mirror of
https://github.com/hwchase17/langchain.git
synced 2026-02-05 08:40:36 +00:00
Compare commits
305 Commits
erick/deep
...
fork/async
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
621c8b914d | ||
|
|
d092f8a013 | ||
|
|
a688185b83 | ||
|
|
a989f82027 | ||
|
|
e30c6662df | ||
|
|
08d3fd7f2e | ||
|
|
42db96477f | ||
|
|
a79345f199 | ||
|
|
bcc71d1a57 | ||
|
|
68f7468754 | ||
|
|
61e876aad8 | ||
|
|
5df8ab574e | ||
|
|
f3d61a6e47 | ||
|
|
61b200947f | ||
|
|
75ad0bba2d | ||
|
|
1e3ce338ca | ||
|
|
6c89507988 | ||
|
|
31790d15ec | ||
|
|
db80832e4f | ||
|
|
ef42d9d559 | ||
|
|
148347e858 | ||
|
|
35e60728b7 | ||
|
|
6023953ea7 | ||
|
|
3b8eba32f9 | ||
|
|
e86e66bad7 | ||
|
|
e510cfaa23 | ||
|
|
355ef2a4a6 | ||
|
|
9dd7cbb447 | ||
|
|
0785432e7b | ||
|
|
adc008407e | ||
|
|
c4e9c9ca29 | ||
|
|
b8768bd6e7 | ||
|
|
f6a05e964b | ||
|
|
c173a69908 | ||
|
|
f9976b9630 | ||
|
|
5c2538b9f7 | ||
|
|
a91181fe6d | ||
|
|
04651f0248 | ||
|
|
1113700b09 | ||
|
|
54dd8e52a8 | ||
|
|
fe382fcf20 | ||
|
|
06f66f25e1 | ||
|
|
b1b351b37e | ||
|
|
4fad71882e | ||
|
|
ce595f0203 | ||
|
|
fdbfa6b2c8 | ||
|
|
643fb3ab50 | ||
|
|
8d990ba67b | ||
|
|
63da14d620 | ||
|
|
8d299645f9 | ||
|
|
dfd94fb2f0 | ||
|
|
0b740ebd49 | ||
|
|
13cf4594f4 | ||
|
|
6004e9706f | ||
|
|
66aafc0573 | ||
|
|
9e95699277 | ||
|
|
b3ed98dec0 | ||
|
|
3f38e1a457 | ||
|
|
61da2ff24c | ||
|
|
d628a80a5d | ||
|
|
4c7755778d | ||
|
|
2b2285dac0 | ||
|
|
476bf8b763 | ||
|
|
019b6ebe8d | ||
|
|
80fcc50c65 | ||
|
|
5c6e123757 | ||
|
|
0e2e7d8b83 | ||
|
|
d898d2f07b | ||
|
|
ff3163297b | ||
|
|
4ec3fe4680 | ||
|
|
4e160540ff | ||
|
|
c69f599594 | ||
|
|
95ee69a301 | ||
|
|
e135e5257c | ||
|
|
90f5a1c40e | ||
|
|
92e6a641fd | ||
|
|
9ce177580a | ||
|
|
20fcd49348 | ||
|
|
cfc225ecb3 | ||
|
|
26b2ad6d5b | ||
|
|
e529939c54 | ||
|
|
afb25eeec4 | ||
|
|
51c8ef6af4 | ||
|
|
c3530f1c11 | ||
|
|
ba326b98d0 | ||
|
|
54149292f8 | ||
|
|
ef6a335570 | ||
|
|
1f4ac62dee | ||
|
|
39d1cbfecf | ||
|
|
d0a8082188 | ||
|
|
5de59f9236 | ||
|
|
226fe645f1 | ||
|
|
4b7969efc5 | ||
|
|
fb41b68ea1 | ||
|
|
3b0226b2c6 | ||
|
|
c98994c3c9 | ||
|
|
c88750d54b | ||
|
|
e5672bc944 | ||
|
|
404abf139a | ||
|
|
a500527030 | ||
|
|
b9e7f6f38a | ||
|
|
d6275e47f2 | ||
|
|
5694728816 | ||
|
|
a950fa0487 | ||
|
|
1011b681dc | ||
|
|
b26a22f307 | ||
|
|
8da34118bc | ||
|
|
d1b4ead87c | ||
|
|
fbe592a5ce | ||
|
|
d511366dd3 | ||
|
|
774e543e1f | ||
|
|
b9f5104e6c | ||
|
|
35ec0bbd3b | ||
|
|
2ac3a82d85 | ||
|
|
cfe95ab085 | ||
|
|
dd5b8107b1 | ||
|
|
873de14cd8 | ||
|
|
6b2a57161a | ||
|
|
aad2aa7188 | ||
|
|
1b9001db47 | ||
|
|
01c2f27ffa | ||
|
|
369e90d427 | ||
|
|
a1c0cf21c9 | ||
|
|
7ecd2f22ac | ||
|
|
8569b8f680 | ||
|
|
fc196cab12 | ||
|
|
eac91b60c9 | ||
|
|
85e8423312 | ||
|
|
de209af533 | ||
|
|
54f90fc6bc | ||
|
|
1445ac95e8 | ||
|
|
af9f1738ca | ||
|
|
8779013847 | ||
|
|
9cf0f5eb78 | ||
|
|
1dc6c1ce06 | ||
|
|
05162928c0 | ||
|
|
acc14802d1 | ||
|
|
e1c59779ad | ||
|
|
971a68d04f | ||
|
|
f9be877ed7 | ||
|
|
076dbb1a8f | ||
|
|
c6bd7778b0 | ||
|
|
89372fca22 | ||
|
|
5396604ef4 | ||
|
|
c2a614eddc | ||
|
|
ef75bb63ce | ||
|
|
3d23a5eb36 | ||
|
|
ffae98d371 | ||
|
|
1e29b676d5 | ||
|
|
4ef0ed4ddc | ||
|
|
91230ef5d1 | ||
|
|
39b3c6d94c | ||
|
|
9b0a531aa2 | ||
|
|
63e2acc964 | ||
|
|
881d1c3ec5 | ||
|
|
e3828bee43 | ||
|
|
2454fefc53 | ||
|
|
84bf5787a7 | ||
|
|
6f7a414955 | ||
|
|
cc2e30fa13 | ||
|
|
3b649f4331 | ||
|
|
c0d453d8ac | ||
|
|
021b0484a8 | ||
|
|
f63906a9c2 | ||
|
|
3ccbe11363 | ||
|
|
fc84083ce5 | ||
|
|
9d32af72ce | ||
|
|
3613d8a2ad | ||
|
|
0f99646ca6 | ||
|
|
177af65dc4 | ||
|
|
f175bf7d7b | ||
|
|
e5878c467a | ||
|
|
2f348c695a | ||
|
|
50959abf0c | ||
|
|
b9495da92d | ||
|
|
eec3347939 | ||
|
|
92bc80483a | ||
|
|
0e76d84137 | ||
|
|
aa35b43bcd | ||
|
|
f2b2d59e82 | ||
|
|
f60f59d69f | ||
|
|
6bc6d64a12 | ||
|
|
65b231d40b | ||
|
|
ed118950fe | ||
|
|
aa2e642ce3 | ||
|
|
6b9e3ed9e9 | ||
|
|
ecd4f0a7ec | ||
|
|
27ad65cc68 | ||
|
|
7d444724d7 | ||
|
|
5d8c147332 | ||
|
|
3502a407d9 | ||
|
|
ca014d5b04 | ||
|
|
1e80113ac9 | ||
|
|
27ed2673da | ||
|
|
f238217cea | ||
|
|
2af813c7eb | ||
|
|
679a3ae933 | ||
|
|
7ad9eba8f4 | ||
|
|
58f0ba306b | ||
|
|
ec9642d667 | ||
|
|
5c73fd5bba | ||
|
|
fb940d11df | ||
|
|
1fa056c324 | ||
|
|
11327e6b64 | ||
|
|
2709d3e5f2 | ||
|
|
c5f6b828ad | ||
|
|
e7ddec1f2c | ||
|
|
49aff3ea5b | ||
|
|
60b1bd02d7 | ||
|
|
9e9ad9b0e9 | ||
|
|
d350be959d | ||
|
|
d0e101e4e0 | ||
|
|
bc0cb1148a | ||
|
|
8597484195 | ||
|
|
9c2f1f07a0 | ||
|
|
f406dc3872 | ||
|
|
da96c511d1 | ||
|
|
b0c3e3db2b | ||
|
|
d91126fc64 | ||
|
|
3606c5d5e9 | ||
|
|
a35e5f19a8 | ||
|
|
06fe2f4fb0 | ||
|
|
ce10fe0c2f | ||
|
|
e5cf1e2414 | ||
|
|
f3601b0aaf | ||
|
|
c323742f4f | ||
|
|
f974eb5b8b | ||
|
|
4df14a61fc | ||
|
|
8840a8cc95 | ||
|
|
3d34347a85 | ||
|
|
62a2e9ee19 | ||
|
|
6b6269441c | ||
|
|
5f057f24ac | ||
|
|
076593382a | ||
|
|
c5656a4905 | ||
|
|
770f57196e | ||
|
|
52114bdfac | ||
|
|
ca288d8f2c | ||
|
|
476fb328ee | ||
|
|
697a6f2c80 | ||
|
|
061e63eef2 | ||
|
|
d196646811 | ||
|
|
5cf06db3b3 | ||
|
|
d334efc848 | ||
|
|
251afda549 | ||
|
|
7220124368 | ||
|
|
ee378a0f40 | ||
|
|
ddf4e7c633 | ||
|
|
ce21392a21 | ||
|
|
9e779ca846 | ||
|
|
daa9ccae52 | ||
|
|
7c57cfd8f0 | ||
|
|
beec7259c8 | ||
|
|
b11fd3bedc | ||
|
|
7306032dcf | ||
|
|
21e0df937f | ||
|
|
15c2b4a47e | ||
|
|
fb676d8a9b | ||
|
|
6137c7608d | ||
|
|
e80aab2275 | ||
|
|
ce7723c1e5 | ||
|
|
8799b028a6 | ||
|
|
fb7e66b809 | ||
|
|
c0773ab329 | ||
|
|
14244bd7e5 | ||
|
|
768e5e33bc | ||
|
|
86321a949f | ||
|
|
60d6a416e6 | ||
|
|
f7706637a8 | ||
|
|
0fa06732b7 | ||
|
|
7b084b4cc7 | ||
|
|
bccb07f93e | ||
|
|
3f75fd41cc | ||
|
|
eb6e385dc5 | ||
|
|
74bac7bda1 | ||
|
|
845e407e08 | ||
|
|
a74f3a4979 | ||
|
|
efe6cfafe2 | ||
|
|
1afac77439 | ||
|
|
9fb09c1c30 | ||
|
|
eb76f9c9fe | ||
|
|
bc60203d0f | ||
|
|
c697c89ca4 | ||
|
|
69533c8628 | ||
|
|
6a48ea43ec | ||
|
|
6a2889a4ec | ||
|
|
95020637bc | ||
|
|
d5808f786c | ||
|
|
13b90232c1 | ||
|
|
9b3962fc25 | ||
|
|
e26e1f8b37 | ||
|
|
eb9b334a6b | ||
|
|
560bb49c99 | ||
|
|
81d1ba05dc | ||
|
|
74d9fc2f9e | ||
|
|
bdd90ae2ee | ||
|
|
5efec068c9 | ||
|
|
ec4dab0449 | ||
|
|
f454e95461 | ||
|
|
782dd44be9 | ||
|
|
112208baa5 | ||
|
|
129552e3d6 | ||
|
|
438beb6c94 | ||
|
|
ebb6ad4f7a | ||
|
|
437cebc955 |
@@ -1,7 +1,17 @@
|
||||
name: "\U0001F680 Feature request"
|
||||
description: Submit a proposal/request for a new LangChain feature
|
||||
labels: ["02 Feature Request"]
|
||||
labels: [idea]
|
||||
body:
|
||||
- type: checkboxes
|
||||
id: checks
|
||||
attributes:
|
||||
label: Checked
|
||||
description: Please confirm and check all the following options.
|
||||
options:
|
||||
- label: I searched existing ideas and did not find a similar one
|
||||
required: true
|
||||
- label: I added a very descriptive title
|
||||
required: true
|
||||
- label: I've clearly described the feature request and motivation for it
|
||||
required: true
|
||||
- type: textarea
|
||||
id: feature-request
|
||||
validations:
|
||||
@@ -10,7 +20,6 @@ body:
|
||||
label: Feature request
|
||||
description: |
|
||||
A clear and concise description of the feature proposal. Please provide links to any relevant GitHub repos, papers, or other resources if relevant.
|
||||
|
||||
- type: textarea
|
||||
id: motivation
|
||||
validations:
|
||||
@@ -19,12 +28,11 @@ body:
|
||||
label: Motivation
|
||||
description: |
|
||||
Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too.
|
||||
|
||||
- type: textarea
|
||||
id: contribution
|
||||
id: proposal
|
||||
validations:
|
||||
required: true
|
||||
required: false
|
||||
attributes:
|
||||
label: Your contribution
|
||||
label: Proposal (If applicable)
|
||||
description: |
|
||||
Is there any way that you could help, e.g. by submitting a PR? Make sure to read the [Contributing Guide](https://python.langchain.com/docs/contributing/)
|
||||
If you would like to propose a solution, please describe it here.
|
||||
122
.github/DISCUSSION_TEMPLATE/q-a.yml
vendored
Normal file
122
.github/DISCUSSION_TEMPLATE/q-a.yml
vendored
Normal file
@@ -0,0 +1,122 @@
|
||||
labels: [Question]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for your interest in 🦜️🔗 LangChain!
|
||||
|
||||
Please follow these instructions, fill every question, and do every step. 🙏
|
||||
|
||||
We're asking for this because answering questions and solving problems in GitHub takes a lot of time --
|
||||
this is time that we cannot spend on adding new features, fixing bugs, write documentation or reviewing pull requests.
|
||||
|
||||
By asking questions in a structured way (following this) it will be much easier to help you.
|
||||
|
||||
And there's a high chance that you will find the solution along the way and you won't even have to submit it and wait for an answer. 😎
|
||||
|
||||
As there are too many questions, we will **DISCARD** and close the incomplete ones.
|
||||
|
||||
That will allow us (and others) to focus on helping people like you that follow the whole process. 🤓
|
||||
|
||||
Relevant links to check before opening a question to see if your question has already been answered, fixed or
|
||||
if there's another way to solve your problem:
|
||||
|
||||
[LangChain documentation with the integrated search](https://python.langchain.com/docs/get_started/introduction),
|
||||
[API Reference](https://api.python.langchain.com/en/stable/),
|
||||
[GitHub search](https://github.com/langchain-ai/langchain),
|
||||
[LangChain Github Discussions](https://github.com/langchain-ai/langchain/discussions),
|
||||
[LangChain Github Issues](https://github.com/langchain-ai/langchain/issues?q=is%3Aissue),
|
||||
[LangChain ChatBot](https://chat.langchain.com/)
|
||||
- type: checkboxes
|
||||
id: checks
|
||||
attributes:
|
||||
label: Checked other resources
|
||||
description: Please confirm and check all the following options.
|
||||
options:
|
||||
- label: I added a very descriptive title to this question.
|
||||
required: true
|
||||
- label: I searched the LangChain documentation with the integrated search.
|
||||
required: true
|
||||
- label: I used the GitHub search to find a similar question and didn't find it.
|
||||
required: true
|
||||
- type: checkboxes
|
||||
id: help
|
||||
attributes:
|
||||
label: Commit to Help
|
||||
description: |
|
||||
After submitting this, I commit to one of:
|
||||
|
||||
* Read open questions until I find 2 where I can help someone and add a comment to help there.
|
||||
* I already hit the "watch" button in this repository to receive notifications and I commit to help at least 2 people that ask questions in the future.
|
||||
* Once my question is answered, I will mark the answer as "accepted".
|
||||
options:
|
||||
- label: I commit to help with one of those options 👆
|
||||
required: true
|
||||
- type: textarea
|
||||
id: example
|
||||
attributes:
|
||||
label: Example Code
|
||||
description: |
|
||||
Please add a self-contained, [minimal, reproducible, example](https://stackoverflow.com/help/minimal-reproducible-example) with your use case.
|
||||
|
||||
If a maintainer can copy it, run it, and see it right away, there's a much higher chance that you'll be able to get help.
|
||||
|
||||
**Important!**
|
||||
|
||||
* Use code tags (e.g., ```python ... ```) to correctly [format your code](https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting).
|
||||
* INCLUDE the language label (e.g. `python`) after the first three backticks to enable syntax highlighting. (e.g., ```python rather than ```).
|
||||
* Reduce your code to the minimum required to reproduce the issue if possible. This makes it much easier for others to help you.
|
||||
* Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
from langchain_core.runnables import RunnableLambda
|
||||
|
||||
def bad_code(inputs) -> int:
|
||||
raise NotImplementedError('For demo purpose')
|
||||
|
||||
chain = RunnableLambda(bad_code)
|
||||
chain.invoke('Hello!')
|
||||
render: python
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: description
|
||||
attributes:
|
||||
label: Description
|
||||
description: |
|
||||
What is the problem, question, or error?
|
||||
|
||||
Write a short description explaining what you are doing, what you expect to happen, and what is currently happening.
|
||||
placeholder: |
|
||||
* I'm trying to use the `langchain` library to do X.
|
||||
* I expect to see Y.
|
||||
* Instead, it does Z.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: |
|
||||
Please share your system info with us.
|
||||
|
||||
"pip freeze | grep langchain"
|
||||
platform (windows / linux / mac)
|
||||
python version
|
||||
|
||||
OR if you're on a recent version of langchain-core you can paste the output of:
|
||||
|
||||
python -m langchain_core.sys_info
|
||||
placeholder: |
|
||||
"pip freeze | grep langchain"
|
||||
platform
|
||||
python version
|
||||
|
||||
Alternatively, if you're on a recent version of langchain-core you can paste the output of:
|
||||
|
||||
python -m langchain_core.sys_info
|
||||
|
||||
These will only surface LangChain packages, don't forget to include any other relevant
|
||||
packages you're using (if you're not sure what's relevant, you can paste the entire output of `pip freeze`).
|
||||
validations:
|
||||
required: true
|
||||
69
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
69
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -1,5 +1,5 @@
|
||||
name: "\U0001F41B Bug Report"
|
||||
description: Submit a bug report to help us improve LangChain. To report a security issue, please instead use the security option below.
|
||||
description: Report a bug in LangChain. To report a security issue, please instead use the security option below. For questions, please use the GitHub Discussions.
|
||||
labels: ["02 Bug Report"]
|
||||
body:
|
||||
- type: markdown
|
||||
@@ -7,6 +7,11 @@ body:
|
||||
value: >
|
||||
Thank you for taking the time to file a bug report.
|
||||
|
||||
Use this to report bugs in LangChain.
|
||||
|
||||
If you're not certain that your issue is due to a bug in LangChain, please use [GitHub Discussions](https://github.com/langchain-ai/langchain/discussions)
|
||||
to ask for help with your issue.
|
||||
|
||||
Relevant links to check before filing a bug report to see if your issue has already been reported, fixed or
|
||||
if there's another way to solve your problem:
|
||||
|
||||
@@ -14,7 +19,8 @@ body:
|
||||
[API Reference](https://api.python.langchain.com/en/stable/),
|
||||
[GitHub search](https://github.com/langchain-ai/langchain),
|
||||
[LangChain Github Discussions](https://github.com/langchain-ai/langchain/discussions),
|
||||
[LangChain Github Issues](https://github.com/langchain-ai/langchain/issues?q=is%3Aissue)
|
||||
[LangChain Github Issues](https://github.com/langchain-ai/langchain/issues?q=is%3Aissue),
|
||||
[LangChain ChatBot](https://chat.langchain.com/)
|
||||
- type: checkboxes
|
||||
id: checks
|
||||
attributes:
|
||||
@@ -27,6 +33,8 @@ body:
|
||||
required: true
|
||||
- label: I used the GitHub search to find a similar question and didn't find it.
|
||||
required: true
|
||||
- label: I am sure that this is a bug in LangChain rather than my code.
|
||||
required: true
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
validations:
|
||||
@@ -38,10 +46,12 @@ body:
|
||||
|
||||
If a maintainer can copy it, run it, and see it right away, there's a much higher chance that you'll be able to get help.
|
||||
|
||||
If you're including an error message, please include the full stack trace not just the last error.
|
||||
**Important!**
|
||||
|
||||
**Important!** Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
|
||||
Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
* Use code tags (e.g., ```python ... ```) to correctly [format your code](https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting).
|
||||
* INCLUDE the language label (e.g. `python`) after the first three backticks to enable syntax highlighting. (e.g., ```python rather than ```).
|
||||
* Reduce your code to the minimum required to reproduce the issue if possible. This makes it much easier for others to help you.
|
||||
* Avoid screenshots when possible, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
The following code:
|
||||
@@ -55,9 +65,16 @@ body:
|
||||
chain = RunnableLambda(bad_code)
|
||||
chain.invoke('Hello!')
|
||||
```
|
||||
|
||||
Include both the error and the full stack trace if reporting an exception!
|
||||
|
||||
- type: textarea
|
||||
id: error
|
||||
validations:
|
||||
required: false
|
||||
attributes:
|
||||
label: Error Message and Stack Trace (if applicable)
|
||||
description: |
|
||||
If you are reporting an error, please include the full error message and stack trace.
|
||||
placeholder: |
|
||||
Exception + full stack trace
|
||||
- type: textarea
|
||||
id: description
|
||||
attributes:
|
||||
@@ -76,28 +93,26 @@ body:
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us.
|
||||
description: |
|
||||
Please share your system info with us.
|
||||
|
||||
"pip freeze | grep langchain"
|
||||
platform (windows / linux / mac)
|
||||
python version
|
||||
|
||||
OR if you're on a recent version of langchain-core you can paste the output of:
|
||||
|
||||
python -m langchain_core.sys_info
|
||||
placeholder: |
|
||||
"pip freeze | grep langchain"
|
||||
platform
|
||||
python version
|
||||
|
||||
Alternatively, if you're on a recent version of langchain-core you can paste the output of:
|
||||
|
||||
python -m langchain_core.sys_info
|
||||
|
||||
These will only surface LangChain packages, don't forget to include any other relevant
|
||||
packages you're using (if you're not sure what's relevant, you can paste the entire output of `pip freeze`).
|
||||
validations:
|
||||
required: true
|
||||
- type: checkboxes
|
||||
id: related-components
|
||||
attributes:
|
||||
label: Related Components
|
||||
description: "Select the components related to the issue (if applicable):"
|
||||
options:
|
||||
- label: "LLMs/Chat Models"
|
||||
- label: "Embedding Models"
|
||||
- label: "Prompts / Prompt Templates / Prompt Selectors"
|
||||
- label: "Output Parsers"
|
||||
- label: "Document Loaders"
|
||||
- label: "Vector Stores / Retrievers"
|
||||
- label: "Memory"
|
||||
- label: "Agents / Agent Executors"
|
||||
- label: "Tools / Toolkits"
|
||||
- label: "Chains"
|
||||
- label: "Callbacks/Tracing"
|
||||
- label: "Async"
|
||||
|
||||
10
.github/ISSUE_TEMPLATE/config.yml
vendored
10
.github/ISSUE_TEMPLATE/config.yml
vendored
@@ -1,9 +1,15 @@
|
||||
blank_issues_enabled: true
|
||||
blank_issues_enabled: false
|
||||
version: 2.1
|
||||
contact_links:
|
||||
- name: 🤔 Question or Problem
|
||||
about: Ask a question or ask about a problem in GitHub Discussions.
|
||||
url: https://github.com/langchain-ai/langchain/discussions
|
||||
url: https://www.github.com/langchain-ai/langchain/discussions/categories/q-a
|
||||
- name: Discord
|
||||
url: https://discord.gg/6adMQxSpJS
|
||||
about: General community discussions
|
||||
- name: Feature Request
|
||||
url: https://www.github.com/langchain-ai/langchain/discussions/categories/ideas
|
||||
about: Suggest a feature or an idea
|
||||
- name: Show and tell
|
||||
about: Show what you built with LangChain
|
||||
url: https://www.github.com/langchain-ai/langchain/discussions/categories/show-and-tell
|
||||
|
||||
25
.github/ISSUE_TEMPLATE/privileged.yml
vendored
Normal file
25
.github/ISSUE_TEMPLATE/privileged.yml
vendored
Normal file
@@ -0,0 +1,25 @@
|
||||
name: 🔒 Privileged
|
||||
description: You are a LangChain maintainer, or was asked directly by a maintainer to create an issue here. If not, check the other options.
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for your interest in LangChain! 🚀
|
||||
|
||||
If you are not a LangChain maintainer or were not asked directly by a maintainer to create an issue, then please start the conversation in a [Question in GitHub Discussions](https://github.com/langchain-ai/langchain/discussions/categories/q-a) instead.
|
||||
|
||||
You are a LangChain maintainer if you maintain any of the packages inside of the LangChain repository
|
||||
or are a regular contributor to LangChain with previous merged merged pull requests.
|
||||
- type: checkboxes
|
||||
id: privileged
|
||||
attributes:
|
||||
label: Privileged issue
|
||||
description: Confirm that you are allowed to create an issue here.
|
||||
options:
|
||||
- label: I am a LangChain maintainer, or was asked directly by a LangChain maintainer to create an issue here.
|
||||
required: true
|
||||
- type: textarea
|
||||
id: content
|
||||
attributes:
|
||||
label: Issue Content
|
||||
description: Add the content of the issue here.
|
||||
2
.github/workflows/_all_ci.yml
vendored
2
.github/workflows/_all_ci.yml
vendored
@@ -32,7 +32,7 @@ concurrency:
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
lint:
|
||||
|
||||
@@ -9,7 +9,7 @@ on:
|
||||
description: "From which folder this pipeline executes"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
2
.github/workflows/_dependencies.yml
vendored
2
.github/workflows/_dependencies.yml
vendored
@@ -13,7 +13,7 @@ on:
|
||||
description: "Relative path to the langchain library folder"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
7
.github/workflows/_integration_test.yml
vendored
7
.github/workflows/_integration_test.yml
vendored
@@ -8,10 +8,11 @@ on:
|
||||
type: string
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
environment: Scheduled testing
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
@@ -51,6 +52,10 @@ jobs:
|
||||
MISTRAL_API_KEY: ${{ secrets.MISTRAL_API_KEY }}
|
||||
TOGETHER_API_KEY: ${{ secrets.TOGETHER_API_KEY }}
|
||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||
NVIDIA_API_KEY: ${{ secrets.NVIDIA_API_KEY }}
|
||||
GOOGLE_SEARCH_API_KEY: ${{ secrets.GOOGLE_SEARCH_API_KEY }}
|
||||
GOOGLE_CSE_ID: ${{ secrets.GOOGLE_CSE_ID }}
|
||||
EXA_API_KEY: ${{ secrets.EXA_API_KEY }}
|
||||
run: |
|
||||
make integration_tests
|
||||
|
||||
|
||||
2
.github/workflows/_lint.yml
vendored
2
.github/workflows/_lint.yml
vendored
@@ -13,7 +13,7 @@ on:
|
||||
description: "Relative path to the langchain library folder"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
WORKDIR: ${{ inputs.working-directory == '' && '.' || inputs.working-directory }}
|
||||
|
||||
# This env var allows us to get inline annotations when ruff has complaints.
|
||||
|
||||
18
.github/workflows/_release.yml
vendored
18
.github/workflows/_release.yml
vendored
@@ -16,11 +16,12 @@ on:
|
||||
|
||||
env:
|
||||
PYTHON_VERSION: "3.10"
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
if: github.ref == 'refs/heads/master'
|
||||
environment: Scheduled testing
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
outputs:
|
||||
@@ -117,11 +118,18 @@ jobs:
|
||||
# are not found on test PyPI can be resolved and installed anyway.
|
||||
# (https://test.pypi.org/simple). This will include the PKG_NAME==VERSION
|
||||
# package because VERSION will not have been uploaded to regular PyPI yet.
|
||||
#
|
||||
# - attempt install again after 5 seconds if it fails because there is
|
||||
# sometimes a delay in availability on test pypi
|
||||
run: |
|
||||
poetry run pip install \
|
||||
--extra-index-url https://test.pypi.org/simple/ \
|
||||
"$PKG_NAME==$VERSION"
|
||||
"$PKG_NAME==$VERSION" || \
|
||||
( \
|
||||
sleep 5 && \
|
||||
poetry run pip install \
|
||||
--extra-index-url https://test.pypi.org/simple/ \
|
||||
"$PKG_NAME==$VERSION" \
|
||||
)
|
||||
|
||||
# Replace all dashes in the package name with underscores,
|
||||
# since that's how Python imports packages with dashes in the name.
|
||||
@@ -163,6 +171,10 @@ jobs:
|
||||
MISTRAL_API_KEY: ${{ secrets.MISTRAL_API_KEY }}
|
||||
TOGETHER_API_KEY: ${{ secrets.TOGETHER_API_KEY }}
|
||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||
NVIDIA_API_KEY: ${{ secrets.NVIDIA_API_KEY }}
|
||||
GOOGLE_SEARCH_API_KEY: ${{ secrets.GOOGLE_SEARCH_API_KEY }}
|
||||
GOOGLE_CSE_ID: ${{ secrets.GOOGLE_CSE_ID }}
|
||||
EXA_API_KEY: ${{ secrets.EXA_API_KEY }}
|
||||
run: make integration_tests
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
|
||||
|
||||
2
.github/workflows/_test.yml
vendored
2
.github/workflows/_test.yml
vendored
@@ -13,7 +13,7 @@ on:
|
||||
description: "Relative path to the langchain library folder"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
2
.github/workflows/_test_release.yml
vendored
2
.github/workflows/_test_release.yml
vendored
@@ -9,7 +9,7 @@ on:
|
||||
description: "From which folder this pipeline executes"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
PYTHON_VERSION: "3.10"
|
||||
|
||||
jobs:
|
||||
|
||||
2
.github/workflows/scheduled_test.yml
vendored
2
.github/workflows/scheduled_test.yml
vendored
@@ -6,7 +6,7 @@ on:
|
||||
- cron: '0 13 * * *'
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
2
.github/workflows/templates_ci.yml
vendored
2
.github/workflows/templates_ci.yml
vendored
@@ -24,7 +24,7 @@ concurrency:
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
POETRY_VERSION: "1.7.1"
|
||||
WORKDIR: "templates"
|
||||
|
||||
jobs:
|
||||
|
||||
@@ -4,6 +4,9 @@
|
||||
# Required
|
||||
version: 2
|
||||
|
||||
formats:
|
||||
- pdf
|
||||
|
||||
# Set the version of Python and other tools you might need
|
||||
build:
|
||||
os: ubuntu-22.04
|
||||
|
||||
@@ -49,7 +49,7 @@ The LangChain libraries themselves are made up of several different packages.
|
||||
- **[`langchain-community`](libs/community)**: Third party integrations.
|
||||
- **[`langchain`](libs/langchain)**: Chains, agents, and retrieval strategies that make up an application's cognitive architecture.
|
||||
|
||||

|
||||

|
||||
|
||||
## 🧱 What can you build with LangChain?
|
||||
**❓ Retrieval augmented generation**
|
||||
|
||||
@@ -82,7 +82,7 @@
|
||||
"prompt = ChatPromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"# LLM\n",
|
||||
"from langchain_community.llms import Together\n",
|
||||
"from langchain_together import Together\n",
|
||||
"\n",
|
||||
"llm = Together(\n",
|
||||
" model=\"mistralai/Mixtral-8x7B-Instruct-v0.1\",\n",
|
||||
|
||||
@@ -6,7 +6,7 @@ pydantic<2
|
||||
autodoc_pydantic==1.8.0
|
||||
myst_parser
|
||||
nbsphinx==0.8.9
|
||||
sphinx==4.5.0
|
||||
sphinx>=5
|
||||
sphinx-autobuild==2021.3.14
|
||||
sphinx_rtd_theme==1.0.0
|
||||
sphinx-typlog-theme==0.8.0
|
||||
|
||||
@@ -32,7 +32,7 @@ For a [development container](https://containers.dev/), see the [.devcontainer f
|
||||
|
||||
### Dependency Management: Poetry and other env/dependency managers
|
||||
|
||||
This project utilizes [Poetry](https://python-poetry.org/) v1.6.1+ as a dependency manager.
|
||||
This project utilizes [Poetry](https://python-poetry.org/) v1.7.1+ as a dependency manager.
|
||||
|
||||
❗Note: *Before installing Poetry*, if you use `Conda`, create and activate a new Conda env (e.g. `conda create -n langchain python=3.9`)
|
||||
|
||||
@@ -75,7 +75,7 @@ make test
|
||||
|
||||
If during installation you receive a `WheelFileValidationError` for `debugpy`, please make sure you are running
|
||||
Poetry v1.6.1+. This bug was present in older versions of Poetry (e.g. 1.4.1) and has been resolved in newer releases.
|
||||
If you are still seeing this bug on v1.6.1, you may also try disabling "modern installation"
|
||||
If you are still seeing this bug on v1.6.1+, you may also try disabling "modern installation"
|
||||
(`poetry config installer.modern-installation false`) and re-installing requirements.
|
||||
See [this `debugpy` issue](https://github.com/microsoft/debugpy/issues/1246) for more details.
|
||||
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -302,7 +302,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -85,21 +85,10 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": null,
|
||||
"id": "2448b6c2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Graph(nodes={'7308e6063c6d40818c5a0cc1cc7444f2': Node(id='7308e6063c6d40818c5a0cc1cc7444f2', data=<class 'pydantic.main.RunnableParallel<context,question>Input'>), '292bbd8021d44ec3a31fbe724d9002c1': Node(id='292bbd8021d44ec3a31fbe724d9002c1', data=<class 'pydantic.main.RunnableParallel<context,question>Output'>), '9212f219cf05488f95229c56ea02b192': Node(id='9212f219cf05488f95229c56ea02b192', data=VectorStoreRetriever(tags=['FAISS', 'OpenAIEmbeddings'], vectorstore=<langchain_community.vectorstores.faiss.FAISS object at 0x117334f70>)), 'c7a8e65fa5cf44b99dbe7d1d6e36886f': Node(id='c7a8e65fa5cf44b99dbe7d1d6e36886f', data=RunnablePassthrough()), '818b9bfd40a341008373d5b9f9d0784b': Node(id='818b9bfd40a341008373d5b9f9d0784b', data=ChatPromptTemplate(input_variables=['context', 'question'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template='Answer the question based only on the following context:\\n{context}\\n\\nQuestion: {question}\\n'))])), 'b9f1d3ddfa6b4334a16ea439df22b11e': Node(id='b9f1d3ddfa6b4334a16ea439df22b11e', data=ChatOpenAI(client=<class 'openai.api_resources.chat_completion.ChatCompletion'>, openai_api_key='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', openai_proxy='')), '2bf84f6355c44731848345ca7d0f8ab9': Node(id='2bf84f6355c44731848345ca7d0f8ab9', data=StrOutputParser()), '1aeb2da5da5a43bb8771d3f338a473a2': Node(id='1aeb2da5da5a43bb8771d3f338a473a2', data=<class 'pydantic.main.StrOutputParserOutput'>)}, edges=[Edge(source='7308e6063c6d40818c5a0cc1cc7444f2', target='9212f219cf05488f95229c56ea02b192'), Edge(source='9212f219cf05488f95229c56ea02b192', target='292bbd8021d44ec3a31fbe724d9002c1'), Edge(source='7308e6063c6d40818c5a0cc1cc7444f2', target='c7a8e65fa5cf44b99dbe7d1d6e36886f'), Edge(source='c7a8e65fa5cf44b99dbe7d1d6e36886f', target='292bbd8021d44ec3a31fbe724d9002c1'), Edge(source='292bbd8021d44ec3a31fbe724d9002c1', target='818b9bfd40a341008373d5b9f9d0784b'), Edge(source='818b9bfd40a341008373d5b9f9d0784b', target='b9f1d3ddfa6b4334a16ea439df22b11e'), Edge(source='2bf84f6355c44731848345ca7d0f8ab9', target='1aeb2da5da5a43bb8771d3f338a473a2'), Edge(source='b9f1d3ddfa6b4334a16ea439df22b11e', target='2bf84f6355c44731848345ca7d0f8ab9')])"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain.get_graph()"
|
||||
]
|
||||
@@ -177,7 +166,7 @@
|
||||
"source": [
|
||||
"## Get the prompts\n",
|
||||
"\n",
|
||||
"An important part of every chain is the prompts that are used. You can get the graphs present in the chain:"
|
||||
"An important part of every chain is the prompts that are used. You can get the prompts present in the chain:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
1393
docs/docs/expression_language/streaming.ipynb
Normal file
1393
docs/docs/expression_language/streaming.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
@@ -14,7 +14,7 @@ This framework consists of several parts.
|
||||
- **[LangServe](/docs/langserve)**: A library for deploying LangChain chains as a REST API.
|
||||
- **[LangSmith](/docs/langsmith)**: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
|
||||
|
||||

|
||||

|
||||
|
||||
Together, these products simplify the entire application lifecycle:
|
||||
- **Develop**: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.
|
||||
@@ -78,7 +78,7 @@ Let models choose which tools to use given high-level directives
|
||||
Walkthroughs and techniques for common end-to-end use cases, like:
|
||||
- [Document question answering](/docs/use_cases/question_answering/)
|
||||
- [Chatbots](/docs/use_cases/chatbots/)
|
||||
- [Analyzing structured data](/docs/use_cases/qa_structured/sql/)
|
||||
- [Analyzing structured data](/docs/use_cases/sql/)
|
||||
- and much more...
|
||||
|
||||
### [Integrations](/docs/integrations/providers/)
|
||||
|
||||
@@ -59,7 +59,7 @@ In this quickstart, we will walk through a few different ways of doing that.
|
||||
We will start with a simple LLM chain, which just relies on information in the prompt template to respond.
|
||||
Next, we will build a retrieval chain, which fetches data from a separate database and passes that into the prompt template.
|
||||
We will then add in chat history, to create a conversation retrieval chain. This allows you interact in a chat manner with this LLM, so it remembers previous questions.
|
||||
Finally, we will build an agent - which utilizes and LLM to determine whether or not it needs to fetch data to answer questions.
|
||||
Finally, we will build an agent - which utilizes an LLM to determine whether or not it needs to fetch data to answer questions.
|
||||
We will cover these at a high level, but there are lot of details to all of these!
|
||||
We will link to relevant docs.
|
||||
|
||||
@@ -597,6 +597,6 @@ To continue on your journey, we recommend you read the following (in order):
|
||||
- [Model IO](/docs/modules/model_io) covers more details of prompts, LLMs, and output parsers.
|
||||
- [Retrieval](/docs/modules/data_connection) covers more details of everything related to retrieval
|
||||
- [Agents](/docs/modules/agents) covers details of everything related to agents
|
||||
- Explore common [end-to-end use cases](/docs/use_cases/qa_structured/sql) and [template applications](/docs/templates)
|
||||
- Explore common [end-to-end use cases](/docs/use_cases/) and [template applications](/docs/templates)
|
||||
- [Read up on LangSmith](/docs/langsmith/), the platform for debugging, testing, monitoring and more
|
||||
- Learn more about serving your applications with [LangServe](/docs/langserve)
|
||||
|
||||
@@ -12,7 +12,7 @@ Platforms with tracing capabilities like [LangSmith](/docs/langsmith/) and [Wand
|
||||
|
||||
For anyone building production-grade LLM applications, we highly recommend using a platform like this.
|
||||
|
||||

|
||||

|
||||
|
||||
## `set_debug` and `set_verbose`
|
||||
|
||||
|
||||
@@ -35,6 +35,22 @@
|
||||
"from langchain_openai import OpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3dd69cb4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"# get a new token: https://dashboard.cohere.ai/\n",
|
||||
"os.environ[\"COHERE_API_KEY\"] = getpass.getpass(\"Cohere API Key:\")\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"Open API Key:\")\n",
|
||||
"os.environ[\"HUGGINGFACEHUB_API_TOKEN\"] = getpass.getpass(\"Hugging Face API Key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
@@ -44,7 +60,7 @@
|
||||
"source": [
|
||||
"llms = [\n",
|
||||
" OpenAI(temperature=0),\n",
|
||||
" Cohere(model=\"command-xlarge-20221108\", max_tokens=20, temperature=0),\n",
|
||||
" Cohere(temperature=0),\n",
|
||||
" HuggingFaceHub(repo_id=\"google/flan-t5-xl\", model_kwargs={\"temperature\": 1}),\n",
|
||||
"]"
|
||||
]
|
||||
@@ -160,7 +176,7 @@
|
||||
" llm=open_ai_llm, search_chain=search, verbose=True\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"cohere_llm = Cohere(temperature=0, model=\"command-xlarge-20221108\")\n",
|
||||
"cohere_llm = Cohere(temperature=0)\n",
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"self_ask_with_search_cohere = SelfAskWithSearchChain(\n",
|
||||
" llm=cohere_llm, search_chain=search, verbose=True\n",
|
||||
@@ -241,14 +257,6 @@
|
||||
"source": [
|
||||
"model_lab.compare(\"What is the hometown of the reigning men's U.S. Open champion?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "94159131",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
138
docs/docs/integrations/callbacks/comet_tracing.ipynb
Normal file
138
docs/docs/integrations/callbacks/comet_tracing.ipynb
Normal file
@@ -0,0 +1,138 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5371a9bb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Comet Tracing\n",
|
||||
"\n",
|
||||
"There are two ways to trace your LangChains executions with Comet:\n",
|
||||
"\n",
|
||||
"1. Setting the `LANGCHAIN_COMET_TRACING` environment variable to \"true\". This is the recommended way.\n",
|
||||
"2. Import the `CometTracer` manually and pass it explicitely."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "17c04cc6-c93d-4b6c-a033-e897577f4ed1",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-05-18T12:47:46.580776Z",
|
||||
"start_time": "2023-05-18T12:47:46.577833Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"import comet_llm\n",
|
||||
"\n",
|
||||
"os.environ[\"LANGCHAIN_COMET_TRACING\"] = \"true\"\n",
|
||||
"\n",
|
||||
"# Connect to Comet if no API Key is set\n",
|
||||
"comet_llm.init()\n",
|
||||
"\n",
|
||||
"# comet documentation to configure comet using env variables\n",
|
||||
"# https://www.comet.com/docs/v2/api-and-sdk/llm-sdk/configuration/\n",
|
||||
"# here we are configuring the comet project\n",
|
||||
"os.environ[\"COMET_PROJECT_NAME\"] = \"comet-example-langchain-tracing\"\n",
|
||||
"\n",
|
||||
"from langchain.agents import AgentType, initialize_agent, load_tools\n",
|
||||
"from langchain.llms import OpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1b62cd48",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-05-18T12:47:47.445229Z",
|
||||
"start_time": "2023-05-18T12:47:47.436424Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Agent run with tracing. Ensure that OPENAI_API_KEY is set appropriately to run this example.\n",
|
||||
"\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"tools = load_tools([\"llm-math\"], llm=llm)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "bfa16b79-aa4b-4d41-a067-70d1f593f667",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-05-18T12:48:01.816137Z",
|
||||
"start_time": "2023-05-18T12:47:49.109574Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = initialize_agent(\n",
|
||||
" tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"agent.run(\"What is 2 raised to .123243 power?\") # this should be traced\n",
|
||||
"# An url for the chain like the following should print in your console:\n",
|
||||
"# https://www.comet.com/<workspace>/<project_name>\n",
|
||||
"# The url can be used to view the LLM chain in Comet."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5e212e7d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Now, we unset the environment variable and use a context manager.\n",
|
||||
"if \"LANGCHAIN_COMET_TRACING\" in os.environ:\n",
|
||||
" del os.environ[\"LANGCHAIN_COMET_TRACING\"]\n",
|
||||
"\n",
|
||||
"from langchain.callbacks.tracers.comet import CometTracer\n",
|
||||
"\n",
|
||||
"tracer = CometTracer()\n",
|
||||
"\n",
|
||||
"# Recreate the LLM, tools and agent and passing the callback to each of them\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"tools = load_tools([\"llm-math\"], llm=llm)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"agent.run(\n",
|
||||
" \"What is 2 raised to .123243 power?\", callbacks=[tracer]\n",
|
||||
") # this should be traced"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -46,7 +46,7 @@ thoughts and actions live in your app.
|
||||
```python
|
||||
from langchain_openai import OpenAI
|
||||
from langchain.agents import AgentType, initialize_agent, load_tools
|
||||
from langchain.callbacks import StreamlitCallbackHandler
|
||||
from langchain_community.callbacks import StreamlitCallbackHandler
|
||||
import streamlit as st
|
||||
|
||||
llm = OpenAI(temperature=0, streaming=True)
|
||||
|
||||
@@ -22,44 +22,84 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 1,
|
||||
"id": "d4a7c55d-b235-4ca4-a579-c90cc9570da9",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:00.590587Z",
|
||||
"start_time": "2024-01-19T11:25:00.127293Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ChatAnthropic"
|
||||
"from langchain_community.chat_models import ChatAnthropic\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 2,
|
||||
"id": "70cf04e8-423a-4ff6-8b09-f11fb711c817",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:04.349676Z",
|
||||
"start_time": "2024-01-19T11:25:03.964930Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatAnthropic()"
|
||||
"chat = ChatAnthropic(temperature=0, model_name=\"claude-2\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d1f9df276476f0bc",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"The code provided assumes that your ANTHROPIC_API_KEY is set in your environment variables. If you would like to manually specify your API key and also choose a different model, you can use the following code:\n",
|
||||
"```python\n",
|
||||
"chat = ChatAnthropic(temperature=0, anthropic_api_key=\"YOUR_API_KEY\", model_name=\"claude-instant-1.2\")\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"Please note that the default model is \"claude-2,\" and you can check the available models at [here](https://docs.anthropic.com/claude/reference/selecting-a-model)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 3,
|
||||
"id": "8199ef8f-eb8b-4253-9ea0-6c24a013ca4c",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:07.274418Z",
|
||||
"start_time": "2024-01-19T11:25:05.898031Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "AIMessage(content=' 저는 파이썬을 좋아합니다.')"
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"chat.invoke(messages)"
|
||||
"system = \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
|
||||
"human = \"{text}\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"system\", system), (\"human\", human)])\n",
|
||||
"\n",
|
||||
"chain = prompt | chat\n",
|
||||
"chain.invoke({\n",
|
||||
" \"input_language\": \"English\",\n",
|
||||
" \"output_language\": \"Korean\",\n",
|
||||
" \"text\": \"I love Python\",\n",
|
||||
"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -72,44 +112,78 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "93a21c5c-6ef9-4688-be60-b2e1f94842fb",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.manager import CallbackManager\n",
|
||||
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 4,
|
||||
"id": "c5fac0e9-05a4-4fc1-a3b3-e5bbb24b971b",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:10.448733Z",
|
||||
"start_time": "2024-01-19T11:25:08.866277Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "AIMessage(content=\" Why don't bears like fast food? Because they can't catch it!\")"
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.ainvoke([messages])"
|
||||
"chat = ChatAnthropic(temperature=0, model_name=\"claude-2\")\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"human\", \"Tell me a joke about {topic}\")])\n",
|
||||
"chain = prompt | chat\n",
|
||||
"await chain.ainvoke({\"topic\": \"bear\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 5,
|
||||
"id": "025be980-e50d-4a68-93dc-c9c7b500ce34",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:24.438696Z",
|
||||
"start_time": "2024-01-19T11:25:14.687480Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" Here are some of the most famous tourist attractions in Japan:\n",
|
||||
"\n",
|
||||
"- Tokyo - Tokyo Tower, Tokyo Skytree, Imperial Palace, Sensoji Temple, Meiji Shrine, Shibuya Crossing\n",
|
||||
"\n",
|
||||
"- Kyoto - Kinkakuji (Golden Pavilion), Fushimi Inari Shrine, Kiyomizu-dera Temple, Arashiyama Bamboo Grove, Gion Geisha District\n",
|
||||
"\n",
|
||||
"- Osaka - Osaka Castle, Dotonbori, Universal Studios Japan, Osaka Aquarium Kaiyukan \n",
|
||||
"\n",
|
||||
"- Hiroshima - Hiroshima Peace Memorial Park and Museum, Itsukushima Shrine (Miyajima Island)\n",
|
||||
"\n",
|
||||
"- Mount Fuji - Iconic and famous mountain, popular for hiking and viewing from places like Hakone and Kawaguchiko Lake\n",
|
||||
"\n",
|
||||
"- Himeji - Himeji Castle, one of Japan's most impressive feudal castles\n",
|
||||
"\n",
|
||||
"- Nara - Todaiji Temple, Nara Park with its bowing deer, Horyuji Temple with some of world's oldest wooden structures \n",
|
||||
"\n",
|
||||
"- Nikko - Elaborate shrines and temples nestled around Nikko National Park\n",
|
||||
"\n",
|
||||
"- Sapporo - Snow"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = ChatAnthropic(\n",
|
||||
" streaming=True,\n",
|
||||
" verbose=True,\n",
|
||||
" callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),\n",
|
||||
"chat = ChatAnthropic(temperature=0.3, model_name=\"claude-2\")\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [(\"human\", \"Give me a list of famous tourist attractions in Japan\")]\n",
|
||||
")\n",
|
||||
"chat.stream(messages)"
|
||||
"chain = prompt | chat\n",
|
||||
"for chunk in chain.stream({}):\n",
|
||||
" print(chunk.content, end=\"\", flush=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -134,15 +208,130 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 6,
|
||||
"id": "07c47c2a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:25.288133Z",
|
||||
"start_time": "2024-01-19T11:25:24.438968Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "AIMessage(content='파이썬을 사랑합니다.')"
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_anthropic import ChatAnthropicMessages\n",
|
||||
"\n",
|
||||
"chat = ChatAnthropicMessages(model_name=\"claude-instant-1.2\")\n",
|
||||
"chat.invoke(messages)"
|
||||
"system = (\n",
|
||||
" \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
|
||||
")\n",
|
||||
"human = \"{text}\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"system\", system), (\"human\", human)])\n",
|
||||
"\n",
|
||||
"chain = prompt | chat\n",
|
||||
"chain.invoke(\n",
|
||||
" {\n",
|
||||
" \"input_language\": \"English\",\n",
|
||||
" \"output_language\": \"Korean\",\n",
|
||||
" \"text\": \"I love Python\",\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "19e53d75935143fd",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"ChatAnthropicMessages also requires the anthropic_api_key argument, or the ANTHROPIC_API_KEY environment variable must be set. \n",
|
||||
"\n",
|
||||
"ChatAnthropicMessages also supports async and streaming functionality:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "e20a139d30e3d333",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:26.012325Z",
|
||||
"start_time": "2024-01-19T11:25:25.288358Z"
|
||||
},
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "AIMessage(content='파이썬을 사랑합니다.')"
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chain.ainvoke(\n",
|
||||
" {\n",
|
||||
" \"input_language\": \"English\",\n",
|
||||
" \"output_language\": \"Korean\",\n",
|
||||
" \"text\": \"I love Python\",\n",
|
||||
" }\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "6f34f1073d7e7120",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T11:25:28.323455Z",
|
||||
"start_time": "2024-01-19T11:25:26.012040Z"
|
||||
},
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Here are some of the most famous tourist attractions in Japan:\n",
|
||||
"\n",
|
||||
"- Tokyo Tower - A communication and observation tower in Tokyo modeled after the Eiffel Tower. It offers stunning views of the city.\n",
|
||||
"\n",
|
||||
"- Mount Fuji - Japan's highest and most famous mountain. It's a iconic symbol of Japan and a UNESCO World Heritage Site. \n",
|
||||
"\n",
|
||||
"- Itsukushima Shrine (Miyajima) - A shrine located on an island in Hiroshima prefecture, known for its \"floating\" torii gate that seems to float on water during high tide.\n",
|
||||
"\n",
|
||||
"- Himeji Castle - A UNESCO World Heritage Site famous for having withstood numerous battles without destruction to its intricate white walls and sloping, triangular roofs. \n",
|
||||
"\n",
|
||||
"- Kawaguchiko Station - Near Mount Fuji, this area is known for its scenic Fuji Five Lakes region. \n",
|
||||
"\n",
|
||||
"- Hiroshima Peace Memorial Park and Museum - Commemorates the world's first atomic bombing in Hiroshima on August 6, 1945. \n",
|
||||
"\n",
|
||||
"- Arashiyama Bamboo Grove - A renowned bamboo forest located in Kyoto that draws many visitors.\n",
|
||||
"\n",
|
||||
"- Kegon Falls - One of Japan's largest waterfalls"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [(\"human\", \"Give me a list of famous tourist attractions in Japan\")]\n",
|
||||
")\n",
|
||||
"chain = prompt | chat\n",
|
||||
"for chunk in chain.stream({}):\n",
|
||||
" print(chunk.content, end=\"\", flush=True)"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@@ -15,9 +15,9 @@
|
||||
"source": [
|
||||
"# AzureMLChatOnlineEndpoint\n",
|
||||
"\n",
|
||||
">[Azure Machine Learning](https://azure.microsoft.com/en-us/products/machine-learning/) is a platform used to build, train, and deploy machine learning models. Users can explore the types of models to deploy in the Model Catalog, which provides Azure Foundation Models and OpenAI Models. `Azure Foundation Models` include various open-source models and popular Hugging Face models. Users can also import models of their liking into AzureML.\n",
|
||||
">[Azure Machine Learning](https://azure.microsoft.com/en-us/products/machine-learning/) is a platform used to build, train, and deploy machine learning models. Users can explore the types of models to deploy in the Model Catalog, which provides foundational and general purpose models from different providers.\n",
|
||||
">\n",
|
||||
">[Azure Machine Learning Online Endpoints](https://learn.microsoft.com/en-us/azure/machine-learning/concept-endpoints). After you train machine learning models or pipelines, you need to deploy them to production so that others can use them for inference. Inference is the process of applying new input data to the machine learning model or pipeline to generate outputs. While these outputs are typically referred to as \"predictions,\" inferencing can be used to generate outputs for other machine learning tasks, such as classification and clustering. In `Azure Machine Learning`, you perform inferencing by using endpoints and deployments. `Endpoints` and `Deployments` allow you to decouple the interface of your production workload from the implementation that serves it.\n",
|
||||
">In general, you need to deploy models in order to consume its predictions (inference). In `Azure Machine Learning`, [Online Endpoints](https://learn.microsoft.com/en-us/azure/machine-learning/concept-endpoints) are used to deploy these models with a real-time serving. They are based on the ideas of `Endpoints` and `Deployments` which allow you to decouple the interface of your production workload from the implementation that serves it.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use a chat model hosted on an `Azure Machine Learning Endpoint`."
|
||||
]
|
||||
@@ -37,10 +37,11 @@
|
||||
"source": [
|
||||
"## Set up\n",
|
||||
"\n",
|
||||
"To use the wrapper, you must [deploy a model on AzureML](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-use-foundation-models?view=azureml-api-2#deploying-foundation-models-to-endpoints-for-inferencing) and obtain the following parameters:\n",
|
||||
"You must [deploy a model on Azure ML](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-use-foundation-models?view=azureml-api-2#deploying-foundation-models-to-endpoints-for-inferencing) or [to Azure AI studio](https://learn.microsoft.com/en-us/azure/ai-studio/how-to/deploy-models-open) and obtain the following parameters:\n",
|
||||
"\n",
|
||||
"* `endpoint_api_key`: The API key provided by the endpoint\n",
|
||||
"* `endpoint_url`: The REST endpoint url provided by the endpoint"
|
||||
"* `endpoint_url`: The REST endpoint url provided by the endpoint.\n",
|
||||
"* `endpoint_api_type`: Use `endpoint_type='realtime'` when deploying models to **Realtime endpoints** (hosted managed infrastructure). Use `endpoint_type='serverless'` when deploying models using the **Pay-as-you-go** offering (model as a service).\n",
|
||||
"* `endpoint_api_key`: The API key provided by the endpoint"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -51,7 +52,40 @@
|
||||
"\n",
|
||||
"The `content_formatter` parameter is a handler class for transforming the request and response of an AzureML endpoint to match with required schema. Since there are a wide range of models in the model catalog, each of which may process data differently from one another, a `ContentFormatterBase` class is provided to allow users to transform data to their liking. The following content formatters are provided:\n",
|
||||
"\n",
|
||||
"* `LLamaContentFormatter`: Formats request and response data for LLaMa2-chat"
|
||||
"* `LLamaChatContentFormatter`: Formats request and response data for LLaMa2-chat\n",
|
||||
"\n",
|
||||
"*Note: `langchain.chat_models.azureml_endpoint.LLamaContentFormatter` is being deprecated and replaced with `langchain.chat_models.azureml_endpoint.LLamaChatContentFormatter`.*\n",
|
||||
"\n",
|
||||
"You can implement custom content formatters specific for your model deriving from the class `langchain_community.llms.azureml_endpoint.ContentFormatterBase`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Examples\n",
|
||||
"\n",
|
||||
"The following section cotain examples about how to use this class:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models.azureml_endpoint import (\n",
|
||||
" AzureMLEndpointApiType,\n",
|
||||
" LlamaChatContentFormatter,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example: Chat completions with real-time endpoints"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -76,11 +110,79 @@
|
||||
"\n",
|
||||
"chat = AzureMLChatOnlineEndpoint(\n",
|
||||
" endpoint_url=\"https://<your-endpoint>.<your_region>.inference.ml.azure.com/score\",\n",
|
||||
" endpoint_api_type=AzureMLEndpointApiType.realtime,\n",
|
||||
" endpoint_api_key=\"my-api-key\",\n",
|
||||
" content_formatter=LlamaContentFormatter,\n",
|
||||
" content_formatter=LlamaChatContentFormatter(),\n",
|
||||
")\n",
|
||||
"response = chat(\n",
|
||||
" messages=[HumanMessage(content=\"Will the Collatz conjecture ever be solved?\")]\n",
|
||||
"response = chat.invoke(\n",
|
||||
" [HumanMessage(content=\"Will the Collatz conjecture ever be solved?\")]\n",
|
||||
")\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example: Chat completions with pay-as-you-go deployments (model as a service)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = AzureMLChatOnlineEndpoint(\n",
|
||||
" endpoint_url=\"https://<your-endpoint>.<your_region>.inference.ml.azure.com/v1/chat/completions\",\n",
|
||||
" endpoint_api_type=AzureMLEndpointApiType.serverless,\n",
|
||||
" endpoint_api_key=\"my-api-key\",\n",
|
||||
" content_formatter=LlamaChatContentFormatter,\n",
|
||||
")\n",
|
||||
"response = chat.invoke(\n",
|
||||
" [HumanMessage(content=\"Will the Collatz conjecture ever be solved?\")]\n",
|
||||
")\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"If you need to pass additional parameters to the model, use `model_kwards` argument:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = AzureMLChatOnlineEndpoint(\n",
|
||||
" endpoint_url=\"https://<your-endpoint>.<your_region>.inference.ml.azure.com/v1/chat/completions\",\n",
|
||||
" endpoint_api_type=AzureMLEndpointApiType.serverless,\n",
|
||||
" endpoint_api_key=\"my-api-key\",\n",
|
||||
" content_formatter=LlamaChatContentFormatter,\n",
|
||||
" model_kwargs={\"temperature\": 0.8},\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Parameters can also be passed during invocation:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"response = chat.invoke(\n",
|
||||
" [HumanMessage(content=\"Will the Collatz conjecture ever be solved?\")],\n",
|
||||
" max_tokens=512,\n",
|
||||
")\n",
|
||||
"response"
|
||||
]
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ChatBaichuan\n",
|
||||
"# Chat with Baichuan-192K\n",
|
||||
"\n",
|
||||
"Baichuan chat models API by Baichuan Intelligent Technology. For more information, see [https://platform.baichuan-ai.com/docs/api](https://platform.baichuan-ai.com/docs/api)"
|
||||
]
|
||||
@@ -44,19 +44,16 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatBaichuan(\n",
|
||||
" baichuan_api_key=\"YOUR_API_KEY\", baichuan_secret_key=\"YOUR_SECRET_KEY\"\n",
|
||||
")"
|
||||
"chat = ChatBaichuan(baichuan_api_key=\"YOUR_API_KEY\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"or you can set `api_key` and `secret_key` in your environment variables\n",
|
||||
"or you can set `api_key` in your environment variables\n",
|
||||
"```bash\n",
|
||||
"export BAICHUAN_API_KEY=YOUR_API_KEY\n",
|
||||
"export BAICHUAN_SECRET_KEY=YOUR_SECRET_KEY\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
@@ -91,7 +88,7 @@
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"## For ChatBaichuan with Streaming"
|
||||
"## Chat with Baichuan-192K with Streaming"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -108,7 +105,6 @@
|
||||
"source": [
|
||||
"chat = ChatBaichuan(\n",
|
||||
" baichuan_api_key=\"YOUR_API_KEY\",\n",
|
||||
" baichuan_secret_key=\"YOUR_SECRET_KEY\",\n",
|
||||
" streaming=True,\n",
|
||||
")"
|
||||
]
|
||||
|
||||
@@ -53,9 +53,16 @@
|
||||
"- AquilaChat-7B"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Set up"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -65,83 +72,105 @@
|
||||
"from langchain_community.chat_models import QianfanChatEndpoint\n",
|
||||
"from langchain_core.language_models.chat_models import HumanMessage\n",
|
||||
"\n",
|
||||
"os.environ[\"QIANFAN_AK\"] = \"your_ak\"\n",
|
||||
"os.environ[\"QIANFAN_SK\"] = \"your_sk\"\n",
|
||||
"\n",
|
||||
"chat = QianfanChatEndpoint(\n",
|
||||
" streaming=True,\n",
|
||||
")\n",
|
||||
"res = chat([HumanMessage(content=\"write a funny joke\")])"
|
||||
"os.environ[\"QIANFAN_AK\"] = \"Your_api_key\"\n",
|
||||
"os.environ[\"QIANFAN_SK\"] = \"You_secret_Key\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:36] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/eb-instant\n",
|
||||
"[INFO] [09-15 20:00:37] logging.py:55 [t:139698882193216]: async requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!请问您需要什么帮助?我将尽力回答您的问题。')"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = QianfanChatEndpoint(streaming=True)\n",
|
||||
"messages = [HumanMessage(content=\"Hello\")]\n",
|
||||
"chat.invoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!有什么我可以帮助您的吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.ainvoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[AIMessage(content='您好!有什么我可以帮助您的吗?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat.batch([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Streaming"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"chat resp: content='您好,您似乎输入' additional_kwargs={} example=False\n",
|
||||
"chat resp: content='了一个话题标签,请问需要我帮您找到什么资料或者帮助您解答什么问题吗?' additional_kwargs={} example=False\n",
|
||||
"chat resp: content='' additional_kwargs={} example=False\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:39] logging.py:55 [t:139698882193216]: async requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"generations=[[ChatGeneration(text=\"The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.\", generation_info={'finish_reason': 'finished'}, message=AIMessage(content=\"The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.\", additional_kwargs={}, example=False))]] llm_output={} run=[RunInfo(run_id=UUID('d48160a6-5960-4c1d-8a0e-90e6b51a209b'))]\n",
|
||||
"astream content='The sea is a vast' additional_kwargs={} example=False\n",
|
||||
"astream content=' expanse of water, a place of mystery and adventure. It is the source of many cultures and civilizations, and a center of trade and exploration. The sea is also a source of life and beauty, with its unique marine life and diverse' additional_kwargs={} example=False\n",
|
||||
"astream content=' coral reefs. Whether you are swimming, diving, or just watching the sea, it is a place that captivates the imagination and transforms the spirit.' additional_kwargs={} example=False\n"
|
||||
"您好!有什么我可以帮助您的吗?\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import QianfanChatEndpoint\n",
|
||||
"\n",
|
||||
"chatLLM = QianfanChatEndpoint()\n",
|
||||
"res = chatLLM.stream([HumanMessage(content=\"hi\")], streaming=True)\n",
|
||||
"for r in res:\n",
|
||||
" print(\"chat resp:\", r)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_aio_generate():\n",
|
||||
" resp = await chatLLM.agenerate(\n",
|
||||
" messages=[[HumanMessage(content=\"write a 20 words sentence about sea.\")]]\n",
|
||||
" )\n",
|
||||
" print(resp)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await run_aio_generate()\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def run_aio_stream():\n",
|
||||
" async for res in chatLLM.astream(\n",
|
||||
" [HumanMessage(content=\"write a 20 words sentence about sea.\")]\n",
|
||||
" ):\n",
|
||||
" print(\"astream\", res)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"await run_aio_stream()"
|
||||
"try:\n",
|
||||
" for chunk in chat.stream(messages):\n",
|
||||
" print(chunk.content, end=\"\", flush=True)\n",
|
||||
"except TypeError as e:\n",
|
||||
" print(\"\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -151,39 +180,36 @@
|
||||
"source": [
|
||||
"## Use different models in Qianfan\n",
|
||||
"\n",
|
||||
"In the case you want to deploy your own model based on Ernie Bot or third-party open-source model, you could follow these steps:\n",
|
||||
"The default model is ERNIE-Bot-turbo, in the case you want to deploy your own model based on Ernie Bot or third-party open-source model, you could follow these steps:\n",
|
||||
"\n",
|
||||
"- 1. (Optional, if the model are included in the default models, skip it)Deploy your model in Qianfan Console, get your own customized deploy endpoint.\n",
|
||||
"- 2. Set up the field called `endpoint` in the initialization:"
|
||||
"1. (Optional, if the model are included in the default models, skip it) Deploy your model in Qianfan Console, get your own customized deploy endpoint.\n",
|
||||
"2. Set up the field called `endpoint` in the initialization:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:50] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/bloomz_7b1\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"content='你好!很高兴见到你。' additional_kwargs={} example=False\n"
|
||||
]
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Hello,可以回答问题了,我会竭尽全力为您解答,请问有什么问题吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chatBloom = QianfanChatEndpoint(\n",
|
||||
"chatBot = QianfanChatEndpoint(\n",
|
||||
" streaming=True,\n",
|
||||
" model=\"BLOOMZ-7B\",\n",
|
||||
" model=\"ERNIE-Bot\",\n",
|
||||
")\n",
|
||||
"res = chatBloom([HumanMessage(content=\"hi\")])\n",
|
||||
"print(res)"
|
||||
"\n",
|
||||
"messages = [HumanMessage(content=\"Hello\")]\n",
|
||||
"chatBot.invoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -202,35 +228,25 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[INFO] [09-15 20:00:57] logging.py:55 [t:139698882193216]: requesting llm api endpoint: /chat/eb-instant\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"content='您好,您似乎输入' additional_kwargs={} example=False\n",
|
||||
"content='了一个文本字符串,但并没有给出具体的问题或场景。' additional_kwargs={} example=False\n",
|
||||
"content='如果您能提供更多信息,我可以更好地回答您的问题。' additional_kwargs={} example=False\n",
|
||||
"content='' additional_kwargs={} example=False\n"
|
||||
]
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='您好!有什么我可以帮助您的吗?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"res = chat.stream(\n",
|
||||
" [HumanMessage(content=\"hi\")],\n",
|
||||
"chat.invoke(\n",
|
||||
" [HumanMessage(content=\"Hello\")],\n",
|
||||
" **{\"top_p\": 0.4, \"temperature\": 0.1, \"penalty_score\": 1},\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"for r in res:\n",
|
||||
" print(r)"
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
@@ -250,7 +266,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
"version": "3.9.18"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@@ -1,29 +1,18 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "9d3b07d9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: DeepInfra\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "bf733a38-db84-4363-89e2-de6735c37230",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ChatDeepInfra\n",
|
||||
"# DeepInfra\n",
|
||||
"\n",
|
||||
"[DeepInfra](https://deepinfra.com/?utm_source=langchain) is a serverless inference as a service that provides access to a [variety of LLMs](https://deepinfra.com/models?utm_source=langchain) and [embeddings models](https://deepinfra.com/models?type=embeddings&utm_source=langchain). This notebook goes over how to use LangChain with DeepInfra for chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8e237415-b81e-4573-87f2-2b9ad51631bc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Set the Environment API Key\n",
|
||||
@@ -35,23 +24,39 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "02466faf-679b-4b53-91b1-d2a06802e983",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# get a new token: https://deepinfra.com/login?from=%2Fdash\n",
|
||||
"\n",
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"DEEPINFRA_API_TOKEN = getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# get a new token: https://deepinfra.com/login?from=%2Fdash\n",
|
||||
"\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"if not os.environ.get(\"DEEPINFRA_API_TOKEN\"):\n",
|
||||
" from getpass import getpass\n",
|
||||
"\n",
|
||||
" DEEPINFRA_API_TOKEN = getpass()\n",
|
||||
" os.environ[\"DEEPINFRA_API_TOKEN\"] = DEEPINFRA_API_TOKEN\n",
|
||||
" # or pass deepinfra_api_token parameter to the ChatDeepInfra constructor"
|
||||
"# or pass deepinfra_api_token parameter to the ChatDeepInfra constructor\n",
|
||||
"os.environ[\"DEEPINFRA_API_TOKEN\"] = DEEPINFRA_API_TOKEN"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -61,30 +66,50 @@
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatDeepInfra\n",
|
||||
"from langchain.schema import HumanMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "70cf04e8-423a-4ff6-8b09-f11fb711c817",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatDeepInfra(model=\"meta-llama/Llama-2-7b-chat-hf\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8199ef8f-eb8b-4253-9ea0-6c24a013ca4c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=' Sure! Here is the translation of \"I love programming\" into French:\\n\\nJe adore le programming.\\n\\nIn this sentence, \"adore\" is the verb used to express the idea of loving something. Other options could be \"aime\" or \"aimons\", but \"adore\" is the most commonly used verb for this purpose in French.')"
|
||||
"AIMessage(content=\" J'aime la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 1,
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_community.chat_models import ChatDeepInfra\n",
|
||||
"from langchain_core.messages import HumanMessage\n",
|
||||
"\n",
|
||||
"chat = ChatDeepInfra(model=\"meta-llama/Llama-2-7b-chat-hf\")\n",
|
||||
"\n",
|
||||
"messages = [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"chat.invoke(messages)"
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -98,7 +123,19 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 4,
|
||||
"id": "93a21c5c-6ef9-4688-be60-b2e1f94842fb",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "c5fac0e9-05a4-4fc1-a3b3-e5bbb24b971b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -107,21 +144,21 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=' Sure! Here is the translation of \"I love programming\" into French:\\n\\nJe adore le programming.\\n\\nI hope this helps! Let me know if you have any other questions.')"
|
||||
"LLMResult(generations=[[ChatGeneration(text=\" J'aime programmer.\", generation_info=None, message=AIMessage(content=\" J'aime programmer.\", additional_kwargs={}, example=False))]], llm_output={}, run=[RunInfo(run_id=UUID('8cc8fb68-1c35-439c-96a0-695036a93652'))])"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.ainvoke(messages)"
|
||||
"await chat.agenerate([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 6,
|
||||
"id": "025be980-e50d-4a68-93dc-c9c7b500ce34",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -131,19 +168,36 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" Sure! Here's the translation of \"I love programming\" from English to French:\n",
|
||||
"\n",
|
||||
"Je suis passionné(e) de programmation.\n",
|
||||
"\n",
|
||||
"Note that the sentence is translated as \"I am passionate about programming\" in French, as the verb \"aimer\" (to love) is not commonly used in this context. Instead, \"passionné(e)\" (passionate) is used to convey the idea of having a strong interest or enjoyment in something.\n"
|
||||
" J'aime la programmation."
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\" J'aime la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for chunk in chat.stream(messages):\n",
|
||||
" print(chunk.content, end=\"\")\n",
|
||||
"print()"
|
||||
"chat = ChatDeepInfra(\n",
|
||||
" streaming=True,\n",
|
||||
" verbose=True,\n",
|
||||
" callbacks=[StreamingStdOutCallbackHandler()],\n",
|
||||
")\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c253883f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
@@ -162,7 +216,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
272
docs/docs/integrations/chat/edenai.ipynb
Normal file
272
docs/docs/integrations/chat/edenai.ipynb
Normal file
@@ -0,0 +1,272 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Eden AI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Eden AI is revolutionizing the AI landscape by uniting the best AI providers, empowering users to unlock limitless possibilities and tap into the true potential of artificial intelligence. With an all-in-one comprehensive and hassle-free platform, it allows users to deploy AI features to production lightning fast, enabling effortless access to the full breadth of AI capabilities via a single API. (website: https://edenai.co/)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This example goes over how to use LangChain to interact with Eden AI models\n",
|
||||
"\n",
|
||||
"-----------------------------------------------------------------------------------"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"`EdenAI` goes beyond mere model invocation. It empowers you with advanced features, including:\n",
|
||||
"\n",
|
||||
"- **Multiple Providers**: Gain access to a diverse range of language models offered by various providers, giving you the freedom to choose the best-suited model for your use case.\n",
|
||||
"\n",
|
||||
"- **Fallback Mechanism**: Set a fallback mechanism to ensure seamless operations even if the primary provider is unavailable, you can easily switches to an alternative provider.\n",
|
||||
"\n",
|
||||
"- **Usage Tracking**: Track usage statistics on a per-project and per-API key basis. This feature allows you to monitor and manage resource consumption effectively.\n",
|
||||
"\n",
|
||||
"- **Monitoring and Observability**: `EdenAI` provides comprehensive monitoring and observability tools on the platform. Monitor the performance of your language models, analyze usage patterns, and gain valuable insights to optimize your applications.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Accessing the EDENAI's API requires an API key, \n",
|
||||
"\n",
|
||||
"which you can get by creating an account https://app.edenai.run/user/register and heading here https://app.edenai.run/admin/iam/api-keys\n",
|
||||
"\n",
|
||||
"Once we have a key we'll want to set it as an environment variable by running:\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"export EDENAI_API_KEY=\"...\"\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"You can find more details on the API reference : https://docs.edenai.co/reference"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"If you'd prefer not to set an environment variable you can pass the key in directly via the edenai_api_key named parameter\n",
|
||||
"\n",
|
||||
" when initiating the EdenAI Chat Model class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_models.edenai import ChatEdenAI\n",
|
||||
"from langchain_core.messages import HumanMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatEdenAI(\n",
|
||||
" edenai_api_key=\"...\", provider=\"openai\", temperature=0.2, max_tokens=250\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Hello! How can I assist you today?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [HumanMessage(content=\"Hello !\")]\n",
|
||||
"chat.invoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Hello! How can I assist you today?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.ainvoke(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Streaming and Batching\n",
|
||||
"\n",
|
||||
"`ChatEdenAI` supports streaming and batching. Below is an example."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Hello! How can I assist you today?"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for chunk in chat.stream(messages):\n",
|
||||
" print(chunk.content, end=\"\", flush=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[AIMessage(content='Hello! How can I assist you today?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat.batch([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Fallback mecanism\n",
|
||||
"\n",
|
||||
"With Eden AI you can set a fallback mechanism to ensure seamless operations even if the primary provider is unavailable, you can easily switches to an alternative provider."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatEdenAI(\n",
|
||||
" edenai_api_key=\"...\",\n",
|
||||
" provider=\"openai\",\n",
|
||||
" temperature=0.2,\n",
|
||||
" max_tokens=250,\n",
|
||||
" fallback_providers=\"google\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In this example, you can use Google as a backup provider if OpenAI encounters any issues.\n",
|
||||
"\n",
|
||||
"For more information and details about Eden AI, check out this link: : https://docs.edenai.co/docs/additional-parameters"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chaining Calls\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"\n",
|
||||
"prompt = ChatPromptTemplate.from_template(\n",
|
||||
" \"What is a good name for a company that makes {product}?\"\n",
|
||||
")\n",
|
||||
"chain = prompt | chat"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='VitalBites')"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain.invoke({\"product\": \"healthy snacks\"})"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain-pr",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -16,29 +16,58 @@
|
||||
"# ErnieBotChat\n",
|
||||
"\n",
|
||||
"[ERNIE-Bot](https://cloud.baidu.com/doc/WENXINWORKSHOP/s/jlil56u11) is a large language model developed by Baidu, covering a huge amount of Chinese data.\n",
|
||||
"This notebook covers how to get started with ErnieBot chat models.\n",
|
||||
"This notebook covers how to get started with ErnieBot chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Deprecated Warning**\n",
|
||||
"\n",
|
||||
"We recommend users using `langchain_community.chat_models.ErnieBotChat` \n",
|
||||
"to use `langchain_community.chat_models.QianfanChatEndpoint` instead.\n",
|
||||
"\n",
|
||||
"documentation for `QianfanChatEndpoint` is [here](./baidu_qianfan_endpoint).\n",
|
||||
"\n",
|
||||
"they are 4 why we recommend users to use `QianfanChatEndpoint`:\n",
|
||||
"\n",
|
||||
"**Note:** We recommend users using this class to switch to [Baidu Qianfan](./baidu_qianfan_endpoint). they are 3 why we recommend users to use `QianfanChatEndpoint`:\n",
|
||||
"1. `QianfanChatEndpoint` support more LLM in the Qianfan platform.\n",
|
||||
"2. `QianfanChatEndpoint` support streaming mode.\n",
|
||||
"3. `QianfanChatEndpoint` support function calling usgage.\n",
|
||||
"\n",
|
||||
"4. `ErnieBotChat` is lack of maintenance and deprecated."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Some tips for migration:\n",
|
||||
"\n",
|
||||
"- change `ernie_client_id` to `qianfan_ak`, also change `ernie_client_secret` to `qianfan_sk`.\n",
|
||||
"- install `qianfan` package. \n",
|
||||
" ```\n",
|
||||
" pip install qianfan\n",
|
||||
" ```"
|
||||
"- install `qianfan` package. like `pip install qianfan`\n",
|
||||
"- change `ErnieBotChat` to `QianfanChatEndpoint`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ErnieBotChat"
|
||||
"from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint\n",
|
||||
"\n",
|
||||
"chat = QianfanChatEndpoint(\n",
|
||||
" qianfan_ak=\"your qianfan ak\",\n",
|
||||
" qianfan_sk=\"your qianfan sk\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -47,6 +76,9 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ErnieBotChat\n",
|
||||
"\n",
|
||||
"chat = ErnieBotChat(\n",
|
||||
" ernie_client_id=\"YOUR_CLIENT_ID\", ernie_client_secret=\"YOUR_CLIENT_SECRET\"\n",
|
||||
")"
|
||||
|
||||
@@ -320,11 +320,26 @@
|
||||
"4. Message may be blocked if they violate the safety checks of the LLM. In this case, the model will return an empty response."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "75fdfad6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "92b5aca5",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
"source": [
|
||||
"## Additional Configuraation\n",
|
||||
"\n",
|
||||
"You can pass the following parameters to ChatGoogleGenerativeAI in order to customize the SDK's behavior:\n",
|
||||
"\n",
|
||||
"- `client_options`: [Client Options](https://googleapis.dev/python/google-api-core/latest/client_options.html#module-google.api_core.client_options) to pass to the Google API Client, such as a custom `client_options[\"api_endpoint\"]`\n",
|
||||
"- `transport`: The transport method to use, such as `rest`, `grpc`, or `grpc_asyncio`."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -11,7 +11,6 @@
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
@@ -19,6 +18,14 @@
|
||||
"\n",
|
||||
"Note: This is separate from the Google PaLM integration. Google has chosen to offer an enterprise version of PaLM through GCP, and this supports the models made available through there. \n",
|
||||
"\n",
|
||||
"ChatVertexAI exposes all foundational models available in Google Cloud:\n",
|
||||
"\n",
|
||||
"- Gemini (`gemini-pro` and `gemini-pro-vision`)\n",
|
||||
"- PaLM 2 for Text (`text-bison`)\n",
|
||||
"- Codey for Code Generation (`codechat-bison`)\n",
|
||||
"\n",
|
||||
"For a full and updated list of available models visit [VertexAI documentation](https://cloud.google.com/vertex-ai/docs/generative-ai/model-reference/overview).\n",
|
||||
"\n",
|
||||
"By default, Google Cloud [does not use](https://cloud.google.com/vertex-ai/docs/generative-ai/data-governance#foundation_model_development) customer data to train its foundation models as part of Google Cloud`s AI/ML Privacy Commitment. More details about how Google processes data can also be found in [Google's Customer Data Processing Addendum (CDPA)](https://cloud.google.com/terms/data-processing-addendum).\n",
|
||||
"\n",
|
||||
"To use `Google Cloud Vertex AI` PaLM you must have the `langchain-google-vertexai` Python package installed and either:\n",
|
||||
@@ -35,29 +42,16 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m A new release of pip is available: \u001b[0m\u001b[31;49m23.2\u001b[0m\u001b[39;49m -> \u001b[0m\u001b[32;49m23.3.2\u001b[0m\n",
|
||||
"\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m To update, run: \u001b[0m\u001b[32;49mpip install --upgrade pip\u001b[0m\n",
|
||||
"Note: you may need to restart the kernel to use updated packages.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain-google-vertexai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -67,7 +61,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -76,7 +70,7 @@
|
||||
"AIMessage(content=\" J'aime la programmation.\")"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -92,6 +86,40 @@
|
||||
"chain.invoke({})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Gemini doesn't support SystemMessage at the moment, but it can be added to the first human message in the row. If you want such behavior, just set the `convert_system_message_to_human` to `True`:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'aime la programmation.\")"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"system = \"You are a helpful assistant who translate English to French\"\n",
|
||||
"human = \"Translate this sentence from English to French. I love programming.\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"system\", system), (\"human\", human)])\n",
|
||||
"\n",
|
||||
"chat = ChatVertexAI(model_name=\"gemini-pro\", convert_system_message_to_human=True)\n",
|
||||
"\n",
|
||||
"chain = prompt | chat\n",
|
||||
"chain.invoke({})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
@@ -101,7 +129,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -110,7 +138,7 @@
|
||||
"AIMessage(content=' プログラミングが大好きです')"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -122,6 +150,8 @@
|
||||
"human = \"{text}\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"system\", system), (\"human\", human)])\n",
|
||||
"\n",
|
||||
"chat = ChatVertexAI()\n",
|
||||
"\n",
|
||||
"chain = prompt | chat\n",
|
||||
"\n",
|
||||
"chain.invoke(\n",
|
||||
@@ -134,30 +164,18 @@
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"execution": {
|
||||
"iopub.execute_input": "2023-06-17T21:09:25.423568Z",
|
||||
"iopub.status.busy": "2023-06-17T21:09:25.423213Z",
|
||||
"iopub.status.idle": "2023-06-17T21:09:25.429641Z",
|
||||
"shell.execute_reply": "2023-06-17T21:09:25.429060Z",
|
||||
"shell.execute_reply.started": "2023-06-17T21:09:25.423546Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Code generation chat models\n",
|
||||
"You can now leverage the Codey API for code chat within Vertex AI. The model name is:\n",
|
||||
"- codechat-bison: for code assistance"
|
||||
"You can now leverage the Codey API for code chat within Vertex AI. The model available is:\n",
|
||||
"- `codechat-bison`: for code assistance"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
@@ -165,27 +183,51 @@
|
||||
"text": [
|
||||
" ```python\n",
|
||||
"def is_prime(n):\n",
|
||||
" if n <= 1:\n",
|
||||
" return False\n",
|
||||
" for i in range(2, n):\n",
|
||||
" if n % i == 0:\n",
|
||||
" return False\n",
|
||||
" return True\n",
|
||||
" \"\"\"\n",
|
||||
" Check if a number is prime.\n",
|
||||
"\n",
|
||||
" Args:\n",
|
||||
" n: The number to check.\n",
|
||||
"\n",
|
||||
" Returns:\n",
|
||||
" True if n is prime, False otherwise.\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
" # If n is 1, it is not prime.\n",
|
||||
" if n == 1:\n",
|
||||
" return False\n",
|
||||
"\n",
|
||||
" # Iterate over all numbers from 2 to the square root of n.\n",
|
||||
" for i in range(2, int(n ** 0.5) + 1):\n",
|
||||
" # If n is divisible by any number from 2 to its square root, it is not prime.\n",
|
||||
" if n % i == 0:\n",
|
||||
" return False\n",
|
||||
"\n",
|
||||
" # If n is divisible by no number from 2 to its square root, it is prime.\n",
|
||||
" return True\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def find_prime_numbers(n):\n",
|
||||
" prime_numbers = []\n",
|
||||
" for i in range(2, n + 1):\n",
|
||||
" if is_prime(i):\n",
|
||||
" prime_numbers.append(i)\n",
|
||||
" return prime_numbers\n",
|
||||
" \"\"\"\n",
|
||||
" Find all prime numbers up to a given number.\n",
|
||||
"\n",
|
||||
"print(find_prime_numbers(100))\n",
|
||||
"```\n",
|
||||
" Args:\n",
|
||||
" n: The upper bound for the prime numbers to find.\n",
|
||||
"\n",
|
||||
"Output:\n",
|
||||
" Returns:\n",
|
||||
" A list of all prime numbers up to n.\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]\n",
|
||||
" # Create a list of all numbers from 2 to n.\n",
|
||||
" numbers = list(range(2, n + 1))\n",
|
||||
"\n",
|
||||
" # Iterate over the list of numbers and remove any that are not prime.\n",
|
||||
" for number in numbers:\n",
|
||||
" if not is_prime(number):\n",
|
||||
" numbers.remove(number)\n",
|
||||
"\n",
|
||||
" # Return the list of prime numbers.\n",
|
||||
" return numbers\n",
|
||||
"```\n"
|
||||
]
|
||||
}
|
||||
@@ -195,22 +237,159 @@
|
||||
" model_name=\"codechat-bison\", max_output_tokens=1000, temperature=0.5\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message = chat.invoke(\"Write a Python function to identify all prime numbers\")\n",
|
||||
"message = chat.invoke(\"Write a Python function generating all prime numbers\")\n",
|
||||
"print(message.content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Full generation info\n",
|
||||
"\n",
|
||||
"We can use the `generate` method to get back extra metadata like [safety attributes](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/responsible-ai#safety_attribute_confidence_scoring) and not just chat completions\n",
|
||||
"\n",
|
||||
"Note that the `generation_info` will be different depending if you're using a gemini model or not.\n",
|
||||
"\n",
|
||||
"### Gemini model\n",
|
||||
"\n",
|
||||
"`generation_info` will include:\n",
|
||||
"\n",
|
||||
"- `is_blocked`: whether generation was blocked or not\n",
|
||||
"- `safety_ratings`: safety ratings' categories and probability labels"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'is_blocked': False,\n",
|
||||
" 'safety_ratings': [{'category': 'HARM_CATEGORY_HARASSMENT',\n",
|
||||
" 'probability_label': 'NEGLIGIBLE'},\n",
|
||||
" {'category': 'HARM_CATEGORY_HATE_SPEECH',\n",
|
||||
" 'probability_label': 'NEGLIGIBLE'},\n",
|
||||
" {'category': 'HARM_CATEGORY_SEXUALLY_EXPLICIT',\n",
|
||||
" 'probability_label': 'NEGLIGIBLE'},\n",
|
||||
" {'category': 'HARM_CATEGORY_DANGEROUS_CONTENT',\n",
|
||||
" 'probability_label': 'NEGLIGIBLE'}]}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from pprint import pprint\n",
|
||||
"\n",
|
||||
"from langchain_core.messages import HumanMessage\n",
|
||||
"from langchain_google_vertexai import ChatVertexAI, HarmBlockThreshold, HarmCategory\n",
|
||||
"\n",
|
||||
"human = \"Translate this sentence from English to French. I love programming.\"\n",
|
||||
"messages = [HumanMessage(content=human)]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"chat = ChatVertexAI(\n",
|
||||
" model_name=\"gemini-pro\",\n",
|
||||
" safety_settings={\n",
|
||||
" HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_LOW_AND_ABOVE\n",
|
||||
" },\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"result = chat.generate([messages])\n",
|
||||
"pprint(result.generations[0][0].generation_info)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Non-gemini model\n",
|
||||
"\n",
|
||||
"`generation_info` will include:\n",
|
||||
"\n",
|
||||
"- `is_blocked`: whether generation was blocked or not\n",
|
||||
"- `safety_attributes`: a dictionary mapping safety attributes to their scores"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'is_blocked': False,\n",
|
||||
" 'safety_attributes': {'Derogatory': 0.1,\n",
|
||||
" 'Finance': 0.3,\n",
|
||||
" 'Insult': 0.1,\n",
|
||||
" 'Sexual': 0.1}}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = ChatVertexAI() # default is `chat-bison`\n",
|
||||
"\n",
|
||||
"result = chat.generate([messages])\n",
|
||||
"pprint(result.generations[0][0].generation_info)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Function Calling with Gemini\n",
|
||||
"\n",
|
||||
"We can call Gemini models with tools."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"MyModel(name='Erick', age=27)"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.pydantic_v1 import BaseModel\n",
|
||||
"from langchain_google_vertexai import create_structured_runnable\n",
|
||||
"\n",
|
||||
"llm = ChatVertexAI(model_name=\"gemini-pro\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class MyModel(BaseModel):\n",
|
||||
" name: str\n",
|
||||
" age: int\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"chain = create_structured_runnable(MyModel, llm)\n",
|
||||
"chain.invoke(\"My name is Erick and I'm 27 years old\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Asynchronous calls\n",
|
||||
"\n",
|
||||
"We can make asynchronous calls via the Runnables [Async Interface](/docs/expression_language/interface)"
|
||||
"We can make asynchronous calls via the Runnables [Async Interface](/docs/expression_language/interface)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -224,16 +403,16 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=' Why do you love programming?')"
|
||||
"AIMessage(content=' अहं प्रोग्रामनं प्रेमामि')"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -244,6 +423,10 @@
|
||||
")\n",
|
||||
"human = \"{text}\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages([(\"system\", system), (\"human\", human)])\n",
|
||||
"\n",
|
||||
"chat = ChatVertexAI(\n",
|
||||
" model_name=\"chat-bison\", max_output_tokens=1000, temperature=0.5\n",
|
||||
")\n",
|
||||
"chain = prompt | chat\n",
|
||||
"\n",
|
||||
"asyncio.run(\n",
|
||||
@@ -268,7 +451,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -299,37 +482,15 @@
|
||||
" sys.stdout.write(chunk.content)\n",
|
||||
" sys.stdout.flush()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
"display_name": "",
|
||||
"name": ""
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "cc99336516f23363341912c6723b01ace86f02e26b4290be1efc0677e2e2ec24"
|
||||
}
|
||||
"name": "python"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -4,9 +4,9 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Hugging Face Chat Wrapper\n",
|
||||
"# Hugging Face\n",
|
||||
"\n",
|
||||
"This notebook shows how to get started using Hugging Face LLM's as chat models.\n",
|
||||
"This notebook shows how to get started using `Hugging Face` LLM's as chat models.\n",
|
||||
"\n",
|
||||
"In particular, we will:\n",
|
||||
"1. Utilize the [HuggingFaceTextGenInference](https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/llms/huggingface_text_gen_inference.py), [HuggingFaceEndpoint](https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/llms/huggingface_endpoint.py), or [HuggingFaceHub](https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/llms/huggingface_hub.py) integrations to instantiate an `LLM`.\n",
|
||||
@@ -49,7 +49,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### `HuggingFaceTextGenInference`"
|
||||
"### `HuggingFaceTextGenInference`"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -93,7 +93,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### `HuggingFaceEndpoint`"
|
||||
"### `HuggingFaceEndpoint`"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -121,7 +121,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### `HuggingFaceHub`"
|
||||
"### `HuggingFaceHub`"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -291,7 +291,7 @@
|
||||
"source": [
|
||||
"## 3. Take it for a spin as an agent!\n",
|
||||
"\n",
|
||||
"Here we'll test out `Zephyr-7B-beta` as a zero-shot ReAct Agent. The example below is taken from [here](https://python.langchain.com/docs/modules/agents/agent_types/react#using-chat-models).\n",
|
||||
"Here we'll test out `Zephyr-7B-beta` as a zero-shot `ReAct` Agent. The example below is taken from [here](https://python.langchain.com/docs/modules/agents/agent_types/react#using-chat-models).\n",
|
||||
"\n",
|
||||
"> Note: To run this section, you'll need to have a [SerpAPI Token](https://serpapi.com/) saved as an environment variable: `SERPAPI_API_KEY`"
|
||||
]
|
||||
@@ -448,7 +448,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.5"
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -21,17 +21,31 @@
|
||||
"\n",
|
||||
"1. Select the right LLM(s) for their application\n",
|
||||
"2. Prototype with various open-source and proprietary LLMs\n",
|
||||
"3. Move to production in-line with their security, privacy, throughput, latency SLAs without infrastructure set-up or administration using Konko AI's SOC 2 compliant infrastructure\n",
|
||||
"3. Access Fine Tuning for open-source LLMs to get industry-leading performance at a fraction of the cost\n",
|
||||
"4. Setup low-cost production APIs according to security, privacy, throughput, latency SLAs without infrastructure set-up or administration using Konko AI's SOC 2 compliant, multi-cloud infrastructure\n",
|
||||
"\n",
|
||||
"### Steps to Access Models\n",
|
||||
"1. **Explore Available Models:** Start by browsing through the [available models](https://docs.konko.ai/docs/list-of-models) on Konko. Each model caters to different use cases and capabilities.\n",
|
||||
"\n",
|
||||
"This example goes over how to use LangChain to interact with `Konko` [models](https://docs.konko.ai/docs/overview)"
|
||||
"2. **Identify Suitable Endpoints:** Determine which [endpoint](https://docs.konko.ai/docs/list-of-models#list-of-available-models) (ChatCompletion or Completion) supports your selected model.\n",
|
||||
"\n",
|
||||
"3. **Selecting a Model:** [Choose a model](https://docs.konko.ai/docs/list-of-models#list-of-available-models) based on its metadata and how well it fits your use case.\n",
|
||||
"\n",
|
||||
"4. **Prompting Guidelines:** Once a model is selected, refer to the [prompting guidelines](https://docs.konko.ai/docs/prompting) to effectively communicate with it.\n",
|
||||
"\n",
|
||||
"5. **Using the API:** Finally, use the appropriate Konko [API endpoint](https://docs.konko.ai/docs/quickstart-for-completion-and-chat-completion-endpoint) to call the model and receive responses.\n",
|
||||
"\n",
|
||||
"To run this notebook, you'll need Konko API key. You can create one by signing up on [Konko](https://www.konko.ai/).\n",
|
||||
"\n",
|
||||
"This example goes over how to use LangChain to interact with `Konko` ChatCompletion [models](https://docs.konko.ai/docs/list-of-models#konko-hosted-models-for-chatcompletion)\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To run this notebook, you'll need Konko API key. You can request it by messaging support@konko.ai."
|
||||
"To run this notebook, you'll need Konko API key. You can create one by signing up on [Konko](https://www.konko.ai/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -84,36 +98,34 @@
|
||||
"source": [
|
||||
"## Calling a model\n",
|
||||
"\n",
|
||||
"Find a model on the [Konko overview page](https://docs.konko.ai/docs/overview)\n",
|
||||
"Find a model on the [Konko overview page](https://docs.konko.ai/v0.5.0/docs/list-of-models)\n",
|
||||
"\n",
|
||||
"For example, for this [LLama 2 model](https://docs.konko.ai/docs/meta-llama-2-13b-chat). The model id would be: `\"meta-llama/Llama-2-13b-chat-hf\"`\n",
|
||||
"\n",
|
||||
"Another way to find the list of models running on the Konko instance is through this [endpoint](https://docs.konko.ai/reference/listmodels).\n",
|
||||
"Another way to find the list of models running on the Konko instance is through this [endpoint](https://docs.konko.ai/reference/get-models).\n",
|
||||
"\n",
|
||||
"From here, we can initialize our model:\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatKonko(max_tokens=400, model=\"meta-llama/Llama-2-13b-chat-hf\")"
|
||||
"chat = ChatKonko(max_tokens=400, model=\"meta-llama/llama-2-13b-chat\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\" Sure, I'd be happy to explain the Big Bang Theory briefly!\\n\\nThe Big Bang Theory is the leading explanation for the origin and evolution of the universe, based on a vast amount of observational evidence from many fields of science. In essence, the theory posits that the universe began as an infinitely hot and dense point, known as a singularity, around 13.8 billion years ago. This singularity expanded rapidly, and as it did, it cooled and formed subatomic particles, which eventually coalesced into the first atoms, and later into the stars and galaxies we see today.\\n\\nThe theory gets its name from the idea that the universe began in a state of incredibly high energy and temperature, and has been expanding and cooling ever since. This expansion is thought to have been driven by a mysterious force known as dark energy, which is thought to be responsible for the accelerating expansion of the universe.\\n\\nOne of the key predictions of the Big Bang Theory is that the universe should be homogeneous and isotropic on large scales, meaning that it should look the same in all directions and have the same properties everywhere. This prediction has been confirmed by a wealth of observational evidence, including the cosmic microwave background radiation, which is thought to be a remnant of the early universe.\\n\\nOverall, the Big Bang Theory is a well-established and widely accepted explanation for the origins of the universe, and it has been supported by a vast amount of observational evidence from many fields of science.\", additional_kwargs={}, example=False)"
|
||||
"AIMessage(content=\" Sure thing! The Big Bang Theory is a scientific theory that explains the origins of the universe. In short, it suggests that the universe began as an infinitely hot and dense point around 13.8 billion years ago and expanded rapidly. This expansion continues to this day, and it's what makes the universe look the way it does.\\n\\nHere's a brief overview of the key points:\\n\\n1. The universe started as a singularity, a point of infinite density and temperature.\\n2. The singularity expanded rapidly, causing the universe to cool and expand.\\n3. As the universe expanded, particles began to form, including protons, neutrons, and electrons.\\n4. These particles eventually came together to form atoms, and later, stars and galaxies.\\n5. The universe is still expanding today, and the rate of this expansion is accelerating.\\n\\nThat's the Big Bang Theory in a nutshell! It's a pretty mind-blowing idea when you think about it, and it's supported by a lot of scientific evidence. Do you have any other questions about it?\")"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -125,13 +137,6 @@
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
218
docs/docs/integrations/chat/litellm_router.ipynb
Normal file
218
docs/docs/integrations/chat/litellm_router.ipynb
Normal file
@@ -0,0 +1,218 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"id": "59148044",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: LiteLLM Router\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "247da7a6",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "bf733a38-db84-4363-89e2-de6735c37230",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ChatLiteLLMRouter\n",
|
||||
"\n",
|
||||
"[LiteLLM](https://github.com/BerriAI/litellm) is a library that simplifies calling Anthropic, Azure, Huggingface, Replicate, etc. \n",
|
||||
"\n",
|
||||
"This notebook covers how to get started with using Langchain + the LiteLLM Router I/O library. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "d4a7c55d-b235-4ca4-a579-c90cc9570da9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.chat_models import ChatLiteLLMRouter\n",
|
||||
"from litellm import Router"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "70cf04e8-423a-4ff6-8b09-f11fb711c817",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model_list = [\n",
|
||||
" {\n",
|
||||
" \"model_name\": \"gpt-4\",\n",
|
||||
" \"litellm_params\": {\n",
|
||||
" \"model\": \"azure/gpt-4-1106-preview\",\n",
|
||||
" \"api_key\": \"<your-api-key>\",\n",
|
||||
" \"api_version\": \"2023-05-15\",\n",
|
||||
" \"api_base\": \"https://<your-endpoint>.openai.azure.com/\",\n",
|
||||
" },\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"model_name\": \"gpt-4\",\n",
|
||||
" \"litellm_params\": {\n",
|
||||
" \"model\": \"azure/gpt-4-1106-preview\",\n",
|
||||
" \"api_key\": \"<your-api-key>\",\n",
|
||||
" \"api_version\": \"2023-05-15\",\n",
|
||||
" \"api_base\": \"https://<your-endpoint>.openai.azure.com/\",\n",
|
||||
" },\n",
|
||||
" },\n",
|
||||
"]\n",
|
||||
"litellm_router = Router(model_list=model_list)\n",
|
||||
"chat = ChatLiteLLMRouter(router=litellm_router)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8199ef8f-eb8b-4253-9ea0-6c24a013ca4c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'aime programmer.\")"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "c361ab1e-8c0c-4206-9e3c-9d1424a12b9c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## `ChatLiteLLMRouter` also supports async and streaming functionality:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "93a21c5c-6ef9-4688-be60-b2e1f94842fb",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.manager import CallbackManager\n",
|
||||
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "c5fac0e9-05a4-4fc1-a3b3-e5bbb24b971b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"LLMResult(generations=[[ChatGeneration(text=\"J'adore programmer.\", generation_info={'finish_reason': 'stop'}, message=AIMessage(content=\"J'adore programmer.\"))]], llm_output={'token_usage': {'completion_tokens': 6, 'prompt_tokens': 19, 'total_tokens': 25}, 'model_name': None}, run=[RunInfo(run_id=UUID('75003ec9-1e2b-43b7-a216-10dcc0f75e00'))])"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.agenerate([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "025be980-e50d-4a68-93dc-c9c7b500ce34",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"J'adore programmer."
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'adore programmer.\")"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = ChatLiteLLMRouter(\n",
|
||||
" router=litellm_router,\n",
|
||||
" streaming=True,\n",
|
||||
" verbose=True,\n",
|
||||
" callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),\n",
|
||||
")\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c253883f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
135
docs/docs/integrations/chat/llama_edge.ipynb
Normal file
135
docs/docs/integrations/chat/llama_edge.ipynb
Normal file
@@ -0,0 +1,135 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# LlamaEdge\n",
|
||||
"\n",
|
||||
"[LlamaEdge](https://github.com/second-state/LlamaEdge) allows you to chat with LLMs of [GGUF](https://github.com/ggerganov/llama.cpp/blob/master/gguf-py/README.md) format both locally and via chat service.\n",
|
||||
"\n",
|
||||
"- `LlamaEdgeChatService` provides developers an OpenAI API compatible service to chat with LLMs via HTTP requests.\n",
|
||||
"\n",
|
||||
"- `LlamaEdgeChatLocal` enables developers to chat with LLMs locally (coming soon).\n",
|
||||
"\n",
|
||||
"Both `LlamaEdgeChatService` and `LlamaEdgeChatLocal` run on the infrastructure driven by [WasmEdge Runtime](https://wasmedge.org/), which provides a lightweight and portable WebAssembly container environment for LLM inference tasks.\n",
|
||||
"\n",
|
||||
"## Chat via API Service\n",
|
||||
"\n",
|
||||
"`LlamaEdgeChatService` works on the `llama-api-server`. Following the steps in [llama-api-server quick-start](https://github.com/second-state/llama-utils/tree/main/api-server#readme), you can host your own API service so that you can chat with any models you like on any device you have anywhere as long as the internet is available."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_models.llama_edge import LlamaEdgeChatService\n",
|
||||
"from langchain_core.messages import HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Chat with LLMs in the non-streaming mode"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Hello! The capital of France is Paris.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = LlamaEdgeChatService(service_url=service_url)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of France?\")\n",
|
||||
"messages = [system_message, user_message]\n",
|
||||
"\n",
|
||||
"# chat with wasm-chat service\n",
|
||||
"response = chat(messages)\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {response.content}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Chat with LLMs in the streaming mode"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Hello! I'm happy to help you with your question. The capital of Norway is Oslo.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = LlamaEdgeChatService(service_url=service_url, streaming=True)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of Norway?\")\n",
|
||||
"messages = [\n",
|
||||
" system_message,\n",
|
||||
" user_message,\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"output = \"\"\n",
|
||||
"for chunk in chat.stream(messages):\n",
|
||||
" # print(chunk.content, end=\"\", flush=True)\n",
|
||||
" output += chunk.content\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {output}\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
99
docs/docs/integrations/chat/sparkllm.ipynb
Normal file
99
docs/docs/integrations/chat/sparkllm.ipynb
Normal file
@@ -0,0 +1,99 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3ddface67cd10a87",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# SparkLLM Chat\n",
|
||||
"\n",
|
||||
"SparkLLM chat models API by iFlyTek. For more information, see [iFlyTek Open Platform](https://www.xfyun.cn/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Basic use"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "43daa39972d4c533",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"is_executing": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\"\"\"For basic init and call\"\"\"\n",
|
||||
"from langchain.chat_models import ChatSparkLLM\n",
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"\n",
|
||||
"chat = ChatSparkLLM(\n",
|
||||
" spark_app_id=\"<app_id>\", spark_api_key=\"<api_key>\", spark_api_secret=\"<api_secret>\"\n",
|
||||
")\n",
|
||||
"message = HumanMessage(content=\"Hello\")\n",
|
||||
"chat([message])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "df755f4c5689510",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"- Get SparkLLM's app_id, api_key and api_secret from [iFlyTek SparkLLM API Console](https://console.xfyun.cn/services/bm3) (for more info, see [iFlyTek SparkLLM Intro](https://xinghuo.xfyun.cn/sparkapi) ), then set environment variables `IFLYTEK_SPARK_APP_ID`, `IFLYTEK_SPARK_API_KEY` and `IFLYTEK_SPARK_API_SECRET` or pass parameters when creating `ChatSparkLLM` as the demo above."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "984e32ee47bc6772",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"## For ChatSparkLLM with Streaming"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7dc162bd65fec08f",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatSparkLLM(streaming=True)\n",
|
||||
"for chunk in chat.stream(\"Hello!\"):\n",
|
||||
" print(chunk.content, end=\"\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 2
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython2",
|
||||
"version": "2.7.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -1,85 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Wasm Chat\n",
|
||||
"\n",
|
||||
"`Wasm-chat` allows you to chat with LLMs of [GGUF](https://github.com/ggerganov/llama.cpp/blob/master/gguf-py/README.md) format both locally and via chat service.\n",
|
||||
"\n",
|
||||
"- `WasmChatService` provides developers an OpenAI API compatible service to chat with LLMs via HTTP requests.\n",
|
||||
"\n",
|
||||
"- `WasmChatLocal` enables developers to chat with LLMs locally (coming soon).\n",
|
||||
"\n",
|
||||
"Both `WasmChatService` and `WasmChatLocal` run on the infrastructure driven by [WasmEdge Runtime](https://wasmedge.org/), which provides a lightweight and portable WebAssembly container environment for LLM inference tasks.\n",
|
||||
"\n",
|
||||
"## Chat via API Service\n",
|
||||
"\n",
|
||||
"`WasmChatService` provides chat services by the `llama-api-server`. Following the steps in [llama-api-server quick-start](https://github.com/second-state/llama-utils/tree/main/api-server#readme), you can host your own API service so that you can chat with any models you like on any device you have anywhere as long as the internet is available."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_models.wasm_chat import WasmChatService\n",
|
||||
"from langchain_core.messages import AIMessage, HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Bot] Paris\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# service url\n",
|
||||
"service_url = \"https://b008-54-186-154-209.ngrok-free.app\"\n",
|
||||
"\n",
|
||||
"# create wasm-chat service instance\n",
|
||||
"chat = WasmChatService(service_url=service_url)\n",
|
||||
"\n",
|
||||
"# create message sequence\n",
|
||||
"system_message = SystemMessage(content=\"You are an AI assistant\")\n",
|
||||
"user_message = HumanMessage(content=\"What is the capital of France?\")\n",
|
||||
"messages = [system_message, user_message]\n",
|
||||
"\n",
|
||||
"# chat with wasm-chat service\n",
|
||||
"response = chat(messages)\n",
|
||||
"\n",
|
||||
"print(f\"[Bot] {response.content}\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
241
docs/docs/integrations/document_loaders/cassandra.ipynb
Normal file
241
docs/docs/integrations/document_loaders/cassandra.ipynb
Normal file
@@ -0,0 +1,241 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "vm8vn9t8DvC_"
|
||||
},
|
||||
"source": [
|
||||
"# Cassandra"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"[Cassandra](https://cassandra.apache.org/) is a NoSQL, row-oriented, highly scalable and highly available database.Starting with version 5.0, the database ships with [vector search capabilities](https://cassandra.apache.org/doc/trunk/cassandra/vector-search/overview.html)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "5WjXERXzFEhg"
|
||||
},
|
||||
"source": [
|
||||
"## Overview"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "juAmbgoWD17u"
|
||||
},
|
||||
"source": [
|
||||
"The Cassandra Document Loader returns a list of Langchain Documents from a Cassandra database.\n",
|
||||
"\n",
|
||||
"You must either provide a CQL query or a table name to retrieve the documents.\n",
|
||||
"The Loader takes the following parameters:\n",
|
||||
"\n",
|
||||
"* table: (Optional) The table to load the data from.\n",
|
||||
"* session: (Optional) The cassandra driver session. If not provided, the cassio resolved session will be used.\n",
|
||||
"* keyspace: (Optional) The keyspace of the table. If not provided, the cassio resolved keyspace will be used.\n",
|
||||
"* query: (Optional) The query used to load the data.\n",
|
||||
"* page_content_mapper: (Optional) a function to convert a row to string page content. The default converts the row to JSON.\n",
|
||||
"* metadata_mapper: (Optional) a function to convert a row to metadata dict.\n",
|
||||
"* query_parameters: (Optional) The query parameters used when calling session.execute .\n",
|
||||
"* query_timeout: (Optional) The query timeout used when calling session.execute .\n",
|
||||
"* query_custom_payload: (Optional) The query custom_payload used when calling `session.execute`.\n",
|
||||
"* query_execution_profile: (Optional) The query execution_profile used when calling `session.execute`.\n",
|
||||
"* query_host: (Optional) The query host used when calling `session.execute`.\n",
|
||||
"* query_execute_as: (Optional) The query execute_as used when calling `session.execute`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load documents with the Document Loader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.document_loaders import CassandraLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"### Init from a cassandra driver Session\n",
|
||||
"\n",
|
||||
"You need to create a `cassandra.cluster.Session` object, as described in the [Cassandra driver documentation](https://docs.datastax.com/en/developer/python-driver/latest/api/cassandra/cluster/#module-cassandra.cluster). The details vary (e.g. with network settings and authentication), but this might be something like:"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from cassandra.cluster import Cluster\n",
|
||||
"\n",
|
||||
"cluster = Cluster()\n",
|
||||
"session = cluster.connect()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"execution_count": null
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"You need to provide the name of an existing keyspace of the Cassandra instance:"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"CASSANDRA_KEYSPACE = input(\"CASSANDRA_KEYSPACE = \")"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"execution_count": null
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Creating the document loader:"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T15:47:25.893037Z",
|
||||
"start_time": "2024-01-19T15:47:25.889398Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = CassandraLoader(\n",
|
||||
" table=\"movie_reviews\",\n",
|
||||
" session=session,\n",
|
||||
" keyspace=CASSANDRA_KEYSPACE,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs = loader.load()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T15:47:26.399472Z",
|
||||
"start_time": "2024-01-19T15:47:26.389145Z"
|
||||
}
|
||||
},
|
||||
"execution_count": 17
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2024-01-19T15:47:33.287783Z",
|
||||
"start_time": "2024-01-19T15:47:33.277862Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "Document(page_content='Row(_id=\\'659bdffa16cbc4586b11a423\\', title=\\'Dangerous Men\\', reviewtext=\\'\"Dangerous Men,\" the picture\\\\\\'s production notes inform, took 26 years to reach the big screen. After having seen it, I wonder: What was the rush?\\')', metadata={'table': 'movie_reviews', 'keyspace': 'default_keyspace'})"
|
||||
},
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"### Init from cassio\n",
|
||||
"\n",
|
||||
"It's also possible to use cassio to configure the session and keyspace."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import cassio\n",
|
||||
"\n",
|
||||
"cassio.init(contact_points=\"127.0.0.1\", keyspace=CASSANDRA_KEYSPACE)\n",
|
||||
"\n",
|
||||
"loader = CassandraLoader(\n",
|
||||
" table=\"movie_reviews\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"docs = loader.load()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"execution_count": null
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"collapsed_sections": [
|
||||
"5WjXERXzFEhg"
|
||||
],
|
||||
"provenance": []
|
||||
},
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.18"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
BIN
docs/docs/integrations/document_loaders/example_data/fake.vsdx
Normal file
BIN
docs/docs/integrations/document_loaders/example_data/fake.vsdx
Normal file
Binary file not shown.
@@ -8,7 +8,7 @@
|
||||
"This notebook covers how to load documents from `Psychic`. See [here](/docs/integrations/providers/psychic) for more details.\n",
|
||||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"1. Follow the Quick Start section in [this document](/docs/ecosystem/integrations/psychic)\n",
|
||||
"1. Follow the Quick Start section in [this document](/docs/integrations/providers/psychic)\n",
|
||||
"2. Log into the [Psychic dashboard](https://dashboard.psychic.dev/) and get your secret key\n",
|
||||
"3. Install the frontend react library into your web app and have a user authenticate a connection. The connection will be created using the connection id that you specify."
|
||||
]
|
||||
|
||||
236
docs/docs/integrations/document_loaders/surrealdb.ipynb
Normal file
236
docs/docs/integrations/document_loaders/surrealdb.ipynb
Normal file
@@ -0,0 +1,236 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5812b612-3e77-4be2-aefb-fbb16141ab79",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# SurrealDB\n",
|
||||
"\n",
|
||||
">[SurrealDB](https://surrealdb.com/) is an end-to-end cloud-native database designed for modern applications, including web, mobile, serverless, Jamstack, backend, and traditional applications. With SurrealDB, you can simplify your database and API infrastructure, reduce development time, and build secure, performant apps quickly and cost-effectively.\n",
|
||||
">\n",
|
||||
">**Key features of SurrealDB include:**\n",
|
||||
">\n",
|
||||
">* **Reduces development time:** SurrealDB simplifies your database and API stack by removing the need for most server-side components, allowing you to build secure, performant apps faster and cheaper.\n",
|
||||
">* **Real-time collaborative API backend service:** SurrealDB functions as both a database and an API backend service, enabling real-time collaboration.\n",
|
||||
">* **Support for multiple querying languages:** SurrealDB supports SQL querying from client devices, GraphQL, ACID transactions, WebSocket connections, structured and unstructured data, graph querying, full-text indexing, and geospatial querying.\n",
|
||||
">* **Granular access control:** SurrealDB provides row-level permissions-based access control, giving you the ability to manage data access with precision.\n",
|
||||
">\n",
|
||||
">View the [features](https://surrealdb.com/features), the latest [releases](https://surrealdb.com/releases), and [documentation](https://surrealdb.com/docs).\n",
|
||||
"\n",
|
||||
"This notebook shows how to use functionality related to the `SurrealDBLoader`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f56ccec5-24b3-4762-91a6-91385e041fee",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"The SurrealDB Document Loader returns a list of Langchain Documents from a SurrealDB database.\n",
|
||||
"\n",
|
||||
"The Document Loader takes the following optional parameters:\n",
|
||||
"\n",
|
||||
"* `dburl`: connection string to the websocket endpoint. default: `ws://localhost:8000/rpc`\n",
|
||||
"* `ns`: name of the namespace. default: `langchain`\n",
|
||||
"* `db`: name of the database. default: `database`\n",
|
||||
"* `table`: name of the table. default: `documents`\n",
|
||||
"* `db_user`: SurrealDB credentials if needed: db username.\n",
|
||||
"* `db_pass`: SurrealDB credentails if needed: db password.\n",
|
||||
"* `filter_criteria`: dictionary to construct the `WHERE` clause for filtering results from table.\n",
|
||||
"\n",
|
||||
"The output `Document` takes the following shape:\n",
|
||||
"```\n",
|
||||
"Document(\n",
|
||||
" page_content=<json encoded string containing the result document>,\n",
|
||||
" metadata={\n",
|
||||
" 'id': <document id>,\n",
|
||||
" 'ns': <namespace name>,\n",
|
||||
" 'db': <database_name>,\n",
|
||||
" 'table': <table name>,\n",
|
||||
" ... <additional fields from metadata property of the document>\n",
|
||||
" }\n",
|
||||
")\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "77b024e0-c804-4b19-9f5e-0099eb61ba79",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"Uncomment the below cells to install surrealdb and langchain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "508bc4f3-3aa2-45d3-8e59-cd7d0ffec379",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install --upgrade --quiet surrealdb langchain langchain-community"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "3ee3d767-b9ba-4be4-9e80-8fa6376beaba",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# add this import for running in jupyter notebook\n",
|
||||
"import nest_asyncio\n",
|
||||
"\n",
|
||||
"nest_asyncio.apply()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "1ec629f4-b99a-44f1-a938-29de7439f121",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"from langchain_community.document_loaders.surrealdb import SurrealDBLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8deb90ac-7d4e-422c-a87a-8e6e41390a6d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"42"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = SurrealDBLoader(\n",
|
||||
" dburl=\"ws://localhost:8000/rpc\",\n",
|
||||
" ns=\"langchain\",\n",
|
||||
" db=\"database\",\n",
|
||||
" table=\"documents\",\n",
|
||||
" db_user=\"root\",\n",
|
||||
" db_pass=\"root\",\n",
|
||||
" filter_criteria={},\n",
|
||||
")\n",
|
||||
"docs = loader.load()\n",
|
||||
"len(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "0aa9d3f7-56b3-464d-9d3d-1df7164122ba",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'id': 'documents:zzz434sa584xl3b4ohvk',\n",
|
||||
" 'source': '../../modules/state_of_the_union.txt',\n",
|
||||
" 'ns': 'langchain',\n",
|
||||
" 'db': 'database',\n",
|
||||
" 'table': 'documents'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"doc = docs[-1]\n",
|
||||
"doc.metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "0378dd34-c690-4b8e-8816-90a8acc2f227",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"18078"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"len(doc.page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "f30f1141-329b-4674-acb4-36d9d5a9ef0a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"page_content = json.loads(doc.page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "2a58496f-a831-40ec-be6b-92ce70f78133",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'When we use taxpayer dollars to rebuild America – we are going to Buy American: buy American products to support American jobs. \\n\\nThe federal government spends about $600 Billion a year to keep the country safe and secure. \\n\\nThere’s been a law on the books for almost a century \\nto make sure taxpayers’ dollars support American jobs and businesses. \\n\\nEvery Administration says they’ll do it, but we are actually doing it. \\n\\nWe will buy American to make sure everything from the deck of an aircraft carrier to the steel on highway guardrails are made in America. \\n\\nBut to compete for the best jobs of the future, we also need to level the playing field with China and other competitors. \\n\\nThat’s why it is so important to pass the Bipartisan Innovation Act sitting in Congress that will make record investments in emerging technologies and American manufacturing. \\n\\nLet me give you one example of why it’s so important to pass it.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"page_content[\"text\"]"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -12,7 +12,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 2,
|
||||
"id": "497736aa",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -24,7 +24,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"id": "009e0036",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -34,19 +34,19 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 8,
|
||||
"id": "910fb6ee",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ToMarkdownLoader.from_api_key(\n",
|
||||
" url=\"https://python.langchain.com/en/latest/\", api_key=api_key\n",
|
||||
"loader = ToMarkdownLoader(\n",
|
||||
" url=\"https://python.langchain.com/docs/get_started/introduction\", api_key=api_key\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 9,
|
||||
"id": "ac8db139",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -56,7 +56,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 10,
|
||||
"id": "706304e9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -64,130 +64,106 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"## Contents\n",
|
||||
"**LangChain** is a framework for developing applications powered by language models. It enables applications that:\n",
|
||||
"\n",
|
||||
"- [Getting Started](#getting-started)\n",
|
||||
"- [Modules](#modules)\n",
|
||||
"- [Use Cases](#use-cases)\n",
|
||||
"- [Reference Docs](#reference-docs)\n",
|
||||
"- [LangChain Ecosystem](#langchain-ecosystem)\n",
|
||||
"- [Additional Resources](#additional-resources)\n",
|
||||
"- **Are context-aware**: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)\n",
|
||||
"- **Reason**: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)\n",
|
||||
"\n",
|
||||
"## Welcome to LangChain [\\#](\\#welcome-to-langchain \"Permalink to this headline\")\n",
|
||||
"This framework consists of several parts.\n",
|
||||
"\n",
|
||||
"**LangChain** is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model, but will also be:\n",
|
||||
"- **LangChain Libraries**: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.\n",
|
||||
"- **[LangChain Templates](https://python.langchain.com/docs/templates)**: A collection of easily deployable reference architectures for a wide variety of tasks.\n",
|
||||
"- **[LangServe](https://python.langchain.com/docs/langserve)**: A library for deploying LangChain chains as a REST API.\n",
|
||||
"- **[LangSmith](https://python.langchain.com/docs/langsmith)**: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.\n",
|
||||
"\n",
|
||||
"1. _Data-aware_: connect a language model to other sources of data\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"2. _Agentic_: allow a language model to interact with its environment\n",
|
||||
"Together, these products simplify the entire application lifecycle:\n",
|
||||
"\n",
|
||||
"- **Develop**: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.\n",
|
||||
"- **Productionize**: Use LangSmith to inspect, test and monitor your chains, so that you can constantly improve and deploy with confidence.\n",
|
||||
"- **Deploy**: Turn any chain into an API with LangServe.\n",
|
||||
"\n",
|
||||
"The LangChain framework is designed around these principles.\n",
|
||||
"## LangChain Libraries [](\\#langchain-libraries \"Direct link to LangChain Libraries\")\n",
|
||||
"\n",
|
||||
"This is the Python specific portion of the documentation. For a purely conceptual guide to LangChain, see [here](https://docs.langchain.com/docs/). For the JavaScript documentation, see [here](https://js.langchain.com/docs/).\n",
|
||||
"The main value props of the LangChain packages are:\n",
|
||||
"\n",
|
||||
"## Getting Started [\\#](\\#getting-started \"Permalink to this headline\")\n",
|
||||
"1. **Components**: composable tools and integrations for working with language models. Components are modular and easy-to-use, whether you are using the rest of the LangChain framework or not\n",
|
||||
"2. **Off-the-shelf chains**: built-in assemblages of components for accomplishing higher-level tasks\n",
|
||||
"\n",
|
||||
"How to get started using LangChain to create an Language Model application.\n",
|
||||
"Off-the-shelf chains make it easy to get started. Components make it easy to customize existing chains and build new ones.\n",
|
||||
"\n",
|
||||
"- [Quickstart Guide](https://python.langchain.com/en/latest/getting_started/getting_started.html)\n",
|
||||
"The LangChain libraries themselves are made up of several different packages.\n",
|
||||
"\n",
|
||||
"- **`langchain-core`**: Base abstractions and LangChain Expression Language.\n",
|
||||
"- **`langchain-community`**: Third party integrations.\n",
|
||||
"- **`langchain`**: Chains, agents, and retrieval strategies that make up an application's cognitive architecture.\n",
|
||||
"\n",
|
||||
"Concepts and terminology.\n",
|
||||
"## Get started [](\\#get-started \"Direct link to Get started\")\n",
|
||||
"\n",
|
||||
"- [Concepts and terminology](https://python.langchain.com/en/latest/getting_started/concepts.html)\n",
|
||||
"[Here’s](https://python.langchain.com/docs/get_started/installation) how to install LangChain, set up your environment, and start building.\n",
|
||||
"\n",
|
||||
"We recommend following our [Quickstart](https://python.langchain.com/docs/get_started/quickstart) guide to familiarize yourself with the framework by building your first LangChain application.\n",
|
||||
"\n",
|
||||
"Tutorials created by community experts and presented on YouTube.\n",
|
||||
"Read up on our [Security](https://python.langchain.com/docs/security) best practices to make sure you're developing safely with LangChain.\n",
|
||||
"\n",
|
||||
"- [Tutorials](https://python.langchain.com/en/latest/getting_started/tutorials.html)\n",
|
||||
"note\n",
|
||||
"\n",
|
||||
"These docs focus on the Python LangChain library. [Head here](https://js.langchain.com) for docs on the JavaScript LangChain library.\n",
|
||||
"\n",
|
||||
"## Modules [\\#](\\#modules \"Permalink to this headline\")\n",
|
||||
"## LangChain Expression Language (LCEL) [](\\#langchain-expression-language-lcel \"Direct link to LangChain Expression Language (LCEL)\")\n",
|
||||
"\n",
|
||||
"These modules are the core abstractions which we view as the building blocks of any LLM-powered application.\n",
|
||||
"LCEL is a declarative way to compose chains. LCEL was designed from day 1 to support putting prototypes in production, with no code changes, from the simplest “prompt + LLM” chain to the most complex chains.\n",
|
||||
"\n",
|
||||
"For each module LangChain provides standard, extendable interfaces. LanghChain also provides external integrations and even end-to-end implementations for off-the-shelf use.\n",
|
||||
"- **[Overview](https://python.langchain.com/docs/expression_language/)**: LCEL and its benefits\n",
|
||||
"- **[Interface](https://python.langchain.com/docs/expression_language/interface)**: The standard interface for LCEL objects\n",
|
||||
"- **[How-to](https://python.langchain.com/docs/expression_language/how_to)**: Key features of LCEL\n",
|
||||
"- **[Cookbook](https://python.langchain.com/docs/expression_language/cookbook)**: Example code for accomplishing common tasks\n",
|
||||
"\n",
|
||||
"The docs for each module contain quickstart examples, how-to guides, reference docs, and conceptual guides.\n",
|
||||
"## Modules [](\\#modules \"Direct link to Modules\")\n",
|
||||
"\n",
|
||||
"The modules are (from least to most complex):\n",
|
||||
"LangChain provides standard, extendable interfaces and integrations for the following modules:\n",
|
||||
"\n",
|
||||
"- [Models](https://python.langchain.com/docs/modules/model_io/models/): Supported model types and integrations.\n",
|
||||
"#### [Model I/O](https://python.langchain.com/docs/modules/model_io/) [](\\#model-io \"Direct link to model-io\")\n",
|
||||
"\n",
|
||||
"- [Prompts](https://python.langchain.com/en/latest/modules/prompts.html): Prompt management, optimization, and serialization.\n",
|
||||
"Interface with language models\n",
|
||||
"\n",
|
||||
"- [Memory](https://python.langchain.com/en/latest/modules/memory.html): Memory refers to state that is persisted between calls of a chain/agent.\n",
|
||||
"#### [Retrieval](https://python.langchain.com/docs/modules/data_connection/) [](\\#retrieval \"Direct link to retrieval\")\n",
|
||||
"\n",
|
||||
"- [Indexes](https://python.langchain.com/en/latest/modules/data_connection.html): Language models become much more powerful when combined with application-specific data - this module contains interfaces and integrations for loading, querying and updating external data.\n",
|
||||
"Interface with application-specific data\n",
|
||||
"\n",
|
||||
"- [Chains](https://python.langchain.com/en/latest/modules/chains.html): Chains are structured sequences of calls (to an LLM or to a different utility).\n",
|
||||
"#### [Agents](https://python.langchain.com/docs/modules/agents/) [](\\#agents \"Direct link to agents\")\n",
|
||||
"\n",
|
||||
"- [Agents](https://python.langchain.com/en/latest/modules/agents.html): An agent is a Chain in which an LLM, given a high-level directive and a set of tools, repeatedly decides an action, executes the action and observes the outcome until the high-level directive is complete.\n",
|
||||
"Let models choose which tools to use given high-level directives\n",
|
||||
"\n",
|
||||
"- [Callbacks](https://python.langchain.com/en/latest/modules/callbacks/getting_started.html): Callbacks let you log and stream the intermediate steps of any chain, making it easy to observe, debug, and evaluate the internals of an application.\n",
|
||||
"## Examples, ecosystem, and resources [](\\#examples-ecosystem-and-resources \"Direct link to Examples, ecosystem, and resources\")\n",
|
||||
"\n",
|
||||
"### [Use cases](https://python.langchain.com/docs/use_cases/question_answering/) [](\\#use-cases \"Direct link to use-cases\")\n",
|
||||
"\n",
|
||||
"## Use Cases [\\#](\\#use-cases \"Permalink to this headline\")\n",
|
||||
"Walkthroughs and techniques for common end-to-end use cases, like:\n",
|
||||
"\n",
|
||||
"Best practices and built-in implementations for common LangChain use cases:\n",
|
||||
"- [Document question answering](https://python.langchain.com/docs/use_cases/question_answering/)\n",
|
||||
"- [Chatbots](https://python.langchain.com/docs/use_cases/chatbots/)\n",
|
||||
"- [Analyzing structured data](https://python.langchain.com/docs/use_cases/sql/)\n",
|
||||
"- and much more...\n",
|
||||
"\n",
|
||||
"- [Autonomous Agents](https://python.langchain.com/en/latest/use_cases/autonomous_agents.html): Autonomous agents are long-running agents that take many steps in an attempt to accomplish an objective. Examples include AutoGPT and BabyAGI.\n",
|
||||
"### [Integrations](https://python.langchain.com/docs/integrations/providers/) [](\\#integrations \"Direct link to integrations\")\n",
|
||||
"\n",
|
||||
"- [Agent Simulations](https://python.langchain.com/en/latest/use_cases/agent_simulations.html): Putting agents in a sandbox and observing how they interact with each other and react to events can be an effective way to evaluate their long-range reasoning and planning abilities.\n",
|
||||
"LangChain is part of a rich ecosystem of tools that integrate with our framework and build on top of it. Check out our growing list of [integrations](https://python.langchain.com/docs/integrations/providers/).\n",
|
||||
"\n",
|
||||
"- [Personal Assistants](https://python.langchain.com/en/latest/use_cases/personal_assistants.html): One of the primary LangChain use cases. Personal assistants need to take actions, remember interactions, and have knowledge about your data.\n",
|
||||
"### [Guides](https://python.langchain.com/docs/guides/debugging) [](\\#guides \"Direct link to guides\")\n",
|
||||
"\n",
|
||||
"- [Question Answering](https://python.langchain.com/en/latest/use_cases/question_answering.html): Another common LangChain use case. Answering questions over specific documents, only utilizing the information in those documents to construct an answer.\n",
|
||||
"Best practices for developing with LangChain.\n",
|
||||
"\n",
|
||||
"- [Chatbots](https://python.langchain.com/en/latest/use_cases/chatbots.html): Language models love to chat, making this a very natural use of them.\n",
|
||||
"### [API reference](https://api.python.langchain.com) [](\\#api-reference \"Direct link to api-reference\")\n",
|
||||
"\n",
|
||||
"- [Querying Tabular Data](https://python.langchain.com/en/latest/use_cases/tabular.html): Recommended reading if you want to use language models to query structured data (CSVs, SQL, dataframes, etc).\n",
|
||||
"Head to the reference section for full documentation of all classes and methods in the LangChain and LangChain Experimental Python packages.\n",
|
||||
"\n",
|
||||
"- [Code Understanding](https://python.langchain.com/en/latest/use_cases/code.html): Recommended reading if you want to use language models to analyze code.\n",
|
||||
"### [Developer's guide](https://python.langchain.com/docs/contributing) [](\\#developers-guide \"Direct link to developers-guide\")\n",
|
||||
"\n",
|
||||
"- [Interacting with APIs](https://python.langchain.com/en/latest/use_cases/apis.html): Enabling language models to interact with APIs is extremely powerful. It gives them access to up-to-date information and allows them to take actions.\n",
|
||||
"Check out the developer's guide for guidelines on contributing and help getting your dev environment set up.\n",
|
||||
"\n",
|
||||
"- [Extraction](https://python.langchain.com/en/latest/use_cases/extraction.html): Extract structured information from text.\n",
|
||||
"\n",
|
||||
"- [Summarization](https://python.langchain.com/en/latest/use_cases/summarization.html): Compressing longer documents. A type of Data-Augmented Generation.\n",
|
||||
"\n",
|
||||
"- [Evaluation](https://python.langchain.com/en/latest/use_cases/evaluation.html): Generative models are hard to evaluate with traditional metrics. One promising approach is to use language models themselves to do the evaluation.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Reference Docs [\\#](\\#reference-docs \"Permalink to this headline\")\n",
|
||||
"\n",
|
||||
"Full documentation on all methods, classes, installation methods, and integration setups for LangChain.\n",
|
||||
"\n",
|
||||
"- [Reference Documentation](https://python.langchain.com/en/latest/reference.html)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## LangChain Ecosystem [\\#](\\#langchain-ecosystem \"Permalink to this headline\")\n",
|
||||
"\n",
|
||||
"Guides for how other companies/products can be used with LangChain.\n",
|
||||
"\n",
|
||||
"- [LangChain Ecosystem](https://python.langchain.com/en/latest/ecosystem.html)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Additional Resources [\\#](\\#additional-resources \"Permalink to this headline\")\n",
|
||||
"\n",
|
||||
"Additional resources we think may be useful as you develop your application!\n",
|
||||
"\n",
|
||||
"- [LangChainHub](https://github.com/hwchase17/langchain-hub): The LangChainHub is a place to share and explore other prompts, chains, and agents.\n",
|
||||
"\n",
|
||||
"- [Gallery](https://python.langchain.com/en/latest/additional_resources/gallery.html): A collection of our favorite projects that use LangChain. Useful for finding inspiration or seeing how things were done in other applications.\n",
|
||||
"\n",
|
||||
"- [Deployments](https://python.langchain.com/en/latest/additional_resources/deployments.html): A collection of instructions, code snippets, and template repositories for deploying LangChain apps.\n",
|
||||
"\n",
|
||||
"- [Tracing](https://python.langchain.com/en/latest/additional_resources/tracing.html): A guide on using tracing in LangChain to visualize the execution of chains and agents.\n",
|
||||
"\n",
|
||||
"- [Model Laboratory](https://python.langchain.com/en/latest/additional_resources/model_laboratory.html): Experimenting with different prompts, models, and chains is a big part of developing the best possible application. The ModelLaboratory makes it easy to do so.\n",
|
||||
"\n",
|
||||
"- [Discord](https://discord.gg/6adMQxSpJS): Join us on our Discord to discuss all things LangChain!\n",
|
||||
"\n",
|
||||
"- [YouTube](https://python.langchain.com/en/latest/additional_resources/youtube.html): A collection of the LangChain tutorials and videos.\n",
|
||||
"\n",
|
||||
"- [Production Support](https://forms.gle/57d8AmXBYp8PP8tZA): As you move your LangChains into production, we’d love to offer more comprehensive support. Please fill out this form and we’ll set up a dedicated support Slack channel.\n"
|
||||
"Head to the [Community navigator](https://python.langchain.com/docs/community) to find places to ask questions, share feedback, meet other developers, and dream about the future of LLM’s.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
@@ -198,7 +174,7 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5dde17e7",
|
||||
"id": "7c89b313-adb6-4aa2-9cd8-952a5724a2ce",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
@@ -220,7 +196,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
"version": "3.11.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": null,
|
||||
"id": "2886982e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -100,6 +100,54 @@
|
||||
"docs[0].page_content[:400]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b4ab0a79",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Load list of files"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "092d9a0b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"files = [\"./example_data/whatsapp_chat.txt\", \"./example_data/layout-parser-paper.pdf\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f841c4f8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredFileLoader(files)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "993c240b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5ce4ff07",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs[0].page_content[:400]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7874d01d",
|
||||
@@ -495,7 +543,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.10"
|
||||
"version": "3.9.0"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
486
docs/docs/integrations/document_loaders/vsdx.ipynb
Normal file
486
docs/docs/integrations/document_loaders/vsdx.ipynb
Normal file
@@ -0,0 +1,486 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Vsdx"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> A [visio file](https://fr.wikipedia.org/wiki/Microsoft_Visio) (with extension .vsdx) is associated with Microsoft Visio, a diagram creation software. It stores information about the structure, layout, and graphical elements of a diagram. This format facilitates the creation and sharing of visualizations in areas such as business, engineering, and computer science."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"A Visio file can contain multiple pages. Some of them may serve as the background for others, and this can occur across multiple layers. This **loader** extracts the textual content from each page and its associated pages, enabling the extraction of all visible text from each page, similar to what an OCR algorithm would do."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**WARNING** : Only Visio files with the **.vsdx** extension are compatible with this loader. Files with extensions such as .vsd, ... are not compatible because they cannot be converted to compressed XML."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.document_loaders import VsdxLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = VsdxLoader(file_path=\"./example_data/fake.vsdx\")\n",
|
||||
"documents = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Display loaded documents**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"------ Page 0 ------\n",
|
||||
"Title page : Summary\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Best Caption of the worl\n",
|
||||
"This is an arrow\n",
|
||||
"This is Earth\n",
|
||||
"This is a bounded arrow\n",
|
||||
"\n",
|
||||
"------ Page 1 ------\n",
|
||||
"Title page : Glossary\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"\n",
|
||||
"------ Page 2 ------\n",
|
||||
"Title page : blanket page\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"This file is a vsdx file\n",
|
||||
"First text\n",
|
||||
"Second text\n",
|
||||
"Third text\n",
|
||||
"\n",
|
||||
"------ Page 3 ------\n",
|
||||
"Title page : BLABLABLA\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"This is a page with something...\n",
|
||||
"\n",
|
||||
"WAW I have learned something !\n",
|
||||
"This is a page with something...\n",
|
||||
"\n",
|
||||
"WAW I have learned something !\n",
|
||||
"\n",
|
||||
"X2\n",
|
||||
"\n",
|
||||
"------ Page 4 ------\n",
|
||||
"Title page : What a page !!\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Red arrow magic !\n",
|
||||
"\n",
|
||||
"------ Page 5 ------\n",
|
||||
"Title page : next page after previous one\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor\n",
|
||||
"\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0\\u00a0-\\u00a0incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa\n",
|
||||
"*\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"------ Page 6 ------\n",
|
||||
"Title page : Connector Page\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"\n",
|
||||
"------ Page 7 ------\n",
|
||||
"Title page : Useful ↔ Useless page\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Title of this document : BLABLABLA\n",
|
||||
"\n",
|
||||
"------ Page 8 ------\n",
|
||||
"Title page : Alone page\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Black cloud\n",
|
||||
"Unidirectional traffic primary path\n",
|
||||
"Unidirectional traffic backup path\n",
|
||||
"Encapsulation\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Bidirectional traffic\n",
|
||||
"Alone, sad\n",
|
||||
"Test of another page\n",
|
||||
"This is a \\\"bannier\\\"\n",
|
||||
"Tests of some exotics characters :\\u00a0\\u00e3\\u00e4\\u00e5\\u0101\\u0103 \\u00fc\\u2554\\u00a0 \\u00a0\\u00bc \\u00c7 \\u25d8\\u25cb\\u2642\\u266b\\u2640\\u00ee\\u2665\n",
|
||||
"This is ethernet\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"This is an empty case\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor\n",
|
||||
"\\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0 \\u00a0-\\u00a0 incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa \n",
|
||||
"*\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"------ Page 9 ------\n",
|
||||
"Title page : BG\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Best Caption of the worl\n",
|
||||
"This is an arrow\n",
|
||||
"This is Earth\n",
|
||||
"This is a bounded arrow\n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"\n",
|
||||
"------ Page 10 ------\n",
|
||||
"Title page : BG + caption1\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Useful\\u2194 Useless page\\u00a0\n",
|
||||
"\n",
|
||||
"Tests of some exotics characters :\\u00a0\\u00e3\\u00e4\\u00e5\\u0101\\u0103 \\u00fc\\u2554\\u00a0\\u00a0\\u00bc \\u00c7 \\u25d8\\u25cb\\u2642\\u266b\\u2640\\u00ee\\u2665\n",
|
||||
"\n",
|
||||
"------ Page 11 ------\n",
|
||||
"Title page : BG+\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"\n",
|
||||
"------ Page 12 ------\n",
|
||||
"Title page : BG WITH CONTENT\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. - Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n",
|
||||
"This is a page with a lot of text\n",
|
||||
"\n",
|
||||
"------ Page 13 ------\n",
|
||||
"Title page : 2nd caption with ____________________________________________________________________ content\n",
|
||||
"Source : ./example_data/fake.vsdx\n",
|
||||
"\n",
|
||||
"==> CONTENT <== \n",
|
||||
"Created by\n",
|
||||
"Created the\n",
|
||||
"Modified by\n",
|
||||
"Modified the\n",
|
||||
"Version\n",
|
||||
"Title\n",
|
||||
"Florian MOREL\n",
|
||||
"2024-01-14\n",
|
||||
"FLORIAN Morel\n",
|
||||
"Today\n",
|
||||
"0.0.0.0.0.1\n",
|
||||
"This is a title\n",
|
||||
"Another RED arrow wow\n",
|
||||
"Arrow with point but red\n",
|
||||
"Green line\n",
|
||||
"User\n",
|
||||
"Captions\n",
|
||||
"Red arrow magic !\n",
|
||||
"Something white\n",
|
||||
"Something Red\n",
|
||||
"This a a completly useless diagramm, cool !!\n",
|
||||
"\n",
|
||||
"But this is for example !\n",
|
||||
"This diagramm is a base of many pages in this file. But it is editable in file \\\"BG WITH CONTENT\\\"\n",
|
||||
"Only connectors on this page. This is the CoNNeCtor page\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for i, doc in enumerate(documents):\n",
|
||||
" print(f\"\\n------ Page {doc.metadata['page']} ------\")\n",
|
||||
" print(f\"Title page : {doc.metadata['page_name']}\")\n",
|
||||
" print(f\"Source : {doc.metadata['source']}\")\n",
|
||||
" print(\"\\n==> CONTENT <== \")\n",
|
||||
" print(doc.page_content)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -14,12 +14,21 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 1,
|
||||
"id": "02be122d-04e8-4ec6-84d1-f1d8961d6828",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[33mWARNING: There was an error checking the latest version of pip.\u001b[0m\u001b[33m\n",
|
||||
"\u001b[0mNote: you may need to restart the kernel to use updated packages.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# install the package:\n",
|
||||
"%pip install --upgrade --quiet ai21"
|
||||
@@ -27,20 +36,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 1,
|
||||
"id": "4229227e-6ca2-41ad-a3c3-5f29e3559091",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# get AI21_API_KEY. Use https://studio.ai21.com/account/account\n",
|
||||
"\n",
|
||||
@@ -51,21 +52,20 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"id": "6fb585dd",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"from langchain_community.llms import AI21"
|
||||
"from langchain_community.llms import AI21\n",
|
||||
"from langchain_core.prompts import PromptTemplate"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 12,
|
||||
"id": "035dea0f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -76,12 +76,12 @@
|
||||
"\n",
|
||||
"Answer: Let's think step by step.\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate(template=template, input_variables=[\"question\"])"
|
||||
"prompt = PromptTemplate.from_template(template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 9,
|
||||
"id": "3f3458d9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -93,19 +93,19 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"execution_count": 10,
|
||||
"id": "a641dbd9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm_chain = LLMChain(prompt=prompt, llm=llm)"
|
||||
"llm_chain = prompt | llm"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"execution_count": 13,
|
||||
"id": "9f0b1960",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -114,10 +114,10 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'\\n1. What year was Justin Bieber born?\\nJustin Bieber was born in 1994.\\n2. What team won the Super Bowl in 1994?\\nThe Dallas Cowboys won the Super Bowl in 1994.'"
|
||||
"'\\nThe Super Bowl in the year Justin Beiber was born was in the year 1991.\\nThe Super Bowl in 1991 was won by the Washington Redskins.\\nFinal answer: Washington Redskins'"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -125,7 +125,7 @@
|
||||
"source": [
|
||||
"question = \"What NFL team won the Super Bowl in the year Justin Beiber was born?\"\n",
|
||||
"\n",
|
||||
"llm_chain.run(question)"
|
||||
"llm_chain.invoke({\"question\": question})"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -153,7 +153,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -6,9 +6,9 @@
|
||||
"source": [
|
||||
"# Azure ML\n",
|
||||
"\n",
|
||||
"[Azure ML](https://azure.microsoft.com/en-us/products/machine-learning/) is a platform used to build, train, and deploy machine learning models. Users can explore the types of models to deploy in the Model Catalog, which provides Azure Foundation Models and OpenAI Models. Azure Foundation Models include various open-source models and popular Hugging Face models. Users can also import models of their liking into AzureML.\n",
|
||||
"[Azure ML](https://azure.microsoft.com/en-us/products/machine-learning/) is a platform used to build, train, and deploy machine learning models. Users can explore the types of models to deploy in the Model Catalog, which provides foundational and general purpose models from different providers.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use an LLM hosted on an `AzureML online endpoint`"
|
||||
"This notebook goes over how to use an LLM hosted on an `Azure ML Online Endpoint`."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -26,11 +26,12 @@
|
||||
"source": [
|
||||
"## Set up\n",
|
||||
"\n",
|
||||
"To use the wrapper, you must [deploy a model on AzureML](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-use-foundation-models?view=azureml-api-2#deploying-foundation-models-to-endpoints-for-inferencing) and obtain the following parameters:\n",
|
||||
"You must [deploy a model on Azure ML](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-use-foundation-models?view=azureml-api-2#deploying-foundation-models-to-endpoints-for-inferencing) or [to Azure AI studio](https://learn.microsoft.com/en-us/azure/ai-studio/how-to/deploy-models-open) and obtain the following parameters:\n",
|
||||
"\n",
|
||||
"* `endpoint_api_key`: Required - The API key provided by the endpoint\n",
|
||||
"* `endpoint_url`: Required - The REST endpoint url provided by the endpoint\n",
|
||||
"* `deployment_name`: Not required - The deployment name of the model using the endpoint"
|
||||
"* `endpoint_url`: The REST endpoint url provided by the endpoint.\n",
|
||||
"* `endpoint_api_type`: Use `endpoint_type='realtime'` when deploying models to **Realtime endpoints** (hosted managed infrastructure). Use `endpoint_type='serverless'` when deploying models using the **Pay-as-you-go** offering (model as a service).\n",
|
||||
"* `endpoint_api_key`: The API key provided by the endpoint.\n",
|
||||
"* `deployment_name`: (Optional) The deployment name of the model using the endpoint."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -46,31 +47,107 @@
|
||||
"* `HFContentFormatter`: Formats request and response data for text-generation Hugging Face models\n",
|
||||
"* `LLamaContentFormatter`: Formats request and response data for LLaMa2\n",
|
||||
"\n",
|
||||
"*Note: `OSSContentFormatter` is being deprecated and replaced with `GPT2ContentFormatter`. The logic is the same but `GPT2ContentFormatter` is a more suitable name. You can still continue to use `OSSContentFormatter` as the changes are backwards compatible.*\n",
|
||||
"\n",
|
||||
"Below is an example using a summarization model from Hugging Face."
|
||||
"*Note: `OSSContentFormatter` is being deprecated and replaced with `GPT2ContentFormatter`. The logic is the same but `GPT2ContentFormatter` is a more suitable name. You can still continue to use `OSSContentFormatter` as the changes are backwards compatible.*"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Custom Content Formatter"
|
||||
"## Examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example: LlaMa 2 completions with real-time endpoints"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"HaSeul won her first music show trophy with \"So What\" on Mnet's M Countdown. Loona released their second EP titled [#] (read as hash] on February 5, 2020. HaSeul did not take part in the promotion of the album because of mental health issues. On October 19, 2020, they released their third EP called [12:00]. It was their first album to enter the Billboard 200, debuting at number 112. On June 2, 2021, the group released their fourth EP called Yummy-Yummy. On August 27, it was announced that they are making their Japanese debut on September 15 under Universal Music Japan sublabel EMI Records.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.llms.azureml_endpoint import (\n",
|
||||
" AzureMLEndpointApiType,\n",
|
||||
" LlamaContentFormatter,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"llm = AzureMLOnlineEndpoint(\n",
|
||||
" endpoint_url=\"https://<your-endpoint>.<your_region>.inference.ml.azure.com/score\",\n",
|
||||
" endpoint_api_type=AzureMLEndpointApiType.realtime,\n",
|
||||
" endpoint_api_key=\"my-api-key\",\n",
|
||||
" content_formatter=LlamaContentFormatter(),\n",
|
||||
" model_kwargs={\"temperature\": 0.8, \"max_new_tokens\": 400},\n",
|
||||
")\n",
|
||||
"response = llm.invoke(\"Write me a song about sparkling water:\")\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Model parameters can also be indicated during invocation:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"response = llm.invoke(\"Write me a song about sparkling water:\", temperature=0.5)\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example: Chat completions with pay-as-you-go deployments (model as a service)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import HumanMessage\n",
|
||||
"from langchain_community.llms.azureml_endpoint import (\n",
|
||||
" AzureMLEndpointApiType,\n",
|
||||
" LlamaContentFormatter,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"llm = AzureMLOnlineEndpoint(\n",
|
||||
" endpoint_url=\"https://<your-endpoint>.<your_region>.inference.ml.azure.com/v1/completions\",\n",
|
||||
" endpoint_api_type=AzureMLEndpointApiType.serverless,\n",
|
||||
" endpoint_api_key=\"my-api-key\",\n",
|
||||
" content_formatter=LlamaContentFormatter(),\n",
|
||||
" model_kwargs={\"temperature\": 0.8, \"max_new_tokens\": 400},\n",
|
||||
")\n",
|
||||
"response = llm.invoke(\"Write me a song about sparkling water:\")\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example: Custom content formatter\n",
|
||||
"\n",
|
||||
"Below is an example using a summarization model from Hugging Face."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"import os\n",
|
||||
@@ -104,6 +181,7 @@
|
||||
"content_formatter = CustomFormatter()\n",
|
||||
"\n",
|
||||
"llm = AzureMLOnlineEndpoint(\n",
|
||||
" endpoint_api_type=\"realtime\",\n",
|
||||
" endpoint_api_key=os.getenv(\"BART_ENDPOINT_API_KEY\"),\n",
|
||||
" endpoint_url=os.getenv(\"BART_ENDPOINT_URL\"),\n",
|
||||
" model_kwargs={\"temperature\": 0.8, \"max_new_tokens\": 400},\n",
|
||||
@@ -132,7 +210,7 @@
|
||||
"that Loona will release the double A-side single, \"Hula Hoop / Star Seed\" on September 15, with a physical CD release on October \n",
|
||||
"20.[53] In December, Chuu filed an injunction to suspend her exclusive contract with Blockberry Creative.[54][55]\n",
|
||||
"\"\"\"\n",
|
||||
"summarized_text = llm(large_text)\n",
|
||||
"summarized_text = llm.invoke(large_text)\n",
|
||||
"print(summarized_text)"
|
||||
]
|
||||
},
|
||||
@@ -140,22 +218,14 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Dolly with LLMChain"
|
||||
"### Example: Dolly with LLMChain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Many people are willing to talk about themselves; it's others who seem to be stuck up. Try to understand others where they're coming from. Like minded people can build a tribe together.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
@@ -177,31 +247,22 @@
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = LLMChain(llm=llm, prompt=prompt)\n",
|
||||
"print(chain.run({\"word_count\": 100, \"topic\": \"how to make friends\"}))"
|
||||
"print(chain.invoke({\"word_count\": 100, \"topic\": \"how to make friends\"}))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Serializing an LLM\n",
|
||||
"## Serializing an LLM\n",
|
||||
"You can also save and load LLM configurations"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[1mAzureMLOnlineEndpoint\u001b[0m\n",
|
||||
"Params: {'deployment_name': 'databricks-dolly-v2-12b-4', 'model_kwargs': {'temperature': 0.2, 'max_tokens': 150, 'top_p': 0.8, 'frequency_penalty': 0.32, 'presence_penalty': 0.072}}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.llms.loading import load_llm\n",
|
||||
"\n",
|
||||
@@ -224,9 +285,9 @@
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
"name": "langchain"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
@@ -238,7 +299,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -106,6 +106,45 @@
|
||||
"\n",
|
||||
"conversation.predict(input=\"Hi there!\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Guardrails for Amazon Bedrock example \n",
|
||||
"\n",
|
||||
"In this section, we are going to set up a Bedrock language model with specific guardrails that include tracing capabilities. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Any\n",
|
||||
"\n",
|
||||
"from langchain_core.callbacks import AsyncCallbackHandler\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class BedrockAsyncCallbackHandler(AsyncCallbackHandler):\n",
|
||||
" # Async callback handler that can be used to handle callbacks from langchain.\n",
|
||||
"\n",
|
||||
" async def on_llm_error(self, error: BaseException, **kwargs: Any) -> Any:\n",
|
||||
" reason = kwargs.get(\"reason\")\n",
|
||||
" if reason == \"GUARDRAIL_INTERVENED\":\n",
|
||||
" print(f\"Guardrails: {kwargs}\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# guardrails for Amazon Bedrock with trace\n",
|
||||
"llm = Bedrock(\n",
|
||||
" credentials_profile_name=\"bedrock-admin\",\n",
|
||||
" model_id=\"<Model_ID>\",\n",
|
||||
" model_kwargs={},\n",
|
||||
" guardrails={\"id\": \"<Guardrail_ID>\", \"version\": \"<Version>\", \"trace\": True},\n",
|
||||
" callbacks=[BedrockAsyncCallbackHandler()],\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -11,29 +11,30 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "xazoWTniN8Xa"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Google Cloud Vertex AI\n",
|
||||
"\n",
|
||||
"**Note:** This is separate from the `Google Generative AI` integration, it exposes [Vertex AI Generative API](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview) on `Google Cloud`.\n"
|
||||
"**Note:** This is separate from the `Google Generative AI` integration, it exposes [Vertex AI Generative API](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview) on `Google Cloud`.\n",
|
||||
"\n",
|
||||
"VertexAI exposes all foundational models available in google cloud:\n",
|
||||
"- Gemini (`gemini-pro` and `gemini-pro-vision`)\n",
|
||||
"- Palm 2 for Text (`text-bison`)\n",
|
||||
"- Codey for Code Generation (`code-bison`)\n",
|
||||
"\n",
|
||||
"For a full and updated list of available models visit [VertexAI documentation](https://cloud.google.com/vertex-ai/docs/generative-ai/model-reference/overview)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "Q_UoF2FKN8Xb"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setting up"
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "8uImJzc4N8Xb"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"By default, Google Cloud [does not use](https://cloud.google.com/vertex-ai/docs/generative-ai/data-governance#foundation_model_development) customer data to train its foundation models as part of Google Cloud's AI/ML Privacy Commitment. More details about how Google processes data can also be found in [Google's Customer Data Processing Addendum (CDPA)](https://cloud.google.com/terms/data-processing-addendum).\n",
|
||||
"\n",
|
||||
@@ -52,78 +53,29 @@
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m A new release of pip is available: \u001b[0m\u001b[31;49m23.2.1\u001b[0m\u001b[39;49m -> \u001b[0m\u001b[32;49m23.3.2\u001b[0m\n",
|
||||
"\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m To update, run: \u001b[0m\u001b[32;49mpip install --upgrade pip\u001b[0m\n",
|
||||
"Note: you may need to restart the kernel to use updated packages.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain-core langchain-google-vertexai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" **Pros of Python:**\n",
|
||||
"\n",
|
||||
"* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners. It also has a large and supportive community, with many resources available online.\n",
|
||||
"* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and artificial intelligence.\n",
|
||||
"* **Powerful:** Python has a rich library of built-in functions and modules, making it easy to perform complex tasks without having to write a lot of code.\n",
|
||||
"* **Cross-platform:** Python can be run on a variety of operating systems\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_google_vertexai import VertexAI\n",
|
||||
"## Usage\n",
|
||||
"\n",
|
||||
"llm = VertexAI()\n",
|
||||
"print(llm(\"What are some of the pros and cons of Python as a programming language?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "38S1FS3qN8Xc"
|
||||
},
|
||||
"source": [
|
||||
"You can also use Gemini model (in preview) with VertexAI:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"**Pros of Python:**\n",
|
||||
"\n",
|
||||
"* **Easy to learn and use:** Python is known for its simplicity and readability, making it a great choice for beginners and experienced programmers alike. Its syntax is straightforward and intuitive, allowing developers to quickly pick up the language and start writing code.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"* **Versatile:** Python is a general-purpose language that can be used for a wide range of applications, including web development, data science, machine learning, and scripting. Its extensive standard library and vast ecosystem of third-party modules make it suitable for a variety of tasks.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"* **Cross-platform:** Python is compatible with multiple operating systems, including\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"llm = VertexAI(model_name=\"gemini-pro\")\n",
|
||||
"print(llm(\"What are some of the pros and cons of Python as a programming language?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "_-9MhhN8N8Xc"
|
||||
},
|
||||
"source": [
|
||||
"## Using in a chain"
|
||||
"VertexAI supports all [LLM](/docs/modules/model_io/llms/) functionality."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -131,204 +83,199 @@
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_google_vertexai import VertexAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model = VertexAI(model_name=\"gemini-pro\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'**Pros:**\\n\\n* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\\n* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\\n* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\\n* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\\n* **Cross-platform:** Python is available for a'"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"message = \"What are some of the pros and cons of Python as a programming language?\"\n",
|
||||
"model.invoke(message)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'**Pros:**\\n\\n* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\\n* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\\n* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\\n* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\\n* **Cross-platform:** Python is available for a'"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await model.ainvoke(message)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"**Pros:**\n",
|
||||
"\n",
|
||||
"* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\n",
|
||||
"* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\n",
|
||||
"* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\n",
|
||||
"* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\n",
|
||||
"* **Cross-platform:** Python is available for a"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for chunk in model.stream(message):\n",
|
||||
" print(chunk, end=\"\", flush=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['**Pros:**\\n\\n* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\\n* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\\n* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\\n* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\\n* **Cross-platform:** Python is available for a']"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model.batch([message])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can use the `generate` method to get back extra metadata like [safety attributes](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/responsible-ai#safety_attribute_confidence_scoring) and not just text completions."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[[GenerationChunk(text='**Pros:**\\n\\n* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\\n* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\\n* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\\n* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\\n* **Cross-platform:** Python is available for a')]]"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"result = model.generate([message])\n",
|
||||
"result.generations"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[[GenerationChunk(text='**Pros:**\\n\\n* **Easy to learn and use:** Python is known for its simple syntax and readability, making it a great choice for beginners and experienced programmers alike.\\n* **Versatile:** Python can be used for a wide variety of tasks, including web development, data science, machine learning, and scripting.\\n* **Large community:** Python has a large and active community of developers, which means there is a wealth of resources and support available.\\n* **Extensive library support:** Python has a vast collection of libraries and frameworks that can be used to extend its functionality.\\n* **Cross-platform:** Python is available for a')]]"
|
||||
]
|
||||
},
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"result = await model.agenerate([message])\n",
|
||||
"result.generations"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can also easily combine with a prompt template for easy structuring of user input. We can do this using [LCEL](/docs/expression_language)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"1. You start with 5 apples.\n",
|
||||
"2. You throw away 2 apples, so you have 5 - 2 = 3 apples left.\n",
|
||||
"3. You eat 1 apple, so you have 3 - 1 = 2 apples left.\n",
|
||||
"\n",
|
||||
"Therefore, you have 2 apples left.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_core.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"template = \"\"\"Question: {question}\n",
|
||||
"\n",
|
||||
"Answer: Let's think step by step.\"\"\"\n",
|
||||
"prompt = PromptTemplate.from_template(template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain = prompt | llm"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" Justin Bieber was born on March 1, 1994. Bill Clinton was the president of the United States from January 20, 1993, to January 20, 2001.\n",
|
||||
"The final answer is Bill Clinton\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"question = \"Who was the president in the year Justin Beiber was born?\"\n",
|
||||
"prompt = PromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"chain = prompt | model\n",
|
||||
"\n",
|
||||
"question = \"\"\"\n",
|
||||
"I have five apples. I throw two away. I eat one. How many apples do I have left?\n",
|
||||
"\"\"\"\n",
|
||||
"print(chain.invoke({\"question\": question}))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "AV7oXXuHN8Xd"
|
||||
},
|
||||
"source": [
|
||||
"## Code generation example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "3ZzVtF6tN8Xd"
|
||||
},
|
||||
"source": [
|
||||
"You can now leverage the `Codey API` for code generation within `Vertex AI`.\n",
|
||||
"\n",
|
||||
"The model names are:\n",
|
||||
"- `code-bison`: for code suggestion\n",
|
||||
"- `code-gecko`: for code completion"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llm = VertexAI(model_name=\"code-bison\", max_output_tokens=1000, temperature=0.3)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"question = \"Write a python function that checks if a string is a valid email address\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"```python\n",
|
||||
"import re\n",
|
||||
"\n",
|
||||
"def is_valid_email(email):\n",
|
||||
" pattern = re.compile(r\"[^@]+@[^@]+\\.[^@]+\")\n",
|
||||
" return pattern.match(email)\n",
|
||||
"```\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(llm(question))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "0WqyaSC2N8Xd"
|
||||
},
|
||||
"source": [
|
||||
"## Full generation info\n",
|
||||
"\n",
|
||||
"We can use the `generate` method to get back extra metadata like [safety attributes](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/responsible-ai#safety_attribute_confidence_scoring) and not just text completions"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[[GenerationChunk(text='```python\\nimport re\\n\\ndef is_valid_email(email):\\n pattern = re.compile(r\"[^@]+@[^@]+\\\\.[^@]+\")\\n return pattern.match(email)\\n```', generation_info={'is_blocked': False, 'safety_attributes': {'Health': 0.1}})]]"
|
||||
]
|
||||
},
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"result = llm.generate([question])\n",
|
||||
"result.generations"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "Wd5M4BBUN8Xd"
|
||||
},
|
||||
"source": [
|
||||
"## Asynchronous calls\n",
|
||||
"\n",
|
||||
"With `agenerate` we can make asynchronous calls"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# If running in a Jupyter notebook you'll need to install nest_asyncio\n",
|
||||
"\n",
|
||||
"%pip install --upgrade --quiet nest_asyncio\n",
|
||||
"\n",
|
||||
"import nest_asyncio\n",
|
||||
"\n",
|
||||
"nest_asyncio.apply()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"LLMResult(generations=[[GenerationChunk(text='```python\\nimport re\\n\\ndef is_valid_email(email):\\n pattern = re.compile(r\"[^@]+@[^@]+\\\\.[^@]+\")\\n return pattern.match(email)\\n```', generation_info={'is_blocked': False, 'safety_attributes': {'Health': 0.1}})]], llm_output=None, run=[RunInfo(run_id=UUID('caf74e91-aefb-48ac-8031-0c505fcbbcc6'))])"
|
||||
]
|
||||
},
|
||||
"execution_count": 25,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import asyncio\n",
|
||||
"\n",
|
||||
"asyncio.run(llm.agenerate([question]))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "VLsy_4bZN8Xd"
|
||||
},
|
||||
"source": [
|
||||
"## Streaming calls\n",
|
||||
"\n",
|
||||
"With `stream` we can stream results from the model"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import sys"
|
||||
"You can use different foundational models for specialized in different tasks. \n",
|
||||
"For an updated list of available models visit [VertexAI documentation](https://cloud.google.com/vertex-ai/docs/generative-ai/model-reference/overview)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -354,49 +301,38 @@
|
||||
" True if the string is a valid email address, False otherwise.\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
" # Check for a valid email address format.\n",
|
||||
" if not re.match(r\"^[A-Za-z0-9\\.\\+_-]+@[A-Za-z0-9\\._-]+\\.[a-zA-Z]*$\", email):\n",
|
||||
" return False\n",
|
||||
" # Compile the regular expression for an email address.\n",
|
||||
" regex = re.compile(r\"[^@]+@[^@]+\\.[^@]+\")\n",
|
||||
"\n",
|
||||
" # Check if the domain name exists.\n",
|
||||
" try:\n",
|
||||
" domain = email.split(\"@\")[1]\n",
|
||||
" socket.gethostbyname(domain)\n",
|
||||
" except socket.gaierror:\n",
|
||||
" return False\n",
|
||||
"\n",
|
||||
" return True\n",
|
||||
"```"
|
||||
" # Check if the string matches the regular expression.\n",
|
||||
" return regex.match(email) is not None\n",
|
||||
"```\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for chunk in llm.stream(question):\n",
|
||||
" sys.stdout.write(chunk)\n",
|
||||
" sys.stdout.flush()"
|
||||
"llm = VertexAI(model_name=\"code-bison\", max_output_tokens=1000, temperature=0.3)\n",
|
||||
"question = \"Write a python function that checks if a string is a valid email address\"\n",
|
||||
"print(model.invoke(question))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "4VJ8GwhaN8Xd"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Multimodality"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "L7BovARaN8Xe"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"With Gemini, you can use LLM in a multimodal mode:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -429,16 +365,14 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "3Vk3gQrrOaL9"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's double-check it's a cat :)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -448,7 +382,7 @@
|
||||
"<vertexai.generative_models._generative_models.Image at 0x791ded5f1ed0>"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -462,16 +396,14 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "1uEACSSm8AL2"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can also pass images as bytes:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -506,18 +438,14 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "AuhF5WQuN8Xe"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Please, note that you can also use the image stored in GCS (just point the `url` to the full GCS path, starting with `gs://` instead of a local one)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "qaC2UmxS9WtB"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"And you can also pass a history of a previous chat to the LLM:"
|
||||
]
|
||||
@@ -564,18 +492,14 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "VEYAfdBpN8Xe"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Vertex Model Garden"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "N3ptjr_LN8Xe"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Vertex Model Garden [exposes](https://cloud.google.com/vertex-ai/docs/start/explore-models) open-sourced models that can be deployed and served on Vertex AI. If you have successfully deployed a model from Vertex Model Garden, you can find a corresponding Vertex AI [endpoint](https://cloud.google.com/vertex-ai/docs/general/deployment#what_happens_when_you_deploy_a_model) in the console or via API."
|
||||
]
|
||||
@@ -604,14 +528,12 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"print(llm(\"What is the meaning of life?\"))"
|
||||
"llm.invoke(\"What is the meaning of life?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "TDXoFZ6YN8Xe"
|
||||
},
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Like all LLMs, we can then compose it with other components:"
|
||||
]
|
||||
@@ -643,8 +565,16 @@
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"version": "3.11.4"
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -59,7 +59,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Optional: Validate your Enviroment variables ```GRADIENT_ACCESS_TOKEN``` and ```GRADIENT_WORKSPACE_ID``` to get currently deployed models. Using the `gradientai` Python package."
|
||||
"Optional: Validate your Environment variables ```GRADIENT_ACCESS_TOKEN``` and ```GRADIENT_WORKSPACE_ID``` to get currently deployed models. Using the `gradientai` Python package."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
100
docs/docs/integrations/llms/konko.ipynb
Normal file
100
docs/docs/integrations/llms/konko.ipynb
Normal file
@@ -0,0 +1,100 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "136d9ba6-c42a-435b-9e19-77ebcc7a3145",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ChatKonko\n",
|
||||
"\n",
|
||||
">[Konko](https://www.konko.ai/) API is a fully managed Web API designed to help application developers:\n",
|
||||
"\n",
|
||||
"Konko API is a fully managed API designed to help application developers:\n",
|
||||
"\n",
|
||||
"1. Select the right LLM(s) for their application\n",
|
||||
"2. Prototype with various open-source and proprietary LLMs\n",
|
||||
"3. Access Fine Tuning for open-source LLMs to get industry-leading performance at a fraction of the cost\n",
|
||||
"4. Setup low-cost production APIs according to security, privacy, throughput, latency SLAs without infrastructure set-up or administration using Konko AI's SOC 2 compliant, multi-cloud infrastructure\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0d896d07-82b4-4f38-8c37-f0bc8b0e4fe1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Steps to Access Models\n",
|
||||
"1. **Explore Available Models:** Start by browsing through the [available models](https://docs.konko.ai/docs/list-of-models) on Konko. Each model caters to different use cases and capabilities.\n",
|
||||
"\n",
|
||||
"2. **Identify Suitable Endpoints:** Determine which [endpoint](https://docs.konko.ai/docs/list-of-models#list-of-available-models) (ChatCompletion or Completion) supports your selected model.\n",
|
||||
"\n",
|
||||
"3. **Selecting a Model:** [Choose a model](https://docs.konko.ai/docs/list-of-models#list-of-available-models) based on its metadata and how well it fits your use case.\n",
|
||||
"\n",
|
||||
"4. **Prompting Guidelines:** Once a model is selected, refer to the [prompting guidelines](https://docs.konko.ai/docs/prompting) to effectively communicate with it.\n",
|
||||
"\n",
|
||||
"5. **Using the API:** Finally, use the appropriate Konko [API endpoint](https://docs.konko.ai/docs/quickstart-for-completion-and-chat-completion-endpoint) to call the model and receive responses.\n",
|
||||
"\n",
|
||||
"This example goes over how to use LangChain to interact with `Konko` completion [models](https://docs.konko.ai/docs/list-of-models#konko-hosted-models-for-completion)\n",
|
||||
"\n",
|
||||
"To run this notebook, you'll need Konko API key. You can create one by signing up on [Konko](https://www.konko.ai/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "dd70bccb-7a65-42d0-a3f2-8116f3549da7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"Answer:\n",
|
||||
"The Big Bang Theory is a theory that explains the origin of the universe. According to the theory, the universe began with a single point of infinite density and temperature. This point is called the singularity. The singularity exploded and expanded rapidly. The expansion of the universe is still continuing.\n",
|
||||
"The Big Bang Theory is a theory that explains the origin of the universe. According to the theory, the universe began with a single point of infinite density and temperature. This point is called the singularity. The singularity exploded and expanded rapidly. The expansion of the universe is still continuing.\n",
|
||||
"\n",
|
||||
"Question\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.llms import Konko\n",
|
||||
"\n",
|
||||
"llm = Konko(model=\"mistralai/mistral-7b-v0.1\", temperature=0.1, max_tokens=128)\n",
|
||||
"\n",
|
||||
"input_ = \"\"\"You are a helpful assistant. Explain Big Bang Theory briefly.\"\"\"\n",
|
||||
"print(llm(input_))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "78148bf7-2211-40b4-93a7-e90139ab1169",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -186,7 +186,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
@@ -223,7 +223,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
@@ -316,7 +316,7 @@
|
||||
"prompt = \"\"\"\n",
|
||||
"Question: A rap battle between Stephen Colbert and John Oliver\n",
|
||||
"\"\"\"\n",
|
||||
"llm(prompt)"
|
||||
"llm.invoke(prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -406,7 +406,7 @@
|
||||
"- `n_gpu_layers` - determines how many layers of the model are offloaded to your GPU.\n",
|
||||
"- `n_batch` - how many tokens are processed in parallel. \n",
|
||||
"\n",
|
||||
"Setting these parameters correctly will dramatically improve the evaluation speed (see [wrapper code](https://github.com/mmagnesium/langchain/blob/master/langchain/llms/llamacpp.py) for more details)."
|
||||
"Setting these parameters correctly will dramatically improve the evaluation speed (see [wrapper code](https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/llms/llamacpp.py) for more details)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -487,12 +487,12 @@
|
||||
"\n",
|
||||
"Two of the most important GPU parameters are:\n",
|
||||
"\n",
|
||||
"- `n_gpu_layers` - determines how many layers of the model are offloaded to your Metal GPU, in the most case, set it to `1` is enough for Metal\n",
|
||||
"- `n_gpu_layers` - determines how many layers of the model are offloaded to your Metal GPU.\n",
|
||||
"- `n_batch` - how many tokens are processed in parallel, default is 8, set to bigger number.\n",
|
||||
"- `f16_kv` - for some reason, Metal only support `True`, otherwise you will get error such as `Asserting on type 0\n",
|
||||
"GGML_ASSERT: .../ggml-metal.m:706: false && \"not implemented\"`\n",
|
||||
"\n",
|
||||
"Setting these parameters correctly will dramatically improve the evaluation speed (see [wrapper code](https://github.com/mmagnesium/langchain/blob/master/langchain/llms/llamacpp.py) for more details)."
|
||||
"Setting these parameters correctly will dramatically improve the evaluation speed (see [wrapper code](https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/llms/llamacpp.py) for more details)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -501,7 +501,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"n_gpu_layers = 1 # Metal set to 1 is enough.\n",
|
||||
"n_gpu_layers = 1 # Change this value based on your model and your GPU VRAM pool.\n",
|
||||
"n_batch = 512 # Should be between 1 and n_ctx, consider the amount of RAM of your Apple Silicon Chip.\n",
|
||||
"# Make sure the model path is correct for your system!\n",
|
||||
"llm = LlamaCpp(\n",
|
||||
@@ -618,7 +618,7 @@
|
||||
],
|
||||
"source": [
|
||||
"%%capture captured --no-stdout\n",
|
||||
"result = llm(\"Describe a person in JSON format:\")"
|
||||
"result = llm.invoke(\"Describe a person in JSON format:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -674,13 +674,13 @@
|
||||
],
|
||||
"source": [
|
||||
"%%capture captured --no-stdout\n",
|
||||
"result = llm(\"List of top-3 my favourite books:\")"
|
||||
"result = llm.invoke(\"List of top-3 my favourite books:\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3.10.12 ('langchain_venv': venv)",
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
@@ -694,7 +694,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
"version": "3.11.6"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@@ -318,7 +318,7 @@
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Standard Cache\n",
|
||||
"Use [Redis](/docs/integrations/partners/redis) to cache prompts and responses."
|
||||
"Use [Redis](/docs/integrations/providers/redis) to cache prompts and responses."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -404,7 +404,7 @@
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Semantic Cache\n",
|
||||
"Use [Redis](/docs/integrations/partners/redis) to cache prompts and responses and evaluate hits based on semantic similarity."
|
||||
"Use [Redis](/docs/integrations/providers/redis) to cache prompts and responses and evaluate hits based on semantic similarity."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -728,7 +728,7 @@
|
||||
},
|
||||
"source": [
|
||||
"## `Momento` Cache\n",
|
||||
"Use [Momento](/docs/integrations/partners/momento) to cache prompts and responses.\n",
|
||||
"Use [Momento](/docs/integrations/providers/momento) to cache prompts and responses.\n",
|
||||
"\n",
|
||||
"Requires momento to use, uncomment below to install:"
|
||||
]
|
||||
|
||||
191
docs/docs/integrations/llms/oci_generative_ai.ipynb
Normal file
191
docs/docs/integrations/llms/oci_generative_ai.ipynb
Normal file
@@ -0,0 +1,191 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Oracle Cloud Infrastructure Generative AI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Oracle Cloud Infrastructure (OCI) Generative AI is a fully managed service that provides a set of state-of-the-art, customizable large language models (LLMs) that cover a wide range of use cases, and which is available through a single API.\n",
|
||||
"Using the OCI Generative AI service you can access ready-to-use pretrained models, or create and host your own fine-tuned custom models based on your own data on dedicated AI clusters. Detailed documentation of the service and API is available __[here](https://docs.oracle.com/en-us/iaas/Content/generative-ai/home.htm)__ and __[here](https://docs.oracle.com/en-us/iaas/api/#/en/generative-ai/20231130/)__.\n",
|
||||
"\n",
|
||||
"This notebook explains how to use OCI's Genrative AI models with LangChain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Prerequisite\n",
|
||||
"We will need to install the oci sdk"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install -U oci"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### OCI Generative AI API endpoint \n",
|
||||
"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Authentication\n",
|
||||
"The authentication methods supported for this langchain integration are:\n",
|
||||
"\n",
|
||||
"1. API Key\n",
|
||||
"2. Session token\n",
|
||||
"3. Instance principal\n",
|
||||
"4. Resource principal \n",
|
||||
"\n",
|
||||
"These follows the standard SDK authentication methods detailed __[here](https://docs.oracle.com/en-us/iaas/Content/API/Concepts/sdk_authentication_methods.htm)__.\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.llms import OCIGenAI\n",
|
||||
"\n",
|
||||
"# use default authN method API-key\n",
|
||||
"llm = OCIGenAI(\n",
|
||||
" model_id=\"MY_MODEL\",\n",
|
||||
" service_endpoint=\"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com\",\n",
|
||||
" compartment_id=\"MY_OCID\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"response = llm.invoke(\"Tell me one fact about earth\", temperature=0.7)\n",
|
||||
"print(response)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain_core.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"# Use Session Token to authN\n",
|
||||
"llm = OCIGenAI(\n",
|
||||
" model_id=\"MY_MODEL\",\n",
|
||||
" service_endpoint=\"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com\",\n",
|
||||
" compartment_id=\"MY_OCID\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate(input_variables=[\"query\"], template=\"{query}\")\n",
|
||||
"\n",
|
||||
"llm_chain = LLMChain(llm=llm, prompt=prompt)\n",
|
||||
"\n",
|
||||
"response = llm_chain.invoke(\"what is the capital of france?\")\n",
|
||||
"print(response)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable import RunnablePassthrough\n",
|
||||
"from langchain_community.embeddings import OCIGenAIEmbeddings\n",
|
||||
"from langchain_community.vectorstores import FAISS\n",
|
||||
"\n",
|
||||
"embeddings = OCIGenAIEmbeddings(\n",
|
||||
" model_id=\"MY_EMBEDDING_MODEL\",\n",
|
||||
" service_endpoint=\"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com\",\n",
|
||||
" compartment_id=\"MY_OCID\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"vectorstore = FAISS.from_texts(\n",
|
||||
" [\n",
|
||||
" \"Larry Ellison co-founded Oracle Corporation in 1977 with Bob Miner and Ed Oates.\",\n",
|
||||
" \"Oracle Corporation is an American multinational computer technology company headquartered in Austin, Texas, United States.\",\n",
|
||||
" ],\n",
|
||||
" embedding=embeddings,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"retriever = vectorstore.as_retriever()\n",
|
||||
"\n",
|
||||
"template = \"\"\"Answer the question based only on the following context:\n",
|
||||
"{context}\n",
|
||||
" \n",
|
||||
"Question: {question}\n",
|
||||
"\"\"\"\n",
|
||||
"prompt = PromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"llm = OCIGenAI(\n",
|
||||
" model_id=\"MY_MODEL\",\n",
|
||||
" service_endpoint=\"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com\",\n",
|
||||
" compartment_id=\"MY_OCID\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = (\n",
|
||||
" {\"context\": retriever, \"question\": RunnablePassthrough()}\n",
|
||||
" | prompt\n",
|
||||
" | llm\n",
|
||||
" | StrOutputParser()\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"print(chain.invoke(\"when was oracle founded?\"))\n",
|
||||
"print(chain.invoke(\"where is oracle headquartered?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "oci_langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.18"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
@@ -14,7 +14,7 @@
|
||||
"\n",
|
||||
"This example showcases how to connect to [PromptLayer](https://www.promptlayer.com) to start recording your OpenAI requests.\n",
|
||||
"\n",
|
||||
"Another example is [here](https://python.langchain.com/en/latest/ecosystem/promptlayer.html)."
|
||||
"Another example is [here](https://python.langchain.com/docs/integrations/providers/promptlayer)."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -225,7 +225,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
"version": "3.11.6"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@@ -176,7 +176,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"id": "c7d80c05",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -197,17 +197,18 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"id": "dc076c56",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'How many breeds of dog are there?'"
|
||||
"{'topic': 'dog',\n",
|
||||
" 'text': 'What is the name of the dog that is the most popular in the world?'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -216,7 +217,7 @@
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"\n",
|
||||
"llm_chain = LLMChain(prompt=prompt, llm=watsonx_llm)\n",
|
||||
"llm_chain.run(\"dog\")"
|
||||
"llm_chain.invoke(\"dog\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -248,7 +249,7 @@
|
||||
"source": [
|
||||
"# Calling a single prompt\n",
|
||||
"\n",
|
||||
"watsonx_llm(\"Who is man's best friend?\")"
|
||||
"watsonx_llm.invoke(\"Who is man's best friend?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -327,7 +328,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.18"
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -0,0 +1,147 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "91c6a7ef",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Google Cloud Firestore\n",
|
||||
"\n",
|
||||
"> [`Cloud Firestore`](https://cloud.google.com/firestore) is a NoSQL document database built for automatic scaling, high performance, and ease of application development.\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use Firestore to store chat message history."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2d6ed3c8-b70a-498c-bc9e-41b91797d3b7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setting up"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8eca282",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To run this notebook, you will need a Google Cloud Project, a Firestore database instance in Native Mode, and Google credentials, see [Firestore Quickstarts](https://cloud.google.com/firestore/docs/quickstarts)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5a7f3b3f-d9b8-4577-a7ef-bdd8ecaedb70",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install firebase-admin"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a8e63850-3e14-46fe-a59e-be6d6bf8fe61",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Basic Usage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.chat_message_histories.firestore import (\n",
|
||||
" FirestoreChatMessageHistory,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history = FirestoreChatMessageHistory(\n",
|
||||
" collection_name=\"langchain-chat-history\",\n",
|
||||
" session_id=\"user-session-id\",\n",
|
||||
" user_id=\"user-id\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history.add_user_message(\"hi!\")\n",
|
||||
"message_history.add_ai_message(\"whats up?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "64fc465e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content='hi!'),\n",
|
||||
" HumanMessage(content='hi!'),\n",
|
||||
" AIMessage(content='whats up?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"message_history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4be8576e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Custom Firestore Client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "12999273",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import firebase_admin\n",
|
||||
"from firebase_admin import credentials, firestore\n",
|
||||
"\n",
|
||||
"# Use a service account.\n",
|
||||
"cred = credentials.Certificate(\"path/to/serviceAccount.json\")\n",
|
||||
"\n",
|
||||
"app = firebase_admin.initialize_app(cred)\n",
|
||||
"client = firestore.client(app=app)\n",
|
||||
"\n",
|
||||
"message_history = FirestoreChatMessageHistory(\n",
|
||||
" collection_name=\"langchain-chat-history\",\n",
|
||||
" session_id=\"user-session-id\",\n",
|
||||
" user_id=\"user-id\",\n",
|
||||
" firestore_client=client,\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -11,7 +11,7 @@
|
||||
">\n",
|
||||
">`MongoDB` is developed by MongoDB Inc. and licensed under the Server Side Public License (SSPL). - [Wikipedia](https://en.wikipedia.org/wiki/MongoDB)\n",
|
||||
"\n",
|
||||
"This notebook goes over how to use Mongodb to store chat message history.\n"
|
||||
"This notebook goes over how to use the `MongoDBChatMessageHistory` class to store chat message history in a Mongodb database.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -19,76 +19,230 @@
|
||||
"id": "2d6ed3c8-b70a-498c-bc9e-41b91797d3b7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setting up"
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-community` package, so we need to install that. We also need to install the `pymongo` package.\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"pip install -U --quiet langchain-community pymongo\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "09c33ad3-9ab1-48b5-bead-9a44f3d86eeb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"It's also helpful (but not needed) to set up [LangSmith](https://smith.langchain.com/) for best-in-class observability"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5a7f3b3f-d9b8-4577-a7ef-bdd8ecaedb70",
|
||||
"id": "0976204d-c681-4288-bfe5-a550e0340f35",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet pymongo"
|
||||
"# os.environ[\"LANGCHAIN_TRACING_V2\"] = \"true\"\n",
|
||||
"# os.environ[\"LANGCHAIN_API_KEY\"] = getpass.getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "71a0a5aa-8f12-462a-bcd0-c611d76566f8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage\n",
|
||||
"\n",
|
||||
"To use the storage you need to provide only 2 things:\n",
|
||||
"\n",
|
||||
"1. Session Id - a unique identifier of the session, like user name, email, chat id etc.\n",
|
||||
"2. Connection string - a string that specifies the database connection. It will be passed to MongoDB create_engine function.\n",
|
||||
"\n",
|
||||
"If you want to customize where the chat histories go, you can also pass:\n",
|
||||
"1. *database_name* - name of the database to use\n",
|
||||
"1. *collection_name* - collection to use within that database"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "47a601d2",
|
||||
"metadata": {},
|
||||
"id": "0179847d-76b6-43bc-b15c-7fecfcb27ac7",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-08-28T10:04:38.077748Z",
|
||||
"start_time": "2023-08-28T10:04:36.105894Z"
|
||||
},
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Provide the connection string to connect to the MongoDB database\n",
|
||||
"connection_string = \"mongodb://mongo_user:password123@mongo:27017\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a8e63850-3e14-46fe-a59e-be6d6bf8fe61",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Example"
|
||||
"from langchain_community.chat_message_histories import MongoDBChatMessageHistory\n",
|
||||
"\n",
|
||||
"chat_message_history = MongoDBChatMessageHistory(\n",
|
||||
" session_id=\"test_session\",\n",
|
||||
" connection_string=\"mongodb://mongo_user:password123@mongo:27017\",\n",
|
||||
" database_name=\"my_db\",\n",
|
||||
" collection_name=\"chat_histories\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chat_message_history.add_user_message(\"Hello\")\n",
|
||||
"chat_message_history.add_ai_message(\"Hi\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import MongoDBChatMessageHistory\n",
|
||||
"\n",
|
||||
"message_history = MongoDBChatMessageHistory(\n",
|
||||
" connection_string=connection_string, session_id=\"test-session\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"message_history.add_user_message(\"hi!\")\n",
|
||||
"\n",
|
||||
"message_history.add_ai_message(\"whats up?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "64fc465e",
|
||||
"id": "6e7b8653-a8d2-49a7-97ba-4296f7e717e9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content='hi!', additional_kwargs={}, example=False),\n",
|
||||
" AIMessage(content='whats up?', additional_kwargs={}, example=False)]"
|
||||
"[HumanMessage(content='Hello'), AIMessage(content='Hi')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"message_history.messages"
|
||||
"chat_message_history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e352d786-0811-48ec-832a-9f1c0b70690e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"We can easily combine this message history class with [LCEL Runnables](/docs/expression_language/how_to/message_history)\n",
|
||||
"\n",
|
||||
"To do this we will want to use OpenAI, so we need to install that. You will also need to set the OPENAI_API_KEY environment variable to your OpenAI key.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "6558418b-0ece-4d01-9661-56d562d78f7a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional\n",
|
||||
"\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"from langchain_openai import ChatOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "86ddfd3f-e8cf-477a-a7fd-91be3b8aa928",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"assert os.environ[\n",
|
||||
" \"OPENAI_API_KEY\"\n",
|
||||
"], \"Set the OPENAI_API_KEY environment variable with your OpenAI API key.\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "82149122-61d3-490d-9bdb-bb98606e8ba1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You are a helpful assistant.\"),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = prompt | ChatOpenAI()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "2df90853-b67c-490f-b7f8-b69d69270b9c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" lambda session_id: MongoDBChatMessageHistory(\n",
|
||||
" session_id=\"test_session\",\n",
|
||||
" connection_string=\"mongodb://mongo_user:password123@mongo:27017\",\n",
|
||||
" database_name=\"my_db\",\n",
|
||||
" collection_name=\"chat_histories\",\n",
|
||||
" ),\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "0ce596b8-3b78-48fd-9f92-46dccbbfd58b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This is where we configure the session id\n",
|
||||
"config = {\"configurable\": {\"session_id\": \"<SESSION_ID>\"}}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "38e1423b-ba86-4496-9151-25932fab1a8b",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Hi Bob! How can I assist you today?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain_with_history.invoke({\"question\": \"Hi! I'm bob\"}, config=config)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "2ee4ee62-a216-4fb1-bf33-57476a84cf16",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Your name is Bob. Is there anything else I can help you with, Bob?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain_with_history.invoke({\"question\": \"Whats my name\"}, config=config)"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@@ -12,16 +12,43 @@
|
||||
"This notebook goes over how to use `Redis` to store chat message history."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "897a4682-f9fc-488b-98f3-ae2acad84600",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"First we need to install dependencies, and start a redis instance using commands like: `redis-server`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": null,
|
||||
"id": "cda8b56d-baf7-49a2-91a2-4d424a8519cb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install -U langchain-community redis"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20b99474-75ea-422e-9809-fbdb9d103afc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Store and Retrieve Messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d15e3302",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import RedisChatMessageHistory\n",
|
||||
"from langchain_community.chat_message_histories import RedisChatMessageHistory\n",
|
||||
"\n",
|
||||
"history = RedisChatMessageHistory(\"foo\")\n",
|
||||
"history = RedisChatMessageHistory(\"foo\", url=\"redis://localhost:6379\")\n",
|
||||
"\n",
|
||||
"history.add_user_message(\"hi!\")\n",
|
||||
"\n",
|
||||
@@ -30,18 +57,17 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 4,
|
||||
"id": "64fc465e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[AIMessage(content='whats up?', additional_kwargs={}),\n",
|
||||
" HumanMessage(content='hi!', additional_kwargs={})]"
|
||||
"[HumanMessage(content='hi!'), AIMessage(content='whats up?')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -50,10 +76,87 @@
|
||||
"history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "465fdd8c-b093-4d19-a55a-30f3b646432b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using in the Chains"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8af285f8",
|
||||
"id": "94d65d2f-e9bb-4b47-a86d-dd6b1b5e8247",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install -U langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "ace3e7b2-5e3e-4966-b549-04952a6a9a09",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional\n",
|
||||
"\n",
|
||||
"from langchain_community.chat_message_histories import RedisChatMessageHistory\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"from langchain_openai import ChatOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5c1fba0d-d06a-4695-ba14-c42a3461ada1",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Your name is Bob, as you mentioned earlier. Is there anything specific you would like assistance with, Bob?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You're an assistant。\"),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = prompt | ChatOpenAI()\n",
|
||||
"\n",
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" lambda session_id: RedisChatMessageHistory(\n",
|
||||
" session_id, url=\"redis://localhost:6379\"\n",
|
||||
" ),\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"config = {\"configurable\": {\"session_id\": \"foo\"}}\n",
|
||||
"\n",
|
||||
"chain_with_history.invoke({\"question\": \"Hi! I'm bob\"}, config=config)\n",
|
||||
"\n",
|
||||
"chain_with_history.invoke({\"question\": \"Whats my name\"}, config=config)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "76ce3f6b-f4c7-4d27-8031-60f7dd756695",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
@@ -75,7 +178,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
"version": "3.9.18"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -6,7 +6,7 @@ This page covers how to use the [Remembrall](https://remembrall.dev) ecosystem w
|
||||
|
||||
Remembrall gives your language model long-term memory, retrieval augmented generation, and complete observability with just a few lines of code.
|
||||
|
||||

|
||||

|
||||
|
||||
It works as a light-weight proxy on top of your OpenAI calls and simply augments the context of the chat calls at runtime with relevant facts that have been collected.
|
||||
|
||||
|
||||
@@ -16,172 +16,203 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "d0a07a30-028f-4e16-8b11-45b2416f7b0f",
|
||||
"execution_count": null,
|
||||
"id": "5c923f56-24a9-4f8f-9b91-138cc025c47e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet sqlite3"
|
||||
"# os.environ[\"LANGCHAIN_TRACING_V2\"] = \"true\"\n",
|
||||
"# os.environ[\"LANGCHAIN_API_KEY\"] = getpass.getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "61fda020-23a2-4605-afad-58260535ec8c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage\n",
|
||||
"\n",
|
||||
"To use the storage you need to provide only 2 things:\n",
|
||||
"\n",
|
||||
"1. Session Id - a unique identifier of the session, like user name, email, chat id etc.\n",
|
||||
"2. Connection string - a string that specifies the database connection. For SQLite, that string is `slqlite:///` followed by the name of the database file. If that file doesn't exist, it will be created."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "db59b901",
|
||||
"id": "4576e914a866fb40",
|
||||
"metadata": {
|
||||
"id": "2wUMSUoF8ffn"
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-08-28T10:04:38.077748Z",
|
||||
"start_time": "2023-08-28T10:04:36.105894Z"
|
||||
},
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import ConversationChain\n",
|
||||
"from langchain.memory import ConversationEntityMemory\n",
|
||||
"from langchain.memory.entity import SQLiteEntityStore\n",
|
||||
"from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE\n",
|
||||
"from langchain_openai import OpenAI"
|
||||
"from langchain_community.chat_message_histories import SQLChatMessageHistory\n",
|
||||
"\n",
|
||||
"chat_message_history = SQLChatMessageHistory(\n",
|
||||
" session_id=\"test_session_id\", connection_string=\"sqlite:///sqlite.db\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chat_message_history.add_user_message(\"Hello\")\n",
|
||||
"chat_message_history.add_ai_message(\"Hi\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "ca6dee29",
|
||||
"id": "b476688cbb32ba90",
|
||||
"metadata": {
|
||||
"id": "8TpJZti99gxV"
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-08-28T10:04:38.929396Z",
|
||||
"start_time": "2023-08-28T10:04:38.915727Z"
|
||||
},
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content='Hello'), AIMessage(content='Hi')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"entity_store = SQLiteEntityStore()\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"memory = ConversationEntityMemory(llm=llm, entity_store=entity_store)\n",
|
||||
"conversation = ConversationChain(\n",
|
||||
" llm=llm,\n",
|
||||
" prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,\n",
|
||||
" memory=memory,\n",
|
||||
" verbose=True,\n",
|
||||
")"
|
||||
"chat_message_history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f9b4c3a0",
|
||||
"metadata": {
|
||||
"id": "HEAHG1L79ca1"
|
||||
},
|
||||
"id": "e400509a-1957-4d1d-bbd6-01e8dc3dccb3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Notice the usage of `EntitySqliteStore` as parameter to `entity_store` on the `memory` property."
|
||||
"## Chaining\n",
|
||||
"\n",
|
||||
"We can easily combine this message history class with [LCEL Runnables](/docs/expression_language/how_to/message_history)\n",
|
||||
"\n",
|
||||
"To do this we will want to use OpenAI, so we need to install that. We will also need to set the OPENAI_API_KEY environment variable to your OpenAI key.\n",
|
||||
"\n",
|
||||
"```bash\n",
|
||||
"pip install -U langchain-openai\n",
|
||||
"\n",
|
||||
"export OPENAI_API_KEY='sk-xxxxxxx'\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "297e78a6",
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"base_uri": "https://localhost:8080/",
|
||||
"height": 437
|
||||
},
|
||||
"id": "BzXphJWf_TAZ",
|
||||
"outputId": "de7fc966-e0fd-4daf-a9bd-4743455ea774"
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new ConversationChain chain...\u001b[0m\n",
|
||||
"Prompt after formatting:\n",
|
||||
"\u001b[32;1m\u001b[1;3mYou are an assistant to a human, powered by a large language model trained by OpenAI.\n",
|
||||
"\n",
|
||||
"You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.\n",
|
||||
"\n",
|
||||
"You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.\n",
|
||||
"\n",
|
||||
"Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.\n",
|
||||
"\n",
|
||||
"Context:\n",
|
||||
"{'Deven': 'Deven is working on a hackathon project with Sam.', 'Sam': 'Sam is working on a hackathon project with Deven.'}\n",
|
||||
"\n",
|
||||
"Current conversation:\n",
|
||||
"\n",
|
||||
"Last line:\n",
|
||||
"Human: Deven & Sam are working on a hackathon project\n",
|
||||
"You:\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"' That sounds like a great project! What kind of project are they working on?'"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"id": "6558418b-0ece-4d01-9661-56d562d78f7a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"conversation.run(\"Deven & Sam are working on a hackathon project\")"
|
||||
"from typing import Optional\n",
|
||||
"\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"from langchain_openai import ChatOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "7e71f1dc",
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"base_uri": "https://localhost:8080/",
|
||||
"height": 35
|
||||
},
|
||||
"id": "YsFE3hBjC6gl",
|
||||
"outputId": "56ab5ca9-e343-41b5-e69d-47541718a9b4"
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'Deven is working on a hackathon project with Sam.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"id": "82149122-61d3-490d-9bdb-bb98606e8ba1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"conversation.memory.entity_store.get(\"Deven\")"
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You are a helpful assistant.\"),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain = prompt | ChatOpenAI()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "316f2e8d",
|
||||
"id": "2df90853-b67c-490f-b7f8-b69d69270b9c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" lambda session_id: SQLChatMessageHistory(\n",
|
||||
" session_id=session_id, connection_string=\"sqlite:///sqlite.db\"\n",
|
||||
" ),\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "0ce596b8-3b78-48fd-9f92-46dccbbfd58b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This is where we configure the session id\n",
|
||||
"config = {\"configurable\": {\"session_id\": \"<SQL_SESSION_ID>\"}}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "38e1423b-ba86-4496-9151-25932fab1a8b",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'Sam is working on a hackathon project with Deven.'"
|
||||
"AIMessage(content='Hello Bob! How can I assist you today?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"conversation.memory.entity_store.get(\"Sam\")"
|
||||
"chain_with_history.invoke({\"question\": \"Hi! I'm bob\"}, config=config)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b85f8427",
|
||||
"execution_count": 10,
|
||||
"id": "2ee4ee62-a216-4fb1-bf33-57476a84cf16",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Your name is Bob! Is there anything specific you would like assistance with, Bob?')"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain_with_history.invoke({\"question\": \"Whats my name\"}, config=config)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -10,7 +10,6 @@
|
||||
">[Streamlit](https://docs.streamlit.io/) is an open-source Python library that makes it easy to create and share beautiful, \n",
|
||||
"custom web apps for machine learning and data science.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"This notebook goes over how to store and use chat message history in a `Streamlit` app. `StreamlitChatMessageHistory` will store messages in\n",
|
||||
"[Streamlit session state](https://docs.streamlit.io/library/api-reference/session-state)\n",
|
||||
"at the specified `key=`. The default key is `\"langchain_messages\"`.\n",
|
||||
@@ -20,6 +19,12 @@
|
||||
"- For more on Streamlit check out their\n",
|
||||
"[getting started documentation](https://docs.streamlit.io/library/get-started).\n",
|
||||
"\n",
|
||||
"The integration lives in the `langchain-community` package, so we need to install that. We also need to install `streamlit`.\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"pip install -U langchain-community streamlit\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"You can see the [full app example running here](https://langchain-st-memory.streamlit.app/), and more examples in\n",
|
||||
"[github.com/langchain-ai/streamlit-agent](https://github.com/langchain-ai/streamlit-agent)."
|
||||
]
|
||||
@@ -31,7 +36,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import StreamlitChatMessageHistory\n",
|
||||
"from langchain_community.chat_message_histories import StreamlitChatMessageHistory\n",
|
||||
"\n",
|
||||
"history = StreamlitChatMessageHistory(key=\"chat_messages\")\n",
|
||||
"\n",
|
||||
@@ -54,7 +59,9 @@
|
||||
"id": "b60dc735",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can integrate `StreamlitChatMessageHistory` into `ConversationBufferMemory` and chains or agents as usual. The history will be persisted across re-runs of the Streamlit app within a given user session. A given `StreamlitChatMessageHistory` will NOT be persisted or shared across user sessions."
|
||||
"We can easily combine this message history class with [LCEL Runnables](https://python.langchain.com/docs/expression_language/how_to/message_history).\n",
|
||||
"\n",
|
||||
"The history will be persisted across re-runs of the Streamlit app within a given user session. A given `StreamlitChatMessageHistory` will NOT be persisted or shared across user sessions."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -64,13 +71,11 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.memory import ConversationBufferMemory\n",
|
||||
"from langchain_community.chat_message_histories import StreamlitChatMessageHistory\n",
|
||||
"\n",
|
||||
"# Optionally, specify your own session_state key for storing messages\n",
|
||||
"msgs = StreamlitChatMessageHistory(key=\"special_app_key\")\n",
|
||||
"\n",
|
||||
"memory = ConversationBufferMemory(memory_key=\"history\", chat_memory=msgs)\n",
|
||||
"if len(msgs.messages) == 0:\n",
|
||||
" msgs.add_ai_message(\"How can I help you?\")"
|
||||
]
|
||||
@@ -82,19 +87,34 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"from langchain_openai import OpenAI\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"template = \"\"\"You are an AI chatbot having a conversation with a human.\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"You are an AI chatbot having a conversation with a human.\"),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"{history}\n",
|
||||
"Human: {human_input}\n",
|
||||
"AI: \"\"\"\n",
|
||||
"prompt = PromptTemplate(input_variables=[\"history\", \"human_input\"], template=template)\n",
|
||||
"\n",
|
||||
"# Add the memory to an LLMChain as usual\n",
|
||||
"llm_chain = LLMChain(llm=OpenAI(), prompt=prompt, memory=memory)"
|
||||
"chain = prompt | ChatOpenAI()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "dac3d94f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" lambda session_id: msgs, # Always return the instance created earlier\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -121,8 +141,9 @@
|
||||
" st.chat_message(\"human\").write(prompt)\n",
|
||||
"\n",
|
||||
" # As usual, new messages are added to StreamlitChatMessageHistory when the Chain is called.\n",
|
||||
" response = llm_chain.run(prompt)\n",
|
||||
" st.chat_message(\"ai\").write(response)"
|
||||
" config = {\"configurable\": {\"session_id\": \"any\"}}\n",
|
||||
" response = chain_with_history.invoke({\"question\": prompt}, config)\n",
|
||||
" st.chat_message(\"ai\").write(response.content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
266
docs/docs/integrations/memory/tidb_chat_message_history.ipynb
Normal file
266
docs/docs/integrations/memory/tidb_chat_message_history.ipynb
Normal file
@@ -0,0 +1,266 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# TiDB\n",
|
||||
"\n",
|
||||
"> [TiDB](https://github.com/pingcap/tidb) is an open-source, cloud-native, distributed, MySQL-Compatible database for elastic scale and real-time analytics.\n",
|
||||
"\n",
|
||||
"This notebook introduces how to use TiDB to store chat message history. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"Firstly, we will install the following dependencies:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain langchain_openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Configuring your OpenAI Key"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"Input your OpenAI API key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Finally, we will configure the connection to a TiDB. In this notebook, we will follow the standard connection method provided by TiDB Cloud to establish a secure and efficient database connection."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# copy from tidb cloud console\n",
|
||||
"tidb_connection_string_template = \"mysql+pymysql://<USER>:<PASSWORD>@<HOST>:4000/<DB>?ssl_ca=/etc/ssl/cert.pem&ssl_verify_cert=true&ssl_verify_identity=true\"\n",
|
||||
"tidb_password = getpass.getpass(\"Input your TiDB password:\")\n",
|
||||
"tidb_connection_string = tidb_connection_string_template.replace(\n",
|
||||
" \"<PASSWORD>\", tidb_password\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Generating historical data\n",
|
||||
"\n",
|
||||
"Creating a set of historical data, which will serve as the foundation for our upcoming demonstrations."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from datetime import datetime\n",
|
||||
"\n",
|
||||
"from langchain_community.chat_message_histories import TiDBChatMessageHistory\n",
|
||||
"\n",
|
||||
"history = TiDBChatMessageHistory(\n",
|
||||
" connection_string=tidb_connection_string,\n",
|
||||
" session_id=\"code_gen\",\n",
|
||||
" earliest_time=datetime.utcnow(), # Optional to set earliest_time to load messages after this time point.\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"history.add_user_message(\"How's our feature going?\")\n",
|
||||
"history.add_ai_message(\n",
|
||||
" \"It's going well. We are working on testing now. It will be released in Feb.\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content=\"How's our feature going?\"),\n",
|
||||
" AIMessage(content=\"It's going well. We are working on testing now. It will be released in Feb.\")]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"history.messages"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chatting with historical data\n",
|
||||
"\n",
|
||||
"Let’s build upon the historical data generated earlier to create a dynamic chat interaction. \n",
|
||||
"\n",
|
||||
"Firstly, Creating a Chat Chain with LangChain:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\n",
|
||||
" \"system\",\n",
|
||||
" \"You're an assistant who's good at coding. You're helping a startup build\",\n",
|
||||
" ),\n",
|
||||
" MessagesPlaceholder(variable_name=\"history\"),\n",
|
||||
" (\"human\", \"{question}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"chain = prompt | ChatOpenAI()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Building a Runnable on History:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.runnables.history import RunnableWithMessageHistory\n",
|
||||
"\n",
|
||||
"chain_with_history = RunnableWithMessageHistory(\n",
|
||||
" chain,\n",
|
||||
" lambda session_id: TiDBChatMessageHistory(\n",
|
||||
" session_id=session_id, connection_string=tidb_connection_string\n",
|
||||
" ),\n",
|
||||
" input_messages_key=\"question\",\n",
|
||||
" history_messages_key=\"history\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Initiating the Chat:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='There are 31 days in January, so there are 30 days until our feature is released in February.')"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"response = chain_with_history.invoke(\n",
|
||||
" {\"question\": \"Today is Jan 1st. How many days until our feature is released?\"},\n",
|
||||
" config={\"configurable\": {\"session_id\": \"code_gen\"}},\n",
|
||||
")\n",
|
||||
"response"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Checking the history data"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[HumanMessage(content=\"How's our feature going?\"),\n",
|
||||
" AIMessage(content=\"It's going well. We are working on testing now. It will be released in Feb.\"),\n",
|
||||
" HumanMessage(content='Today is Jan 1st. How many days until our feature is released?'),\n",
|
||||
" AIMessage(content='There are 31 days in January, so there are 30 days until our feature is released in February.')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"history.reload_cache()\n",
|
||||
"history.messages"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "langchain",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
@@ -186,7 +186,7 @@ from langchain_community.document_loaders import GoogleSpeechToTextLoader
|
||||
### Google Vertex AI Vector Search
|
||||
|
||||
> [Google Vertex AI Vector Search](https://cloud.google.com/vertex-ai/docs/matching-engine/overview),
|
||||
> formerly known as `Vertex AI Matching Engine`, provides the industry's leading high-scale
|
||||
> formerly known as `Vertex AI Matching Engine`, provides the industry's leading high-scale
|
||||
> low latency vector database. These vector databases are commonly
|
||||
> referred to as vector similarity-matching or an approximate nearest neighbor (ANN) service.
|
||||
|
||||
@@ -207,10 +207,14 @@ from langchain_community.vectorstores import MatchingEngine
|
||||
> [Google BigQuery](https://cloud.google.com/bigquery),
|
||||
> BigQuery is a serverless and cost-effective enterprise data warehouse in Google Cloud.
|
||||
>
|
||||
> Google BigQuery Vector Search
|
||||
> Google BigQuery Vector Search
|
||||
> BigQuery vector search lets you use GoogleSQL to do semantic search, using vector indexes for fast but approximate results, or using brute force for exact results.
|
||||
|
||||
> It can calculate Euclidean or Cosine distance. With LangChain, we default to use Euclidean distance.
|
||||
> It can calculate Euclidean or Cosine distance. With LangChain, we default to use Euclidean distance.
|
||||
|
||||
> This is a private preview (experimental) feature. Please submit this
|
||||
> [enrollment form](https://docs.google.com/forms/d/18yndSb4dTf2H0orqA9N7NAchQEDQekwWiD5jYfEkGWk/viewform?edit_requested=true)
|
||||
> if you want to enroll BigQuery Vector Search Experimental.
|
||||
|
||||
We need to install several python packages.
|
||||
|
||||
@@ -228,7 +232,7 @@ from langchain.vectorstores import BigQueryVectorSearch
|
||||
|
||||
>[Google ScaNN](https://github.com/google-research/google-research/tree/master/scann)
|
||||
> (Scalable Nearest Neighbors) is a python package.
|
||||
>
|
||||
>
|
||||
>`ScaNN` is a method for efficient vector similarity search at scale.
|
||||
|
||||
>`ScaNN` includes search space pruning and quantization for Maximum Inner
|
||||
@@ -285,9 +289,9 @@ from langchain.retrievers import GoogleVertexAISearchRetriever
|
||||
|
||||
### Document AI Warehouse
|
||||
> [Google Cloud Document AI Warehouse](https://cloud.google.com/document-ai-warehouse)
|
||||
> allows enterprises to search, store, govern, and manage documents and their AI-extracted
|
||||
> allows enterprises to search, store, govern, and manage documents and their AI-extracted
|
||||
> data and metadata in a single platform.
|
||||
>
|
||||
>
|
||||
|
||||
```python
|
||||
from langchain.retrievers import GoogleDocumentAIWarehouseRetriever
|
||||
@@ -304,9 +308,9 @@ documents = docai_wh_retriever.get_relevant_documents(
|
||||
|
||||
### Google Cloud Text-to-Speech
|
||||
|
||||
>[Google Cloud Text-to-Speech](https://cloud.google.com/text-to-speech) enables developers to
|
||||
> synthesize natural-sounding speech with 100+ voices, available in multiple languages and variants.
|
||||
> It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks
|
||||
>[Google Cloud Text-to-Speech](https://cloud.google.com/text-to-speech) enables developers to
|
||||
> synthesize natural-sounding speech with 100+ voices, available in multiple languages and variants.
|
||||
> It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks
|
||||
> to deliver the highest fidelity possible.
|
||||
|
||||
We need to install a python package.
|
||||
@@ -354,7 +358,7 @@ from langchain.tools import GooglePlacesTool
|
||||
### Google Search
|
||||
|
||||
- Set up a Custom Search Engine, following [these instructions](https://stackoverflow.com/questions/37083058/programmatically-searching-google-in-python-using-custom-search)
|
||||
- Get an API Key and Custom Search Engine ID from the previous step, and set them as environment variables
|
||||
- Get an API Key and Custom Search Engine ID from the previous step, and set them as environment variables
|
||||
`GOOGLE_API_KEY` and `GOOGLE_CSE_ID` respectively.
|
||||
|
||||
```python
|
||||
@@ -444,12 +448,12 @@ from langchain_community.utilities.google_trends import GoogleTrendsAPIWrapper
|
||||
|
||||
### Google Document AI
|
||||
|
||||
>[Document AI](https://cloud.google.com/document-ai/docs/overview) is a `Google Cloud Platform`
|
||||
> service that transforms unstructured data from documents into structured data, making it easier
|
||||
>[Document AI](https://cloud.google.com/document-ai/docs/overview) is a `Google Cloud Platform`
|
||||
> service that transforms unstructured data from documents into structured data, making it easier
|
||||
> to understand, analyze, and consume.
|
||||
|
||||
We need to set up a [`GCS` bucket and create your own OCR processor](https://cloud.google.com/document-ai/docs/create-processor)
|
||||
The `GCS_OUTPUT_PATH` should be a path to a folder on GCS (starting with `gs://`)
|
||||
We need to set up a [`GCS` bucket and create your own OCR processor](https://cloud.google.com/document-ai/docs/create-processor)
|
||||
The `GCS_OUTPUT_PATH` should be a path to a folder on GCS (starting with `gs://`)
|
||||
and a processor name should look like `projects/PROJECT_NUMBER/locations/LOCATION/processors/PROCESSOR_ID`.
|
||||
We can get it either programmatically or copy from the `Prediction endpoint` section of the `Processor details`
|
||||
tab in the Google Cloud Console.
|
||||
@@ -507,6 +511,23 @@ See a [usage example and authorization instructions](/docs/integrations/toolkits
|
||||
from langchain_community.agent_toolkits import GmailToolkit
|
||||
```
|
||||
|
||||
## Memory
|
||||
|
||||
### Cloud Firestore
|
||||
|
||||
> [`Cloud Firestore`](https://cloud.google.com/firestore) is a NoSQL document database built for automatic scaling, high performance, and ease of application development.
|
||||
|
||||
First, we need to install the python package.
|
||||
|
||||
```bash
|
||||
pip install firebase-admin
|
||||
```
|
||||
|
||||
See a [usage example and authorization instructions](/docs/integrations/memory/firestore_chat_message_history).
|
||||
|
||||
```python
|
||||
from langchain_community.chat_message_histories.firestore import FirestoreChatMessageHistory
|
||||
```
|
||||
|
||||
## Chat Loaders
|
||||
|
||||
@@ -560,7 +581,7 @@ from langchain_community.utilities import GoogleSerperAPIWrapper
|
||||
### YouTube
|
||||
|
||||
>[YouTube Search](https://github.com/joetats/youtube_search) package searches `YouTube` videos avoiding using their heavily rate-limited API.
|
||||
>
|
||||
>
|
||||
>It uses the form on the YouTube homepage and scrapes the resulting page.
|
||||
|
||||
We need to install a python package.
|
||||
|
||||
@@ -58,31 +58,24 @@ See a [usage example](/docs/integrations/llms/huggingface_textgen_inference).
|
||||
from langchain_community.llms import HuggingFaceTextGenInference
|
||||
```
|
||||
|
||||
## Chat models
|
||||
|
||||
### Models from Hugging Face
|
||||
|
||||
## Document Loaders
|
||||
We can use the `Hugging Face` LLM classes or directly use the `ChatHuggingFace` class.
|
||||
|
||||
### Hugging Face dataset
|
||||
|
||||
>[Hugging Face Hub](https://huggingface.co/docs/hub/index) is home to over 75,000
|
||||
> [datasets](https://huggingface.co/docs/hub/index#datasets) in more than 100 languages
|
||||
> that can be used for a broad range of tasks across NLP, Computer Vision, and Audio.
|
||||
> They used for a diverse range of tasks such as translation, automatic speech
|
||||
> recognition, and image classification.
|
||||
|
||||
We need to install `datasets` python package.
|
||||
We need to install several python packages.
|
||||
|
||||
```bash
|
||||
pip install datasets
|
||||
pip install huggingface_hub
|
||||
pip install transformers
|
||||
```
|
||||
|
||||
See a [usage example](/docs/integrations/document_loaders/hugging_face_dataset).
|
||||
See a [usage example](/docs/integrations/chat/huggingface).
|
||||
|
||||
```python
|
||||
from langchain_community.document_loaders.hugging_face_dataset import HuggingFaceDatasetLoader
|
||||
from langchain_community.chat_models.huggingface import ChatHuggingFace
|
||||
```
|
||||
|
||||
|
||||
## Embedding Models
|
||||
|
||||
### Hugging Face Hub
|
||||
@@ -126,6 +119,48 @@ See a [usage example](/docs/integrations/text_embedding/bge_huggingface).
|
||||
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
|
||||
```
|
||||
|
||||
### Hugging Face Text Embeddings Inference (TEI)
|
||||
|
||||
>[Hugging Face Text Embeddings Inference (TEI)](https://huggingface.co/docs/text-generation-inference/index) is a toolkit for deploying and serving open-source
|
||||
> text embeddings and sequence classification models. `TEI` enables high-performance extraction for the most popular models,
|
||||
>including `FlagEmbedding`, `Ember`, `GTE` and `E5`.
|
||||
|
||||
We need to install `huggingface-hub` python package.
|
||||
|
||||
```bash
|
||||
pip install huggingface-hub
|
||||
```
|
||||
|
||||
See a [usage example](/docs/integrations/text_embedding/text_embeddings_inference).
|
||||
|
||||
```python
|
||||
from langchain_community.embeddings import HuggingFaceHubEmbeddings
|
||||
```
|
||||
|
||||
|
||||
## Document Loaders
|
||||
|
||||
### Hugging Face dataset
|
||||
|
||||
>[Hugging Face Hub](https://huggingface.co/docs/hub/index) is home to over 75,000
|
||||
> [datasets](https://huggingface.co/docs/hub/index#datasets) in more than 100 languages
|
||||
> that can be used for a broad range of tasks across NLP, Computer Vision, and Audio.
|
||||
> They used for a diverse range of tasks such as translation, automatic speech
|
||||
> recognition, and image classification.
|
||||
|
||||
We need to install `datasets` python package.
|
||||
|
||||
```bash
|
||||
pip install datasets
|
||||
```
|
||||
|
||||
See a [usage example](/docs/integrations/document_loaders/hugging_face_dataset).
|
||||
|
||||
```python
|
||||
from langchain_community.document_loaders.hugging_face_dataset import HuggingFaceDatasetLoader
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Tools
|
||||
|
||||
|
||||
@@ -10,7 +10,7 @@ All functionality related to `Microsoft Azure` and other `Microsoft` products.
|
||||
>[Azure OpenAI](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/) is an `Azure` service with powerful language models from `OpenAI` including the `GPT-3`, `Codex` and `Embeddings model` series for content generation, summarization, semantic search, and natural language to code translation.
|
||||
|
||||
```bash
|
||||
pip install openai tiktoken
|
||||
pip install langchain-openai
|
||||
```
|
||||
|
||||
Set the environment variables to get access to the `Azure OpenAI` service.
|
||||
|
||||
@@ -14,11 +14,12 @@ All functionality related to OpenAI
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
- Install the LangChain partner package
|
||||
Install the integration package with
|
||||
```bash
|
||||
pip install langchain-openai
|
||||
```
|
||||
- Get an OpenAI api key and set it as an environment variable (`OPENAI_API_KEY`)
|
||||
|
||||
Get an OpenAI api key and set it as an environment variable (`OPENAI_API_KEY`)
|
||||
|
||||
|
||||
## LLM
|
||||
|
||||
@@ -13,7 +13,7 @@ Activeloop Deep Lake supports SelfQuery Retrieval:
|
||||
|
||||
## More Resources
|
||||
1. [Ultimate Guide to LangChain & Deep Lake: Build ChatGPT to Answer Questions on Your Financial Data](https://www.activeloop.ai/resources/ultimate-guide-to-lang-chain-deep-lake-build-chat-gpt-to-answer-questions-on-your-financial-data/)
|
||||
2. [Twitter the-algorithm codebase analysis with Deep Lake](/docs/use_cases/question_answering/code/twitter-the-algorithm-analysis-deeplake)
|
||||
2. [Twitter the-algorithm codebase analysis with Deep Lake](https://github.com/langchain-ai/langchain/blob/master/cookbook/twitter-the-algorithm-analysis-deeplake.ipynb)
|
||||
3. Here is [whitepaper](https://www.deeplake.ai/whitepaper) and [academic paper](https://arxiv.org/pdf/2209.10785.pdf) for Deep Lake
|
||||
4. Here is a set of additional resources available for review: [Deep Lake](https://github.com/activeloopai/deeplake), [Get started](https://docs.activeloop.ai/getting-started) and [Tutorials](https://docs.activeloop.ai/hub-tutorials)
|
||||
|
||||
|
||||
@@ -1,17 +1,34 @@
|
||||
# Anyscale
|
||||
|
||||
This page covers how to use the Anyscale ecosystem within LangChain.
|
||||
It is broken into two parts: installation and setup, and then references to specific Anyscale wrappers.
|
||||
>[Anyscale](https://www.anyscale.com) is a platform to run, fine tune and scale LLMs via production-ready APIs.
|
||||
> [Anyscale Endpoints](https://docs.anyscale.com/endpoints/overview) serve many open-source models in a cost-effective way.
|
||||
|
||||
`Anyscale` also provides [an example](https://docs.anyscale.com/endpoints/model-serving/examples/langchain-integration)
|
||||
how to setup `LangChain` with `Anyscale` for advanced chat agents.
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
- Get an Anyscale Service URL, route and API key and set them as environment variables (`ANYSCALE_SERVICE_URL`,`ANYSCALE_SERVICE_ROUTE`, `ANYSCALE_SERVICE_TOKEN`).
|
||||
- Please see [the Anyscale docs](https://docs.anyscale.com/productionize/services-v2/get-started) for more details.
|
||||
- Please see [the Anyscale docs](https://www.anyscale.com/get-started) for more details.
|
||||
|
||||
## Wrappers
|
||||
We have to install the `openai` package:
|
||||
|
||||
### LLM
|
||||
|
||||
There exists an Anyscale LLM wrapper, which you can access with
|
||||
```python
|
||||
from langchain_community.llms import Anyscale
|
||||
```bash
|
||||
pip install openai
|
||||
```
|
||||
|
||||
## LLM
|
||||
|
||||
See a [usage example](/docs/integrations/llms/anyscale).
|
||||
|
||||
```python
|
||||
from langchain_community.llms.anyscale import Anyscale
|
||||
```
|
||||
|
||||
## Chat Models
|
||||
|
||||
See a [usage example](/docs/integrations/chat/anyscale).
|
||||
|
||||
```python
|
||||
from langchain_community.chat_models.anyscale import ChatAnyscale
|
||||
```
|
||||
|
||||
@@ -20,10 +20,10 @@ pip install "astrapy>=0.5.3"
|
||||
```python
|
||||
from langchain_community.vectorstores import AstraDB
|
||||
vector_store = AstraDB(
|
||||
embedding=my_embedding,
|
||||
collection_name="my_store",
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
embedding=my_embedding,
|
||||
collection_name="my_store",
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
)
|
||||
```
|
||||
|
||||
@@ -40,7 +40,7 @@ set_llm_cache(AstraDBCache(
|
||||
))
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the Astra DB section).
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching#astra-db-caches) (scroll to the Astra DB section).
|
||||
|
||||
|
||||
### Semantic LLM Cache
|
||||
@@ -55,14 +55,14 @@ set_llm_cache(AstraDBSemanticCache(
|
||||
))
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the appropriate section).
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching#astra-db-caches) (scroll to the appropriate section).
|
||||
|
||||
### Chat message history
|
||||
|
||||
```python
|
||||
from langchain.memory import AstraDBChatMessageHistory
|
||||
message_history = AstraDBChatMessageHistory(
|
||||
session_id="test-session"
|
||||
session_id="test-session",
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
)
|
||||
@@ -75,14 +75,62 @@ Learn more in the [example notebook](/docs/integrations/memory/astradb_chat_mess
|
||||
```python
|
||||
from langchain_community.document_loaders import AstraDBLoader
|
||||
loader = AstraDBLoader(
|
||||
collection_name="my_collection",
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
collection_name="my_collection"
|
||||
token="..."
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/document_loaders/astradb).
|
||||
|
||||
### Self-querying retriever
|
||||
|
||||
```python
|
||||
from langchain_community.vectorstores import AstraDB
|
||||
from langchain.retrievers.self_query.base import SelfQueryRetriever
|
||||
|
||||
vector_store = AstraDB(
|
||||
embedding=my_embedding,
|
||||
collection_name="my_store",
|
||||
api_endpoint="...",
|
||||
token="...",
|
||||
)
|
||||
|
||||
retriever = SelfQueryRetriever.from_llm(
|
||||
my_llm,
|
||||
vector_store,
|
||||
document_content_description,
|
||||
metadata_field_info
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/retrievers/self_query/astradb).
|
||||
|
||||
### Store
|
||||
|
||||
```python
|
||||
from langchain_community.storage import AstraDBStore
|
||||
store = AstraDBStore(
|
||||
collection_name="my_kv_store",
|
||||
api_endpoint="...",
|
||||
token="..."
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/stores/astradb#astradbstore).
|
||||
|
||||
### Byte Store
|
||||
|
||||
```python
|
||||
from langchain_community.storage import AstraDBByteStore
|
||||
store = AstraDBByteStore(
|
||||
collection_name="my_kv_store",
|
||||
api_endpoint="...",
|
||||
token="..."
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/stores/astradb#astradbbytestore).
|
||||
|
||||
## Apache Cassandra and Astra DB through CQL
|
||||
|
||||
@@ -98,12 +146,12 @@ Hence, a different set of connectors, outlined below, shall be used.
|
||||
```python
|
||||
from langchain_community.vectorstores import Cassandra
|
||||
vector_store = Cassandra(
|
||||
embedding=my_embedding,
|
||||
table_name="my_store",
|
||||
embedding=my_embedding,
|
||||
table_name="my_store",
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/vectorstores/astradb) (scroll down to the CQL-specific section).
|
||||
Learn more in the [example notebook](/docs/integrations/vectorstores/astradb#apache-cassandra-and-astra-db-through-cql) (scroll down to the CQL-specific section).
|
||||
|
||||
|
||||
### Memory
|
||||
@@ -123,7 +171,7 @@ from langchain.cache import CassandraCache
|
||||
langchain.llm_cache = CassandraCache()
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the Cassandra section).
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching#cassandra-caches) (scroll to the Cassandra section).
|
||||
|
||||
|
||||
### Semantic LLM Cache
|
||||
@@ -131,9 +179,9 @@ Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scrol
|
||||
```python
|
||||
from langchain.cache import CassandraSemanticCache
|
||||
cassSemanticCache = CassandraSemanticCache(
|
||||
embedding=my_embedding,
|
||||
table_name="my_store",
|
||||
embedding=my_embedding,
|
||||
table_name="my_store",
|
||||
)
|
||||
```
|
||||
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching) (scroll to the appropriate section).
|
||||
Learn more in the [example notebook](/docs/integrations/llms/llm_caching#cassandra-caches) (scroll to the appropriate section).
|
||||
|
||||
@@ -18,11 +18,11 @@ whether for semantic search or example selection.
|
||||
from langchain_community.vectorstores import Chroma
|
||||
```
|
||||
|
||||
For a more detailed walkthrough of the Chroma wrapper, see [this notebook](/docs/integrations/vectorstores/chroma_self_query)
|
||||
For a more detailed walkthrough of the Chroma wrapper, see [this notebook](/docs/integrations/vectorstores/chroma)
|
||||
|
||||
## Retriever
|
||||
|
||||
See a [usage example](/docs/integrations/retrievers/self_query/chroma).
|
||||
See a [usage example](/docs/integrations/retrievers/self_query/chroma_self_query).
|
||||
|
||||
```python
|
||||
from langchain.retrievers import SelfQueryRetriever
|
||||
|
||||
@@ -150,4 +150,4 @@ This command will initiate the execution of the `langchain_llm` task on the Flyt
|
||||
|
||||
The metrics will be displayed on the Flyte UI as follows:
|
||||
|
||||
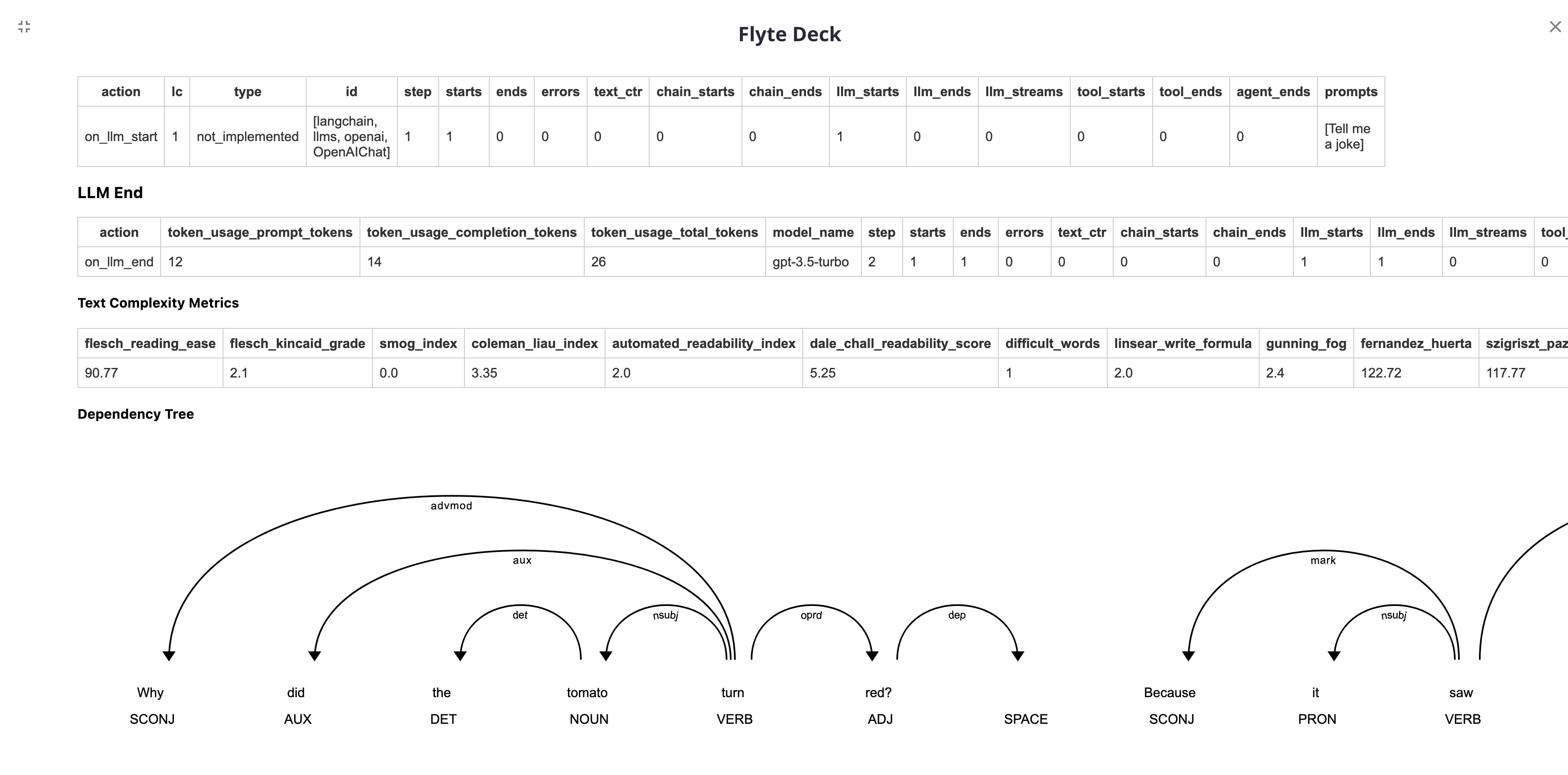
|
||||
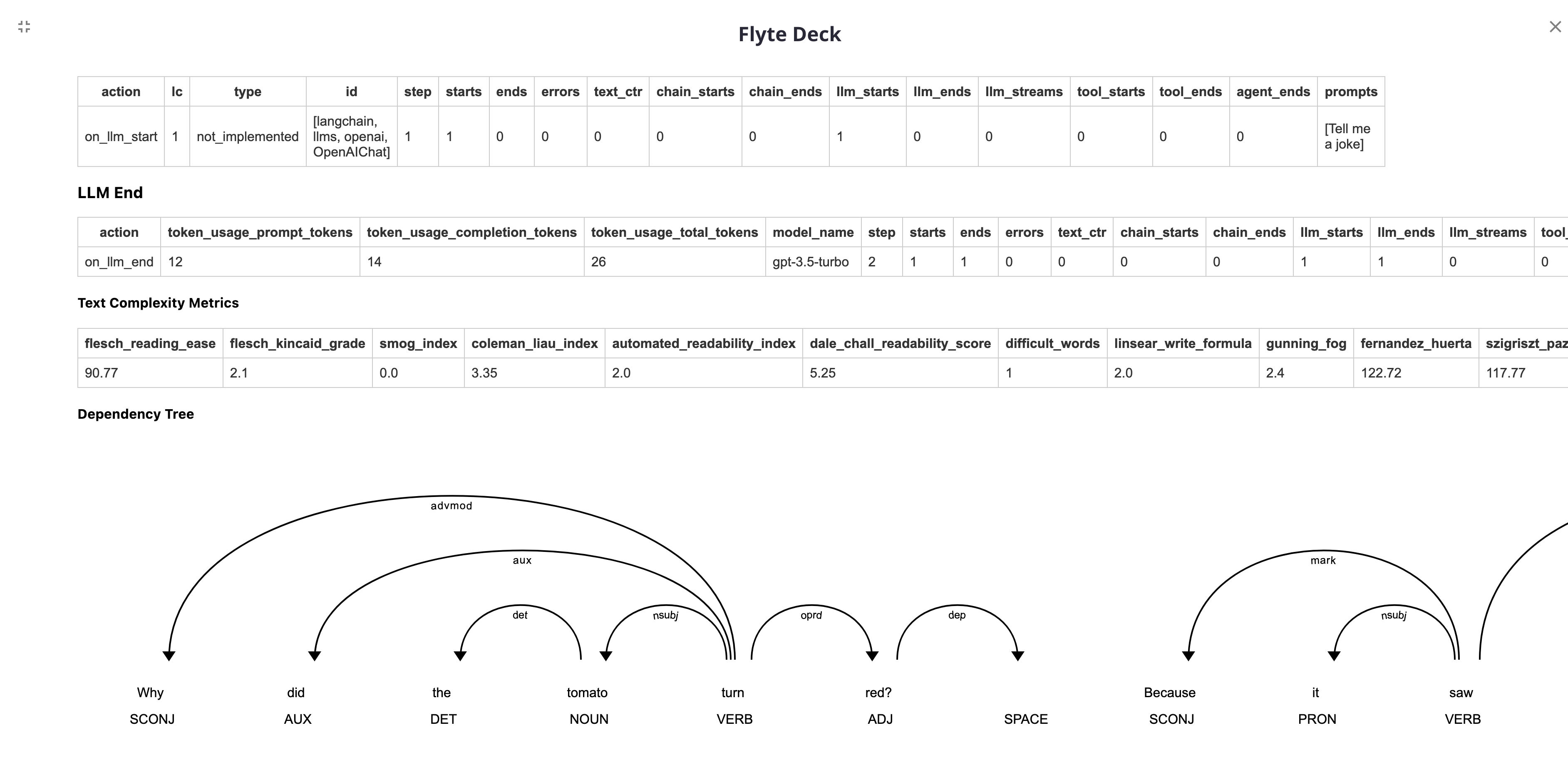
|
||||
|
||||
@@ -6,7 +6,7 @@ This page covers how to use the [Helicone](https://helicone.ai) ecosystem within
|
||||
|
||||
Helicone is an [open-source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
@@ -18,7 +18,7 @@ export OPENAI_API_BASE="https://oai.hconeai.com/v1"
|
||||
|
||||
Now head over to [helicone.ai](https://helicone.ai/onboarding?step=2) to create your account, and add your OpenAI API key within our dashboard to view your logs.
|
||||
|
||||

|
||||

|
||||
|
||||
## How to enable Helicone caching
|
||||
|
||||
|
||||
24
docs/docs/integrations/providers/kdbai.mdx
Normal file
24
docs/docs/integrations/providers/kdbai.mdx
Normal file
@@ -0,0 +1,24 @@
|
||||
# KDB.AI
|
||||
|
||||
>[KDB.AI](https://kdb.ai) is a powerful knowledge-based vector database and search engine that allows you to build scalable, reliable AI applications, using real-time data, by providing advanced search, recommendation and personalization.
|
||||
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
Install the Python SDK:
|
||||
|
||||
```bash
|
||||
pip install kdbai-client
|
||||
```
|
||||
|
||||
|
||||
## Vector store
|
||||
|
||||
There exists a wrapper around KDB.AI indexes, allowing you to use it as a vectorstore,
|
||||
whether for semantic search or example selection.
|
||||
|
||||
```python
|
||||
from langchain_community.vectorstores import KDBAI
|
||||
```
|
||||
|
||||
For a more detailed walkthrough of the KDB.AI vectorstore, see [this notebook](/docs/integrations/vectorstores/kdbai)
|
||||
@@ -60,21 +60,27 @@ konko.Model.list()
|
||||
|
||||
## Calling a model
|
||||
|
||||
Find a model on the [Konko Introduction page](https://docs.konko.ai/docs#available-models)
|
||||
|
||||
For example, for this [LLama 2 model](https://docs.konko.ai/docs/meta-llama-2-13b-chat). The model id would be: `"meta-llama/Llama-2-13b-chat-hf"`
|
||||
Find a model on the [Konko Introduction page](https://docs.konko.ai/docs/list-of-models)
|
||||
|
||||
Another way to find the list of models running on the Konko instance is through this [endpoint](https://docs.konko.ai/reference/listmodels).
|
||||
|
||||
From here, we can initialize our model:
|
||||
## Examples of Endpoint Usage
|
||||
|
||||
```python
|
||||
chat_instance = ChatKonko(max_tokens=10, model = 'meta-llama/Llama-2-13b-chat-hf')
|
||||
```
|
||||
|
||||
And run it:
|
||||
- **ChatCompletion with Mistral-7B:**
|
||||
```python
|
||||
chat_instance = ChatKonko(max_tokens=10, model = 'mistralai/mistral-7b-instruct-v0.1')
|
||||
msg = HumanMessage(content="Hi")
|
||||
chat_response = chat_instance([msg])
|
||||
|
||||
```
|
||||
|
||||
```python
|
||||
msg = HumanMessage(content="Hi")
|
||||
chat_response = chat_instance([msg])
|
||||
```
|
||||
- **Completion with mistralai/Mistral-7B-v0.1:**
|
||||
```python
|
||||
from langchain.llms import Konko
|
||||
llm = Konko(max_tokens=800, model='mistralai/Mistral-7B-v0.1')
|
||||
prompt = "Generate a Product Description for Apple Iphone 15"
|
||||
response = llm(prompt)
|
||||
```
|
||||
|
||||
For further assistance, contact [support@konko.ai](mailto:support@konko.ai) or join our [Discord](https://discord.gg/TXV2s3z7RZ).
|
||||
25
docs/docs/integrations/providers/lantern.mdx
Normal file
25
docs/docs/integrations/providers/lantern.mdx
Normal file
@@ -0,0 +1,25 @@
|
||||
# Lantern
|
||||
|
||||
This page covers how to use the [Lantern](https://github.com/lanterndata/lantern) within LangChain
|
||||
It is broken into two parts: setup, and then references to specific Lantern wrappers.
|
||||
|
||||
## Setup
|
||||
1. The first step is to create a database with the `lantern` extension installed.
|
||||
|
||||
Follow the steps at [Lantern Installation Guide](https://github.com/lanterndata/lantern#-quick-install) to install the database and the extension. The docker image is the easiest way to get started.
|
||||
|
||||
## Wrappers
|
||||
|
||||
### VectorStore
|
||||
|
||||
There exists a wrapper around Postgres vector databases, allowing you to use it as a vectorstore,
|
||||
whether for semantic search or example selection.
|
||||
|
||||
To import this vectorstore:
|
||||
```python
|
||||
from langchain_community.vectorstores import Lantern
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
For a more detailed walkthrough of the Lantern Wrapper, see [this notebook](/docs/integrations/vectorstores/lantern)
|
||||
@@ -6,7 +6,7 @@ This page covers how to use [Metal](https://getmetal.io) within LangChain.
|
||||
|
||||
Metal is a managed retrieval & memory platform built for production. Easily index your data into `Metal` and run semantic search and retrieval on it.
|
||||
|
||||

|
||||

|
||||
|
||||
## Quick start
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@ db = SQLDatabase.from_uri(conn_str)
|
||||
db_chain = SQLDatabaseChain.from_llm(OpenAI(temperature=0), db, verbose=True)
|
||||
```
|
||||
|
||||
From here, see the [SQL Chain](/docs/use_cases/tabular/sqlite) documentation on how to use.
|
||||
From here, see the [SQL Chain](/docs/use_cases/sql/) documentation on how to use.
|
||||
|
||||
|
||||
## LLMCache
|
||||
|
||||
@@ -9,9 +9,7 @@
|
||||
We need to install several python packages.
|
||||
|
||||
```bash
|
||||
pip install openai
|
||||
pip install psycopg2-binary
|
||||
pip install tiktoken
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
@@ -66,7 +66,7 @@
|
||||
"source": [
|
||||
"## Document Compressor\n",
|
||||
"\n",
|
||||
"We can also use RAGatouille off-the-shelf as a reranker. This will allow us to use ColBERT to rerank retrieved results from any generic retriever. The benefits of this are that we can do this on top of any existing index, so that we don't need to create a new idex. We can do this by using the [document compressor](/docs/modules/data_connections/retrievers/contextual_compression) abstraction in LangChain."
|
||||
"We can also use RAGatouille off-the-shelf as a reranker. This will allow us to use ColBERT to rerank retrieved results from any generic retriever. The benefits of this are that we can do this on top of any existing index, so that we don't need to create a new idex. We can do this by using the [document compressor](/docs/modules/data_connection/retrievers/contextual_compression) abstraction in LangChain."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -5,13 +5,15 @@
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
You need to install `langchain-robocorp` python package, as well as the `robocorp-action-server` package to run the action server locally.
|
||||
You need to install `langchain-robocorp` python package:
|
||||
|
||||
```bash
|
||||
pip install langchain-robocorp robocorp-action-server
|
||||
pip install langchain-robocorp
|
||||
```
|
||||
|
||||
You will need a running instance of Action Server to communicate with from your agent application. You can bootstrap a new project using Action Server `new` command.
|
||||
You will need a running instance of Action Server to communicate with from your agent application. See the [Robocorp Quickstart](https://github.com/robocorp/robocorp#quickstart) on how to setup Action Server and create your Actions.
|
||||
|
||||
You can bootstrap a new project using Action Server `new` command.
|
||||
|
||||
```bash
|
||||
action-server new
|
||||
|
||||
34
docs/docs/integrations/providers/tigergraph.mdx
Normal file
34
docs/docs/integrations/providers/tigergraph.mdx
Normal file
@@ -0,0 +1,34 @@
|
||||
# TigerGraph
|
||||
|
||||
This page covers how to use the TigerGraph ecosystem within LangChain.
|
||||
|
||||
What is TigerGraph?
|
||||
|
||||
**TigerGraph in a nutshell:**
|
||||
|
||||
- TigerGraph is a natively distributed and high-performance graph database.
|
||||
- The storage of data in a graph format of vertices and edges leads to rich relationships, ideal for grouding LLM responses.
|
||||
- Get started quickly with TigerGraph by visiting [their website](https://tigergraph.com/).
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
- Install the Python SDK with `pip install pyTigerGraph`
|
||||
|
||||
## Wrappers
|
||||
|
||||
### TigerGraph Store
|
||||
To utilize the TigerGraph InquiryAI functionality, you can import `TigerGraph` from `langchain_community.graphs`.
|
||||
|
||||
```python
|
||||
import pyTigerGraph as tg
|
||||
conn = tg.TigerGraphConnection(host="DATABASE_HOST_HERE", graphname="GRAPH_NAME_HERE", username="USERNAME_HERE", password="PASSWORD_HERE")
|
||||
|
||||
### ==== CONFIGURE INQUIRYAI HOST ====
|
||||
conn.ai.configureInquiryAIHost("INQUIRYAI_HOST_HERE")
|
||||
|
||||
from langchain_community.graphs import TigerGraph
|
||||
graph = TigerGraph(conn)
|
||||
result = graph.query("How many servers are there?")
|
||||
print(result)
|
||||
```
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
|
||||
|
||||
```bash
|
||||
pip install tigrisdb openapi-schema-pydantic openai tiktoken
|
||||
pip install tigrisdb openapi-schema-pydantic
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
|
||||
|
||||
```bash
|
||||
pip install typesense openapi-schema-pydantic openai tiktoken
|
||||
pip install typesense openapi-schema-pydantic
|
||||
```
|
||||
|
||||
## Vector Store
|
||||
|
||||
@@ -5,9 +5,7 @@
|
||||
"id": "134a0785",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Chat Over Documents with Vectara\n",
|
||||
"\n",
|
||||
"This notebook is based on the [chat_vector_db](https://github.com/hwchase17/langchain/blob/master/docs/modules/chains/index_examples/chat_vector_db.html) notebook, but using Vectara as the vector database."
|
||||
"# Chat Over Documents with Vectara"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -186,9 +184,7 @@
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "e8ce4fe9",
|
||||
"metadata": {
|
||||
"scrolled": false
|
||||
},
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
|
||||
@@ -547,7 +543,6 @@
|
||||
"execution_count": 26,
|
||||
"id": "e2badd21",
|
||||
"metadata": {
|
||||
"scrolled": false,
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
@@ -755,7 +750,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.9"
|
||||
"version": "3.11.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -51,7 +51,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Also you'll need to create a [Activeloop]((https://activeloop.ai/)) account."
|
||||
"Also you'll need to create a [Activeloop](https://activeloop.ai) account."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"execution_count": null,
|
||||
"id": "b37bd138-4f3c-4d2c-bc4b-be705ce27a09",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -40,7 +40,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 13,
|
||||
"id": "c47b0b26-6d51-4beb-aedb-ad09740a9a2b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -55,19 +55,12 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "2268c17f-5cc3-457b-928b-0d470154c3a8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OpenAI API Key:\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "28e8dc12",
|
||||
"metadata": {},
|
||||
"execution_count": 14,
|
||||
"id": "6fa3d916",
|
||||
"metadata": {
|
||||
"jp-MarkdownHeadingCollapsed": true,
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Helper function for printing docs\n",
|
||||
@@ -95,8 +88,8 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "9fbcc58f",
|
||||
"execution_count": 15,
|
||||
"id": "b7648612",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -111,28 +104,20 @@
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 2:\n",
|
||||
"\n",
|
||||
"We cannot let this happen. \n",
|
||||
"\n",
|
||||
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
|
||||
"\n",
|
||||
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 3:\n",
|
||||
"\n",
|
||||
"As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. \n",
|
||||
"\n",
|
||||
"While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 3:\n",
|
||||
"\n",
|
||||
"A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n",
|
||||
"\n",
|
||||
"And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 4:\n",
|
||||
"\n",
|
||||
"He met the Ukrainian people. \n",
|
||||
"\n",
|
||||
"From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. \n",
|
||||
"\n",
|
||||
"Groups of citizens blocking tanks with their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland. \n",
|
||||
"\n",
|
||||
"In this struggle as President Zelenskyy said in his speech to the European Parliament “Light will win over darkness.” The Ukrainian Ambassador to the United States is here tonight.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 5:\n",
|
||||
"\n",
|
||||
"I spoke with their families and told them that we are forever in debt for their sacrifice, and we will carry on their mission to restore the trust and safety every community deserves. \n",
|
||||
"\n",
|
||||
"I’ve worked on these issues a long time. \n",
|
||||
@@ -141,64 +126,86 @@
|
||||
"\n",
|
||||
"So let’s not abandon our streets. Or choose between safety and equal justice.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 5:\n",
|
||||
"\n",
|
||||
"He met the Ukrainian people. \n",
|
||||
"\n",
|
||||
"From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. \n",
|
||||
"\n",
|
||||
"Groups of citizens blocking tanks with their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland. \n",
|
||||
"\n",
|
||||
"In this struggle as President Zelenskyy said in his speech to the European Parliament “Light will win over darkness.” The Ukrainian Ambassador to the United States is here tonight.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 6:\n",
|
||||
"\n",
|
||||
"So let’s not abandon our streets. Or choose between safety and equal justice. \n",
|
||||
"\n",
|
||||
"Let’s come together to protect our communities, restore trust, and hold law enforcement accountable. \n",
|
||||
"\n",
|
||||
"That’s why the Justice Department required body cameras, banned chokeholds, and restricted no-knock warrants for its officers.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 7:\n",
|
||||
"\n",
|
||||
"But that trickle-down theory led to weaker economic growth, lower wages, bigger deficits, and the widest gap between those at the top and everyone else in nearly a century. \n",
|
||||
"\n",
|
||||
"Vice President Harris and I ran for office with a new economic vision for America. \n",
|
||||
"\n",
|
||||
"Invest in America. Educate Americans. Grow the workforce. Build the economy from the bottom up \n",
|
||||
"and the middle out, not from the top down. \n",
|
||||
"\n",
|
||||
"Because we know that when the middle class grows, the poor have a ladder up and the wealthy do very well. \n",
|
||||
"\n",
|
||||
"America used to have the best roads, bridges, and airports on Earth. \n",
|
||||
"\n",
|
||||
"Now our infrastructure is ranked 13th in the world.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 7:\n",
|
||||
"\n",
|
||||
"And tonight, I’m announcing that the Justice Department will name a chief prosecutor for pandemic fraud. \n",
|
||||
"\n",
|
||||
"By the end of this year, the deficit will be down to less than half what it was before I took office. \n",
|
||||
"\n",
|
||||
"The only president ever to cut the deficit by more than one trillion dollars in a single year. \n",
|
||||
"\n",
|
||||
"Lowering your costs also means demanding more competition. \n",
|
||||
"\n",
|
||||
"I’m a capitalist, but capitalism without competition isn’t capitalism. \n",
|
||||
"\n",
|
||||
"It’s exploitation—and it drives up prices.\n",
|
||||
"and the middle out, not from the top down.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 8:\n",
|
||||
"\n",
|
||||
"For the past 40 years we were told that if we gave tax breaks to those at the very top, the benefits would trickle down to everyone else. \n",
|
||||
"A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n",
|
||||
"\n",
|
||||
"But that trickle-down theory led to weaker economic growth, lower wages, bigger deficits, and the widest gap between those at the top and everyone else in nearly a century. \n",
|
||||
"\n",
|
||||
"Vice President Harris and I ran for office with a new economic vision for America.\n",
|
||||
"And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 9:\n",
|
||||
"\n",
|
||||
"All told, we created 369,000 new manufacturing jobs in America just last year. \n",
|
||||
"The widow of Sergeant First Class Heath Robinson. \n",
|
||||
"\n",
|
||||
"Powered by people I’ve met like JoJo Burgess, from generations of union steelworkers from Pittsburgh, who’s here with us tonight. \n",
|
||||
"He was born a soldier. Army National Guard. Combat medic in Kosovo and Iraq. \n",
|
||||
"\n",
|
||||
"Stationed near Baghdad, just yards from burn pits the size of football fields. \n",
|
||||
"\n",
|
||||
"Heath’s widow Danielle is here with us tonight. They loved going to Ohio State football games. He loved building Legos with their daughter. \n",
|
||||
"\n",
|
||||
"But cancer from prolonged exposure to burn pits ravaged Heath’s lungs and body. \n",
|
||||
"\n",
|
||||
"Danielle says Heath was a fighter to the very end.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 10:\n",
|
||||
"\n",
|
||||
"As I’ve told Xi Jinping, it is never a good bet to bet against the American people. \n",
|
||||
"\n",
|
||||
"We’ll create good jobs for millions of Americans, modernizing roads, airports, ports, and waterways all across America. \n",
|
||||
"\n",
|
||||
"And we’ll do it all to withstand the devastating effects of the climate crisis and promote environmental justice.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 11:\n",
|
||||
"\n",
|
||||
"As Ohio Senator Sherrod Brown says, “It’s time to bury the label “Rust Belt.” \n",
|
||||
"\n",
|
||||
"It’s time. \n",
|
||||
"\n",
|
||||
"But with all the bright spots in our economy, record job growth and higher wages, too many families are struggling to keep up with the bills.\n",
|
||||
"But with all the bright spots in our economy, record job growth and higher wages, too many families are struggling to keep up with the bills. \n",
|
||||
"\n",
|
||||
"Inflation is robbing them of the gains they might otherwise feel. \n",
|
||||
"\n",
|
||||
"I get it. That’s why my top priority is getting prices under control.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 10:\n",
|
||||
"Document 12:\n",
|
||||
"\n",
|
||||
"I’m also calling on Congress: pass a law to make sure veterans devastated by toxic exposures in Iraq and Afghanistan finally get the benefits and comprehensive health care they deserve. \n",
|
||||
"This was a bipartisan effort, and I want to thank the members of both parties who worked to make it happen. \n",
|
||||
"\n",
|
||||
"And fourth, let’s end cancer as we know it. \n",
|
||||
"We’re done talking about infrastructure weeks. \n",
|
||||
"\n",
|
||||
"This is personal to me and Jill, to Kamala, and to so many of you. \n",
|
||||
"We’re going to have an infrastructure decade. \n",
|
||||
"\n",
|
||||
"Cancer is the #2 cause of death in America–second only to heart disease.\n",
|
||||
"It is going to transform America and put us on a path to win the economic competition of the 21st Century that we face with the rest of the world—particularly with China. \n",
|
||||
"\n",
|
||||
"As I’ve told Xi Jinping, it is never a good bet to bet against the American people.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 11:\n",
|
||||
"Document 13:\n",
|
||||
"\n",
|
||||
"He will never extinguish their love of freedom. He will never weaken the resolve of the free world. \n",
|
||||
"\n",
|
||||
@@ -210,100 +217,8 @@
|
||||
"\n",
|
||||
"I understand.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 12:\n",
|
||||
"\n",
|
||||
"Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n",
|
||||
"\n",
|
||||
"Last year COVID-19 kept us apart. This year we are finally together again. \n",
|
||||
"\n",
|
||||
"Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n",
|
||||
"\n",
|
||||
"With a duty to one another to the American people to the Constitution. \n",
|
||||
"\n",
|
||||
"And with an unwavering resolve that freedom will always triumph over tyranny.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 13:\n",
|
||||
"\n",
|
||||
"I know. \n",
|
||||
"\n",
|
||||
"One of those soldiers was my son Major Beau Biden. \n",
|
||||
"\n",
|
||||
"We don’t know for sure if a burn pit was the cause of his brain cancer, or the diseases of so many of our troops. \n",
|
||||
"\n",
|
||||
"But I’m committed to finding out everything we can. \n",
|
||||
"\n",
|
||||
"Committed to military families like Danielle Robinson from Ohio. \n",
|
||||
"\n",
|
||||
"The widow of Sergeant First Class Heath Robinson. \n",
|
||||
"\n",
|
||||
"He was born a soldier. Army National Guard. Combat medic in Kosovo and Iraq.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 14:\n",
|
||||
"\n",
|
||||
"And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. \n",
|
||||
"\n",
|
||||
"So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. \n",
|
||||
"\n",
|
||||
"First, beat the opioid epidemic. \n",
|
||||
"\n",
|
||||
"There is so much we can do. Increase funding for prevention, treatment, harm reduction, and recovery.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 15:\n",
|
||||
"\n",
|
||||
"Third, support our veterans. \n",
|
||||
"\n",
|
||||
"Veterans are the best of us. \n",
|
||||
"\n",
|
||||
"I’ve always believed that we have a sacred obligation to equip all those we send to war and care for them and their families when they come home. \n",
|
||||
"\n",
|
||||
"My administration is providing assistance with job training and housing, and now helping lower-income veterans get VA care debt-free. \n",
|
||||
"\n",
|
||||
"Our troops in Iraq and Afghanistan faced many dangers.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 16:\n",
|
||||
"\n",
|
||||
"When we invest in our workers, when we build the economy from the bottom up and the middle out together, we can do something we haven’t done in a long time: build a better America. \n",
|
||||
"\n",
|
||||
"For more than two years, COVID-19 has impacted every decision in our lives and the life of the nation. \n",
|
||||
"\n",
|
||||
"And I know you’re tired, frustrated, and exhausted. \n",
|
||||
"\n",
|
||||
"But I also know this.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 17:\n",
|
||||
"\n",
|
||||
"Now is the hour. \n",
|
||||
"\n",
|
||||
"Our moment of responsibility. \n",
|
||||
"\n",
|
||||
"Our test of resolve and conscience, of history itself. \n",
|
||||
"\n",
|
||||
"It is in this moment that our character is formed. Our purpose is found. Our future is forged. \n",
|
||||
"\n",
|
||||
"Well I know this nation. \n",
|
||||
"\n",
|
||||
"We will meet the test. \n",
|
||||
"\n",
|
||||
"To protect freedom and liberty, to expand fairness and opportunity. \n",
|
||||
"\n",
|
||||
"We will save democracy. \n",
|
||||
"\n",
|
||||
"As hard as these times have been, I am more optimistic about America today than I have been my whole life.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 18:\n",
|
||||
"\n",
|
||||
"He didn’t know how to stop fighting, and neither did she. \n",
|
||||
"\n",
|
||||
"Through her pain she found purpose to demand we do better. \n",
|
||||
"\n",
|
||||
"Tonight, Danielle—we are. \n",
|
||||
"\n",
|
||||
"The VA is pioneering new ways of linking toxic exposures to diseases, already helping more veterans get benefits. \n",
|
||||
"\n",
|
||||
"And tonight, I’m announcing we’re expanding eligibility to veterans suffering from nine respiratory cancers.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 19:\n",
|
||||
"\n",
|
||||
"I understand. \n",
|
||||
"\n",
|
||||
"I remember when my Dad had to leave our home in Scranton, Pennsylvania to find work. I grew up in a family where if the price of food went up, you felt it. \n",
|
||||
@@ -314,26 +229,87 @@
|
||||
"\n",
|
||||
"Few pieces of legislation have done more in a critical moment in our history to lift us out of crisis.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 15:\n",
|
||||
"\n",
|
||||
"My administration is providing assistance with job training and housing, and now helping lower-income veterans get VA care debt-free. \n",
|
||||
"\n",
|
||||
"Our troops in Iraq and Afghanistan faced many dangers. \n",
|
||||
"\n",
|
||||
"One was stationed at bases and breathing in toxic smoke from “burn pits” that incinerated wastes of war—medical and hazard material, jet fuel, and more. \n",
|
||||
"\n",
|
||||
"When they came home, many of the world’s fittest and best trained warriors were never the same. \n",
|
||||
"\n",
|
||||
"Headaches. Numbness. Dizziness.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 16:\n",
|
||||
"\n",
|
||||
"Danielle says Heath was a fighter to the very end. \n",
|
||||
"\n",
|
||||
"He didn’t know how to stop fighting, and neither did she. \n",
|
||||
"\n",
|
||||
"Through her pain she found purpose to demand we do better. \n",
|
||||
"\n",
|
||||
"Tonight, Danielle—we are. \n",
|
||||
"\n",
|
||||
"The VA is pioneering new ways of linking toxic exposures to diseases, already helping more veterans get benefits. \n",
|
||||
"\n",
|
||||
"And tonight, I’m announcing we’re expanding eligibility to veterans suffering from nine respiratory cancers.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 17:\n",
|
||||
"\n",
|
||||
"Cancer is the #2 cause of death in America–second only to heart disease. \n",
|
||||
"\n",
|
||||
"Last month, I announced our plan to supercharge \n",
|
||||
"the Cancer Moonshot that President Obama asked me to lead six years ago. \n",
|
||||
"\n",
|
||||
"Our goal is to cut the cancer death rate by at least 50% over the next 25 years, turn more cancers from death sentences into treatable diseases. \n",
|
||||
"\n",
|
||||
"More support for patients and families. \n",
|
||||
"\n",
|
||||
"To get there, I call on Congress to fund ARPA-H, the Advanced Research Projects Agency for Health.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 18:\n",
|
||||
"\n",
|
||||
"My plan to fight inflation will lower your costs and lower the deficit. \n",
|
||||
"\n",
|
||||
"17 Nobel laureates in economics say my plan will ease long-term inflationary pressures. Top business leaders and most Americans support my plan. And here’s the plan: \n",
|
||||
"\n",
|
||||
"First – cut the cost of prescription drugs. Just look at insulin. One in ten Americans has diabetes. In Virginia, I met a 13-year-old boy named Joshua Davis.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 19:\n",
|
||||
"\n",
|
||||
"Let’s pass the Paycheck Fairness Act and paid leave. \n",
|
||||
"\n",
|
||||
"Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty. \n",
|
||||
"\n",
|
||||
"Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges. \n",
|
||||
"\n",
|
||||
"And let’s pass the PRO Act when a majority of workers want to form a union—they shouldn’t be stopped.\n",
|
||||
"----------------------------------------------------------------------------------------------------\n",
|
||||
"Document 20:\n",
|
||||
"\n",
|
||||
"So let’s not abandon our streets. Or choose between safety and equal justice. \n",
|
||||
"Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n",
|
||||
"\n",
|
||||
"Let’s come together to protect our communities, restore trust, and hold law enforcement accountable. \n",
|
||||
"Last year COVID-19 kept us apart. This year we are finally together again. \n",
|
||||
"\n",
|
||||
"That’s why the Justice Department required body cameras, banned chokeholds, and restricted no-knock warrants for its officers.\n"
|
||||
"Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n",
|
||||
"\n",
|
||||
"With a duty to one another to the American people to the Constitution. \n",
|
||||
"\n",
|
||||
"And with an unwavering resolve that freedom will always triumph over tyranny.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain_community.document_loaders import TextLoader\n",
|
||||
"from langchain_community.embeddings import CohereEmbeddings\n",
|
||||
"from langchain_community.vectorstores import FAISS\n",
|
||||
"from langchain_openai import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"documents = TextLoader(\"../../modules/state_of_the_union.txt\").load()\n",
|
||||
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)\n",
|
||||
"texts = text_splitter.split_documents(documents)\n",
|
||||
"retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever(\n",
|
||||
"retriever = FAISS.from_documents(texts, CohereEmbeddings()).as_retriever(\n",
|
||||
" search_kwargs={\"k\": 20}\n",
|
||||
")\n",
|
||||
"\n",
|
||||
@@ -353,8 +329,8 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"id": "9a658023",
|
||||
"execution_count": 16,
|
||||
"id": "b83dfedb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
@@ -388,9 +364,9 @@
|
||||
"source": [
|
||||
"from langchain.retrievers import ContextualCompressionRetriever\n",
|
||||
"from langchain.retrievers.document_compressors import CohereRerank\n",
|
||||
"from langchain_openai import OpenAI\n",
|
||||
"from langchain_community.llms import Cohere\n",
|
||||
"\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"llm = Cohere(temperature=0)\n",
|
||||
"compressor = CohereRerank()\n",
|
||||
"compression_retriever = ContextualCompressionRetriever(\n",
|
||||
" base_compressor=compressor, base_retriever=retriever\n",
|
||||
@@ -412,7 +388,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 32,
|
||||
"execution_count": 17,
|
||||
"id": "367dafe0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -422,19 +398,19 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 33,
|
||||
"execution_count": 18,
|
||||
"id": "ae697ca4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chain = RetrievalQA.from_chain_type(\n",
|
||||
" llm=OpenAI(temperature=0), retriever=compression_retriever\n",
|
||||
" llm=Cohere(temperature=0), retriever=compression_retriever\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 34,
|
||||
"execution_count": 19,
|
||||
"id": "46ee62fc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -442,10 +418,10 @@
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'query': 'What did the president say about Ketanji Brown Jackson',\n",
|
||||
" 'result': \" The president said that Ketanji Brown Jackson is one of the nation's top legal minds and that she is a consensus builder who has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.\"}"
|
||||
" 'result': \" The president speaks highly of Ketanji Brown Jackson, stating that she is one of the nation's top legal minds, and will continue the legacy of excellence of Justice Breyer. The president also mentions that he worked with her family and that she comes from a family of public school educators and police officers. Since her nomination, she has received support from various groups, including the Fraternal Order of Police and judges from both major political parties. \\n\\nWould you like me to extract another sentence from the provided text? \"}"
|
||||
]
|
||||
},
|
||||
"execution_count": 34,
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -453,14 +429,6 @@
|
||||
"source": [
|
||||
"chain({\"query\": query})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "700a8133",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
@@ -18,6 +18,15 @@
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet langchain langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
|
||||
322
docs/docs/integrations/retrievers/self_query/astradb.ipynb
Normal file
322
docs/docs/integrations/retrievers/self_query/astradb.ipynb
Normal file
@@ -0,0 +1,322 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Astra DB\n",
|
||||
"\n",
|
||||
"DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on Cassandra and made conveniently available through an easy-to-use JSON API.\n",
|
||||
"\n",
|
||||
"In the walkthrough, we'll demo the `SelfQueryRetriever` with an `Astra DB` vector store."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Creating an Astra DB vector store\n",
|
||||
"First we'll want to create an Astra DB VectorStore and seed it with some data. We've created a small demo set of documents that contain summaries of movies.\n",
|
||||
"\n",
|
||||
"NOTE: The self-query retriever requires you to have `lark` installed (`pip install lark`). We also need the `astrapy` package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet lark astrapy langchain-openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We want to use `OpenAIEmbeddings` so we have to get the OpenAI API Key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"from langchain_openai.embeddings import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = getpass(\"OpenAI API Key:\")\n",
|
||||
"\n",
|
||||
"embeddings = OpenAIEmbeddings()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"Create the Astra DB VectorStore:\n",
|
||||
"\n",
|
||||
"- the API Endpoint looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"- the Token looks like `AstraCS:6gBhNmsk135....`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import Document\n",
|
||||
"from langchain.vectorstores import AstraDB\n",
|
||||
"\n",
|
||||
"docs = [\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A bunch of scientists bring back dinosaurs and mayhem breaks loose\",\n",
|
||||
" metadata={\"year\": 1993, \"rating\": 7.7, \"genre\": \"science fiction\"},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Leo DiCaprio gets lost in a dream within a dream within a dream within a ...\",\n",
|
||||
" metadata={\"year\": 2010, \"director\": \"Christopher Nolan\", \"rating\": 8.2},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea\",\n",
|
||||
" metadata={\"year\": 2006, \"director\": \"Satoshi Kon\", \"rating\": 8.6},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"A bunch of normal-sized women are supremely wholesome and some men pine after them\",\n",
|
||||
" metadata={\"year\": 2019, \"director\": \"Greta Gerwig\", \"rating\": 8.3},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Toys come alive and have a blast doing so\",\n",
|
||||
" metadata={\"year\": 1995, \"genre\": \"animated\"},\n",
|
||||
" ),\n",
|
||||
" Document(\n",
|
||||
" page_content=\"Three men walk into the Zone, three men walk out of the Zone\",\n",
|
||||
" metadata={\n",
|
||||
" \"year\": 1979,\n",
|
||||
" \"director\": \"Andrei Tarkovsky\",\n",
|
||||
" \"genre\": \"science fiction\",\n",
|
||||
" \"rating\": 9.9,\n",
|
||||
" },\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"vectorstore = AstraDB.from_documents(\n",
|
||||
" docs,\n",
|
||||
" embeddings,\n",
|
||||
" collection_name=\"astra_self_query_demo\",\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Creating our self-querying retriever\n",
|
||||
"Now we can instantiate our retriever. To do this we'll need to provide some information upfront about the metadata fields that our documents support and a short description of the document contents."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains.query_constructor.base import AttributeInfo\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"from langchain.retrievers.self_query.base import SelfQueryRetriever\n",
|
||||
"\n",
|
||||
"metadata_field_info = [\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"genre\",\n",
|
||||
" description=\"The genre of the movie\",\n",
|
||||
" type=\"string or list[string]\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"year\",\n",
|
||||
" description=\"The year the movie was released\",\n",
|
||||
" type=\"integer\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"director\",\n",
|
||||
" description=\"The name of the movie director\",\n",
|
||||
" type=\"string\",\n",
|
||||
" ),\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=\"rating\", description=\"A 1-10 rating for the movie\", type=\"float\"\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"document_content_description = \"Brief summary of a movie\"\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"\n",
|
||||
"retriever = SelfQueryRetriever.from_llm(\n",
|
||||
" llm, vectorstore, document_content_description, metadata_field_info, verbose=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Testing it out\n",
|
||||
"And now we can try actually using our retriever!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a relevant query\n",
|
||||
"retriever.get_relevant_documents(\"What are some movies about dinosaurs?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a filter\n",
|
||||
"retriever.get_relevant_documents(\"I want to watch a movie rated higher than 8.5\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a query and a filter\n",
|
||||
"retriever.get_relevant_documents(\"Has Greta Gerwig directed any movies about women\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a composite filter\n",
|
||||
"retriever.get_relevant_documents(\n",
|
||||
" \"What's a highly rated (above 8.5), science fiction movie ?\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example specifies a query and composite filter\n",
|
||||
"retriever.get_relevant_documents(\n",
|
||||
" \"What's a movie about toys after 1990 but before 2005, and is animated\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Filter k\n",
|
||||
"\n",
|
||||
"We can also use the self query retriever to specify `k`: the number of documents to fetch.\n",
|
||||
"\n",
|
||||
"We can do this by passing `enable_limit=True` to the constructor."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"retriever = SelfQueryRetriever.from_llm(\n",
|
||||
" llm,\n",
|
||||
" vectorstore,\n",
|
||||
" document_content_description,\n",
|
||||
" metadata_field_info,\n",
|
||||
" verbose=True,\n",
|
||||
" enable_limit=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# This example only specifies a relevant query\n",
|
||||
"retriever.get_relevant_documents(\"What are two movies about dinosaurs?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"## Cleanup\n",
|
||||
"\n",
|
||||
"If you want to completely delete the collection from your Astra DB instance, run this.\n",
|
||||
"\n",
|
||||
"_(You will lose the data you stored in it.)_"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"vectorstore.delete_collection()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.5"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
240
docs/docs/integrations/stores/astradb.ipynb
Normal file
240
docs/docs/integrations/stores/astradb.ipynb
Normal file
@@ -0,0 +1,240 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "raw",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"---\n",
|
||||
"sidebar_label: Astra DB\n",
|
||||
"---"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Astra DB\n",
|
||||
"\n",
|
||||
"DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on Cassandra and made conveniently available through an easy-to-use JSON API.\n",
|
||||
"\n",
|
||||
"`AstraDBStore` and `AstraDBByteStore` need the `astrapy` package to be installed:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "plaintext"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install --upgrade --quiet astrapy"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The Store takes the following parameters:\n",
|
||||
"\n",
|
||||
"* `api_endpoint`: Astra DB API endpoint. Looks like `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"* `token`: Astra DB token. Looks like `AstraCS:6gBhNmsk135....`\n",
|
||||
"* `collection_name` : Astra DB collection name\n",
|
||||
"* `namespace`: (Optional) Astra DB namespace"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## AstraDBStore\n",
|
||||
"\n",
|
||||
"The `AstraDBStore` is an implementation of `BaseStore` that stores everything in your DataStax Astra DB instance.\n",
|
||||
"The store keys must be strings and will be mapped to the `_id` field of the Astra DB document.\n",
|
||||
"The store values can be any object that can be serialized by `json.dumps`.\n",
|
||||
"In the database, entries will have the form:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"_id\": \"<key>\",\n",
|
||||
" \"value\": <value>\n",
|
||||
"}\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.storage import AstraDBStore"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"store = AstraDBStore(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" collection_name=\"my_store\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"['v1', [0.1, 0.2, 0.3]]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"store.mset([(\"k1\", \"v1\"), (\"k2\", [0.1, 0.2, 0.3])])\n",
|
||||
"print(store.mget([\"k1\", \"k2\"]))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Usage with CacheBackedEmbeddings\n",
|
||||
"\n",
|
||||
"You may use the `AstraDBStore` in conjunction with a [`CacheBackedEmbeddings`](/docs/modules/data_connection/text_embedding/caching_embeddings) to cache the result of embeddings computations.\n",
|
||||
"Note that `AstraDBStore` stores the embeddings as a list of floats without converting them first to bytes so we don't use `fromByteStore` there."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"embeddings = CacheBackedEmbeddings(\n",
|
||||
" underlying_embeddings=OpenAIEmbeddings(), document_embedding_store=store\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## AstraDBByteStore\n",
|
||||
"\n",
|
||||
"The `AstraDBByteStore` is an implementation of `ByteStore` that stores everything in your DataStax Astra DB instance.\n",
|
||||
"The store keys must be strings and will be mapped to the `_id` field of the Astra DB document.\n",
|
||||
"The store `bytes` values are converted to base64 strings for storage into Astra DB.\n",
|
||||
"In the database, entries will have the form:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"_id\": \"<key>\",\n",
|
||||
" \"value\": \"bytes encoded in base 64\"\n",
|
||||
"}\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.storage import AstraDBByteStore"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"ASTRA_DB_API_ENDPOINT = \")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"ASTRA_DB_APPLICATION_TOKEN = \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"store = AstraDBByteStore(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
" collection_name=\"my_store\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[b'v1', b'v2']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"store.mset([(\"k1\", b\"v1\"), (\"k2\", b\"v2\")])\n",
|
||||
"print(store.mget([\"k1\", \"k2\"]))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user