||||
reverse_order=False, paths: list = None):
|
||||
cmd = 'whatchanged --pretty={}'.format('%ct' if commit_time else '%at')
|
||||
if merge: cmd += ' -m'
|
||||
if first_parent: cmd += ' --first-parent'
|
||||
if reverse_order: cmd += ' --reverse'
|
||||
def log(
|
||||
self,
|
||||
merge=False,
|
||||
first_parent=False,
|
||||
commit_time=False,
|
||||
reverse_order=False,
|
||||
paths: list = None,
|
||||
):
|
||||
cmd = "whatchanged --pretty={}".format("%ct" if commit_time else "%at")
|
||||
if merge:
|
||||
cmd += " -m"
|
||||
if first_parent:
|
||||
cmd += " --first-parent"
|
||||
if reverse_order:
|
||||
cmd += " --reverse"
|
||||
return self._run(cmd, paths)
|
||||
|
||||
def describe(self):
|
||||
return self._run('describe --tags', check=True)[0]
|
||||
return self._run("describe --tags", check=True)[0]
|
||||
|
||||
def terminate(self):
|
||||
if self._proc is None:
|
||||
@@ -345,18 +458,22 @@ class Git:
|
||||
pass
|
||||
|
||||
def _get_repo_dirs(self):
|
||||
return (os.path.normpath(_) for _ in
|
||||
self._run('rev-parse --show-toplevel --absolute-git-dir', check=True))
|
||||
return (
|
||||
os.path.normpath(_)
|
||||
for _ in self._run(
|
||||
"rev-parse --show-toplevel --absolute-git-dir", check=True
|
||||
)
|
||||
)
|
||||
|
||||
def _run(self, cmdstr: str, paths: list = None, output=True, check=False):
|
||||
cmdlist = self.gitcmd + shlex.split(cmdstr)
|
||||
if paths:
|
||||
cmdlist.append('--')
|
||||
cmdlist.append("--")
|
||||
cmdlist.extend(paths)
|
||||
popen_args = dict(universal_newlines=True, encoding='utf8')
|
||||
popen_args = dict(universal_newlines=True, encoding="utf8")
|
||||
if not self.errors:
|
||||
popen_args['stderr'] = subprocess.DEVNULL
|
||||
log.trace("Executing: %s", ' '.join(cmdlist))
|
||||
popen_args["stderr"] = subprocess.DEVNULL
|
||||
log.trace("Executing: %s", " ".join(cmdlist))
|
||||
if not output:
|
||||
return subprocess.call(cmdlist, **popen_args)
|
||||
if check:
|
||||
@@ -379,30 +496,26 @@ def parse_log(filelist, dirlist, stats, git, merge=False, filterlist=None):
|
||||
mtime = 0
|
||||
datestr = isodate(0)
|
||||
for line in git.log(
|
||||
merge,
|
||||
args.first_parent,
|
||||
args.commit_time,
|
||||
args.reverse_order,
|
||||
filterlist
|
||||
merge, args.first_parent, args.commit_time, args.reverse_order, filterlist
|
||||
):
|
||||
stats['loglines'] += 1
|
||||
stats["loglines"] += 1
|
||||
|
||||
# Blank line between Date and list of files
|
||||
if not line:
|
||||
continue
|
||||
|
||||
# Date line
|
||||
if line[0] != ':': # Faster than `not line.startswith(':')`
|
||||
stats['commits'] += 1
|
||||
if line[0] != ":": # Faster than `not line.startswith(':')`
|
||||
stats["commits"] += 1
|
||||
mtime = int(line)
|
||||
if args.unique_times:
|
||||
mtime = get_mtime_ns(mtime, stats['commits'])
|
||||
mtime = get_mtime_ns(mtime, stats["commits"])
|
||||
if args.debug:
|
||||
datestr = isodate(mtime)
|
||||
continue
|
||||
|
||||
# File line: three tokens if it describes a renaming, otherwise two
|
||||
tokens = line.split('\t')
|
||||
tokens = line.split("\t")
|
||||
|
||||
# Possible statuses:
|
||||
# M: Modified (content changed)
|
||||
@@ -411,7 +524,7 @@ def parse_log(filelist, dirlist, stats, git, merge=False, filterlist=None):
|
||||
# T: Type changed: to/from regular file, symlinks, submodules
|
||||
# R099: Renamed (moved), with % of unchanged content. 100 = pure rename
|
||||
# Not possible in log: C=Copied, U=Unmerged, X=Unknown, B=pairing Broken
|
||||
status = tokens[0].split(' ')[-1]
|
||||
status = tokens[0].split(" ")[-1]
|
||||
file = tokens[-1]
|
||||
|
||||
# Handles non-ASCII chars and OS path separator
|
||||
@@ -419,56 +532,76 @@ def parse_log(filelist, dirlist, stats, git, merge=False, filterlist=None):
|
||||
|
||||
def do_file():
|
||||
if args.skip_older_than_commit and get_mtime_path(file) <= mtime:
|
||||
stats['skip'] += 1
|
||||
stats["skip"] += 1
|
||||
return
|
||||
if args.debug:
|
||||
log.debug("%d\t%d\t%d\t%s\t%s",
|
||||
stats['loglines'], stats['commits'], stats['files'],
|
||||
datestr, file)
|
||||
log.debug(
|
||||
"%d\t%d\t%d\t%s\t%s",
|
||||
stats["loglines"],
|
||||
stats["commits"],
|
||||
stats["files"],
|
||||
datestr,
|
||||
file,
|
||||
)
|
||||
try:
|
||||
touch(os.path.join(git.workdir, file), mtime)
|
||||
stats['touches'] += 1
|
||||
stats["touches"] += 1
|
||||
except Exception as e:
|
||||
log.error("ERROR: %s: %s", e, file)
|
||||
stats['errors'] += 1
|
||||
stats["errors"] += 1
|
||||
|
||||
def do_dir():
|
||||
if args.debug:
|
||||
log.debug("%d\t%d\t-\t%s\t%s",
|
||||
stats['loglines'], stats['commits'],
|
||||
datestr, "{}/".format(dirname or '.'))
|
||||
log.debug(
|
||||
"%d\t%d\t-\t%s\t%s",
|
||||
stats["loglines"],
|
||||
stats["commits"],
|
||||
datestr,
|
||||
"{}/".format(dirname or "."),
|
||||
)
|
||||
try:
|
||||
touch(os.path.join(git.workdir, dirname), mtime)
|
||||
stats['dirtouches'] += 1
|
||||
stats["dirtouches"] += 1
|
||||
except Exception as e:
|
||||
log.error("ERROR: %s: %s", e, dirname)
|
||||
stats['direrrors'] += 1
|
||||
stats["direrrors"] += 1
|
||||
|
||||
if file in filelist:
|
||||
stats['files'] -= 1
|
||||
stats["files"] -= 1
|
||||
filelist.remove(file)
|
||||
do_file()
|
||||
|
||||
if args.dirs and status in ('A', 'D'):
|
||||
if args.dirs and status in ("A", "D"):
|
||||
dirname = os.path.dirname(file)
|
||||
if dirname in dirlist:
|
||||
dirlist.remove(dirname)
|
||||
do_dir()
|
||||
|
||||
# All files done?
|
||||
if not stats['files']:
|
||||
if not stats["files"]:
|
||||
git.terminate()
|
||||
return
|
||||
|
||||
|
||||
# Main Logic ##################################################################
|
||||
|
||||
|
||||
def main():
|
||||
start = time.time() # yes, Wall time. CPU time is not realistic for users.
|
||||
stats = {_: 0 for _ in ('loglines', 'commits', 'touches', 'skip', 'errors',
|
||||
'dirtouches', 'direrrors')}
|
||||
stats = {
|
||||
_: 0
|
||||
for _ in (
|
||||
"loglines",
|
||||
"commits",
|
||||
"touches",
|
||||
"skip",
|
||||
"errors",
|
||||
"dirtouches",
|
||||
"direrrors",
|
||||
)
|
||||
}
|
||||
|
||||
logging.basicConfig(level=args.loglevel, format='%(message)s')
|
||||
logging.basicConfig(level=args.loglevel, format="%(message)s")
|
||||
log.trace("Arguments: %s", args)
|
||||
|
||||
# First things first: Where and Who are we?
|
||||
@@ -499,13 +632,16 @@ def main():
|
||||
|
||||
# Symlink (to file, to dir or broken - git handles the same way)
|
||||
if not UPDATE_SYMLINKS and os.path.islink(fullpath):
|
||||
log.warning("WARNING: Skipping symlink, no OS support for updates: %s",
|
||||
path)
|
||||
log.warning(
|
||||
"WARNING: Skipping symlink, no OS support for updates: %s", path
|
||||
)
|
||||
continue
|
||||
|
||||
# skip files which are older than given threshold
|
||||
if (args.skip_older_than
|
||||
and start - get_mtime_path(fullpath) > args.skip_older_than):
|
||||
if (
|
||||
args.skip_older_than
|
||||
and start - get_mtime_path(fullpath) > args.skip_older_than
|
||||
):
|
||||
continue
|
||||
|
||||
# Always add files relative to worktree root
|
||||
@@ -519,15 +655,17 @@ def main():
|
||||
else:
|
||||
dirty = set(git.ls_dirty())
|
||||
if dirty:
|
||||
log.warning("WARNING: Modified files in the working directory were ignored."
|
||||
"\nTo include such files, commit your changes or use --force.")
|
||||
log.warning(
|
||||
"WARNING: Modified files in the working directory were ignored."
|
||||
"\nTo include such files, commit your changes or use --force."
|
||||
)
|
||||
filelist -= dirty
|
||||
|
||||
# Build dir list to be processed
|
||||
dirlist = set(os.path.dirname(_) for _ in filelist) if args.dirs else set()
|
||||
|
||||
stats['totalfiles'] = stats['files'] = len(filelist)
|
||||
log.info("{0:,} files to be processed in work dir".format(stats['totalfiles']))
|
||||
stats["totalfiles"] = stats["files"] = len(filelist)
|
||||
log.info("{0:,} files to be processed in work dir".format(stats["totalfiles"]))
|
||||
|
||||
if not filelist:
|
||||
# Nothing to do. Exit silently and without errors, just like git does
|
||||
@@ -544,10 +682,18 @@ def main():
|
||||
if args.missing and not args.merge:
|
||||
filterlist = list(filelist)
|
||||
missing = len(filterlist)
|
||||
log.info("{0:,} files not found in log, trying merge commits".format(missing))
|
||||
log.info(
|
||||
"{0:,} files not found in log, trying merge commits".format(missing)
|
||||
)
|
||||
for i in range(0, missing, STEPMISSING):
|
||||
parse_log(filelist, dirlist, stats, git,
|
||||
merge=True, filterlist=filterlist[i:i + STEPMISSING])
|
||||
parse_log(
|
||||
filelist,
|
||||
dirlist,
|
||||
stats,
|
||||
git,
|
||||
merge=True,
|
||||
filterlist=filterlist[i : i + STEPMISSING],
|
||||
)
|
||||
|
||||
# Still missing some?
|
||||
for file in filelist:
|
||||
@@ -556,29 +702,33 @@ def main():
|
||||
# Final statistics
|
||||
# Suggestion: use git-log --before=mtime to brag about skipped log entries
|
||||
def log_info(msg, *a, width=13):
|
||||
ifmt = '{:%d,}' % (width,) # not using 'n' for consistency with ffmt
|
||||
ffmt = '{:%d,.2f}' % (width,)
|
||||
ifmt = "{:%d,}" % (width,) # not using 'n' for consistency with ffmt
|
||||
ffmt = "{:%d,.2f}" % (width,)
|
||||
# %-formatting lacks a thousand separator, must pre-render with .format()
|
||||
log.info(msg.replace('%d', ifmt).replace('%f', ffmt).format(*a))
|
||||
log.info(msg.replace("%d", ifmt).replace("%f", ffmt).format(*a))
|
||||
|
||||
log_info(
|
||||
"Statistics:\n"
|
||||
"%f seconds\n"
|
||||
"%d log lines processed\n"
|
||||
"%d commits evaluated",
|
||||
time.time() - start, stats['loglines'], stats['commits'])
|
||||
"Statistics:\n%f seconds\n%d log lines processed\n%d commits evaluated",
|
||||
time.time() - start,
|
||||
stats["loglines"],
|
||||
stats["commits"],
|
||||
)
|
||||
|
||||
if args.dirs:
|
||||
if stats['direrrors']: log_info("%d directory update errors", stats['direrrors'])
|
||||
log_info("%d directories updated", stats['dirtouches'])
|
||||
if stats["direrrors"]:
|
||||
log_info("%d directory update errors", stats["direrrors"])
|
||||
log_info("%d directories updated", stats["dirtouches"])
|
||||
|
||||
if stats['touches'] != stats['totalfiles']:
|
||||
log_info("%d files", stats['totalfiles'])
|
||||
if stats['skip']: log_info("%d files skipped", stats['skip'])
|
||||
if stats['files']: log_info("%d files missing", stats['files'])
|
||||
if stats['errors']: log_info("%d file update errors", stats['errors'])
|
||||
if stats["touches"] != stats["totalfiles"]:
|
||||
log_info("%d files", stats["totalfiles"])
|
||||
if stats["skip"]:
|
||||
log_info("%d files skipped", stats["skip"])
|
||||
if stats["files"]:
|
||||
log_info("%d files missing", stats["files"])
|
||||
if stats["errors"]:
|
||||
log_info("%d file update errors", stats["errors"])
|
||||
|
||||
log_info("%d files updated", stats['touches'])
|
||||
log_info("%d files updated", stats["touches"])
|
||||
|
||||
if args.test:
|
||||
log.info("TEST RUN - No files modified!")
|
||||
|
||||
11
.github/workflows/_release.yml
vendored
11
.github/workflows/_release.yml
vendored
@@ -220,7 +220,7 @@ jobs:
|
||||
with:
|
||||
python-version: ${{ env.PYTHON_VERSION }}
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
- uses: actions/download-artifact@v5
|
||||
with:
|
||||
name: dist
|
||||
path: ${{ inputs.working-directory }}/dist/
|
||||
@@ -379,7 +379,7 @@ jobs:
|
||||
with:
|
||||
python-version: ${{ env.PYTHON_VERSION }}
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
- uses: actions/download-artifact@v5
|
||||
if: startsWith(inputs.working-directory, 'libs/core')
|
||||
with:
|
||||
name: dist
|
||||
@@ -388,11 +388,12 @@ jobs:
|
||||
- name: Test against ${{ matrix.partner }}
|
||||
if: startsWith(inputs.working-directory, 'libs/core')
|
||||
run: |
|
||||
# Identify latest tag
|
||||
# Identify latest tag, excluding pre-releases
|
||||
LATEST_PACKAGE_TAG="$(
|
||||
git ls-remote --tags origin "langchain-${{ matrix.partner }}*" \
|
||||
| awk '{print $2}' \
|
||||
| sed 's|refs/tags/||' \
|
||||
| grep -Ev '==[^=]*(\.?dev[0-9]*|\.?rc[0-9]*)$' \
|
||||
| sort -Vr \
|
||||
| head -n 1
|
||||
)"
|
||||
@@ -446,7 +447,7 @@ jobs:
|
||||
with:
|
||||
python-version: ${{ env.PYTHON_VERSION }}
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
- uses: actions/download-artifact@v5
|
||||
with:
|
||||
name: dist
|
||||
path: ${{ inputs.working-directory }}/dist/
|
||||
@@ -485,7 +486,7 @@ jobs:
|
||||
with:
|
||||
python-version: ${{ env.PYTHON_VERSION }}
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
- uses: actions/download-artifact@v5
|
||||
with:
|
||||
name: dist
|
||||
path: ${{ inputs.working-directory }}/dist/
|
||||
|
||||
2
.github/workflows/_test.yml
vendored
2
.github/workflows/_test.yml
vendored
@@ -79,4 +79,4 @@ jobs:
|
||||
# grep will exit non-zero if the target message isn't found,
|
||||
# and `set -e` above will cause the step to fail.
|
||||
echo "$STATUS" | grep 'nothing to commit, working tree clean'
|
||||
|
||||
|
||||
|
||||
2
.github/workflows/_test_pydantic.yml
vendored
2
.github/workflows/_test_pydantic.yml
vendored
@@ -64,4 +64,4 @@ jobs:
|
||||
|
||||
# grep will exit non-zero if the target message isn't found,
|
||||
# and `set -e` above will cause the step to fail.
|
||||
echo "$STATUS" | grep 'nothing to commit, working tree clean'
|
||||
echo "$STATUS" | grep 'nothing to commit, working tree clean'
|
||||
|
||||
2
.github/workflows/_test_release.yml
vendored
2
.github/workflows/_test_release.yml
vendored
@@ -85,7 +85,7 @@ jobs:
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
- uses: actions/download-artifact@v5
|
||||
with:
|
||||
name: test-dist
|
||||
path: ${{ inputs.working-directory }}/dist/
|
||||
|
||||
1
.github/workflows/check_diffs.yml
vendored
1
.github/workflows/check_diffs.yml
vendored
@@ -30,6 +30,7 @@ jobs:
|
||||
build:
|
||||
name: 'Detect Changes & Set Matrix'
|
||||
runs-on: ubuntu-latest
|
||||
if: ${{ !contains(github.event.pull_request.labels.*.name, 'ci-ignore') }}
|
||||
steps:
|
||||
- name: '📋 Checkout Code'
|
||||
uses: actions/checkout@v4
|
||||
|
||||
@@ -11,4 +11,4 @@
|
||||
"MD046": {
|
||||
"style": "fenced"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
4
.vscode/settings.json
vendored
4
.vscode/settings.json
vendored
@@ -21,7 +21,7 @@
|
||||
"[python]": {
|
||||
"editor.formatOnSave": true,
|
||||
"editor.codeActionsOnSave": {
|
||||
"source.organizeImports": "explicit",
|
||||
"source.organizeImports.ruff": "explicit",
|
||||
"source.fixAll": "explicit"
|
||||
},
|
||||
"editor.defaultFormatter": "charliermarsh.ruff"
|
||||
@@ -77,4 +77,6 @@
|
||||
"editor.tabSize": 2,
|
||||
"editor.insertSpaces": true
|
||||
},
|
||||
"python.terminal.activateEnvironment": false,
|
||||
"python.defaultInterpreterPath": "./.venv/bin/python"
|
||||
}
|
||||
|
||||
@@ -63,4 +63,4 @@ Notebook | Description
|
||||
[rag-locally-on-intel-cpu.ipynb](https://github.com/langchain-ai/langchain/tree/master/cookbook/rag-locally-on-intel-cpu.ipynb) | Perform Retrieval-Augmented-Generation (RAG) on locally downloaded open-source models using langchain and open source tools and execute it on Intel Xeon CPU. We showed an example of how to apply RAG on Llama 2 model and enable it to answer the queries related to Intel Q1 2024 earnings release.
|
||||
[visual_RAG_vdms.ipynb](https://github.com/langchain-ai/langchain/tree/master/cookbook/visual_RAG_vdms.ipynb) | Performs Visual Retrieval-Augmented-Generation (RAG) using videos and scene descriptions generated by open source models.
|
||||
[contextual_rag.ipynb](https://github.com/langchain-ai/langchain/tree/master/cookbook/contextual_rag.ipynb) | Performs contextual retrieval-augmented generation (RAG) prepending chunk-specific explanatory context to each chunk before embedding.
|
||||
[rag-agents-locally-on-intel-cpu.ipynb](https://github.com/langchain-ai/langchain/tree/master/cookbook/local_rag_agents_intel_cpu.ipynb) | Build a RAG agent locally with open source models that routes questions through one of two paths to find answers. The agent generates answers based on documents retrieved from either the vector database or retrieved from web search. If the vector database lacks relevant information, the agent opts for web search. Open-source models for LLM and embeddings are used locally on an Intel Xeon CPU to execute this pipeline.
|
||||
[rag-agents-locally-on-intel-cpu.ipynb](https://github.com/langchain-ai/langchain/tree/master/cookbook/local_rag_agents_intel_cpu.ipynb) | Build a RAG agent locally with open source models that routes questions through one of two paths to find answers. The agent generates answers based on documents retrieved from either the vector database or retrieved from web search. If the vector database lacks relevant information, the agent opts for web search. Open-source models for LLM and embeddings are used locally on an Intel Xeon CPU to execute this pipeline.
|
||||
|
||||
@@ -79,6 +79,17 @@
|
||||
"tool_executor = ToolExecutor(tools)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "168152fc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"📘 **Note on `SystemMessage` usage with LangGraph-based agents**\n",
|
||||
"\n",
|
||||
"When constructing the `messages` list for an agent, you *must* manually include any `SystemMessage`s.\n",
|
||||
"Unlike some agent executors in LangChain that set a default, LangGraph requires explicit inclusion."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fe6e8f78-1ef7-42ad-b2bf-835ed5850553",
|
||||
|
||||
@@ -97,7 +97,7 @@ def _load_module_members(module_path: str, namespace: str) -> ModuleMembers:
|
||||
if type(type_) is typing_extensions._TypedDictMeta: # type: ignore
|
||||
kind: ClassKind = "TypedDict"
|
||||
elif type(type_) is typing._TypedDictMeta: # type: ignore
|
||||
kind: ClassKind = "TypedDict"
|
||||
kind = "TypedDict"
|
||||
elif (
|
||||
issubclass(type_, Runnable)
|
||||
and issubclass(type_, BaseModel)
|
||||
@@ -189,7 +189,7 @@ def _load_package_modules(
|
||||
if isinstance(package_directory, str)
|
||||
else package_directory
|
||||
)
|
||||
modules_by_namespace = {}
|
||||
modules_by_namespace: Dict[str, ModuleMembers] = {}
|
||||
|
||||
# Get the high level package name
|
||||
package_name = package_path.name
|
||||
@@ -217,11 +217,7 @@ def _load_package_modules(
|
||||
# Get the full namespace of the module
|
||||
namespace = str(relative_module_name).replace(".py", "").replace("/", ".")
|
||||
# Keep only the top level namespace
|
||||
# (but make special exception for content_blocks and messages.v1)
|
||||
if namespace == "messages.content_blocks" or namespace == "messages.v1":
|
||||
top_namespace = namespace # Keep full namespace for content_blocks
|
||||
else:
|
||||
top_namespace = namespace.split(".")[0]
|
||||
top_namespace = namespace.split(".")[0]
|
||||
|
||||
try:
|
||||
# If submodule is present, we need to construct the paths in a slightly
|
||||
@@ -549,7 +545,14 @@ def _build_index(dirs: List[str]) -> None:
|
||||
"ai21": "AI21",
|
||||
"ibm": "IBM",
|
||||
}
|
||||
ordered = ["core", "langchain", "text-splitters", "community", "experimental"]
|
||||
ordered = [
|
||||
"core",
|
||||
"langchain",
|
||||
"text-splitters",
|
||||
"community",
|
||||
"experimental",
|
||||
"standard-tests",
|
||||
]
|
||||
main_ = [dir_ for dir_ in ordered if dir_ in dirs]
|
||||
integrations = sorted(dir_ for dir_ in dirs if dir_ not in main_)
|
||||
doc = """# LangChain Python API Reference
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# Async programming with langchain
|
||||
# Async programming with LangChain
|
||||
|
||||
:::info Prerequisites
|
||||
* [Runnable interface](/docs/concepts/runnables)
|
||||
@@ -12,7 +12,7 @@ You are expected to be familiar with asynchronous programming in Python before r
|
||||
This guide specifically focuses on what you need to know to work with LangChain in an asynchronous context, assuming that you are already familiar with asynchronous programming.
|
||||
:::
|
||||
|
||||
## Langchain asynchronous APIs
|
||||
## LangChain asynchronous APIs
|
||||
|
||||
Many LangChain APIs are designed to be asynchronous, allowing you to build efficient and responsive applications.
|
||||
|
||||
|
||||
@@ -53,17 +53,29 @@ This is how you use MessagesPlaceholder.
|
||||
|
||||
```python
|
||||
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain_core.messages import HumanMessage
|
||||
from langchain_core.messages import HumanMessage, AIMessage
|
||||
|
||||
prompt_template = ChatPromptTemplate([
|
||||
("system", "You are a helpful assistant"),
|
||||
MessagesPlaceholder("msgs")
|
||||
])
|
||||
|
||||
# Simple example with one message
|
||||
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})
|
||||
|
||||
# More complex example with conversation history
|
||||
messages_to_pass = [
|
||||
HumanMessage(content="What's the capital of France?"),
|
||||
AIMessage(content="The capital of France is Paris."),
|
||||
HumanMessage(content="And what about Germany?")
|
||||
]
|
||||
|
||||
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
|
||||
print(formatted_prompt)
|
||||
```
|
||||
|
||||
This will produce a list of two messages, the first one being a system message, and the second one being the HumanMessage we passed in.
|
||||
|
||||
This will produce a list of four messages total: the system message plus the three messages we passed in (two HumanMessages and one AIMessage).
|
||||
If we had passed in 5 messages, then it would have produced 6 messages in total (the system message plus the 5 passed in).
|
||||
This is useful for letting a list of messages be slotted into a particular spot.
|
||||
|
||||
|
||||
@@ -31,7 +31,7 @@ The key attributes that correspond to the tool's **schema**:
|
||||
The key methods to execute the function associated with the **tool**:
|
||||
|
||||
- **invoke**: Invokes the tool with the given arguments.
|
||||
- **ainvoke**: Invokes the tool with the given arguments, asynchronously. Used for [async programming with Langchain](/docs/concepts/async).
|
||||
- **ainvoke**: Invokes the tool with the given arguments, asynchronously. Used for [async programming with LangChain](/docs/concepts/async).
|
||||
|
||||
## Create tools using the `@tool` decorator
|
||||
|
||||
@@ -171,6 +171,26 @@ Please see the [InjectedState](https://langchain-ai.github.io/langgraph/referenc
|
||||
|
||||
Please see the [InjectedStore](https://langchain-ai.github.io/langgraph/reference/prebuilt/#langgraph.prebuilt.tool_node.InjectedStore) documentation for more details.
|
||||
|
||||
## Tool Artifacts vs. Injected State
|
||||
|
||||
Although similar conceptually, tool artifacts in LangChain and [injected state in LangGraph](https://langchain-ai.github.io/langgraph/reference/agents/#langgraph.prebuilt.tool_node.InjectedState) serve different purposes and operate at different levels of abstraction.
|
||||
|
||||
**Tool Artifacts**
|
||||
|
||||
- **Purpose:** Store and pass data between tool executions within a single chain/workflow
|
||||
- **Scope:** Limited to tool-to-tool communication
|
||||
- **Lifecycle:** Tied to individual tool calls and their immediate context
|
||||
- **Usage:** Temporary storage for intermediate results that tools need to share
|
||||
|
||||
**Injected State (LangGraph)**
|
||||
|
||||
- **Purpose:** Maintain persistent state across the entire graph execution
|
||||
- **Scope:** Global to the entire graph workflow
|
||||
- **Lifecycle:** Persists throughout the entire graph execution and can be saved/restored
|
||||
- **Usage:** Long-term state management, conversation memory, user context, workflow checkpointing
|
||||
|
||||
Tool artifacts are ephemeral data passed between tools, while injected state is persistent workflow-level state that survives across multiple steps, tool calls, and even execution sessions in LangGraph.
|
||||
|
||||
## Best practices
|
||||
|
||||
When designing tools to be used by models, keep the following in mind:
|
||||
|
||||
@@ -9,6 +9,14 @@ This project utilizes [uv](https://docs.astral.sh/uv/) v0.5+ as a dependency man
|
||||
|
||||
Install `uv`: **[documentation on how to install it](https://docs.astral.sh/uv/getting-started/installation/)**.
|
||||
|
||||
### Windows Users
|
||||
|
||||
If you're on Windows and don't have `make` installed, you can install it via:
|
||||
- **Option 1**: Install via [Chocolatey](https://chocolatey.org/): `choco install make`
|
||||
- **Option 2**: Install via [Scoop](https://scoop.sh/): `scoop install make`
|
||||
- **Option 3**: Use [Windows Subsystem for Linux (WSL)](https://docs.microsoft.com/en-us/windows/wsl/)
|
||||
- **Option 4**: Use the direct `uv` commands shown in the sections below
|
||||
|
||||
## Different packages
|
||||
|
||||
This repository contains multiple packages:
|
||||
@@ -48,7 +56,11 @@ uv sync
|
||||
Then verify dependency installation:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make test
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --group test pytest -n auto --disable-socket --allow-unix-socket tests/unit_tests
|
||||
```
|
||||
|
||||
## Testing
|
||||
@@ -61,7 +73,11 @@ If you add new logic, please add a unit test.
|
||||
To run unit tests:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make test
|
||||
|
||||
# If you don't have make (Windows alternative):
|
||||
uv run --group test pytest -n auto --disable-socket --allow-unix-socket tests/unit_tests
|
||||
```
|
||||
|
||||
There are also [integration tests and code-coverage](../testing.mdx) available.
|
||||
@@ -72,7 +88,12 @@ If you are only developing `langchain_core`, you can simply install the dependen
|
||||
|
||||
```bash
|
||||
cd libs/core
|
||||
|
||||
# If you have `make` installed:
|
||||
make test
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --group test pytest -n auto --disable-socket --allow-unix-socket tests/unit_tests
|
||||
```
|
||||
|
||||
## Formatting and linting
|
||||
@@ -86,20 +107,37 @@ Formatting for this project is done via [ruff](https://docs.astral.sh/ruff/rules
|
||||
To run formatting for docs, cookbook and templates:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make format
|
||||
|
||||
# If you don't have make (Windows alternative):
|
||||
uv run --all-groups ruff format .
|
||||
uv run --all-groups ruff check --fix .
|
||||
```
|
||||
|
||||
To run formatting for a library, run the same command from the relevant library directory:
|
||||
|
||||
```bash
|
||||
cd libs/{LIBRARY}
|
||||
|
||||
# If you have `make` installed:
|
||||
make format
|
||||
|
||||
# If you don't have make (Windows alternative):
|
||||
uv run --all-groups ruff format .
|
||||
uv run --all-groups ruff check --fix .
|
||||
```
|
||||
|
||||
Additionally, you can run the formatter only on the files that have been modified in your current branch as compared to the master branch using the format_diff command:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make format_diff
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
# First, get the list of modified files:
|
||||
git diff --relative=libs/langchain --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$' | xargs uv run --all-groups ruff format
|
||||
git diff --relative=libs/langchain --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$' | xargs uv run --all-groups ruff check --fix
|
||||
```
|
||||
|
||||
This is especially useful when you have made changes to a subset of the project and want to ensure your changes are properly formatted without affecting the rest of the codebase.
|
||||
@@ -111,20 +149,40 @@ Linting for this project is done via a combination of [ruff](https://docs.astral
|
||||
To run linting for docs, cookbook and templates:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make lint
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --all-groups ruff check .
|
||||
uv run --all-groups ruff format . --diff
|
||||
uv run --all-groups mypy . --cache-dir .mypy_cache
|
||||
```
|
||||
|
||||
To run linting for a library, run the same command from the relevant library directory:
|
||||
|
||||
```bash
|
||||
cd libs/{LIBRARY}
|
||||
|
||||
# If you have `make` installed:
|
||||
make lint
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --all-groups ruff check .
|
||||
uv run --all-groups ruff format . --diff
|
||||
uv run --all-groups mypy . --cache-dir .mypy_cache
|
||||
```
|
||||
|
||||
In addition, you can run the linter only on the files that have been modified in your current branch as compared to the master branch using the lint_diff command:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make lint_diff
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
# First, get the list of modified files:
|
||||
git diff --relative=libs/langchain --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$' | xargs uv run --all-groups ruff check
|
||||
git diff --relative=libs/langchain --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$' | xargs uv run --all-groups ruff format --diff
|
||||
git diff --relative=libs/langchain --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$' | xargs uv run --all-groups mypy --cache-dir .mypy_cache
|
||||
```
|
||||
|
||||
This can be very helpful when you've made changes to only certain parts of the project and want to ensure your changes meet the linting standards without having to check the entire codebase.
|
||||
@@ -139,13 +197,21 @@ Note that `codespell` finds common typos, so it could have false-positive (corre
|
||||
To check spelling for this project:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make spell_check
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --all-groups codespell --toml pyproject.toml
|
||||
```
|
||||
|
||||
To fix spelling in place:
|
||||
|
||||
```bash
|
||||
# If you have `make` installed:
|
||||
make spell_fix
|
||||
|
||||
# If you don't have `make` (Windows alternative):
|
||||
uv run --all-groups codespell --toml pyproject.toml -w
|
||||
```
|
||||
|
||||
If codespell is incorrectly flagging a word, you can skip spellcheck for that word by adding it to the codespell config in the `pyproject.toml` file.
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
"\n",
|
||||
":::tip\n",
|
||||
"\n",
|
||||
"The **default** implementation does **not** provide support for token-by-token streaming, but it ensures that the the model can be swapped in for any other model as it supports the same standard interface.\n",
|
||||
"The **default** implementation does **not** provide support for token-by-token streaming, but it ensures that the model can be swapped in for any other model as it supports the same standard interface.\n",
|
||||
"\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
|
||||
@@ -323,7 +323,7 @@
|
||||
"source": [
|
||||
"## RAG based approach\n",
|
||||
"\n",
|
||||
"Another simple idea is to chunk up the text, but instead of extracting information from every chunk, just focus on the the most relevant chunks.\n",
|
||||
"Another simple idea is to chunk up the text, but instead of extracting information from every chunk, just focus on the most relevant chunks.\n",
|
||||
"\n",
|
||||
":::caution\n",
|
||||
"It can be difficult to identify which chunks are relevant.\n",
|
||||
|
||||
@@ -104,7 +104,7 @@
|
||||
"source": [
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"`filter_messages` can be used in an imperatively (like above) or declaratively, making it easy to compose with other components in a chain:"
|
||||
"`filter_messages` can be used imperatively (like above) or declaratively, making it easy to compose with other components in a chain:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -34,7 +34,7 @@ These are the core building blocks you can use when building applications.
|
||||
[Chat Models](/docs/concepts/chat_models) are newer forms of language models that take messages in and output a message.
|
||||
See [supported integrations](/docs/integrations/chat/) for details on getting started with chat models from a specific provider.
|
||||
|
||||
- [How to: init any model in one line](/docs/how_to/chat_models_universal_init/)
|
||||
- [How to: initialize any model in one line](/docs/how_to/chat_models_universal_init/)
|
||||
- [How to: work with local models](/docs/how_to/local_llms)
|
||||
- [How to: do function/tool calling](/docs/how_to/tool_calling)
|
||||
- [How to: get models to return structured output](/docs/how_to/structured_output)
|
||||
|
||||
@@ -199,7 +199,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def _clear():\n",
|
||||
" \"\"\"Hacky helper method to clear content. See the `full` mode section to to understand why it works.\"\"\"\n",
|
||||
" \"\"\"Hacky helper method to clear content. See the `full` mode section to understand why it works.\"\"\"\n",
|
||||
" index([], record_manager, vectorstore, cleanup=\"full\", source_id_key=\"source\")"
|
||||
]
|
||||
},
|
||||
|
||||
@@ -46,7 +46,7 @@
|
||||
"\n",
|
||||
"1. [`llama.cpp`](https://github.com/ggerganov/llama.cpp): C++ implementation of llama inference code with [weight optimization / quantization](https://finbarr.ca/how-is-llama-cpp-possible/)\n",
|
||||
"2. [`gpt4all`](https://docs.gpt4all.io/index.html): Optimized C backend for inference\n",
|
||||
"3. [`Ollama`](https://ollama.ai/): Bundles model weights and environment into an app that runs on device and serves the LLM\n",
|
||||
"3. [`ollama`](https://github.com/ollama/ollama): Bundles model weights and environment into an app that runs on device and serves the LLM\n",
|
||||
"4. [`llamafile`](https://github.com/Mozilla-Ocho/llamafile): Bundles model weights and everything needed to run the model in a single file, allowing you to run the LLM locally from this file without any additional installation steps\n",
|
||||
"\n",
|
||||
"In general, these frameworks will do a few things:\n",
|
||||
@@ -74,12 +74,12 @@
|
||||
"\n",
|
||||
"## Quickstart\n",
|
||||
"\n",
|
||||
"[`Ollama`](https://ollama.ai/) is one way to easily run inference on macOS.\n",
|
||||
"[Ollama](https://ollama.com/) is one way to easily run inference on macOS.\n",
|
||||
" \n",
|
||||
"The instructions [here](https://github.com/jmorganca/ollama?tab=readme-ov-file#ollama) provide details, which we summarize:\n",
|
||||
"The instructions [here](https://github.com/ollama/ollama?tab=readme-ov-file#ollama) provide details, which we summarize:\n",
|
||||
" \n",
|
||||
"* [Download and run](https://ollama.ai/download) the app\n",
|
||||
"* From command line, fetch a model from this [list of options](https://github.com/jmorganca/ollama): e.g., `ollama pull llama3.1:8b`\n",
|
||||
"* From command line, fetch a model from this [list of options](https://ollama.com/search): e.g., `ollama pull gpt-oss:20b`\n",
|
||||
"* When the app is running, all models are automatically served on `localhost:11434`\n"
|
||||
]
|
||||
},
|
||||
@@ -95,7 +95,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": null,
|
||||
"id": "86178adb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -111,11 +111,11 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_ollama import OllamaLLM\n",
|
||||
"from langchain_ollama import ChatOllama\n",
|
||||
"\n",
|
||||
"llm = OllamaLLM(model=\"llama3.1:8b\")\n",
|
||||
"llm = ChatOllama(model=\"gpt-oss:20b\", validate_model_on_init=True)\n",
|
||||
"\n",
|
||||
"llm.invoke(\"The first man on the moon was ...\")"
|
||||
"llm.invoke(\"The first man on the moon was ...\").content"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -200,7 +200,7 @@
|
||||
"\n",
|
||||
"### Running Apple silicon GPU\n",
|
||||
"\n",
|
||||
"`Ollama` and [`llamafile`](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#gpu-support) will automatically utilize the GPU on Apple devices.\n",
|
||||
"`ollama` and [`llamafile`](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#gpu-support) will automatically utilize the GPU on Apple devices.\n",
|
||||
" \n",
|
||||
"Other frameworks require the user to set up the environment to utilize the Apple GPU.\n",
|
||||
"\n",
|
||||
@@ -212,15 +212,15 @@
|
||||
"\n",
|
||||
"In particular, ensure that conda is using the correct virtual environment that you created (`miniforge3`).\n",
|
||||
"\n",
|
||||
"E.g., for me:\n",
|
||||
"e.g., for me:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"```shell\n",
|
||||
"conda activate /Users/rlm/miniforge3/envs/llama\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"With the above confirmed, then:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"```shell\n",
|
||||
"CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir\n",
|
||||
"```"
|
||||
]
|
||||
@@ -236,20 +236,16 @@
|
||||
"\n",
|
||||
"1. [`HuggingFace`](https://huggingface.co/TheBloke) - Many quantized model are available for download and can be run with framework such as [`llama.cpp`](https://github.com/ggerganov/llama.cpp). You can also download models in [`llamafile` format](https://huggingface.co/models?other=llamafile) from HuggingFace.\n",
|
||||
"2. [`gpt4all`](https://gpt4all.io/index.html) - The model explorer offers a leaderboard of metrics and associated quantized models available for download \n",
|
||||
"3. [`Ollama`](https://github.com/jmorganca/ollama) - Several models can be accessed directly via `pull`\n",
|
||||
"3. [`ollama`](https://github.com/jmorganca/ollama) - Several models can be accessed directly via `pull`\n",
|
||||
"\n",
|
||||
"### Ollama\n",
|
||||
"\n",
|
||||
"With [Ollama](https://github.com/jmorganca/ollama), fetch a model via `ollama pull <model family>:<tag>`:\n",
|
||||
"\n",
|
||||
"* E.g., for Llama 2 7b: `ollama pull llama2` will download the most basic version of the model (e.g., smallest # parameters and 4 bit quantization)\n",
|
||||
"* We can also specify a particular version from the [model list](https://github.com/jmorganca/ollama?tab=readme-ov-file#model-library), e.g., `ollama pull llama2:13b`\n",
|
||||
"* See the full set of parameters on the [API reference page](https://python.langchain.com/api_reference/community/llms/langchain_community.llms.ollama.Ollama.html)"
|
||||
"With [Ollama](https://github.com/ollama/ollama), fetch a model via `ollama pull <model family>:<tag>`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 42,
|
||||
"execution_count": null,
|
||||
"id": "8ecd2f78",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -265,7 +261,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"llm = OllamaLLM(model=\"llama2:13b\")\n",
|
||||
"llm = ChatOllama(model=\"gpt-oss:20b\")\n",
|
||||
"llm.invoke(\"The first man on the moon was ... think step by step\")"
|
||||
]
|
||||
},
|
||||
@@ -694,7 +690,7 @@
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
@@ -708,7 +704,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.5"
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -88,7 +88,7 @@
|
||||
"source": [
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"`merge_message_runs` can be used in an imperatively (like above) or declaratively, making it easy to compose with other components in a chain:"
|
||||
"`merge_message_runs` can be used imperatively (like above) or declaratively, making it easy to compose with other components in a chain:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"id": "f2195672-0cab-4967-ba8a-c6544635547d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# How deal with high cardinality categoricals when doing query analysis\n",
|
||||
"# How to deal with high-cardinality categoricals when doing query analysis\n",
|
||||
"\n",
|
||||
"You may want to do query analysis to create a filter on a categorical column. One of the difficulties here is that you usually need to specify the EXACT categorical value. The issue is you need to make sure the LLM generates that categorical value exactly. This can be done relatively easy with prompting when there are only a few values that are valid. When there are a high number of valid values then it becomes more difficult, as those values may not fit in the LLM context, or (if they do) there may be too many for the LLM to properly attend to.\n",
|
||||
"\n",
|
||||
|
||||
@@ -614,6 +614,7 @@
|
||||
" HumanMessage(\"Now about caterpillars\", name=\"example_user\"),\n",
|
||||
" AIMessage(\n",
|
||||
" \"\",\n",
|
||||
" name=\"example_assistant\",\n",
|
||||
" tool_calls=[\n",
|
||||
" {\n",
|
||||
" \"name\": \"joke\",\n",
|
||||
@@ -909,7 +910,7 @@
|
||||
" ),\n",
|
||||
" (\"human\", \"{query}\"),\n",
|
||||
" ]\n",
|
||||
").partial(schema=People.schema())\n",
|
||||
").partial(schema=People.model_json_schema())\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Custom parser\n",
|
||||
|
||||
@@ -52,7 +52,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ChatHuggingFace](https://python.langchain.com/api_reference/huggingface/chat_models/langchain_huggingface.chat_models.huggingface.ChatHuggingFace.html) | [langchain_huggingface](https://python.langchain.com/api_reference/huggingface/index.html) | ✅ | ❌ | ❌ |  |  |\n",
|
||||
"| [ChatHuggingFace](https://python.langchain.com/api_reference/huggingface/chat_models/langchain_huggingface.chat_models.huggingface.ChatHuggingFace.html) | [langchain-huggingface](https://python.langchain.com/api_reference/huggingface/index.html) | ✅ | ❌ | ❌ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| [Tool calling](/docs/how_to/tool_calling) | [Structured output](/docs/how_to/structured_output/) | JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
@@ -61,7 +61,7 @@
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"To access `langchain_huggingface` models you'll need to create a/an `Hugging Face` account, get an API key, and install the `langchain_huggingface` integration package.\n",
|
||||
"To access `langchain_huggingface` models you'll need to create a `Hugging Face` account, get an API key, and install the `langchain-huggingface` integration package.\n",
|
||||
"\n",
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/chat/mistral) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ChatMistralAI](https://python.langchain.com/api_reference/mistralai/chat_models/langchain_mistralai.chat_models.ChatMistralAI.html) | [langchain_mistralai](https://python.langchain.com/api_reference/mistralai/index.html) | ❌ | beta | ✅ |  |  |\n",
|
||||
"| [ChatMistralAI](https://python.langchain.com/api_reference/mistralai/chat_models/langchain_mistralai.chat_models.ChatMistralAI.html) | [langchain-mistralai](https://python.langchain.com/api_reference/mistralai/index.html) | ❌ | beta | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| [Tool calling](/docs/how_to/tool_calling) | [Structured output](/docs/how_to/structured_output/) | JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
@@ -34,7 +34,7 @@
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"To access `ChatMistralAI` models you'll need to create a Mistral account, get an API key, and install the `langchain_mistralai` integration package.\n",
|
||||
"To access `ChatMistralAI` models you'll need to create a Mistral account, get an API key, and install the `langchain-mistralai` integration package.\n",
|
||||
"\n",
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
@@ -80,7 +80,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain Mistral integration lives in the `langchain_mistralai` package:"
|
||||
"The LangChain Mistral integration lives in the `langchain-mistralai` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -90,7 +90,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_mistralai"
|
||||
"%pip install -qU langchain-mistralai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -41,7 +41,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ChatNVIDIA](https://python.langchain.com/api_reference/nvidia_ai_endpoints/chat_models/langchain_nvidia_ai_endpoints.chat_models.ChatNVIDIA.html) | [langchain_nvidia_ai_endpoints](https://python.langchain.com/api_reference/nvidia_ai_endpoints/index.html) | ✅ | beta | ❌ |  |  |\n",
|
||||
"| [ChatNVIDIA](https://python.langchain.com/api_reference/nvidia_ai_endpoints/chat_models/langchain_nvidia_ai_endpoints.chat_models.ChatNVIDIA.html) | [langchain-nvidia-ai-endpoints](https://python.langchain.com/api_reference/nvidia_ai_endpoints/index.html) | ✅ | beta | ❌ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| [Tool calling](/docs/how_to/tool_calling) | [Structured output](/docs/how_to/structured_output/) | JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
@@ -102,7 +102,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain NVIDIA AI Endpoints integration lives in the `langchain_nvidia_ai_endpoints` package:"
|
||||
"The LangChain NVIDIA AI Endpoints integration lives in the `langchain-nvidia-ai-endpoints` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -17,9 +17,9 @@
|
||||
"source": [
|
||||
"# ChatOllama\n",
|
||||
"\n",
|
||||
"[Ollama](https://ollama.ai/) allows you to run open-source large language models, such as Llama 2, locally.\n",
|
||||
"[Ollama](https://ollama.com/) allows you to run open-source large language models, such as `got-oss`, locally.\n",
|
||||
"\n",
|
||||
"Ollama bundles model weights, configuration, and data into a single package, defined by a Modelfile.\n",
|
||||
"`ollama` bundles model weights, configuration, and data into a single package, defined by a Modelfile.\n",
|
||||
"\n",
|
||||
"It optimizes setup and configuration details, including GPU usage.\n",
|
||||
"\n",
|
||||
@@ -28,14 +28,14 @@
|
||||
"## Overview\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/v0.2/docs/integrations/chat/ollama) | Package downloads | Package latest |\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/chat/ollama) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ChatOllama](https://python.langchain.com/v0.2/api_reference/ollama/chat_models/langchain_ollama.chat_models.ChatOllama.html) | [langchain-ollama](https://python.langchain.com/v0.2/api_reference/ollama/index.html) | ✅ | ❌ | ✅ |  |  |\n",
|
||||
"| [ChatOllama](https://python.langchain.com/api_reference/ollama/chat_models/langchain_ollama.chat_models.ChatOllama.html#chatollama) | [langchain-ollama](https://python.langchain.com/api_reference/ollama/index.html) | ✅ | ❌ | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| [Tool calling](/docs/how_to/tool_calling/) | [Structured output](/docs/how_to/structured_output/) | JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
"| :---: |:----------------------------------------------------:| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ |\n",
|
||||
"| ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -45,17 +45,17 @@
|
||||
" * macOS users can install via Homebrew with `brew install ollama` and start with `brew services start ollama`\n",
|
||||
"* Fetch available LLM model via `ollama pull <name-of-model>`\n",
|
||||
" * View a list of available models via the [model library](https://ollama.ai/library)\n",
|
||||
" * e.g., `ollama pull llama3`\n",
|
||||
" * e.g., `ollama pull gpt-oss:20b`\n",
|
||||
"* This will download the default tagged version of the model. Typically, the default points to the latest, smallest sized-parameter model.\n",
|
||||
"\n",
|
||||
"> On Mac, the models will be download to `~/.ollama/models`\n",
|
||||
">\n",
|
||||
"> On Linux (or WSL), the models will be stored at `/usr/share/ollama/.ollama/models`\n",
|
||||
"\n",
|
||||
"* Specify the exact version of the model of interest as such `ollama pull vicuna:13b-v1.5-16k-q4_0` (View the [various tags for the `Vicuna`](https://ollama.ai/library/vicuna/tags) model in this instance)\n",
|
||||
"* Specify the exact version of the model of interest as such `ollama pull gpt-oss:20b` (View the [various tags for the `Vicuna`](https://ollama.ai/library/vicuna/tags) model in this instance)\n",
|
||||
"* To view all pulled models, use `ollama list`\n",
|
||||
"* To chat directly with a model from the command line, use `ollama run <name-of-model>`\n",
|
||||
"* View the [Ollama documentation](https://github.com/ollama/ollama/tree/main/docs) for more commands. You can run `ollama help` in the terminal to see available commands.\n"
|
||||
"* View the [Ollama documentation](https://github.com/ollama/ollama/blob/main/docs/README.md) for more commands. You can run `ollama help` in the terminal to see available commands.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -102,7 +102,11 @@
|
||||
"id": "b18bd692076f7cf7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Make sure you're using the latest Ollama version for structured outputs. Update by running:"
|
||||
":::warning\n",
|
||||
"Make sure you're using the latest Ollama version!\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
"Update by running:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -257,10 +261,10 @@
|
||||
"source": [
|
||||
"## Tool calling\n",
|
||||
"\n",
|
||||
"We can use [tool calling](/docs/concepts/tool_calling/) with an LLM [that has been fine-tuned for tool use](https://ollama.com/search?&c=tools) such as `llama3.1`:\n",
|
||||
"We can use [tool calling](/docs/concepts/tool_calling/) with an LLM [that has been fine-tuned for tool use](https://ollama.com/search?&c=tools) such as `gpt-oss`:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"ollama pull llama3.1\n",
|
||||
"ollama pull gpt-oss:20b\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Details on creating custom tools are available in [this guide](/docs/how_to/custom_tools/). Below, we demonstrate how to create a tool using the `@tool` decorator on a normal python function."
|
||||
@@ -268,7 +272,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"execution_count": null,
|
||||
"id": "f767015f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -300,7 +304,8 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"llm = ChatOllama(\n",
|
||||
" model=\"llama3.1\",\n",
|
||||
" model=\"gpt-oss:20b\",\n",
|
||||
" validate_model_on_init=True,\n",
|
||||
" temperature=0,\n",
|
||||
").bind_tools([validate_user])\n",
|
||||
"\n",
|
||||
@@ -321,9 +326,7 @@
|
||||
"source": [
|
||||
"## Multi-modal\n",
|
||||
"\n",
|
||||
"Ollama has support for multi-modal LLMs, such as [bakllava](https://ollama.com/library/bakllava) and [llava](https://ollama.com/library/llava).\n",
|
||||
"\n",
|
||||
" ollama pull bakllava\n",
|
||||
"Ollama has limited support for multi-modal LLMs, such as [gemma3](https://ollama.com/library/gemma3)\n",
|
||||
"\n",
|
||||
"Be sure to update Ollama so that you have the most recent version to support multi-modal."
|
||||
]
|
||||
@@ -518,7 +521,7 @@
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
@@ -532,7 +535,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.4"
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -447,6 +447,163 @@
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c5d9d19d-8ab1-4d9d-b3a0-56ee4e89c528",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Custom tools\n",
|
||||
"\n",
|
||||
":::info Requires ``langchain-openai>=0.3.29``\n",
|
||||
"\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
"[Custom tools](https://platform.openai.com/docs/guides/function-calling#custom-tools) support tools with arbitrary string inputs. They can be particularly useful when you expect your string arguments to be long or complex."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "a47c809b-852f-46bd-8b9e-d9534c17213d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"================================\u001b[1m Human Message \u001b[0m=================================\n",
|
||||
"\n",
|
||||
"Use the tool to calculate 3^3.\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"[{'id': 'rs_6894ff5747c0819d9b02fc5645b0be9c000169fd9fb68d99', 'summary': [], 'type': 'reasoning'}, {'call_id': 'call_7SYwMSQPbbEqFcKlKOpXeEux', 'input': 'print(3**3)', 'name': 'execute_code', 'type': 'custom_tool_call', 'id': 'ctc_6894ff5b9f54819d8155a63638d34103000169fd9fb68d99', 'status': 'completed'}]\n",
|
||||
"Tool Calls:\n",
|
||||
" execute_code (call_7SYwMSQPbbEqFcKlKOpXeEux)\n",
|
||||
" Call ID: call_7SYwMSQPbbEqFcKlKOpXeEux\n",
|
||||
" Args:\n",
|
||||
" __arg1: print(3**3)\n",
|
||||
"=================================\u001b[1m Tool Message \u001b[0m=================================\n",
|
||||
"Name: execute_code\n",
|
||||
"\n",
|
||||
"[{'type': 'custom_tool_call_output', 'output': '27'}]\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"[{'type': 'text', 'text': '27', 'annotations': [], 'id': 'msg_6894ff5db3b8819d9159b3a370a25843000169fd9fb68d99'}]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_openai import ChatOpenAI, custom_tool\n",
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"@custom_tool\n",
|
||||
"def execute_code(code: str) -> str:\n",
|
||||
" \"\"\"Execute python code.\"\"\"\n",
|
||||
" return \"27\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-5\", output_version=\"responses/v1\")\n",
|
||||
"\n",
|
||||
"agent = create_react_agent(llm, [execute_code])\n",
|
||||
"\n",
|
||||
"input_message = {\"role\": \"user\", \"content\": \"Use the tool to calculate 3^3.\"}\n",
|
||||
"for step in agent.stream(\n",
|
||||
" {\"messages\": [input_message]},\n",
|
||||
" stream_mode=\"values\",\n",
|
||||
"):\n",
|
||||
" step[\"messages\"][-1].pretty_print()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5ef93be6-6d4c-4eea-acfd-248774074082",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<details>\n",
|
||||
"<summary>Context-free grammars</summary>\n",
|
||||
"\n",
|
||||
"OpenAI supports the specification of a [context-free grammar](https://platform.openai.com/docs/guides/function-calling#context-free-grammars) for custom tool inputs in `lark` or `regex` format. See [OpenAI docs](https://platform.openai.com/docs/guides/function-calling#context-free-grammars) for details. The `format` parameter can be passed into `@custom_tool` as shown below:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "2ae04586-be33-49c6-8947-7867801d868f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"================================\u001b[1m Human Message \u001b[0m=================================\n",
|
||||
"\n",
|
||||
"Use the tool to calculate 3^3.\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"[{'id': 'rs_689500828a8481a297ff0f98e328689c0681550c89797f43', 'summary': [], 'type': 'reasoning'}, {'call_id': 'call_jzH01RVhu6EFz7yUrOFXX55s', 'input': '3 * 3 * 3', 'name': 'do_math', 'type': 'custom_tool_call', 'id': 'ctc_6895008d57bc81a2b84d0993517a66b90681550c89797f43', 'status': 'completed'}]\n",
|
||||
"Tool Calls:\n",
|
||||
" do_math (call_jzH01RVhu6EFz7yUrOFXX55s)\n",
|
||||
" Call ID: call_jzH01RVhu6EFz7yUrOFXX55s\n",
|
||||
" Args:\n",
|
||||
" __arg1: 3 * 3 * 3\n",
|
||||
"=================================\u001b[1m Tool Message \u001b[0m=================================\n",
|
||||
"Name: do_math\n",
|
||||
"\n",
|
||||
"[{'type': 'custom_tool_call_output', 'output': '27'}]\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"[{'type': 'text', 'text': '27', 'annotations': [], 'id': 'msg_6895009776b881a2a25f0be8507d08f20681550c89797f43'}]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_openai import ChatOpenAI, custom_tool\n",
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"\n",
|
||||
"grammar = \"\"\"\n",
|
||||
"start: expr\n",
|
||||
"expr: term (SP ADD SP term)* -> add\n",
|
||||
"| term\n",
|
||||
"term: factor (SP MUL SP factor)* -> mul\n",
|
||||
"| factor\n",
|
||||
"factor: INT\n",
|
||||
"SP: \" \"\n",
|
||||
"ADD: \"+\"\n",
|
||||
"MUL: \"*\"\n",
|
||||
"%import common.INT\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"format_ = {\"type\": \"grammar\", \"syntax\": \"lark\", \"definition\": grammar}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# highlight-next-line\n",
|
||||
"@custom_tool(format=format_)\n",
|
||||
"def do_math(input_string: str) -> str:\n",
|
||||
" \"\"\"Do a mathematical operation.\"\"\"\n",
|
||||
" return \"27\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-5\", output_version=\"responses/v1\")\n",
|
||||
"\n",
|
||||
"agent = create_react_agent(llm, [do_math])\n",
|
||||
"\n",
|
||||
"input_message = {\"role\": \"user\", \"content\": \"Use the tool to calculate 3^3.\"}\n",
|
||||
"for step in agent.stream(\n",
|
||||
" {\"messages\": [input_message]},\n",
|
||||
" stream_mode=\"values\",\n",
|
||||
"):\n",
|
||||
" step[\"messages\"][-1].pretty_print()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c63430c9-c7b0-4e92-a491-3f165dddeb8f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"</details>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "84833dd0-17e9-4269-82ed-550639d65751",
|
||||
|
||||
@@ -69,7 +69,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_agentql"
|
||||
"%pip install -qU langchain-agentql"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -310,7 +310,7 @@
|
||||
"from langchain_openai import OpenAI\n",
|
||||
"\n",
|
||||
"chain = load_qa_chain(llm=OpenAI(), chain_type=\"map_reduce\")\n",
|
||||
"query = [\"Who are the autors?\"]\n",
|
||||
"query = [\"Who are the authors?\"]\n",
|
||||
"\n",
|
||||
"chain.run(input_documents=documents, question=query)"
|
||||
]
|
||||
|
||||
@@ -25,7 +25,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet azureml-fsspec, azure-ai-generative"
|
||||
"%pip install --upgrade --quiet azureml-fsspec azure-ai-generative"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -16,7 +16,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [BSHTMLLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.html_bs.BSHTMLLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [BSHTMLLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.html_bs.BSHTMLLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -52,7 +52,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **bs4**."
|
||||
"Install **langchain-community** and **bs4**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -61,7 +61,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community bs4"
|
||||
"%pip install -qU langchain-community bs4"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -245,7 +245,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -q --progress-bar off --no-warn-conflicts langchain-core langchain-huggingface langchain_milvus langchain python-dotenv"
|
||||
"%pip install -q --progress-bar off --no-warn-conflicts langchain-core langchain-huggingface langchain-milvus langchain python-dotenv"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl/)|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [FireCrawlLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.firecrawl.FireCrawlLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"| [FireCrawlLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.firecrawl.FireCrawlLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/document_loaders/file_loaders/json/)|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [JSONLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.json_loader.JSONLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"| [JSONLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.json_loader.JSONLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -51,7 +51,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **jq**:"
|
||||
"Install **langchain-community** and **jq**:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -60,7 +60,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community jq "
|
||||
"%pip install -qU langchain-community jq "
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [MathPixPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.MathpixPDFLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [MathPixPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.MathpixPDFLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community**."
|
||||
"Install **langchain-community**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -69,7 +69,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community"
|
||||
"%pip install -qU langchain-community"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"source": [
|
||||
"[Socrata](https://dev.socrata.com/foundry/data.sfgov.org/vw6y-z8j6) provides an API for city open data. \n",
|
||||
"\n",
|
||||
"For a dataset such as [SF crime](https://data.sfgov.org/Public-Safety/Police-Department-Incident-Reports-Historical-2003/tmnf-yvry), to to the `API` tab on top right. \n",
|
||||
"For a dataset such as [SF crime](https://data.sfgov.org/Public-Safety/Police-Department-Incident-Reports-Historical-2003/tmnf-yvry), see the `API` tab on top right. \n",
|
||||
"\n",
|
||||
"That provides you with the `dataset identifier`.\n",
|
||||
"\n",
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"|:-----------------------------------------------------------------------------------------------------------------------------------------------------| :--- | :---: | :---: | :---: |\n",
|
||||
"| [PDFMinerLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PDFMinerLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ |\n",
|
||||
"| [PDFMinerLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PDFMinerLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ |\n",
|
||||
"\n",
|
||||
"--------- \n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **pdfminer**."
|
||||
"Install **langchain-community** and **pdfminer**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -82,7 +82,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community pdfminer.six"
|
||||
"%pip install -qU langchain-community pdfminer.six"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -938,7 +938,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_openai"
|
||||
"%pip install -qU langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PDFPlumberLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PDFPlumberLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [PDFPlumberLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PDFPlumberLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -47,7 +47,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community**."
|
||||
"Install **langchain-community**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -56,7 +56,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community"
|
||||
"%pip install -qU langchain-community"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -117,7 +117,7 @@
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The fields:\n",
|
||||
" - `es_host_url` is the endpoint to to MetadataIQ Elasticsearch database\n",
|
||||
" - `es_host_url` is the endpoint to MetadataIQ Elasticsearch database\n",
|
||||
" - `es_index_index` is the name of the index where PowerScale writes it file system metadata\n",
|
||||
" - `es_api_key` is the **encoded** version of your elasticsearch API key\n",
|
||||
" - `folder_path` is the path on PowerScale to be queried for changes"
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PyMuPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyMuPDFLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [PyMuPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyMuPDFLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"\n",
|
||||
"--------- \n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **pymupdf**."
|
||||
"Install **langchain-community** and **pymupdf**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -71,7 +71,7 @@
|
||||
"start_time": "2025-01-16T09:48:33.057015Z"
|
||||
}
|
||||
},
|
||||
"source": "%pip install -qU langchain_community pymupdf",
|
||||
"source": "%pip install -qU langchain-community pymupdf",
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
@@ -569,7 +569,7 @@
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"%pip install -qU langchain_openai"
|
||||
"%pip install -qU langchain-openai"
|
||||
],
|
||||
"outputs": [
|
||||
{
|
||||
|
||||
@@ -23,7 +23,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PyMuPDF4LLMLoader](https://github.com/lakinduboteju/langchain-pymupdf4llm) | [langchain_pymupdf4llm](https://pypi.org/project/langchain-pymupdf4llm) | ✅ | ❌ | ❌ |\n",
|
||||
"| [PyMuPDF4LLMLoader](https://github.com/lakinduboteju/langchain-pymupdf4llm) | [langchain-pymupdf4llm](https://pypi.org/project/langchain-pymupdf4llm) | ✅ | ❌ | ❌ |\n",
|
||||
"\n",
|
||||
"### Loader features\n",
|
||||
"\n",
|
||||
@@ -61,7 +61,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **langchain-pymupdf4llm**."
|
||||
"Install **langchain-community** and **langchain-pymupdf4llm**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -78,7 +78,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community langchain-pymupdf4llm"
|
||||
"%pip install -qU langchain-community langchain-pymupdf4llm"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -554,7 +554,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_openai"
|
||||
"%pip install -qU langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PyPDFDirectoryLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFDirectoryLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [PyPDFDirectoryLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFDirectoryLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -53,7 +53,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community**."
|
||||
"Install **langchain-community**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -74,7 +74,7 @@
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": "%pip install -qU langchain_community pypdf pillow"
|
||||
"source": "%pip install -qU langchain-community pypdf pillow"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PyPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [PyPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
" \n",
|
||||
"--------- \n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **pypdf**."
|
||||
"Install **langchain-community** and **pypdf**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -81,7 +81,7 @@
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": "%pip install -qU langchain_community pypdfium2"
|
||||
"source": "%pip install -qU langchain-community pypdfium2"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -802,7 +802,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_openai"
|
||||
"%pip install -qU langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [PyPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [PyPDFLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.pdf.PyPDFLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
" \n",
|
||||
"--------- \n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community** and **pypdf**."
|
||||
"Install **langchain-community** and **pypdf**."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -82,7 +82,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community pypdf"
|
||||
"%pip install -qU langchain-community pypdf"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -818,7 +818,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_openai"
|
||||
"%pip install -qU langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/recursive_url_loader/)|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [RecursiveUrlLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.recursive_url_loader.RecursiveUrlLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"| [RecursiveUrlLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.recursive_url_loader.RecursiveUrlLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
|
||||
@@ -11,7 +11,7 @@
|
||||
"\n",
|
||||
"This loader fetches the text from the Posts of Subreddits or Reddit users, using the `praw` Python package.\n",
|
||||
"\n",
|
||||
"Make a [Reddit Application](https://www.reddit.com/prefs/apps/) and initialize the loader with with your Reddit API credentials."
|
||||
"Make a [Reddit Application](https://www.reddit.com/prefs/apps/) and initialize the loader with your Reddit API credentials."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/sitemap/)|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [SiteMapLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.sitemap.SitemapLoader.html#langchain_community.document_loaders.sitemap.SitemapLoader) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"| [SiteMapLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.sitemap.SitemapLoader.html#langchain_community.document_loaders.sitemap.SitemapLoader) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -51,7 +51,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"Install **langchain_community**."
|
||||
"Install **langchain-community**."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -16,7 +16,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/document_loaders/file_loaders/unstructured/)|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [UnstructuredLoader](https://python.langchain.com/api_reference/unstructured/document_loaders/langchain_unstructured.document_loaders.UnstructuredLoader.html) | [langchain_unstructured](https://python.langchain.com/api_reference/unstructured/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"| [UnstructuredLoader](https://python.langchain.com/api_reference/unstructured/document_loaders/langchain_unstructured.document_loaders.UnstructuredLoader.html) | [langchain-unstructured](https://python.langchain.com/api_reference/unstructured/index.html) | ✅ | ❌ | ✅ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
|
||||
@@ -151,10 +151,10 @@
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This is a page with something...\n",
|
||||
"\n",
|
||||
"WAW I have learned something !\n",
|
||||
@@ -183,10 +183,10 @@
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
@@ -219,10 +219,10 @@
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor\n",
|
||||
"\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0-\\u00a0incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in\n",
|
||||
"\n",
|
||||
@@ -252,10 +252,10 @@
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"\n",
|
||||
"------ Page 7 ------\n",
|
||||
"Title page : Useful ↔ Useless page\n",
|
||||
@@ -276,10 +276,10 @@
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Title of this document : BLABLABLA\n",
|
||||
"\n",
|
||||
"------ Page 8 ------\n",
|
||||
@@ -359,10 +359,10 @@
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Useful\\u2194 Useless page\\u00a0\n",
|
||||
"\n",
|
||||
"Tests of some exotics characters :\\u00a0\\u00e3\\u00e4\\u00e5\\u0101\\u0103 \\u00fc\\u2554\\u00a0\\u00a0\\u00bc \\u00c7 \\u25d8\\u25cb\\u2642\\u266b\\u2640\\u00ee\\u2665\n",
|
||||
@@ -444,10 +444,10 @@
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"This a completely useless diagram, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This diagram is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Only connectors on this page. This is the CoNNeCtor page\n"
|
||||
]
|
||||
}
|
||||
|
||||
@@ -20,7 +20,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support|\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [WebBaseLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.web_base.WebBaseLoader.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"| [WebBaseLoader](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.web_base.WebBaseLoader.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ❌ | ❌ | \n",
|
||||
"### Loader features\n",
|
||||
"| Source | Document Lazy Loading | Native Async Support\n",
|
||||
"| :---: | :---: | :---: | \n",
|
||||
@@ -44,7 +44,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community beautifulsoup4"
|
||||
"%pip install -qU langchain-community beautifulsoup4"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -261,7 +261,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU upstash_redis"
|
||||
"%pip install -qU upstash-redis"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -1543,7 +1543,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install -qU langchain_astradb\n",
|
||||
"%pip install -qU langchain-astradb\n",
|
||||
"\n",
|
||||
"import getpass\n",
|
||||
"\n",
|
||||
@@ -2683,7 +2683,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_couchbase"
|
||||
"%pip install -qU langchain-couchbase"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -34,7 +34,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain_aws"
|
||||
"%pip install --upgrade --quiet langchain-aws"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -22,7 +22,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/docs/integrations/llms/cohere/) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [Cohere](https://python.langchain.com/api_reference/community/llms/langchain_community.llms.cohere.Cohere.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ❌ | beta | ✅ |  |  |\n"
|
||||
"| [Cohere](https://python.langchain.com/api_reference/community/llms/langchain_community.llms.cohere.Cohere.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ❌ | beta | ✅ |  |  |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -22,7 +22,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | [JS support](https://js.langchain.com/v0.1/docs/integrations/llms/fireworks/) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [Fireworks](https://python.langchain.com/api_reference/fireworks/llms/langchain_fireworks.llms.Fireworks.html#langchain_fireworks.llms.Fireworks) | [langchain_fireworks](https://python.langchain.com/api_reference/fireworks/index.html) | ❌ | ❌ | ✅ |  |  |"
|
||||
"| [Fireworks](https://python.langchain.com/api_reference/fireworks/llms/langchain_fireworks.llms.Fireworks.html#langchain_fireworks.llms.Fireworks) | [langchain-fireworks](https://python.langchain.com/api_reference/fireworks/index.html) | ❌ | ❌ | ✅ |  |  |"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -59,7 +59,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"You need to install the `langchain_fireworks` python package for the rest of the notebook to work."
|
||||
"You need to install the `langchain-fireworks` python package for the rest of the notebook to work."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -44,9 +44,7 @@
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet llama-cpp-python"
|
||||
]
|
||||
"source": "%pip install --upgrade --quiet llama-cpp-python"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -64,9 +62,7 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
]
|
||||
"source": "!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -80,9 +76,7 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
]
|
||||
"source": "!CMAKE_ARGS=\"-DGGML_CUDA=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -100,9 +94,7 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
]
|
||||
"source": "!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -116,9 +108,7 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir"
|
||||
]
|
||||
"source": "!CMAKE_ARGS=\"-DLLAMA_METAL=on\" FORCE_CMAKE=1 pip install llama-cpp-python --force-reinstall --no-binary :all: --no-cache-dir"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -174,9 +164,7 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!python -m pip install -e . --force-reinstall --no-cache-dir"
|
||||
]
|
||||
"source": "!python -m pip install -e . --force-reinstall --no-cache-dir"
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
@@ -718,4 +706,4 @@
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
}
|
||||
@@ -29,7 +29,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | Serializable | JS support | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: | :---: |\n",
|
||||
"| [NVIDIA](https://python.langchain.com/api_reference/nvidia_ai_endpoints/llms/langchain_nvidia_ai_endpoints.chat_models.ChatNVIDIA.html) | [langchain_nvidia_ai_endpoints](https://python.langchain.com/api_reference/nvidia_ai_endpoints/index.html) | ✅ | beta | ❌ |  |  |\n",
|
||||
"| [NVIDIA](https://python.langchain.com/api_reference/nvidia_ai_endpoints/llms/langchain_nvidia_ai_endpoints.chat_models.ChatNVIDIA.html) | [langchain-nvidia-ai-endpoints](https://python.langchain.com/api_reference/nvidia_ai_endpoints/index.html) | ✅ | beta | ❌ |  |  |\n",
|
||||
"\n",
|
||||
"### Model features\n",
|
||||
"| JSON mode | [Image input](/docs/how_to/multimodal_inputs/) | Audio input | Video input | [Token-level streaming](/docs/how_to/chat_streaming/) | Native async | [Token usage](/docs/how_to/chat_token_usage_tracking/) | [Logprobs](/docs/how_to/logprobs/) |\n",
|
||||
@@ -71,7 +71,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain NVIDIA AI Endpoints integration lives in the `langchain_nvidia_ai_endpoints` package:"
|
||||
"The LangChain NVIDIA AI Endpoints integration lives in the `langchain-nvidia-ai-endpoints` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
38
docs/docs/integrations/providers/anchor_browser.mdx
Normal file
38
docs/docs/integrations/providers/anchor_browser.mdx
Normal file
@@ -0,0 +1,38 @@
|
||||
# Anchor Browser
|
||||
|
||||
[Anchor](https://anchorbrowser.io?utm=langchain) is the platform for AI Agentic browser automation, which solves the challenge of automating workflows for web applications that lack APIs or have limited API coverage. It simplifies the creation, deployment, and management of browser-based automations, transforming complex web interactions into simple API endpoints.
|
||||
|
||||
`langchain-anchorbrowser` provides 3 main tools:
|
||||
- `AnchorContentTool` - For web content extractions in Markdown or HTML format.
|
||||
- `AnchorScreenshotTool` - For web page screenshots.
|
||||
- `AnchorWebTaskTools` - To perform web tasks.
|
||||
|
||||
## Quickstart
|
||||
|
||||
### Installation
|
||||
|
||||
Install the package:
|
||||
|
||||
```bash
|
||||
pip install langchain-anchorbrowser
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Import and utilize your intended tool. The full list of Anchor Browser available tools see **Tool Features** table in [Anchor Browser tool page](/docs/integrations/tools/anchor_browser)
|
||||
|
||||
```python
|
||||
from langchain_anchorbrowser import AnchorContentTool
|
||||
|
||||
# Get Markdown Content for https://www.anchorbrowser.io
|
||||
AnchorContentTool().invoke(
|
||||
{"url": "https://www.anchorbrowser.io", "format": "markdown"}
|
||||
)
|
||||
```
|
||||
|
||||
## Additional Resources
|
||||
|
||||
- [PyPi](https://pypi.org/project/langchain-anchorbrowser)
|
||||
- [Github](https://github.com/anchorbrowser/langchain-anchorbrowser)
|
||||
- [Anchor Browser Docs](https://docs.anchorbrowser.io/introduction?utm=langchain)
|
||||
- [Anchor Browser API Reference](https://docs.anchorbrowser.io/api-reference/ai-tools/perform-web-task?utm=langchain)
|
||||
@@ -929,6 +929,41 @@ from langchain_google_community.gmail.search import GmailSearch
|
||||
from langchain_google_community.gmail.send_message import GmailSendMessage
|
||||
```
|
||||
|
||||
### MCP Toolbox
|
||||
|
||||
[MCP Toolbox](https://github.com/googleapis/genai-toolbox) provides a simple and efficient way to connect to your databases, including those on Google Cloud like [Cloud SQL](https://cloud.google.com/sql/docs) and [AlloyDB](https://cloud.google.com/alloydb/docs/overview). With MCP Toolbox, you can seamlessly integrate your database with LangChain to build powerful, data-driven applications.
|
||||
|
||||
#### Installation
|
||||
|
||||
To get started, [install the Toolbox server and client](https://github.com/googleapis/genai-toolbox/releases/).
|
||||
|
||||
|
||||
[Configure](https://googleapis.github.io/genai-toolbox/getting-started/configure/) a `tools.yaml` to define your tools, and then execute toolbox to start the server:
|
||||
|
||||
```bash
|
||||
toolbox --tools-file "tools.yaml"
|
||||
```
|
||||
|
||||
Then, install the Toolbox client:
|
||||
|
||||
```bash
|
||||
pip install toolbox-langchain
|
||||
```
|
||||
|
||||
#### Getting Started
|
||||
|
||||
Here is a quick example of how to use MCP Toolbox to connect to your database:
|
||||
|
||||
```python
|
||||
from toolbox_langchain import ToolboxClient
|
||||
|
||||
async with ToolboxClient("http://127.0.0.1:5000") as client:
|
||||
|
||||
tools = client.load_toolset()
|
||||
```
|
||||
|
||||
See [usage example and setup instructions](/docs/integrations/tools/toolbox).
|
||||
|
||||
### Memory
|
||||
|
||||
Store conversation history using Google Cloud databases.
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# ChatGradient
|
||||
# DigitalOcean Gradient
|
||||
|
||||
This will help you getting started with DigitalOcean Gradient [chat models](/docs/concepts/chat_models).
|
||||
|
||||
|
||||
@@ -1,14 +1,14 @@
|
||||
# Ollama
|
||||
|
||||
>[Ollama](https://ollama.com/) allows you to run open-source large language models,
|
||||
> such as [Llama3.1](https://ai.meta.com/blog/meta-llama-3-1/), locally.
|
||||
> such as [gpt-oss](https://ollama.com/library/gpt-oss), locally.
|
||||
>
|
||||
>`Ollama` bundles model weights, configuration, and data into a single package, defined by a Modelfile.
|
||||
>It optimizes setup and configuration details, including GPU usage.
|
||||
>For a complete list of supported models and model variants, see the [Ollama model library](https://ollama.ai/library).
|
||||
|
||||
See [this guide](/docs/how_to/local_llms) for more details
|
||||
on how to use `Ollama` with LangChain.
|
||||
See [this guide](/docs/how_to/local_llms#ollama) for more details
|
||||
on how to use `ollama` with LangChain.
|
||||
|
||||
## Installation and Setup
|
||||
### Ollama installation
|
||||
@@ -26,7 +26,7 @@ ollama serve
|
||||
After starting ollama, run `ollama pull <name-of-model>` to download a model from the [Ollama model library](https://ollama.ai/library):
|
||||
|
||||
```bash
|
||||
ollama pull llama3.1
|
||||
ollama pull gpt-oss:20b
|
||||
```
|
||||
|
||||
- This will download the default tagged version of the model. Typically, the default points to the latest, smallest sized-parameter model.
|
||||
|
||||
26
docs/docs/integrations/providers/scrapeless.mdx
Normal file
26
docs/docs/integrations/providers/scrapeless.mdx
Normal file
@@ -0,0 +1,26 @@
|
||||
# Scrapeless
|
||||
|
||||
[Scrapeless](https://scrapeless.com) offers flexible and feature-rich data acquisition services with extensive parameter customization and multi-format export support.
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
```bash
|
||||
pip install langchain-scrapeless
|
||||
```
|
||||
|
||||
You'll need to set up your Scrapeless API key:
|
||||
|
||||
```python
|
||||
import os
|
||||
os.environ["SCRAPELESS_API_KEY"] = "your-api-key"
|
||||
```
|
||||
|
||||
## Tools
|
||||
|
||||
The Scrapeless integration provides several tools:
|
||||
|
||||
- [ScrapelessDeepSerpGoogleSearchTool](/docs/integrations/tools/scrapeless_scraping_api) - Enables comprehensive extraction of Google SERP data across all result types.
|
||||
- [ScrapelessDeepSerpGoogleTrendsTool](/docs/integrations/tools/scrapeless_scraping_api) - Retrieves keyword trend data from Google, including popularity over time, regional interest, and related searches.
|
||||
- [ScrapelessUniversalScrapingTool](/docs/integrations/tools/scrapeless_universal_scraping) - Access and extract data from JS-Render websites that typically block bots.
|
||||
- [ScrapelessCrawlerCrawlTool](/docs/integrations/tools/scrapeless_crawl) - Crawl a website and its linked pages to extract comprehensive data.
|
||||
- [ScrapelessCrawlerScrapeTool](/docs/integrations/tools/scrapeless_crawl) - Extract information from a single webpage.
|
||||
23
docs/docs/integrations/providers/toolbox-langchain.mdx
Normal file
23
docs/docs/integrations/providers/toolbox-langchain.mdx
Normal file
@@ -0,0 +1,23 @@
|
||||
# MCP Toolbox
|
||||
|
||||
The [MCP Toolbox](https://googleapis.github.io/genai-toolbox/getting-started/introduction/) in LangChain allows you to equip an agent with a set of tools. When the agent receives a query, it can intelligently select and use the most appropriate tool provided by MCP Toolbox to fulfill the request.
|
||||
|
||||
## What is it?
|
||||
|
||||
MCP Toolbox is essentially a container for your tools. Think of it as a multi-tool device for your agent; it can hold any tools you create. The agent then decides which specific tool to use based on the user's input.
|
||||
|
||||
This is particularly useful when you have an agent that needs to perform a variety of tasks that require different capabilities.
|
||||
|
||||
## Installation
|
||||
|
||||
To get started, you'll need to install the necessary package:
|
||||
|
||||
```bash
|
||||
pip install toolbox-langchain
|
||||
```
|
||||
|
||||
## Tutorial
|
||||
|
||||
For a complete, step-by-step guide on how to create, configure, and use MCP Toolbox with your agents, please refer to our detailed Jupyter notebook tutorial.
|
||||
|
||||
**[➡️ View the full tutorial here](/docs/integrations/tools/toolbox)**.
|
||||
@@ -67,7 +67,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community wikipedia"
|
||||
"%pip install -qU langchain-community wikipedia"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -31,7 +31,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | JS support | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [AstraDBByteStore](https://python.langchain.com/api_reference/astradb/storage/langchain_astradb.storage.AstraDBByteStore.html) | [langchain_astradb](https://python.langchain.com/api_reference/astradb/index.html) | ❌ | ❌ |  |  |\n",
|
||||
"| [AstraDBByteStore](https://python.langchain.com/api_reference/astradb/storage/langchain_astradb.storage.AstraDBByteStore.html) | [langchain-astradb](https://python.langchain.com/api_reference/astradb/index.html) | ❌ | ❌ |  |  |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain AstraDB integration lives in the `langchain_astradb` package:"
|
||||
"The LangChain AstraDB integration lives in the `langchain-astradb` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -69,7 +69,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_astradb"
|
||||
"%pip install -qU langchain-astradb"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -29,7 +29,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | [JS support](https://js.langchain.com/docs/integrations/stores/cassandra_storage) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [CassandraByteStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.cassandra.CassandraByteStore.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ✅ |  |  |\n",
|
||||
"| [CassandraByteStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.cassandra.CassandraByteStore.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -44,7 +44,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain `CassandraByteStore` integration lives in the `langchain_community` package. You'll also need to install the `cassio` package or the `cassandra-driver` package as a peer dependency depending on which initialization method you're using:"
|
||||
"The LangChain `CassandraByteStore` integration lives in the `langchain-community` package. You'll also need to install the `cassio` package or the `cassandra-driver` package as a peer dependency depending on which initialization method you're using:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -53,7 +53,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community\n",
|
||||
"%pip install -qU langchain-community\n",
|
||||
"%pip install -qU cassandra-driver\n",
|
||||
"%pip install -qU cassio"
|
||||
]
|
||||
|
||||
@@ -29,7 +29,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | JS support | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [ElasticsearchEmbeddingsCache](https://python.langchain.com/api_reference/elasticsearch/cache/langchain_elasticsearch.cache.ElasticsearchEmbeddingsCache.html) | [langchain_elasticsearch](https://python.langchain.com/api_reference/elasticsearch/index.html) | ✅ | ❌ |  |  |\n",
|
||||
"| [ElasticsearchEmbeddingsCache](https://python.langchain.com/api_reference/elasticsearch/cache/langchain_elasticsearch.cache.ElasticsearchEmbeddingsCache.html) | [langchain-elasticsearch](https://python.langchain.com/api_reference/elasticsearch/index.html) | ✅ | ❌ |  |  |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -42,7 +42,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain `ElasticsearchEmbeddingsCache` integration lives in the `__package_name__` package:"
|
||||
"The LangChain `ElasticsearchEmbeddingsCache` integration lives in the `langchain-elasticsearch` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -51,7 +51,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_elasticsearch"
|
||||
"%pip install -qU langchain-elasticsearch"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -29,7 +29,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | [JS support](https://js.langchain.com/docs/integrations/stores/in_memory/) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [InMemoryByteStore](https://python.langchain.com/api_reference/core/stores/langchain_core.stores.InMemoryByteStore.html) | [langchain_core](https://python.langchain.com/api_reference/core/index.html) | ✅ | ✅ |  |  |"
|
||||
"| [InMemoryByteStore](https://python.langchain.com/api_reference/core/stores/langchain_core.stores.InMemoryByteStore.html) | [langchain-core](https://python.langchain.com/api_reference/core/index.html) | ✅ | ✅ |  |  |"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -38,7 +38,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain `InMemoryByteStore` integration lives in the `langchain_core` package:"
|
||||
"The LangChain `InMemoryByteStore` integration lives in the `langchain-core` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -47,7 +47,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_core"
|
||||
"%pip install -qU langchain-core"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -29,7 +29,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | [JS support](https://js.langchain.com/docs/integrations/stores/ioredis_storage) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [RedisStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.redis.RedisStore.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ✅ |  |  |\n",
|
||||
"| [RedisStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.redis.RedisStore.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ✅ | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -42,7 +42,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain `RedisStore` integration lives in the `langchain_community` package:"
|
||||
"The LangChain `RedisStore` integration lives in the `langchain-community` package:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -51,7 +51,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community redis"
|
||||
"%pip install -qU langchain-community redis"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -31,7 +31,7 @@
|
||||
"\n",
|
||||
"| Class | Package | Local | [JS support](https://js.langchain.com/docs/integrations/stores/upstash_redis_storage) | Package downloads | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: | :---: |\n",
|
||||
"| [UpstashRedisByteStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.upstash_redis.UpstashRedisByteStore.html) | [langchain_community](https://python.langchain.com/api_reference/community/index.html) | ❌ | ✅ |  |  |\n",
|
||||
"| [UpstashRedisByteStore](https://python.langchain.com/api_reference/community/storage/langchain_community.storage.upstash_redis.UpstashRedisByteStore.html) | [langchain-community](https://python.langchain.com/api_reference/community/index.html) | ❌ | ✅ |  |  |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
@@ -60,7 +60,7 @@
|
||||
"source": [
|
||||
"### Installation\n",
|
||||
"\n",
|
||||
"The LangChain Upstash integration lives in the `langchain_community` package. You'll also need to install the `upstash-redis` package as a peer dependency:"
|
||||
"The LangChain Upstash integration lives in the `langchain-community` package. You'll also need to install the `upstash-redis` package as a peer dependency:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -69,7 +69,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain_community upstash-redis"
|
||||
"%pip install -qU langchain-community upstash-redis"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -411,7 +411,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain faiss-cpu tiktoken langchain_community\n",
|
||||
"%pip install --upgrade --quiet langchain faiss-cpu tiktoken langchain-community\n",
|
||||
"\n",
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
|
||||
@@ -55,7 +55,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --quiet -U langchain_agentql"
|
||||
"%pip install --quiet -U langchain-agentql"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
307
docs/docs/integrations/tools/anchor_browser.ipynb
Normal file
307
docs/docs/integrations/tools/anchor_browser.ipynb
Normal file
@@ -0,0 +1,307 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "2ce4bdbc",
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "raw"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: anchor_browser\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a6f91f20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Anchor Browser\n",
|
||||
"\n",
|
||||
"Anchor is a platform for AI Agentic browser automation, which solves the challenge of automating workflows for web applications that lack APIs or have limited API coverage. It simplifies the creation, deployment, and management of browser-based automations, transforming complex web interactions into simple API endpoints.\n",
|
||||
"\n",
|
||||
"This notebook provides a quick overview for getting started with Anchor Browser tools. For more information of Anchor Browser visit [Anchorbrowser.io](https://anchorbrowser.io?utm=langchain) or the [Anchor Browser Docs](https://docs.anchorbrowser.io?utm=langchain)\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"Anchor Browser package for LangChain is [langchain-anchorbrowser](https://pypi.org/project/langchain-anchorbrowser), and the current latest version is .\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Tool features\n",
|
||||
"| Tool Name | Package | Description | Parameters |\n",
|
||||
"| :--- | :--- | :--- | :---|\n",
|
||||
"| `AnchorContentTool` | langchain-anchorbrowser | Extract text content from web pages | `url`, `format` |\n",
|
||||
"| `AnchorScreenshotTool` | langchain-anchorbrowser | Take screenshots of web pages | `url`, `width`, `height`, `image_quality`, `wait`, `scroll_all_content`, `capture_full_height`, `s3_target_address` |\n",
|
||||
"| `AnchorWebTaskToolKit` | langchain-anchorbrowser | Perform intelligent web tasks using AI (Simple & Advanced modes) | see below |\n",
|
||||
"\n",
|
||||
"The parameters allowed in `langchain-anchorbrowser` are only a subset of those listed in the Anchor Browser API reference respectively: [Get Webpage Content](https://docs.anchorbrowser.io/sdk-reference/tools/get-webpage-content?utm=langchain), [Screenshot Webpage](https://docs.anchorbrowser.io/sdk-reference/tools/screenshot-webpage?utm=langchain), and [Perform Web Task](https://docs.anchorbrowser.io/sdk-reference/ai-tools/perform-web-task?utm=langchain).\n",
|
||||
"\n",
|
||||
"**Info:** Anchor currently implements `SimpleAnchorWebTaskTool` and `AdvancedAnchorWebTaskTool` tools for langchain with `browser_use` agent. For \n",
|
||||
"\n",
|
||||
"#### AnchorWebTaskToolKit Tools\n",
|
||||
"\n",
|
||||
"The difference between each tool in this toolkit is the pydantic configuration structure.\n",
|
||||
"| Tool Name | Package | Parameters |\n",
|
||||
"| :--- | :--- | :--- |\n",
|
||||
"| `SimpleAnchorWebTaskTool` | langchain-anchorbrowser | prompt, url |\n",
|
||||
"| `AdvancedAnchorWebTaskTool` | langchain-anchorbrowser | prompt, url, output_schema |\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-anchorbrowser` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f85b4089",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --quiet -U langchain-anchorbrowser"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b15e9266",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"Use your Anchor Browser Credentials. Get them on Anchor Browser [API Keys page](https://app.anchorbrowser.io/api-keys?utm=langchain) as needed."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "e0b178a2-8816-40ca-b57c-ccdd86dde9c9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"if not os.environ.get(\"ANCHORBROWSER_API_KEY\"):\n",
|
||||
" os.environ[\"ANCHORBROWSER_API_KEY\"] = getpass.getpass(\"ANCHORBROWSER API key:\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1c97218f-f366-479d-8bf7-fe9f2f6df73f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation\n",
|
||||
"\n",
|
||||
"Instantiace easily Anchor Browser tools instances."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8b3ddfe9-ca79-494c-a7ab-1f56d9407a64",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_anchorbrowser import (\n",
|
||||
" AnchorContentTool,\n",
|
||||
" AnchorScreenshotTool,\n",
|
||||
" AdvancedAnchorWebTaskTool,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"anchor_content_tool = AnchorContentTool()\n",
|
||||
"anchor_screenshot_tool = AnchorScreenshotTool()\n",
|
||||
"anchor_advanced_web_task_tool = AdvancedAnchorWebTaskTool()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "74147a1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n",
|
||||
"\n",
|
||||
"### [Invoke directly with args](/docs/concepts/tools/#use-the-tool-directly)\n",
|
||||
"\n",
|
||||
"The full available argument list appear above in the tool features table."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "65310a8b-eb0c-4d9e-a618-4f4abe2414fc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Get Markdown Content for https://www.anchorbrowser.io\n",
|
||||
"anchor_content_tool.invoke(\n",
|
||||
" {\"url\": \"https://www.anchorbrowser.io\", \"format\": \"markdown\"}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Get a Screenshot for https://docs.anchorbrowser.io\n",
|
||||
"anchor_screenshot_tool.invoke(\n",
|
||||
" {\"url\": \"https://docs.anchorbrowser.io\", \"width\": 1280, \"height\": 720}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Get a Screenshot for https://docs.anchorbrowser.io\n",
|
||||
"anchor_advanced_web_task_tool.invoke(\n",
|
||||
" {\n",
|
||||
" \"prompt\": \"Collect the node names and their CPU average %\",\n",
|
||||
" \"url\": \"https://play.grafana.org/a/grafana-k8s-app/navigation/nodes?from=now-1h&to=now&refresh=1m\",\n",
|
||||
" \"output_schema\": {\n",
|
||||
" \"nodes_cpu_usage\": [\n",
|
||||
" {\"node\": \"string\", \"cluster\": \"string\", \"cpu_avg_percentage\": \"number\"}\n",
|
||||
" ]\n",
|
||||
" },\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d6e73897",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### [Invoke with ToolCall](/docs/concepts/tool_calling/#tool-execution)\n",
|
||||
"\n",
|
||||
"We can also invoke the tool with a model-generated ToolCall, in which case a ToolMessage will be returned:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f90e33a7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This is usually generated by a model, but we'll create a tool call directly for demo purposes.\n",
|
||||
"model_generated_tool_call = {\n",
|
||||
" \"args\": {\"url\": \"https://www.anchorbrowser.io\", \"format\": \"markdown\"},\n",
|
||||
" \"id\": \"1\",\n",
|
||||
" \"name\": anchor_content_tool.name,\n",
|
||||
" \"type\": \"tool_call\",\n",
|
||||
"}\n",
|
||||
"anchor_content_tool.invoke(model_generated_tool_call)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "659f9fbd-6fcf-445f-aa8c-72d8e60154bd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"We can use our tool in a chain by first binding it to a [tool-calling model](/docs/how_to/tool_calling/) and then calling it:\n",
|
||||
"## Use within an agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c67bfd54",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "af3123ad-7a02-40e5-b58e-7d56e23e5830",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import init_chat_model\n",
|
||||
"\n",
|
||||
"llm = init_chat_model(model=\"gpt-4o\", model_provider=\"openai\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "210511c8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"if not os.environ.get(\"OPENAI_API_KEY\"):\n",
|
||||
" os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OPENAI API key:\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fdbf35b5-3aaf-4947-9ec6-48c21533fb95",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_core.runnables import RunnableConfig, chain\n",
|
||||
"\n",
|
||||
"prompt = ChatPromptTemplate(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You are a helpful assistant.\"),\n",
|
||||
" (\"human\", \"{user_input}\"),\n",
|
||||
" (\"placeholder\", \"{messages}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# specifying tool_choice will force the model to call this tool.\n",
|
||||
"llm_with_tools = llm.bind_tools(\n",
|
||||
" [anchor_content_tool], tool_choice=anchor_content_tool.name\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"llm_chain = prompt | llm_with_tools\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"@chain\n",
|
||||
"def tool_chain(user_input: str, config: RunnableConfig):\n",
|
||||
" input_ = {\"user_input\": user_input}\n",
|
||||
" ai_msg = llm_chain.invoke(input_, config=config)\n",
|
||||
" tool_msgs = anchor_content_tool.batch(ai_msg.tool_calls, config=config)\n",
|
||||
" return llm_chain.invoke({**input_, \"messages\": [ai_msg, *tool_msgs]}, config=config)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tool_chain.invoke(input())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4ac8146c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
" - [PyPi](https://pypi.org/project/langchain-anchorbrowser)\n",
|
||||
" - [Github](https://github.com/anchorbrowser/langchain-anchorbrowser)\n",
|
||||
" - [Anchor Browser Docs](https://docs.anchorbrowser.io/introduction?utm=langchain)\n",
|
||||
" - [Anchor Browser API Reference](https://docs.anchorbrowser.io/api-reference/ai-tools/perform-web-task?utm=langchain)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -85,7 +85,7 @@
|
||||
"Install the following Python modules:\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"pip install ipykernel python-dotenv cassio langchain_openai langchain langchain-community langchainhub\n",
|
||||
"pip install ipykernel python-dotenv cassio langchain-openai langchain langchain-community langchainhub\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"### .env file\n",
|
||||
|
||||
@@ -51,7 +51,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain-community langchain_openai"
|
||||
"%pip install -qU langchain-community langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
446
docs/docs/integrations/tools/scrapeless_crawl.ipynb
Normal file
446
docs/docs/integrations/tools/scrapeless_crawl.ipynb
Normal file
File diff suppressed because one or more lines are too long
474
docs/docs/integrations/tools/scrapeless_scraping_api.ipynb
Normal file
474
docs/docs/integrations/tools/scrapeless_scraping_api.ipynb
Normal file
File diff suppressed because one or more lines are too long
339
docs/docs/integrations/tools/scrapeless_universal_scraping.ipynb
Normal file
339
docs/docs/integrations/tools/scrapeless_universal_scraping.ipynb
Normal file
@@ -0,0 +1,339 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a6f91f20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Scrapeless\n",
|
||||
"\n",
|
||||
"**Scrapeless** offers flexible and feature-rich data acquisition services with extensive parameter customization and multi-format export support. These capabilities empower LangChain to integrate and leverage external data more effectively. The core functional modules include:\n",
|
||||
"\n",
|
||||
"**DeepSerp**\n",
|
||||
"- **Google Search**: Enables comprehensive extraction of Google SERP data across all result types.\n",
|
||||
" - Supports selection of localized Google domains (e.g., `google.com`, `google.ad`) to retrieve region-specific search results.\n",
|
||||
" - Pagination supported for retrieving results beyond the first page.\n",
|
||||
" - Supports a search result filtering toggle to control whether to exclude duplicate or similar content.\n",
|
||||
"- **Google Trends**: Retrieves keyword trend data from Google, including popularity over time, regional interest, and related searches.\n",
|
||||
" - Supports multi-keyword comparison.\n",
|
||||
" - Supports multiple data types: `interest_over_time`, `interest_by_region`, `related_queries`, and `related_topics`.\n",
|
||||
" - Allows filtering by specific Google properties (Web, YouTube, News, Shopping) for source-specific trend analysis.\n",
|
||||
"\n",
|
||||
"**Universal Scraping**\n",
|
||||
"- Designed for modern, JavaScript-heavy websites, allowing dynamic content extraction.\n",
|
||||
" - Global premium proxy support for bypassing geo-restrictions and improving reliability.\n",
|
||||
"\n",
|
||||
"**Crawler**\n",
|
||||
"- **Crawl**: Recursively crawl a website and its linked pages to extract site-wide content.\n",
|
||||
" - Supports configurable crawl depth and scoped URL targeting.\n",
|
||||
"- **Scrape**: Extract content from a single webpage with high precision.\n",
|
||||
" - Supports \"main content only\" extraction to exclude ads, footers, and other non-essential elements.\n",
|
||||
" - Allows batch scraping of multiple standalone URLs.\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"### Integration details\n",
|
||||
"\n",
|
||||
"| Class | Package | Serializable | JS support | Package latest |\n",
|
||||
"| :--- | :--- | :---: | :---: | :---: |\n",
|
||||
"| [ScrapelessUniversalScrapingTool](https://pypi.org/project/langchain-scrapeless/) | [langchain-scrapeless](https://pypi.org/project/langchain-scrapeless/) | ✅ | ❌ |  |\n",
|
||||
"\n",
|
||||
"### Tool features\n",
|
||||
"\n",
|
||||
"|Native async|Returns artifact|Return data|\n",
|
||||
"|:-:|:-:|:-:|\n",
|
||||
"|✅|✅|html, markdown, links, metadata, structured content|\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-scrapeless` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "ca676665",
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "raw"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"!pip install langchain-scrapeless"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b15e9266",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"You'll need a Scrapeless API key to use this tool. You can set it as an environment variable:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e0b178a2-8816-40ca-b57c-ccdd86dde9c9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"SCRAPELESS_API_KEY\"] = \"your-api-key\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1c97218f-f366-479d-8bf7-fe9f2f6df73f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation\n",
|
||||
"\n",
|
||||
"Here we show how to instantiate an instance of the Scrapeless Universal Scraping Tool. This tool allows you to scrape any website using a headless browser with JavaScript rendering capabilities, customizable output types, and geo-specific proxy support.\n",
|
||||
"\n",
|
||||
"The tool accepts the following parameters during instantiation:\n",
|
||||
"- `url` (required, str): The URL of the website to scrape.\n",
|
||||
"- `headless` (optional, bool): Whether to use a headless browser. Default is True.\n",
|
||||
"- `js_render` (optional, bool): Whether to enable JavaScript rendering. Default is True.\n",
|
||||
"- `js_wait_until` (optional, str): Defines when to consider the JavaScript-rendered page ready. Default is `'domcontentloaded'`. Options include:\n",
|
||||
" - `load`: Wait until the page is fully loaded.\n",
|
||||
" - `domcontentloaded`: Wait until the DOM is fully loaded.\n",
|
||||
" - `networkidle0`: Wait until the network is idle.\n",
|
||||
" - `networkidle2`: Wait until the network is idle for 2 seconds.\n",
|
||||
"- `outputs` (optional, str): The specific type of data to extract from the page. Options include:\n",
|
||||
" - `phone_numbers`\n",
|
||||
" - `headings`\n",
|
||||
" - `images`\n",
|
||||
" - `audios`\n",
|
||||
" - `videos`\n",
|
||||
" - `links`\n",
|
||||
" - `menus`\n",
|
||||
" - `hashtags`\n",
|
||||
" - `emails`\n",
|
||||
" - `metadata`\n",
|
||||
" - `tables`\n",
|
||||
" - `favicon`\n",
|
||||
"- `response_type` (optional, str): Defines the format of the response. Default is `'html'`. Options include:\n",
|
||||
" - `html`: Return the raw HTML of the page.\n",
|
||||
" - `plaintext`: Return the plain text content.\n",
|
||||
" - `markdown`: Return a Markdown version of the page.\n",
|
||||
" - `png`: Return a PNG screenshot.\n",
|
||||
" - `jpeg`: Return a JPEG screenshot.\n",
|
||||
"- `response_image_full_page` (optional, bool): Whether to capture and return a full-page image when using screenshot output (png or jpeg). Default is False.\n",
|
||||
"- `selector` (optional, str): A specific CSS selector to scope scraping within a part of the page. Default is `None`.\n",
|
||||
"- `proxy_country` (optional, str): Two-letter country code for geo-specific proxy access (e.g., `'us'`, `'gb'`, `'de'`, `'jp'`). Default is `'ANY'`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "74147a1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n",
|
||||
"\n",
|
||||
"### Basic Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "65310a8b-eb0c-4d9e-a618-4f4abe2414fc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"<!DOCTYPE html><html><head>\n",
|
||||
" <title>Example Domain</title>\n",
|
||||
"\n",
|
||||
" <meta charset=\"utf-8\">\n",
|
||||
" <meta http-equiv=\"Content-type\" content=\"text/html; charset=utf-8\">\n",
|
||||
" <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n",
|
||||
" <style type=\"text/css\">\n",
|
||||
" body {\n",
|
||||
" background-color: #f0f0f2;\n",
|
||||
" margin: 0;\n",
|
||||
" padding: 0;\n",
|
||||
" font-family: -apple-system, system-ui, BlinkMacSystemFont, \"Segoe UI\", \"Open Sans\", \"Helvetica Neue\", Helvetica, Arial, sans-serif;\n",
|
||||
" \n",
|
||||
" }\n",
|
||||
" div {\n",
|
||||
" width: 600px;\n",
|
||||
" margin: 5em auto;\n",
|
||||
" padding: 2em;\n",
|
||||
" background-color: #fdfdff;\n",
|
||||
" border-radius: 0.5em;\n",
|
||||
" box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);\n",
|
||||
" }\n",
|
||||
" a:link, a:visited {\n",
|
||||
" color: #38488f;\n",
|
||||
" text-decoration: none;\n",
|
||||
" }\n",
|
||||
" @media (max-width: 700px) {\n",
|
||||
" div {\n",
|
||||
" margin: 0 auto;\n",
|
||||
" width: auto;\n",
|
||||
" }\n",
|
||||
" }\n",
|
||||
" </style> \n",
|
||||
"</head>\n",
|
||||
"\n",
|
||||
"<body>\n",
|
||||
"<div>\n",
|
||||
" <h1>Example Domain</h1>\n",
|
||||
" <p>This domain is for use in illustrative examples in documents. You may use this\n",
|
||||
" domain in literature without prior coordination or asking for permission.</p>\n",
|
||||
" <p><a href=\"https://www.iana.org/domains/example\">More information...</a></p>\n",
|
||||
"</div>\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"</body></html>\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"# Basic usage\n",
|
||||
"result = tool.invoke(\"https://example.com\")\n",
|
||||
"print(result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d6e73897",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Advanced Usage with Parameters"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f90e33a7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"# Well hello there.\n",
|
||||
"\n",
|
||||
"Welcome to exmaple.com.\n",
|
||||
"Chances are you got here by mistake (example.com, anyone?)\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"result = tool.invoke({\"url\": \"https://exmaple.com\", \"response_type\": \"markdown\"})\n",
|
||||
"print(result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "659f9fbd-6fcf-445f-aa8c-72d8e60154bd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Use within an agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "af3123ad-7a02-40e5-b58e-7d56e23e5830",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"================================\u001b[1m Human Message \u001b[0m=================================\n",
|
||||
"\n",
|
||||
"Use the scrapeless scraping tool to fetch https://www.scrapeless.com/en and extract the h1 tag.\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"Tool Calls:\n",
|
||||
" scrapeless_universal_scraping (call_jBrvMVL2ixhvf6gklhi7Gqtb)\n",
|
||||
" Call ID: call_jBrvMVL2ixhvf6gklhi7Gqtb\n",
|
||||
" Args:\n",
|
||||
" url: https://www.scrapeless.com/en\n",
|
||||
" outputs: headings\n",
|
||||
"=================================\u001b[1m Tool Message \u001b[0m=================================\n",
|
||||
"Name: scrapeless_universal_scraping\n",
|
||||
"\n",
|
||||
"{\"headings\":[\"Effortless Web Scraping Toolkitfor Business and Developers\",\"4.8\",\"4.5\",\"8.5\",\"A Flexible Toolkit for Accessing Public Web Data\",\"Deep SerpApi\",\"Scraping Browser\",\"Universal Scraping API\",\"Customized Services\",\"From Simple Data Scraping to Complex Anti-Bot Challenges, Scrapeless Has You Covered.\",\"Fully Compatible with Key Programming Languages and Tools\",\"Enterprise-level Data Scraping Solution\",\"Customized Data Scraping Solutions\",\"High Concurrency and High-Performance Scraping\",\"Data Cleaning and Transformation\",\"Real-Time Data Push and API Integration\",\"Data Security and Privacy Protection\",\"Enterprise-level SLA\",\"Why Scrapeless: Simplify Your Data Flow Effortlessly.\",\"Articles\",\"Organized Fresh Data\",\"Prices\",\"No need to hassle with browser maintenance\",\"Reviews\",\"Only pay for successful requests\",\"Products\",\"Fully scalable\",\"Unleash Your Competitive Edgein Data within the Industry\",\"Regulate Compliance for All Users\",\"Web Scraping Blog\",\"Scrapeless MCP Server Is Officially Live! Build Your Ultimate AI-Web Connector\",\"Product Updates | New Profile Feature\",\"How to Track Your Ranking on ChatGPT?\",\"For Scraping\",\"For Data\",\"For AI\",\"Top Scraper API\",\"Learning Center\",\"Legal\"]}\n",
|
||||
"==================================\u001b[1m Ai Message \u001b[0m==================================\n",
|
||||
"\n",
|
||||
"The h1 tag extracted from the website https://www.scrapeless.com/en is \"Effortless Web Scraping Toolkit for Business and Developers\".\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"from langchain_scrapeless import ScrapelessUniversalScrapingTool\n",
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI()\n",
|
||||
"\n",
|
||||
"tool = ScrapelessUniversalScrapingTool()\n",
|
||||
"\n",
|
||||
"# Use the tool with an agent\n",
|
||||
"tools = [tool]\n",
|
||||
"agent = create_react_agent(llm, tools)\n",
|
||||
"\n",
|
||||
"for chunk in agent.stream(\n",
|
||||
" {\n",
|
||||
" \"messages\": [\n",
|
||||
" (\n",
|
||||
" \"human\",\n",
|
||||
" \"Use the scrapeless scraping tool to fetch https://www.scrapeless.com/en and extract the h1 tag.\",\n",
|
||||
" )\n",
|
||||
" ]\n",
|
||||
" },\n",
|
||||
" stream_mode=\"values\",\n",
|
||||
"):\n",
|
||||
" chunk[\"messages\"][-1].pretty_print()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4ac8146c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
"- [Scrapeless Documentation](https://docs.scrapeless.com/en/universal-scraping-api/quickstart/introduction/)\n",
|
||||
"- [Scrapeless API Reference](https://apidocs.scrapeless.com/api-12948840)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.12.11"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
378
docs/docs/integrations/tools/toolbox.ipynb
Normal file
378
docs/docs/integrations/tools/toolbox.ipynb
Normal file
@@ -0,0 +1,378 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "554b9f85",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# MCP Toolbox for Databases\n",
|
||||
"\n",
|
||||
"Integrate your databases with LangChain agents using MCP Toolbox.\n",
|
||||
"\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"[MCP Toolbox for Databases](https://github.com/googleapis/genai-toolbox) is an open source MCP server for databases. It was designed with enterprise-grade and production-quality in mind. It enables you to develop tools easier, faster, and more securely by handling the complexities such as connection pooling, authentication, and more.\n",
|
||||
"\n",
|
||||
"Toolbox Tools can be seemlessly integrated with Langchain applications. For more\n",
|
||||
"information on [getting\n",
|
||||
"started](https://googleapis.github.io/genai-toolbox/getting-started/local_quickstart/) or\n",
|
||||
"[configuring](https://googleapis.github.io/genai-toolbox/getting-started/configure/)\n",
|
||||
"MCP Toolbox, see the\n",
|
||||
"[documentation](https://googleapis.github.io/genai-toolbox/getting-started/introduction/).\n",
|
||||
"\n",
|
||||
"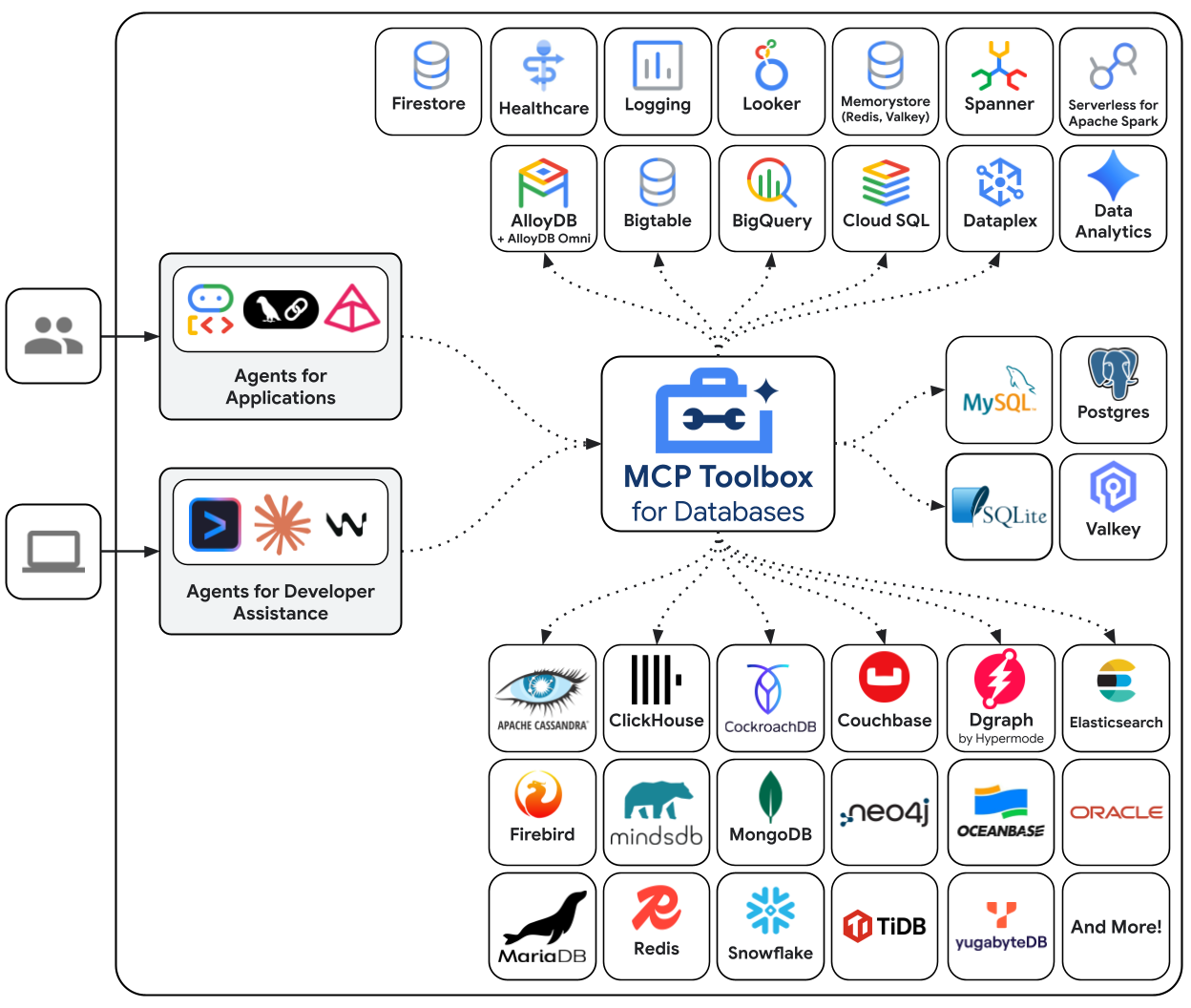"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "788ff64c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"This guide assumes you have already done the following:\n",
|
||||
"\n",
|
||||
"1. Installed [Python 3.9+](https://wiki.python.org/moin/BeginnersGuide/Download) and [pip](https://pip.pypa.io/en/stable/installation/).\n",
|
||||
"2. Installed [PostgreSQL 16+ and the `psql` command-line client](https://www.postgresql.org/download/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4847d196",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 1. Setup your Database\n",
|
||||
"\n",
|
||||
"First, let's set up a PostgreSQL database. We'll create a new database, a dedicated user for MCP Toolbox, and a `hotels` table with some sample data.\n",
|
||||
"\n",
|
||||
"Connect to PostgreSQL using the `psql` command. You may need to adjust the command based on your PostgreSQL setup (e.g., if you need to specify a host or a different superuser).\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"psql -U postgres\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Now, run the following SQL commands to create the user, database, and grant the necessary permissions:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"CREATE USER toolbox_user WITH PASSWORD 'my-password';\n",
|
||||
"CREATE DATABASE toolbox_db;\n",
|
||||
"GRANT ALL PRIVILEGES ON DATABASE toolbox_db TO toolbox_user;\n",
|
||||
"ALTER DATABASE toolbox_db OWNER TO toolbox_user;\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Connect to your newly created database with the new user:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"\\c toolbox_db toolbox_user\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Finally, create the `hotels` table and insert some data:\n",
|
||||
"\n",
|
||||
"```sql\n",
|
||||
"CREATE TABLE hotels(\n",
|
||||
" id INTEGER NOT NULL PRIMARY KEY,\n",
|
||||
" name VARCHAR NOT NULL,\n",
|
||||
" location VARCHAR NOT NULL,\n",
|
||||
" price_tier VARCHAR NOT NULL,\n",
|
||||
" booked BIT NOT NULL\n",
|
||||
");\n",
|
||||
"\n",
|
||||
"INSERT INTO hotels(id, name, location, price_tier, booked)\n",
|
||||
"VALUES \n",
|
||||
" (1, 'Hilton Basel', 'Basel', 'Luxury', B'0'),\n",
|
||||
" (2, 'Marriott Zurich', 'Zurich', 'Upscale', B'0'),\n",
|
||||
" (3, 'Hyatt Regency Basel', 'Basel', 'Upper Upscale', B'0');\n",
|
||||
"```\n",
|
||||
"You can now exit `psql` by typing `\\q`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "855133f8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 2. Install MCP Toolbox\n",
|
||||
"\n",
|
||||
"Next, we will install MCP Toolbox, define our tools in a `tools.yaml` configuration file, and run the MCP Toolbox server.\n",
|
||||
"\n",
|
||||
"For **macOS** users, the easiest way to install is with [Homebrew](https://formulae.brew.sh/formula/mcp-toolbox):\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"brew install mcp-toolbox\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"For other platforms, [download the latest MCP Toolbox binary for your operating system and architecture.](https://github.com/googleapis/genai-toolbox/releases)\n",
|
||||
"\n",
|
||||
"Create a `tools.yaml` file. This file defines the data sources MCP Toolbox can connect to and the tools it can expose to your agent. For production use, always use environment variables for secrets.\n",
|
||||
"\n",
|
||||
"```yaml\n",
|
||||
"sources:\n",
|
||||
" my-pg-source:\n",
|
||||
" kind: postgres\n",
|
||||
" host: 127.0.0.1\n",
|
||||
" port: 5432\n",
|
||||
" database: toolbox_db\n",
|
||||
" user: toolbox_user\n",
|
||||
" password: my-password\n",
|
||||
"\n",
|
||||
"tools:\n",
|
||||
" search-hotels-by-location:\n",
|
||||
" kind: postgres-sql\n",
|
||||
" source: my-pg-source\n",
|
||||
" description: Search for hotels based on location.\n",
|
||||
" parameters:\n",
|
||||
" - name: location\n",
|
||||
" type: string\n",
|
||||
" description: The location of the hotel.\n",
|
||||
" statement: SELECT id, name, location, price_tier FROM hotels WHERE location ILIKE '%' || $1 || '%';\n",
|
||||
" book-hotel:\n",
|
||||
" kind: postgres-sql\n",
|
||||
" source: my-pg-source\n",
|
||||
" description: >-\n",
|
||||
" Book a hotel by its ID. If the hotel is successfully booked, returns a confirmation message.\n",
|
||||
" parameters:\n",
|
||||
" - name: hotel_id\n",
|
||||
" type: integer\n",
|
||||
" description: The ID of the hotel to book.\n",
|
||||
" statement: UPDATE hotels SET booked = B'1' WHERE id = $1;\n",
|
||||
"\n",
|
||||
"toolsets:\n",
|
||||
" hotel_toolset:\n",
|
||||
" - search-hotels-by-location\n",
|
||||
" - book-hotel\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Now, in a separate terminal window, start the MCP Toolbox server. If you installed via Homebrew, you can just run `toolbox`. If you downloaded the binary manually, you'll need to run `./toolbox` from the directory where you saved it:\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"toolbox --tools-file \"tools.yaml\"\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"MCP Toolbox will start on `http://127.0.0.1:5000` by default and will hot-reload if you make changes to your `tools.yaml` file."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b9b2f041",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Instantiation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d4c31f3b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install toolbox-langchain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "14a68a49",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" search_tool = await client.aload_tool(\"search-hotels-by-location\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "95eec50c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Invocation\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8e99351b",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[{\"id\":1,\"location\":\"Basel\",\"name\":\"Hilton Basel\",\"price_tier\":\"Luxury\"},{\"id\":3,\"location\":\"Basel\",\"name\":\"Hyatt Regency Basel\",\"price_tier\":\"Upper Upscale\"}]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" search_tool = await client.aload_tool(\"search-hotels-by-location\")\n",
|
||||
" results = search_tool.invoke({\"location\": \"Basel\"})\n",
|
||||
" print(results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9e8dbd39",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Use within an agent\n",
|
||||
"\n",
|
||||
"Now for the fun part! We'll install the required LangChain packages and create an agent that can use the tools we defined in MCP Toolbox."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9b716a84",
|
||||
"metadata": {
|
||||
"id": "install-packages"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U --quiet toolbox-langchain langgraph langchain-google-vertexai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "affda34b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"With the packages installed, we can define our agent. We will use `ChatVertexAI` for the model and `ToolboxClient` to load our tools. The `create_react_agent` from `langgraph.prebuilt` creates a robust agent that can reason about which tools to call.\n",
|
||||
"\n",
|
||||
"**Note:** Ensure your MCP Toolbox server is running in a separate terminal before executing the code below."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "ddd82892",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langgraph.prebuilt import create_react_agent\n",
|
||||
"from langchain_google_vertexai import ChatVertexAI\n",
|
||||
"from langgraph.checkpoint.memory import MemorySaver\n",
|
||||
"from toolbox_langchain import ToolboxClient\n",
|
||||
"\n",
|
||||
"prompt = \"\"\"\n",
|
||||
"You're a helpful hotel assistant. You handle hotel searching and booking.\n",
|
||||
"When the user searches for a hotel, list the full details for each hotel found: id, name, location, and price tier.\n",
|
||||
"Always use the hotel ID for booking operations.\n",
|
||||
"For any bookings, provide a clear confirmation message.\n",
|
||||
"Don't ask for clarification or confirmation from the user; perform the requested action directly.\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_queries(agent_executor):\n",
|
||||
" config = {\"configurable\": {\"thread_id\": \"hotel-thread-1\"}}\n",
|
||||
"\n",
|
||||
" # --- Query 1: Search for hotels ---\n",
|
||||
" query1 = \"I need to find a hotel in Basel.\"\n",
|
||||
" print(f'\\n--- USER: \"{query1}\" ---')\n",
|
||||
" inputs1 = {\"messages\": [(\"user\", prompt + query1)]}\n",
|
||||
" async for event in agent_executor.astream_events(\n",
|
||||
" inputs1, config=config, version=\"v2\"\n",
|
||||
" ):\n",
|
||||
" if event[\"event\"] == \"on_chat_model_end\" and event[\"data\"][\"output\"].content:\n",
|
||||
" print(f\"--- AGENT: ---\\n{event['data']['output'].content}\")\n",
|
||||
"\n",
|
||||
" # --- Query 2: Book a hotel ---\n",
|
||||
" query2 = \"Great, please book the Hyatt Regency Basel for me.\"\n",
|
||||
" print(f'\\n--- USER: \"{query2}\" ---')\n",
|
||||
" inputs2 = {\"messages\": [(\"user\", query2)]}\n",
|
||||
" async for event in agent_executor.astream_events(\n",
|
||||
" inputs2, config=config, version=\"v2\"\n",
|
||||
" ):\n",
|
||||
" if event[\"event\"] == \"on_chat_model_end\" and event[\"data\"][\"output\"].content:\n",
|
||||
" print(f\"--- AGENT: ---\\n{event['data']['output'].content}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "54552733",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run the agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9f7c199b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"async def main():\n",
|
||||
" await run_hotel_agent()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_hotel_agent():\n",
|
||||
" model = ChatVertexAI(model_name=\"gemini-2.5-flash\")\n",
|
||||
"\n",
|
||||
" # Load the tools from the running MCP Toolbox server\n",
|
||||
" async with ToolboxClient(\"http://127.0.0.1:5000\") as client:\n",
|
||||
" tools = await client.aload_toolset(\"hotel_toolset\")\n",
|
||||
"\n",
|
||||
" agent = create_react_agent(model, tools, checkpointer=MemorySaver())\n",
|
||||
"\n",
|
||||
" await run_queries(agent)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await main()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "79bce43d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You've successfully connected a LangChain agent to a local database using MCP Toolbox! 🥳\n",
|
||||
"\n",
|
||||
"## API reference\n",
|
||||
"\n",
|
||||
"The primary class for this integration is `ToolboxClient`.\n",
|
||||
"\n",
|
||||
"For more information, see the following resources:\n",
|
||||
"- [Toolbox Official Documentation](https://googleapis.github.io/genai-toolbox/)\n",
|
||||
"- [Toolbox GitHub Repository](https://github.com/googleapis/genai-toolbox)\n",
|
||||
"- [Toolbox LangChain SDK](https://github.com/googleapis/mcp-toolbox-python-sdk/tree/main/packages/toolbox-langchain)\n",
|
||||
"\n",
|
||||
"MCP Toolbox has a variety of features to make developing Gen AI tools for databases seamless:\n",
|
||||
"- [Authenticated Parameters](https://googleapis.github.io/genai-toolbox/resources/tools/#authenticated-parameters): Bind tool inputs to values from OIDC tokens automatically, making it easy to run sensitive queries without potentially leaking data\n",
|
||||
"- [Authorized Invocations](https://googleapis.github.io/genai-toolbox/resources/tools/#authorized-invocations): Restrict access to use a tool based on the users Auth token\n",
|
||||
"- [OpenTelemetry](https://googleapis.github.io/genai-toolbox/how-to/export_telemetry/): Get metrics and tracing from MCP Toolbox with [OpenTelemetry](https://opentelemetry.io/docs/)\n",
|
||||
"\n",
|
||||
"# Community and Support\n",
|
||||
"\n",
|
||||
"We encourage you to get involved with the community:\n",
|
||||
"- ⭐️ Head over to the [GitHub repository](https://github.com/googleapis/genai-toolbox) to get started and follow along with updates.\n",
|
||||
"- 📚 Dive into the [official documentation](https://googleapis.github.io/genai-toolbox/getting-started/introduction/) for more advanced features and configurations.\n",
|
||||
"- 💬 Join our [Discord server](https://discord.com/invite/a4XjGqtmnG) to connect with the community and ask questions."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -19,7 +19,7 @@
|
||||
"\n",
|
||||
"> [Firestore](https://cloud.google.com/firestore) is a serverless document-oriented database that scales to meet any demand. Extend your database application to build AI-powered experiences leveraging Firestore's Langchain integrations.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use [Firestore](https://cloud.google.com/firestore) to to store vectors and query them using the `FirestoreVectorStore` class.\n",
|
||||
"This notebook goes over how to use [Firestore](https://cloud.google.com/firestore) to store vectors and query them using the `FirestoreVectorStore` class.\n",
|
||||
"\n",
|
||||
"[](https://colab.research.google.com/github/googleapis/langchain-google-firestore-python/blob/main/docs/vectorstores.ipynb)"
|
||||
]
|
||||
|
||||
@@ -29,8 +29,8 @@
|
||||
" Please refer to the instructions in:\n",
|
||||
" [www.jaguardb.com](http://www.jaguardb.com)\n",
|
||||
" For quick setup in docker environment:\n",
|
||||
" docker pull jaguardb/jaguardb_with_http\n",
|
||||
" docker run -d -p 8888:8888 -p 8080:8080 --name jaguardb_with_http jaguardb/jaguardb_with_http\n",
|
||||
" docker pull jaguardb/jaguardb\n",
|
||||
" docker run -d -p 8888:8888 -p 8080:8080 --name jaguardb jaguardb/jaguardb\n",
|
||||
"\n",
|
||||
"2. You must install the http client package for JaguarDB:\n",
|
||||
" ```\n",
|
||||
|
||||
@@ -36,7 +36,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"pip install -qU langchain_milvus"
|
||||
"pip install -qU langchain-milvus"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -9,13 +9,13 @@
|
||||
"\n",
|
||||
"> An implementation of LangChain vectorstore abstraction using `postgres` as the backend and utilizing the `pgvector` extension.\n",
|
||||
"\n",
|
||||
"The code lives in an integration package called: [langchain_postgres](https://github.com/langchain-ai/langchain-postgres/).\n",
|
||||
"The code lives in an integration package called: [langchain-postgres](https://github.com/langchain-ai/langchain-postgres/).\n",
|
||||
"\n",
|
||||
"## Status\n",
|
||||
"\n",
|
||||
"This code has been ported over from `langchain_community` into a dedicated package called `langchain-postgres`. The following changes have been made:\n",
|
||||
"This code has been ported over from `langchain-community` into a dedicated package called `langchain-postgres`. The following changes have been made:\n",
|
||||
"\n",
|
||||
"* langchain_postgres works only with psycopg3. Please update your connnecion strings from `postgresql+psycopg2://...` to `postgresql+psycopg://langchain:langchain@...` (yes, it's the driver name is `psycopg` not `psycopg3`, but it'll use `psycopg3`.\n",
|
||||
"* `langchain-postgres` works only with psycopg3. Please update your connnecion strings from `postgresql+psycopg2://...` to `postgresql+psycopg://langchain:langchain@...` (yes, it's the driver name is `psycopg` not `psycopg3`, but it'll use `psycopg3`.\n",
|
||||
"* The schema of the embedding store and collection have been changed to make add_documents work correctly with user specified ids.\n",
|
||||
"* One has to pass an explicit connection object now.\n",
|
||||
"\n",
|
||||
@@ -35,7 +35,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install -qU langchain_postgres"
|
||||
"pip install -qU langchain-postgres"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -43,7 +43,7 @@
|
||||
"id": "0dd87fcc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can run the following command to spin up a a postgres container with the `pgvector` extension:"
|
||||
"You can run the following command to spin up a postgres container with the `pgvector` extension:"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -63,7 +63,7 @@
|
||||
"source": [
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"There are no credentials needed to run this notebook, just make sure you downloaded the `langchain_postgres` package and correctly started the postgres container."
|
||||
"There are no credentials needed to run this notebook, just make sure you downloaded the `langchain-postgres` package and correctly started the postgres container."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
"\n",
|
||||
"This notebook goes over how to use the `PGVectorStore` API.\n",
|
||||
"\n",
|
||||
"The code lives in an integration package called: [langchain_postgres](https://github.com/langchain-ai/langchain-postgres/)."
|
||||
"The code lives in an integration package called: [langchain-postgres](https://github.com/langchain-ai/langchain-postgres/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -61,7 +61,7 @@
|
||||
"source": [
|
||||
"## Credentials\n",
|
||||
"\n",
|
||||
"There are no credentials needed to run this notebook, just make sure you downloaded the `langchain_sqlserver` package\n",
|
||||
"There are no credentials needed to run this notebook, just make sure you downloaded the `langchain-sqlserver` package\n",
|
||||
"If you want to get best in-class automated tracing of your model calls you can also set your [LangSmith](https://docs.smith.langchain.com/) API key by uncommenting below:"
|
||||
]
|
||||
},
|
||||
|
||||
@@ -193,7 +193,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You should additionally not pass `ToolMessages` back to to a model if they are not preceded by an `AIMessage` with tool calls. For example, this will fail:"
|
||||
"You should additionally not pass `ToolMessages` back to a model if they are not preceded by an `AIMessage` with tool calls. For example, this will fail:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user