mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-04 16:20:16 +00:00
Compare commits
118 Commits
bagatur/do
...
erick/core
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
07f930b174 | ||
|
|
ce62c90f28 | ||
|
|
b57df42279 | ||
|
|
6b6269441c | ||
|
|
5f057f24ac | ||
|
|
076593382a | ||
|
|
c5656a4905 | ||
|
|
770f57196e | ||
|
|
52114bdfac | ||
|
|
ca288d8f2c | ||
|
|
476fb328ee | ||
|
|
697a6f2c80 | ||
|
|
061e63eef2 | ||
|
|
d196646811 | ||
|
|
5cf06db3b3 | ||
|
|
d334efc848 | ||
|
|
251afda549 | ||
|
|
7220124368 | ||
|
|
ee378a0f40 | ||
|
|
ddf4e7c633 | ||
|
|
ce21392a21 | ||
|
|
9e779ca846 | ||
|
|
daa9ccae52 | ||
|
|
7c57cfd8f0 | ||
|
|
beec7259c8 | ||
|
|
b11fd3bedc | ||
|
|
7306032dcf | ||
|
|
21e0df937f | ||
|
|
15c2b4a47e | ||
|
|
fb676d8a9b | ||
|
|
6137c7608d | ||
|
|
e80aab2275 | ||
|
|
ce7723c1e5 | ||
|
|
8799b028a6 | ||
|
|
fb7e66b809 | ||
|
|
c0773ab329 | ||
|
|
14244bd7e5 | ||
|
|
768e5e33bc | ||
|
|
86321a949f | ||
|
|
60d6a416e6 | ||
|
|
f7706637a8 | ||
|
|
0fa06732b7 | ||
|
|
7b084b4cc7 | ||
|
|
bccb07f93e | ||
|
|
3f75fd41cc | ||
|
|
eb6e385dc5 | ||
|
|
74bac7bda1 | ||
|
|
845e407e08 | ||
|
|
a74f3a4979 | ||
|
|
efe6cfafe2 | ||
|
|
1afac77439 | ||
|
|
9fb09c1c30 | ||
|
|
eb76f9c9fe | ||
|
|
bc60203d0f | ||
|
|
c697c89ca4 | ||
|
|
69533c8628 | ||
|
|
6a48ea43ec | ||
|
|
6a2889a4ec | ||
|
|
95020637bc | ||
|
|
d5808f786c | ||
|
|
13b90232c1 | ||
|
|
9b3962fc25 | ||
|
|
e26e1f8b37 | ||
|
|
eb9b334a6b | ||
|
|
560bb49c99 | ||
|
|
81d1ba05dc | ||
|
|
74d9fc2f9e | ||
|
|
bdd90ae2ee | ||
|
|
5efec068c9 | ||
|
|
ec4dab0449 | ||
|
|
f454e95461 | ||
|
|
782dd44be9 | ||
|
|
112208baa5 | ||
|
|
129552e3d6 | ||
|
|
438beb6c94 | ||
|
|
ebb6ad4f7a | ||
|
|
437cebc955 | ||
|
|
80d41a8da3 | ||
|
|
623f87c888 | ||
|
|
44101b6b0e | ||
|
|
46b7a8d913 | ||
|
|
c11dbefedc | ||
|
|
c56060bb7d | ||
|
|
611f18c944 | ||
|
|
d5aa277b94 | ||
|
|
9e1ed17bfb | ||
|
|
97411e998f | ||
|
|
6d299a55c0 | ||
|
|
e6240fecab | ||
|
|
38523d7c57 | ||
|
|
2895ca87cf | ||
|
|
ee708739c3 | ||
|
|
18411c379c | ||
|
|
9c871f427b | ||
|
|
a06db53c37 | ||
|
|
21a1538949 | ||
|
|
45f49ca439 | ||
|
|
c425e6f740 | ||
|
|
65980c22b8 | ||
|
|
e182d630f7 | ||
|
|
6432494f9d | ||
|
|
79124fd71d | ||
|
|
20abe24819 | ||
|
|
a1d7f2b3e1 | ||
|
|
feb41c5e28 | ||
|
|
85a4594ed7 | ||
|
|
33dccf0f66 | ||
|
|
942071bf57 | ||
|
|
0c95f3a981 | ||
|
|
323941a90a | ||
|
|
3e0cd11f51 | ||
|
|
70b6315b23 | ||
|
|
656e87beb9 | ||
|
|
04a5a37e92 | ||
|
|
ae67ba4dbb | ||
|
|
91ec9da534 | ||
|
|
7be72e1103 | ||
|
|
ee5bd986de |
143
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
143
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -5,60 +5,84 @@ body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: >
|
||||
Thank you for taking the time to file a bug report. Before creating a new
|
||||
issue, please make sure to take a few moments to check the issue tracker
|
||||
for existing issues about the bug.
|
||||
Thank you for taking the time to file a bug report.
|
||||
|
||||
Relevant links to check before filing a bug report to see if your issue has already been reported, fixed or
|
||||
if there's another way to solve your problem:
|
||||
|
||||
[LangChain documentation with the integrated search](https://python.langchain.com/docs/get_started/introduction),
|
||||
[API Reference](https://api.python.langchain.com/en/stable/),
|
||||
[GitHub search](https://github.com/langchain-ai/langchain),
|
||||
[LangChain Github Discussions](https://github.com/langchain-ai/langchain/discussions),
|
||||
[LangChain Github Issues](https://github.com/langchain-ai/langchain/issues?q=is%3Aissue)
|
||||
- type: checkboxes
|
||||
id: checks
|
||||
attributes:
|
||||
label: Checked other resources
|
||||
description: Please confirm and check all the following options.
|
||||
options:
|
||||
- label: I added a very descriptive title to this issue.
|
||||
required: true
|
||||
- label: I searched the LangChain documentation with the integrated search.
|
||||
required: true
|
||||
- label: I used the GitHub search to find a similar question and didn't find it.
|
||||
required: true
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Example Code
|
||||
description: |
|
||||
Please add a self-contained, [minimal, reproducible, example](https://stackoverflow.com/help/minimal-reproducible-example) with your use case.
|
||||
|
||||
If a maintainer can copy it, run it, and see it right away, there's a much higher chance that you'll be able to get help.
|
||||
|
||||
If you're including an error message, please include the full stack trace not just the last error.
|
||||
|
||||
**Important!** Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
|
||||
Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
The following code:
|
||||
|
||||
```python
|
||||
from langchain_core.runnables import RunnableLambda
|
||||
|
||||
def bad_code(inputs) -> int:
|
||||
raise NotImplementedError('For demo purpose')
|
||||
|
||||
chain = RunnableLambda(bad_code)
|
||||
chain.invoke('Hello!')
|
||||
```
|
||||
|
||||
Include both the error and the full stack trace if reporting an exception!
|
||||
|
||||
- type: textarea
|
||||
id: description
|
||||
attributes:
|
||||
label: Description
|
||||
description: |
|
||||
What is the problem, question, or error?
|
||||
|
||||
Write a short description telling what you are doing, what you expect to happen, and what is currently happening.
|
||||
placeholder: |
|
||||
* I'm trying to use the `langchain` library to do X.
|
||||
* I expect to see Y.
|
||||
* Instead, it does Z.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us.
|
||||
placeholder: LangChain version, platform, python version, ...
|
||||
placeholder: |
|
||||
"pip freeze | grep langchain"
|
||||
platform
|
||||
python version
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: who-can-help
|
||||
attributes:
|
||||
label: Who can help?
|
||||
description: |
|
||||
Your issue will be replied to more quickly if you can figure out the right person to tag with @
|
||||
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
|
||||
|
||||
The core maintainers strive to read all issues, but tagging them will help them prioritize.
|
||||
|
||||
Please tag fewer than 3 people.
|
||||
|
||||
@hwchase17 - project lead
|
||||
|
||||
Tracing / Callbacks
|
||||
- @agola11
|
||||
|
||||
Async
|
||||
- @agola11
|
||||
|
||||
DataLoader Abstractions
|
||||
- @eyurtsev
|
||||
|
||||
LLM/Chat Wrappers
|
||||
- @hwchase17
|
||||
- @agola11
|
||||
|
||||
Tools / Toolkits
|
||||
- ...
|
||||
|
||||
placeholder: "@Username ..."
|
||||
|
||||
- type: checkboxes
|
||||
id: information-scripts-examples
|
||||
attributes:
|
||||
label: Information
|
||||
description: "The problem arises when using:"
|
||||
options:
|
||||
- label: "The official example notebooks/scripts"
|
||||
- label: "My own modified scripts"
|
||||
|
||||
- type: checkboxes
|
||||
id: related-components
|
||||
attributes:
|
||||
@@ -77,30 +101,3 @@ body:
|
||||
- label: "Chains"
|
||||
- label: "Callbacks/Tracing"
|
||||
- label: "Async"
|
||||
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Reproduction
|
||||
description: |
|
||||
Please provide a [code sample](https://stackoverflow.com/help/minimal-reproducible-example) that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
|
||||
If you have code snippets, error messages, stack traces please provide them here as well.
|
||||
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
|
||||
Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
Steps to reproduce the behavior:
|
||||
|
||||
1.
|
||||
2.
|
||||
3.
|
||||
|
||||
- type: textarea
|
||||
id: expected-behavior
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Expected behavior
|
||||
description: "A clear and concise description of what you would expect to happen."
|
||||
|
||||
18
.github/ISSUE_TEMPLATE/other.yml
vendored
18
.github/ISSUE_TEMPLATE/other.yml
vendored
@@ -1,18 +0,0 @@
|
||||
name: Other Issue
|
||||
description: Raise an issue that wouldn't be covered by the other templates.
|
||||
title: "Issue: <Please write a comprehensive title after the 'Issue: ' prefix>"
|
||||
labels: [04 - Other]
|
||||
|
||||
body:
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: "Issue you'd like to raise."
|
||||
description: >
|
||||
Please describe the issue you'd like to raise as clearly as possible.
|
||||
Make sure to include any relevant links or references.
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: "Suggestion:"
|
||||
description: >
|
||||
Please outline a suggestion to improve the issue here.
|
||||
4
.github/actions/poetry_setup/action.yml
vendored
4
.github/actions/poetry_setup/action.yml
vendored
@@ -28,6 +28,7 @@ runs:
|
||||
steps:
|
||||
- uses: actions/setup-python@v5
|
||||
name: Setup python ${{ inputs.python-version }}
|
||||
id: setup-python
|
||||
with:
|
||||
python-version: ${{ inputs.python-version }}
|
||||
|
||||
@@ -74,7 +75,8 @@ runs:
|
||||
env:
|
||||
POETRY_VERSION: ${{ inputs.poetry-version }}
|
||||
PYTHON_VERSION: ${{ inputs.python-version }}
|
||||
run: pipx install "poetry==$POETRY_VERSION" --python "python$PYTHON_VERSION" --verbose
|
||||
# Install poetry using the python version installed by setup-python step.
|
||||
run: pipx install "poetry==$POETRY_VERSION" --python '${{ steps.setup-python.outputs.python-path }}' --verbose
|
||||
|
||||
- name: Restore pip and poetry cached dependencies
|
||||
uses: actions/cache@v3
|
||||
|
||||
11
.github/workflows/_release.yml
vendored
11
.github/workflows/_release.yml
vendored
@@ -117,11 +117,18 @@ jobs:
|
||||
# are not found on test PyPI can be resolved and installed anyway.
|
||||
# (https://test.pypi.org/simple). This will include the PKG_NAME==VERSION
|
||||
# package because VERSION will not have been uploaded to regular PyPI yet.
|
||||
#
|
||||
# - attempt install again after 5 seconds if it fails because there is
|
||||
# sometimes a delay in availability on test pypi
|
||||
run: |
|
||||
poetry run pip install \
|
||||
--extra-index-url https://test.pypi.org/simple/ \
|
||||
"$PKG_NAME==$VERSION"
|
||||
"$PKG_NAME==$VERSION" || \
|
||||
( \
|
||||
sleep 5 && \
|
||||
poetry run pip install \
|
||||
--extra-index-url https://test.pypi.org/simple/ \
|
||||
"$PKG_NAME==$VERSION" \
|
||||
)
|
||||
|
||||
# Replace all dashes in the package name with underscores,
|
||||
# since that's how Python imports packages with dashes in the name.
|
||||
|
||||
@@ -49,7 +49,7 @@ The LangChain libraries themselves are made up of several different packages.
|
||||
- **[`langchain-community`](libs/community)**: Third party integrations.
|
||||
- **[`langchain`](libs/langchain)**: Chains, agents, and retrieval strategies that make up an application's cognitive architecture.
|
||||
|
||||

|
||||

|
||||
|
||||
## 🧱 What can you build with LangChain?
|
||||
**❓ Retrieval augmented generation**
|
||||
|
||||
156
cookbook/together_ai.ipynb
Normal file
156
cookbook/together_ai.ipynb
Normal file
@@ -0,0 +1,156 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0fc0309d-4d49-4bb5-bec0-bd92c6fddb28",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Together AI + RAG\n",
|
||||
" \n",
|
||||
"[Together AI](https://python.langchain.com/docs/integrations/llms/together) has a broad set of OSS LLMs via inference API.\n",
|
||||
"\n",
|
||||
"See [here](https://api.together.xyz/playground). We use `\"mistralai/Mixtral-8x7B-Instruct-v0.1` for RAG on the Mixtral paper.\n",
|
||||
"\n",
|
||||
"Download the paper:\n",
|
||||
"https://arxiv.org/pdf/2401.04088.pdf"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d12fb75a-f707-48d5-82a5-efe2d041813c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"! pip install --quiet pypdf chromadb tiktoken openai langchain-together"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9ab49327-0532-4480-804c-d066c302a322",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Load\n",
|
||||
"from langchain_community.document_loaders import PyPDFLoader\n",
|
||||
"\n",
|
||||
"loader = PyPDFLoader(\"~/Desktop/mixtral.pdf\")\n",
|
||||
"data = loader.load()\n",
|
||||
"\n",
|
||||
"# Split\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"\n",
|
||||
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=0)\n",
|
||||
"all_splits = text_splitter.split_documents(data)\n",
|
||||
"\n",
|
||||
"# Add to vectorDB\n",
|
||||
"from langchain_community.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain_community.vectorstores import Chroma\n",
|
||||
"\n",
|
||||
"\"\"\"\n",
|
||||
"from langchain_together.embeddings import TogetherEmbeddings\n",
|
||||
"embeddings = TogetherEmbeddings(model=\"togethercomputer/m2-bert-80M-8k-retrieval\")\n",
|
||||
"\"\"\"\n",
|
||||
"vectorstore = Chroma.from_documents(\n",
|
||||
" documents=all_splits,\n",
|
||||
" collection_name=\"rag-chroma\",\n",
|
||||
" embedding=OpenAIEmbeddings(),\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"retriever = vectorstore.as_retriever()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "4efaddd9-3dbb-455c-ba54-0ad7f2d2ce0f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.output_parsers import StrOutputParser\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_core.pydantic_v1 import BaseModel\n",
|
||||
"from langchain_core.runnables import RunnableParallel, RunnablePassthrough\n",
|
||||
"\n",
|
||||
"# RAG prompt\n",
|
||||
"template = \"\"\"Answer the question based only on the following context:\n",
|
||||
"{context}\n",
|
||||
"\n",
|
||||
"Question: {question}\n",
|
||||
"\"\"\"\n",
|
||||
"prompt = ChatPromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"# LLM\n",
|
||||
"from langchain_community.llms import Together\n",
|
||||
"\n",
|
||||
"llm = Together(\n",
|
||||
" model=\"mistralai/Mixtral-8x7B-Instruct-v0.1\",\n",
|
||||
" temperature=0.0,\n",
|
||||
" max_tokens=2000,\n",
|
||||
" top_k=1,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# RAG chain\n",
|
||||
"chain = (\n",
|
||||
" RunnableParallel({\"context\": retriever, \"question\": RunnablePassthrough()})\n",
|
||||
" | prompt\n",
|
||||
" | llm\n",
|
||||
" | StrOutputParser()\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "88b1ee51-1b0f-4ebf-bb32-e50e843f0eeb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'\\nAnswer: The architectural details of Mixtral are as follows:\\n- Dimension (dim): 4096\\n- Number of layers (n\\\\_layers): 32\\n- Dimension of each head (head\\\\_dim): 128\\n- Hidden dimension (hidden\\\\_dim): 14336\\n- Number of heads (n\\\\_heads): 32\\n- Number of kv heads (n\\\\_kv\\\\_heads): 8\\n- Context length (context\\\\_len): 32768\\n- Vocabulary size (vocab\\\\_size): 32000\\n- Number of experts (num\\\\_experts): 8\\n- Number of top k experts (top\\\\_k\\\\_experts): 2\\n\\nMixtral is based on a transformer architecture and uses the same modifications as described in [18], with the notable exceptions that Mixtral supports a fully dense context length of 32k tokens, and the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively. This technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Mixtral is pretrained with multilingual data using a context size of 32k tokens. It either matches or exceeds the performance of Llama 2 70B and GPT-3.5, over several benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain.invoke(\"What are the Architectural details of Mixtral?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "755cf871-26b7-4e30-8b91-9ffd698470f4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Trace: \n",
|
||||
"\n",
|
||||
"https://smith.langchain.com/public/935fd642-06a6-4b42-98e3-6074f93115cd/r"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -177,7 +177,7 @@
|
||||
"source": [
|
||||
"## Get the prompts\n",
|
||||
"\n",
|
||||
"An important part of every chain is the prompts that are used. You can get the graphs present in the chain:"
|
||||
"An important part of every chain is the prompts that are used. You can get the prompts present in the chain:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -14,7 +14,7 @@ This framework consists of several parts.
|
||||
- **[LangServe](/docs/langserve)**: A library for deploying LangChain chains as a REST API.
|
||||
- **[LangSmith](/docs/langsmith)**: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
|
||||
|
||||

|
||||

|
||||
|
||||
Together, these products simplify the entire application lifecycle:
|
||||
- **Develop**: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.
|
||||
|
||||
@@ -182,7 +182,14 @@ You can then use a retriever to fetch only the most relevant pieces and pass tho
|
||||
In this process, we will look up relevant documents from a *Retriever* and then pass them into the prompt.
|
||||
A Retriever can be backed by anything - a SQL table, the internet, etc - but in this instance we will populate a vector store and use that as a retriever. For more information on vectorstores, see [this documentation](/docs/modules/data_connection/vectorstores).
|
||||
|
||||
First, we need to load the data that we want to index:
|
||||
First, we need to load the data that we want to index. In order to do this, we will use the WebBaseLoader. This requires installing [BeautifulSoup](https://beautiful-soup-4.readthedocs.io/en/latest/):
|
||||
|
||||
```
|
||||
```shell
|
||||
pip install beautifulsoup4
|
||||
```
|
||||
|
||||
After that, we can import and use WebBaseLoader.
|
||||
|
||||
|
||||
```python
|
||||
|
||||
@@ -12,7 +12,7 @@ Platforms with tracing capabilities like [LangSmith](/docs/langsmith/) and [Wand
|
||||
|
||||
For anyone building production-grade LLM applications, we highly recommend using a platform like this.
|
||||
|
||||

|
||||

|
||||
|
||||
## `set_debug` and `set_verbose`
|
||||
|
||||
|
||||
@@ -201,7 +201,7 @@
|
||||
"\n",
|
||||
"* E.g., for Llama-7b: `ollama pull llama2` will download the most basic version of the model (e.g., smallest # parameters and 4 bit quantization)\n",
|
||||
"* We can also specify a particular version from the [model list](https://github.com/jmorganca/ollama?tab=readme-ov-file#model-library), e.g., `ollama pull llama2:13b`\n",
|
||||
"* See the full set of parameters on the [API reference page](https://api.python.langchain.com/en/latest/llms/langchain.llms.ollama.Ollama.html)"
|
||||
"* See the full set of parameters on the [API reference page](https://api.python.langchain.com/en/latest/llms/langchain_community.llms.ollama.Ollama.html)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -241,7 +241,7 @@
|
||||
"\n",
|
||||
"As noted above, see the [API reference](https://api.python.langchain.com/en/latest/llms/langchain.llms.llamacpp.LlamaCpp.html?highlight=llamacpp#langchain.llms.llamacpp.LlamaCpp) for the full set of parameters. \n",
|
||||
"\n",
|
||||
"From the [llama.cpp docs](https://python.langchain.com/docs/integrations/llms/llamacpp), a few are worth commenting on:\n",
|
||||
"From the [llama.cpp API reference docs](https://api.python.langchain.com/en/latest/llms/langchain_community.llms.llamacpp.LlamaCpp.htm), a few are worth commenting on:\n",
|
||||
"\n",
|
||||
"`n_gpu_layers`: number of layers to be loaded into GPU memory\n",
|
||||
"\n",
|
||||
@@ -378,9 +378,9 @@
|
||||
"source": [
|
||||
"### GPT4All\n",
|
||||
"\n",
|
||||
"We can use model weights downloaded from [GPT4All](https://python.langchain.com/docs/integrations/llms/gpt4all) model explorer.\n",
|
||||
"We can use model weights downloaded from [GPT4All](/docs/integrations/llms/gpt4all) model explorer.\n",
|
||||
"\n",
|
||||
"Similar to what is shown above, we can run inference and use [the API reference](https://api.python.langchain.com/en/latest/llms/langchain.llms.gpt4all.GPT4All.html?highlight=gpt4all#langchain.llms.gpt4all.GPT4All) to set parameters of interest."
|
||||
"Similar to what is shown above, we can run inference and use [the API reference](https://api.python.langchain.com/en/latest/llms/langchain_community.llms.gpt4all.GPT4All.html) to set parameters of interest."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -390,7 +390,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install gpt4all\n"
|
||||
"%pip install gpt4all"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -582,9 +582,9 @@
|
||||
"source": [
|
||||
"## Use cases\n",
|
||||
"\n",
|
||||
"Given an `llm` created from one of the models above, you can use it for [many use cases](docs/use_cases).\n",
|
||||
"Given an `llm` created from one of the models above, you can use it for [many use cases](/docs/use_cases/).\n",
|
||||
"\n",
|
||||
"For example, here is a guide to [RAG](docs/use_cases/question_answering/local_retrieval_qa) with local LLMs.\n",
|
||||
"For example, here is a guide to [RAG](/docs/use_cases/question_answering/local_retrieval_qa) with local LLMs.\n",
|
||||
"\n",
|
||||
"In general, use cases for local LLMs can be driven by at least two factors:\n",
|
||||
"\n",
|
||||
@@ -611,7 +611,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -54,18 +54,17 @@
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:29] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"## Set up"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\"\"\"For basic init and call\"\"\"\n",
|
||||
"import os\n",
|
||||
@@ -73,85 +72,105 @@
|
||||
"from langchain_community.chat_models import QianfanChatEndpoint\n",
|
||||
"from langchain_core.language_models.chat_models import HumanMessage\n",
|
||||
"\n",
|
||||
"os.environ[\"QIANFAN_AK\"] = \"your_ak\"\n",
|
||||
"os.environ[\"QIANFAN_SK\"] = \"your_sk\"\n",
|
||||
"\n",
|
||||
"chat = QianfanChatEndpoint(\n",
|
||||
" streaming=True,\n",
|
||||
")\n",
|
||||
"res = chat([HumanMessage(content=\"write a funny joke\")])"
|
||||
"os.environ[\"QIANFAN_AK\"] = \"Your_api_key\"\n",
|
||||
"os.environ[\"QIANFAN_SK\"] = \"You_secret_Key\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:36] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/eb-instant\n",
|
||||
"[INFO] [09-15 20:00:37] logging.py:55 [t:139698882193216]: async requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!请问您需要什么帮助?我将尽力回答您的问题。')"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = QianfanChatEndpoint(streaming=True)\n",
|
||||
"messages = [HumanMessage(content=\"Hello\")]\n",
|
||||
"chat.invoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!有什么我可以帮助您的吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.ainvoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[AIMessage(content='您好!有什么我可以帮助您的吗?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat.batch([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Streaming"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"chat resp: content='您好,您似乎输入' additional_kwargs={} example=False\n",
|
||||
"chat resp: content='了一个话题标签,请问需要我帮您找到什么资料或者帮助您解答什么问题吗?' additional_kwargs={} example=False\n",
|
||||
"chat resp: content='' additional_kwargs={} example=False\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:39] logging.py:55 [t:139698882193216]: async requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"generations=[[ChatGeneration(text=\"The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.\", generation_info={'finish_reason': 'finished'}, message=AIMessage(content=\"The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.\", additional_kwargs={}, example=False))]] llm_output={} run=[RunInfo(run_id=UUID('d48160a6-5960-4c1d-8a0e-90e6b51a209b'))]\n",
|
||||
"astream content='The sea is a vast' additional_kwargs={} example=False\n",
|
||||
"astream content=' expanse of water, a place of mystery and adventure. It is the source of many cultures and civilizations, and a center of trade and exploration. The sea is also a source of life and beauty, with its unique marine life and diverse' additional_kwargs={} example=False\n",
|
||||
"astream content=' coral reefs. Whether you are swimming, diving, or just watching the sea, it is a place that captivates the imagination and transforms the spirit.' additional_kwargs={} example=False\n"
|
||||
"您好!有什么我可以帮助您的吗?\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import QianfanChatEndpoint\n",
|
||||
"\n",
|
||||
"chatLLM = QianfanChatEndpoint(\n",
|
||||
" streaming=True,\n",
|
||||
")\n",
|
||||
"res = chatLLM.stream([HumanMessage(content=\"hi\")], streaming=True)\n",
|
||||
"for r in res:\n",
|
||||
" print(\"chat resp:\", r)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_aio_generate():\n",
|
||||
" resp = await chatLLM.agenerate(\n",
|
||||
" messages=[[HumanMessage(content=\"write a 20 words sentence about sea.\")]]\n",
|
||||
" )\n",
|
||||
" print(resp)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await run_aio_generate()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_aio_stream():\n",
|
||||
" async for res in chatLLM.astream(\n",
|
||||
" [HumanMessage(content=\"write a 20 words sentence about sea.\")]\n",
|
||||
" ):\n",
|
||||
" print(\"astream\", res)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await run_aio_stream()"
|
||||
"try:\n",
|
||||
" for chunk in chat.stream(messages):\n",
|
||||
" print(chunk.content, end=\"\", flush=True)\n",
|
||||
"except TypeError as e:\n",
|
||||
" print(\"\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -161,39 +180,36 @@
|
||||
"source": [
|
||||
"## Use different models in Qianfan\n",
|
||||
"\n",
|
||||
"In the case you want to deploy your own model based on Ernie Bot or third-party open-source model, you could follow these steps:\n",
|
||||
"The default model is ERNIE-Bot-turbo, in the case you want to deploy your own model based on Ernie Bot or third-party open-source model, you could follow these steps:\n",
|
||||
"\n",
|
||||
"- 1. (Optional, if the model are included in the default models, skip it)Deploy your model in Qianfan Console, get your own customized deploy endpoint.\n",
|
||||
"- 2. Set up the field called `endpoint` in the initialization:"
|
||||
"1. (Optional, if the model are included in the default models, skip it) Deploy your model in Qianfan Console, get your own customized deploy endpoint.\n",
|
||||
"2. Set up the field called `endpoint` in the initialization:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:50] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/bloomz_7b1\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"content='你好!很高兴见到你。' additional_kwargs={} example=False\n"
|
||||
]
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Hello,可以回答问题了,我会竭尽全力为您解答,请问有什么问题吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chatBloom = QianfanChatEndpoint(\n",
|
||||
"chatBot = QianfanChatEndpoint(\n",
|
||||
" streaming=True,\n",
|
||||
" model=\"BLOOMZ-7B\",\n",
|
||||
" model=\"ERNIE-Bot\",\n",
|
||||
")\n",
|
||||
"res = chatBloom([HumanMessage(content=\"hi\")])\n",
|
||||
"print(res)"
|
||||
"\n",
|
||||
"messages = [HumanMessage(content=\"Hello\")]\n",
|
||||
"chatBot.invoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -212,35 +228,25 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:57] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"content='您好,您似乎输入' additional_kwargs={} example=False\n",
|
||||
"content='了一个文本字符串,但并没有给出具体的问题或场景。' additional_kwargs={} example=False\n",
|
||||
"content='如果您能提供更多信息,我可以更好地回答您的问题。' additional_kwargs={} example=False\n",
|
||||
"content='' additional_kwargs={} example=False\n"
|
||||
]
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!有什么我可以帮助您的吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"res = chat.stream(\n",
|
||||
" [HumanMessage(content=\"hi\")],\n",
|
||||
"chat.invoke(\n",
|
||||
" [HumanMessage(content=\"Hello\")],\n",
|
||||
" **{\"top_p\": 0.4, \"temperature\": 0.1, \"penalty_score\": 1},\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"for r in res:\n",
|
||||
" print(r)"
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
@@ -260,11 +266,11 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
"version": "3.9.18"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "6fa70026b407ae751a5c9e6bd7f7d482379da8ad616f98512780b705c84ee157"
|
||||
"hash": "58f7cb64c3a06383b7f18d2a11305edccbad427293a2b4afa7abe8bfc810d4bb"
|
||||
}
|
||||
}
|
||||
},
|
||||
|
||||
@@ -16,29 +16,58 @@
|
||||
"# ErnieBotChat\n",
|
||||
"\n",
|
||||
"[ERNIE-Bot](https://cloud.baidu.com/doc/WENXINWORKSHOP/s/jlil56u11) is a large language model developed by Baidu, covering a huge amount of Chinese data.\n",
|
||||
"This notebook covers how to get started with ErnieBot chat models.\n",
|
||||
"This notebook covers how to get started with ErnieBot chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Deprecated Warning**\n",
|
||||
"\n",
|
||||
"We recommend users using `langchain_community.chat_models.ErnieBotChat` \n",
|
||||
"to use `langchain_community.chat_models.QianfanChatEndpoint` instead.\n",
|
||||
"\n",
|
||||
"documentation for `QianfanChatEndpoint` is [here](./baidu_qianfan_endpoint).\n",
|
||||
"\n",
|
||||
"they are 4 why we recommend users to use `QianfanChatEndpoint`:\n",
|
||||
"\n",
|
||||
"**Note:** We recommend users using this class to switch to [Baidu Qianfan](./baidu_qianfan_endpoint). they are 3 why we recommend users to use `QianfanChatEndpoint`:\n",
|
||||
"1. `QianfanChatEndpoint` support more LLM in the Qianfan platform.\n",
|
||||
"2. `QianfanChatEndpoint` support streaming mode.\n",
|
||||
"3. `QianfanChatEndpoint` support function calling usgage.\n",
|
||||
"\n",
|
||||
"4. `ErnieBotChat` is lack of maintenance and deprecated."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Some tips for migration:\n",
|
||||
"\n",
|
||||
"- change `ernie_client_id` to `qianfan_ak`, also change `ernie_client_secret` to `qianfan_sk`.\n",
|
||||
"- install `qianfan` package. \n",
|
||||
" ```\n",
|
||||
" pip install qianfan\n",
|
||||
" ```"
|
||||
"- install `qianfan` package. like `pip install qianfan`\n",
|
||||
"- change `ErnieBotChat` to `QianfanChatEndpoint`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ErnieBotChat"
|
||||
"from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint\n",
|
||||
"\n",
|
||||
"chat = QianfanChatEndpoint(\n",
|
||||
" qianfan_ak=\"your qianfan ak\",\n",
|
||||
" qianfan_sk=\"your qianfan sk\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -47,6 +76,9 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ErnieBotChat\n",
|
||||
"\n",
|
||||
"chat = ErnieBotChat(\n",
|
||||
" ernie_client_id=\"YOUR_CLIENT_ID\", ernie_client_secret=\"YOUR_CLIENT_SECRET\"\n",
|
||||
")"
|
||||
|
||||
135
docs/docs/integrations/chat/llama_edge.ipynb
Normal file
135
docs/docs/integrations/chat/llama_edge.ipynb
Normal file
@@ -0,0 +1,135 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# LlamaEdge\n",
|
||||
"\n",
|
||||
"[LlamaEdge](https://github.com/second-state/LlamaEdge) allows you to chat with LLMs of [GGUF](https://github.com/ggerganov/llama.cpp/blob/master/gguf-py/README.md) format both locally and via chat service.\n",
|
||||
"\n",
|
||||
"- `LlamaEdgeChatService` provides developers an OpenAI API compatible service to chat with LLMs via HTTP requests.\n",
|
||||
"\n",
|
||||
"- `LlamaEdgeChatLocal` enables developers to chat with LLMs locally (coming soon).\n",
|
||||
"\n",
|
||||
"Both `LlamaEdgeChatService` and `LlamaEdgeChatLocal` run on the infrastructure driven by [WasmEdge Runtime](https://wasmedge.org/), which provides a lightweight and portable WebAssembly container environment for LLM inference tasks.\n",
|
||||
"\n",
|
||||
"## Chat via API Service\n",
|
||||
"\n",
|
||||
"`LlamaEdgeChatService` works on the `llama-api-server`. Following the steps in [llama-api-server quick-start](https://github.com/second-state/llama-utils/tree/main/api-server#readme), you can host your own API service so that you can chat with any models you like on any device you have anywhere as long as the internet is available."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_models.llama_edge import LlamaEdgeChatService\n",
|
||||
"from langchain_core.messages import HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Chat with LLMs in the non-streaming mode"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Hello! The capital of France is Paris.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = LlamaEdgeChatService(service_url=service_url)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of France?\")\n",
|
||||
"messages = [system_message, user_message]\n",
|
||||
"\n",
|
||||
"# chat with wasm-chat service\n",
|
||||
"response = chat(messages)\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {response.content}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Chat with LLMs in the streaming mode"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Hello! I'm happy to help you with your question. The capital of Norway is Oslo.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = LlamaEdgeChatService(service_url=service_url, streaming=True)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of Norway?\")\n",
|
||||
"messages = [\n",
|
||||
" system_message,\n",
|
||||
" user_message,\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"output = \"\"\n",
|
||||
"for chunk in chat.stream(messages):\n",
|
||||
" # print(chunk.content, end=\"\", flush=True)\n",
|
||||
" output += chunk.content\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {output}\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -1,85 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Wasm Chat\n",
|
||||
"\n",
|
||||
"`Wasm-chat` allows you to chat with LLMs of [GGUF](https://github.com/ggerganov/llama.cpp/blob/master/gguf-py/README.md) format both locally and via chat service.\n",
|
||||
"\n",
|
||||
"- `WasmChatService` provides developers an OpenAI API compatible service to chat with LLMs via HTTP requests.\n",
|
||||
"\n",
|
||||
"- `WasmChatLocal` enables developers to chat with LLMs locally (coming soon).\n",
|
||||
"\n",
|
||||
"Both `WasmChatService` and `WasmChatLocal` run on the infrastructure driven by [WasmEdge Runtime](https://wasmedge.org/), which provides a lightweight and portable WebAssembly container environment for LLM inference tasks.\n",
|
||||
"\n",
|
||||
"## Chat via API Service\n",
|
||||
"\n",
|
||||
"`WasmChatService` provides chat services by the `llama-api-server`. Following the steps in [llama-api-server quick-start](https://github.com/second-state/llama-utils/tree/main/api-server#readme), you can host your own API service so that you can chat with any models you like on any device you have anywhere as long as the internet is available."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_models.wasm_chat import WasmChatService\n",
|
||||
"from langchain_core.messages import AIMessage, HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Paris\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = WasmChatService(service_url=service_url)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of France?\")\n",
|
||||
"messages = [system_message, user_message]\n",
|
||||
"\n",
|
||||
"# chat with wasm-chat service\n",
|
||||
"response = chat(messages)\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {response.content}\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
236
docs/docs/integrations/document_loaders/surrealdb.ipynb
Normal file
236
docs/docs/integrations/document_loaders/surrealdb.ipynb
Normal file
@@ -0,0 +1,236 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5812b612-3e77-4be2-aefb-fbb16141ab79",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# SurrealDB\n",
|
||||
"\n",
|
||||
">[SurrealDB](https://surrealdb.com/) is an end-to-end cloud-native database designed for modern applications, including web, mobile, serverless, Jamstack, backend, and traditional applications. With SurrealDB, you can simplify your database and API infrastructure, reduce development time, and build secure, performant apps quickly and cost-effectively.\n",
|
||||
">\n",
|
||||
">**Key features of SurrealDB include:**\n",
|
||||
">\n",
|
||||
">* **Reduces development time:** SurrealDB simplifies your database and API stack by removing the need for most server-side components, allowing you to build secure, performant apps faster and cheaper.\n",
|
||||
">* **Real-time collaborative API backend service:** SurrealDB functions as both a database and an API backend service, enabling real-time collaboration.\n",
|
||||
">* **Support for multiple querying languages:** SurrealDB supports SQL querying from client devices, GraphQL, ACID transactions, WebSocket connections, structured and unstructured data, graph querying, full-text indexing, and geospatial querying.\n",
|
||||
">* **Granular access control:** SurrealDB provides row-level permissions-based access control, giving you the ability to manage data access with precision.\n",
|
||||
">\n",
|
||||
">View the [features](https://surrealdb.com/features), the latest [releases](https://surrealdb.com/releases), and [documentation](https://surrealdb.com/docs).\n",
|
||||
"\n",
|
||||
"This notebook shows how to use functionality related to the `SurrealDBLoader`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f56ccec5-24b3-4762-91a6-91385e041fee",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"The SurrealDB Document Loader returns a list of Langchain Documents from a SurrealDB database.\n",
|
||||
"\n",
|
||||
"The Document Loader takes the following optional parameters:\n",
|
||||
"\n",
|
||||
"* `dburl`: connection string to the websocket endpoint. default: `ws://localhost:8000/rpc`\n",
|
||||
"* `ns`: name of the namespace. default: `langchain`\n",
|
||||
"* `db`: name of the database. default: `database`\n",
|
||||
"* `table`: name of the table. default: `documents`\n",
|
||||
"* `db_user`: SurrealDB credentials if needed: db username.\n",
|
||||
"* `db_pass`: SurrealDB credentails if needed: db password.\n",
|
||||
"* `filter_criteria`: dictionary to construct the `WHERE` clause for filtering results from table.\n",
|
||||
"\n",
|
||||
"The output `Document` takes the following shape:\n",
|
||||
"```\n",
|
||||
"Document(\n",
|
||||
" page_content=<json encoded string containing the result document>,\n",
|
||||
" metadata={\n",
|
||||
" 'id': <document id>,\n",
|
||||
" 'ns': <namespace name>,\n",
|
||||
" 'db': <database_name>,\n",
|
||||
" 'table': <table name>,\n",
|
||||
" ... <additional fields from metadata property of the document>\n",
|
||||
" }\n",
|
||||
")\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "77b024e0-c804-4b19-9f5e-0099eb61ba79",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"Uncomment the below cells to install surrealdb and langchain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "508bc4f3-3aa2-45d3-8e59-cd7d0ffec379",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install --upgrade --quiet surrealdb langchain langchain-community"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "3ee3d767-b9ba-4be4-9e80-8fa6376beaba",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# add this import for running in jupyter notebook\n",
|
||||
"import nest_asyncio\n",
|
||||
"\n",
|
||||
"nest_asyncio.apply()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "1ec629f4-b99a-44f1-a938-29de7439f121",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"from langchain_community.document_loaders.surrealdb import SurrealDBLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8deb90ac-7d4e-422c-a87a-8e6e41390a6d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"42"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = SurrealDBLoader(\n",
|
||||
" dburl=\"ws://localhost:8000/rpc\",\n",
|
||||
" ns=\"langchain\",\n",
|
||||
" db=\"database\",\n",
|
||||
" table=\"documents\",\n",
|
||||
" db_user=\"root\",\n",
|
||||
" db_pass=\"root\",\n",
|
||||
" filter_criteria={},\n",
|
||||
")\n",
|
||||
"docs = loader.load()\n",
|
||||
"len(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "0aa9d3f7-56b3-464d-9d3d-1df7164122ba",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'id': 'documents:zzz434sa584xl3b4ohvk',\n",
|
||||
" 'source': '../../modules/state_of_the_union.txt',\n",
|
||||
" 'ns': 'langchain',\n",
|
||||
" 'db': 'database',\n",
|
||||
" 'table': 'documents'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"doc = docs[-1]\n",
|
||||
"doc.metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "0378dd34-c690-4b8e-8816-90a8acc2f227",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"18078"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"len(doc.page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "f30f1141-329b-4674-acb4-36d9d5a9ef0a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"page_content = json.loads(doc.page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "2a58496f-a831-40ec-be6b-92ce70f78133",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'When we use taxpayer dollars to rebuild America – we are going to Buy American: buy American products to support American jobs. \\n\\nThe federal government spends about $600 Billion a year to keep the country safe and secure. \\n\\nThere’s been a law on the books for almost a century \\nto make sure taxpayers’ dollars support American jobs and businesses. \\n\\nEvery Administration says they’ll do it, but we are actually doing it. \\n\\nWe will buy American to make sure everything from the deck of an aircraft carrier to the steel on highway guardrails are made in America. \\n\\nBut to compete for the best jobs of the future, we also need to level the playing field with China and other competitors. \\n\\nThat’s why it is so important to pass the Bipartisan Innovation Act sitting in Congress that will make record investments in emerging technologies and American manufacturing. \\n\\nLet me give you one example of why it’s so important to pass it.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"page_content[\"text\"]"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -14,12 +14,21 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 1,
|
||||
"id": "02be122d-04e8-4ec6-84d1-f1d8961d6828",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[33mWARNING: There was an error checking the latest version of pip.\u001b[0m\u001b[33m\n",
|
||||
"\u001b[0mNote: you may need to restart the kernel to use updated packages.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# install the package:\n",
|
||||
"%pip install --upgrade --quiet ai21"
|
||||
@@ -27,20 +36,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 1,
|
||||
"id": "4229227e-6ca2-41ad-a3c3-5f29e3559091",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# get AI21_API_KEY. Use https://studio.ai21.com/account/account\n",
|
||||
"\n",
|
||||
@@ -51,21 +52,20 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"id": "6fb585dd",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"from langchain_community.llms import AI21"
|
||||
"from langchain_community.llms import AI21\n",
|
||||
"from langchain_core.prompts import PromptTemplate"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 12,
|
||||
"id": "035dea0f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -76,12 +76,12 @@
|
||||
"\n",
|
||||
"Answer: Let's think step by step.\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate(template=template, input_variables=[\"question\"])"
|
||||
"prompt = PromptTemplate.from_template(template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 9,
|
||||
"id": "3f3458d9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -93,19 +93,19 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"execution_count": 10,
|
||||
"id": "a641dbd9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(prompt=prompt, llm=llm)"
|
||||
"llm_chain = prompt | llm"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"execution_count": 13,
|
||||
"id": "9f0b1960",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -114,10 +114,10 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'\\n1. What year was Justin Bieber born?\\nJustin Bieber was born in 1994.\\n2. What team won the Super Bowl in 1994?\\nThe Dallas Cowboys won the Super Bowl in 1994.'"
|
||||
"'\\nThe Super Bowl in the year Justin Beiber was born was in the year 1991.\\nThe Super Bowl in 1991 was won by the Washington Redskins.\\nFinal answer: Washington Redskins'"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -125,7 +125,7 @@
|
||||
"source": [
|
||||
"question = \"What NFL team won the Super Bowl in the year Justin Beiber was born?\"\n",
|
||||
"\n",
|
||||
"llm_chain.run(question)"
|
||||
"llm_chain.invoke({\"question\": question})"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -153,7 +153,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -127,10 +127,8 @@
|
||||
"Setup the user id and app id where the model resides. You can find a list of public models on https://clarifai.com/explore/models\n",
|
||||
"\n",
|
||||
"You will have to also initialize the model id and if needed, the model version id. Some models have many versions, you can choose the one appropriate for your task.\n",
|
||||
"\n",
|
||||
" or\n",
|
||||
" \n",
|
||||
"You can use the model_url (for ex: \"https://clarifai.com/anthropic/completion/models/claude-v2\") for intialization."
|
||||
" \n",
|
||||
"Alternatively, You can use the model_url (for ex: \"https://clarifai.com/anthropic/completion/models/claude-v2\") for intialization."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -18,7 +18,17 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": null,
|
||||
"id": "1ecdb29d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain-together"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "e7b7170d-d7c5-4890-9714-a37238343805",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -37,7 +47,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_community.llms import Together\n",
|
||||
"from langchain_together import Together\n",
|
||||
"\n",
|
||||
"llm = Together(\n",
|
||||
" model=\"togethercomputer/RedPajama-INCITE-7B-Base\",\n",
|
||||
@@ -51,15 +61,15 @@
|
||||
"You provide succinct and accurate answers. Answer the following question: \n",
|
||||
"\n",
|
||||
"What is a large language model?\"\"\"\n",
|
||||
"print(llm(input_))"
|
||||
"print(llm.invoke(input_))"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "poetry-venv",
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "poetry-venv"
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
@@ -71,7 +81,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -0,0 +1,147 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "91c6a7ef",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Google Cloud Firestore\n",
|
||||
"\n",
|
||||
"> [`Cloud Firestore`](https://cloud.google.com/firestore) is a NoSQL document database built for automatic scaling, high performance, and ease of application development.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use Firestore to store chat message history."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2d6ed3c8-b70a-498c-bc9e-41b91797d3b7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setting up"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8eca282",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To run this notebook, you will need a Google Cloud Project, a Firestore database instance in Native Mode, and Google credentials, see [Firestore Quickstarts](https://cloud.google.com/firestore/docs/quickstarts)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5a7f3b3f-d9b8-4577-a7ef-bdd8ecaedb70",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install firebase-admin"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a8e63850-3e14-46fe-a59e-be6d6bf8fe61",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Basic Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_message_histories.firestore import (\n",
|
||||
" FirestoreChatMessageHistory,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history = FirestoreChatMessageHistory(\n",
|
||||
" collection_name=\"langchain-chat-history\",\n",
|
||||
" session_id=\"user-session-id\",\n",
|
||||
" user_id=\"user-id\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history.add_user_message(\"hi!\")\n",
|
||||
"message_history.add_ai_message(\"whats up?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "64fc465e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content='hi!'),\n",
|
||||
" HumanMessage(content='hi!'),\n",
|
||||
" AIMessage(content='whats up?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"message_history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4be8576e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Custom Firestore Client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "12999273",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import firebase_admin\n",
|
||||
"from firebase_admin import credentials, firestore\n",
|
||||
"\n",
|
||||
"# Use a service account.\n",
|
||||
"cred = credentials.Certificate(\"path/to/serviceAccount.json\")\n",
|
||||
"\n",
|
||||
"app = firebase_admin.initialize_app(cred)\n",
|
||||
"client = firestore.client(app=app)\n",
|
||||
"\n",
|
||||
"message_history = FirestoreChatMessageHistory(\n",
|
||||
" collection_name=\"langchain-chat-history\",\n",
|
||||
" session_id=\"user-session-id\",\n",
|
||||
" user_id=\"user-id\",\n",
|
||||
" firestore_client=client,\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -12,16 +12,43 @@
|
||||
"This notebook goes over how to use `Redis` to store chat message history."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "897a4682-f9fc-488b-98f3-ae2acad84600",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"First we need to install dependencies, and start a redis instance using commands like: `redis-server`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": null,
|
||||
"id": "cda8b56d-baf7-49a2-91a2-4d424a8519cb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install -U langchain-community redis"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20b99474-75ea-422e-9809-fbdb9d103afc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Store and Retrieve Messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import RedisChatMessageHistory\n",
|
||||
"from langchain_community.chat_message_histories import RedisChatMessageHistory\n",
|
||||
"\n",
|
||||
"history = RedisChatMessageHistory(\"foo\")\n",
|
||||
"history = RedisChatMessageHistory(\"foo\", url=\"redis://localhost:6379\")\n",
|
||||
"\n",
|
||||
"history.add_user_message(\"hi!\")\n",
|
||||
"\n",
|
||||
@@ -30,18 +57,17 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 4,
|
||||
"id": "64fc465e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[AIMessage(content='whats up?', additional_kwargs={}),\n",
|
||||
" HumanMessage(content='hi!', additional_kwargs={})]"
|
||||
"[HumanMessage(content='hi!'), AIMessage(content='whats up?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -50,10 +76,85 @@
|
||||
"history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "465fdd8c-b093-4d19-a55a-30f3b646432b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using in the Chains"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8af285f8",
|
||||
"id": "94d65d2f-e9bb-4b47-a86d-dd6b1b5e8247",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install -U langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "ace3e7b2-5e3e-4966-b549-04952a6a9a09",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional\n",
|
||||
"\n",
|
||||
"from langchain_community.chat_message_histories import RedisChatMessageHistory\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"from langchain_openai import ChatOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5c1fba0d-d06a-4695-ba14-c42a3461ada1",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Your name is Bob, as you mentioned earlier. Is there anything specific you would like assistance with, Bob?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You're an assistant。\"),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = prompt | ChatOpenAI()\n",
|
||||
"\n",
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" RedisChatMessageHistory,\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"config = {\"configurable\": {\"session_id\": \"foo\"}}\n",
|
||||
"\n",
|
||||
"chain_with_history.invoke({\"question\": \"Hi! I'm bob\"}, config=config)\n",
|
||||
"\n",
|
||||
"chain_with_history.invoke({\"question\": \"Whats my name\"}, config=config)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "76ce3f6b-f4c7-4d27-8031-60f7dd756695",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
@@ -75,7 +176,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
"version": "3.9.18"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -6,7 +6,7 @@ This page covers how to use the [Remembrall](https://remembrall.dev) ecosystem w
|
||||
|
||||
Remembrall gives your language model long-term memory, retrieval augmented generation, and complete observability with just a few lines of code.
|
||||
|
||||

|
||||

|
||||
|
||||
It works as a light-weight proxy on top of your OpenAI calls and simply augments the context of the chat calls at runtime with relevant facts that have been collected.
|
||||
|
||||
|
||||
@@ -186,7 +186,7 @@ from langchain_community.document_loaders import GoogleSpeechToTextLoader
|
||||
### Google Vertex AI Vector Search
|
||||
|
||||
> [Google Vertex AI Vector Search](https://cloud.google.com/vertex-ai/docs/matching-engine/overview),
|
||||
> formerly known as `Vertex AI Matching Engine`, provides the industry's leading high-scale
|
||||
> formerly known as `Vertex AI Matching Engine`, provides the industry's leading high-scale
|
||||
> low latency vector database. These vector databases are commonly
|
||||
> referred to as vector similarity-matching or an approximate nearest neighbor (ANN) service.
|
||||
|
||||
@@ -207,7 +207,7 @@ from langchain_community.vectorstores import MatchingEngine
|
||||
> [Google BigQuery](https://cloud.google.com/bigquery),
|
||||
> BigQuery is a serverless and cost-effective enterprise data warehouse in Google Cloud.
|
||||
>
|
||||
> Google BigQuery Vector Search
|
||||
> Google BigQuery Vector Search
|
||||
> BigQuery vector search lets you use GoogleSQL to do semantic search, using vector indexes for fast but approximate results, or using brute force for exact results.
|
||||
|
||||
> It can calculate Euclidean or Cosine distance. With LangChain, we default to use Euclidean distance.
|
||||
@@ -228,7 +228,7 @@ from langchain.vectorstores import BigQueryVectorSearch
|
||||
|
||||
>[Google ScaNN](https://github.com/google-research/google-research/tree/master/scann)
|
||||
> (Scalable Nearest Neighbors) is a python package.
|
||||
>
|
||||
>
|
||||
>`ScaNN` is a method for efficient vector similarity search at scale.
|
||||
|
||||
>`ScaNN` includes search space pruning and quantization for Maximum Inner
|
||||
@@ -285,9 +285,9 @@ from langchain.retrievers import GoogleVertexAISearchRetriever
|
||||
|
||||
### Document AI Warehouse
|
||||
> [Google Cloud Document AI Warehouse](https://cloud.google.com/document-ai-warehouse)
|
||||
> allows enterprises to search, store, govern, and manage documents and their AI-extracted
|
||||
> allows enterprises to search, store, govern, and manage documents and their AI-extracted
|
||||
> data and metadata in a single platform.
|
||||
>
|
||||
>
|
||||
|
||||
```python
|
||||
from langchain.retrievers import GoogleDocumentAIWarehouseRetriever
|
||||
@@ -304,9 +304,9 @@ documents = docai_wh_retriever.get_relevant_documents(
|
||||
|
||||
### Google Cloud Text-to-Speech
|
||||
|
||||
>[Google Cloud Text-to-Speech](https://cloud.google.com/text-to-speech) enables developers to
|
||||
> synthesize natural-sounding speech with 100+ voices, available in multiple languages and variants.
|
||||
> It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks
|
||||
>[Google Cloud Text-to-Speech](https://cloud.google.com/text-to-speech) enables developers to
|
||||
> synthesize natural-sounding speech with 100+ voices, available in multiple languages and variants.
|
||||
> It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks
|
||||
> to deliver the highest fidelity possible.
|
||||
|
||||
We need to install a python package.
|
||||
@@ -354,7 +354,7 @@ from langchain.tools import GooglePlacesTool
|
||||
### Google Search
|
||||
|
||||
- Set up a Custom Search Engine, following [these instructions](https://stackoverflow.com/questions/37083058/programmatically-searching-google-in-python-using-custom-search)
|
||||
- Get an API Key and Custom Search Engine ID from the previous step, and set them as environment variables
|
||||
- Get an API Key and Custom Search Engine ID from the previous step, and set them as environment variables
|
||||
`GOOGLE_API_KEY` and `GOOGLE_CSE_ID` respectively.
|
||||
|
||||
```python
|
||||
@@ -444,12 +444,12 @@ from langchain_community.utilities.google_trends import GoogleTrendsAPIWrapper
|
||||
|
||||
### Google Document AI
|
||||
|
||||
>[Document AI](https://cloud.google.com/document-ai/docs/overview) is a `Google Cloud Platform`
|
||||
> service that transforms unstructured data from documents into structured data, making it easier
|
||||
>[Document AI](https://cloud.google.com/document-ai/docs/overview) is a `Google Cloud Platform`
|
||||
> service that transforms unstructured data from documents into structured data, making it easier
|
||||
> to understand, analyze, and consume.
|
||||
|
||||
We need to set up a [`GCS` bucket and create your own OCR processor](https://cloud.google.com/document-ai/docs/create-processor)
|
||||
The `GCS_OUTPUT_PATH` should be a path to a folder on GCS (starting with `gs://`)
|
||||
We need to set up a [`GCS` bucket and create your own OCR processor](https://cloud.google.com/document-ai/docs/create-processor)
|
||||
The `GCS_OUTPUT_PATH` should be a path to a folder on GCS (starting with `gs://`)
|
||||
and a processor name should look like `projects/PROJECT_NUMBER/locations/LOCATION/processors/PROCESSOR_ID`.
|
||||
We can get it either programmatically or copy from the `Prediction endpoint` section of the `Processor details`
|
||||
tab in the Google Cloud Console.
|
||||
@@ -507,6 +507,23 @@ See a [usage example and authorization instructions](/docs/integrations/toolkits
|
||||
from langchain_community.agent_toolkits import GmailToolkit
|
||||
```
|
||||
|
||||
## Memory
|
||||
|
||||
### Cloud Firestore
|
||||
|
||||
> [`Cloud Firestore`](https://cloud.google.com/firestore) is a NoSQL document database built for automatic scaling, high performance, and ease of application development.
|
||||
|
||||
First, we need to install the python package.
|
||||
|
||||
```bash
|
||||
pip install firebase-admin
|
||||
```
|
||||
|
||||
See a [usage example and authorization instructions](/docs/integrations/memory/firestore_chat_message_history).
|
||||
|
||||
```python
|
||||
from langchain_community.chat_message_histories.firestore import FirestoreChatMessageHistory
|
||||
```
|
||||
|
||||
## Chat Loaders
|
||||
|
||||
@@ -560,7 +577,7 @@ from langchain_community.utilities import GoogleSerperAPIWrapper
|
||||
### YouTube
|
||||
|
||||
>[YouTube Search](https://github.com/joetats/youtube_search) package searches `YouTube` videos avoiding using their heavily rate-limited API.
|
||||
>
|
||||
>
|
||||
>It uses the form on the YouTube homepage and scrapes the resulting page.
|
||||
|
||||
We need to install a python package.
|
||||
|
||||
@@ -10,7 +10,7 @@ All functionality related to `Microsoft Azure` and other `Microsoft` products.
|
||||
>[Azure OpenAI](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/) is an `Azure` service with powerful language models from `OpenAI` including the `GPT-3`, `Codex` and `Embeddings model` series for content generation, summarization, semantic search, and natural language to code translation.
|
||||
|
||||
```bash
|
||||
pip install openai tiktoken
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
Set the environment variables to get access to the `Azure OpenAI` service.
|
||||
|
||||
@@ -13,16 +13,14 @@ All functionality related to OpenAI
|
||||
>[ChatGPT](https://chat.openai.com) is the Artificial Intelligence (AI) chatbot developed by `OpenAI`.
|
||||
|
||||
## Installation and Setup
|
||||
- Install the Python SDK with
|
||||
|
||||
Install the integration package with
|
||||
```bash
|
||||
pip install openai
|
||||
```
|
||||
- Get an OpenAI api key and set it as an environment variable (`OPENAI_API_KEY`)
|
||||
- If you want to use OpenAI's tokenizer (only available for Python 3.9+), install it
|
||||
```bash
|
||||
pip install tiktoken
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
Get an OpenAI api key and set it as an environment variable (`OPENAI_API_KEY`)
|
||||
|
||||
|
||||
## LLM
|
||||
|
||||
|
||||
@@ -70,6 +70,19 @@ message_history = AstraDBChatMessageHistory(
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/memory/astradb_chat_message_history).
|
||||
|
||||
### Document loader
|
||||
|
||||
```python
|
||||
from langchain_community.document_loaders import AstraDBLoader
|
||||
loader = AstraDBLoader(
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
collection_name="my_collection"
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/document_loaders/astradb).
|
||||
|
||||
|
||||
## Apache Cassandra and Astra DB through CQL
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ For a more detailed walkthrough of the Chroma wrapper, see [this notebook](/docs
|
||||
|
||||
## Retriever
|
||||
|
||||
See a [usage example](/docs/integrations/retrievers/self_query/chroma).
|
||||
See a [usage example](/docs/integrations/retrievers/self_query/chroma_self_query).
|
||||
|
||||
```python
|
||||
from langchain.retrievers import SelfQueryRetriever
|
||||
|
||||
@@ -58,10 +58,8 @@ print(rag.get_relevant_documents("What is cohere ai?"))
|
||||
### Text Embedding
|
||||
|
||||
```python
|
||||
from langchain_community.chat_models import ChatCohere
|
||||
from langchain.retrievers import CohereRagRetriever
|
||||
from langchain_core.documents import Document
|
||||
from langchain_community.embeddings import CohereEmbeddings
|
||||
|
||||
rag = CohereRagRetriever(llm=ChatCohere())
|
||||
print(rag.get_relevant_documents("What is cohere ai?"))
|
||||
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
|
||||
print(embeddings.embed_documents(["This is a test document."]))
|
||||
```
|
||||
|
||||
1183
docs/docs/integrations/providers/dspy.ipynb
Normal file
1183
docs/docs/integrations/providers/dspy.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
@@ -150,4 +150,4 @@ This command will initiate the execution of the `langchain_llm` task on the Flyt
|
||||
|
||||
The metrics will be displayed on the Flyte UI as follows:
|
||||
|
||||
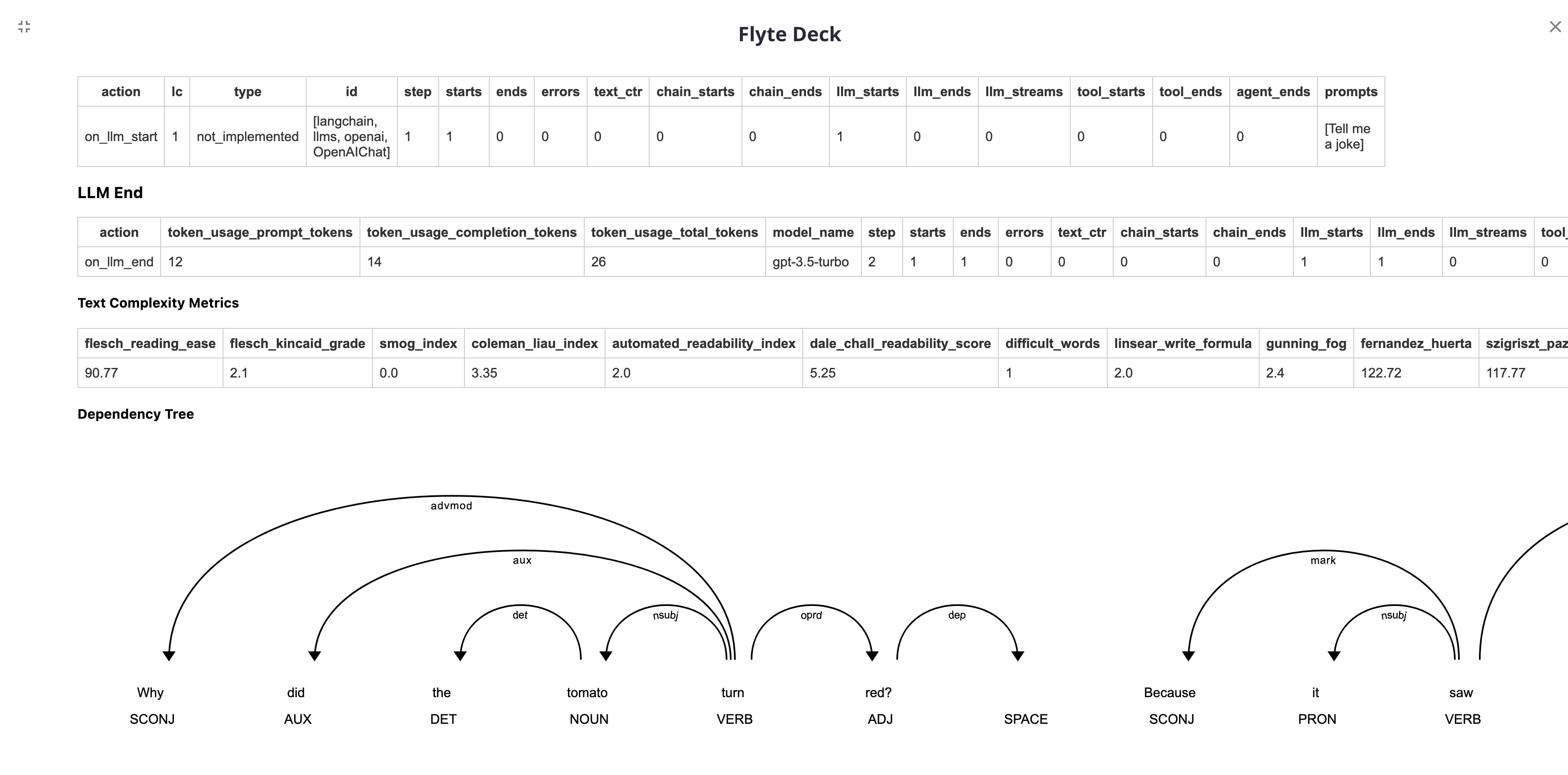
|
||||
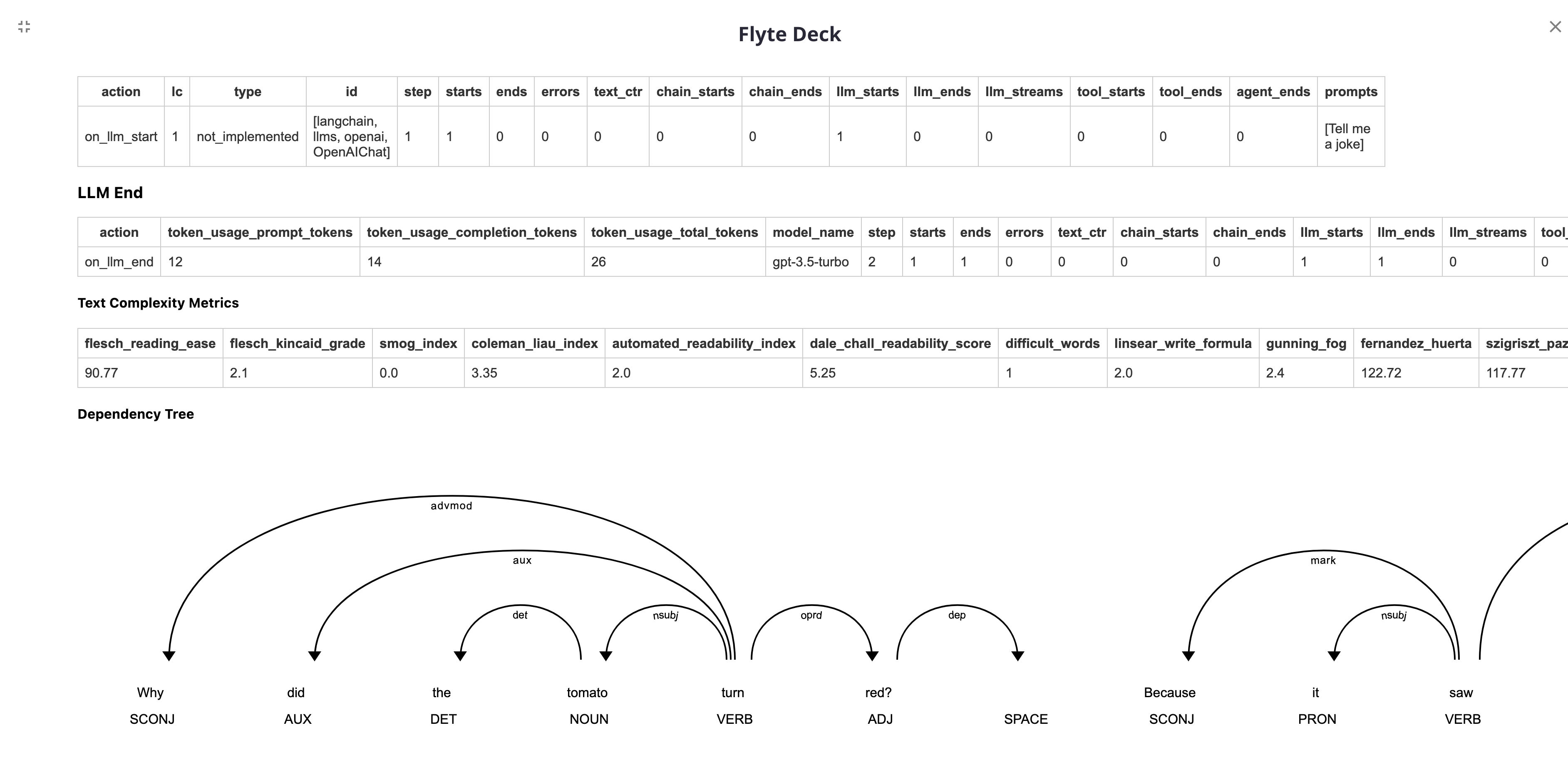
|
||||
|
||||
@@ -6,7 +6,7 @@ This page covers how to use the [Helicone](https://helicone.ai) ecosystem within
|
||||
|
||||
Helicone is an [open-source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
@@ -18,7 +18,7 @@ export OPENAI_API_BASE="https://oai.hconeai.com/v1"
|
||||
|
||||
Now head over to [helicone.ai](https://helicone.ai/onboarding?step=2) to create your account, and add your OpenAI API key within our dashboard to view your logs.
|
||||
|
||||

|
||||

|
||||
|
||||
## How to enable Helicone caching
|
||||
|
||||
|
||||
25
docs/docs/integrations/providers/lantern.mdx
Normal file
25
docs/docs/integrations/providers/lantern.mdx
Normal file
@@ -0,0 +1,25 @@
|
||||
# Lantern
|
||||
|
||||
This page covers how to use the [Lantern](https://github.com/lanterndata/lantern) within LangChain
|
||||
It is broken into two parts: setup, and then references to specific Lantern wrappers.
|
||||
|
||||
## Setup
|
||||
1. The first step is to create a database with the `lantern` extension installed.
|
||||
|
||||
Follow the steps at [Lantern Installation Guide](https://github.com/lanterndata/lantern#-quick-install) to install the database and the extension. The docker image is the easiest way to get started.
|
||||
|
||||
## Wrappers
|
||||
|
||||
### VectorStore
|
||||
|
||||
There exists a wrapper around Postgres vector databases, allowing you to use it as a vectorstore,
|
||||
whether for semantic search or example selection.
|
||||
|
||||
To import this vectorstore:
|
||||
```python
|
||||
from langchain_community.vectorstores import Lantern
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
For a more detailed walkthrough of the Lantern Wrapper, see [this notebook](/docs/integrations/vectorstores/lantern)
|
||||
@@ -6,7 +6,7 @@ This page covers how to use [Metal](https://getmetal.io) within LangChain.
|
||||
|
||||
Metal is a managed retrieval & memory platform built for production. Easily index your data into `Metal` and run semantic search and retrieval on it.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
|
||||
@@ -9,9 +9,7 @@
|
||||
We need to install several python packages.
|
||||
|
||||
```bash
|
||||
pip install openai
|
||||
pip install psycopg2-binary
|
||||
pip install tiktoken
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
266
docs/docs/integrations/providers/ragatouille.ipynb
Normal file
266
docs/docs/integrations/providers/ragatouille.ipynb
Normal file
@@ -0,0 +1,266 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d19521dc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# RAGatouille\n",
|
||||
"\n",
|
||||
"[RAGatouille](https://github.com/bclavie/RAGatouille) makes it as simple as can be to use ColBERT! [ColBERT](https://github.com/stanford-futuredata/ColBERT) is a fast and accurate retrieval model, enabling scalable BERT-based search over large text collections in tens of milliseconds.\n",
|
||||
"\n",
|
||||
"There are multiple ways that we can use RAGatouille.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `ragatouille` package.\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"pip install -U ragatouille\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "00de63d0",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Jan 10, 10:53:28] Loading segmented_maxsim_cpp extension (set COLBERT_LOAD_TORCH_EXTENSION_VERBOSE=True for more info)...\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/Users/harrisonchase/.pyenv/versions/3.10.1/envs/langchain/lib/python3.10/site-packages/torch/cuda/amp/grad_scaler.py:125: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.\n",
|
||||
" warnings.warn(\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from ragatouille import RAGPretrainedModel\n",
|
||||
"\n",
|
||||
"RAG = RAGPretrainedModel.from_pretrained(\"colbert-ir/colbertv2.0\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "59d069ef",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Retriever\n",
|
||||
"\n",
|
||||
"We can use RAGatouille as a retriever. For more information on this, see the [RAGatouille Retriever](/docs/integrations/retrievers/ragatouille)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6407e18e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Document Compressor\n",
|
||||
"\n",
|
||||
"We can also use RAGatouille off-the-shelf as a reranker. This will allow us to use ColBERT to rerank retrieved results from any generic retriever. The benefits of this are that we can do this on top of any existing index, so that we don't need to create a new idex. We can do this by using the [document compressor](/docs/modules/data_connections/retrievers/contextual_compression) abstraction in LangChain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "16d16022",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup Vanilla Retriever\n",
|
||||
"\n",
|
||||
"First, let's set up a vanilla retriever as an example."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "6ee6af64",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import requests\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain_community.vectorstores import FAISS\n",
|
||||
"from langchain_openai import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def get_wikipedia_page(title: str):\n",
|
||||
" \"\"\"\n",
|
||||
" Retrieve the full text content of a Wikipedia page.\n",
|
||||
"\n",
|
||||
" :param title: str - Title of the Wikipedia page.\n",
|
||||
" :return: str - Full text content of the page as raw string.\n",
|
||||
" \"\"\"\n",
|
||||
" # Wikipedia API endpoint\n",
|
||||
" URL = \"https://en.wikipedia.org/w/api.php\"\n",
|
||||
"\n",
|
||||
" # Parameters for the API request\n",
|
||||
" params = {\n",
|
||||
" \"action\": \"query\",\n",
|
||||
" \"format\": \"json\",\n",
|
||||
" \"titles\": title,\n",
|
||||
" \"prop\": \"extracts\",\n",
|
||||
" \"explaintext\": True,\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" # Custom User-Agent header to comply with Wikipedia's best practices\n",
|
||||
" headers = {\"User-Agent\": \"RAGatouille_tutorial/0.0.1 (ben@clavie.eu)\"}\n",
|
||||
"\n",
|
||||
" response = requests.get(URL, params=params, headers=headers)\n",
|
||||
" data = response.json()\n",
|
||||
"\n",
|
||||
" # Extracting page content\n",
|
||||
" page = next(iter(data[\"query\"][\"pages\"].values()))\n",
|
||||
" return page[\"extract\"] if \"extract\" in page else None\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"text = get_wikipedia_page(\"Hayao_Miyazaki\")\n",
|
||||
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)\n",
|
||||
"texts = text_splitter.create_documents([text])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "22b9dbf7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever(\n",
|
||||
" search_kwargs={\"k\": 10}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "50f54a7d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='collaborative projects. In April 1984, Miyazaki opened his own office in Suginami Ward, naming it Nibariki.')"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs = retriever.invoke(\"What animation studio did Miyazaki found\")\n",
|
||||
"docs[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ef72bb50",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can see that the result isn't super relevant to the question asked"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6c09c803",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using ColBERT as a reranker"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "9653b742",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/Users/harrisonchase/.pyenv/versions/3.10.1/envs/langchain/lib/python3.10/site-packages/torch/amp/autocast_mode.py:250: UserWarning: User provided device_type of 'cuda', but CUDA is not available. Disabling\n",
|
||||
" warnings.warn(\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.retrievers import ContextualCompressionRetriever\n",
|
||||
"\n",
|
||||
"compression_retriever = ContextualCompressionRetriever(\n",
|
||||
" base_compressor=RAG.as_langchain_document_compressor(), base_retriever=retriever\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"compressed_docs = compression_retriever.get_relevant_documents(\n",
|
||||
" \"What animation studio did Miyazaki found\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "35aaceee",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='In June 1985, Miyazaki, Takahata, Tokuma and Suzuki founded the animation production company Studio Ghibli, with funding from Tokuma Shoten. Studio Ghibli\\'s first film, Laputa: Castle in the Sky (1986), employed the same production crew of Nausicaä. Miyazaki\\'s designs for the film\\'s setting were inspired by Greek architecture and \"European urbanistic templates\". Some of the architecture in the film was also inspired by a Welsh mining town; Miyazaki witnessed the mining strike upon his first', metadata={'relevance_score': 26.5194149017334})"
|
||||
]
|
||||
},
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"compressed_docs[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6c2bbefc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This answer is much more relevant!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3746b734",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -5,13 +5,15 @@
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
You need to install `langchain-robocorp` python package, as well as the `robocorp-action-server` package to run the action server locally.
|
||||
You need to install `langchain-robocorp` python package:
|
||||
|
||||
```bash
|
||||
pip install langchain-robocorp robocorp-action-server
|
||||
pip install langchain-robocorp
|
||||
```
|
||||
|
||||
You will need a running instance of Action Server to communicate with from your agent application. You can bootstrap a new project using Action Server `new` command.
|
||||
You will need a running instance of Action Server to communicate with from your agent application. See the [Robocorp Quickstart](https://github.com/robocorp/robocorp#quickstart) on how to setup Action Server and create your Actions.
|
||||
|
||||
You can bootstrap a new project using Action Server `new` command.
|
||||
|
||||
```bash
|
||||
action-server new
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
|
||||
|
||||
```bash
|
||||
pip install tigrisdb openapi-schema-pydantic openai tiktoken
|
||||
pip install tigrisdb openapi-schema-pydantic
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
|
||||
|
||||
```bash
|
||||
pip install typesense openapi-schema-pydantic openai tiktoken
|
||||
pip install typesense openapi-schema-pydantic
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
@@ -18,6 +18,15 @@
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
|
||||
322
docs/docs/integrations/retrievers/self_query/astradb.ipynb
Normal file
322
docs/docs/integrations/retrievers/self_query/astradb.ipynb
Normal file
@@ -0,0 +1,322 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Astra DB\n",
|
||||
"\n",
|
||||
"DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on Cassandra and made conveniently available through an easy-to-use JSON API.\n",
|
||||
"\n",
|
||||
"In the walkthrough, we'll demo the `SelfQueryRetriever` with an `Astra DB` vector store."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Creating an Astra DB vector store\n",
|
||||
"First we'll want to create an Astra DB VectorStore and seed it with some data. We've created a small demo set of documents that contain summaries of movies.\n",
|
||||
"\n",
|
||||
"NOTE: The self-query retriever requires you to have `lark` installed (`pip install lark`). We also need the `astrapy` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet lark astrapy langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We want to use `OpenAIEmbeddings` so we have to get the OpenAI API Key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"from langchain_openai.embeddings import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass(\"OpenAI API Key:\")\n",
|
||||
"\n",
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"Create the Astra DB VectorStore:\n",
|
||||
"\n",
|
||||
"- the API Endpoint looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"- the Token looks like `AstraCS:6gBhNmsk135....`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import Document\n",
|
||||
"from langchain.vectorstores import AstraDB\n",
|
||||
"\n",
|
||||
"docs = [\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A bunch of scientists bring back dinosaurs and mayhem breaks loose\",\n",
|
||||
" metadata={\"year\": 1993, \"rating\": 7.7, \"genre\": \"science fiction\"},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Leo DiCaprio gets lost in a dream within a dream within a dream within a ...\",\n",
|
||||
" metadata={\"year\": 2010, \"director\": \"Christopher Nolan\", \"rating\": 8.2},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea\",\n",
|
||||
" metadata={\"year\": 2006, \"director\": \"Satoshi Kon\", \"rating\": 8.6},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A bunch of normal-sized women are supremely wholesome and some men pine after them\",\n",
|
||||
" metadata={\"year\": 2019, \"director\": \"Greta Gerwig\", \"rating\": 8.3},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Toys come alive and have a blast doing so\",\n",
|
||||
" metadata={\"year\": 1995, \"genre\": \"animated\"},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Three men walk into the Zone, three men walk out of the Zone\",\n",
|
||||
" metadata={\n",
|
||||
" \"year\": 1979,\n",
|
||||
" \"director\": \"Andrei Tarkovsky\",\n",
|
||||
" \"genre\": \"science fiction\",\n",
|
||||
" \"rating\": 9.9,\n",
|
||||
" },\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"vectorstore = AstraDB.from_documents(\n",
|
||||
" docs,\n",
|
||||
" embeddings,\n",
|
||||
" collection_name=\"astra_self_query_demo\",\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Creating our self-querying retriever\n",
|
||||
"Now we can instantiate our retriever. To do this we'll need to provide some information upfront about the metadata fields that our documents support and a short description of the document contents."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains.query_constructor.base import AttributeInfo\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"from langchain.retrievers.self_query.base import SelfQueryRetriever\n",
|
||||
"\n",
|
||||
"metadata_field_info = [\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"genre\",\n",
|
||||
" description=\"The genre of the movie\",\n",
|
||||
" type=\"string or list[string]\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"year\",\n",
|
||||
" description=\"The year the movie was released\",\n",
|
||||
" type=\"integer\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"director\",\n",
|
||||
" description=\"The name of the movie director\",\n",
|
||||
" type=\"string\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"rating\", description=\"A 1-10 rating for the movie\", type=\"float\"\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"document_content_description = \"Brief summary of a movie\"\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"\n",
|
||||
"retriever = SelfQueryRetriever.from_llm(\n",
|
||||
" llm, vectorstore, document_content_description, metadata_field_info, verbose=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Testing it out\n",
|
||||
"And now we can try actually using our retriever!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a relevant query\n",
|
||||
"retriever.get_relevant_documents(\"What are some movies about dinosaurs?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a filter\n",
|
||||
"retriever.get_relevant_documents(\"I want to watch a movie rated higher than 8.5\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a query and a filter\n",
|
||||
"retriever.get_relevant_documents(\"Has Greta Gerwig directed any movies about women\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a composite filter\n",
|
||||
"retriever.get_relevant_documents(\n",
|
||||
" \"What's a highly rated (above 8.5), science fiction movie ?\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a query and composite filter\n",
|
||||
"retriever.get_relevant_documents(\n",
|
||||
" \"What's a movie about toys after 1990 but before 2005, and is animated\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Filter k\n",
|
||||
"\n",
|
||||
"We can also use the self query retriever to specify `k`: the number of documents to fetch.\n",
|
||||
"\n",
|
||||
"We can do this by passing `enable_limit=True` to the constructor."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"retriever = SelfQueryRetriever.from_llm(\n",
|
||||
" llm,\n",
|
||||
" vectorstore,\n",
|
||||
" document_content_description,\n",
|
||||
" metadata_field_info,\n",
|
||||
" verbose=True,\n",
|
||||
" enable_limit=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a relevant query\n",
|
||||
"retriever.get_relevant_documents(\"What are two movies about dinosaurs?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"## Cleanup\n",
|
||||
"\n",
|
||||
"If you want to completely delete the collection from your Astra DB instance, run this.\n",
|
||||
"\n",
|
||||
"_(You will lose the data you stored in it.)_"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"vectorstore.delete_collection()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
240
docs/docs/integrations/stores/astradb.ipynb
Normal file
240
docs/docs/integrations/stores/astradb.ipynb
Normal file
@@ -0,0 +1,240 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: Astra DB\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Astra DB\n",
|
||||
"\n",
|
||||
"DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on Cassandra and made conveniently available through an easy-to-use JSON API.\n",
|
||||
"\n",
|
||||
"`AstraDBStore` and `AstraDBByteStore` need the `astrapy` package to be installed:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "plaintext"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet astrapy"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The Store takes the following parameters:\n",
|
||||
"\n",
|
||||
"* `api_endpoint`: Astra DB API endpoint. Looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"* `token`: Astra DB token. Looks like `AstraCS:6gBhNmsk135....`\n",
|
||||
"* `collection_name` : Astra DB collection name\n",
|
||||
"* `namespace`: (Optional) Astra DB namespace"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## AstraDBStore\n",
|
||||
"\n",
|
||||
"The `AstraDBStore` is an implementation of `BaseStore` that stores everything in your DataStax Astra DB instance.\n",
|
||||
"The store keys must be strings and will be mapped to the `_id` field of the Astra DB document.\n",
|
||||
"The store values can be any object that can be serialized by `json.dumps`.\n",
|
||||
"In the database, entries will have the form:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"_id\": \"<key>\",\n",
|
||||
" \"value\": <value>\n",
|
||||
"}\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.storage import AstraDBStore"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"store = AstraDBStore(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" collection_name=\"my_store\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"['v1', [0.1, 0.2, 0.3]]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"store.mset([(\"k1\", \"v1\"), (\"k2\", [0.1, 0.2, 0.3])])\n",
|
||||
"print(store.mget([\"k1\", \"k2\"]))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Usage with CacheBackedEmbeddings\n",
|
||||
"\n",
|
||||
"You may use the `AstraDBStore` in conjunction with a [`CacheBackedEmbeddings`](/docs/modules/data_connection/text_embedding/caching_embeddings) to cache the result of embeddings computations.\n",
|
||||
"Note that `AstraDBStore` stores the embeddings as a list of floats without converting them first to bytes so we don't use `fromByteStore` there."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"embeddings = CacheBackedEmbeddings(\n",
|
||||
" underlying_embeddings=OpenAIEmbeddings(), document_embedding_store=store\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## AstraDBByteStore\n",
|
||||
"\n",
|
||||
"The `AstraDBByteStore` is an implementation of `ByteStore` that stores everything in your DataStax Astra DB instance.\n",
|
||||
"The store keys must be strings and will be mapped to the `_id` field of the Astra DB document.\n",
|
||||
"The store `bytes` values are converted to base64 strings for storage into Astra DB.\n",
|
||||
"In the database, entries will have the form:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"_id\": \"<key>\",\n",
|
||||
" \"value\": \"bytes encoded in base 64\"\n",
|
||||
"}\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.storage import AstraDBByteStore"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"store = AstraDBByteStore(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" collection_name=\"my_store\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[b'v1', b'v2']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"store.mset([(\"k1\", b\"v1\"), (\"k2\", b\"v2\")])\n",
|
||||
"print(store.mget([\"k1\", \"k2\"]))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -50,20 +50,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": null,
|
||||
"id": "3f5dc9d7-65e3-4b5b-9086-3327d016cfe0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Please login and get your API key from https://clarifai.com/settings/security\n",
|
||||
"from getpass import getpass\n",
|
||||
|
||||
@@ -10,6 +10,51 @@
|
||||
"which converts text into a vector form represented by numerical values, and is used in text retrieval, information recommendation, knowledge mining and other scenarios."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Deprecated Warning**\n",
|
||||
"\n",
|
||||
"We recommend users using `langchain_community.embeddings.ErnieEmbeddings` \n",
|
||||
"to use `langchain_community.embeddings.QianfanEmbeddingsEndpoint` instead.\n",
|
||||
"\n",
|
||||
"documentation for `QianfanEmbeddingsEndpoint` is [here](./baidu_qianfan_endpoint).\n",
|
||||
"\n",
|
||||
"they are 2 why we recommend users to use `QianfanEmbeddingsEndpoint`:\n",
|
||||
"\n",
|
||||
"1. `QianfanEmbeddingsEndpoint` support more embedding model in the Qianfan platform.\n",
|
||||
"2. `ErnieEmbeddings` is lack of maintenance and deprecated."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Some tips for migration:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.embeddings import QianfanEmbeddingsEndpoint\n",
|
||||
"\n",
|
||||
"embeddings = QianfanEmbeddingsEndpoint(\n",
|
||||
" qianfan_ak=\"your qianfan ak\",\n",
|
||||
" qianfan_sk=\"your qianfan sk\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -106,7 +106,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Enter your HF Inference API Key:\n",
|
||||
@@ -148,6 +148,75 @@
|
||||
"query_result = embeddings.embed_query(text)\n",
|
||||
"query_result[:3]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "19ef2d31",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Hugging Face Hub\n",
|
||||
"We can also generate embeddings locally via the Hugging Face Hub package, which requires us to install ``huggingface_hub ``"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "39e85945",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install huggingface_hub"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c78a2779",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.embeddings import HuggingFaceHubEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "116f3ce7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"embeddings = HuggingFaceHubEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d6f97ee9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"This is a test document.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fb6adc67",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result = embeddings.embed_query(text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1f42c311",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query_result[:3]"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -17,7 +17,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -30,13 +30,18 @@
|
||||
"source": [
|
||||
"## Assign Environmental Variables\n",
|
||||
"\n",
|
||||
"The toolkit will read the AMADEUS_CLIENT_ID and AMADEUS_CLIENT_SECRET environmental variables to authenticate the user so you need to set them here. You will also need to set your OPENAI_API_KEY to use the agent later."
|
||||
"The toolkit will read the AMADEUS_CLIENT_ID and AMADEUS_CLIENT_SECRET environmental variables to authenticate the user, so you need to set them here. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:45:56.531388579Z",
|
||||
"start_time": "2024-01-13T17:45:56.523533018Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Set environmental variables here\n",
|
||||
@@ -44,7 +49,6 @@
|
||||
"\n",
|
||||
"os.environ[\"AMADEUS_CLIENT_ID\"] = \"CLIENT_ID\"\n",
|
||||
"os.environ[\"AMADEUS_CLIENT_SECRET\"] = \"CLIENT_SECRET\"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"API_KEY\"\n",
|
||||
"# os.environ[\"AMADEUS_HOSTNAME\"] = \"production\" or \"test\""
|
||||
]
|
||||
},
|
||||
@@ -57,11 +61,39 @@
|
||||
"To start, you need to create the toolkit, so you can access its tools later."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"By default, `AmadeusToolkit` uses `ChatOpenAI` to identify airports closest to a given location. To use it, just set `OPENAI_API_KEY`.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
"collapsed": false,
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:45:56.557041160Z",
|
||||
"start_time": "2024-01-13T17:45:56.530682481Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"YOUR_OPENAI_KEY\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": [],
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:45:58.431168124Z",
|
||||
"start_time": "2024-01-13T17:45:56.536269739Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -71,6 +103,35 @@
|
||||
"tools = toolkit.get_tools()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"Alternatively, you can use any LLM supported by langchain, e.g. `HuggingFaceHub`. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.llms import HuggingFaceHub\n",
|
||||
"\n",
|
||||
"os.environ[\"HUGGINGFACEHUB_API_TOKEN\"] = \"YOUR_HF_API_TOKEN\"\n",
|
||||
"\n",
|
||||
"llm = HuggingFaceHub(\n",
|
||||
" repo_id=\"tiiuae/falcon-7b-instruct\",\n",
|
||||
" model_kwargs={\"temperature\": 0.5, \"max_length\": 64},\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"toolkit_hf = AmadeusToolkit(llm=llm)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
@@ -78,91 +139,76 @@
|
||||
"## Use Amadeus Toolkit within an Agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import AgentType, initialize_agent\n",
|
||||
"from langchain_openai import OpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools=tools,\n",
|
||||
" llm=llm,\n",
|
||||
" verbose=False,\n",
|
||||
" agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'The closest airport to Cali, Colombia is Alfonso Bonilla Aragón International Airport (CLO).'"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
"tags": [],
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:46:00.148691365Z",
|
||||
"start_time": "2024-01-13T17:45:59.317173243Z"
|
||||
}
|
||||
],
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent.run(\"What is the name of the airport in Cali, Colombia?\")"
|
||||
"from langchain import hub\n",
|
||||
"from langchain.agents import AgentExecutor, create_react_agent\n",
|
||||
"from langchain_openai import ChatOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'The cheapest flight on August 23, 2023 leaving Dallas, Texas before noon to Lincoln, Nebraska has a departure time of 16:42 and a total price of 276.08 EURO.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
"tags": [],
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:46:01.270044101Z",
|
||||
"start_time": "2024-01-13T17:46:00.148988945Z"
|
||||
}
|
||||
],
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent.run(\n",
|
||||
" \"What is the departure time of the cheapest flight on August 23, 2023 leaving Dallas, Texas before noon to Lincoln, Nebraska?\"\n",
|
||||
"llm = ChatOpenAI(temperature=0)\n",
|
||||
"\n",
|
||||
"prompt = hub.pull(\"hwchase17/react\")\n",
|
||||
"agent = create_react_agent(llm, tools, prompt)\n",
|
||||
"\n",
|
||||
"agent_executor = AgentExecutor(\n",
|
||||
" agent=agent,\n",
|
||||
" tools=tools,\n",
|
||||
" verbose=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-13T17:46:06.176227412Z",
|
||||
"start_time": "2024-01-13T17:46:01.272468682Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001B[1m> Entering new AgentExecutor chain...\u001B[0m\n",
|
||||
"\u001B[32;1m\u001B[1;3mI should use the closest_airport tool to find the airport in Cali, Colombia.\n",
|
||||
"Action: closest_airport\n",
|
||||
"Action Input: location= \"Cali, Colombia\"\u001B[0m\u001B[36;1m\u001B[1;3mcontent='{\\n \"iataCode\": \"CLO\"\\n}'\u001B[0m\u001B[32;1m\u001B[1;3mThe airport in Cali, Colombia is called CLO.\n",
|
||||
"Final Answer: CLO\u001B[0m\n",
|
||||
"\n",
|
||||
"\u001B[1m> Finished chain.\u001B[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'The earliest flight on August 23, 2023 leaving Dallas, Texas to Lincoln, Nebraska lands in Lincoln, Nebraska at 16:07.'"
|
||||
]
|
||||
"text/plain": "{'input': 'What is the name of the airport in Cali, Colombia?',\n 'output': 'CLO'}"
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
@@ -170,52 +216,67 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent.run(\n",
|
||||
" \"At what time does earliest flight on August 23, 2023 leaving Dallas, Texas to Lincoln, Nebraska land in Nebraska?\"\n",
|
||||
"agent_executor.invoke({\"input\": \"What is the name of the airport in Cali, Colombia?\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor.invoke(\n",
|
||||
" {\n",
|
||||
" \"input\": \"What is the departure time of the cheapest flight on August 23, 2023 leaving Dallas, Texas before noon to Lincoln, Nebraska?\"\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'The cheapest flight between Portland, Oregon to Dallas, TX on October 3, 2023 is a Spirit Airlines flight with a total price of 84.02 EURO and a total travel time of 8 hours and 43 minutes.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent.run(\n",
|
||||
" \"What is the full travel time for the cheapest flight between Portland, Oregon to Dallas, TX on October 3, 2023?\"\n",
|
||||
"agent_executor.invoke(\n",
|
||||
" {\n",
|
||||
" \"input\": \"At what time does earliest flight on August 23, 2023 leaving Dallas, Texas to Lincoln, Nebraska land in Nebraska?\"\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'Dear Paul,\\n\\nI am writing to request that you book the earliest flight from DFW to DCA on Aug 28, 2023. The flight details are as follows:\\n\\nFlight 1: DFW to ATL, departing at 7:15 AM, arriving at 10:25 AM, flight number 983, carrier Delta Air Lines\\nFlight 2: ATL to DCA, departing at 12:15 PM, arriving at 2:02 PM, flight number 759, carrier Delta Air Lines\\n\\nThank you for your help.\\n\\nSincerely,\\nSantiago'"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent.run(\n",
|
||||
" \"Please draft a concise email from Santiago to Paul, Santiago's travel agent, asking him to book the earliest flight from DFW to DCA on Aug 28, 2023. Include all flight details in the email.\"\n",
|
||||
"agent_executor.invoke(\n",
|
||||
" {\n",
|
||||
" \"input\": \"What is the full travel time for the cheapest flight between Portland, Oregon to Dallas, TX on October 3, 2023?\"\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_executor.invoke(\n",
|
||||
" {\n",
|
||||
" \"input\": \"Please draft a concise email from Santiago to Paul, Santiago's travel agent, asking him to book the earliest flight from DFW to DCA on Aug 28, 2023. Include all flight details in the email.\"\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
|
||||
@@ -7,9 +7,13 @@
|
||||
"source": [
|
||||
"# Robocorp\n",
|
||||
"\n",
|
||||
"This notebook covers how to get started with [Robocorp Action Server](https://github.com/robocorp/robo/tree/master/action_server/docs) action toolkit and LangChain.\n",
|
||||
"This notebook covers how to get started with [Robocorp Action Server](https://github.com/robocorp/robocorp) action toolkit and LangChain.\n",
|
||||
"\n",
|
||||
"## Installation"
|
||||
"## Installation\n",
|
||||
"\n",
|
||||
"First, see the [Robocorp Quickstart](https://github.com/robocorp/robocorp#quickstart) on how to setup Action Server and create your Actions.\n",
|
||||
"\n",
|
||||
"In your LangChain application, install the `langchain-robocorp` package: "
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -19,24 +23,8 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Install package and Action Server\n",
|
||||
"%pip install --upgrade --quiet langchain-robocorp robocorp-action-server"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8e2ca5c5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Action Server setup\n",
|
||||
"\n",
|
||||
"You will need a running instance of Action Server to communicate with from your agent application. You can bootstrap a new project using Action Server `new` command.\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"!action-server new\n",
|
||||
"cd ./your-project-name\n",
|
||||
"action-server start\n",
|
||||
"```\n"
|
||||
"# Install package\n",
|
||||
"%pip install --upgrade --quiet langchain-robocorp"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
112
docs/docs/integrations/tools/polygon.ipynb
Normal file
112
docs/docs/integrations/tools/polygon.ipynb
Normal file
@@ -0,0 +1,112 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "245a954a",
|
||||
"metadata": {
|
||||
"id": "245a954a"
|
||||
},
|
||||
"source": [
|
||||
"# Polygon Stock Market API\n",
|
||||
"\n",
|
||||
">[Polygon](https://polygon.io/) The Polygon.io Stocks API provides REST endpoints that let you query the latest market data from all US stock exchanges.\n",
|
||||
"\n",
|
||||
"Use the ``PolygonAPIWrapper`` to get stock market data like the latest quote for a ticker."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "34bb5968",
|
||||
"metadata": {
|
||||
"id": "34bb5968",
|
||||
"is_executing": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"POLYGON_API_KEY\"] = getpass.getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "ac4910f8",
|
||||
"metadata": {
|
||||
"id": "ac4910f8",
|
||||
"is_executing": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.utilities.polygon import PolygonAPIWrapper"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "84b8f773",
|
||||
"metadata": {
|
||||
"id": "84b8f773"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"polygon = PolygonAPIWrapper()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "068991a6",
|
||||
"metadata": {
|
||||
"id": "068991a6",
|
||||
"outputId": "c5cdc6ec-03cf-4084-cc6f-6ae792d91d39"
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'results': {'P': 185.86, 'S': 1, 'T': 'AAPL', 'X': 11, 'i': [604], 'p': 185.81, 'q': 106551669, 's': 2, 't': 1705098436014023700, 'x': 12, 'y': 1705098436014009300, 'z': 3}}"
|
||||
]
|
||||
},
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"polygon.run(\"get_last_quote\", \"AAPL\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"provenance": []
|
||||
},
|
||||
"kernelspec": {
|
||||
"name": "venv",
|
||||
"language": "python",
|
||||
"display_name": "venv"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "53f3bc57609c7a84333bb558594977aa5b4026b1d6070b93987956689e367341"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -113,10 +113,63 @@
|
||||
"requests.get(\"https://www.google.com\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4b0bf1d0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"If you need the output to be decoded from JSON, you can use the ``JsonRequestsWrapper``."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "3f27ee3d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"Type - <class 'dict'>\n",
|
||||
"\n",
|
||||
"Content: \n",
|
||||
"```\n",
|
||||
"{'count': 5707, 'name': 'jackson', 'age': 38}\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_community.utilities.requests import JsonRequestsWrapper\n",
|
||||
"\n",
|
||||
"requests = JsonRequestsWrapper()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"rval = requests.get(\"https://api.agify.io/?name=jackson\")\n",
|
||||
"\n",
|
||||
"print(\n",
|
||||
" f\"\"\"\n",
|
||||
"\n",
|
||||
"Type - {type(rval)}\n",
|
||||
"\n",
|
||||
"Content: \n",
|
||||
"```\n",
|
||||
"{rval}\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\"\"\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3f27ee3d",
|
||||
"id": "52a1aa15",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
@@ -138,7 +191,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -324,6 +324,24 @@
|
||||
"docs = store.similarity_search_by_vector(query_vector, filter={\"len\": 6})\n",
|
||||
"print(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Explore job satistics with BigQuery Job Id"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"job_id = \"\" # @param {type:\"string\"}\n",
|
||||
"# Debug and explore the job statistics with a BigQuery Job id.\n",
|
||||
"store.explore_job_stats(job_id)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -75,7 +75,7 @@
|
||||
" )\n",
|
||||
"```\n",
|
||||
"### Authentication\n",
|
||||
"For production, we recommend you run with security enabled. To connect with login credentials, you can use the parameters `api_key` or `es_user` and `es_password`.\n",
|
||||
"For production, we recommend you run with security enabled. To connect with login credentials, you can use the parameters `es_api_key` or `es_user` and `es_password`.\n",
|
||||
"\n",
|
||||
"Example:\n",
|
||||
"```python\n",
|
||||
@@ -720,7 +720,7 @@
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Customise the Query\n",
|
||||
"With `custom_query` parameter at search, you are able to adjust the query that is used to retrieve documents from Elasticsearch. This is useful if you want to want to use a more complex query, to support linear boosting of fields."
|
||||
"With `custom_query` parameter at search, you are able to adjust the query that is used to retrieve documents from Elasticsearch. This is useful if you want to use a more complex query, to support linear boosting of fields."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
659
docs/docs/integrations/vectorstores/lantern.ipynb
Normal file
659
docs/docs/integrations/vectorstores/lantern.ipynb
Normal file
@@ -0,0 +1,659 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Lantern\n",
|
||||
"\n",
|
||||
">[Lantern](https://github.com/lanterndata/lantern) is an open-source vector similarity search for `Postgres`\n",
|
||||
"\n",
|
||||
"It supports:\n",
|
||||
"- Exact and approximate nearest neighbor search\n",
|
||||
"- L2 squared distance, hamming distance, and cosine distance\n",
|
||||
"\n",
|
||||
"This notebook shows how to use the Postgres vector database (`Lantern`)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"See the [installation instruction](https://github.com/lanterndata/lantern#-quick-install)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We want to use `OpenAIEmbeddings` so we have to get the OpenAI API Key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Pip install necessary package\n",
|
||||
"!pip install openai\n",
|
||||
"!pip install psycopg2-binary\n",
|
||||
"!pip install tiktoken"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:02:16.802456Z",
|
||||
"start_time": "2023-09-09T08:02:07.065604Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"OpenAI API Key: ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OpenAI API Key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:02:19.742896Z",
|
||||
"start_time": "2023-09-09T08:02:19.732527Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"False"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"## Loading Environment Variables\n",
|
||||
"from typing import List, Tuple\n",
|
||||
"\n",
|
||||
"from dotenv import load_dotenv\n",
|
||||
"\n",
|
||||
"load_dotenv()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:02:23.144824Z",
|
||||
"start_time": "2023-09-09T08:02:22.047801Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.text_splitter import CharacterTextSplitter\n",
|
||||
"from langchain_community.document_loaders import TextLoader\n",
|
||||
"from langchain_community.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain_community.vectorstores import Lantern\n",
|
||||
"from langchain_core.documents import Document"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:02:25.452472Z",
|
||||
"start_time": "2023-09-09T08:02:25.441563Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = TextLoader(\"../../modules/state_of_the_union.txt\")\n",
|
||||
"documents = loader.load()\n",
|
||||
"text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)\n",
|
||||
"docs = text_splitter.split_documents(documents)\n",
|
||||
"\n",
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:02:28.174088Z",
|
||||
"start_time": "2023-09-09T08:02:28.162698Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"DB Connection String: ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Lantern needs the connection string to the database.\n",
|
||||
"# Example postgresql://postgres:postgres@localhost:5432/postgres\n",
|
||||
"CONNECTION_STRING = getpass.getpass(\"DB Connection String:\")\n",
|
||||
"\n",
|
||||
"# # Alternatively, you can create it from environment variables.\n",
|
||||
"# import os\n",
|
||||
"\n",
|
||||
"# CONNECTION_STRING = Lantern.connection_string_from_db_params(\n",
|
||||
"# driver=os.environ.get(\"LANTERN_DRIVER\", \"psycopg2\"),\n",
|
||||
"# host=os.environ.get(\"LANTERN_HOST\", \"localhost\"),\n",
|
||||
"# port=int(os.environ.get(\"LANTERN_PORT\", \"5432\")),\n",
|
||||
"# database=os.environ.get(\"LANTERN_DATABASE\", \"postgres\"),\n",
|
||||
"# user=os.environ.get(\"LANTERN_USER\", \"postgres\"),\n",
|
||||
"# password=os.environ.get(\"LANTERN_PASSWORD\", \"postgres\"),\n",
|
||||
"# )\n",
|
||||
"\n",
|
||||
"# or you can pass it via `LANTERN_CONNECTION_STRING` env variable"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## Similarity Search with Cosine Distance (Default)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:04:16.696625Z",
|
||||
"start_time": "2023-09-09T08:02:31.817790Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# The Lantern Module will try to create a table with the name of the collection.\n",
|
||||
"# So, make sure that the collection name is unique and the user has the permission to create a table.\n",
|
||||
"\n",
|
||||
"COLLECTION_NAME = \"state_of_the_union_test\"\n",
|
||||
"\n",
|
||||
"db = Lantern.from_documents(\n",
|
||||
" embedding=embeddings,\n",
|
||||
" documents=docs,\n",
|
||||
" collection_name=COLLECTION_NAME,\n",
|
||||
" connection_string=CONNECTION_STRING,\n",
|
||||
" pre_delete_collection=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:05:11.104135Z",
|
||||
"start_time": "2023-09-09T08:05:10.548998Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
"docs_with_score = db.similarity_search_with_score(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:05:13.532334Z",
|
||||
"start_time": "2023-09-09T08:05:13.523191Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.18440479\n",
|
||||
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
|
||||
"\n",
|
||||
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
|
||||
"\n",
|
||||
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
|
||||
"\n",
|
||||
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.21727282\n",
|
||||
"A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n",
|
||||
"\n",
|
||||
"And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. \n",
|
||||
"\n",
|
||||
"We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. \n",
|
||||
"\n",
|
||||
"We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. \n",
|
||||
"\n",
|
||||
"We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. \n",
|
||||
"\n",
|
||||
"We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.22621095\n",
|
||||
"And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong. \n",
|
||||
"\n",
|
||||
"As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. \n",
|
||||
"\n",
|
||||
"While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice. \n",
|
||||
"\n",
|
||||
"And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. \n",
|
||||
"\n",
|
||||
"So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. \n",
|
||||
"\n",
|
||||
"First, beat the opioid epidemic.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.22654456\n",
|
||||
"Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers. \n",
|
||||
"\n",
|
||||
"And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up. \n",
|
||||
"\n",
|
||||
"That ends on my watch. \n",
|
||||
"\n",
|
||||
"Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect. \n",
|
||||
"\n",
|
||||
"We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees. \n",
|
||||
"\n",
|
||||
"Let’s pass the Paycheck Fairness Act and paid leave. \n",
|
||||
"\n",
|
||||
"Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty. \n",
|
||||
"\n",
|
||||
"Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.\n",
|
||||
"--------------------------------------------------------------------------------\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for doc, score in docs_with_score:\n",
|
||||
" print(\"-\" * 80)\n",
|
||||
" print(\"Score: \", score)\n",
|
||||
" print(doc.page_content)\n",
|
||||
" print(\"-\" * 80)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## Maximal Marginal Relevance Search (MMR)\n",
|
||||
"Maximal marginal relevance optimizes for similarity to query AND diversity among selected documents."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:05:23.276819Z",
|
||||
"start_time": "2023-09-09T08:05:21.972256Z"
|
||||
},
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs_with_score = db.max_marginal_relevance_search_with_score(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-09-09T08:05:27.478580Z",
|
||||
"start_time": "2023-09-09T08:05:27.470138Z"
|
||||
},
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.18440479\n",
|
||||
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
|
||||
"\n",
|
||||
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
|
||||
"\n",
|
||||
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
|
||||
"\n",
|
||||
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.23515457\n",
|
||||
"We can’t change how divided we’ve been. But we can change how we move forward—on COVID-19 and other issues we must face together. \n",
|
||||
"\n",
|
||||
"I recently visited the New York City Police Department days after the funerals of Officer Wilbert Mora and his partner, Officer Jason Rivera. \n",
|
||||
"\n",
|
||||
"They were responding to a 9-1-1 call when a man shot and killed them with a stolen gun. \n",
|
||||
"\n",
|
||||
"Officer Mora was 27 years old. \n",
|
||||
"\n",
|
||||
"Officer Rivera was 22. \n",
|
||||
"\n",
|
||||
"Both Dominican Americans who’d grown up on the same streets they later chose to patrol as police officers. \n",
|
||||
"\n",
|
||||
"I spoke with their families and told them that we are forever in debt for their sacrifice, and we will carry on their mission to restore the trust and safety every community deserves. \n",
|
||||
"\n",
|
||||
"I’ve worked on these issues a long time. \n",
|
||||
"\n",
|
||||
"I know what works: Investing in crime prevention and community police officers who’ll walk the beat, who’ll know the neighborhood, and who can restore trust and safety.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.24478757\n",
|
||||
"One was stationed at bases and breathing in toxic smoke from “burn pits” that incinerated wastes of war—medical and hazard material, jet fuel, and more. \n",
|
||||
"\n",
|
||||
"When they came home, many of the world’s fittest and best trained warriors were never the same. \n",
|
||||
"\n",
|
||||
"Headaches. Numbness. Dizziness. \n",
|
||||
"\n",
|
||||
"A cancer that would put them in a flag-draped coffin. \n",
|
||||
"\n",
|
||||
"I know. \n",
|
||||
"\n",
|
||||
"One of those soldiers was my son Major Beau Biden. \n",
|
||||
"\n",
|
||||
"We don’t know for sure if a burn pit was the cause of his brain cancer, or the diseases of so many of our troops. \n",
|
||||
"\n",
|
||||
"But I’m committed to finding out everything we can. \n",
|
||||
"\n",
|
||||
"Committed to military families like Danielle Robinson from Ohio. \n",
|
||||
"\n",
|
||||
"The widow of Sergeant First Class Heath Robinson. \n",
|
||||
"\n",
|
||||
"He was born a soldier. Army National Guard. Combat medic in Kosovo and Iraq. \n",
|
||||
"\n",
|
||||
"Stationed near Baghdad, just yards from burn pits the size of football fields. \n",
|
||||
"\n",
|
||||
"Heath’s widow Danielle is here with us tonight. They loved going to Ohio State football games. He loved building Legos with their daughter.\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"--------------------------------------------------------------------------------\n",
|
||||
"Score: 0.25137997\n",
|
||||
"And I’m taking robust action to make sure the pain of our sanctions is targeted at Russia’s economy. And I will use every tool at our disposal to protect American businesses and consumers. \n",
|
||||
"\n",
|
||||
"Tonight, I can announce that the United States has worked with 30 other countries to release 60 Million barrels of oil from reserves around the world. \n",
|
||||
"\n",
|
||||
"America will lead that effort, releasing 30 Million barrels from our own Strategic Petroleum Reserve. And we stand ready to do more if necessary, unified with our allies. \n",
|
||||
"\n",
|
||||
"These steps will help blunt gas prices here at home. And I know the news about what’s happening can seem alarming. \n",
|
||||
"\n",
|
||||
"But I want you to know that we are going to be okay. \n",
|
||||
"\n",
|
||||
"When the history of this era is written Putin’s war on Ukraine will have left Russia weaker and the rest of the world stronger. \n",
|
||||
"\n",
|
||||
"While it shouldn’t have taken something so terrible for people around the world to see what’s at stake now everyone sees it clearly.\n",
|
||||
"--------------------------------------------------------------------------------\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for doc, score in docs_with_score:\n",
|
||||
" print(\"-\" * 80)\n",
|
||||
" print(\"Score: \", score)\n",
|
||||
" print(doc.page_content)\n",
|
||||
" print(\"-\" * 80)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Working with vectorstore\n",
|
||||
"\n",
|
||||
"Above, we created a vectorstore from scratch. However, often times we want to work with an existing vectorstore.\n",
|
||||
"In order to do that, we can initialize it directly."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"store = Lantern(\n",
|
||||
" collection_name=COLLECTION_NAME,\n",
|
||||
" connection_string=CONNECTION_STRING,\n",
|
||||
" embedding_function=embeddings,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Add documents\n",
|
||||
"We can add documents to the existing vectorstore."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['f8164598-aa28-11ee-a037-acde48001122']"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"store.add_documents([Document(page_content=\"foo\")])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs_with_score = db.similarity_search_with_score(\"foo\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(Document(page_content='foo'), -1.1920929e-07)"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs_with_score[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(Document(page_content='And let’s pass the PRO Act when a majority of workers want to form a union—they shouldn’t be stopped. \\n\\nWhen we invest in our workers, when we build the economy from the bottom up and the middle out together, we can do something we haven’t done in a long time: build a better America. \\n\\nFor more than two years, COVID-19 has impacted every decision in our lives and the life of the nation. \\n\\nAnd I know you’re tired, frustrated, and exhausted. \\n\\nBut I also know this. \\n\\nBecause of the progress we’ve made, because of your resilience and the tools we have, tonight I can say \\nwe are moving forward safely, back to more normal routines. \\n\\nWe’ve reached a new moment in the fight against COVID-19, with severe cases down to a level not seen since last July. \\n\\nJust a few days ago, the Centers for Disease Control and Prevention—the CDC—issued new mask guidelines. \\n\\nUnder these new guidelines, most Americans in most of the country can now be mask free.', metadata={'source': '../../modules/state_of_the_union.txt'}),\n",
|
||||
" 0.24038416)"
|
||||
]
|
||||
},
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs_with_score[1]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Overriding a vectorstore\n",
|
||||
"\n",
|
||||
"If you have an existing collection, you override it by doing `from_documents` and setting `pre_delete_collection` = True \n",
|
||||
"This will delete the collection before re-populating it"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"db = Lantern.from_documents(\n",
|
||||
" documents=docs,\n",
|
||||
" embedding=embeddings,\n",
|
||||
" collection_name=COLLECTION_NAME,\n",
|
||||
" connection_string=CONNECTION_STRING,\n",
|
||||
" pre_delete_collection=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs_with_score = db.similarity_search_with_score(\"foo\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(Document(page_content='And let’s pass the PRO Act when a majority of workers want to form a union—they shouldn’t be stopped. \\n\\nWhen we invest in our workers, when we build the economy from the bottom up and the middle out together, we can do something we haven’t done in a long time: build a better America. \\n\\nFor more than two years, COVID-19 has impacted every decision in our lives and the life of the nation. \\n\\nAnd I know you’re tired, frustrated, and exhausted. \\n\\nBut I also know this. \\n\\nBecause of the progress we’ve made, because of your resilience and the tools we have, tonight I can say \\nwe are moving forward safely, back to more normal routines. \\n\\nWe’ve reached a new moment in the fight against COVID-19, with severe cases down to a level not seen since last July. \\n\\nJust a few days ago, the Centers for Disease Control and Prevention—the CDC—issued new mask guidelines. \\n\\nUnder these new guidelines, most Americans in most of the country can now be mask free.', metadata={'source': '../../modules/state_of_the_union.txt'}),\n",
|
||||
" 0.2403456)"
|
||||
]
|
||||
},
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs_with_score[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Using a VectorStore as a Retriever"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"retriever = store.as_retriever()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"tags=['Lantern', 'OpenAIEmbeddings'] vectorstore=<langchain_community.vectorstores.lantern.Lantern object at 0x11d02f9d0>\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(retriever)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
@@ -6,7 +6,7 @@
|
||||
"source": [
|
||||
"# PGVecto.rs\n",
|
||||
"\n",
|
||||
"This notebook shows how to use functionality related to the Postgres vector database ([pgvecto.rs](https://github.com/tensorchord/pgvecto.rs)). You need to install SQLAlchemy >= 2 manually."
|
||||
"This notebook shows how to use functionality related to the Postgres vector database ([pgvecto.rs](https://github.com/tensorchord/pgvecto.rs))."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -15,10 +15,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"## Loading Environment Variables\n",
|
||||
"from dotenv import load_dotenv\n",
|
||||
"\n",
|
||||
"load_dotenv()"
|
||||
"%pip install \"pgvecto_rs[sdk]\""
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -32,8 +29,8 @@
|
||||
"from langchain.docstore.document import Document\n",
|
||||
"from langchain.text_splitter import CharacterTextSplitter\n",
|
||||
"from langchain_community.document_loaders import TextLoader\n",
|
||||
"from langchain_community.vectorstores.pgvecto_rs import PGVecto_rs\n",
|
||||
"from langchain_openai import OpenAIEmbeddings"
|
||||
"from langchain_community.embeddings.fake import FakeEmbeddings\n",
|
||||
"from langchain_community.vectorstores.pgvecto_rs import PGVecto_rs"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -42,12 +39,12 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = TextLoader(\"../../../state_of_the_union.txt\")\n",
|
||||
"loader = TextLoader(\"../../modules/state_of_the_union.txt\")\n",
|
||||
"documents = loader.load()\n",
|
||||
"text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)\n",
|
||||
"docs = text_splitter.split_documents(documents)\n",
|
||||
"\n",
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
"embeddings = FakeEmbeddings(size=3)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -176,7 +173,17 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
"docs: List[Document] = db1.similarity_search(query, k=4)"
|
||||
"docs: List[Document] = db1.similarity_search(query, k=4)\n",
|
||||
"for doc in docs:\n",
|
||||
" print(doc.page_content)\n",
|
||||
" print(\"======================\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Similarity Search with Filter"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -185,6 +192,36 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from pgvecto_rs.sdk.filters import meta_contains\n",
|
||||
"\n",
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
"docs: List[Document] = db1.similarity_search(\n",
|
||||
" query, k=4, filter=meta_contains({\"source\": \"../../modules/state_of_the_union.txt\"})\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"for doc in docs:\n",
|
||||
" print(doc.page_content)\n",
|
||||
" print(\"======================\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Or:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
"docs: List[Document] = db1.similarity_search(\n",
|
||||
" query, k=4, filter={\"source\": \"../../modules/state_of_the_union.txt\"}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"for doc in docs:\n",
|
||||
" print(doc.page_content)\n",
|
||||
" print(\"======================\")"
|
||||
@@ -207,7 +244,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
"version": "3.11.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet surrealdb langchain langchain-community"
|
||||
"# %pip install --upgrade --quiet surrealdb langchain langchain-community"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -54,6 +54,19 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "1c2d942d-5d90-4f9f-af96-dff976e4510f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# add this import for running in jupyter notebook\n",
|
||||
"import nest_asyncio\n",
|
||||
"\n",
|
||||
"nest_asyncio.apply()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "e49be085-ddf1-4028-8c0c-97836ce4a873",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -68,7 +81,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": 3,
|
||||
"id": "38222aee-adc5-44c2-913c-97977b394cf5",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -92,28 +105,28 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 4,
|
||||
"id": "ff9d0304-1e11-4db2-9454-1350db7907e6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['documents:th7j29cjsx6495wluo7e',\n",
|
||||
" 'documents:qkqhhjnl7ahbhr07euky',\n",
|
||||
" 'documents:8kd6xw8o7y0l171iqry0',\n",
|
||||
" 'documents:33ejf42dlkmavol9si74',\n",
|
||||
" 'documents:f7y4dbs7eitqz58xt1p5']"
|
||||
"['documents:38hz49bv1p58f5lrvrdc',\n",
|
||||
" 'documents:niayw63vzwm2vcbh6w2s',\n",
|
||||
" 'documents:it1fa3ktplbuye43n0ch',\n",
|
||||
" 'documents:il8f7vgbbp9tywmsn98c',\n",
|
||||
" 'documents:vza4c6cqje0avqd58gal']"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"db = SurrealDBStore(\n",
|
||||
" dburl=\"http://localhost:8000/rpc\", # url for the hosted SurrealDB database\n",
|
||||
" dburl=\"ws://localhost:8000/rpc\", # url for the hosted SurrealDB database\n",
|
||||
" embedding_function=embeddings,\n",
|
||||
" db_user=\"root\", # SurrealDB credentials if needed: db username\n",
|
||||
" db_pass=\"root\", # SurrealDB credentials if needed: db password\n",
|
||||
@@ -145,7 +158,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 5,
|
||||
"id": "73d66563-4e1f-4edf-9e95-5fc9adcfa2cb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -153,7 +166,7 @@
|
||||
"await db.adelete()\n",
|
||||
"\n",
|
||||
"db = await SurrealDBStore.afrom_documents(\n",
|
||||
" dburl=\"http://localhost:8000/rpc\", # url for the hosted SurrealDB database\n",
|
||||
" dburl=\"ws://localhost:8000/rpc\", # url for the hosted SurrealDB database\n",
|
||||
" embedding=embeddings,\n",
|
||||
" documents=docs,\n",
|
||||
" db_user=\"root\", # SurrealDB credentials if needed: db username\n",
|
||||
@@ -174,7 +187,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 6,
|
||||
"id": "aa28a7f8-41d0-4299-84eb-91d1576e8a63",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -187,7 +200,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 7,
|
||||
"id": "1eb16d2a-b466-456a-b412-5e74bb8523dd",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -229,7 +242,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 8,
|
||||
"id": "8e9eef05-1516-469a-ad36-880c69aef7a9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -241,7 +254,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 9,
|
||||
"id": "bd5fb0e4-2a94-4bb4-af8a-27327ecb1a7f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -250,11 +263,11 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'id': 'documents:639m99rzwqlm9imcwg13'}),\n",
|
||||
" 0.39839545290036454)"
|
||||
"(Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'id': 'documents:slgdlhjkfknhqo15xz0w', 'source': '../../modules/state_of_the_union.txt'}),\n",
|
||||
" 0.39839531721941895)"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -280,7 +293,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
248
docs/docs/integrations/vectorstores/vikingdb.ipynb
Normal file
248
docs/docs/integrations/vectorstores/vikingdb.ipynb
Normal file
@@ -0,0 +1,248 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "96ff9e912bfe9d8",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# viking DB\n",
|
||||
"\n",
|
||||
">[viking DB](https://www.volcengine.com/docs/6459/1163946) is a database that stores, indexes, and manages massive embedding vectors generated by deep neural networks and other machine learning (ML) models.\n",
|
||||
"\n",
|
||||
"This notebook shows how to use functionality related to the VikingDB vector database.\n",
|
||||
"\n",
|
||||
"To run, you should have a [viking DB instance up and running](https://www.volcengine.com/docs/6459/1165058).\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "dd771e02d8a93a0",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install --upgrade volcengine"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "12719205caed0d18",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"We want to use VikingDBEmbeddings so we have to get the VikingDB API Key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "fbfb32665b4a3640",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-21T09:53:24.186916Z",
|
||||
"start_time": "2023-12-21T09:53:24.179524Z"
|
||||
},
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OpenAI API Key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d8c983d329237fa4",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import TextLoader\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain.vectorstores.vikingdb import VikingDB, VikingDBConfig\n",
|
||||
"from langchain_openai import OpenAIEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1a4aea2eaeb2261",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = TextLoader(\"./test.txt\")\n",
|
||||
"documents = loader.load()\n",
|
||||
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=10, chunk_overlap=0)\n",
|
||||
"docs = text_splitter.split_documents(documents)\n",
|
||||
"\n",
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "bfd593f3deabfaf8",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"db = VikingDB.from_documents(\n",
|
||||
" docs,\n",
|
||||
" embeddings,\n",
|
||||
" connection_args=VikingDBConfig(\n",
|
||||
" host=\"host\", region=\"region\", ak=\"ak\", sk=\"sk\", scheme=\"http\"\n",
|
||||
" ),\n",
|
||||
" drop_old=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "50e6ee12ca7eec39",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-21T10:01:47.355894Z",
|
||||
"start_time": "2023-12-21T10:01:47.334789Z"
|
||||
},
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
"docs = db.similarity_search(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "b6b81f5995c79ef0",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-21T10:01:47.771478Z",
|
||||
"start_time": "2023-12-21T10:01:47.731485Z"
|
||||
},
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs[0].page_content"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a2d932c1290478ee",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"### Compartmentalize the data with viking DB Collections\n",
|
||||
"\n",
|
||||
"You can store different unrelated documents in different collections within same viking DB instance to maintain the context"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "907de4eb10626d2a",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"Here's how you can create a new collection"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "4f5a59ba40f7985f",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"db = VikingDB.from_documents(\n",
|
||||
" docs,\n",
|
||||
" embeddings,\n",
|
||||
" connection_args=VikingDBConfig(\n",
|
||||
" host=\"host\", region=\"region\", ak=\"ak\", sk=\"sk\", scheme=\"http\"\n",
|
||||
" ),\n",
|
||||
" collection_name=\"collection_1\",\n",
|
||||
" drop_old=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7c8eada37b17d992",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"And here is how you retrieve that stored collection"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "883ec678d47c9adc",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"db = VikingDB.from_documents(\n",
|
||||
" embeddings,\n",
|
||||
" connection_args=VikingDBConfig(\n",
|
||||
" host=\"host\", region=\"region\", ak=\"ak\", sk=\"sk\", scheme=\"http\"\n",
|
||||
" ),\n",
|
||||
" collection_name=\"collection_1\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2f0be30cfe70083d",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"After retreival you can go on querying it as usual."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 2
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython2",
|
||||
"version": "2.7.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
@@ -30,12 +30,12 @@ Whether this agent requires the model to support any additional parameters. Some
|
||||
|
||||
Our commentary on when you should consider using this agent type.
|
||||
|
||||
| Agent Type | Intended Model Type | Supports Chat History | Supports Multi-Input Tools | Supports Parallel Function Calling | Required Model Params | When to Use |
|
||||
|--------------------------------------------|---------------------|-----------------------|----------------------------|-------------------------------------|----------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [OpenAI Tools](./openai_tools) | Chat | ✅ | ✅ | ✅ | `tools` | If you are using a recent OpenAI model (`1106` onwards) |
|
||||
| [OpenAI Functions](./openai_functions_agent)| Chat | ✅ | ✅ | | `functions` | If you are using an OpenAI model, or an open-source model that has been finetuned for function calling and exposes the same `functions` parameters as OpenAI |
|
||||
| [XML](./xml_agent) | LLM | ✅ | | | | If you are using Anthropic models, or other models good at XML |
|
||||
| [Structured Chat](./structured_chat) | Chat | ✅ | ✅ | | | If you need to support tools with multiple inputs |
|
||||
| [JSON Chat](./json_agent) | Chat | ✅ | | | | If you are using a model good at JSON |
|
||||
| [ReAct](./react) | LLM | ✅ | | | | If you are using a simple model |
|
||||
| [Self Ask With Search](./self_ask_with_search)| LLM | | | | | If you are using a simple model and only have one search tool |
|
||||
| Agent Type | Intended Model Type | Supports Chat History | Supports Multi-Input Tools | Supports Parallel Function Calling | Required Model Params | When to Use | API |
|
||||
|--------------------------------------------|---------------------|-----------------------|----------------------------|-------------------------------------|----------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------|
|
||||
| [OpenAI Tools](./openai_tools) | Chat | ✅ | ✅ | ✅ | `tools` | If you are using a recent OpenAI model (`1106` onwards) | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.openai_tools.base.create_openai_tools_agent.html) |
|
||||
| [OpenAI Functions](./openai_functions_agent)| Chat | ✅ | ✅ | | `functions` | If you are using an OpenAI model, or an open-source model that has been finetuned for function calling and exposes the same `functions` parameters as OpenAI | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.openai_functions_agent.base.create_openai_functions_agent.html) |
|
||||
| [XML](./xml_agent) | LLM | ✅ | | | | If you are using Anthropic models, or other models good at XML | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.xml.base.create_xml_agent.html) |
|
||||
| [Structured Chat](./structured_chat) | Chat | ✅ | ✅ | | | If you need to support tools with multiple inputs | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.structured_chat.base.create_structured_chat_agent.html) |
|
||||
| [JSON Chat](./json_agent) | Chat | ✅ | | | | If you are using a model good at JSON | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.json_chat.base.create_json_chat_agent.html) |
|
||||
| [ReAct](./react) | LLM | ✅ | | | | If you are using a simple model | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.react.agent.create_react_agent.html) |
|
||||
| [Self Ask With Search](./self_ask_with_search)| LLM | | | | | If you are using a simple model and only have one search tool | [Ref](https://api.python.langchain.com/en/latest/agents/langchain.agents.self_ask_with_search.base.create_self_ask_with_search_agent.html) |
|
||||
@@ -19,9 +19,27 @@
|
||||
"\n",
|
||||
"Certain OpenAI models (like gpt-3.5-turbo-0613 and gpt-4-0613) have been fine-tuned to detect when a function should be called and respond with the inputs that should be passed to the function. In an API call, you can describe functions and have the model intelligently choose to output a JSON object containing arguments to call those functions. The goal of the OpenAI Function APIs is to more reliably return valid and useful function calls than a generic text completion or chat API.\n",
|
||||
"\n",
|
||||
"A number of open source models have adopted the same format for function calls and have also fine-tuned the model to detect when a function should be called.\n",
|
||||
"\n",
|
||||
"The OpenAI Functions Agent is designed to work with these models.\n",
|
||||
"\n",
|
||||
"Install `openai`, `tavily-python` packages which are required as the LangChain packages call them internally."
|
||||
"Install `openai`, `tavily-python` packages which are required as the LangChain packages call them internally.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
":::info\n",
|
||||
"\n",
|
||||
"OpenAI API has deprecated `functions` in favor of `tools`. The difference between the two is that the `tools` API allows the model to request that multiple functions be invoked at once, which can reduce response times in some architectures. It's recommended to use the tools agent for OpenAI models.\n",
|
||||
"\n",
|
||||
"See the following links for more information:\n",
|
||||
"\n",
|
||||
"[OpenAI chat create](https://platform.openai.com/docs/api-reference/chat/create)\n",
|
||||
"\n",
|
||||
"[OpenAI function calling](https://platform.openai.com/docs/guides/function-calling)\n",
|
||||
":::\n",
|
||||
"\n",
|
||||
":::tip\n",
|
||||
"The `functions` format remains relevant for open source models and providers that have adopted it, and this agent is expected to work for such models.\n",
|
||||
":::\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -260,7 +278,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -17,9 +17,26 @@
|
||||
"source": [
|
||||
"# OpenAI tools\n",
|
||||
"\n",
|
||||
"Certain OpenAI models have been finetuned to work with with **tool calling**. This is very similar but different from **function calling**, and thus requires a separate agent type.\n",
|
||||
"Newer OpenAI models have been fine-tuned to detect when **one or more** function(s) should be called and respond with the inputs that should be passed to the function(s). In an API call, you can describe functions and have the model intelligently choose to output a JSON object containing arguments to call these functions. The goal of the OpenAI tools APIs is to more reliably return valid and useful function calls than what can be done using a generic text completion or chat API.\n",
|
||||
"\n",
|
||||
"The key difference between tools and functions lies in their availability and application within the chat environment. **Tools** are specialized capabilities directly accessible in the chat interface, designed for interactive and immediate use, such as generating images or executing code. In contrast, **functions** are more about invoking specific computational tasks or algorithms, typically as part of a larger process or application. This distinction underscores the tailored nature of each tool and function, ensuring they are optimally suited for their respective roles within the chat environment."
|
||||
"OpenAI termed the capability to invoke a **single** function as **functions**, and the capability to invoke **one or more** funcitons as **tools**.\n",
|
||||
"\n",
|
||||
":::tip\n",
|
||||
"\n",
|
||||
"In the OpenAI Chat API, **functions** are now considered a legacy options that is deprecated in favor of **tools**.\n",
|
||||
"\n",
|
||||
"If you're creating agents using OpenAI models, you should be using this OpenAI Tools agent rather than the OpenAI functions agent.\n",
|
||||
"\n",
|
||||
"Using **tools** allows the model to request that more than one function will be called upon when appropriate. \n",
|
||||
"\n",
|
||||
"In some situations, this can help signficantly reduce the time that it takes an agent to achieve its goal.\n",
|
||||
"\n",
|
||||
"See \n",
|
||||
" \n",
|
||||
"* [OpenAI chat create](https://platform.openai.com/docs/api-reference/chat/create) \n",
|
||||
"* [OpenAI function calling](https://platform.openai.com/docs/guides/function-calling)\n",
|
||||
"\n",
|
||||
":::"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -130,14 +147,14 @@
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001B[1m> Entering new AgentExecutor chain...\u001B[0m\n",
|
||||
"\u001B[32;1m\u001B[1;3m\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `tavily_search_results_json` with `{'query': 'LangChain'}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001B[0m\u001B[36;1m\u001B[1;3m[{'url': 'https://www.ibm.com/topics/langchain', 'content': 'LangChain is essentially a library of abstractions for Python and Javascript, representing common steps and concepts LangChain is an open source orchestration framework for the development of applications using large language models other LangChain features, like the eponymous chains. LangChain provides integrations for over 25 different embedding methods, as well as for over 50 different vector storesLangChain is a tool for building applications using large language models (LLMs) like chatbots and virtual agents. It simplifies the process of programming and integration with external data sources and software workflows. It supports Python and Javascript languages and supports various LLM providers, including OpenAI, Google, and IBM.'}]\u001B[0m\u001B[32;1m\u001B[1;3mLangChain is an open source orchestration framework for the development of applications using large language models. It is essentially a library of abstractions for Python and Javascript, representing common steps and concepts. LangChain simplifies the process of programming and integration with external data sources and software workflows. It supports various large language model providers, including OpenAI, Google, and IBM. You can find more information about LangChain on the IBM website: [LangChain - IBM](https://www.ibm.com/topics/langchain)\u001B[0m\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3m[{'url': 'https://www.ibm.com/topics/langchain', 'content': 'LangChain is essentially a library of abstractions for Python and Javascript, representing common steps and concepts LangChain is an open source orchestration framework for the development of applications using large language models other LangChain features, like the eponymous chains. LangChain provides integrations for over 25 different embedding methods, as well as for over 50 different vector storesLangChain is a tool for building applications using large language models (LLMs) like chatbots and virtual agents. It simplifies the process of programming and integration with external data sources and software workflows. It supports Python and Javascript languages and supports various LLM providers, including OpenAI, Google, and IBM.'}]\u001b[0m\u001b[32;1m\u001b[1;3mLangChain is an open source orchestration framework for the development of applications using large language models. It is essentially a library of abstractions for Python and Javascript, representing common steps and concepts. LangChain simplifies the process of programming and integration with external data sources and software workflows. It supports various large language model providers, including OpenAI, Google, and IBM. You can find more information about LangChain on the IBM website: [LangChain - IBM](https://www.ibm.com/topics/langchain)\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001B[1m> Finished chain.\u001B[0m\n"
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -176,10 +193,10 @@
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001B[1m> Entering new AgentExecutor chain...\u001B[0m\n",
|
||||
"\u001B[32;1m\u001B[1;3mYour name is Bob.\u001B[0m\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mYour name is Bob.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001B[1m> Finished chain.\u001B[0m\n"
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -235,7 +252,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -17,7 +17,7 @@
|
||||
"source": [
|
||||
"# Structured chat\n",
|
||||
"\n",
|
||||
"The structured chat agent is capable of using multi-input tools.\n"
|
||||
"The structured chat agent is capable of using multi-input tools."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -237,7 +237,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -17,7 +17,14 @@
|
||||
"source": [
|
||||
"# XML Agent\n",
|
||||
"\n",
|
||||
"Some language models (like Anthropic's Claude) are particularly good at reasoning/writing XML. This goes over how to use an agent that uses XML when prompting. "
|
||||
"Some language models (like Anthropic's Claude) are particularly good at reasoning/writing XML. This goes over how to use an agent that uses XML when prompting. \n",
|
||||
"\n",
|
||||
":::tip\n",
|
||||
"\n",
|
||||
"* Use with regular LLMs, not with chat models.\n",
|
||||
"* Use only with unstructured tools; i.e., tools that accept a single string input.\n",
|
||||
"* See [AgentTypes](../index) documentation for more agent types.\n",
|
||||
":::"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -217,7 +224,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -44,6 +44,7 @@ LangChain offers many different types of text splitters. Below is a table listin
|
||||
| Code | Code (Python, JS) specific characters | | Splits text based on characters specific to coding languages. 15 different languages are available to choose from. |
|
||||
| Token | Tokens | | Splits text on tokens. There exist a few different ways to measure tokens. |
|
||||
| Character | A user defined character | | Splits text based on a user defined character. One of the simpler methods. |
|
||||
| [Experimental] Semantic Chunker | Sentences | | First splits on sentences. Then combines ones next to each other if they are semantically similar enough. Taken from [Greg Kamradt](https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb) |
|
||||
|
||||
|
||||
## Evaluate text splitters
|
||||
|
||||
@@ -0,0 +1,145 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c3ee8d00",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Semantic Chunking\n",
|
||||
"\n",
|
||||
"Splits the text based on semantic similarity.\n",
|
||||
"\n",
|
||||
"Taken from Greg Kamradt's wonderful notebook:\n",
|
||||
"https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb\n",
|
||||
"\n",
|
||||
"All credit to him.\n",
|
||||
"\n",
|
||||
"At a high level, this splits into sentences, then groups into groups of 3\n",
|
||||
"sentences, and then merges one that are similar in the embedding space."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "542f4427",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Install Dependencies"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d8c58769",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install --quiet langchain_experimental langchain_openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c20cdf54",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load Example Data"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "313fb032",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This is a long document we can split up.\n",
|
||||
"with open(\"../../state_of_the_union.txt\") as f:\n",
|
||||
" state_of_the_union = f.read()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f7436e15",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Create Text Splitter"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "a88ff70c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_experimental.text_splitter import SemanticChunker\n",
|
||||
"from langchain_openai.embeddings import OpenAIEmbeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "613d4a3b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text_splitter = SemanticChunker(OpenAIEmbeddings())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "91b14834",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Split Text"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "295ec095",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. Last year COVID-19 kept us apart. This year we are finally together again. Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. With a duty to one another to the American people to the Constitution. And with an unwavering resolve that freedom will always triumph over tyranny. Six days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. He thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. He met the Ukrainian people. From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. Groups of citizens blocking tanks with their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland. In this struggle as President Zelenskyy said in his speech to the European Parliament “Light will win over darkness.” The Ukrainian Ambassador to the United States is here tonight. Let each of us here tonight in this Chamber send an unmistakable signal to Ukraine and to the world. Please rise if you are able and show that, Yes, we the United States of America stand with the Ukrainian people. Throughout our history we’ve learned this lesson when dictators do not pay a price for their aggression they cause more chaos. They keep moving.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs = text_splitter.create_documents([state_of_the_union])\n",
|
||||
"print(docs[0].page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a9a3b9cd",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -14,7 +14,7 @@ This section of the documentation covers everything related to the *retrieval* s
|
||||
Although this sounds simple, it can be subtly complex.
|
||||
This encompasses several key modules.
|
||||
|
||||

|
||||

|
||||
|
||||
**[Document loaders](/docs/modules/data_connection/document_loaders/)**
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -35,22 +35,31 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc_list = [\n",
|
||||
"doc_list_1 = [\n",
|
||||
" \"I like apples\",\n",
|
||||
" \"I like oranges\",\n",
|
||||
" \"Apples and oranges are fruits\",\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"# initialize the bm25 retriever and faiss retriever\n",
|
||||
"bm25_retriever = BM25Retriever.from_texts(doc_list)\n",
|
||||
"bm25_retriever = BM25Retriever.from_texts(\n",
|
||||
" doc_list_1, metadatas=[{\"source\": 1}] * len(doc_list_1)\n",
|
||||
")\n",
|
||||
"bm25_retriever.k = 2\n",
|
||||
"\n",
|
||||
"doc_list_2 = [\n",
|
||||
" \"You like apples\",\n",
|
||||
" \"You like oranges\",\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"embedding = OpenAIEmbeddings()\n",
|
||||
"faiss_vectorstore = FAISS.from_texts(doc_list, embedding)\n",
|
||||
"faiss_vectorstore = FAISS.from_texts(\n",
|
||||
" doc_list_2, embedding, metadatas=[{\"source\": 2}] * len(doc_list_2)\n",
|
||||
")\n",
|
||||
"faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={\"k\": 2})\n",
|
||||
"\n",
|
||||
"# initialize the ensemble retriever\n",
|
||||
@@ -61,26 +70,92 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='I like apples'),\n",
|
||||
" Document(page_content='Apples and oranges are fruits')]"
|
||||
"[Document(page_content='You like apples', metadata={'source': 2}),\n",
|
||||
" Document(page_content='I like apples', metadata={'source': 1}),\n",
|
||||
" Document(page_content='You like oranges', metadata={'source': 2}),\n",
|
||||
" Document(page_content='Apples and oranges are fruits', metadata={'source': 1})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs = ensemble_retriever.get_relevant_documents(\"apples\")\n",
|
||||
"docs = ensemble_retriever.invoke(\"apples\")\n",
|
||||
"docs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Runtime Configuration\n",
|
||||
"\n",
|
||||
"We can also configure the retrievers at runtime. In order to do this, we need to mark the fields as configurable"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.runnables import ConfigurableField"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"faiss_retriever = faiss_vectorstore.as_retriever(\n",
|
||||
" search_kwargs={\"k\": 2}\n",
|
||||
").configurable_fields(\n",
|
||||
" search_kwargs=ConfigurableField(\n",
|
||||
" id=\"search_kwargs_faiss\",\n",
|
||||
" name=\"Search Kwargs\",\n",
|
||||
" description=\"The search kwargs to use\",\n",
|
||||
" )\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ensemble_retriever = EnsembleRetriever(\n",
|
||||
" retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"config = {\"configurable\": {\"search_kwargs_faiss\": {\"k\": 1}}}\n",
|
||||
"docs = ensemble_retriever.invoke(\"apples\", config=config)\n",
|
||||
"docs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Notice that this only returns one source from the FAISS retriever, because we pass in the relevant configuration at run time"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
"\n",
|
||||
"A self-querying retriever is one that, as the name suggests, has the ability to query itself. Specifically, given any natural language query, the retriever uses a query-constructing LLM chain to write a structured query and then applies that structured query to its underlying VectorStore. This allows the retriever to not only use the user-input query for semantic similarity comparison with the contents of stored documents but to also extract filters from the user query on the metadata of stored documents and to execute those filters.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Get started\n",
|
||||
"For demonstration purposes we'll use a `Chroma` vector store. We've created a small demo set of documents that contain summaries of movies.\n",
|
||||
@@ -561,7 +561,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -17,10 +17,10 @@ The base Embeddings class in LangChain provides two methods: one for embedding d
|
||||
|
||||
### Setup
|
||||
|
||||
To start we'll need to install the OpenAI Python package:
|
||||
To start we'll need to install the OpenAI partner package:
|
||||
|
||||
```bash
|
||||
pip install openai
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
Accessing the API requires an API key, which you can get by creating an account and heading [here](https://platform.openai.com/account/api-keys). Once we have a key we'll want to set it as an environment variable by running:
|
||||
|
||||
@@ -12,7 +12,7 @@ vectors, and then at query time to embed the unstructured query and retrieve the
|
||||
'most similar' to the embedded query. A vector store takes care of storing embedded data and performing vector search
|
||||
for you.
|
||||
|
||||

|
||||

|
||||
|
||||
## Get started
|
||||
|
||||
|
||||
@@ -36,7 +36,7 @@ A chain will interact with its memory system twice in a given run.
|
||||
1. AFTER receiving the initial user inputs but BEFORE executing the core logic, a chain will READ from its memory system and augment the user inputs.
|
||||
2. AFTER executing the core logic but BEFORE returning the answer, a chain will WRITE the inputs and outputs of the current run to memory, so that they can be referred to in future runs.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
## Building memory into a system
|
||||
|
||||
@@ -24,10 +24,10 @@
|
||||
"\n",
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"For this example we'll need to install the OpenAI Python package:\n",
|
||||
"For this example we'll need to install the OpenAI partner package:\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"pip install openai\n",
|
||||
"pip install langchain-openai\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Accessing the API requires an API key, which you can get by creating an account and heading [here](https://platform.openai.com/account/api-keys). Once we have a key we'll want to set it as an environment variable by running:\n",
|
||||
|
||||
@@ -9,7 +9,7 @@ sidebar_class_name: hidden
|
||||
|
||||
The core element of any language model application is...the model. LangChain gives you the building blocks to interface with any language model.
|
||||
|
||||

|
||||

|
||||
|
||||
## [Conceptual Guide](/docs/modules/model_io/concepts)
|
||||
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
hide_table_of_contents: true
|
||||
---
|
||||
# Output Parsers
|
||||
|
||||
@@ -29,17 +30,17 @@ LangChain has lots of different types of output parsers. This is a list of outpu
|
||||
|
||||
**Description**: Our commentary on this output parser and when to use it.
|
||||
|
||||
| Name | Supports Streaming | Has Format Instructions | Calls LLM | Input Type | Output Type | Description | | |
|
||||
|-----------------|--------------------|-------------------------------|-----------|----------------------------------|----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|---|
|
||||
| [OpenAIFunctions](./types/openai_functions) | ✅ | (Passes `functions` to model) | | `Message` (with `function_call`) | JSON object | Uses OpenAI function calling to structure the return output. If you are using a model that supports function calling, this is generally the most reliable method. | | |
|
||||
| [JSON](./types/json) | ✅ | ✅ | | `str \| Message` | JSON object | Returns a JSON object as specified. You can specify a Pydantic model and it will return JSON for that model. Probably the most reliable output parser for getting structured data that does NOT use function calling. | | |
|
||||
| [XML](./types/xml) | ✅ | ✅ | | `str \| Message` | `dict` | Returns a dictionary of tags. Use when XML output is needed. Use with models that are good at writing XML (like Anthropic's). | | |
|
||||
| [CSV](./types/csv) | ✅ | ✅ | | `str \| Message` | `List[str]` | Returns a list of comma separated values. | | |
|
||||
| [OutputFixing](./types/output_fixing) | | | ✅ | `str \| Message` | | Wraps another output parser. If that output parser errors, then this will pass the error message and the bad output to an LLM and ask it to fix the output. | | |
|
||||
| [RetryWithError](./types/retry) | | | ✅ | `str \| Message` | | Wraps another output parser. If that output parser errors, then this will pass the original inputs, the bad output, and the error message to an LLM and ask it to fix it. Compared to OutputFixingParser, this one also sends the original instructions. | | |
|
||||
| [Pydantic](./types/pydantic) | | ✅ | | `str \| Message` | `pydantic.BaseModel` | Takes a user defined Pydantic model and returns data in that format. | | |
|
||||
| [YAML](./types/yaml) | | ✅ | | `str \| Message` | `pydantic.BaseModel` | Takes a user defined Pydantic model and returns data in that format. Uses YAML to encode it. | | |
|
||||
| [PandasDataFrame](./types/pandas_dataframe) | | ✅ | | `str \| Message` | `dict` | Useful for doing operations with pandas DataFrames. | | |
|
||||
| [Enum](./types/enum) | | ✅ | | `str \| Message` | `Enum` | Parses response into one of the provided enum values. | | |
|
||||
| [Datetime](./types/datetime) | | ✅ | | `str \| Message` | `datetime.datetime` | Parses response into a datetime string. | | |
|
||||
| [Structured](./types/structured) | | ✅ | | `str \| Message` | `Dict[str, str]` | An output parser that returns structured information. It is less powerful than other output parsers since it only allows for fields to be strings. This can be useful when you are working with smaller LLMs. | | |
|
||||
| Name | Supports Streaming | Has Format Instructions | Calls LLM | Input Type | Output Type | Description |
|
||||
|-----------------|--------------------|-------------------------------|-----------|----------------------------------|----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [OpenAIFunctions](./types/openai_functions) | ✅ | (Passes `functions` to model) | | `Message` (with `function_call`) | JSON object | Uses OpenAI function calling to structure the return output. If you are using a model that supports function calling, this is generally the most reliable method. |
|
||||
| [JSON](./types/json) | ✅ | ✅ | | `str \| Message` | JSON object | Returns a JSON object as specified. You can specify a Pydantic model and it will return JSON for that model. Probably the most reliable output parser for getting structured data that does NOT use function calling. |
|
||||
| [XML](./types/xml) | ✅ | ✅ | | `str \| Message` | `dict` | Returns a dictionary of tags. Use when XML output is needed. Use with models that are good at writing XML (like Anthropic's). |
|
||||
| [CSV](./types/csv) | ✅ | ✅ | | `str \| Message` | `List[str]` | Returns a list of comma separated values. |
|
||||
| [OutputFixing](./types/output_fixing) | | | ✅ | `str \| Message` | | Wraps another output parser. If that output parser errors, then this will pass the error message and the bad output to an LLM and ask it to fix the output. |
|
||||
| [RetryWithError](./types/retry) | | | ✅ | `str \| Message` | | Wraps another output parser. If that output parser errors, then this will pass the original inputs, the bad output, and the error message to an LLM and ask it to fix it. Compared to OutputFixingParser, this one also sends the original instructions. |
|
||||
| [Pydantic](./types/pydantic) | | ✅ | | `str \| Message` | `pydantic.BaseModel` | Takes a user defined Pydantic model and returns data in that format. |
|
||||
| [YAML](./types/yaml) | | ✅ | | `str \| Message` | `pydantic.BaseModel` | Takes a user defined Pydantic model and returns data in that format. Uses YAML to encode it. |
|
||||
| [PandasDataFrame](./types/pandas_dataframe) | | ✅ | | `str \| Message` | `dict` | Useful for doing operations with pandas DataFrames. |
|
||||
| [Enum](./types/enum) | | ✅ | | `str \| Message` | `Enum` | Parses response into one of the provided enum values. |
|
||||
| [Datetime](./types/datetime) | | ✅ | | `str \| Message` | `datetime.datetime` | Parses response into a datetime string. |
|
||||
| [Structured](./types/structured) | | ✅ | | `str \| Message` | `Dict[str, str]` | An output parser that returns structured information. It is less powerful than other output parsers since it only allows for fields to be strings. This can be useful when you are working with smaller LLMs. |
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_position: 3\n",
|
||||
"title: Output parsers\n",
|
||||
"title: Quickstart\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
|
||||
@@ -0,0 +1 @@
|
||||
label: 'Types'
|
||||
@@ -16,10 +16,10 @@ import CodeBlock from "@theme/CodeBlock";
|
||||
<Tabs>
|
||||
<TabItem value="openai" label="OpenAI" default>
|
||||
|
||||
First we'll need to install their Python package:
|
||||
First we'll need to install their partner package:
|
||||
|
||||
```shell
|
||||
pip install openai
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
Accessing the API requires an API key, which you can get by creating an account and heading [here](https://platform.openai.com/account/api-keys). Once we have a key we'll want to set it as an environment variable by running:
|
||||
|
||||
@@ -1,3 +1,2 @@
|
||||
label: 'Q&A over structured data'
|
||||
collapsed: false
|
||||
position: 0.1
|
||||
|
||||
@@ -399,24 +399,6 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"**Improvements**\n",
|
||||
"\n",
|
||||
"The performance of the `SQLDatabaseChain` can be enhanced in several ways:\n",
|
||||
"\n",
|
||||
"- [Adding sample rows](#adding-sample-rows)\n",
|
||||
"- [Specifying custom table information](/docs/integrations/tools/sqlite#custom-table-info)\n",
|
||||
"- [Using Query Checker](/docs/integrations/tools/sqlite#use-query-checker) self-correct invalid SQL using parameter `use_query_checker=True`\n",
|
||||
"- [Customizing the LLM Prompt](/docs/integrations/tools/sqlite#customize-prompt) include specific instructions or relevant information, using parameter `prompt=CUSTOM_PROMPT`\n",
|
||||
"- [Get intermediate steps](/docs/integrations/tools/sqlite#return-intermediate-steps) access the SQL statement as well as the final result using parameter `return_intermediate_steps=True`\n",
|
||||
"- [Limit the number of rows](/docs/integrations/tools/sqlite#choosing-how-to-limit-the-number-of-rows-returned) a query will return using parameter `top_k=5`\n",
|
||||
"\n",
|
||||
"You might find [SQLDatabaseSequentialChain](/docs/integrations/tools/sqlite#sqldatabasesequentialchain)\n",
|
||||
"useful for cases in which the number of tables in the database is large.\n",
|
||||
"\n",
|
||||
"This `Sequential Chain` handles the process of:\n",
|
||||
"\n",
|
||||
"1. Determining which tables to use based on the user question\n",
|
||||
"2. Calling the normal SQL database chain using only relevant tables\n",
|
||||
"\n",
|
||||
"**Adding Sample Rows**\n",
|
||||
"\n",
|
||||
@@ -1269,7 +1251,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -11,7 +11,7 @@
|
||||
"\n",
|
||||
"LangChain has [integrations](https://integrations.langchain.com/) with many open-source LLMs that can be run locally.\n",
|
||||
"\n",
|
||||
"See [here](docs/guides/local_llms) for setup instructions for these LLMs. \n",
|
||||
"See [here](/docs/guides/local_llms) for setup instructions for these LLMs. \n",
|
||||
"\n",
|
||||
"For example, here we show how to run `GPT4All` or `LLaMA2` locally (e.g., on your laptop) using local embeddings and a local LLM.\n",
|
||||
"\n",
|
||||
@@ -141,11 +141,11 @@
|
||||
"\n",
|
||||
"Note: new versions of `llama-cpp-python` use GGUF model files (see [here](https://github.com/abetlen/llama-cpp-python/pull/633)).\n",
|
||||
"\n",
|
||||
"If you have an existing GGML model, see [here](docs/integrations/llms/llamacpp) for instructions for conversion for GGUF. \n",
|
||||
"If you have an existing GGML model, see [here](/docs/integrations/llms/llamacpp) for instructions for conversion for GGUF. \n",
|
||||
" \n",
|
||||
"And / or, you can download a GGUF converted model (e.g., [here](https://huggingface.co/TheBloke)).\n",
|
||||
"\n",
|
||||
"Finally, as noted in detail [here](docs/guides/local_llms) install `llama-cpp-python`"
|
||||
"Finally, as noted in detail [here](/docs/guides/local_llms) install `llama-cpp-python`"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -201,7 +201,7 @@
|
||||
"id": "fcf81052",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Setting model parameters as noted in the [llama.cpp docs](https://python.langchain.com/docs/integrations/llms/llamacpp)."
|
||||
"Setting model parameters as noted in the [llama.cpp docs](/docs/integrations/llms/llamacpp)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -230,7 +230,7 @@
|
||||
"id": "3831b16a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Note that these indicate that [Metal was enabled properly](https://python.langchain.com/docs/integrations/llms/llamacpp):\n",
|
||||
"Note that these indicate that [Metal was enabled properly](/docs/integrations/llms/llamacpp):\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"ggml_metal_init: allocating\n",
|
||||
@@ -304,7 +304,7 @@
|
||||
"\n",
|
||||
"Similarly, we can use `GPT4All`.\n",
|
||||
"\n",
|
||||
"[Download the GPT4All model binary](https://python.langchain.com/docs/integrations/llms/gpt4all).\n",
|
||||
"[Download the GPT4All model binary](/docs/integrations/llms/gpt4all).\n",
|
||||
"\n",
|
||||
"The Model Explorer on the [GPT4All](https://gpt4all.io/index.html) is a great way to choose and download a model.\n",
|
||||
"\n",
|
||||
|
||||
@@ -27,7 +27,7 @@
|
||||
"\n",
|
||||
"**Step 2: Add that parameter as a configurable field for the chain**\n",
|
||||
"\n",
|
||||
"This will let you easily call the chain and configure any relevant flags at runtime. See [this documentation](docs/expression_language/how_to/configure) for more information on configuration.\n",
|
||||
"This will let you easily call the chain and configure any relevant flags at runtime. See [this documentation](/docs/expression_language/how_to/configure) for more information on configuration.\n",
|
||||
"\n",
|
||||
"**Step 3: Call the chain with that configurable field**\n",
|
||||
"\n",
|
||||
@@ -298,14 +298,6 @@
|
||||
" config={\"configurable\": {\"search_kwargs\": {\"namespace\": \"ankush\"}}},\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e3aa0b9e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -55,7 +55,7 @@
|
||||
"\n",
|
||||
"#### Retrieval and generation\n",
|
||||
"4. **Retrieve**: Given a user input, relevant splits are retrieved from storage using a [Retriever](/docs/modules/data_connection/retrievers/).\n",
|
||||
"5. **Generate**: A [ChatModel](/docs/modules/model_io/chat) / [LLM](/docs/modules/model_io/llms/) produces an answer using a prompt that includes the question and the retrieved data"
|
||||
"5. **Generate**: A [ChatModel](/docs/modules/model_io/chat/) / [LLM](/docs/modules/model_io/llms/) produces an answer using a prompt that includes the question and the retrieved data"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -449,7 +449,7 @@
|
||||
"`TextSplitter`: Object that splits a list of `Document`s into smaller chunks. Subclass of `DocumentTransformer`s.\n",
|
||||
"- Explore `Context-aware splitters`, which keep the location (\"context\") of each split in the original `Document`:\n",
|
||||
" - [Markdown files](/docs/modules/data_connection/document_transformers/markdown_header_metadata)\n",
|
||||
" - [Code (py or js)](docs/integrations/document_loaders/source_code)\n",
|
||||
" - [Code (py or js)](/docs/integrations/document_loaders/source_code)\n",
|
||||
" - [Scientific papers](/docs/integrations/document_loaders/grobid)\n",
|
||||
"- [Interface](https://api.python.langchain.com/en/latest/text_splitter/langchain.text_splitter.TextSplitter.html): API reference for the base interface.\n",
|
||||
"\n",
|
||||
@@ -865,7 +865,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.1"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
BIN
docs/static/img/self_querying.jpg
vendored
BIN
docs/static/img/self_querying.jpg
vendored
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 94 KiB After Width: | Height: | Size: 73 KiB |
@@ -1422,7 +1422,7 @@
|
||||
},
|
||||
{
|
||||
"source": "/docs/integrations/tools/sqlite",
|
||||
"destination": "/docs/use_cases/qa_structured/sqlite"
|
||||
"destination": "/docs/use_cases/qa_structured/sql"
|
||||
},
|
||||
{
|
||||
"source": "/en/latest/modules/callbacks/filecallbackhandler.html",
|
||||
|
||||
@@ -15,7 +15,7 @@ LangChain Community contains third-party integrations that implement the base in
|
||||
|
||||
For full documentation see the [API reference](https://api.python.langchain.com/en/stable/community_api_reference.html).
|
||||
|
||||

|
||||

|
||||
|
||||
## 📕 Releases & Versioning
|
||||
|
||||
|
||||
@@ -1 +1 @@
|
||||
langchain-core==0.1.7
|
||||
langchain-core==0.1.9
|
||||
@@ -1,7 +1,8 @@
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import TYPE_CHECKING, List
|
||||
from typing import TYPE_CHECKING, List, Optional
|
||||
|
||||
from langchain_core.language_models import BaseLanguageModel
|
||||
from langchain_core.pydantic_v1 import Field
|
||||
|
||||
from langchain_community.agent_toolkits.base import BaseToolkit
|
||||
@@ -18,6 +19,7 @@ class AmadeusToolkit(BaseToolkit):
|
||||
"""Toolkit for interacting with Amadeus which offers APIs for travel."""
|
||||
|
||||
client: Client = Field(default_factory=authenticate)
|
||||
llm: Optional[BaseLanguageModel] = Field(default=None)
|
||||
|
||||
class Config:
|
||||
"""Pydantic config."""
|
||||
@@ -27,6 +29,6 @@ class AmadeusToolkit(BaseToolkit):
|
||||
def get_tools(self) -> List[BaseTool]:
|
||||
"""Get the tools in the toolkit."""
|
||||
return [
|
||||
AmadeusClosestAirport(),
|
||||
AmadeusClosestAirport(llm=self.llm),
|
||||
AmadeusFlightSearch(),
|
||||
]
|
||||
|
||||
@@ -68,10 +68,12 @@ MODEL_COST_PER_1K_TOKENS = {
|
||||
"babbage-002-finetuned": 0.0016,
|
||||
"davinci-002-finetuned": 0.012,
|
||||
"gpt-3.5-turbo-0613-finetuned": 0.012,
|
||||
"gpt-3.5-turbo-1106-finetuned": 0.012,
|
||||
# Fine Tuned output
|
||||
"babbage-002-finetuned-completion": 0.0016,
|
||||
"davinci-002-finetuned-completion": 0.012,
|
||||
"gpt-3.5-turbo-0613-finetuned-completion": 0.016,
|
||||
"gpt-3.5-turbo-1106-finetuned-completion": 0.016,
|
||||
# Azure Fine Tuned input
|
||||
"babbage-002-azure-finetuned": 0.0004,
|
||||
"davinci-002-azure-finetuned": 0.002,
|
||||
|
||||
@@ -39,6 +39,7 @@ from langchain_community.chat_models.javelin_ai_gateway import ChatJavelinAIGate
|
||||
from langchain_community.chat_models.jinachat import JinaChat
|
||||
from langchain_community.chat_models.konko import ChatKonko
|
||||
from langchain_community.chat_models.litellm import ChatLiteLLM
|
||||
from langchain_community.chat_models.llama_edge import LlamaEdgeChatService
|
||||
from langchain_community.chat_models.minimax import MiniMaxChat
|
||||
from langchain_community.chat_models.mlflow import ChatMlflow
|
||||
from langchain_community.chat_models.mlflow_ai_gateway import ChatMLflowAIGateway
|
||||
@@ -49,12 +50,11 @@ from langchain_community.chat_models.promptlayer_openai import PromptLayerChatOp
|
||||
from langchain_community.chat_models.tongyi import ChatTongyi
|
||||
from langchain_community.chat_models.vertexai import ChatVertexAI
|
||||
from langchain_community.chat_models.volcengine_maas import VolcEngineMaasChat
|
||||
from langchain_community.chat_models.wasm_chat import WasmChatService
|
||||
from langchain_community.chat_models.yandex import ChatYandexGPT
|
||||
from langchain_community.chat_models.zhipuai import ChatZhipuAI
|
||||
|
||||
__all__ = [
|
||||
"WasmChatService",
|
||||
"LlamaEdgeChatService",
|
||||
"ChatOpenAI",
|
||||
"BedrockChat",
|
||||
"AzureChatOpenAI",
|
||||
|
||||
@@ -18,7 +18,9 @@ logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@deprecated(
|
||||
since="0.1.0", removal="0.2.0", alternative="langchain_openai.AzureChatOpenAI"
|
||||
since="0.0.10",
|
||||
removal="0.2.0",
|
||||
alternative_import="langchain_openai.AzureChatOpenAI",
|
||||
)
|
||||
class AzureChatOpenAI(ChatOpenAI):
|
||||
"""`Azure OpenAI` Chat Completion API.
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from typing import Any, AsyncIterator, Dict, Iterator, List, Mapping, Optional, cast
|
||||
|
||||
@@ -244,7 +242,14 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
"""
|
||||
if self.streaming:
|
||||
completion = ""
|
||||
token_usage = {}
|
||||
chat_generation_info: Dict = {}
|
||||
for chunk in self._stream(messages, stop, run_manager, **kwargs):
|
||||
chat_generation_info = (
|
||||
chunk.generation_info
|
||||
if chunk.generation_info is not None
|
||||
else chat_generation_info
|
||||
)
|
||||
completion += chunk.text
|
||||
lc_msg = AIMessage(content=completion, additional_kwargs={})
|
||||
gen = ChatGeneration(
|
||||
@@ -253,7 +258,10 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
)
|
||||
return ChatResult(
|
||||
generations=[gen],
|
||||
llm_output={"token_usage": {}, "model_name": self.model},
|
||||
llm_output={
|
||||
"token_usage": chat_generation_info.get("usage", {}),
|
||||
"model_name": self.model,
|
||||
},
|
||||
)
|
||||
params = self._convert_prompt_msg_params(messages, **kwargs)
|
||||
response_payload = self.client.do(**params)
|
||||
@@ -279,7 +287,13 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
if self.streaming:
|
||||
completion = ""
|
||||
token_usage = {}
|
||||
chat_generation_info: Dict = {}
|
||||
async for chunk in self._astream(messages, stop, run_manager, **kwargs):
|
||||
chat_generation_info = (
|
||||
chunk.generation_info
|
||||
if chunk.generation_info is not None
|
||||
else chat_generation_info
|
||||
)
|
||||
completion += chunk.text
|
||||
|
||||
lc_msg = AIMessage(content=completion, additional_kwargs={})
|
||||
@@ -289,7 +303,10 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
)
|
||||
return ChatResult(
|
||||
generations=[gen],
|
||||
llm_output={"token_usage": {}, "model_name": self.model},
|
||||
llm_output={
|
||||
"token_usage": chat_generation_info.get("usage", {}),
|
||||
"model_name": self.model,
|
||||
},
|
||||
)
|
||||
params = self._convert_prompt_msg_params(messages, **kwargs)
|
||||
response_payload = await self.client.ado(**params)
|
||||
@@ -315,16 +332,19 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
**kwargs: Any,
|
||||
) -> Iterator[ChatGenerationChunk]:
|
||||
params = self._convert_prompt_msg_params(messages, **kwargs)
|
||||
params["stream"] = True
|
||||
for res in self.client.do(**params):
|
||||
if res:
|
||||
msg = _convert_dict_to_message(res)
|
||||
additional_kwargs = msg.additional_kwargs.get("function_call", {})
|
||||
chunk = ChatGenerationChunk(
|
||||
text=res["result"],
|
||||
message=AIMessageChunk(
|
||||
content=msg.content,
|
||||
role="assistant",
|
||||
additional_kwargs=msg.additional_kwargs,
|
||||
additional_kwargs=additional_kwargs,
|
||||
),
|
||||
generation_info=msg.additional_kwargs,
|
||||
)
|
||||
yield chunk
|
||||
if run_manager:
|
||||
@@ -338,16 +358,19 @@ class QianfanChatEndpoint(BaseChatModel):
|
||||
**kwargs: Any,
|
||||
) -> AsyncIterator[ChatGenerationChunk]:
|
||||
params = self._convert_prompt_msg_params(messages, **kwargs)
|
||||
params["stream"] = True
|
||||
async for res in await self.client.ado(**params):
|
||||
if res:
|
||||
msg = _convert_dict_to_message(res)
|
||||
additional_kwargs = msg.additional_kwargs.get("function_call", {})
|
||||
chunk = ChatGenerationChunk(
|
||||
text=res["result"],
|
||||
message=AIMessageChunk(
|
||||
content=msg.content,
|
||||
role="assistant",
|
||||
additional_kwargs=msg.additional_kwargs,
|
||||
additional_kwargs=additional_kwargs,
|
||||
),
|
||||
generation_info=msg.additional_kwargs,
|
||||
)
|
||||
yield chunk
|
||||
if run_manager:
|
||||
|
||||
@@ -3,6 +3,7 @@ import threading
|
||||
from typing import Any, Dict, List, Mapping, Optional
|
||||
|
||||
import requests
|
||||
from langchain_core._api.deprecation import deprecated
|
||||
from langchain_core.callbacks import CallbackManagerForLLMRun
|
||||
from langchain_core.language_models.chat_models import BaseChatModel
|
||||
from langchain_core.messages import (
|
||||
@@ -30,6 +31,10 @@ def _convert_message_to_dict(message: BaseMessage) -> dict:
|
||||
return message_dict
|
||||
|
||||
|
||||
@deprecated(
|
||||
since="0.0.13",
|
||||
alternative="langchain_community.chat_models.QianfanChatEndpoint",
|
||||
)
|
||||
class ErnieBotChat(BaseChatModel):
|
||||
"""`ERNIE-Bot` large language model.
|
||||
|
||||
|
||||
@@ -1,18 +1,26 @@
|
||||
import json
|
||||
import logging
|
||||
from typing import Any, Dict, List, Mapping, Optional
|
||||
import re
|
||||
from typing import Any, Dict, Iterator, List, Mapping, Optional, Type
|
||||
|
||||
import requests
|
||||
from langchain_core.callbacks import CallbackManagerForLLMRun
|
||||
from langchain_core.language_models.chat_models import BaseChatModel
|
||||
from langchain_core.language_models.chat_models import (
|
||||
BaseChatModel,
|
||||
generate_from_stream,
|
||||
)
|
||||
from langchain_core.messages import (
|
||||
AIMessage,
|
||||
AIMessageChunk,
|
||||
BaseMessage,
|
||||
BaseMessageChunk,
|
||||
ChatMessage,
|
||||
ChatMessageChunk,
|
||||
HumanMessage,
|
||||
HumanMessageChunk,
|
||||
SystemMessage,
|
||||
)
|
||||
from langchain_core.outputs import ChatGeneration, ChatResult
|
||||
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
|
||||
from langchain_core.pydantic_v1 import root_validator
|
||||
from langchain_core.utils import get_pydantic_field_names
|
||||
|
||||
@@ -45,10 +53,26 @@ def _convert_message_to_dict(message: BaseMessage) -> dict:
|
||||
return message_dict
|
||||
|
||||
|
||||
class WasmChatService(BaseChatModel):
|
||||
def _convert_delta_to_message_chunk(
|
||||
_dict: Mapping[str, Any], default_class: Type[BaseMessageChunk]
|
||||
) -> BaseMessageChunk:
|
||||
role = _dict.get("role")
|
||||
content = _dict.get("content") or ""
|
||||
|
||||
if role == "user" or default_class == HumanMessageChunk:
|
||||
return HumanMessageChunk(content=content)
|
||||
elif role == "assistant" or default_class == AIMessageChunk:
|
||||
return AIMessageChunk(content=content)
|
||||
elif role or default_class == ChatMessageChunk:
|
||||
return ChatMessageChunk(content=content, role=role)
|
||||
else:
|
||||
return default_class(content=content)
|
||||
|
||||
|
||||
class LlamaEdgeChatService(BaseChatModel):
|
||||
"""Chat with LLMs via `llama-api-server`
|
||||
|
||||
For the information about `llama-api-server`, visit https://github.com/second-state/llama-utils
|
||||
For the information about `llama-api-server`, visit https://github.com/second-state/LlamaEdge
|
||||
"""
|
||||
|
||||
request_timeout: int = 60
|
||||
@@ -57,6 +81,8 @@ class WasmChatService(BaseChatModel):
|
||||
"""URL of WasmChat service"""
|
||||
model: str = "NA"
|
||||
"""model name, default is `NA`."""
|
||||
streaming: bool = False
|
||||
"""Whether to stream the results or not."""
|
||||
|
||||
class Config:
|
||||
"""Configuration for this pydantic object."""
|
||||
@@ -96,6 +122,12 @@ class WasmChatService(BaseChatModel):
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> ChatResult:
|
||||
if self.streaming:
|
||||
stream_iter = self._stream(
|
||||
messages=messages, stop=stop, run_manager=run_manager, **kwargs
|
||||
)
|
||||
return generate_from_stream(stream_iter)
|
||||
|
||||
res = self._chat(messages, **kwargs)
|
||||
|
||||
if res.status_code != 200:
|
||||
@@ -105,6 +137,64 @@ class WasmChatService(BaseChatModel):
|
||||
|
||||
return self._create_chat_result(response)
|
||||
|
||||
def _stream(
|
||||
self,
|
||||
messages: List[BaseMessage],
|
||||
stop: Optional[List[str]] = None,
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> Iterator[ChatGenerationChunk]:
|
||||
res = self._chat(messages, **kwargs)
|
||||
|
||||
default_chunk_class = AIMessageChunk
|
||||
substring = '"object":"chat.completion.chunk"}'
|
||||
for line in res.iter_lines():
|
||||
chunks = []
|
||||
if line:
|
||||
json_string = line.decode("utf-8")
|
||||
|
||||
# Find all positions of the substring
|
||||
positions = [m.start() for m in re.finditer(substring, json_string)]
|
||||
positions = [-1 * len(substring)] + positions
|
||||
|
||||
for i in range(len(positions) - 1):
|
||||
chunk = json.loads(
|
||||
json_string[
|
||||
positions[i] + len(substring) : positions[i + 1]
|
||||
+ len(substring)
|
||||
]
|
||||
)
|
||||
chunks.append(chunk)
|
||||
|
||||
for chunk in chunks:
|
||||
if not isinstance(chunk, dict):
|
||||
chunk = chunk.dict()
|
||||
if len(chunk["choices"]) == 0:
|
||||
continue
|
||||
|
||||
choice = chunk["choices"][0]
|
||||
chunk = _convert_delta_to_message_chunk(
|
||||
choice["delta"], default_chunk_class
|
||||
)
|
||||
if (
|
||||
choice.get("finish_reason") is not None
|
||||
and choice.get("finish_reason") == "stop"
|
||||
):
|
||||
break
|
||||
finish_reason = choice.get("finish_reason")
|
||||
generation_info = (
|
||||
dict(finish_reason=finish_reason)
|
||||
if finish_reason is not None
|
||||
else None
|
||||
)
|
||||
default_chunk_class = chunk.__class__
|
||||
chunk = ChatGenerationChunk(
|
||||
message=chunk, generation_info=generation_info
|
||||
)
|
||||
yield chunk
|
||||
if run_manager:
|
||||
run_manager.on_llm_new_token(chunk.text, chunk=chunk)
|
||||
|
||||
def _chat(self, messages: List[BaseMessage], **kwargs: Any) -> requests.Response:
|
||||
if self.service_url is None:
|
||||
res = requests.models.Response()
|
||||
@@ -114,10 +204,17 @@ class WasmChatService(BaseChatModel):
|
||||
|
||||
service_url = f"{self.service_url}/v1/chat/completions"
|
||||
|
||||
payload = {
|
||||
"model": self.model,
|
||||
"messages": [_convert_message_to_dict(m) for m in messages],
|
||||
}
|
||||
if self.streaming:
|
||||
payload = {
|
||||
"model": self.model,
|
||||
"messages": [_convert_message_to_dict(m) for m in messages],
|
||||
"stream": self.streaming,
|
||||
}
|
||||
else:
|
||||
payload = {
|
||||
"model": self.model,
|
||||
"messages": [_convert_message_to_dict(m) for m in messages],
|
||||
}
|
||||
|
||||
res = requests.post(
|
||||
url=service_url,
|
||||
@@ -144,7 +144,9 @@ def _convert_delta_to_message_chunk(
|
||||
return default_class(content=content)
|
||||
|
||||
|
||||
@deprecated(since="0.1.0", removal="0.2.0", alternative="langchain_openai.ChatOpenAI")
|
||||
@deprecated(
|
||||
since="0.0.10", removal="0.2.0", alternative_import="langchain_openai.ChatOpenAI"
|
||||
)
|
||||
class ChatOpenAI(BaseChatModel):
|
||||
"""`OpenAI` Chat large language models API.
|
||||
|
||||
|
||||
@@ -315,9 +315,7 @@ class ChatTongyi(BaseChatModel):
|
||||
)
|
||||
resp = await asyncio.get_running_loop().run_in_executor(
|
||||
None,
|
||||
functools.partial(
|
||||
self.completion_with_retry, **{"run_manager": run_manager, **params}
|
||||
),
|
||||
functools.partial(self.completion_with_retry, **params),
|
||||
)
|
||||
generations.append(
|
||||
ChatGeneration(**self._chat_generation_from_qwen_resp(resp))
|
||||
|
||||
@@ -9,6 +9,7 @@ from typing import TYPE_CHECKING, Any, Dict, Iterator, List, Optional, Union, ca
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import requests
|
||||
from langchain_core._api.deprecation import deprecated
|
||||
from langchain_core.callbacks import (
|
||||
AsyncCallbackManagerForLLMRun,
|
||||
CallbackManagerForLLMRun,
|
||||
@@ -203,6 +204,11 @@ def _get_question(messages: List[BaseMessage]) -> HumanMessage:
|
||||
return question
|
||||
|
||||
|
||||
@deprecated(
|
||||
since="0.0.12",
|
||||
removal="0.2.0",
|
||||
alternative_import="langchain_google_vertexai.ChatVertexAI",
|
||||
)
|
||||
class ChatVertexAI(_VertexAICommon, BaseChatModel):
|
||||
"""`Vertex AI` Chat large language models API."""
|
||||
|
||||
|
||||
@@ -180,6 +180,7 @@ from langchain_community.document_loaders.snowflake_loader import SnowflakeLoade
|
||||
from langchain_community.document_loaders.spreedly import SpreedlyLoader
|
||||
from langchain_community.document_loaders.srt import SRTLoader
|
||||
from langchain_community.document_loaders.stripe import StripeLoader
|
||||
from langchain_community.document_loaders.surrealdb import SurrealDBLoader
|
||||
from langchain_community.document_loaders.telegram import (
|
||||
TelegramChatApiLoader,
|
||||
TelegramChatFileLoader,
|
||||
@@ -360,6 +361,7 @@ __all__ = [
|
||||
"SnowflakeLoader",
|
||||
"SpreedlyLoader",
|
||||
"StripeLoader",
|
||||
"SurrealDBLoader",
|
||||
"TelegramChatApiLoader",
|
||||
"TelegramChatFileLoader",
|
||||
"TelegramChatLoader",
|
||||
|
||||
@@ -48,6 +48,8 @@ class AzureAIDocumentIntelligenceLoader(BaseLoader):
|
||||
the default value from SDK.
|
||||
api_model: str
|
||||
The model name or ID to be used for form recognition in Azure.
|
||||
mode: Optional[str]
|
||||
The type of content representation of the generated Documents.
|
||||
|
||||
Examples:
|
||||
---------
|
||||
@@ -56,7 +58,8 @@ class AzureAIDocumentIntelligenceLoader(BaseLoader):
|
||||
... api_endpoint="https://endpoint.azure.com",
|
||||
... api_key="APIKEY",
|
||||
... api_version="2023-10-31-preview",
|
||||
... model="prebuilt-document"
|
||||
... model="prebuilt-document",
|
||||
... mode="markdown"
|
||||
... )
|
||||
"""
|
||||
|
||||
|
||||
@@ -64,7 +64,7 @@ class OpenAIWhisperParser(BaseBlobParser):
|
||||
file_obj.name = f"part_{split_number}.mp3"
|
||||
|
||||
# Transcribe
|
||||
print(f"Transcribing part {split_number+1}!")
|
||||
print(f"Transcribing part {split_number + 1}!")
|
||||
attempts = 0
|
||||
while attempts < 3:
|
||||
try:
|
||||
@@ -116,6 +116,8 @@ class OpenAIWhisperParserLocal(BaseBlobParser):
|
||||
self,
|
||||
device: str = "0",
|
||||
lang_model: Optional[str] = None,
|
||||
batch_size: int = 8,
|
||||
chunk_length: int = 30,
|
||||
forced_decoder_ids: Optional[Tuple[Dict]] = None,
|
||||
):
|
||||
"""Initialize the parser.
|
||||
@@ -126,6 +128,10 @@ class OpenAIWhisperParserLocal(BaseBlobParser):
|
||||
Defaults to None.
|
||||
forced_decoder_ids: id states for decoder in a multilanguage model.
|
||||
Defaults to None.
|
||||
batch_size: batch size used for decoding
|
||||
Defaults to 8.
|
||||
chunk_length: chunk length used during inference.
|
||||
Defaults to 30s.
|
||||
"""
|
||||
try:
|
||||
from transformers import pipeline
|
||||
@@ -141,47 +147,37 @@ class OpenAIWhisperParserLocal(BaseBlobParser):
|
||||
"torch package not found, please install it with " "`pip install torch`"
|
||||
)
|
||||
|
||||
# set device, cpu by default check if there is a GPU available
|
||||
# Determine the device to use
|
||||
if device == "cpu":
|
||||
self.device = "cpu"
|
||||
if lang_model is not None:
|
||||
self.lang_model = lang_model
|
||||
print("WARNING! Model override. Using model: ", self.lang_model)
|
||||
else:
|
||||
# unless overridden, use the small base model on cpu
|
||||
self.lang_model = "openai/whisper-base"
|
||||
else:
|
||||
if torch.cuda.is_available():
|
||||
self.device = "cuda:0"
|
||||
# check GPU memory and select automatically the model
|
||||
mem = torch.cuda.get_device_properties(self.device).total_memory / (
|
||||
1024**2
|
||||
)
|
||||
if mem < 5000:
|
||||
rec_model = "openai/whisper-base"
|
||||
elif mem < 7000:
|
||||
rec_model = "openai/whisper-small"
|
||||
elif mem < 12000:
|
||||
rec_model = "openai/whisper-medium"
|
||||
else:
|
||||
rec_model = "openai/whisper-large"
|
||||
self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# check if model is overridden
|
||||
if lang_model is not None:
|
||||
self.lang_model = lang_model
|
||||
print("WARNING! Model override. Might not fit in your GPU")
|
||||
else:
|
||||
self.lang_model = rec_model
|
||||
if self.device == "cpu":
|
||||
default_model = "openai/whisper-base"
|
||||
self.lang_model = lang_model if lang_model else default_model
|
||||
else:
|
||||
# Set the language model based on the device and available memory
|
||||
mem = torch.cuda.get_device_properties(self.device).total_memory / (1024**2)
|
||||
if mem < 5000:
|
||||
rec_model = "openai/whisper-base"
|
||||
elif mem < 7000:
|
||||
rec_model = "openai/whisper-small"
|
||||
elif mem < 12000:
|
||||
rec_model = "openai/whisper-medium"
|
||||
else:
|
||||
"cpu"
|
||||
rec_model = "openai/whisper-large"
|
||||
self.lang_model = lang_model if lang_model else rec_model
|
||||
|
||||
print("Using the following model: ", self.lang_model)
|
||||
|
||||
self.batch_size = batch_size
|
||||
|
||||
# load model for inference
|
||||
self.pipe = pipeline(
|
||||
"automatic-speech-recognition",
|
||||
model=self.lang_model,
|
||||
chunk_length_s=30,
|
||||
chunk_length_s=chunk_length,
|
||||
device=self.device,
|
||||
)
|
||||
if forced_decoder_ids is not None:
|
||||
@@ -224,7 +220,7 @@ class OpenAIWhisperParserLocal(BaseBlobParser):
|
||||
|
||||
y, sr = librosa.load(file_obj, sr=16000)
|
||||
|
||||
prediction = self.pipe(y.copy(), batch_size=8)["text"]
|
||||
prediction = self.pipe(y.copy(), batch_size=self.batch_size)["text"]
|
||||
|
||||
yield Document(
|
||||
page_content=prediction,
|
||||
|
||||
@@ -98,7 +98,7 @@ class AzureAIDocumentIntelligenceParser(BaseBlobParser):
|
||||
|
||||
if self.mode in ["single", "markdown"]:
|
||||
yield from self._generate_docs_single(result)
|
||||
elif self.mode == ["page"]:
|
||||
elif self.mode in ["page"]:
|
||||
yield from self._generate_docs_page(result)
|
||||
else:
|
||||
yield from self._generate_docs_object(result)
|
||||
@@ -116,7 +116,7 @@ class AzureAIDocumentIntelligenceParser(BaseBlobParser):
|
||||
|
||||
if self.mode in ["single", "markdown"]:
|
||||
yield from self._generate_docs_single(result)
|
||||
elif self.mode == ["page"]:
|
||||
elif self.mode in ["page"]:
|
||||
yield from self._generate_docs_page(result)
|
||||
else:
|
||||
yield from self._generate_docs_object(result)
|
||||
|
||||
@@ -0,0 +1,97 @@
|
||||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
from typing import Any, Dict, List, Optional
|
||||
|
||||
from langchain_core.documents import Document
|
||||
|
||||
from langchain_community.document_loaders.base import BaseLoader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class SurrealDBLoader(BaseLoader):
|
||||
"""Load SurrealDB documents."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
filter_criteria: Optional[Dict] = None,
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
try:
|
||||
from surrealdb import Surreal
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"""Cannot import from surrealdb.
|
||||
please install with `pip install surrealdb`."""
|
||||
) from e
|
||||
|
||||
self.dburl = kwargs.pop("dburl", "ws://localhost:8000/rpc")
|
||||
|
||||
if self.dburl[0:2] == "ws":
|
||||
self.sdb = Surreal(self.dburl)
|
||||
else:
|
||||
raise ValueError("Only websocket connections are supported at this time.")
|
||||
|
||||
self.filter_criteria = filter_criteria or {}
|
||||
|
||||
if "table" in self.filter_criteria:
|
||||
raise ValueError(
|
||||
"key `table` is not a valid criteria for `filter_criteria` argument."
|
||||
)
|
||||
|
||||
self.ns = kwargs.pop("ns", "langchain")
|
||||
self.db = kwargs.pop("db", "database")
|
||||
self.table = kwargs.pop("table", "documents")
|
||||
self.sdb = Surreal(self.dburl)
|
||||
self.kwargs = kwargs
|
||||
|
||||
asyncio.run(self.initialize())
|
||||
|
||||
async def initialize(self) -> None:
|
||||
"""
|
||||
Initialize connection to surrealdb database
|
||||
and authenticate if credentials are provided
|
||||
"""
|
||||
await self.sdb.connect()
|
||||
if "db_user" in self.kwargs and "db_pass" in self.kwargs:
|
||||
user = self.kwargs.get("db_user")
|
||||
password = self.kwargs.get("db_pass")
|
||||
await self.sdb.signin({"user": user, "pass": password})
|
||||
|
||||
await self.sdb.use(self.ns, self.db)
|
||||
|
||||
def load(self) -> List[Document]:
|
||||
async def _load() -> List[Document]:
|
||||
await self.initialize()
|
||||
return await self.aload()
|
||||
|
||||
return asyncio.run(_load())
|
||||
|
||||
async def aload(self) -> List[Document]:
|
||||
"""Load data into Document objects."""
|
||||
|
||||
query = "SELECT * FROM type::table($table)"
|
||||
if self.filter_criteria is not None and len(self.filter_criteria) > 0:
|
||||
query += " WHERE "
|
||||
for idx, key in enumerate(self.filter_criteria):
|
||||
query += f""" {"AND" if idx > 0 else ""} {key} = ${key}"""
|
||||
|
||||
metadata = {
|
||||
"ns": self.ns,
|
||||
"db": self.db,
|
||||
"table": self.table,
|
||||
}
|
||||
results = await self.sdb.query(
|
||||
query, {"table": self.table, **self.filter_criteria}
|
||||
)
|
||||
|
||||
return [
|
||||
(
|
||||
Document(
|
||||
page_content=json.dumps(result),
|
||||
metadata={"id": result["id"], **result["metadata"], **metadata},
|
||||
)
|
||||
)
|
||||
for result in results[0]["result"]
|
||||
]
|
||||
@@ -66,7 +66,27 @@ class DoctranPropertyExtractor(BaseDocumentTransformer):
|
||||
async def atransform_documents(
|
||||
self, documents: Sequence[Document], **kwargs: Any
|
||||
) -> Sequence[Document]:
|
||||
raise NotImplementedError
|
||||
"""Extracts properties from text documents using doctran."""
|
||||
try:
|
||||
from doctran import Doctran, ExtractProperty
|
||||
|
||||
doctran = Doctran(
|
||||
openai_api_key=self.openai_api_key, openai_model=self.openai_api_model
|
||||
)
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"Install doctran to use this parser. (pip install doctran)"
|
||||
)
|
||||
properties = [ExtractProperty(**property) for property in self.properties]
|
||||
for d in documents:
|
||||
doctran_doc = (
|
||||
doctran.parse(content=d.page_content)
|
||||
.extract(properties=properties)
|
||||
.execute()
|
||||
)
|
||||
|
||||
d.metadata["extracted_properties"] = doctran_doc.extracted_properties
|
||||
return documents
|
||||
|
||||
def transform_documents(
|
||||
self, documents: Sequence[Document], **kwargs: Any
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user