mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-12 12:11:34 +00:00
Compare commits
1 Commits
v0.0.341
...
bagatur/se
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a990b63443 |
@@ -34,12 +34,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"execution_count": null,
|
||||
"id": "5740fc70-c513-4ff4-9d72-cfc098f85fef",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"! pip install langchain docugami==0.0.8 dgml-utils==0.3.0 pydantic langchainhub chromadb hnswlib --upgrade --quiet"
|
||||
"! pip install langchain docugami==0.0.4 dgml-utils==0.2.0 pydantic langchainhub chromadb --upgrade --quiet"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -76,7 +76,98 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 45,
|
||||
"id": "fc0767d4-9155-4591-855c-ef2e14e0e10f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"import tempfile\n",
|
||||
"from pathlib import Path\n",
|
||||
"from pprint import pprint\n",
|
||||
"from time import sleep\n",
|
||||
"from typing import Dict, List\n",
|
||||
"\n",
|
||||
"import requests\n",
|
||||
"from docugami import Docugami\n",
|
||||
"from docugami.types import Document as DocugamiDocument\n",
|
||||
"\n",
|
||||
"api_key = os.environ.get(\"DOCUGAMI_API_KEY\")\n",
|
||||
"if not api_key:\n",
|
||||
" raise Exception(\"Please set Docugami API key environment variable\")\n",
|
||||
"\n",
|
||||
"client = Docugami()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def upload_files(local_paths: List[str], docset_name: str) -> List[DocugamiDocument]:\n",
|
||||
" docset_list_response = client.docsets.list(name=docset_name)\n",
|
||||
" if docset_list_response and docset_list_response.docsets:\n",
|
||||
" # Docset already exists with this name\n",
|
||||
" docset_id = docset_list_response.docsets[0]\n",
|
||||
" else:\n",
|
||||
" dg_docset = client.docsets.create(name=docset_name)\n",
|
||||
" docset_id = dg_docset.id\n",
|
||||
"\n",
|
||||
" document_list_response = client.documents.list(limit=int(1e5))\n",
|
||||
" dg_docs: List[DocugamiDocument] = []\n",
|
||||
" if document_list_response and document_list_response.documents:\n",
|
||||
" new_names = [Path(f).name for f in local_paths]\n",
|
||||
"\n",
|
||||
" dg_docs = [\n",
|
||||
" d\n",
|
||||
" for d in document_list_response.documents\n",
|
||||
" if Path(d.name).name in new_names\n",
|
||||
" ]\n",
|
||||
" existing_names = [Path(d.name).name for d in dg_docs]\n",
|
||||
"\n",
|
||||
" # Upload any files not previously uploaded\n",
|
||||
" for f in local_paths:\n",
|
||||
" if Path(f).name not in existing_names:\n",
|
||||
" dg_docs.append(\n",
|
||||
" client.documents.contents.upload(\n",
|
||||
" file=Path(f).absolute(),\n",
|
||||
" docset_id=docset_id,\n",
|
||||
" )\n",
|
||||
" )\n",
|
||||
" return dg_docs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def wait_for_xml(dg_docs: List[DocugamiDocument]) -> dict[str, str]:\n",
|
||||
" dgml_paths: dict[str, str] = {}\n",
|
||||
" while len(dgml_paths) < len(dg_docs):\n",
|
||||
" for doc in dg_docs:\n",
|
||||
" doc = client.documents.retrieve(doc.id) # update with latest\n",
|
||||
" current_status = doc.status\n",
|
||||
" if current_status == \"Error\":\n",
|
||||
" raise Exception(\n",
|
||||
" \"Document could not be processed, please confirm it is not a zero length, corrupt or password protected file\"\n",
|
||||
" )\n",
|
||||
" elif current_status == \"Ready\":\n",
|
||||
" dgml_url = doc.docset.url + f\"/documents/{doc.id}/dgml\"\n",
|
||||
" headers = {\"Authorization\": f\"Bearer {api_key}\"}\n",
|
||||
" dgml_response = requests.get(dgml_url, headers=headers)\n",
|
||||
" if not dgml_response.ok:\n",
|
||||
" raise Exception(\n",
|
||||
" f\"Could not download DGML artifact {dgml_url}: {dgml_response.status_code}\"\n",
|
||||
" )\n",
|
||||
" dgml_contents = dgml_response.text\n",
|
||||
" with tempfile.NamedTemporaryFile(delete=False, mode=\"w\") as temp_file:\n",
|
||||
" temp_file.write(dgml_contents)\n",
|
||||
" temp_file_path = temp_file.name\n",
|
||||
" dgml_paths[doc.name] = temp_file_path\n",
|
||||
"\n",
|
||||
" print(f\"{len(dgml_paths)} docs done processing out of {len(dg_docs)}...\")\n",
|
||||
"\n",
|
||||
" if len(dgml_paths) == len(dg_docs):\n",
|
||||
" # done\n",
|
||||
" return dgml_paths\n",
|
||||
" else:\n",
|
||||
" sleep(30) # try again in a bit"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 46,
|
||||
"id": "ce0b2b21-7623-46e7-ae2c-3a9f67e8b9b9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -84,22 +175,18 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'Report_CEN23LA277_192541.pdf': '/tmp/tmpa0c77x46',\n",
|
||||
" 'Report_CEN23LA338_192753.pdf': '/tmp/tmpaftfld2w',\n",
|
||||
" 'Report_CEN23LA363_192876.pdf': '/tmp/tmpn7gp6be2',\n",
|
||||
" 'Report_CEN23LA394_192995.pdf': '/tmp/tmp9udymprf',\n",
|
||||
" 'Report_ERA23LA114_106615.pdf': '/tmp/tmpxdjbh4r_',\n",
|
||||
" 'Report_WPR23LA254_192532.pdf': '/tmp/tmpz6h75a0h'}\n"
|
||||
"6 docs done processing out of 6...\n",
|
||||
"{'Report_CEN23LA277_192541.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmpel3o0rpg',\n",
|
||||
" 'Report_CEN23LA338_192753.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmpgugb9ut1',\n",
|
||||
" 'Report_CEN23LA363_192876.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmp3_gf2sky',\n",
|
||||
" 'Report_CEN23LA394_192995.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmpwmfgoxkl',\n",
|
||||
" 'Report_ERA23LA114_106615.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmptibrz2yu',\n",
|
||||
" 'Report_WPR23LA254_192532.pdf': '/var/folders/0h/6cchx4k528bdj8cfcsdm0dqr0000gn/T/tmpvazrbbsi'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from pprint import pprint\n",
|
||||
"\n",
|
||||
"from docugami import Docugami\n",
|
||||
"from docugami.lib.upload import upload_to_named_docset, wait_for_dgml\n",
|
||||
"\n",
|
||||
"#### START DOCSET INFO (please change this values as needed)\n",
|
||||
"#### START DOCSET INFO (please change)\n",
|
||||
"DOCSET_NAME = \"NTSB Aviation Incident Reports\"\n",
|
||||
"FILE_PATHS = [\n",
|
||||
" \"/Users/tjaffri/ntsb/Report_CEN23LA277_192541.pdf\",\n",
|
||||
@@ -110,15 +197,13 @@
|
||||
" \"/Users/tjaffri/ntsb/Report_WPR23LA254_192532.pdf\",\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"# Note: Please specify ~6 (or more!) similar files to process together as a document set\n",
|
||||
"# This is currently a requirement for Docugami to automatically detect motifs\n",
|
||||
"# across the document set to generate a semantic XML Knowledge Graph.\n",
|
||||
"assert len(FILE_PATHS) > 5, \"Please provide at least 6 files\"\n",
|
||||
"assert (\n",
|
||||
" len(FILE_PATHS) > 5\n",
|
||||
") # Please specify ~6 (or more!) similar files to process together as a document set\n",
|
||||
"#### END DOCSET INFO\n",
|
||||
"\n",
|
||||
"dg_client = Docugami()\n",
|
||||
"dg_docs = upload_to_named_docset(dg_client, FILE_PATHS, DOCSET_NAME)\n",
|
||||
"dgml_paths = wait_for_dgml(dg_client, dg_docs)\n",
|
||||
"dg_docs = upload_files(FILE_PATHS, DOCSET_NAME)\n",
|
||||
"dgml_paths = wait_for_xml(dg_docs)\n",
|
||||
"\n",
|
||||
"pprint(dgml_paths)"
|
||||
]
|
||||
@@ -143,7 +228,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 47,
|
||||
"id": "05fcdd57-090f-44bf-a1fb-2c3609c80e34",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -152,13 +237,13 @@
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"found 30 chunks, here are the first few\n",
|
||||
"<AviationInvestigationFinalReport-section>Aviation </AviationInvestigationFinalReport-section>Investigation Final Report\n",
|
||||
"<table><tbody><tr><td>Location: </td> <td><Location><TownName>Elbert</TownName>, <USState>Colorado </USState></Location></td> <td>Accident Number: </td> <td><AccidentNumber>CEN23LA277 </AccidentNumber></td></tr> <tr><td><LocationDateTime>Date & Time: </LocationDateTime></td> <td><DateTime><EventDate>June 26, 2023</EventDate>, <EventTime>11:00 Local </EventTime></DateTime></td> <td><DateTimeAccidentNumber>Registration: </DateTimeAccidentNumber></td> <td><Registration>N23161 </Registration></td></tr> <tr><td><LocationAircraft>Aircraft: </LocationAircraft></td> <td><AircraftType>Piper <AircraftType>J3C-50 </AircraftType></AircraftType></td> <td><AircraftAccidentNumber>Aircraft Damage: </AircraftAccidentNumber></td> <td><AircraftDamage>Substantial </AircraftDamage></td></tr> <tr><td><LocationDefiningEvent>Defining Event: </LocationDefiningEvent></td> <td><DefiningEvent>Nose over/nose down </DefiningEvent></td> <td><DefiningEventAccidentNumber>Injuries: </DefiningEventAccidentNumber></td> <td><Injuries><Minor>1 </Minor>Minor </Injuries></td></tr> <tr><td><LocationFlightConductedUnder>Flight Conducted Under: </LocationFlightConductedUnder></td> <td><FlightConductedUnder><Part91-cell>Part <RegulationPart>91</RegulationPart>: General aviation - Personal </Part91-cell></FlightConductedUnder></td><td/><td><FlightConductedUnderCEN23LA277/></td></tr></tbody></table>\n",
|
||||
"Aviation Investigation Final Report\n",
|
||||
"<table><tbody><tr><td>Location: </td> <td><Location><TownName>Elbert</TownName>, <USState>Colorado </USState></Location></td> <td>Accident Number: </td> <td><AccidentNumber>CEN23LA277 </AccidentNumber></td></tr> <tr><td><LocationDateTime>Date & Time: </LocationDateTime></td> <td><DateTime><EventDate>June 26, 2023</EventDate>, <EventTime>11:00 Local </EventTime></DateTime></td> <td><DateTimeAccidentNumber>Registration: </DateTimeAccidentNumber></td> <td><Registration>N23161 </Registration></td></tr> <tr><td><LocationAircraft>Aircraft: </LocationAircraft></td> <td><Aircraft>Piper <AircraftType>J3C-50 </AircraftType></Aircraft></td> <td><AircraftAccidentNumber>Aircraft Damage: </AircraftAccidentNumber></td> <td><AircraftDamage>Substantial </AircraftDamage></td></tr> <tr><td><LocationDefiningEvent>Defining Event: </LocationDefiningEvent></td> <td><DefiningEvent>Nose over/nose down </DefiningEvent></td> <td><DefiningEventAccidentNumber>Injuries: </DefiningEventAccidentNumber></td> <td><Injuries><Minor>1 </Minor>Minor </Injuries></td></tr> <tr><td><LocationFlightConductedUnder>Flight Conducted Under: </LocationFlightConductedUnder></td> <td><Part91-cell>Part <RegulationPart>91</RegulationPart>: General aviation - Personal </Part91-cell></td><td/><td><FlightConductedUnderCEN23LA277/></td></tr></tbody></table>\n",
|
||||
"Analysis\n",
|
||||
"<TakeoffAccident> <Analysis>The pilot reported that, as the tail lifted during takeoff, the airplane veered left. He attempted to correct with full right rudder and full brakes. However, the airplane subsequently nosed over resulting in substantial damage to the fuselage, lift struts, rudder, and vertical stabilizer. </Analysis></TakeoffAccident>\n",
|
||||
"<TakeoffAccident> The pilot reported that, as the tail lifted during takeoff, the airplane veered left. He attempted to correct with full right rudder and full brakes. However, the airplane subsequently nosed over resulting in substantial damage to the fuselage, lift struts, rudder, and vertical stabilizer. </TakeoffAccident>\n",
|
||||
"<AircraftCondition> The pilot reported that there were no preaccident mechanical malfunctions or anomalies with the airplane that would have precluded normal operation. </AircraftCondition>\n",
|
||||
"<WindConditions> At about the time of the accident, wind was from <WindDirection>180</WindDirection>° at <WindConditions>5 </WindConditions>knots. The pilot decided to depart on runway <Runway>35 </Runway>due to the prevailing airport traffic. He stated that departing with “more favorable wind conditions” may have prevented the accident. </WindConditions>\n",
|
||||
"<ProbableCauseAndFindings-section>Probable Cause and Findings </ProbableCauseAndFindings-section>\n",
|
||||
"Probable Cause and Findings\n",
|
||||
"<ProbableCause> The <ProbableCause>National Transportation Safety Board </ProbableCause>determines the probable cause(s) of this accident to be: </ProbableCause>\n",
|
||||
"<AccidentCause> The pilot's loss of directional control during takeoff and subsequent excessive use of brakes which resulted in a nose-over. Contributing to the accident was his decision to takeoff downwind. </AccidentCause>\n",
|
||||
"Page 1 of <PageNumber>5 </PageNumber>\n"
|
||||
@@ -166,8 +251,6 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from pathlib import Path\n",
|
||||
"\n",
|
||||
"from dgml_utils.segmentation import get_chunks_str\n",
|
||||
"\n",
|
||||
"# Here we just read the first file, you can do the same for others\n",
|
||||
@@ -200,7 +283,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 48,
|
||||
"id": "8a4b49e0-de78-4790-a930-ad7cf324697a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -260,7 +343,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 109,
|
||||
"id": "7b697d30-1e94-47f0-87e8-f81d4b180da2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -270,14 +353,12 @@
|
||||
"39"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"execution_count": 109,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import requests\n",
|
||||
"\n",
|
||||
"# Download XML from known URL\n",
|
||||
"dgml = requests.get(\n",
|
||||
" \"https://raw.githubusercontent.com/docugami/dgml-utils/main/python/tests/test_data/article/Jane%20Doe.xml\"\n",
|
||||
@@ -288,7 +369,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 98,
|
||||
"id": "14714576-6e1d-499b-bcc8-39140bb2fd78",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -298,7 +379,7 @@
|
||||
"{'h1': 9, 'div': 12, 'p': 3, 'lim h1': 9, 'lim': 1, 'table': 1, 'h1 div': 4}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"execution_count": 98,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -319,7 +400,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 99,
|
||||
"id": "5462f29e-fd59-4e0e-9493-ea3b560e523e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -352,7 +433,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 100,
|
||||
"id": "2b4ece00-2e43-4254-adc9-66dbb79139a6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -390,7 +471,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 101,
|
||||
"id": "08350119-aa22-4ec1-8f65-b1316a0d4123",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -418,7 +499,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"execution_count": 112,
|
||||
"id": "bcac8294-c54a-4b6e-af9d-3911a69620b2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -465,7 +546,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"execution_count": 113,
|
||||
"id": "8e275736-3408-4d7a-990e-4362c88e81f8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -496,7 +577,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"execution_count": 114,
|
||||
"id": "1b12536a-1303-41ad-9948-4eb5a5f32614",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -513,7 +594,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"execution_count": 115,
|
||||
"id": "8d8b567c-b442-4bf0-b639-04bd89effc62",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -538,7 +619,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"execution_count": 116,
|
||||
"id": "346c3a02-8fea-4f75-a69e-fc9542b99dbc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -600,7 +681,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"execution_count": 117,
|
||||
"id": "f2489de4-51e3-48b4-bbcd-ed9171deadf3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -644,17 +725,10 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"execution_count": 120,
|
||||
"id": "636e992f-823b-496b-a082-8b4fcd479de5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
@@ -696,7 +770,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"execution_count": 121,
|
||||
"id": "0e4a2f43-dd48-4ae3-8e27-7e87d169965f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -706,7 +780,7 @@
|
||||
"669"
|
||||
]
|
||||
},
|
||||
"execution_count": 20,
|
||||
"execution_count": 121,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -721,7 +795,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"execution_count": 124,
|
||||
"id": "56b78fb3-603d-4343-ae72-be54a3c5dd72",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -746,7 +820,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"execution_count": 125,
|
||||
"id": "d3cc5ba9-8553-4eda-a5d1-b799751186af",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -758,7 +832,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"execution_count": 126,
|
||||
"id": "d7c73faf-74cb-400d-8059-b69e2493de38",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -770,7 +844,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"execution_count": 127,
|
||||
"id": "4c553722-be42-42ce-83b8-76a17f323f1c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -780,7 +854,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"execution_count": 128,
|
||||
"id": "65dce40b-f1c3-494a-949e-69a9c9544ddb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -790,7 +864,7 @@
|
||||
"'The number of training tokens for LLaMA2 is 2.0T for all parameter sizes.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 25,
|
||||
"execution_count": 128,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -885,37 +959,14 @@
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"```"
|
||||
"``"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "867f8e11-384c-4aa1-8b3e-c59fb8d5fd7d",
|
||||
"id": "0879349e-7298-4f2c-b246-f1142e97a8e5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Finally, you can ask other questions that rely on more subtle parsing of the table, e.g.:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "d38f1459-7d2b-40df-8dcd-e747f85eb144",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'The learning rate for LLaMA2 was 3.0 × 10−4 for the 7B and 13B models, and 1.5 × 10−4 for the 34B and 70B models.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"llama2_chain.invoke(\"What was the learning rate for LLaMA2?\")"
|
||||
]
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -1,118 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6125a85e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Microsoft OneNote\n",
|
||||
"\n",
|
||||
"This notebook covers how to load documents from `OneNote`.\n",
|
||||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"1. Register an application with the [Microsoft identity platform](https://learn.microsoft.com/en-us/azure/active-directory/develop/quickstart-register-app) instructions.\n",
|
||||
"2. When registration finishes, the Azure portal displays the app registration's Overview pane. You see the Application (client) ID. Also called the `client ID`, this value uniquely identifies your application in the Microsoft identity platform.\n",
|
||||
"3. During the steps you will be following at **item 1**, you can set the redirect URI as `http://localhost:8000/callback`\n",
|
||||
"4. During the steps you will be following at **item 1**, generate a new password (`client_secret`) under Application Secrets section.\n",
|
||||
"5. Follow the instructions at this [document](https://learn.microsoft.com/en-us/azure/active-directory/develop/quickstart-configure-app-expose-web-apis#add-a-scope) to add the following `SCOPES` (`Notes.Read`) to your application.\n",
|
||||
"6. You need to install the msal and bs4 packages using the commands `pip install msal` and `pip install beautifulsoup4`.\n",
|
||||
"7. At the end of the steps you must have the following values: \n",
|
||||
"- `CLIENT_ID`\n",
|
||||
"- `CLIENT_SECRET`\n",
|
||||
"\n",
|
||||
"## 🧑 Instructions for ingesting your documents from OneNote\n",
|
||||
"\n",
|
||||
"### 🔑 Authentication\n",
|
||||
"\n",
|
||||
"By default, the `OneNoteLoader` expects that the values of `CLIENT_ID` and `CLIENT_SECRET` must be stored as environment variables named `MS_GRAPH_CLIENT_ID` and `MS_GRAPH_CLIENT_SECRET` respectively. You could pass those environment variables through a `.env` file at the root of your application or using the following command in your script.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"os.environ['MS_GRAPH_CLIENT_ID'] = \"YOUR CLIENT ID\"\n",
|
||||
"os.environ['MS_GRAPH_CLIENT_SECRET'] = \"YOUR CLIENT SECRET\"\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"This loader uses an authentication called [*on behalf of a user*](https://learn.microsoft.com/en-us/graph/auth-v2-user?context=graph%2Fapi%2F1.0&view=graph-rest-1.0). It is a 2 step authentication with user consent. When you instantiate the loader, it will call will print a url that the user must visit to give consent to the app on the required permissions. The user must then visit this url and give consent to the application. Then the user must copy the resulting page url and paste it back on the console. The method will then return True if the login attempt was successful.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from langchain.document_loaders.onenote import OneNoteLoader\n",
|
||||
"\n",
|
||||
"loader = OneNoteLoader(notebook_name=\"NOTEBOOK NAME\", section_name=\"SECTION NAME\", page_title=\"PAGE TITLE\")\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Once the authentication has been done, the loader will store a token (`onenote_graph_token.txt`) at `~/.credentials/` folder. This token could be used later to authenticate without the copy/paste steps explained earlier. To use this token for authentication, you need to change the `auth_with_token` parameter to True in the instantiation of the loader.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from langchain.document_loaders.onenote import OneNoteLoader\n",
|
||||
"\n",
|
||||
"loader = OneNoteLoader(notebook_name=\"NOTEBOOK NAME\", section_name=\"SECTION NAME\", page_title=\"PAGE TITLE\", auth_with_token=True)\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Alternatively, you can also pass the token directly to the loader. This is useful when you want to authenticate with a token that was generated by another application. For instance, you can use the [Microsoft Graph Explorer](https://developer.microsoft.com/en-us/graph/graph-explorer) to generate a token and then pass it to the loader.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from langchain.document_loaders.onenote import OneNoteLoader\n",
|
||||
"\n",
|
||||
"loader = OneNoteLoader(notebook_name=\"NOTEBOOK NAME\", section_name=\"SECTION NAME\", page_title=\"PAGE TITLE\", access_token=\"TOKEN\")\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"### 🗂️ Documents loader\n",
|
||||
"\n",
|
||||
"#### 📑 Loading pages from a OneNote Notebook\n",
|
||||
"\n",
|
||||
"`OneNoteLoader` can load pages from OneNote notebooks stored in OneDrive. You can specify any combination of `notebook_name`, `section_name`, `page_title` to filter for pages under a specific notebook, under a specific section, or with a specific title respectively. For instance, you want to load all pages that are stored under a section called `Recipes` within any of your notebooks OneDrive.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from langchain.document_loaders.onenote import OneNoteLoader\n",
|
||||
"\n",
|
||||
"loader = OneNoteLoader(section_name=\"Recipes\", auth_with_token=True)\n",
|
||||
"documents = loader.load()\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"#### 📑 Loading pages from a list of Page IDs\n",
|
||||
"\n",
|
||||
"Another possibility is to provide a list of `object_ids` for each page you want to load. For that, you will need to query the [Microsoft Graph API](https://developer.microsoft.com/en-us/graph/graph-explorer) to find all the documents ID that you are interested in. This [link](https://learn.microsoft.com/en-us/graph/onenote-get-content#page-collection) provides a list of endpoints that will be helpful to retrieve the documents ID.\n",
|
||||
"\n",
|
||||
"For instance, to retrieve information about all pages that are stored in your notebooks, you need make a request to: `https://graph.microsoft.com/v1.0/me/onenote/pages`. Once you have the list of IDs that you are interested in, then you can instantiate the loader with the following parameters.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from langchain.document_loaders.onenote import OneNoteLoader\n",
|
||||
"\n",
|
||||
"loader = OneNoteLoader(object_ids=[\"ID_1\", \"ID_2\"], auth_with_token=True)\n",
|
||||
"documents = loader.load()\n",
|
||||
"```\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "bb36fe41",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -550,7 +550,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In the first example, supply the path to the specified `json.gbnf` file in order to produce JSON:"
|
||||
"In the first example, supply the path to the specifed `json.gbnf` file in order to produce JSON:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -912,7 +912,7 @@
|
||||
"source": [
|
||||
"## `Cassandra` caches\n",
|
||||
"\n",
|
||||
"You can use Cassandra / Astra DB through CQL for caching LLM responses, choosing from the exact-match `CassandraCache` or the (vector-similarity-based) `CassandraSemanticCache`.\n",
|
||||
"You can use Cassandra / Astra DB for caching LLM responses, choosing from the exact-match `CassandraCache` or the (vector-similarity-based) `CassandraSemanticCache`.\n",
|
||||
"\n",
|
||||
"Let's see both in action in the following cells."
|
||||
]
|
||||
@@ -924,7 +924,7 @@
|
||||
"source": [
|
||||
"#### Connect to the DB\n",
|
||||
"\n",
|
||||
"First you need to establish a `Session` to the DB and to specify a _keyspace_ for the cache table(s). The following gets you connected to Astra DB through CQL (see e.g. [here](https://cassio.org/start_here/#vector-database) for more backends and connection options)."
|
||||
"First you need to establish a `Session` to the DB and to specify a _keyspace_ for the cache table(s). The following gets you started with an Astra DB instance (see e.g. [here](https://cassio.org/start_here/#vector-database) for more backends and connection options)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -1132,214 +1132,6 @@
|
||||
"print(llm(\"How come we always see one face of the moon?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8712f8fc-bb89-4164-beb9-c672778bbd91",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## `Astra DB` Caches"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "173041d9-e4af-4f68-8461-d302bfc7e1bd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can easily use [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) as an LLM cache, with either the \"exact\" or the \"semantic-based\" cache.\n",
|
||||
"\n",
|
||||
"Make sure you have a running database (it must be a Vector-enabled database to use the Semantic cache) and get the required credentials on your Astra dashboard:\n",
|
||||
"\n",
|
||||
"- the API Endpoint looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"- the Token looks like `AstraCS:6gBhNmsk135....`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "feb510b6-99a3-4228-8e11-563051f8178e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"ASTRA_DB_API_ENDPOINT = https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass.getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ee6d587f-4b7c-43f4-9e90-5129c842a143",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Astra DB exact LLM cache\n",
|
||||
"\n",
|
||||
"This will avoid invoking the LLM when the supplied prompt is _exactly_ the same as one encountered already:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "ad63c146-ee41-4896-90ee-29fcc39f0ed5",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.cache import AstraDBCache\n",
|
||||
"from langchain.globals import set_llm_cache\n",
|
||||
"\n",
|
||||
"set_llm_cache(\n",
|
||||
" AstraDBCache(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" )\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "83e0fb02-e8eb-4483-9eb1-55b5e14c4487",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"There is no definitive answer to this question as it depends on the interpretation of the terms \"true fakery\" and \"fake truth\". However, one possible interpretation is that a true fakery is a counterfeit or imitation that is intended to deceive, whereas a fake truth is a false statement that is presented as if it were true.\n",
|
||||
"CPU times: user 70.8 ms, sys: 4.13 ms, total: 74.9 ms\n",
|
||||
"Wall time: 2.06 s\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"\n",
|
||||
"print(llm(\"Is a true fakery the same as a fake truth?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "4d20d498-fe28-4e26-8531-2b31c52ee687",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"There is no definitive answer to this question as it depends on the interpretation of the terms \"true fakery\" and \"fake truth\". However, one possible interpretation is that a true fakery is a counterfeit or imitation that is intended to deceive, whereas a fake truth is a false statement that is presented as if it were true.\n",
|
||||
"CPU times: user 15.1 ms, sys: 3.7 ms, total: 18.8 ms\n",
|
||||
"Wall time: 531 ms\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"\n",
|
||||
"print(llm(\"Is a true fakery the same as a fake truth?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "524b94fa-6162-4880-884d-d008749d14e2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Astra DB Semantic cache\n",
|
||||
"\n",
|
||||
"This cache will do a semantic similarity search and return a hit if it finds a cached entry that is similar enough, For this, you need to provide an `Embeddings` instance of your choice."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "dc329c55-1cc4-4b74-94f9-61f8990fb214",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"embedding = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "83952a90-ab14-4e59-87c0-d2bdc1d43e43",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.cache import AstraDBSemanticCache\n",
|
||||
"\n",
|
||||
"set_llm_cache(\n",
|
||||
" AstraDBSemanticCache(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" embedding=embedding,\n",
|
||||
" collection_name=\"demo_semantic_cache\",\n",
|
||||
" )\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "d74b249a-94d5-42d0-af74-f7565a994dea",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"There is no definitive answer to this question since it presupposes a great deal about the nature of truth itself, which is a matter of considerable philosophical debate. It is possible, however, to construct scenarios in which something could be considered true despite being false, such as if someone sincerely believes something to be true even though it is not.\n",
|
||||
"CPU times: user 65.6 ms, sys: 15.3 ms, total: 80.9 ms\n",
|
||||
"Wall time: 2.72 s\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"\n",
|
||||
"print(llm(\"Are there truths that are false?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "11973d73-d2f4-46bd-b229-1c589df9b788",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"There is no definitive answer to this question since it presupposes a great deal about the nature of truth itself, which is a matter of considerable philosophical debate. It is possible, however, to construct scenarios in which something could be considered true despite being false, such as if someone sincerely believes something to be true even though it is not.\n",
|
||||
"CPU times: user 29.3 ms, sys: 6.21 ms, total: 35.5 ms\n",
|
||||
"Wall time: 1.03 s\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"\n",
|
||||
"print(llm(\"Is is possible that something false can be also true?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0c69d84d",
|
||||
|
||||
@@ -1,147 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "90cd3ded",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Astra DB \n",
|
||||
"\n",
|
||||
"> DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on Cassandra and made conveniently available through an easy-to-use JSON API.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use Astra DB to store chat message history."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f507f58b-bf22-4a48-8daf-68d869bcd1ba",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setting up\n",
|
||||
"\n",
|
||||
"To run this notebook you need a running Astra DB. Get the connection secrets on your Astra dashboard:\n",
|
||||
"\n",
|
||||
"- the API Endpoint looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`;\n",
|
||||
"- the Token looks like `AstraCS:6gBhNmsk135...`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d7092199",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install --quiet \"astrapy>=0.6.2\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e3d97b65",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Set up the database connection parameters and secrets"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "163d97f0",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"ASTRA_DB_API_ENDPOINT = https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass.getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "55860b2d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Depending on whether local or cloud-based Astra DB, create the corresponding database connection \"Session\" object."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "36c163e8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import AstraDBChatMessageHistory\n",
|
||||
"\n",
|
||||
"message_history = AstraDBChatMessageHistory(\n",
|
||||
" session_id=\"test-session\",\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history.add_user_message(\"hi!\")\n",
|
||||
"\n",
|
||||
"message_history.add_ai_message(\"whats up?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "64fc465e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content='hi!'), AIMessage(content='whats up?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"message_history.messages"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -29,47 +29,6 @@ vector_store = AstraDB(
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/vectorstores/astradb).
|
||||
|
||||
### LLM Cache
|
||||
|
||||
```python
|
||||
from langchain.globals import set_llm_cache
|
||||
from langchain.cache import AstraDBCache
|
||||
set_llm_cache(AstraDBCache(
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
))
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the Astra DB section).
|
||||
|
||||
|
||||
### Semantic LLM Cache
|
||||
|
||||
```python
|
||||
from langchain.globals import set_llm_cache
|
||||
from langchain.cache import AstraDBSemanticCache
|
||||
set_llm_cache(AstraDBSemanticCache(
|
||||
embedding=my_embedding,
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
))
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the appropriate section).
|
||||
|
||||
### Chat message history
|
||||
|
||||
```python
|
||||
from langchain.memory import AstraDBChatMessageHistory
|
||||
message_history = AstraDBChatMessageHistory(
|
||||
session_id="test-session"
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/memory/astradb_chat_message_history).
|
||||
|
||||
|
||||
## Apache Cassandra and Astra DB through CQL
|
||||
|
||||
|
||||
@@ -1,182 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Outline\n",
|
||||
"\n",
|
||||
">[Outline](https://www.getoutline.com/) is an open-source collaborative knowledge base platform designed for team information sharing.\n",
|
||||
"\n",
|
||||
"This notebook shows how to retrieve documents from your Outline instance into the Document format that is used downstream."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You first need to [create an api key](https://www.getoutline.com/developers#section/Authentication) for your Outline instance. Then you need to set the following environment variables:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"OUTLINE_API_KEY\"] = \"xxx\"\n",
|
||||
"os.environ[\"OUTLINE_INSTANCE_URL\"] = \"https://app.getoutline.com\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"`OutlineRetriever` has these arguments:\n",
|
||||
"- optional `top_k_results`: default=3. Use it to limit number of documents retrieved.\n",
|
||||
"- optional `load_all_available_meta`: default=False. By default only the most important fields retrieved: `title`, `source` (the url of the document). If True, other fields also retrieved.\n",
|
||||
"- optional `doc_content_chars_max` default=4000. Use it to limit the number of characters for each document retrieved.\n",
|
||||
"\n",
|
||||
"`get_relevant_documents()` has one argument, `query`: free text which used to find documents in your Outline instance."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Running retriever"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.retrievers import OutlineRetriever"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"retriever = OutlineRetriever()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='This walkthrough demonstrates how to use an agent optimized for conversation. Other agents are often optimized for using tools to figure out the best response, which is not ideal in a conversational setting where you may want the agent to be able to chat with the user as well.\\n\\nIf we compare it to the standard ReAct agent, the main difference is the prompt. We want it to be much more conversational.\\n\\nfrom langchain.agents import AgentType, Tool, initialize_agent\\n\\nfrom langchain.llms import OpenAI\\n\\nfrom langchain.memory import ConversationBufferMemory\\n\\nfrom langchain.utilities import SerpAPIWrapper\\n\\nsearch = SerpAPIWrapper() tools = \\\\[ Tool( name=\"Current Search\", func=search.run, description=\"useful for when you need to answer questions about current events or the current state of the world\", ), \\\\]\\n\\n\\\\\\nllm = OpenAI(temperature=0)\\n\\nUsing LCEL\\n\\nWe will first show how to create this agent using LCEL\\n\\nfrom langchain import hub\\n\\nfrom langchain.agents.format_scratchpad import format_log_to_str\\n\\nfrom langchain.agents.output_parsers import ReActSingleInputOutputParser\\n\\nfrom langchain.tools.render import render_text_description\\n\\nprompt = hub.pull(\"hwchase17/react-chat\")\\n\\nprompt = prompt.partial( tools=render_text_description(tools), tool_names=\", \".join(\\\\[[t.name](http://t.name) for t in tools\\\\]), )\\n\\nllm_with_stop = llm.bind(stop=\\\\[\"\\\\nObservation\"\\\\])\\n\\nagent = ( { \"input\": lambda x: x\\\\[\"input\"\\\\], \"agent_scratchpad\": lambda x: format_log_to_str(x\\\\[\"intermediate_steps\"\\\\]), \"chat_history\": lambda x: x\\\\[\"chat_history\"\\\\], } | prompt | llm_with_stop | ReActSingleInputOutputParser() )\\n\\nfrom langchain.agents import AgentExecutor\\n\\nmemory = ConversationBufferMemory(memory_key=\"chat_history\") agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, memory=memory)\\n\\nagent_executor.invoke({\"input\": \"hi, i am bob\"})\\\\[\"output\"\\\\]\\n\\n```\\n> Entering new AgentExecutor chain...\\n\\nThought: Do I need to use a tool? No\\nFinal Answer: Hi Bob, nice to meet you! How can I help you today?\\n\\n> Finished chain.\\n```\\n\\n\\\\\\n\\'Hi Bob, nice to meet you! How can I help you today?\\'\\n\\nagent_executor.invoke({\"input\": \"whats my name?\"})\\\\[\"output\"\\\\]\\n\\n```\\n> Entering new AgentExecutor chain...\\n\\nThought: Do I need to use a tool? No\\nFinal Answer: Your name is Bob.\\n\\n> Finished chain.\\n```\\n\\n\\\\\\n\\'Your name is Bob.\\'\\n\\nagent_executor.invoke({\"input\": \"what are some movies showing 9/21/2023?\"})\\\\[\"output\"\\\\]\\n\\n```\\n> Entering new AgentExecutor chain...\\n\\nThought: Do I need to use a tool? Yes\\nAction: Current Search\\nAction Input: Movies showing 9/21/2023[\\'September 2023 Movies: The Creator • Dumb Money • Expend4bles • The Kill Room • The Inventor • The Equalizer 3 • PAW Patrol: The Mighty Movie, ...\\'] Do I need to use a tool? No\\nFinal Answer: According to current search, some movies showing on 9/21/2023 are The Creator, Dumb Money, Expend4bles, The Kill Room, The Inventor, The Equalizer 3, and PAW Patrol: The Mighty Movie.\\n\\n> Finished chain.\\n```\\n\\n\\\\\\n\\'According to current search, some movies showing on 9/21/2023 are The Creator, Dumb Money, Expend4bles, The Kill Room, The Inventor, The Equalizer 3, and PAW Patrol: The Mighty Movie.\\'\\n\\n\\\\\\nUse the off-the-shelf agent\\n\\nWe can also create this agent using the off-the-shelf agent class\\n\\nagent_executor = initialize_agent( tools, llm, agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory, )\\n\\nUse a chat model\\n\\nWe can also use a chat model here. The main difference here is in the prompts used.\\n\\nfrom langchain import hub\\n\\nfrom langchain.chat_models import ChatOpenAI\\n\\nprompt = hub.pull(\"hwchase17/react-chat-json\") chat_model = ChatOpenAI(temperature=0, model=\"gpt-4\")\\n\\nprompt = prompt.partial( tools=render_text_description(tools), tool_names=\", \".join(\\\\[[t.name](http://t.name) for t in tools\\\\]), )\\n\\nchat_model_with_stop = chat_model.bind(stop=\\\\[\"\\\\nObservation\"\\\\])\\n\\nfrom langchain.agents.format_scratchpad import format_log_to_messages\\n\\nfrom langchain.agents.output_parsers import JSONAgentOutputParser\\n\\n# We need some extra steering, or the c', metadata={'title': 'Conversational', 'source': 'https://d01.getoutline.com/doc/conversational-B5dBkUgQ4b'}),\n",
|
||||
" Document(page_content='Quickstart\\n\\nIn this quickstart we\\'ll show you how to:\\n\\nGet setup with LangChain, LangSmith and LangServe\\n\\nUse the most basic and common components of LangChain: prompt templates, models, and output parsers\\n\\nUse LangChain Expression Language, the protocol that LangChain is built on and which facilitates component chaining\\n\\nBuild a simple application with LangChain\\n\\nTrace your application with LangSmith\\n\\nServe your application with LangServe\\n\\nThat\\'s a fair amount to cover! Let\\'s dive in.\\n\\nSetup\\n\\nInstallation\\n\\nTo install LangChain run:\\n\\nPip\\n\\nConda\\n\\npip install langchain\\n\\nFor more details, see our Installation guide.\\n\\nEnvironment\\n\\nUsing LangChain will usually require integrations with one or more model providers, data stores, APIs, etc. For this example, we\\'ll use OpenAI\\'s model APIs.\\n\\nFirst we\\'ll need to install their Python package:\\n\\npip install openai\\n\\nAccessing the API requires an API key, which you can get by creating an account and heading here. Once we have a key we\\'ll want to set it as an environment variable by running:\\n\\nexport OPENAI_API_KEY=\"...\"\\n\\nIf you\\'d prefer not to set an environment variable you can pass the key in directly via the openai_api_key named parameter when initiating the OpenAI LLM class:\\n\\nfrom langchain.chat_models import ChatOpenAI\\n\\nllm = ChatOpenAI(openai_api_key=\"...\")\\n\\nLangSmith\\n\\nMany of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.\\n\\nNote that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:\\n\\nexport LANGCHAIN_TRACING_V2=\"true\" export LANGCHAIN_API_KEY=...\\n\\nLangServe\\n\\nLangServe helps developers deploy LangChain chains as a REST API. You do not need to use LangServe to use LangChain, but in this guide we\\'ll show how you can deploy your app with LangServe.\\n\\nInstall with:\\n\\npip install \"langserve\\\\[all\\\\]\"\\n\\nBuilding with LangChain\\n\\nLangChain provides many modules that can be used to build language model applications. Modules can be used as standalones in simple applications and they can be composed for more complex use cases. Composition is powered by LangChain Expression Language (LCEL), which defines a unified Runnable interface that many modules implement, making it possible to seamlessly chain components.\\n\\nThe simplest and most common chain contains three things:\\n\\nLLM/Chat Model: The language model is the core reasoning engine here. In order to work with LangChain, you need to understand the different types of language models and how to work with them. Prompt Template: This provides instructions to the language model. This controls what the language model outputs, so understanding how to construct prompts and different prompting strategies is crucial. Output Parser: These translate the raw response from the language model to a more workable format, making it easy to use the output downstream. In this guide we\\'ll cover those three components individually, and then go over how to combine them. Understanding these concepts will set you up well for being able to use and customize LangChain applications. Most LangChain applications allow you to configure the model and/or the prompt, so knowing how to take advantage of this will be a big enabler.\\n\\nLLM / Chat Model\\n\\nThere are two types of language models:\\n\\nLLM: underlying model takes a string as input and returns a string\\n\\nChatModel: underlying model takes a list of messages as input and returns a message\\n\\nStrings are simple, but what exactly are messages? The base message interface is defined by BaseMessage, which has two required attributes:\\n\\ncontent: The content of the message. Usually a string. role: The entity from which the BaseMessage is coming. LangChain provides several ob', metadata={'title': 'Quick Start', 'source': 'https://d01.getoutline.com/doc/quick-start-jGuGGGOTuL'}),\n",
|
||||
" Document(page_content='This walkthrough showcases using an agent to implement the [ReAct](https://react-lm.github.io/) logic.\\n\\n```javascript\\nfrom langchain.agents import AgentType, initialize_agent, load_tools\\nfrom langchain.llms import OpenAI\\n```\\n\\nFirst, let\\'s load the language model we\\'re going to use to control the agent.\\n\\n```javascript\\nllm = OpenAI(temperature=0)\\n```\\n\\nNext, let\\'s load some tools to use. Note that the llm-math tool uses an LLM, so we need to pass that in.\\n\\n```javascript\\ntools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\\n```\\n\\n## Using LCEL[\\u200b](https://python.langchain.com/docs/modules/agents/agent_types/react#using-lcel \"Direct link to Using LCEL\")\\n\\nWe will first show how to create the agent using LCEL\\n\\n```javascript\\nfrom langchain import hub\\nfrom langchain.agents.format_scratchpad import format_log_to_str\\nfrom langchain.agents.output_parsers import ReActSingleInputOutputParser\\nfrom langchain.tools.render import render_text_description\\n```\\n\\n```javascript\\nprompt = hub.pull(\"hwchase17/react\")\\nprompt = prompt.partial(\\n tools=render_text_description(tools),\\n tool_names=\", \".join([t.name for t in tools]),\\n)\\n```\\n\\n```javascript\\nllm_with_stop = llm.bind(stop=[\"\\\\nObservation\"])\\n```\\n\\n```javascript\\nagent = (\\n {\\n \"input\": lambda x: x[\"input\"],\\n \"agent_scratchpad\": lambda x: format_log_to_str(x[\"intermediate_steps\"]),\\n }\\n | prompt\\n | llm_with_stop\\n | ReActSingleInputOutputParser()\\n)\\n```\\n\\n```javascript\\nfrom langchain.agents import AgentExecutor\\n```\\n\\n```javascript\\nagent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)\\n```\\n\\n```javascript\\nagent_executor.invoke(\\n {\\n \"input\": \"Who is Leo DiCaprio\\'s girlfriend? What is her current age raised to the 0.43 power?\"\\n }\\n)\\n```\\n\\n```javascript\\n \\n \\n > Entering new AgentExecutor chain...\\n I need to find out who Leo DiCaprio\\'s girlfriend is and then calculate her age raised to the 0.43 power.\\n Action: Search\\n Action Input: \"Leo DiCaprio girlfriend\"model Vittoria Ceretti I need to find out Vittoria Ceretti\\'s age\\n Action: Search\\n Action Input: \"Vittoria Ceretti age\"25 years I need to calculate 25 raised to the 0.43 power\\n Action: Calculator\\n Action Input: 25^0.43Answer: 3.991298452658078 I now know the final answer\\n Final Answer: Leo DiCaprio\\'s girlfriend is Vittoria Ceretti and her current age raised to the 0.43 power is 3.991298452658078.\\n \\n > Finished chain.\\n\\n\\n\\n\\n\\n {\\'input\\': \"Who is Leo DiCaprio\\'s girlfriend? What is her current age raised to the 0.43 power?\",\\n \\'output\\': \"Leo DiCaprio\\'s girlfriend is Vittoria Ceretti and her current age raised to the 0.43 power is 3.991298452658078.\"}\\n```\\n\\n## Using ZeroShotReactAgent[\\u200b](https://python.langchain.com/docs/modules/agents/agent_types/react#using-zeroshotreactagent \"Direct link to Using ZeroShotReactAgent\")\\n\\nWe will now show how to use the agent with an off-the-shelf agent implementation\\n\\n```javascript\\nagent_executor = initialize_agent(\\n tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True\\n)\\n```\\n\\n```javascript\\nagent_executor.invoke(\\n {\\n \"input\": \"Who is Leo DiCaprio\\'s girlfriend? What is her current age raised to the 0.43 power?\"\\n }\\n)\\n```\\n\\n```javascript\\n \\n \\n > Entering new AgentExecutor chain...\\n I need to find out who Leo DiCaprio\\'s girlfriend is and then calculate her age raised to the 0.43 power.\\n Action: Search\\n Action Input: \"Leo DiCaprio girlfriend\"\\n Observation: model Vittoria Ceretti\\n Thought: I need to find out Vittoria Ceretti\\'s age\\n Action: Search\\n Action Input: \"Vittoria Ceretti age\"\\n Observation: 25 years\\n Thought: I need to calculate 25 raised to the 0.43 power\\n Action: Calculator\\n Action Input: 25^0.43\\n Observation: Answer: 3.991298452658078\\n Thought: I now know the final answer\\n Final Answer: Leo DiCaprio\\'s girlfriend is Vittoria Ceretti and her current age raised to the 0.43 power is 3.991298452658078.\\n \\n > Finished chain.\\n\\n\\n\\n\\n\\n {\\'input\\': \"Who is L', metadata={'title': 'ReAct', 'source': 'https://d01.getoutline.com/doc/react-d6rxRS1MHk'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"retriever.get_relevant_documents(query=\"LangChain\", doc_content_chars_max=100)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Answering Questions on Outline Documents"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass(\"OpenAI API Key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import ConversationalRetrievalChain\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"\n",
|
||||
"model = ChatOpenAI(model_name=\"gpt-3.5-turbo\")\n",
|
||||
"qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'question': 'what is langchain?',\n",
|
||||
" 'chat_history': {},\n",
|
||||
" 'answer': \"LangChain is a framework for developing applications powered by language models. It provides a set of libraries and tools that enable developers to build context-aware and reasoning-based applications. LangChain allows you to connect language models to various sources of context, such as prompt instructions, few-shot examples, and content, to enhance the model's responses. It also supports the composition of multiple language model components using LangChain Expression Language (LCEL). Additionally, LangChain offers off-the-shelf chains, templates, and integrations for easy application development. LangChain can be used in conjunction with LangSmith for debugging and monitoring chains, and with LangServe for deploying applications as a REST API.\"}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"qa({\"question\": \"what is langchain?\", \"chat_history\": {}})"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -22,7 +22,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from pydantic.v1 import BaseModel, Field\n",
|
||||
"import pydantic\n",
|
||||
"from langchain.agents import AgentType, initialize_agent\n",
|
||||
"from langchain.agents.tools import Tool\n",
|
||||
"from langchain.chains import LLMMathChain\n",
|
||||
@@ -65,12 +65,12 @@
|
||||
"primes = {998: 7901, 999: 7907, 1000: 7919}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class CalculatorInput(BaseModel):\n",
|
||||
" question: str = Field()\n",
|
||||
"class CalculatorInput(pydantic.BaseModel):\n",
|
||||
" question: str = pydantic.Field()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class PrimeInput(BaseModel):\n",
|
||||
" n: int = Field()\n",
|
||||
"class PrimeInput(pydantic.BaseModel):\n",
|
||||
" n: int = pydantic.Field()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def is_prime(n: int) -> bool:\n",
|
||||
|
||||
@@ -743,7 +743,7 @@
|
||||
"- [Docs](/docs/modules/model_io/llms)\n",
|
||||
"- [Integrations](/docs/integrations/llms): Explore over 75 `LLM` integrations.\n",
|
||||
"\n",
|
||||
"See a guide on RAG with locally-running models [here](/docs/use_cases/question_answering/local_retrieval_qa)."
|
||||
"See a guide on RAG with locally-running models [here](/docs/modules/use_cases/question_answering/local_retrieval_qa)."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -13,7 +13,7 @@ tests:
|
||||
poetry run pytest $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw --snapshot-update --now . -- -vv -x tests/unit_tests
|
||||
poetry run ptw --snapshot-update --now . -- -x tests/unit_tests
|
||||
|
||||
|
||||
######################
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
from langchain_core.language_models.base import (
|
||||
BaseLanguageModel,
|
||||
LanguageModelInput,
|
||||
LanguageModelOutput,
|
||||
get_tokenizer,
|
||||
)
|
||||
from langchain_core.language_models.chat_models import BaseChatModel, SimpleChatModel
|
||||
@@ -15,5 +14,4 @@ __all__ = [
|
||||
"LLM",
|
||||
"LanguageModelInput",
|
||||
"get_tokenizer",
|
||||
"LanguageModelOutput",
|
||||
]
|
||||
|
||||
@@ -8,7 +8,6 @@ import yaml
|
||||
|
||||
from langchain_core.output_parsers.string import StrOutputParser
|
||||
from langchain_core.prompts.base import BasePromptTemplate
|
||||
from langchain_core.prompts.chat import ChatPromptTemplate
|
||||
from langchain_core.prompts.few_shot import FewShotPromptTemplate
|
||||
from langchain_core.prompts.prompt import PromptTemplate
|
||||
from langchain_core.utils import try_load_from_hub
|
||||
@@ -155,21 +154,7 @@ def _load_prompt_from_file(file: Union[str, Path]) -> BasePromptTemplate:
|
||||
return load_prompt_from_config(config)
|
||||
|
||||
|
||||
def _load_chat_prompt(config: Dict) -> ChatPromptTemplate:
|
||||
"""Load chat prompt from config"""
|
||||
|
||||
messages = config.pop("messages")
|
||||
template = messages[0]["prompt"].pop("template") if messages else None
|
||||
config.pop("input_variables")
|
||||
|
||||
if not template:
|
||||
raise ValueError("Can't load chat prompt without template")
|
||||
|
||||
return ChatPromptTemplate.from_template(template=template, **config)
|
||||
|
||||
|
||||
type_to_loader_dict: Dict[str, Callable[[dict], BasePromptTemplate]] = {
|
||||
"prompt": _load_prompt,
|
||||
"few_shot": _load_few_shot_prompt,
|
||||
"chat": _load_chat_prompt,
|
||||
}
|
||||
|
||||
@@ -1204,9 +1204,7 @@ class RunnableSerializable(Serializable, Runnable[Input, Output]):
|
||||
def configurable_alternatives(
|
||||
self,
|
||||
which: ConfigurableField,
|
||||
*,
|
||||
default_key: str = "default",
|
||||
prefix_keys: bool = False,
|
||||
**kwargs: Union[Runnable[Input, Output], Callable[[], Runnable[Input, Output]]],
|
||||
) -> RunnableSerializable[Input, Output]:
|
||||
from langchain_core.runnables.configurable import (
|
||||
@@ -1214,11 +1212,7 @@ class RunnableSerializable(Serializable, Runnable[Input, Output]):
|
||||
)
|
||||
|
||||
return RunnableConfigurableAlternatives(
|
||||
which=which,
|
||||
default=self,
|
||||
alternatives=kwargs,
|
||||
default_key=default_key,
|
||||
prefix_keys=prefix_keys,
|
||||
which=which, default=self, alternatives=kwargs, default_key=default_key
|
||||
)
|
||||
|
||||
|
||||
|
||||
@@ -220,7 +220,6 @@ class RunnableConfigurableFields(DynamicRunnable[Input, Output]):
|
||||
annotation=spec.annotation
|
||||
or self.default.__fields__[field_name].annotation,
|
||||
default=getattr(self.default, field_name),
|
||||
is_shared=spec.is_shared,
|
||||
)
|
||||
if isinstance(spec, ConfigurableField)
|
||||
else make_options_spec(
|
||||
@@ -299,12 +298,6 @@ class RunnableConfigurableAlternatives(DynamicRunnable[Input, Output]):
|
||||
]
|
||||
|
||||
default_key: str = "default"
|
||||
"""The enum value to use for the default option. Defaults to "default"."""
|
||||
|
||||
prefix_keys: bool
|
||||
"""Whether to prefix configurable fields of each alternative with a namespace
|
||||
of the form <which.id>==<alternative_key>, eg. a key named "temperature" used by
|
||||
the alternative named "gpt3" becomes "model==gpt3/temperature"."""
|
||||
|
||||
@property
|
||||
def config_specs(self) -> List[ConfigurableFieldSpec]:
|
||||
@@ -320,37 +313,21 @@ class RunnableConfigurableAlternatives(DynamicRunnable[Input, Output]):
|
||||
),
|
||||
)
|
||||
_enums_for_spec[self.which] = cast(Type[StrEnum], which_enum)
|
||||
return get_unique_config_specs(
|
||||
# which alternative
|
||||
[
|
||||
ConfigurableFieldSpec(
|
||||
id=self.which.id,
|
||||
name=self.which.name,
|
||||
description=self.which.description,
|
||||
annotation=which_enum,
|
||||
default=self.default_key,
|
||||
is_shared=self.which.is_shared,
|
||||
),
|
||||
]
|
||||
# config specs of the default option
|
||||
+ (
|
||||
[
|
||||
prefix_config_spec(s, f"{self.which.id}=={self.default_key}")
|
||||
for s in self.default.config_specs
|
||||
]
|
||||
if self.prefix_keys
|
||||
else self.default.config_specs
|
||||
)
|
||||
# config specs of the alternatives
|
||||
+ [
|
||||
prefix_config_spec(s, f"{self.which.id}=={alt_key}")
|
||||
if self.prefix_keys
|
||||
else s
|
||||
for alt_key, alt in self.alternatives.items()
|
||||
if isinstance(alt, RunnableSerializable)
|
||||
for s in alt.config_specs
|
||||
]
|
||||
)
|
||||
return [
|
||||
ConfigurableFieldSpec(
|
||||
id=self.which.id,
|
||||
name=self.which.name,
|
||||
description=self.which.description,
|
||||
annotation=which_enum,
|
||||
default=self.default_key,
|
||||
),
|
||||
*self.default.config_specs,
|
||||
] + [
|
||||
s
|
||||
for alt in self.alternatives.values()
|
||||
if isinstance(alt, RunnableSerializable)
|
||||
for s in alt.config_specs
|
||||
]
|
||||
|
||||
def configurable_fields(
|
||||
self, **kwargs: AnyConfigurableField
|
||||
@@ -378,23 +355,6 @@ class RunnableConfigurableAlternatives(DynamicRunnable[Input, Output]):
|
||||
raise ValueError(f"Unknown alternative: {which}")
|
||||
|
||||
|
||||
def prefix_config_spec(
|
||||
spec: ConfigurableFieldSpec, prefix: str
|
||||
) -> ConfigurableFieldSpec:
|
||||
return (
|
||||
ConfigurableFieldSpec(
|
||||
id=f"{prefix}/{spec.id}",
|
||||
name=spec.name,
|
||||
description=spec.description,
|
||||
annotation=spec.annotation,
|
||||
default=spec.default,
|
||||
is_shared=spec.is_shared,
|
||||
)
|
||||
if not spec.is_shared
|
||||
else spec
|
||||
)
|
||||
|
||||
|
||||
def make_options_spec(
|
||||
spec: Union[ConfigurableFieldSingleOption, ConfigurableFieldMultiOption],
|
||||
description: Optional[str],
|
||||
@@ -417,7 +377,6 @@ def make_options_spec(
|
||||
description=spec.description or description,
|
||||
annotation=enum,
|
||||
default=spec.default,
|
||||
is_shared=spec.is_shared,
|
||||
)
|
||||
else:
|
||||
return ConfigurableFieldSpec(
|
||||
@@ -426,5 +385,4 @@ def make_options_spec(
|
||||
description=spec.description or description,
|
||||
annotation=Sequence[enum], # type: ignore[valid-type]
|
||||
default=spec.default,
|
||||
is_shared=spec.is_shared,
|
||||
)
|
||||
|
||||
@@ -169,7 +169,6 @@ class RunnableWithMessageHistory(RunnableBindingBase):
|
||||
name="Session ID",
|
||||
description="Unique identifier for a session.",
|
||||
default="",
|
||||
is_shared=True,
|
||||
),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -62,11 +62,7 @@ class RunnablePassthrough(RunnableSerializable[Other, Other]):
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
from langchain_core.runnables import (
|
||||
RunnableLambda,
|
||||
RunnableParallel,
|
||||
RunnablePassthrough,
|
||||
)
|
||||
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
|
||||
|
||||
runnable = RunnableParallel(
|
||||
origin=RunnablePassthrough(),
|
||||
@@ -76,7 +72,7 @@ class RunnablePassthrough(RunnableSerializable[Other, Other]):
|
||||
runnable.invoke(1) # {'origin': 1, 'modified': 2}
|
||||
|
||||
|
||||
def fake_llm(prompt: str) -> str: # Fake LLM for the example
|
||||
def fake_llm(prompt: str) -> str: # Fake LLM for the example
|
||||
return "completion"
|
||||
|
||||
chain = RunnableLambda(fake_llm) | {
|
||||
@@ -93,7 +89,7 @@ class RunnablePassthrough(RunnableSerializable[Other, Other]):
|
||||
|
||||
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
|
||||
|
||||
def fake_llm(prompt: str) -> str: # Fake LLM for the example
|
||||
def fake_llm(prompt: str) -> str: # Fake LLM for the example
|
||||
return "completion"
|
||||
|
||||
runnable = {
|
||||
|
||||
@@ -257,7 +257,6 @@ class ConfigurableField(NamedTuple):
|
||||
name: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
annotation: Optional[Any] = None
|
||||
is_shared: bool = False
|
||||
|
||||
def __hash__(self) -> int:
|
||||
return hash((self.id, self.annotation))
|
||||
@@ -272,7 +271,6 @@ class ConfigurableFieldSingleOption(NamedTuple):
|
||||
|
||||
name: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
is_shared: bool = False
|
||||
|
||||
def __hash__(self) -> int:
|
||||
return hash((self.id, tuple(self.options.keys()), self.default))
|
||||
@@ -287,7 +285,6 @@ class ConfigurableFieldMultiOption(NamedTuple):
|
||||
|
||||
name: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
is_shared: bool = False
|
||||
|
||||
def __hash__(self) -> int:
|
||||
return hash((self.id, tuple(self.options.keys()), tuple(self.default)))
|
||||
@@ -302,12 +299,11 @@ class ConfigurableFieldSpec(NamedTuple):
|
||||
"""A field that can be configured by the user. It is a specification of a field."""
|
||||
|
||||
id: str
|
||||
annotation: Any
|
||||
name: Optional[str]
|
||||
description: Optional[str]
|
||||
|
||||
name: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
default: Any = None
|
||||
is_shared: bool = False
|
||||
default: Any
|
||||
annotation: Any
|
||||
|
||||
|
||||
def get_unique_config_specs(
|
||||
|
||||
20
libs/core/poetry.lock
generated
20
libs/core/poetry.lock
generated
@@ -1147,16 +1147,6 @@ files = [
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:5bbe06f8eeafd38e5d0a4894ffec89378b6c6a625ff57e3028921f8ff59318ac"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win32.whl", hash = "sha256:dd15ff04ffd7e05ffcb7fe79f1b98041b8ea30ae9234aed2a9168b5797c3effb"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win_amd64.whl", hash = "sha256:134da1eca9ec0ae528110ccc9e48041e0828d79f24121a1a146161103c76e686"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_universal2.whl", hash = "sha256:f698de3fd0c4e6972b92290a45bd9b1536bffe8c6759c62471efaa8acb4c37bc"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:aa57bd9cf8ae831a362185ee444e15a93ecb2e344c8e52e4d721ea3ab6ef1823"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ffcc3f7c66b5f5b7931a5aa68fc9cecc51e685ef90282f4a82f0f5e9b704ad11"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47d4f1c5f80fc62fdd7777d0d40a2e9dda0a05883ab11374334f6c4de38adffd"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1f67c7038d560d92149c060157d623c542173016c4babc0c1913cca0564b9939"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:9aad3c1755095ce347e26488214ef77e0485a3c34a50c5a5e2471dff60b9dd9c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_i686.whl", hash = "sha256:14ff806850827afd6b07a5f32bd917fb7f45b046ba40c57abdb636674a8b559c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8f9293864fe09b8149f0cc42ce56e3f0e54de883a9de90cd427f191c346eb2e1"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win32.whl", hash = "sha256:715d3562f79d540f251b99ebd6d8baa547118974341db04f5ad06d5ea3eb8007"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win_amd64.whl", hash = "sha256:1b8dd8c3fd14349433c79fa8abeb573a55fc0fdd769133baac1f5e07abf54aeb"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:8e254ae696c88d98da6555f5ace2279cf7cd5b3f52be2b5cf97feafe883b58d2"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:cb0932dc158471523c9637e807d9bfb93e06a95cbf010f1a38b98623b929ef2b"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9402b03f1a1b4dc4c19845e5c749e3ab82d5078d16a2a4c2cd2df62d57bb0707"},
|
||||
@@ -1922,7 +1912,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:69b023b2b4daa7548bcfbd4aa3da05b3a74b772db9e23b982788168117739938"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:81e0b275a9ecc9c0c0c07b4b90ba548307583c125f54d5b6946cfee6360c733d"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:ba336e390cd8e4d1739f42dfe9bb83a3cc2e80f567d8805e11b46f4a943f5515"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:326c013efe8048858a6d312ddd31d56e468118ad4cdeda36c719bf5bb6192290"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win32.whl", hash = "sha256:bd4af7373a854424dabd882decdc5579653d7868b8fb26dc7d0e99f823aa5924"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win_amd64.whl", hash = "sha256:fd1592b3fdf65fff2ad0004b5e363300ef59ced41c2e6b3a99d4089fa8c5435d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:6965a7bc3cf88e5a1c3bd2e0b5c22f8d677dc88a455344035f03399034eb3007"},
|
||||
@@ -1930,15 +1919,8 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:42f8152b8dbc4fe7d96729ec2b99c7097d656dc1213a3229ca5383f973a5ed6d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:062582fca9fabdd2c8b54a3ef1c978d786e0f6b3a1510e0ac93ef59e0ddae2bc"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:d2b04aac4d386b172d5b9692e2d2da8de7bfb6c387fa4f801fbf6fb2e6ba4673"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:e7d73685e87afe9f3b36c799222440d6cf362062f78be1013661b00c5c6f678b"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win32.whl", hash = "sha256:1635fd110e8d85d55237ab316b5b011de701ea0f29d07611174a1b42f1444741"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win_amd64.whl", hash = "sha256:bf07ee2fef7014951eeb99f56f39c9bb4af143d8aa3c21b1677805985307da34"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:855fb52b0dc35af121542a76b9a84f8d1cd886ea97c84703eaa6d88e37a2ad28"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:40df9b996c2b73138957fe23a16a4f0ba614f4c0efce1e9406a184b6d07fa3a9"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:6c22bec3fbe2524cde73d7ada88f6566758a8f7227bfbf93a408a9d86bcc12a0"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8d4e9c88387b0f5c7d5f281e55304de64cf7f9c0021a3525bd3b1c542da3b0e4"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win32.whl", hash = "sha256:d483d2cdf104e7c9fa60c544d92981f12ad66a457afae824d146093b8c294c54"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win_amd64.whl", hash = "sha256:0d3304d8c0adc42be59c5f8a4d9e3d7379e6955ad754aa9d6ab7a398b59dd1df"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:50550eb667afee136e9a77d6dc71ae76a44df8b3e51e41b77f6de2932bfe0f47"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:1fe35611261b29bd1de0070f0b2f47cb6ff71fa6595c077e42bd0c419fa27b98"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:704219a11b772aea0d8ecd7058d0082713c3562b4e271b849ad7dc4a5c90c13c"},
|
||||
@@ -1955,7 +1937,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:a0cd17c15d3bb3fa06978b4e8958dcdc6e0174ccea823003a106c7d4d7899ac5"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:28c119d996beec18c05208a8bd78cbe4007878c6dd15091efb73a30e90539696"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7e07cbde391ba96ab58e532ff4803f79c4129397514e1413a7dc761ccd755735"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:49a183be227561de579b4a36efbb21b3eab9651dd81b1858589f796549873dd6"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win32.whl", hash = "sha256:184c5108a2aca3c5b3d3bf9395d50893a7ab82a38004c8f61c258d4428e80206"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win_amd64.whl", hash = "sha256:1e2722cc9fbb45d9b87631ac70924c11d3a401b2d7f410cc0e3bbf249f2dca62"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:9eb6caa9a297fc2c2fb8862bc5370d0303ddba53ba97e71f08023b6cd73d16a8"},
|
||||
@@ -1963,7 +1944,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:5773183b6446b2c99bb77e77595dd486303b4faab2b086e7b17bc6bef28865f6"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:b786eecbdf8499b9ca1d697215862083bd6d2a99965554781d0d8d1ad31e13a0"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:bc1bf2925a1ecd43da378f4db9e4f799775d6367bdb94671027b73b393a7c42c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:04ac92ad1925b2cff1db0cfebffb6ffc43457495c9b3c39d3fcae417d7125dc5"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win32.whl", hash = "sha256:faca3bdcf85b2fc05d06ff3fbc1f83e1391b3e724afa3feba7d13eeab355484c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win_amd64.whl", hash = "sha256:510c9deebc5c0225e8c96813043e62b680ba2f9c50a08d3724c7f28a747d1486"},
|
||||
{file = "PyYAML-6.0.1.tar.gz", hash = "sha256:bfdf460b1736c775f2ba9f6a92bca30bc2095067b8a9d77876d1fad6cc3b4a43"},
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[tool.poetry]
|
||||
name = "langchain-core"
|
||||
version = "0.0.6"
|
||||
version = "0.0.4"
|
||||
description = "Building applications with LLMs through composability"
|
||||
authors = []
|
||||
license = "MIT"
|
||||
|
||||
1378
libs/core/tests/unit_tests/__snapshots__/test_serialization.ambr
Normal file
1378
libs/core/tests/unit_tests/__snapshots__/test_serialization.ambr
Normal file
File diff suppressed because it is too large
Load Diff
@@ -7,7 +7,6 @@ EXPECTED_ALL = [
|
||||
"BaseLLM",
|
||||
"LLM",
|
||||
"LanguageModelInput",
|
||||
"LanguageModelOutput",
|
||||
"get_tokenizer",
|
||||
]
|
||||
|
||||
|
||||
59
libs/core/tests/unit_tests/load/__snapshots__/test_dump.ambr
Normal file
59
libs/core/tests/unit_tests/load/__snapshots__/test_dump.ambr
Normal file
@@ -0,0 +1,59 @@
|
||||
# serializer version: 1
|
||||
# name: test_person
|
||||
'''
|
||||
{
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"tests",
|
||||
"unit_tests",
|
||||
"load",
|
||||
"test_dump",
|
||||
"Person"
|
||||
],
|
||||
"kwargs": {
|
||||
"secret": {
|
||||
"lc": 1,
|
||||
"type": "secret",
|
||||
"id": [
|
||||
"SECRET"
|
||||
]
|
||||
},
|
||||
"you_can_see_me": "hello"
|
||||
}
|
||||
}
|
||||
'''
|
||||
# ---
|
||||
# name: test_person.1
|
||||
'''
|
||||
{
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"tests",
|
||||
"unit_tests",
|
||||
"load",
|
||||
"test_dump",
|
||||
"SpecialPerson"
|
||||
],
|
||||
"kwargs": {
|
||||
"another_secret": {
|
||||
"lc": 1,
|
||||
"type": "secret",
|
||||
"id": [
|
||||
"ANOTHER_SECRET"
|
||||
]
|
||||
},
|
||||
"secret": {
|
||||
"lc": 1,
|
||||
"type": "secret",
|
||||
"id": [
|
||||
"SECRET"
|
||||
]
|
||||
},
|
||||
"another_visible": "bye",
|
||||
"you_can_see_me": "hello"
|
||||
}
|
||||
}
|
||||
'''
|
||||
# ---
|
||||
46
libs/core/tests/unit_tests/load/test_dump.py
Normal file
46
libs/core/tests/unit_tests/load/test_dump.py
Normal file
@@ -0,0 +1,46 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
from langchain_core.load.dump import dumps
|
||||
from langchain_core.load.serializable import Serializable
|
||||
|
||||
|
||||
class Person(Serializable):
|
||||
secret: str
|
||||
|
||||
you_can_see_me: str = "hello"
|
||||
|
||||
@classmethod
|
||||
def is_lc_serializable(cls) -> bool:
|
||||
return True
|
||||
|
||||
@property
|
||||
def lc_secrets(self) -> Dict[str, str]:
|
||||
return {"secret": "SECRET"}
|
||||
|
||||
@property
|
||||
def lc_attributes(self) -> Dict[str, str]:
|
||||
return {"you_can_see_me": self.you_can_see_me}
|
||||
|
||||
|
||||
class SpecialPerson(Person):
|
||||
another_secret: str
|
||||
|
||||
another_visible: str = "bye"
|
||||
|
||||
# Gets merged with parent class's secrets
|
||||
@property
|
||||
def lc_secrets(self) -> Dict[str, str]:
|
||||
return {"another_secret": "ANOTHER_SECRET"}
|
||||
|
||||
# Gets merged with parent class's attributes
|
||||
@property
|
||||
def lc_attributes(self) -> Dict[str, str]:
|
||||
return {"another_visible": self.another_visible}
|
||||
|
||||
|
||||
def test_person(snapshot: Any) -> None:
|
||||
p = Person(secret="hello")
|
||||
assert dumps(p, pretty=True) == snapshot
|
||||
sp = SpecialPerson(another_secret="Wooo", secret="Hmm")
|
||||
assert dumps(sp, pretty=True) == snapshot
|
||||
assert Person.lc_id() == ["tests", "unit_tests", "load", "test_dump", "Person"]
|
||||
@@ -1020,118 +1020,6 @@ def test_configurable_alts_factory() -> None:
|
||||
assert fake_llm.with_config(configurable={"llm": "chat"}).invoke("...") == "b"
|
||||
|
||||
|
||||
def test_configurable_fields_prefix_keys() -> None:
|
||||
fake_chat = FakeListChatModel(responses=["b"]).configurable_fields(
|
||||
responses=ConfigurableFieldMultiOption(
|
||||
id="responses",
|
||||
name="Chat Responses",
|
||||
options={
|
||||
"hello": "A good morning to you!",
|
||||
"bye": "See you later!",
|
||||
"helpful": "How can I help you?",
|
||||
},
|
||||
default=["hello", "bye"],
|
||||
),
|
||||
# (sleep is a configurable field in FakeListChatModel)
|
||||
sleep=ConfigurableField(
|
||||
id="chat_sleep",
|
||||
is_shared=True,
|
||||
),
|
||||
)
|
||||
fake_llm = (
|
||||
FakeListLLM(responses=["a"])
|
||||
.configurable_fields(
|
||||
responses=ConfigurableField(
|
||||
id="responses",
|
||||
name="LLM Responses",
|
||||
description="A list of fake responses for this LLM",
|
||||
)
|
||||
)
|
||||
.configurable_alternatives(
|
||||
ConfigurableField(id="llm", name="LLM"),
|
||||
chat=fake_chat | StrOutputParser(),
|
||||
prefix_keys=True,
|
||||
)
|
||||
)
|
||||
prompt = PromptTemplate.from_template("Hello, {name}!").configurable_fields(
|
||||
template=ConfigurableFieldSingleOption(
|
||||
id="prompt_template",
|
||||
name="Prompt Template",
|
||||
description="The prompt template for this chain",
|
||||
options={
|
||||
"hello": "Hello, {name}!",
|
||||
"good_morning": "A very good morning to you, {name}!",
|
||||
},
|
||||
default="hello",
|
||||
)
|
||||
)
|
||||
|
||||
chain = prompt | fake_llm
|
||||
|
||||
assert chain.config_schema().schema() == {
|
||||
"title": "RunnableSequenceConfig",
|
||||
"type": "object",
|
||||
"properties": {"configurable": {"$ref": "#/definitions/Configurable"}},
|
||||
"definitions": {
|
||||
"LLM": {
|
||||
"title": "LLM",
|
||||
"description": "An enumeration.",
|
||||
"enum": ["chat", "default"],
|
||||
"type": "string",
|
||||
},
|
||||
"Chat_Responses": {
|
||||
"title": "Chat Responses",
|
||||
"description": "An enumeration.",
|
||||
"enum": ["hello", "bye", "helpful"],
|
||||
"type": "string",
|
||||
},
|
||||
"Prompt_Template": {
|
||||
"title": "Prompt Template",
|
||||
"description": "An enumeration.",
|
||||
"enum": ["hello", "good_morning"],
|
||||
"type": "string",
|
||||
},
|
||||
"Configurable": {
|
||||
"title": "Configurable",
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"prompt_template": {
|
||||
"title": "Prompt Template",
|
||||
"description": "The prompt template for this chain",
|
||||
"default": "hello",
|
||||
"allOf": [{"$ref": "#/definitions/Prompt_Template"}],
|
||||
},
|
||||
"llm": {
|
||||
"title": "LLM",
|
||||
"default": "default",
|
||||
"allOf": [{"$ref": "#/definitions/LLM"}],
|
||||
},
|
||||
# not prefixed because marked as shared
|
||||
"chat_sleep": {
|
||||
"title": "Chat Sleep",
|
||||
"type": "number",
|
||||
},
|
||||
# prefixed for "chat" option
|
||||
"llm==chat/responses": {
|
||||
"title": "Chat Responses",
|
||||
"default": ["hello", "bye"],
|
||||
"type": "array",
|
||||
"items": {"$ref": "#/definitions/Chat_Responses"},
|
||||
},
|
||||
# prefixed for "default" option
|
||||
"llm==default/responses": {
|
||||
"title": "LLM Responses",
|
||||
"description": "A list of fake responses for this LLM",
|
||||
"default": ["a"],
|
||||
"type": "array",
|
||||
"items": {"type": "string"},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
def test_configurable_fields_example() -> None:
|
||||
fake_chat = FakeListChatModel(responses=["b"]).configurable_fields(
|
||||
responses=ConfigurableFieldMultiOption(
|
||||
|
||||
1378
libs/core/tests/unit_tests/serialization/v0_0_341/snapshot.ambr
Normal file
1378
libs/core/tests/unit_tests/serialization/v0_0_341/snapshot.ambr
Normal file
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,400 @@
|
||||
import json
|
||||
from typing import Any
|
||||
|
||||
from langchain_core.documents.base import Document
|
||||
from langchain_core.load.load import load
|
||||
from langchain_core.load.serializable import Serializable
|
||||
from langchain_core.messages.ai import AIMessage, AIMessageChunk
|
||||
from langchain_core.messages.base import BaseMessage, BaseMessageChunk
|
||||
from langchain_core.messages.chat import ChatMessage, ChatMessageChunk
|
||||
from langchain_core.messages.function import FunctionMessage, FunctionMessageChunk
|
||||
from langchain_core.messages.human import HumanMessage, HumanMessageChunk
|
||||
from langchain_core.messages.system import SystemMessage, SystemMessageChunk
|
||||
from langchain_core.messages.tool import ToolMessage, ToolMessageChunk
|
||||
from langchain_core.output_parsers.list import (
|
||||
CommaSeparatedListOutputParser,
|
||||
MarkdownListOutputParser,
|
||||
NumberedListOutputParser,
|
||||
)
|
||||
from langchain_core.output_parsers.string import StrOutputParser
|
||||
from langchain_core.outputs.chat_generation import ChatGeneration, ChatGenerationChunk
|
||||
from langchain_core.outputs.generation import Generation, GenerationChunk
|
||||
from langchain_core.prompts.chat import (
|
||||
AIMessagePromptTemplate,
|
||||
ChatMessagePromptTemplate,
|
||||
ChatPromptTemplate,
|
||||
HumanMessagePromptTemplate,
|
||||
MessagesPlaceholder,
|
||||
SystemMessagePromptTemplate,
|
||||
)
|
||||
from langchain_core.prompts.few_shot import (
|
||||
FewShotChatMessagePromptTemplate,
|
||||
FewShotPromptTemplate,
|
||||
)
|
||||
from langchain_core.prompts.few_shot_with_templates import FewShotPromptWithTemplates
|
||||
from langchain_core.prompts.pipeline import PipelinePromptTemplate
|
||||
from langchain_core.prompts.prompt import PromptTemplate
|
||||
from langchain_core.runnables import ConfigurableField
|
||||
from langchain_core.runnables.base import (
|
||||
RunnableBinding,
|
||||
RunnableBindingBase,
|
||||
RunnableEach,
|
||||
RunnableEachBase,
|
||||
RunnableMap,
|
||||
RunnableParallel,
|
||||
RunnableSequence,
|
||||
)
|
||||
from langchain_core.runnables.branch import RunnableBranch
|
||||
from langchain_core.runnables.configurable import (
|
||||
RunnableConfigurableAlternatives,
|
||||
RunnableConfigurableFields,
|
||||
)
|
||||
from langchain_core.runnables.fallbacks import RunnableWithFallbacks
|
||||
from langchain_core.runnables.history import RunnableWithMessageHistory
|
||||
from langchain_core.runnables.passthrough import RunnableAssign, RunnablePassthrough
|
||||
from langchain_core.runnables.retry import RunnableRetry
|
||||
from langchain_core.runnables.router import RouterRunnable
|
||||
from tests.unit_tests.fake.memory import ChatMessageHistory
|
||||
|
||||
with open("tests/unit_tests/serialization/v0_0_341/snapshot.ambr") as f:
|
||||
SNAPSHOTS = f.read()
|
||||
SNAPSHOT_MAP = {
|
||||
x.split("\n")[0][15:]: json.loads(x.split("'''")[1])
|
||||
for x in SNAPSHOTS.split("# name: ")
|
||||
if not x.startswith("#")
|
||||
}
|
||||
|
||||
|
||||
def load_snapshot(snake_case_class: str) -> str:
|
||||
return SNAPSHOT_MAP[snake_case_class]
|
||||
|
||||
|
||||
def test_deserialize_system_message() -> None:
|
||||
snapshot = load_snapshot("system_message")
|
||||
obj: Any = SystemMessage(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_system_message_chunk() -> None:
|
||||
snapshot = load_snapshot("system_message_chunk")
|
||||
obj: Any = SystemMessageChunk(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_ai_message() -> None:
|
||||
snapshot = load_snapshot("ai_message")
|
||||
obj: Any = AIMessage(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_ai_message_chunk() -> None:
|
||||
snapshot = load_snapshot("ai_message_chunk")
|
||||
obj: Any = AIMessageChunk(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_human_message() -> None:
|
||||
snapshot = load_snapshot("human_message")
|
||||
obj: Any = HumanMessage(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_human_message_chunk() -> None:
|
||||
snapshot = load_snapshot("human_message_chunk")
|
||||
obj: Any = HumanMessageChunk(content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_message() -> None:
|
||||
snapshot = load_snapshot("chat_message")
|
||||
obj: Any = ChatMessage(content="", role="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_message_chunk() -> None:
|
||||
snapshot = load_snapshot("chat_message_chunk")
|
||||
obj: Any = ChatMessageChunk(content="", role="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_tool_message() -> None:
|
||||
snapshot = load_snapshot("tool_message")
|
||||
obj: Any = ToolMessage(content="", tool_call_id="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_tool_message_chunk() -> None:
|
||||
snapshot = load_snapshot("tool_message_chunk")
|
||||
obj: Any = ToolMessageChunk(content="", tool_call_id="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_base_message() -> None:
|
||||
snapshot = load_snapshot("base_message")
|
||||
obj: Any = BaseMessage(content="", type="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_base_message_chunk() -> None:
|
||||
snapshot = load_snapshot("base_message_chunk")
|
||||
obj: Any = BaseMessageChunk(content="", type="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_function_message() -> None:
|
||||
snapshot = load_snapshot("function_message")
|
||||
obj: Any = FunctionMessage(content="", name="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_function_message_chunk() -> None:
|
||||
snapshot = load_snapshot("function_message_chunk")
|
||||
obj: Any = FunctionMessageChunk(content="", name="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_configurable_alternatives() -> None:
|
||||
snapshot = load_snapshot("runnable_configurable_alternatives")
|
||||
obj: Any = RunnableConfigurableAlternatives(
|
||||
default=RunnablePassthrough(), which=ConfigurableField(id=""), alternatives={}
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_configurable_fields() -> None:
|
||||
snapshot = load_snapshot("runnable_configurable_fields")
|
||||
obj: Any = RunnableConfigurableFields(default=RunnablePassthrough(), fields={})
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_branch() -> None:
|
||||
snapshot = load_snapshot("runnable_branch")
|
||||
obj: Any = RunnableBranch(
|
||||
(RunnablePassthrough(), RunnablePassthrough()), RunnablePassthrough()
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_retry() -> None:
|
||||
snapshot = load_snapshot("runnable_retry")
|
||||
obj: Any = RunnableRetry(bound=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_with_fallbacks() -> None:
|
||||
snapshot = load_snapshot("runnable_with_fallbacks")
|
||||
obj: Any = RunnableWithFallbacks(
|
||||
runnable=RunnablePassthrough(), fallbacks=(RunnablePassthrough(),)
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_router_runnable() -> None:
|
||||
snapshot = load_snapshot("router_runnable")
|
||||
obj: Any = RouterRunnable({"": RunnablePassthrough()})
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_assign() -> None:
|
||||
snapshot = load_snapshot("runnable_assign")
|
||||
obj: Any = RunnableAssign(mapper=RunnableParallel({}))
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_passthrough() -> None:
|
||||
snapshot = load_snapshot("runnable_passthrough")
|
||||
obj: Any = RunnablePassthrough()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_binding() -> None:
|
||||
snapshot = load_snapshot("runnable_binding")
|
||||
obj: Any = RunnableBinding(bound=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_binding_base() -> None:
|
||||
snapshot = load_snapshot("runnable_binding_base")
|
||||
obj: Any = RunnableBindingBase(bound=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_each() -> None:
|
||||
snapshot = load_snapshot("runnable_each")
|
||||
obj: Any = RunnableEach(bound=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_each_base() -> None:
|
||||
snapshot = load_snapshot("runnable_each_base")
|
||||
obj: Any = RunnableEachBase(bound=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_map() -> None:
|
||||
snapshot = load_snapshot("runnable_map")
|
||||
obj: Any = RunnableMap()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_parallel() -> None:
|
||||
snapshot = load_snapshot("runnable_parallel")
|
||||
obj: Any = RunnableParallel()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_sequence() -> None:
|
||||
snapshot = load_snapshot("runnable_sequence")
|
||||
obj: Any = RunnableSequence(first=RunnablePassthrough(), last=RunnablePassthrough())
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_runnable_with_message_history() -> None:
|
||||
snapshot = load_snapshot("runnable_with_message_history")
|
||||
|
||||
def get_chat_history(session_id: str) -> ChatMessageHistory:
|
||||
return ChatMessageHistory()
|
||||
|
||||
obj: Any = RunnableWithMessageHistory(RunnablePassthrough(), get_chat_history)
|
||||
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_serializable() -> None:
|
||||
snapshot = load_snapshot("serializable")
|
||||
obj = Serializable()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_comma_separated_list_output_parser() -> None:
|
||||
snapshot = load_snapshot("comma_separated_list_output_parser")
|
||||
obj = CommaSeparatedListOutputParser()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_markdown_list_output_parser() -> None:
|
||||
snapshot = load_snapshot("markdown_list_output_parser")
|
||||
obj = MarkdownListOutputParser()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_numbered_list_output_parser() -> None:
|
||||
snapshot = load_snapshot("numbered_list_output_parser")
|
||||
obj = NumberedListOutputParser()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_str_output_parser() -> None:
|
||||
snapshot = load_snapshot("str_output_parser")
|
||||
obj = StrOutputParser()
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_few_shot_prompt_with_templates() -> None:
|
||||
snapshot = load_snapshot("few_shot_prompt_with_templates")
|
||||
obj: Any = FewShotPromptWithTemplates(
|
||||
example_prompt=PromptTemplate.from_template(""),
|
||||
suffix=PromptTemplate.from_template(""),
|
||||
examples=[],
|
||||
input_variables=[],
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_few_shot_chat_message_prompt_template() -> None:
|
||||
snapshot = load_snapshot("few_shot_chat_message_prompt_template")
|
||||
obj: Any = FewShotChatMessagePromptTemplate(
|
||||
example_prompt=HumanMessagePromptTemplate.from_template(""), examples=[]
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_few_shot_prompt_template() -> None:
|
||||
snapshot = load_snapshot("few_shot_prompt_template")
|
||||
obj: Any = FewShotPromptTemplate(
|
||||
example_prompt=PromptTemplate.from_template(""),
|
||||
suffix="",
|
||||
examples=[],
|
||||
input_variables=[],
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_ai_message_prompt_template() -> None:
|
||||
snapshot = load_snapshot("ai_message_prompt_template")
|
||||
obj: Any = AIMessagePromptTemplate.from_template("")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_message_prompt_template() -> None:
|
||||
snapshot = load_snapshot("chat_message_prompt_template")
|
||||
obj: Any = ChatMessagePromptTemplate.from_template("", role="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_prompt_template() -> None:
|
||||
snapshot = load_snapshot("chat_prompt_template")
|
||||
obj: Any = ChatPromptTemplate.from_template("", role="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_human_message_prompt_template() -> None:
|
||||
snapshot = load_snapshot("human_message_prompt_template")
|
||||
obj: Any = HumanMessagePromptTemplate.from_template("")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_messages_placeholder() -> None:
|
||||
snapshot = load_snapshot("messages_placeholder")
|
||||
obj: Any = MessagesPlaceholder(variable_name="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_system_message_prompt_template() -> None:
|
||||
snapshot = load_snapshot("system_message_prompt_template")
|
||||
obj: Any = SystemMessagePromptTemplate.from_template("")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_pipeline_prompt_template() -> None:
|
||||
snapshot = load_snapshot("pipeline_prompt_template")
|
||||
obj: Any = PipelinePromptTemplate(
|
||||
pipeline_prompts=[], final_prompt=PromptTemplate.from_template("")
|
||||
)
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_prompt_template() -> None:
|
||||
snapshot = load_snapshot("prompt_template")
|
||||
obj: Any = PromptTemplate.from_template("")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_document() -> None:
|
||||
snapshot = load_snapshot("document")
|
||||
obj: Any = Document(page_content="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_generation() -> None:
|
||||
snapshot = load_snapshot("generation")
|
||||
obj: Any = Generation(text="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_generation_chunk() -> None:
|
||||
snapshot = load_snapshot("generation_chunk")
|
||||
obj: Any = GenerationChunk(text="")
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_generation() -> None:
|
||||
snapshot = load_snapshot("chat_generation")
|
||||
obj: Any = ChatGeneration(message=AIMessage(content=""))
|
||||
assert load(snapshot) == obj
|
||||
|
||||
|
||||
def test_deserialize_chat_generation_chunk() -> None:
|
||||
snapshot = load_snapshot("chat_generation_chunk")
|
||||
obj: Any = ChatGenerationChunk(message=AIMessage(content=""))
|
||||
assert load(snapshot) == obj
|
||||
334
libs/core/tests/unit_tests/test_serialization.py
Normal file
334
libs/core/tests/unit_tests/test_serialization.py
Normal file
@@ -0,0 +1,334 @@
|
||||
from typing import Any
|
||||
|
||||
from langchain_core.documents.base import Document
|
||||
from langchain_core.load.dump import dumps
|
||||
from langchain_core.load.serializable import Serializable
|
||||
from langchain_core.messages.ai import AIMessage, AIMessageChunk
|
||||
from langchain_core.messages.base import BaseMessage, BaseMessageChunk
|
||||
from langchain_core.messages.chat import ChatMessage, ChatMessageChunk
|
||||
from langchain_core.messages.function import FunctionMessage, FunctionMessageChunk
|
||||
from langchain_core.messages.human import HumanMessage, HumanMessageChunk
|
||||
from langchain_core.messages.system import SystemMessage, SystemMessageChunk
|
||||
from langchain_core.messages.tool import ToolMessage, ToolMessageChunk
|
||||
from langchain_core.output_parsers.list import (
|
||||
CommaSeparatedListOutputParser,
|
||||
MarkdownListOutputParser,
|
||||
NumberedListOutputParser,
|
||||
)
|
||||
from langchain_core.output_parsers.string import StrOutputParser
|
||||
from langchain_core.outputs.chat_generation import ChatGeneration, ChatGenerationChunk
|
||||
from langchain_core.outputs.generation import Generation, GenerationChunk
|
||||
from langchain_core.prompts.chat import (
|
||||
AIMessagePromptTemplate,
|
||||
ChatMessagePromptTemplate,
|
||||
ChatPromptTemplate,
|
||||
HumanMessagePromptTemplate,
|
||||
MessagesPlaceholder,
|
||||
SystemMessagePromptTemplate,
|
||||
)
|
||||
from langchain_core.prompts.few_shot import (
|
||||
FewShotChatMessagePromptTemplate,
|
||||
FewShotPromptTemplate,
|
||||
)
|
||||
from langchain_core.prompts.few_shot_with_templates import FewShotPromptWithTemplates
|
||||
from langchain_core.prompts.pipeline import PipelinePromptTemplate
|
||||
from langchain_core.prompts.prompt import PromptTemplate
|
||||
from langchain_core.runnables import ConfigurableField
|
||||
from langchain_core.runnables.base import (
|
||||
RunnableBinding,
|
||||
RunnableBindingBase,
|
||||
RunnableEach,
|
||||
RunnableEachBase,
|
||||
RunnableMap,
|
||||
RunnableParallel,
|
||||
RunnableSequence,
|
||||
)
|
||||
from langchain_core.runnables.branch import RunnableBranch
|
||||
from langchain_core.runnables.configurable import (
|
||||
RunnableConfigurableAlternatives,
|
||||
RunnableConfigurableFields,
|
||||
)
|
||||
from langchain_core.runnables.fallbacks import RunnableWithFallbacks
|
||||
from langchain_core.runnables.history import RunnableWithMessageHistory
|
||||
from langchain_core.runnables.passthrough import RunnableAssign, RunnablePassthrough
|
||||
from langchain_core.runnables.retry import RunnableRetry
|
||||
from langchain_core.runnables.router import RouterRunnable
|
||||
from tests.unit_tests.fake.memory import ChatMessageHistory
|
||||
|
||||
|
||||
def test_serialize_system_message(snapshot: Any) -> None:
|
||||
obj: Any = SystemMessage(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_system_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = SystemMessageChunk(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_ai_message(snapshot: Any) -> None:
|
||||
obj: Any = AIMessage(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_ai_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = AIMessageChunk(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_human_message(snapshot: Any) -> None:
|
||||
obj: Any = HumanMessage(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_human_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = HumanMessageChunk(content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_message(snapshot: Any) -> None:
|
||||
obj: Any = ChatMessage(content="", role="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = ChatMessageChunk(content="", role="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_tool_message(snapshot: Any) -> None:
|
||||
obj: Any = ToolMessage(content="", tool_call_id="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_tool_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = ToolMessageChunk(content="", tool_call_id="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_base_message(snapshot: Any) -> None:
|
||||
obj: Any = BaseMessage(content="", type="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_base_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = BaseMessageChunk(content="", type="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_function_message(snapshot: Any) -> None:
|
||||
obj: Any = FunctionMessage(content="", name="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_function_message_chunk(snapshot: Any) -> None:
|
||||
obj: Any = FunctionMessageChunk(content="", name="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_configurable_alternatives(snapshot: Any) -> None:
|
||||
obj: Any = RunnableConfigurableAlternatives(
|
||||
default=RunnablePassthrough(), which=ConfigurableField(id=""), alternatives={}
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_configurable_fields(snapshot: Any) -> None:
|
||||
obj: Any = RunnableConfigurableFields(default=RunnablePassthrough(), fields={})
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_branch(snapshot: Any) -> None:
|
||||
obj: Any = RunnableBranch(
|
||||
(RunnablePassthrough(), RunnablePassthrough()), RunnablePassthrough()
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_retry(snapshot: Any) -> None:
|
||||
obj: Any = RunnableRetry(bound=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_with_fallbacks(snapshot: Any) -> None:
|
||||
obj: Any = RunnableWithFallbacks(
|
||||
runnable=RunnablePassthrough(), fallbacks=(RunnablePassthrough(),)
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_router_runnable(snapshot: Any) -> None:
|
||||
obj: Any = RouterRunnable({"": RunnablePassthrough()})
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_assign(snapshot: Any) -> None:
|
||||
obj: Any = RunnableAssign(mapper=RunnableParallel({}))
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_passthrough(snapshot: Any) -> None:
|
||||
obj: Any = RunnablePassthrough()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_binding(snapshot: Any) -> None:
|
||||
obj: Any = RunnableBinding(bound=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_binding_base(snapshot: Any) -> None:
|
||||
obj: Any = RunnableBindingBase(bound=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_each(snapshot: Any) -> None:
|
||||
obj: Any = RunnableEach(bound=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_each_base(snapshot: Any) -> None:
|
||||
obj: Any = RunnableEachBase(bound=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_map(snapshot: Any) -> None:
|
||||
obj: Any = RunnableMap()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_parallel(snapshot: Any) -> None:
|
||||
obj: Any = RunnableParallel()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_sequence(snapshot: Any) -> None:
|
||||
obj: Any = RunnableSequence(first=RunnablePassthrough(), last=RunnablePassthrough())
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_runnable_with_message_history(snapshot: Any) -> None:
|
||||
def get_chat_history(session_id: str) -> ChatMessageHistory:
|
||||
return ChatMessageHistory()
|
||||
|
||||
obj: Any = RunnableWithMessageHistory(RunnablePassthrough(), get_chat_history)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_serializable(snapshot: Any) -> None:
|
||||
obj: Any = Serializable()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_comma_separated_list_output_parser(snapshot: Any) -> None:
|
||||
obj: Any = CommaSeparatedListOutputParser()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_markdown_list_output_parser(snapshot: Any) -> None:
|
||||
obj: Any = MarkdownListOutputParser()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_numbered_list_output_parser(snapshot: Any) -> None:
|
||||
obj: Any = NumberedListOutputParser()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_str_output_parser(snapshot: Any) -> None:
|
||||
obj: Any = StrOutputParser()
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_few_shot_prompt_with_templates(snapshot: Any) -> None:
|
||||
obj: Any = FewShotPromptWithTemplates(
|
||||
example_prompt=PromptTemplate.from_template(""),
|
||||
suffix=PromptTemplate.from_template(""),
|
||||
examples=[],
|
||||
input_variables=[],
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_few_shot_chat_message_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = FewShotChatMessagePromptTemplate(
|
||||
example_prompt=HumanMessagePromptTemplate.from_template(""), examples=[]
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_few_shot_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = FewShotPromptTemplate(
|
||||
example_prompt=PromptTemplate.from_template(""),
|
||||
suffix="",
|
||||
examples=[],
|
||||
input_variables=[],
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_ai_message_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = AIMessagePromptTemplate.from_template("")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_message_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = ChatMessagePromptTemplate.from_template("", role="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = ChatPromptTemplate.from_template("", role="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_human_message_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = HumanMessagePromptTemplate.from_template("")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_messages_placeholder(snapshot: Any) -> None:
|
||||
obj: Any = MessagesPlaceholder(variable_name="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_system_message_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = SystemMessagePromptTemplate.from_template("")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_pipeline_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = PipelinePromptTemplate(
|
||||
pipeline_prompts=[], final_prompt=PromptTemplate.from_template("")
|
||||
)
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_prompt_template(snapshot: Any) -> None:
|
||||
obj: Any = PromptTemplate.from_template("")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_document(snapshot: Any) -> None:
|
||||
obj: Any = Document(page_content="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_generation(snapshot: Any) -> None:
|
||||
obj: Any = Generation(text="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_generation_chunk(snapshot: Any) -> None:
|
||||
obj: Any = GenerationChunk(text="")
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_generation(snapshot: Any) -> None:
|
||||
obj: Any = ChatGeneration(message=AIMessage(content=""))
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
|
||||
|
||||
def test_serialize_chat_generation_chunk(snapshot: Any) -> None:
|
||||
obj: Any = ChatGenerationChunk(message=AIMessage(content=""))
|
||||
assert dumps(obj, pretty=True) == snapshot
|
||||
24
libs/experimental/poetry.lock
generated
24
libs/experimental/poetry.lock
generated
@@ -1736,16 +1736,6 @@ files = [
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:5bbe06f8eeafd38e5d0a4894ffec89378b6c6a625ff57e3028921f8ff59318ac"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win32.whl", hash = "sha256:dd15ff04ffd7e05ffcb7fe79f1b98041b8ea30ae9234aed2a9168b5797c3effb"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win_amd64.whl", hash = "sha256:134da1eca9ec0ae528110ccc9e48041e0828d79f24121a1a146161103c76e686"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_universal2.whl", hash = "sha256:f698de3fd0c4e6972b92290a45bd9b1536bffe8c6759c62471efaa8acb4c37bc"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:aa57bd9cf8ae831a362185ee444e15a93ecb2e344c8e52e4d721ea3ab6ef1823"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ffcc3f7c66b5f5b7931a5aa68fc9cecc51e685ef90282f4a82f0f5e9b704ad11"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47d4f1c5f80fc62fdd7777d0d40a2e9dda0a05883ab11374334f6c4de38adffd"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1f67c7038d560d92149c060157d623c542173016c4babc0c1913cca0564b9939"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:9aad3c1755095ce347e26488214ef77e0485a3c34a50c5a5e2471dff60b9dd9c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_i686.whl", hash = "sha256:14ff806850827afd6b07a5f32bd917fb7f45b046ba40c57abdb636674a8b559c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8f9293864fe09b8149f0cc42ce56e3f0e54de883a9de90cd427f191c346eb2e1"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win32.whl", hash = "sha256:715d3562f79d540f251b99ebd6d8baa547118974341db04f5ad06d5ea3eb8007"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win_amd64.whl", hash = "sha256:1b8dd8c3fd14349433c79fa8abeb573a55fc0fdd769133baac1f5e07abf54aeb"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:8e254ae696c88d98da6555f5ace2279cf7cd5b3f52be2b5cf97feafe883b58d2"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:cb0932dc158471523c9637e807d9bfb93e06a95cbf010f1a38b98623b929ef2b"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9402b03f1a1b4dc4c19845e5c749e3ab82d5078d16a2a4c2cd2df62d57bb0707"},
|
||||
@@ -2920,7 +2910,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:69b023b2b4daa7548bcfbd4aa3da05b3a74b772db9e23b982788168117739938"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:81e0b275a9ecc9c0c0c07b4b90ba548307583c125f54d5b6946cfee6360c733d"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:ba336e390cd8e4d1739f42dfe9bb83a3cc2e80f567d8805e11b46f4a943f5515"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:326c013efe8048858a6d312ddd31d56e468118ad4cdeda36c719bf5bb6192290"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win32.whl", hash = "sha256:bd4af7373a854424dabd882decdc5579653d7868b8fb26dc7d0e99f823aa5924"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win_amd64.whl", hash = "sha256:fd1592b3fdf65fff2ad0004b5e363300ef59ced41c2e6b3a99d4089fa8c5435d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:6965a7bc3cf88e5a1c3bd2e0b5c22f8d677dc88a455344035f03399034eb3007"},
|
||||
@@ -2928,15 +2917,8 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:42f8152b8dbc4fe7d96729ec2b99c7097d656dc1213a3229ca5383f973a5ed6d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:062582fca9fabdd2c8b54a3ef1c978d786e0f6b3a1510e0ac93ef59e0ddae2bc"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:d2b04aac4d386b172d5b9692e2d2da8de7bfb6c387fa4f801fbf6fb2e6ba4673"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:e7d73685e87afe9f3b36c799222440d6cf362062f78be1013661b00c5c6f678b"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win32.whl", hash = "sha256:1635fd110e8d85d55237ab316b5b011de701ea0f29d07611174a1b42f1444741"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win_amd64.whl", hash = "sha256:bf07ee2fef7014951eeb99f56f39c9bb4af143d8aa3c21b1677805985307da34"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:855fb52b0dc35af121542a76b9a84f8d1cd886ea97c84703eaa6d88e37a2ad28"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:40df9b996c2b73138957fe23a16a4f0ba614f4c0efce1e9406a184b6d07fa3a9"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:6c22bec3fbe2524cde73d7ada88f6566758a8f7227bfbf93a408a9d86bcc12a0"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8d4e9c88387b0f5c7d5f281e55304de64cf7f9c0021a3525bd3b1c542da3b0e4"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win32.whl", hash = "sha256:d483d2cdf104e7c9fa60c544d92981f12ad66a457afae824d146093b8c294c54"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win_amd64.whl", hash = "sha256:0d3304d8c0adc42be59c5f8a4d9e3d7379e6955ad754aa9d6ab7a398b59dd1df"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:50550eb667afee136e9a77d6dc71ae76a44df8b3e51e41b77f6de2932bfe0f47"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:1fe35611261b29bd1de0070f0b2f47cb6ff71fa6595c077e42bd0c419fa27b98"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:704219a11b772aea0d8ecd7058d0082713c3562b4e271b849ad7dc4a5c90c13c"},
|
||||
@@ -2953,7 +2935,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:a0cd17c15d3bb3fa06978b4e8958dcdc6e0174ccea823003a106c7d4d7899ac5"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:28c119d996beec18c05208a8bd78cbe4007878c6dd15091efb73a30e90539696"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7e07cbde391ba96ab58e532ff4803f79c4129397514e1413a7dc761ccd755735"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:49a183be227561de579b4a36efbb21b3eab9651dd81b1858589f796549873dd6"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win32.whl", hash = "sha256:184c5108a2aca3c5b3d3bf9395d50893a7ab82a38004c8f61c258d4428e80206"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win_amd64.whl", hash = "sha256:1e2722cc9fbb45d9b87631ac70924c11d3a401b2d7f410cc0e3bbf249f2dca62"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:9eb6caa9a297fc2c2fb8862bc5370d0303ddba53ba97e71f08023b6cd73d16a8"},
|
||||
@@ -2961,7 +2942,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:5773183b6446b2c99bb77e77595dd486303b4faab2b086e7b17bc6bef28865f6"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:b786eecbdf8499b9ca1d697215862083bd6d2a99965554781d0d8d1ad31e13a0"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:bc1bf2925a1ecd43da378f4db9e4f799775d6367bdb94671027b73b393a7c42c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:04ac92ad1925b2cff1db0cfebffb6ffc43457495c9b3c39d3fcae417d7125dc5"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win32.whl", hash = "sha256:faca3bdcf85b2fc05d06ff3fbc1f83e1391b3e724afa3feba7d13eeab355484c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win_amd64.whl", hash = "sha256:510c9deebc5c0225e8c96813043e62b680ba2f9c50a08d3724c7f28a747d1486"},
|
||||
{file = "PyYAML-6.0.1.tar.gz", hash = "sha256:bfdf460b1736c775f2ba9f6a92bca30bc2095067b8a9d77876d1fad6cc3b4a43"},
|
||||
@@ -3909,9 +3889,7 @@ python-versions = ">=3.7"
|
||||
files = [
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:638c2c0b6b4661a4fd264f6fb804eccd392745c5887f9317feb64bb7cb03b3ea"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:e3b5036aa326dc2df50cba3c958e29b291a80f604b1afa4c8ce73e78e1c9f01d"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:787af80107fb691934a01889ca8f82a44adedbf5ef3d6ad7d0f0b9ac557e0c34"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:c14eba45983d2f48f7546bb32b47937ee2cafae353646295f0e99f35b14286ab"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-musllinux_1_1_aarch64.whl", hash = "sha256:0666031df46b9badba9bed00092a1ffa3aa063a5e68fa244acd9f08070e936d3"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:89a01238fcb9a8af118eaad3ffcc5dedaacbd429dc6fdc43fe430d3a941ff965"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-win32.whl", hash = "sha256:cabafc7837b6cec61c0e1e5c6d14ef250b675fa9c3060ed8a7e38653bd732ff8"},
|
||||
{file = "SQLAlchemy-2.0.23-cp310-cp310-win_amd64.whl", hash = "sha256:87a3d6b53c39cd173990de2f5f4b83431d534a74f0e2f88bd16eabb5667e65c6"},
|
||||
@@ -3948,9 +3926,7 @@ files = [
|
||||
{file = "SQLAlchemy-2.0.23-cp38-cp38-win_amd64.whl", hash = "sha256:964971b52daab357d2c0875825e36584d58f536e920f2968df8d581054eada4b"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:616fe7bcff0a05098f64b4478b78ec2dfa03225c23734d83d6c169eb41a93e55"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:0e680527245895aba86afbd5bef6c316831c02aa988d1aad83c47ffe92655e74"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:9585b646ffb048c0250acc7dad92536591ffe35dba624bb8fd9b471e25212a35"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4895a63e2c271ffc7a81ea424b94060f7b3b03b4ea0cd58ab5bb676ed02f4221"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-musllinux_1_1_aarch64.whl", hash = "sha256:cc1d21576f958c42d9aec68eba5c1a7d715e5fc07825a629015fe8e3b0657fb0"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:967c0b71156f793e6662dd839da54f884631755275ed71f1539c95bbada9aaab"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-win32.whl", hash = "sha256:0a8c6aa506893e25a04233bc721c6b6cf844bafd7250535abb56cb6cc1368884"},
|
||||
{file = "SQLAlchemy-2.0.23-cp39-cp39-win_amd64.whl", hash = "sha256:f3420d00d2cb42432c1d0e44540ae83185ccbbc67a6054dcc8ab5387add6620b"},
|
||||
|
||||
@@ -1239,318 +1239,3 @@ class SQLAlchemyMd5Cache(BaseCache):
|
||||
@staticmethod
|
||||
def get_md5(input_string: str) -> str:
|
||||
return hashlib.md5(input_string.encode()).hexdigest()
|
||||
|
||||
|
||||
ASTRA_DB_CACHE_DEFAULT_COLLECTION_NAME = "langchain_astradb_cache"
|
||||
|
||||
|
||||
class AstraDBCache(BaseCache):
|
||||
"""
|
||||
Cache that uses Astra DB as a backend.
|
||||
|
||||
It uses a single collection as a kv store
|
||||
The lookup keys, combined in the _id of the documents, are:
|
||||
- prompt, a string
|
||||
- llm_string, a deterministic str representation of the model parameters.
|
||||
(needed to prevent same-prompt-different-model collisions)
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
collection_name: str = ASTRA_DB_CACHE_DEFAULT_COLLECTION_NAME,
|
||||
token: Optional[str] = None,
|
||||
api_endpoint: Optional[str] = None,
|
||||
astra_db_client: Optional[Any] = None, # 'astrapy.db.AstraDB' if passed
|
||||
namespace: Optional[str] = None,
|
||||
):
|
||||
"""
|
||||
Create an AstraDB cache using a collection for storage.
|
||||
|
||||
Args (only keyword-arguments accepted):
|
||||
collection_name (str): name of the Astra DB collection to create/use.
|
||||
token (Optional[str]): API token for Astra DB usage.
|
||||
api_endpoint (Optional[str]): full URL to the API endpoint,
|
||||
such as "https://<DB-ID>-us-east1.apps.astra.datastax.com".
|
||||
astra_db_client (Optional[Any]): *alternative to token+api_endpoint*,
|
||||
you can pass an already-created 'astrapy.db.AstraDB' instance.
|
||||
namespace (Optional[str]): namespace (aka keyspace) where the
|
||||
collection is created. Defaults to the database's "default namespace".
|
||||
"""
|
||||
try:
|
||||
from astrapy.db import (
|
||||
AstraDB as LibAstraDB,
|
||||
)
|
||||
except (ImportError, ModuleNotFoundError):
|
||||
raise ImportError(
|
||||
"Could not import a recent astrapy python package. "
|
||||
"Please install it with `pip install --upgrade astrapy`."
|
||||
)
|
||||
# Conflicting-arg checks:
|
||||
if astra_db_client is not None:
|
||||
if token is not None or api_endpoint is not None:
|
||||
raise ValueError(
|
||||
"You cannot pass 'astra_db_client' to AstraDB if passing "
|
||||
"'token' and 'api_endpoint'."
|
||||
)
|
||||
|
||||
self.collection_name = collection_name
|
||||
self.token = token
|
||||
self.api_endpoint = api_endpoint
|
||||
self.namespace = namespace
|
||||
|
||||
if astra_db_client is not None:
|
||||
self.astra_db = astra_db_client
|
||||
else:
|
||||
self.astra_db = LibAstraDB(
|
||||
token=self.token,
|
||||
api_endpoint=self.api_endpoint,
|
||||
namespace=self.namespace,
|
||||
)
|
||||
self.collection = self.astra_db.create_collection(
|
||||
collection_name=self.collection_name,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _make_id(prompt: str, llm_string: str) -> str:
|
||||
return f"{_hash(prompt)}#{_hash(llm_string)}"
|
||||
|
||||
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
|
||||
"""Look up based on prompt and llm_string."""
|
||||
doc_id = self._make_id(prompt, llm_string)
|
||||
item = self.collection.find_one(
|
||||
filter={
|
||||
"_id": doc_id,
|
||||
},
|
||||
projection={
|
||||
"body_blob": 1,
|
||||
},
|
||||
)["data"]["document"]
|
||||
if item is not None:
|
||||
generations = _loads_generations(item["body_blob"])
|
||||
# this protects against malformed cached items:
|
||||
if generations is not None:
|
||||
return generations
|
||||
else:
|
||||
return None
|
||||
else:
|
||||
return None
|
||||
|
||||
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
|
||||
"""Update cache based on prompt and llm_string."""
|
||||
doc_id = self._make_id(prompt, llm_string)
|
||||
blob = _dumps_generations(return_val)
|
||||
self.collection.upsert(
|
||||
{
|
||||
"_id": doc_id,
|
||||
"body_blob": blob,
|
||||
},
|
||||
)
|
||||
|
||||
def delete_through_llm(
|
||||
self, prompt: str, llm: LLM, stop: Optional[List[str]] = None
|
||||
) -> None:
|
||||
"""
|
||||
A wrapper around `delete` with the LLM being passed.
|
||||
In case the llm(prompt) calls have a `stop` param, you should pass it here
|
||||
"""
|
||||
llm_string = get_prompts(
|
||||
{**llm.dict(), **{"stop": stop}},
|
||||
[],
|
||||
)[1]
|
||||
return self.delete(prompt, llm_string=llm_string)
|
||||
|
||||
def delete(self, prompt: str, llm_string: str) -> None:
|
||||
"""Evict from cache if there's an entry."""
|
||||
doc_id = self._make_id(prompt, llm_string)
|
||||
return self.collection.delete_one(doc_id)
|
||||
|
||||
def clear(self, **kwargs: Any) -> None:
|
||||
"""Clear cache. This is for all LLMs at once."""
|
||||
self.astra_db.truncate_collection(self.collection_name)
|
||||
|
||||
|
||||
ASTRA_DB_SEMANTIC_CACHE_DEFAULT_THRESHOLD = 0.85
|
||||
ASTRA_DB_CACHE_DEFAULT_COLLECTION_NAME = "langchain_astradb_semantic_cache"
|
||||
ASTRA_DB_SEMANTIC_CACHE_EMBEDDING_CACHE_SIZE = 16
|
||||
|
||||
|
||||
class AstraDBSemanticCache(BaseCache):
|
||||
"""
|
||||
Cache that uses Astra DB as a vector-store backend for semantic
|
||||
(i.e. similarity-based) lookup.
|
||||
|
||||
It uses a single (vector) collection and can store
|
||||
cached values from several LLMs, so the LLM's 'llm_string' is stored
|
||||
in the document metadata.
|
||||
|
||||
You can choose the preferred similarity (or use the API default) --
|
||||
remember the threshold might require metric-dependend tuning.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
collection_name: str = ASTRA_DB_CACHE_DEFAULT_COLLECTION_NAME,
|
||||
token: Optional[str] = None,
|
||||
api_endpoint: Optional[str] = None,
|
||||
astra_db_client: Optional[Any] = None, # 'astrapy.db.AstraDB' if passed
|
||||
namespace: Optional[str] = None,
|
||||
embedding: Embeddings,
|
||||
metric: Optional[str] = None,
|
||||
similarity_threshold: float = ASTRA_DB_SEMANTIC_CACHE_DEFAULT_THRESHOLD,
|
||||
):
|
||||
"""
|
||||
Initialize the cache with all relevant parameters.
|
||||
Args:
|
||||
|
||||
collection_name (str): name of the Astra DB collection to create/use.
|
||||
token (Optional[str]): API token for Astra DB usage.
|
||||
api_endpoint (Optional[str]): full URL to the API endpoint,
|
||||
such as "https://<DB-ID>-us-east1.apps.astra.datastax.com".
|
||||
astra_db_client (Optional[Any]): *alternative to token+api_endpoint*,
|
||||
you can pass an already-created 'astrapy.db.AstraDB' instance.
|
||||
namespace (Optional[str]): namespace (aka keyspace) where the
|
||||
collection is created. Defaults to the database's "default namespace".
|
||||
embedding (Embedding): Embedding provider for semantic
|
||||
encoding and search.
|
||||
metric: the function to use for evaluating similarity of text embeddings.
|
||||
Defaults to 'cosine' (alternatives: 'euclidean', 'dot_product')
|
||||
similarity_threshold (float, optional): the minimum similarity
|
||||
for accepting a (semantic-search) match.
|
||||
|
||||
The default score threshold is tuned to the default metric.
|
||||
Tune it carefully yourself if switching to another distance metric.
|
||||
"""
|
||||
try:
|
||||
from astrapy.db import (
|
||||
AstraDB as LibAstraDB,
|
||||
)
|
||||
except (ImportError, ModuleNotFoundError):
|
||||
raise ImportError(
|
||||
"Could not import a recent astrapy python package. "
|
||||
"Please install it with `pip install --upgrade astrapy`."
|
||||
)
|
||||
# Conflicting-arg checks:
|
||||
if astra_db_client is not None:
|
||||
if token is not None or api_endpoint is not None:
|
||||
raise ValueError(
|
||||
"You cannot pass 'astra_db_client' to AstraDB if passing "
|
||||
"'token' and 'api_endpoint'."
|
||||
)
|
||||
|
||||
self.embedding = embedding
|
||||
self.metric = metric
|
||||
self.similarity_threshold = similarity_threshold
|
||||
|
||||
# The contract for this class has separate lookup and update:
|
||||
# in order to spare some embedding calculations we cache them between
|
||||
# the two calls.
|
||||
# Note: each instance of this class has its own `_get_embedding` with
|
||||
# its own lru.
|
||||
@lru_cache(maxsize=ASTRA_DB_SEMANTIC_CACHE_EMBEDDING_CACHE_SIZE)
|
||||
def _cache_embedding(text: str) -> List[float]:
|
||||
return self.embedding.embed_query(text=text)
|
||||
|
||||
self._get_embedding = _cache_embedding
|
||||
self.embedding_dimension = self._get_embedding_dimension()
|
||||
|
||||
self.collection_name = collection_name
|
||||
self.token = token
|
||||
self.api_endpoint = api_endpoint
|
||||
self.namespace = namespace
|
||||
|
||||
if astra_db_client is not None:
|
||||
self.astra_db = astra_db_client
|
||||
else:
|
||||
self.astra_db = LibAstraDB(
|
||||
token=self.token,
|
||||
api_endpoint=self.api_endpoint,
|
||||
namespace=self.namespace,
|
||||
)
|
||||
self.collection = self.astra_db.create_collection(
|
||||
collection_name=self.collection_name,
|
||||
dimension=self.embedding_dimension,
|
||||
metric=self.metric,
|
||||
)
|
||||
|
||||
def _get_embedding_dimension(self) -> int:
|
||||
return len(self._get_embedding(text="This is a sample sentence."))
|
||||
|
||||
@staticmethod
|
||||
def _make_id(prompt: str, llm_string: str) -> str:
|
||||
return f"{_hash(prompt)}#{_hash(llm_string)}"
|
||||
|
||||
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
|
||||
"""Update cache based on prompt and llm_string."""
|
||||
doc_id = self._make_id(prompt, llm_string)
|
||||
llm_string_hash = _hash(llm_string)
|
||||
embedding_vector = self._get_embedding(text=prompt)
|
||||
body = _dumps_generations(return_val)
|
||||
#
|
||||
self.collection.upsert(
|
||||
{
|
||||
"_id": doc_id,
|
||||
"body_blob": body,
|
||||
"llm_string_hash": llm_string_hash,
|
||||
"$vector": embedding_vector,
|
||||
}
|
||||
)
|
||||
|
||||
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
|
||||
"""Look up based on prompt and llm_string."""
|
||||
hit_with_id = self.lookup_with_id(prompt, llm_string)
|
||||
if hit_with_id is not None:
|
||||
return hit_with_id[1]
|
||||
else:
|
||||
return None
|
||||
|
||||
def lookup_with_id(
|
||||
self, prompt: str, llm_string: str
|
||||
) -> Optional[Tuple[str, RETURN_VAL_TYPE]]:
|
||||
"""
|
||||
Look up based on prompt and llm_string.
|
||||
If there are hits, return (document_id, cached_entry) for the top hit
|
||||
"""
|
||||
prompt_embedding: List[float] = self._get_embedding(text=prompt)
|
||||
llm_string_hash = _hash(llm_string)
|
||||
|
||||
hit = self.collection.vector_find_one(
|
||||
vector=prompt_embedding,
|
||||
filter={
|
||||
"llm_string_hash": llm_string_hash,
|
||||
},
|
||||
fields=["body_blob", "_id"],
|
||||
include_similarity=True,
|
||||
)
|
||||
|
||||
if hit is None or hit["$similarity"] < self.similarity_threshold:
|
||||
return None
|
||||
else:
|
||||
generations = _loads_generations(hit["body_blob"])
|
||||
if generations is not None:
|
||||
# this protects against malformed cached items:
|
||||
return (hit["_id"], generations)
|
||||
else:
|
||||
return None
|
||||
|
||||
def lookup_with_id_through_llm(
|
||||
self, prompt: str, llm: LLM, stop: Optional[List[str]] = None
|
||||
) -> Optional[Tuple[str, RETURN_VAL_TYPE]]:
|
||||
llm_string = get_prompts(
|
||||
{**llm.dict(), **{"stop": stop}},
|
||||
[],
|
||||
)[1]
|
||||
return self.lookup_with_id(prompt, llm_string=llm_string)
|
||||
|
||||
def delete_by_document_id(self, document_id: str) -> None:
|
||||
"""
|
||||
Given this is a "similarity search" cache, an invalidation pattern
|
||||
that makes sense is first a lookup to get an ID, and then deleting
|
||||
with that ID. This is for the second step.
|
||||
"""
|
||||
self.collection.delete_one(document_id)
|
||||
|
||||
def clear(self, **kwargs: Any) -> None:
|
||||
"""Clear the *whole* semantic cache."""
|
||||
self.astra_db.truncate_collection(self.collection_name)
|
||||
|
||||
@@ -14,9 +14,7 @@ class CypherQueryCorrector:
|
||||
|
||||
property_pattern = re.compile(r"\{.+?\}")
|
||||
node_pattern = re.compile(r"\(.+?\)")
|
||||
path_pattern = re.compile(
|
||||
r"(\([^\,\(\)]*?(\{.+\})?[^\,\(\)]*?\))(<?-)(\[.*?\])?(->?)(\([^\,\(\)]*?(\{.+\})?[^\,\(\)]*?\))"
|
||||
)
|
||||
path_pattern = re.compile(r"\(.*\).*-.*-.*\(.*\)")
|
||||
node_relation_node_pattern = re.compile(
|
||||
r"(\()+(?P<left_node>[^()]*?)\)(?P<relation>.*?)\((?P<right_node>[^()]*?)(\))+"
|
||||
)
|
||||
@@ -64,17 +62,7 @@ class CypherQueryCorrector:
|
||||
Args:
|
||||
query: cypher query
|
||||
"""
|
||||
paths = []
|
||||
idx = 0
|
||||
while matched := self.path_pattern.findall(query[idx:]):
|
||||
matched = matched[0]
|
||||
matched = [
|
||||
m for i, m in enumerate(matched) if i not in [1, len(matched) - 1]
|
||||
]
|
||||
path = "".join(matched)
|
||||
idx = query.find(path) + len(path) - len(matched[-1])
|
||||
paths.append(path)
|
||||
return paths
|
||||
return re.findall(self.path_pattern, query)
|
||||
|
||||
def judge_direction(self, relation: str) -> str:
|
||||
"""
|
||||
|
||||
@@ -317,8 +317,6 @@ class GoogleDriveLoader(BaseLoader, BaseModel):
|
||||
docs = loader.load()
|
||||
for doc in docs:
|
||||
doc.metadata["source"] = f"https://drive.google.com/file/d/{id}/view"
|
||||
if "title" not in doc.metadata:
|
||||
doc.metadata["title"] = f"{file.get('name')}"
|
||||
return docs
|
||||
|
||||
else:
|
||||
|
||||
@@ -1,216 +0,0 @@
|
||||
"""Loads data from OneNote Notebooks"""
|
||||
from pathlib import Path
|
||||
from typing import Dict, Iterator, List, Optional
|
||||
|
||||
import requests
|
||||
|
||||
from langchain.docstore.document import Document
|
||||
from langchain.document_loaders.base import BaseLoader
|
||||
from langchain.pydantic_v1 import BaseModel, BaseSettings, Field, FilePath, SecretStr
|
||||
|
||||
|
||||
class _OneNoteGraphSettings(BaseSettings):
|
||||
client_id: str = Field(..., env="MS_GRAPH_CLIENT_ID")
|
||||
client_secret: SecretStr = Field(..., env="MS_GRAPH_CLIENT_SECRET")
|
||||
|
||||
class Config:
|
||||
"""Config for OneNoteGraphSettings."""
|
||||
|
||||
env_prefix = ""
|
||||
case_sentive = False
|
||||
env_file = ".env"
|
||||
|
||||
|
||||
class OneNoteLoader(BaseLoader, BaseModel):
|
||||
"""Load pages from OneNote notebooks."""
|
||||
|
||||
settings: _OneNoteGraphSettings = Field(default_factory=_OneNoteGraphSettings)
|
||||
"""Settings for the Microsoft Graph API client."""
|
||||
auth_with_token: bool = False
|
||||
"""Whether to authenticate with a token or not. Defaults to False."""
|
||||
access_token: str = ""
|
||||
"""Personal access token"""
|
||||
onenote_api_base_url: str = "https://graph.microsoft.com/v1.0/me/onenote"
|
||||
"""URL of Microsoft Graph API for OneNote"""
|
||||
authority_url = "https://login.microsoftonline.com/consumers/"
|
||||
"""A URL that identifies a token authority"""
|
||||
token_path: FilePath = Path.home() / ".credentials" / "onenote_graph_token.txt"
|
||||
"""Path to the file where the access token is stored"""
|
||||
notebook_name: Optional[str] = None
|
||||
"""Filter on notebook name"""
|
||||
section_name: Optional[str] = None
|
||||
"""Filter on section name"""
|
||||
page_title: Optional[str] = None
|
||||
"""Filter on section name"""
|
||||
object_ids: Optional[List[str]] = None
|
||||
""" The IDs of the objects to load data from."""
|
||||
|
||||
def lazy_load(self) -> Iterator[Document]:
|
||||
"""
|
||||
Get pages from OneNote notebooks.
|
||||
|
||||
Returns:
|
||||
A list of Documents with attributes:
|
||||
- page_content
|
||||
- metadata
|
||||
- title
|
||||
"""
|
||||
self._auth()
|
||||
|
||||
try:
|
||||
from bs4 import BeautifulSoup
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"beautifulsoup4 package not found, please install it with "
|
||||
"`pip install bs4`"
|
||||
)
|
||||
|
||||
if self.object_ids is not None:
|
||||
for object_id in self.object_ids:
|
||||
page_content_html = self._get_page_content(object_id)
|
||||
soup = BeautifulSoup(page_content_html, "html.parser")
|
||||
page_title = ""
|
||||
title_tag = soup.title
|
||||
if title_tag:
|
||||
page_title = title_tag.get_text(strip=True)
|
||||
page_content = soup.get_text(separator="\n", strip=True)
|
||||
yield Document(
|
||||
page_content=page_content, metadata={"title": page_title}
|
||||
)
|
||||
else:
|
||||
request_url = self._url
|
||||
|
||||
while request_url != "":
|
||||
response = requests.get(request_url, headers=self._headers, timeout=10)
|
||||
response.raise_for_status()
|
||||
pages = response.json()
|
||||
|
||||
for page in pages["value"]:
|
||||
page_id = page["id"]
|
||||
page_content_html = self._get_page_content(page_id)
|
||||
soup = BeautifulSoup(page_content_html, "html.parser")
|
||||
page_title = ""
|
||||
title_tag = soup.title
|
||||
if title_tag:
|
||||
page_content = soup.get_text(separator="\n", strip=True)
|
||||
yield Document(
|
||||
page_content=page_content, metadata={"title": page_title}
|
||||
)
|
||||
|
||||
if "@odata.nextLink" in pages:
|
||||
request_url = pages["@odata.nextLink"]
|
||||
else:
|
||||
request_url = ""
|
||||
|
||||
def load(self) -> List[Document]:
|
||||
"""
|
||||
Get pages from OneNote notebooks.
|
||||
|
||||
Returns:
|
||||
A list of Documents with attributes:
|
||||
- page_content
|
||||
- metadata
|
||||
- title
|
||||
"""
|
||||
return list(self.lazy_load())
|
||||
|
||||
def _get_page_content(self, page_id: str) -> str:
|
||||
"""Get page content from OneNote API"""
|
||||
request_url = self.onenote_api_base_url + f"/pages/{page_id}/content"
|
||||
response = requests.get(request_url, headers=self._headers, timeout=10)
|
||||
response.raise_for_status()
|
||||
return response.text
|
||||
|
||||
@property
|
||||
def _headers(self) -> Dict[str, str]:
|
||||
"""Return headers for requests to OneNote API"""
|
||||
return {
|
||||
"Authorization": f"Bearer {self.access_token}",
|
||||
}
|
||||
|
||||
@property
|
||||
def _scopes(self) -> List[str]:
|
||||
"""Return required scopes."""
|
||||
return ["Notes.Read"]
|
||||
|
||||
def _auth(self) -> None:
|
||||
"""Authenticate with Microsoft Graph API"""
|
||||
if self.access_token != "":
|
||||
return
|
||||
|
||||
if self.auth_with_token:
|
||||
with self.token_path.open("r") as token_file:
|
||||
self.access_token = token_file.read()
|
||||
else:
|
||||
try:
|
||||
from msal import ConfidentialClientApplication
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"MSAL package not found, please install it with `pip install msal`"
|
||||
) from e
|
||||
|
||||
client_instance = ConfidentialClientApplication(
|
||||
client_id=self.settings.client_id,
|
||||
client_credential=self.settings.client_secret.get_secret_value(),
|
||||
authority=self.authority_url,
|
||||
)
|
||||
|
||||
authorization_request_url = client_instance.get_authorization_request_url(
|
||||
self._scopes
|
||||
)
|
||||
print("Visit the following url to give consent:")
|
||||
print(authorization_request_url)
|
||||
authorization_url = input("Paste the authenticated url here:\n")
|
||||
|
||||
authorization_code = authorization_url.split("code=")[1].split("&")[0]
|
||||
access_token_json = client_instance.acquire_token_by_authorization_code(
|
||||
code=authorization_code, scopes=self._scopes
|
||||
)
|
||||
self.access_token = access_token_json["access_token"]
|
||||
|
||||
try:
|
||||
if not self.token_path.parent.exists():
|
||||
self.token_path.parent.mkdir(parents=True)
|
||||
except Exception as e:
|
||||
raise Exception(
|
||||
f"Could not create the folder {self.token_path.parent} "
|
||||
+ "to store the access token."
|
||||
) from e
|
||||
|
||||
with self.token_path.open("w") as token_file:
|
||||
token_file.write(self.access_token)
|
||||
|
||||
@property
|
||||
def _url(self) -> str:
|
||||
"""Create URL for getting page ids from the OneNoteApi API."""
|
||||
query_params_list = []
|
||||
filter_list = []
|
||||
expand_list = []
|
||||
|
||||
query_params_list.append("$select=id")
|
||||
if self.notebook_name is not None:
|
||||
filter_list.append(
|
||||
"parentNotebook/displayName%20eq%20"
|
||||
+ f"'{self.notebook_name.replace(' ', '%20')}'"
|
||||
)
|
||||
expand_list.append("parentNotebook")
|
||||
if self.section_name is not None:
|
||||
filter_list.append(
|
||||
"parentSection/displayName%20eq%20"
|
||||
+ f"'{self.section_name.replace(' ', '%20')}'"
|
||||
)
|
||||
expand_list.append("parentSection")
|
||||
if self.page_title is not None:
|
||||
filter_list.append(
|
||||
"title%20eq%20" + f"'{self.page_title.replace(' ', '%20')}'"
|
||||
)
|
||||
|
||||
if len(expand_list) > 0:
|
||||
query_params_list.append("$expand=" + ",".join(expand_list))
|
||||
if len(filter_list) > 0:
|
||||
query_params_list.append("$filter=" + "%20and%20".join(filter_list))
|
||||
|
||||
query_params = "&".join(query_params_list)
|
||||
if query_params != "":
|
||||
query_params = "?" + query_params
|
||||
return f"{self.onenote_api_base_url}/pages{query_params}"
|
||||
@@ -32,7 +32,6 @@ from langchain.memory.buffer import (
|
||||
)
|
||||
from langchain.memory.buffer_window import ConversationBufferWindowMemory
|
||||
from langchain.memory.chat_message_histories import (
|
||||
AstraDBChatMessageHistory,
|
||||
CassandraChatMessageHistory,
|
||||
ChatMessageHistory,
|
||||
CosmosDBChatMessageHistory,
|
||||
@@ -69,7 +68,6 @@ from langchain.memory.vectorstore import VectorStoreRetrieverMemory
|
||||
from langchain.memory.zep_memory import ZepMemory
|
||||
|
||||
__all__ = [
|
||||
"AstraDBChatMessageHistory",
|
||||
"CassandraChatMessageHistory",
|
||||
"ChatMessageHistory",
|
||||
"CombinedMemory",
|
||||
|
||||
@@ -1,6 +1,3 @@
|
||||
from langchain.memory.chat_message_histories.astradb import (
|
||||
AstraDBChatMessageHistory,
|
||||
)
|
||||
from langchain.memory.chat_message_histories.cassandra import (
|
||||
CassandraChatMessageHistory,
|
||||
)
|
||||
@@ -34,7 +31,6 @@ from langchain.memory.chat_message_histories.xata import XataChatMessageHistory
|
||||
from langchain.memory.chat_message_histories.zep import ZepChatMessageHistory
|
||||
|
||||
__all__ = [
|
||||
"AstraDBChatMessageHistory",
|
||||
"ChatMessageHistory",
|
||||
"CassandraChatMessageHistory",
|
||||
"CosmosDBChatMessageHistory",
|
||||
|
||||
@@ -1,114 +0,0 @@
|
||||
"""Astra DB - based chat message history, based on astrapy."""
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
import time
|
||||
import typing
|
||||
from typing import List, Optional
|
||||
|
||||
if typing.TYPE_CHECKING:
|
||||
from astrapy.db import AstraDB as LibAstraDB
|
||||
|
||||
from langchain_core.chat_history import BaseChatMessageHistory
|
||||
from langchain_core.messages import (
|
||||
BaseMessage,
|
||||
message_to_dict,
|
||||
messages_from_dict,
|
||||
)
|
||||
|
||||
DEFAULT_COLLECTION_NAME = "langchain_message_store"
|
||||
|
||||
|
||||
class AstraDBChatMessageHistory(BaseChatMessageHistory):
|
||||
"""Chat message history that stores history in Astra DB.
|
||||
|
||||
Args (only keyword-arguments accepted):
|
||||
session_id: arbitrary key that is used to store the messages
|
||||
of a single chat session.
|
||||
collection_name (str): name of the Astra DB collection to create/use.
|
||||
token (Optional[str]): API token for Astra DB usage.
|
||||
api_endpoint (Optional[str]): full URL to the API endpoint,
|
||||
such as "https://<DB-ID>-us-east1.apps.astra.datastax.com".
|
||||
astra_db_client (Optional[Any]): *alternative to token+api_endpoint*,
|
||||
you can pass an already-created 'astrapy.db.AstraDB' instance.
|
||||
namespace (Optional[str]): namespace (aka keyspace) where the
|
||||
collection is created. Defaults to the database's "default namespace".
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
session_id: str,
|
||||
collection_name: str = DEFAULT_COLLECTION_NAME,
|
||||
token: Optional[str] = None,
|
||||
api_endpoint: Optional[str] = None,
|
||||
astra_db_client: Optional[LibAstraDB] = None, # type 'astrapy.db.AstraDB'
|
||||
namespace: Optional[str] = None,
|
||||
) -> None:
|
||||
"""Create an Astra DB chat message history."""
|
||||
try:
|
||||
from astrapy.db import AstraDB as LibAstraDB
|
||||
except (ImportError, ModuleNotFoundError):
|
||||
raise ImportError(
|
||||
"Could not import a recent astrapy python package. "
|
||||
"Please install it with `pip install --upgrade astrapy`."
|
||||
)
|
||||
|
||||
# Conflicting-arg checks:
|
||||
if astra_db_client is not None:
|
||||
if token is not None or api_endpoint is not None:
|
||||
raise ValueError(
|
||||
"You cannot pass 'astra_db_client' to AstraDB if passing "
|
||||
"'token' and 'api_endpoint'."
|
||||
)
|
||||
|
||||
self.session_id = session_id
|
||||
self.collection_name = collection_name
|
||||
self.token = token
|
||||
self.api_endpoint = api_endpoint
|
||||
self.namespace = namespace
|
||||
if astra_db_client is not None:
|
||||
self.astra_db = astra_db_client
|
||||
else:
|
||||
self.astra_db = LibAstraDB(
|
||||
token=self.token,
|
||||
api_endpoint=self.api_endpoint,
|
||||
namespace=self.namespace,
|
||||
)
|
||||
self.collection = self.astra_db.create_collection(self.collection_name)
|
||||
|
||||
@property
|
||||
def messages(self) -> List[BaseMessage]: # type: ignore
|
||||
"""Retrieve all session messages from DB"""
|
||||
message_blobs = [
|
||||
doc["body_blob"]
|
||||
for doc in sorted(
|
||||
self.collection.paginated_find(
|
||||
filter={
|
||||
"session_id": self.session_id,
|
||||
},
|
||||
projection={
|
||||
"timestamp": 1,
|
||||
"body_blob": 1,
|
||||
},
|
||||
),
|
||||
key=lambda _doc: _doc["timestamp"],
|
||||
)
|
||||
]
|
||||
items = [json.loads(message_blob) for message_blob in message_blobs]
|
||||
messages = messages_from_dict(items)
|
||||
return messages
|
||||
|
||||
def add_message(self, message: BaseMessage) -> None:
|
||||
"""Write a message to the table"""
|
||||
self.collection.insert_one(
|
||||
{
|
||||
"timestamp": time.time(),
|
||||
"session_id": self.session_id,
|
||||
"body_blob": json.dumps(message_to_dict(message)),
|
||||
}
|
||||
)
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear session memory from DB"""
|
||||
self.collection.delete_many(filter={"session_id": self.session_id})
|
||||
@@ -7,9 +7,6 @@ from langchain_core.prompts.chat import (
|
||||
ChatMessagePromptTemplate,
|
||||
ChatPromptTemplate,
|
||||
HumanMessagePromptTemplate,
|
||||
MessageLike,
|
||||
MessageLikeRepresentation,
|
||||
MessagePromptTemplateT,
|
||||
MessagesPlaceholder,
|
||||
SystemMessagePromptTemplate,
|
||||
_convert_to_message,
|
||||
@@ -30,7 +27,4 @@ __all__ = [
|
||||
"ChatPromptValueConcrete",
|
||||
"_convert_to_message",
|
||||
"_create_template_from_message_type",
|
||||
"MessagePromptTemplateT",
|
||||
"MessageLike",
|
||||
"MessageLikeRepresentation",
|
||||
]
|
||||
|
||||
@@ -50,7 +50,6 @@ from langchain.retrievers.metal import MetalRetriever
|
||||
from langchain.retrievers.milvus import MilvusRetriever
|
||||
from langchain.retrievers.multi_query import MultiQueryRetriever
|
||||
from langchain.retrievers.multi_vector import MultiVectorRetriever
|
||||
from langchain.retrievers.outline import OutlineRetriever
|
||||
from langchain.retrievers.parent_document_retriever import ParentDocumentRetriever
|
||||
from langchain.retrievers.pinecone_hybrid_search import PineconeHybridSearchRetriever
|
||||
from langchain.retrievers.pubmed import PubMedRetriever
|
||||
@@ -93,7 +92,6 @@ __all__ = [
|
||||
"MetalRetriever",
|
||||
"MilvusRetriever",
|
||||
"MultiQueryRetriever",
|
||||
"OutlineRetriever",
|
||||
"PineconeHybridSearchRetriever",
|
||||
"PubMedRetriever",
|
||||
"RemoteLangChainRetriever",
|
||||
|
||||
@@ -1,20 +0,0 @@
|
||||
from typing import List
|
||||
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.retrievers import BaseRetriever
|
||||
|
||||
from langchain.callbacks.manager import CallbackManagerForRetrieverRun
|
||||
from langchain.utilities.outline import OutlineAPIWrapper
|
||||
|
||||
|
||||
class OutlineRetriever(BaseRetriever, OutlineAPIWrapper):
|
||||
"""Retriever for Outline API.
|
||||
|
||||
It wraps run() to get_relevant_documents().
|
||||
It uses all OutlineAPIWrapper arguments without any change.
|
||||
"""
|
||||
|
||||
def _get_relevant_documents(
|
||||
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
|
||||
) -> List[Document]:
|
||||
return self.run(query=query)
|
||||
@@ -1,3 +1,3 @@
|
||||
from langchain_core.caches import RETURN_VAL_TYPE, BaseCache
|
||||
from langchain_core.caches import BaseCache
|
||||
|
||||
__all__ = ["BaseCache", "RETURN_VAL_TYPE"]
|
||||
__all__ = ["BaseCache"]
|
||||
|
||||
@@ -1,15 +1,4 @@
|
||||
from langchain_core.language_models import (
|
||||
BaseLanguageModel,
|
||||
LanguageModelInput,
|
||||
LanguageModelOutput,
|
||||
get_tokenizer,
|
||||
)
|
||||
from langchain_core.language_models import BaseLanguageModel, get_tokenizer
|
||||
from langchain_core.language_models.base import _get_token_ids_default_method
|
||||
|
||||
__all__ = [
|
||||
"get_tokenizer",
|
||||
"BaseLanguageModel",
|
||||
"_get_token_ids_default_method",
|
||||
"LanguageModelInput",
|
||||
"LanguageModelOutput",
|
||||
]
|
||||
__all__ = ["get_tokenizer", "BaseLanguageModel", "_get_token_ids_default_method"]
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
from langchain_core.messages import (
|
||||
AIMessage,
|
||||
AIMessageChunk,
|
||||
AnyMessage,
|
||||
BaseMessage,
|
||||
BaseMessageChunk,
|
||||
ChatMessage,
|
||||
@@ -47,5 +46,4 @@ __all__ = [
|
||||
"_message_to_dict",
|
||||
"_message_from_dict",
|
||||
"message_to_dict",
|
||||
"AnyMessage",
|
||||
]
|
||||
|
||||
@@ -7,7 +7,6 @@ from langchain_core.output_parsers import (
|
||||
BaseTransformOutputParser,
|
||||
StrOutputParser,
|
||||
)
|
||||
from langchain_core.output_parsers.base import T
|
||||
|
||||
# Backwards compatibility.
|
||||
NoOpOutputParser = StrOutputParser
|
||||
@@ -21,5 +20,4 @@ __all__ = [
|
||||
"NoOpOutputParser",
|
||||
"StrOutputParser",
|
||||
"OutputParserException",
|
||||
"T",
|
||||
]
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
from langchain_core.runnables.base import (
|
||||
Other,
|
||||
Runnable,
|
||||
RunnableBinding,
|
||||
RunnableBindingBase,
|
||||
@@ -7,22 +6,16 @@ from langchain_core.runnables.base import (
|
||||
RunnableEachBase,
|
||||
RunnableGenerator,
|
||||
RunnableLambda,
|
||||
RunnableLike,
|
||||
RunnableParallel,
|
||||
RunnableSequence,
|
||||
RunnableSerializable,
|
||||
coerce_to_runnable,
|
||||
)
|
||||
from langchain_core.runnables.utils import Input, Output
|
||||
|
||||
# Backwards compatibility.
|
||||
RunnableMap = RunnableParallel
|
||||
|
||||
__all__ = [
|
||||
"Input",
|
||||
"Output",
|
||||
"RunnableLike",
|
||||
"Other",
|
||||
"Runnable",
|
||||
"RunnableSerializable",
|
||||
"RunnableSequence",
|
||||
|
||||
@@ -1,11 +1,3 @@
|
||||
from langchain_core.runnables.history import (
|
||||
GetSessionHistoryCallable,
|
||||
MessagesOrDictWithMessages,
|
||||
RunnableWithMessageHistory,
|
||||
)
|
||||
from langchain_core.runnables.history import RunnableWithMessageHistory
|
||||
|
||||
__all__ = [
|
||||
"RunnableWithMessageHistory",
|
||||
"GetSessionHistoryCallable",
|
||||
"MessagesOrDictWithMessages",
|
||||
]
|
||||
__all__ = ["RunnableWithMessageHistory"]
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
from langchain_core.runnables.retry import RunnableRetry, U
|
||||
from langchain_core.runnables.retry import RunnableRetry
|
||||
|
||||
__all__ = ["RunnableRetry", "U"]
|
||||
__all__ = ["RunnableRetry"]
|
||||
|
||||
@@ -1,7 +1,5 @@
|
||||
from langchain_core.runnables.utils import (
|
||||
Addable,
|
||||
AddableDict,
|
||||
AnyConfigurableField,
|
||||
ConfigurableField,
|
||||
ConfigurableFieldMultiOption,
|
||||
ConfigurableFieldSingleOption,
|
||||
@@ -46,6 +44,4 @@ __all__ = [
|
||||
"gather_with_concurrency",
|
||||
"Input",
|
||||
"Output",
|
||||
"Addable",
|
||||
"AnyConfigurableField",
|
||||
]
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
from langchain_core.stores import BaseStore, K, V
|
||||
from langchain_core.stores import BaseStore
|
||||
|
||||
__all__ = ["BaseStore", "K", "V"]
|
||||
__all__ = ["BaseStore"]
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
from langchain_core.vectorstores import VST, VectorStore, VectorStoreRetriever
|
||||
from langchain_core.vectorstores import VectorStore, VectorStoreRetriever
|
||||
|
||||
__all__ = ["VectorStore", "VectorStoreRetriever", "VST"]
|
||||
__all__ = ["VectorStore", "VectorStoreRetriever"]
|
||||
|
||||
@@ -122,12 +122,6 @@ def _import_openweathermap() -> Any:
|
||||
return OpenWeatherMapAPIWrapper
|
||||
|
||||
|
||||
def _import_outline() -> Any:
|
||||
from langchain.utilities.outline import OutlineAPIWrapper
|
||||
|
||||
return OutlineAPIWrapper
|
||||
|
||||
|
||||
def _import_portkey() -> Any:
|
||||
from langchain.utilities.portkey import Portkey
|
||||
|
||||
@@ -257,8 +251,6 @@ def __getattr__(name: str) -> Any:
|
||||
return _import_metaphor_search()
|
||||
elif name == "OpenWeatherMapAPIWrapper":
|
||||
return _import_openweathermap()
|
||||
elif name == "OutlineAPIWrapper":
|
||||
return _import_outline()
|
||||
elif name == "Portkey":
|
||||
return _import_portkey()
|
||||
elif name == "PowerBIDataset":
|
||||
@@ -313,7 +305,6 @@ __all__ = [
|
||||
"MaxComputeAPIWrapper",
|
||||
"MetaphorSearchAPIWrapper",
|
||||
"OpenWeatherMapAPIWrapper",
|
||||
"OutlineAPIWrapper",
|
||||
"Portkey",
|
||||
"PowerBIDataset",
|
||||
"PubMedAPIWrapper",
|
||||
|
||||
@@ -1,96 +0,0 @@
|
||||
"""Util that calls Outline."""
|
||||
import logging
|
||||
from typing import Any, Dict, List, Optional
|
||||
|
||||
import requests
|
||||
from langchain_core.documents import Document
|
||||
from langchain_core.pydantic_v1 import BaseModel, root_validator
|
||||
|
||||
from langchain.utils import get_from_dict_or_env
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
OUTLINE_MAX_QUERY_LENGTH = 300
|
||||
|
||||
|
||||
class OutlineAPIWrapper(BaseModel):
|
||||
"""Wrapper around OutlineAPI.
|
||||
|
||||
This wrapper will use the Outline API to query the documents of your instance.
|
||||
By default it will return the document content of the top-k results.
|
||||
It limits the document content by doc_content_chars_max.
|
||||
"""
|
||||
|
||||
top_k_results: int = 3
|
||||
load_all_available_meta: bool = False
|
||||
doc_content_chars_max: int = 4000
|
||||
outline_instance_url: Optional[str] = None
|
||||
outline_api_key: Optional[str] = None
|
||||
outline_search_endpoint: str = "/api/documents.search"
|
||||
|
||||
@root_validator()
|
||||
def validate_environment(cls, values: Dict) -> Dict:
|
||||
"""Validate that instance url and api key exists in environment."""
|
||||
outline_instance_url = get_from_dict_or_env(
|
||||
values, "outline_instance_url", "OUTLINE_INSTANCE_URL"
|
||||
)
|
||||
values["outline_instance_url"] = outline_instance_url
|
||||
|
||||
outline_api_key = get_from_dict_or_env(
|
||||
values, "outline_api_key", "OUTLINE_API_KEY"
|
||||
)
|
||||
values["outline_api_key"] = outline_api_key
|
||||
|
||||
return values
|
||||
|
||||
def _result_to_document(self, outline_res: Any) -> Document:
|
||||
main_meta = {
|
||||
"title": outline_res["document"]["title"],
|
||||
"source": self.outline_instance_url + outline_res["document"]["url"],
|
||||
}
|
||||
add_meta = (
|
||||
{
|
||||
"id": outline_res["document"]["id"],
|
||||
"ranking": outline_res["ranking"],
|
||||
"collection_id": outline_res["document"]["collectionId"],
|
||||
"parent_document_id": outline_res["document"]["parentDocumentId"],
|
||||
"revision": outline_res["document"]["revision"],
|
||||
"created_by": outline_res["document"]["createdBy"]["name"],
|
||||
}
|
||||
if self.load_all_available_meta
|
||||
else {}
|
||||
)
|
||||
doc = Document(
|
||||
page_content=outline_res["document"]["text"][: self.doc_content_chars_max],
|
||||
metadata={
|
||||
**main_meta,
|
||||
**add_meta,
|
||||
},
|
||||
)
|
||||
return doc
|
||||
|
||||
def _outline_api_query(self, query: str) -> List:
|
||||
raw_result = requests.post(
|
||||
f"{self.outline_instance_url}{self.outline_search_endpoint}",
|
||||
data={"query": query, "limit": self.top_k_results},
|
||||
headers={"Authorization": f"Bearer {self.outline_api_key}"},
|
||||
)
|
||||
|
||||
if not raw_result.ok:
|
||||
raise ValueError("Outline API returned an error: ", raw_result.text)
|
||||
|
||||
return raw_result.json()["data"]
|
||||
|
||||
def run(self, query: str) -> List[Document]:
|
||||
"""
|
||||
Run Outline search and get the document content plus the meta information.
|
||||
|
||||
Returns: a list of documents.
|
||||
|
||||
"""
|
||||
results = self._outline_api_query(query[:OUTLINE_MAX_QUERY_LENGTH])
|
||||
docs = []
|
||||
for result in results[: self.top_k_results]:
|
||||
if doc := self._result_to_document(result):
|
||||
docs.append(doc)
|
||||
return docs
|
||||
16
libs/langchain/poetry.lock
generated
16
libs/langchain/poetry.lock
generated
@@ -4128,13 +4128,13 @@ tests = ["pandas (>=1.4)", "pytest", "pytest-asyncio", "pytest-mock"]
|
||||
|
||||
[[package]]
|
||||
name = "langchain-core"
|
||||
version = "0.0.6"
|
||||
version = "0.0.4"
|
||||
description = "Building applications with LLMs through composability"
|
||||
optional = false
|
||||
python-versions = ">=3.8.1,<4.0"
|
||||
files = [
|
||||
{file = "langchain_core-0.0.6-py3-none-any.whl", hash = "sha256:dcc727ff811159e09fc1d72caae4aaea892611349d5c3fc1c18b3a19573faf27"},
|
||||
{file = "langchain_core-0.0.6.tar.gz", hash = "sha256:cffd1031764d838ad2a2f3f64477b710923ddad58eb9fe3130ff94b3669e8dd8"},
|
||||
{file = "langchain_core-0.0.4-py3-none-any.whl", hash = "sha256:f4c6812db462a298a5c2a59d5c041565e68ab5ed9e8790008fbb85cdc54e8667"},
|
||||
{file = "langchain_core-0.0.4.tar.gz", hash = "sha256:8e50cc7cc76d577c1da41ea290e22ea893ccc4cd0e4486c9df4f0c01d434bb0e"},
|
||||
]
|
||||
|
||||
[package.dependencies]
|
||||
@@ -4848,13 +4848,13 @@ tests = ["pytest (>=4.6)"]
|
||||
|
||||
[[package]]
|
||||
name = "msal"
|
||||
version = "1.25.0"
|
||||
version = "1.24.1"
|
||||
description = "The Microsoft Authentication Library (MSAL) for Python library"
|
||||
optional = true
|
||||
python-versions = ">=2.7"
|
||||
files = [
|
||||
{file = "msal-1.25.0-py2.py3-none-any.whl", hash = "sha256:386df621becb506bc315a713ec3d4d5b5d6163116955c7dde23622f156b81af6"},
|
||||
{file = "msal-1.25.0.tar.gz", hash = "sha256:f44329fdb59f4f044c779164a34474b8a44ad9e4940afbc4c3a3a2bbe90324d9"},
|
||||
{file = "msal-1.24.1-py2.py3-none-any.whl", hash = "sha256:ce4320688f95c301ee74a4d0e9dbcfe029a63663a8cc61756f40d0d0d36574ad"},
|
||||
{file = "msal-1.24.1.tar.gz", hash = "sha256:aa0972884b3c6fdec53d9a0bd15c12e5bd7b71ac1b66d746f54d128709f3f8f8"},
|
||||
]
|
||||
|
||||
[package.dependencies]
|
||||
@@ -11075,7 +11075,7 @@ cli = ["typer"]
|
||||
cohere = ["cohere"]
|
||||
docarray = ["docarray"]
|
||||
embeddings = ["sentence-transformers"]
|
||||
extended-testing = ["aiosqlite", "aleph-alpha-client", "anthropic", "arxiv", "assemblyai", "atlassian-python-api", "beautifulsoup4", "bibtexparser", "cassio", "chardet", "dashvector", "esprima", "faiss-cpu", "feedparser", "fireworks-ai", "geopandas", "gitpython", "google-cloud-documentai", "gql", "html2text", "javelin-sdk", "jinja2", "jq", "jsonschema", "lxml", "markdownify", "motor", "msal", "mwparserfromhell", "mwxml", "newspaper3k", "numexpr", "openai", "openai", "openapi-pydantic", "pandas", "pdfminer-six", "pgvector", "psychicapi", "py-trello", "pymupdf", "pypdf", "pypdfium2", "pyspark", "rank-bm25", "rapidfuzz", "rapidocr-onnxruntime", "requests-toolbelt", "rspace_client", "scikit-learn", "sqlite-vss", "streamlit", "sympy", "telethon", "timescale-vector", "tqdm", "upstash-redis", "xata", "xmltodict"]
|
||||
extended-testing = ["aiosqlite", "aleph-alpha-client", "anthropic", "arxiv", "assemblyai", "atlassian-python-api", "beautifulsoup4", "bibtexparser", "cassio", "chardet", "dashvector", "esprima", "faiss-cpu", "feedparser", "fireworks-ai", "geopandas", "gitpython", "google-cloud-documentai", "gql", "html2text", "javelin-sdk", "jinja2", "jq", "jsonschema", "lxml", "markdownify", "motor", "mwparserfromhell", "mwxml", "newspaper3k", "numexpr", "openai", "openai", "openapi-pydantic", "pandas", "pdfminer-six", "pgvector", "psychicapi", "py-trello", "pymupdf", "pypdf", "pypdfium2", "pyspark", "rank-bm25", "rapidfuzz", "rapidocr-onnxruntime", "requests-toolbelt", "rspace_client", "scikit-learn", "sqlite-vss", "streamlit", "sympy", "telethon", "timescale-vector", "tqdm", "upstash-redis", "xata", "xmltodict"]
|
||||
javascript = ["esprima"]
|
||||
llms = ["clarifai", "cohere", "huggingface_hub", "manifest-ml", "nlpcloud", "openai", "openlm", "torch", "transformers"]
|
||||
openai = ["openai", "tiktoken"]
|
||||
@@ -11085,4 +11085,4 @@ text-helpers = ["chardet"]
|
||||
[metadata]
|
||||
lock-version = "2.0"
|
||||
python-versions = ">=3.8.1,<4.0"
|
||||
content-hash = "37e62f668e1acddc4e462fdac5f694af3916b6edbd1ccde0a54c9a57524d6c92"
|
||||
content-hash = "56fad2f9566f5553affb797fc78041f15f2d4b95f35e69f79f8a7c0a3db384d4"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[tool.poetry]
|
||||
name = "langchain"
|
||||
version = "0.0.341"
|
||||
version = "0.0.339rc1"
|
||||
description = "Building applications with LLMs through composability"
|
||||
authors = []
|
||||
license = "MIT"
|
||||
@@ -12,7 +12,7 @@ langchain-server = "langchain.server:main"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain-core = "^0.0.6"
|
||||
langchain-core = "^0.0.4"
|
||||
pydantic = ">=1,<3"
|
||||
SQLAlchemy = ">=1.4,<3"
|
||||
requests = "^2"
|
||||
@@ -143,7 +143,6 @@ azure-ai-textanalytics = {version = "^5.3.0", optional = true}
|
||||
google-cloud-documentai = {version = "^2.20.1", optional = true}
|
||||
fireworks-ai = {version = "^0.6.0", optional = true, python = ">=3.9,<4.0"}
|
||||
javelin-sdk = {version = "^0.1.8", optional = true}
|
||||
msal = {version = "^1.25.0", optional = true}
|
||||
|
||||
|
||||
[tool.poetry.group.test.dependencies]
|
||||
@@ -342,7 +341,6 @@ extended_testing = [
|
||||
"atlassian-python-api",
|
||||
"mwparserfromhell",
|
||||
"mwxml",
|
||||
"msal",
|
||||
"pandas",
|
||||
"telethon",
|
||||
"psychicapi",
|
||||
|
||||
@@ -1,99 +0,0 @@
|
||||
"""
|
||||
Test AstraDB caches. Requires an Astra DB vector instance.
|
||||
|
||||
Required to run this test:
|
||||
- a recent `astrapy` Python package available
|
||||
- an Astra DB instance;
|
||||
- the two environment variables set:
|
||||
export ASTRA_DB_API_ENDPOINT="https://<DB-ID>-us-east1.apps.astra.datastax.com"
|
||||
export ASTRA_DB_APPLICATION_TOKEN="AstraCS:........."
|
||||
- optionally this as well (otherwise defaults are used):
|
||||
export ASTRA_DB_KEYSPACE="my_keyspace"
|
||||
"""
|
||||
import os
|
||||
from typing import Iterator
|
||||
|
||||
import pytest
|
||||
from langchain_core.outputs import Generation, LLMResult
|
||||
|
||||
from langchain.cache import AstraDBCache, AstraDBSemanticCache
|
||||
from langchain.globals import get_llm_cache, set_llm_cache
|
||||
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
|
||||
from tests.unit_tests.llms.fake_llm import FakeLLM
|
||||
|
||||
|
||||
def _has_env_vars() -> bool:
|
||||
return all(
|
||||
[
|
||||
"ASTRA_DB_APPLICATION_TOKEN" in os.environ,
|
||||
"ASTRA_DB_API_ENDPOINT" in os.environ,
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
@pytest.fixture(scope="module")
|
||||
def astradb_cache() -> Iterator[AstraDBCache]:
|
||||
cache = AstraDBCache(
|
||||
collection_name="lc_integration_test_cache",
|
||||
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
|
||||
api_endpoint=os.environ["ASTRA_DB_API_ENDPOINT"],
|
||||
namespace=os.environ.get("ASTRA_DB_KEYSPACE"),
|
||||
)
|
||||
yield cache
|
||||
cache.astra_db.delete_collection("lc_integration_test_cache")
|
||||
|
||||
|
||||
@pytest.fixture(scope="module")
|
||||
def astradb_semantic_cache() -> Iterator[AstraDBSemanticCache]:
|
||||
fake_embe = FakeEmbeddings()
|
||||
sem_cache = AstraDBSemanticCache(
|
||||
collection_name="lc_integration_test_sem_cache",
|
||||
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
|
||||
api_endpoint=os.environ["ASTRA_DB_API_ENDPOINT"],
|
||||
namespace=os.environ.get("ASTRA_DB_KEYSPACE"),
|
||||
embedding=fake_embe,
|
||||
)
|
||||
yield sem_cache
|
||||
sem_cache.astra_db.delete_collection("lc_integration_test_cache")
|
||||
|
||||
|
||||
@pytest.mark.requires("astrapy")
|
||||
@pytest.mark.skipif(not _has_env_vars(), reason="Missing Astra DB env. vars")
|
||||
class TestAstraDBCaches:
|
||||
def test_astradb_cache(self, astradb_cache: AstraDBCache) -> None:
|
||||
set_llm_cache(astradb_cache)
|
||||
llm = FakeLLM()
|
||||
params = llm.dict()
|
||||
params["stop"] = None
|
||||
llm_string = str(sorted([(k, v) for k, v in params.items()]))
|
||||
get_llm_cache().update("foo", llm_string, [Generation(text="fizz")])
|
||||
output = llm.generate(["foo"])
|
||||
print(output)
|
||||
expected_output = LLMResult(
|
||||
generations=[[Generation(text="fizz")]],
|
||||
llm_output={},
|
||||
)
|
||||
print(expected_output)
|
||||
assert output == expected_output
|
||||
astradb_cache.clear()
|
||||
|
||||
def test_cassandra_semantic_cache(
|
||||
self, astradb_semantic_cache: AstraDBSemanticCache
|
||||
) -> None:
|
||||
set_llm_cache(astradb_semantic_cache)
|
||||
llm = FakeLLM()
|
||||
params = llm.dict()
|
||||
params["stop"] = None
|
||||
llm_string = str(sorted([(k, v) for k, v in params.items()]))
|
||||
get_llm_cache().update("foo", llm_string, [Generation(text="fizz")])
|
||||
output = llm.generate(["bar"]) # same embedding as 'foo'
|
||||
expected_output = LLMResult(
|
||||
generations=[[Generation(text="fizz")]],
|
||||
llm_output={},
|
||||
)
|
||||
assert output == expected_output
|
||||
# clear the cache
|
||||
astradb_semantic_cache.clear()
|
||||
output = llm.generate(["bar"]) # 'fizz' is erased away now
|
||||
assert output != expected_output
|
||||
astradb_semantic_cache.clear()
|
||||
@@ -1,104 +0,0 @@
|
||||
import os
|
||||
from typing import Iterable
|
||||
|
||||
import pytest
|
||||
from langchain_core.messages import AIMessage, HumanMessage
|
||||
|
||||
from langchain.memory import ConversationBufferMemory
|
||||
from langchain.memory.chat_message_histories.astradb import (
|
||||
AstraDBChatMessageHistory,
|
||||
)
|
||||
|
||||
|
||||
def _has_env_vars() -> bool:
|
||||
return all(
|
||||
[
|
||||
"ASTRA_DB_APPLICATION_TOKEN" in os.environ,
|
||||
"ASTRA_DB_API_ENDPOINT" in os.environ,
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
@pytest.fixture(scope="function")
|
||||
def history1() -> Iterable[AstraDBChatMessageHistory]:
|
||||
history1 = AstraDBChatMessageHistory(
|
||||
session_id="session-test-1",
|
||||
collection_name="langchain_cmh_test",
|
||||
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
|
||||
api_endpoint=os.environ["ASTRA_DB_API_ENDPOINT"],
|
||||
namespace=os.environ.get("ASTRA_DB_KEYSPACE"),
|
||||
)
|
||||
yield history1
|
||||
history1.astra_db.delete_collection("langchain_cmh_test")
|
||||
|
||||
|
||||
@pytest.fixture(scope="function")
|
||||
def history2() -> Iterable[AstraDBChatMessageHistory]:
|
||||
history2 = AstraDBChatMessageHistory(
|
||||
session_id="session-test-2",
|
||||
collection_name="langchain_cmh_test",
|
||||
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
|
||||
api_endpoint=os.environ["ASTRA_DB_API_ENDPOINT"],
|
||||
namespace=os.environ.get("ASTRA_DB_KEYSPACE"),
|
||||
)
|
||||
yield history2
|
||||
history2.astra_db.delete_collection("langchain_cmh_test")
|
||||
|
||||
|
||||
@pytest.mark.requires("astrapy")
|
||||
@pytest.mark.skipif(not _has_env_vars(), reason="Missing Astra DB env. vars")
|
||||
def test_memory_with_message_store(history1: AstraDBChatMessageHistory) -> None:
|
||||
"""Test the memory with a message store."""
|
||||
memory = ConversationBufferMemory(
|
||||
memory_key="baz",
|
||||
chat_memory=history1,
|
||||
return_messages=True,
|
||||
)
|
||||
|
||||
assert memory.chat_memory.messages == []
|
||||
|
||||
# add some messages
|
||||
memory.chat_memory.add_ai_message("This is me, the AI")
|
||||
memory.chat_memory.add_user_message("This is me, the human")
|
||||
|
||||
messages = memory.chat_memory.messages
|
||||
expected = [
|
||||
AIMessage(content="This is me, the AI"),
|
||||
HumanMessage(content="This is me, the human"),
|
||||
]
|
||||
assert messages == expected
|
||||
|
||||
# clear the store
|
||||
memory.chat_memory.clear()
|
||||
|
||||
assert memory.chat_memory.messages == []
|
||||
|
||||
|
||||
@pytest.mark.requires("astrapy")
|
||||
@pytest.mark.skipif(not _has_env_vars(), reason="Missing Astra DB env. vars")
|
||||
def test_memory_separate_session_ids(
|
||||
history1: AstraDBChatMessageHistory, history2: AstraDBChatMessageHistory
|
||||
) -> None:
|
||||
"""Test that separate session IDs do not share entries."""
|
||||
memory1 = ConversationBufferMemory(
|
||||
memory_key="mk1",
|
||||
chat_memory=history1,
|
||||
return_messages=True,
|
||||
)
|
||||
memory2 = ConversationBufferMemory(
|
||||
memory_key="mk2",
|
||||
chat_memory=history2,
|
||||
return_messages=True,
|
||||
)
|
||||
|
||||
memory1.chat_memory.add_ai_message("Just saying.")
|
||||
|
||||
assert memory2.chat_memory.messages == []
|
||||
|
||||
memory2.chat_memory.clear()
|
||||
|
||||
assert memory1.chat_memory.messages != []
|
||||
|
||||
memory1.chat_memory.clear()
|
||||
|
||||
assert memory1.chat_memory.messages == []
|
||||
@@ -1,116 +0,0 @@
|
||||
"""Integration test for Outline API Wrapper."""
|
||||
from typing import List
|
||||
|
||||
import pytest
|
||||
import responses
|
||||
from langchain_core.documents import Document
|
||||
|
||||
from langchain.utilities import OutlineAPIWrapper
|
||||
|
||||
OUTLINE_INSTANCE_TEST_URL = "https://app.getoutline.com"
|
||||
OUTLINE_SUCCESS_RESPONSE = {
|
||||
"data": [
|
||||
{
|
||||
"ranking": 0.3911583,
|
||||
"context": "Testing Context",
|
||||
"document": {
|
||||
"id": "abb2bf15-a597-4255-8b19-b742e3d037bf",
|
||||
"url": "/doc/quick-start-jGuGGGOTuL",
|
||||
"title": "Test Title",
|
||||
"text": "Testing Content",
|
||||
"createdBy": {"name": "John Doe"},
|
||||
"revision": 3,
|
||||
"collectionId": "93f182a4-a591-4d47-83f0-752e7bb2065c",
|
||||
"parentDocumentId": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
"status": 200,
|
||||
"ok": True,
|
||||
}
|
||||
|
||||
OUTLINE_EMPTY_RESPONSE = {
|
||||
"data": [],
|
||||
"status": 200,
|
||||
"ok": True,
|
||||
}
|
||||
|
||||
OUTLINE_ERROR_RESPONSE = {
|
||||
"ok": False,
|
||||
"error": "authentication_required",
|
||||
"status": 401,
|
||||
"message": "Authentication error",
|
||||
}
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def api_client() -> OutlineAPIWrapper:
|
||||
return OutlineAPIWrapper(
|
||||
outline_api_key="api_key", outline_instance_url=OUTLINE_INSTANCE_TEST_URL
|
||||
)
|
||||
|
||||
|
||||
def assert_docs(docs: List[Document], all_meta: bool = False) -> None:
|
||||
for doc in docs:
|
||||
assert doc.page_content
|
||||
assert doc.metadata
|
||||
main_meta = {"title", "source"}
|
||||
assert set(doc.metadata).issuperset(main_meta)
|
||||
if all_meta:
|
||||
assert len(set(doc.metadata)) > len(main_meta)
|
||||
else:
|
||||
assert len(set(doc.metadata)) == len(main_meta)
|
||||
|
||||
|
||||
@responses.activate
|
||||
def test_run_success(api_client: OutlineAPIWrapper) -> None:
|
||||
responses.add(
|
||||
responses.POST,
|
||||
api_client.outline_instance_url + api_client.outline_search_endpoint,
|
||||
json=OUTLINE_SUCCESS_RESPONSE,
|
||||
status=200,
|
||||
)
|
||||
|
||||
docs = api_client.run("Testing")
|
||||
assert_docs(docs, all_meta=False)
|
||||
|
||||
|
||||
@responses.activate
|
||||
def test_run_success_all_meta(api_client: OutlineAPIWrapper) -> None:
|
||||
api_client.load_all_available_meta = True
|
||||
responses.add(
|
||||
responses.POST,
|
||||
api_client.outline_instance_url + api_client.outline_search_endpoint,
|
||||
json=OUTLINE_SUCCESS_RESPONSE,
|
||||
status=200,
|
||||
)
|
||||
|
||||
docs = api_client.run("Testing")
|
||||
assert_docs(docs, all_meta=True)
|
||||
|
||||
|
||||
@responses.activate
|
||||
def test_run_no_result(api_client: OutlineAPIWrapper) -> None:
|
||||
responses.add(
|
||||
responses.POST,
|
||||
api_client.outline_instance_url + api_client.outline_search_endpoint,
|
||||
json=OUTLINE_EMPTY_RESPONSE,
|
||||
status=200,
|
||||
)
|
||||
|
||||
docs = api_client.run("No Result Test")
|
||||
assert not docs
|
||||
|
||||
|
||||
@responses.activate
|
||||
def test_run_error(api_client: OutlineAPIWrapper) -> None:
|
||||
responses.add(
|
||||
responses.POST,
|
||||
api_client.outline_instance_url + api_client.outline_search_endpoint,
|
||||
json=OUTLINE_ERROR_RESPONSE,
|
||||
status=401,
|
||||
)
|
||||
try:
|
||||
api_client.run("Testing")
|
||||
except Exception as e:
|
||||
assert "Outline API returned an error:" in str(e)
|
||||
@@ -506,7 +506,3 @@ RETURN a.title AS title, c.text AS text, a.date AS date
|
||||
ORDER BY date DESC LIMIT 3"
|
||||
"MATCH (n:`Some Label`)-[:`SOME REL TYPE üäß`]->(m:`Sömé Øther Læbel`) RETURN n,m","(Some Label, SOME REL TYPE üäß, Sömé Øther Læbel)","MATCH (n:`Some Label`)-[:`SOME REL TYPE üäß`]->(m:`Sömé Øther Læbel`) RETURN n,m"
|
||||
"MATCH (n:`Some Label`)<-[:`SOME REL TYPE üäß`]-(m:`Sömé Øther Læbel`) RETURN n,m","(Some Label, SOME REL TYPE üäß, Sömé Øther Læbel)","MATCH (n:`Some Label`)-[:`SOME REL TYPE üäß`]->(m:`Sömé Øther Læbel`) RETURN n,m"
|
||||
"MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)","(Movie, IN_GENRE, Genre), (User, RATED, Movie), (Actor, ACTED_IN, Movie), (Actor, DIRECTED, Movie), (Director, DIRECTED, Movie), (Director, ACTED_IN, Movie), (Person, ACTED_IN, Movie), (Person, DIRECTED, Movie)","MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)"
|
||||
"MATCH (a:Actor)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name","(Movie, IN_GENRE, Genre), (User, RATED, Movie), (Actor, ACTED_IN, Movie), (Actor, DIRECTED, Movie), (Director, DIRECTED, Movie), (Director, ACTED_IN, Movie), (Person, ACTED_IN, Movie), (Person, DIRECTED, Movie)","MATCH (a:Actor)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g1:Genre), (a)-[:ACTED_IN]->(:Movie)-[:IN_GENRE]->(g2:Genre) WHERE g1.name = 'Comedy' AND g2.name = 'Action' RETURN DISTINCT a.name"
|
||||
"MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1","(Movie, IN_GENRE, Genre), (User, RATED, Movie), (Actor, ACTED_IN, Movie), (Actor, DIRECTED, Movie), (Director, DIRECTED, Movie), (Director, ACTED_IN, Movie), (Person, ACTED_IN, Movie), (Person, DIRECTED, Movie)","MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, COUNT(m) AS movieCount ORDER BY movieCount DESC LIMIT 1"
|
||||
"MATCH (g:Genre)<-[:IN_GENRE]-(m:Movie) RETURN g.name, COUNT(m) AS movieCount","(Movie, IN_GENRE, Genre), (User, RATED, Movie), (Actor, ACTED_IN, Movie), (Actor, DIRECTED, Movie), (Director, DIRECTED, Movie), (Director, ACTED_IN, Movie), (Person, ACTED_IN, Movie), (Person, DIRECTED, Movie)","MATCH (g:Genre)<-[:IN_GENRE]-(m:Movie) RETURN g.name, COUNT(m) AS movieCount"
|
||||
|
||||
|
@@ -1,165 +0,0 @@
|
||||
import os
|
||||
from typing import Any
|
||||
from unittest.mock import Mock
|
||||
|
||||
import pytest
|
||||
from _pytest.monkeypatch import MonkeyPatch
|
||||
from pytest_mock import MockerFixture
|
||||
|
||||
from langchain.docstore.document import Document
|
||||
from langchain.document_loaders.onenote import OneNoteLoader
|
||||
|
||||
|
||||
def test_initialization() -> None:
|
||||
os.environ["MS_GRAPH_CLIENT_ID"] = "CLIENT_ID"
|
||||
os.environ["MS_GRAPH_CLIENT_SECRET"] = "CLIENT_SECRET"
|
||||
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
section_name="test_section",
|
||||
page_title="test_title",
|
||||
access_token="access_token",
|
||||
)
|
||||
assert loader.notebook_name == "test_notebook"
|
||||
assert loader.section_name == "test_section"
|
||||
assert loader.page_title == "test_title"
|
||||
assert loader.access_token == "access_token"
|
||||
assert loader._headers == {
|
||||
"Authorization": "Bearer access_token",
|
||||
}
|
||||
|
||||
|
||||
@pytest.mark.requires("bs4")
|
||||
def test_load(mocker: MockerFixture) -> None:
|
||||
os.environ["MS_GRAPH_CLIENT_ID"] = "CLIENT_ID"
|
||||
os.environ["MS_GRAPH_CLIENT_SECRET"] = "CLIENT_SECRET"
|
||||
|
||||
mocker.patch(
|
||||
"requests.get",
|
||||
return_value=mocker.MagicMock(json=lambda: {"value": []}, links=None),
|
||||
)
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
section_name="test_section",
|
||||
page_title="test_title",
|
||||
access_token="access_token",
|
||||
)
|
||||
documents = loader.load()
|
||||
assert documents == []
|
||||
|
||||
mocker.patch(
|
||||
"langchain.document_loaders.onenote.OneNoteLoader._get_page_content",
|
||||
return_value=(
|
||||
"<html><head><title>Test Title</title></head>"
|
||||
"<body><p>Test Content</p></body></html>"
|
||||
),
|
||||
)
|
||||
loader = OneNoteLoader(object_ids=["test_id"], access_token="access_token")
|
||||
documents = loader.load()
|
||||
assert documents == [
|
||||
Document(
|
||||
page_content="Test Title\nTest Content", metadata={"title": "Test Title"}
|
||||
)
|
||||
]
|
||||
|
||||
|
||||
class FakeConfidentialClientApplication(Mock):
|
||||
def get_authorization_request_url(self, *args: Any, **kwargs: Any) -> str:
|
||||
return "fake_authorization_url"
|
||||
|
||||
|
||||
@pytest.mark.requires("msal")
|
||||
def test_msal_import(monkeypatch: MonkeyPatch, mocker: MockerFixture) -> None:
|
||||
os.environ["MS_GRAPH_CLIENT_ID"] = "CLIENT_ID"
|
||||
os.environ["MS_GRAPH_CLIENT_SECRET"] = "CLIENT_SECRET"
|
||||
|
||||
monkeypatch.setattr("builtins.input", lambda _: "invalid_url")
|
||||
mocker.patch(
|
||||
"msal.ConfidentialClientApplication",
|
||||
return_value=FakeConfidentialClientApplication(),
|
||||
)
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
section_name="test_section",
|
||||
page_title="test_title",
|
||||
)
|
||||
with pytest.raises(IndexError):
|
||||
loader._auth()
|
||||
|
||||
|
||||
def test_url() -> None:
|
||||
os.environ["MS_GRAPH_CLIENT_ID"] = "CLIENT_ID"
|
||||
os.environ["MS_GRAPH_CLIENT_SECRET"] = "CLIENT_SECRET"
|
||||
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
section_name="test_section",
|
||||
page_title="test_title",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$expand=parentNotebook,parentSection"
|
||||
"&$filter=parentNotebook/displayName%20eq%20'test_notebook'"
|
||||
"%20and%20parentSection/displayName%20eq%20'test_section'"
|
||||
"%20and%20title%20eq%20'test_title'"
|
||||
)
|
||||
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
section_name="test_section",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$expand=parentNotebook,parentSection"
|
||||
"&$filter=parentNotebook/displayName%20eq%20'test_notebook'"
|
||||
"%20and%20parentSection/displayName%20eq%20'test_section'"
|
||||
)
|
||||
|
||||
loader = OneNoteLoader(
|
||||
notebook_name="test_notebook",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$expand=parentNotebook"
|
||||
"&$filter=parentNotebook/displayName%20eq%20'test_notebook'"
|
||||
)
|
||||
|
||||
loader = OneNoteLoader(
|
||||
section_name="test_section",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$expand=parentSection"
|
||||
"&$filter=parentSection/displayName%20eq%20'test_section'"
|
||||
)
|
||||
|
||||
loader = OneNoteLoader(
|
||||
section_name="test_section",
|
||||
page_title="test_title",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$expand=parentSection"
|
||||
"&$filter=parentSection/displayName%20eq%20'test_section'"
|
||||
"%20and%20title%20eq%20'test_title'"
|
||||
)
|
||||
|
||||
loader = OneNoteLoader(
|
||||
page_title="test_title",
|
||||
access_token="access_token",
|
||||
onenote_api_base_url="https://graph.microsoft.com/v1.0/me/onenote",
|
||||
)
|
||||
assert loader._url == (
|
||||
"https://graph.microsoft.com/v1.0/me/onenote/pages?$select=id"
|
||||
"&$filter=title%20eq%20'test_title'"
|
||||
)
|
||||
@@ -1,7 +1,6 @@
|
||||
from langchain.memory import __all__
|
||||
|
||||
EXPECTED_ALL = [
|
||||
"AstraDBChatMessageHistory",
|
||||
"CassandraChatMessageHistory",
|
||||
"ChatMessageHistory",
|
||||
"CombinedMemory",
|
||||
|
||||
@@ -1,9 +1,6 @@
|
||||
from langchain.prompts.chat import __all__
|
||||
|
||||
EXPECTED_ALL = [
|
||||
"MessageLike",
|
||||
"MessageLikeRepresentation",
|
||||
"MessagePromptTemplateT",
|
||||
"AIMessagePromptTemplate",
|
||||
"BaseChatPromptTemplate",
|
||||
"BaseMessagePromptTemplate",
|
||||
|
||||
@@ -23,7 +23,6 @@ EXPECTED_ALL = [
|
||||
"MetalRetriever",
|
||||
"MilvusRetriever",
|
||||
"MultiQueryRetriever",
|
||||
"OutlineRetriever",
|
||||
"PineconeHybridSearchRetriever",
|
||||
"PubMedRetriever",
|
||||
"RemoteLangChainRetriever",
|
||||
|
||||
@@ -13,10 +13,6 @@ EXPECTED_ALL = [
|
||||
"RunnableSequence",
|
||||
"RunnableSerializable",
|
||||
"coerce_to_runnable",
|
||||
"Input",
|
||||
"Output",
|
||||
"Other",
|
||||
"RunnableLike",
|
||||
]
|
||||
|
||||
|
||||
|
||||
@@ -1,10 +1,6 @@
|
||||
from langchain.schema.runnable.history import __all__
|
||||
|
||||
EXPECTED_ALL = [
|
||||
"RunnableWithMessageHistory",
|
||||
"GetSessionHistoryCallable",
|
||||
"MessagesOrDictWithMessages",
|
||||
]
|
||||
EXPECTED_ALL = ["RunnableWithMessageHistory"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from langchain.schema.runnable.retry import __all__
|
||||
|
||||
EXPECTED_ALL = ["RunnableRetry", "U"]
|
||||
EXPECTED_ALL = ["RunnableRetry"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -22,8 +22,6 @@ EXPECTED_ALL = [
|
||||
"indent_lines_after_first",
|
||||
"Input",
|
||||
"Output",
|
||||
"Addable",
|
||||
"AnyConfigurableField",
|
||||
]
|
||||
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from langchain.schema.cache import __all__
|
||||
|
||||
EXPECTED_ALL = ["BaseCache", "RETURN_VAL_TYPE"]
|
||||
EXPECTED_ALL = ["BaseCache"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -1,12 +1,6 @@
|
||||
from langchain.schema.language_model import __all__
|
||||
|
||||
EXPECTED_ALL = [
|
||||
"BaseLanguageModel",
|
||||
"_get_token_ids_default_method",
|
||||
"get_tokenizer",
|
||||
"LanguageModelOutput",
|
||||
"LanguageModelInput",
|
||||
]
|
||||
EXPECTED_ALL = ["BaseLanguageModel", "_get_token_ids_default_method", "get_tokenizer"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -22,7 +22,6 @@ EXPECTED_ALL = [
|
||||
"merge_content",
|
||||
"messages_from_dict",
|
||||
"messages_to_dict",
|
||||
"AnyMessage",
|
||||
]
|
||||
|
||||
|
||||
|
||||
@@ -9,7 +9,6 @@ EXPECTED_ALL = [
|
||||
"NoOpOutputParser",
|
||||
"OutputParserException",
|
||||
"StrOutputParser",
|
||||
"T",
|
||||
]
|
||||
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from langchain.schema.storage import __all__
|
||||
|
||||
EXPECTED_ALL = ["BaseStore", "K", "V"]
|
||||
EXPECTED_ALL = ["BaseStore"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from langchain.schema.vectorstore import __all__
|
||||
|
||||
EXPECTED_ALL = ["VectorStore", "VectorStoreRetriever", "VST"]
|
||||
EXPECTED_ALL = ["VectorStore", "VectorStoreRetriever"]
|
||||
|
||||
|
||||
def test_all_imports() -> None:
|
||||
|
||||
@@ -20,7 +20,6 @@ EXPECTED_ALL = [
|
||||
"MaxComputeAPIWrapper",
|
||||
"MetaphorSearchAPIWrapper",
|
||||
"OpenWeatherMapAPIWrapper",
|
||||
"OutlineAPIWrapper",
|
||||
"Portkey",
|
||||
"PowerBIDataset",
|
||||
"PubMedAPIWrapper",
|
||||
|
||||
62
poetry.lock
generated
62
poetry.lock
generated
@@ -987,7 +987,7 @@ files = [
|
||||
{file = "greenlet-3.0.0-cp311-cp311-musllinux_1_1_aarch64.whl", hash = "sha256:0b72b802496cccbd9b31acea72b6f87e7771ccfd7f7927437d592e5c92ed703c"},
|
||||
{file = "greenlet-3.0.0-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:527cd90ba3d8d7ae7dceb06fda619895768a46a1b4e423bdb24c1969823b8362"},
|
||||
{file = "greenlet-3.0.0-cp311-cp311-win_amd64.whl", hash = "sha256:37f60b3a42d8b5499be910d1267b24355c495064f271cfe74bf28b17b099133c"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-macosx_10_9_universal2.whl", hash = "sha256:1482fba7fbed96ea7842b5a7fc11d61727e8be75a077e603e8ab49d24e234383"},
|
||||
{file = "greenlet-3.0.0-cp311-universal2-macosx_10_9_universal2.whl", hash = "sha256:c3692ecf3fe754c8c0f2c95ff19626584459eab110eaab66413b1e7425cd84e9"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-macosx_13_0_arm64.whl", hash = "sha256:be557119bf467d37a8099d91fbf11b2de5eb1fd5fc5b91598407574848dc910f"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:73b2f1922a39d5d59cc0e597987300df3396b148a9bd10b76a058a2f2772fc04"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:d1e22c22f7826096ad503e9bb681b05b8c1f5a8138469b255eb91f26a76634f2"},
|
||||
@@ -997,6 +997,7 @@ files = [
|
||||
{file = "greenlet-3.0.0-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:952256c2bc5b4ee8df8dfc54fc4de330970bf5d79253c863fb5e6761f00dda35"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:269d06fa0f9624455ce08ae0179430eea61085e3cf6457f05982b37fd2cefe17"},
|
||||
{file = "greenlet-3.0.0-cp312-cp312-win_amd64.whl", hash = "sha256:9adbd8ecf097e34ada8efde9b6fec4dd2a903b1e98037adf72d12993a1c80b51"},
|
||||
{file = "greenlet-3.0.0-cp312-universal2-macosx_10_9_universal2.whl", hash = "sha256:553d6fb2324e7f4f0899e5ad2c427a4579ed4873f42124beba763f16032959af"},
|
||||
{file = "greenlet-3.0.0-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:c6b5ce7f40f0e2f8b88c28e6691ca6806814157ff05e794cdd161be928550f4c"},
|
||||
{file = "greenlet-3.0.0-cp37-cp37m-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:ecf94aa539e97a8411b5ea52fc6ccd8371be9550c4041011a091eb8b3ca1d810"},
|
||||
{file = "greenlet-3.0.0-cp37-cp37m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:80dcd3c938cbcac986c5c92779db8e8ce51a89a849c135172c88ecbdc8c056b7"},
|
||||
@@ -1029,7 +1030,6 @@ files = [
|
||||
{file = "greenlet-3.0.0-cp39-cp39-win32.whl", hash = "sha256:0d3f83ffb18dc57243e0151331e3c383b05e5b6c5029ac29f754745c800f8ed9"},
|
||||
{file = "greenlet-3.0.0-cp39-cp39-win_amd64.whl", hash = "sha256:831d6f35037cf18ca5e80a737a27d822d87cd922521d18ed3dbc8a6967be50ce"},
|
||||
{file = "greenlet-3.0.0-cp39-universal2-macosx_11_0_x86_64.whl", hash = "sha256:a048293392d4e058298710a54dfaefcefdf49d287cd33fb1f7d63d55426e4355"},
|
||||
{file = "greenlet-3.0.0.tar.gz", hash = "sha256:19834e3f91f485442adc1ee440171ec5d9a4840a1f7bd5ed97833544719ce10b"},
|
||||
]
|
||||
|
||||
[package.extras]
|
||||
@@ -1627,7 +1627,7 @@ files = [
|
||||
|
||||
[[package]]
|
||||
name = "langchain"
|
||||
version = "0.0.339rc3"
|
||||
version = "0.0.335"
|
||||
description = "Building applications with LLMs through composability"
|
||||
optional = false
|
||||
python-versions = ">=3.8.1,<4.0"
|
||||
@@ -1640,7 +1640,6 @@ anyio = "<4.0"
|
||||
async-timeout = {version = "^4.0.0", markers = "python_version < \"3.11\""}
|
||||
dataclasses-json = ">= 0.5.7, < 0.7"
|
||||
jsonpatch = "^1.33"
|
||||
langchain-core = "^0.0.6"
|
||||
langsmith = "~0.0.63"
|
||||
numpy = "^1"
|
||||
pydantic = ">=1,<3"
|
||||
@@ -1650,17 +1649,17 @@ SQLAlchemy = ">=1.4,<3"
|
||||
tenacity = "^8.1.0"
|
||||
|
||||
[package.extras]
|
||||
all = ["O365 (>=2.0.26,<3.0.0)", "aleph-alpha-client (>=2.15.0,<3.0.0)", "amadeus (>=8.1.0)", "arxiv (>=1.4,<2.0)", "atlassian-python-api (>=3.36.0,<4.0.0)", "awadb (>=0.3.9,<0.4.0)", "azure-ai-formrecognizer (>=3.2.1,<4.0.0)", "azure-ai-textanalytics (>=5.3.0,<6.0.0)", "azure-ai-vision (>=0.11.1b1,<0.12.0)", "azure-cognitiveservices-speech (>=1.28.0,<2.0.0)", "azure-cosmos (>=4.4.0b1,<5.0.0)", "azure-identity (>=1.12.0,<2.0.0)", "beautifulsoup4 (>=4,<5)", "clarifai (>=9.1.0)", "clickhouse-connect (>=0.5.14,<0.6.0)", "cohere (>=4,<5)", "deeplake (>=3.8.3,<4.0.0)", "docarray[hnswlib] (>=0.32.0,<0.33.0)", "duckduckgo-search (>=3.8.3,<4.0.0)", "elasticsearch (>=8,<9)", "esprima (>=4.0.1,<5.0.0)", "faiss-cpu (>=1,<2)", "google-api-python-client (==2.70.0)", "google-auth (>=2.18.1,<3.0.0)", "google-search-results (>=2,<3)", "gptcache (>=0.1.7)", "html2text (>=2020.1.16,<2021.0.0)", "huggingface_hub (>=0,<1)", "jinja2 (>=3,<4)", "jq (>=1.4.1,<2.0.0)", "lancedb (>=0.1,<0.2)", "langkit (>=0.0.6,<0.1.0)", "lark (>=1.1.5,<2.0.0)", "librosa (>=0.10.0.post2,<0.11.0)", "lxml (>=4.9.2,<5.0.0)", "manifest-ml (>=0.0.1,<0.0.2)", "marqo (>=1.2.4,<2.0.0)", "momento (>=1.13.0,<2.0.0)", "nebula3-python (>=3.4.0,<4.0.0)", "neo4j (>=5.8.1,<6.0.0)", "networkx (>=2.6.3,<4)", "nlpcloud (>=1,<2)", "nltk (>=3,<4)", "nomic (>=1.0.43,<2.0.0)", "openai (<2)", "openlm (>=0.0.5,<0.0.6)", "opensearch-py (>=2.0.0,<3.0.0)", "pdfminer-six (>=20221105,<20221106)", "pexpect (>=4.8.0,<5.0.0)", "pgvector (>=0.1.6,<0.2.0)", "pinecone-client (>=2,<3)", "pinecone-text (>=0.4.2,<0.5.0)", "psycopg2-binary (>=2.9.5,<3.0.0)", "pymongo (>=4.3.3,<5.0.0)", "pyowm (>=3.3.0,<4.0.0)", "pypdf (>=3.4.0,<4.0.0)", "pytesseract (>=0.3.10,<0.4.0)", "python-arango (>=7.5.9,<8.0.0)", "pyvespa (>=0.33.0,<0.34.0)", "qdrant-client (>=1.3.1,<2.0.0)", "rdflib (>=6.3.2,<7.0.0)", "redis (>=4,<5)", "requests-toolbelt (>=1.0.0,<2.0.0)", "sentence-transformers (>=2,<3)", "singlestoredb (>=0.7.1,<0.8.0)", "tensorflow-text (>=2.11.0,<3.0.0)", "tigrisdb (>=1.0.0b6,<2.0.0)", "tiktoken (>=0.3.2,<0.6.0)", "torch (>=1,<3)", "transformers (>=4,<5)", "weaviate-client (>=3,<4)", "wikipedia (>=1,<2)", "wolframalpha (==5.0.0)"]
|
||||
azure = ["azure-ai-formrecognizer (>=3.2.1,<4.0.0)", "azure-ai-textanalytics (>=5.3.0,<6.0.0)", "azure-ai-vision (>=0.11.1b1,<0.12.0)", "azure-cognitiveservices-speech (>=1.28.0,<2.0.0)", "azure-core (>=1.26.4,<2.0.0)", "azure-cosmos (>=4.4.0b1,<5.0.0)", "azure-identity (>=1.12.0,<2.0.0)", "azure-search-documents (==11.4.0b8)", "openai (<2)"]
|
||||
all = ["O365 (>=2.0.26,<3.0.0)", "aleph-alpha-client (>=2.15.0,<3.0.0)", "amadeus (>=8.1.0)", "arxiv (>=1.4,<2.0)", "atlassian-python-api (>=3.36.0,<4.0.0)", "awadb (>=0.3.9,<0.4.0)", "azure-ai-formrecognizer (>=3.2.1,<4.0.0)", "azure-ai-vision (>=0.11.1b1,<0.12.0)", "azure-cognitiveservices-speech (>=1.28.0,<2.0.0)", "azure-cosmos (>=4.4.0b1,<5.0.0)", "azure-identity (>=1.12.0,<2.0.0)", "beautifulsoup4 (>=4,<5)", "clarifai (>=9.1.0)", "clickhouse-connect (>=0.5.14,<0.6.0)", "cohere (>=4,<5)", "deeplake (>=3.8.3,<4.0.0)", "docarray[hnswlib] (>=0.32.0,<0.33.0)", "duckduckgo-search (>=3.8.3,<4.0.0)", "elasticsearch (>=8,<9)", "esprima (>=4.0.1,<5.0.0)", "faiss-cpu (>=1,<2)", "google-api-python-client (==2.70.0)", "google-auth (>=2.18.1,<3.0.0)", "google-search-results (>=2,<3)", "gptcache (>=0.1.7)", "html2text (>=2020.1.16,<2021.0.0)", "huggingface_hub (>=0,<1)", "jinja2 (>=3,<4)", "jq (>=1.4.1,<2.0.0)", "lancedb (>=0.1,<0.2)", "langkit (>=0.0.6,<0.1.0)", "lark (>=1.1.5,<2.0.0)", "librosa (>=0.10.0.post2,<0.11.0)", "lxml (>=4.9.2,<5.0.0)", "manifest-ml (>=0.0.1,<0.0.2)", "marqo (>=1.2.4,<2.0.0)", "momento (>=1.13.0,<2.0.0)", "nebula3-python (>=3.4.0,<4.0.0)", "neo4j (>=5.8.1,<6.0.0)", "networkx (>=2.6.3,<4)", "nlpcloud (>=1,<2)", "nltk (>=3,<4)", "nomic (>=1.0.43,<2.0.0)", "openai (>=0,<1)", "openlm (>=0.0.5,<0.0.6)", "opensearch-py (>=2.0.0,<3.0.0)", "pdfminer-six (>=20221105,<20221106)", "pexpect (>=4.8.0,<5.0.0)", "pgvector (>=0.1.6,<0.2.0)", "pinecone-client (>=2,<3)", "pinecone-text (>=0.4.2,<0.5.0)", "psycopg2-binary (>=2.9.5,<3.0.0)", "pymongo (>=4.3.3,<5.0.0)", "pyowm (>=3.3.0,<4.0.0)", "pypdf (>=3.4.0,<4.0.0)", "pytesseract (>=0.3.10,<0.4.0)", "python-arango (>=7.5.9,<8.0.0)", "pyvespa (>=0.33.0,<0.34.0)", "qdrant-client (>=1.3.1,<2.0.0)", "rdflib (>=6.3.2,<7.0.0)", "redis (>=4,<5)", "requests-toolbelt (>=1.0.0,<2.0.0)", "sentence-transformers (>=2,<3)", "singlestoredb (>=0.7.1,<0.8.0)", "tensorflow-text (>=2.11.0,<3.0.0)", "tigrisdb (>=1.0.0b6,<2.0.0)", "tiktoken (>=0.3.2,<0.6.0)", "torch (>=1,<3)", "transformers (>=4,<5)", "weaviate-client (>=3,<4)", "wikipedia (>=1,<2)", "wolframalpha (==5.0.0)"]
|
||||
azure = ["azure-ai-formrecognizer (>=3.2.1,<4.0.0)", "azure-ai-vision (>=0.11.1b1,<0.12.0)", "azure-cognitiveservices-speech (>=1.28.0,<2.0.0)", "azure-core (>=1.26.4,<2.0.0)", "azure-cosmos (>=4.4.0b1,<5.0.0)", "azure-identity (>=1.12.0,<2.0.0)", "azure-search-documents (==11.4.0b8)", "openai (>=0,<1)"]
|
||||
clarifai = ["clarifai (>=9.1.0)"]
|
||||
cli = ["typer (>=0.9.0,<0.10.0)"]
|
||||
cohere = ["cohere (>=4,<5)"]
|
||||
docarray = ["docarray[hnswlib] (>=0.32.0,<0.33.0)"]
|
||||
embeddings = ["sentence-transformers (>=2,<3)"]
|
||||
extended-testing = ["aiosqlite (>=0.19.0,<0.20.0)", "aleph-alpha-client (>=2.15.0,<3.0.0)", "anthropic (>=0.3.11,<0.4.0)", "arxiv (>=1.4,<2.0)", "assemblyai (>=0.17.0,<0.18.0)", "atlassian-python-api (>=3.36.0,<4.0.0)", "beautifulsoup4 (>=4,<5)", "bibtexparser (>=1.4.0,<2.0.0)", "cassio (>=0.1.0,<0.2.0)", "chardet (>=5.1.0,<6.0.0)", "dashvector (>=1.0.1,<2.0.0)", "esprima (>=4.0.1,<5.0.0)", "faiss-cpu (>=1,<2)", "feedparser (>=6.0.10,<7.0.0)", "fireworks-ai (>=0.6.0,<0.7.0)", "geopandas (>=0.13.1,<0.14.0)", "gitpython (>=3.1.32,<4.0.0)", "google-cloud-documentai (>=2.20.1,<3.0.0)", "gql (>=3.4.1,<4.0.0)", "html2text (>=2020.1.16,<2021.0.0)", "javelin-sdk (>=0.1.8,<0.2.0)", "jinja2 (>=3,<4)", "jq (>=1.4.1,<2.0.0)", "jsonschema (>1)", "lxml (>=4.9.2,<5.0.0)", "markdownify (>=0.11.6,<0.12.0)", "motor (>=3.3.1,<4.0.0)", "msal (>=1.25.0,<2.0.0)", "mwparserfromhell (>=0.6.4,<0.7.0)", "mwxml (>=0.3.3,<0.4.0)", "newspaper3k (>=0.2.8,<0.3.0)", "numexpr (>=2.8.6,<3.0.0)", "openai (<2)", "openai (<2)", "openapi-pydantic (>=0.3.2,<0.4.0)", "pandas (>=2.0.1,<3.0.0)", "pdfminer-six (>=20221105,<20221106)", "pgvector (>=0.1.6,<0.2.0)", "psychicapi (>=0.8.0,<0.9.0)", "py-trello (>=0.19.0,<0.20.0)", "pymupdf (>=1.22.3,<2.0.0)", "pypdf (>=3.4.0,<4.0.0)", "pypdfium2 (>=4.10.0,<5.0.0)", "pyspark (>=3.4.0,<4.0.0)", "rank-bm25 (>=0.2.2,<0.3.0)", "rapidfuzz (>=3.1.1,<4.0.0)", "rapidocr-onnxruntime (>=1.3.2,<2.0.0)", "requests-toolbelt (>=1.0.0,<2.0.0)", "rspace_client (>=2.5.0,<3.0.0)", "scikit-learn (>=1.2.2,<2.0.0)", "sqlite-vss (>=0.1.2,<0.2.0)", "streamlit (>=1.18.0,<2.0.0)", "sympy (>=1.12,<2.0)", "telethon (>=1.28.5,<2.0.0)", "timescale-vector (>=0.0.1,<0.0.2)", "tqdm (>=4.48.0)", "upstash-redis (>=0.15.0,<0.16.0)", "xata (>=1.0.0a7,<2.0.0)", "xmltodict (>=0.13.0,<0.14.0)"]
|
||||
extended-testing = ["aiosqlite (>=0.19.0,<0.20.0)", "aleph-alpha-client (>=2.15.0,<3.0.0)", "anthropic (>=0.3.11,<0.4.0)", "arxiv (>=1.4,<2.0)", "assemblyai (>=0.17.0,<0.18.0)", "atlassian-python-api (>=3.36.0,<4.0.0)", "beautifulsoup4 (>=4,<5)", "bibtexparser (>=1.4.0,<2.0.0)", "cassio (>=0.1.0,<0.2.0)", "chardet (>=5.1.0,<6.0.0)", "dashvector (>=1.0.1,<2.0.0)", "esprima (>=4.0.1,<5.0.0)", "faiss-cpu (>=1,<2)", "feedparser (>=6.0.10,<7.0.0)", "fireworks-ai (>=0.6.0,<0.7.0)", "geopandas (>=0.13.1,<0.14.0)", "gitpython (>=3.1.32,<4.0.0)", "google-cloud-documentai (>=2.20.1,<3.0.0)", "gql (>=3.4.1,<4.0.0)", "html2text (>=2020.1.16,<2021.0.0)", "jinja2 (>=3,<4)", "jq (>=1.4.1,<2.0.0)", "jsonschema (>1)", "lxml (>=4.9.2,<5.0.0)", "markdownify (>=0.11.6,<0.12.0)", "motor (>=3.3.1,<4.0.0)", "mwparserfromhell (>=0.6.4,<0.7.0)", "mwxml (>=0.3.3,<0.4.0)", "newspaper3k (>=0.2.8,<0.3.0)", "numexpr (>=2.8.6,<3.0.0)", "openai (>=0,<1)", "openai (>=0,<1)", "openapi-pydantic (>=0.3.2,<0.4.0)", "pandas (>=2.0.1,<3.0.0)", "pdfminer-six (>=20221105,<20221106)", "pgvector (>=0.1.6,<0.2.0)", "psychicapi (>=0.8.0,<0.9.0)", "py-trello (>=0.19.0,<0.20.0)", "pymupdf (>=1.22.3,<2.0.0)", "pypdf (>=3.4.0,<4.0.0)", "pypdfium2 (>=4.10.0,<5.0.0)", "pyspark (>=3.4.0,<4.0.0)", "rank-bm25 (>=0.2.2,<0.3.0)", "rapidfuzz (>=3.1.1,<4.0.0)", "rapidocr-onnxruntime (>=1.3.2,<2.0.0)", "requests-toolbelt (>=1.0.0,<2.0.0)", "rspace_client (>=2.5.0,<3.0.0)", "scikit-learn (>=1.2.2,<2.0.0)", "sqlite-vss (>=0.1.2,<0.2.0)", "streamlit (>=1.18.0,<2.0.0)", "sympy (>=1.12,<2.0)", "telethon (>=1.28.5,<2.0.0)", "timescale-vector (>=0.0.1,<0.0.2)", "tqdm (>=4.48.0)", "upstash-redis (>=0.15.0,<0.16.0)", "xata (>=1.0.0a7,<2.0.0)", "xmltodict (>=0.13.0,<0.14.0)"]
|
||||
javascript = ["esprima (>=4.0.1,<5.0.0)"]
|
||||
llms = ["clarifai (>=9.1.0)", "cohere (>=4,<5)", "huggingface_hub (>=0,<1)", "manifest-ml (>=0.0.1,<0.0.2)", "nlpcloud (>=1,<2)", "openai (<2)", "openlm (>=0.0.5,<0.0.6)", "torch (>=1,<3)", "transformers (>=4,<5)"]
|
||||
openai = ["openai (<2)", "tiktoken (>=0.3.2,<0.6.0)"]
|
||||
llms = ["clarifai (>=9.1.0)", "cohere (>=4,<5)", "huggingface_hub (>=0,<1)", "manifest-ml (>=0.0.1,<0.0.2)", "nlpcloud (>=1,<2)", "openai (>=0,<1)", "openlm (>=0.0.5,<0.0.6)", "torch (>=1,<3)", "transformers (>=4,<5)"]
|
||||
openai = ["openai (>=0,<1)", "tiktoken (>=0.3.2,<0.6.0)"]
|
||||
qdrant = ["qdrant-client (>=1.3.1,<2.0.0)"]
|
||||
text-helpers = ["chardet (>=5.1.0,<6.0.0)"]
|
||||
|
||||
@@ -1668,23 +1667,6 @@ text-helpers = ["chardet (>=5.1.0,<6.0.0)"]
|
||||
type = "directory"
|
||||
url = "libs/langchain"
|
||||
|
||||
[[package]]
|
||||
name = "langchain-core"
|
||||
version = "0.0.6"
|
||||
description = "Building applications with LLMs through composability"
|
||||
optional = false
|
||||
python-versions = ">=3.8.1,<4.0"
|
||||
files = [
|
||||
{file = "langchain_core-0.0.6-py3-none-any.whl", hash = "sha256:dcc727ff811159e09fc1d72caae4aaea892611349d5c3fc1c18b3a19573faf27"},
|
||||
{file = "langchain_core-0.0.6.tar.gz", hash = "sha256:cffd1031764d838ad2a2f3f64477b710923ddad58eb9fe3130ff94b3669e8dd8"},
|
||||
]
|
||||
|
||||
[package.dependencies]
|
||||
jsonpatch = ">=1.33,<2.0"
|
||||
langsmith = ">=0.0.63,<0.1.0"
|
||||
pydantic = ">=1,<3"
|
||||
tenacity = ">=8.1.0,<9.0.0"
|
||||
|
||||
[[package]]
|
||||
name = "langsmith"
|
||||
version = "0.0.63"
|
||||
@@ -1782,16 +1764,6 @@ files = [
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:5bbe06f8eeafd38e5d0a4894ffec89378b6c6a625ff57e3028921f8ff59318ac"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win32.whl", hash = "sha256:dd15ff04ffd7e05ffcb7fe79f1b98041b8ea30ae9234aed2a9168b5797c3effb"},
|
||||
{file = "MarkupSafe-2.1.3-cp311-cp311-win_amd64.whl", hash = "sha256:134da1eca9ec0ae528110ccc9e48041e0828d79f24121a1a146161103c76e686"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_universal2.whl", hash = "sha256:f698de3fd0c4e6972b92290a45bd9b1536bffe8c6759c62471efaa8acb4c37bc"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:aa57bd9cf8ae831a362185ee444e15a93ecb2e344c8e52e4d721ea3ab6ef1823"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ffcc3f7c66b5f5b7931a5aa68fc9cecc51e685ef90282f4a82f0f5e9b704ad11"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47d4f1c5f80fc62fdd7777d0d40a2e9dda0a05883ab11374334f6c4de38adffd"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1f67c7038d560d92149c060157d623c542173016c4babc0c1913cca0564b9939"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:9aad3c1755095ce347e26488214ef77e0485a3c34a50c5a5e2471dff60b9dd9c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_i686.whl", hash = "sha256:14ff806850827afd6b07a5f32bd917fb7f45b046ba40c57abdb636674a8b559c"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8f9293864fe09b8149f0cc42ce56e3f0e54de883a9de90cd427f191c346eb2e1"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win32.whl", hash = "sha256:715d3562f79d540f251b99ebd6d8baa547118974341db04f5ad06d5ea3eb8007"},
|
||||
{file = "MarkupSafe-2.1.3-cp312-cp312-win_amd64.whl", hash = "sha256:1b8dd8c3fd14349433c79fa8abeb573a55fc0fdd769133baac1f5e07abf54aeb"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:8e254ae696c88d98da6555f5ace2279cf7cd5b3f52be2b5cf97feafe883b58d2"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:cb0932dc158471523c9637e807d9bfb93e06a95cbf010f1a38b98623b929ef2b"},
|
||||
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9402b03f1a1b4dc4c19845e5c749e3ab82d5078d16a2a4c2cd2df62d57bb0707"},
|
||||
@@ -2767,7 +2739,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:69b023b2b4daa7548bcfbd4aa3da05b3a74b772db9e23b982788168117739938"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:81e0b275a9ecc9c0c0c07b4b90ba548307583c125f54d5b6946cfee6360c733d"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:ba336e390cd8e4d1739f42dfe9bb83a3cc2e80f567d8805e11b46f4a943f5515"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:326c013efe8048858a6d312ddd31d56e468118ad4cdeda36c719bf5bb6192290"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win32.whl", hash = "sha256:bd4af7373a854424dabd882decdc5579653d7868b8fb26dc7d0e99f823aa5924"},
|
||||
{file = "PyYAML-6.0.1-cp310-cp310-win_amd64.whl", hash = "sha256:fd1592b3fdf65fff2ad0004b5e363300ef59ced41c2e6b3a99d4089fa8c5435d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:6965a7bc3cf88e5a1c3bd2e0b5c22f8d677dc88a455344035f03399034eb3007"},
|
||||
@@ -2775,15 +2746,8 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:42f8152b8dbc4fe7d96729ec2b99c7097d656dc1213a3229ca5383f973a5ed6d"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:062582fca9fabdd2c8b54a3ef1c978d786e0f6b3a1510e0ac93ef59e0ddae2bc"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:d2b04aac4d386b172d5b9692e2d2da8de7bfb6c387fa4f801fbf6fb2e6ba4673"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:e7d73685e87afe9f3b36c799222440d6cf362062f78be1013661b00c5c6f678b"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win32.whl", hash = "sha256:1635fd110e8d85d55237ab316b5b011de701ea0f29d07611174a1b42f1444741"},
|
||||
{file = "PyYAML-6.0.1-cp311-cp311-win_amd64.whl", hash = "sha256:bf07ee2fef7014951eeb99f56f39c9bb4af143d8aa3c21b1677805985307da34"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:855fb52b0dc35af121542a76b9a84f8d1cd886ea97c84703eaa6d88e37a2ad28"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:40df9b996c2b73138957fe23a16a4f0ba614f4c0efce1e9406a184b6d07fa3a9"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:6c22bec3fbe2524cde73d7ada88f6566758a8f7227bfbf93a408a9d86bcc12a0"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8d4e9c88387b0f5c7d5f281e55304de64cf7f9c0021a3525bd3b1c542da3b0e4"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win32.whl", hash = "sha256:d483d2cdf104e7c9fa60c544d92981f12ad66a457afae824d146093b8c294c54"},
|
||||
{file = "PyYAML-6.0.1-cp312-cp312-win_amd64.whl", hash = "sha256:0d3304d8c0adc42be59c5f8a4d9e3d7379e6955ad754aa9d6ab7a398b59dd1df"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:50550eb667afee136e9a77d6dc71ae76a44df8b3e51e41b77f6de2932bfe0f47"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:1fe35611261b29bd1de0070f0b2f47cb6ff71fa6595c077e42bd0c419fa27b98"},
|
||||
{file = "PyYAML-6.0.1-cp36-cp36m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:704219a11b772aea0d8ecd7058d0082713c3562b4e271b849ad7dc4a5c90c13c"},
|
||||
@@ -2800,7 +2764,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:a0cd17c15d3bb3fa06978b4e8958dcdc6e0174ccea823003a106c7d4d7899ac5"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:28c119d996beec18c05208a8bd78cbe4007878c6dd15091efb73a30e90539696"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7e07cbde391ba96ab58e532ff4803f79c4129397514e1413a7dc761ccd755735"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:49a183be227561de579b4a36efbb21b3eab9651dd81b1858589f796549873dd6"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win32.whl", hash = "sha256:184c5108a2aca3c5b3d3bf9395d50893a7ab82a38004c8f61c258d4428e80206"},
|
||||
{file = "PyYAML-6.0.1-cp38-cp38-win_amd64.whl", hash = "sha256:1e2722cc9fbb45d9b87631ac70924c11d3a401b2d7f410cc0e3bbf249f2dca62"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:9eb6caa9a297fc2c2fb8862bc5370d0303ddba53ba97e71f08023b6cd73d16a8"},
|
||||
@@ -2808,7 +2771,6 @@ files = [
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:5773183b6446b2c99bb77e77595dd486303b4faab2b086e7b17bc6bef28865f6"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:b786eecbdf8499b9ca1d697215862083bd6d2a99965554781d0d8d1ad31e13a0"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:bc1bf2925a1ecd43da378f4db9e4f799775d6367bdb94671027b73b393a7c42c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:04ac92ad1925b2cff1db0cfebffb6ffc43457495c9b3c39d3fcae417d7125dc5"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win32.whl", hash = "sha256:faca3bdcf85b2fc05d06ff3fbc1f83e1391b3e724afa3feba7d13eeab355484c"},
|
||||
{file = "PyYAML-6.0.1-cp39-cp39-win_amd64.whl", hash = "sha256:510c9deebc5c0225e8c96813043e62b680ba2f9c50a08d3724c7f28a747d1486"},
|
||||
{file = "PyYAML-6.0.1.tar.gz", hash = "sha256:bfdf460b1736c775f2ba9f6a92bca30bc2095067b8a9d77876d1fad6cc3b4a43"},
|
||||
@@ -3488,14 +3450,6 @@ files = [
|
||||
{file = "SQLAlchemy-2.0.21-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:b69f1f754d92eb1cc6b50938359dead36b96a1dcf11a8670bff65fd9b21a4b09"},
|
||||
{file = "SQLAlchemy-2.0.21-cp311-cp311-win32.whl", hash = "sha256:af520a730d523eab77d754f5cf44cc7dd7ad2d54907adeb3233177eeb22f271b"},
|
||||
{file = "SQLAlchemy-2.0.21-cp311-cp311-win_amd64.whl", hash = "sha256:141675dae56522126986fa4ca713739d00ed3a6f08f3c2eb92c39c6dfec463ce"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:56628ca27aa17b5890391ded4e385bf0480209726f198799b7e980c6bd473bd7"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:db726be58837fe5ac39859e0fa40baafe54c6d54c02aba1d47d25536170b690f"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:e7421c1bfdbb7214313919472307be650bd45c4dc2fcb317d64d078993de045b"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:632784f7a6f12cfa0e84bf2a5003b07660addccf5563c132cd23b7cc1d7371a9"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:f6f7276cf26145a888f2182a98f204541b519d9ea358a65d82095d9c9e22f917"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:2a1f7ffac934bc0ea717fa1596f938483fb8c402233f9b26679b4f7b38d6ab6e"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-win32.whl", hash = "sha256:bfece2f7cec502ec5f759bbc09ce711445372deeac3628f6fa1c16b7fb45b682"},
|
||||
{file = "SQLAlchemy-2.0.21-cp312-cp312-win_amd64.whl", hash = "sha256:526b869a0f4f000d8d8ee3409d0becca30ae73f494cbb48801da0129601f72c6"},
|
||||
{file = "SQLAlchemy-2.0.21-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:7614f1eab4336df7dd6bee05bc974f2b02c38d3d0c78060c5faa4cd1ca2af3b8"},
|
||||
{file = "SQLAlchemy-2.0.21-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:d59cb9e20d79686aa473e0302e4a82882d7118744d30bb1dfb62d3c47141b3ec"},
|
||||
{file = "SQLAlchemy-2.0.21-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:a95aa0672e3065d43c8aa80080cdd5cc40fe92dc873749e6c1cf23914c4b83af"},
|
||||
|
||||
@@ -9,8 +9,6 @@ The package utilizes a full-text index for efficient mapping of text values to d
|
||||
|
||||
In the provided example, the full-text index is used to map names of people and movies from the user's query to corresponding database entries.
|
||||
|
||||
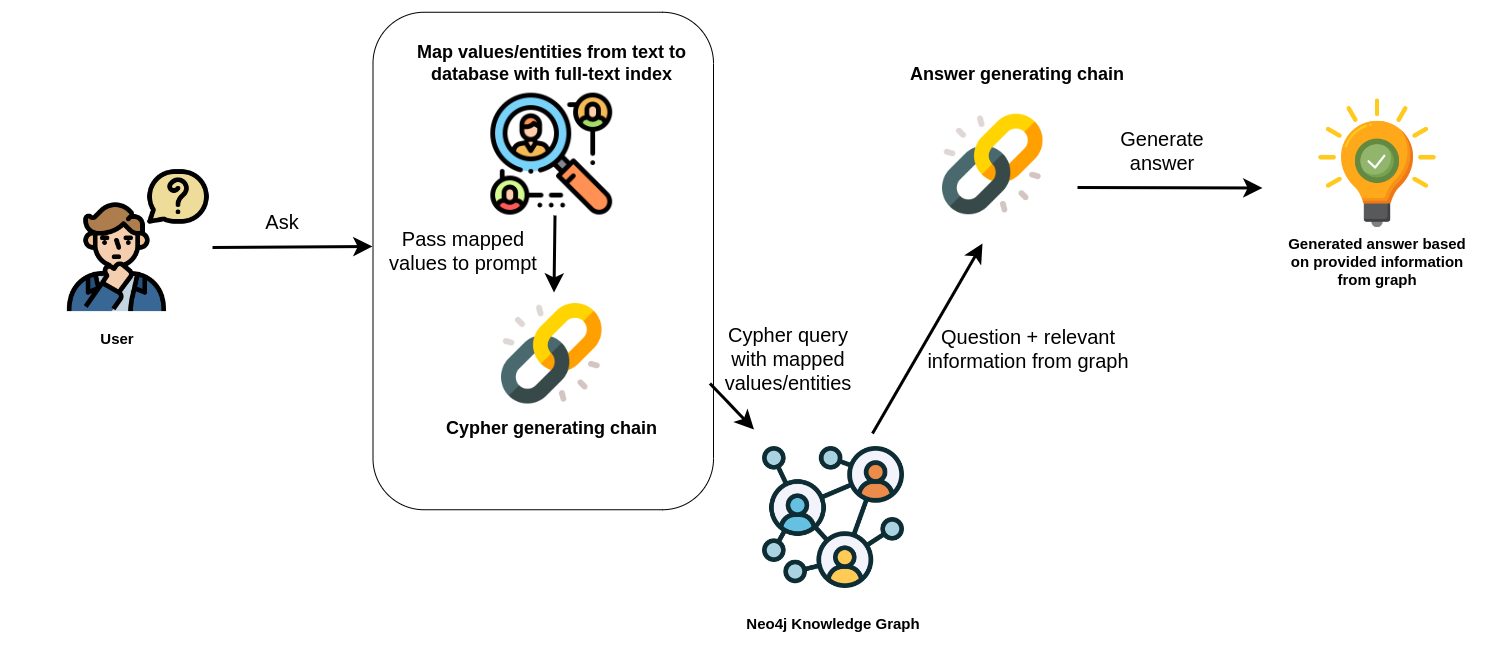
|
||||
|
||||
## Environment Setup
|
||||
|
||||
The following environment variables need to be set:
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 468 KiB |
@@ -7,8 +7,6 @@ Additionally, it features a conversational memory module that stores the dialogu
|
||||
The conversation memory is uniquely maintained for each user session, ensuring personalized interactions.
|
||||
To facilitate this, please supply both the `user_id` and `session_id` when using the conversation chain.
|
||||
|
||||
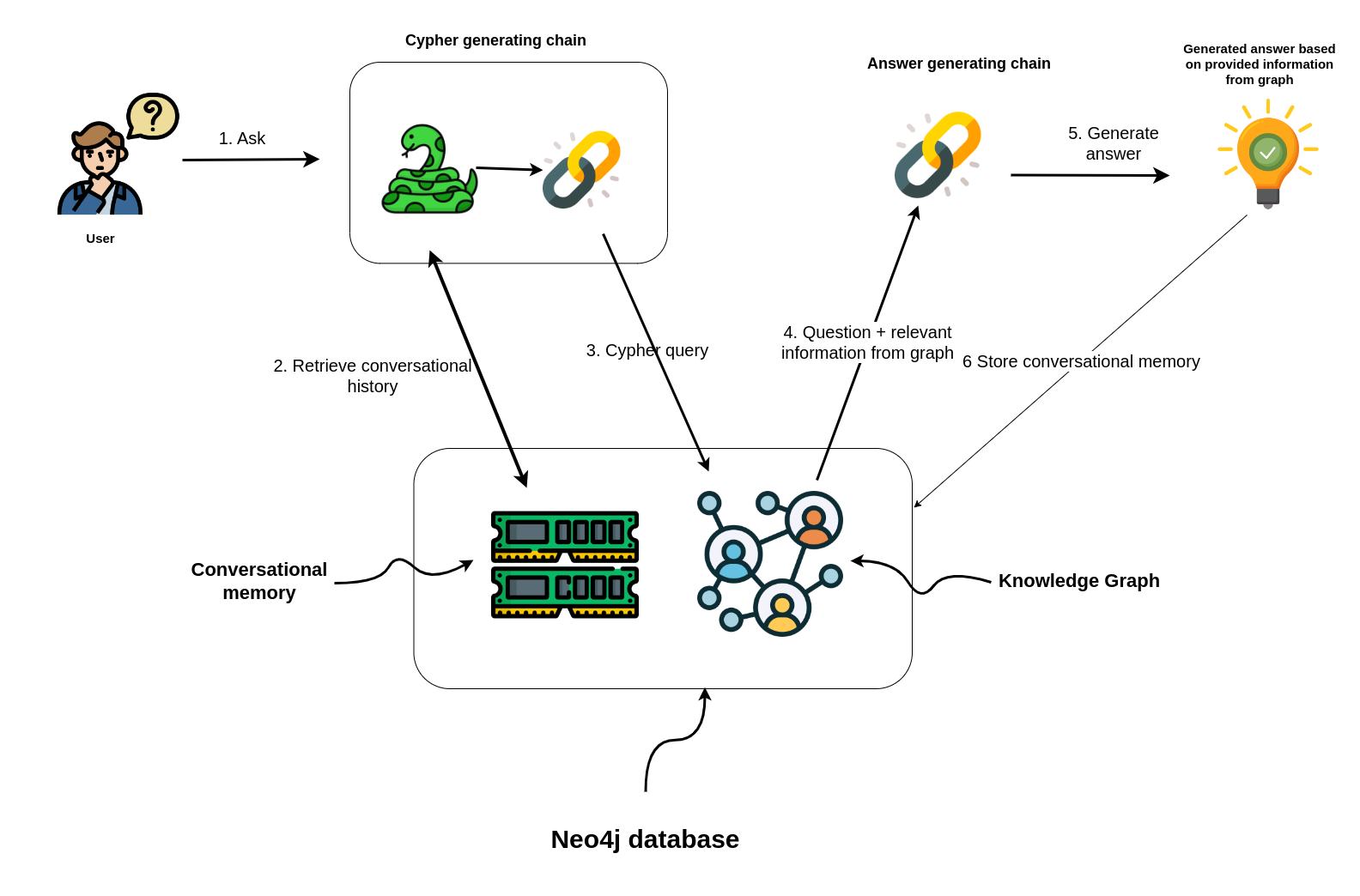
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Define the following environment variables:
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 560 KiB |
@@ -5,8 +5,6 @@ This template allows you to interact with a Neo4j graph database in natural lang
|
||||
|
||||
It transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
|
||||
|
||||
[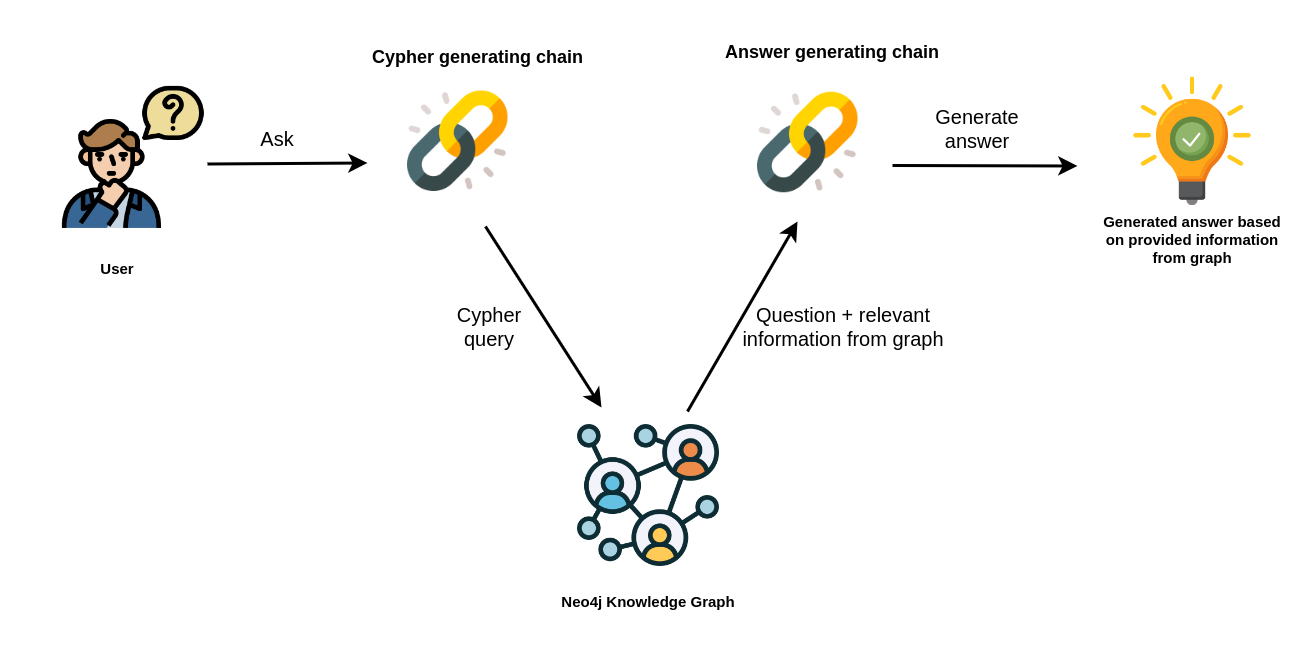](https://medium.com/neo4j/langchain-cypher-search-tips-tricks-f7c9e9abca4d)
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Define the following environment variables:
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 357 KiB |
1
templates/skeleton-of-thought/.gitignore
vendored
1
templates/skeleton-of-thought/.gitignore
vendored
@@ -1 +0,0 @@
|
||||
__pycache__
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,70 +0,0 @@
|
||||
# skeleton-of-thought
|
||||
|
||||
Implements "Skeleton of Thought" from [this](https://sites.google.com/view/sot-llm) paper.
|
||||
|
||||
This technique makes it possible to generate longer generates more quickly by first generating a skeleton, then generating each point of the outline.
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
||||
|
||||
To get your `OPENAI_API_KEY`, navigate to [API keys](https://platform.openai.com/account/api-keys) on your OpenAI account and create a new secret key.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U langchain-cli
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package skeleton-of-thought
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add skeleton-of-thought
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from skeleton_of_thought import chain as skeleton_of_thought_chain
|
||||
|
||||
add_routes(app, skeleton_of_thought_chain, path="/skeleton-of-thought")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/skeleton-of-thought/playground](http://127.0.0.1:8000/skeleton-of-thought/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/skeleton-of-thought")
|
||||
```
|
||||
@@ -1,24 +0,0 @@
|
||||
[tool.poetry]
|
||||
name = "skeleton-of-thought"
|
||||
version = "0.0.1"
|
||||
description = ""
|
||||
authors = []
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.313, <0.1"
|
||||
openai = "^0.28.1"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.4"
|
||||
fastapi = "^0.104.0"
|
||||
sse-starlette = "^1.6.5"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "skeleton_of_thought"
|
||||
export_attr = "chain"
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -1,3 +0,0 @@
|
||||
from skeleton_of_thought.chain import chain
|
||||
|
||||
__all__ = ["chain"]
|
||||
@@ -1,96 +0,0 @@
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.pydantic_v1 import BaseModel
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.runnable import RunnablePassthrough
|
||||
|
||||
skeleton_generator_template = """[User:] You’re an organizer responsible for only \
|
||||
giving the skeleton (not the full content) for answering the question.
|
||||
Provide the skeleton in a list of points (numbered 1., 2., 3., etc.) to answer \
|
||||
the question. \
|
||||
Instead of writing a full sentence, each skeleton point should be very short \
|
||||
with only 3∼5 words. \
|
||||
Generally, the skeleton should have 3∼10 points. Now, please provide the skeleton \
|
||||
for the following question.
|
||||
{question}
|
||||
Skeleton:
|
||||
[Assistant:] 1."""
|
||||
|
||||
skeleton_generator_prompt = ChatPromptTemplate.from_template(
|
||||
skeleton_generator_template
|
||||
)
|
||||
|
||||
skeleton_generator_chain = (
|
||||
skeleton_generator_prompt | ChatOpenAI() | StrOutputParser() | (lambda x: "1. " + x)
|
||||
)
|
||||
|
||||
point_expander_template = """[User:] You’re responsible for continuing \
|
||||
the writing of one and only one point in the overall answer to the following question.
|
||||
{question}
|
||||
The skeleton of the answer is
|
||||
{skeleton}
|
||||
Continue and only continue the writing of point {point_index}. \
|
||||
Write it **very shortly** in 1∼2 sentence and do not continue with other points!
|
||||
[Assistant:] {point_index}. {point_skeleton}"""
|
||||
|
||||
point_expander_prompt = ChatPromptTemplate.from_template(point_expander_template)
|
||||
|
||||
point_expander_chain = RunnablePassthrough.assign(
|
||||
continuation=point_expander_prompt | ChatOpenAI() | StrOutputParser()
|
||||
) | (lambda x: x["point_skeleton"].strip() + " " + x["continuation"])
|
||||
|
||||
|
||||
def parse_numbered_list(input_str):
|
||||
"""Parses a numbered list into a list of dictionaries
|
||||
|
||||
Each element having two keys:
|
||||
'index' for the index in the numbered list, and 'point' for the content.
|
||||
"""
|
||||
# Split the input string into lines
|
||||
lines = input_str.split("\n")
|
||||
|
||||
# Initialize an empty list to store the parsed items
|
||||
parsed_list = []
|
||||
|
||||
for line in lines:
|
||||
# Split each line at the first period to separate the index from the content
|
||||
parts = line.split(". ", 1)
|
||||
|
||||
if len(parts) == 2:
|
||||
# Convert the index part to an integer
|
||||
# and strip any whitespace from the content
|
||||
index = int(parts[0])
|
||||
point = parts[1].strip()
|
||||
|
||||
# Add a dictionary to the parsed list
|
||||
parsed_list.append({"point_index": index, "point_skeleton": point})
|
||||
|
||||
return parsed_list
|
||||
|
||||
|
||||
def create_list_elements(_input):
|
||||
skeleton = _input["skeleton"]
|
||||
numbered_list = parse_numbered_list(skeleton)
|
||||
for el in numbered_list:
|
||||
el["skeleton"] = skeleton
|
||||
el["question"] = _input["question"]
|
||||
return numbered_list
|
||||
|
||||
|
||||
def get_final_answer(expanded_list):
|
||||
final_answer_str = "Here's a comprehensive answer:\n\n"
|
||||
for i, el in enumerate(expanded_list):
|
||||
final_answer_str += f"{i+1}. {el}\n\n"
|
||||
return final_answer_str
|
||||
|
||||
|
||||
class ChainInput(BaseModel):
|
||||
question: str
|
||||
|
||||
|
||||
chain = (
|
||||
RunnablePassthrough.assign(skeleton=skeleton_generator_chain)
|
||||
| create_list_elements
|
||||
| point_expander_chain.map()
|
||||
| get_final_answer
|
||||
).with_types(input_type=ChainInput)
|
||||
Reference in New Issue
Block a user