mirror of
https://github.com/hpcaitech/ColossalAI.git
synced 2025-04-29 12:15:39 +00:00
Compare commits
318 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
46ed5d856b | ||
|
|
7ecdf9a211 | ||
|
|
44d4053fec | ||
|
|
6d676ee0e9 | ||
|
|
56fe130b15 | ||
|
|
f32861ccc5 | ||
|
|
b9e60559b8 | ||
|
|
7595c453a5 | ||
|
|
53834b74b9 | ||
|
|
0171884664 | ||
|
|
9379cbd668 | ||
|
|
24dee8f0b7 | ||
|
|
f73ae55394 | ||
|
|
f8b9e88484 | ||
|
|
d54642a263 | ||
|
|
d20c8ffd97 | ||
|
|
ce0ec40811 | ||
|
|
5ff5323538 | ||
|
|
014837e725 | ||
|
|
ec73f1b5e2 | ||
|
|
5c09d726a6 | ||
|
|
2b415e5999 | ||
|
|
17062c83b9 | ||
|
|
ca0aa2365d | ||
|
|
97e60cbbcb | ||
|
|
5b094a836b | ||
|
|
ee81366cac | ||
|
|
479067e9bc | ||
|
|
7fdef9fd6b | ||
|
|
a9bedc7a43 | ||
|
|
af06d162cf | ||
|
|
836992438f | ||
|
|
8b0ed61490 | ||
|
|
5f82bfa636 | ||
|
|
fa9d0318e4 | ||
|
|
130229fdcb | ||
|
|
aaafb38851 | ||
|
|
e994c64568 | ||
|
|
de3d371f65 | ||
|
|
8d826a336e | ||
|
|
6280cb18b8 | ||
|
|
ab856fd308 | ||
|
|
8ecff0cb7f | ||
|
|
8fddbab04c | ||
|
|
152162a80e | ||
|
|
cf519dac6a | ||
|
|
5caad13055 | ||
|
|
e0c68ab6d3 | ||
|
|
184a653704 | ||
|
|
5fa657f0a1 | ||
|
|
eb69e640e5 | ||
|
|
b90835bd32 | ||
|
|
8e08c27e19 | ||
|
|
d4a436051d | ||
|
|
5a03d2696d | ||
|
|
cc40fe0e6f | ||
|
|
c2fe3137e2 | ||
|
|
a2596519fd | ||
|
|
30a9443132 | ||
|
|
7a60161035 | ||
|
|
a15ab139ad | ||
|
|
13ffa08cfa | ||
|
|
2f583c1549 | ||
|
|
c2e8f61592 | ||
|
|
89a9a600bc | ||
|
|
4294ae83bb | ||
|
|
80a8ca916a | ||
|
|
dee63cc5ef | ||
|
|
6d6cafabe2 | ||
|
|
b10339df7c | ||
|
|
19baab5fd5 | ||
|
|
58d8b8a2dd | ||
|
|
5ddad486ca | ||
|
|
3b1d7d1ae8 | ||
|
|
2bcd0b6844 | ||
|
|
cd61353bae | ||
|
|
62c13e7969 | ||
|
|
dcd41d0973 | ||
|
|
83cf2f84fb | ||
|
|
bc7eeade33 | ||
|
|
fd92789af2 | ||
|
|
6be9862aaf | ||
|
|
3dc08c8a5a | ||
|
|
8ff7d0c780 | ||
|
|
fe9208feac | ||
|
|
3201377e94 | ||
|
|
23199e34cc | ||
|
|
d891e50617 | ||
|
|
e1e86f9f1f | ||
|
|
4c8e85ee0d | ||
|
|
703bb5c18d | ||
|
|
4e0e99bb6a | ||
|
|
1507a7528f | ||
|
|
0002ae5956 | ||
|
|
dc2cdaf3e8 | ||
|
|
efe3042bb2 | ||
|
|
6b2c506fc5 | ||
|
|
5ecc27e150 | ||
|
|
f98384aef6 | ||
|
|
646b3c5a90 | ||
|
|
b635dd0669 | ||
|
|
3532f77b90 | ||
|
|
3fab92166e | ||
|
|
f4daf04270 | ||
|
|
6705dad41b | ||
|
|
91ed32c256 | ||
|
|
6fb1322db1 | ||
|
|
65c8297710 | ||
|
|
cfd9eda628 | ||
|
|
cbaa104216 | ||
|
|
dabc2e7430 | ||
|
|
f9546ba0be | ||
|
|
4fa6b9509c | ||
|
|
63314ce4e4 | ||
|
|
10e4f7da72 | ||
|
|
37e35230ff | ||
|
|
827ef3ee9a | ||
|
|
bdb125f83f | ||
|
|
f20b066c59 | ||
|
|
b582319273 | ||
|
|
0ad3129cb9 | ||
|
|
0b14a5512e | ||
|
|
696fced0d7 | ||
|
|
dc032172c3 | ||
|
|
f393867cff | ||
|
|
6eb8832366 | ||
|
|
683179cefd | ||
|
|
0a01e2a453 | ||
|
|
216d54e374 | ||
|
|
fdd84b9087 | ||
|
|
a35a078f08 | ||
|
|
13946c4448 | ||
|
|
c54c4fcd15 | ||
|
|
8fd25d6e09 | ||
|
|
b3db1058ec | ||
|
|
5ce6dd75bf | ||
|
|
26e553937b | ||
|
|
c3b5caff0e | ||
|
|
c650a906db | ||
|
|
e9032fb0b2 | ||
|
|
e96a0761ea | ||
|
|
0d3a85d04f | ||
|
|
4a68efb7da | ||
|
|
cc1b0efc17 | ||
|
|
d383449fc4 | ||
|
|
17904cb5bf | ||
|
|
4a6f31eb0c | ||
|
|
80d24ae519 | ||
|
|
dae39999d7 | ||
|
|
7cf9df07bc | ||
|
|
0bf46c54af | ||
|
|
9e767643dd | ||
|
|
3b0df30362 | ||
|
|
0bc9a870c0 | ||
|
|
caab4a307f | ||
|
|
afe845ff15 | ||
|
|
a292554179 | ||
|
|
971b16a74f | ||
|
|
d77e66a577 | ||
|
|
eea37da6fa | ||
|
|
8b8e282441 | ||
|
|
698c8b9804 | ||
|
|
6aface9316 | ||
|
|
193030f696 | ||
|
|
eb5ba40def | ||
|
|
39e2597426 | ||
|
|
0d3b0bd864 | ||
|
|
2d362ac090 | ||
|
|
2e4cbe3a2d | ||
|
|
2ee6235cfa | ||
|
|
f7acfa1bd5 | ||
|
|
53823118f2 | ||
|
|
dcc44aab8d | ||
|
|
1f703e0ef4 | ||
|
|
88b3f0698c | ||
|
|
2eb36839c6 | ||
|
|
12b44012d9 | ||
|
|
0d8e82a024 | ||
|
|
4c82bfcc54 | ||
|
|
64aad96723 | ||
|
|
3353042525 | ||
|
|
f1c3266a94 | ||
|
|
1a5847e6d1 | ||
|
|
52289e4c63 | ||
|
|
02636c5bef | ||
|
|
81272e9d00 | ||
|
|
4cf79fa275 | ||
|
|
26493b97d3 | ||
|
|
f5c84af0b0 | ||
|
|
0a51319113 | ||
|
|
3f09a6145f | ||
|
|
20722a8c93 | ||
|
|
887d2d579b | ||
|
|
4dd03999ec | ||
|
|
1a2e90dcc1 | ||
|
|
406f984063 | ||
|
|
88fa096d78 | ||
|
|
597b206001 | ||
|
|
ceb1e262e7 | ||
|
|
0978080a69 | ||
|
|
b2483c8e31 | ||
|
|
ed97d3a5d3 | ||
|
|
f1a3a326c4 | ||
|
|
b4d2377d4c | ||
|
|
e4aadeee20 | ||
|
|
8241c0c054 | ||
|
|
ad3fa4f49c | ||
|
|
4b9bec8176 | ||
|
|
b480eec738 | ||
|
|
7739629b9d | ||
|
|
ccabcf6485 | ||
|
|
76ea16466f | ||
|
|
9179d4088e | ||
|
|
afb26de873 | ||
|
|
0c10afd372 | ||
|
|
53cb9606bd | ||
|
|
c297e21bea | ||
|
|
fe71917851 | ||
|
|
0b2d55c4ab | ||
|
|
91e596d017 | ||
|
|
ae486ce005 | ||
|
|
75c963686f | ||
|
|
19d1510ea2 | ||
|
|
62cdac6b7b | ||
|
|
d1d1ab871e | ||
|
|
65daa87627 | ||
|
|
7bedd03739 | ||
|
|
f7c5485ed6 | ||
|
|
7e737df5ad | ||
|
|
70793ce9ed | ||
|
|
12d043ca00 | ||
|
|
606b0891ed | ||
|
|
5b4c12381b | ||
|
|
cb01c0d5ce | ||
|
|
034020bd04 | ||
|
|
59bcf56c60 | ||
|
|
c3dc9b4dba | ||
|
|
6c39f0b144 | ||
|
|
b2952a5982 | ||
|
|
96d0fbc531 | ||
|
|
067e18f7e9 | ||
|
|
74b03de3f9 | ||
|
|
70c9924d0d | ||
|
|
52d346f2a5 | ||
|
|
46037c2ccd | ||
|
|
803878b2fd | ||
|
|
7077d38d5a | ||
|
|
2cddeac717 | ||
|
|
877d94bb8c | ||
|
|
09d6280d3e | ||
|
|
404b16faf3 | ||
|
|
3e2b6132b7 | ||
|
|
74eccac0db | ||
|
|
dc583aa576 | ||
|
|
0b5bbe9ce4 | ||
|
|
102b784a10 | ||
|
|
8dbb86899d | ||
|
|
014faf6c5a | ||
|
|
9b9b76bdcd | ||
|
|
e28e05345b | ||
|
|
5ed5e8cfba | ||
|
|
fe24789eb1 | ||
|
|
13b48ac0aa | ||
|
|
b5bfeb2efd | ||
|
|
37443cc7e4 | ||
|
|
46c069b0db | ||
|
|
0fad23c691 | ||
|
|
a249e71946 | ||
|
|
8ae8525bdf | ||
|
|
0b76b57cd6 | ||
|
|
f9b6fcf81f | ||
|
|
1aeb5e8847 | ||
|
|
66fbf2ecb7 | ||
|
|
30f4e31a33 | ||
|
|
09c5f72595 | ||
|
|
060892162a | ||
|
|
bcf0181ecd | ||
|
|
7b38964e3a | ||
|
|
9664b1bc19 | ||
|
|
c8332b9cb5 | ||
|
|
6fd9e86864 | ||
|
|
de1bf08ed0 | ||
|
|
8a3ff4f315 | ||
|
|
ad35a987d3 | ||
|
|
2069472e96 | ||
|
|
5fd0592767 | ||
|
|
5fb958cc83 | ||
|
|
a521ffc9f8 | ||
|
|
9688e19b32 | ||
|
|
b0e15d563e | ||
|
|
12fe8b5858 | ||
|
|
c5f582f666 | ||
|
|
4ec17a7cdf | ||
|
|
150505cbb8 | ||
|
|
d49550fb49 | ||
|
|
d08c99be0d | ||
|
|
f585d4e38e | ||
|
|
8cc8f645cd | ||
|
|
544b7a38a1 | ||
|
|
62661cde22 | ||
|
|
845ea7214e | ||
|
|
09d5ffca1a | ||
|
|
e86127925a | ||
|
|
5b969fd831 | ||
|
|
d0bdb51f48 | ||
|
|
6a20f07b80 | ||
|
|
5a310b9ee1 | ||
|
|
457a0de79f | ||
|
|
9470701110 | ||
|
|
51f916b11d | ||
|
|
1f1b856354 | ||
|
|
66018749f3 | ||
|
|
e88190184a | ||
|
|
1e1959467e | ||
|
|
dbfa7d39fc | ||
|
|
e17f835df7 | ||
|
|
6991819a97 | ||
|
|
f5a52e1600 |
.compatibility.cuda_ext.json.pre-commit-config.yamlREADME.md
.github
ISSUE_TEMPLATE
workflows
build_on_pr.ymlbuild_on_schedule.ymlcompatiblity_test_on_dispatch.ymlcompatiblity_test_on_pr.ymlcompatiblity_test_on_schedule.ymlcuda_ext_check_before_merge.ymldoc_check_on_pr.ymldoc_test_on_pr.ymldoc_test_on_schedule.ymlexample_check_on_dispatch.ymlexample_check_on_pr.ymlexample_check_on_schedule.ymlrelease_test_pypi_before_merge.ymlrun_chatgpt_examples.ymlrun_chatgpt_unit_tests.ymlrun_colossalqa_unit_tests.yml
applications
Colossal-LLaMA
README.md
colossal_llama
dataset
utils
dataset
inference
requirements.txtsetup.pytrain.example.shtrain.pyversion.txtColossalChat
.gitignoreREADME.md
benchmarks
benchmark_dpo.shbenchmark_kto.shbenchmark_orpo.pybenchmark_orpo.shbenchmark_sft.pybenchmark_sft.shbenchmark_simpo.shdummy_dataset.pyprepare_dummy_test_dataset.py
coati
dataset
experience_buffer
experience_maker
models
trainer
utils/reward_score
conversation_template
01-ai_Yi-1.5-9B-Chat.jsonMiniCPM-2b.jsonQwen_Qwen1.5-110B-Chat.jsonQwen_Qwen1.5-32B-Chat.jsonQwen_Qwen2.5-3B.jsonTHUDM_chatglm2-6b.jsonTHUDM_chatglm3-6b.jsonbaichuan-inc_Baichuan2-13B-Chat.jsoncolossal-llama2.jsondeepseek-ai_DeepSeek-V2-Lite.jsonllama2.jsonmicrosoft_phi-2.jsonmistralai_Mixtral-8x7B-Instruct-v0.1.jsontiny-llama.json
examples
@ -1,3 +1,3 @@
|
||||
2.1.0-12.1.0
|
||||
2.2.2-12.1.0
|
||||
2.3.0-12.1.0
|
||||
2.4.0-12.4.1
|
||||
2.5.1-12.4.1
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
{
|
||||
"build": [
|
||||
{
|
||||
"torch_command": "pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121",
|
||||
"torch_command": "pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121",
|
||||
"cuda_image": "hpcaitech/cuda-conda:12.1"
|
||||
},
|
||||
{
|
||||
"torch_command": "pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118",
|
||||
"cuda_image": "hpcaitech/cuda-conda:11.8"
|
||||
"torch_command": "pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124",
|
||||
"cuda_image": "hpcaitech/cuda-conda:12.4"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
20
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
20
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -15,6 +15,26 @@ body:
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: The bug has not been fixed in the latest main branch
|
||||
options:
|
||||
- label: I have checked the latest main branch
|
||||
required: true
|
||||
|
||||
- type: dropdown
|
||||
id: share_script
|
||||
attributes:
|
||||
label: Do you feel comfortable sharing a concise (minimal) script that reproduces the error? :)
|
||||
description: If not, please share your setting/training config, and/or point to the line in the repo that throws the error.
|
||||
If the issue is not easily reproducible by us, it will reduce the likelihood of getting responses.
|
||||
options:
|
||||
- Yes, I will share a minimal reproducible script.
|
||||
- No, I prefer not to share.
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 🐛 Describe the bug
|
||||
|
||||
13
.github/workflows/build_on_pr.yml
vendored
13
.github/workflows/build_on_pr.yml
vendored
@ -87,10 +87,10 @@ jobs:
|
||||
name: Build and Test Colossal-AI
|
||||
needs: detect
|
||||
if: needs.detect.outputs.anyLibraryFileChanged == 'true'
|
||||
runs-on: [self-hosted, gpu]
|
||||
runs-on: ubuntu-latest
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
options: --gpus all --rm -v /dev/shm -v /data/scratch:/data/scratch
|
||||
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --shm-size=2g --rm -v /dev/shm -v /data/scratch:/data/scratch
|
||||
timeout-minutes: 90
|
||||
defaults:
|
||||
run:
|
||||
@ -117,7 +117,7 @@ jobs:
|
||||
cd TensorNVMe
|
||||
conda install cmake
|
||||
pip install -r requirements.txt
|
||||
DISABLE_URING=1 pip install -v .
|
||||
DISABLE_URING=1 pip install -v --no-cache-dir .
|
||||
|
||||
- name: Store TensorNVMe Cache
|
||||
run: |
|
||||
@ -141,7 +141,7 @@ jobs:
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
pip install -r requirements/requirements-test.txt
|
||||
pip install --no-cache-dir -r requirements/requirements-test.txt
|
||||
|
||||
- name: Store Colossal-AI Cache
|
||||
run: |
|
||||
@ -166,6 +166,7 @@ jobs:
|
||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
||||
LLAMA_PATH: /data/scratch/llama-tiny
|
||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
|
||||
- name: Collate artifact
|
||||
env:
|
||||
@ -199,7 +200,7 @@ jobs:
|
||||
fi
|
||||
|
||||
- name: Upload test coverage artifact
|
||||
uses: actions/upload-artifact@v3
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: report
|
||||
path: report/
|
||||
|
||||
5
.github/workflows/build_on_schedule.yml
vendored
5
.github/workflows/build_on_schedule.yml
vendored
@ -12,7 +12,7 @@ jobs:
|
||||
if: github.repository == 'hpcaitech/ColossalAI'
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /dev/shm -v /data/scratch/:/data/scratch/
|
||||
timeout-minutes: 90
|
||||
steps:
|
||||
@ -57,7 +57,7 @@ jobs:
|
||||
[ ! -z "$(ls -A /github/home/cuda_ext_cache/)" ] && cp -r /github/home/cuda_ext_cache/* /__w/ColossalAI/ColossalAI/
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
cp -r /__w/ColossalAI/ColossalAI/build /github/home/cuda_ext_cache/
|
||||
pip install -r requirements/requirements-test.txt
|
||||
pip install --no-cache-dir -r requirements/requirements-test.txt
|
||||
|
||||
- name: Unit Testing
|
||||
if: steps.check-avai.outputs.avai == 'true'
|
||||
@ -70,6 +70,7 @@ jobs:
|
||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
|
||||
LLAMA_PATH: /data/scratch/llama-tiny
|
||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
|
||||
- name: Notify Lark
|
||||
id: message-preparation
|
||||
|
||||
@ -64,7 +64,7 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
pip install --no-cache-dir -r requirements/requirements-test.txt
|
||||
|
||||
- name: Install tensornvme
|
||||
@ -79,3 +79,4 @@ jobs:
|
||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||
LLAMA_PATH: /data/scratch/llama-tiny
|
||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
|
||||
@ -58,7 +58,7 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
pip install --no-cache-dir -r requirements/requirements-test.txt
|
||||
|
||||
- name: Install tensornvme
|
||||
@ -73,3 +73,4 @@ jobs:
|
||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||
LLAMA_PATH: /data/scratch/llama-tiny
|
||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
|
||||
@ -52,7 +52,7 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
pip install --no-cache-dir -r requirements/requirements-test.txt
|
||||
|
||||
- name: Install tensornvme
|
||||
@ -67,6 +67,7 @@ jobs:
|
||||
LD_LIBRARY_PATH: /github/home/.tensornvme/lib
|
||||
LLAMA_PATH: /data/scratch/llama-tiny
|
||||
MOE_TENSOR_PATH: /data/scratch/moe_tensors
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
|
||||
- name: Notify Lark
|
||||
id: message-preparation
|
||||
|
||||
@ -51,4 +51,4 @@ jobs:
|
||||
|
||||
- name: Build
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
|
||||
1
.github/workflows/doc_check_on_pr.yml
vendored
1
.github/workflows/doc_check_on_pr.yml
vendored
@ -58,6 +58,7 @@ jobs:
|
||||
# there is no main branch, so it's safe to checkout the main branch from the merged branch
|
||||
# docer will rebase the remote main branch to the merged branch, so we have to config user
|
||||
- name: Make the merged branch main
|
||||
|
||||
run: |
|
||||
cd ColossalAI
|
||||
git checkout -b main
|
||||
|
||||
4
.github/workflows/doc_test_on_pr.yml
vendored
4
.github/workflows/doc_test_on_pr.yml
vendored
@ -56,7 +56,7 @@ jobs:
|
||||
needs: detect-changed-doc
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm
|
||||
timeout-minutes: 30
|
||||
defaults:
|
||||
@ -89,7 +89,7 @@ jobs:
|
||||
- name: Install ColossalAI
|
||||
run: |
|
||||
source activate pytorch
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
|
||||
- name: Test the Doc
|
||||
run: |
|
||||
|
||||
4
.github/workflows/doc_test_on_schedule.yml
vendored
4
.github/workflows/doc_test_on_schedule.yml
vendored
@ -12,7 +12,7 @@ jobs:
|
||||
name: Test the changed Doc
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm
|
||||
timeout-minutes: 60
|
||||
steps:
|
||||
@ -32,7 +32,7 @@ jobs:
|
||||
|
||||
- name: Install ColossalAI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
|
||||
- name: Install Doc Test Requirements
|
||||
run: |
|
||||
|
||||
@ -45,7 +45,7 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix: ${{fromJson(needs.manual_check_matrix_preparation.outputs.matrix)}}
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||
timeout-minutes: 15
|
||||
steps:
|
||||
@ -53,7 +53,7 @@ jobs:
|
||||
uses: actions/checkout@v3
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
- name: Test the example
|
||||
run: |
|
||||
dir=${{ matrix.directory }}
|
||||
|
||||
5
.github/workflows/example_check_on_pr.yml
vendored
5
.github/workflows/example_check_on_pr.yml
vendored
@ -9,6 +9,7 @@ on:
|
||||
paths:
|
||||
- "examples/**"
|
||||
- "!examples/**.md"
|
||||
- ".github/workflows/example_check_on_pr.yml"
|
||||
|
||||
jobs:
|
||||
# This is for changed example files detect and output a matrix containing all the corresponding directory name.
|
||||
@ -89,7 +90,7 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix: ${{fromJson(needs.detect-changed-example.outputs.matrix)}}
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||
timeout-minutes: 30
|
||||
concurrency:
|
||||
@ -107,7 +108,7 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
|
||||
- name: Store Colossal-AI Cache
|
||||
run: |
|
||||
|
||||
@ -34,7 +34,7 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix: ${{fromJson(needs.matrix_preparation.outputs.matrix)}}
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/ -v /dev/shm
|
||||
timeout-minutes: 30
|
||||
steps:
|
||||
@ -43,7 +43,7 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v .
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
|
||||
- name: Traverse all files
|
||||
run: |
|
||||
|
||||
@ -49,6 +49,7 @@ jobs:
|
||||
# we need to install the requirements.txt first
|
||||
# as test-pypi may not contain the distributions for libs listed in the txt file
|
||||
pip install -r requirements/requirements.txt
|
||||
pip install -U setuptools==68.2.2 wheel
|
||||
pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.python.org/pypi colossalai==$VERSION
|
||||
env:
|
||||
VERSION: ${{ steps.prep-version.outputs.version }}
|
||||
|
||||
14
.github/workflows/run_chatgpt_examples.yml
vendored
14
.github/workflows/run_chatgpt_examples.yml
vendored
@ -19,7 +19,7 @@ jobs:
|
||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data --shm-size=10.24gb
|
||||
timeout-minutes: 60
|
||||
defaults:
|
||||
@ -31,18 +31,17 @@ jobs:
|
||||
|
||||
- name: Install Colossal-AI
|
||||
run: |
|
||||
BUILD_EXT=1 pip install -v -e .
|
||||
pip install --no-cache-dir -v -e .
|
||||
|
||||
- name: Install ChatGPT
|
||||
run: |
|
||||
cd applications/ColossalChat
|
||||
pip install -v .
|
||||
export BUILD_EXT=1
|
||||
pip install -r examples/requirements.txt
|
||||
pip install --no-cache-dir -v .
|
||||
pip install --no-cache-dir -r examples/requirements.txt
|
||||
|
||||
- name: Install Transformers
|
||||
run: |
|
||||
pip install transformers==4.36.2
|
||||
pip install --no-cache-dir transformers==4.36.2
|
||||
|
||||
- name: Execute Examples
|
||||
run: |
|
||||
@ -52,6 +51,7 @@ jobs:
|
||||
mkdir sft_data
|
||||
mkdir prompt_data
|
||||
mkdir preference_data
|
||||
mkdir kto_data
|
||||
./tests/test_data_preparation.sh
|
||||
./tests/test_train.sh
|
||||
env:
|
||||
@ -60,4 +60,6 @@ jobs:
|
||||
PRETRAINED_MODEL_PATH: ./models
|
||||
SFT_DATASET: ./sft_data
|
||||
PROMPT_DATASET: ./prompt_data
|
||||
PROMPT_RLVR_DATASET: ./prompt_data
|
||||
PREFERENCE_DATASET: ./preference_data
|
||||
KTO_DATASET: ./kto_data
|
||||
|
||||
2
.github/workflows/run_chatgpt_unit_tests.yml
vendored
2
.github/workflows/run_chatgpt_unit_tests.yml
vendored
@ -19,7 +19,7 @@ jobs:
|
||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data
|
||||
timeout-minutes: 30
|
||||
defaults:
|
||||
|
||||
@ -19,7 +19,7 @@ jobs:
|
||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
|
||||
image: hpcaitech/pytorch-cuda:2.2.2-12.1.0
|
||||
volumes:
|
||||
- /data/scratch/test_data_colossalqa:/data/scratch/test_data_colossalqa
|
||||
- /data/scratch/llama-tiny:/data/scratch/llama-tiny
|
||||
|
||||
@ -12,23 +12,24 @@ repos:
|
||||
hooks:
|
||||
- id: isort
|
||||
name: sort all imports (python)
|
||||
args: ["--profile", "black"] # avoid conflict with black
|
||||
|
||||
- repo: https://github.com/psf/black-pre-commit-mirror
|
||||
rev: 24.4.2
|
||||
rev: 24.10.0
|
||||
hooks:
|
||||
- id: black
|
||||
name: black formatter
|
||||
args: ['--line-length=120', '--target-version=py37', '--target-version=py38', '--target-version=py39','--target-version=py310']
|
||||
|
||||
- repo: https://github.com/pre-commit/mirrors-clang-format
|
||||
rev: v18.1.8
|
||||
rev: v19.1.5
|
||||
hooks:
|
||||
- id: clang-format
|
||||
name: clang formatter
|
||||
types_or: [c++, c]
|
||||
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.6.0
|
||||
rev: v5.0.0
|
||||
hooks:
|
||||
- id: check-yaml
|
||||
- id: check-merge-conflict
|
||||
|
||||
32
README.md
32
README.md
@ -9,7 +9,7 @@
|
||||
<a href="https://www.colossalai.org/"> Documentation </a> |
|
||||
<a href="https://github.com/hpcaitech/ColossalAI/tree/main/examples"> Examples </a> |
|
||||
<a href="https://github.com/hpcaitech/ColossalAI/discussions"> Forum </a> |
|
||||
<a href="https://cloud.luchentech.com/">GPU Cloud Playground </a> |
|
||||
<a href="https://colossalai.org/zh-Hans/docs/get_started/bonus/">GPU Cloud Playground </a> |
|
||||
<a href="https://hpc-ai.com/blog"> Blog </a></h3>
|
||||
|
||||
[](https://github.com/hpcaitech/ColossalAI/stargazers)
|
||||
@ -25,16 +25,34 @@
|
||||
|
||||
</div>
|
||||
|
||||
## Get Started with Colossal-AI Without Setup
|
||||
|
||||
Access high-end, on-demand compute for your research instantly—no setup needed.
|
||||
|
||||
Sign up now and get $10 in credits!
|
||||
|
||||
Limited Academic Bonuses:
|
||||
|
||||
* Top up $1,000 and receive 300 credits
|
||||
* Top up $500 and receive 100 credits
|
||||
|
||||
<div align="center">
|
||||
<a href="https://hpc-ai.com/?utm_source=github&utm_medium=social&utm_campaign=promotion-colossalai">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/colossalai/img/2-2.gif" width="850" />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
## Latest News
|
||||
* [2025/02] [DeepSeek 671B Fine-Tuning Guide Revealed—Unlock the Upgraded DeepSeek Suite with One Click, AI Players Ecstatic!](https://company.hpc-ai.com/blog/shocking-release-deepseek-671b-fine-tuning-guide-revealed-unlock-the-upgraded-deepseek-suite-with-one-click-ai-players-ecstatic)
|
||||
* [2024/12] [The development cost of video generation models has saved by 50%! Open-source solutions are now available with H200 GPU vouchers](https://company.hpc-ai.com/blog/the-development-cost-of-video-generation-models-has-saved-by-50-open-source-solutions-are-now-available-with-h200-gpu-vouchers) [[code]](https://github.com/hpcaitech/Open-Sora/blob/main/scripts/train.py) [[vouchers]](https://colossalai.org/zh-Hans/docs/get_started/bonus/)
|
||||
* [2024/10] [How to build a low-cost Sora-like app? Solutions for you](https://company.hpc-ai.com/blog/how-to-build-a-low-cost-sora-like-app-solutions-for-you)
|
||||
* [2024/09] [Singapore Startup HPC-AI Tech Secures 50 Million USD in Series A Funding to Build the Video Generation AI Model and GPU Platform](https://company.hpc-ai.com/blog/singapore-startup-hpc-ai-tech-secures-50-million-usd-in-series-a-funding-to-build-the-video-generation-ai-model-and-gpu-platform)
|
||||
* [2024/09] [Reducing AI Large Model Training Costs by 30% Requires Just a Single Line of Code From FP8 Mixed Precision Training Upgrades](https://company.hpc-ai.com/blog/reducing-ai-large-model-training-costs-by-30-requires-just-a-single-line-of-code-from-fp8-mixed-precision-training-upgrades)
|
||||
* [2024/06] [Open-Sora Continues Open Source: Generate Any 16-Second 720p HD Video with One Click, Model Weights Ready to Use](https://hpc-ai.com/blog/open-sora-from-hpc-ai-tech-team-continues-open-source-generate-any-16-second-720p-hd-video-with-one-click-model-weights-ready-to-use)
|
||||
* [2024/05] [Large AI Models Inference Speed Doubled, Colossal-Inference Open Source Release](https://hpc-ai.com/blog/colossal-inference)
|
||||
* [2024/04] [Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
|
||||
* [2024/04] [Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series](https://hpc-ai.com/blog/most-cost-effective-solutions-for-inference-fine-tuning-and-pretraining-tailored-to-llama3-series)
|
||||
* [2024/03] [314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here](https://hpc-ai.com/blog/314-billion-parameter-grok-1-inference-accelerated-by-3.8x-efficient-and-easy-to-use-pytorchhuggingface-version-is-here)
|
||||
* [2024/03] [Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models](https://hpc-ai.com/blog/open-sora-v1.0)
|
||||
* [2024/03] [Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million](https://hpc-ai.com/blog/open-sora)
|
||||
* [2024/01] [Inference Performance Improved by 46%, Open Source Solution Breaks the Length Limit of LLM for Multi-Round Conversations](https://hpc-ai.com/blog/Colossal-AI-SwiftInfer)
|
||||
* [2023/07] [HPC-AI Tech Raises 22 Million USD in Series A Funding](https://www.hpc-ai.tech/blog/hpc-ai-tech-raises-22-million-usd-in-series-a-funding-to-fuel-team-expansion-and-business-growth)
|
||||
|
||||
## Table of Contents
|
||||
<ul>
|
||||
@ -420,7 +438,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
|
||||
## Installation
|
||||
|
||||
Requirements:
|
||||
- PyTorch >= 2.1
|
||||
- PyTorch >= 2.2
|
||||
- Python >= 3.7
|
||||
- CUDA >= 11.0
|
||||
- [NVIDIA GPU Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0 (V100/RTX20 and higher)
|
||||
|
||||
@ -30,7 +30,7 @@ Colossal-LLaMA
|
||||
- [Install](#install)
|
||||
- [0. Pre-requisite](#0-pre-requisite)
|
||||
- [1. Install required packages](#1-install-required-packages)
|
||||
- [2. Install `xentropy`, `layer_norm` and `rotary`](#2-install-xentropy-layer_norm-and-rotary)
|
||||
- [2. Install Apex](#2-install-apex)
|
||||
- [How to run](#how-to-run)
|
||||
- [1. Init Tokenizer Preparation](#1-init-tokenizer-preparation)
|
||||
- [2. Init Model Preparation](#2-init-model-preparation)
|
||||
@ -297,17 +297,13 @@ Here is details about CLI arguments:
|
||||
#### 1. Install required packages
|
||||
```
|
||||
cd Colossal-LLaMA
|
||||
pip install -r requirements.txt
|
||||
pip install -e .
|
||||
```
|
||||
#### 2. Install `xentropy`, `layer_norm` and `rotary`
|
||||
|
||||
#### 2. Install Apex
|
||||
```bash
|
||||
git clone git@github.com:Dao-AILab/flash-attention.git
|
||||
# At the root folder
|
||||
cd csrc/xentropy && pip install .
|
||||
# At the root folder
|
||||
cd csrc/layer_norm && pip install .
|
||||
# At the root folder
|
||||
cd csrc/rotary && pip install .
|
||||
git clone git@github.com:NVIDIA/apex.git
|
||||
# Install from source.
|
||||
```
|
||||
|
||||
### How to run
|
||||
@ -427,25 +423,33 @@ Make sure master node can access all nodes (including itself) by ssh without pas
|
||||
Here is details about CLI arguments:
|
||||
* Pre-trained model path: `--pretrained`. Path to the pre-trained model in Hugging Face format.
|
||||
* Dataset path: `--dataset`. Path to the pre-tokenized dataset.
|
||||
* Booster plugin: `--plugin`. `gemini`, `gemini_auto`, `zero2`,`zero2_cpu` and `3d` are supported.For more details, please refer to [Booster plugins](https://colossalai.org/docs/basics/booster_plugins/).
|
||||
* Booster plugin: `--plugin`. `ddp`,`gemini`, `gemini_auto`, `zero2`,`zero2_cpu` and `3d` are supported.For more details, please refer to [Booster plugins](https://colossalai.org/docs/basics/booster_plugins/).
|
||||
* Intermediate checkpoint to load: `--load_checkpoint`. Path to the intermediate checkpoint. Saved checkpoint contains the states for `lr_scheduler`, `optimizer`,`running_states.json` and `modelling`. If `load_checkpoint` points to the `modelling` folder, only the model weights will be loaded without any other states to support multi-stage training.
|
||||
* Save interval: `--save_interval`. The interval (steps) of saving checkpoints. The default value is 1000.
|
||||
* Checkpoint directory: `--save_dir`. The directory path to save checkpoint and intermediate states. Intermediate states include `lr_scheduler`, `optimizer`,`running_states.json` and `modelling`.
|
||||
* Tensorboard directory: `--tensorboard_dir`. The path to save tensorboard logs.
|
||||
* Configuration file: `--config_file`. The path to save the configuration file.
|
||||
* Number of epochs: `--num_epochs`. Number of training epochs. The default value is 1.
|
||||
* Micro batch size: `--micro_batch_size`. Batch size per GPU. The default value is 1.
|
||||
* Batch size: `--batch_size`. Batch size per GPU. The default value is 1. For PP, it refers to number of samples per step.
|
||||
* Learning rate: `--lr`. The default value is 3e-4.
|
||||
* Max length: `--max_length`. Max context length. The default value is 4096.
|
||||
* Mixed precision: `--mixed_precision`. The default value is "fp16". "fp16" and "bf16" are supported.
|
||||
* Gradient clipping: `--gradient_clipping`. The default value is 1.0.
|
||||
* Weight decay: `-w`, `--weight_decay`. The default value is 0.1.
|
||||
* Warmup steps: `-s`, `--warmup_steps`. The default value is calculated by 0.025 warmup ratio.
|
||||
* Weight decay: `--weight_decay`. The default value is 0.1.
|
||||
* Warmup steps: `--warmup_steps`. The default value is calculated by 0.025 warmup ratio.
|
||||
* Gradient checkpointing: `--use_grad_checkpoint`. The default value is `False`. This saves memory at the cost of speed. You'd better enable this option when training with a large batch size.
|
||||
* Flash attention: `--use_flash_attn`. If you want to use flash attention, you must install `flash-attn` and related packages. The default value is `False`. This is helpful to accelerate training while saving memory. We recommend you always use flash attention.
|
||||
* Freeze non-embedding parameters: `--freeze_non_embeds_params`. Freeze non-embedding parameters. It can be helpful to align embeddings after extending vocabulary size.
|
||||
* Tensor parallelism size: `--tp`. TP size for 3d Parallelism. The default value is 1.
|
||||
* Zero stage: `--zero`. Zero stage for 3d Parallelism. The default value is 1.
|
||||
* Tensor parallelism size: `--tp`. TP size for 3d parallelism. The default value is 1. Used for 3d plugin.
|
||||
* Pipeline parallelism size: `--pp`. PP size for 3d parallelism. The default value is 1. Used for 3d plugin.
|
||||
* Sequence parallelism size: `--sp`. SP size for 3d parallelism. The default value is 1. Used for 3d plugin.
|
||||
* Zero stage: `--zero`. Zero stage for 3d Parallelism. The default value is 1. Used for 3d plugin.
|
||||
* Sequence parallelism mode: `--sp_mode`. SP mode, used for 3d plugin. Choose from "split_gather", "ring", "all_to_all".
|
||||
* Switch for sequence parallelism: `--enable_sequence_parallelism`. Whether to enable SP, used for 3d plugin.
|
||||
* Zero CPU offload: `--zero_cpu_offload`. Whether to use offloading, used for 3d plugin.
|
||||
* Micro batch size: `--microbatch_size`. Batch size for each process in PP, used for 3d plugin.
|
||||
* Number of dummy sample: `--num_samples`. Number of samples for benchmarking.
|
||||
* Benchmark switch: `--benchmark`. Benchmark performance using random dataset.
|
||||
|
||||
##### 4.2 Arguments for Supervised Fine-tuning
|
||||
We add support for gradient accumulation and NEFTuning for supervised fine-tuning and thus there are two more arguments apart from the arguments listed in [4.1 Arguments for Pretraining](#41-arguments-for-pretraining).
|
||||
|
||||
@ -100,7 +100,7 @@ LLaMA3_Conv = Conversation(
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.ADD_BOS_EOS_TOKEN,
|
||||
seps=["<|begin_of_text|>", "<|end_of_text|>"],
|
||||
seps=["<|begin_of_text|>", "<|eot_id|>"],
|
||||
)
|
||||
|
||||
default_conversation = LLaMA3_Conv
|
||||
|
||||
@ -0,0 +1,24 @@
|
||||
import torch
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
from colossalai.accelerator import get_accelerator
|
||||
|
||||
|
||||
class RandomDataset(Dataset):
|
||||
def __init__(self, num_samples: int = 1000, max_length: int = 2048, vocab_size: int = 32000):
|
||||
self.num_samples = num_samples
|
||||
self.max_length = max_length
|
||||
self.input_ids = torch.randint(
|
||||
0, vocab_size, (num_samples, max_length), device=get_accelerator().get_current_device()
|
||||
)
|
||||
self.attention_mask = torch.ones_like(self.input_ids)
|
||||
|
||||
def __len__(self):
|
||||
return self.num_samples
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return {
|
||||
"input_ids": self.input_ids[idx],
|
||||
"attention_mask": self.attention_mask[idx],
|
||||
"labels": self.input_ids[idx],
|
||||
}
|
||||
@ -88,7 +88,7 @@ def supervised_tokenize_sft(
|
||||
|
||||
assert (
|
||||
tokenizer.bos_token == conversation_template.seps[0] and tokenizer.eos_token == conversation_template.seps[1]
|
||||
), "`bos_token` and `eos_token` should be the same with `conversation_template.seps`."
|
||||
), f"`bos_token`{tokenizer.bos_token} and `eos_token`{tokenizer.eos_token} should be the same with `conversation_template.seps`{conversation_template.seps}."
|
||||
|
||||
if ignore_index is None:
|
||||
ignore_index = IGNORE_INDEX
|
||||
|
||||
@ -43,6 +43,7 @@ def save_checkpoint(
|
||||
step: int,
|
||||
batch_size: int,
|
||||
coordinator: DistCoordinator,
|
||||
use_lora: bool = False,
|
||||
) -> None:
|
||||
"""
|
||||
Save model checkpoint, optimizer, LR scheduler and intermedidate running states.
|
||||
@ -51,7 +52,10 @@ def save_checkpoint(
|
||||
save_dir = os.path.join(save_dir, f"epoch-{epoch}_step-{step}")
|
||||
os.makedirs(os.path.join(save_dir, "modeling"), exist_ok=True)
|
||||
|
||||
booster.save_model(model, os.path.join(save_dir, "modeling"), shard=True)
|
||||
if use_lora:
|
||||
booster.save_lora_as_pretrained(model, os.path.join(save_dir, "modeling"))
|
||||
else:
|
||||
booster.save_model(model, os.path.join(save_dir, "modeling"), shard=True)
|
||||
|
||||
booster.save_optimizer(optimizer, os.path.join(save_dir, "optimizer"), shard=True)
|
||||
booster.save_lr_scheduler(lr_scheduler, os.path.join(save_dir, "lr_scheduler"))
|
||||
|
||||
@ -1,352 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import math
|
||||
from types import MethodType
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
from transformers.models.llama.configuration_llama import LlamaConfig
|
||||
from transformers.models.llama.modeling_llama import (
|
||||
LlamaAttention,
|
||||
LlamaForCausalLM,
|
||||
LlamaModel,
|
||||
LlamaRMSNorm,
|
||||
apply_rotary_pos_emb,
|
||||
repeat_kv,
|
||||
)
|
||||
|
||||
from colossalai.accelerator import get_accelerator
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
if get_accelerator().name == "cuda":
|
||||
from flash_attn.bert_padding import pad_input, unpad_input
|
||||
from flash_attn.flash_attn_interface import flash_attn_func, flash_attn_varlen_kvpacked_func
|
||||
from flash_attn.ops.rms_norm import rms_norm
|
||||
|
||||
def _prepare_decoder_attention_mask(
|
||||
self: LlamaModel,
|
||||
attention_mask: torch.BoolTensor,
|
||||
input_shape: torch.Size,
|
||||
inputs_embeds: torch.Tensor,
|
||||
past_key_values_length: int,
|
||||
) -> Optional[torch.Tensor]:
|
||||
"""
|
||||
Decoder attetion mask
|
||||
"""
|
||||
if past_key_values_length > 0 and attention_mask is not None:
|
||||
attention_mask = torch.cat(
|
||||
tensors=(
|
||||
torch.full(
|
||||
size=(input_shape[0], past_key_values_length),
|
||||
fill_value=True,
|
||||
dtype=attention_mask.dtype,
|
||||
device=attention_mask.device,
|
||||
),
|
||||
attention_mask,
|
||||
),
|
||||
dim=-1,
|
||||
) # (bsz, past_key_values_length + q_len)
|
||||
if attention_mask is not None and torch.all(attention_mask):
|
||||
return None # Faster
|
||||
return attention_mask
|
||||
|
||||
def attention_forward(
|
||||
self: LlamaAttention,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
"""
|
||||
Re-define LLaMA-2 `LlamaAttention` forward method using flash-attention.
|
||||
"""
|
||||
if output_attentions:
|
||||
logger.warning(
|
||||
"Argument `output_attentions` is not supported for flash-attention patched `LlamaAttention`, "
|
||||
"return `None` instead."
|
||||
)
|
||||
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
if self.config.pretraining_tp > 1:
|
||||
q_slicing, kv_slicing = (
|
||||
dim // self.config.pretraining_tp
|
||||
for dim in (
|
||||
self.num_heads * self.head_dim,
|
||||
self.num_key_value_heads * self.head_dim,
|
||||
)
|
||||
) # `Tuple[int, int]`
|
||||
q_slices, k_slices, v_slices = (
|
||||
proj.weight.split(slicing, dim=0)
|
||||
for proj, slicing in (
|
||||
(self.q_proj, q_slicing),
|
||||
(self.k_proj, kv_slicing),
|
||||
(self.v_proj, kv_slicing),
|
||||
)
|
||||
) # Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor], Tuple[torch.Tensor]]
|
||||
q, k, v = (
|
||||
torch.cat(
|
||||
[F.linear(hidden_states, slices[i]) for i in range(self.config.pretraining_tp)],
|
||||
dim=-1,
|
||||
)
|
||||
for slices in (q_slices, k_slices, v_slices)
|
||||
)
|
||||
# `Tuple[torch.Tensor, torch.Tensor, torch.Tensor]` of shape:
|
||||
# (bsz, q_len, num_heads * head_dim),
|
||||
# (bsz, q_len, num_key_value_heads * head_dim),
|
||||
# (bsz, q_len, num_key_value_heads * head_dim)
|
||||
else:
|
||||
q, k, v = (proj(hidden_states) for proj in (self.q_proj, self.k_proj, self.v_proj))
|
||||
# `Tuple[torch.Tensor, torch.Tensor, torch.Tensor]` of shape:
|
||||
# (bsz, q_len, num_heads * head_dim),
|
||||
# (bsz, q_len, num_key_value_heads * head_dim),
|
||||
# (bsz, q_len, num_key_value_heads * head_dim)
|
||||
|
||||
# (bsz, q_len, num_heads * head_dim) -> (bsz, num_heads, q_len, head_dim);
|
||||
# (bsz, q_len, num_key_value_heads * head_dim) -> (bsz, num_key_value_heads, q_len, head_dim);
|
||||
# (bsz, q_len, num_key_value_heads * head_dim) -> (bsz, num_key_value_heads, q_len, head_dim)
|
||||
q, k, v = (
|
||||
states.view(bsz, q_len, num_heads, self.head_dim).transpose(1, 2)
|
||||
for states, num_heads in (
|
||||
(q, self.num_heads),
|
||||
(k, self.num_key_value_heads),
|
||||
(v, self.num_key_value_heads),
|
||||
)
|
||||
)
|
||||
kv_len = k.shape[-2] # initially, `kv_len` == `q_len`
|
||||
past_kv_len = 0
|
||||
if past_key_value is not None:
|
||||
# if `past_key_value` is not None, `kv_len` > `q_len`.
|
||||
past_kv_len = past_key_value[0].shape[-2]
|
||||
kv_len += past_kv_len
|
||||
|
||||
# two `torch.Tensor` objs of shape (1, 1, kv_len, head_dim)
|
||||
cos, sin = self.rotary_emb(v, seq_len=kv_len)
|
||||
# (bsz, num_heads, q_len, head_dim), (bsz, num_key_value_heads, q_len, head_dim)
|
||||
q, k = apply_rotary_pos_emb(q=q, k=k, cos=cos, sin=sin, position_ids=position_ids)
|
||||
if past_key_value is not None:
|
||||
# reuse k, v, self_attention
|
||||
k = torch.cat([past_key_value[0], k], dim=2)
|
||||
v = torch.cat([past_key_value[1], v], dim=2)
|
||||
|
||||
past_key_value = (k, v) if use_cache else None
|
||||
|
||||
# repeat k/v heads if n_kv_heads < n_heads
|
||||
k = repeat_kv(hidden_states=k, n_rep=self.num_key_value_groups)
|
||||
# (bsz, num_key_value_heads, q_len, head_dim) -> (bsz, num_heads, q_len, head_dim)
|
||||
v = repeat_kv(hidden_states=v, n_rep=self.num_key_value_groups)
|
||||
# (bsz, num_key_value_heads, q_len, head_dim) -> (bsz, num_heads, q_len, head_dim)
|
||||
|
||||
key_padding_mask = attention_mask
|
||||
# (bsz, num_heads, q_len, head_dim) -> (bsz, q_len, num_heads, head_dim)
|
||||
q, k, v = (states.transpose(1, 2) for states in (q, k, v))
|
||||
|
||||
if past_kv_len > 0:
|
||||
q = torch.cat(
|
||||
tensors=(
|
||||
torch.full(
|
||||
size=(bsz, past_kv_len, self.num_heads, self.head_dim),
|
||||
fill_value=0.0,
|
||||
dtype=q.dtype,
|
||||
device=q.device,
|
||||
),
|
||||
q,
|
||||
),
|
||||
dim=1,
|
||||
) # (bsz, past_kv_len + q_len, num_heads, head_dim)
|
||||
|
||||
if key_padding_mask is None:
|
||||
# (bsz, past_kv_len + q_len, num_heads, head_dim)
|
||||
output = flash_attn_func(q=q, k=k, v=v, dropout_p=0.0, softmax_scale=None, causal=True) # (bsz, )
|
||||
output = rearrange(
|
||||
output, pattern="... h d -> ... (h d)"
|
||||
) # (bsz, past_kv_len + q_len, num_heads * head_dim)
|
||||
else:
|
||||
q, indices, cu_q_lens, max_q_len = unpad_input(hidden_states=q, attention_mask=key_padding_mask)
|
||||
kv, _, cu_kv_lens, max_kv_len = unpad_input(
|
||||
hidden_states=torch.stack(tensors=(k, v), dim=2),
|
||||
attention_mask=key_padding_mask,
|
||||
)
|
||||
output_unpad = flash_attn_varlen_kvpacked_func(
|
||||
q=q,
|
||||
kv=kv,
|
||||
cu_seqlens_q=cu_q_lens,
|
||||
cu_seqlens_k=cu_kv_lens,
|
||||
max_seqlen_q=max_q_len,
|
||||
max_seqlen_k=max_kv_len,
|
||||
dropout_p=0.0,
|
||||
softmax_scale=None,
|
||||
causal=True,
|
||||
)
|
||||
output = pad_input(
|
||||
hidden_states=rearrange(output_unpad, pattern="nnz h d -> nnz (h d)"),
|
||||
indices=indices,
|
||||
batch=bsz,
|
||||
seqlen=past_kv_len + q_len,
|
||||
) # (bsz, past_kv_len + q_len, num_heads * head_dim)
|
||||
|
||||
if past_kv_len > 0:
|
||||
# Strip off the zero query outputs.
|
||||
output = output[:, past_kv_len:, ...] # (bsz, q_len, num_heads * head_dim)
|
||||
output = self.o_proj(output) # (bsz, q_len, hidden_size)
|
||||
return output, None, past_key_value
|
||||
|
||||
def rms_norm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Formard function for RMS Norm
|
||||
"""
|
||||
return rms_norm(x=hidden_states, weight=self.weight, epsilon=self.variance_epsilon)
|
||||
|
||||
def replace_with_flash_attention(model: LlamaForCausalLM) -> None:
|
||||
for name, module in model.named_modules():
|
||||
if isinstance(module, LlamaAttention):
|
||||
module.forward = MethodType(attention_forward, module)
|
||||
if isinstance(module, LlamaModel):
|
||||
module._prepare_decoder_attention_mask = MethodType(_prepare_decoder_attention_mask, module)
|
||||
if isinstance(module, LlamaRMSNorm):
|
||||
module.forward = MethodType(rms_norm_forward, module)
|
||||
|
||||
elif get_accelerator().name == "npu":
|
||||
import torch_npu
|
||||
|
||||
class NPULlamaAttention(LlamaAttention):
|
||||
use_flash: bool = True
|
||||
|
||||
def __init__(self, config: LlamaConfig):
|
||||
super().__init__(config)
|
||||
self.setup()
|
||||
|
||||
def setup(self):
|
||||
self._softmax_scale = 1 / math.sqrt(self.head_dim)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
if self.config.pretraining_tp > 1:
|
||||
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
|
||||
query_slices = self.q_proj.weight.split(
|
||||
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
|
||||
)
|
||||
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
||||
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
||||
|
||||
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
query_states = torch.cat(query_states, dim=-1)
|
||||
|
||||
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
key_states = torch.cat(key_states, dim=-1)
|
||||
|
||||
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
value_states = torch.cat(value_states, dim=-1)
|
||||
|
||||
else:
|
||||
query_states = self.q_proj(hidden_states)
|
||||
key_states = self.k_proj(hidden_states)
|
||||
value_states = self.v_proj(hidden_states)
|
||||
|
||||
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
kv_seq_len = key_states.shape[-2]
|
||||
if past_key_value is not None:
|
||||
kv_seq_len += past_key_value[0].shape[-2]
|
||||
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
||||
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
||||
|
||||
if past_key_value is not None:
|
||||
# reuse k, v, self_attention
|
||||
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
||||
|
||||
past_key_value = (key_states, value_states) if use_cache else None
|
||||
|
||||
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
||||
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
||||
|
||||
if not self.use_flash:
|
||||
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
||||
|
||||
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
||||
f" {attn_weights.size()}"
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
||||
)
|
||||
attn_weights = attn_weights + attention_mask
|
||||
|
||||
# upcast attention to fp32
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
else:
|
||||
attn_output, *_ = torch_npu.npu_fusion_attention(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
self.num_heads,
|
||||
"BNSD",
|
||||
atten_mask=attention_mask.bool(),
|
||||
scale=self._softmax_scale,
|
||||
padding_mask=None,
|
||||
pre_tockens=65535,
|
||||
next_tockens=0,
|
||||
keep_prob=1.0,
|
||||
inner_precise=0,
|
||||
)
|
||||
|
||||
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
||||
raise ValueError(
|
||||
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
||||
f" {attn_output.size()}"
|
||||
)
|
||||
|
||||
attn_output = attn_output.transpose(1, 2).contiguous()
|
||||
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
||||
|
||||
if self.config.pretraining_tp > 1:
|
||||
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
|
||||
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
|
||||
attn_output = sum(
|
||||
[F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
)
|
||||
else:
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
if not output_attentions:
|
||||
attn_weights = None
|
||||
|
||||
return attn_output, attn_weights, past_key_value
|
||||
|
||||
class NPURMSNorm(LlamaRMSNorm):
|
||||
def forward(self, hidden_states):
|
||||
return torch_npu.npu_rms_norm(hidden_states, self.weight, epsilon=self.variance_epsilon)[0]
|
||||
|
||||
def replace_with_flash_attention(model: LlamaForCausalLM) -> None:
|
||||
for name, module in model.named_modules():
|
||||
if isinstance(module, LlamaAttention):
|
||||
module.__class__ = NPULlamaAttention
|
||||
module.setup()
|
||||
if isinstance(module, LlamaRMSNorm):
|
||||
module.__class__ = NPURMSNorm
|
||||
36
applications/Colossal-LLaMA/colossal_llama/utils/utils.py
Normal file
36
applications/Colossal-LLaMA/colossal_llama/utils/utils.py
Normal file
@ -0,0 +1,36 @@
|
||||
"""
|
||||
Utils for Colossal-LLaMA
|
||||
"""
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
|
||||
from colossalai.booster import Plugin
|
||||
|
||||
|
||||
def all_reduce_mean(tensor: torch.Tensor, plugin: Plugin = None) -> torch.Tensor:
|
||||
if plugin is not None:
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM, group=plugin.dp_group)
|
||||
tensor.div_(plugin.dp_size)
|
||||
else:
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
tensor.div_(dist.get_world_size())
|
||||
return tensor
|
||||
|
||||
|
||||
def get_model_numel(model: torch.nn.Module) -> int:
|
||||
return sum(p.numel() for p in model.parameters())
|
||||
|
||||
|
||||
def format_numel_str(numel: int) -> str:
|
||||
B = 1024**3
|
||||
M = 1024**2
|
||||
K = 1024
|
||||
if numel >= B:
|
||||
return f"{numel / B:.2f} B"
|
||||
elif numel >= M:
|
||||
return f"{numel / M:.2f} M"
|
||||
elif numel >= K:
|
||||
return f"{numel / K:.2f} K"
|
||||
else:
|
||||
return f"{numel}"
|
||||
@ -10,7 +10,7 @@ import math
|
||||
import os
|
||||
from multiprocessing import cpu_count
|
||||
|
||||
from colossal_llama.dataset.conversation import LLaMA2_Conv
|
||||
from colossal_llama.dataset.conversation import LLaMA2_Conv, LLaMA3_Conv
|
||||
from colossal_llama.dataset.spliced_and_tokenized_dataset import supervised_tokenize_sft
|
||||
from datasets import dataset_dict, load_dataset
|
||||
from transformers import AddedToken, AutoTokenizer
|
||||
@ -75,6 +75,8 @@ def main():
|
||||
# Prepare to the tokenizer.
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir)
|
||||
|
||||
default_conversation = LLaMA3_Conv
|
||||
|
||||
# Fix </s> split issue: https://github.com/huggingface/transformers/issues/23833
|
||||
if args.llama_version == 2:
|
||||
tokenizer.add_tokens(AddedToken("</s>", normalized=False, special=True), special_tokens=True)
|
||||
@ -1,15 +1,15 @@
|
||||
torch==2.1.2
|
||||
huggingface-hub
|
||||
packaging==24.0
|
||||
colossalai==0.3.6
|
||||
colossalai>=0.4.0
|
||||
autoflake==2.2.1
|
||||
black==23.9.1
|
||||
transformers==4.34.1
|
||||
transformers>=4.39.3
|
||||
tensorboard==2.14.0
|
||||
six==1.16.0
|
||||
datasets
|
||||
ninja==1.11.1
|
||||
flash-attn>=2.0.0,<=2.0.5
|
||||
flash-attn
|
||||
tqdm
|
||||
sentencepiece==0.1.99
|
||||
protobuf<=3.20.0
|
||||
|
||||
37
applications/Colossal-LLaMA/setup.py
Normal file
37
applications/Colossal-LLaMA/setup.py
Normal file
@ -0,0 +1,37 @@
|
||||
from setuptools import find_packages, setup
|
||||
|
||||
|
||||
def fetch_requirements(path):
|
||||
with open(path, "r") as fd:
|
||||
return [r.strip() for r in fd.readlines()]
|
||||
|
||||
|
||||
def fetch_readme():
|
||||
with open("README.md", encoding="utf-8") as f:
|
||||
return f.read()
|
||||
|
||||
|
||||
def fetch_version():
|
||||
with open("version.txt", "r") as f:
|
||||
return f.read().strip()
|
||||
|
||||
|
||||
setup(
|
||||
name="colossal_llama",
|
||||
version=fetch_version(),
|
||||
packages=find_packages(exclude=("*.egg-info",)),
|
||||
description="Continual Pre-training and SFT for LLaMA",
|
||||
long_description=fetch_readme(),
|
||||
long_description_content_type="text/markdown",
|
||||
license="Apache Software License 2.0",
|
||||
url="https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA",
|
||||
install_requires=fetch_requirements("requirements.txt"),
|
||||
python_requires=">=3.7",
|
||||
classifiers=[
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Environment :: GPU :: NVIDIA CUDA",
|
||||
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||
"Topic :: System :: Distributed Computing",
|
||||
],
|
||||
)
|
||||
@ -1,13 +1,20 @@
|
||||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
|
||||
# NCCL IB environment variables
|
||||
export NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1
|
||||
export NCCL_IB_DISABLE=0
|
||||
export NCCL_SOCKET_IFNAME=eth0
|
||||
export NCCL_IB_GID_INDEX=3
|
||||
export NCCL_IB_TIMEOUT=23
|
||||
export NCCL_IB_RETRY_CNT=7
|
||||
export OMP_NUM_THREADS=8
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 8
|
||||
|
||||
PROJECT_NAME=""
|
||||
PARENT_SAVE_DIR=""
|
||||
|
||||
@ -11,24 +11,25 @@ import resource
|
||||
from contextlib import nullcontext
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from colossal_llama.dataset.dummy_dataset import RandomDataset
|
||||
from colossal_llama.dataset.loader import (
|
||||
DataCollatorForSupervisedDataset,
|
||||
StatefulDistributedSampler,
|
||||
load_tokenized_dataset,
|
||||
)
|
||||
from colossal_llama.utils.ckpt_io import load_checkpoint, save_checkpoint
|
||||
from colossal_llama.utils.flash_attention_patch import replace_with_flash_attention
|
||||
from colossal_llama.utils.froze import freeze_non_embeds_parameters
|
||||
from colossal_llama.utils.neftune_patch import activate_neftune, deactivate_neftune
|
||||
from colossal_llama.utils.utils import all_reduce_mean, format_numel_str, get_model_numel
|
||||
from peft import LoraConfig
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer, LlamaForCausalLM
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import colossalai
|
||||
from colossalai.accelerator import get_accelerator
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
|
||||
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.lazy import LazyInitContext
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||
@ -36,103 +37,7 @@ from colossalai.nn.optimizer import HybridAdam
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
|
||||
def get_model_numel(model: torch.nn.Module) -> int:
|
||||
return sum(p.numel() for p in model.parameters())
|
||||
|
||||
|
||||
def format_numel_str(numel: int) -> str:
|
||||
B = 1024**3
|
||||
M = 1024**2
|
||||
K = 1024
|
||||
if numel >= B:
|
||||
return f"{numel / B:.2f} B"
|
||||
elif numel >= M:
|
||||
return f"{numel / M:.2f} M"
|
||||
elif numel >= K:
|
||||
return f"{numel / K:.2f} K"
|
||||
else:
|
||||
return f"{numel}"
|
||||
|
||||
|
||||
def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
tensor = tensor.data
|
||||
tensor.div_(dist.get_world_size())
|
||||
return tensor
|
||||
|
||||
|
||||
def main() -> None:
|
||||
# ==============================
|
||||
# Parse Arguments
|
||||
# ==============================
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--pretrained",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Address of the pre-trained modeling",
|
||||
)
|
||||
parser.add_argument("--dataset", nargs="+", default=[])
|
||||
parser.add_argument(
|
||||
"--plugin",
|
||||
type=str,
|
||||
default="gemini",
|
||||
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d"],
|
||||
help="Choose which plugin to use",
|
||||
)
|
||||
parser.add_argument("--load_checkpoint", type=str, default=None, help="Load checkpoint")
|
||||
parser.add_argument("--save_interval", type=int, default=1000, help="Save interval")
|
||||
parser.add_argument("--save_dir", type=str, default="checkpoint_dir", help="Checkpoint directory")
|
||||
parser.add_argument("--tensorboard_dir", type=str, default="logs_dir", help="Tensorboard directory")
|
||||
parser.add_argument("--config_file", type=str, default="config_file", help="Config file")
|
||||
parser.add_argument("--num_epochs", type=int, default=1, help="Number of training epochs")
|
||||
parser.add_argument("--accumulation_steps", type=int, default=1, help="Number of accumulation steps")
|
||||
parser.add_argument("--micro_batch_size", type=int, default=2, help="Batch size of each process")
|
||||
parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate")
|
||||
parser.add_argument("--max_length", type=int, default=8192, help="Model max length")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="fp16",
|
||||
choices=["fp16", "bf16"],
|
||||
help="Mixed precision",
|
||||
)
|
||||
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||
parser.add_argument(
|
||||
"--use_grad_checkpoint",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use gradient checkpointing",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_flash_attn",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use flash-attention",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_neft",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use NEFTune",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--freeze_non_embeds_params",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Freeze non embeddings parameters",
|
||||
)
|
||||
parser.add_argument("--tp", type=int, default=1)
|
||||
parser.add_argument("--zero", type=int, default=1)
|
||||
parser.add_argument("--pad_token", choices=["eos", "unk"], default="eos")
|
||||
parser.add_argument("--padding_mode", choices=["max_length", "longest"], default="max_length")
|
||||
args = parser.parse_args()
|
||||
|
||||
with open(args.config_file, "w") as f:
|
||||
json.dump(args.__dict__, f, indent=4)
|
||||
|
||||
def train(args) -> None:
|
||||
# ==============================
|
||||
# Initialize Distributed Training
|
||||
# ==============================
|
||||
@ -141,21 +46,28 @@ def main() -> None:
|
||||
coordinator = DistCoordinator()
|
||||
|
||||
# ==============================
|
||||
# Initialize Tensorboard
|
||||
# Initialize Tensorboard and Save Config
|
||||
# ==============================
|
||||
if coordinator.is_master():
|
||||
os.makedirs(args.tensorboard_dir, exist_ok=True)
|
||||
writer = SummaryWriter(args.tensorboard_dir)
|
||||
|
||||
with open(args.config_file, "w") as f:
|
||||
json.dump(args.__dict__, f, indent=4)
|
||||
|
||||
# ==============================
|
||||
# Initialize Booster
|
||||
# ==============================
|
||||
if args.plugin == "gemini":
|
||||
if args.plugin == "ddp":
|
||||
plugin = TorchDDPPlugin(find_unused_parameters=True if args.use_grad_checkpoint is False else False)
|
||||
elif args.plugin == "gemini":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_gradient_accumulation=(args.accumulation_steps > 1),
|
||||
enable_fused_normalization=get_accelerator().is_available(),
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "gemini_auto":
|
||||
plugin = GeminiPlugin(
|
||||
@ -164,6 +76,8 @@ def main() -> None:
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_gradient_accumulation=(args.accumulation_steps > 1),
|
||||
enable_fused_normalization=get_accelerator().is_available(),
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "zero2":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
@ -183,10 +97,17 @@ def main() -> None:
|
||||
elif args.plugin == "3d":
|
||||
plugin = HybridParallelPlugin(
|
||||
tp_size=args.tp,
|
||||
pp_size=1,
|
||||
zero_stage=args.zero,
|
||||
pp_size=args.pp,
|
||||
sp_size=args.sp,
|
||||
sequence_parallelism_mode=args.sp_mode,
|
||||
zero_stage=args.zero_stage,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
enable_fused_normalization=get_accelerator().is_available(),
|
||||
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||
max_norm=args.grad_clip,
|
||||
precision=args.mixed_precision,
|
||||
microbatch_size=args.microbatch_size,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||
@ -196,32 +117,52 @@ def main() -> None:
|
||||
# ======================================================
|
||||
# Initialize Tokenizer, Dataset, Collator and Dataloader
|
||||
# ======================================================
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrained, trust_remote_code=True)
|
||||
if args.pad_token == "eos":
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
try:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
except AttributeError:
|
||||
coordinator.print_on_master(f"pad_token can't be set")
|
||||
elif args.pad_token == "unk":
|
||||
tokenizer.pad_token = tokenizer.unk_token
|
||||
try:
|
||||
tokenizer.pad_token = tokenizer.unk_token
|
||||
except AttributeError:
|
||||
coordinator.print_on_master(f"pad_token can't be set")
|
||||
tokenizer.add_bos_token = False
|
||||
tokenizer.add_eos_token = False
|
||||
|
||||
coordinator.print_on_master(f"Configuration file will be saved at: {args.config_file}")
|
||||
coordinator.print_on_master(f"Tensorboard logs will be saved at: {args.tensorboard_dir}")
|
||||
coordinator.print_on_master(f"Model checkpoint will be saved at: {args.save_dir}")
|
||||
|
||||
coordinator.print_on_master(f"Load dataset: {args.dataset}")
|
||||
|
||||
dataset = load_tokenized_dataset(dataset_paths=args.dataset, mode="train")
|
||||
data_collator = DataCollatorForSupervisedDataset(
|
||||
tokenizer=tokenizer, max_length=args.max_length, padding=args.padding_mode
|
||||
)
|
||||
dataloader = plugin.prepare_dataloader(
|
||||
dataset=dataset,
|
||||
batch_size=args.micro_batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
distributed_sampler_cls=StatefulDistributedSampler,
|
||||
coordinator.print_on_master(
|
||||
f"Training Info:\nConfig file: {args.config_file} \nTensorboard logs: {args.tensorboard_dir} \nModel checkpoint: {args.save_dir}"
|
||||
)
|
||||
|
||||
if args.benchmark:
|
||||
coordinator.print_on_master(f"Run benchmark with {args.num_samples} random samples.")
|
||||
dataset = RandomDataset(
|
||||
num_samples=args.num_samples, max_length=args.max_length, vocab_size=tokenizer.vocab_size
|
||||
)
|
||||
dataloader = plugin.prepare_dataloader(
|
||||
dataset,
|
||||
batch_size=args.batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
seed=42,
|
||||
distributed_sampler_cls=StatefulDistributedSampler,
|
||||
)
|
||||
else:
|
||||
coordinator.print_on_master(f"Load dataset: {args.dataset}")
|
||||
dataset = load_tokenized_dataset(dataset_paths=args.dataset, mode="train")
|
||||
data_collator = DataCollatorForSupervisedDataset(
|
||||
tokenizer=tokenizer, max_length=args.max_length, padding=args.padding_mode
|
||||
)
|
||||
dataloader = plugin.prepare_dataloader(
|
||||
dataset=dataset,
|
||||
batch_size=args.batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
distributed_sampler_cls=StatefulDistributedSampler,
|
||||
)
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Max device memory after data loader: {accelerator.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
@ -229,25 +170,32 @@ def main() -> None:
|
||||
# ======================================================
|
||||
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||
# ======================================================
|
||||
# When training the ChatGLM model, LoRA and gradient checkpointing are incompatible.
|
||||
init_ctx = (
|
||||
LazyInitContext(default_device=get_current_device())
|
||||
if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
|
||||
if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin)) and args.lora_rank == 0
|
||||
else nullcontext()
|
||||
)
|
||||
with init_ctx:
|
||||
model = LlamaForCausalLM.from_pretrained(args.pretrained)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.pretrained,
|
||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||
trust_remote_code=True,
|
||||
)
|
||||
# Freeze part of parameters.
|
||||
if args.freeze_non_embeds_params:
|
||||
freeze_non_embeds_parameters(model=model)
|
||||
|
||||
if args.lora_rank > 0:
|
||||
lora_config = LoraConfig(task_type="CAUSAL_LM", r=args.lora_rank, lora_alpha=32, lora_dropout=0.1)
|
||||
model = booster.enable_lora(model, lora_config=lora_config)
|
||||
|
||||
# this is essential, otherwise the grad checkpoint will not work.
|
||||
model.train()
|
||||
|
||||
if args.use_grad_checkpoint:
|
||||
model.gradient_checkpointing_enable()
|
||||
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={"use_reentrant": False})
|
||||
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||
if args.use_flash_attn:
|
||||
replace_with_flash_attention(model=model)
|
||||
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
||||
|
||||
model_numel = get_model_numel(model)
|
||||
coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
|
||||
@ -336,74 +284,137 @@ def main() -> None:
|
||||
|
||||
for epoch in range(start_epoch, args.num_epochs):
|
||||
dataloader.sampler.set_epoch(epoch=epoch)
|
||||
pbar = tqdm(
|
||||
desc=f"Epoch {epoch}",
|
||||
disable=not coordinator.is_master(),
|
||||
total=num_steps_per_epoch,
|
||||
initial=start_step // args.accumulation_steps,
|
||||
)
|
||||
total_loss = torch.tensor(0.0, device=get_current_device())
|
||||
for step, batch in enumerate(dataloader, start=start_step):
|
||||
batch = {k: v.to(get_current_device()) for k, v in batch.items() if isinstance(v, torch.Tensor)}
|
||||
|
||||
batch_output = model(**batch)
|
||||
|
||||
loss = batch_output.loss / args.accumulation_steps
|
||||
total_loss.add_(loss.data)
|
||||
|
||||
booster.backward(loss=loss, optimizer=optimizer)
|
||||
|
||||
if (step + 1) % args.accumulation_steps == 0:
|
||||
if isinstance(plugin, HybridParallelPlugin) and plugin.pp_size > 1:
|
||||
data_iter = iter(dataloader)
|
||||
step_bar = tqdm(
|
||||
range(len(dataloader)),
|
||||
desc="Step",
|
||||
disable=not (coordinator._local_rank == coordinator._world_size - 1),
|
||||
)
|
||||
for step in step_bar:
|
||||
outputs = booster.execute_pipeline(
|
||||
data_iter,
|
||||
model,
|
||||
criterion=lambda outputs, inputs: outputs[0],
|
||||
optimizer=optimizer,
|
||||
return_loss=True,
|
||||
)
|
||||
loss = outputs["loss"]
|
||||
if booster.plugin.stage_manager.is_last_stage():
|
||||
global_loss = all_reduce_mean(loss, plugin)
|
||||
if coordinator._local_rank == coordinator._world_size - 1:
|
||||
step_bar.set_postfix({"train/loss": global_loss.item()})
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
all_reduce_mean(tensor=total_loss)
|
||||
pbar.set_postfix({"Loss": f"{total_loss.item():.4f}"})
|
||||
if coordinator.is_master():
|
||||
global_step = (epoch * num_steps_per_epoch) + (step + 1) // args.accumulation_steps
|
||||
writer.add_scalar(tag="Loss", scalar_value=total_loss.item(), global_step=global_step)
|
||||
writer.add_scalar(
|
||||
tag="Learning Rate",
|
||||
scalar_value=lr_scheduler.get_last_lr()[0],
|
||||
global_step=global_step,
|
||||
# Save modeling.
|
||||
save_model_condition = args.save_interval > 0 and (step + 1) % args.save_interval == 0
|
||||
|
||||
if not args.skip_save_each_epoch:
|
||||
save_model_condition = save_model_condition or (step + 1) == len(dataloader)
|
||||
|
||||
if save_model_condition and not args.benchmark:
|
||||
coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Deactivate NEFTune before saving model.")
|
||||
deactivate_neftune(model, handle)
|
||||
|
||||
accelerator.empty_cache()
|
||||
save_checkpoint(
|
||||
save_dir=args.save_dir,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optimizer,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=epoch,
|
||||
step=step + 1,
|
||||
batch_size=args.batch_size,
|
||||
coordinator=coordinator,
|
||||
use_lora=(args.lora_rank > 0),
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {step + 1} at folder {args.save_dir}"
|
||||
)
|
||||
total_loss.fill_(0.0)
|
||||
pbar.update()
|
||||
# Save modeling.
|
||||
|
||||
if (args.save_interval > 0 and (step + 1) % (args.save_interval * args.accumulation_steps) == 0) or (
|
||||
step + 1
|
||||
) == len(dataloader):
|
||||
coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Activate NEFTune.")
|
||||
model, handle = activate_neftune(model)
|
||||
else:
|
||||
pbar = tqdm(
|
||||
desc=f"Epoch {epoch}",
|
||||
disable=not coordinator.is_master(),
|
||||
total=num_steps_per_epoch,
|
||||
initial=start_step // args.accumulation_steps,
|
||||
)
|
||||
total_loss = torch.tensor(0.0, device=get_current_device())
|
||||
for step, batch in enumerate(dataloader, start=start_step):
|
||||
batch = {k: v.to(get_current_device()) for k, v in batch.items() if isinstance(v, torch.Tensor)}
|
||||
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Deactivate NEFTune before saving model.")
|
||||
deactivate_neftune(model, handle)
|
||||
batch_output = model(**batch)
|
||||
|
||||
accelerator.empty_cache()
|
||||
save_checkpoint(
|
||||
save_dir=args.save_dir,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optimizer,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=epoch,
|
||||
step=step + 1,
|
||||
batch_size=args.micro_batch_size,
|
||||
coordinator=coordinator,
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {step + 1} at folder {args.save_dir}"
|
||||
loss = batch_output.loss / args.accumulation_steps
|
||||
total_loss.add_(loss.data)
|
||||
|
||||
booster.backward(loss=loss, optimizer=optimizer)
|
||||
|
||||
if (step + 1) % args.accumulation_steps == 0:
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
all_reduce_mean(tensor=total_loss)
|
||||
pbar.set_postfix({"Loss": f"{total_loss.item():.4f}"})
|
||||
if coordinator.is_master():
|
||||
global_step = (epoch * num_steps_per_epoch) + (step + 1) // args.accumulation_steps
|
||||
writer.add_scalar(tag="Loss", scalar_value=total_loss.item(), global_step=global_step)
|
||||
writer.add_scalar(
|
||||
tag="Learning Rate",
|
||||
scalar_value=lr_scheduler.get_last_lr()[0],
|
||||
global_step=global_step,
|
||||
)
|
||||
total_loss.fill_(0.0)
|
||||
pbar.update()
|
||||
|
||||
# Save modeling.
|
||||
save_model_condition = (
|
||||
args.save_interval > 0 and (step + 1) % (args.save_interval * args.accumulation_steps) == 0
|
||||
)
|
||||
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Activate NEFTune.")
|
||||
model, handle = activate_neftune(model)
|
||||
if not args.skip_save_each_epoch:
|
||||
save_model_condition = save_model_condition or (step + 1) == len(dataloader)
|
||||
|
||||
# Delete cache.
|
||||
# del batch, batch_labels, batch_output, loss
|
||||
accelerator.empty_cache()
|
||||
if save_model_condition and not args.benchmark:
|
||||
coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Deactivate NEFTune before saving model.")
|
||||
deactivate_neftune(model, handle)
|
||||
|
||||
accelerator.empty_cache()
|
||||
save_checkpoint(
|
||||
save_dir=args.save_dir,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optimizer,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=epoch,
|
||||
step=step + 1,
|
||||
batch_size=args.batch_size,
|
||||
coordinator=coordinator,
|
||||
use_lora=(args.lora_rank > 0),
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {step + 1} at folder {args.save_dir}"
|
||||
)
|
||||
|
||||
if args.use_neft:
|
||||
coordinator.print_on_master("Activate NEFTune.")
|
||||
model, handle = activate_neftune(model)
|
||||
|
||||
# Delete cache.
|
||||
# del batch, batch_labels, batch_output, loss
|
||||
accelerator.empty_cache()
|
||||
|
||||
# the continue epochs are not resumed, so we need to reset the sampler start index and start step
|
||||
dataloader.sampler.set_start_index(start_index=0)
|
||||
@ -414,12 +425,115 @@ def main() -> None:
|
||||
deactivate_neftune(model, handle)
|
||||
|
||||
# Final save.
|
||||
coordinator.print_on_master("Start saving final model checkpoint")
|
||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||
coordinator.print_on_master(f"Saved final model checkpoint at epoch {epoch} at folder {args.save_dir}")
|
||||
if not args.benchmark:
|
||||
coordinator.print_on_master("Start saving final model checkpoint")
|
||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||
coordinator.print_on_master(f"Saved final model checkpoint at epoch {epoch} at folder {args.save_dir}")
|
||||
|
||||
coordinator.print_on_master(f"Max device memory usage: {accelerator.max_memory_allocated()/1024**2:.2f} MB")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
parser = argparse.ArgumentParser()
|
||||
# Basic training information.
|
||||
parser.add_argument(
|
||||
"--pretrained",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Address of the pre-trained model",
|
||||
)
|
||||
parser.add_argument("--load_checkpoint", type=str, default=None, help="Load checkpoint for continuous training.")
|
||||
parser.add_argument("--dataset", nargs="+", default=[])
|
||||
parser.add_argument(
|
||||
"--plugin",
|
||||
type=str,
|
||||
default="gemini",
|
||||
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d", "ddp"],
|
||||
help="Choose which plugin to use",
|
||||
)
|
||||
parser.add_argument("--save_interval", type=int, default=1000, help="Save interval")
|
||||
parser.add_argument("--save_dir", type=str, default="checkpoint_dir", help="Checkpoint directory")
|
||||
parser.add_argument("--tensorboard_dir", type=str, default="logs_dir", help="Tensorboard directory")
|
||||
parser.add_argument("--config_file", type=str, default="config_file", help="Config file")
|
||||
# Training parameters
|
||||
parser.add_argument("--num_epochs", type=int, default=1, help="Number of training epochs")
|
||||
parser.add_argument("--accumulation_steps", type=int, default=1, help="Number of accumulation steps")
|
||||
parser.add_argument("--batch_size", type=int, default=2, help="Global Batch size of each process")
|
||||
parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate")
|
||||
parser.add_argument("--max_length", type=int, default=8192, help="Model max length")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="fp16",
|
||||
choices=["fp16", "bf16"],
|
||||
help="Mixed precision",
|
||||
)
|
||||
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||
parser.add_argument(
|
||||
"--use_grad_checkpoint",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use gradient checkpointing",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_flash_attn",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use flash-attention",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_neft",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Use NEFTune",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--freeze_non_embeds_params",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Freeze non embeddings parameters",
|
||||
)
|
||||
parser.add_argument("--pad_token", choices=["eos", "unk"], default="eos")
|
||||
parser.add_argument("--padding_mode", choices=["max_length", "longest"], default="max_length")
|
||||
parser.add_argument(
|
||||
"--skip_save_each_epoch",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Skip saving the model checkpoint after each epoch is completed.",
|
||||
)
|
||||
|
||||
# Additional arguments for 3d plugin.
|
||||
parser.add_argument("--tp", type=int, default=1, help="TP size, used for 3d plugin.")
|
||||
parser.add_argument("--pp", type=int, default=1, help="PP size, used for 3d plugin.")
|
||||
parser.add_argument("--sp", type=int, default=1, help="SP size, used for 3d plugin.")
|
||||
parser.add_argument("--zero_stage", type=int, default=0, help="Zero stage, used for 3d plugin.", choices=[0, 1, 2])
|
||||
parser.add_argument(
|
||||
"--sp_mode",
|
||||
type=str,
|
||||
default="split_gather",
|
||||
choices=["split_gather", "ring", "all_to_all"],
|
||||
help="SP mode, used for 3d plugin.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--enable_sequence_parallelism",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="Whether to enable SP, used for 3d plugin.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--zero_cpu_offload", default=False, action="store_true", help="Whether to use offloading, used for 3d plugin."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--microbatch_size", type=int, default=1, help="Batch size for each process in PP, used for 3d plugin."
|
||||
)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="lora rank when using lora to train.")
|
||||
|
||||
# Additional arguments for benchmark.
|
||||
parser.add_argument("--num_samples", type=int, default=500, help="Number of samples for benchmarking.")
|
||||
parser.add_argument(
|
||||
"--benchmark", action="store_true", default=False, help="Benchmark performance using random dataset."
|
||||
)
|
||||
args = parser.parse_args()
|
||||
train(args)
|
||||
|
||||
@ -1 +1 @@
|
||||
1.0.0
|
||||
1.1.0
|
||||
|
||||
11
applications/ColossalChat/.gitignore
vendored
11
applications/ColossalChat/.gitignore
vendored
@ -146,14 +146,25 @@ docs/.build
|
||||
examples/wandb/
|
||||
examples/logs/
|
||||
examples/output/
|
||||
examples/training_scripts/logs
|
||||
examples/training_scripts/wandb
|
||||
examples/training_scripts/output
|
||||
|
||||
examples/awesome-chatgpt-prompts/
|
||||
examples/inference/round.txt
|
||||
temp/
|
||||
|
||||
# ColossalChat
|
||||
applications/ColossalChat/logs
|
||||
applications/ColossalChat/models
|
||||
applications/ColossalChat/sft_data
|
||||
applications/ColossalChat/kto_data
|
||||
applications/ColossalChat/prompt_data
|
||||
applications/ColossalChat/preference_data
|
||||
applications/ColossalChat/temp
|
||||
|
||||
# Testing data
|
||||
/kto_data/
|
||||
/preference_data/
|
||||
/prompt_data/
|
||||
/sft_data/
|
||||
|
||||
@ -7,29 +7,23 @@
|
||||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [What is ColossalChat and Coati ?](#what-is-colossalchat-and-coati-)
|
||||
- [What is ColossalChat?](#what-is-colossalchat)
|
||||
- [Online demo](#online-demo)
|
||||
- [Install](#install)
|
||||
- [Install the environment](#install-the-environment)
|
||||
- [Install the Transformers](#install-the-transformers)
|
||||
- [How to use?](#how-to-use)
|
||||
- [Introduction](#introduction)
|
||||
- [Supervised datasets collection](#step-1-data-collection)
|
||||
- [RLHF Training Stage1 - Supervised instructs tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||
- [RLHF Training Stage2 - Training reward model](#rlhf-training-stage2---training-reward-model)
|
||||
- [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#rlhf-training-stage3---proximal-policy-optimization)
|
||||
- [Alternative Option for RLHF: GRPO](#alternative-option-for-rlhf-group-relative-policy-optimization-grpo)
|
||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
||||
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
||||
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [SFT for DeepSeek V3/R1](#sft-for-deepseek-v3)
|
||||
- [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
|
||||
- [Coati7B examples](#coati7b-examples)
|
||||
- [Generation](#generation)
|
||||
- [Open QA](#open-qa)
|
||||
- [Limitation for LLaMA-finetuned models](#limitation)
|
||||
- [Limitation of dataset](#limitation)
|
||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization)
|
||||
- [FAQ](#faq)
|
||||
- [How to save/load checkpoint](#faq)
|
||||
- [How to train with limited resources](#faq)
|
||||
- [The Plan](#the-plan)
|
||||
- [Real-time progress](#real-time-progress)
|
||||
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
|
||||
- [Quick Preview](#quick-preview)
|
||||
- [Authors](#authors)
|
||||
@ -38,9 +32,9 @@
|
||||
|
||||
---
|
||||
|
||||
## What Is ColossalChat And Coati ?
|
||||
## What is ColossalChat?
|
||||
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) is the project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI) project.
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalChat) is a project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI).
|
||||
|
||||
Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
|
||||
|
||||
@ -51,8 +45,6 @@ The Coati package provides a unified large language model framework that has imp
|
||||
- Supervised instructions fine-tuning
|
||||
- Training reward model
|
||||
- Reinforcement learning with human feedback
|
||||
- Quantization inference
|
||||
- Fast model deploying
|
||||
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
|
||||
|
||||
<div align="center">
|
||||
@ -100,105 +92,28 @@ More details can be found in the latest news.
|
||||
conda create -n colossal-chat python=3.10.9 (>=3.8.7)
|
||||
conda activate colossal-chat
|
||||
|
||||
# Install flash-attention
|
||||
git clone -b v2.0.5 https://github.com/Dao-AILab/flash-attention.git
|
||||
cd $FLASH_ATTENTION_ROOT/
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/xentropy
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/layer_norm
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/rotary
|
||||
pip install .
|
||||
|
||||
# Clone Colossalai
|
||||
# Clone ColossalAI
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
|
||||
# Install ColossalAI
|
||||
# Install ColossalAI, make sure you have torch installed before using BUILD_EXT=1.
|
||||
cd $COLOSSAL_AI_ROOT
|
||||
BUILD_EXT=1 pip install .
|
||||
|
||||
# Install ColossalChat
|
||||
cd $COLOSSAL_AI_ROOT/applications/Chat
|
||||
cd $COLOSSAL_AI_ROOT/applications/ColossalChat
|
||||
pip install .
|
||||
```
|
||||
|
||||
## How To Use?
|
||||
## Introduction
|
||||
|
||||
### RLHF Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
#### Step 1: Data Collection
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
...
|
||||
]
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
|
||||
|
||||
In this code, we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the [example guideline](./examples/README.md) on how to format and tokenize data.
|
||||
|
||||
#### Step 3: Training
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./examples/training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. More details can be found in [example guideline](./examples/README.md).
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage2 - Training Reward Model
|
||||
|
||||
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
||||
|
||||
#### Step 1: Data Collection
|
||||
Below shows the preference dataset format used in training the reward model.
|
||||
|
||||
```json
|
||||
[
|
||||
{"context": [
|
||||
{
|
||||
"from": "human",
|
||||
"content": "Introduce butterflies species in Oregon."
|
||||
}
|
||||
]
|
||||
"chosen": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
|
||||
},
|
||||
...
|
||||
],
|
||||
"rejected": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
|
||||
},
|
||||
...
|
||||
]
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./examples/data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
|
||||
#### Step 3: Training
|
||||
You can run [train_rm.sh](./examples/training_scripts/train_rm.sh) to start the reward model training. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage3 - Proximal Policy Optimization
|
||||
|
||||
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
||||
@ -207,83 +122,25 @@ In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimi
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
||||
</p>
|
||||
|
||||
#### Step 1: Data Collection
|
||||
PPO uses two kind of training data--- the prompt data and the sft data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
}
|
||||
...
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Data Preprocessing
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./examples/data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
|
||||
#### Step 3: Training
|
||||
You can run the [train_ppo.sh](./examples/training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
```bash
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectual
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
|
||||
--prompt_dataset ${prompt_dataset[@]} \ # List of string, the prompt dataset
|
||||
--ptx_dataset ${ptx_dataset[@]} \ # List of string, the SFT data used in the SFT stage
|
||||
--ptx_batch_size 1 \ # batch size for calculate ptx loss
|
||||
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
|
||||
--num_episodes 2000 \ # number of episodes to train
|
||||
--num_collect_steps 1 \
|
||||
--num_update_steps 1 \
|
||||
--experience_batch_size 8 \
|
||||
--train_batch_size 4 \
|
||||
--accumulation_steps 2
|
||||
```
|
||||
|
||||
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameter of actor and critic.
|
||||
|
||||
- Without tensor parallelism,
|
||||
```
|
||||
experience buffer size
|
||||
= num_process * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_process
|
||||
```
|
||||
|
||||
- With tensor parallelism,
|
||||
```
|
||||
num_tp_group = num_process / tp
|
||||
experience buffer size
|
||||
= num_tp_group * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_tp_group
|
||||
```
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||
### Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### DPO Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Please refer the [sft section](#dpo-training-stage1---supervised-instructs-tuning) in the PPO part.
|
||||
|
||||
### DPO Training Stage2 - DPO Training
|
||||
#### Step 1: Data Collection & Preparation
|
||||
For DPO training, you only need the preference dataset. Please follow the instruction in the [preference dataset preparation section](#rlhf-training-stage2---training-reward-model) to prepare the preference data for DPO training.
|
||||
|
||||
#### Step 2: Training
|
||||
You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
## Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||
### Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||
Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||
### Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||
Odds Ratio Preference Optimization (ORPO) from this [paper](https://arxiv.org/pdf/2403.07691) is a reference model free alignment method that use a mixture of SFT loss and a reinforcement leanring loss calculated based on odds-ratio-based implicit reward to makes the training more efficient and stable. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### Alternative Option For RLHF: Group Relative Policy Optimization (GRPO)
|
||||
We support the main algorithm used to train DeepSeek R1 model, a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### SFT for DeepSeek V3
|
||||
We support fine-tuning DeepSeek V3/R1 model with LoRA. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### Inference Quantization and Serving - After Training
|
||||
|
||||
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
|
||||
@ -293,181 +150,7 @@ We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inferen
|
||||
Online inference server scripts can help you deploy your own services.
|
||||
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
## Coati7B examples
|
||||
|
||||
### Generation
|
||||
|
||||
<details><summary><b>E-mail</b></summary>
|
||||
|
||||
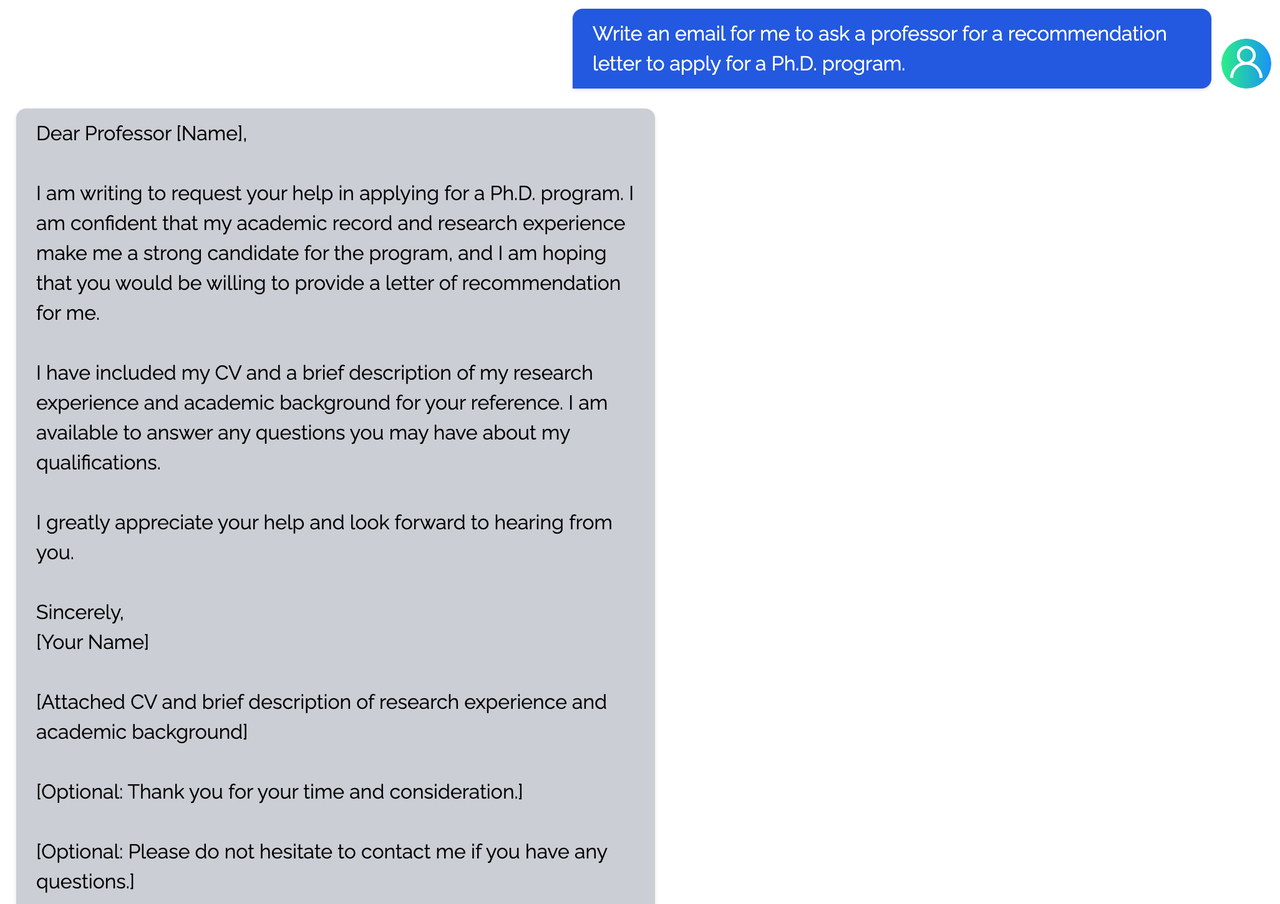
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>coding</b></summary>
|
||||
|
||||
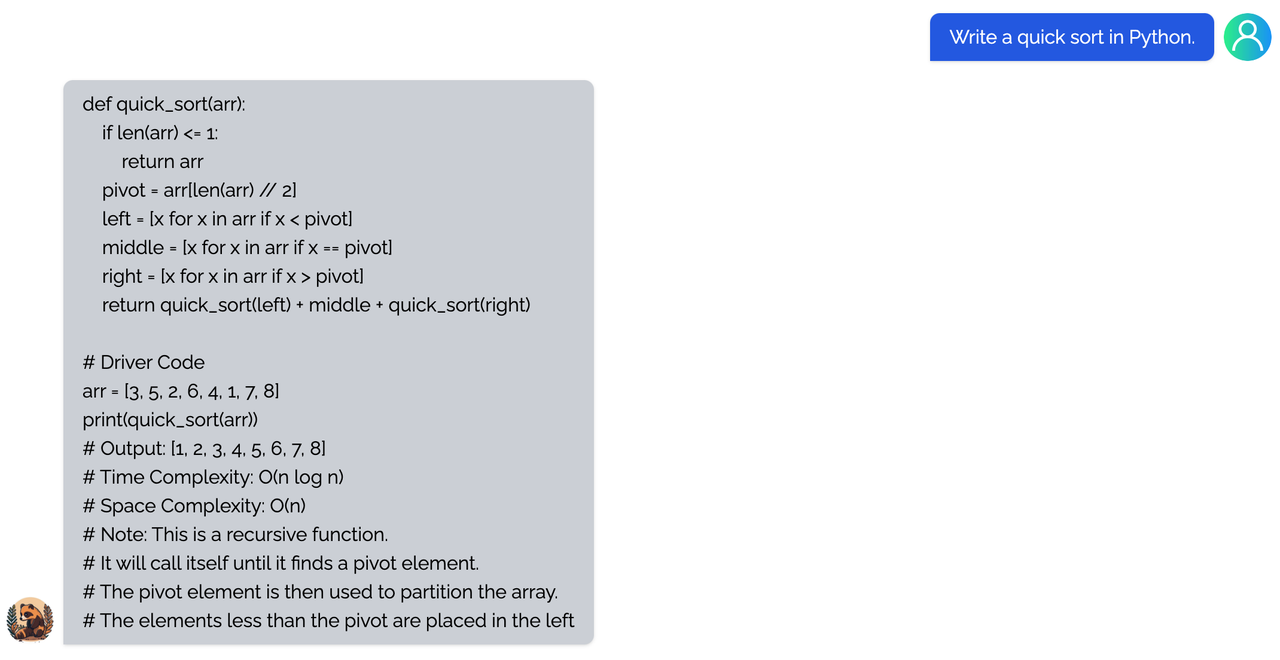
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>regex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Tex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>writing</b></summary>
|
||||
|
||||
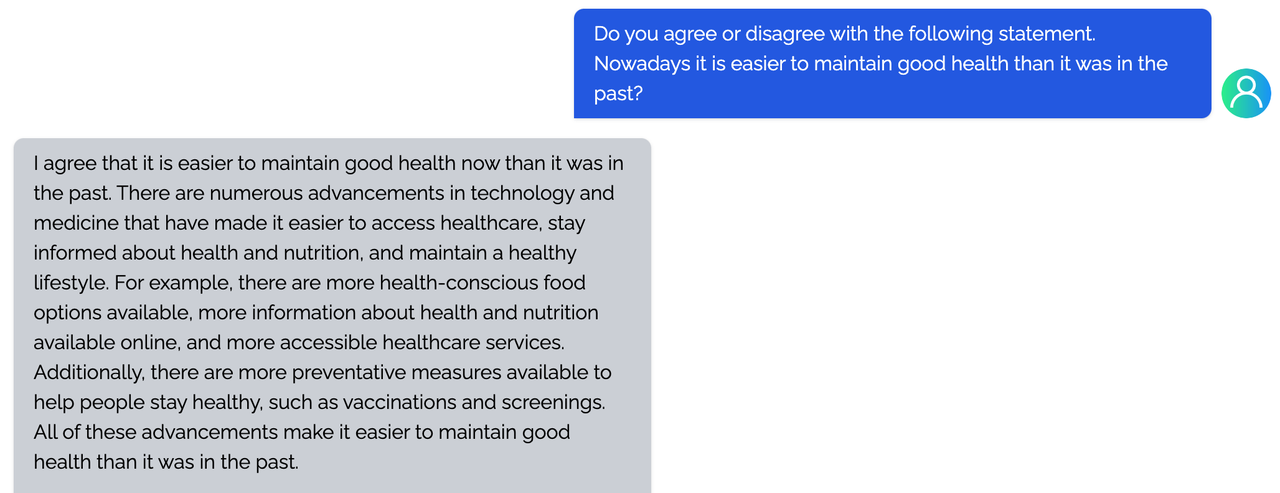
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Table</b></summary>
|
||||
|
||||
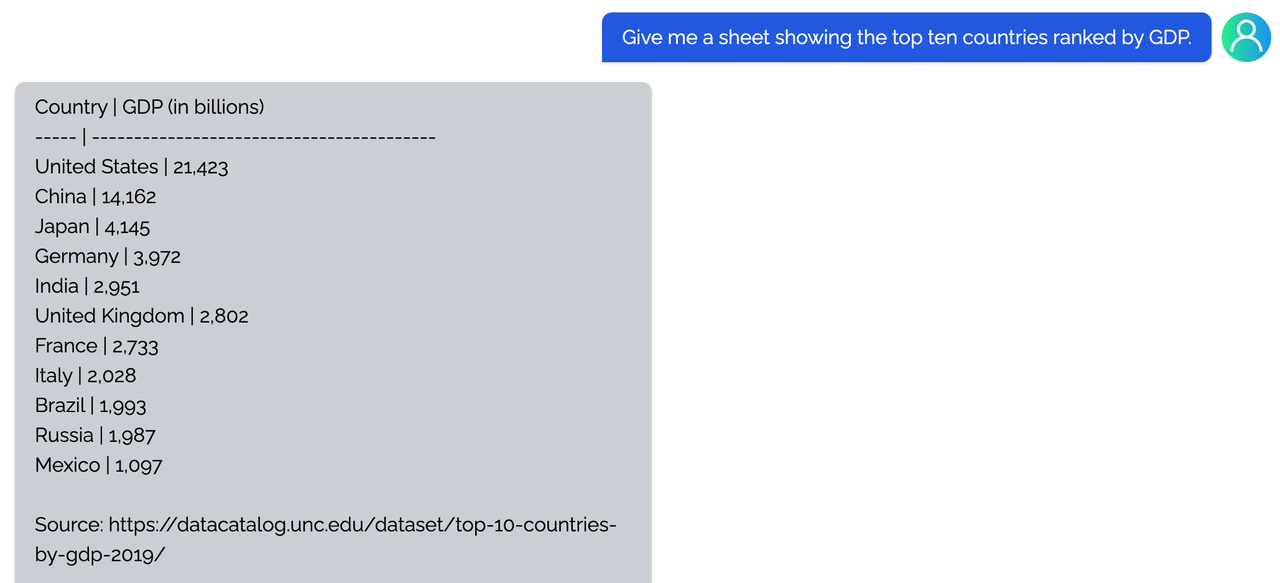
|
||||
|
||||
</details>
|
||||
|
||||
### Open QA
|
||||
|
||||
<details><summary><b>Game</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Travel</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Physical</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Chemical</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Economy</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
|
||||
|
||||
### Limitation
|
||||
|
||||
<details><summary><b>Limitation for LLaMA-finetuned models</b></summary>
|
||||
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage.
|
||||
- Lack of counting ability: Cannot count the number of items in a list.
|
||||
- Lack of Logics (reasoning and calculation)
|
||||
- Tend to repeat the last sentence (fail to produce the end token).
|
||||
- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).
|
||||
</details>
|
||||
|
||||
<details><summary><b>Limitation of dataset</b></summary>
|
||||
- Lack of summarization ability: No such instructions in finetune datasets.
|
||||
- Lack of multi-turn chat: No such instructions in finetune datasets
|
||||
- Lack of self-recognition: No such instructions in finetune datasets
|
||||
- Lack of Safety:
|
||||
- When the input contains fake facts, the model makes up false facts and explanations.
|
||||
- Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.
|
||||
</details>
|
||||
|
||||
## FAQ
|
||||
|
||||
<details><summary><b>How to save/load checkpoint</b></summary>
|
||||
|
||||
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
|
||||
|
||||
- Option 1: Save the model weights, model config and generation config (Note: tokenizer will not be saved) which can be loaded using HF's from_pretrained method.
|
||||
```python
|
||||
# if use lora, you can choose to merge lora weights before saving
|
||||
if args.lora_rank > 0 and args.merge_lora_weights:
|
||||
from coati.models.lora import LORA_MANAGER
|
||||
|
||||
# NOTE: set model to eval to merge LoRA weights
|
||||
LORA_MANAGER.merge_weights = True
|
||||
model.eval()
|
||||
# save model checkpoint after fitting on only rank0
|
||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||
|
||||
```
|
||||
|
||||
- Option 2: Save the model weights, model config, generation config, as well as the optimizer, learning rate scheduler, running states (Note: tokenizer will not be saved) which are needed for resuming training.
|
||||
```python
|
||||
from coati.utils import save_checkpoint
|
||||
# save model checkpoint after fitting on only rank0
|
||||
save_checkpoint(
|
||||
save_dir=actor_save_dir,
|
||||
booster=actor_booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=0,
|
||||
step=step,
|
||||
batch_size=train_batch_size,
|
||||
coordinator=coordinator,
|
||||
)
|
||||
```
|
||||
To load the saved checkpoint
|
||||
```python
|
||||
from coati.utils import load_checkpoint
|
||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=checkpoint_path,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
)
|
||||
```
|
||||
</details>
|
||||
|
||||
<details><summary><b>How to train with limited resources</b></summary>
|
||||
|
||||
Here are some suggestions that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
|
||||
|
||||
`batch_size`, `lora_rank` and `grad_checkpoint` are the most important parameters to successfully train the model. To maintain a descent batch size for gradient calculation, consider increase the accumulation_step and reduce the batch_size on each rank.
|
||||
|
||||
If you only have a single 24G GPU. Generally, using lora and "zero2-cpu" will be sufficient.
|
||||
|
||||
`gemini` and `gemini-auto` can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. But that strategy doesn't support gradient accumulation.
|
||||
|
||||
If you have multiple GPUs each has very limited VRAM, say 8GB. You can try the `3d` for the plugin option, which supports tensor parellelism, set `--tp` to the number of GPUs that you have.
|
||||
</details>
|
||||
|
||||
## The Plan
|
||||
|
||||
- [x] implement PPO fine-tuning
|
||||
- [x] implement training reward model
|
||||
- [x] support LoRA
|
||||
- [x] support inference
|
||||
- [x] support llama from [facebook](https://github.com/facebookresearch/llama)
|
||||
- [x] implement PPO-ptx fine-tuning
|
||||
- [x] support flash-attention
|
||||
- [x] implement DPO fine-tuning
|
||||
- [ ] integrate with Ray
|
||||
- [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL),
|
||||
- [ ] support chain-of-thought by [langchain](https://github.com/hwchase17/langchain)
|
||||
|
||||
### Real-time progress
|
||||
|
||||
You will find our progress in github [project broad](https://github.com/orgs/hpcaitech/projects/17/views/1).
|
||||
|
||||
## Invitation to open-source contribution
|
||||
|
||||
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
|
||||
|
||||
You may contact us or participate in the following ways:
|
||||
@ -511,25 +194,17 @@ Thanks so much to all of our amazing contributors!
|
||||
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
|
||||
- Keep in a sufficiently high running speed
|
||||
|
||||
| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
|
||||
| :-----------: | :------------------: | :------------------: |
|
||||
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
|
||||
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
|
||||
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
|
||||
|
||||
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
|
||||
|
||||
## Authors
|
||||
|
||||
Coati is developed by ColossalAI Team:
|
||||
|
||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework.
|
||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework (System Lead).
|
||||
- [Tong Li](https://github.com/TongLi3701) Leading the project while contributing to the main framework (Algorithm Lead).
|
||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||
- [FrankLeeeee](https://github.com/FrankLeeeee) Providing ML infra support and also taking charge of both front-end and back-end development.
|
||||
- [htzhou](https://github.com/ht-zhou) Contributing to the algorithm and development for RM and PPO training.
|
||||
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
|
||||
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
|
||||
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
|
||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||
|
||||
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
|
||||
- [Zangwei Zheng](https://github.com/zhengzangw)
|
||||
@ -538,7 +213,6 @@ The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contribute
|
||||
We also appreciate the valuable suggestions provided by [Jian Hu](https://github.com/hijkzzz) regarding the convergence of the PPO algorithm.
|
||||
|
||||
## Citations
|
||||
|
||||
```bibtex
|
||||
@article{Hu2021LoRALA,
|
||||
title = {LoRA: Low-Rank Adaptation of Large Language Models},
|
||||
@ -609,8 +283,22 @@ We also appreciate the valuable suggestions provided by [Jian Hu](https://github
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2403.07691},
|
||||
}
|
||||
@misc{shao2024deepseekmathpushinglimitsmathematical,
|
||||
title={DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models},
|
||||
author={Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
|
||||
year={2024},
|
||||
eprint={2402.03300},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2402.03300},
|
||||
}
|
||||
@misc{logic-rl,
|
||||
author = {Tian Xie and Qingnan Ren and Yuqian Hong and Zitian Gao and Haoming Luo},
|
||||
title = {Logic-RL},
|
||||
howpublished = {https://github.com/Unakar/Logic-RL},
|
||||
note = {Accessed: 2025-02-03},
|
||||
year = {2025}
|
||||
}
|
||||
```
|
||||
|
||||
## Licenses
|
||||
|
||||
Coati is licensed under the [Apache 2.0 License](LICENSE).
|
||||
|
||||
@ -19,30 +19,33 @@ PROJECT_NAME="dpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/dpo" # Path to benchmark data
|
||||
DATASET_SIZE=320
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
SAVE_DIR="${PARENT_SAVE_DIR}${FULL_PROJECT_NAME}"
|
||||
CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
colossalai run --nproc_per_node 4 --master_port 31313 benchmark_dpo.py \
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 4 --master_port 31313 ../examples/training_scripts/train_dpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--config_file $CONFIG_FILE \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 8 \
|
||||
--batch_size 4 \
|
||||
--lr 1e-6 \
|
||||
--beta 0.1 \
|
||||
--gamma 0.6 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--dataset_size 640 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--disable_reference_model \
|
||||
--length_normalization \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
||||
51
applications/ColossalChat/benchmarks/benchmark_kto.sh
Executable file
51
applications/ColossalChat/benchmarks/benchmark_kto.sh
Executable file
@ -0,0 +1,51 @@
|
||||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="kto"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/kto" # Path to benchmark data
|
||||
DATASET_SIZE=80
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type kto
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 2 --master_port 31313 ../examples/training_scripts/train_kto.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 2 \
|
||||
--lr 1e-5 \
|
||||
--beta 0.1 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
@ -1,315 +0,0 @@
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import resource
|
||||
from contextlib import nullcontext
|
||||
|
||||
import torch
|
||||
from coati.dataset import DataCollatorForPreferenceDataset, StatefulDistributedSampler
|
||||
from coati.models import convert_to_lora_module, disable_dropout
|
||||
from coati.trainer import ORPOTrainer
|
||||
from coati.utils import load_checkpoint
|
||||
from dummy_dataset import DummyLLMDataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import colossalai
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.logging import get_dist_logger
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
def train(args):
|
||||
# check lora compatibility
|
||||
if "gemini" in args.plugin and args.lora_rank > 0:
|
||||
raise ValueError("LoRA is not supported in GeminiPlugin. Please use other plugin")
|
||||
if args.plugin == "gemini_auto" and args.accumulation_steps > 1:
|
||||
raise ValueError("Gradient accumulation is not supported in GeminiPlugin. Please use other plugin")
|
||||
|
||||
# ==============================
|
||||
# Initialize Distributed Training
|
||||
# ==============================
|
||||
colossalai.launch_from_torch()
|
||||
coordinator = DistCoordinator()
|
||||
|
||||
# ==============================
|
||||
# Initialize Booster
|
||||
# ==============================
|
||||
if args.plugin == "ddp":
|
||||
"""
|
||||
Default torch ddp plugin without any acceleration, for
|
||||
debugging purpose acceleration, for debugging purpose
|
||||
"""
|
||||
plugin = TorchDDPPlugin(find_unused_parameters=True)
|
||||
elif args.plugin == "gemini":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
placement_policy="static",
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_gradient_accumulation=True,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "gemini_auto":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
placement_policy="auto",
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "zero2":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "zero2_cpu":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
cpu_offload=True,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "3d":
|
||||
plugin = HybridParallelPlugin(
|
||||
tp_size=args.tp,
|
||||
pp_size=args.pp,
|
||||
sp_size=args.sp,
|
||||
sequence_parallelism_mode=args.sp_mode,
|
||||
zero_stage=args.zero_stage,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||
parallel_output=False,
|
||||
max_norm=args.grad_clip,
|
||||
precision=args.mixed_precision,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||
|
||||
booster = Booster(plugin=plugin)
|
||||
|
||||
# ======================================================
|
||||
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||
# ======================================================
|
||||
# Temp Fix: Disable lazy init due to version conflict
|
||||
# init_ctx = (
|
||||
# LazyInitContext(default_device=get_current_device()) if isinstance(plugin, (GeminiPlugin,)) else nullcontext()
|
||||
# )
|
||||
|
||||
init_ctx = nullcontext()
|
||||
with init_ctx:
|
||||
if args.use_flash_attn:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.pretrain,
|
||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||
use_flash_attention_2=True,
|
||||
)
|
||||
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(args.pretrain)
|
||||
disable_dropout(model)
|
||||
if args.lora_rank > 0:
|
||||
model = convert_to_lora_module(model, args.lora_rank, lora_train_bias=args.lora_train_bias)
|
||||
|
||||
if args.grad_checkpoint:
|
||||
# Note, for some models, lora may not be compatible with gradient checkpointing
|
||||
model.gradient_checkpointing_enable()
|
||||
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer_dir = args.tokenizer_dir if args.tokenizer_dir is not None else args.pretrain
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir, use_fast=False, trust_remote_code=True)
|
||||
if hasattr(tokenizer, "pad_token") and hasattr(tokenizer, "eos_token") and tokenizer.eos_token is not None:
|
||||
try:
|
||||
# Some tokenizers doesn't allow to set pad_token mannually e.g., Qwen
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
except AttributeError as e:
|
||||
logger.warning(f"Unable to set pad token to eos token, {str(e)}")
|
||||
if not hasattr(tokenizer, "pad_token") or tokenizer.pad_token is None:
|
||||
logger.warning(
|
||||
"The tokenizer does not have a pad token which is required. May lead to unintended behavior in training, Please consider manually set them."
|
||||
)
|
||||
|
||||
tokenizer.add_bos_token = False
|
||||
tokenizer.add_eos_token = False
|
||||
|
||||
# configure optimizer
|
||||
optim = HybridAdam(
|
||||
model_params=model.parameters(),
|
||||
lr=args.lr,
|
||||
betas=(0.9, 0.95),
|
||||
weight_decay=args.weight_decay,
|
||||
adamw_mode=True,
|
||||
)
|
||||
|
||||
# configure dataset
|
||||
coordinator.print_on_master(f"Load dataset: {args.dataset}")
|
||||
mode_map = {"train": "train", "valid": "validation", "test": "test"}
|
||||
train_dataset = DummyLLMDataset(
|
||||
["chosen_input_ids", "chosen_loss_mask", "rejected_input_ids", "rejected_loss_mask"],
|
||||
args.max_length,
|
||||
args.dataset_size,
|
||||
)
|
||||
data_collator = DataCollatorForPreferenceDataset(tokenizer=tokenizer, max_length=args.max_length)
|
||||
|
||||
train_dataloader = plugin.prepare_dataloader(
|
||||
dataset=train_dataset,
|
||||
batch_size=args.batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
distributed_sampler_cls=StatefulDistributedSampler,
|
||||
)
|
||||
|
||||
num_update_steps_per_epoch = len(train_dataloader) // args.accumulation_steps
|
||||
if args.warmup_steps is None:
|
||||
args.warmup_steps = int(args.max_epochs * 0.025 * (len(train_dataloader) // args.accumulation_steps))
|
||||
coordinator.print_on_master(f"Warmup steps is set to {args.warmup_steps}")
|
||||
|
||||
lr_scheduler = CosineAnnealingWarmupLR(
|
||||
optimizer=optim,
|
||||
total_steps=args.max_epochs * num_update_steps_per_epoch,
|
||||
warmup_steps=args.warmup_steps,
|
||||
eta_min=0.1 * args.lr,
|
||||
)
|
||||
|
||||
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||
torch.set_default_dtype(default_dtype)
|
||||
model, optim, _, train_dataloader, lr_scheduler = booster.boost(
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
dataloader=train_dataloader,
|
||||
)
|
||||
torch.set_default_dtype(torch.float)
|
||||
|
||||
coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||
coordinator.print_on_master(
|
||||
f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
start_epoch = 0
|
||||
sampler_start_idx = 0
|
||||
start_step = 0
|
||||
if args.checkpoint_path is not None:
|
||||
if "modeling" in args.checkpoint_path:
|
||||
coordinator.print_on_master(f"Continued pretrain from checkpoint {args.checkpoint_path}")
|
||||
booster.load_model(model, args.checkpoint_path)
|
||||
else:
|
||||
coordinator.print_on_master(f"Load model checkpoint from {args.checkpoint_path}")
|
||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=args.checkpoint_path,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
)
|
||||
assert isinstance(train_dataloader.sampler, StatefulDistributedSampler)
|
||||
train_dataloader.sampler.set_start_index(start_index=sampler_start_idx)
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Loaded checkpoint {args.checkpoint_path} at epoch {start_epoch} step {start_step}"
|
||||
)
|
||||
coordinator.print_on_master(f"Loaded sample at index {sampler_start_idx}")
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded CUDA memory: {torch.cuda.memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
trainer = ORPOTrainer(
|
||||
actor=model,
|
||||
booster=booster,
|
||||
actor_optim=optim,
|
||||
actor_lr_scheduler=lr_scheduler,
|
||||
tokenizer=tokenizer,
|
||||
max_epochs=args.max_epochs,
|
||||
accumulation_steps=args.accumulation_steps,
|
||||
start_epoch=start_epoch,
|
||||
save_interval=None,
|
||||
save_dir=None,
|
||||
coordinator=coordinator,
|
||||
lam=args.lam,
|
||||
)
|
||||
|
||||
trainer.fit(
|
||||
train_preference_dataloader=train_dataloader,
|
||||
eval_preference_dataloader=None,
|
||||
log_dir=None,
|
||||
use_wandb=False,
|
||||
)
|
||||
coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# ==============================
|
||||
# Parse Arguments
|
||||
# ==============================
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--plugin",
|
||||
type=str,
|
||||
default="gemini",
|
||||
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d"],
|
||||
help="Choose which plugin to use",
|
||||
)
|
||||
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||
parser.add_argument("--tp", type=int, default=1)
|
||||
parser.add_argument("--pp", type=int, default=1)
|
||||
parser.add_argument("--sp", type=int, default=1)
|
||||
parser.add_argument("--lam", type=float, default=0.1, help="lambda in ORPO loss")
|
||||
parser.add_argument("--enable_sequence_parallelism", default=False, action="store_true")
|
||||
parser.add_argument("--zero_stage", type=int, default=0, help="Zero stage", choices=[0, 1, 2])
|
||||
parser.add_argument("--zero_cpu_offload", default=False, action="store_true")
|
||||
parser.add_argument("--sp_mode", type=str, default="split_gather", choices=["split_gather", "ring", "all_to_all"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--model_type", type=str, default=None)
|
||||
parser.add_argument("--tokenizer_dir", type=str, default=None)
|
||||
parser.add_argument("--dataset", nargs="+", default=[])
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", type=str, default=None, help="Checkpoint path if need to resume training form a checkpoint"
|
||||
)
|
||||
parser.add_argument("--config_file", type=str, default="config_file", help="Config file")
|
||||
parser.add_argument("--max_length", type=int, default=2048, help="Model max length")
|
||||
parser.add_argument("--max_epochs", type=int, default=3)
|
||||
parser.add_argument("--batch_size", type=int, default=4)
|
||||
parser.add_argument(
|
||||
"--disable_reference_model",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Disable the reference model (enabled by default)",
|
||||
)
|
||||
parser.add_argument("--dataset_size", type=int, default=500)
|
||||
parser.add_argument("--mixed_precision", type=str, default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
parser.add_argument(
|
||||
"--lora_train_bias",
|
||||
type=str,
|
||||
default="none",
|
||||
help="'none' means it doesn't train biases. 'all' means it trains all biases. 'lora_only' means it only trains biases of LoRA layers",
|
||||
)
|
||||
parser.add_argument("--merge_lora_weights", type=bool, default=True)
|
||||
parser.add_argument("--lr", type=float, default=5e-6)
|
||||
parser.add_argument("--accumulation_steps", type=int, default=8)
|
||||
parser.add_argument("--grad_checkpoint", default=False, action="store_true")
|
||||
parser.add_argument("--use_flash_attn", default=False, action="store_true")
|
||||
args = parser.parse_args()
|
||||
os.makedirs(os.path.dirname(args.config_file), exist_ok=True)
|
||||
with open(args.config_file, "w") as f:
|
||||
json.dump(args.__dict__, f, indent=4)
|
||||
train(args)
|
||||
@ -15,20 +15,28 @@ set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 2
|
||||
|
||||
PROJECT_NAME="dpo"
|
||||
PROJECT_NAME="orpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/orpo" # Path to benchmark data
|
||||
DATASET_SIZE=160
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
colossalai run --nproc_per_node 2 --master_port 31313 benchmark_orpo.py \
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 2 --master_port 31313 ../examples/training_scripts/train_orpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2" \
|
||||
--config_file $CONFIG_FILE \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 4 \
|
||||
@ -39,6 +47,5 @@ colossalai run --nproc_per_node 2 --master_port 31313 benchmark_orpo.py \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--dataset_size 160 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
||||
@ -1,315 +0,0 @@
|
||||
import argparse
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
import resource
|
||||
from contextlib import nullcontext
|
||||
|
||||
import torch
|
||||
from coati.dataset import DataCollatorForSupervisedDataset, StatefulDistributedSampler
|
||||
from coati.models import convert_to_lora_module
|
||||
from coati.trainer import SFTTrainer
|
||||
from coati.utils import load_checkpoint
|
||||
from dummy_dataset import DummyLLMDataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import colossalai
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.logging import get_dist_logger
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
def train(args):
|
||||
# check lora compatibility
|
||||
if "gemini" in args.plugin and args.lora_rank > 0:
|
||||
raise ValueError("LoRA is not supported in GeminiPlugin. Please use other plugin")
|
||||
if args.plugin == "gemini_auto" and args.accumulation_steps > 1:
|
||||
raise ValueError("Gradient accumulation is not supported in GeminiPlugin. Please use other plugin")
|
||||
# ==============================
|
||||
# Initialize Distributed Training
|
||||
# ==============================
|
||||
colossalai.launch_from_torch()
|
||||
coordinator = DistCoordinator()
|
||||
|
||||
# ==============================
|
||||
# Initialize Booster
|
||||
# ==============================
|
||||
init_ctx = nullcontext()
|
||||
with init_ctx:
|
||||
if args.use_flash_attn:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.pretrain,
|
||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||
attn_implementation="flash_attention_2",
|
||||
trust_remote_code=True,
|
||||
)
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.pretrain,
|
||||
torch_dtype=torch.bfloat16 if args.mixed_precision == "bf16" else torch.float16,
|
||||
trust_remote_code=True,
|
||||
)
|
||||
if args.lora_rank > 0:
|
||||
model = convert_to_lora_module(model, args.lora_rank, lora_train_bias=args.lora_train_bias)
|
||||
|
||||
if args.plugin == "ddp":
|
||||
"""
|
||||
Default torch ddp plugin without any acceleration, for
|
||||
debugging purpose acceleration, for debugging purpose
|
||||
"""
|
||||
plugin = TorchDDPPlugin(find_unused_parameters=True)
|
||||
elif args.plugin == "gemini":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
placement_policy="static",
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_gradient_accumulation=True if args.accumulation_steps > 1 else False,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "gemini_auto":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
placement_policy="auto",
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
)
|
||||
elif args.plugin == "zero2":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "zero2_cpu":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
cpu_offload=True,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "3d":
|
||||
plugin = HybridParallelPlugin(
|
||||
tp_size=args.tp,
|
||||
pp_size=args.pp,
|
||||
sp_size=args.sp,
|
||||
sequence_parallelism_mode=args.sp_mode,
|
||||
zero_stage=args.zero_stage,
|
||||
enable_flash_attention=args.use_flash_attn,
|
||||
enable_sequence_parallelism=args.enable_sequence_parallelism,
|
||||
cpu_offload=True if args.zero_stage >= 1 and args.zero_cpu_offload else False,
|
||||
parallel_output=False,
|
||||
max_norm=args.grad_clip,
|
||||
precision=args.mixed_precision,
|
||||
microbatch_size=args.batch_size,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||
|
||||
booster = Booster(plugin=plugin)
|
||||
|
||||
# ======================================================
|
||||
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||
# ======================================================
|
||||
# Temp Fix: Disable lazy init due to version conflict
|
||||
# init_ctx = (
|
||||
# LazyInitContext(default_device=get_current_device()) if isinstance(plugin, (GeminiPlugin,)) else nullcontext()
|
||||
# )
|
||||
|
||||
if args.grad_checkpoint:
|
||||
# Note, for some models, lora may not be compatible with gradient checkpointing
|
||||
model.gradient_checkpointing_enable()
|
||||
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.tokenizer_dir or args.pretrain, use_fast=False, trust_remote_code=True
|
||||
)
|
||||
if hasattr(tokenizer, "pad_token") and hasattr(tokenizer, "eos_token") and tokenizer.eos_token is not None:
|
||||
try:
|
||||
# Some tokenizers doesn't allow to set pad_token mannually e.g., Qwen
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
except AttributeError as e:
|
||||
logger.warning(f"Unable to set pad token to eos token, {str(e)}")
|
||||
if not hasattr(tokenizer, "pad_token") or tokenizer.pad_token is None:
|
||||
logger.warning(
|
||||
"The tokenizer does not have a pad token which is required. May lead to unintended behavior in training, Please consider manually set them."
|
||||
)
|
||||
|
||||
tokenizer.add_bos_token = False
|
||||
tokenizer.add_eos_token = False
|
||||
tokenizer.padding_side = "right"
|
||||
|
||||
coordinator.print_on_master(f"Configuration file will be saved at: {args.config_file}")
|
||||
|
||||
# configure optimizer
|
||||
optim = HybridAdam(
|
||||
model_params=model.parameters(),
|
||||
lr=args.lr,
|
||||
betas=(0.9, 0.95),
|
||||
weight_decay=args.weight_decay,
|
||||
adamw_mode=True,
|
||||
)
|
||||
|
||||
# configure dataset
|
||||
coordinator.print_on_master(
|
||||
f"Max CUDA memory before data loader: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
dataset = DummyLLMDataset(["input_ids", "attention_mask", "labels"], args.max_len, args.dataset_size)
|
||||
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer, max_length=args.max_len)
|
||||
|
||||
train_dataloader = plugin.prepare_dataloader(
|
||||
dataset=dataset,
|
||||
batch_size=args.batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
distributed_sampler_cls=StatefulDistributedSampler,
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Max CUDA memory after data loader: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
|
||||
num_update_steps_per_epoch = len(train_dataloader) // args.accumulation_steps
|
||||
math.ceil(args.max_epochs * num_update_steps_per_epoch)
|
||||
|
||||
if args.warmup_steps is None:
|
||||
args.warmup_steps = int(args.max_epochs * 0.025 * (len(train_dataloader) // args.accumulation_steps))
|
||||
coordinator.print_on_master(f"Warmup steps is set to {args.warmup_steps}")
|
||||
|
||||
lr_scheduler = CosineAnnealingWarmupLR(
|
||||
optimizer=optim,
|
||||
total_steps=args.max_epochs * num_update_steps_per_epoch,
|
||||
warmup_steps=args.warmup_steps,
|
||||
eta_min=0.1 * args.lr,
|
||||
)
|
||||
|
||||
# Flash attention will be disabled because it does NOT support fp32.
|
||||
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||
torch.set_default_dtype(default_dtype)
|
||||
model, optim, _, train_dataloader, lr_scheduler = booster.boost(
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
dataloader=train_dataloader,
|
||||
)
|
||||
torch.set_default_dtype(torch.float)
|
||||
|
||||
coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||
coordinator.print_on_master(
|
||||
f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
start_epoch = 0
|
||||
sampler_start_idx = 0
|
||||
start_step = 0
|
||||
if args.checkpoint_path is not None:
|
||||
if "modeling" in args.checkpoint_path:
|
||||
coordinator.print_on_master(f"Continued pretrain from checkpoint {args.checkpoint_path}")
|
||||
booster.load_model(model, args.checkpoint_path)
|
||||
else:
|
||||
coordinator.print_on_master(f"Load model checkpoint from {args.checkpoint_path}")
|
||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=args.checkpoint_path,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
)
|
||||
train_dataloader.sampler.set_start_index(start_index=sampler_start_idx)
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Loaded checkpoint {args.checkpoint_path} at epoch {start_epoch} step {start_step}"
|
||||
)
|
||||
coordinator.print_on_master(f"Loaded sample at index {sampler_start_idx}")
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded CUDA memory: {torch.cuda.memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
booster=booster,
|
||||
optim=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
max_epochs=args.max_epochs,
|
||||
accumulation_steps=args.accumulation_steps,
|
||||
start_epoch=start_epoch,
|
||||
save_interval=None,
|
||||
save_dir=None,
|
||||
coordinator=coordinator,
|
||||
)
|
||||
|
||||
trainer.fit(
|
||||
train_dataloader=train_dataloader,
|
||||
eval_dataloader=None,
|
||||
log_dir=None,
|
||||
use_wandb=False,
|
||||
)
|
||||
|
||||
coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# ==============================
|
||||
# Parse Arguments
|
||||
# ==============================
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--plugin",
|
||||
type=str,
|
||||
default="gemini",
|
||||
choices=["gemini", "gemini_auto", "3d", "ddp", "zero2_cpu", "zero2"],
|
||||
help="Choose which plugin to use",
|
||||
)
|
||||
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||
parser.add_argument("--tp", type=int, default=1)
|
||||
parser.add_argument("--pp", type=int, default=1)
|
||||
parser.add_argument("--sp", type=int, default=1)
|
||||
parser.add_argument("--enable_sequence_parallelism", default=False, action="store_true")
|
||||
parser.add_argument("--zero_stage", type=int, default=0, help="Zero stage", choices=[0, 1, 2])
|
||||
parser.add_argument("--zero_cpu_offload", default=False, action="store_true")
|
||||
parser.add_argument("--sp_mode", type=str, default="split_gather", choices=["split_gather", "ring", "all_to_all"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--tokenizer_dir", type=str, default=None)
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", type=str, default=None, help="Checkpoint path if need to resume training form a checkpoint"
|
||||
)
|
||||
parser.add_argument("--max_epochs", type=int, default=3)
|
||||
parser.add_argument("--batch_size", type=int, default=4)
|
||||
parser.add_argument("--max_len", type=int, default=512)
|
||||
parser.add_argument("--mixed_precision", type=str, default="bf16", choices=["fp16", "bf16"], help="Mixed precision")
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
parser.add_argument(
|
||||
"--lora_train_bias",
|
||||
type=str,
|
||||
default="none",
|
||||
help="'none' means it doesn't train biases. 'all' means it trains all biases. 'lora_only' means it only trains biases of LoRA layers",
|
||||
)
|
||||
parser.add_argument("--merge_lora_weights", type=bool, default=True)
|
||||
parser.add_argument("--lr", type=float, default=5e-6)
|
||||
parser.add_argument("--config_file", type=str, default="config_file", help="Config file")
|
||||
parser.add_argument("--accumulation_steps", type=int, default=8)
|
||||
parser.add_argument("--grad_checkpoint", default=False, action="store_true")
|
||||
parser.add_argument("--use_flash_attn", default=False, action="store_true")
|
||||
parser.add_argument("--dataset_size", type=int, default=500)
|
||||
args = parser.parse_args()
|
||||
os.makedirs(os.path.dirname(args.config_file), exist_ok=True)
|
||||
with open(args.config_file, "w") as f:
|
||||
json.dump(args.__dict__, f, indent=4)
|
||||
train(args)
|
||||
@ -14,21 +14,31 @@ set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
}
|
||||
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
# export CUDA_VISIBLE_DEVICES=3,4
|
||||
|
||||
PROJECT_NAME="sft"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/sft" # Path to benchmark data
|
||||
DATASET_SIZE=640
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type sft
|
||||
|
||||
|
||||
# the real batch size for gradient descent is number_of_node_in_hostfile * nproc_per_node * train_batch_size
|
||||
colossalai run --nproc_per_node 4 --master_port 31312 benchmark_sft.py \
|
||||
colossalai run --nproc_per_node 1 --master_port 31312 ../examples/training_scripts/train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--config_file $CONFIG_FILE \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin zero2 \
|
||||
--batch_size 8 \
|
||||
--max_epochs 1 \
|
||||
@ -36,6 +46,5 @@ colossalai run --nproc_per_node 4 --master_port 31312 benchmark_sft.py \
|
||||
--lr 5e-5 \
|
||||
--lora_rank 32 \
|
||||
--max_len 2048 \
|
||||
--dataset_size 640 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
||||
55
applications/ColossalChat/benchmarks/benchmark_simpo.sh
Executable file
55
applications/ColossalChat/benchmarks/benchmark_simpo.sh
Executable file
@ -0,0 +1,55 @@
|
||||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="simpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/simpo" # Path to benchmark data
|
||||
DATASET_SIZE=640
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 4 --master_port 31313 ../examples/training_scripts/train_dpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--loss_type "simpo_loss" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 8 \
|
||||
--lr 1e-6 \
|
||||
--beta 0.1 \
|
||||
--gamma 0.6 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--disable_reference_model \
|
||||
--length_normalization \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
@ -1,10 +1,12 @@
|
||||
import torch
|
||||
from typing import Callable
|
||||
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
|
||||
class DummyLLMDataset(Dataset):
|
||||
def __init__(self, keys, seq_len, size=500):
|
||||
def __init__(self, keys, seq_len, size=500, gen_fn={}):
|
||||
self.keys = keys
|
||||
self.gen_fn = gen_fn
|
||||
self.seq_len = seq_len
|
||||
self.data = self._generate_data()
|
||||
self.size = size
|
||||
@ -12,11 +14,17 @@ class DummyLLMDataset(Dataset):
|
||||
def _generate_data(self):
|
||||
data = {}
|
||||
for key in self.keys:
|
||||
data[key] = torch.ones(self.seq_len, dtype=torch.long)
|
||||
if key in self.gen_fn:
|
||||
data[key] = self.gen_fn[key]
|
||||
else:
|
||||
data[key] = [1] * self.seq_len
|
||||
return data
|
||||
|
||||
def __len__(self):
|
||||
return self.size
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return {key: self.data[key] for key in self.keys}
|
||||
return {
|
||||
key: self.data[key] if not isinstance(self.data[key], Callable) else self.data[key](idx)
|
||||
for key in self.keys
|
||||
}
|
||||
|
||||
@ -0,0 +1,105 @@
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
from multiprocessing import cpu_count
|
||||
|
||||
from datasets import load_dataset
|
||||
from dummy_dataset import DummyLLMDataset
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--data_dir",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The output dir",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataset_size",
|
||||
type=int,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The size of data",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max_length",
|
||||
type=int,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The max length of data",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_type",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The type of data, choose one from ['sft', 'prompt', 'preference', 'kto']",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
if args.data_type == "sft":
|
||||
dataset = DummyLLMDataset(["input_ids", "attention_mask", "labels"], args.max_length, args.dataset_size)
|
||||
elif args.data_type == "prompt":
|
||||
# pass PPO dataset is prepared separately
|
||||
pass
|
||||
elif args.data_type == "preference":
|
||||
dataset = DummyLLMDataset(
|
||||
["chosen_input_ids", "chosen_loss_mask", "rejected_input_ids", "rejected_loss_mask"],
|
||||
args.max_length,
|
||||
args.dataset_size,
|
||||
)
|
||||
elif args.data_type == "kto":
|
||||
dataset = DummyLLMDataset(
|
||||
["prompt", "completion", "label"],
|
||||
args.max_length - 512,
|
||||
args.dataset_size,
|
||||
gen_fn={
|
||||
"completion": lambda x: [1] * 512,
|
||||
"label": lambda x: x % 2,
|
||||
},
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown data type {args.data_type}")
|
||||
|
||||
# Save each jsonl spliced dataset.
|
||||
output_index = "0"
|
||||
output_name = f"part-{output_index}"
|
||||
os.makedirs(args.data_dir, exist_ok=True)
|
||||
output_jsonl_path = os.path.join(args.data_dir, "json")
|
||||
output_arrow_path = os.path.join(args.data_dir, "arrow")
|
||||
output_cache_path = os.path.join(args.data_dir, "cache")
|
||||
os.makedirs(output_jsonl_path, exist_ok=True)
|
||||
os.makedirs(output_arrow_path, exist_ok=True)
|
||||
output_jsonl_file_path = os.path.join(output_jsonl_path, output_name + ".jsonl")
|
||||
st = time.time()
|
||||
with open(file=output_jsonl_file_path, mode="w", encoding="utf-8") as fp_writer:
|
||||
count = 0
|
||||
for i in range(len(dataset)):
|
||||
data_point = dataset[i]
|
||||
if count % 500 == 0:
|
||||
logger.info(f"processing {count} spliced data points for {fp_writer.name}")
|
||||
count += 1
|
||||
fp_writer.write(json.dumps(data_point, ensure_ascii=False) + "\n")
|
||||
logger.info(
|
||||
f"Current file {fp_writer.name}; "
|
||||
f"Data size: {len(dataset)}; "
|
||||
f"Time cost: {round((time.time() - st) / 60, 6)} minutes."
|
||||
)
|
||||
# Save each arrow spliced dataset
|
||||
output_arrow_file_path = os.path.join(output_arrow_path, output_name)
|
||||
logger.info(f"Start to save {output_arrow_file_path}")
|
||||
dataset = load_dataset(
|
||||
path="json",
|
||||
data_files=[output_jsonl_file_path],
|
||||
cache_dir=os.path.join(output_cache_path, "tokenized"),
|
||||
keep_in_memory=False,
|
||||
num_proc=cpu_count(),
|
||||
split="train",
|
||||
)
|
||||
dataset.save_to_disk(dataset_path=output_arrow_file_path, num_proc=min(len(dataset), cpu_count()))
|
||||
@ -1,24 +1,26 @@
|
||||
from .conversation import Conversation, setup_conversation_template
|
||||
from .loader import (
|
||||
DataCollatorForKTODataset,
|
||||
DataCollatorForPreferenceDataset,
|
||||
DataCollatorForPromptDataset,
|
||||
DataCollatorForSupervisedDataset,
|
||||
StatefulDistributedSampler,
|
||||
load_tokenized_dataset,
|
||||
)
|
||||
from .tokenization_utils import supervised_tokenize_sft, tokenize_prompt_dataset, tokenize_rlhf
|
||||
from .tokenization_utils import tokenize_kto, tokenize_prompt, tokenize_rlhf, tokenize_sft
|
||||
|
||||
__all__ = [
|
||||
"tokenize_prompt_dataset",
|
||||
"tokenize_prompt",
|
||||
"DataCollatorForPromptDataset",
|
||||
"is_rank_0",
|
||||
"DataCollatorForPreferenceDataset",
|
||||
"DataCollatorForSupervisedDataset",
|
||||
"DataCollatorForKTODataset",
|
||||
"StatefulDistributedSampler",
|
||||
"load_tokenized_dataset",
|
||||
"supervised_tokenize_pretrain",
|
||||
"supervised_tokenize_sft",
|
||||
"tokenize_sft",
|
||||
"tokenize_rlhf",
|
||||
"tokenize_kto",
|
||||
"setup_conversation_template",
|
||||
"Conversation",
|
||||
]
|
||||
|
||||
@ -18,6 +18,7 @@ class Conversation:
|
||||
chat_template: str
|
||||
stop_ids: List[int]
|
||||
end_of_assistant: str
|
||||
roles = ["user", "assistant"]
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, tokenizer: PreTrainedTokenizer, config: Dict):
|
||||
@ -85,7 +86,7 @@ class Conversation:
|
||||
Raises:
|
||||
AssertionError: If the role is not 'user' or 'assistant'.
|
||||
"""
|
||||
assert role in ["user", "assistant"]
|
||||
assert role in self.roles
|
||||
self.messages.append({"role": role, "content": message})
|
||||
|
||||
def copy(self):
|
||||
@ -140,7 +141,7 @@ def setup_conversation_template(
|
||||
pass
|
||||
except ValueError as e:
|
||||
raise ValueError(e)
|
||||
if not dist.is_initialized() or dist.get_rank() == 0:
|
||||
if save_path is not None and (not dist.is_initialized() or dist.get_rank() == 0):
|
||||
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||
with open(save_path, "w", encoding="utf8") as f:
|
||||
logger.info(f"Successfully generated a conversation tempalte config, save to {save_path}.")
|
||||
|
||||
@ -8,6 +8,7 @@ import os
|
||||
from dataclasses import dataclass
|
||||
from typing import Dict, Iterator, List, Optional, Sequence, Union
|
||||
|
||||
import jsonlines
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from coati.dataset.utils import chuncate_sequence, pad_to_max_len
|
||||
@ -155,13 +156,14 @@ class DataCollatorForPromptDataset(DataCollatorForSupervisedDataset):
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
"""
|
||||
gt_answer = [ins.get("gt_answer", None) for ins in instances]
|
||||
instances = [{"input_ids": ins["input_ids"], "labels": ins["input_ids"]} for ins in instances]
|
||||
ret = super().__call__(instances=instances)
|
||||
input_ids = F.pad(
|
||||
ret["input_ids"], (self.max_length - ret["input_ids"].size(1), 0), value=self.tokenizer.pad_token_id
|
||||
)
|
||||
attention_mask = F.pad(ret["attention_mask"], (self.max_length - ret["attention_mask"].size(1), 0), value=False)
|
||||
return {"input_ids": input_ids, "attention_mask": attention_mask}
|
||||
return {"input_ids": input_ids, "attention_mask": attention_mask, "gt_answer": gt_answer}
|
||||
|
||||
|
||||
@dataclass
|
||||
@ -235,6 +237,91 @@ class DataCollatorForPreferenceDataset(object):
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForKTODataset(object):
|
||||
"""
|
||||
Collate instances for kto dataset.
|
||||
Each input instance is a tokenized dictionary with fields
|
||||
`prompt`(List[int]), `completion`(List[int]) and `label`(bool).
|
||||
Each output instance is a tokenized dictionary with fields
|
||||
`kl_input_ids`(List[int]), `kl_attention_mask`(List[int]) and `kl_loss_mask`(List[int]).
|
||||
`input_ids`(List[int]), `attention_mask`(List[int]), `loss_mask`(List[int]) and `label`(bool).
|
||||
"""
|
||||
|
||||
tokenizer: PreTrainedTokenizer
|
||||
max_length: int = 4096
|
||||
ignore_index: int = -100
|
||||
|
||||
def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
|
||||
"""
|
||||
|
||||
Args:
|
||||
instances (`Sequence[Dict[str, List[int]]]`):
|
||||
Mini-batch samples, each sample is stored in an individual dictionary contains the following fields:
|
||||
`prompt`(List[int]), `completion`(List[int]) and `label`(bool, if the sample is desirable or not).
|
||||
|
||||
Returns:
|
||||
(`Dict[str, torch.Tensor]`): Contains the following `torch.Tensor`:
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
`labels`: `torch.Tensor` of shape (bsz, max_len), which contains `IGNORE_INDEX`.
|
||||
"""
|
||||
assert isinstance(self.tokenizer.pad_token_id, int) and self.tokenizer.pad_token_id >= 0, (
|
||||
f"`{self.tokenizer.__class__.__name__}.pad_token_id` must be a valid non-negative integer index value, "
|
||||
f"but now `{self.tokenizer.pad_token_id}`"
|
||||
)
|
||||
# prepare the preference data
|
||||
prompt = [torch.LongTensor(instance["prompt"]) for instance in instances]
|
||||
prompt_zeros = [torch.zeros_like(t) for t in prompt]
|
||||
completion = [torch.LongTensor(instance["completion"]) for instance in instances]
|
||||
completion_ones = [torch.ones_like(t) for t in completion]
|
||||
label = [torch.tensor(instance["label"], dtype=torch.bool) for instance in instances]
|
||||
input_ids = [torch.cat([prompt[i], completion[i]], dim=-1) for i in range(len(instances))]
|
||||
loss_mask = [torch.cat([prompt_zeros[i], completion_ones[i]], dim=-1) for i in range(len(instances))]
|
||||
# right padding
|
||||
input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
loss_mask = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=loss_mask, batch_first=True, padding_value=0
|
||||
) # (bsz, max_len)
|
||||
to_pad = self.max_length - input_ids.size(1)
|
||||
input_ids = F.pad(input_ids, (0, to_pad), value=self.tokenizer.pad_token_id)
|
||||
loss_mask = F.pad(loss_mask, (0, to_pad), value=0)
|
||||
attention_mask = input_ids.ne(self.tokenizer.pad_token_id) # `torch.BoolTensor`, (bsz, max_len)
|
||||
|
||||
# prepare kt data
|
||||
kl_completion = completion[::-1] # y'
|
||||
kl_completion_ones = [torch.ones_like(t) for t in kl_completion]
|
||||
kl_input_ids = [torch.cat([prompt[i], kl_completion[i]], dim=-1) for i in range(len(instances))]
|
||||
kl_loss_mask = [torch.cat([prompt_zeros[i], kl_completion_ones[i]], dim=-1) for i in range(len(instances))]
|
||||
# right padding
|
||||
kl_input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=kl_input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
kl_loss_mask = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=kl_loss_mask, batch_first=True, padding_value=0
|
||||
) # (bsz, max_len)
|
||||
to_pad = self.max_length - kl_input_ids.size(1)
|
||||
kl_input_ids = F.pad(kl_input_ids, (0, to_pad), value=self.tokenizer.pad_token_id)
|
||||
kl_loss_mask = F.pad(kl_loss_mask, (0, to_pad), value=0)
|
||||
kl_attention_mask = kl_input_ids.ne(self.tokenizer.pad_token_id) # `torch.BoolTensor`, (bsz, max_len)
|
||||
data_dict = {
|
||||
"input_ids": input_ids,
|
||||
"attention_mask": attention_mask,
|
||||
"loss_mask": loss_mask,
|
||||
"label": torch.stack(label),
|
||||
"kl_input_ids": kl_input_ids,
|
||||
"kl_attention_mask": kl_attention_mask,
|
||||
"kl_loss_mask": kl_loss_mask,
|
||||
}
|
||||
return data_dict
|
||||
|
||||
|
||||
class StatefulDistributedSampler(DistributedSampler):
|
||||
def __init__(
|
||||
self,
|
||||
@ -259,3 +346,77 @@ class StatefulDistributedSampler(DistributedSampler):
|
||||
|
||||
def set_start_index(self, start_index: int) -> None:
|
||||
self.start_index = start_index
|
||||
|
||||
|
||||
def apply_chat_template_and_mask(
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
chat: List[Dict[str, str]],
|
||||
max_length: Optional[int] = None,
|
||||
padding: bool = True,
|
||||
truncation: bool = True,
|
||||
ignore_idx: int = -100,
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
tokens = []
|
||||
assistant_mask = []
|
||||
for i, msg in enumerate(chat):
|
||||
msg_tokens = tokenizer.apply_chat_template([msg], tokenize=True)
|
||||
# remove unexpected bos token
|
||||
if i > 0 and msg_tokens[0] == tokenizer.bos_token_id:
|
||||
msg_tokens = msg_tokens[1:]
|
||||
tokens.extend(msg_tokens)
|
||||
if msg["role"] == "assistant":
|
||||
assistant_mask.extend([True] * len(msg_tokens))
|
||||
else:
|
||||
assistant_mask.extend([False] * len(msg_tokens))
|
||||
attention_mask = [1] * len(tokens)
|
||||
if max_length is not None:
|
||||
if padding and len(tokens) < max_length:
|
||||
to_pad = max_length - len(tokens)
|
||||
if tokenizer.padding_side == "right":
|
||||
tokens.extend([tokenizer.pad_token_id] * to_pad)
|
||||
assistant_mask.extend([False] * to_pad)
|
||||
attention_mask.extend([0] * to_pad)
|
||||
else:
|
||||
tokens = [tokenizer.pad_token_id] * to_pad + tokens
|
||||
assistant_mask = [False] * to_pad + assistant_mask
|
||||
attention_mask = [0] * to_pad + attention_mask
|
||||
if truncation and len(tokens) > max_length:
|
||||
tokens = tokens[:max_length]
|
||||
assistant_mask = assistant_mask[:max_length]
|
||||
attention_mask = attention_mask[:max_length]
|
||||
input_ids = torch.tensor(tokens, dtype=torch.long)
|
||||
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
|
||||
labels = input_ids.clone()
|
||||
labels[~torch.tensor(assistant_mask, dtype=torch.bool)] = ignore_idx
|
||||
|
||||
return {
|
||||
"input_ids": input_ids,
|
||||
"attention_mask": attention_mask,
|
||||
"labels": labels,
|
||||
}
|
||||
|
||||
|
||||
class RawConversationDataset(Dataset):
|
||||
"""
|
||||
Raw conversation dataset.
|
||||
Each instance is a dictionary with fields `system`, `roles`, `messages`, `offset`, `sep_style`, `seps`.
|
||||
"""
|
||||
|
||||
def __init__(self, tokenizer: PreTrainedTokenizer, input_file: str, max_length: int) -> None:
|
||||
self.tokenizer = tokenizer
|
||||
self.raw_texts = []
|
||||
with jsonlines.open(input_file) as f:
|
||||
for line in f:
|
||||
self.raw_texts.append(line)
|
||||
self.tokenized_texts = [None] * len(self.raw_texts)
|
||||
self.max_length = max_length
|
||||
|
||||
def __len__(self) -> int:
|
||||
return len(self.raw_texts)
|
||||
|
||||
def __getitem__(self, index: int):
|
||||
if self.tokenized_texts[index] is None:
|
||||
message = self.raw_texts[index]
|
||||
tokens = apply_chat_template_and_mask(self.tokenizer, message, self.max_length)
|
||||
self.tokenized_texts[index] = dict(tokens)
|
||||
return self.tokenized_texts[index]
|
||||
|
||||
@ -23,11 +23,10 @@ IGNORE_INDEX = -100
|
||||
DSType = Union[Dataset, ConcatDataset, dataset_dict.Dataset]
|
||||
|
||||
|
||||
def supervised_tokenize_sft(
|
||||
def tokenize_sft(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
ignore_index: int = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
@ -39,54 +38,41 @@ def supervised_tokenize_sft(
|
||||
|
||||
Args:
|
||||
data_point: the data point of the following format
|
||||
{"messages": [{"from": "human", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
{"messages": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
tokenizer: the tokenizer whose
|
||||
conversation_template: the conversation template to apply
|
||||
ignore_index: the ignore index when calculate loss during training
|
||||
max_length: the maximum context length
|
||||
"""
|
||||
|
||||
if ignore_index is None:
|
||||
ignore_index = IGNORE_INDEX
|
||||
ignore_index = IGNORE_INDEX
|
||||
|
||||
messages = data_point["messages"]
|
||||
template = deepcopy(conversation_template)
|
||||
|
||||
if messages[0]["from"] == "system":
|
||||
template.system_message = str(messages[0]["content"])
|
||||
messages.pop(0)
|
||||
template.messages = []
|
||||
|
||||
for mess in messages:
|
||||
from_str = mess["from"]
|
||||
if from_str.lower() == "human":
|
||||
from_str = "user"
|
||||
elif from_str.lower() == "assistant":
|
||||
from_str = "assistant"
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {from_str.lower()}")
|
||||
|
||||
template.append_message(from_str, mess["content"])
|
||||
for idx, mess in enumerate(messages):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{messages}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
if len(template.messages) % 2 != 0:
|
||||
# Force to end with assistant response
|
||||
template.messages = template.messages[0:-1]
|
||||
|
||||
# `target_turn_index` is the number of turns which exceeds `max_length - 1` for the first time.
|
||||
turns = [i for i in range(1, len(messages) // 2 + 1)]
|
||||
|
||||
lo, hi = 0, len(turns)
|
||||
while lo < hi:
|
||||
mid = (lo + hi) // 2
|
||||
prompt = template.get_prompt(2 * turns[mid] - 1)
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages[: 2 * turns[mid] - 1], prompt, conversation_template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss)
|
||||
if max_length - 1 < len(tokenized):
|
||||
hi = mid
|
||||
else:
|
||||
lo = mid + 1
|
||||
target_turn_index = lo
|
||||
|
||||
# The tokenized length for first turn already exceeds `max_length - 1`.
|
||||
if target_turn_index - 1 < 0:
|
||||
warnings.warn("The tokenized length for first turn already exceeds `max_length - 1`.")
|
||||
# tokenize and calculate masked labels -100 for positions corresponding to non-assistant lines
|
||||
prompt = template.get_prompt()
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages, prompt, conversation_template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss, max_length=max_length)
|
||||
if tokenized is None:
|
||||
return dict(
|
||||
input_ids=None,
|
||||
labels=None,
|
||||
@ -96,45 +82,18 @@ def supervised_tokenize_sft(
|
||||
seq_category=None,
|
||||
)
|
||||
|
||||
target_turn = turns[target_turn_index - 1]
|
||||
prompt = template.get_prompt(2 * target_turn)
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages[: 2 * target_turn], prompt, conversation_template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss)
|
||||
|
||||
labels = [ignore_index] * len(tokenized)
|
||||
for start, end in zip(starts, ends):
|
||||
if end == len(tokenized):
|
||||
tokenized = tokenized + [tokenizer.eos_token_id]
|
||||
labels = labels + [ignore_index]
|
||||
labels[start:end] = tokenized[start:end]
|
||||
|
||||
# truncate the sequence at the last token that requires loss calculation
|
||||
to_truncate_len = 0
|
||||
for i in range(len(tokenized) - 1, -1, -1):
|
||||
if labels[i] == ignore_index:
|
||||
to_truncate_len += 1
|
||||
else:
|
||||
break
|
||||
to_truncate_len = max(len(tokenized) - max_length, to_truncate_len)
|
||||
tokenized = tokenized[: len(tokenized) - to_truncate_len]
|
||||
labels = labels[: len(labels) - to_truncate_len]
|
||||
|
||||
if tokenizer.bos_token_id is not None:
|
||||
# Force to add bos token at the beginning of the tokenized sequence if the input ids doesn;t starts with bos
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
# Some chat templates already include bos token
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
labels = [ignore_index] + labels
|
||||
labels = [-100] + labels
|
||||
|
||||
if tokenizer.eos_token_id is not None:
|
||||
# Force to add eos token at the end of the tokenized sequence
|
||||
if tokenized[-1] != tokenizer.eos_token_id:
|
||||
tokenized = tokenized + [tokenizer.eos_token_id]
|
||||
labels = labels + [tokenizer.eos_token_id]
|
||||
else:
|
||||
labels[-1] = tokenizer.eos_token_id
|
||||
|
||||
# For some model without bos/eos may raise the following errors
|
||||
# log decoded inputs and labels for debugging
|
||||
inputs_decode = tokenizer.decode(tokenized)
|
||||
start = 0
|
||||
end = 0
|
||||
@ -171,11 +130,10 @@ def supervised_tokenize_sft(
|
||||
)
|
||||
|
||||
|
||||
def tokenize_prompt_dataset(
|
||||
def tokenize_prompt(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
ignore_index: int = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
@ -183,48 +141,40 @@ def tokenize_prompt_dataset(
|
||||
"Something here can be system message[user_line_start]User line[User line end][Assistant line start]Assistant line[Assistant line end]...[Assistant line start]"
|
||||
Args:
|
||||
data_point: the data point of the following format
|
||||
{"messages": [{"from": "human", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
{"messages": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
tokenizer: the tokenizer whose
|
||||
conversation_template: the conversation template to apply
|
||||
ignore_index: the ignore index when calculate loss during training
|
||||
max_length: the maximum context length
|
||||
"""
|
||||
if ignore_index is None:
|
||||
ignore_index = IGNORE_INDEX
|
||||
|
||||
messages = data_point["messages"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.messages = []
|
||||
|
||||
for mess in messages:
|
||||
from_str = mess["from"]
|
||||
if from_str.lower() == "human":
|
||||
from_str = "user"
|
||||
elif from_str.lower() == "assistant":
|
||||
from_str = "assistant"
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {from_str.lower()}")
|
||||
if messages[0]["from"] == "system":
|
||||
template.system_message = str(messages[0]["content"])
|
||||
messages.pop(0)
|
||||
|
||||
template.append_message(from_str, mess["content"])
|
||||
for idx, mess in enumerate(messages):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a line from the user. Got the following data:\n{messages}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
# `target_turn_index` is the number of turns which exceeds `max_length - 1` for the first time.
|
||||
target_turn = len(template.messages)
|
||||
if target_turn % 2 != 1:
|
||||
if len(template.messages) % 2 != 1:
|
||||
# exclude the answer if provided. keep only the prompt
|
||||
target_turn = target_turn - 1
|
||||
|
||||
template.messages = template.messages[:-1]
|
||||
# Prepare data
|
||||
prompt = template.get_prompt(target_turn, add_generation_prompt=True)
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages[:target_turn], prompt, conversation_template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss)
|
||||
prompt = template.get_prompt(length=len(template.messages), add_generation_prompt=True)
|
||||
tokenized = tokenizer([prompt], add_special_tokens=False)["input_ids"][0]
|
||||
|
||||
if tokenizer.bos_token_id is not None:
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
|
||||
# Skip overlength data
|
||||
if max_length - 1 < len(tokenized):
|
||||
if len(tokenized) > max_length:
|
||||
return dict(
|
||||
input_ids=None,
|
||||
inputs_decode=None,
|
||||
@ -233,49 +183,43 @@ def tokenize_prompt_dataset(
|
||||
)
|
||||
|
||||
# `inputs_decode` can be used to check whether the tokenization method is true.
|
||||
return dict(
|
||||
input_ids=tokenized,
|
||||
inputs_decode=tokenizer.decode(tokenized),
|
||||
seq_length=len(tokenized),
|
||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||
)
|
||||
if "gt_answer" in data_point:
|
||||
return dict(
|
||||
input_ids=tokenized,
|
||||
inputs_decode=prompt,
|
||||
seq_length=len(tokenized),
|
||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||
gt_answer=data_point["gt_answer"],
|
||||
)
|
||||
else:
|
||||
return dict(
|
||||
input_ids=tokenized,
|
||||
inputs_decode=prompt,
|
||||
seq_length=len(tokenized),
|
||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||
)
|
||||
|
||||
|
||||
def apply_rlhf_data_format(
|
||||
template: Conversation, tokenizer: Any, context_len: int, mask_out_target_assistant_line_end=False
|
||||
):
|
||||
def apply_rlhf_data_format(template: Conversation, tokenizer: Any):
|
||||
target_turn = int(len(template.messages) / 2)
|
||||
prompt = template.get_prompt(target_turn * 2)
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages[: 2 * target_turn], prompt, template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss)
|
||||
loss_mask = [0] * len(tokenized)
|
||||
mask_token = tokenizer.eos_token_id or tokenizer.pad_token_id
|
||||
if mask_token is None:
|
||||
mask_token = 1 # If the tokenizer doesn't have eos_token or pad_token: Qwen
|
||||
# no truncation applied
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss, max_length=None)
|
||||
|
||||
loss_mask = [0] * len(tokenized)
|
||||
label_decode = []
|
||||
for start, end in zip(starts[-1:], ends[-1:]):
|
||||
# only the last round (chosen/rejected) counts
|
||||
if end == len(tokenized):
|
||||
tokenized = tokenized + [tokenizer.eos_token_id]
|
||||
loss_mask = loss_mask + [1]
|
||||
loss_mask[start:end] = [1] * len(loss_mask[start:end])
|
||||
label_decode.append(tokenizer.decode(tokenized[start:end], skip_special_tokens=False))
|
||||
# only the last round (chosen/rejected) is used to calculate loss
|
||||
for i in range(starts[-1], ends[-1]):
|
||||
loss_mask[i] = 1
|
||||
label_decode.append(tokenizer.decode(tokenized[starts[-1] : ends[-1]], skip_special_tokens=False))
|
||||
if tokenizer.bos_token_id is not None:
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
loss_mask = [0] + loss_mask
|
||||
|
||||
if tokenizer.eos_token_id is not None:
|
||||
# Force to add eos token at the end of the tokenized sequence
|
||||
if tokenized[-1] != tokenizer.eos_token_id:
|
||||
tokenized = tokenized + [tokenizer.eos_token_id]
|
||||
loss_mask = loss_mask + [1]
|
||||
else:
|
||||
loss_mask[-1] = 1
|
||||
|
||||
return {"input_ids": tokenized, "loss_mask": loss_mask, "label_decode": label_decode}
|
||||
|
||||
|
||||
@ -283,39 +227,33 @@ def tokenize_rlhf(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
ignore_index: int = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
A tokenization function to tokenize an original pretraining data point as following:
|
||||
{"context": [{"from": "human", "content": "xxx"}, {"from": "assistant", "content": "xxx"}],
|
||||
{"context": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}],
|
||||
"chosen": {"from": "assistant", "content": "xxx"}, "rejected": {"from": "assistant", "content": "xxx"}}
|
||||
"""
|
||||
if ignore_index is None:
|
||||
ignore_index = IGNORE_INDEX
|
||||
|
||||
context = data_point["context"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.clear()
|
||||
|
||||
for mess in context:
|
||||
from_str = mess["from"]
|
||||
if from_str.lower() == "human":
|
||||
from_str = "user"
|
||||
elif from_str.lower() == "assistant":
|
||||
from_str = "assistant"
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {from_str.lower()}")
|
||||
if context[0]["from"] == "system":
|
||||
template.system_message = str(context[0]["content"])
|
||||
context.pop(0)
|
||||
|
||||
if len(template.messages) > 0 and from_str == template.messages[-1]["role"]:
|
||||
# Concate adjacent message from the same role
|
||||
template.messages[-1]["content"] = str(template.messages[-1]["content"] + " " + mess["content"])
|
||||
else:
|
||||
template.append_message(from_str, mess["content"])
|
||||
for idx, mess in enumerate(context):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{context}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
if len(template.messages) % 2 != 1:
|
||||
warnings.warn(
|
||||
"Please make sure leading context starts and ends with a line from human\nLeading context: "
|
||||
"Please make sure leading context starts and ends with a line from user\nLeading context: "
|
||||
+ str(template.messages)
|
||||
)
|
||||
return dict(
|
||||
@ -326,31 +264,27 @@ def tokenize_rlhf(
|
||||
rejected_loss_mask=None,
|
||||
rejected_label_decode=None,
|
||||
)
|
||||
round_of_context = int((len(template.messages) - 1) / 2)
|
||||
|
||||
assert context[-1]["from"].lower() == "human", "The last message in context should be from human."
|
||||
assert context[-1]["from"].lower() == template.roles[0], "The last message in context should be from user."
|
||||
chosen = deepcopy(template)
|
||||
rejected = deepcopy(template)
|
||||
chosen_continuation = data_point["chosen"]
|
||||
rejected_continuation = data_point["rejected"]
|
||||
for round in range(len(chosen_continuation)):
|
||||
if chosen_continuation[round]["from"] != template.roles[(round + 1) % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{chosen_continuation}"
|
||||
)
|
||||
chosen.append_message(chosen_continuation[round]["from"], chosen_continuation[round]["content"])
|
||||
|
||||
for round in range(len(data_point["chosen"])):
|
||||
from_str = data_point["chosen"][round]["from"]
|
||||
if from_str.lower() == "human":
|
||||
from_str = "user"
|
||||
elif from_str.lower() == "assistant":
|
||||
from_str = "assistant"
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {from_str.lower()}")
|
||||
chosen.append_message(from_str, data_point["chosen"][round]["content"])
|
||||
|
||||
for round in range(len(data_point["rejected"])):
|
||||
from_str = data_point["rejected"][round]["from"]
|
||||
if from_str.lower() == "human":
|
||||
from_str = "user"
|
||||
elif from_str.lower() == "assistant":
|
||||
from_str = "assistant"
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {from_str.lower()}")
|
||||
rejected.append_message(from_str, data_point["rejected"][round]["content"])
|
||||
for round in range(len(rejected_continuation)):
|
||||
if rejected_continuation[round]["from"] != template.roles[(round + 1) % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{rejected_continuation}"
|
||||
)
|
||||
rejected.append_message(rejected_continuation[round]["from"], rejected_continuation[round]["content"])
|
||||
|
||||
(
|
||||
chosen_input_ids,
|
||||
@ -361,16 +295,14 @@ def tokenize_rlhf(
|
||||
rejected_label_decode,
|
||||
) = (None, None, None, None, None, None)
|
||||
|
||||
chosen_data_packed = apply_rlhf_data_format(chosen, tokenizer, round_of_context)
|
||||
chosen_data_packed = apply_rlhf_data_format(chosen, tokenizer)
|
||||
(chosen_input_ids, chosen_loss_mask, chosen_label_decode) = (
|
||||
chosen_data_packed["input_ids"],
|
||||
chosen_data_packed["loss_mask"],
|
||||
chosen_data_packed["label_decode"],
|
||||
)
|
||||
|
||||
rejected_data_packed = apply_rlhf_data_format(
|
||||
rejected, tokenizer, round_of_context, mask_out_target_assistant_line_end=True
|
||||
)
|
||||
rejected_data_packed = apply_rlhf_data_format(rejected, tokenizer)
|
||||
(rejected_input_ids, rejected_loss_mask, rejected_label_decode) = (
|
||||
rejected_data_packed["input_ids"],
|
||||
rejected_data_packed["loss_mask"],
|
||||
@ -387,7 +319,7 @@ def tokenize_rlhf(
|
||||
rejected_label_decode=None,
|
||||
)
|
||||
# Check if loss mask is all 0s (no loss), this may happen when the tokenized length is too long
|
||||
if chosen_loss_mask[1:].count(1) == 0 or rejected_loss_mask[1:].count(1) == 0:
|
||||
if chosen_loss_mask.count(1) == 0 or rejected_loss_mask.count(1) == 0:
|
||||
return dict(
|
||||
chosen_input_ids=None,
|
||||
chosen_loss_mask=None,
|
||||
@ -405,3 +337,66 @@ def tokenize_rlhf(
|
||||
"rejected_loss_mask": rejected_loss_mask,
|
||||
"rejected_label_decode": rejected_label_decode,
|
||||
}
|
||||
|
||||
|
||||
def tokenize_kto(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
Tokenize a dataset for KTO training
|
||||
The raw input data is conversation that have the following format
|
||||
{
|
||||
"prompt": [{"from": "user", "content": "xxx"}...],
|
||||
"completion": {"from": "assistant", "content": "xxx"},
|
||||
"label": true/false
|
||||
}
|
||||
It returns three fields
|
||||
The context, which contain the query and the assistant start,
|
||||
the completion, which only contains the assistance's answer,
|
||||
and a binary label, which indicates if the sample is prefered or not
|
||||
"""
|
||||
prompt = data_point["prompt"]
|
||||
completion = data_point["completion"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.clear()
|
||||
|
||||
if prompt[0]["from"] == "system":
|
||||
template.system_message = str(prompt[0]["content"])
|
||||
prompt.pop(0)
|
||||
|
||||
if prompt[0].get("from", None) != "user":
|
||||
raise ValueError("conversation should start with user")
|
||||
if completion.get("from", None) != "assistant":
|
||||
raise ValueError("conversation should end with assistant")
|
||||
|
||||
for mess in prompt:
|
||||
if mess.get("from", None) == "user":
|
||||
template.append_message("user", mess["content"])
|
||||
elif mess.get("from", None) == "assistant":
|
||||
template.append_message("assistant", mess["content"])
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {mess.get('from', None)}")
|
||||
generation_prompt = template.get_prompt(len(prompt), add_generation_prompt=True)
|
||||
template.append_message("assistant", completion["content"])
|
||||
full_prompt = template.get_prompt(len(prompt) + 1, add_generation_prompt=False)
|
||||
tokenized_full_prompt = tokenizer(full_prompt, add_special_tokens=False)["input_ids"]
|
||||
if len(tokenized_full_prompt) + 1 > max_length:
|
||||
return dict(prompt=None, completion=None, label=None, input_id_decode=None, completion_decode=None)
|
||||
tokenized_generation_prompt = tokenizer(generation_prompt, add_special_tokens=False)["input_ids"]
|
||||
tokenized_completion = tokenized_full_prompt[len(tokenized_generation_prompt) :]
|
||||
tokenized_completion = deepcopy(tokenized_completion)
|
||||
if tokenizer.bos_token_id is not None and tokenized_generation_prompt[0] != tokenizer.bos_token_id:
|
||||
tokenized_generation_prompt = [tokenizer.bos_token_id] + tokenized_generation_prompt
|
||||
decoded_full_prompt = tokenizer.decode(tokenized_full_prompt, skip_special_tokens=False)
|
||||
decoded_completion = tokenizer.decode(tokenized_completion, skip_special_tokens=False)
|
||||
|
||||
return {
|
||||
"prompt": tokenized_generation_prompt,
|
||||
"completion": tokenized_completion,
|
||||
"label": data_point["label"],
|
||||
"input_id_decode": decoded_full_prompt,
|
||||
"completion_decode": decoded_completion,
|
||||
}
|
||||
|
||||
@ -88,7 +88,13 @@ def find_first_occurrence_subsequence(seq: torch.Tensor, subseq: torch.Tensor, s
|
||||
return -1
|
||||
|
||||
|
||||
def tokenize_and_concatenate(tokenizer: PreTrainedTokenizer, text: List[str], require_loss: List[bool]):
|
||||
def tokenize_and_concatenate(
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
text: List[str],
|
||||
require_loss: List[bool],
|
||||
max_length: int,
|
||||
discard_non_loss_tokens_at_tail: bool = True,
|
||||
):
|
||||
"""
|
||||
Tokenizes a list of texts using the provided tokenizer and concatenates the tokenized outputs.
|
||||
|
||||
@ -96,6 +102,13 @@ def tokenize_and_concatenate(tokenizer: PreTrainedTokenizer, text: List[str], re
|
||||
tokenizer (PreTrainedTokenizer): The tokenizer to use for tokenization.
|
||||
text (List[str]): The list of texts to tokenize.
|
||||
require_loss (List[bool]): A list of boolean values indicating whether each text requires loss calculation.
|
||||
max_length: used to truncate the input ids
|
||||
discard_non_loss_tokens_at_tail: whether to discard the non-loss tokens at the tail
|
||||
|
||||
if the first round has already exeeded max length
|
||||
- if the user query already exeeded max length, discard the sample
|
||||
- if only the first assistant response exeeded max length, truncate the response to fit the max length
|
||||
else keep the first several complete rounds of the conversations until max length is reached
|
||||
|
||||
Returns:
|
||||
Tuple[List[int], List[int], List[int]]: A tuple containing the concatenated tokenized input ids,
|
||||
@ -106,10 +119,18 @@ def tokenize_and_concatenate(tokenizer: PreTrainedTokenizer, text: List[str], re
|
||||
loss_ends = []
|
||||
for s, r in zip(text, require_loss):
|
||||
tokenized = tokenizer(s, add_special_tokens=False)["input_ids"]
|
||||
if r:
|
||||
loss_starts.append(len(input_ids))
|
||||
loss_ends.append(len(input_ids) + len(tokenized))
|
||||
input_ids.extend(tokenized)
|
||||
if not max_length or len(input_ids) + len(tokenized) <= max_length or len(loss_ends) == 0:
|
||||
if r:
|
||||
loss_starts.append(len(input_ids))
|
||||
loss_ends.append(len(input_ids) + len(tokenized))
|
||||
input_ids.extend(tokenized)
|
||||
if max_length and loss_starts[0] >= max_length:
|
||||
return None, None, None
|
||||
if discard_non_loss_tokens_at_tail:
|
||||
input_ids = input_ids[: loss_ends[-1]]
|
||||
if max_length:
|
||||
input_ids = input_ids[:max_length]
|
||||
loss_ends[-1] = min(max_length, loss_ends[-1])
|
||||
return input_ids, loss_starts, loss_ends
|
||||
|
||||
|
||||
@ -125,6 +146,12 @@ def split_templated_prompt_into_chunks(messages: List[Dict[str, str]], prompt: s
|
||||
content_length = (
|
||||
prompt.find(end_of_assistant, first_occur + content_length) + len(end_of_assistant) - first_occur
|
||||
)
|
||||
# if the tokenized content start with a leading space, we want to keep it in loss calculation
|
||||
# e.g., Assistant: I am saying...
|
||||
# if the tokenized content doesn't start with a leading space, we only need to keep the content in loss calculation
|
||||
# e.g.,
|
||||
# Assistant: # '\n' as line breaker
|
||||
# I am saying...
|
||||
if prompt[first_occur - 1] != " ":
|
||||
chunks.append(prompt[start_idx:first_occur])
|
||||
chunks.append(prompt[first_occur : first_occur + content_length])
|
||||
|
||||
@ -27,6 +27,8 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
||||
self.target_device = torch.device(f"cuda:{torch.cuda.current_device()}")
|
||||
# TODO(ver217): add prefetch
|
||||
self.items: List[BufferItem] = []
|
||||
self.rng_sequence = []
|
||||
self.ptr = 0
|
||||
|
||||
@torch.no_grad()
|
||||
def append(self, experience: Experience) -> None:
|
||||
@ -40,6 +42,9 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
||||
if samples_to_remove > 0:
|
||||
logger.warning(f"Experience buffer is full. Removing {samples_to_remove} samples.")
|
||||
self.items = self.items[samples_to_remove:]
|
||||
self.rng_sequence = [i for i in range(len(self.items))]
|
||||
random.shuffle(self.rng_sequence)
|
||||
self.ptr = 0
|
||||
|
||||
def clear(self) -> None:
|
||||
self.items.clear()
|
||||
@ -52,7 +57,10 @@ class NaiveExperienceBuffer(ExperienceBuffer):
|
||||
Returns:
|
||||
A batch of sampled experiences.
|
||||
"""
|
||||
items = random.sample(self.items, self.sample_batch_size)
|
||||
items = []
|
||||
for _ in range(self.sample_batch_size):
|
||||
self.ptr = (self.ptr + 1) % len(self.items)
|
||||
items.append(self.items[self.rng_sequence[self.ptr]])
|
||||
experience = make_experience_batch(items)
|
||||
if self.cpu_offload:
|
||||
experience.to_device(self.target_device)
|
||||
|
||||
@ -2,6 +2,8 @@
|
||||
experience maker.
|
||||
"""
|
||||
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from coati.dataset.utils import find_first_occurrence_subsequence
|
||||
@ -38,14 +40,27 @@ class NaiveExperienceMaker(ExperienceMaker):
|
||||
kl_coef: float = 0.01,
|
||||
gamma: float = 1.0,
|
||||
lam: float = 0.95,
|
||||
use_grpo: bool = False,
|
||||
num_generation: int = 8,
|
||||
inference_batch_size: int = None,
|
||||
logits_forward_batch_size: int = 2,
|
||||
) -> None:
|
||||
super().__init__(actor, critic, reward_model, initial_model)
|
||||
self.tokenizer = tokenizer
|
||||
self.kl_coef = kl_coef
|
||||
self.gamma = gamma
|
||||
self.lam = lam
|
||||
self.use_grpo = use_grpo
|
||||
self.num_generation = num_generation
|
||||
self.inference_batch_size = inference_batch_size
|
||||
self.logits_forward_batch_size = logits_forward_batch_size
|
||||
if not self.use_grpo:
|
||||
assert self.critic is not None, "Critic model is required for PPO training."
|
||||
else:
|
||||
assert self.critic is None, "Critic model is not required for GRPO training."
|
||||
assert self.num_generation > 1, "Number of generations should be greater than 1 for GRPO training."
|
||||
|
||||
@torch.no_grad()
|
||||
@torch.inference_mode()
|
||||
def calculate_advantage(self, value: torch.Tensor, reward: torch.Tensor, num_actions: int) -> torch.Tensor:
|
||||
"""
|
||||
Calculates the advantage values for each action based on the value and reward tensors.
|
||||
@ -69,7 +84,9 @@ class NaiveExperienceMaker(ExperienceMaker):
|
||||
return advantages
|
||||
|
||||
@torch.no_grad()
|
||||
def make_experience(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **generate_kwargs) -> Experience:
|
||||
def make_experience(
|
||||
self, input_ids: torch.Tensor, attention_mask: torch.Tensor, gt_answer: Any = None, **generate_kwargs
|
||||
) -> Experience:
|
||||
"""
|
||||
Generates an experience using the given input_ids and attention_mask.
|
||||
|
||||
@ -83,98 +100,204 @@ class NaiveExperienceMaker(ExperienceMaker):
|
||||
|
||||
"""
|
||||
self.actor.eval()
|
||||
self.critic.eval()
|
||||
if self.critic:
|
||||
self.critic.eval()
|
||||
self.initial_model.eval()
|
||||
self.reward_model.eval()
|
||||
pad_token_id = self.tokenizer.pad_token_id
|
||||
|
||||
stop_token_ids = generate_kwargs.get("stop_token_ids", None)
|
||||
if isinstance(stop_token_ids, int):
|
||||
stop_token_ids = [[stop_token_ids]]
|
||||
elif isinstance(stop_token_ids[0], int):
|
||||
stop_token_ids = [stop_token_ids]
|
||||
elif isinstance(stop_token_ids[0], list):
|
||||
pass
|
||||
else:
|
||||
raise ValueError(
|
||||
f"stop_token_ids should be a list of list of integers, a list of integers or an integers. got {stop_token_ids}"
|
||||
)
|
||||
generate_kwargs["stop_token_ids"] = stop_token_ids
|
||||
torch.manual_seed(41) # for tp, gurantee the same input for reward model
|
||||
|
||||
sequences = generate(self.actor, input_ids, self.tokenizer, **generate_kwargs)
|
||||
if self.use_grpo and self.num_generation > 1:
|
||||
# Generate multiple responses for each prompt
|
||||
input_ids = input_ids.repeat_interleave(self.num_generation, dim=0)
|
||||
gt_answer_tmp = []
|
||||
for t in gt_answer:
|
||||
gt_answer_tmp.extend([t] * self.num_generation)
|
||||
gt_answer = gt_answer_tmp
|
||||
if self.inference_batch_size is None:
|
||||
self.inference_batch_size = input_ids.size(0)
|
||||
|
||||
# Pad to max length
|
||||
sequences = F.pad(sequences, (0, generate_kwargs["max_length"] - sequences.size(1)), value=pad_token_id)
|
||||
sequence_length = sequences.size(1)
|
||||
batch_sequences = []
|
||||
batch_input_ids_rm = []
|
||||
batch_attention_mask_rm = []
|
||||
batch_attention_mask = []
|
||||
batch_r = []
|
||||
batch_action_log_probs = []
|
||||
batch_base_action_log_probs = []
|
||||
batch_action_mask = []
|
||||
num_actions = 0
|
||||
|
||||
# Calculate auxiliary tensors
|
||||
attention_mask = None
|
||||
if pad_token_id is not None:
|
||||
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
||||
for inference_mini_batch_id in range(0, input_ids.size(0), self.inference_batch_size):
|
||||
s, e = inference_mini_batch_id, inference_mini_batch_id + self.inference_batch_size
|
||||
if input_ids[s:e].size(0) == 0:
|
||||
break
|
||||
sequences = generate(self.actor, input_ids[s:e], self.tokenizer, **generate_kwargs)
|
||||
# pad to max_len, you don't want to get an OOM error after a thousands of steps
|
||||
sequences = F.pad(sequences, (0, generate_kwargs["max_length"] - sequences.size(1)), value=pad_token_id)
|
||||
|
||||
input_len = input_ids.size(1)
|
||||
if stop_token_ids is None:
|
||||
# End the sequence with eos token
|
||||
eos_token_id = self.tokenizer.eos_token_id
|
||||
if eos_token_id is None:
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
else:
|
||||
# Left padding may be applied, only mask action
|
||||
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
||||
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
||||
else:
|
||||
# stop_token_ids are given, generation ends with stop_token_ids
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
for i in range(sequences.size(0)):
|
||||
stop_index = find_first_occurrence_subsequence(
|
||||
sequences[i][input_len:], torch.tensor(stop_token_ids).to(sequences.device)
|
||||
)
|
||||
if stop_index == -1:
|
||||
# Sequence does not contain stop_token_ids, this should never happen BTW
|
||||
logger.warning(
|
||||
"Generated sequence does not contain stop_token_ids. Please check your chat template config"
|
||||
)
|
||||
# Pad to max length
|
||||
sequence_length = sequences.size(1)
|
||||
|
||||
# Calculate auxiliary tensors
|
||||
attention_mask = None
|
||||
if pad_token_id is not None:
|
||||
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
||||
|
||||
input_len = input_ids.size(1)
|
||||
if stop_token_ids is None:
|
||||
# End the sequence with eos token
|
||||
eos_token_id = self.tokenizer.eos_token_id
|
||||
if eos_token_id is None:
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
else:
|
||||
# Keep stop tokens
|
||||
stop_index = input_len + stop_index
|
||||
action_mask[i, stop_index + len(stop_token_ids) :] = False
|
||||
|
||||
generation_end_index = (action_mask == True).sum(dim=-1) - 1
|
||||
action_mask[:, :input_len] = False
|
||||
action_mask = action_mask[:, 1:]
|
||||
action_mask = action_mask[:, -(sequences.size(1) - input_len) :]
|
||||
num_actions = action_mask.size(1)
|
||||
|
||||
actor_output = self.actor(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
||||
action_log_probs = calc_action_log_probs(actor_output, sequences, num_actions)
|
||||
|
||||
base_model_output = self.initial_model(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
||||
|
||||
base_action_log_probs = calc_action_log_probs(base_model_output, sequences, num_actions)
|
||||
|
||||
# Convert to right padding for the reward model and the critic model
|
||||
input_ids_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
attention_mask_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
for i in range(sequences.size(0)):
|
||||
sequence = sequences[i]
|
||||
bos_index = (sequence != pad_token_id).nonzero().reshape([-1])[0]
|
||||
eos_index = generation_end_index[i]
|
||||
sequence_to_pad = sequence[bos_index:eos_index]
|
||||
sequence_padded = F.pad(
|
||||
sequence_to_pad, (0, sequence_length - sequence_to_pad.size(0)), value=self.tokenizer.pad_token_id
|
||||
)
|
||||
input_ids_rm[i] = sequence_padded
|
||||
if sequence_length - sequence_to_pad.size(0) > 0:
|
||||
attention_mask_rm[i, : sequence_to_pad.size(0) + 1] = 1
|
||||
# Left padding may be applied, only mask action
|
||||
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
||||
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
||||
else:
|
||||
attention_mask_rm[i, :] = 1
|
||||
attention_mask_rm = attention_mask_rm.to(dtype=torch.bool)
|
||||
# stop_token_ids are given, generation ends with stop_token_ids
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
for i in range(sequences.size(0)):
|
||||
stop_token_pos = [
|
||||
find_first_occurrence_subsequence(
|
||||
sequences[i][input_len:], torch.tensor(stop_token_id).to(sequences.device)
|
||||
)
|
||||
for stop_token_id in stop_token_ids
|
||||
]
|
||||
stop_index = min([i for i in stop_token_pos if i != -1], default=-1)
|
||||
stop_token_id = stop_token_ids[stop_token_pos.index(stop_index)]
|
||||
if stop_index == -1:
|
||||
# Sequence does not contain stop_token_ids, this should never happen BTW
|
||||
logger.warning(
|
||||
"Generated sequence does not contain stop_token_ids. Please check your chat template config"
|
||||
)
|
||||
print(self.tokenizer.decode(sequences[i], skip_special_tokens=True))
|
||||
else:
|
||||
# Keep stop tokens
|
||||
stop_index = input_len + stop_index
|
||||
action_mask[i, stop_index + len(stop_token_id) :] = False
|
||||
|
||||
r = self.reward_model(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
)
|
||||
generation_end_index = (action_mask == True).sum(dim=-1) - 1
|
||||
action_mask[:, :input_len] = False
|
||||
action_mask = action_mask[:, 1:]
|
||||
action_mask = action_mask[:, -(sequences.size(1) - input_len) :]
|
||||
num_actions = action_mask.size(1)
|
||||
torch.cuda.empty_cache()
|
||||
with torch.inference_mode():
|
||||
actor_output = []
|
||||
base_model_output = []
|
||||
for i in range(0, sequences.size(0), self.logits_forward_batch_size):
|
||||
actor_output.append(
|
||||
self.actor(
|
||||
input_ids=sequences[i : i + self.logits_forward_batch_size],
|
||||
attention_mask=attention_mask[i : i + self.logits_forward_batch_size],
|
||||
use_cache=False,
|
||||
)["logits"]
|
||||
)
|
||||
base_model_output.append(
|
||||
self.initial_model(
|
||||
input_ids=sequences[i : i + self.logits_forward_batch_size],
|
||||
attention_mask=attention_mask[i : i + self.logits_forward_batch_size],
|
||||
use_cache=False,
|
||||
)["logits"]
|
||||
)
|
||||
actor_output = torch.cat(actor_output, dim=0)
|
||||
base_model_output = torch.cat(base_model_output, dim=0)
|
||||
action_log_probs = calc_action_log_probs(actor_output, sequences, num_actions)
|
||||
base_action_log_probs = calc_action_log_probs(base_model_output, sequences, num_actions)
|
||||
|
||||
value = self.critic(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
)
|
||||
reward, kl = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
|
||||
value = value[:, -num_actions:] * action_mask
|
||||
advantages = self.calculate_advantage(value, reward, num_actions)
|
||||
# Convert to right padding for the reward model and the critic model
|
||||
input_ids_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
response_start = []
|
||||
response_end = []
|
||||
attention_mask_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
for i in range(sequences.size(0)):
|
||||
sequence = sequences[i]
|
||||
bos_index = (sequence != pad_token_id).nonzero().reshape([-1])[0]
|
||||
eos_index = generation_end_index[i] + 1 # include the stop token
|
||||
sequence_to_pad = sequence[bos_index:eos_index]
|
||||
response_start.append(input_len - bos_index)
|
||||
response_end.append(eos_index - bos_index)
|
||||
sequence_padded = F.pad(
|
||||
sequence_to_pad, (0, sequence_length - sequence_to_pad.size(0)), value=self.tokenizer.pad_token_id
|
||||
)
|
||||
input_ids_rm[i] = sequence_padded
|
||||
if sequence_length - sequence_to_pad.size(0) > 0:
|
||||
attention_mask_rm[i, : sequence_to_pad.size(0) + 1] = 1
|
||||
else:
|
||||
attention_mask_rm[i, :] = 1
|
||||
attention_mask_rm = attention_mask_rm.to(dtype=torch.bool)
|
||||
|
||||
advantages = advantages.detach()
|
||||
value = value.detach()
|
||||
r = self.reward_model(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
response_start=response_start,
|
||||
response_end=response_end,
|
||||
gt_answer=gt_answer[s:e],
|
||||
)
|
||||
|
||||
batch_sequences.append(sequences)
|
||||
batch_input_ids_rm.append(input_ids_rm)
|
||||
batch_attention_mask_rm.append(attention_mask_rm)
|
||||
batch_attention_mask.append(attention_mask)
|
||||
batch_r.append(r)
|
||||
batch_action_log_probs.append(action_log_probs.cpu())
|
||||
batch_base_action_log_probs.append(base_action_log_probs.cpu())
|
||||
batch_action_mask.append(action_mask)
|
||||
|
||||
sequences = torch.cat(batch_sequences, dim=0)
|
||||
input_ids_rm = torch.cat(batch_input_ids_rm, dim=0)
|
||||
attention_mask_rm = torch.cat(batch_attention_mask_rm, dim=0)
|
||||
attention_mask = torch.cat(batch_attention_mask, dim=0)
|
||||
r = torch.cat(batch_r, dim=0)
|
||||
action_log_probs = torch.cat(batch_action_log_probs, dim=0).to(sequences.device)
|
||||
base_action_log_probs = torch.cat(batch_base_action_log_probs, dim=0).to(sequences.device)
|
||||
action_mask = torch.cat(batch_action_mask, dim=0).to(sequences.device)
|
||||
if not self.use_grpo:
|
||||
value = self.critic(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
)
|
||||
value = value[:, -num_actions:] * action_mask
|
||||
reward, kl = compute_reward(
|
||||
r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask
|
||||
)
|
||||
advantages = self.calculate_advantage(value, reward, num_actions)
|
||||
advantages = advantages.detach()
|
||||
value = value.detach()
|
||||
else:
|
||||
# GRPO advantage calculation
|
||||
kl = torch.sum(
|
||||
-self.kl_coef * (action_log_probs - base_action_log_probs) * action_mask, dim=-1
|
||||
) / torch.sum(
|
||||
action_mask, dim=-1
|
||||
) # address numerical instability issue
|
||||
r = kl + r
|
||||
mean_gr = r.view(-1, self.num_generation).mean(dim=1)
|
||||
std_gr = r.view(-1, self.num_generation).std(dim=1)
|
||||
mean_gr = mean_gr.repeat_interleave(self.num_generation, dim=0)
|
||||
std_gr = std_gr.repeat_interleave(self.num_generation, dim=0)
|
||||
advantages = (r - mean_gr) / (std_gr + 1e-4)
|
||||
value = r.detach() # dummy value
|
||||
r = r.detach()
|
||||
|
||||
return Experience(sequences, action_log_probs, value, r, kl, advantages, attention_mask, action_mask)
|
||||
return Experience(
|
||||
sequences.cpu(),
|
||||
action_log_probs.cpu(),
|
||||
value.cpu(),
|
||||
r.cpu(),
|
||||
kl.cpu(),
|
||||
advantages.cpu(),
|
||||
attention_mask.cpu(),
|
||||
action_mask.cpu(),
|
||||
)
|
||||
|
||||
@ -1,22 +1,26 @@
|
||||
from .base import BaseModel
|
||||
from .critic import Critic
|
||||
from .generation import generate, generate_streaming, prepare_inputs_fn, update_model_kwargs_fn
|
||||
from .lora import convert_to_lora_module
|
||||
from .loss import DpoLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
|
||||
from .lora import LoraConfig, convert_to_lora_module, lora_manager
|
||||
from .loss import DpoLoss, KTOLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
|
||||
from .reward_model import RewardModel
|
||||
from .rlvr_reward_model import RLVRRewardModel
|
||||
from .utils import disable_dropout
|
||||
|
||||
__all__ = [
|
||||
"BaseModel",
|
||||
"Critic",
|
||||
"RewardModel",
|
||||
"RLVRRewardModel",
|
||||
"PolicyLoss",
|
||||
"ValueLoss",
|
||||
"LogSigLoss",
|
||||
"LogExpLoss",
|
||||
"LoraConfig",
|
||||
"lora_manager",
|
||||
"convert_to_lora_module",
|
||||
"DpoLoss",
|
||||
"generate",
|
||||
"KTOLoss" "generate",
|
||||
"generate_streaming",
|
||||
"disable_dropout",
|
||||
"update_model_kwargs_fn",
|
||||
|
||||
@ -42,7 +42,6 @@ class BaseModel(nn.Module):
|
||||
out = self.model(dummy_input)
|
||||
self.last_hidden_state_size = out.last_hidden_state.shape[-1]
|
||||
self.model = self.model.cpu()
|
||||
# print("self.last_hidden_state_size: ",self.last_hidden_state_size)
|
||||
|
||||
def resize_token_embeddings(self, *args, **kwargs):
|
||||
"""
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
import copy
|
||||
from typing import Any, Callable, List, Optional
|
||||
|
||||
import torch
|
||||
@ -88,13 +89,14 @@ def update_model_kwargs_fn(outputs: dict, new_mask, **model_kwargs) -> dict:
|
||||
return model_kwargs
|
||||
|
||||
|
||||
def prepare_inputs_fn(input_ids: torch.Tensor, pad_token_id: int, **model_kwargs) -> dict:
|
||||
def prepare_inputs_fn(input_ids: torch.Tensor, **model_kwargs) -> dict:
|
||||
model_kwargs["input_ids"] = input_ids
|
||||
return model_kwargs
|
||||
|
||||
|
||||
def _sample(
|
||||
model: Any,
|
||||
tokenizer: Any,
|
||||
input_ids: torch.Tensor,
|
||||
max_length: int,
|
||||
early_stopping: bool = True,
|
||||
@ -137,8 +139,8 @@ def _sample(
|
||||
if max_new_tokens is None:
|
||||
max_new_tokens = max_length - context_length
|
||||
if context_length + max_new_tokens > max_length or max_new_tokens == 0:
|
||||
print("Exeeded length limitation")
|
||||
return input_ids
|
||||
|
||||
logits_processor = _prepare_logits_processor(top_k, top_p, temperature)
|
||||
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
||||
past = None
|
||||
@ -183,18 +185,14 @@ def _sample(
|
||||
|
||||
if stop_token_ids is not None:
|
||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
for stop_token_id in stop_token_ids:
|
||||
tokens_to_check = input_ids[:, -len(stop_token_id) :]
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_id).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
|
||||
# Stop when each sentence is finished if early_stopping=True
|
||||
if (early_stopping and _is_sequence_finished(unfinished_sequences)) or i == context_length + max_new_tokens - 1:
|
||||
if i == context_length + max_new_tokens - 1:
|
||||
# Force to end with stop token ids
|
||||
input_ids[input_ids[:, -1] != pad_token_id, -len(stop_token_ids) :] = (
|
||||
torch.LongTensor(stop_token_ids).to(input_ids.device).long()
|
||||
)
|
||||
return input_ids
|
||||
|
||||
|
||||
@ -237,8 +235,10 @@ def generate(
|
||||
raise NotImplementedError
|
||||
elif is_sample_gen_mode:
|
||||
# Run sample
|
||||
generation_kwargs = copy.deepcopy(model_kwargs)
|
||||
res = _sample(
|
||||
model,
|
||||
tokenizer,
|
||||
input_ids,
|
||||
max_length,
|
||||
early_stopping=early_stopping,
|
||||
@ -249,8 +249,9 @@ def generate(
|
||||
temperature=temperature,
|
||||
prepare_inputs_fn=prepare_inputs_fn,
|
||||
update_model_kwargs_fn=update_model_kwargs_fn,
|
||||
**model_kwargs,
|
||||
**generation_kwargs,
|
||||
)
|
||||
del generation_kwargs
|
||||
return res
|
||||
elif is_beam_gen_mode:
|
||||
raise NotImplementedError
|
||||
@ -350,11 +351,17 @@ def _sample_streaming(
|
||||
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
|
||||
|
||||
if stop_token_ids is not None:
|
||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
if isinstance(stop_token_ids[0], int):
|
||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
else:
|
||||
for stop_token_id in stop_token_ids:
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_id).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
|
||||
# Stop when each sentence is finished if early_stopping=True
|
||||
if (
|
||||
|
||||
@ -5,10 +5,11 @@ LORA utils
|
||||
import dataclasses
|
||||
import math
|
||||
import warnings
|
||||
from typing import Optional
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import loralib as lora
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
@ -18,148 +19,349 @@ logger = get_dist_logger()
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class LoRAManager:
|
||||
merge_weights: bool = False
|
||||
class LoraManager:
|
||||
able_to_merge: bool = True
|
||||
|
||||
|
||||
LORA_MANAGER = LoRAManager()
|
||||
lora_manager = LoraManager()
|
||||
|
||||
|
||||
class LoraLinear(lora.LoRALayer, nn.Module):
|
||||
"""Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear."""
|
||||
@dataclasses.dataclass
|
||||
class LoraConfig:
|
||||
r: int = 0
|
||||
lora_alpha: int = 32
|
||||
linear_lora_dropout: float = 0.1
|
||||
embedding_lora_dropout: float = 0.0
|
||||
lora_train_bias: str = "none"
|
||||
lora_initialization_method: str = "kaiming_uniform"
|
||||
target_modules: List = None
|
||||
|
||||
@classmethod
|
||||
def from_file(cls, config_file: str):
|
||||
import json
|
||||
|
||||
with open(config_file, "r") as f:
|
||||
config = json.load(f)
|
||||
return cls(**config)
|
||||
|
||||
|
||||
class LoraBase(lora.LoRALayer, nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
weight: nn.Parameter,
|
||||
bias: Optional[nn.Parameter],
|
||||
r: int = 0,
|
||||
lora_alpha: int = 1,
|
||||
lora_dropout: float = 0.0,
|
||||
# Set this to True if the layer to replace stores weight like (fan_in, fan_out)
|
||||
fan_in_fan_out: bool = False,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.1,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
nn.Module.__init__(self)
|
||||
lora.LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=False)
|
||||
self.weight = weight
|
||||
self.bias = bias
|
||||
|
||||
out_features, in_features = weight.shape
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
|
||||
self.fan_in_fan_out = fan_in_fan_out
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
|
||||
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
self.reset_parameters()
|
||||
if fan_in_fan_out:
|
||||
self.weight.data = self.weight.data.T
|
||||
self.r = r
|
||||
self.lora_alpha = lora_alpha
|
||||
self.lora_dropout = nn.Dropout(lora_dropout)
|
||||
self.merged = False
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
self.weight = None
|
||||
self.bias = None
|
||||
self.lora_A = None
|
||||
self.lora_B = None
|
||||
|
||||
def reset_parameters(self):
|
||||
if hasattr(self, "lora_A"):
|
||||
# Initialize A with the default values for nn.Linear and set B to zero.
|
||||
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B)
|
||||
if self.lora_initialization_method == "kaiming_uniform" or self.weight.size() != (
|
||||
self.out_features,
|
||||
self.in_features,
|
||||
):
|
||||
# Initialize A with the default values for nn.Linear and set B to zero.
|
||||
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B)
|
||||
elif self.lora_initialization_method == "PiSSA":
|
||||
# PiSSA method in this paper: https://arxiv.org/abs/2404.02948
|
||||
# Assume the SVD of the original weights is W = USV^T
|
||||
# Initialize a frozen weight to U[:,r:]S[r:,r:]V^T[:,r:] to store less significent part of W
|
||||
# Only A, B are trainable, which are initialized to S[r:,:r]^0.5V^T[:,:r] and U[:,:r]S[r:,:r] respectively
|
||||
# self.scaling = 1.
|
||||
# SVD
|
||||
U, S, Vh = torch.svd_lowrank(
|
||||
self.weight.to(torch.float32).data, self.r, niter=4
|
||||
) # U: [out_features, in_features], S: [in_features], V: [in_features, in_features]
|
||||
# weight_backup = self.weight.clone()
|
||||
|
||||
# Initialize A, B
|
||||
S = S / self.scaling
|
||||
self.lora_B.data = (U @ torch.diag(torch.sqrt(S))).to(torch.float32).contiguous()
|
||||
self.lora_A.data = (torch.diag(torch.sqrt(S)) @ Vh.T).to(torch.float32).contiguous()
|
||||
# Initialize weight
|
||||
# To reduce floating point error, we use residual instead of directly using U[:, :self.r] @ S[:self.r] @ Vh[:self.r, :]
|
||||
self.weight.data = (
|
||||
((self.weight - self.scaling * self.lora_B @ self.lora_A)).contiguous().to(self.weight.dtype)
|
||||
)
|
||||
self.lora_A.requires_grad = True
|
||||
self.lora_B.requires_grad = True
|
||||
else:
|
||||
raise ValueError(f"Unknown LoRA initialization method {self.lora_initialization_method}")
|
||||
|
||||
def train(self, mode: bool = True):
|
||||
"""
|
||||
This function runs when model.train() is invoked. It is used to prepare the linear layer for training
|
||||
"""
|
||||
|
||||
def T(w):
|
||||
return w.T if self.fan_in_fan_out else w
|
||||
|
||||
self.training = mode
|
||||
if LORA_MANAGER.merge_weights:
|
||||
if mode and self.merged:
|
||||
warnings.warn("Invoke module.train() would unmerge LoRA weights.")
|
||||
raise NotImplementedError("LoRA unmerge is not tested.")
|
||||
# Make sure that the weights are not merged
|
||||
if self.r > 0:
|
||||
if not hasattr(self, "lora_A") or not hasattr(self, "lora_B"):
|
||||
# FIXME(csric): temporary fix
|
||||
self.lora_A = nn.Parameter(self.weight.new_empty((self.r, self.in_features)))
|
||||
self.lora_B = nn.Parameter(self.weight.new_empty((self.out_features, self.r)))
|
||||
self.reset_parameters()
|
||||
else:
|
||||
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
|
||||
self.merged = False
|
||||
elif not mode and not self.merged:
|
||||
warnings.warn("Invoke module.eval() would merge LoRA weights.")
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
|
||||
delattr(self, "lora_A")
|
||||
delattr(self, "lora_B")
|
||||
self.merged = True
|
||||
if mode and self.merged:
|
||||
warnings.warn("Invoke module.train() would unmerge LoRA weights.")
|
||||
raise NotImplementedError("LoRA unmerge is not tested.")
|
||||
elif not mode and not self.merged and lora_manager.able_to_merge:
|
||||
warnings.warn("Invoke module.eval() would merge LoRA weights.")
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += self.lora_B @ self.lora_A * self.scaling
|
||||
delattr(self, "lora_A")
|
||||
delattr(self, "lora_B")
|
||||
self.merged = True
|
||||
|
||||
return self
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
def T(w):
|
||||
return w.T if self.fan_in_fan_out else w
|
||||
|
||||
class LoraLinear(LoraBase):
|
||||
"""Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
weight: nn.Parameter,
|
||||
bias: Union[nn.Parameter, bool],
|
||||
r: int = 0,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.0,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
super().__init__(
|
||||
r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, lora_initialization_method=lora_initialization_method
|
||||
)
|
||||
self.weight = weight
|
||||
self.bias = bias
|
||||
if bias is True:
|
||||
self.bias = nn.Parameter(torch.zeros(weight.shape[0]))
|
||||
if bias is not None:
|
||||
self.bias.requires_grad = True
|
||||
|
||||
out_features, in_features = weight.shape
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
assert lora_initialization_method in ["kaiming_uniform", "PiSSA"]
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Parameter(torch.randn((r, in_features)))
|
||||
self.lora_B = nn.Parameter(torch.randn((out_features, r)))
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
self.reset_parameters()
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
if self.r > 0 and not self.merged:
|
||||
result = F.linear(x, T(self.weight), bias=self.bias)
|
||||
if self.r > 0:
|
||||
result = result + (self.lora_dropout(x) @ self.lora_A.t() @ self.lora_B.t()) * self.scaling
|
||||
result = F.linear(x, self.weight, bias=self.bias)
|
||||
result = result + (self.lora_dropout(x) @ self.lora_A.t() @ self.lora_B.t()) * self.scaling
|
||||
return result
|
||||
else:
|
||||
return F.linear(x, T(self.weight), bias=self.bias)
|
||||
return F.linear(x, self.weight, bias=self.bias)
|
||||
|
||||
|
||||
def _lora_linear_wrapper(linear: nn.Linear, lora_rank: int) -> LoraLinear:
|
||||
class LoraEmbedding(LoraBase):
|
||||
"""Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
weight: nn.Parameter,
|
||||
r: int = 0,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.1,
|
||||
num_embeddings: int = None,
|
||||
embedding_dim: int = None,
|
||||
padding_idx: Optional[int] = None,
|
||||
max_norm: Optional[float] = None,
|
||||
norm_type: float = 2.0,
|
||||
scale_grad_by_freq: bool = False,
|
||||
sparse: bool = False,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
super().__init__(
|
||||
r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, lora_initialization_method=lora_initialization_method
|
||||
)
|
||||
self.padding_idx = padding_idx
|
||||
self.max_norm = max_norm
|
||||
self.norm_type = norm_type
|
||||
self.scale_grad_by_freq = scale_grad_by_freq
|
||||
self.sparse = sparse
|
||||
self.num_embeddings = num_embeddings
|
||||
self.embedding_dim = embedding_dim
|
||||
|
||||
self.weight = weight
|
||||
|
||||
in_features, out_features = num_embeddings, embedding_dim
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
assert lora_initialization_method in ["kaiming_uniform", "PiSSA"]
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Parameter(torch.randn((r, in_features)))
|
||||
self.lora_B = nn.Parameter(torch.randn((out_features, r)))
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
|
||||
# reset parameters
|
||||
nn.init.zeros_(self.lora_A)
|
||||
nn.init.normal_(self.lora_B)
|
||||
|
||||
def _embed(self, x: torch.Tensor, weight) -> torch.Tensor:
|
||||
return F.embedding(
|
||||
x,
|
||||
weight,
|
||||
padding_idx=self.padding_idx,
|
||||
max_norm=self.max_norm,
|
||||
norm_type=self.norm_type,
|
||||
scale_grad_by_freq=self.scale_grad_by_freq,
|
||||
sparse=self.sparse,
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
base_embedding = self._embed(x, self.weight)
|
||||
# base_embedding.requires_grad = True # force the embedding layer to be trainable for gradient checkpointing
|
||||
if self.r > 0 and not self.merged:
|
||||
lora_A_embedding = self._embed(x, self.lora_A.t())
|
||||
embedding = base_embedding + (lora_A_embedding @ self.lora_B.t()) * self.scaling
|
||||
return embedding
|
||||
else:
|
||||
return base_embedding
|
||||
|
||||
def train(self, mode: bool = True):
|
||||
"""
|
||||
This function runs when model.train() is invoked. It is used to prepare the linear layer for training
|
||||
"""
|
||||
|
||||
self.training = mode
|
||||
if mode and self.merged:
|
||||
warnings.warn("Invoke module.train() would unmerge LoRA weights.")
|
||||
raise NotImplementedError("LoRA unmerge is not tested.")
|
||||
elif not mode and not self.merged and lora_manager.able_to_merge:
|
||||
warnings.warn("Invoke module.eval() would merge LoRA weights.")
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += self.lora_A.t() @ self.lora_B.t() * self.scaling
|
||||
delattr(self, "lora_A")
|
||||
delattr(self, "lora_B")
|
||||
self.merged = True
|
||||
|
||||
return self
|
||||
|
||||
|
||||
def _lora_linear_wrapper(linear: nn.Linear, lora_config: LoraConfig) -> LoraLinear:
|
||||
"""
|
||||
Wraps a linear layer with LoRA functionality.
|
||||
|
||||
Args:
|
||||
linear (nn.Linear): The linear layer to be wrapped.
|
||||
lora_rank (int): The rank of the LoRA decomposition.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
LoraLinear: The wrapped linear layer with LoRA functionality.
|
||||
"""
|
||||
assert (
|
||||
lora_rank <= linear.in_features
|
||||
), f"LoRA rank ({lora_rank}) must be less than or equal to in features ({linear.in_features})"
|
||||
lora_linear = LoraLinear(linear.weight, linear.bias, r=lora_rank)
|
||||
lora_config.r <= linear.in_features
|
||||
), f"LoRA rank ({lora_config.r}) must be less than or equal to in features ({linear.in_features})"
|
||||
bias = None
|
||||
if lora_config.lora_train_bias in ["all", "lora"]:
|
||||
bias = linear.bias
|
||||
if bias is None:
|
||||
bias = True
|
||||
lora_linear = LoraLinear(
|
||||
linear.weight, bias, r=lora_config.r, lora_initialization_method=lora_config.lora_initialization_method
|
||||
)
|
||||
return lora_linear
|
||||
|
||||
|
||||
def _convert_to_lora_recursively(module: nn.Module, lora_rank: int) -> None:
|
||||
def _convert_to_lora_recursively(module: nn.Module, parent_name: str, lora_config: LoraConfig) -> None:
|
||||
"""
|
||||
Recursively converts the given module and its children to LoRA (Low-Rank Approximation) form.
|
||||
|
||||
Args:
|
||||
module (nn.Module): The module to convert to LoRA form.
|
||||
lora_rank (int): The rank of the LoRA approximation.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
parent_name (str): The name of the parent module.
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
for name, child in module.named_children():
|
||||
if isinstance(child, nn.Linear):
|
||||
setattr(module, name, _lora_linear_wrapper(child, lora_rank))
|
||||
if lora_config.target_modules is None or any(
|
||||
[name in target_module for target_module in lora_config.target_modules]
|
||||
):
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(f"Converting {parent_name}.{name} to LoRA")
|
||||
setattr(module, name, _lora_linear_wrapper(child, lora_config))
|
||||
elif isinstance(child, nn.Embedding):
|
||||
if lora_config.target_modules is None or any(
|
||||
[name in target_module for target_module in lora_config.target_modules]
|
||||
):
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(f"Converting {parent_name}.{name} to LoRA")
|
||||
setattr(
|
||||
module,
|
||||
name,
|
||||
LoraEmbedding(
|
||||
child.weight,
|
||||
r=lora_config.r,
|
||||
lora_alpha=lora_config.lora_alpha,
|
||||
lora_dropout=lora_config.embedding_lora_dropout,
|
||||
num_embeddings=child.num_embeddings,
|
||||
embedding_dim=child.embedding_dim,
|
||||
padding_idx=child.padding_idx,
|
||||
max_norm=child.max_norm,
|
||||
norm_type=child.norm_type,
|
||||
scale_grad_by_freq=child.scale_grad_by_freq,
|
||||
sparse=child.sparse,
|
||||
lora_initialization_method=lora_config.lora_initialization_method,
|
||||
),
|
||||
)
|
||||
else:
|
||||
_convert_to_lora_recursively(child, lora_rank)
|
||||
_convert_to_lora_recursively(child, f"{parent_name}.{name}", lora_config)
|
||||
|
||||
|
||||
def convert_to_lora_module(module: nn.Module, lora_rank: int, lora_train_bias: str = "none") -> nn.Module:
|
||||
def convert_to_lora_module(module: nn.Module, lora_config: LoraConfig) -> nn.Module:
|
||||
"""Convert a torch.nn.Module to a LoRA module.
|
||||
|
||||
Args:
|
||||
module (nn.Module): The module to convert.
|
||||
lora_rank (int): LoRA rank.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
nn.Module: The converted module.
|
||||
"""
|
||||
if lora_rank <= 0:
|
||||
if lora_config.r <= 0:
|
||||
return module
|
||||
_convert_to_lora_recursively(module, lora_rank)
|
||||
lora.mark_only_lora_as_trainable(module, lora_train_bias)
|
||||
# make all parameter not trainable, if lora_train_bias is "all", set bias to trainable
|
||||
total_parameter_size = 0
|
||||
for name, p in module.named_parameters():
|
||||
p.requires_grad = False
|
||||
if "bias" in name and lora_config.lora_train_bias == "all":
|
||||
p.requires_grad = True
|
||||
total_parameter_size += p.numel()
|
||||
_convert_to_lora_recursively(module, "", lora_config)
|
||||
trainable_parameter_size = 0
|
||||
for name, p in module.named_parameters():
|
||||
if p.requires_grad == True:
|
||||
trainable_parameter_size += p.numel()
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(
|
||||
f"Trainable parameter size: {trainable_parameter_size/1024/1024:.2f}M\nOriginal trainable parameter size: {total_parameter_size/1024/1024:.2f}M\nPercentage: {trainable_parameter_size/total_parameter_size*100:.2f}%"
|
||||
)
|
||||
return module
|
||||
|
||||
@ -5,6 +5,7 @@ loss functions
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
|
||||
from .utils import masked_mean
|
||||
@ -45,7 +46,10 @@ class PolicyLoss(nn.Module):
|
||||
action_mask: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
skip = False
|
||||
ratio_ = ((log_probs - old_log_probs) * action_mask).exp()
|
||||
if action_mask is None:
|
||||
ratio_ = (log_probs - old_log_probs).exp()
|
||||
else:
|
||||
ratio_ = ((log_probs - old_log_probs) * action_mask).exp()
|
||||
|
||||
# note that if dropout is disabled (recommanded), ratio will always be 1.
|
||||
if ratio_.mean() > self.skip_threshold:
|
||||
@ -55,7 +59,10 @@ class PolicyLoss(nn.Module):
|
||||
surr1 = ratio * advantages
|
||||
surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
|
||||
loss = -torch.min(surr1, surr2)
|
||||
loss = masked_mean(loss, action_mask)
|
||||
if action_mask is not None:
|
||||
loss = masked_mean(loss, action_mask)
|
||||
else:
|
||||
loss = loss.mean(dim=1)
|
||||
loss = loss.mean()
|
||||
return loss, skip, ratio_.max()
|
||||
|
||||
@ -80,8 +87,10 @@ class ValueLoss(nn.Module):
|
||||
values_clipped = old_values + (values - old_values).clamp(-self.clip_eps, self.clip_eps)
|
||||
surr1 = (values_clipped - returns) ** 2
|
||||
surr2 = (values - returns) ** 2
|
||||
loss = torch.max(surr1, surr2) / torch.sum(action_mask)
|
||||
loss = torch.sum(loss * action_mask)
|
||||
if action_mask is not None:
|
||||
loss = torch.sum(torch.max(surr1, surr2) / torch.sum(action_mask) * action_mask)
|
||||
else:
|
||||
loss = torch.mean(torch.max(surr1, surr2))
|
||||
return 0.5 * loss
|
||||
|
||||
|
||||
@ -144,10 +153,11 @@ class DpoLoss(nn.Module):
|
||||
else:
|
||||
# If no reference model is provided
|
||||
ref_logratios = 0.0
|
||||
|
||||
pi_logratios = logprob_actor_chosen.sum(-1) - logprob_actor_reject.sum(-1)
|
||||
logits = pi_logratios - ref_logratios - self.gamma / self.beta
|
||||
losses = -torch.nn.functional.logsigmoid(self.beta * logits)
|
||||
|
||||
loss = losses.mean()
|
||||
# Calculate rewards for logging
|
||||
if logprob_ref_chosen is not None:
|
||||
chosen_rewards = self.beta * (logprob_actor_chosen.sum(-1) - logprob_ref_chosen.sum(-1)).detach()
|
||||
@ -158,7 +168,7 @@ class DpoLoss(nn.Module):
|
||||
else:
|
||||
rejected_rewards = self.beta * logprob_actor_reject.sum(-1).detach()
|
||||
|
||||
return losses, chosen_rewards, rejected_rewards
|
||||
return loss, chosen_rewards, rejected_rewards
|
||||
|
||||
|
||||
class LogSigLoss(nn.Module):
|
||||
@ -201,7 +211,72 @@ class OddsRatioLoss(nn.Module):
|
||||
chosen_odds_masked = torch.sum(chosen_odds * chosen_loss_mask.float()) / torch.sum(chosen_loss_mask)
|
||||
reject_odds = reject_logp - torch.log(-torch.exp(reject_logp) + 1.0001)
|
||||
reject_odds_masked = torch.sum(reject_odds * reject_loss_mask.float()) / torch.sum(reject_loss_mask)
|
||||
# print("chosen_odds_masked", chosen_odds_masked[0], "reject_odds_masked", reject_odds_masked[0])
|
||||
log_odds_ratio = chosen_odds_masked - reject_odds_masked
|
||||
ratio = torch.log(torch.nn.functional.sigmoid(log_odds_ratio))
|
||||
return ratio.to(dtype=torch.bfloat16), log_odds_ratio
|
||||
|
||||
|
||||
class KTOLoss(nn.Module):
|
||||
def __init__(self, beta: float = 0.1, desirable_weight: float = 1.0, undesirable_weight: float = 1.0):
|
||||
"""
|
||||
Args:
|
||||
beta: The temperature parameter in the KTO paper.
|
||||
desirable_weight: The weight for the desirable responses.
|
||||
undesirable_weight: The weight for the undesirable
|
||||
"""
|
||||
super().__init__()
|
||||
self.beta = beta
|
||||
self.desirable_weight = desirable_weight
|
||||
self.undesirable_weight = undesirable_weight
|
||||
|
||||
def forward(
|
||||
self,
|
||||
chosen_logps: torch.Tensor,
|
||||
rejected_logps: torch.Tensor,
|
||||
kl_logps: torch.Tensor,
|
||||
ref_chosen_logps: torch.Tensor,
|
||||
ref_rejected_logps: torch.Tensor,
|
||||
ref_kl_logps: torch.Tensor,
|
||||
):
|
||||
"""
|
||||
Reference:
|
||||
https://github.com/huggingface/trl/blob/a2adfb836a90d1e37b1253ab43dace05f1241e04/trl/trainer/kto_trainer.py#L585
|
||||
|
||||
Compute the KTO loss for a batch of policy and reference model log probabilities.
|
||||
Args:
|
||||
chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
|
||||
rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
|
||||
kl_logps: KL divergence of the policy model. Shape: (batch_size,)
|
||||
ref_chosen_logps: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
|
||||
ref_rejected_logps: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
|
||||
ref_kl_logps: KL divergence of the reference model. Shape: (batch_size,)
|
||||
beta: The temperature parameter in the DPO paper.
|
||||
desirable_weight: The weight for the desirable responses.
|
||||
undesirable_weight: The weight for the undesirable responses.
|
||||
|
||||
Refer to the KTO paper for details about hyperparameters https://arxiv.org/pdf/2402.01306
|
||||
"""
|
||||
kl = (kl_logps - ref_kl_logps).mean().detach()
|
||||
# all gather
|
||||
dist.all_reduce(kl, op=dist.ReduceOp.SUM)
|
||||
kl = (kl / dist.get_world_size()).clamp(min=0)
|
||||
|
||||
if chosen_logps.shape[0] != 0 and ref_chosen_logps.shape[0] != 0:
|
||||
chosen_logratios = chosen_logps - ref_chosen_logps
|
||||
chosen_losses = 1 - nn.functional.sigmoid(self.beta * (chosen_logratios - kl))
|
||||
chosen_rewards = self.beta * chosen_logratios.detach()
|
||||
else:
|
||||
chosen_losses = torch.Tensor([]).to(kl_logps.device)
|
||||
chosen_rewards = torch.Tensor([]).to(kl_logps.device)
|
||||
|
||||
if rejected_logps.shape[0] != 0 and ref_rejected_logps.shape[0] != 0:
|
||||
rejected_logratios = rejected_logps - ref_rejected_logps
|
||||
rejected_losses = 1 - nn.functional.sigmoid(self.beta * (kl - rejected_logratios))
|
||||
rejected_rewards = self.beta * rejected_logratios.detach()
|
||||
else:
|
||||
rejected_losses = torch.Tensor([]).to(kl_logps.device)
|
||||
rejected_rewards = torch.Tensor([]).to(kl_logps.device)
|
||||
|
||||
losses = torch.cat((self.desirable_weight * chosen_losses, self.undesirable_weight * rejected_losses), 0).mean()
|
||||
|
||||
return losses, chosen_rewards, rejected_rewards, kl
|
||||
|
||||
@ -25,7 +25,9 @@ class RewardModel(BaseModel):
|
||||
self.value_head = nn.Linear(self.last_hidden_state_size, 1)
|
||||
self.value_head.weight.data.normal_(mean=0.0, std=1 / (self.last_hidden_state_size + 1))
|
||||
|
||||
def forward(self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
def forward(
|
||||
self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None, **kwargs
|
||||
) -> torch.Tensor:
|
||||
outputs = self.model(input_ids, attention_mask=attention_mask)
|
||||
|
||||
last_hidden_states = outputs["last_hidden_state"]
|
||||
|
||||
50
applications/ColossalChat/coati/models/rlvr_reward_model.py
Normal file
50
applications/ColossalChat/coati/models/rlvr_reward_model.py
Normal file
@ -0,0 +1,50 @@
|
||||
"""
|
||||
reward model
|
||||
"""
|
||||
|
||||
from typing import Callable, List, Optional
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
class RLVRRewardModel:
|
||||
"""
|
||||
RLVRReward model class. Support varifiable reward.
|
||||
|
||||
Args:
|
||||
reward_fn_list List: list of reward functions
|
||||
**kwargs: all other kwargs as in reward functions
|
||||
"""
|
||||
|
||||
def __init__(self, reward_fn_list: List[Callable], **kwargs) -> None:
|
||||
self.reward_fn_list = reward_fn_list
|
||||
self.kwargs = kwargs
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
input_ids: torch.LongTensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
response_start: List = None,
|
||||
response_end: List = None,
|
||||
gt_answer: List = None,
|
||||
) -> torch.Tensor:
|
||||
# apply varifiable reward
|
||||
bs = input_ids.size(0)
|
||||
rewards = torch.zeros(bs, device=input_ids.device)
|
||||
for i in range(bs):
|
||||
for reward_fn in self.reward_fn_list:
|
||||
rewards[i] += reward_fn(
|
||||
input_ids[i],
|
||||
attention_mask[i],
|
||||
response_start=response_start[i],
|
||||
response_end=response_end[i],
|
||||
gt_answer=gt_answer[i],
|
||||
**self.kwargs,
|
||||
)
|
||||
return rewards
|
||||
|
||||
def to(self, device):
|
||||
return self
|
||||
|
||||
def eval(self):
|
||||
return self
|
||||
@ -50,8 +50,8 @@ def _log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor) -> torch.
|
||||
torch.Tensor: The log probabilities corresponding to the labels.
|
||||
"""
|
||||
log_probs = F.log_softmax(logits, dim=-1)
|
||||
log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
|
||||
return log_probs_labels.squeeze(-1)
|
||||
per_label_logps = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
|
||||
return per_label_logps.squeeze(-1)
|
||||
|
||||
|
||||
def calc_action_log_probs(logits: torch.Tensor, sequences: torch.LongTensor, num_actions: int) -> torch.Tensor:
|
||||
@ -138,6 +138,21 @@ def disable_dropout(model: torch.nn.Module):
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
for module in model.modules():
|
||||
if isinstance(module, torch.nn.Dropout):
|
||||
module.p = 0.0
|
||||
if model is not None:
|
||||
for module in model.modules():
|
||||
if isinstance(module, torch.nn.Dropout):
|
||||
module.p = 0.0
|
||||
|
||||
|
||||
def repad_to_left(tensor, tokenizer):
|
||||
repadded_input_ids = []
|
||||
max_non_padded_seq_len = 0
|
||||
for i in range(tensor.size(0)):
|
||||
non_pad_indices = (tensor[i] != tokenizer.pad_token_id).nonzero(as_tuple=True)[0]
|
||||
start, end = non_pad_indices.min(), non_pad_indices.max()
|
||||
repadded_input_ids.append(tensor[i][start : end + 1])
|
||||
max_non_padded_seq_len = max(max_non_padded_seq_len, repadded_input_ids[-1].size(0))
|
||||
repadded_input_ids = [
|
||||
F.pad(t, (max_non_padded_seq_len - t.size(0), 0), value=tokenizer.pad_token_id) for t in repadded_input_ids
|
||||
]
|
||||
return torch.stack(repadded_input_ids)
|
||||
|
||||
@ -1,8 +1,20 @@
|
||||
from .base import OLTrainer, SLTrainer
|
||||
from .dpo import DPOTrainer
|
||||
from .grpo import GRPOTrainer
|
||||
from .kto import KTOTrainer
|
||||
from .orpo import ORPOTrainer
|
||||
from .ppo import PPOTrainer
|
||||
from .rm import RewardModelTrainer
|
||||
from .sft import SFTTrainer
|
||||
|
||||
__all__ = ["SLTrainer", "OLTrainer", "RewardModelTrainer", "SFTTrainer", "PPOTrainer", "DPOTrainer", "ORPOTrainer"]
|
||||
__all__ = [
|
||||
"SLTrainer",
|
||||
"OLTrainer",
|
||||
"RewardModelTrainer",
|
||||
"SFTTrainer",
|
||||
"PPOTrainer",
|
||||
"DPOTrainer",
|
||||
"ORPOTrainer",
|
||||
"KTOTrainer",
|
||||
"GRPOTrainer",
|
||||
]
|
||||
|
||||
@ -16,7 +16,7 @@ from coati.experience_buffer import NaiveExperienceBuffer
|
||||
from coati.experience_maker import Experience
|
||||
from torch.optim import Optimizer
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster import Booster, Plugin
|
||||
|
||||
from .utils import is_rank_0
|
||||
|
||||
@ -38,6 +38,7 @@ class SLTrainer(ABC):
|
||||
max_epochs: int,
|
||||
model: nn.Module,
|
||||
optimizer: Optimizer,
|
||||
plugin: Plugin,
|
||||
start_epoch: int = 0,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
@ -45,6 +46,7 @@ class SLTrainer(ABC):
|
||||
self.max_epochs = max_epochs
|
||||
self.model = model
|
||||
self.optimizer = optimizer
|
||||
self.plugin = plugin
|
||||
self.start_epoch = start_epoch
|
||||
|
||||
@abstractmethod
|
||||
@ -94,6 +96,7 @@ class OLTrainer(ABC):
|
||||
self.sample_buffer = sample_buffer
|
||||
self.dataloader_pin_memory = dataloader_pin_memory
|
||||
self.callbacks = callbacks
|
||||
self.num_train_step = 0
|
||||
|
||||
@contextmanager
|
||||
def _fit_ctx(self) -> None:
|
||||
@ -210,5 +213,6 @@ class OLTrainer(ABC):
|
||||
self._update_phase(update_step)
|
||||
# NOTE: this is for on-policy algorithms
|
||||
self.data_buffer.clear()
|
||||
if self.save_interval > 0 and (episode + 1) % (self.save_interval) == 0:
|
||||
self._save_checkpoint(episode + 1)
|
||||
|
||||
if self.num_train_step > 0 and (self.num_train_step + 1) % (self.save_interval) == 0:
|
||||
self._save_checkpoint(self.num_train_step + 1)
|
||||
|
||||
@ -6,6 +6,7 @@ import os
|
||||
from typing import Any, Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.models.loss import DpoLoss
|
||||
from coati.models.utils import calc_masked_log_probs
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
@ -13,10 +14,11 @@ from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from tqdm import tqdm, trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster import Booster, Plugin
|
||||
from colossalai.booster.plugin import HybridParallelPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
@ -26,7 +28,7 @@ from .utils import is_rank_0, to_device
|
||||
|
||||
class DPOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for PPO algorithm.
|
||||
Trainer for DPO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
@ -50,23 +52,28 @@ class DPOTrainer(SLTrainer):
|
||||
ref_model: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
plugin: Plugin,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
beta: float = 0.1,
|
||||
gamma: float = 0.0,
|
||||
length_normalization: bool = False,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, start_epoch=start_epoch)
|
||||
super().__init__(
|
||||
booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, plugin=plugin, start_epoch=start_epoch
|
||||
)
|
||||
self.ref_model = ref_model
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.actor_loss_fn = DpoLoss(beta, gamma)
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
@ -91,18 +98,25 @@ class DPOTrainer(SLTrainer):
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
|
||||
init_criterion = (
|
||||
dist.get_rank() == dist.get_world_size() - 1
|
||||
if isinstance(self.plugin, HybridParallelPlugin) and self.plugin.pp_size > 1
|
||||
else is_rank_0()
|
||||
)
|
||||
|
||||
if use_wandb and init_criterion:
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-dpo", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
if log_dir is not None and init_criterion:
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "dpo")
|
||||
log_dir = os.path.join(log_dir, "DPO")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
@ -112,162 +126,13 @@ class DPOTrainer(SLTrainer):
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
self.model.train()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
if isinstance(self.plugin, HybridParallelPlugin) and self.plugin.pp_size > 1:
|
||||
step_bar = tqdm(
|
||||
range(len(self.train_dataloader)),
|
||||
desc="Step",
|
||||
disable=not (dist.get_rank() == dist.get_world_size() - 1),
|
||||
)
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
actor_all_logits = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
if self.ref_model is not None:
|
||||
self.ref_model.eval()
|
||||
with torch.no_grad():
|
||||
ref_all_logits = self.ref_model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
else:
|
||||
logprob_ref_chosen = None
|
||||
logprob_ref_reject = None
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
logprob_actor_chosen,
|
||||
logprob_actor_reject,
|
||||
logprob_ref_chosen if logprob_ref_chosen is not None else None,
|
||||
logprob_ref_reject if logprob_ref_reject is not None else None,
|
||||
chosen_loss_mask[:, 1:],
|
||||
reject_loss_mask[:, 1:],
|
||||
)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float().mean()
|
||||
|
||||
# DPO Loss
|
||||
loss = losses.mean()
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
|
||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.num_train_step += 1
|
||||
step_bar.update()
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/accuracy",
|
||||
self.accumulative_meter.get("accuracy"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
if self.save_dir is not None and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.ref_model.eval()
|
||||
self.coordinator.print_on_master("\nStart evaluation...")
|
||||
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
with torch.no_grad():
|
||||
for i, batch in enumerate(self.eval_dataloader):
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
@ -284,16 +149,152 @@ class DPOTrainer(SLTrainer):
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
# Calculate logits from reference model.
|
||||
if self.ref_model is not None:
|
||||
self.ref_model.eval()
|
||||
with torch.no_grad():
|
||||
ref_all_logits = self.ref_model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
else:
|
||||
logprob_ref_chosen = None
|
||||
logprob_ref_reject = None
|
||||
|
||||
# Merge chosen and reject
|
||||
inputs_ids = torch.stack([item for tup in zip(chosen_input_ids, reject_input_ids) for item in tup])
|
||||
attention_mask = torch.stack(
|
||||
[item for tup in zip(chosen_attention_mask, reject_attention_mask) for item in tup]
|
||||
)
|
||||
loss_mask = torch.stack([item for tup in zip(chosen_loss_mask, reject_loss_mask) for item in tup])
|
||||
logprob_ref = torch.stack([item for tup in zip(logprob_ref_chosen, logprob_ref_reject) for item in tup])
|
||||
|
||||
data_iter = iter(
|
||||
[
|
||||
{
|
||||
"input_ids": inputs_ids,
|
||||
"attention_mask": attention_mask,
|
||||
"loss_mask": loss_mask,
|
||||
"logprob_ref": logprob_ref,
|
||||
}
|
||||
]
|
||||
)
|
||||
rewards = []
|
||||
|
||||
def _criterion(outputs, inputs):
|
||||
loss, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
calc_masked_log_probs(
|
||||
outputs["logits"][0::2],
|
||||
inputs["input_ids"][0::2],
|
||||
inputs["loss_mask"][0::2][:, 1:],
|
||||
self.length_normalization,
|
||||
),
|
||||
calc_masked_log_probs(
|
||||
outputs["logits"][1::2],
|
||||
inputs["input_ids"][1::2],
|
||||
inputs["loss_mask"][1::2][:, 1:],
|
||||
self.length_normalization,
|
||||
),
|
||||
inputs["logprob_ref"][0::2] if inputs["logprob_ref"] is not None else None,
|
||||
inputs["logprob_ref"][1::2] if inputs["logprob_ref"] is not None else None,
|
||||
inputs["loss_mask"][0::2][:, 1:],
|
||||
inputs["loss_mask"][1::2][:, 1:],
|
||||
)
|
||||
rewards.append(chosen_rewards)
|
||||
rewards.append(rejected_rewards)
|
||||
return loss
|
||||
|
||||
outputs = self.booster.execute_pipeline(
|
||||
data_iter,
|
||||
self.model,
|
||||
criterion=_criterion,
|
||||
optimizer=self.optimizer,
|
||||
return_loss=True,
|
||||
)
|
||||
loss = outputs["loss"]
|
||||
if self.booster.plugin.stage_manager.is_last_stage():
|
||||
chosen_rewards, rejected_rewards = rewards[0], rewards[1]
|
||||
global_loss = all_reduce_mean(loss, self.plugin)
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
step_bar.set_postfix(
|
||||
{
|
||||
"train/loss": global_loss.item(),
|
||||
"train/lr": self.actor_scheduler.get_last_lr()[0],
|
||||
"train/chosen_rewards": chosen_rewards.to(torch.float16).mean().item(),
|
||||
"train/rejected_rewards": rejected_rewards.to(torch.float16).mean().item(),
|
||||
}
|
||||
)
|
||||
step_bar.update()
|
||||
self.accumulative_meter.add("loss", global_loss.item())
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add(
|
||||
"rejected_rewards", rejected_rewards.to(torch.float16).mean().item()
|
||||
)
|
||||
if self.writer is not None:
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), i)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), i
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
i,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards")
|
||||
- self.accumulative_meter.get("rejected_rewards"),
|
||||
i,
|
||||
)
|
||||
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
else:
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
actor_all_logits = self.model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
@ -302,22 +303,26 @@ class DPOTrainer(SLTrainer):
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
self.ref_model.eval()
|
||||
if self.ref_model is not None:
|
||||
self.ref_model.eval()
|
||||
with torch.no_grad():
|
||||
ref_all_logits = self.ref_model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
else:
|
||||
logprob_ref_chosen = None
|
||||
logprob_ref_reject = None
|
||||
|
||||
ref_all_logits = self.ref_model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
loss, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
logprob_actor_chosen,
|
||||
logprob_actor_reject,
|
||||
logprob_ref_chosen if logprob_ref_chosen is not None else None,
|
||||
@ -326,7 +331,9 @@ class DPOTrainer(SLTrainer):
|
||||
reject_loss_mask[:, 1:],
|
||||
)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float().mean()
|
||||
loss = losses.mean()
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
@ -335,16 +342,302 @@ class DPOTrainer(SLTrainer):
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add(
|
||||
"margin", (chosen_rewards_mean - rejected_rewards_mean).to(torch.float16).mean().item()
|
||||
)
|
||||
step_bar.update()
|
||||
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "accuracy", "margin"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
step_bar.set_postfix(
|
||||
{
|
||||
"train/loss": self.accumulative_meter.get("loss"),
|
||||
"train/chosen_rewards": self.accumulative_meter.get("chosen_rewards"),
|
||||
"train/rejected_rewards": self.accumulative_meter.get("rejected_rewards"),
|
||||
"train/accuracy": self.accumulative_meter.get("accuracy"),
|
||||
}
|
||||
)
|
||||
step_bar.update()
|
||||
if self.writer and is_rank_0():
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards")
|
||||
- self.accumulative_meter.get("rejected_rewards"),
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/accuracy",
|
||||
self.accumulative_meter.get("accuracy"),
|
||||
global_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
self.num_train_step += 1
|
||||
|
||||
if self.save_dir is not None and self.num_train_step > 0 and self.num_train_step % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=self.num_train_step,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.ref_model.eval()
|
||||
self.accumulative_meter.reset()
|
||||
self.coordinator.print_on_master("\nStart evaluation...")
|
||||
|
||||
if isinstance(self.plugin, HybridParallelPlugin) and self.plugin.pp_size > 1:
|
||||
step_bar = tqdm(
|
||||
range(len(self.eval_dataloader)),
|
||||
desc="Step",
|
||||
disable=not (dist.get_rank() == dist.get_world_size() - 1),
|
||||
)
|
||||
with torch.no_grad():
|
||||
for _, batch in enumerate(self.eval_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
# Calculate logits from reference model.
|
||||
if self.ref_model is not None:
|
||||
self.ref_model.eval()
|
||||
with torch.no_grad():
|
||||
ref_all_logits = self.ref_model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
else:
|
||||
logprob_ref_chosen = None
|
||||
logprob_ref_reject = None
|
||||
|
||||
# Merge chosen and reject
|
||||
inputs_ids = torch.stack([item for tup in zip(chosen_input_ids, reject_input_ids) for item in tup])
|
||||
attention_mask = torch.stack(
|
||||
[item for tup in zip(chosen_attention_mask, reject_attention_mask) for item in tup]
|
||||
)
|
||||
loss_mask = torch.stack([item for tup in zip(chosen_loss_mask, reject_loss_mask) for item in tup])
|
||||
logprob_ref = torch.stack(
|
||||
[item for tup in zip(logprob_ref_chosen, logprob_ref_reject) for item in tup]
|
||||
)
|
||||
|
||||
data_iter = iter(
|
||||
[
|
||||
{
|
||||
"input_ids": inputs_ids,
|
||||
"attention_mask": attention_mask,
|
||||
"loss_mask": loss_mask,
|
||||
"logprob_ref": logprob_ref,
|
||||
}
|
||||
]
|
||||
)
|
||||
rewards = []
|
||||
|
||||
def _criterion(outputs, inputs):
|
||||
loss, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
calc_masked_log_probs(
|
||||
outputs["logits"][0::2],
|
||||
inputs["input_ids"][0::2],
|
||||
inputs["loss_mask"][0::2][:, 1:],
|
||||
self.length_normalization,
|
||||
),
|
||||
calc_masked_log_probs(
|
||||
outputs["logits"][1::2],
|
||||
inputs["input_ids"][1::2],
|
||||
inputs["loss_mask"][1::2][:, 1:],
|
||||
self.length_normalization,
|
||||
),
|
||||
inputs["logprob_ref"][0::2] if inputs["logprob_ref"] is not None else None,
|
||||
inputs["logprob_ref"][1::2] if inputs["logprob_ref"] is not None else None,
|
||||
inputs["loss_mask"][0::2][:, 1:],
|
||||
inputs["loss_mask"][1::2][:, 1:],
|
||||
)
|
||||
rewards.append(chosen_rewards)
|
||||
rewards.append(rejected_rewards)
|
||||
return loss
|
||||
|
||||
outputs = self.booster.execute_pipeline(
|
||||
data_iter,
|
||||
self.model,
|
||||
criterion=_criterion,
|
||||
optimizer=self.optimizer,
|
||||
return_loss=True,
|
||||
)
|
||||
loss = outputs["loss"]
|
||||
if self.booster.plugin.stage_manager.is_last_stage():
|
||||
chosen_rewards, rejected_rewards = rewards[0], rewards[1]
|
||||
global_loss = all_reduce_mean(loss, self.plugin)
|
||||
chosen_rewards_mean = all_reduce_mean(chosen_rewards, self.plugin)
|
||||
rejected_rewards_mean = all_reduce_mean(rejected_rewards, self.plugin)
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
step_bar.set_postfix(
|
||||
{
|
||||
"eval/loss": global_loss.item(),
|
||||
"eval/lr": self.actor_scheduler.get_last_lr()[0],
|
||||
"eval/chosen_rewards": chosen_rewards.to(torch.float16).mean().item(),
|
||||
"eval/rejected_rewards": rejected_rewards.to(torch.float16).mean().item(),
|
||||
}
|
||||
)
|
||||
self.accumulative_meter.add(
|
||||
"chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item()
|
||||
)
|
||||
self.accumulative_meter.add(
|
||||
"rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item()
|
||||
)
|
||||
self.accumulative_meter.add("loss", global_loss.to(torch.float16).item())
|
||||
step_bar.update()
|
||||
if self.booster.plugin.stage_manager.is_last_stage():
|
||||
msg = "\nEvaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
print(msg)
|
||||
else:
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
with torch.no_grad():
|
||||
for i, batch in enumerate(self.eval_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
actor_all_logits = self.model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
ref_all_logits = self.ref_model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
logprob_actor_chosen,
|
||||
logprob_actor_reject,
|
||||
logprob_ref_chosen if logprob_ref_chosen is not None else None,
|
||||
logprob_ref_reject if logprob_ref_reject is not None else None,
|
||||
chosen_loss_mask[:, 1:],
|
||||
reject_loss_mask[:, 1:],
|
||||
)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float().mean()
|
||||
loss = losses.mean()
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add(
|
||||
"rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item()
|
||||
)
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add(
|
||||
"margin", (chosen_rewards_mean - rejected_rewards_mean).to(torch.float16).mean().item()
|
||||
)
|
||||
step_bar.set_postfix(
|
||||
{
|
||||
"eval/loss": self.accumulative_meter.get("loss"),
|
||||
"eval/chosen_rewards": self.accumulative_meter.get("chosen_rewards"),
|
||||
"eval/rejected_rewards": self.accumulative_meter.get("rejected_rewards"),
|
||||
"eval/accuracy": self.accumulative_meter.get("accuracy"),
|
||||
}
|
||||
)
|
||||
step_bar.update()
|
||||
|
||||
msg = "\nEvaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "accuracy", "margin"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
if self.save_dir is not None:
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
||||
386
applications/ColossalChat/coati/trainer/grpo.py
Executable file
386
applications/ColossalChat/coati/trainer/grpo.py
Executable file
@ -0,0 +1,386 @@
|
||||
"""
|
||||
GRPO trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Dict, List, Optional, Union
|
||||
|
||||
import torch
|
||||
import wandb
|
||||
from coati.experience_buffer import NaiveExperienceBuffer
|
||||
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||
from coati.models import RewardModel, RLVRRewardModel
|
||||
from coati.models.loss import GPTLMLoss, PolicyLoss
|
||||
from coati.models.utils import calc_action_log_probs
|
||||
from coati.trainer.callbacks import Callback
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader, DistributedSampler
|
||||
from tqdm import tqdm
|
||||
from transformers import PreTrainedModel, PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import OLTrainer
|
||||
from .utils import AnnealingScheduler, CycledDataLoader, is_rank_0, to_device
|
||||
|
||||
|
||||
def _set_default_generate_kwargs(actor: PreTrainedModel) -> Dict:
|
||||
"""
|
||||
Set default keyword arguments for generation based on the actor model.
|
||||
|
||||
Args:
|
||||
actor (PreTrainedModel): The actor model.
|
||||
|
||||
Returns:
|
||||
Dict: A dictionary containing the default keyword arguments for generation.
|
||||
"""
|
||||
unwrapped_model = actor.unwrap()
|
||||
new_kwargs = {}
|
||||
# use huggingface models method directly
|
||||
if hasattr(unwrapped_model, "prepare_inputs_for_generation"):
|
||||
new_kwargs["prepare_inputs_fn"] = unwrapped_model.prepare_inputs_for_generation
|
||||
if hasattr(unwrapped_model, "_update_model_kwargs_for_generation"):
|
||||
new_kwargs["update_model_kwargs_fn"] = unwrapped_model._update_model_kwargs_for_generation
|
||||
return new_kwargs
|
||||
|
||||
|
||||
class GRPOTrainer(OLTrainer):
|
||||
"""
|
||||
Trainer for GRPO algorithm.
|
||||
|
||||
Args:
|
||||
strategy (Booster): the strategy to use for training
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
reward_model (RewardModel): the reward model in rlhf algorithm to make reward of sentences
|
||||
initial_model (Actor): the initial model in rlhf algorithm to generate reference logics to limit the update of actor
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
|
||||
train_batch_size (int, defaults to 8): the batch size to use for training
|
||||
buffer_limit (int, defaults to 0): the max_size limitation of buffer
|
||||
buffer_cpu_offload (bool, defaults to True): whether to offload buffer to cpu
|
||||
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
|
||||
vf_coef (float, defaults to 1.0): the coefficient of value loss
|
||||
ptx_coef (float, defaults to 0.9): the coefficient of ptx loss
|
||||
value_clip (float, defaults to 0.4): the clip coefficient of value loss
|
||||
sample_buffer (bool, defaults to False): whether to sample from buffer
|
||||
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||
offload_inference_models (bool, defaults to True): whether to offload inference models to cpu during training process
|
||||
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||
generate_kwargs (dict, optional): the kwargs to use while model generating
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor_booster: Booster,
|
||||
actor: PreTrainedModel,
|
||||
reward_model: Union[RewardModel, RLVRRewardModel],
|
||||
initial_model: PreTrainedModel,
|
||||
actor_optim: Optimizer,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
kl_coef: float = 0.1,
|
||||
ptx_coef: float = 0.9,
|
||||
train_batch_size: int = 8,
|
||||
buffer_limit: int = 0,
|
||||
buffer_cpu_offload: bool = True,
|
||||
eps_clip: float = 0.2,
|
||||
vf_coef: float = 1.0,
|
||||
value_clip: float = 0.2,
|
||||
sample_buffer: bool = False,
|
||||
dataloader_pin_memory: bool = True,
|
||||
offload_inference_models: bool = True,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
use_tp: bool = False,
|
||||
num_generation: int = 8,
|
||||
inference_batch_size: int = None,
|
||||
logits_forward_batch_size: int = None,
|
||||
temperature_annealing_config: Optional[Dict] = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
callbacks: List[Callback] = [],
|
||||
**generate_kwargs,
|
||||
) -> None:
|
||||
if isinstance(actor_booster, GeminiPlugin):
|
||||
assert not offload_inference_models, "GeminiPlugin is not compatible with manual model.to('cpu')"
|
||||
|
||||
data_buffer = NaiveExperienceBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
|
||||
super().__init__(actor_booster, None, data_buffer, sample_buffer, dataloader_pin_memory, callbacks=callbacks)
|
||||
self.generate_kwargs = _set_default_generate_kwargs(actor)
|
||||
self.generate_kwargs.update(generate_kwargs)
|
||||
|
||||
self.actor = actor
|
||||
self.actor_booster = actor_booster
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.experience_maker = NaiveExperienceMaker(
|
||||
self.actor,
|
||||
None,
|
||||
reward_model,
|
||||
initial_model,
|
||||
self.tokenizer,
|
||||
kl_coef,
|
||||
use_grpo=True,
|
||||
num_generation=num_generation,
|
||||
inference_batch_size=inference_batch_size,
|
||||
logits_forward_batch_size=logits_forward_batch_size,
|
||||
)
|
||||
if temperature_annealing_config:
|
||||
# use annealing
|
||||
self.temperature_annealing_scheduler = AnnealingScheduler(
|
||||
temperature_annealing_config["start_temperature"],
|
||||
temperature_annealing_config["end_temperature"],
|
||||
temperature_annealing_config["annealing_warmup_steps"],
|
||||
temperature_annealing_config["annealing_steps"],
|
||||
)
|
||||
else:
|
||||
self.temperature_annealing_scheduler = None
|
||||
|
||||
self.train_batch_size = train_batch_size
|
||||
|
||||
self.actor_loss_fn = PolicyLoss(eps_clip)
|
||||
self.vf_coef = vf_coef
|
||||
self.ptx_loss_fn = GPTLMLoss()
|
||||
self.ptx_coef = ptx_coef
|
||||
self.actor_optim = actor_optim
|
||||
self.save_interval = save_interval
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.coordinator = coordinator
|
||||
self.actor_save_dir = os.path.join(save_dir, "actor")
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.use_tp = use_tp
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
self.offload_inference_models = offload_inference_models
|
||||
self.device = get_current_device()
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
prompt_dataloader: DataLoader,
|
||||
pretrain_dataloader: Optional[DataLoader] = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.prompt_dataloader = CycledDataLoader(prompt_dataloader)
|
||||
self.pretrain_dataloader = CycledDataLoader(pretrain_dataloader) if pretrain_dataloader is not None else None
|
||||
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-grpo", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "grpo")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _setup_update_phrase_dataload(self):
|
||||
"""
|
||||
why not use distributed_dataloader?
|
||||
if tp is used, input on each rank is the same and we use the same dataloader to feed same experience to all ranks
|
||||
if tp is not used, input on each rank is different and we expect different experiences to be fed to each rank
|
||||
"""
|
||||
self.dataloader = DataLoader(
|
||||
self.data_buffer,
|
||||
batch_size=self.train_batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
pin_memory=self.dataloader_pin_memory,
|
||||
collate_fn=self.data_buffer.collate_fn,
|
||||
)
|
||||
|
||||
def _make_experience(self, collect_step: int) -> Experience:
|
||||
"""
|
||||
Make experience
|
||||
"""
|
||||
prompts = self.prompt_dataloader.next()
|
||||
if self.offload_inference_models:
|
||||
# TODO(ver217): this may be controlled by strategy if they are prepared by strategy
|
||||
self.experience_maker.initial_model.to(self.device)
|
||||
self.experience_maker.reward_model.to(self.device)
|
||||
if self.temperature_annealing_scheduler:
|
||||
self.generate_kwargs["temperature"] = self.temperature_annealing_scheduler.get_temperature()
|
||||
return self.experience_maker.make_experience(
|
||||
input_ids=prompts["input_ids"].to(get_current_device()),
|
||||
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
||||
gt_answer=prompts["gt_answer"],
|
||||
**self.generate_kwargs,
|
||||
)
|
||||
|
||||
def _training_step(self, experience: Experience):
|
||||
"""
|
||||
Args:
|
||||
experience:
|
||||
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
||||
"""
|
||||
self.actor.train()
|
||||
num_actions = experience.action_log_probs.size(1)
|
||||
# policy loss
|
||||
|
||||
actor_logits = self.actor(input_ids=experience.sequences, attention_mask=experience.attention_mask)[
|
||||
"logits"
|
||||
] # [batch size, prompt_length + response_length]
|
||||
action_log_probs = calc_action_log_probs(actor_logits, experience.sequences, num_actions)
|
||||
actor_loss, to_skip, max_ratio = self.actor_loss_fn(
|
||||
action_log_probs,
|
||||
experience.action_log_probs,
|
||||
experience.advantages.unsqueeze(dim=-1).repeat_interleave(action_log_probs.size(-1), dim=-1),
|
||||
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||
)
|
||||
# sequence that is not end properly are not counted in token cost
|
||||
token_cost = torch.sum(
|
||||
(experience.sequences[:, -num_actions:] != self.tokenizer.pad_token_id).to(torch.float), axis=-1
|
||||
).to(actor_logits.device)
|
||||
end_properly = experience.sequences[:, -1] == self.tokenizer.pad_token_id
|
||||
mean_token_cost = torch.sum(token_cost * end_properly) / torch.sum(end_properly)
|
||||
actor_loss = (1 - self.ptx_coef) * actor_loss
|
||||
if not to_skip:
|
||||
self.actor_booster.backward(loss=actor_loss, optimizer=self.actor_optim)
|
||||
|
||||
# ptx loss
|
||||
if self.ptx_coef != 0:
|
||||
batch = self.pretrain_dataloader.next()
|
||||
batch = to_device(batch, self.device)
|
||||
outputs = self.actor(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
|
||||
ptx_loss = outputs.loss
|
||||
ptx_loss = self.ptx_coef * ptx_loss
|
||||
self.actor_booster.backward(loss=ptx_loss, optimizer=self.actor_optim)
|
||||
|
||||
# sync
|
||||
actor_loss_mean = all_reduce_mean(tensor=actor_loss)
|
||||
max_ratio_mean = all_reduce_mean(tensor=max_ratio)
|
||||
reward_mean = all_reduce_mean(tensor=experience.reward.mean())
|
||||
advantages_mean = all_reduce_mean(tensor=experience.advantages.mean())
|
||||
kl_mean = all_reduce_mean(tensor=experience.kl.mean())
|
||||
mean_token_cost = all_reduce_mean(tensor=mean_token_cost)
|
||||
if self.ptx_coef != 0:
|
||||
ptx_loss_mean = all_reduce_mean(tensor=ptx_loss)
|
||||
|
||||
self.accumulative_meter.add("actor_loss", actor_loss_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("max_ratio", max_ratio_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("reward", reward_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("advantages", advantages_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("skip_ratio", 1.0 if to_skip else 0.0)
|
||||
self.accumulative_meter.add("mean_token_cost", mean_token_cost.to(torch.float16).item())
|
||||
self.accumulative_meter.add("kl", kl_mean.to(torch.float16).item())
|
||||
if self.ptx_coef != 0:
|
||||
self.accumulative_meter.add("ptx_loss", ptx_loss_mean.to(torch.float16).mean().item())
|
||||
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.actor_optim.step()
|
||||
self.actor_optim.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
if self.temperature_annealing_scheduler:
|
||||
self.temperature_annealing_scheduler.step_forward()
|
||||
|
||||
# preparing logging model output and corresponding rewards.
|
||||
if self.num_train_step % 10 == 0:
|
||||
response_text = self.experience_maker.tokenizer.batch_decode(
|
||||
experience.sequences, skip_special_tokens=True
|
||||
)
|
||||
for i in range(len(response_text)):
|
||||
response_text[i] = response_text[i] + f"\n\nReward: {experience.reward[i]}"
|
||||
|
||||
if self.writer and is_rank_0() and "wandb_run" in self.__dict__:
|
||||
# log output to wandb
|
||||
my_table = wandb.Table(
|
||||
columns=[f"sample response {i}" for i in range(len(response_text))], data=[response_text]
|
||||
)
|
||||
try:
|
||||
self.wandb_run.log({"sample_response": my_table})
|
||||
except OSError as e:
|
||||
self.coordinator.print_on_master(e)
|
||||
elif self.writer and is_rank_0():
|
||||
for line in response_text:
|
||||
self.coordinator.print_on_master(line)
|
||||
|
||||
if self.writer and is_rank_0():
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
self.writer.add_scalar("train/max_ratio", self.accumulative_meter.get("max_ratio"), global_step)
|
||||
self.writer.add_scalar("train/skip_ratio", self.accumulative_meter.get("skip_ratio"), global_step)
|
||||
self.writer.add_scalar("train/actor_loss", self.accumulative_meter.get("actor_loss"), global_step)
|
||||
self.writer.add_scalar("train/lr_actor", self.actor_optim.param_groups[0]["lr"], global_step)
|
||||
if self.ptx_coef != 0:
|
||||
self.writer.add_scalar("train/ptx_loss", self.accumulative_meter.get("ptx_loss"), global_step)
|
||||
self.writer.add_scalar("reward", self.accumulative_meter.get("reward"), global_step)
|
||||
self.writer.add_scalar("token_cost", self.accumulative_meter.get("mean_token_cost"), global_step)
|
||||
self.writer.add_scalar("approx_kl", self.accumulative_meter.get("kl"), global_step)
|
||||
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), global_step)
|
||||
self.accumulative_meter.reset()
|
||||
self.num_train_step += 1
|
||||
|
||||
def _learn(self, update_step: int):
|
||||
"""
|
||||
Perform the learning step of the PPO algorithm.
|
||||
|
||||
Args:
|
||||
update_step (int): The current update step.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
if self.offload_inference_models:
|
||||
self.experience_maker.initial_model.to("cpu")
|
||||
self.experience_maker.reward_model.to("cpu")
|
||||
# buffer may be empty at first, we should rebuild at each training
|
||||
if self.sample_buffer:
|
||||
experience = self.data_buffer.sample()
|
||||
self._on_learn_batch_start()
|
||||
experience.to_device(self.device)
|
||||
self._training_step(experience)
|
||||
self._on_learn_batch_end(experience)
|
||||
else:
|
||||
if isinstance(self.dataloader.sampler, DistributedSampler):
|
||||
self.dataloader.sampler.set_epoch(update_step)
|
||||
pbar = tqdm(self.dataloader, desc=f"Train epoch [{update_step + 1}]", disable=not is_rank_0())
|
||||
for experience in pbar:
|
||||
self._on_learn_batch_start()
|
||||
experience.to_device(self.device)
|
||||
self._training_step(experience)
|
||||
self._on_learn_batch_end(experience)
|
||||
|
||||
def _save_checkpoint(self, num_train_step: int = 0):
|
||||
"""
|
||||
Save the actor checkpoints with running states.
|
||||
|
||||
Args:
|
||||
num_train_step (int): The current num_train_step number.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
|
||||
self.coordinator.print_on_master("\nStart saving actor checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.actor_save_dir,
|
||||
booster=self.actor_booster,
|
||||
model=self.actor,
|
||||
optimizer=self.actor_optim,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=0,
|
||||
step=num_train_step + 1,
|
||||
batch_size=self.train_batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved actor checkpoint at episode {(num_train_step + 1)} at folder {self.actor_save_dir}"
|
||||
)
|
||||
353
applications/ColossalChat/coati/trainer/kto.py
Executable file
353
applications/ColossalChat/coati/trainer/kto.py
Executable file
@ -0,0 +1,353 @@
|
||||
"""
|
||||
KTO trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Any, Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.models.loss import KTOLoss
|
||||
from coati.models.utils import calc_masked_log_probs
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster, Plugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class KTOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for KTO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
ref_model (Critic): the reference model in ppo algorithm
|
||||
booster (Strategy): the strategy to use for training
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
actor_lr_scheduler (_LRScheduler): the lr scheduler to use for actor model
|
||||
tokenizer (PreTrainedTokenizerBase): the tokenizer to use for encoding
|
||||
max_epochs (int, defaults to 1): the max number of epochs to train
|
||||
accumulation_steps (int): the number of steps to accumulate gradients
|
||||
start_epoch (int, defaults to 0): the start epoch, non-zero if resumed from a checkpoint
|
||||
save_interval (int): the interval to save model checkpoints, default to 0, which means no checkpoint will be saved during trainning
|
||||
save_dir (str): the directory to save checkpoints
|
||||
coordinator (DistCoordinator): the coordinator to use for distributed logging
|
||||
beta (float, defaults to 0.1): the beta parameter in kto loss
|
||||
desirable_weight (float, defaults to 1.0): the weight for desirable reward
|
||||
undesirable_weight (float, defaults to 1.0): the weight for undesirable reward
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor: Any,
|
||||
ref_model: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
plugin: Plugin,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
beta: float = 0.1,
|
||||
desirable_weight: float = 1.0,
|
||||
undesirable_weight: float = 1.0,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(
|
||||
booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, plugin=plugin, start_epoch=start_epoch
|
||||
)
|
||||
self.ref_model = ref_model
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.kto_loss = KTOLoss(beta=beta, desirable_weight=desirable_weight, undesirable_weight=undesirable_weight)
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
self.desirable_weight = desirable_weight
|
||||
self.undesirable_weight = undesirable_weight
|
||||
self.beta = beta
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_preference_dataloader: DataLoader = None,
|
||||
eval_preference_dataloader: DataLoader = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-kto", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "kto")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
self.model.train()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(input_ids, attention_mask, loss_mask, label, kl_input_ids, kl_attention_mask, kl_loss_mask) = (
|
||||
batch["input_ids"],
|
||||
batch["attention_mask"],
|
||||
batch["loss_mask"],
|
||||
batch["label"],
|
||||
batch["kl_input_ids"],
|
||||
batch["kl_attention_mask"],
|
||||
batch["kl_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
loss_mask = loss_mask.fill_(1.0)
|
||||
kl_loss_mask = kl_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = input_ids.size()[0]
|
||||
|
||||
# actor logits
|
||||
with torch.no_grad():
|
||||
# calculate KL term with KT data
|
||||
kl_logits = self.model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logits = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logprob = calc_masked_log_probs(logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
kl_logprob = calc_masked_log_probs(kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
chosen_index = [i for i in range(batch_size) if label[i] == 1]
|
||||
rejected_index = [i for i in range(batch_size) if label[i] == 0]
|
||||
chosen_logprob = logprob[chosen_index]
|
||||
rejected_logprob = logprob[rejected_index]
|
||||
with torch.no_grad():
|
||||
ref_kl_logits = self.ref_model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
ref_logits = self.ref_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logprob = calc_masked_log_probs(ref_logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
ref_kl_logprob = calc_masked_log_probs(ref_kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
ref_chosen_logprob = ref_logprob[chosen_index]
|
||||
ref_rejected_logprob = ref_logprob[rejected_index]
|
||||
|
||||
loss, chosen_rewards, rejected_rewards, kl = self.kto_loss(
|
||||
chosen_logprob, rejected_logprob, kl_logprob, ref_chosen_logprob, ref_rejected_logprob, ref_kl_logprob
|
||||
)
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_reward_mean = chosen_rewards.mean()
|
||||
chosen_rewards_list = [
|
||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
||||
]
|
||||
dist.all_gather(chosen_rewards_list, chosen_reward_mean)
|
||||
rejected_reward_mean = rejected_rewards.mean()
|
||||
rejected_rewards_list = [
|
||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
||||
]
|
||||
dist.all_gather(rejected_rewards_list, rejected_reward_mean)
|
||||
chosen_rewards_list = [i for i in chosen_rewards_list if not i.isnan()]
|
||||
rejected_rewards_list = [i for i in rejected_rewards_list if not i.isnan()]
|
||||
chosen_rewards_mean = (
|
||||
torch.stack(chosen_rewards_list).mean()
|
||||
if len(chosen_rewards_list) > 0
|
||||
else torch.tensor(torch.nan, dtype=loss.dtype, device=loss.device)
|
||||
)
|
||||
rejected_rewards_mean = (
|
||||
torch.stack(rejected_rewards_list).mean()
|
||||
if len(rejected_rewards_list) > 0
|
||||
else torch.tensor(torch.nan, dtype=loss.dtype, device=loss.device)
|
||||
)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
||||
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
step_bar.update()
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
global_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
if self.save_dir is not None and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
self.num_train_step += 1
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(input_ids, attention_mask, loss_mask, label, kl_input_ids, kl_attention_mask, kl_loss_mask) = (
|
||||
batch["input_ids"],
|
||||
batch["attention_mask"],
|
||||
batch["loss_mask"],
|
||||
batch["label"],
|
||||
batch["kl_input_ids"],
|
||||
batch["kl_attention_mask"],
|
||||
batch["kl_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
loss_mask = loss_mask.fill_(1.0)
|
||||
kl_loss_mask = kl_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = input_ids.size()[0]
|
||||
|
||||
# actor logits
|
||||
with torch.no_grad():
|
||||
# calculate KL term with KT data
|
||||
kl_logits = self.model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logits = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logprob = calc_masked_log_probs(logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
kl_logprob = calc_masked_log_probs(kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
chosen_index = [i for i in range(batch_size) if label[i] == 1]
|
||||
rejected_index = [i for i in range(batch_size) if label[i] == 0]
|
||||
chosen_logprob = logprob[chosen_index]
|
||||
rejected_logprob = logprob[rejected_index]
|
||||
with torch.no_grad():
|
||||
ref_kl_logits = self.ref_model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logits = self.ref_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logprob = calc_masked_log_probs(ref_logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
ref_kl_logprob = calc_masked_log_probs(ref_kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
ref_chosen_logprob = ref_logprob[chosen_index]
|
||||
ref_rejected_logprob = ref_logprob[rejected_index]
|
||||
|
||||
loss, chosen_rewards, rejected_rewards, kl = self.kto_loss(
|
||||
chosen_logprob, rejected_logprob, kl_logprob, ref_chosen_logprob, ref_rejected_logprob, ref_kl_logprob
|
||||
)
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards.mean())
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards.mean())
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
||||
self.accumulative_meter.add(
|
||||
"margin", (chosen_rewards_mean - rejected_rewards_mean).to(torch.float16).mean().item()
|
||||
)
|
||||
step_bar.update()
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "margin"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
@ -16,7 +16,7 @@ from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster import Booster, Plugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
@ -26,7 +26,7 @@ from .utils import is_rank_0, to_device
|
||||
|
||||
class ORPOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for PPO algorithm.
|
||||
Trainer for ORPO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
@ -48,17 +48,21 @@ class ORPOTrainer(SLTrainer):
|
||||
actor: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
plugin: Plugin,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
lam: float = 0.1,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, start_epoch=start_epoch)
|
||||
super().__init__(
|
||||
booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, plugin=plugin, start_epoch=start_epoch
|
||||
)
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.odds_ratio_loss_fn = OddsRatioLoss()
|
||||
@ -67,6 +71,7 @@ class ORPOTrainer(SLTrainer):
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.lam = lam
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
@ -130,6 +135,11 @@ class ORPOTrainer(SLTrainer):
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
actor_out = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
@ -174,35 +184,35 @@ class ORPOTrainer(SLTrainer):
|
||||
self.accumulative_meter.add("log_odds_ratio", log_odds_ratio.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
|
||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.num_train_step += 1
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
step_bar.update()
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/accuracy",
|
||||
self.accumulative_meter.get("accuracy"),
|
||||
self.num_train_step,
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/log_odds_ratio",
|
||||
self.accumulative_meter.get("log_odds_ratio"),
|
||||
self.num_train_step,
|
||||
global_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
@ -223,6 +233,7 @@ class ORPOTrainer(SLTrainer):
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
self.num_train_step += 1
|
||||
|
||||
step_bar.close()
|
||||
|
||||
@ -263,6 +274,11 @@ class ORPOTrainer(SLTrainer):
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
actor_out = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
|
||||
@ -3,13 +3,13 @@ PPO trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Dict, List, Optional
|
||||
from typing import Dict, List, Optional, Union
|
||||
|
||||
import torch
|
||||
import wandb
|
||||
from coati.experience_buffer import NaiveExperienceBuffer
|
||||
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||
from coati.models import Critic, RewardModel
|
||||
from coati.models import Critic, RewardModel, RLVRRewardModel
|
||||
from coati.models.loss import GPTLMLoss, PolicyLoss, ValueLoss
|
||||
from coati.models.utils import calc_action_log_probs
|
||||
from coati.trainer.callbacks import Callback
|
||||
@ -84,7 +84,7 @@ class PPOTrainer(OLTrainer):
|
||||
critic_booster: Booster,
|
||||
actor: PreTrainedModel,
|
||||
critic: Critic,
|
||||
reward_model: RewardModel,
|
||||
reward_model: Union[RewardModel, RLVRRewardModel],
|
||||
initial_model: PreTrainedModel,
|
||||
actor_optim: Optimizer,
|
||||
critic_optim: Optimizer,
|
||||
@ -102,6 +102,7 @@ class PPOTrainer(OLTrainer):
|
||||
sample_buffer: bool = False,
|
||||
dataloader_pin_memory: bool = True,
|
||||
offload_inference_models: bool = True,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
@ -140,6 +141,7 @@ class PPOTrainer(OLTrainer):
|
||||
self.actor_optim = actor_optim
|
||||
self.critic_optim = critic_optim
|
||||
self.save_interval = save_interval
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.coordinator = coordinator
|
||||
self.actor_save_dir = os.path.join(save_dir, "actor")
|
||||
self.critic_save_dir = os.path.join(save_dir, "critic")
|
||||
@ -208,6 +210,7 @@ class PPOTrainer(OLTrainer):
|
||||
return self.experience_maker.make_experience(
|
||||
input_ids=prompts["input_ids"].to(get_current_device()),
|
||||
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
||||
gt_answer=prompts["gt_answer"],
|
||||
**self.generate_kwargs,
|
||||
)
|
||||
|
||||
@ -217,7 +220,6 @@ class PPOTrainer(OLTrainer):
|
||||
experience:
|
||||
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
||||
"""
|
||||
self.num_train_step += 1
|
||||
self.actor.train()
|
||||
self.critic.train()
|
||||
num_actions = experience.action_log_probs.size(1)
|
||||
@ -229,7 +231,10 @@ class PPOTrainer(OLTrainer):
|
||||
action_log_probs = calc_action_log_probs(actor_logits, experience.sequences, num_actions)
|
||||
|
||||
actor_loss, to_skip, max_ratio = self.actor_loss_fn(
|
||||
action_log_probs, experience.action_log_probs, experience.advantages, action_mask=experience.action_mask
|
||||
action_log_probs,
|
||||
experience.action_log_probs,
|
||||
experience.advantages,
|
||||
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||
)
|
||||
actor_loss = (1 - self.ptx_coef) * actor_loss
|
||||
if not to_skip:
|
||||
@ -249,7 +254,10 @@ class PPOTrainer(OLTrainer):
|
||||
input_ids=experience.sequences, attention_mask=experience.attention_mask
|
||||
) # [batch size, prompt_length + response_length]
|
||||
critic_loss = self.critic_loss_fn(
|
||||
values[:, -num_actions:], experience.values, experience.advantages, action_mask=experience.action_mask
|
||||
values[:, -num_actions:],
|
||||
experience.values,
|
||||
experience.advantages,
|
||||
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||
)
|
||||
critic_loss = critic_loss * self.vf_coef
|
||||
self.critic_booster.backward(loss=critic_loss, optimizer=self.critic_optim)
|
||||
@ -285,7 +293,7 @@ class PPOTrainer(OLTrainer):
|
||||
self.critic_scheduler.step()
|
||||
|
||||
# preparing logging model output and corresponding rewards.
|
||||
if self.num_train_step % 10 == 1:
|
||||
if self.num_train_step % 10 == 0:
|
||||
response_text = self.experience_maker.tokenizer.batch_decode(
|
||||
experience.sequences, skip_special_tokens=True
|
||||
)
|
||||
@ -327,6 +335,7 @@ class PPOTrainer(OLTrainer):
|
||||
self.writer.add_scalar("value", self.accumulative_meter.get("value"), self.num_train_step)
|
||||
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), self.num_train_step)
|
||||
self.accumulative_meter.reset()
|
||||
self.num_train_step += 1
|
||||
|
||||
def _learn(self, update_step: int):
|
||||
"""
|
||||
|
||||
@ -15,7 +15,7 @@ from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster import Booster, Plugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
@ -48,6 +48,7 @@ class RewardModelTrainer(SLTrainer):
|
||||
model: Any,
|
||||
booster: Booster,
|
||||
optimizer: Optimizer,
|
||||
plugin: Plugin,
|
||||
lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
loss_fn: Optional[Callable] = None,
|
||||
@ -59,7 +60,9 @@ class RewardModelTrainer(SLTrainer):
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=model, optimizer=optimizer, start_epoch=start_epoch)
|
||||
super().__init__(
|
||||
booster, max_epochs=max_epochs, model=model, optimizer=optimizer, plugin=plugin, start_epoch=start_epoch
|
||||
)
|
||||
self.actor_scheduler = lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.loss_fn = loss_fn if loss_fn is not None else LogSigLoss(beta=beta)
|
||||
@ -147,29 +150,29 @@ class RewardModelTrainer(SLTrainer):
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", accuracy_mean.mean().to(torch.float16).item())
|
||||
|
||||
if (i + 1) % self.accumulation_steps == 0:
|
||||
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
step_bar.update()
|
||||
self.num_train_step += 1
|
||||
|
||||
# Logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], global_step)
|
||||
self.writer.add_scalar(
|
||||
"train/dist",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
global_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/reward_chosen", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
"train/reward_chosen", self.accumulative_meter.get("chosen_rewards"), global_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/reward_reject", self.accumulative_meter.get("rejected_rewards"), self.num_train_step
|
||||
"train/reward_reject", self.accumulative_meter.get("rejected_rewards"), global_step
|
||||
)
|
||||
self.writer.add_scalar("train/acc", self.accumulative_meter.get("accuracy"), self.num_train_step)
|
||||
self.writer.add_scalar("train/acc", self.accumulative_meter.get("accuracy"), global_step)
|
||||
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
@ -190,6 +193,7 @@ class RewardModelTrainer(SLTrainer):
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {(i + 1)/self.accumulation_steps} at folder {self.save_dir}"
|
||||
)
|
||||
self.num_train_step += 1
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch):
|
||||
|
||||
@ -6,14 +6,16 @@ import os
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from tqdm import tqdm, trange
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import HybridParallelPlugin, Plugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
|
||||
from .base import SLTrainer
|
||||
@ -40,13 +42,15 @@ class SFTTrainer(SLTrainer):
|
||||
optim: Optimizer,
|
||||
lr_scheduler: _LRScheduler,
|
||||
max_epochs: int = 2,
|
||||
plugin: Plugin = None,
|
||||
accumulation_steps: int = 8,
|
||||
apply_loss_mask: bool = True,
|
||||
start_epoch=0,
|
||||
save_interval: int = None,
|
||||
save_dir: str = None,
|
||||
coordinator: Optional[DistCoordinator] = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs, model, optim, start_epoch=start_epoch)
|
||||
super().__init__(booster, max_epochs, model, optim, plugin, start_epoch=start_epoch)
|
||||
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.scheduler = lr_scheduler
|
||||
@ -55,6 +59,7 @@ class SFTTrainer(SLTrainer):
|
||||
self.coordinator = coordinator
|
||||
self.num_train_step = 0
|
||||
self.num_eval_step = 0
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
|
||||
def _before_fit(
|
||||
@ -92,56 +97,85 @@ class SFTTrainer(SLTrainer):
|
||||
|
||||
def _train(self, epoch: int):
|
||||
self.model.train()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
batch_size = batch["input_ids"].size(0)
|
||||
outputs = self.model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
|
||||
loss = outputs.loss
|
||||
step_bar.set_description(f"Epoch {epoch + 1}/{self.max_epochs} Loss: {loss.detach().cpu().item():.4f}")
|
||||
if isinstance(self.plugin, HybridParallelPlugin) and self.plugin.pp_size > 1:
|
||||
data_iter = iter(self.train_dataloader)
|
||||
step_bar = tqdm(
|
||||
range(len(self.train_dataloader)),
|
||||
desc="Step",
|
||||
disable=not (dist.get_rank() == dist.get_world_size() - 1),
|
||||
)
|
||||
for step in step_bar:
|
||||
outputs = self.booster.execute_pipeline(
|
||||
data_iter,
|
||||
self.model,
|
||||
criterion=lambda outputs, inputs: outputs[0],
|
||||
optimizer=self.optimizer,
|
||||
return_loss=True,
|
||||
)
|
||||
loss = outputs["loss"]
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.booster.plugin.stage_manager.is_last_stage():
|
||||
global_loss = all_reduce_mean(loss, self.plugin)
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
step_bar.set_postfix({"train/loss": global_loss.item()})
|
||||
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
|
||||
# Gradient accumulation
|
||||
if (i + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.scheduler.step()
|
||||
else:
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
batch_size = batch["input_ids"].size(0)
|
||||
outputs = self.model(
|
||||
batch["input_ids"],
|
||||
attention_mask=batch["attention_mask"],
|
||||
labels=batch["labels"] if self.apply_loss_mask else batch["input_ids"],
|
||||
)
|
||||
loss = outputs.loss
|
||||
|
||||
if self.writer:
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.scheduler.get_last_lr()[0], self.num_train_step)
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
|
||||
# Gradient accumulation
|
||||
if (self.num_train_step + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.scheduler.step()
|
||||
global_step = (self.num_train_step + 1) / self.accumulation_steps
|
||||
step_bar.set_postfix({"train/loss": self.accumulative_meter.get("loss")})
|
||||
if self.writer:
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), global_step)
|
||||
self.writer.add_scalar("train/lr", self.scheduler.get_last_lr()[0], global_step)
|
||||
self.accumulative_meter.reset()
|
||||
step_bar.update()
|
||||
self.num_train_step += 1
|
||||
self.accumulative_meter.reset()
|
||||
step_bar.update()
|
||||
|
||||
# Save checkpoint
|
||||
if (
|
||||
self.save_dir is not None
|
||||
and self.save_interval is not None
|
||||
and (self.num_train_step + 1) % self.save_interval == 0
|
||||
):
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.scheduler,
|
||||
epoch=epoch,
|
||||
step=self.num_train_step + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.num_train_step} at folder {self.save_dir}"
|
||||
)
|
||||
# Save checkpoint
|
||||
if (
|
||||
self.save_dir is not None
|
||||
and self.save_interval is not None
|
||||
and (self.num_train_step + 1) % self.save_interval == 0
|
||||
):
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.scheduler,
|
||||
epoch=epoch,
|
||||
step=self.num_train_step + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.num_train_step} at folder {self.save_dir}"
|
||||
)
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
@ -151,23 +185,64 @@ class SFTTrainer(SLTrainer):
|
||||
self.accumulative_meter.reset()
|
||||
self.model.eval()
|
||||
with torch.no_grad():
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for batch in self.eval_dataloader:
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
outputs = self.model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
|
||||
loss_mean = all_reduce_mean(tensor=outputs.loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.item(), count_update=batch["input_ids"].size(0))
|
||||
step_bar.update()
|
||||
loss_mean = self.accumulative_meter.get("loss")
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
if isinstance(self.plugin, HybridParallelPlugin) and self.plugin.pp_size > 1:
|
||||
data_iter = iter(self.eval_dataloader)
|
||||
step_bar = tqdm(
|
||||
range(len(self.eval_dataloader)),
|
||||
desc="Step",
|
||||
disable=not (dist.get_rank() == dist.get_world_size() - 1),
|
||||
)
|
||||
for step in step_bar:
|
||||
outputs = self.booster.execute_pipeline(
|
||||
data_iter,
|
||||
self.model,
|
||||
criterion=lambda outputs, inputs: outputs[0],
|
||||
optimizer=self.optimizer,
|
||||
return_loss=True,
|
||||
)
|
||||
loss = outputs["loss"]
|
||||
if self.booster.plugin.stage_manager.is_last_stage():
|
||||
global_loss = all_reduce_mean(loss, self.plugin)
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
step_bar.set_postfix({"eval/loss": global_loss.item()})
|
||||
self.accumulative_meter.add("loss", global_loss.item())
|
||||
|
||||
if dist.get_rank() == dist.get_world_size() - 1:
|
||||
loss_mean = self.accumulative_meter.get("loss")
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
print(msg)
|
||||
if self.save_dir is not None:
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
||||
else:
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for batch in self.eval_dataloader:
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
outputs = self.model(
|
||||
batch["input_ids"],
|
||||
attention_mask=batch["attention_mask"],
|
||||
labels=batch["labels"] if self.apply_loss_mask else batch["input_ids"],
|
||||
)
|
||||
loss_mean = all_reduce_mean(tensor=outputs.loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.item(), count_update=batch["input_ids"].size(0))
|
||||
step_bar.update()
|
||||
|
||||
loss_mean = self.accumulative_meter.get("loss")
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
if self.save_dir is not None:
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
||||
@ -9,6 +9,29 @@ import torch.distributed as dist
|
||||
from torch.utils._pytree import tree_map
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
from colossalai.booster import Plugin
|
||||
|
||||
|
||||
class AnnealingScheduler:
|
||||
def __init__(self, start, end, warmup_steps=100, annealing_step=2000):
|
||||
self.start = start
|
||||
self.end = end
|
||||
self.warmup_steps = warmup_steps
|
||||
self.step = 0
|
||||
self.annealing_step = annealing_step
|
||||
|
||||
def get_temperature(self):
|
||||
if self.step <= self.warmup_steps:
|
||||
return self.start # Stop annealing after warm-up steps
|
||||
elif self.step >= self.annealing_step:
|
||||
return self.end
|
||||
# Linear annealing
|
||||
temp = self.start - (self.step / self.annealing_step) * (self.start - self.end)
|
||||
return temp
|
||||
|
||||
def step_forward(self):
|
||||
self.step += 1
|
||||
|
||||
|
||||
class CycledDataLoader:
|
||||
"""
|
||||
@ -85,7 +108,7 @@ def to_device(x: Any, device: torch.device) -> Any:
|
||||
return tree_map(_to, x)
|
||||
|
||||
|
||||
def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
|
||||
def all_reduce_mean(tensor: torch.Tensor, plugin: Plugin = None) -> torch.Tensor:
|
||||
"""
|
||||
Perform all-reduce operation on the given tensor and compute the mean across all processes.
|
||||
|
||||
@ -95,8 +118,13 @@ def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
|
||||
Returns:
|
||||
torch.Tensor: The reduced tensor with mean computed across all processes.
|
||||
"""
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
tensor.div_(dist.get_world_size())
|
||||
# All reduce mean across DP group
|
||||
if plugin is not None:
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM, group=plugin.dp_group)
|
||||
tensor.div_(plugin.dp_size)
|
||||
else:
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
tensor.div_(dist.get_world_size())
|
||||
return tensor
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,4 @@
|
||||
from .competition import math_competition_reward_fn
|
||||
from .gsm8k import gsm8k_reward_fn
|
||||
|
||||
__all__ = ["gsm8k_reward_fn", "math_competition_reward_fn"]
|
||||
@ -0,0 +1,26 @@
|
||||
import torch
|
||||
|
||||
from .utils import extract_solution, validate_response_structure
|
||||
|
||||
|
||||
def math_competition_reward_fn(input_ids, attention_mask, **kwargs):
|
||||
# apply varifiable reward
|
||||
# reward 10 points if the final answer is correct, reward 1 point if format is correct
|
||||
|
||||
gt_answer = kwargs["gt_answer"]
|
||||
tokenizer = kwargs["tokenizer"]
|
||||
s, e = kwargs["response_start"], kwargs["response_end"]
|
||||
reward = torch.tensor(0.0).to(input_ids.device)
|
||||
if gt_answer is None:
|
||||
return reward
|
||||
decoded_final_answer = tokenizer.decode(input_ids[s : e + 1], skip_special_tokens=True)
|
||||
final_answer, processed_str = extract_solution(decoded_final_answer)
|
||||
|
||||
format_valid = validate_response_structure(processed_str, kwargs["tags"])
|
||||
if not format_valid:
|
||||
return reward
|
||||
else:
|
||||
reward += 1.0
|
||||
if gt_answer.strip().replace(" ", "").lower() == final_answer.strip().replace(" ", "").lower():
|
||||
reward = reward + 9.0
|
||||
return reward
|
||||
31
applications/ColossalChat/coati/utils/reward_score/gsm8k.py
Normal file
31
applications/ColossalChat/coati/utils/reward_score/gsm8k.py
Normal file
@ -0,0 +1,31 @@
|
||||
import torch
|
||||
|
||||
from .utils import extract_solution, validate_response_structure
|
||||
|
||||
|
||||
def gsm8k_reward_fn(input_ids, attention_mask, **kwargs):
|
||||
# apply varifiable reward
|
||||
# reward 10 points if the final answer is correct, reward 1 point if format is correct
|
||||
|
||||
gt_answer = kwargs["gt_answer"]
|
||||
tokenizer = kwargs["tokenizer"]
|
||||
s, e = kwargs["response_start"], kwargs["response_end"]
|
||||
reward = torch.tensor(0.0).to(input_ids.device)
|
||||
if gt_answer is None:
|
||||
return reward
|
||||
decoded_final_answer = tokenizer.decode(input_ids[s:e], skip_special_tokens=True)
|
||||
final_answer, processed_str = extract_solution(decoded_final_answer)
|
||||
is_valid = True
|
||||
try:
|
||||
int(final_answer.strip())
|
||||
except Exception:
|
||||
is_valid = False
|
||||
|
||||
format_valid = validate_response_structure(processed_str, kwargs["tags"])
|
||||
if not is_valid or not format_valid:
|
||||
return reward
|
||||
else:
|
||||
reward += 1.0
|
||||
if gt_answer.strip().replace(" ", "").lower() == final_answer.strip().replace(" ", "").lower():
|
||||
reward = reward + 9.0
|
||||
return reward
|
||||
76
applications/ColossalChat/coati/utils/reward_score/utils.py
Normal file
76
applications/ColossalChat/coati/utils/reward_score/utils.py
Normal file
@ -0,0 +1,76 @@
|
||||
# Copyright Unakar
|
||||
# Modified from https://github.com/Unakar/Logic-RL/blob/086373176ac198c97277ff50f4b6e7e1bfe669d3/verl/utils/reward_score/kk.py#L99
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import re
|
||||
from typing import Dict, Optional, Tuple
|
||||
|
||||
|
||||
def validate_response_structure(processed_str: str, tags: Dict = None) -> bool:
|
||||
"""Performs comprehensive validation of response structure.
|
||||
|
||||
Args:
|
||||
processed_str: Processed response string from the model
|
||||
|
||||
Returns:
|
||||
Boolean indicating whether all formatting requirements are met
|
||||
"""
|
||||
validation_passed = True
|
||||
# Check required tags
|
||||
if tags is None:
|
||||
tags = {
|
||||
"think_start": {"text": "<think>", "num_occur": 1},
|
||||
"think_end": {"text": "</think>", "num_occur": 1},
|
||||
"answer_start": {"text": "<answer>", "num_occur": 1},
|
||||
"answer_end": {"text": "</answer>", "num_occur": 1},
|
||||
}
|
||||
positions = {}
|
||||
for tag_name, tag_info in tags.items():
|
||||
tag_str = tag_info["text"]
|
||||
expected_count = tag_info["num_occur"]
|
||||
count = processed_str.count(tag_str)
|
||||
positions[tag_name] = pos = processed_str.find(tag_str)
|
||||
if count != expected_count:
|
||||
validation_passed = False
|
||||
# Verify tag order
|
||||
if (
|
||||
positions["think_start"] > positions["think_end"]
|
||||
or positions["think_end"] > positions["answer_start"]
|
||||
or positions["answer_start"] > positions["answer_end"]
|
||||
):
|
||||
validation_passed = False
|
||||
if len(processed_str) - positions["answer_end"] != len(tags["answer_end"]["text"]):
|
||||
validation_passed = False
|
||||
return validation_passed
|
||||
|
||||
|
||||
def extract_solution(solution_str: str) -> Tuple[Optional[str], str]:
|
||||
"""Extracts the final answer from the model's response string.
|
||||
|
||||
Args:
|
||||
solution_str: Raw response string from the language model
|
||||
|
||||
Returns:
|
||||
Tuple containing (extracted_answer, processed_string)
|
||||
"""
|
||||
|
||||
# Extract final answer using XML-style tags
|
||||
answer_pattern = r"<answer>(.*?)</answer>"
|
||||
matches = list(re.finditer(answer_pattern, solution_str, re.DOTALL))
|
||||
|
||||
if not matches:
|
||||
return None, solution_str
|
||||
|
||||
final_answer = matches[-1].group(1).strip()
|
||||
return final_answer, solution_str
|
||||
@ -0,0 +1,8 @@
|
||||
{
|
||||
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
122753
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
@ -0,0 +1,9 @@
|
||||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
151645,
|
||||
151643
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
@ -0,0 +1,26 @@
|
||||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Now the user asks you to solve a math problem that involves reasoning. After thinking, when you finally reach a conclusion, clearly output the final answer without explanation within the <answer> </answer> tags, your final answer should be a integer without unit, currency mark, thousands separator or other text. i.e., <answer> 123 </answer>.\n",
|
||||
"stop_ids": [
|
||||
151643
|
||||
],
|
||||
"end_of_assistant": "<|endoftext|>",
|
||||
"response_format_tags": {
|
||||
"think_start": {
|
||||
"text": "<think>",
|
||||
"num_occur": 1
|
||||
},
|
||||
"think_end": {
|
||||
"text": "</think>",
|
||||
"num_occur": 1
|
||||
},
|
||||
"answer_start": {
|
||||
"text": "<answer>",
|
||||
"num_occur": 1
|
||||
},
|
||||
"answer_end": {
|
||||
"text": "</answer>",
|
||||
"num_occur": 1
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,8 @@
|
||||
{
|
||||
"chat_template": "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "</s>"
|
||||
}
|
||||
@ -2,13 +2,12 @@
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
|
||||
- [Examples](#examples)
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Install Requirements](#install-requirements)
|
||||
- [Get Start with ColossalRun](#get-start-with-colossalrun)
|
||||
- [Training Configuration](#training-configuration)
|
||||
- [Parameter Efficient Finetuning (PEFT)](#parameter-efficient-finetuning-peft)
|
||||
- [RLHF Stage 1: Supervised Instruction Tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||
- [Step 1: Data Collection](#step-1-data-collection)
|
||||
- [Step 2: Preprocessing](#step-2-preprocessing)
|
||||
@ -26,11 +25,14 @@
|
||||
- [Reward](#reward)
|
||||
- [KL Divergence](#approximate-kl-divergence)
|
||||
- [Note on PPO Training](#note-on-ppo-training)
|
||||
- [GRPO Training and DeepSeek R1 reproduction](#grpo-training-and-deepseek-r1-reproduction)
|
||||
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
|
||||
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
|
||||
- [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
|
||||
- [List of Supported Models](#list-of-supported-models)
|
||||
- [Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [Alternative Option For RLHF: Odds Ratio Preference Optimization](#alternative-option-for-rlhf-odds-ratio-preference-optimization)
|
||||
- [SFT for DeepSeek V3](#sft-for-deepseek-v3)
|
||||
- [Hardware Requirements](#hardware-requirements)
|
||||
- [Inference example](#inference-example)
|
||||
- [Attention](#attention)
|
||||
@ -46,9 +48,6 @@
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## Get Start with ColossalRun
|
||||
|
||||
|
||||
@ -82,8 +81,6 @@ Make sure the master node can access all nodes (including itself) by ssh without
|
||||
This section gives a simple introduction on different training strategies that you can use and how to use them with our boosters and plugins to reduce training time and VRAM consumption. For more details regarding training strategies, please refer to [here](https://colossalai.org/docs/concepts/paradigms_of_parallelism). For details regarding boosters and plugins, please refer to [here](https://colossalai.org/docs/basics/booster_plugins).
|
||||
|
||||
|
||||
|
||||
|
||||
<details><summary><b>Gemini (Zero3)</b></summary>
|
||||
|
||||
|
||||
@ -375,35 +372,6 @@ colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile trai
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Low Rank Adaption</b></summary>
|
||||
|
||||
|
||||
Details about Low Rank Adaption (LoRA) can be found in the paper: [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685). It dramatically reduces the VRAM consumption at the cost of sacrifice model capability. It is suitable for training LLM with constrained resources.
|
||||
|
||||
|
||||
To enable LoRA, set --lora_rank to a positive value (usually between 20 and 64).
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--lora_rank 32 \ # This enables LoRA
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Other Training Arguments</b></summary>
|
||||
|
||||
|
||||
@ -418,6 +386,7 @@ colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile trai
|
||||
- save_dir: path to store the model checkpoints.
|
||||
- max_length: input will be padded/truncated to max_length before feeding to the model.
|
||||
- max_epochs: number of epochs to train.
|
||||
- disable_loss_mask: whether to use the loss mask to mask the loss or not. For example, in SFT, if the loss mask is disabled, the model will compute the loss across all tokens in the sequence, if the loss mask is applied, only tokens correspond to the assistant responses will contribute to the final loss.
|
||||
- batch_size: training batch size.
|
||||
- mixed_precision: precision to use in training. Support 'fp16' and 'bf16'. Note that some devices may not support the 'bf16' option, please refer to [Nvidia](https://developer.nvidia.com/) to check compatibility.
|
||||
- save_interval: save the model weights as well as optimizer/scheduler states every save_interval steps/episodes.
|
||||
@ -428,6 +397,60 @@ colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile trai
|
||||
- use_wandb: if this flag is up, you can view logs on wandb.
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
### Parameter Efficient Finetuning (PEFT)
|
||||
|
||||
Currently, we have support LoRA (low-rank adaptation) and PiSSA (principal singular values and singular vectors adaptation). Both help to reduce the running-time VRAM consumption as well as timing at the cost of overall model performance.
|
||||
|
||||
|
||||
<details><summary><b>Low Rank Adaption and PiSSA</b></summary>
|
||||
|
||||
|
||||
Details about Low Rank Adaption (LoRA) can be found in the paper: [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685). Details about Principal Singular Values and Singular Vectors Adaptation (PiSSA) can be found in the paper: [PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models](https://arxiv.org/abs/2404.02948). Both help to reduce the running-time VRAM consumption as well as timing at the cost of overall model performance. It is suitable for training LLM with constrained resources.
|
||||
|
||||
To use LoRA/PiSSA in training, please create a config file as in the following example and set the `--lora_config` to that configuration file.
|
||||
|
||||
```json
|
||||
{
|
||||
"r": 128,
|
||||
"embedding_lora_dropout": 0.0,
|
||||
"linear_lora_dropout": 0.1,
|
||||
"lora_alpha": 32,
|
||||
"lora_train_bias": "all",
|
||||
"lora_initialization_method": "PiSSA",
|
||||
"target_modules": ["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj", "embed_tokens"]
|
||||
}
|
||||
```
|
||||
#### Lora Parameters
|
||||
- r: lora rank
|
||||
- embedding_lora_dropout: dropout probability for embedding layer
|
||||
- linear_lora_dropout: dropout probability for linear layer
|
||||
- lora_alpha: lora alpha, controls how much the adaptor can deviate from the pretrained model.
|
||||
- lora_train_bias: whether to add trainable bias to lora layers, choose from "all" (all layers (including but not limited to lora layers) will have trainable biases), "none" (no trainable biases), "lora" (only lora layers will have trainable biases)
|
||||
- lora_initialization_method: how to initialize lora weights, choose one from ["kaiming_uniform", "PiSSA"], default to "kaiming_uniform". Use "kaiming_uniform" for standard LoRA and "PiSSA" for PiSSA.
|
||||
- target_modules: which module(s) should be converted to lora layers, if the module's name contain the keywords in target modules and the module is a linear or embedding layer, the module will be converted. Otherwise, the module will be frozen. Setting this field to None will automatically convert all linear and embedding layer to their LoRA counterparts. Note that this example only works for LLaMA, for other models, you need to modify it.
|
||||
|
||||
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--lora_config /PATH/TO/THE/LORA/CONFIG/FILE.json \ # Setting this enables LoRA
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
@ -438,26 +461,24 @@ Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of
|
||||
|
||||
|
||||
#### Step 1: Data Collection
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following JSONL format.
|
||||
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
...
|
||||
]
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
...
|
||||
]
|
||||
]
|
||||
},
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
@ -471,9 +492,15 @@ In this code we provide a flexible way for users to set the conversation templat
|
||||
- Step 1: (Optional). Define your conversation template. You need to provide a conversation template config file similar to the config files under the ./config/conversation_template directory. This config should include the following fields.
|
||||
```json
|
||||
{
|
||||
"chat_template": (Optional), A string of chat_template used for formatting chat data. If not set (None), will use the default chat template of the provided tokenizer. If a path to a huggingface model or local model is provided, will use the chat_template of that model. To use a custom chat template, you need to manually set this field. For more details on how to write a chat template in Jinja format, please read https://huggingface.co/docs/transformers/main/chat_templating,
|
||||
"system_message": A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added,
|
||||
"end_of_assistant": The token(s) in string that denotes the end of assistance's response. For example, in the ChatGLM2 prompt format,
|
||||
"chat_template": "A string of chat_template used for formatting chat data",
|
||||
"system_message": "A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added",
|
||||
"end_of_assistant": "The token(s) in string that denotes the end of assistance's response",
|
||||
"stop_ids": "A list of integers corresponds to the `end_of_assistant` tokens that indicate the end of assistance's response during the rollout stage of PPO training"
|
||||
}
|
||||
```
|
||||
* `chat_template`: (Optional), A string of chat_template used for formatting chat data. If not set (None), will use the default chat template of the provided tokenizer. If a path to a huggingface model or local model is provided, will use the chat_template of that model. To use a custom chat template, you need to manually set this field. For more details on how to write a chat template in Jinja format, please read https://huggingface.co/docs/transformers/main/chat_templating.
|
||||
* `system_message`: A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added.
|
||||
* `end_of_assistant`: The token(s) in string that denotes the end of assistance's response". For example, in the ChatGLM2 prompt format,
|
||||
```
|
||||
<|im_start|>system
|
||||
system messages
|
||||
@ -482,15 +509,13 @@ In this code we provide a flexible way for users to set the conversation templat
|
||||
<|im_start|>user
|
||||
How far is the moon? <|im_end|>
|
||||
<|im_start|>assistant\n The moon is about 384,400 kilometers away from Earth.<|im_end|>...
|
||||
```
|
||||
the end_of_assistant tokens are "<|im_end|>"
|
||||
"stop_ids": (Optional), A list of integers corresponds to the `end_of_assistant` tokens that indicate the end of assistance's response during the rollout stage of PPO training. It's recommended to set this manually for PPO training. If not set, will set to tokenizer.eos_token_ids automatically
|
||||
}
|
||||
```
|
||||
On your first run of the data preparation script, you only need to define the "chat_template" (if you want to use custom chat template) and the "system message" (if you want to use a custom system message),
|
||||
```
|
||||
the `end_of_assistant` tokens are "<|im_end|>"
|
||||
* `stop_ids`: (Optional), A list of integers corresponds to the `end_of_assistant` tokens that indicate the end of assistance's response during the rollout stage of PPO training. It's recommended to set this manually for PPO training. If not set, will set to tokenizer.eos_token_ids automatically.
|
||||
|
||||
On your first run of the data preparation script, you only need to define the `chat_template` (if you want to use custom chat template) and the `system message` (if you want to use a custom system message)
|
||||
|
||||
- Step 2: Run the data preparation script--- [prepare_sft_dataset.sh](./examples/data_preparation_scripts/prepare_sft_dataset.sh). Note that whether or not you have skipped the first step, you need to provide the path to the conversation template config file (via the conversation_template_config arg). If you skipped the first step, an auto-generated conversation template will be stored at the designated file path.
|
||||
- Step 2: Run the data preparation script--- [prepare_sft_dataset.sh](./data_preparation_scripts/prepare_sft_dataset.sh). Note that whether or not you have skipped the first step, you need to provide the path to the conversation template config file (via the conversation_template_config arg). If you skipped the first step, an auto-generated conversation template will be stored at the designated file path.
|
||||
|
||||
|
||||
- Step 3: (Optional) Check the correctness of the processed data. We provided an easy way for you to do a manual checking on the processed data by checking the "$SAVE_DIR/jsonl/part-XXXX.jsonl" files.
|
||||
@ -510,7 +535,7 @@ Human: <s> what are some pranks with a pen i can do?</s> Assistant: <s> Are you
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./examples/training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
### RLHF Training Stage2 - Training Reward Model
|
||||
@ -527,7 +552,7 @@ Below shows the preference dataset format used in training the reward model.
|
||||
[
|
||||
{"context": [
|
||||
{
|
||||
"from": "human",
|
||||
"from": "user",
|
||||
"content": "Introduce butterflies species in Oregon."
|
||||
}
|
||||
]
|
||||
@ -552,11 +577,11 @@ Below shows the preference dataset format used in training the reward model.
|
||||
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./examples/data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
You can run [train_rm.sh](./examples/training_scripts/train_rm.sh) to start the reward model training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
You can run [train_rm.sh](./training_scripts/train_rm.sh) to start the reward model training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
#### Features and Tricks in RM Training
|
||||
@ -596,7 +621,7 @@ In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimi
|
||||
|
||||
|
||||
#### Step 1: Data Collection
|
||||
PPO uses two kinds of training data--- the prompt data and the pretrain data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
PPO uses two kinds of training data--- the prompt data and the pretrain data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "user" and thus the "assistant" needs to generate a response to answer to the "user". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
|
||||
|
||||
```json
|
||||
@ -604,7 +629,7 @@ PPO uses two kinds of training data--- the prompt data and the pretrain data (op
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
}
|
||||
...
|
||||
@ -627,14 +652,14 @@ The second dataset--- pretrained dataset is optional, provide it if you want to
|
||||
]
|
||||
```
|
||||
#### Step 2: Preprocessing
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./examples/data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
|
||||
|
||||
You can use the SFT dataset you prepared in the SFT stage or prepare a new one from different source for the ptx dataset. The ptx data is used to calculate ptx loss, which stabilizes the training according to the [InstructGPT paper](https://arxiv.org/pdf/2203.02155.pdf).
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
You can run the [train_ppo.sh](./examples/training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
You can run the [train_ppo.sh](./training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
```bash
|
||||
@ -699,10 +724,69 @@ Answer: The causes of this problem are two-fold. Check your reward model, make s
|
||||
#### Q4: Generation is garbage
|
||||
Answer: Yes, this happens and is well documented by other implementations. After training for too many episodes, the actor gradually deviate from its original state, which may leads to decrease in language modeling capabilities. A way to fix this is to add supervised loss during PPO. Set ptx_coef to an non-zero value (between 0 and 1), which balances PPO loss and sft loss.
|
||||
|
||||
## GRPO Training and DeepSeek R1 reproduction
|
||||
We support GRPO (Group Relative Policy Optimization), which is the reinforcement learning algorithm used in DeepSeek R1 paper. In this section, we will walk through GRPO training with an example trying to reproduce Deepseek R1's results in mathematical problem solving.
|
||||
|
||||
**Note: Currently, our PPO and GRPO pipelines are still under extensive development (integration with Ray and the inference engine). The speed is primarily limited by the rollout process, as we are using a naive generation approach without any acceleration. This experiment is focused solely on verifying the correctness of the GRPO algorithm. We will open-source the new version of code as soon as possible, so please stay tuned.**
|
||||
|
||||
### GRPO Model Selection
|
||||
We finally select the base version of [Qwen2.5-3B](https://huggingface.co/Qwen/Qwen2.5-3B). We also did experiments on the instruct version [Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) but the later one fails to explore more diversed output. We recommend to use base models (without SFT) and use a few SFT steps (see [SFT section](#rlhf-training-stage1---supervised-instructs-tuning)) to correct the base model's output format before GRPO.
|
||||
|
||||
### Reinforcement Learning with Verifiable Reward
|
||||
Both the PPO and the GRPO support reinforcement learning with verifiable reward (RLVR). In this experiment on mathematical problem solving, we define the reward function as following, in the following definition, forward is correct if there are exactly one pair of <think></think>, <answer></answer> tags in the response and the order of the tags is correct.
|
||||
|
||||
- reward=0, if format is incorrect.
|
||||
- reward=1, if format is correct but the answer doesn't match the ground truth answer exactly.
|
||||
- reward=10, if format is correct and the answer match the ground truth answer exactly.
|
||||
|
||||
### Step 1: Data Collection & Preparation
|
||||
For GPRO training, you only need the prompt dataset. Please follow the instruction in the [prompt dataset preparation](#rlhf-training-stage3---proximal-policy-optimization) to prepare the prompt data for GPRO training. In our reproduction experiment, we use the [qwedsacf/competition_math dataset](https://huggingface.co/datasets/qwedsacf/competition_math), which is available on Huggingface.
|
||||
|
||||
### Step 2: Training
|
||||
You can run the [train_grpo.sh](./training_scripts/train_grpo.sh) to start GRPO training. The script share most of its arguments with the PPO script (please refer to the [PPO training section](#step-3-training) for more details). Here are some unique arguments for GRPO.
|
||||
|
||||
```bash
|
||||
--num_generations 8 \ # number of roll outs to collect for each prompt
|
||||
--inference_batch_size 8 \ # batch size used during roll out
|
||||
--logits_forward_batch_size 1 \ # batch size used to calculate logits for GRPO training
|
||||
--initial_temperature \ # initial temperature for annealing algorithm
|
||||
--final_temperature \ # final temperature for annealing algorithm
|
||||
```
|
||||
|
||||
As the GRPO requires to collect a group of response from each prompt (usually greater than 8), the effective batch size will satisfy the following constraints,
|
||||
|
||||
- Without tensor parallelism,
|
||||
```
|
||||
experience buffer size
|
||||
= num_process * num_collect_steps * experience_batch_size * num_generations
|
||||
= train_batch_size * accumulation_steps * num_process
|
||||
```
|
||||
|
||||
- With tensor parallelism,
|
||||
```
|
||||
num_tp_group = num_process / tp
|
||||
experience buffer size
|
||||
= num_tp_group * num_collect_steps * experience_batch_size * num_generations
|
||||
= train_batch_size * accumulation_steps * num_tp_group
|
||||
```
|
||||
|
||||
During roll out, we perform rebatching to prevent out of memory both before roll out and before calculating logits. Please choose a proper setting for the "inference_batch_size" and the "logits_forward_batch_size" based on your device.
|
||||
|
||||
### GRPO Result
|
||||
#### Reward and Response Length
|
||||
<div style="display: flex; justify-content: space-between;">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/reward.png" style="width: 48%;" />
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost.png" style="width: 48%;" />
|
||||
</div>
|
||||
|
||||
#### Response Length Distribution (After Training) and Sample response
|
||||
<div style="display: flex; justify-content: space-between;">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost_eval.png" style="width: 48%;" />
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/sample.png" style="width: 48%;" />
|
||||
</div>
|
||||
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization
|
||||
|
||||
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
|
||||
|
||||
|
||||
@ -718,7 +802,7 @@ For DPO training, you only need the preference dataset. Please follow the instru
|
||||
|
||||
|
||||
#### Step 2: Training
|
||||
You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options. Following the trend of recent research on DPO-like alignment methods, we added option for the user to choose from, including whether to do length normalization , reward shaping and whether to use a reference model in calculating implicit reward. Here are those options,
|
||||
You can run the [train_dpo.sh](./training_scripts/train_dpo.sh) to start DPO training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options. Following the trend of recent research on DPO-like alignment methods, we added option for the user to choose from, including whether to do length normalization , reward shaping and whether to use a reference model in calculating implicit reward. Here are those options,
|
||||
|
||||
```
|
||||
--beta 0.1 \ # the temperature in DPO loss, Default to 0.1
|
||||
@ -735,7 +819,7 @@ You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to star
|
||||
### Alternative Option For RLHF: Simple Preference Optimization
|
||||
|
||||
We support the method introduced in the paper [SimPO: Simple Preference Optimization
|
||||
with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which is a reference model free aligment method that add length normalization and reward shaping to the DPO loss to enhance training stability and efficiency. As the method doesn't deviate too much from DPO, we add support for length normalization and SimPO reward shaping in our DPO implementation. To use SimPO in alignment, use the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) script, set the `loss_type` to `simpo_loss`, you can also set the value for temperature (`beta`) and reward target margin (`gamma`) but it is optional.
|
||||
with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which is a reference model free aligment method that add length normalization and reward shaping to the DPO loss to enhance training stability and efficiency. As the method doesn't deviate too much from DPO, we add support for length normalization and SimPO reward shaping in our DPO implementation. To use SimPO in alignment, use the [train_dpo.sh](./training_scripts/train_dpo.sh) script, set the `loss_type` to `simpo_loss`, you can also set the value for temperature (`beta`) and reward target margin (`gamma`) but it is optional.
|
||||
|
||||
#### SimPO Result
|
||||
<p align="center">
|
||||
@ -744,15 +828,139 @@ with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which i
|
||||
|
||||
|
||||
### Alternative Option For RLHF: Odds Ratio Preference Optimization
|
||||
We support the method introduced in the paper [ORPO: Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) (ORPO). Which is a reference model free aligment method that mixes the SFT loss with a reinforcement learning loss that uses odds ratio as the implicit reward to enhance training stability and efficiency. Simply set the flag to disable the use of the reference model, set the reward target margin and enable length normalization in the DPO training script. To use ORPO in alignment, use the [train_orpo.sh](./examples/training_scripts/train_orpo.sh) script, You can set the value for `lambda` (which determine how strongly the reinforcement learning loss affect the training) but it is optional.
|
||||
We support the method introduced in the paper [ORPO: Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) (ORPO). Which is a reference model free aligment method that mixes the SFT loss with a reinforcement learning loss that uses odds ratio as the implicit reward to enhance training stability and efficiency. To use ORPO in alignment, use the [train_orpo.sh](./training_scripts/train_orpo.sh) script, You can set the value for `lambda` (which determine how strongly the reinforcement learning loss affect the training) but it is optional.
|
||||
|
||||
#### ORPO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/ORPO_margin.png">
|
||||
</p>
|
||||
|
||||
## Hardware Requirements
|
||||
### Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results.
|
||||
|
||||
For KTO data preparation, please use the script [prepare_kto_dataset.sh](./examples/data_preparation_scripts/prepare_kto_dataset.sh). You will need preference data, different from DPO and its derivatives, you no longer need a pair of chosen/rejected response for the same input. You only need data whose response is associated with a preference label--- whether the response is okay or not, read the papre for more details. You also need to convert your data to the following intermediate format before you run the data preparation script.
|
||||
|
||||
```jsonl
|
||||
{
|
||||
"prompt": [
|
||||
{
|
||||
"from": "user",
|
||||
"content": "What are some praise words in english?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Here's an incomplete list.\n\nexcellent, fantastic, impressive ..."
|
||||
},
|
||||
{
|
||||
"from": "user",
|
||||
"content": "What's your favorite one?"
|
||||
}
|
||||
],
|
||||
"completion": {
|
||||
"from": "assistant",
|
||||
"content": "impressive."
|
||||
},
|
||||
"label": true
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
For training, use the [train_kto.sh](./examples/training_scripts/train_orpo.sh) script, You may need to set the value for `beta` (which determine how strongly the reinforcement learning loss affect the training), `desirable_weight` and `undesirable_weight` if your data is biased (has unequal number of chosen and rejected samples).
|
||||
|
||||
#### KTO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/KTO.png">
|
||||
</p>
|
||||
|
||||
|
||||
### SFT for DeepSeek V3
|
||||
We add a script to supervised-fintune the DeepSeek V3/R1 model with LoRA. The script is located in `examples/training_scripts/lora_fintune.py`. The script is similar to the SFT script for Coati7B, but with a few differences. This script is compatible with Peft.
|
||||
|
||||
#### Dataset preparation
|
||||
|
||||
This script receives JSONL format file as input dataset. Each line of dataset should be a list of chat dialogues. E.g.
|
||||
```json
|
||||
[{"role": "user", "content": "Hello, how are you?"}, {"role": "assistant", "content": "I'm doing great. How can I help you today?"}]
|
||||
```
|
||||
```json
|
||||
[{"role": "user", "content": "火烧赤壁 曹操为何不拨打119求救?"}, {"role": "assistant", "content": "因为在三国时期,还没有电话和现代的消防系统,所以曹操无法拨打119求救。"}]
|
||||
```
|
||||
|
||||
The dialogues can by multiple turns and it can contain system prompt. For more details, see the [chat_templating](https://huggingface.co/docs/transformers/main/chat_templating).
|
||||
|
||||
#### Model weights preparation
|
||||
|
||||
We use bf16 weights for finetuning. If you downloaded fp8 DeepSeek V3/R1 weights, you can use the [script](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py) to convert the weights to bf16 via GPU. For Ascend NPU, you can use this [script](https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/fp8_cast_bf16.py).
|
||||
|
||||
We have also added details on how to load and reason with lora models.
|
||||
```python
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
)
|
||||
from peft import (
|
||||
PeftModel
|
||||
)
|
||||
import torch
|
||||
|
||||
# Set model path
|
||||
model_name = "Qwen/Qwen2.5-3B"
|
||||
lora_adapter = "Qwen2.5-3B_lora" # Your lora model Path
|
||||
merged_model_path = "Qwen2.5-3B_merged"
|
||||
|
||||
######
|
||||
# How to Load lora Model
|
||||
######
|
||||
# 1.Load base model
|
||||
base_model = AutoModelForCausalLM.from_pretrained(
|
||||
model_name,
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="auto",
|
||||
trust_remote_code=True
|
||||
)
|
||||
|
||||
# 2.Load lora model
|
||||
peft_model = PeftModel.from_pretrained(
|
||||
base_model,
|
||||
lora_adapter,
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
# 3.Merge lora model
|
||||
merged_model = peft_model.merge_and_unload()
|
||||
|
||||
# 4.Load tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_name,
|
||||
trust_remote_code=True,
|
||||
pad_token="<|endoftext|>"
|
||||
)
|
||||
|
||||
# 5.Save merged lora model
|
||||
merged_model.save_pretrained(
|
||||
merged_model_path,
|
||||
safe_serialization=True
|
||||
)
|
||||
tokenizer.save_pretrained(merged_model_path)
|
||||
|
||||
# 6.Run Inference
|
||||
test_input = tokenizer("Instruction: Finding prime numbers up to 100\nAnswer:", return_tensors="pt").to("cuda")
|
||||
output = merged_model.generate(**test_input, max_new_tokens=100)
|
||||
print(tokenizer.decode(output[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
After preparing the dataset and model weights, you can run the script with the following command:
|
||||
```bash
|
||||
colossalai run --hostfile path-to-host-file --nproc_per_node 8 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
|
||||
```
|
||||
|
||||
For more details of each argument, you can run `python lora_finetune.py --help`.
|
||||
|
||||
The sample command does not use CPU offload to get better throughput. The minimum hardware requirement for sample command is 32 ascend 910B NPUs (with `ep=8,pp=4`) or 24 H100/H800 GPUs (with `ep=8,pp=3`). If you enable CPU offload by `--zero_cpu_offload`, the hardware requirement can be further reduced.
|
||||
|
||||
## Hardware Requirements
|
||||
For SFT, we recommend using zero2 or zero2-cpu for 7B model and tp is your model is extra large. We tested the VRAM consumption on a dummy dataset with a sequence length of 2048. In all experiments, we use H800 GPUs with 80GB VRAM and enable gradient checkpointing and flash attention.
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=22457.98 MB
|
||||
@ -801,35 +1009,17 @@ For ORPO, we recommend using zero2 or zero2-cpu. We tested the VRAM consumption
|
||||
- zero2, micro batch size=4, VRAM Usage=45309.52 MB
|
||||
- zero2, micro batch size=8, VRAM Usage=58086.37 MB
|
||||
|
||||
## List of Supported Models
|
||||
|
||||
For SFT, we support the following models/series:
|
||||
- Colossal-LLaMA-2
|
||||
- ChatGLM2
|
||||
- ChatGLM3 (only with zero2, zero2_cpu plugin)
|
||||
- Baichuan2
|
||||
- LLaMA2
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
For PPO and DPO, we theoratically support the following models/series (without guarantee):
|
||||
- Colossal-LLaMA-2 (tested)
|
||||
- ChatGLM2
|
||||
- Baichuan2
|
||||
- LLaMA2 (tested)
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
*-* The zero2, zero2_cpu plugin also support a wide range of chat models not listed above.
|
||||
For KTO, we recommend using zero2-cpu or zero2 plugin, We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=2, VRAM Usage=35241.98 MB
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=38989.37 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2_cpu, micro batch size=2, VRAM_USAGE=32443.22 MB
|
||||
- zero2, micro batch size=4, VRAM_USAGE=59307.97 MB
|
||||
|
||||
## Inference example
|
||||
|
||||
|
||||
We support different inference options, including int8 and int4 quantization.
|
||||
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
|
||||
## Attention
|
||||
|
||||
|
||||
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.
|
||||
|
||||
@ -40,7 +40,7 @@ import random
|
||||
import time
|
||||
from multiprocessing import cpu_count
|
||||
|
||||
from coati.dataset import setup_conversation_template, supervised_tokenize_sft, tokenize_prompt_dataset, tokenize_rlhf
|
||||
from coati.dataset import setup_conversation_template, tokenize_kto, tokenize_prompt, tokenize_rlhf, tokenize_sft
|
||||
from datasets import dataset_dict, load_dataset
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
@ -56,8 +56,8 @@ def main():
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
choices=["sft", "prompt", "preference"],
|
||||
help="Type of dataset, chose from 'sft', 'prompt', 'preference'.",
|
||||
choices=["sft", "prompt", "preference", "kto"],
|
||||
help="Type of dataset, chose from 'sft', 'prompt', 'preference'. 'kto'",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_input_dirs",
|
||||
@ -73,8 +73,7 @@ def main():
|
||||
"--conversation_template_config",
|
||||
type=str,
|
||||
default="conversation_template_config",
|
||||
help="Path \
|
||||
to save conversation template config files.",
|
||||
help="Path to save conversation template config files.",
|
||||
)
|
||||
parser.add_argument("--data_cache_dir", type=str, default="cache", help="Data cache directory")
|
||||
parser.add_argument(
|
||||
@ -199,11 +198,13 @@ def main():
|
||||
)
|
||||
|
||||
if args.type == "sft":
|
||||
preparation_function = supervised_tokenize_sft
|
||||
preparation_function = tokenize_sft
|
||||
elif args.type == "prompt":
|
||||
preparation_function = tokenize_prompt_dataset
|
||||
preparation_function = tokenize_prompt
|
||||
elif args.type == "preference":
|
||||
preparation_function = tokenize_rlhf
|
||||
elif args.type == "kto":
|
||||
preparation_function = tokenize_kto
|
||||
else:
|
||||
raise ValueError("Unknow dataset type. Please choose one from ['sft', 'prompt', 'preference']")
|
||||
|
||||
@ -228,10 +229,13 @@ def main():
|
||||
keep_in_memory=False,
|
||||
num_proc=min(len(dataset), cpu_count()),
|
||||
)
|
||||
|
||||
dataset = dataset.filter(
|
||||
lambda data: data["chosen_input_ids" if args.type == "preference" else "input_ids"] is not None
|
||||
)
|
||||
if args.type == "kto":
|
||||
filter_by = "completion"
|
||||
elif args.type == "preference":
|
||||
filter_by = "chosen_input_ids"
|
||||
else:
|
||||
filter_by = "input_ids"
|
||||
dataset = dataset.filter(lambda data: data[filter_by] is not None)
|
||||
|
||||
# Save each jsonl spliced dataset.
|
||||
output_index = "0" * (5 - len(str(index))) + str(index)
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
SAVE_DIR=""
|
||||
|
||||
rm -rf $SAVE_DIR/cache
|
||||
rm -rf $SAVE_DIR/jsonl
|
||||
rm -rf $SAVE_DIR/arrow
|
||||
|
||||
python prepare_dataset.py --type kto \
|
||||
--data_input_dirs /PATH/TO/KTO/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 1024
|
||||
@ -10,4 +10,5 @@ python prepare_dataset.py --type preference \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 1024
|
||||
|
||||
@ -10,4 +10,5 @@ python prepare_dataset.py --type prompt \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 300
|
||||
|
||||
@ -11,3 +11,4 @@ python prepare_dataset.py --type sft \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 4096
|
||||
|
||||
@ -53,8 +53,8 @@ def load_model_and_tokenizer(model_path, tokenizer_path, device="cuda", **kwargs
|
||||
tuple: A tuple containing the loaded model and tokenizer.
|
||||
"""
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_path, **kwargs)
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_path, **kwargs, trust_remote_code=True).to(torch.bfloat16)
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, trust_remote_code=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
model.to(device)
|
||||
|
||||
@ -151,7 +151,6 @@ def main(args):
|
||||
chat_io.prompt_for_output("assistant")
|
||||
|
||||
prompt = conv.get_prompt(add_generation_prompt=True)
|
||||
print(prompt + "<end_of_prompt>")
|
||||
input_ids = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)["input_ids"].to(
|
||||
torch.cuda.current_device()
|
||||
)
|
||||
|
||||
@ -1,181 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import pandas as pd
|
||||
import ray
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
get_tokenizer_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_maker = {
|
||||
"local_rank": "0",
|
||||
"rank": "0",
|
||||
"world_size": "1",
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = get_tokenizer_from_args(args.model)
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).half().cuda()
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=["maker1"],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
def model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_ref = ExperienceMakerHolder.options(name="maker1", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[f"trainer{i}" for i in range(args.num_trainers)],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
experience_batch_size=args.experience_batch_size,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
total_steps = args.experience_batch_size * args.experience_steps // (args.num_trainers * args.train_batch_size)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def build_dataloader():
|
||||
def tokenize_fn(texts):
|
||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
||||
return {k: v.cuda() for k, v in batch.items()}
|
||||
|
||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
||||
return dataloader
|
||||
|
||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_path", type=str, default=None)
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
@ -1,201 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import pandas as pd
|
||||
import ray
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_receivers_per_sender,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig, AutoTokenizer
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_makers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_makers),
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_makers)
|
||||
]
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
def model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_refs = [
|
||||
ExperienceMakerHolder.options(name=f"maker{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[
|
||||
f"trainer{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_makers, args.num_trainers, allow_idle_sender=False)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
for i, env_info_maker in enumerate(env_info_makers)
|
||||
]
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain, lora_rank=args.lora_rank).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain, lora_rank=args.lora_rank).half().cuda()
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=[
|
||||
f"maker{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_trainers, args.num_makers, allow_idle_sender=True)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def build_dataloader():
|
||||
def tokenize_fn(texts):
|
||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
||||
return {k: v.cuda() for k, v in batch.items()}
|
||||
|
||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
||||
return dataloader
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
for experience_holder_ref in experience_holder_refs:
|
||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
||||
|
||||
total_steps = (
|
||||
args.experience_batch_size
|
||||
* args.experience_steps
|
||||
* args.num_makers
|
||||
// (args.num_trainers * args.train_batch_size)
|
||||
)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_path", type=str, default=None)
|
||||
parser.add_argument("--num_makers", type=int, default=1)
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user